Submitted:
27 May 2026
Posted:
28 May 2026
You are already at the latest version
Abstract
This paper presents TALOS, a beyond-state-of-the-art unified-reusable 6G CryptoProcessor architecture for high-assurance symmetric security services under a 256-bit private-key operating baseline. The work is driven by a fundamental hardware-design challenge: future 6G systems will require simultaneous support for heterogeneous strong symmetric primitives; yet conventional per-cipher hardware replication is area-intensive, power-inefficient, and structurally unflexible. TALOS addresses this problem through a processor oriented architecture that combines a Hierarchical Common Data Path (HCDP) with a three-tier cryptographic encapsulation model spanning AES-256, Snow 5G/SNOW-V class, and ZUC-256. The proposed methodology separates reusable structures by exact operator class: Tier-1 captures native nonlinear substitutions, Tier-2 captures bounded arithmetic nonlinearities through micro-S-box compilation, and Tier-3 captures shared permutations, XOR, affine, diffusion, and state-transport fabrics. This decomposition enables for exact operator-level unification without forcing structurally dissimilar cipher families into an artificial common form. As a result, TALOS preserves cipher correctness while exposing the strongest realistic sharing opportunities across the substitution, arithmetic, and linear transport layers. The architecture further supports (CIA) confidentiality processing together with integrity- and authentication-supporting service integration through a common control and resource framework. In contrast to monolithic universal-box concepts or loosely aggregated multi-core designs, TALOS establishes a disciplined and scalable hardware taxonomy for crypto-agile 6G symmetric-core realization. The proposed framework, therefore, advances the state of the art by unifying rigorous methodological exactness, architectural reuse, and implementation-oriented practicality within a single CryptoProcessor design paradigm.
Keywords:
6G security
; CryptoProcessor architecture
; crypto-agile hardware
; S-box reuse
; common data path
1. Introduction
The transition toward 6G-class communication infrastructures is expected to intensify the need for cryptographic hardware that is simultaneously high-throughput, implementation-aware, and structurally adaptable to heterogeneous security procedures. In such environments, confidentiality, integrity, authentication support, and control-plane protection can no longer be treated as isolated software conveniences; instead, they must be sustained by reusable and scalable hardware substrates capable of operating under strict area, latency, energy, and integration constraints. This requirement becomes even more pronounced from a post-quantum transition perspective, where strong symmetric cryptography remains a practical long-term pillar, while system architects must also account for crypto-agility, interoperability, and implementation sustainability. Consequently, the design of future 6G cryptographic engines must move beyond ad hoc per-cipher integration and toward methodical hardware unification.
A key lesson from previous mobile-security processor research is that substantial implementation gains can be achieved when common cryptographic structures are extracted and reused instead of replicated. In particular, the earlier universal LTE CryptoProcessor architecture [1] demonstrated that common substitution resources and common datapath selections can reduce implementation costs and improve hardware efficiency compared to atomic multi-core integration. That earlier design introduced a processor-style organization composed of a universal encryption unit, a common data path hardware block, a common S-box indexation module, and dedicated integrity and authentication service units. Although that framework was developed for the 4G LTE/SAE cipher family, its architectural insight remains highly relevant: the strongest gains arise when common operator classes are recognized explicitly and then mapped onto reusable hardware structures rather than embedded separately inside each cipher core.
However, direct reuse of that earlier methodology is no longer sufficient for a 6G-oriented symmetric security engine. The reason is that the target 256-bit candidate private-key primitives do not share one natural structural form [2]. AES-256 is a substitution–permutation block cipher with a highly regular nonlinear and diffusion organization. The SNOW 5G/SNOW-V class is a stateful stream cipher whose functionality emerges from coupled state recurrences, bounded word-level arithmetic, AES-round reuse, and structured byte permutations. ZUC-256 is also a stream cipher, but with a markedly different internal organization based on a prime-field LFSR, bit reorganization, fixed linear transforms, bounded arithmetic, and native ZUC substitution layers. A naive universal-box design would therefore either force unlike operators into an artificial common representation or preserve correctness at the cost of excessive hardware duplication. The fundamental challenge is not simply to place several ciphers on one chip but to identify the correct semantic depth at which unification remains both exact and architecturally meaningful.
TALOS addresses this challenge through a new hardware-design methodology centered on a three-tier encapsulation model and a Hierarchical Common Data Path (HCDP). The central idea is to separate reusable cryptographic structures by exact operator class. Tier-1 captures native nonlinear substitutions that are already intrinsic to the cipher family, such as AES substitutions and ZUC-native substitution layers. Tier-2 captures bounded arithmetic nonlinearities through micro-S-box compilation, thereby covering carry-bearing and correction-bearing subfunctions that are exact but not naturally expressible as native cryptographic S-boxes. Tier-3 captures all shared permutations, routing, XOR, affine, diffusion, and state-transport fabrics. The HCDP then acts as the processor-level scheduling and movement backbone that dispatches operands, manages intermediate states, supports recursion and retiming, and connects the three tiers into one coherent execution substrate. In this way, TALOS does not unify cipher families by collapsing them into a single monolithic box but by organizing them into a reusable hierarchy of exact nonlinear and linear primitives.
This architectural stance is well aligned with the current evolution of symmetric security in mobile systems. The emergence of 256-bit algorithm families based on AES, Snow, and ZUC in modern 3GPP security specifications shows that a heterogeneous strong-symmetric baseline is technically meaningful in practice. At the same time, ongoing 3GPP studies on the transition to PQC and security for the 6G system indicate that future security architectures will need to accommodate migration, coexistence, and flexibility of implementation rather than a single rigid cryptographic realization. TALOS, therefore, adopts AES-256, Snow 5G/SNOW-V-class, and ZUC-256 as a serious working baseline for 6G-oriented symmetric-core hardware, not as a claim of finalized 6G standardization, but as a realistic engineering design point for a reusable and crypto-agile CryptoProcessor.
The remainder of this manuscript is organized as follows. Section 1.1 reviews previous CryptoProcessor and crypto-agile hardware efforts. Section 1.2 presents the TALOS operator taxonomy and the 3-tier architectural methodology. Section 3 describes the proposed RTL-oriented hardware organization and HCDP-based execution substrate. Section 4 evaluates the hardware performance and efficiency results against the non-optimized baseline. Finally, Section 5 concludes the manuscript and outlines future research directions.
1.1. Related Work
Research on cryptographic processors has historically progressed along three partially overlapping directions: compact standalone security engines, integrated multi-algorithm processors for wireless and embedded systems, and, more recently, crypto-agile shared architectures. Early hardware CryptoProcessor studies established the feasibility of integrating multiple cryptographic services within unified embedded security platforms, while compact multi-coder and mobile-security designs demonstrated that substantial hardware gains can be achieved when common operator structures are reused instead of replicated [3,4,5]. In the wireless-security domain, this direction was reinforced by LTE-terminal-oriented accelerator studies and by compact implementations of KASUMI, SNOW-3G, and related cipher cores, which emphasized area, throughput, and energy efficiency under embedded constraints [6,7,8].
A second important line of work investigated structural sharing between stream-cipher families. In particular, integrated accelerator designs for multiple stream ciphers showed that shared arithmetic, state-handling, and control logic can reduce implementation costs when participating algorithms expose sufficiently aligned datapath behavior [9]. Similarly, comparative implementations oriented to FPGA of ZUC, SNOW-3G, and related stream ciphers clarified that dominant hardware costs often arise not only from nonlinear substitution, but also from state evolution, extraction, and bounded arithmetic, thus motivating more disciplined forms of operator-level reuse [10]. These studies are highly relevant to TALOS because they confirm that cross-cipher commonality is real but generally remain restricted either to a narrow algorithm family or to coarse-grained sharing.
The closest architectural precursor to TALOS is the universal 4G LTE CryptoProcessor of Bikos and Sklavos, which introduced two design principles that remain fundamental to this manuscript: a Common Data Path and a Common S-box Indexation strategy [1]. That design unified KASUMI, SNOW-3G, MILENAGE, and ZUC inside a processor-style security architecture and reported hardware benefits through shared substitution logic and shared datapath segments relative to standalone per-cipher realizations. However, its unification logic was developed for the LTE/SAE algorithm panel and for an earlier generation of mobile-security requirements. TALOS departs from that framework in two decisive ways. First, it targets a new 256-bit symmetric baseline centered on AES-256, the SNOW 5G/SNOW-V class, and ZUC-256. Second, it replaces heuristic commonality extraction with an exact operator taxonomy in which native substitutions, bounded arithmetic nonlinearities, and shared linear/permutation structures are separated into distinct reusable architectural tiers.
A third body of work is the algorithmic and standards literature defining the primitives that TALOS seeks to unify. AES remains the canonical substitution–permutation baseline, with its algebraic structure clarified by Murphy and Robshaw and its normative form maintained in the updated FIPS 197 specification [11,12]. On the stream-cipher side, SNOW-V provides the modern public design basis for the Snow 5G class, combining dual LFSRs, bounded 32-bit lane arithmetic, and AES-round reuse inside the FSM [13]. ZUC-256, in turn, combines a prime-field LFSR, bit reorganization, fixed linear transforms, bounded arithmetic, and native ZUC substitutions, as formalized in the public addendum and accompanied by public cryptanalytic studies such as work based on spectral-analysis [14,15]. At the standards level, 3GPP has already defined the 256-bit algorithm families based on Snow, AES, and ZUC in TS 35.240, TS 35.243, and TS 35.246, making the heterogeneous 256-bit symmetric baseline adopted in TALOS a realistic engineering design point rather than a purely hypothetical construction [16,17,18].
Recent work has shifted decisively toward crypto-agile architectures in the post-quantum era. Although much of this literature addresses public-key or signature accelerators rather than mobile symmetric-core engines, it is highly relevant to TALOS because it demonstrates a broader architectural transition from fixed single-algorithm hardware to reusable multi-algorithm substrates. Aikata et al. presented a unified CryptoProcessor for lattice-based signature and key exchange, showing that programmable shared resources can support structurally related post-quantum primitives within a compact hardware framework [19]. This trend has become even more pronounced in 2026. Adams Bridge integrates ML-KEM and ML-DSA within a unified accelerator architecture oriented toward silicon reuse and transition support [20]. RISQrypt advances a hardware-software co-design approach for agile PQC deployment [21]. Unified hardware for hash-based and stateless key/signature generation extends the shared-architecture principle to hash-based cryptography [22]. Parameterizable HQC hardware studies also emphasize reusable arithmetic and configurable data paths as practical routes to implementation agility [23]. These contributions are not direct predecessors of TALOS in the mobile symmetric-cipher setting, but they strongly validate the broader architectural premise that exact multi-primitive support and disciplined reuse are now central objectives in modern cryptographic hardware.
The broader standards and migration context also reinforce this direction. NIST finalized the first three post-quantum FIPS standards in 2024, namely FIPS 203, FIPS 204, and FIPS 205, and subsequently issued transition guidance through NIST IR 8547 [24,25,26,27]. In parallel, 3GPP Release-20 studies now explicitly include both both transition to post-quantum cryptography and security for the 6G system [28,29]. This context does not, by itself, define a unified 6G symmetric CryptoProcessor, but it clearly indicates that future hardware security engines must support coexistence, migration, and implementation flexibility rather than a single, rigid cryptographic realization.
Against this background, the gap addressed by TALOS can be stated precisely. Existing work either: i) optimizes individual mobile-security ciphers; ii) shares coarse datapath structures across earlier mobile cipher panels; or iii) develops unified post-quantum accelerators for public-key families. What remains missing is an exact implementation-oriented unification methodology for a heterogeneous 6G-relevant private-key baseline that spans AES-256, Snow 5G/SNOW-V class, and ZUC-256 without collapsing them into an artificial single primitive class. TALOS addresses this gap by introducing a 3-tier reusable architecture and a Hierarchical Common Data Path that jointly separates native substitutions, bounded arithmetic nonlinearities, and shared linear/permutation structures at the correct semantic depth. In that sense, TALOS is positioned not as a minor extension of prior common-datapath or common-S-box ideas, but as a new operator-exact framework for unified, reusable 6G symmetric CryptoProcessor design.
1.2. TALOS Beyond-State-of-the-Art (SotA) Contribution: 3-Tier Encapsulation
The central, beyond-state-of-the-art claim of TALOS is that a practically unified 6G CryptoProcessor should not be sought through a monolithic “universal mega-table” or through full per-cipher hardware duplication, but through a hierarchically encapsulated 3-tier substrate. In this substrate, native cryptographic substitutions are isolated in Tier-1, bounded arithmetic nonlinearities are compiled into Tier-2 micro-S-boxes, and all routing, permutation, XOR, affine, and diffusion logic are absorbed into Tier-3. This decomposition is necessary because the target 256-bit symmetric candidates do not share a single natural algebraic form: AES-256 is strongly substitution–permutation based, whereas Snow 5G/SNOW-V class and ZUC-256 combine stateful recurrence, bounded word-level arithmetic, and structured linear transport. A single-tier unification, therefore, either wastes area through over-generalization or loses exactness through oversimplification. [13,14,30,31,32]
Figure 1.
Minimal abstraction of the proposed 3-tier encapsulation principle. Tier-1 captures native nonlinear substitutions, Tier-2 captures bounded arithmetic micro-substitutions, and Tier-3 captures permutation and linear fabrics.
Figure 1.
Minimal abstraction of the proposed 3-tier encapsulation principle. Tier-1 captures native nonlinear substitutions, Tier-2 captures bounded arithmetic micro-substitutions, and Tier-3 captures permutation and linear fabrics.

More precisely, the proposed contribution is the introduction of a necessary separation of the reusable cryptographic structure by operator class. Tier-1 contains only native nonlinear boxes that are already intrinsic to the cipher family, such as AES substitutions and ZUC-native substitution layers. Tier-2 contains exact bounded nonlinear maps generated by compilation, especially carry-bearing and correction-bearing micro-arithmetic slices. Tier-3 contains the shared sparse fabric for byte-by-bit permutation, XOR, affine transforms, rotations, shuffles, linear diffusion, and state transport. This gives TALOS a reusable hardware basis that is sufficiently expressive to preserve exact cipher behavior while remaining substantially more structured than a naive all-in-one common-box construction.
The manuscript claims the following technical advances:
- 1.
- Exact operator unification: the architecture unifies AES-256, Snow 5G/SNOW-V-class, and ZUC-256 without forcing them into an artificial single primitive class.
- 2.
- Hierarchical reuse: reuse is achieved at the correct semantic depth—native substitution reuse in Tier-1, arithmetic reuse in Tier-2, and transport/diffusion reuse in Tier-3.
- 3.
- Scalable hardware mapping: the decomposition is directly compatible with a common datapath, microcoded dispatch, and mode-controlled recursion, making it implementable in RTL rather than remaining a purely conceptual abstraction.
- 4.
- 6G relevance: the model aligns with a realistic candidate symmetric-core baseline in which 256-bit AES, Snow, and ZUC-family primitives are treated as viable quantum-resistant private-key engines for future mobile security architectures.
The reason why this framework is beyond the current state of the art is not merely that it combines multiple ciphers but that it formalizes how they should be combined. Prior unification logic is often strongest either at the level of common datapath sharing or at the level of isolated S-box reuse. TALOS advances beyond that point by introducing a tier-separable unification rule: what is natively nonlinear must remain native, what is bounded nonlinear must be box-compiled, and what is linear or positional must be realized through a shared sparse fabric. This is the key step that makes a unified-reusable 6G CryptoProcessor both technically exact and architecturally defensible.
Consequently, the necessity of the 3-tier concept is twofold. First, it prevents category errors in hardware unification, e.g., treating stream-cipher recurrence logic as if it were merely another byte S-box layer. Second, it exposes the strongest realistic sharing opportunities: AES-native substitution reuse, modular-adder micro-slice reuse, and unified permutation/XOR/state-transport reuse across the three cipher families. The resulting architecture is therefore not just a shared implementation platform, but a disciplined hardware taxonomy for future symmetric-core 6G security engines.
2. Review of Quantum-Resistant Crypto Algorithms for 6G Security
AES-256, Snow 5G (SNOW-V class) and ZUC-256 are strong candidates for quantum-resistant symmetric primitives for 6G security, consistent with the current 3GPP move toward 256-bit algorithm suites, although 6G standardization has not yet finalized the symmetric algorithm set. To elaborate further, the strongest part of the present research claim is that 256-bit symmetric cryptography is widely regarded as the right direction for quantum-resistant symmetric protection (for the 5G/6G-and beyond era). NIST says that symmetric cryptography is affected by Grover’s algorithm “less dramatically” than public-key cryptography, and that AES-192 and AES-256 should remain safe for a very long time [33,34], and [35]; technically speaking, NIST’s PQC effort is mainly about replacing public-key mechanisms, not symmetric ciphers. In fact, 3GPP already has three 256-bit 5G algorithm families under its security work: Snow 5G with 256-NEA4 / 256-NIA4 / 256-NCA4, AES-based 256-NEA5 / 256-NIA5 / 256-NCA5, and ZUC-based 256-NEA6 / 256-NIA6 / 256-NCA6. That means that an AES/SNOW/ZUC triad at the 256-bit level is already a real standards trajectory in mobile security, not a purely speculative invention [36,37,38], and [39].
Despite the absence of an officially selected final 6G cipher set (under standardization), the 3GPP is still only in the study phase for both transitioning to PQC and ensuring security for the 6G system; Release 20 is for studies, and Release 21 is planned for normative 6G work [40,41], and [42]. At the same time, 3GPP’s broader 6G work is still in the study phase, and the 6G-IA vision documents describe post-quantum cryptography and zero-trust as important 6G directions rather than a finalized algorithm menu. ETSI also recommends starting the PQ transition even when some standards are still evolving [43,44], and [45]. Even with this ongoing standardization context, this research aims to reuse AES-256, SNOW 5G/SNOW-V-class 256-bit, and ZUC-256 as the three symmetric core primitives of the TALOS (our fully modulear 6G CryptoProcessor).
Technically speaking, the previously mentioned powerful cipher family sets, by themselves, do not automatically guaranty all of:
- confidentiality,
- integrity,
- authentication.
inside an envisioned standalone 6G CryptoProcessor as such. More precisely, because (1) encryption/decryption cores primarily provide confidentiality, (2) integrity usually requires a dedicated integrity construction, MAC, or authenticated-encryption framework, and (3) authentication usually also depends on higher-layer protocol logic, key management, challenge-response, or signature/KEM support, not only on the cipher engine itself.
That technological distinction matters because the leading PQ algorithms now standardized by NIST are not Substitution Permutation Networks (SPN)-style ciphers dominated by substitution/permutation layers. NIST’s current finalized PQ standards are the Module-Lattice-Based key encapsulation Mechanism (ML-KEM) for key encapsulation, the Module-Lattice-Based Digital Signature Algorithm (ML-DSA) for digital signatures, and the Stateless hash-based Digital Signature Algorithm (SLH-DSA) for hash-based signatures. ML-KEM and ML-DSA are explicitly module-lattice-based, while SLH-DSA is explicitly stateless hash-based [46], and [47]. arithmetic for ML-KEM/ML-DSA, (2) Keccak/SHAKE hashing and sampling, (3) hash-tree/Forest of Random Subsets (FORS)/eXtended Merkle Signature Scheme (XMSS)-style operations for SLH-DSA, (4) and possibly Fast Fourier Transformation (FFT)/Gaussian sampling if the Fast Fourier Transform-over-NTRU-Lattice-Based Digital Signature Algorithm (FN-DSA) enters the target set later. NIST has also selected Hamming Quasi-Cyclic (HQC) for standardization to diversify key-establishment options, which strengthens the case for a crypto-agile architecture rather than a fixed single-structure datapath [48,49] and [50].
Due to the exact technical assumptions and NIST standard design criteria (under process) for the Confidentiality, Integrity, and Availability (CIA) enhancement of the 6G cellular protocol, looking at TALOS objectively from a theoretical standpoint, primarily as an ultra-efficient area-space 6G CryptoProcessor leveraging reusable hardware security modules, is, in fact, feasible. However, reusable modules should be defined at the level of shared arithmetic and hashing kernels, not as a universal common S-box for all PQ algorithms [2]. That revised claim is strongly supported by recent state-of-the-art hardware work. Current unified PQC architectures already share arithmetic, Keccak, sampling, and memory resources across ML-KEM and ML-DSA; other work focuses on a single-resource unified NTT accelerator for both schemes; and separate work shows that SLH-DSA benefits enormously from a specialized shared hash unit rather than an S-box-centric design [51,52], and [53].
The final major caveat is implementation security. In PQ hardware, the shared-module strategy is attractive for area and power but creates real side-channel and fault-resistance design pressures. Recent work on masked NTT hardware explicitly frames PQ accelerators as needing side-channel-resistance evidence for FIPS 140-3 style validation, and recent SLH-DSA hardware work shows that dedicated secure hashing is a first-order concern, not an afterthought [54], and [55].
So, in a more realistic technological feasibility manner, any 6G CryptoProcessor would likely have a reusable kernel set, such as:
- 1.
- a configurable NTT/INTT butterfly engine,
- 2.
- shared modular multiply/reduce/add units,
- 3.
- a unified Keccak/SHAKE/SHA-3 engine,
- 4.
- a sampler/randomness/rejection-sampling block,
- 5.
- a hash-tree engine for SLH-DSA,
- 6.
- shared SRAM/memory scheduling/DMA,
- 7.
To maintain alignment with the previously established architectural vision, alongside adopting the (1) algebraic simplification concept by [2] and, most importantly, (2) the "boxification" property of the S-P/Boxes (confusion and diffusion properties) of [1], TALOS manages to unify reusable arithmetic, transform, hashing, sampling, and memory subsystems across post-quantum algorithms, extending the common-datapath philosophy of the (previous) 4G cryptographic processor [1] beyond S-box reuse toward a crypto-agile reusable hardware kernel architecture.
2.1. AES-256
AES-256 is the 256-bit key member of the AES family standardized in FIPS 197. It operates on a fixed 128-bit data block and is defined through a substitution–permutation network (SPN) over a byte state. In a post-quantum symmetric-core discussion, AES-256 is relevant not because it is part of NIST’s post-quantum public-key standards, but because NIST continues to regard AES with key sizes 128, 192, and 256 bits as deployable, and because 3GPP has already introduced an AES-based 256 bit algorithm set for 5G systems, namely 256-NEA5, 256-NIA5, and 256-NCA5 [30,58,59,60]. From a 6G hardware-design perspective, AES-256 is therefore a strong candidate private-key primitive for confidentiality-oriented and security-supporting symmetric procedures.
2.1.1. Canonical Parameters

Table 1.
Canonical AES-256 parameters.
| Parameter | Value |
|---|---|
| Block length | 128 bits |
| Key length | 256 bits |
| State size | bytes = 16 bytes |
| Number of key words | 8 words ( bits) |
| Number of block words | 4 words ( bits) |
| Number of rounds | 14 |
| Expanded key size | words |
| Round-key count | 15 round keys (including initial key addition) |
Let the 128-bit input block be mapped into the byte state
where each is one byte in represented with the irreducible polynomial AES
2.1.2. Core Operations
AES-256 encryption is built from four round transformations: SubBytes, ShiftRows, MixColumns, and AddRoundKey. Decryption uses the inverse transforms InvSubBytes, InvShiftRows, InvMixColumns, and the same round keys in reverse order [30].
SubBytes
Each byte of the state is replaced independently through the AES S-box:
The S-box is defined as the composition of:
- 1.
- multiplicative inversion in , with ,
- 2.
- a fixed affine transformation over .
Formally,
where A is a fixed binary matrix , c is a fixed 8-bit constant, and is computed in with the convention [30].
ShiftRows
The rows of the state are cyclically shifted left by offsets bytes:
This is a byte-permutation stage and introduces inter-column diffusion before column mixing.
MixColumns
Each column is transformed independently by multiplication with a fixed MDS matrix over :
Here, denote fixed field elements in byte notation. This operation is linear over and is the main intra-column diffusion layer.
AddRoundKey
A 128-bit round key is XORed with the state:
This is the only step that injects secret-key material into the round state.
2.1.3. Inverse Transformations for Decryption
Decryption applies:
- InvShiftRows: cyclic right shifts by bytes,
- InvSubBytes: inverse AES S-box,
- InvMixColumns: multiplication by the inverse fixed matrix over ,
- AddRoundKey: XOR with the corresponding round key in reverse round order.
2.1.4. AES-256 Key Expansion
Let the 256-bit cipher key be partitioned into eight 32-bit words:
The AES-256 key schedule expands these into 60 words:
which are grouped into 15 round keys:
The expansion rule is the following.
for , where
The auxiliary operations are as follows:
- ,
- applies the AES S-box bytewise to a 32-bit word,
- is the round constant word sequence defined in FIPS 197.
Table 2.
AES-256 key schedule structure
| Index class | Recurrence |
|---|---|
| loaded directly from the 256-bit user key | |
| otherwise |
Architecturally, AES-256 has a more involved key expansion than AES-128 because the extra branch in must be supported in addition to the branch.
2.1.5. Encryption Flow
AES-256 encryption consists of:
- 1.
- initial AddRoundKey,
- 2.
- 13 full rounds,
- 3.
- 1 final round without MixColumns.
Table 3.
AES-256 encryption round structure
| Stage | Operations |
|---|---|
| Initial whitening | |
| Rounds 1–13 | SubBytes→ShiftRows→MixColumns→AddRoundKey |
| Round 14 | SubBytes→ShiftRows→AddRoundKey |
| Output |
| Algorithm 1:AES-256 encryption. |
|
2.1.6. Decryption Flow
Decryption inverts the round structure:
- 1.
- initial AddRoundKey with the last round key,
- 2.
- 13 inverse full rounds,
- 3.
- final inverse round without InvMixColumns.
Table 4.
AES-256 decryption round structure
| Stage | Operations |
|---|---|
| Initial step | |
| Rounds 13–1 | InvShiftRows→InvSubBytes→AddRoundKey→InvMixColumns |
| Final round | InvShiftRows→InvSubBytes→AddRoundKey with |
| Output |
| Algorithm 2:AES-256 decryption |
|
Figure 2.
Compact AES-256 encryption structure for hardware or architectural discussion.

2.1.7. Hardware-Oriented Interpretation
For a box-centric 6G CryptoProcessor architecture, AES-256 naturally decomposes into the following.
- Native nonlinear primitive tier-1: forward and inverse AES S-box,
- Tier-3 linear/permutation primitives: ShiftRows, MixColumns, InvMixColumns, AddRoundKey and key-schedule XOR/rotation wiring,
- Control-plane sequencing: round counter, key-expansion controller, and encryption/decryption mode control.
Table 5.
AES-256 hardware decomposition in a tiered CryptoProcessor
| AES-256 function | Mathematical nature | Architectural mapping |
|---|---|---|
| SubBytes / InvSubBytes | nonlinear byte substitution | Tier-1 native S-box bank |
| ShiftRows / InvShiftRows | byte permutation | Tier-3 P-box |
| MixColumns / InvMixColumns | linear transform over | Tier-3 linear fabric |
| AddRoundKey | XOR / affine mixing | Tier-3 XOR fabric |
| KeyExpansion | mixed substitution + rotation + XOR | Tier-1 + Tier-3 + control |
AES-256 remains a highly structured, implementation-friendly symmetric primitive: its nonlinear core is localized in the byte S-box, while its diffusion and key-injection layers are sparse and regular. This separation is especially attractive for a 6G-oriented shared CryptoProcessor because it enables strong reuse of a native substitution block together with common linear, permutation and XOR fabrics [30,58,59].
2.2. Snow 5G / SNOW-V-Class
The SNOW 5G / SNOW-V class is a 256-bit key stream-cipher candidate relevant to future 6G-oriented symmetric security discussions. The public SNOW-V design was proposed as a high-speed member of the SNOW family for software-oriented 5G environments, with a 256-bit key, a 128-bit IV, two coupled 16-stage LFSRs over , three 128-bit FSM registers, two AES round-function instances in the FSM, and a 128-bit keystream output per step [13]. ETSI TS 35.240 defines the Snow 5G based 256-bit algorithm set for 5G, namely 256-NEA4, 256-NIA4 and 256-NCA4, which makes the family a standards-relevant mobile-security primitive even though the public algorithm specification is redacted [31]. In a post-quantum setting, NIST continues to regard strong symmetric cryptography as viable for long-term use, and 3GPP has initiated Release-20 studies on PQC transition and security for the 6G system [58,61,62]. For these reasons, the SNOW 5G / SNOW-V-class is a technically credible working candidate private-key primitive for a 6G CryptoProcessor.
2.2.1. Canonical Parameters
Table 6.
Canonical parameters of Snow 5G / SNOW-V-class
| Parameter | Value / Description |
|---|---|
| Primitive class | Stream cipher / keystream generator |
| Key length | 256 bits |
| IV length | 128 bits |
| LFSR structure | Two LFSRs, each of length 16, cell size 16 bits |
| FSM structure | Three 128-bit registers |
| AES-related logic | Two AES encryption-round applications in FSM update |
| Keystream output per step | 128 bits |
| Initialization length | 16 initialization steps |
| Parallel word addition | Four independent 32-bit additions over a 128-bit word |
| Claimed security target | 256-bit key-search complexity target |
Let the two LFSRs be denoted by
where each cell is a 16-bit element of . The FSM consists of three 128-bit registers
For compact notation, define the 128-bit word slices
We denote by the lane-wise addition of four 32-bit words inside a 128-bit vector:
means that the four 32-bit subwords are added modulo with carry propagation inside each 32-bit lane only.
2.2.2. Core State Equations
Keystream Output Equation
The 128-bit keystream block at time t is
FSM Update Equations
Let denote one AES encryption round, and in SNOW-V, the round constants satisfy
Then the FSM updates are made
The permutation of byte is
Architecturally, can be viewed as one AES round with zero round key, i.e., an SPN-like linear / nonlinear map built from AES byte substitutions and diffusion.
LFSR Update Equations
Let and be roots of the respective 16-bit field-defining polynomials
Then the two LFSR recurrences are
In implementation terms, the public reference pseudocode updates the registers eight times per higher-level step, forming temporary words and shifting both LFSRs accordingly.
Table 7.
Core operator view of SNOW-V / Snow 5G-class
| Component | Mathematical nature | Role |
|---|---|---|
| extraction | word/byte selection | forms 128-bit FSM inputs from LFSR state |
| 4-lane modulo- addition | nonlinear arithmetic mixing for keystream | |
| ⊕ with | XOR / affine mixing | final keystream output mixing |
| byte permutation | inter-byte diffusion inside FSM update | |
| AES round-based nonlinear/linear map | updates and | |
| LFSR-A / LFSR-B | linear recurrences over | long-state evolution and diffusion |
2.2.3. Key/IV Loading and Initialization
Unlike AES-256, SNOW-V does not use an internal AES-like key-expansion schedule that derives round keys. Instead, the primitive consumes a 256-bit secret key and a 128-bit IV and loads them directly into the LFSR state, followed by a 16-step state-mixing initialization procedure [13]. In mobile systems, any higher-layer derivation of session keys is external to the primitive itself.
Let the key be
with each a 16-bit word, and the IV be
with each a 16-bit word.
The initial loading is
The initialization then executes for 16 steps. In each step:
- 1.
- form from ,
- 2.
- compute ,
- 3.
- update the FSM,
- 4.
- update the LFSRs,
- 5.
- XOR z into ,
- 6.
- at , XOR into ,
- 7.
- at , XOR in .
| Algorithm 3:SNOW-V-class initialization |
|
Table 8.
SNOW-V initialization summary
| Stage | Operation |
|---|---|
| Load A-LFSR | , |
| Load B-LFSR | , |
| Reset FSM | |
| Mixing loop | 16 update steps with z fed back into |
| Late key injection | At XOR into ; at XOR into |
| Usage limits | At most keystream per key/IV pair; at most IVs per key |
2.2.4. Keystream Generation
After initialization, the running-key mode is simple:
- 1.
- form from ,
- 2.
- compute ,
- 3.
- update FSM,
- 4.
- update LFSRs,
- 5.
- output z.
| Algorithm 4:SNOW-V-class keystream generation |
|
2.2.5. Encryption and Decryption
Because the SNOW-V class is a stream cipher, there is no separate inverse round structure analogous to AES decryption. Instead, the primitive generates a keystream and both encryption and decryption are performed by XOR with the same keystream sequence:
Thus:
- encryption = plaintext XOR keystream,
- decryption = ciphertext XOR the identical keystream regenerated from the same key, IV, and state evolution.
Table 9.
SNOW-V-class protection functions at the primitive and mode level
| Function | Primitive-level meaning | Realization |
|---|---|---|
| Confidentiality | stream encryption | XOR plaintext/ciphertext with keystream |
| Decryption | same operation as encryption | regenerate keystream and XOR again |
| Integrity / authentication | not intrinsic to keystream core alone | mode/system-level construction (e.g. Snow-5G family or AEAD mode) |
| AEAD option | authenticated encryption | SNOW-V paper proposes a GMAC/GHASH-based AEAD mode |
Figure 3.
Compact SNOW-V / Snow 5G-class structure for architectural discussion.

2.2.6. Hardware-Oriented Tiered Interpretation
For a 6G tiered CryptoProcessor, Snow 5G / SNOW-V-class naturally maps into a mixed Tier-1 / Tier-2 / Tier-3 structure:
- Native nonlinear primitive tier 1: AES round S-box reuse inside .
- Tier-2 micro-S-box arithmetic: four-lane modulo- addition and related bounded arithmetic slices.
- Linear / permutation fabric of level 3:, extraction, XOR networks, and LFSR recurrences on .
Table 10.
SNOW-V-class hardware decomposition in a tiered CryptoProcessor
| SNOW-V function | Mathematical nature | Architectural mapping |
|---|---|---|
| in FSM | nonlinear + linear AES round map | Tier-1 native S-box reuse + Tier-3 diffusion |
| operations | bounded lane-wise arithmetic | Tier-2 micro-S-box fabric |
| byte permutation | Tier-3 P-box | |
| formation | state extraction / routing | Tier-3 routing fabric |
| LFSR-A / LFSR-B update | linear recurrences over | Tier-3 linear fabric |
| Output XOR | affine/XOR mixing | Tier-3 XOR fabric |
| Initialization feedback | state mixing + late key injection | control plane + Tier-2/Tier-3 support |
2.2.7. Note on Integrity and Authenticated Encryption
The public SNOW-V paper also proposes an AEAD mode of operation in which a GMAC/GHASH-style framework is combined with the 128-bit keystream output, yielding an authenticated-encryption mode of SNOW-V-GCM-style [13]. At the 3GPP algorithm-family level, the Snow 5G-based 256-bit set explicitly names confidentiality, integrity, and authenticated-encryption functions as 256-NEA4, 256-NIA4 and 256-NCA4 [31]. Consequently, it is technically sound to describe the SNOW 5G / SNOW-V class as a confidentiality-oriented symmetric core that can participate in broader integrity/authentication service constructions.
Snow 5G / SNOW-V class differs fundamentally from AES-256 in that it is a stateful keystream generator rather than a fixed-round block cipher. Its hardware and architectural interest comes from the co-existence of three reusable structures: linear dual-LFSR evolution over , bounded 32-bit-lane arithmetic, and AES-round reuse inside the FSM. This makes it particularly well aligned with a shared 3-tier CryptoProcessor substrate in which Tier-1 captures native substitution reuse from AES, Tier-2 captures arithmetic micro-slices, and Tier-3 captures permutation, XOR, and linear state transport [13,31].
2.3. ZUC-256
ZUC-256 is a 256-bit-key stream cipher in the ZUC family and is a technically credible private-key candidate for a future 6G-oriented symmetric CryptoProcessor. The public 2021 addendum states that ZUC-256, together with AES-256 and SNOW 5G, is specified as a core primitive in the 3GPP algorithm family 256-NEA6, 256-NIA6, and 256-NCA6 for 5G applications targeting 256-bit security [32,63]. In architectural terms, ZUC-256 is especially relevant because it combines: (i) a 16-stage LFSR over , (ii) a bit-reorganization layer that extracts four 32-bit words from the LFSR state, and (iii) a small finite-state machine (FSM) with two 32-bit state registers, fixed linear transformations , and native ZUC S-boxes [63,64]. This makes ZUC-256 a strong example of a cipher whose exact realization naturally spans all three tiers of the proposed common-box architecture.
2.3.1. Canonical Parameters
Table 11.
Canonical parameters of ZUC-256
| Parameter | Value / Description |
|---|---|
| Primitive class | Stream cipher / keystream generator |
| Key length | 256 bits |
| IV length (addendum scheme) | 128 bits |
| LFSR size | 16 cells |
| Cell width | 31 bits |
| LFSR field | / modulo- recurrence |
| FSM state | Two 32-bit registers |
| BR output | Four 32-bit words |
| S-box structure | in 4 parallel byte positions |
| Initialization length | 33 rounds (32 initialization-mode steps + 1 work-mode transition) |
| Keystream granularity | 32-bit word per clock / step |
| Frame guidance in addendum | 20,000-bit keystream per frame (625 words) |
Let the LFSR state be
where each is a 31-bit element in the set . Let the FSM registers be
The bit-reorganization layer produces
2.3.2. Core Operations
Bit Reorganization (BR)
The addendum defines the four 32-bit BR words as
where denotes the upper 16 bits of the cell and denotes the lower 16 bits of the cell [63].
FSM Function
The core FSM function is the following.
where:
Keystream Output
The 32-bit keystream word is
LFSR Update in Initialization Mode
Let us
The addendum defines the initialization-mode recurrence as
where is a 31-bit feedback-derived quantity during initialization. If , it is replaced by p; if , it is also replaced by p. The register shift is then performed as
LFSR Update in Work Mode
Table 12.
Core operator view of ZUC-256
| Component | Mathematical nature | Role |
|---|---|---|
| BR extraction | bit/word reorganization | forms from LFSR state |
| XOR + modulo- addition | keystream and FSM nonlinear mixing | |
| addition / XOR mixing | internal FSM preparation | |
| fixed 32-bit linear maps | diffusion before substitution | |
| 4-byte substitution layer | native nonlinear core | |
| LFSR recurrence | linear recurrence modulo | long-state evolution and diffusion |
| Output | XOR mixing | 32-bit keystream word generation |
2.3.3. Key/IV Loading and Initialization
Unlike AES-256, ZUC-256 does not have an internal round-key schedule. Its symmetric secret material is consumed through a direct key/IV loading scheme followed by a 33-step initialization process. The 2021 addendum specifically modifies ZUC-256 to support an exact 128-bit IV while keeping the key at 256 bits [63].
Let the key be
with each an 8-bit byte, and the IV be
with each an 8-bit byte. Let denote the 7-bit constants defined in the addendum.
The key/IV loading equations are
The addendum initialization then proceeds as follows:
- 1.
- load the LFSR cells as above,
- 2.
- set ,
- 3.
-
for :
- (a)
- perform bit reorganization,
- (b)
- compute ,
- (c)
- run LFSRWithInitializationMode,
- 4.
- perform one final bit reorganization,
- 5.
- compute and discard one extra Z,
- 6.
- switch to LFSRWithWorkMode().
| Algorithm 5:ZUC-256 initialization (addendum form) |
|
Table 13.
ZUC-256 initialization summary
| Stage | Operation |
|---|---|
| Key/IV load | 16 LFSR cells loaded from 32 key bytes, 16 IV bytes, and 16 constants |
| FSM reset | |
| Initialization loop | 32 rounds of BR → F → LFSR initialization update with |
| Work-mode transition | one final BR and F call, discard Z, then enter work mode |
| Public addendum goal | exact 128-bit IV support with 256-bit key |
2.3.4. Keystream Generation
Once initialized, ZUC-256 generates one 32-bit keystream word per work-mode step:
- 1.
- perform bit reorganization,
- 2.
- compute ,
- 3.
- update the LFSR in work mode,
- 4.
- output Z.
| Algorithm 6:ZUC-256 keystream generation |
|
The addendum further states that the stream cipher generates 20,000 keystream bits per frame, i.e., 625 words, after which key/IV resynchronization is performed with the key and constants fixed and the IV changed to a new value [63].
2.3.5. Encryption, Decryption, and MAC/AE Context
At the stream-cipher core level, encryption and decryption both reduce to XOR with the generated keystream:
Thus, there is no separate inverse round structure analogous to AES decryption.
The addendum also explicitly describes a MAC-generation mode and states that tag sizes of 32, 64, and 128 bits are supported [63]. At the standards-family level, ETSI TS 35.246 names ZUC-based 256-bit confidentiality, integrity, and authenticated-encryption functions as 256-NEA6, 256-NIA6, and 256-NCA6, respectively, although the public ETSI document places the detailed technical provisions in the unredacted version [32].
Table 14.
ZUC-256 protection functions at the primitive and system level
| Function | Primitive-level meaning | Realization |
|---|---|---|
| Confidentiality | stream encryption | XOR plaintext/ciphertext with keystream |
| Decryption | same operation as encryption | regenerate keystream and XOR again |
| Integrity / authentication | supported in broader ZUC-256 family context | MAC or AE construction, not only raw keystream core |
| AE family naming | 256-NCA6 | standards-family authenticated-encryption designation |
Figure 4.
Compact ZUC-256 structure for architectural discussion.

2.3.6. Hardware-Oriented Tiered Interpretation
For a 6G tiered CryptoProcessor, ZUC-256 naturally maps into all three shared tiers:
- Native nonlinear primitive tier 1: the ZUC S-box layer .
- Tier-2 micro-S-box arithmetic: modulo- additions and modulo- correction logic in a bounded arithmetic decomposition.
- Linear / permutation fabric of level 3: bit reorganization, XOR networks, fixed linear maps , and LFSR state transport/update.
Table 15.
ZUC-256 hardware decomposition in a tiered CryptoProcessor
| ZUC-256 function | Mathematical nature | Architectural mapping |
|---|---|---|
| native byte substitution | Tier-1 native S-box bank | |
| ⊞ inside F | bounded modulo- arithmetic | Tier-2 micro-S-box fabric |
| LFSR modulo- correction | bounded arithmetic / correction | Tier-2 + Tier-3 support |
| Bit reorganization | bit/word permutation | Tier-3 P-box / routing fabric |
| fixed linear diffusion | Tier-3 linear fabric | |
| Output and internal XORs | affine/XOR mixing | Tier-3 XOR fabric |
| Initialization sequencing | state loading + control + work-mode transition | control plane + Tier-2/Tier-3 support |
2.3.7. Public Cryptanalytic Context
The public analysis literature has examined ZUC-256 from several angles. The spectral-analysis work cited by the user is one of the public works studying distinguisher-oriented analysis of ZUC-256, and later public observations reported efficient binary approximations of the FSM with empirical correlation around , while also discussing derived distinguisher and correlation-attack considerations at complexities still far above practical deployment targets [64,65]. These results are important for architectural awareness, but they do not change the standards-family role of ZUC-256 as a candidate 256-bit mobile-security primitive.
ZUC-256 differs from AES-256 and Snow 5G / SNOW-V-class in that its nonlinear core is relatively small and highly localized, while much of its state evolution is governed by structured BR routing, fixed linear maps, and prime-field LFSR recurrences. This makes it particularly attractive for a shared box-centric hardware substrate: Tier-1 captures the native ZUC S-box reuse, Tier-2 captures arithmetic and correction micro-slices, and Tier-3 captures BR, XOR, linear maps, and state transport. The 2021 addendum further strengthens its engineering relevance by providing a direct 256-bit key / 128-bit IV initialization scheme aligned with contemporary mobile-system expectations [32,63].
3. Proposed CryptoProcessor: Methodological Architecture Description
3.1. Scope, Purpose, and Design Stance
This section depicts the proposed TALOS 6G CryptoProcessor research program: to derive an exact operator taxonomy for AES-256, Snow 5G / SNOW-V-class, and ZUC-256; to identify which operators remain native S-boxes, which must be compiled into micro-S-boxes, and which are best realized as shared permutation/linear fabrics; and to define the final box-centric 3-tier substrate.
The key design stance is that the phrase fully and solely S-boxes and P-boxes is used here in an expanded hardware sense: all bounded nonlinear subfunctions are realized exactly as native or micro-S-boxes, while all linear, affine, routing, and diffusion operators are realized by a configurable P-box/linear fabric. This preserves technical rigor for AES-256 and makes the same statement exact, though compiled rather than natural, for the SNOW 5G/SNOW-V-class and ZUC-256.
The common datapath philosophy inherited from the earlier 4G LTE CryptoProcessor work, (ii) the motivation to transform core algebraic functions into reusable S-box and P-box structures, (iii) the Murphy–Robshaw algebraic interpretation of AES, (iv) NIST FIPS 197 for AES-256, (v) the public SNOW-V design paper, (vi) the ZUC-256 addendum and public structural analyzes, and (vii) the 3GPP Series-35 256-bit algorithm-family baseline.
3.2. Brief Abbreviation
The central methodological result is that AES-256, the SNOW 5G/SNOW-V class, and ZUC-256 can be placed on a single shared hardware substrate, but not at the same semantic depth. AES-256 is naturally substitution–permutation based. Snow and ZUC-256 are stateful stream ciphers whose arithmetic and state-update structures must be compiled into the same substrate through bounded nonlinear decomposition, lane-sliced arithmetic boxification, and shared linear fabrics.
Accordingly, the proposed substrate is organized as follows:
- Tier 1 native S-box bank: exact cryptographic substitution components that already exist as canonical nonlinear tables or affine–inversion compositions.
- Array of tier 2 micro-S-box arithmetic libraries: realizations of the exact truth-table of bounded nonlinear arithmetic slices, especially addition, carry, and correction subfunctions.
- Tier 3 shared P-box / linear fabric: configurable byte and bit permutations, rotations, affine maps, finite-field constant multipliers, tap extraction, and routing.
The resulting architecture is exact at the operator level and implementation-oriented at the hardware level. It forms the analytical basis for Step A.2, where the box library can be minimized, clustered, physically scheduled, and evaluated under area, latency, throughput, and side-channel constraints.
3.3. Source Basis and Cryptographic Scope
The project scope is a 6G-oriented 256-bit symmetric-core substrate spanning three candidate primitives: AES-256, Snow 5G / SNOW-V-class, and ZUC-256. The purpose is not to claim that 6G standardization has fixed its final cipher suite, but to show that the already existing 256-bit AES, Snow, and ZUC-family algorithm sets provide a technically serious working baseline for a future symmetric cryptographic core.
The abstract state / output model used throughout this section is as follows.
The goal of Step A.1 is to decompose the transition and output function F of each cipher into bounded nonlinear blocks and linear, affine or routing blocks and then map them to the proposed 3-tier substrate.
Figure 5.
Step A.1 compiler flow extracted from the design draft.

3.4. Formal Step A.1 Methodology
3.4.1. Definitions
Native S-box. A standard nonlinear substitution component already present in a cipher specification or algebraically derivable as a closed or substitution mapping.
Micro-S-box. A bounded nonlinear truth-table component introduced by the compiler to realize arithmetic or mixed-domain logic exactly. Typical widths are 1-bit, 4-bit, 8-bit, or nibble-plus-carry slices.
P-box / linear fabric. A configurable network implementing pure permutation, routing, rotation, byte shuffling, affine linear mapping, XOR, fixed-coefficient multiplication over a finite field, or any composition thereof.
3.4.2. Classification Rule
If an operator is nonlinear and its input width is naturally small, keep it in Tier 1. If an operator is nonlinear because of carry propagation, modular correction, or mixed-domain compression, decompose it into bounded slices and place the slices in Tier 2. If an operator is linear, affine, or purely positional, place it in Tier 3. If a large operator mixes linear and nonlinear pieces, split it until every primitive is exclusively nonlinear-bounded or linear/affine.
3.4.3. Exactness Rule
Every bounded nonlinear map
is realizable exactly as a lookup-based S-box. Every linear / affine map of the form
is realizable exactly as a configurable linear fabric.
3.4.4. Expanded Interpretation of P-box
Classical P-boxes are pure permutations. In TALOS, the term P-box / linear fabric is intentionally broader: it includes permutations, rotations, concatenations, matrix-based diffusion, constant multipliers, XOR meshes, and bit-reorganization planes. This broader definition is necessary to handle Snow and ZUC-256 without loss of accuracy.
3.4.5. Bounding Principle
Use native tables for AES and ZUC byte substitutions. Use 1-bit or 4-bit carry slices for additions. Do not boxify large sparse linear transforms into giant lookup tables when a sparse shared linear fabric is cheaper and clearer. Merge consecutive linear stages aggressively, but never across nonlinear boundaries.
Figure 6.
Final 3-tier S/P substrate extracted from the design draft.

3.5. Exact Operator Taxonomy for AES-256
AES-256 is the natural anchor of the box-centric methodology. FIPS 197 defines AES-256 with rounds and keywords; operationally,
The AES S-box can be summarized as follows.
followed by the affine output bit relation;
ShiftRows is
and MixColumns uses the fixed matrix;
AddRoundKey is simply
Table 16.
Exact operator taxonomy for AES-256
| AES-256 operator | Role | Exact nature | Tier | Reason |
|---|---|---|---|---|
| SubBytes | confusion | nonlinear bijection | Tier 1 | Native AES S-box |
| InvSubBytes | decryption confusion | nonlinear bijection | Tier 1 | Optional inverse table |
| ShiftRows | diffusion / routing | byte permutation | Tier 3 | Pure P-box |
| MixColumns | diffusion | linear matrix | Tier 3 | Sparse shared linear fabric |
| AddRoundKey | affine injection | bitwise XOR | Tier 3 | Pure affine fabric |
| SubWord | key-schedule nonlinearity | 4 parallel AES S-boxes | Tier 1 | Reuses NSB_AES |
| RotWord | routing | word rotation / byte permutation | Tier 3 | Pure P-box |
| Rcon injection | affine constant injection | XOR constant | Tier 3 | Pure affine fabric |
AES-256 therefore aligns almost perfectly with the desired box-centric substrate. The Tier 2 is unnecessary in the forward datapath unless arithmetic-only implementation variants are introduced. The dominant split is Tier 1 for the native substitution bank and Tier 3 for the permutation, matrix, and key-injection fabrics.
3.6. Exact Operator Taxonomy for Snow 5G / SNOW-V-class
The public SNOW-V design preserves the decomposition of the SNOW-family into an LFSR part and an FSM part. The two field-defining polynomials are
The LFSR recurrences are
The keystream and FSM updates are
with
Table 17.
Exact operator taxonomy for Snow 5G / SNOW-V-class
| Snow operator | Role | Exact nature | Tier | Reason |
|---|---|---|---|---|
| LFSR-A recurrence | state update | linear recurrence over | Tier 3 | Constant multipliers are linear |
| LFSR-B recurrence | state update | linear recurrence over | Tier 3 | Constant multipliers are linear |
| Tap extraction | routing | word concatenation / register selection | Tier 3 | Pure P-box routing |
| mixing | XOR | Tier 3 | Pure linear fabric | |
| ADD32_4LANE in FSM |
mixing | 4 parallel 32-bit additions |
Tier 2 | Carry-bearing arithmetic |
| output function | addition plus XOR | Tier 2 + Tier 3 |
Addition in Tier 2, XOR in Tier 3 |
|
| AESR in FSM | nonlinear / diffusion macro |
SubBytes + ShiftRows + MixColumns |
Tier 1 + Tier 3 |
Reuses AES substrate |
| permutation | routing / diffusion |
byte transposition | Tier 3 | Pure P-box |
Snow is not a natural SPN, but one full step cleanly decomposes into shared linear fabrics, Tier 2 lane-wise arithmetic boxification for the 4-lane additions, and Tier / Tier 3 reuse of the round substrate AES inside AESR.
3.7. Exact Operator Taxonomy for ZUC-256
ZUC-256 preserves the classic decomposition into a 16-stage LFSR, bit reorganization, and a nonlinear F function. Let us
The path of the LFSR coefficient is summarized by
The bit-reorganization words are
The output and FSM relations are
where
Table 18.
Exact operator taxonomy for ZUC-256
| ZUC-256 operator | Role | Exact nature | Tier | Reason |
|---|---|---|---|---|
| 31-bit LFSR shift | state transport | positional shift | Tier 3 | Pure routing |
| Coefficient multiplication by | linear recurrence | constant multiply in | Tier 3 | Rotation/wiring plus coefficient path |
| Prime-field correction / zero-remap | state update correction | bounded arithmetic | Tier 2 + Tier 3 | Requires correction slices |
| BR extraction | routing | bit slicing + concatenation | Tier 3 | Pure P-box |
| XOR mix in F | mixing | XOR | Tier 3 | Pure linear fabric |
| ADD32 in F and output | mixing | 32-bit modular addition | Tier 2 | Carry-bearing nonlinear arithmetic |
| diffusion | 32x32 linear transforms | Tier 3 | Rotation/XOR fabric | |
| and | confusion | native substitutions | Tier 1 | Keep as exact native boxes |
| composed confusion | 32x32 juxtaposed S-box bank | Tier 1 | Direct composed bank |
ZUC-256 therefore fits the 3-tier substrate exactly if the prime-field coefficient path and BR// logic are assigned to Tier 3, the modulo- and modulo- correction logic to Tier 2, and the native ZUC substitutions to Tier 1.
3.8. Cross-Cipher Commonality Matrix
Table 19.
Cross-cipher commonality matrix
| Reusable kernel | AES-256 | Snow | ZUC-256 | Implementation note |
|---|---|---|---|---|
| 8x8 AES S-box | Yes | Yes inside AESR | No | Tier 1 NSB_AES |
| 8x8 ZUC | No | No | Yes | Tier 1 NSB_ZUC0 |
| 8x8 ZUC | No | No | Yes | Tier 1 NSB_ZUC1 |
| Byte permutation engine | Yes | Yes | Limited | ShiftRows, , routing |
| 32-bit modular adder slices | No | Yes | Yes | Shared Tier 2 macro |
| constant-multiply fabric | No | Yes | No | Snow-only Tier 3 |
| coefficient path | No | No | Yes | ZUC-only Tier 3/Tier 2 |
| XOR / key injection fabric | Yes | Yes | Yes | Shared Tier 3 mesh |
| Mode / schedule controller | Yes | Yes | Yes | Shared top-level control plane |
The strongest sharing opportunities are therefore not all nonlinear tables merged into one literal mega-table, but AES S-box reuse across AES and Snow’s AESR path, modular-adder micro-slice reuse across Snow and ZUC, and a unified byte/bit permutation and XOR fabric across all three ciphers.
3.9. Final 3-Tier S/P Logic and Canonical Box Library
The final output of Step A.1 is a named box library.
3.9.1. Tier 1 native S-box bank
- NSB_AES: exact AES S-box, , used 16-way in SubBytes and 4-way in SubWord.
- NSB_InvAES: optional inverse AES S-box for decrypting datapaths.
- NSB_ZUC0: exact ZUC native substitution table or logic.
- NSB_ZUC1: exact ZUC native substitution table or logic.
- NSB_ZUC32: composed bank that implements as four native parallel tables.
- NSB_AESR16: fully composed macro-organization of 16 parallel NSB_AES instances feeding the AES ShiftRows/MixColumns linear fabric inside Snow’s AESR path.
3.9.2. Tier 2 micro-S-box arithmetic library
- muSB_FA: 1-bit full-adder slice, exact map .
- muSB_ADD4: 4-bit ripple or carry-look-ahead slice built from muSB_FA cells.
- muSB_ADD8: optional 8-bit slice for speed/area trade-offs.
- muSB _ADD32 _4LANE: macro using 4 independent 32-bit addition lanes; reused by Snow and ZUC.
- muSB_MODP31_CORR: bounded correction slice realizing the prime-field correction behavior of ZUC’s LFSR update path.
3.9.3. Tier 3 shared P-box / linear fabric catalogue
- P _AES _SHIFTROWS: 16-byte permutation implementing AES ShiftRows:
- LF _AES _MIXCOL: shared byte-matrix linear fabric for MixColumns.
- P_sigma: Snowbyte-permutation and transposition fabric:
- LF _GF16 _A and LF _GF16 _B: Snow constant-multiply fabrics for , , and .
- P _TAP _SNOW: extraction and packing fabric for and words from LFSRs.
- P _BR _ZUC: ZUC bit-reorganization fabric implementing extraction.
- LF _ZUC _L1 and LF _ZUC _L2: 32-bit rotation/XOR diffusion fabrics.
- LF _ZUC _P31: ZUC prime-field coefficient path for multipliers , , , , and .
- LF _XOR _KEY: shared XOR/ affinity constant/round-key injection mesh.
After Step A.1, the final architecture is neither AES plus adapters nor a single giant universal table. It is a disciplined mixed library in which exact nonlinear operations are isolated cleanly from shared sparse linear logic.
3.10. Pseudocode for Step A.1 Compilation and Box Realization
| Algorithm 7:CANONICAL_BOXIFY(CipherSpec) |
|
| Algorithm 8:AES256_ROUND_BOXIFIED(State, RoundKey) |
|
| Algorithm 9:SNOWV_STEP_BOXIFIED(A, B, , , ) |
|
| Algorithm 10:ZUC256_STEP_BOXIFIED(S[0..15], , ) |
|
| Algorithm 11:BUILD_FINAL_LIBRARY() |
|
3.11. Equivalence Obligations, Security Notes, and Implementation Cautions
The compiler and hardware mapping must satisfy the following obligations:
- AES: prove round-by-round equivalence against FIPS 197 test vectors.
- Snow: preserve exact cycle timing and lane separation for ADD32_4LANE and recurrences.
- ZUC: preserve exact BR extraction, transforms, , and prime-field correction semantics.
A unified substrate reduces the area only if control muxing and retiming overhead do not dominate. If physical resistance to the side-channel is a target, shared fabrics require mode-aware masking or hiding strategies.
This methodology is stronger than a naive single-universal-table claim because a monolithic table across all nonlinear and linear logic would be exact but impractical. Step A.1 replaces that naive claim with a constructive and implementable rule: exact nonlinear pieces go to native or micro-S boxes; exact linear and affine pieces go to sparse shared fabrics.
3.12. TALOS Architectural Components
The TALOS architectural organization is conceived as a processor-oriented symmetric-security engine that preserves the integration logic of the earlier universal mobile CryptoProcessor paradigm while adapting it to a 6G-oriented, 256-bit, multi-cipher operating envelope. In that earlier architecture, the system was explicitly organized as a processor-like structure with datapath, memory, I/O interface, and control logic, and it integrated encryption, integrity, authentication, and key-related processing under one hardware framework. TALOS retains that integration philosophy, but replaces the earlier cipher-family coupling with a new exact operator-level substrate that spans AES-256, Snow 5G/SNOW-V-class, and ZUC-256. The result is a unified hardware organization in which reuse is no longer expressed only as coarse core aggregation, but as structured reuse at the level of nonlinear substitution, bounded arithmetic, and linear or positional transport.
3.12.1. Global TALOS System Organization
At the top level, TALOS is organized as a compact cryptographic processing system containing a host/system interface, internal control logic, shared memory resources, a unified symmetric-core execution fabric, and dedicated service-facing support paths. This choice follows the earlier universal security architecture principle in which the CryptoProcessor must behave as an embedded engine rather than as a loose collection of standalone cipher accelerators. In TALOS, the external system interface is responsible for accepting plaintext, ciphertext, key, IV, nonce, and security-context traffic from a host processor or adjacent platform logic, while the internal control plane performs cipher/mode selection, scheduling, and state supervision. Memory resources provide storage for keying material, intermediate states, microcode or configuration words, and temporary buffers required by high-throughput operation. This processor-style decomposition is essential because the target 6G environment requires not only raw confidentiality throughput, but also configuration agility, deterministic state management, and hardware-visible support for integrity- and authentication-related procedures.
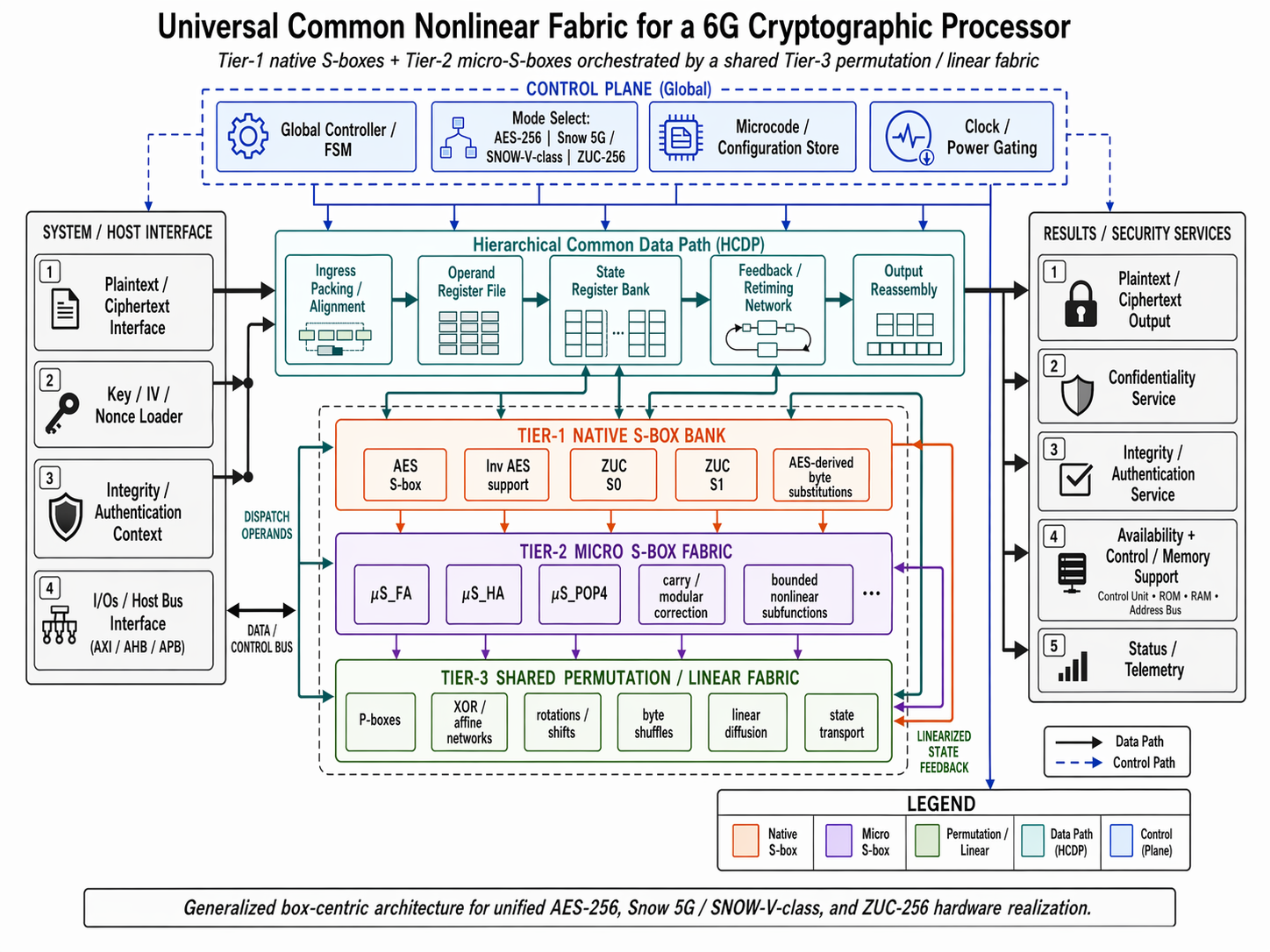
Figure 7.
3-Tier Encapsulation of Shared Reusable Hardware Resources.

3.12.2. TALOS Unified Symmetric-Core Engine
The central computation block of TALOS is the unified symmetric-core engine, which generalizes the earlier Universal Security Architecture Encryption Unit concept into a 6G-ready shared substrate. In the 4G architecture, the encryption unit was explicitly divided into a common data path sub-unit and a common S-box indexation module, reflecting the two major reuse mechanisms of the design. TALOS preserves exactly this architectural insight, but redefines both mechanisms at a finer and more rigorous level. The former common data path concept becomes the Hierarchical Common Data Path (HCDP), which governs operand movement, state-bank access, retiming, routing, output reassembly, and recursive state transport across all supported cipher families. The former common S-box concept becomes a broader box-centric execution substrate consisting of a Tier-1 Native S-box Bank, a Tier-2 Micro-S-box Arithmetic Fabric, and a Tier-3 Shared Permutation / Linear Fabric. In this sense, TALOS should not be understood as a set of complete cipher cores placed side-by-side, but rather as a controlled execution environment in which cipher-specific behavior is synthesized from shared primitives of the appropriate semantic depth.
Figure 8.
The Universal 6G Security Architecture for the proposed CryptoProcessor.

3.12.3. Hierarchical Common Data Path
The HCDP is the principal state-and-transport backbone of TALOS. Its architectural role is analogous to the earlier Common Data Path Hardware Block, which was introduced to emulate common bitwise shifts and shared transport behavior across multiple ciphers. In TALOS, however, the datapath abstraction is expanded far beyond simple common shift support. The HCDP contains ingress packing and alignment logic, operand register files, state register banks, dispatch control toward the 3-tier fabric, feedback and retiming networks, and output reassembly logic. Its purpose is to provide one disciplined movement and scheduling plane for all three target cipher families, regardless of whether the active operation is block-cipher round processing, stream-cipher state evolution, finite-field state transport, or integrity-supporting post-processing. This common datapath is therefore not just a wiring convenience, but the structural condition that allows exact operator-level reuse to remain implementable at RTL scale. Without it, the 3-tier substrate would degrade into disconnected local optimizations instead of a coherent unified architecture.
Figure 9.
The UCSB/UCNF hardware components for the proposed CryptoProcessor.

3.12.4. Tier-1 Native S-box Bank
Tier-1 contains the exact native nonlinear substitution resources that already exist in canonical cipher form. This role is the direct architectural successor of the earlier Common S-box Indexation Module, which unified multiple cipher S-box contents into a single addressable substitution resource implemented in ROM together with pointer or index support. TALOS generalizes that idea without forcing all nonlinear behavior into one literal mega-table. Instead, Tier-1 stores or performs only those substitutions that are already natural, standard, and cryptographically canonical. For the TALOS target set, this includes the AES forward and inverse substitution resources, the native ZUC substitution layers, and the AES-derived byte-level nonlinear reuse needed by the Snow 5G/SNOW-V class family. Tier-1 is therefore the exact repository of native nonlinear constants, and it is accessed through control-visible selection logic rather than through duplicated per-cipher substitution units. This is the appropriate architectural level at which the earlier universal-common-S-box philosophy survives in TALOS.
3.12.5. Tier-2 Micro-S-box Arithmetic Fabric
Tier-2 is new relative to the earlier 4G architecture and constitutes one of the key methodological advances of TALOS. It is introduced because Snow 5G/SNOW-V class and ZUC-256 contain bounded nonlinear arithmetic behavior that is exact but not naturally expressible as a native cryptographic substitution box. The Step A.1 draft formalizes this need by defining the micro-S-box as a bounded truth-table component created by the compiler in order to realize carry-bearing, modular-correction, or mixed-domain arithmetic exactly. Typical examples include full-adder slices, bounded lane-wise modular addition, popcount-style compression fronts, and prime-field correction fragments. In TALOS, these micro-S-boxes are grouped into a shared arithmetic fabric so that repeated bounded nonlinear subfunctions are not duplicated separately inside each cipher realization. This is particularly important for modular-addition reuse between Snow and ZUC, and for exact correction-bearing arithmetic required by ZUC prime-field state evolution. Tier-2 is therefore the architectural bridge between native substitution logic and shared linear fabrics.
3.12.6. Tier-3 Shared Permutation and Linear Fabric
Tier-3 implements the shared positional, affine, and linear operators required by the target cipher families. The Step A.1 draft explicitly broadens the interpretation of the P-box so that it includes not only classical permutations, but also rotations, concatenations, byte shuffles, XOR meshes, affine maps, matrix-based diffusion, fixed-coefficient multiplication over finite fields, tap extraction, bit reorganization, and routing planes. This broader definition is mandatory for TALOS because the SNOW 5G/SNOW-V class and ZUC-256 would otherwise require separate hardwired fabrics for state extraction, finite-field recurrence, and structured diffusion. Tier-3 therefore absorbs AES ShiftRows and MixColumns-class transport/diffusion behavior, Snow byte transposition and finite-field constant multiplication paths, and ZUC bit-reorganization and fixed linear diffusion layers. It is the most expansive of the three tiers and is responsible for the most exact reuse of cross-cipher transport. In architectural terms, Tier-3 is the modern replacement for the older common data path segments that were selected across the cipher cores; the difference is that TALOS makes reuse explicit, named, and compilable.
3.12.7. Integrity-Supporting and Authentication-Supporting Service Units
The earlier architecture separated encryption from integrity and authentication processing through dedicated Reconfigurable Integrity Unit and Reconfigurable Authentication Unit blocks, each controlled according to the selected procedure and each coupled bidirectionally to the system data bus. TALOS retains that separation at the service level, but adapts it to a 6G symmetric-core setting. Rather than binding the integrity- and authentication-supporting logic to legacy UIA/UEA algorithm families, TALOS defines dedicated service-facing units that consume the output of the unified symmetric-core engine and, under control-plane supervision, execute the required integrity-supporting, authentication-supporting, or availability-supporting procedures associated with the selected operating mode. Their architectural role is to keep the symmetric-core substrate focused on exact reusable cryptographic primitives while allowing higher-level security services to be attached without disturbing the shared datapath and box library. This preserves the modularity of the earlier RIU/RAU philosophy while making it compatible with the much richer cipher heterogeneity and control requirements of the TALOS platform.
3.12.8. Architectural Significance for TALOS
The architectural importance of TALOS lies in the fact that it converts the earlier universal-architecture intuition into a stricter, more exact, and more scalable hardware taxonomy. The original design demonstrated that common S-box content and common datapath behavior could reduce area and increase efficiency when compared with atomic per-cipher integration. TALOS extends this principle by recognizing that exact unification is only possible if reuse is separated by operator class. Native substitutions must remain native, bounded arithmetic nonlinearities must be box-compiled into micro-S-box slices, and linear or positional behavior must be absorbed into a shared configurable fabric. The TALOS architectural component hierarchy is therefore not only a block-level design proposal but also the physical interpretation of the Step A.1 methodology. It transforms common-datapath reuse and common-substitution reuse from heuristic implementation tricks into first-class architectural components suitable for a unified 6G CryptoProcessor.
3.13. TALOS Architectural Aftermath
Step A.1 is complete at the architectural-methodology level. AES-256 maps naturally to the box substrate with a dominant split of Tier 1 / Tier 3. Snow maps exactly using shared linear fabrics, native reuse of AES and Tier 2 arithmetic slicing. ZUC-256 maps exactly via native ZUC substitutions, Tier 2 arithmetic and correction slices, and Tier 3 BR, XOR, and linear recurrence fabrics. The resulting methodological description is therefore sufficient to justify a unified 3-tier CryptoProcessor substrate for TALOS.
For completeness, the following selected exact equations are retained from the draft:
Table 20.
Final named S-boxes and P-boxes
| Name | Tier | Function class | Used by |
|---|---|---|---|
| NSB_AES | Tier 1 | Exact AES substitution | AES-256, Snow |
| NSB_InvAES | Tier 1 | Exact inverse AES substitution | AES decrypt |
| NSB_ZUC0 | Tier 1 | Exact ZUC | ZUC-256 |
| NSB_ZUC1 | Tier 1 | Exact ZUC | ZUC-256 |
| NSB_ZUC32 | Tier 1 | Composed |
ZUC-256 |
| muSB_ADD32_4LANE | Tier 2 | 4-lane 32-bit modular add macro |
Snow, ZUC-256 |
| muSB_MODP31_CORR | Tier 2 | Prime-field correction slice | ZUC-256 |
| P_AES_SHIFTROWS | Tier 3 | AES byte permutation | AES-256, Snow |
| LF_AES_MIXCOL | Tier 3 | AES linear diffusion matrix | AES-256, Snow |
| P_sigma | Tier 3 | Snow byte transposition | Snow |
| P_BR_ZUC | Tier 3 | ZUC bit reorganization | ZUC-256 |
| LF_ZUC_L1 / LF_ZUC_L2 |
Tier 3 | ZUC rotation/XOR diffusion | ZUC-256 |
4. Hardware Performance and Efficiency Analysis
This section evaluates the RTL-level hardware behavior of the proposed TALOS architecture against the non-optimized 6G CryptoProcessor baseline. The baseline instantiates isolated cipher-oriented execution resources for AES-256, Snow 5G/SNOW-V class and ZUC-256, while TALOS replaces this coarse replication model with a Hierarchical Common Data Path (HCDP) and a shared Tier-1 / Tier-2 / Tier-3 execution substrate. The profiling results in Figure 10–Figure 11 therefore quantify the practical effect of the proposed operator-exact reuse methodology on latency, cycle behavior, resource footprint, timing closure, throughput, and composite efficiency.
Figure 10.
Last-operation latency comparison in different cipher modes.

The RTL counter profiles show that TALOS reduces the dynamic execution cost for all supported cipher modes. For a fixed profiling run of 1024 processed blocks, the total cycle counter decreases by for AES-256, for Snow-V-256 and for ZUC-256. The last-operation latency counter follows the same trend, decreasing from 14 to 11 cycles for AES-256, from 17 to 14 cycles for Snow-V-256, and from 33 to 26 cycles for ZUC-256. These correspond to latency reductions of , , and , respectively. This behavior confirms that the TALOS HCDP does not merely reduce structural redundancy; it also shortens the effective cipher execution schedule by allowing common routing, retiming, substitution access, arithmetic micro-slices, and output reassembly to be coordinated through a single optimized control/data-movement plane.
Figure 11.
Cycle-count comparison per cipher mode.

Figure 12.
LUT and FF utilization comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture.
Figure 12.
LUT and FF utilization comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture.

Figure 13.
Timing-profile comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture. The and WNS results highlight the improved timing margin achieved by the shared HCDP and three-tier execution substrate.
Figure 13.
Timing-profile comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture. The and WNS results highlight the improved timing margin achieved by the shared HCDP and three-tier execution substrate.

The area profiles further demonstrate the advantage of the TALOS sharing strategy. At the per-mode level, LUT usage is reduced by for AES-256, for Snow-V-256, and for ZUC-256, while FF usage is reduced by , , and , respectively. At the full-package level, where the non-optimized baseline corresponds to an aggregate three-core structure and TALOS corresponds to a unified shared-core package, total LUT usage decreases by , and total FF usage decreases by . BRAM and DSP usage remain effectively unchanged in the reported profile set, indicating that the observed savings are primarily due to logic-level architectural reuse rather than a shift of complexity into memory macros or dedicated arithmetic blocks. This is important for Artix-7-class FPGA deployment because LUT/FF pressure is often the dominant limiting factor in compact CryptoProcessor integration. As shown in Figure 12, TALOS reduces LUT and FF utilization relative to the unoptimized baseline.
Timing behavior also improves under the TALOS organization. The estimated maximum frequency per-mode increases by , , and for AES-256, Snow-V-256, and ZUC-256, respectively. At the package level, the estimated increases by , while the worst negative slack improves from 0.301 to 0.940 ns. The corresponding package-level WNS improvement is numerically large () because the baseline slack is small; nevertheless, the absolute increase is architecturally significant because it indicates that TALOS improves the timing margin despite supporting all three cipher families through a unified fabric. The total negative slack remains zero in both profilers, suggesting that both designs satisfy the assumed timing target, with TALOS offering a stronger closure margin (see Figure 13).
The throughput results are the clearest expression of the HCDP benefit. At 100 MHz, TALOS improves throughput by for AES-256, for Snow-V-256, and for ZUC-256. Under the peak-frequency estimates per-mode, throughput improves by , , and , respectively. In package , the unified TALOS design achieves mode throughput improvements of for AES-256, for Snow-V-256 and for ZUC-256, with an average multi-mode throughput-envelope improvement of . These gains result from the simultaneous reduction of latency cycles and improvement of timing margin, validating the central TALOS claim that exact operator-level sharing can improve both area and throughput rather than trading one for the other (see Figure 14).
Figure 14.
Peak mode-throughput comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture across AES-256, Snow-V-256, and ZUC-256. The results demonstrate the throughput gain achieved by the HCDP-driven shared three-tier execution substrate.
Figure 14.
Peak mode-throughput comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture across AES-256, Snow-V-256, and ZUC-256. The results demonstrate the throughput gain achieved by the HCDP-driven shared three-tier execution substrate.

The power and composite efficiency profiles further strengthen this conclusion. The estimated power of the package on the chip decreases by , while the area performance product (ATP) improves by for AES-256, for Snow-V-256, and for ZUC-256. The corresponding EAT proxy improves by , , and , respectively. At the package level, TALOS improves the average ATP proxy by and the average EAT proxy by . These results indicate that the proposed three-tier architecture is not only smaller and faster but also substantially more efficient under the joint energy-area-throughput evaluation.
Figure 15.
Full-package hardware profiling comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture.
Figure 15.
Full-package hardware profiling comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture.

Overall, the profiling campaign supports the conclusion that TALOS provides a highly favorable hardware-efficiency envelope for 6G-oriented symmetric CryptoProcessor design, achieving lower resource costs, improved timing closure, higher throughput, and stronger composite efficiency than the non-optimized baseline (see Figure 16 and Figure 15).
The package-level profiling matrix in Figure 15 provides a consolidated view of the architectural impact of TALOS when the complete multi-cipher CryptoProcessor is evaluated as a unified hardware package rather than as isolated cipher instances. The resource-utilization profile shows that the optimized design reduces the aggregate LUT and FF footprint relative to the non-optimized baseline, confirming that the HCDP and the Tier-1 / Tier-2 / Tier-3 reusable substrate eliminate redundant per-cipher logic. The timing and power profile further indicate that this reduction does not come at the expense of timing closure; instead, TALOS improves the effective package-level timing margin while also reducing the estimated on-chip power. This behavior is consistent with the intended architectural role of TALOS: shared nonlinear, arithmetic, and linear/permutation resources reduce structural duplication, while centralized dispatch and retiming reduce unnecessary switching activity and improve datapath regularity.
The throughput and composite-efficiency profiles summarize the main hardware advantage of the proposed architecture. TALOS increases the throughput of package mode in AES-256, Snow-V-256, and ZUC-256 while simultaneously improving the efficiency envelopes for area and energy area throughput. Therefore, the observed gains are not isolated to a single metric; they are multi-dimensional and affect area, timing, power, throughput, and composite efficiency at the same time. Overall, the profile results support the analysis.
Figure 16.
Estimated on-chip power comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture across AES-256, Snow-V-256, and ZUC-256 modes. TALOS reduces the power profile through shared hardware reuse, reduced redundant switching, and HCDP-driven execution coordination.
Figure 16.
Estimated on-chip power comparison between the non-optimized baseline CryptoProcessor and the TALOS-optimized architecture across AES-256, Snow-V-256, and ZUC-256 modes. TALOS reduces the power profile through shared hardware reuse, reduced redundant switching, and HCDP-driven execution coordination.

The central claim of this work is that a 6G CryptoProcessor should not be implemented as a simple aggregation of independent cipher cores, but rather as a disciplined, operator-exact reusable architecture. By separating native substitution, bounded arithmetic, and linear/permutation transport into distinct reusable tiers, TALOS achieves a more compact, faster, and more energy-efficient hardware realization suitable for future crypto-agile 6G symmetric-security engines.
5. Conclusions
This paper presents TALOS, a unified and reusable 6G CryptoProcessor architecture designed around a 256-bit private-key security baseline comprising AES-256, Snow 5G/SNOW-V class, and ZUC-256. The main contribution of TALOS is not merely the integration of multiple cipher families into a single hardware platform but the introduction of an operator-exact architectural methodology that separates reusable cryptographic functionality into three disciplined tiers: native nonlinear substitutions, bounded arithmetic micro-S-boxes, and shared permutation/linear fabrics. This 3-tier decomposition, coordinated by the Hierarchical Common Data Path, enables cipher heterogeneity to be handled without forcing structurally different primitives into an artificially monolithic representation.
TALOS advances beyond conventional multi-core CryptoProcessor integration by replacing duplicated per-cipher datapaths with a reusable 3-tier execution substrate coordinated by the HCDP. Tier-1 preserves exact native S-box behavior, Tier-2 captures carry- and correction-bearing arithmetic nonlinearities, and Tier-3 consolidates XOR, affine, rotation, routing, diffusion, and state-transport operations, enabling a cryptographically faithful yet hardware-efficient architecture. The RTL profiling results further validate this design philosophy, showing that TALOS consistently reduces cycle count, latency, LUT/FF footprint, and estimated power while improving timing margin, throughput, area–throughput efficiency, and EAT-oriented composite efficiency, thereby demonstrating a stronger overall hardware-efficiency envelope for crypto-agile symmetric processing in future 6G systems.
In summary, TALOS establishes a new methodological and architectural foundation for unified 6G symmetric cryptographic hardware. By combining exact operator taxonomy, reusable HDL-visible structures, and performance-oriented datapath coordination, TALOS provides a scalable framework for future secure, efficient, and crypto-agile 6G implementations. Future work will focus on full test-vector conformance, side-channel-aware hardening, ASIC-oriented synthesis, deeper pipeline exploration, and the integration of authenticated-encryption service layers under the same reusable architectural substrate.
Author Contributions
Conceptualization, A.N.B.; methodology, A.N.B.; formal analysis, A.N.B.; investigation, A.N.B.; writing—original draft preparation, A.N.B.; writing—review and editing, A.N.B.; supervision, A.N.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data and source code supporting the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Exact Tier-1 and Tier-2 Box Library for TALOS
This appendix consolidates the exact Tier-1 and Tier-2 box material used by the proposed 3-tier TALOS CryptoProcessor architecture. Tier-1 contains the exact native substitution tables directly reused by the architecture, namely the AES forward S-box, AES inverse S-box, ZUC and ZUC . Tier-2 contains the exact arithmetic micro-box templates used to compile bounded carry-bearing logic into box form. Local permutation templates are also included because the compilation flow requires compact, exact wire maps along with the micro-box arithmetic stage.
In the proposed methodology, the logic of the SNOW 5G / SNOW-V class reuses the AES round function and therefore does not introduce a distinct standalone Tier-1 table beyond AES. The Tier-2 outputs for HA and FA are encoded as
while the compressor outputs the population count of the 4-bit input as a single hexadecimal digit . The Tier-2 local P-box templates are exact wiring templates proposed for the architecture and are not cipher-standard tables.
Appendix A.1. Appendix-Level Structural Rationale
The necessity of this appendix is architectural rather than merely documentary. A unified, reusable 6G CryptoProcessor cannot be justified only by high-level block reuse claims; it must expose the exact primitive tables and exact bounded arithmetic templates that are visible to the compiler and to the RTL realization. The present appendix therefore serves three purposes:
- 1.
- fixes the exact native nonlinear tables reused by TALOS in Tier-1;
- 2.
- fixes the exact bounded arithmetic micro-boxes reused by TALOS in Tier-2;
- 3.
- fixes the exact local wiring templates used to normalize or fold local arithmetic outputs before propagating to the shared Tier-3 linear fabric.
This is precisely the level at which the proposed 3-tier abstraction becomes implementable rather than remaining a purely conceptual categorization.
Table A1.
Symbols and abbreviations used in this appendix
| Symbol | Meaning |
|---|---|
| Tier-1 | Native cryptographic substitution layer |
| Tier-2 | Arithmetic micro-S-box layer for bounded nonlinear slices |
| Tier-3 | Shared permutation / linear fabric layer |
| Half-adder micro-box | |
| Full-adder micro-box | |
| 4-bit population-count compressor | |
| S | AES forward S-box |
| AES inverse S-box | |
| ZUC native 8-bit substitution tables | |
| Local interleaving P-box for sums/carries | |
| Local ripple-alignment P-box | |
| Local end-around carry fold P-box | |
| dest←source | Destination wire receives source wire mapping |
| HEX mapping | Hexadecimal indexing of the exact local permutation |
Figure A1.
Appendix-level view of the exact box library used by TALOS. Tier-1 fixes native nonlinear constants, Tier-2 fixes bounded arithmetic nonlinear templates, and Tier-3 support fixes exact local wiring templates required by compiled box realizations.
Figure A1.
Appendix-level view of the exact box library used by TALOS. Tier-1 fixes native nonlinear constants, Tier-2 fixes bounded arithmetic nonlinear templates, and Tier-3 support fixes exact local wiring templates required by compiled box realizations.

Appendix A.2. Tier-1 Native 8×8 Substitution Tables
Indexing convention. Row index = upper nibble, column index = lower nibble, and each cell contains the exact 8-bit hexadecimal substitution value.
Table A2.
Tier-1 AES forward S-box S
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 7C | 77 | 7B | F2 | 6B | 6F | C5 | 30 | 01 | 67 | 2B | FE | D7 | AB | 76 |
| 1 | CA | 82 | C9 | 7D | FA | 59 | 47 | F0 | AD | D4 | A2 | AF | 9C | A4 | 72 | C0 |
| 2 | B7 | FD | 93 | 26 | 36 | 3F | F7 | CC | 34 | A5 | E5 | F1 | 71 | D8 | 31 | 15 |
| 3 | 04 | C7 | 23 | C3 | 18 | 96 | 05 | 9A | 07 | 12 | 80 | E2 | EB | 27 | B2 | 75 |
| 4 | 09 | 83 | 2C | 1A | 1B | 6E | 5A | A0 | 52 | 3B | D6 | B3 | 29 | E3 | 2F | 84 |
| 5 | 53 | D1 | 00 | ED | 20 | FC | B1 | 5B | 6A | CB | BE | 39 | 4A | 4C | 58 | CF |
| 6 | D0 | EF | AA | FB | 43 | 4D | 33 | 85 | 45 | F9 | 02 | 7F | 50 | 3C | 9F | A8 |
| 7 | 51 | A3 | 40 | 8F | 92 | 9D | 38 | F5 | BC | B6 | DA | 21 | 10 | FF | F3 | D2 |
| 8 | CD | 0C | 13 | EC | 5F | 97 | 44 | 17 | C4 | A7 | 7E | 3D | 64 | 5D | 19 | 73 |
| 9 | 60 | 81 | 4F | DC | 22 | 2A | 90 | 88 | 46 | EE | B8 | 14 | DE | 5E | 0B | DB |
| A | E0 | 32 | 3A | 0A | 49 | 06 | 24 | 5C | C2 | D3 | AC | 62 | 91 | 95 | E4 | 79 |
| B | E7 | C8 | 37 | 6D | 8D | D5 | 4E | A9 | 6C | 56 | F4 | EA | 65 | 7A | AE | 08 |
| C | BA | 78 | 25 | 2E | 1C | A6 | B4 | C6 | E8 | DD | 74 | 1F | 4B | BD | 8B | 8A |
| D | 70 | 3E | B5 | 66 | 48 | 03 | F6 | 0E | 61 | 35 | 57 | B9 | 86 | C1 | 1D | 9E |
| E | E1 | F8 | 98 | 11 | 69 | D9 | 8E | 94 | 9B | 1E | 87 | E9 | CE | 55 | 28 | DF |
| F | 8C | A1 | 89 | 0D | BF | E6 | 42 | 68 | 41 | 99 | 2D | 0F | B0 | 54 | BB | 16 |
Table A3.
Tier-1 AES inverse S-box
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 52 | 09 | 6A | D5 | 30 | 36 | A5 | 38 | BF | 40 | A3 | 9E | 81 | F3 | D7 | FB |
| 1 | 7C | E3 | 39 | 82 | 9B | 2F | FF | 87 | 34 | 8E | 43 | 44 | C4 | DE | E9 | CB |
| 2 | 54 | 7B | 94 | 32 | A6 | C2 | 23 | 3D | EE | 4C | 95 | 0B | 42 | FA | C3 | 4E |
| 3 | 08 | 2E | A1 | 66 | 28 | D9 | 24 | B2 | 76 | 5B | A2 | 49 | 6D | 8B | D1 | 25 |
| 4 | 72 | F8 | F6 | 64 | 86 | 68 | 98 | 16 | D4 | A4 | 5C | CC | 5D | 65 | B6 | 92 |
| 5 | 6C | 70 | 48 | 50 | FD | ED | B9 | DA | 5E | 15 | 46 | 57 | A7 | 8D | 9D | 84 |
| 6 | 90 | D8 | AB | 00 | 8C | BC | D3 | 0A | F7 | E4 | 58 | 05 | B8 | B3 | 45 | 06 |
| 7 | D0 | 2C | 1E | 8F | CA | 3F | 0F | 02 | C1 | AF | BD | 03 | 01 | 13 | 8A | 6B |
| 8 | 3A | 91 | 11 | 41 | 4F | 67 | DC | EA | 97 | F2 | CF | CE | F0 | B4 | E6 | 73 |
| 9 | 96 | AC | 74 | 22 | E7 | AD | 35 | 85 | E2 | F9 | 37 | E8 | 1C | 75 | DF | 6E |
| A | 47 | F1 | 1A | 71 | 1D | 29 | C5 | 89 | 6F | B7 | 62 | 0E | AA | 18 | BE | 1B |
| B | FC | 56 | 3E | 4B | C6 | D2 | 79 | 20 | 9A | DB | C0 | FE | 78 | CD | 5A | F4 |
| C | 1F | DD | A8 | 33 | 88 | 07 | C7 | 31 | B1 | 12 | 10 | 59 | 27 | 80 | EC | 5F |
| D | 60 | 51 | 7F | A9 | 19 | B5 | 4A | 0D | 2D | E5 | 7A | 9F | 93 | C9 | 9C | EF |
| E | A0 | E0 | 3B | 4D | AE | 2A | F5 | B0 | C8 | EB | BB | 3C | 83 | 53 | 99 | 61 |
| F | 17 | 2B | 04 | 7E | BA | 77 | D6 | 26 | E1 | 69 | 14 | 63 | 55 | 21 | 0C | 7D |
Table A4.
Tier-1 ZUC
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3E | 72 | 5B | 47 | CA | E0 | 00 | 33 | 04 | D1 | 54 | 98 | 09 | B9 | 6D | CB |
| 1 | 7B | 1B | F9 | 32 | AF | 9D | 6A | A5 | B8 | 2D | FC | 1D | 08 | 53 | 03 | 90 |
| 2 | 4D | 4E | 84 | 99 | E4 | CE | D9 | 91 | DD | B6 | 85 | 48 | 8B | 29 | 6E | AC |
| 3 | CD | C1 | F8 | 1E | 73 | 43 | 69 | C6 | B5 | BD | FD | 39 | 63 | 20 | D4 | 38 |
| 4 | 76 | 7D | B2 | A7 | CF | ED | 57 | C5 | F3 | 2C | BB | 14 | 21 | 06 | 55 | 9B |
| 5 | E3 | EF | 5E | 31 | 4F | 7F | 5A | A4 | 0D | 82 | 51 | 49 | 5F | BA | 58 | 1C |
| 6 | 4A | 16 | D5 | 17 | A8 | 92 | 24 | 1F | 8C | FF | D8 | AE | 2E | 01 | D3 | AD |
| 7 | 3B | 4B | DA | 46 | EB | C9 | DE | 9A | 8F | 87 | D7 | 3A | 80 | 6F | 2F | C8 |
| 8 | B1 | B4 | 37 | F7 | 0A | 22 | 13 | 28 | 7C | CC | 3C | 89 | C7 | C3 | 96 | 56 |
| 9 | 07 | BF | 7E | F0 | 0B | 2B | 97 | 52 | 35 | 41 | 79 | 61 | A6 | 4C | 10 | FE |
| A | BC | 26 | 95 | 88 | 8A | B0 | A3 | FB | C0 | 18 | 94 | F2 | E1 | E5 | E9 | 5D |
| B | D0 | DC | 11 | 66 | 64 | 5C | EC | 59 | 42 | 75 | 12 | F5 | 74 | 9C | AA | 23 |
| C | 0E | 86 | AB | BE | 2A | 02 | E7 | 67 | E6 | 44 | A2 | 6C | C2 | 93 | 9F | F1 |
| D | F6 | FA | 36 | D2 | 50 | 68 | 9E | 62 | 71 | 15 | 3D | D6 | 40 | C4 | E2 | 0F |
| E | 8E | 83 | 77 | 6B | 25 | 05 | 3F | 0C | 30 | EA | 70 | B7 | A1 | E8 | A9 | 65 |
| F | 8D | 27 | 1A | DB | 81 | B3 | A0 | F4 | 45 | 7A | 19 | DF | EE | 78 | 34 | 60 |
Table A5.
Tier-1 ZUC
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 55 | C2 | 63 | 71 | 3B | C8 | 47 | 86 | 9F | 3C | DA | 5B | 29 | AA | FD | 77 |
| 1 | 8C | C5 | 94 | 0C | A6 | 1A | 13 | 00 | E3 | A8 | 16 | 72 | 40 | F9 | F8 | 42 |
| 2 | 44 | 26 | 68 | 96 | 81 | D9 | 45 | 3E | 10 | 76 | C6 | A7 | 8B | 39 | 43 | E1 |
| 3 | 3A | B5 | 56 | 2A | C0 | 6D | B3 | 05 | 22 | 66 | BF | DC | 0B | FA | 62 | 48 |
| 4 | DD | 20 | 11 | 06 | 36 | C9 | C1 | CF | F6 | 27 | 52 | BB | 69 | F5 | D4 | 87 |
| 5 | 7F | 84 | 4C | D2 | 9C | 57 | A4 | BC | 4F | 9A | DF | FE | D6 | 8D | 7A | EB |
| 6 | 2B | 53 | D8 | 5C | A1 | 14 | 17 | FB | 23 | D5 | 7D | 30 | 67 | 73 | 08 | 09 |
| 7 | EE | B7 | 70 | 3F | 61 | B2 | 19 | 8E | 4E | E5 | 4B | 93 | 8F | 5D | DB | A9 |
| 8 | AD | F1 | AE | 2E | CB | 0D | FC | F4 | 2D | 46 | 6E | 1D | 97 | E8 | D1 | E9 |
| 9 | 4D | 37 | A5 | 75 | 5E | 83 | 9E | AB | 82 | 9D | B9 | 1C | E0 | CD | 49 | 89 |
| A | 01 | B6 | BD | 58 | 24 | A2 | 5F | 38 | 78 | 99 | 15 | 90 | 50 | B8 | 95 | E4 |
| B | D0 | 91 | C7 | CE | ED | 0F | B4 | 6F | A0 | CC | F0 | 02 | 4A | 79 | C3 | DE |
| C | A3 | EF | EA | 51 | E6 | 6B | 18 | EC | 1B | 2C | 80 | F7 | 74 | E7 | FF | 21 |
| D | 5A | 6A | 54 | 1E | 41 | 31 | 92 | 35 | C4 | 33 | 07 | 0A | BA | 7E | 0E | 34 |
| E | 88 | B1 | 98 | 7C | F3 | 3D | 60 | 6C | 7B | CA | D3 | 1F | 32 | 65 | 04 | 28 |
| F | 64 | BE | 85 | 9B | 2F | 59 | 8A | D7 | B0 | 25 | AC | AF | 12 | 03 | E2 | F2 |
Appendix A.3. Tier-2 Micro-S-box Templates
Table A6.
Tier-2 micro-S-box : half-adder slice
| ab | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | 1 | 1 | 2 |
Input index is interpreted as a 2-bit word with a as MSB and b as LSB.
Table A7.
Tier-2 micro-S-box : full-adder slice
| abc | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2 | 1 | 2 | 2 | 3 |
Input index is interpreted as a 3-bit word with a as MSB and as LSB.
Table A8.
Tier-2 micro-S-box : 4-bit population-count compressor
| abcd | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2 | 1 | 2 | 2 | 3 | |
| abcd | 8 | 9 | A | B | C | D | E | F |
| 1 | 2 | 2 | 3 | 2 | 3 | 3 | 4 |
This exact table is useful for 4:2-style compression fronts, popcount-based carry-save normalization, and bounded arithmetic canonicalization.
Appendix A.4. Exact Local P-box Templates
All mappings below are destination←source wire maps in hexadecimal indexing. For example,
means that destination wire 1 receives source wire 4.
Table A9.
Tier-2 exact local P-box templates
| Symbol | Definition | HEX mapping |
|---|---|---|
| Interleave four sums and four carries. Source ordering is ; destination ordering is . | 0,4,1,5,2,6,3,7 | |
| Local ripple alignment over an already interleaved vector. | 1,0,3,2,5,4,7,6 | |
| End-around carry fold used as a local 5-wire rotation template; source ordering becomes destination . | 4,0,1,2,3 |
Table A10.
Source note and implementation remarks
| Symbol | Definition | Source note |
|---|---|---|
| AES | Tier-1 AES tables correspond to the standard Rijndael/AES substitution and inverse substitution tables. | FIPS 197-derived constants |
| ZUC | Tier-1 ZUC tables were transcribed from code extracted from the ETSI/SAGE ZUC specification, as mirrored in CryptoMobile ZUC.c. | ETSI/SAGE v1.6 lineage |
| SNOW-V | SNOW-V / Snow-5G-class logic reuses the AES round function in the proposed architecture; therefore the AES S-box is the native Tier-1 substitution basis for that cipher family. | No separate standalone table listed |
Appendix A.5. Technical Elaboration of the next Appendix Tables
Table A6–Table A10 refine the exact interpretation of the Tier-2 bounded nonlinear templates and the provenance of the Tier-1 native tables. Their purpose is not merely descriptive; rather, they provide a formal bridge between the abstract 3-tier architectural model and the exact compiler-visible constant-level primitives used by the TALOS realization flow. In particular, Table A6–Table A8 define the minimal nonlinear arithmetic kernels that can be repeatedly instantiated to represent modular addition, carry propagation, and local compression without collapsing the design into a monolithic arithmetic datapath. Table A9 then specifies the exact local wiring templates needed to normalize or reorder these bounded arithmetic outputs before they are exported to the shared Tier-3 linear/permutation layer. Finally, Table A10 fixes the origin and interpretation of the native substitution constants that underlie the Tier-1 library.
Appendix A.5.5.1. Table A6: Tier-2 half-adder micro-S-box μS HA (2→2).
The half-adder micro-box is the smallest exact nonlinear arithmetic element used in the proposed architecture. The input word is interpreted as a 2-bit binary vector in which a is the most significant input bit and b is the least significant input bit. The output is encoded as
where
Thus, the table entries correspond exactly to the four binary cases
In architectural terms, is important because it isolates the irreducible nonlinear carry-generation event on the smallest possible scale. Although a half-adder alone is not sufficient to model full modular addition, it is a canonical base cell for constructing bounded arithmetic subgraphs, compressor structures, and early partial-sum/carry extraction paths. Within TALOS, it therefore serves as a primitive Tier-2 nonlinear kernel whose behavior is exact, finite, and directly tabulated.
Appendix A.5.5.2. Table A7: Tier-2 full-adder micro-S-box μS FA (3→2).
The full-adder micro-box extends the half-adder by incorporating an incoming carry bit. The input word is interpreted as a 3-bit vector, with a as the MSB and occupying the least significant position. The output again uses the packed encoding
with the exact Boolean relations
and
Consequently, Table A7 enumerates the exact truth table
which compactly represents all eight three-input combinations. This table is central to the TALOS arithmetic-compilation philosophy because 32-bit and 128-bit modular additions are not implemented as monolithic adder macros at the conceptual level, but are instead decomposed into repeated exact full-adder nonlinear slices. In this sense, is the primary Tier-2 operator by which bounded carry-bearing arithmetic is boxified and made structurally compatible with the generalized common nonlinear fabric.
Appendix A.5.5.3. Table A8: Tier-2 population-count micro-S-box μS POP 4 (4→3).
The table creates a 4-bit population-count compressor. For the input vector
the table outputs
encoded as a hexadecimal digit. Hence, the table values are given.
represents the exact Hamming-weight spectrum of the 16 possible 4-bit inputs. The importance of this micro-box lies in the fact that bounded arithmetic compilation is not restricted to pure ripple-carry models. In compressor trees, carry-save normalization, bit-density analysis, and local reduction stages, the relevant nonlinear kernel is often a bounded counting operator rather than a single-bit carry function. Table A8 therefore provides the exact canonical nonlinear template for local weight accumulation and bounded compression fronts. Its inclusion extends the Tier-2 fabric from strict adder emulation to a more general nonlinear arithmetic normalization layer, which is especially useful when the unified datapath must support structurally diverse cipher-internal arithmetic patterns.
Appendix A.5.5.4. Table A9: exact local P-box templates.
The three local permutation templates listed in Table A9 are not global cipher permutations such as AES ShiftRows or SNOW-specific byte transpositions. Instead, they are local normalization templates used immediately around Tier-2 arithmetic micro-box outputs. Their mappings are expressed as destination←source wire assignments in hexadecimal indexing, so that each vector defines an exact finite routing pattern rather than an informal reordering heuristic.
The first template,
interleaves four partial sums and four carries. This is essential when the arithmetic front-end naturally emits grouped sums and grouped carries, but the subsequent stage expects a sum/carry alternation. The second template,
performs local ripple alignment over an already interleaved vector. It effectively swaps adjacent sum/carry positions to expose a routing order more suitable for the next stage of accumulation or feedback. The third template,
implements a 5-wire end-around carry fold by rotating a terminal carry bit into the front position of a local vector. This is especially useful in cyclic correction patterns and end-around arithmetic variants. Collectively, these three templates show that exact Tier-2 realization is not defined only by nonlinear truth tables; it also requires exact local wire-level normalization primitives so that bounded arithmetic outputs can be handed off to Tier-3 in a disciplined and reusable way.
Appendix A.5.5.5. Table A10: source note and implementation remarks.
Table A10 clarifies the provenance and architectural interpretation of the Tier-1 library. The AES row states that the forward and inverse AES tables are the canonical Rijndael substitution constants derived from FIPS 197. This is important because TALOS does not redefine or approximate these substitutions; it reuses them as exact native Tier-1 boxes. The ZUC row indicates that the Tier-1 and tables were transcribed from publicly available code reflecting the ETSI/SAGE lineage. Again, the architectural claim is for exact reuse rather than a synthesized approximation. The SNOW-V row is structurally different: it explicitly notes that the SNOW-V / Snow-5G class logic does not contribute a new standalone table to Tier-1 because the architecture reuses the AES round-function substitution basis already present in the AES-native library.
This distinction is technically important for the TALOS contribution. It shows that native reuse is not synonymous with one-table-for-every cipher. Instead, the correct state-of-the-art extension is selective exact reuse: AES contributes its own native substitution basis; ZUC contributes its own native substitution basis; SNOW-V does not contribute new byte substitution constants because its nonlinear byte-level basis is already covered through AES round reuse. Table A10 therefore formalizes the boundary between true native substitution reuse and higher-level structural reuse and, in doing so, reinforces the necessity of the 3-tier decomposition.
This appendix makes the TALOS box-centric claim concrete: the architecture is not supported by generic symbolic reuse alone, but by an exact library of native substitutions, exact arithmetic micro-boxes, and exact local permutation templates. These tables and maps are the minimal constant-level artifacts required to move from a methodological 3-tier proposal to a compiler-visible and RTL-visible unified CryptoProcessor realization.
Appendix A.6. Abbreviations
Table A11 summarizes the minimal HDL-visible control and execution backbone of TALOS. The HCDP constitutes the shared architectural data path through which all cipher-dependent operands, internal states, and intermediate results are transported, retimed, and reassembled, thereby enabling structural reuse across heterogeneous 256-bit primitives. The GCP provides the corresponding supervisory intelligence, i.e., the mode-aware sequencing and dispatch logic required to coordinate the shared tiers without collapsing them into a monolithic fixed-function core. At the execution level, T1-NSB captures the exact native substitution basis reused directly from the supported cipher families, while T2-MSBF and T3-SPLF jointly realize the compiled nonlinear arithmetic and shared linear/permutation substrate, respectively. Taken together, these four abbreviations define the minimum technical vocabulary needed to describe TALOS as a hierarchically controlled, box-centric, unified-reusable 6G CryptoProcessor rather than as a simple collection of co-located cipher engines.
Table A11.
Ten critical TALOS 3-tier conceptual abbreviations
| Abbreviation | Definition |
|---|---|
| TALOS | Proposed unified-reusable 6G CryptoProcessor architecture based on a hierarchical 3-tier encapsulation of native substitutions, bounded arithmetic micro-boxes, and shared permutation/linear fabrics. |
| HCDP | Hierarchical Common Data Path: the common datapath backbone that time-shares operand ingress, register/state handling, dispatch, feedback/retiming, and output reassembly across the 3-tier cryptographic fabric. |
| Tier-1 | Native S-Box Tier: the first architectural tier containing exact native cryptographic substitution primitives already intrinsic to the supported cipher families, e.g., AES S-boxes and ZUC-native substitution tables. |
| Tier-2 | Micro-S-Box Tier: the second architectural tier containing exact bounded nonlinear arithmetic templates compiled into micro-boxes, e.g., half-adder, full-adder, popcount, carry, and modular-correction slices. |
| Tier-3 | Shared Permutation / Linear Tier: the third architectural tier containing exact permutation, routing, XOR, affine, rotation, shuffle, diffusion, and state-transport fabrics reused across all supported ciphers. |
| T1-NSB | Tier-1 Native S-Box Bank: the concrete hardware/library realization of Tier-1, collecting the exact native substitution tables reused by TALOS. |
| T2-MSBF | Tier-2 Micro-S-Box Fabric: the concrete hardware/library realization of Tier-2, implementing exact bounded nonlinear arithmetic kernels as reusable micro-box arrays. |
| T3-SPLF | Tier-3 Shared Permutation / Linear Fabric: the concrete hardware/library realization of Tier-3, implementing the common sparse interconnect and linear-transform substrate. |
| UCSB | Universal Common S-Box: the original common-substitution philosophy generalized in TALOS into a hierarchical nonlinear fabric rather than a single monolithic universal lookup structure. |
| UCNF | Universal Common Nonlinear Fabric: the generalized TALOS nonlinear substrate obtained by combining Tier-1 native substitution reuse with Tier-2 compiled micro-box arithmetic reuse under Tier-3 orchestration. |
References
- Bikos, A.N.; Sklavos, N. Architecture Design of an Area Efficient High Speed Crypto Processor for 4G LTE. IEEE Trans. Dependable Secur. Comput. 2018, 15, 729–741. [Google Scholar] [CrossRef]
- Murphy, S.; Robshaw, M.J.B. Essential Algebraic Structure within the AES. In Advances in Cryptology — CRYPTO 2002;Lecture Notes in Computer Science; Yung, M., Ed.; Springer: Berlin, Heidelberg, 2002; Vol. 2442, pp. 1–16. [Google Scholar] [CrossRef]
- Kim, H.W.; Lee, S. Design and Implementation of a Private and Public Key Crypto Processor and Its Application to a Security System. IEEE Trans. Consum. Electron. 2004, 50, 214–224. [Google Scholar] [CrossRef]
- Selimis, G.; Sklavos, N.; Koufopavlou, O. Area-Optimized Architecture and VLSI Implementation of Multi-Coder Processor for the WTLS. In Proceedings of the Proceedings of the 46th IEEE Midwest Symposium on Circuits and Systems (MWSCAS 2003), Cairo, Egypt, 30 December 2003; 2003; p. 24–27. 27–. [Google Scholar]
- Kitsos, P.; Sklavos, N.; Koufopavlou, O. UMTS Security: System Architecture and Hardware Implementation. Wirel. Commun. Mob. Comput. 2007, 7, 483–494. [Google Scholar] [CrossRef]
- Hessel, S.; Szczesny, D.; Lohmann, N.; Bilgic, A.; Hausner, J. Implementation and Benchmarking of Hardware Accelerators for Ciphering in LTE Terminals. In Proceedings of the IEEE Global Telecommunications Conference (GLOBECOM 2009), Honolulu, HI, USA, 2009; pp. 2316–2322. [Google Scholar] [CrossRef]
- Yamamoto, D.; Itoh, K.; Yajima, J. A Very Compact Hardware Implementation of the KASUMI Block Cipher. In Information Security Theory and Practices. Security and Privacy of Pervasive Systems and Smart Devices;Lecture Notes in Computer Science; Samarati, P., Tunstall, M., Posegga, J., Markantonakis, K., Sauveron, D., Eds.; Springer: Berlin, Heidelberg, 2010; Vol. 6033, pp. 293–308. [Google Scholar] [CrossRef]
- Traboulsi, S.; Sbeiti, M.; Bruns, F.; Bilgic, A. An Optimized Parallel and Energy-Efficient Implementation of SNOW 3G for LTE Mobile Devices. In Proceedings of the 2010 IEEE 12th International Conference on Communication Technology (ICCT), Nanjing, China, 2010; pp. 535–538. [Google Scholar]
- Gupta, S.S.; Chattopadhyay, A.; Khalid, A. Designing Integrated Accelerator for Stream Ciphers with Structural Similarities. Cryptogr. Commun. 2013, 5, 19–47. [Google Scholar] [CrossRef]
- Kitsos, P.; Sklavos, N.; Provelengios, G.; Skodras, A.N. FPGA-Based Performance Analysis of Stream Ciphers ZUC, Snow3G, Grain V1, Mickey V2, Trivium and E0. Microprocess. Microsyst. 2013, 37, 235–245. [Google Scholar] [CrossRef]
- Murphy, S.; Robshaw, M.J.B. Essential Algebraic Structure within the AES. In Advances in Cryptology — CRYPTO 2002;Lecture Notes in Computer Science; Yung, M., Ed.; Springer: Berlin, Heidelberg, 2002; Vol. 2442, pp. 1–16. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. Advanced Encryption Standard (AES). Technical Report FIPS 197-upd1; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023. [Google Scholar] [CrossRef]
- Ekdahl, P.; Johansson, T.; Maximov, A.; Yang, J. A New SNOW Stream Cipher Called SNOW-V. IACR Trans. Symmetric Cryptol. 2019, 2019, 1–42. [Google Scholar] [CrossRef]
- Zhang, B.; Feng, D.; Jin, C.; Qi, W.F.; Wu, W.; Xu, C.; Wang, Y.; Jiao, L. An Addendum to the ZUC-256 Stream Cipher. Cryptol. ePrint Arch. 2021, Paper 2021/1439. [Google Scholar]
- Yang, J.; Johansson, T.; Maximov, A. Spectral Analysis of ZUC-256. Cryptol. ePrint Arch. 2019, Paper 2019/1352. [Google Scholar] [CrossRef]
- ETSI / 3GPP. 5G; Specification of the Snow 5G based 256-bits algorithm set: Specification of the 256-NEA4 encryption, the 256-NIA4 integrity, and the 256-NCA4 authenticated encryption algorithm for 5G; Document 1: Algorithm Specification. Technical Report ETSI TS 135 240 / 3GPP TS 35.240, ETSI, 2024. Version 18.0.0, Release 18.
- ETSI / 3GPP. 5G; Specification of the AES based 256-bits algorithm set: Specification of the 256-NEA5 encryption, the 256-NIA5 integrity, and the 256-NCA5 authenticated encryption algorithm for 5G; Document 1: Algorithm Specification. Technical Report ETSI TS 135 243 / 3GPP TS 35.243, ETSI, 2024. Version 18.0.0, Release 18.
- ETSI / 3GPP. 5G; Specification of the ZUC based 256-bits algorithm set: Specification of the 256-NEA6 encryption, the 256-NIA6 integrity, and the 256-NCA6 authenticated encryption algorithm for 5G; Document 1: Algorithm Specification. Technical Report ETSI TS 135 246 / 3GPP TS 35.246, ETSI, 2024. Version 18.0.0, Release 18.
- Aikata, A.; Mert, A.C.; Jacquemin, D.; Das, A.; Matthews, D.; Ghosh, S.; Roy, S.S. A Unified Cryptoprocessor for Lattice-Based Signature and Key-Exchange. IEEE Trans. Comput. 2023, 72, 1568–1580. [Google Scholar] [CrossRef]
- Bisheh-Niasar, M.; Karabulut, E.; Upadhyayula, K.; Norris, M.; Pillilli, B. Adams Bridge Accelerator: Bridging the Post-Quantum Transition. Cryptol. ePrint Arch. 2026, Paper 2026/256. [Google Scholar]
- Tosun, T.; Ay, A.U.; Norga, Q.; Kundu, S.; Yazici, M.; Savas, E.; Verbauwhede, I. RISQrypt: Fast, Secure and Agile Hardware-Software Co-Design for Post-Quantum Cryptography. Cryptol. ePrint Arch. 2026, Paper 2026/312. [Google Scholar]
- Zhang, Y.; Chu, Y.; Wei, Y.; Dai, Y.; Shen, Q.; Tian, J. A Unified Hardware Architecture for Stateful and Stateless Hash-Based Key/Signature Generations. Cryptol. ePrint Arch. 2026, Paper 2026/194. [Google Scholar]
- Pandey, N.; Deshpande, S.; Bohra, D.D.; Banerjee, D.S.; Szefer, J.; Roy, D.B. Performance Analysis of Parameterizable HQC Hardware Architecture. Cryptology ePrint Archive, 2026; Paper 2026/592. [Google Scholar]
- National Institute of Standards and Technology. Module-Lattice-Based Key-Encapsulation Mechanism Standard; Technical Report FIPS 203; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. Module-Lattice-Based Digital Signature Standard; Technical Report FIPS 204; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. Stateless Hash-Based Digital Signature Standard; Technical Report FIPS 205; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024. [Google Scholar] [CrossRef]
- Moody, D.; Perlner, R.; Regenscheid, A.; Robinson, A.; Cooper, D. Transition to Post-Quantum Cryptography Standards. In Technical Report NIST IR 8547 (Initial Public Draft); National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024. [Google Scholar] [CrossRef]
- 3GPP. TR 33.703: Study on Transitioning to Post Quantum Cryptography (PQC) in 3GPP. 3GPP Technical Report, Release 20 draft. 2025. [Google Scholar]
- 3GPP. TR 33.801-01; Study on Security for the 6G System. 3GPP Technical Report, Release 20 draft, 2025.
- National Institute of Standards and Technology. Advanced Encryption Standard (AES). Technical Report FIPS 197-upd1. U.S. Department of Commerce, NIST, 2023. [Google Scholar] [CrossRef]
- ETSI / 3GPP. 5G; Specification of the Snow 5G based 256-bits algorithm set: specification of the 256-NEA4 encryption, the 256-NIA4 integrity, and the 256-NCA4 authenticated encryption algorithm for 5G; Document 1: algorithm specification. Technical Report ETSI TS 135 240 / 3GPP TS 35.240, ETSI Version 18.0.0, Release 18, 2024. [Google Scholar]
- ETSI / 3GPP. 5G; Specification of the ZUC based 256-bits algorithm set: Specification of the 256-NEA6 encryption, the 256-NIA6 integrity, and the 256-NCA6 authenticated encryption algorithm for 5G; Document 1: algorithm specification. Technical Report ETSI TS 135 246 / 3GPP TS 35.246, ETSI Version 18.0.0, Release 18, 2024. [Google Scholar]
- Moody, D. The NIST Post-Quantum Cryptography Project. Presentation at MPTS 2026: NIST Workshop on Multi-Party Threshold Schemes, 2026. Presented January 28, 2026. [Google Scholar]
- National Institute of Standards and Technology. Post-Quantum Cryptography: FAQs. Computer Security Resource Center Project Page. Accessed. n.d. (accessed on 1 May 2026).
- National Institute of Standards and Technology. Post-Quantum Cryptography. Computer Security Resource Center Project Page. Accessed. n.d. (accessed on 1 May 2026).
- European Telecommunications Standards Institute. 5G; Specification of the Snow 5G Based 256-Bits Algorithm Set: Specification of the 256-NEA4 Encryption, the 256-NIA4 Integrity, and the 256-NCA4 Authenticated Encryption Algorithm for 5G; Document 1: Algorithm Specification; European Telecommunications Standards Institute; Technical Specification ETSI TS 135 240 V18.0.0 / 3GPP TS 35.240 Release 18, 2024. [Google Scholar]
- 3rd Generation Partnership Project. Specification of the AES Based 256-Bits Algorithm Set: Specification of the 256-NEA5 Encryption, the 256-NIA5 Integrity, and the 256-NCA5 Authenticated Encryption Algorithm for 5G; Document 1: Algorithm Specification Release 18; under change control. 3GPP Dyn. Specif. Rep. 2024. [Google Scholar]
- European Telecommunications Standards Institute. 5G; Specification of the ZUC Based 256-Bits Algorithm Set: Specification of the 256-NEA6 Encryption, the 256-NIA6 Integrity, and the 256-NCA6 Authenticated Encryption Algorithm for 5G; Document 3: Design Conformance Test Data; European Telecommunications Standards Institute; Technical Specification ETSI TS 135 248 V18.0.0 / 3GPP TS 35.248 Release 18, 2024. [Google Scholar]
- 3rd Generation Partnership Project. 3GPP Portal Specifications Search for Work Item 1010012: Addition of 256-Bit Security Algorithms lists specifications TS 35.240–TS 35.248 for Snow 5G, AES, and ZUC 256-bit algorithm sets. 3GPP Portal Accessed. 2026. (accessed on 1 May 2026). [Google Scholar]
- 3rd Generation Partnership Project. Study on Transitioning to Post Quantum Cryptography (PQC) in 3GPP. Technical Report 3GPP TR 33.703 Release 20, 3rd Generation Partnership Project, 2026. Draft specification; latest listed version 0.4.0 uploaded 24 February 2026.
- 3rd Generation Partnership Project. Study on Security for the 6G System. Technical Report 3GPP TR 33.801-01 Release 20, 3rd Generation Partnership Project, 2026. Draft specification; latest listed version 0.3.0 uploaded 24 February 2026.
- 3rd Generation Partnership Project. Release 20. 3GPP Specifications and Technologies Release Page Rel-20 milestones and endorsed deadlines for 5G-Advanced and early 6G studies. Accessed. 2026. (accessed on 1 May 2026). [Google Scholar]
- 3rd Generation Partnership Project. 3GPP Specification Series: 33-Series Security Specifications. 3GPP Dynamic Specification Report; Accessed. n.d. (accessed on 1 May 2026). [Google Scholar]
- 3rd Generation Partnership Project. 6G Scenarios and Performance Requirements. 3GPP News Published. 2024. [Google Scholar]
- Uusitalo, M.; Bernardos, C.J. White Paper on The European Vision for the 6G Network Ecosystem. 6G Smart Networks and Services Industry Association (6G-IA) white paper presentation, 2024. 25 November 2024. [Google Scholar]
- National Institute of Standards and Technology. Federal Information Processing Standards Publication NIST FIPS 203; Module-Lattice-Based Key-Encapsulation Mechanism Standard. National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024. [CrossRef]
- National Institute of Standards and Technology. Module-Lattice-Based Digital Signature Standard. National Institute of Standards and Technology: Gaithersburg, MD, USA; Federal Information Processing Standards Publication NIST FIPS 204, 2024. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. NIST Releases First 3 Finalized Post-Quantum Encryption Standards. In NIST News; 2024. Released August 13, 2024; updated August 29, 2025. [Google Scholar]
- National Institute of Standards and Technology. NIST PQC Standardization Process: HQC Announced as a 4th Round Selection. Computer Security Resource Center News. 2025. Published March 11, 2025.
- Alagic, G.; Bros, M.; Ciadoux, P.; Cooper, D.; Dang, Q.; Dang, T.; Kelsey, J.; Lichtinger, J.; Liu, Y.K.; Miller, C.; et al. Status Report on the Fourth Round of the NIST Post-Quantum Cryptography Standardization Process. In NIST Interagency/Internal Report NIST IR 8545; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2025. [Google Scholar] [CrossRef]
- Bisheh-Niasar, M.; Karabulut, E.; Upadhyayula, K.; Norris, M.; Pillilli, B. Adams Bridge Accelerator: Bridging the Post-Quantum Transition. Cryptol. ePrint Arch. 2026, Report 2026/256. [Google Scholar]
- Mandal, S.; Basu Roy, D. KiD: A Hardware Design Framework Targeting Unified NTT Multiplication for CRYSTALS-Kyber and CRYSTALS-Dilithium on FPGA. arXiv 2023, arXiv:cs. [Google Scholar] [CrossRef]
- Kundi, D.E.S.; Bermudo Mera, J.M.; Strub, P.Y.; Hutter, M. High-Performance NTT Hardware Accelerator to Support ML-KEM and ML-DSA. In Proceedings of the Proceedings of the 2024 Workshop on Attacks and Solutions in Hardware Security (ASHES ’24), Salt Lake City, UT, USA, 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Iskander, R.; Kirah, K. Structural Dependency Analysis for Masked NTT Hardware: Scalable Pre-Silicon Verification of Post-Quantum Cryptographic Accelerators, 2026. arXiv, Version 2, revised 20 April 2026; arXiv:cs. [CrossRef]
- Saarinen, M.J.O. Accelerating SLH-DSA by Two Orders of Magnitude with a Single Hash Unit. In Proceedings of the Proceedings of the 5th NIST Post-Quantum Cryptography Standardization Conference, Rockville, MD, USA, 2024. Presented April 11, 2024. [Google Scholar]
- Truong, Q.D.; Jang, Y.; Lee, H.H. High-Performance Unified Hardware Architecture for ML-DSA and ML-KEM PQC Standards. IEEE Access 2025, 13, 189444–189460. [Google Scholar] [CrossRef]
- Mandal, S.; Roy, D.B. A Lightweight Unified Keccak Module for Efficient Hashing in ML-KEM and ML-DSA. In Proceedings of the Proceedings of the 2025 Quantum Security and Privacy Workshop (QSec ’25), New York, NY, USA, 2025; pp. 34–39. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. Post-Quantum Cryptography FAQs. In NIST Computer Security Resource Center; 2025. [Google Scholar]
- ETSI / 3GPP. 5G; Specification of the AES based 256-bits algorithm set: Specification of the 256-NEA5 encryption, the 256-NIA5 integrity, and the 256-NCA5 authenticated encryption algorithm for 5G; Document 1: algorithm specification. Technical Report ETSI TS 135 243 / 3GPP TS 35.243, ETSI Version 18.0.0, Release 18, 2024. [Google Scholar]
- GPP. 3GPP Specification Series 35: Security Algorithms and Related Specifications. 3GPP Specif. Index 2026. [Google Scholar]
- 3GPP. TR 33.703: Study on transitioning to Post Quantum Cryptography (PQC) in 3GPP. 3GPP DynaReport, Release 20 draft. 2025.
- 3GPP. TR 33.801-01: Study on Security for the 6G system. 3GPP DynaReport, Release 20 draft. 2025.
- Zhang, B.; Feng, D.; Jin, C.; Qi, W.F.; Wu, W.; Xu, C.; Wang, Y.; Jiao, L. An Addendum to the ZUC-256 Stream Cipher. Cryptol. ePrint Arch. 2021, Paper 2021/1439. [Google Scholar]
- Yang, J.; Johansson, T.; Maximov, A. Spectral Analysis of ZUC-256. Cryptol. ePrint Arch. 2019, Paper 2019/1352. [Google Scholar] [CrossRef]
- Maximov, A. Some Observations on ZUC-256 (Extended). Cryptol. ePrint Arch. 2021, Paper 2021/1134. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



