Submitted:
09 June 2026
Posted:
11 June 2026
You are already at the latest version
Abstract
Physical AI systems must respond to real-world events under strict constraints of time, energy and safety. This Perspective clarifies the distinct roles of latency, throughput, bandwidth and world models within a Reflex–Policy architecture and argues that increasingly powerful policy and world models do not eliminate the need for well-designed local reflex layers. On the contrary, reflex layers can dramatically reduce upstream data rates, preserve hard real-time safety, and allow policy models to focus on prediction, planning and rare events. A binary spintronic reflex crossbar has been demonstrated in proof-of-concept form for fast shadow bypass in photovoltaic systems and for battery cell balancing, confirming that non-volatile magnetic rule fabrics can perform sub-millisecond, parallel switching decisions in real physical domains. Multilevel spintronic devices align better with weighted inference on the policy side. Quantitative examples from robotics, automotive and energy systems illustrate how this layered approach can reduce communication bandwidth by 1–3 orders of magnitude while maintaining safety and efficiency. A comparison with existing real-time control technologies, safety microcontrollers, FPGAs and neuromorphic processors, clarifies where spintronic reflexes offer distinct advantages in standby power, non-volatility and inspectable rule logic.
Keywords:
Physical AI
; reflex-policy architecture
; latency
; throughput
; bandwidth
; world models
; spintronics
; MTJ
; MRAM
; robotics
; automotive
; energy systems
1. Introduction: Why Physical AI Needs More Than a Powerful Policy
A large share of visible Physical AI research currently concentrates on the policy side: multimodal models, vision-language-action models, world models and increasingly capable planning systems. These developments are essential. They improve perception, semantic reasoning, generalization and the ability to predict the consequences of actions [1,2,3,10,11,12,13,14,15]. However, a physical machine is not only a policy model attached to motors. It is a chain of sensors, communication links, power electronics, actuators, energy stores and safety functions, each operating with different deadlines.
This Perspective is written for application engineers working in robotics, automotive and energy systems who need a technically grounded way to decide which functions belong close to the physical event and which should be assigned to richer policy or world-model computation. The central position is that the architecture of cooperation between reflex and policy is at least as important as the capability of the policy itself. A strong policy placed above a weak or poorly located reflex layer may still produce a system that is slow, data-hungry, difficult to certify and unnecessarily energy intensive.
The reflex-policy distinction is not a new idea: Brooks' subsumption architecture established layered reactive control for mobile robots in 1986 [2], and hierarchical models of behaviour have been studied extensively in both robotics and cognitive science [3]. What this Perspective adds is threefold. First, it provides a unified quantitative framework, latency, throughput and bandwidth, for engineering decisions about where each function belongs. Second, it proposes and quantifies the role of binary spintronic devices as a specific hardware substrate for the reflex layer, supported by proof-of-concept demonstrations in photovoltaic shadow management and battery cell balancing. Third, it introduces the concept of the world model as teacher: a pipeline through which expensive predictive models compress their knowledge into lightweight, non-volatile rule maps that the reflex layer executes locally without requiring the world model to be present at runtime.
The distinction between reflex and policy is therefore not biological decoration. It is an engineering partition. Reflex layers perform the first local action when waiting is unsafe or wasteful. Policy layers interpret context, compare alternatives and update the rules. World models extend the policy side by imagining possible futures and then transferring what they learn to the layer below.
2. Four Concepts in Simple Engineering Terms
Latency, throughput and bandwidth describe different limitations and should not be used as synonyms. A system can have low latency but poor throughput, or high link bandwidth but low useful throughput. World models introduce a fourth concern: the cost and value of prediction. For transparent comparison, the total event latency can be written as:
Ltotal = Lsensor + Lconditioning + Lconversion + Ldecision + Lcommunication + Lactuation
Raw data rate can be estimated as Rₐₐₐ = Nₐₐₐₐₐₐₐₐₐ × bits per sample × sampling rate, whereas an event path can be estimated as Rₐₐₐₐₐ = event rate × bits per event. Table 1 summarises the four concepts with design-envelope figures and their implications.
2.1. Latency: The Deadline for One Response
Latency is the elapsed time between a physical event and the first useful action. In a robot, the event may be a current spike, impact or loss of contact. In an automotive inverter, it may be an overcurrent or abnormal temperature. In a photovoltaic system, it may be a fast local shadow. The complete latency path includes sensing, conditioning, conversion, communication, decision and actuation. A reflex layer shortens this path by staying physically close to the sensor and actuator. It does not need to understand the whole scene; it only needs to recognize a bounded condition and execute the first safe action. A useful design rule is that the reflex deadline should be at least one order of magnitude shorter than the dominant policy cycle whenever the physical plant can become unsafe during policy computation.
2.2. Throughput: How Many Events can be Handled
Throughput is the number of useful events or decisions completed per unit time. A circuit can react quickly to one input and still fail when hundreds of channels change together. This distinction is important in multi-joint robots, battery packs, distributed photovoltaic generators and sensor-rich vehicles. Parallel comparator arrays and crossbars can evaluate many input-output relationships in the same array cycle, whereas a microcontroller may poll or multiplex channels sequentially. For policy and world models, throughput also includes the number of hypothetical trajectories, candidate actions or predicted futures evaluated per second. High rollout throughput is useful for planning, but it is not a substitute for low physical-event latency.
2.3. Bandwidth: How Much Information Must Move
Bandwidth is the maximum data rate supported by a communication path. In Physical AI, the more important design question is often how much of that capacity must actually be used. Streaming high-resolution current, temperature, force, video and lidar data to a central processor consumes ADC energy, memory traffic, bus capacity and communication power [4,5,6,7,8,9]. A reflex layer can convert continuous data into sparse events. Instead of forwarding an entire waveform, it may report only that an overcurrent occurred, which channel was inhibited, how long the event lasted and whether recovery succeeded. The data-reduction factor C = Rₐₐₐ / Rₐₐₐₐₐ ranges from about 48× to 1,500× in the transparent examples of Table 3.
2.4. World Models: Helping the Machine Think Ahead
A world model is an internal representation of how an environment changes and how actions influence future states. Classical latent world models learn dynamics for control [10,11], while newer multimodal systems generate or reason over interactive environments [12,13,14,15]. Recent examples include Dreamer-style agents that learn by imagined rollouts, Genie 3 for interactive generated environments, Gemini Robotics for embodied reasoning and action, and NVIDIA Cosmos for physical-AI data generation [11,12,13,14,15]. These systems naturally belong mainly to policy layers because they require richer data, memory and computation. Section 6 describes how their knowledge can subsequently be transferred downward to the reflex layer.
The world model predicts; the policy selects; the reflex acts when waiting would be unsafe or wasteful.
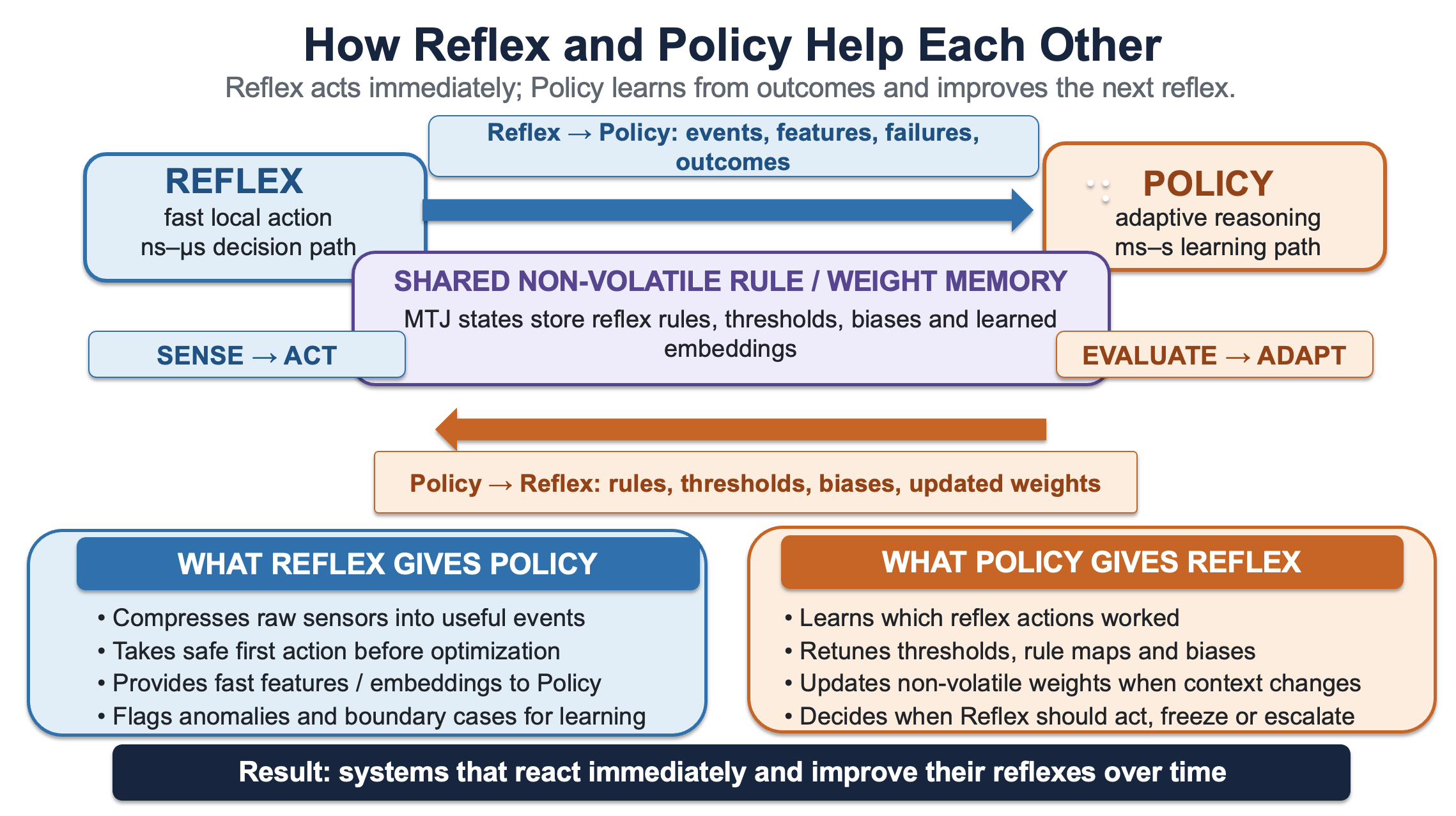
3. Reflex and Policy as Mutually Protective Layers
Reflex and policy should not be understood as competing controllers. They protect each other. The policy protects the reflex by defining thresholds, permissions, safe states, update conditions and forbidden actions. The reflex protects the policy by handling frequent local events, reducing interrupts, preventing unnecessary wake-ups and compressing raw sensor streams into meaningful reports.
This mutual protection can dramatically simplify the effort required from policy layers. Without a reflex partition, a policy processor may be forced to sample every channel, recognize every transient and maintain hard real-time guarantees while also performing perception, planning and learning. With a well-designed reflex layer, the policy can work at a slower and more appropriate timescale, receiving exceptions, summaries and unresolved cases rather than every physical fluctuation. The architecture therefore contains two cooperating loops:
Fast loop: local sensor → reflex rule → immediate actuator, switch or inhibit command.
Slow loop: compressed event → policy/world-model analysis → updated threshold, permission or rule map.
The reflex is not merely a smaller policy. It filters the physical world before the policy sees it. This is why developing the reflex side is as important as improving the policy side. Policy-only progress can make a machine more capable in reasoning while leaving unresolved the practical costs of latency, bandwidth, safety isolation, standby energy and certification.
4. Binary and Multilevel Spintronic Devices Across the Architecture
Spintronic devices use electron spin and magnetic states to store or process information. Magnetic tunnel junctions (MTJs) provide two stable resistance states and form the basic storage element of MRAM. STT-MRAM and embedded MRAM are already commercial or foundry-supported in memory roles [18,19,24,25,26]. The application-specific binary reflex crossbar described here has been demonstrated in proof-of-concept form for two physical-domain applications: fast shadow bypass in photovoltaic systems and battery cell balancing. These demonstrations confirm that non-volatile magnetic rule fabrics can perform parallel, sub-millisecond switching decisions in practical energy-system conditions.
4.1. Binary Devices for Reflex Functions
Binary spintronic devices are naturally suited to decisions with two clear outcomes: allow/block, connect/bypass, wake/sleep, normal/fault, enable/inhibit or safe/unsafe. A binary crossbar stores a permission or rule map non-volatilely: local flags enter along rows, programmed MTJ states select the relevant relationships, and column outputs produce comparator-level decisions. The important point is not that every reflex must use spintronics. A CMOS comparator may be the best solution for a single threshold. The spintronic case becomes stronger when many persistent rules, low standby power, instant-on operation, parallel evaluation or harsh-environment tolerance matter. Binary MTJ arrays have been demonstrated for hardware inference tasks [20], supporting the feasibility of binary magnetic rule fabrics. The energy-domain demonstrations described above extend this plausibility to physical-AI reflex control specifically.
4.2. Multilevel Devices for Policy-Side Inference
Multilevel spintronic devices represent more than two conductance states and can encode weighted values for matrix operations, neural inference and learned control. This richer representation is better aligned with policy functions such as classification, sensor fusion, optimization and model approximation. A recent representative study proposed 2-bit-per-cell MRAM and reported system-level simulation gains of about 1.8× in area, 1.85× in energy and 1.75× in latency relative to its 1-bit baseline; these results are architecture-specific and should not be generalized without validation [21]. Binary and multilevel devices address different architectural needs: binary devices favor clarity, bounded logic and verifiability; multilevel devices favor expressive weighted computation. Using multilevel precision for an allow/block decision may increase readout, calibration and ADC costs without improving the physical response.
4.3. Comparison with Existing Real-Time Control Technologies
Binary spintronic reflex crossbars are not the only technology available for local real-time control. Safety microcontrollers (MCUs based on ARM Cortex-M or similar cores), FPGA-based reflex circuits and neuromorphic processors such as Intel Loihi and SpiNNaker all currently serve reflex functions in automotive and robotics systems. Table 2 positions binary spintronic crossbars against these alternatives across attributes that matter for the reflex layer. The comparison shows that spintronic crossbars share the sub-µs latency and full parallelism of FPGAs but add non-volatility and drastically lower standby power, properties that are uniquely valuable in intermittent-power and harsh-environment nodes. Compared to safety MCUs, spintronic crossbars achieve faster parallel rule evaluation without sequential polling. Compared to neuromorphic processors, binary rule maps offer higher inspectability and simpler certification. No single technology dominates all attributes; the correct choice depends on the specific latency, power, certifiability and programmability requirements of the target application.
4.4. Decision-Power Path Isolation
A spintronic rule array should remain in the decision path, not the main power path. It processes small sensing signals and issues commands; MOSFETs, converters, contactors, motor drives or bypass circuits carry the actual energy. This is analogous to a pilot valve: a small control signal selects what a much larger power stage will do. This separation is especially important in automotive and energy systems. The crossbar does not carry traction current, battery-balancing current or photovoltaic power. It selects a safe route or operating state, allowing a small, low-energy reflex element to coexist with conventional and certifiable power electronics.
5. Application Examples with Illustrative Quantification
Table 3 gives transparent numerical examples of how a local reflex path can reduce the data burden presented to policy. The calculations are not measurements; they use explicit channel counts, bit depths, sampling rates, event rates and event-packet sizes so that readers can replace the assumptions with values from their own systems. The two energy-domain rows are marked as demonstrated, reflecting proof-of-concept results with the binary spintronic crossbar. Continuous raw data may still be retained locally for diagnostics; the table refers to the urgent upward decision path.
5.1. Robotics
Consider a robot joint exposed to an unexpected impact. A world model may predict the consequences of different recovery motions, but the first current clamp or torque inhibit must occur before a rich prediction is complete. The reflex acts first, a deterministic recovery profile executes, and the policy later interprets the event. In the illustrative 30-joint example of Table 3, event compression lowers the urgent upstream data path from 1.92 Mbit/s to 6.4 kbit/s, while local raw data may still be buffered for post-event analysis. A spintronic reflex crossbar in this context would benefit from non-volatile rule retention across power cycles and from parallel evaluation across all joints in a single array read. Validation of the crossbar in a robotic joint remains a logical next step following the energy-domain demonstrations.
5.2. Automotive Systems
Automotive systems combine hard real-time protection with increasingly sophisticated prediction. Local reflexes are appropriate for inverter overcurrent, thermal interlocks, battery-cell permissions and immediate safe-state transitions. Policy and world models are appropriate for route planning, energy management, battery-health prediction and analysis of complex sensor context. A robust architecture prevents a large model or shared processor load from delaying the first protective action. The illustrative inverter example separates a 1–20 µs protection target from policy analysis on a 10 ms to 1 s timescale. The non-volatility advantage of spintronic rule maps is particularly relevant in automotive applications where power-cycle robustness and fail-operational behaviour after communication loss are certification requirements.
5.3. Energy Harvesting and Storage
In photovoltaic and battery systems, physical conditions are distributed and can change faster than aggregate optimization loops. Proof-of-concept demonstrations of the binary spintronic reflex crossbar have been performed in both these domains. In the photovoltaic case, the crossbar responds to fast irradiance changes caused by moving cloud shadows, bypassing affected substrings in the sub-millisecond range while the MPPT policy continues to optimise the modified topology. Measured improvements in harvested energy under partial and dynamic shading conditions confirm that the latency separation between reflex and policy translates into real system benefit. In the battery balancing case, the crossbar performs cell-level switching decisions — enabling or inhibiting balancing current paths — at a speed and parallelism not achievable by a polled microcontroller alone, while the BMS policy retains authority over strategy and safety thresholds. In the transparent 16-substring example, event reporting reduces the urgent communication path from 576 kbit/s to 1.28 kbit/s. The reflex does not replace the MPPT or BMS supervisors; it reduces the number of urgent local decisions that they must process and improves the physical state presented to them.
6. World Models as Teachers, Not First Responders
World models can be especially valuable during design, training and periodic adaptation. They can expose a system to rare combinations of shading, impacts, sensor faults, actuator delays, thermal conditions or traffic situations. Policy optimization can then identify safe responses. The resulting knowledge can be compressed into binary permissions, thresholds, finite-state routines or multilevel weights for deployment below. The pipeline is:
world-model simulation → policy learning → rule/weight extraction → spintronic programming → local execution
This transfer is important because the expensive predictive model does not need to run every time the reflex acts. Rich learning occurs at the policy level; efficient execution occurs locally. The policy can also monitor false positives, false negatives and unresolved events, then update the reflex safely. In this way, world models and reflexes complement rather than replace one another.
Spintronic rule arrays, whether binary or multilevel, can be reprogrammed from insights produced by world models. A world model trained on many partial-shading scenarios — as in the demonstrated PV application — can generate a bounded rule map for a binary crossbar or a conductance matrix for a multilevel inference engine. The world model teaches offline or periodically; the reflex executes online without the world model's full latency and bandwidth overhead. This division of labour is what makes the architecture scalable: as world models grow more capable, the rules they distil into the reflex layer can become more nuanced, without requiring the world model itself to be present in the control loop.
7. A Practical Measurement Framework
Future demonstrators should report system-level metrics, not only device switching energy or model accuracy. The following two-tier framework distinguishes minimum credibility requirements from full benchmarking metrics.
Minimum metrics for any spintronic reflex demonstration:
- Physical-event latency: time from the event at the sensor to the first useful command at the actuator or power switch.
- Reflex throughput and burst capacity: sustained rule evaluations per second and number of simultaneous conditions handled without missed or delayed actions.
- Upward bandwidth reduction: raw data rate before local processing versus compressed event rate after the reflex layer.
- Safety and quality metrics: false positive rate, false negative rate, conflicting-rule behaviour, rollback and operation after policy loss.
Additional metrics for full system-level benchmarking:
- Downward bandwidth: rule-map, threshold and permission update traffic from policy to reflex.
- World-model latency and rollout throughput: time for one prediction cycle and number of candidate futures evaluated per second.
- Energy per useful action: sensing, conversion, memory, communication and decision energy associated with one event, compared with the benefit (energy captured, damage avoided, mission time preserved).
- Comparison baseline: the same physical event handled by a centralized software loop, a conventional CMOS/FPGA reflex and the spintronic crossbar, with all metrics reported side by side.
These metrics make architectural trade-offs visible. A binary reflex may provide lower latency and bandwidth at the cost of a narrower response vocabulary. A multilevel policy accelerator may provide richer inference but require more precise readout and energy. A world model may improve planning while adding latency and data movement. The correct design assigns each function to the lowest layer that can meet safety, precision and adaptation requirements.
8. Implications for Research and Development
The visible progress of Physical AI is increasingly driven by policy-side models. Genie 3, Gemini Robotics and Cosmos illustrate the rapid growth of interactive world generation, embodied reasoning and physical-AI development platforms [13,14,15]. This direction is important, but it should be matched by equal attention to the reflex side. Working on reflex architecture matters for three reasons. First, it removes high-frequency and low-value work from policy processors. Second, it creates deterministic local safety boundaries that remain active when communication, software or higher inference is delayed. Third, it reduces the data and energy required to keep powerful models informed.
A practical research program should, for any target physical event, compare at minimum three implementations: centralized software control, a conventional CMOS or FPGA reflex, and a non-volatile spintronic rule fabric. The comparison should include latency, throughput, bandwidth, energy, rule-update safety and fail-operational behaviour using the two-tier metric framework of Section 7. The photovoltaic and battery demonstrations described here provide one such comparison baseline for energy-domain events; equivalent exercises for robotic joints and automotive protection circuits would establish where binary spintronics provides real system value and where simpler technologies remain preferable.
The key research question is no longer only, “How capable can the policy become?” It is also, “How should reflex and policy divide work so that the whole machine becomes safer, faster and easier to operate?” A well-designed Reflex-Policy architecture is the missing link between advanced models and practical Physical AI deployment.
9. Conclusion
Latency, throughput and bandwidth describe different performance limits. World models add prediction. Reflex layers provide immediate local action; policy layers and world models provide interpretation, planning and learning. The two sides cooperate and protect each other. Binary spintronic reflex crossbars have been demonstrated in proof-of-concept form for fast shadow bypass in photovoltaic systems and for battery cell balancing, confirming that non-volatile magnetic rule fabrics can execute parallel, sub-millisecond switching decisions in practical energy-system conditions and deliver measurable improvements in harvested energy and balancing response.
Binary spintronic devices are well suited to persistent, inspectable and parallel local rule maps. Multilevel spintronic devices are better aligned with weighted inference and policy acceleration. Neither device class is universally superior: each should be placed where its precision, readout cost and non-volatility match the task. Compared to safety MCUs, FPGAs and neuromorphic processors, binary spintronic crossbars offer a distinctive combination of sub-µs parallel rule evaluation, non-volatility across power cycles and very low standby power — properties that are especially valuable in intermittent-power, harsh-environment and certification-sensitive applications.
The main engineering message is simple: Physical AI will not be made efficient and safe by focusing only on increasingly powerful policies. Reflex layers can dramatically simplify the work of policy models, reduce bandwidth and preserve hard real-time action. Designing the cooperation between reflex and policy — and grounding that cooperation in demonstrated hardware — is therefore a central system problem for robotics, automotive and energy applications.
Acknowledgments
Supported by the European Commission EIC Pathfinder MultiSpin.AI, grant no. 101130046.
Conflicts of Interest
The author is employed by IFEVS and declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Data Availability
No new datasets were generated or analysed for this conceptual article.
References
- Sitti, M. Physical intelligence as a new paradigm. Extrem. Mech. Lett. 2021, 46, 101340. [Google Scholar] [CrossRef]
- Brooks, R.A. A robust layered control system for a mobile robot. IEEE J. Robot. Autom. 1986, 2, 14–23. [Google Scholar] [CrossRef]
- Botvinick, M. M. Hierarchical models of behavior and prefrontal function. Trends Cogn. Sci. 2008, 12, 201–208. [Google Scholar] [CrossRef] [PubMed]
- Barroso, L. A.; Hölzle, U. The case for energy-proportional computing. Computer 2007, 40, 33–37. [Google Scholar] [CrossRef]
- Horowitz, M. Computing's energy problem (and what we can do about it). In IEEE International Solid-State Circuits Conference Digest; 2014; pp. 10–14. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J. S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Mead, C. Neuromorphic electronic systems. Proc. IEEE 1990, 78, 1629–1636. [Google Scholar] [CrossRef]
- Roy, K.; Jaiswal, A.; Panda, P. Towards spike-based machine intelligence with neuromorphic computing. Nature 2019, 575, 607–617. [Google Scholar] [CrossRef] [PubMed]
- Yao, M.; et al. Spike-based dynamic computing with asynchronous sensing–computing neuromorphic chip. Nat. Commun. 2024, 15, 4464. [Google Scholar] [CrossRef] [PubMed]
- Ha, D.; Schmidhuber, J. World models. arXiv 2018. [Google Scholar] [CrossRef]
- Hafner, D.; Pasukonis, J.; Ba, J.; Lillicrap, T. Mastering diverse domains through world models. arXiv 2023. [Google Scholar] [CrossRef]
- Zitkovich, B.; et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In Proceedings of the 7th Conference on Robot Learning, PMLR, 2023; 229, pp. 2165–2183. Available online: https://proceedings.mlr.press/v229/zitkovich23a.html.
- Google DeepMind. Genie 3: A new frontier for world models (2025). Available online: https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/.
- Google DeepMind. Gemini Robotics 1.5 brings AI agents into the physical world (2025). Available online: https://deepmind.google/blog/gemini-robotics-15-brings-ai-agents-into-the-physical-world/.
- NVIDIA. Cosmos: World foundation models for Physical AI. Available online: https://www.nvidia.com/en-us/ai/cosmos/ (accessed on 7 June 2026).
- Momeni, A.; et al. Training of physical neural networks. Nature 2025, 645, 53–61. [Google Scholar] [CrossRef] [PubMed]
- Wright, L. G.; et al. Deep physical neural networks trained with backpropagation. Nature 2022, 601, 549–555. [Google Scholar] [CrossRef] [PubMed]
- Pinarbasi, M.; Kent, A. D. Perspectives on spintronics technology development: Giant magnetoresistance to spin-transfer-torque MRAM. APL Mater. 2022, 10, 020901. [Google Scholar] [CrossRef]
- Worledge, D. C.; Hu, G. Spin-transfer torque magnetoresistive random access memory technology status and future directions. Nat. Rev. Electr. Eng. 2024, 1, 730–747. [Google Scholar] [CrossRef]
- Goodwill, J. M.; et al. Implementation of a binary neural network on a passive array of magnetic tunnel junctions. Phys. Rev. Appl. 2022, 18, 014039. [Google Scholar] [CrossRef]
- Gupte, K. K.; et al. Scalable and robust multi-bit spintronic synapses for analog in-memory computing. npj Unconv. Comput. 2026, 3, 8. [Google Scholar] [CrossRef]
- Nguyen, V. D.; et al. Recent progress in spin-orbit torque magnetic random-access memory. npj Spintron. 2024, 2, 48. [Google Scholar] [CrossRef]
- Gokmen, T.; Vlasov, Y. Acceleration of deep neural network training with resistive cross-point devices: Design considerations. Front. Neurosci. 2016, 10, 333. [Google Scholar] [CrossRef] [PubMed]
- Everspin Technologies. EMxxLXB xSPI STT-MRAM datasheet, version 1.6 (2025). Available online: https://www.everspin.com/sites/default/files/EMxxLXB%20Datasheet%20v1.6_0.pdf.
- GlobalFoundries. Embedded Memory: MRAM integrated in 22FDX technology and volume production. Available online: https://gf.com/technologies/embedded-memory/ (accessed on 7 June 2026).
- Samsung Foundry. Specialty Technology: embedded MRAM. Available online: https://semiconductor.samsung.com/foundry/process-technology/specialty-technology/ (accessed on 7 June 2026).

Table 1.
Quantitative interpretation of latency, throughput, bandwidth and world models. The ranges are illustrative design envelopes, not measured results of the proposed architecture. The Genie 3 bandwidth figure refers to uncompressed raw pixel data at the stated frame rate and resolution; model-internal inference traffic differs and is architecture-dependent [13].
Table 1.
Quantitative interpretation of latency, throughput, bandwidth and world models. The ranges are illustrative design envelopes, not measured results of the proposed architecture. The Genie 3 bandwidth figure refers to uncompressed raw pixel data at the stated frame rate and resolution; model-internal inference traffic differs and is architecture-dependent [13].
| Concept | Simple Meaning | Indicative Quantitative Envelope | Design Implication |
|---|---|---|---|
| Latency | End-to-end delay from physical event to first useful action | Reflex target: 0.1 µs–1 ms; deterministic digital control: 10 µs–10 ms; policy/world-model action: 10 ms–seconds | Measure the complete sensor-to-actuator path, not processor time alone. |
| Throughput | Useful events, decisions or predicted futures processed per second | A 64×64 crossbar exposes 4,096 programmed input-output relationships in one array read; world models may operate at video-rate or slower | Low single-event latency does not guarantee adequate burst capacity. |
| Bandwidth | Data capacity or actual data moved per second | Example: 32 ch × 16 bit × 10 kHz = 5.12 Mbit/s raw; 100 events/s × 64 bit = 6.4 kbit/s compressed | Local event compression can reduce upstream traffic by orders of magnitude. |
| World model | Predictive internal representation of state transitions and action consequences | Genie 3 generates interactive environments at 20–24 fps at 720p [13]; uncompressed 24-bit RGB at this rate would require ~531 Mbit/s of raw pixel data — model-internal inference traffic differs and is architecture-dependent | Prediction quality must be weighed against inference latency, data movement and energy. The raw pixel figure is an upper-bound illustration, not an inference cost. |
Table 2.
Comparison of binary spintronic crossbars with existing real-time control technologies and with multilevel spintronic devices. Values from Ref. [21] are representative simulation results for a specific architecture. Demonstrated applications refer to proof-of-concept results in photovoltaic shadow management and battery cell balancing.
Table 2.
Comparison of binary spintronic crossbars with existing real-time control technologies and with multilevel spintronic devices. Values from Ref. [21] are representative simulation results for a specific architecture. Demonstrated applications refer to proof-of-concept results in photovoltaic shadow management and battery cell balancing.
| Attribute | Binary Spintronic Device | Multilevel Spintronic Device | Architectural Consequence |
|---|---|---|---|
| Stored states | 2 stable states (1 bit) | Representative research: 4 levels (2 bits/cell); 2–4 bits explored in simulation [21] | Use the minimum precision that the decision requires. |
| Primary role | Permission maps, interlocks, event routing, wake/inhibit rules | Weighted sums, neural inference, sensor fusion, optimization | Binary aligns with reflex; multilevel aligns with policy acceleration. |
| Readout | Comparator or sense amplifier; one-bit decision | Comparator bank and encoder or multi-bit ADC | Readout often dominates multilevel latency and energy. |
| Parallelism example | 64×64 array stores 4,096 binary relationships evaluated in one array read | Same array stores richer weights but needs more precise aggregation | Parallel array operation does not eliminate peripheral bottlenecks. |
| Demonstrated applications | Fast shadow bypass in PV systems; battery cell balancing — proof-of-concept demonstrated | Multilevel spintronic synapses remain research-stage [21,22] | Device maturity and reflex-module maturity must be assessed separately for each application domain. |
| Maturity | Binary MRAM/eMRAM commercially available in memory roles [18,19,24,25,26]; reflex crossbar demonstrated in PV and battery domains | Multilevel spintronic synapses remain research-stage [21,22] | System-level demonstration distinguishes reflex crossbar from generic MRAM. |
| Validation metric | False trip rate, missed event rate, retention, safe default | Inference accuracy, drift, variability, ADC energy | System-level evaluation should include latency, bandwidth and fail-safe behavior. |
Table 3.
Illustrative system-level quantification. Reduction = raw data rate / event data rate. PV and battery rows reflect domains in which binary spintronic reflex crossbar operation has been demonstrated at proof-of-concept level. All figures are transparent worked examples; actual rates depend on sensor placement, diagnostics, safety standards and event frequency.
Table 3.
Illustrative system-level quantification. Reduction = raw data rate / event data rate. PV and battery rows reflect domains in which binary spintronic reflex crossbar operation has been demonstrated at proof-of-concept level. All figures are transparent worked examples; actual rates depend on sensor placement, diagnostics, safety standards and event frequency.
| Illustrative Context | Centralized Raw Stream Assumption | Compressed Reflex-Event Path | Reduction | Indicative Timing Separation |
|---|---|---|---|---|
| Robot with 30 joints | 30 joints × 4 channels × 16 bit × 1 kHz = 1.92 Mbit/s | 100 significant events/s × 64 bit = 6.4 kbit/s | 300× | Reflex: 0.1–1 ms; policy: 10–100 ms |
| Automotive traction inverter | 6 current/voltage channels × 16 bit × 100 kHz = 9.6 Mbit/s | 100 protection events/s × 64 bit = 6.4 kbit/s | 1,500× | Reflex: 1–20 µs; policy: 10 ms–1 s |
| PV system with 16 substrings (demonstrated) | 16 × 3 channels × 12 bit × 1 kHz = 576 kbit/s | 20 local events/s × 64 bit = 1.28 kbit/s | 450× | Reflex: 10 µs–10 ms; MPPT/policy: 0.1–10 s |
| Battery balancing (demonstrated) | N cells × 3 channels × 12 bit × 1 kHz per cell (scales with pack size) | Cell-level balance events at sparse rate × 64 bit per event | 100–500× | Reflex: 1 µs–1 ms; BMS policy: 0.1–10 s |
| Harvesting IoT node with 6-axis IMU | 6 axes × 16 bit × 1 kHz = 96 kbit/s | 2 qualified events/s × 64 bit = 128 bit/s | 750× | Reflex: 10 µs–10 ms; policy/cloud: 0.1 s–min |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



