
Submitted:
19 November 2023
Posted:
22 November 2023
You are already at the latest version
Abstract
It is a critical issue to allocate redundancy to critical smart grid infrastructure for disaster recovery planning. In this study, we present a framework to combine statistical prediction methods and optimization models for the optimal redundancy allocation problem. First, we develop statistical simulation methods to identify critical nodes of very large-scale smart grid infrastructure based on the topological features of embedding networks, and then present a linear integer programming model based on generalized assignment problem (GAP) for redundancy allocation of critical nodes in smart grid infrastructure. The model is specifically implemented in the context of smart grid infrastructure. The findings demonstrate that the combined approach of statistical simulation and optimization effectively addresses the size limitations inherent in a sole optimization approach. Notably, the optimal solutions for redundancy allocation in very large grid systems highlight that the cost of redundancy is only a fraction of the economic losses incurred due to weather-related outages.
Keywords:
Redundancy allocation
; generalizes assignment problem
; simulation
; smart grid infrastructure
1. Introduction
The advent of the Smart Grid, akin to previous technology revolutions in telecom and the Internet, marks a crucial milestone in modernizing our electric grid. With its implementation, we harness technology to enhance the efficiency, reliability, and affordability of electricity distribution. This transformation shifts our electric system from a centralized, producer-controlled network to a more interactive, consumer-centric model.
Addressing the grid's declining reliability, marked by a surge in outages, the Smart Grid becomes imperative. Currently, these interruptions cost Americans an estimated $150 billion annually. Furthermore, with a projected 30% increase in nationwide electricity demand by 2030, investments of around $1.5 trillion over the next two decades are essential for infrastructure development [1]. By fostering this transition to a smarter grid – a process already underway – and eventually adopting the Smart Grid, electricity will become more affordable, and our environment will benefit from reduced impact. During this transformative period, ensuring fairness, cost-effectiveness, and adequate customer protection will be paramount. The Smart Grid represents a significant leap forward, utilizing data in megabytes to move megawatts of electricity efficiently and reliably into the 21st century [2]. A key feature of the Smart Grid is its ability to conduct continuous self-assessments, allowing it to prevent disruptions proactively rather than merely reacting to them.
Ever-increasing demand coupled with increasing energy prices have prompted the energy industry to develop intelligent strategies for energy tracking, control, and conservation [3]. Electricity disruptions like blackouts can trigger cascading failures affecting banking, communications, and security, particularly in winter when heating is crucial. A Smart Grid enhances power system resilience, ensuring preparedness for storms, earthquakes, and emergencies. Its bidirectional communication reroutes power automatically during outages, minimizing their impact. Smart Grid technology swiftly detects and isolates outages, prioritizing essential services for swift recovery. By integrating customer-owned generators, vital facilities remain operational during crises. Moreover, it addresses aging infrastructure, boosts energy efficiency, raises consumer awareness, and enhances national security, utilizing locally sourced, resilient electricity. On the other hand, interoperability among various grid components, data handling and management across wide geographies with different environmental conditions pose challenges for the traditional smart grids [4].
As systems become increasingly complex and critical to enterprise, the need for optimal redundancy becomes more important to business continuity. Systems failures can stem from a wide variety of causes (refer to the survey article [5]) ranging from the large-scale natural or human-caused disasters that can disrupt an entire region due to a simple electronic part failing. In a recent article, Wang et al. [6] noted that “diversification is one of the most effective approaches to safeguard multitier systems against attacks, failure, and accidents. However, designing such a diversified system poses challenges due to factors such as stochastic user and attacker behaviors, combinatorial-explosive solution space, and multiple conflicting design objectives.” The authors further noted, “diversification is the application of different means for performing a required function. It is currently the best defense against attacks on the flaws of any particular software component.” Smart Grid redundancy is a diversification technique that aims to prevent information technology in the occurrence of a disaster. Smart Grid heavily depends on the IT infrastructure for operations such as cloud computing and edge computing.
In additional to the tens of millions of computers and servers heavily depend on the reliability of IT infrastructure using cloud computing paradigm, the development in the 5G cellular network, Internet of Things (IoT) applications of smart home, smart city, smart transportation of auto-driving has made edge computing an indispensable infrastructure to connect cloud and end users. The emergence of the IoT coupled with the advances in energy management sphere has resulted in the concept of the smart grid as the Internet of Energy (IoE). Krishnan and Jacob [7] propose a hybrid technique in developing an Energy Management System (EMS) for distribution system with IoT framework. As a popular technology, IoE integrates various forms of energy and leverages the internet to collect, organize, optimize, and manage energy networks. Mishra and Singh [8] study energy management techniques in smart cities using IoE in an effort to reveal improvements in clean energy processes.
Edge computing utilizes the resource of cloud servers to direct the data and computing services to a real-time low-latency system at the edge of a network. For example, 5G network in the edge computing infrastructure provides high-bandwidth access to end users on location services, augmented reality, video analytics and data caching [9]. Unlike the data centers of cloud computing, the servers in edge computing of IOT systems must be located close to the end users in order to provide a real-time high bandwidth and low-latency services. Thus, redundancy allocation in edge-to-cloud computing focuses on the network structure of the end user community such as critical nodes and links of social connectivity [10]. The network structure of the user community can be revealed via community detection methods [11]. ML models are popular methods of community detection in edge computing [12,13]. The IoT systems follow the power law distribution [14,15,16,17]. Patsidis et al. [18] employ an architecture which includes edge-cloud communication to extract data-driven insights from microgrids.
In an article addressing the economics modellings of information security, Gordon, and Loeb [19] underscored that an information set is characterized by the loss conditioned on a breach occurring, the probability of a threat occurring, and the vulnerability, defined in the model as the probability of a threat once realized. Interruptions in the services of large-scale service-oriented companies can potentially result in losses amounting to hundreds of millions of dollars per day in revenue. Consequently, these companies must implement specific disaster recovery or disaster avoidance strategies [20].
Cost is always a concern and is part of the redundancy model. Organizations face the challenge of determining the financial allocation for disaster recovery and, within that, the proportion to be allocated to Smart Grid redundancy. Due to the costly nature of redundancy allocation resources companies must select the best options they have to protect their assets [21,22]. It is economically efficiency to protect the critical nodes and links with redundancy resource. Multiple mathematical models have been proposed to identify the critical nodes and links in the Smart Grid (see Table 1).
The mathematical models above encounter challenges when it comes to identifying critical nodes and links in larger-scale problems. Recently, statistical models have been applied to identify the critical nodes and links in very large networks such as social networks and biology networks [27]. These models encompass both model-based and distribution-based methods. They utilize the topological features of the embedding networks for model training and validating the outcomes of critical nodes and links (See Table 2).
Once the critical nodes are identified, redundancy resources are allocated based on the importance of components (nodes) in smart grid infrastructure. The redundancy allocation problem (RAP) is typically formulated with two alternative objectives: maximizing the reliability within the budget constraints or minimizing the system costs to satisfy the minimum system reliability. Kulturel-Konak et al. [30] proposed two integer programming (IP) models to address these alternative RAP objectives and pointed out that these IP models can be converted into 0-1 IP with additional binary decision variables. Shao [31] introduced a 0-1 integer programming solution formulation for RAP. However, this model is highly non-linear and complex. The author provided a specialized dynamic programming procedure for obtaining optimal solutions.
This paper presents a novel linear integer programming approach to address RAP based on the generalized assignment problem (GAP). Over the past few decades, a variety of theoretical and heuristic findings have emerged for GAP, which can be readily applied to the Smart Grid redundancy allocation problem (see for example, [32,33], for a recent survey). Devi et al. [34] conducted an extensive literature review and classified 280 papers on RAP according to the methods employed. Our model here is more general than GAP with applications extending to various scenarios, including multi-skilled workforce assignment [35], the assignment of unmanned aerial vehicles (UAV) [36], and optimal preventive maintenance scheduling in manufacturing environment for related applications and heuristics, see the recent paper by [37] and its references). Two early development of the model regarding multi-skilled workforce applications with some heuristics also may be found in [38,39]. The rest of the paper is organized as follows. In section 2 we first present a framework of combining statistical simulation and optimization model to identify the critical nodes in the edge computing infrastructure using a power grid system as an example, then optimize the redundancy resource allocation with a linear integer programming model. In section 3, we report the computational results in critical nodes. Section 4 summarizes conclusions drawn from this study.
2. Materials and Methods
2.1. Statistical simulation and optimization framework
Statistical simulation for critical nodes is based on the random matrix theory that uses the probability distribution of eigenvalues such as the Tracy Widom (TW) distribution [29].
The critical nodes detection problem can be formulated as a special case of clustering, where critical nodes are assigned to a particular cluster, while the remaining nodes form some disconnected clusters. The number of singleton clusters increases as the number critical nodes increases.
The largest eigenvalues of the adjacency matrix associated with the critical nodes cluster has the TW distribution. Instead of using parametric bootstrap to estimate the TW distribution, it is computationally efficient to run a few simulations to compute the mean and the variance of the distribution. Figure 1 illustrates the statistical simulation-optimization framework used in this study.
To compute the eigenvalues of the graph network, we use spectral clustering method. Initially, the Laplacian matrix is computed, followed by generating eigenvectors. The eigenvectors form an n by n matrix, where each row represents a node, and each column stores an eigenvalue. These eigenvalues are sorted incrementally with those close to zero being removed.
Once the eigenvalues are sorted, the largest k eigenvectors are chosen and stored in a new n by k matrix, which is subsequently normalized. We can assess the TW distribution on the new matrix of eigenvalues. If the matrix of eigenvalues follows the TW distribution, the clustering method described below is applied to the normalized matrix of eigenvalues to obtain the labels and scores of each bank.
The simulation yields a normalized matrix of eigenvalues that can be used to compute the value of signed weight on each edge in the cluster, the critical nodes of that cluster can be computed with the following Integer Programming (IP) optimization model.
s.t.
Denoted by equal to 1 if node i in cluster k and c_max as the maximum number of clusters formed. After the clusters are formed, then the critical nodes are identified using a connected node pairs (CNP) reduction model to minimize the total connectivity of the computer network.
denoted by , = 1, . . ., L, and the number of nodes in each cluster. Once the critical nodes are identified, resources can be allocated to improve the resilience of the network.
2.2. Optimization model for redundancy allocation
Before we present a general linear IP model for GRAP, the notations for optimization model is given as follows:
Parameters and Variables:
D: number of potential disasters +1 (the last one for no disaster occurring),
probability of disaster d occurring, and M: number of components in Smart Grid needs to perform,
: importance weight of components (nodes) in Smart Grid m, and number of solutions (assets) available for component (node) m to select from,
1 if solution is selected for component (node) m, or 0 otherwise,
cost of selecting solution i for component (node) m,
survivability of solution i for component (node) m against disaster d,
failure probability of solution i for component (node) m against disaster d (i.e., ).
a real-valued function defined on vector , for and a utility function defined on vector for and when is the total contribution of applying all or some of available solutions .
Here, we give a general redundancy allocation problem (GRAP). As we mentioned earlier the GRAP has various of applications in different settings, (see [32,33] for explanations, examples, and several heuristic algorithms).
(GRAP)
s.t.
The objective function in this case aims to maximize the overall survivability of all components (nodes) against all potential disasters. Also, note that component (node) m fails against disaster d only when all of its selected solutions fail at the same time. For a component (node) m and a disaster d, we define as the total contribution of applying all or some of available solutions . The utility of such solution application is equal to . It is worth mentioning that GRAP is written in a generic format. When estimating the functions and parameters, one possibility is to use of game theory, see for example [40,41] for a survey.
Moreover, it is important to note that GRAP is a non-linear integer program. However, if and where is a constant weight, then the objective function is separable and linear which is a special case of the generalized assignment problem (GAP) [37]. Although GAP is known to be strongly NP-hard, it is easier to solve compared to a non-linear optimization with a non-separable objective function like the GRAP. A variety of exact and heuristic algorithms are available for GAP (see for example, [28,29], for a recent survey). A variety of exact and heuristic algorithms are available for GAP (see for example, [32,33], for a recent survey).
In the following section, we will demonstrate how the GRAP can be transformed into an optimization with separable objective function, and linear constraints, converting it into a GAP. By taking logarithm from both sides of equality (8), we will have the following.
and
Let and Since then we have and thus, we have
Note that, we have . With this in mind, the GRAP transforms into the following, where the objective function is separable and nonlinear. Please note that the last term in the objective function is constant thus can be ignored.
(GRAP)
s.t.
(5-7, 12)
Since for d=1,…,D, is an array of constants in the objective function and is not part of any constraint, thus in order to maximize S*, for a given d we need to optimize
Now, since for m=1,…,M, is also an array of constants and the decision variable is , for each m we need to be as small as possible under the constraints and thus must be as large as possible. This proves that the RAP is equivalent to the following linear integer program.
s.t. (5-7) and (9-10)
Since , thus we can restate the RAP as the following generalized assignment problem.
s.t.
Constraints (19) are capacitated with the budget limit. Following our recently published method (the r-flip paper [43] and recent papers [35,44]), we implemented a r-flip local search heuristic to improve the assignment. In this r-flip heuristic, we choose r = 2,3, and 4 for the assignment of both components (nodes) and assets that components (nodes) s chose from to improve the survivability. The improvement process based on the r-flip heuristic is implemented by the Tabu Search algorithm with an embedded strategic oscillation, as detailed in .
3. Results
The statistical simulation and optimization experiments are coded in R. We chose a power grid dataset to illustrate the proposed framework (Figure 2). The dataset has 4941 nodes, 6594 edges, with a maximum distance of 45 between the pair of nodes in the graph. The minimal distance for 90% of nodes pairs is 26.
The distribution of degree nodes in power grid follows the power law distribution with p value=0.76, which is greater than 0.05, so the data follows the power law distribution [42]. Figure 3 shows the degree distribution of nodes in the power grid.
The eigenvector of nodes is obtained by using Spectrum function and the smallest eigenvalues are removed from the matrix. Following the TW distribution test, the critical nodes are identified by the optimization model (1)-(4). Figure 4 highlights the results of spectral clustering of critical nodes with large vector size. Figure 5 shows the network structure after the critical nodes are removed from the graph. The cost of redundancy allocation is computed based on the critical nodes by a heuristic algorithm. Table 3 displays the network nodes’ connectivity after the critical nodes are removed and the average nodes’ connectivity are measured by the complement of fragmentation score.
To evaluate the impact of resource allocation costs on the redundancy of critical nodes using benchmark datasets, we first identify critical nodes based on a reliability threshold ranging from 98% to 99% for the power grid system. In this study, we specifically examine power transformers as the primary components. The cost of a power transformer ranges from $600,000 to $4,000,000, with a 15-year life cycle. We randomly assign a cost between $600,000 and $4,000,000 for the critical nodes. Table 4 presents the costs associated with redundancy on critical nodes to maintain 98.79%-99.74% reliability (connectivity). A Congressional Research Service study in 2012 estimated the inflation-adjusted cost of weather-related outages at $25 to $70 billion annually (https://www.energy.gov/articles/economic-benefits-increasing-electric-grid-resilience-weather-outages). Notably, the cost of redundancy is only a fraction of the economic losses incurred due to weather-related outages.
4. Discussion
The Smart Grid incorporates proven technologies to optimize its assets – from power plants to distribution substations and critical infrastructure. These advancements lead to increased power flow through existing assets and provide utilities with precise insights, enabling them to assess the necessity for additional power plants accurately. Operational enhancements span improved load factors to reduce system losses, resulting in a net reduction in utility costs and enhanced overall efficiency.
The results of this study highlight the key strategies to improve the reliability of the Smart Grid:
- Redundancy Planning: Identify critical components in the Smart Grid infrastructure. Allocate redundancy by duplicating these components, ensuring backup systems are in place to seamlessly take over in case of failures.
- Risk Assessment: Conduct a thorough risk analysis to understand potential failure points. Allocate redundancies to the most vulnerable areas identified during this assessment.
- Advanced Monitoring: Implement real-time monitoring systems to detect anomalies and potential failures. Use data analytics to predict failure patterns and allocate redundancies accordingly.
5. Conclusions
In this paper, we presented a framework that combines statistical learning and optimization to identify critical nodes in the smart grid infrastructure. To optimize the resource allocation for critical nodes, we proposed a general redundancy allocation model based on generalized assignment problem (GAP). It includes the generalized redundancy allocation problem (GRAP) as a special case. We gave an equivalent linear GAP of GRAP.
Power outages pose an extensive list of risks, including but not limited to economy, health, and public safety. Only weather-related outages are estimated to cost between $25-70 billion to the US economy annually [45]. Thus, it is vital to develop risk assessment and quick-response plans. Combination of statistical simulation and integer programming-based optimization approach proposed in this study promises an efficient framework for managers and decision-makers in determining the critical components of smart grids and optimizing redundancy allocation for a well-planned, organized, and coordinated course of action to be followed in disaster recovery.
Another implication of this study for managers is the improved capability in assessing risks and vulnerabilities of the smart grid for redundancy allocation while using limited resources in the most efficient way. Performance of smart grids are closely related to the reliability and uncertainties involved. Thus, risk assessment to systematically detect the vulnerabilities with the potential to result in grid failures is an essential component for the future of smart grids.
Author Contributions
Conceptualization, H.W and B.A.; methodology, H.W. and B.A.; software, J.H.; data curation, H.W. and J.H.; writing—original draft preparation, H.W. L.S., and J.H.; writing—review and editing, L.S.; supervision, B.A.; funding acquisition, B.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
Declare conflicts of interest or state “The authors declare no conflict of interest.” Authors must identify and declare any personal circumstances or interest that may be perceived as inappropriately influencing the representation or interpretation of reported research results. Any role of the funders in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results must be declared in this section. If there is no role, please state “The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- https://www.energy.gov/ne/articles/department-energy-report-explores-us-advanced-small-modular-reactors-boost-grid.
- https://www.smartgrid.gov/the_smart_grid/smart_grid.html.
- Saleem, M.U.; Shakir, M.; Usman, M.R.; Bajwa, M.H.T.; Shabbir, N.; Shams Ghahfarokhi, P.; Daniel, K. Integrating Smart Energy Management System with Internet of Things and Cloud Computing for Efficient Demand Side Management in Smart Grids. Energies 2023, 16, 4835. [Google Scholar] [CrossRef]
- Hannan, M.A., Ker, P. J., Mansor, M., Lipu, MS H., Al-Shetwi, A. Q., Alghamdi, S. M., Begum, R.A., Tiong, S.K. Recent advancement of energy internet for emerging energy management technologies: Key features, potential applications, methods and open issues, Energy Reports, 10, 2023, pp. 3970-3992. [CrossRef]
- Galindo, G., and Batta, R. Review of recent developments in OR/MS research in disaster operations management, European Journal of Operational Research, 2013, 230, pp. 201-211. [CrossRef]
- Wang, J., Sharman, R., and Zionts, S. Functionality defense through diversity a design framework to multitier systems, Annals of Operations Research, 2012, 197, (1), pp. 25-45. [CrossRef]
- Priya R. K. and Josephkutty J. An IOT based efficient energy management in smart grid using DHOCSA technique, Sustainable Cities and Society, 79, 2022, 103727.
- Mishra, P., and Singh, G. Energy Management Systems in Sustainable Smart Cities Based on the Internet of Energy: A Technical Review. Energies, 2023, 16(19), 6903. [CrossRef]
- Khan, W.Z., Ahmed, E., Hakak, S., Yaqoob, I., and Ahmed, A. Edge computing A survey, Future Generation Computer Systems, 2019, 97, pp. 219-235.
- Mavromoustakis, C.X., Batalla, J.M., Mastorakis, G., Markakis, E., and Pallis, E. Socially Oriented Edge Computing for Energy Awareness in IoT Architectures, IEEE Communications Magazine, 2018, 56, (7), pp. 139-145. [CrossRef]
- Perveen, A., Abozariba, R., Patwary, M., Aneiba, A., and Jindal, A. Clustering-based Redundancy Minimization for Edge Computing in Future Core Networks, in Editor (Ed.)^(Eds.) Book Clustering-based Redundancy Minimization for Edge Computing in Future Core Networks (2021, edn.), pp. 453-458.
- Shakarami, A., Ghobaei-Arani, M., and Shahidinejad, A. A survey on the computation offloading approaches in mobile edge computing A machine learning-based perspective, Computer Networks, 2020, 182, pp. 107496. [CrossRef]
- Huang, Y., Ma, X., Fan, X., Liu, J., and Gong, W. When deep learning meets edge computing, in Editor (Ed.)^(Eds.) Book When deep learning meets edge computing (2017, edn.), pp. 1-2.
- Sohn, I. Small-World and Scale-Free Network Models for IoT Systems, Mobile Information Systems, 2017, 2017, pp. 6752048. [CrossRef]
- Faloutsos, M., Faloutsos, P., and Faloutsos, C. On power-law relationships of the Internet topology. Proc. Proceedings of the conference on Applications, technologies, architectures, and protocols for computer communication, Cambridge, Massachusetts, USA1999 pp. Pages.
- Bebortta, S., Senapati, D., Rajput, N.K., Singh, A.K., Rathi, V.K., Pandey, H.M., Jaiswal, A.K., Qian, J., and Tiwari, P. Evidence of power-law behavior in cognitive IoT applications, Neural Computing and Applications, 2020, 32, (20), pp. 16043-16055. [CrossRef]
- Zhang, D.-g., Zhu, Y.-n., Zhao, C.-p., and Dai, W.-b. A new constructing approach for a weighted topology of wireless sensor networks based on local-world theory for the Internet of Things (IOT), Computers & Mathematics with Applications, 2012, 64, (5), pp. 1044-1055. [CrossRef]
- Patsidis, A., Dyśko, A., Booth, C., Rousis, A. O., Kalliga, P., & Tzelepis, D. Digital Architecture for Monitoring and Operational Analytics of Multi-Vector Microgrids Utilizing Cloud Computing, Advanced Virtualization Techniques, and Data Analytics Methods. Energies, 16(16), 5908. [CrossRef]
- Gordon, L.A., and Loeb, M.P. The Economics of Information Security Investment, ACM Transactions on Information and System Security, 2002, 5, (4), pp. 438–457.
- Hsu, C., Lee, J.-N., and Straub, D.W. Institutional influences on information systems security innovations, Information Systems Research, 2012, 23, (3-part-2), pp. 918-939. [CrossRef]
- Hua, J., and Bapna, S. The economic impact of cyber terrorism, The Journal of Strategic Information Systems, 2013, 22, (2), pp. 175-186.
- Wang, J., Chaudhury, A., and Rao, H.R. Research Note-A Value-at-Risk Approach to Information Security Investment, Information Systems Research, 2008, 19, (1), pp. 106-120. [CrossRef]
- Kumar, S., and Singh, B.K. Entropy based spatial domain image watermarking and its performance analysis, Multimedia Tools and Applications, 2021, 80, (6), pp. 9315-9331. [CrossRef]
- Veremyev, A., Prokopyev, O.A., and Pasiliao, E.L. An integer programming framework for critical elements detection in graphs, Journal of Combinatorial Optimization, 2014, 28, (1), pp. 233-273. [CrossRef]
- Pavlikov, K. Improved formulations for minimum connectivity network interdiction problems, Computers & Operations Research, 2018, 97, pp. 48-57. [CrossRef]
- Ventresca, M. Global search algorithms using a combinatorial unranking-based problem representation for the critical node detection problem, Computers & Operations Research, 2012, 39, (11), pp. 2763-2775. [CrossRef]
- Zhang, M., Wang, X., Jin, L., Song, M., and Li, Z. A new approach for evaluating node importance in complex networks via deep learning methods, Neurocomputing, 2022, 497, pp. 13-27. [CrossRef]
- Jin, X., Chow, T.W.S., Sun, Y., Shan, J., and Lau, B.C.P. Kuiper test and autoregressive model-based approach for wireless sensor network fault diagnosis, Wireless Networks, 2015, 21, (3), pp. 829-839. [CrossRef]
- Tracy, C.A., and Widom, H. On orthogonal and symplectic matrix ensembles, Communications in Mathematical Physics, 1996, 177, (3), pp. 727-754. [CrossRef]
- Kulturel-Konak, S., Smith, A.E., and Coit, D.W. Efficiently Solving the Redundancy Allocation Problem Using Tabu Search, IIE Transactions, 2003, 35, (6), pp. 515-526. [CrossRef]
- Shao, B.B.M. Optimal redundancy allocation for information technology disaster recovery in the network economy, Dependable and Secure Computing, IEEE Transactions on, 2005, 2, (3), pp. 262-267. [CrossRef]
- Cattrysse, D.G., and Wassenhove, L.N.V. A survey of algorithms for the generalized assignment problem, European Journal of Operational Research, 1992, 60, pp. 260-272.
- Öncan, T. A survey of the generalized assignment problem and its applications, INFOR Information Systems and Operational Research, 2007, 45, (3), pp. 123-141.
- Devi, S., Garg, H. & Garg, D. A review of redundancy allocation problem for two decades bibliometrics and future directions. Artif Intell Rev 56, 7457–7548 (2023). [CrossRef]
- Wang, H., Alidaee, B., Ortiz, J., and Wang, W. The multi-skilled multi-period workforce assignment problem, International Journal of Production Research, 2020, in press, pp. 1-18. [CrossRef]
- Wang, H., Huo, D., and Alidaee, B. Position Unmanned Aerial Vehicles in the Mobile Ad Hoc Network, Journal of Intelligent & Robotic Systems, 2014, 74, (1), pp. 455-464. [CrossRef]
- Alidaee, B., Gao, H., and Wang, H. A note on task assignment of several problems, Computers & Industrial Engineering, 2010, 59, (4), pp. 1015-1018. [CrossRef]
- Campbell, G. Cross-Utilization of Workers Whose Capabilities Differ, Management Science, 1999, 45, (5), pp. 722-732. [CrossRef]
- Campbell, G.M., and Diaby, M. Developing and evaluation of an assignment heuristic for allocating cross-trained workers, European Journal of Operational Research, 2002, 138, pp. 9-20. [CrossRef]
- Sadatdiynov, K., Cui, L., Zhang, L., Huang, J.Z., Salloum, S., and Mahmud, M.S. A review of optimization methods for computation offloading in edge computing networks, Digital Communications and Networks, 2022. [CrossRef]
- Lin, H., Zeadally, S., Chen, Z., Labiod, H., and Wang, L. A survey on computation offloading modeling for edge computing, Journal of Network and Computer Applications, 2020, 169, pp. 102781. [CrossRef]
- Clauset, A., Shalizi, C.R., and Newman, M.E.J. Power-Law Distributions in Empirical Data, SIAM Review, 2009, 51, (4), pp. 661-70. [CrossRef]
- Alidaee, B. Kochenberger, and H. Wang, Theorems Supporting r-flip Search for Pseudo-Boolean Optimization. Int. J. Appl. Metaheuristic Comput., 2010. 1(1): p. 93-109. [CrossRef]
- Wang, H., and Alidaee, B.: ‘Unrelated Parallel Machine Selection and Job Scheduling with the Objective of Minimizing Total Workload and Machine Fixed Costs’, IEEE Transactions on Automation Science and Engineering, 2018, 15, (4), pp. 1955-1963. [CrossRef]
- Volodarsky, M. The Smart Grid, A Smart Investment. ESG Initiative News. February 11, 2021.
Figure 1.
Statistical simulation-optimization framework.
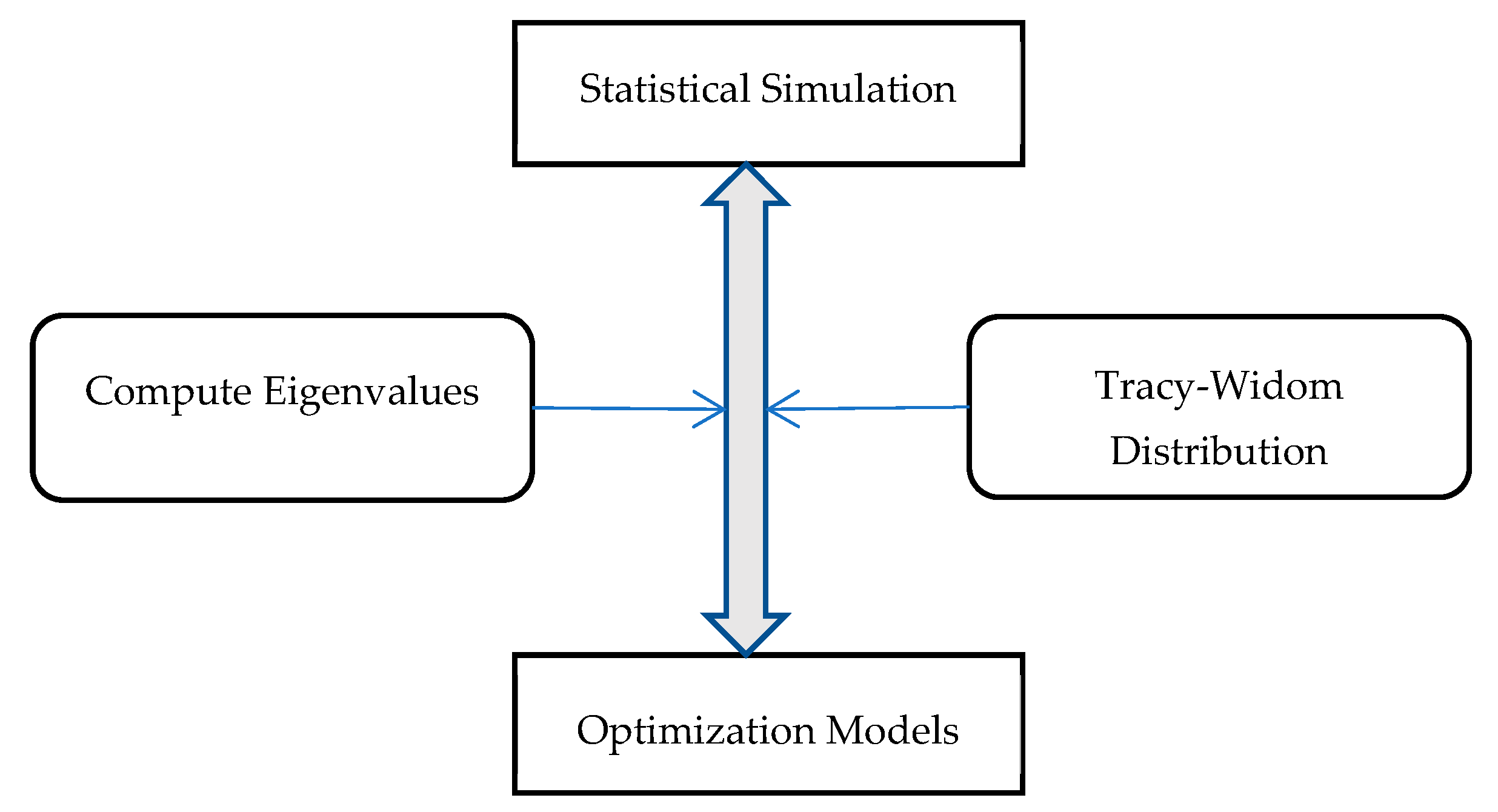
Figure 2.
Node connectivity of power grid.

Figure 3.
Histogram for power grid nodes.
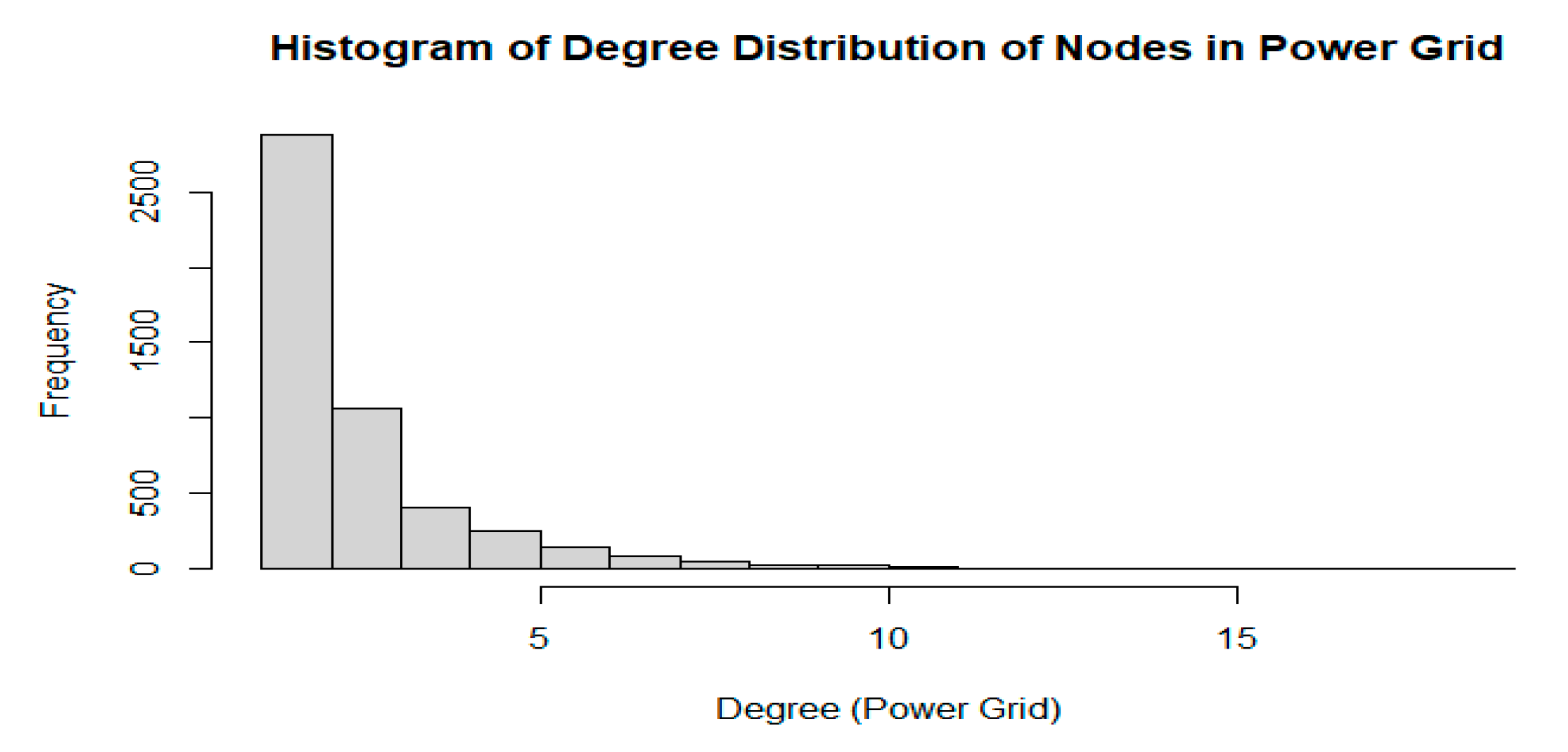
Figure 4.
Results of spectral clustering of critical nodes.
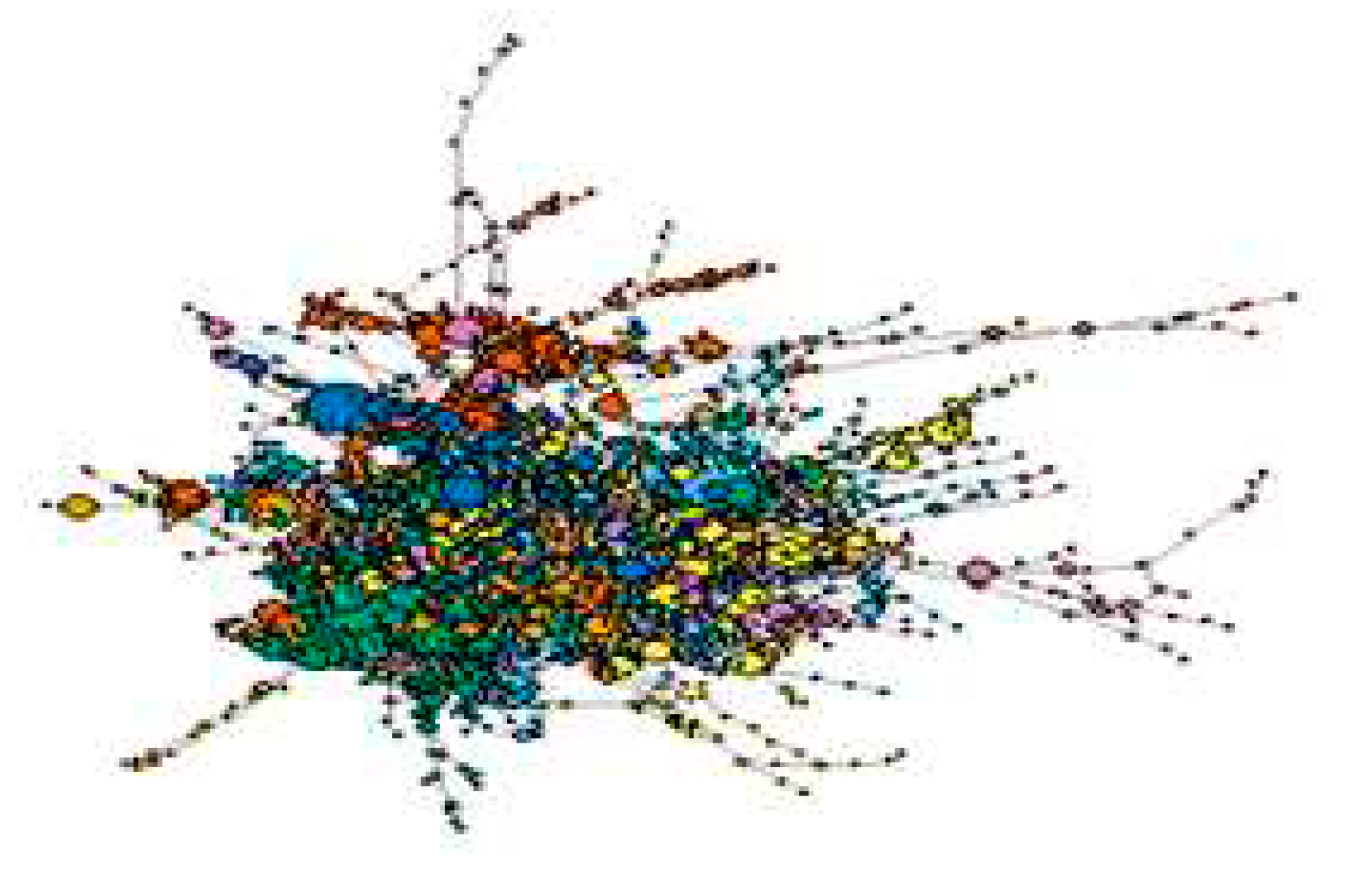
Figure 5.
Results of node connectivity after critical nodes are removed.
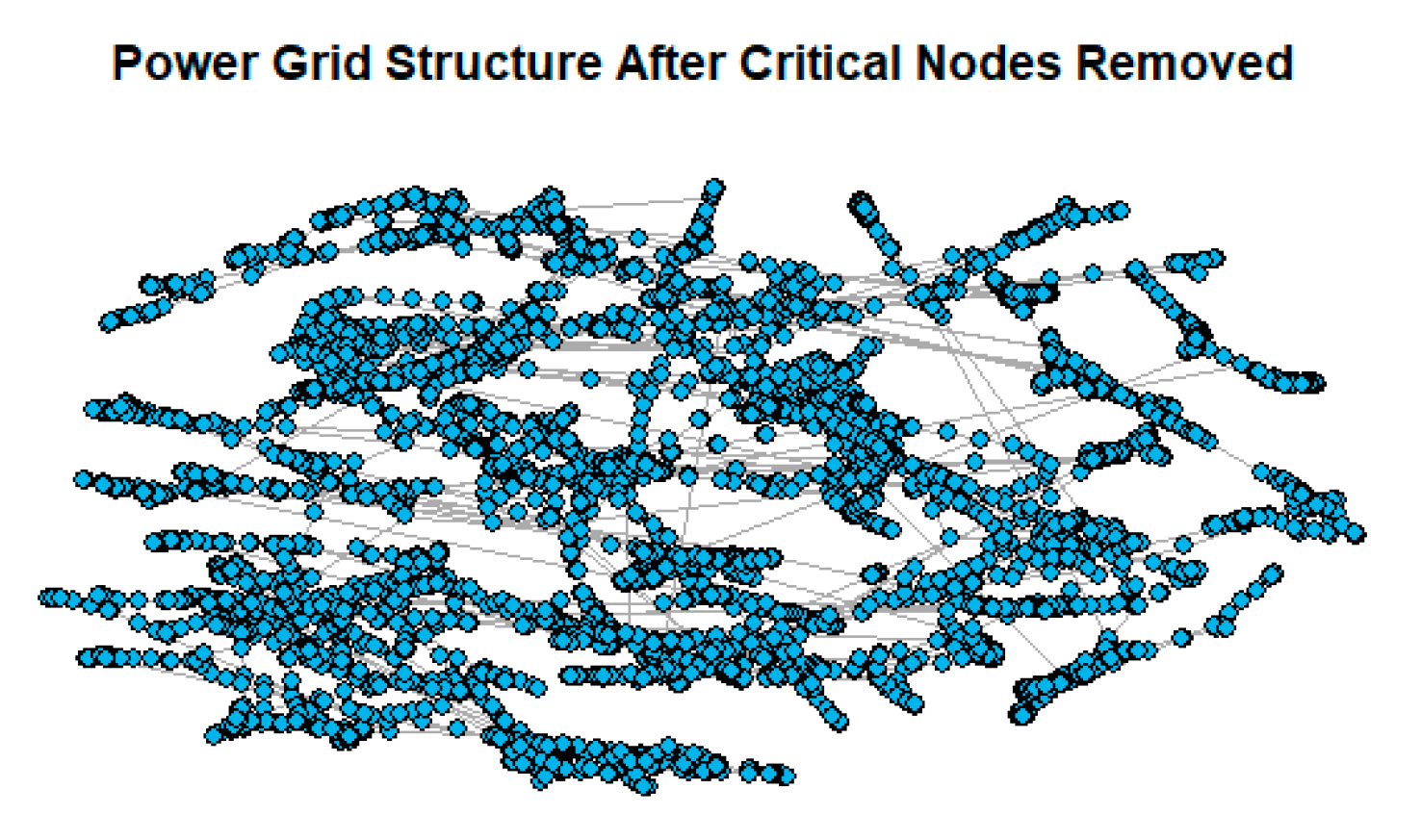

Table 1.
Mathematical Models for Identifying Critical Nodes and Links.
| Class | Methods | Reference |
|---|---|---|
| Entropy-based | Graph neural network | [23] |
| Node Deletion | Mixed integer programming | [24] |
| Network interdiction | Mixed integer linear programming | [25] |
| maximum k-cut problem | Simulated Annealing | [26] |
Table 2.
Mathematical Models for Identifying Critical Nodes and Links.
| Class | Methods | Reference |
|---|---|---|
| Model based | Structure-mechanics | [28] |
| Distribution based | Tracy-widom distribution | [29] |
Table 3.
Statistical Learning of Embedding Networks to Identify Critical Nodes & Links.
| Number of Removed Critical Nodes | Connectivity |
|---|---|
| 5 | 0.0615851 |
| 10 | 0.0605954 |
| 15 | 0.0592443 |
Table 4.
Cost of redundancy on critical components in the power grid system.
| PowerGrid | Size | Critical Nodes | Cost of redundancy | Reliability |
|---|---|---|---|---|
| South Carolina cities | 500 | 13 | $13,744,377 | 99.74% |
| Texas cities | 2,000 | 17 | $19,378,002 | 99.66% |
| Texas state | 6,717 | 31 | $47,454,580 | 99.63% |
| Midwest | 24,000 | 59 | $104,646,071 | 99.61% |
| West-East US | 80,000 | 156 | $312,855,059 | 98.79% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



