
Submitted:
29 May 2024
Posted:
30 May 2024
You are already at the latest version
Abstract
Railway transportation is one of the main modes of long-distance coal transportation, and it is inevitable to cause environmental pollution during the transportation process. In order to improve the environment along the railway and increase the utilization rate of coal resources, this paper proposes a detection algorithm for scattered coal solidification layer during transportation based on the YOLO v8 model, and designs an intelligent recognition model suitable for coal solidification layer detection devices by combining fluorescence detection methods. Through experimental analysis, the model meets the requirements of practical detection and plays a crucial role in environmental protection, with strong practical application value.
Keywords:
railway transportation
; Coal solidification layer
; Image processing
; fluorescence detection
1. Introduction
The distribution of coal resources in our country is uneven. In order for all regions to have sufficient coal resources, the key factor is transportation. As the main transportation tool for coal transportation, although railways have excellent characteristics such as low cost and large one-time transportation volume, they also have a significant impact on the environment [1]. During transportation, due to the use of open cars and frequent external instability factors, coal powder inside the carriage is easily blown away, leading to dust and posing serious hazards to the surrounding environment and human health [2,3]. It can be seen that in order to effectively control the problem of coal dust pollution, it is necessary to further improve the dust suppression quality during coal transportation, study target detection algorithms during coal transportation, and improve the accuracy of target detection tasks, which has important practical significance.
The traditional coal dust detection method mainly relies on manual sampling, but the data obtained from manual sampling has a series of problems such as narrow coverage, long detection cycle, and inability to continuously detect [4]. Therefore, traditional detection methods cannot effectively detect coal dust, and the detection methods urgently need to be upgraded.
Currently, there are two mainstream algorithms for object detection based on deep learning. The first type is a two-stage object detection algorithm represented by Faster R-CNN [5,6,7]. Another type is a single-stage object detection algorithm represented by the YOLO series [8,9,10]. Although the accuracy of two-stage algorithms is generally higher than that of single-stage algorithms, single-stage detection algorithms have high real-time performance and fast speed, and are highly favored by researchers. The YOLO v8 algorithm is the eighth generation of real-time object detection algorithms in the YOLO family. It provides real-time performance while maintaining high precision detection, and has many advantages such as high accuracy and fast speed. The YOLO algorithm has been widely used in various industries. Reference [11] proposes a small target detection method for unmanned aerial vehicle (UAV) aerial photography based on the improved YOLO v8 algorithm. The method uses an optimized gradient allocation strategy, introduces an attention module, and adopts a multi-scale fusion network, greatly improving the accuracy of target detection. Reference [12] used the lightweight YOLO v8 algorithm to detect tomatoes, using depthwise separable convolution technology instead of regular convolution. A dual path attention module was designed, and a feature enhancement module was added to prevent effective feature loss and improve detection accuracy. Reference [13] studied the application of an improved YOLO v8 model in foreign object recognition, optimized and improved the model to ensure transmission security and efficiency. Reference [14] proposes a custom framework model based on image data, which introduces directional loss functions to achieve faster convergence and improve algorithm training and inference capabilities.
This article develops an improved coal solidification layer detection model based on YOLO v8 [15], which uses image-based data. Firstly, change the YOLO v8 activation function SiLu [16] to FReLu [17]. The replaced activation function can better express the target, significantly improving the training and inference capabilities of the detection algorithm. Secondly, due to the low pixel density of the coal solidification layer, it is easy to cause information loss. Therefore, the CBAM attention mechanism module is introduced into the network; The fusion of channel attention and spatial attention improves the accuracy of feature extraction and enhances the accuracy of classification recognition. Finally, fluorescence detection technology is introduced to specifically bind the fluorescent material with the coal solidification layer, emitting fluorescence and enhancing the detection of the coal solidification layer [18,19,20,21].
The remaining content of this article is as follows: The second section introduces the model of object detection and the improvement of algorithms. The third section obtains relevant results through experiments and analyzes them. The last section summarizes the research results.
2. Object Detection Model
Object detection is a hot topic in machine vision perception tasks. In the dust suppression monitoring system for railway coal transportation, the operation of personnel and equipment can play a role in safety supervision and early warning. The overall architecture of the railway coal transportation target detection model proposed in this article is shown in Figure 1. The monitoring system mainly consists of a high-definition imaging unit, an intelligent recognition monitoring unit, a data transmission center, and a user terminal. It can monitor the detection effect of the coal solidification layer in real time and detect abnormal states in the detection process in a timely manner. The monitoring system detects the status of the solidified layer through high-definition imaging equipment, transmits video or image information to relevant departments, and is able to capture and recognize locomotive numbers. The high-definition imaging unit adopts a dual redundant structure to improve the reliability of information during image acquisition. At present, China’s 5G communication technology is developing rapidly, and long-distance transmission is achieved through 5G wireless communication technology.
2.1. YOLO v8 Object Detection Algorithm
The primary prerequisite for achieving abnormal state recognition during the detection process is to perform object detection on the collected images of the monitoring system. Compared to traditional image processing methods that manually select image features and set classification standards, the features obtained by machine vision methods have stronger generalization and robustness, and are suitable for more complex scenes. The recognition of the solidified layer is based on image object detection, and the YOLO v8 network model is selected as the basic structure of the object detection algorithm [22]. Then, the network structure is fine tuned according to the characteristics of complex images and large targets, ultimately achieving the intelligent recognition function of the solidified layer.
In the field of object detection, the YOLO series algorithms are often the preferred choice for a large number of object detection tasks in the industry due to their balance between accurate detection accuracy and efficient running speed. Since researchers proposed the object detection network YOLO in 2016, various versions have been derived, including improved and optimized versions from v1 to v8. The YOLO v8 algorithm has made new improvements to the previous successful detection network models to further improve accuracy and real-time detection. For example, the backbone network has selected C2F modules with richer gradient flow, and adjusted the number of channels for different scale models to form a neural network model with stronger feature representation ability; The detection head adopts the popular decoupling head structure of classification detection separation, which can clearly separate the classification head and detection head; A series of improvements have also been made in the calculation of loss functions and data augmentation, greatly improving the detection accuracy of the model. The network structure of YOLO v8 is shown in Figure 2.
YOLO v8 is roughly divided into three parts: Backbone, Neck, and Head. The Backbone section adopts the basic structure of CSPDarkNet53. The image input is convolved in the first layer to obtain an output with 64 channels. After multiple convolutions, batch normalization, SiLU activation, and C2f modules, the Fast Spatial Pyramid Pooling Layer (SPPF) fuses three scales of spatial pyramid pooling feature maps and inputs them to the Neck section. To obtain richer gradient flow information, the Backbone and Neck sections replace YOLOv5’s C3 structure with a C2f structure, consisting of cross layer concatenated convolutional channels and several residual modules. The Neck section adopts the FPN+PAN architecture, which combines multi-layer semantic information while compensating for the blurred low-level localization features after strengthening multi-layer convolutional pooling; The Head section uses a decoupling head structure to obtain decoupled classification and regression branches. The regression branch uses the integral representation of DFL thinking to output target prediction results at three different scales: large, medium, and small. However, the blurriness of dust suppression monitoring videos hinders the YOLO v8 model’s ability to extract features from images. Therefore, it is necessary to enhance the model to improve its feature extraction ability.
2.2. Introduction of CBAM Attention Module
Due to the insufficient recognition features of coal solidification layer, attention module CBAM is introduced to improve the feature extraction ability of the model [23]. In order to focus the model on learning important features, the CBAM module ignores unimportant features and combines spatial and channel attention mechanisms to form a new structure. Because the CBAM module can adaptively adjust the feature extraction method, introducing the CBAM attention module can improve the performance of convolutional neural networks, overcome the shortcomings of YOLO v8 backbone networks in extracting important information features in fuzzy and dark environments, and have poor generalization ability, thereby improving the performance of the model [24].
When the input feature map of the model is (F is the input feature map, R is the feature map with C channels, H height, and W width), first input the feature map into the channel attention module, output the corresponding attention map, then multiply the input feature map with the attention map, output it through the spatial attention module, perform the same operation, and finally obtain the output feature map. The CBAM network structure diagram is shown in Figure 3, and the process is as follows:
Among them, is element level multiplication, is the final output feature, is a one-dimensional channel attention module diagram, and is a two-dimensional channel attention module diagram. The CBAM attention submodule diagram is shown in Figure 4.
In the channel attention module, the input feature map is first subjected to width and height based average pooling and maximum pooling operations to obtain two different spatial descriptors: and , which are average pooling and maximum pooling features, respectively. These two descriptors are then transmitted to a shared fully connected layer composed of multi-layer perceptrons (MLP) and a hidden layer. Add the obtained output elements one by one and use the sigmoid activation function to obtain the channel attention feature . The expression is as follows:
is the sigmoid activation function, , , and are dimensionality reduction factors.
In the spatial attention module, the input feature map is first subjected to channel based average pooling and maximum pooling operations to obtain feature maps with 2 channels: 和, which are concatenated into a feature descriptor. Finally, the spatial attention map is obtained through the sigmoid activation function, and the expression is as follows:
σ is the sigmoid activation function, and is a convolution with a kernel of .
The CBAM attention mechanism combines channel attention mechanism and spatial attention mechanism to improve the expression ability of feature maps at different levels. The CBAM attention mechanism utilizes channel and spatial attention mechanisms to selectively enhance the network’s attention to key features, reduce irrelevant information interference, improve the model’s performance in tasks such as object detection and image recognition, and enhance the model’s generalization ability and robustness. This article introduces the CBAM attention module into the blue section shown in Figure 5.
2.3. Replacing Activation Functions
In order to improve the expression ability of neural networks for models, solve problems that linear models cannot solve, and enhance the expression ability of convolutional neural networks, this paper replaces the SiLU function (Sigmoid Weighted Linear Unit) with the FReLu activation function [25,26]. FReLu is known as funnel activation in the field of image recognition, which extends ReLU and PReLU to 2D activation by adding funnel conditions to improve machine vision tasks. The expression for this process is as follows:
Due to the high background interference and detection difficulty in the recognition task of the monitoring system, a more powerful feature extraction network is needed in the feature fusion part. NAS-FPN uses NAS (Neural Architecture Search) technology to optimize the architecture of FPN (Feature Pyramid Networks). This method uses search instead of manually planning feature fusion between different scales, making it excellent in feature fusion and not significantly affecting computational speed [27]. The activation characteristics of the FReLu activation function are shown in Figure 6.
From this, it can be seen that using the FReLu activation function has better context capture ability, better expression of fuzzy and small target objects, and enables the system to have a wider activation domain, which plays a crucial role in the construction of the system.
2.4. Introduction of CQDS-MIPS Fluorescence Detection Technology
In this study, the detection process of CQDs-MIPs fluorescence detection technology includes [28]: recognition and capture of target substances, and recognition output of fluorescence signals. The recognition and capture of target substances are achieved through molecular imprinting technology: molecularly imprinted polymers (MIPs) have specificity and can bind with the target substance to form specific recognition sites. When the target substance exists, it interacts with MIPs and is captured at the recognition site. The recognition output of fluorescence signals is achieved through CQDs fluorescence detection technology: after the target substance is combined with CQDs-MIPs composite materials, the fluorescence signal of CQDs changes, which is used as an indicator of the presence of the target substance. The intensity changes of fluorescence signals are measured and recorded to determine the presence of the target substance. Figure 7 reveals the process of CQDs-MIPs fluorescence detection technology.
The fluorescence intelligent recognition monitoring device is set on the fluorescence channel light path of the multi-channel fluorescence microscope, allowing the device to continuously capture the fluorescence emitted by the multi-channel fluorescence microscope, and convert the captured external light information into a signal that can be recognized by the computer system through a microprocessor. Then, the converted signal is sent to the computer system, allowing the computer system to automatically configure the corresponding information based on the signal.
3. Experimental Analysis
3.1. Experimental Environment and Data
The specific experimental environment is shown in Table 1.
The sample data of this experiment was collected through real-time dust suppression monitoring video, which includes image data from different environments, angles, and models. The LabelImg script tool was used to annotate the image data. In order to enhance the generalization ability of the model, 6000 images were randomly selected as the training set and 1500 images as the testing set. The hyperparameters of the model are set based on prior knowledge, and the total epoch of the model is set to 300. To prevent overfitting, the learning rate of the first epoch is set to 0.01, and the learning rate of the last 100 epochs is set to 0.001. Some examples of datasets are shown in Figure 8.
3.2. Recognition Effect of the Model
This study will investigate the basic YOLOv8 network model and YOLOv8 with the introduction of attention modules_ YOLOv8 for C network model and replacement activation function_ F-network model and CQDS-MIPS fluorescence detection technology combined with YOLOv8_ A comparative analysis was conducted on M’s network model. Figure 9 shows the convergence process of the validation set Loss curve. It is not difficult to see that after about 50 iterations, the loss of YOLOv8 ultimately stabilizes at around 0.6; YOLOv8 introducing attention modules and replacing activation functions_ C. The losses of the YOLOv8F network model are stable at 0.5 and 0.3, respectively; And YOLOv8 combined with fluorescence detection technology_ The final loss of the M network model is reduced to around 0.23, which is generally lower than the first three YOLO algorithms.
3.3. Analysis of Model Recognition Effect
After the above model training is completed, we usually use accuracy (P), recall rate (R), average accuracy (mAP), size of storage space occupied (MB), and frame rate per second (FPS) as indicators to evaluate algorithm performance. The calculation formula for several performance indicators is as follows:
Degree refers to the proportion of samples that are truly positive in the model among all samples predicted as positive by the model. In the above formula, True Positions (TP) is the number of samples correctly predicted as positive categories by the model, and False Positions (FP) is the number of samples incorrectly predicted as positive categories by the model. The higher the P-value, the lower the false positive rate. The recall rate refers to the proportion of samples that the model successfully predicts as positive categories among all samples that are truly positive. Among them, False Negatives (FN) is the number of samples that the model incorrectly predicts as negative categories. The higher the R value, the lower the false negative rate. Table 2 shows the comparison of indicators for different models.
From the above table, it can be seen that the improved YOLOv8 has better performance, with a P-value of 97.12%, an R-value of 96.48%, and an average accuracy of 97.38%. These indicators demonstrate the combination of fluorescence detection technology YOLOv8_ The effectiveness of the M model. It can also be seen that the original YOLO_ The detection speed of v8 is slightly better than the improved algorithm model, but the difference in detection accuracy compared to the improved model is too obvious, which can lead to too many false detections and missed detections, unable to meet the needs of actual industrial scene detection.
Overall, the algorithm proposed in this article has advantages such as fewer network parameters, low computational complexity, good algorithm robustness, high detection accuracy, and fast processing speed. It can effectively detect dust in the coal solidification layer, thereby reducing dust emissions during railway coal transportation and achieving dust suppression.
3.4. Ablation Experiment
In order to further verify the effectiveness of each improved module of the algorithm proposed in this article, ablation experiments were conducted on the baseline model. The ablation experiments were gradually carried out by replacing the activation function FReLu, introducing the CBAM attention module, and combining CQDS-MIPS fluorescence detection technology. This study used the same equipment and dataset for experiments, and the experimental results are shown in Table 3, where “√” indicates the introduction of this method.
From Table 9 and Figure 10, it can be seen that in the improved model based on the original YOLO v8 algorithm, both P and R have been improved to varying degrees. Only introducing CQDS-MIPs fluorescence detection technology, the model architecture remains unchanged, so FPS is not affected. Among them, the E model P and R improved by 5.85% and 8.19% respectively, making them the most successful ablation experimental group. However, their computational complexity increased accordingly, and the FPS was lower than the final H model, resulting in a slower recognition speed of the model. By combining FReLu, CBAM, and CQDS MIPs, the improved model achieved P and R of 95.85% and 94.27%, respectively, with a recognition speed of 44 frames per second. Compared to the original model, P and R increased by 4.96% and 6.64% respectively, and FPS increased by 128.28%, significantly improving the recognition speed and accuracy of the original model, and further proving the effectiveness of the improved model.
4. Conclusion
Aiming at the problem of coal dust in the process of railway transportation, this paper innovatively proposes an improved YOLO v8 model, which improves the detection accuracy of coal solidified layer. After a series of experiments, the practicality of the improved model has been proven. The experimental results are as follows:
(1) Firstly, introducing the CBAM attention module into the YOLO v8 model can enhance its feature extraction and anti redundant feature capabilities. Compared with the original YOLO v8 model, the improved model has increased accuracy (P) and recall (R) by 1.79% and 2.01%, respectively, indicating that attention mechanism plays a crucial role in improving the accuracy of object detection tasks.
(2) Replacing FReLU as the activation function effectively maps the activated neuron features by retaining basic features and eliminating redundancy, thereby enhancing the expressive power of convolutional neural networks and improving the frame rate (FPS) of the model to a certain extent. We believe that this can improve real-time performance in practical applications.
(3) The introduction of CQDs-MIPs fluorescence detection technology, with its high sensitivity and resolution, can quickly identify whether the coal solidification layer is damaged, and has great development space in practical application scenarios.
(4) By introducing CBAM, replacing activation functions, and introducing fluorescence detection technology, the accuracy and recognition speed of the improved YOLO v8 model have been significantly improved. In the experiment, the accuracy (P) of the model was 95.85%, the recall (R) was 94.27%, and the recognition speed was 44 frames per second. This indicates that the model has strong practicality in object detection tasks.
Author Contributions
Conceptualization, B.X. and R.Z.; methodology, B.X.; software, R.Z.; validation,.L.D. and K.H.; formal analysis, B.X.; investigation, K.H and L.D.; resources, R.Z.; data curation, K.H.; writing—original draft preparation, B.X.; writing—review and editing, B.X.; visualization, R.Z; supervision, K.H.; project administration, K.H.; funding acquisition, K.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Open Fund of State Key Laboratory in 2022 “Research on Intelligent Diagnosis Technology of Safety Monitoring Sensor Based on Deep Learning Algorithm” (grant number SKLMRDPC21KF23) , Natural Science Research Key Project of Anhui Provincial Department of Education “Research on impact dynamics characteristics and instability modes of deep coal-rock combinations”(grant number 2022AH051573) and Huainan Normal University 2022 Campus level Natural Science Research Project “Research on Large scale Multi antenna Non stationary Characteristics Communication System” (grant number 2022XJYB035).
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, Y.J.; Sun, Q.Q.; Wu, J.J. Research on the low carbon development path of China’s coal industry under carbon peaking & carbon neutral target: Based on the RCPs-SSPs framework. Resources Policy. 2023,86,104091. [CrossRef]
- Lu, M.; Yan, P.; Li, T.C. Research on dust control countermeasures based on Zhangshuanglou Coal Mine Industrial square. Energy Technology and Management. 2023,48,197-198.
- Trechera, P.; Moreno, T. Comprehensive evaluation of potential coal mine dust emissions in an open-pit coal mine in Northwest China. International Journal of Coal Geology. 2021,15,103677. [CrossRef]
- Qiu, J.; Su, Z.T.; Wu, D.H. Study on comprehensive evaluation of coal mine dust health risk. China Mining Magazine. 2021,30,155-162.
- Cao, C.; Wang, B.; Zhang, W. An improved faster R-CNN for small object detection. Ieee Access. 2019, 7: 106838-106846. [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE transactions on pattern analysis and machine intelligence. 2019,43(5): 1483-1498. [CrossRef]
- Richard, B.; Karen, S.;Julio, C. A deep learning system for collotelinite segmentation and coal reflectance determination. International Journal of Coal Geology. 2022,263,104111.
- Li, D.Y.; Wang, G.F.; Guo, Y.C. An identification and positioning method for coal gangue based on lightweight mixed domain attention. International Journal of Coal Preparation and Utilization. 2023,43,1542-1560. [CrossRef]
- Li, M.; He, X.L.; Yuan, X.Y. Multiple factors influence coal and gangue image recognition method and experimental research based on deep learning. International Journal of Coal Preparation and Utilization. 2023,43,1411-1427. [CrossRef]
- Ahmad T, Ma Y, Yahya M, et al. Object detection through modified YOLO neural network[J]. Scientific Programming. 2020, 2020: 1-10.
- Wang, G.; Chen, Y. F.; An, P. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors.2023,23(16),7190. [CrossRef]
- Yang, G.L.; Wang, J.X.; Nie, Z.L. A Lightweight YOLOv8 Tomato Detection Algorithm Combining Feature Enhancement and Attention. Agronomy. 2023,13(7),1824. [CrossRef]
- Luo, B.X.; Kou, Z.M.; Han, C. A “Hardware-Friendly” Foreign Object Identification Method for Belt Conveyors Based on Improved YOLOv8. Applied sciences. 2023,13(20),11464. [CrossRef]
- Xue, Q.L.; Lin, H.F.; Wang, F. FCDM: An Improved Forest Fire Classification and Detection Model Based on YOLOv5. Forests. 2022,13(21),2129. [CrossRef]
- YOLOv8-TensorRT. Available online: https://github.com/triple-Mu/YOLOv8-TensorRT.
- Gou, X.T.; Tao, M.J.; Li, X. Real-time human pose estimation network based on wide receiving domain. Computer Engineering and Design. 2023,44(01),247-254.
- Ma, N.N.; Zhang, X.Y.; Sun, J. Funnel Activation for Visual Recognition. Computer Vision-ECCV 2020. 2020,12356,351-368.
- Guo, X.; Zhou, L.; Liu, X. Fluorescence detection platform of metal-organic frameworks for biomarkers. Colloids and Surfaces B: Biointerfaces. 2023,229,113455. [CrossRef]
- He, H.; Sun, D.W.; Wu, Z. On-off-on fluorescent nanosensing: Materials, detection strategies and recent food applications. Trends in Food Science & Technology. 2022,119:243-256. [CrossRef]
- Sargazi, S.; Fatima, I.; Kiani, M.H. Fluorescent-based nanosensors for selective detection of a wide range of biological macromolecules: A comprehensive review. International Journal of Biological Macromolecules. 2022,206:115-147. [CrossRef]
- Xiong, H.; Qian, N.; Miao, Y. Super-resolution vibrational microscopy by stimulated Raman excited fluorescence. Light: Science & Applications. 2021,10(1):87. [CrossRef]
- Zhang, M.; Zhang, Y.; Zhou, M. Application of Lightweight Convolutional Neural Network for Damage Detection of Conveyor Belt. Appl. Sci. 2021,11,7282. [CrossRef]
- Huang, K.F.; Li, S.Y.; Cai, F. Detection of Large Foreign Objects on Coal Mine Belt Conveyor Based on Improved. Processes. 2023,11,2469. [CrossRef]
- Fu, H.; Song, G.; Wang, Y. Improved YOLOv4 marine target detection combined with CBAM. Symmetry. 2021,13:623. [CrossRef]
- Varshney, M.; Singh, P. Optimizing nonlinear activation function for convolutional neural networks. Signal, Image and Video Processing. 2021, 15(6): 1323-1330. [CrossRef]
- Xiang, X.; Kong, X.; Qiu, Y. Self-supervised monocular trained depth estimation using triplet attention and funnel activation. Neural Processing Letters. 2021,53(6):4489-4506. [CrossRef]
- Li, J.; Huang, Z.; Wang, Y. Sea and Land Segmentation of Optical Remote Sensing Images Based on U-Net Optimization. Remote Sensing. 2022,14(17):4163. [CrossRef]
- Xu, Q.; Xiao, F.; Xu, H. Fluorescent detection of emerging virus based on nanoparticles: From synthesis to application. TrAC Trends in Analytical Chemistry. 2023,161,116999. [CrossRef]
Figure 1.
Monitoring system structure diagram.
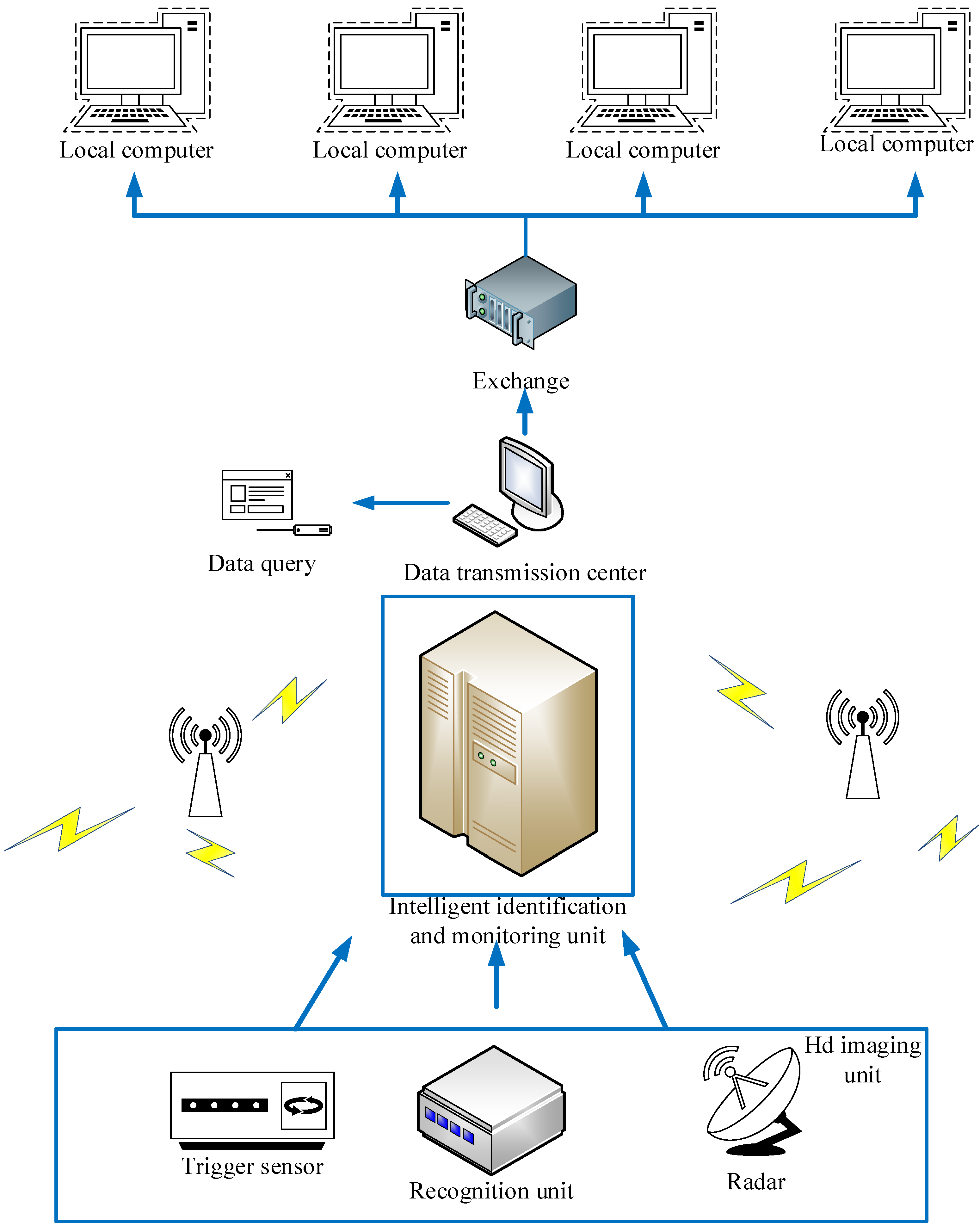
Figure 2.
YOLO v8 network structure diagram.
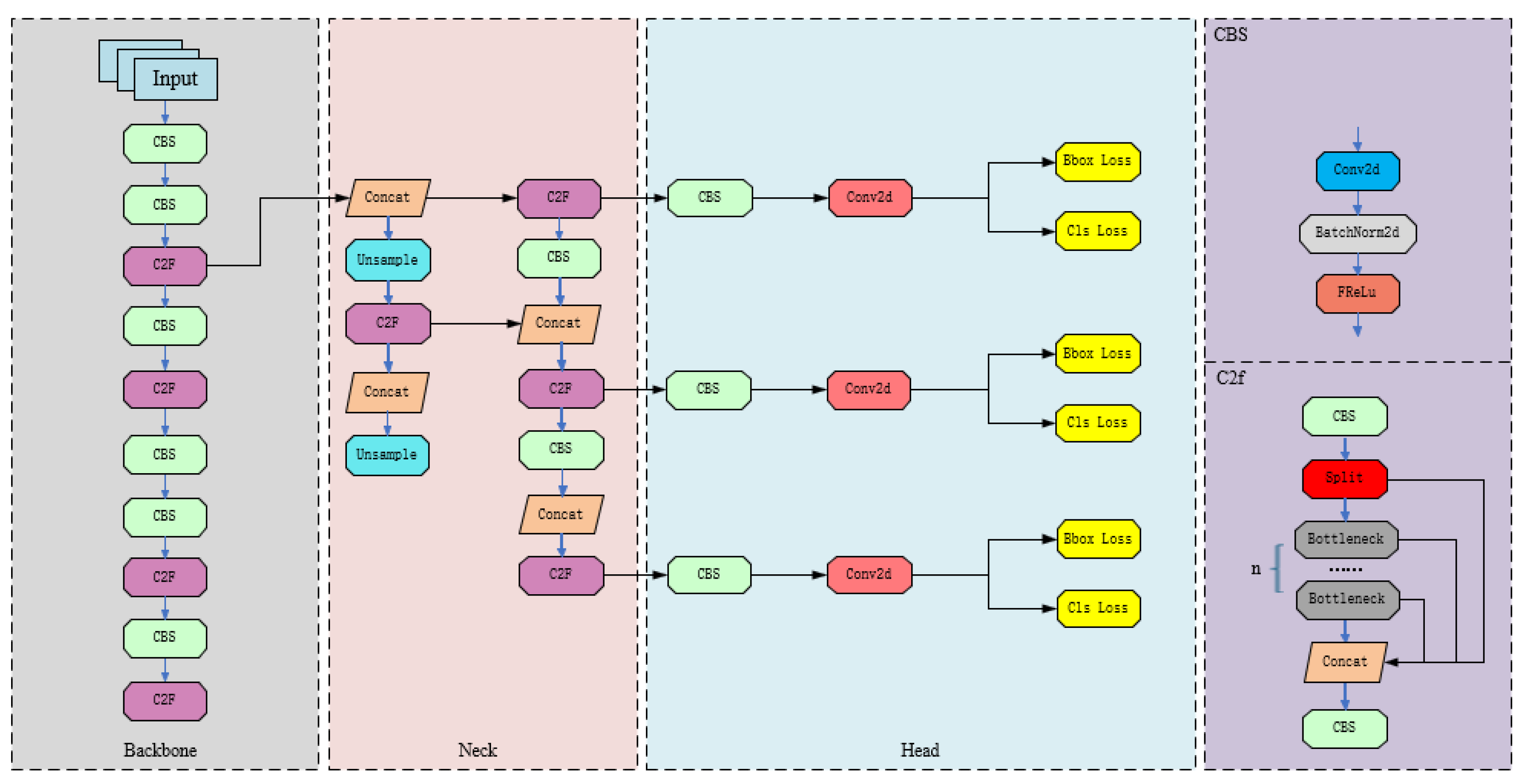
Figure 3.
CBAM Network Structure.
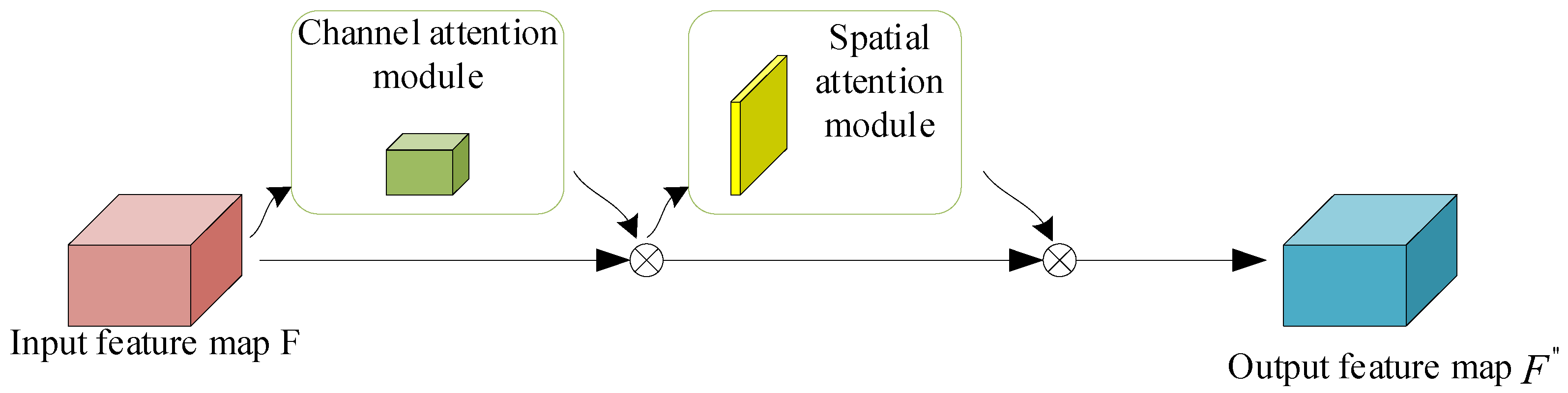
Figure 4.
Structure diagram of CBAM submodule.

Figure 5.
CBAM backbone network structure diagram.

Figure 6.
Characteristics of FReLu activation function.
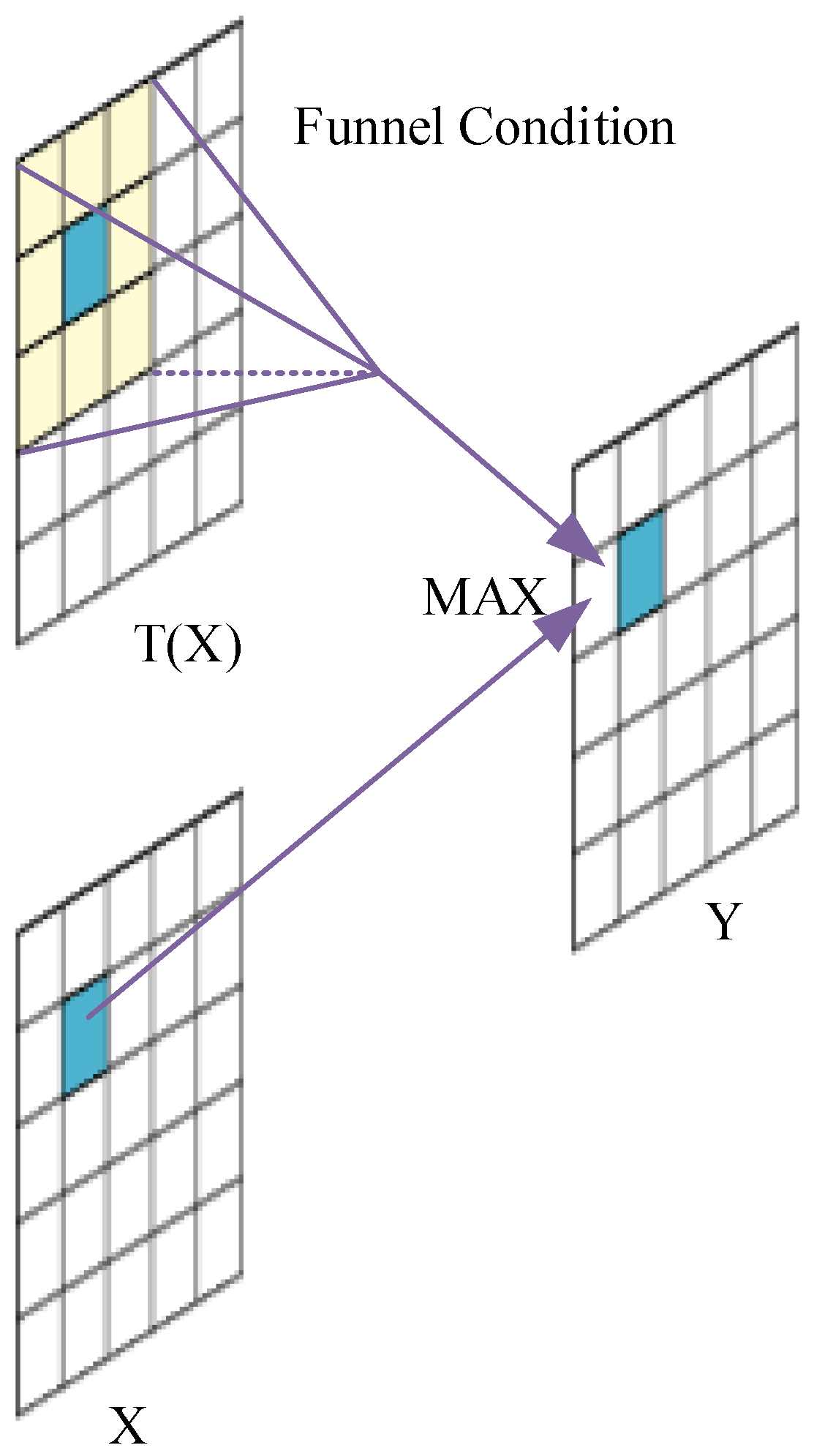
Figure 7.
Schematic diagram of CQDs-MIPs fluorescence detection technology.
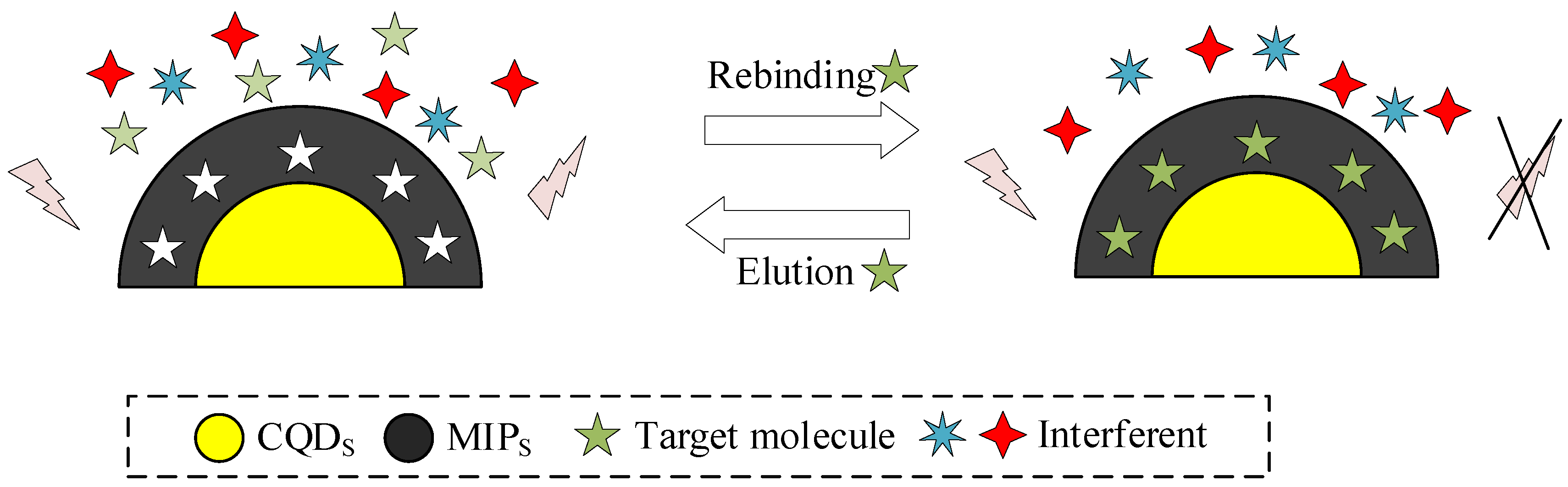
Figure 8.
Monitoring Image Dataset.

Figure 9.
Comparison of loss convergence curves.
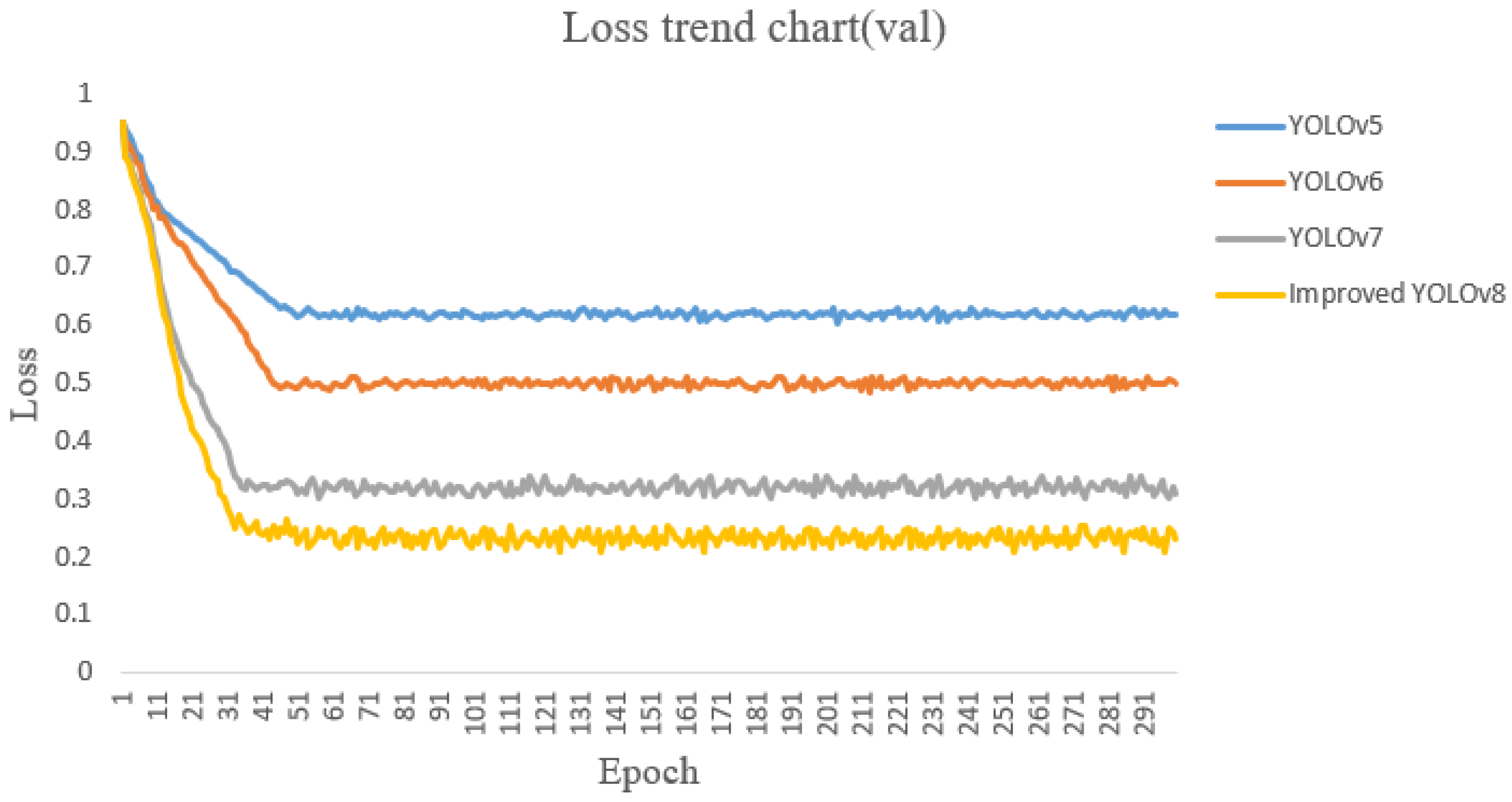
Figure 10.
Results of ablation experiment.
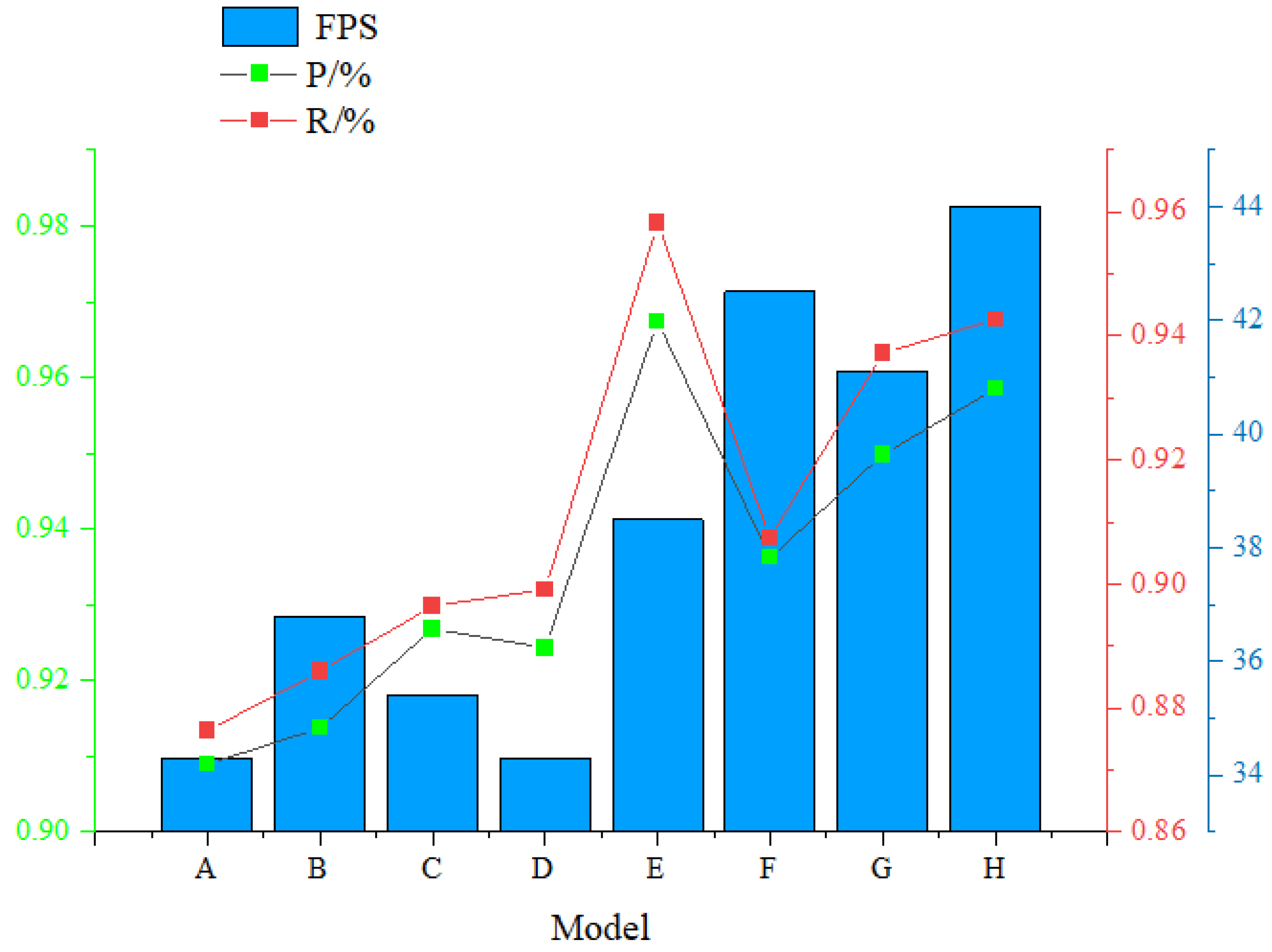

Table 1.
Experimental Environment.
| Configuration name | Version parameter |
| Operating system | Windows 11 |
| CPU | AMD Ryzen 5 5600H |
| GPU | NVIDIA GeForce RTX 3050 |
| Store | 8GB |
| Algorithm framework | PyTorch 1.11.0 |
Table 2.
Comparison of Model Indicators.
| Model | P/% | R/% | mAP@0.5/% | Weight/MB | FPS |
| YOLO_v8 | 91.89 | 87.63 | 84.6 | 7.2 | 34.3 |
| YOLOv8_C | 92.46 | 89.52 | 88.7 | 7.4 | 19.8 |
| YOLOv8_F | 94.38 | 92.87 | 86.9 | 7.6 | 23.5 |
| YOLOv8_M | 97.12 | 95.38 | 90.8 | 7.2 | 32.6 |
Table 3.
Comparison of Objective Indicators in Ablation Experiments.
| Model | YOLO v8 | FReLu | CBAM | CQDS-MIPS | P/% | R/% | FPS |
| A | √ | 90.89 | 87.63 | 34.3 | |||
| B | √ | √ | 91.37 | 88.59 | 36.8 | ||
| C | √ | √ | 92.68 | 89.64 | 35.4 | ||
| D | √ | √ | 92.43 | 89.91 | 34.3 | ||
| E | √ | √ | √ | 96.74 | 95.82 | 38.5 | |
| F | √ | √ | √ | 93.62 | 90.75 | 42.5 | |
| G | √ | √ | √ | 94.98 | 93.72 | 41.1 | |
| H | √ | √ | √ | √ | 95.85 | 94.27 | 44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



