Submitted:
22 May 2026
Posted:
25 May 2026
You are already at the latest version
Abstract
Tabletop role-playing game (TTRPG) research increasingly produces complex multimodal and multimedia evidence, including speech, audiovisual recordings, character sheets, maps, platform traces, session notes, game-state data, and retrospective documentation. However, the field lacks a stable methodological infrastructure for organizing, comparing, retrieving, and reusing these heterogeneous forms of play-derived evidence. This article presents a scoping review of computational, multimodal, multimedia, and knowledge-organization approaches used to analyze TTRPG-derived data. The review followed PRISMA-informed transparency practices, used SPIDER to define the review scope, and synthesized 35 included sources through an extraction matrix, a research-question alignment matrix, and keyword co-occurrence analysis. The findings show that TTRPG research is distributed across publication ecosystems, data types, analytical purposes, and levels of formalization. Existing studies use qualitative interpretation, discourse and conversation analysis, player-experience evaluation, structured datasets, natural language processing, named entity recognition, semantic annotation, AI-assisted generation, and controlled vocabularies. However, these approaches remain weakly coordinated across disciplinary vocabularies, data models, and formalization practices. To address this gap, the article proposes a Polyvocal Semantic Infrastructure that responds to a double ontological problem in TTRPG research: the same object is named in multiple ways, and the same term is used for different objects across communities, systems, and disciplines. Operationalized through a semantic atlas and scope ladder, this infrastructure preserves interpretive plurality while supporting comparison, retrieval, provenance tracking, and future AI-assisted analysis of TTRPG-derived Multimedia Play Data.
Keywords:
analog games
; artificial intelligence
; cataloging
; controlled vocabularies
; data curation
; genre/form terms
; interdisciplinary research
; knowledge organization
; metadata
; multimodal analysis
1. Introduction
Role-playing game research increasingly produces complex multimedia and multimodal evidence, yet the field lacks stable infrastructures for organizing, comparing, retrieving, and reusing that evidence. A single tabletop role-playing game (TTRPG) session may generate speech, gesture, character sheets, maps, rules references, dice outcomes, platform commands, audiovisual recordings, chat logs, digital assets, session notes, and retrospective narratives. These materials are not secondary traces of play. They participate in how play is produced, remembered, interpreted, and reused across sessions, campaigns, platforms, and research contexts. The central problem is that the richness of TTRPG-derived data has outpaced the field’s methodological infrastructure.
This article uses role-playing games (RPGs) as an umbrella term for structured ludonarrative practices in which participants enact fictional roles through rules, narration, interaction, and shared interpretation. This broad category includes tabletop role-playing games (TTRPGs), live-action role-playing games (LARPs), actual play, virtual tabletop (VTT) environments, computer role-playing games (CRPGs), massively multiplayer online role-playing games (MMORPGs), and hybrid role-playing practices that combine in-person and remote participation (Jones 2021; Hope 2017; Boyd and Hejná 2025). However, the primary object of this review is not RPGs in general. The review focuses on TTRPG-derived data, with particular attention to long-term campaigns, because these practices generate persistent, heterogeneous, and analytically demanding records of collaborative play.
TTRPGs are defined here as structured, collaborative role-playing practices in which participants generate fictional events through character action, rule interpretation, shared narration, and human adjudication. This definition distinguishes TTRPGs from adjacent forms while recognizing that their analytical problems often overlap. LARP emphasizes embodied performance and situated interaction within a shared diegetic frame (Gade et al. 2003, 56–64). CRPGs and MMORPGs implement role-playing conventions through computational systems. Actual play transforms play into mediated performance for external audiences. VTTs and hybrid formats introduce platform-mediated traces, including commands, chat logs, tokens, maps, and audiovisual records. These distinctions matter because each form produces different data types, yet methods and concepts often circulate across them without stable semantic alignment.
The need for this distinction is visible in work on controlled vocabularies and role-playing game classification. Smith (2024) shows that existing vocabularies often fail to distinguish TTRPGs from board games, CRPGs, and works about role-playing games. This problem is not merely bibliographic. When terms such as “role-playing game,” “campaign,” “scenario,” “world,” “mechanic,” or “player” shift across domains, researchers may lose clarity about what data are being analyzed, which methods are transferable, and what forms of infrastructure are required. Similar distinctions structure major field syntheses, including Role-Playing Game Studies: A Transmedia Approach (Zagal and Deterding 2018) and The Routledge Handbook of Role-Playing Game Studies (Zagal and Deterding 2024), where tabletop, live-action, digital, and transmedia forms are treated as related but analytically distinct.
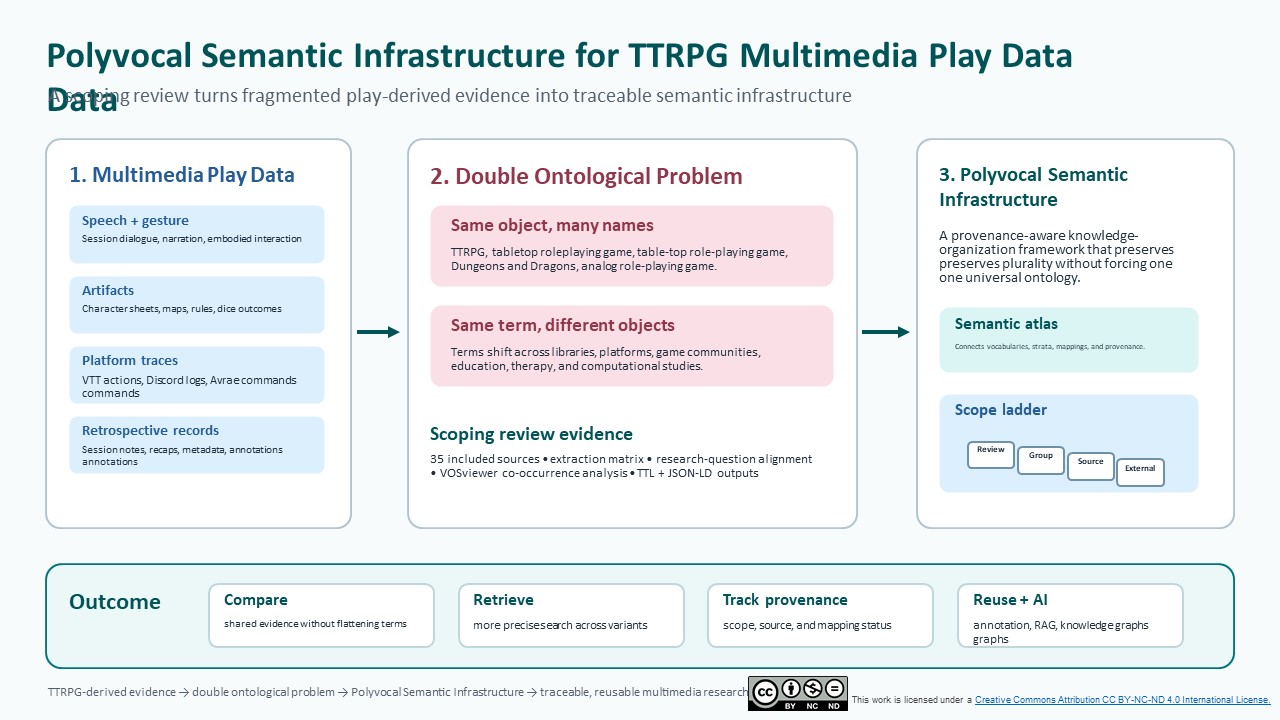
This problem can be described as a double ontological problem. First, the same object of study may appear under several names. A researcher looking for tabletop role-playing games may encounter “role-playing games,” “tabletop roleplaying games,” “table-top role-playing games,” “Dungeons & Dragons,” “Dungeons and Dragons,” “analog role-playing games,” or other adjacent terms. Second, the same label may refer to different objects across cataloging systems, game communities, computational studies, educational research, therapeutic practice, and platform documentation. In practice, this means that a TTRPG source may become difficult to find not because it is absent, but because it has been classified through a different conceptual frame. A book about TTRPGs in an academic library may be indexed through categories closer to board games, recreational materials, or adjacent game taxonomies rather than as part of role-playing game studies. The problem is therefore not only terminological. It is ontological, infrastructural, and epistemic: what cannot be named consistently cannot be reliably retrieved, compared, or reused.
This article, therefore, treats terminology as a methodological problem. A vocabulary, taxonomy, ontology, or metadata scheme is not the phenomenon itself. It is a representational map that foregrounds some relations while obscuring others (León 2025). Complex role-playing practices require attention to both component elements and larger systems (Scheff 2011; Sacksteder 1991). RPGs make this problem especially acute because the same term may refer to a mechanic, artifact, genre, practice, social relation, digital object, or analytical category, depending on the level of observation. As Gary, Collins, Brata Winardy, and Septiana (2023) suggest, role-playing is polysemic, and its structure varies according to the practice under examination.
Accordingly, this review uses TTRPG as the primary analytical category. LARP, Edu-LARP, actual play, VTTs, CRPGs, MMORPGs, therapeutic role-play, analog role-playing games, and hybrid practices are included only when they contribute transferable data types, analytical procedures, methodological frameworks, or knowledge-organization practices relevant to TTRPG-derived data. The review does not attempt to describe every form of play-derived data in RPG studies. Instead, it asks how play-derived data in TTRPGs, especially long-term campaigns, are organized, analyzed, retrieved, and interpreted.
TTRPGs matter to multimedia research because they generate heterogeneous evidence across narrative, procedural, audiovisual, interactional, material, and platform-dependent layers. Contemporary studies examine TTRPGs as collaborative storytelling systems, pedagogical environments, therapeutic interventions, multimodal communication ecologies, computational narrative environments, and sites of identity negotiation (Bowman 2018). Recent work on large language models, fantasy-domain named entity recognition, structured gameplay datasets, AI-supported Game Masters, knowledge-driven scenario generation, and controlled vocabularies has expanded interest in TTRPGs as both cultural artifacts and computationally tractable systems (Owczarek et al. 2026). These studies show that TTRPGs are not only objects of cultural analysis; they are also testbeds for studying how narrative, interaction, rules, media, and data structures interact.
Despite this growth, the field remains semantically and methodologically fragmented. Existing studies often examine isolated dimensions of play, such as narrative structure, player experience, computational assistance, therapeutic intervention, learning outcomes, digital mediation, or cataloging. Fewer studies provide a shared methodological infrastructure for connecting session data, player interaction, knowledge organization, computational analysis, and multimedia evidence. As a result, the same artifact may be interpreted as a ruleset, performance event, learning artifact, computational state, social interaction, audiovisual record, platform trace, or bibliographic object, depending on the research tradition. This instability complicates discoverability, metadata alignment, corpus comparison, computational analysis, and long-term preservation.
The problem becomes more visible when computational methods are introduced. Grounded gameplay datasets suggest that narrative interpretation improves when systems use stable contextual representations. Fantasy-domain natural language processing shows that general-purpose models struggle with domain-specific entities unless supported by specialized annotation and semantic adaptation. Knowledge-driven generation systems depend on structured representations to maintain coherence across narrative and procedural layers. Multimodal educational studies require infrastructures that can connect transcripts, journals, interviews, audiovisual recordings, gameplay logs, and observational data. Together, these studies indicate a common limitation: TTRPG research lacks interoperable semantic infrastructure capable of preserving both computational consistency and interpretive flexibility.
This study responds to that limitation through a scoping review of computational, multimodal, multimedia, and knowledge-organization approaches used to analyze TTRPG-derived data. The central research question is: What methods, techniques, infrastructures, and semantic frameworks are currently used to organize, analyze, retrieve, and interpret play-derived data in TTRPG research? The review follows PRISMA-informed transparency practices, uses SPIDER to specify the phenomenon of interest, evidence type, design logic, and research scope, and synthesizes a final corpus of 35 sources through extraction, research-question alignment, corpus distribution analysis, and keyword co-occurrence mapping. The protocol was registered through the Open Science Framework (OSF) to support traceability and procedural transparency.
The contribution of this article is methodological and infrastructural. Rather than claiming that TTRPGs have not been studied, we argue that existing studies remain distributed across fields that do not yet share a common methodological vocabulary for Multimedia Play Data. We define Multimedia Play Data as the layered, situated, collaborative, and technically mediated evidence generated through role-playing activity. This operational definition includes speech, audiovisual media, rules artifacts, character materials, platform traces, structured game states, annotations, metadata, and retrospective documentation. The review shows that these data are increasingly analyzed through qualitative, computational, multimodal, and knowledge-organization methods, but that these methods remain weakly coordinated across vocabularies, data models, and formalization practices.
To address this gap, the paper proposes a Polyvocal Semantic Infrastructure (PSI). We define PSI as a provenance-aware knowledge-organization framework that coordinates multiple vocabularies, interpretive strata, and semantic mappings without reducing them to a single authoritative ontology. PSI is designed to preserve plurality while enabling retrieval, comparison, reuse, and AI-assisted analysis across heterogeneous forms of TTRPG-derived Multimedia Play Data.
The PSI is operationalized through a semantic atlas and a scope ladder. The semantic atlas coordinates heterogeneous vocabularies, interpretive strata, provenance records, and semantic mappings. The scope ladder organizes concepts by provenance, authority, and visibility across review-scoped vocabularies, group-scoped vocabularies, source-paper vocabularies, and external named vocabularies or authority systems. The purpose is not to impose a universal ontology of role-playing games. Instead, the PSI preserves interpretive plurality while supporting comparison, retrieval, provenance tracking, reuse, and future AI-assisted analysis.
This contribution has three dimensions. Theoretically, the paper reframes TTRPG-derived data as Multimedia Play Data that connect narrative, interaction, material artifacts, platform traces, audiovisual evidence, and retrospective interpretation. Methodologically, it synthesizes how existing studies extract, classify, formalize, normalize, and interpret play-derived evidence. Practically, it identifies requirements for semantic infrastructures that can support future work in TTRPG studies, AI-assisted analysis, digital humanities, game studies, multimedia research, and knowledge organization.
A central operation in this framework is the transformation of metadata into data. Descriptions, classifications, provenance records, semantic mappings, normalization decisions, and interpretive levels are not treated as secondary administrative information. They are treated as evidence for analysis because they show how different communities define, organize, relate, retrieve, and reuse role-playing knowledge. This shift is especially important for multimedia research, where the interpretive value of complex evidence depends on how its contexts, relations, transformations, and provenance are documented.
The remainder of the article is organized as follows. Section 2 reviews related work on TTRPG studies, computational tools, multimodal analysis, player experience, and knowledge organization. Section 3 presents the conceptual framework that informs the semantic atlas and Polyvocal Semantic Infrastructure. Section 4 describes the materials and methods, including the review rationale, research question, search strategy, selection process, extraction matrix, reporting approach, and quality appraisal. Section 5 presents the results across corpus distribution, publication ecosystems, data types, methodological infrastructures, analytical purposes, terminological instability, formalization practices, co-occurrence analysis, and emerging tensions. Section 6 discusses the implications for multimedia research, TTRPG studies, computational analysis, semantic infrastructure design, and provenance-aware knowledge organization. Section 7 concludes by outlining the study’s contributions, limitations, and future research directions.
2. Related Work
The literature relevant to this review can be organized into four overlapping clusters: role-playing as narrative and performance, role-playing in applied educational and therapeutic contexts, computational support for role-playing systems, and knowledge organization for role-playing materials. These clusters do not represent separate fields in practice. They identify recurring research traditions that address different aspects of the same methodological problem: how to interpret, measure, formalize, and retrieve data produced through role-playing activity.
2.1. Role-Playing as Collaborative Narrative, Performance, and Authorship
A first body of work examines role-playing as an emergent form of collaborative narrative, performance, authorship, and social interaction (Laws 2010a; Nguyen and Sageng 2025; Hergenrader 2018; Grouling Cover 2010; Laws 2010b). This literature establishes that role-playing is not a fixed textual object but a situated activity produced through participants, rules, characters, frames, artifacts, and audiences. Its central contribution is conceptual: it shows that the object of analysis is not only the fictional story but also the interactional process through which that story becomes playable, meaningful, and memorable.
Studies of actual play extend this problem by showing how private or semi-private play becomes recorded, edited, circulated, and adapted for spectators. In these cases, role-playing data are transformed into durable media artifacts, including audio recordings, video episodes, transcripts, fan archives, graphic adaptations, and platform-based commentary. This transformation matters for multimedia research because the session no longer functions only as an event. It becomes a mediated object whose narrative, audiovisual, and paratextual layers can be analyzed across different levels of production and reception.
2.2. Role-Playing in Educational, Therapeutic, and Developmental Contexts
A second body of work examines TTRPGs, LARP, Edu-LARP, and analog games in educational, therapeutic, and developmental contexts (Haarman 2025, 2026; Ribeiro 2025; Bowman et al. 2025). These studies investigate learning, communication, collaboration, empathy, identity, metacognition, social skills, and psychological intervention (Rosenblad et al. 2025; Peters et al. 2025). Their relevance to this review is not limited to applied outcomes. They also show that role-playing generates complex evidence across cognitive, affective, social, narrative, and procedural dimensions.
This literature exposes a measurement problem. Role-playing interventions often unfold across sessions, characters, groups, artifacts, and reflective materials. As a result, researchers must relate heterogeneous evidence, such as session transcripts, field notes, journals, surveys, audiovisual recordings, character materials, and participant reflections. These studies therefore demonstrate both the value of role-playing as a learning or therapeutic environment and the difficulty of standardizing data produced through situated, longitudinal, and collaborative play.
2.3. Computational and AI-Supported Approaches to Role-Playing Data
A third body of work develops computational and AI-supported approaches to role-playing data within the broader field of artificial intelligence in games (Shaker et al. 2016; Yannakakis and Togelius 2025). This cluster includes language-model support for Game Masters, structured game-state datasets, natural language processing, fantasy-domain named entity recognition, semantic annotation, procedural content generation, AI Game Masters, and knowledge-driven scenario generation (Mohapatra et al. 2023; Wickramarathna and Ganegoda 2019). These studies position RPGs as testbeds for computational creativity, dialogue modeling, interactive narrative, and human-AI co-creation.
Their methodological importance lies in the need for contextual stability. Computational systems cannot reliably process or generate role-playing content when entities, actions, rules, scenes, player states, and fictional-world relations remain underspecified (Winnicott 2021; Wolf 2025). Work on language models and game-state representation suggests that computational performance improves when systems can access structured information about characters, actions, rules, and context. Similarly, fantasy-domain NLP shows that general-purpose models require domain-specific annotation and semantic adaptation to handle invented names, specialized categories, and fictional-world relations. These studies show that computational support depends not only on model capability but also on the availability of well-structured semantic infrastructure.
2.4. Metadata, Controlled Vocabularies, and Knowledge Organization
A fourth body of work concerns metadata, controlled vocabularies, ontologies, semantic annotation, and knowledge organization (Kneale and Kneale 1985). This literature is central to the present review because role-playing materials are difficult to retrieve, classify, compare, and reuse. Terms such as TTRPG, TRPG, RPG, LARP, actual play, role-play, scenario, campaign, adventure, session, and game system circulate across academic, community, platform, and cataloging contexts with inconsistent meanings.
Smith (2024) is especially important because it shows that existing vocabularies often fail to describe TTRPGs with sufficient precision. The problem includes deficient definitions, weak hierarchical structures, and inadequate disambiguation between subject terms and genre/form terms. This lack of precision has direct implications for research infrastructure. If role-playing materials cannot be consistently named, scoped, and related, then they become difficult to discover, compare, preserve, or integrate into computational workflows. Knowledge organization is, therefore, not a peripheral cataloging concern. It is part of the methodological infrastructure required for multimedia TTRPG research.
2.5. Synthesis: From Separate Literatures to Shared Infrastructure
These four clusters answer different disciplinary questions. Narrative and performance studies ask how role-playing events produce stories, authorship, and meaning. Educational and therapeutic studies ask how participation supports learning, reflection, or psychosocial change. Computational studies ask how systems can process, generate, or support role-playing content. Knowledge-organization studies ask how role-playing materials can be named, classified, retrieved, and preserved. This separation is useful when each field studies a narrow object with stable boundaries.
The separation becomes less adequate when the object is multimedia play data. A recorded TTRPG session may simultaneously function as a performance, a learning environment, a conversational dataset, a multimodal interaction, a narrative artifact, a platform-mediated event, and a candidate for semantic annotation. A character sheet may operate as a rules interface, identity document, game-state record, and computational data source. A campaign recap may serve as memory work, narrative compression, community documentation, and metadata for future play. These examples show that TTRPG-derived data often exceed the categories used to study them.
The gap, therefore, is not an absence of literature. The gap is the absence of a connective methodological vocabulary across data types, analytical procedures, and formalization practices. Existing approaches tend to optimize for local disciplinary goals, including interpretation, assessment, intervention, system performance, metadata consistency, or ontology design. Few frameworks explain how these approaches can be coordinated when the same play materials must be analyzed, formalized, retrieved, and reused across research contexts. This review addresses that gap by synthesizing methods and infrastructures that can support a more interoperable approach to TTRPG-derived multimedia data.
3. Conceptual Framework
This study treats TTRPG-derived data as a problem of semantic coordination rather than simple classification. Role-playing materials often occupy several analytical positions at once. A campaign session, for example, may be examined as narrative production, rules enactment, pedagogical interaction, social exchange, computational state, audiovisual record, or archival artifact. These readings are not mutually exclusive. They become problematic only when one interpretive framework is treated as sufficient for all others. This problem aligns with Smith’s (2024) analysis of controlled vocabularies, which shows that inadequate definitions, weak hierarchical structures, and unstable distinctions between subject and genre/form terms can reduce the discoverability and analytical precision of TTRPG materials.
The framework begins from the principle of polyvocal semantic infrastructure. A polyvocal infrastructure preserves multiple interpretive frameworks while making their relations explicit. This position aligns with knowledge-graph research showing that structured knowledge bases can support information retrieval, question answering, natural language processing, semantic search, entity retrieval, and knowledge injection into language models (Suchanek et al. 2024). Rather than requiring one vocabulary to function as a universal authority, the framework allows distinct vocabularies, ontologies, and classificatory schemes to coexist as linked but non-collapsed systems. This vocabulary is essential for RPG studies because disagreement often reflects disciplinary perspective rather than error.
This principle is especially important for AI-assisted analysis. Retrieval-Augmented Generation (RAG) depends on providing AI systems with semantically organized contextual information rather than relying only on model-internal representations. Knowledge graphs can supply entities, relations, taxonomies, provenance, and constraints that make retrieval more precise and interpretation more accountable. Domain-specific models such as Graphs and Ontologies for Literary Evolution Models (GOLEM) (Pianzola et al. 2025), and broader knowledge bases such as Yet Another Great Ontology (YAGO 4.5) (Suchanek et al. 2024), illustrate why structured semantic context matters. AI systems cannot reliably reason over role-playing data if characters, actions, rules, scenes, player states, fictional entities, and source relations remain underspecified.
The second principle is disagreement-as-data. When one field treats “campaign” as a narrative unit, another as a pedagogical intervention, and another as a persistent game-state structure, the difference should not be normalized away automatically. The disagreement identifies a meaningful shift in analytical purpose. Preserving this shift allows researchers to examine how concepts travel, narrow, broaden, or change across disciplinary, technical, and community contexts.
The third principle is stratum theory. A stratum is an interpretive layer that specifies how a concept is being read within a given semantic scheme. The foundational axiom is that one thing can be many things. A “character,” for example, may function as a fictional person, a player character, a rules object, a narrative role, a performance identity, or a session participant. Multi-cardinality is therefore the default condition: a concept can inhabit several identities, schemes, classifications, and interpretive stances at once. Single-cardinality is not inherent to the entity. It is a contextual constraint applied only when a specific research question requires it. In the same way, a rulebook may be read as an artifact, a rules system, a narrative generator, a bibliographic object, or a source of computational entities. Strata make these readings explicit without requiring one interpretation to displace the others (Figure 1).
The fourth principle is scheme-aware querying. Queries should not assume that all classifications belong to one hierarchy. Instead, data should be retrieved relative to the scheme, stratum, and provenance through which they were produced. A term classified as a mechanic in one scheme may appear as a narrative procedure, interaction protocol, or pedagogical scaffold in another. Scheme-aware querying preserves the interpretive conditions under which a classification was made and reduces the risk of false equivalence across research traditions.
The fifth principle is ontological coexistence. External vocabularies and ontologies are not absorbed into a single master system. They remain distinct semantic systems connected through typed mappings such as exact match, close match, broad match, narrow match, and related match. This structure enables comparison without erasure. It also allows contested definitions to remain visible, traceable, and query able.
The proposed semantic “atlas” operationalizes these principles by combining configurable stratum schemes, provenance-aware mappings, definitional stance relations, and semantic links grounded in established knowledge-organization frameworks. These include the Simple Knowledge Organization System (SKOS), the Simple Knowledge Organization System eXtension for Labels (SKOS-XL), the Provenance Ontology (PROV-O), the International Committee for Documentation Conceptual Reference Model (CIDOC CRM), and the Library Reference Model object-oriented formulation (LRMoo) (Binding 2010). The purpose of the semantic atlas is not to impose a universal ontology of role-playing games. Its purpose is to preserve interpretive plurality while supporting comparison, retrieval, and reuse across heterogeneous TTRPG-derived data.
This conceptual framework guides the review design that follows. The Materials and Methods section explains how the scoping review was specified, registered, searched, screened, and structured to identify the data types, analytical methods, and knowledge-organization practices currently used to study TTRPG-derived multimedia data.
4. Materials and Methods
This study uses a scoping review with evidence mapping to examine how TTRPG-derived data are transformed into analyzable evidence. The review is based on the OSF-registered protocol (see the data availability section), which defines the study as a scoping review of academic and multivocal sources that use computational, multimodal, multimedia, or knowledge-organization approaches to analyze data from tabletop role-playing games and methodologically adjacent forms of role-playing.
The review centers on tabletop role-playing game (TTRPG) data. Adjacent forms, including live-action role-playing games (LARPs), actual play, virtual tabletop (VTT) environments, computer role-playing games (CRPGs), analog role-playing games, and hybrid role-playing practices, were included only when they contributed transferable data types, methods, tools, analytical frameworks, or knowledge-organization practices relevant to TTRPG analysis. This scope preserved the review’s focus while recognizing that methodological innovations relevant to TTRPG-derived data are distributed across multiple role-playing traditions.
A scoping review was appropriate because the literature is methodologically dispersed across game studies, education, psychology, human-computer interaction, artificial intelligence, natural language processing, library and information science, digital humanities, performance studies, and design research. The review did not estimate intervention effectiveness, compare treatments, or produce a meta-analysis. Instead, it mapped source types, data types, analytical methods, computational tools, terminology, formalization practices, and methodological gaps across a heterogeneous corpus.
The review followed the five-stage structure used in scoping review methodology: research question identification, identification of relevant literature, study selection, data extraction, and reporting of results (Mak and Thomas 2022; Yuliawati et al. 2024). The process was informed by PRISMA 2020 and PRISMA-ScR principles for transparency and traceability (Page et al. 2021; Holst et al. 2025). SPIDER was used as a conceptual guide to specify the sample, phenomenon of interest, design logic, evaluation dimensions, and research types included in the review (Methley et al. 2014).
4.1. Methodological Rationale
The review was designed to identify and synthesize how recent RPG studies analyze play-derived data through qualitative, computational, multimodal, multimedia, or knowledge-organization methods. Play-derived data were defined as materials generated through, around, or from role-playing activity, including transcripts, audiovisual recordings, images, maps, character sheets, rules references, platform records, game-state data, session artifacts, digital interactions, and retrospective documentation.
The methodological rationale was not to determine whether role-playing “works” as an intervention, learning activity, or design tool. Rather, the review examined how researchers make role-playing data available for analysis. This mapping included identifying what materials are studied, what methods are used, what analytical purposes guide those methods, how key terms are operationalized, and what gaps limit comparison, reuse, retrieval, or cumulative knowledge-building.
A preliminary exploratory search conducted on April 28, 2026, refined the search logic before formal retrieval. This search identified false positives caused by acronyms shared across fields. In particular, LARP and TRPG retrieved records unrelated to role-playing games, including Ligand-Assisted Reprecipitation Technique and tricuspid regurgitation peak gradient. These findings informed the use of exclusion terms in formal search strings. Screening decisions, however, were based on contextual relevance rather than keyword presence alone.
4.2. Research Question Identification
The following central question guides the review:
How have qualitative, computational, multimodal, multimedia, and knowledge-organization methods been used to analyze play-derived data in role-playing game studies?
This question operationalized the OSF-registered protocol for the manuscript. It focused the review on data types, analytical procedures, tools, infrastructures, terminological patterns, levels of formalization, and methodological gaps.
The central question was addressed through eight sub-questions:
- a)
- What types of sources, formats, and publication channels constitute recent production on the analysis of RPGs and related play-derived data?
- b)
- What types of textual, audio, audiovisual, digital, multimodal, multimedia, or play-derived materials are most frequently analyzed?
- c)
- What methods, techniques, tools, or analytical frameworks are used to study these materials?
- d)
- What analytical purposes guide the use of these methods, techniques, or tools in the included sources?
- e)
- What concepts, descriptors, keywords, and terminological patterns show the greatest frequency, centrality, or relevance within the identified corpus?
- f)
- What levels of formalization, standardization, or knowledge organization appear in the included sources, including taxonomies, ontologies, knowledge graphs, controlled vocabularies, or SKOS-compatible structures?
- g)
- What role do immersion, game mechanics, and character play as objects of analysis within the included sources, and how are they related to collaboration, agency, and narrative co-creation?
- h)
- What methodological gaps, thematic concentrations, visibility biases, or retrieval limitations emerge from the analyzed corpus?
4.3. Identifying Relevant Literature
The review investigated sources published in English or Spanish between 2023 and 2026. This date range reflects the study’s focus on recent methodological developments in role-playing game studies, particularly the expansion of generative AI, semantic annotation, knowledge graphs, controlled vocabularies, structured gameplay datasets, and ontology-oriented approaches.
The search strategy was developed using SPIDER as a conceptual guide rather than as a rigid eligibility filter. The sample included sources on tabletop role-playing games, tabletop role-playing game studies, analog role-playing games, Dungeons & Dragons, LARP, actual play, virtual tabletop environments, and analogous or hybrid role-playing forms when methodologically relevant to TTRPG analysis. The phenomenon of interest was the analysis, organization, formalization, or computational processing of play-derived data. The design included empirical, conceptual, methodological, technical, and review-based work. The evaluation dimension included data types, analytical processes, tools, frameworks, terminology, and levels of formalization. The research type included qualitative, quantitative, mixed-methods, theoretical, computational, technical, grey, and multivocal literature.
Search terms were organized into three Boolean blocks. The first block identified role-playing-related sources using terms such as TTRPG, TRPG, Dungeons & Dragons, LARP, actual play, virtual tabletop, VTT, analog role-playing, and analog games. Dungeons & Dragons was included as a seed term because preliminary searching showed that relevant TTRPG literature does not always use the acronyms TTRPG or TRPG explicitly. The second block captured analytical, multimedia, multimodal, computational, and knowledge-organization concepts, including analysis, multimodal analysis, multimedia analysis, transcript analysis, annotation, ontology, knowledge graph, controlled vocabulary, semantic annotation, natural language processing, named entity recognition, machine learning, visualization, qualitative analysis, and mixed methods. The third block consisted of exclusion terms used to reduce false positives caused by acronym ambiguity.
A preliminary exploratory search conducted on April 28, 2026, identified false positives produced by acronyms shared across fields. In particular, LARP and TRPG retrieved records unrelated to role-playing games, including Ligand-Assisted Reprecipitation Technique and tricuspid regurgitation peak gradient. These findings informed the use of exclusion terms in the formal search strategy. Exclusions were applied only when necessary and were documented by database, interface, date, search string, filters, and number of records retrieved. Full search strings, database-specific syntax adaptations, search dates, filters, and retrieval counts are provided in Appendix A.
The main databases searched were PubMed, Scopus, Web of Science, and Google Scholar. PubMed was used initially to test Boolean syntax and identify acronym ambiguity. Scopus served as the principal interdisciplinary database because it covered computer science, multimedia studies, education, human-computer interaction, digital humanities, and game studies. Web of Science complemented Scopus coverage, and Google Scholar was used to identify sources that may not be consistently indexed in conventional databases.
Supplementary strategies were used to improve coverage. These included backward citation searching, forward citation searching, review of highly cited articles, searches of doctoral theses and dissertations, and citation mapping with tools such as Litmaps 1 when appropriate. Grey and multivocal sources were eligible when they provided methodological, analytical, terminological, technical, or knowledge-organization value. These sources included technical documentation, open repositories, project websites, blogs, podcasts, videos, wikis, forums, and community-based materials.
After the primary search, Primo, ProQuest, and the Directory of Open Access Journals (DOAJ) were consulted as supplementary discovery environments at the recommendation of a content expert. The content expert also recommended additional books and seminal works, resulting in 18 additional resources added to the review corpus. These sources were included only when they met the same criteria of relevance, traceability, accessibility, and methodological contribution used for the primary corpus.
Sources were excluded when RPGs were mentioned only incidentally, metaphorically, or as a secondary example; when they focused exclusively on workplace role training, clinical role-play, simulation, gamification, or strictly digital RPGs without methodological transferability to tabletop, analog, or hybrid role-playing analysis; when no play-derived data, multimedia material, computational method, analytical framework, or knowledge-organization contribution could be identified; or when the full text or sufficient metadata could not be retrieved.
Full search strings, database-specific syntax adaptations, search dates, filters, exclusion terms, and retrieval counts are reported in Appendix A.
4.4. Papers Selection Process
The selection process followed the OSF-registered protocol, which defined the SPIDER fields, eligibility criteria, extraction dimensions, and review questions before formal screening. Sources were eligible when they addressed role-playing games in one or more relevant forms and provided methodological, analytical, computational, multimodal, multimedia, or knowledge-organization relevance.
After database and supplementary searches, all records were imported into the review-management workflow and checked for duplicates. Duplicate records were removed or merged before title and abstract screening. Screening decisions were managed through a group-verdict workflow. Individual reviewer triage decisions were promoted into formal group decisions. Records with unanimous agreement were advanced or excluded through bulk action, while records with disagreement or uncertainty were reserved for manual resolution. No unresolved conflicts remained after reconciliation.
Title and abstract screening excluded records that clearly fell outside the review scope. Records were excluded at this stage when they mentioned RPGs only tangentially, focused on unrelated forms of role-play or simulation, lacked methodological relevance, or did not address play-derived data, analytical methods, computational techniques, multimodal materials, or knowledge-organization practices. Records were retained for full-text review when eligibility could not be determined confidently from the title and abstract alone.
Full-text retrieval was conducted as a distinct PRISMA stage. The team verified DOI accuracy, retrieval status, and access to the full text. Retrieval outcomes were documented to support the PRISMA categories “reports sought for retrieval” and “reports not retrieved.” Full-text sources were assessed against the protocol’s eligibility criteria. Sources were excluded when the full text could not be retrieved, the document was inaccessible because of availability constraints, the record was retracted, or the full text showed that the source did not meet the review criteria.
The identification stage produced 306 records from database searches and 18 additional resources recommended by a content expert, for a total of 324 records before screening. After duplicate management, title and abstract screening, and full-text retrieval, 37 items proceeded to quality appraisal and final eligibility assessment. Two theses were excluded after appraisal because they did not meet the final inclusion criteria. The final corpus consisted of 35 sources. Figure 2 and Figure 3, 4, and 5 report the triage queues, group-verdict workflow, full-text retrieval process, and PRISMA flow summary, respectively.
Figure 2.
Triage queues report. Source: https://akashic-ida.vercel.app/triage.
Figure 2.
Triage queues report. Source: https://akashic-ida.vercel.app/triage.

Figure 3.
Group-verdict screening workflow. Source: https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/decide.
Figure 3.
Group-verdict screening workflow. Source: https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/decide.

Figure 4.
Full-text retrieval and eligibility workflow. Source: https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/eligibility.
Figure 4.
Full-text retrieval and eligibility workflow. Source: https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/eligibility.

Figure 5.
PRISMA flow diagram for study identification, screening, and inclusion.

4.5. Data Extraction
Data extraction was conducted using a structured SPIDER extraction matrix developed from the OSF-registered protocol, the review questions, and the planned evidence-mapping outputs. The matrix recorded, for each included source, the methodological and conceptual features required to synthesize how role-playing game studies analyze play-derived data. The extraction process followed PRISMA-ScR items 14 and 15 by specifying the data items sought from each source and documenting the extraction logic used to populate the review database (see Figure 6). The full source-level extraction matrix is provided in Appendix B. The matrix documents how each included source was coded across key analytical dimensions, including methods, data types, and gaps identified. This appendix functions as an audit trail linking the narrative synthesis to the evidence extracted from individual sources.
Each included source was entered as one row in the extraction matrix. The columns represented the main analytical dimensions of the review: Paper, immersion, mechanics, character, relation, narrative, methods, data_types, knowledge_organization, and gaps_identified. These dimensions corresponded to the review questions and allowed the team to document how each source treated play-derived data, methodological procedures, RPG-specific constructs, and formalization practices.
The Paper column recorded bibliographic identity. The immersion column captured references to immersion, presence, engagement, embodiment, role adoption, and related experiential constructs. The mechanics column documented rules, dice systems, action resolution, character statistics, state tracking, and other procedural elements. The character column recorded how player characters, non-player characters, avatars, roles, or identities were conceptualized. The relation column captured interpersonal, interactional, social, collaborative, or player-system relations.
The narrative column documented treatment of story, authorship, worldbuilding, campaign continuity, actual play, scenario design, or co-created fiction. The methods column recorded qualitative, computational, review-based, design-based, or technical approaches, including discourse analysis, conversation analysis, narrative analysis, scoping review, natural language processing, named entity recognition, semantic annotation, machine learning, and generative AI. The data_types column captured transcripts, audiovisual recordings, Discord logs, Avrae commands, character sheets, maps, structured game states, survey data, interview data, platform traces, technical documentation, and community materials. The knowledge_organization column recorded metadata, controlled vocabularies, taxonomies, ontologies, semantic relations, SKOS-compatible structures, knowledge graphs, annotation schemes, datasets, and formalized categories. The gaps_identified column captured limitations, unresolved problems, methodological constraints, representational biases, retrieval challenges, and future research needs.
Extraction was performed at the source level. Each paper was treated as the primary unit of analysis, even when it contained several methods, data types, or conceptual objects. When a source addressed multiple dimensions, information was recorded across relevant columns. When a dimension was not addressed, the field was left blank rather than inferred. This decision preserved the distinction between explicitly reported information and reviewer interpretation.
The matrix supported both descriptive mapping and interpretive synthesis. Descriptive extraction recorded what each source explicitly reported. Interpretive notes were limited to concise statements clarifying how the source contributed to the review categories. This separation reduced overinterpretation while allowing cross-source comparison.
Human reviewers made all extraction decisions. Digital tools were used to organize the matrix, manage records, track completion, and preserve decision history, but they did not make extraction decisions autonomously. Ambiguous or incomplete entries were flagged for later verification. The final extraction database functioned as both an analytic record and an audit trail linking each included source to the review’s evidence-mapping outputs.
4.6. Reporting Final Results
The final results were reported through descriptive statistics, matrix-based evidence mapping, and interpretive synthesis. Three reporting instruments structured the synthesis. The PRISMA flow diagram documented movement from identification to final inclusion. The SPIDER extraction matrix captured the substantive features of each source. The research-question alignment matrix showed how each paper contributed to the review’s eight analytical sub questions.
To support transparent evidence mapping, the authors developed a research-question alignment matrix (Figure 7). Each row represented one included source, and each column represented one review sub question. Each source-sub question cell was coded using a four-level relevance scheme: Absent, Primary, Secondary, and Mention. Absent indicated that the source did not meaningfully address the sub question. Primary indicated that the sub question was a central focus. Secondary indicated relevant but non-central treatment. Mention indicated a brief or indirect reference. The full research-question alignment matrix is provided in Appendix C. The matrix records how each included source contributed to the review sub questions using four relevance levels: Absent, Mention, Secondary, and Primary. This appendix supports transparency by showing how the synthesis was connected to source-level evidence rather than derived only from narrative interpretation.
The alignment matrix served three reporting functions. First, it identified which sub questions were most strongly represented across the corpus. Second, it cross-checked the extraction matrix against the review questions to ensure alignment between protocol and synthesis. Third, it made visible where the literature was concentrated, partial, or thin. The matrix, therefore, functioned as an intermediate analytical tool between extraction and narrative synthesis.
4.7. Quality Appraisal
Quality appraisal used a source-sensitive assessment strategy because the corpus included empirical, conceptual, methodological, technical, community-based, practice-based, and grey-literature sources. The purpose of the appraisal was not to rank sources by disciplinary prestige or exclude sources because they were non-empirical. Instead, the appraisal assessed whether each source provided sufficient methodological clarity, evidentiary support, and relevance to contribute to the synthesis.
For empirical studies, appraisal focused on the clarity of the research question, fit between design and aim, adequacy of the data source or sample, transparency of collection and analysis procedures, and coherence between evidence and claims. For qualitative studies, attention was given to analytic transparency, contextual grounding, and adequacy of evidence supporting interpretation. For computational and technical studies, appraisal emphasized reproducibility, clarity of data sources, explicitness of methods, tool or model description, and relevance to the analysis or formalization of play-derived data. For conceptual, methodological, and multivocal sources, appraisal focused on relevance, traceability, analytic rigor, and contribution to terminology, data organization, or methodological understanding.
Each source was assessed in relation to the central question and eight sub questions. Appraisal considered whether the source contributed to at least one of the review dimensions: data type, analytical method, computational technique, multimedia or multimodal material, formalization practice, knowledge-organization structure, terminology, or methodological gap. Sources that addressed RPGs but did not provide sufficient methodological, analytical, computational, or knowledge-organization relevance were not retained for the final corpus.
Quality appraisal primarily determined interpretive weight in the synthesis. Sources with clear methods, explicit data descriptions, transparent procedures, and strong alignment with the review questions were treated as stronger evidence. Sources with limited reporting or narrower relevance were retained only when they contributed useful contextual, terminological, or methodological insight. When a source was relevant but methodologically thin, its limitations were documented and considered during synthesis.
The appraisal was conducted after title and abstract screening, full-text retrieval, and initial eligibility assessment. Of the 37 sources that reached final appraisal, two theses were excluded because they did not meet the threshold for methodological relevance and extractable contribution to the evidence-mapping aims. The final corpus consisted of 35 included sources, which were carried forward into the SPIDER extraction matrix and the research-question alignment matrix.
This appraisal strategy aligns with the review’s purpose: to map the methodological infrastructure of RPG research rather than evaluate a single intervention or produce pooled outcome estimates. It preserved distinctions between stronger and weaker forms of evidence while allowing the review to represent the interdisciplinary and multivocal character of role-playing game studies.
4.8. Semantic Vocabulary Outputs
In addition to the extraction and alignment matrices, the review generated machine-readable semantic vocabulary outputs to support reuse, provenance tracking, and future ontology development. These outputs include a Turtle (TTL) file and a JSON-LD file containing classes, instances, concept schemes, labels, mappings, and metadata associated with the semantic vocabulary developed during the review. The files are deposited in the OSF folder for digital ontologies and are treated as supplementary evidence of the review’s knowledge-organization process. Their purpose is not to replace the narrative synthesis, but to make the emerging vocabulary inspectable, reusable, and extensible for future semantic atlas development (DBRF1 and 2 see Additional materials).
5. Results
The review identified a fragmented but increasingly connected methodological landscape for the analysis of TTRPG-derived data. Across the final corpus, sources varied by publication type, disciplinary orientation, data modality, analytical purpose, and degree of formalization. The central finding is that role-playing game studies use a wide range of qualitative, computational, multimodal, multimedia, and knowledge-organization methods, but these methods remain unevenly coordinated across research traditions, data models, and vocabularies.
To make the corpus structure explicit, Table 1 reports the distribution of the 35 included sources. Publication type, publication year, and primary RPG scope are mutually exclusive categories. Methodological/thematic and applied/evidentiary categories are reported according to the primary classification assigned during extraction (see Table 1). The results reported in this section are based on two source-level audit tools. Appendix B provides the extraction matrix documenting methods, data types, and gaps identified for each included source. Appendix C provides the research-question alignment matrix, which records whether each source addressed the review sub questions as a primary focus, secondary focus, brief mention, or absent category. Together, these appendices link the narrative synthesis to the evidence extracted from individual sources.
The distribution shows that the final corpus is balanced between conference papers and journal articles, with conference papers representing 45.7% of the corpus and journal articles representing 42.9%. The concentration of publications in 2023 and 2025 reflects the recent growth of computational, AI-supported, educational, therapeutic, and knowledge-organization work on role-playing game data. The thematic distribution also supports the review’s central claim: the corpus is not organized around a single methodological tradition. TTRPG/D&D-centered sources dominate the corpus, but substantial proportions of the included sources address computational, AI, NLP, or technical methods (37.1%), qualitative or interpretive analysis (34.3%), and knowledge organization or formalization (28.6%). This distribution supports the need for an infrastructure capable of coordinating heterogeneous evidence across computational, interpretive, applied, and semantic traditions. A more granular extraction-based count of methods, data types, frameworks, and analytical purposes is provided in DB1, a CSV of all 150 sources (see Supplemental materials).
Table 2 reports the major methodological patterns identified across the corpus. To preserve readability in the main text, the full source-to-finding evidence mapping is provided in Table S1, which identifies the primary sources supporting each major finding (see Appendix).
Taken together, the results indicate that TTRPG-derived data are increasingly treated as layered evidence. The same play materials may be analyzed as narrative interaction, learning evidence, player experience, computational state, platform trace, audiovisual performance, or semantic resource. This multiplicity is productive, but it also creates challenges for retrieval, comparison, formalization, and reuse.
5.1. Distribution Across Publication Ecosystems
Research on role-playing game data is distributed across interdisciplinary and multivocal publication ecosystems rather than a single disciplinary venue. Relevant sources appeared in conference proceedings, journal articles, theses, book sections, datasets, technical papers, platform documentation, and actual play media. This distribution shows that TTRPG-derived data are not contained within one field, database, or publication genre.
This dispersion has methodological consequences. No single database, vocabulary, or indexing system captures the relevant literature sufficiently. Sources relevant to TTRPG-derived data appear in game studies, education, psychology, human-computer interaction, artificial intelligence, natural language processing, digital humanities, library and information science, and practice-based communities. Effective retrieval, therefore, requires search strategies that combine academic databases, citation tracking, technical venues, community documentation, and platform-based sources.
This finding answers the first review sub question by showing that the corpus is not only interdisciplinary but also infrastructurally dispersed. The dispersion itself becomes part of the methodological problem because search terms, indexing practices, source types, and disciplinary vocabularies vary across the publication ecosystem.
5.2. Multimedia and Multimodal Data
The corpus shows that TTRPG research analyzes several forms of play-derived evidence. These include spoken interaction, transcripts, campaign notes, audiovisual recordings, Discord logs, virtual tabletop traces, maps, character sheets, structured game states, platform commands, and retrospective documentation. These data types differ in analytical affordance and cannot be treated as interchangeable records of the same event.
Spoken interaction supports conversation analysis, discourse analysis, and analysis of turn-taking, framing, and role-switching. Textual records enable narrative coding, named entity recognition, semantic extraction, and evidence mapping. Structured game states support modeling, prediction, and machine learning. Audiovisual media preserve gesture, pacing, tone, embodiment, and performance. Material artifacts, including maps, dice, and character sheets, require interpretive and digitization procedures. Platform traces, including Discord logs and VTT actions, enable interaction analysis and behavioral analytics.
The evidence map, therefore, indicates that TTRPG-derived data operate across narrative, procedural, audiovisual, material, social, and computational layers. Table 3 summarizes the main data modalities and the methods typically associated with them.
The main implication is that TTRPG research increasingly requires multimodal and multimedia infrastructure. A transcript alone may preserve dialogue but lose gesture, pacing, tone, map interaction, dice use, interface action, and material context. Conversely, audiovisual evidence may preserve performance but remain difficult to retrieve, compare, or computationally process without structured metadata and annotation.
5.3. Methods, Techniques, and Analytical Frameworks
The reviewed studies used hybrid methodological infrastructures rather than a single dominant method. Qualitative approaches included discourse analysis, conversation analysis, narrative analysis, ethnography, design-based research, and interpretive coding. Computational approaches included natural language processing, named entity recognition, semantic annotation, structured dataset design, machine learning, and AI-assisted generation.
This pattern suggests that computational methods increasingly coexist with qualitative interpretation. They do not replace human analysis. Instead, they require interpretive grounding to define relevant entities, actions, relations, player states, fictional-world references, rules, and contexts. Conversely, qualitative analysis increasingly benefits from structured data management, annotation, and evidence-mapping procedures when corpora become large, multimodal, or platform-mediated.
A second pattern concerns the degree of formalization. Some sources remain primarily descriptive, while others introduce coding schemes, annotation structures, controlled vocabularies, structured datasets, or AI-oriented knowledge representations. Table 4 summarizes the levels of formalization identified across the corpus (see Table 4).
5.4. Analytical Purposes
The analytical purposes of the included sources clustered around five functions: facilitation, evaluation, learning, intervention, and generation. Facilitation studies examined tools that support Game Masters, players, designers, or research teams. Evaluation studies focused on player experience, system usability, immersion, interaction quality, and learning outcomes. Educational and therapeutic studies analyzed role-playing as a context for development, communication, collaboration, metacognition, or psychological intervention. Computational studies examined role-playing as a testbed for dialogue modeling, narrative generation, entity extraction, state modeling, and human-AI co-creation.
These purposes show that TTRPGs are no longer treated only as narrative artifacts. They are also analyzed as applied interaction systems, learning environments, computational domains, therapeutic contexts, and knowledge-organization problems. The same empirical material may support more than one analytical purpose. For example, a recorded session may function as conversational data, educational interaction, narrative artifact, platform-mediated event, and structured game-state record.
This multi-functionality strengthens the case for semantic infrastructure. When the same material can be used for several forms of analysis, researchers need a way to preserve the conditions under which the material was classified, interpreted, and reused.
5.5. Terminological Instability
Terminological instability emerged as a major methodological issue. Terms such as RPG, TTRPG, TRPG, LARP, actual play, campaign, scenario, immersion, agency, adventure, session, mechanic, and game system circulate across academic, community, platform, and cataloging contexts with inconsistent meanings.
This instability affects more than vocabulary choice. It shapes retrieval, corpus construction, interoperability, and comparison. Controlled vocabulary studies show that existing classification systems often struggle to distinguish TTRPGs from CRPGs, theatrical role-play, training simulations, board games, or works about TTRPGs. Scenario-based studies similarly show that terms used across domains may appear shared while carrying different operational meanings.
The review, therefore, identifies terminology as a methodological condition of analysis. Without explicit definitions, search terms, and classification criteria, studies risk retrieving inconsistent corpora, comparing non-equivalent objects, or formalizing concepts whose meanings differ across contexts. This finding directly supports the need for scheme-aware and provenance-aware approaches to vocabulary design.
5.6. Formalization and Knowledge Organization
Formalization practices ranged from informal description to machine-readable knowledge structures. At the informal level, studies used ethnographic or narrative interpretation without explicit schemas. Semi-structured approaches introduced thematic coding, qualitative matrices, and evidence-mapping tools. More formal approaches used entity tagging, semantic labeling, structured datasets, controlled vocabularies, taxonomies, and semantic relations. The most computationally integrated sources used structured knowledge to support AI-assisted generation, model evaluation, or game-state representation.
This range shows that the field is moving from descriptive categorization toward computationally usable structures. However, the transition remains uneven. Some sources formalize local datasets without making them interoperable. Others prioritize generation, retrieval, or prediction without preserving interpretive context. Knowledge-organization work addresses this problem more directly by showing how definitions, categories, and semantic relations affect discoverability and reuse.
The result supports the need for a polyvocal semantic infrastructure. As part of this formalization process, the review produced two machine-readable vocabulary outputs: a Turtle (TTL) representation and a JSON-LD representation of the semantic vocabulary. These files document the transition from extraction categories and conceptual mappings into reusable semantic structures. They include classes, instances, concept schemes, labels, and provenance-oriented metadata that support future implementation of the semantic atlas. Their inclusion strengthens the evidence that the review’s contribution is not only interpretive but also infrastructural. The problem is not simply that TTRPG research lacks formalization. Rather, existing forms of formalization are difficult to align across schemes, data models, disciplinary vocabularies, and analytical purposes. A semantic infrastructure for this field must therefore support comparison without collapsing local meanings into a single universal ontology.
5.7. Emerging Tensions
The corpus revealed five recurring tensions. First, formalization improves comparison and retrieval, but it may reduce narrative and interpretive nuance. Second, community-generated sources increase visibility and access, but they complicate validation and provenance. Third, AI systems can support Game Masters and researchers, but they may over-structure play practices that depend on improvisation, ambiguity, and local judgment. Fourth, Dungeons & Dragons provides highly visible and processable datasets, but its dominance may bias the field toward fantasy-centric, English-language, and commercially prominent systems. Fifth, broad search terms improve recall, but they also increase false positives and terminological noise (see Table 5).
These tensions indicate that TTRPG research is entering a transitional methodological phase. The field increasingly produces multimedia and multimodal evidence, but existing methods remain difficult to coordinate across retrieval, analysis, annotation, preservation, and computational reuse.
To further examine the conceptual distribution of the corpus, a keyword co-occurrence analysis was conducted in VOSviewer using full counting. The analysis identified 743 keywords across the final corpus. A minimum threshold of five occurrences per keyword was applied, resulting in 24 keywords that met the inclusion threshold. Before generating the visualization, internal coding labels used during the review process were excluded from the selected keyword list, including labels such as _CGE, _Sample, _First run, and other workflow-specific codes that did not represent substantive concepts in the literature.
The co-occurrence analysis also revealed a key finding that supports the review’s broader argument about traceability and terminological instability. Several concepts appeared under multiple lexical variants. For example, terms such as “Dungeons & Dragons,” “Dungeons and Dragons,” and “Dungeon & Dragon” were normalized as Dungeons and Dragons (D&D). Variants such as “role playing game” and “role-playing games” were normalized as role-playing game (RPG). Variants such as “tabletop roleplaying game,” “tabletop role-playing game,” and “tabletop role-playing games” were normalized as table-top role-playing game (TTRPG). Similar normalization was required for adjacent role-playing forms and platforms, including Massively Multiplayer Online Role-Playing Game (MMORPG), educational live-action role-playing games (Edu-LARP), therapeutic role-play (TRP), virtual tabletop (VTT), live-action role-playing games (LARP), and analog role-playing game (ARPG).
This normalization process is analytically important because it shows that keyword variation is not merely a spelling issue. It affects retrieval, corpus construction, bibliometric mapping, and semantic comparison. The need to normalize terms across acronymic, hyphenated, pluralized, and domain-specific variants confirms one of the review’s central findings: TTRPG-related research lacks stable semantic alignment across publication venues and disciplinary vocabularies. The VOSviewer analysis, therefore, provides empirical support for the traceability problem identified in the review (see Figure 8).
The resulting network visualization shows that terms such as Dungeons and Dragons (D&D), table-top role-playing game (TTRPG), role-playing game (RPG), role playing, interactive computer graphics, natural language processing system, and game design occupy visible positions within the network. The visualization also shows temporal clustering across the 2023–2025 period, indicating that computational, AI, game-design, and applied social-scientific terms are increasingly connected within the reviewed corpus.
The co-occurrence visualization supports three findings from the evidence map. First, the corpus is semantically clustered around Dungeons and Dragons and TTRPG-related terminology, which is consistent with the dominance of TTRPG/D&D-centered sources reported in Table 1. Second, computational terms such as natural language processing system and interactive computer graphics appear in the same network as role-playing and game-design terms, supporting the finding that computational and interpretive traditions increasingly intersect. Third, applied social and demographic terms, including adult, male, and humans, show connections to role-playing terms, reflecting the presence of psychological, therapeutic, and social-intervention studies within the corpus.
The visualization should not be interpreted as a comprehensive bibliometric map of the entire field. It represents the semantic structure of the reviewed corpus only. Its value is diagnostic rather than exhaustive: it confirms that the final corpus combines TTRPG-centered terminology, computational methods, game-design discourse, and applied human-subjects research. It also demonstrates that term normalization is a necessary methodological step for any future semantic atlas or knowledge-organization infrastructure for TTRPG-derived data.
6. Discussion
The results show that the central challenge in TTRPG-derived multimedia research is not the absence of analytical methods. The reviewed corpus includes qualitative interpretation, discourse analysis, conversation analysis, player-experience evaluation, structured datasets, named entity recognition, semantic annotation, AI-assisted generation, controlled vocabulary work, and knowledge-organization approaches. The problem is that these methods remain weakly coordinated across data types, disciplinary vocabularies, publication ecosystems, and levels of formalization.
The compact corpus distribution in Table 1 shows that the final corpus is methodologically diverse rather than organized around one dominant research tradition. Conference papers and journal articles are nearly balanced, and the corpus includes computational, qualitative, knowledge-organization, therapeutic, educational, and multimodal studies. The methodological patterns in Table 2 further show that TTRPG-derived data are studied through multiple analytical purposes, including facilitation, evaluation, learning, intervention, generation, formalization, and retrieval. Table 3 and Table 4 show that TTRPG-derived data operate across multiple modalities and levels of formalization, from spoken interaction and material artifacts to structured game states and semantic annotation. Table 5 identifies the tensions that follow from this condition: narrative richness versus computational structure, accessibility versus methodological rigor, human improvisation versus AI assistance, D&D availability versus representational diversity, and retrieval breadth versus terminological precision.
The keyword co-occurrence analysis in Figure 8 reinforces this interpretation. The need to normalize variants such as “Dungeons & Dragons,” “Dungeons and Dragons,” “role playing game,” “role-playing games,” “tabletop roleplaying game,” and “tabletop role-playing games” shows that the traceability problem is not only conceptual. It appears directly in the metadata and keywords used to retrieve, map, and compare the literature. This section interprets those findings through the conceptual framework proposed in this article and develops the scope ladder as a provenance-aware model for semantic coordination.
6.1. From Fragmented Evidence to Semantic Infrastructure
The results indicate that TTRPG-derived data circulate across several knowledge-making environments: scholarly publications, technical datasets, platform records, community archives, actual play media, therapeutic documentation, educational studies, and computational pipelines. This dispersion creates a methodological problem. If relevant sources are distributed across databases, formats, vocabularies, and publication cultures, then retrieval depends not only on search strategy but also on the semantic alignment of the terms used to describe the field.
This point matters for multimedia research because TTRPG-derived data are not reducible to a single evidence type. A campaign session may produce dialogue, gestures, dice outcomes, map interactions, platform commands, character-state changes, GM narration, player reflection, and later recap materials. Each layer may require a different analytical method, but the layers remain connected through the same play event. Without a semantic infrastructure, these materials are difficult to compare, retrieve, annotate, or reuse across studies.
The review, therefore, supports a shift from method accumulation to infrastructure design. Adding more tools is not sufficient if those tools operate within disconnected vocabularies and incompatible data models. The proposed Polyvocal Semantic Infrastructure responds to this problem by coordinating multiple interpretive systems while preserving their provenance, scope, and analytical purpose. Its goal is not to reduce TTRPG research to one authoritative taxonomy, but to make heterogeneous classifications and interpretive positions traceable, comparable, and reusable.
6.2. Terminological Variation as a Traceability Problem
The review shows that vocabulary instability is a structural feature of TTRPG research. Terms such as campaign, scenario, immersion, character, mechanic, player, role, actual play, LARP, VTT, and TTRPG circulate across player communities, game systems, cataloging practices, computational studies, educational research, therapeutic contexts, and performance analysis. These terms are not simply inconsistent. They carry different analytical functions depending on the community, method, and object of study.
The keyword co-occurrence analysis makes this issue empirically visible. Several central concepts appeared under multiple lexical variants and required normalization before the network could be interpreted. These included variants for Dungeons and Dragons, role-playing games, tabletop role-playing games, virtual tabletops, live-action role-playing games, educational LARP, therapeutic role-play, massively multiplayer online role-playing games, and analog role-playing games. These variants affect retrieval because records that belong to the same conceptual area may not be captured together unless the search strategy anticipates spelling, punctuation, acronymic, hyphenation, and pluralization differences.
This finding reframes terminology as a methodological condition rather than a peripheral naming problem. When concepts are flattened into undifferentiated keywords, the result is reduced semantic precision, weaker retrieval, and limited interoperability between studies. Controlled vocabulary research shows this problem in the difficulty of distinguishing TTRPGs from adjacent forms, related media, and works about role-playing games. Computational studies reach a similar problem from another direction: domain-specific entities, fictional-world relations, rules, and gameplay concepts require stable annotation practices before they can be reliably processed.
A provenance-aware approach addresses this problem by preserving the context in which a term is defined, used, or operationalized. In this model, a concept is not only a label. It is also a record of origin, scope, interpretive stance, and use. This approach is especially important for TTRPG studies because the field is transmedia, community-driven, and collaboratively authored. Terms emerge from designers, players, scholars, librarians, software platforms, and archival institutions. A single universal vocabulary would likely erase this plurality. A semantic infrastructure for TTRPG research should therefore support multiple vocabularies while making their relations explicit.
6.3. The Scope Ladder as a Provenance-Aware Semantic Model
To operationalize this approach, this article proposes the scope ladder as a model for organizing concepts by provenance, authority, and visibility. The scope ladder does not replace the semantic atlas introduced in the conceptual framework. Rather, it specifies how concepts can be governed within the atlas. It treats concepts as provenance-bearing entities whose meaning depends partly on the context from which they emerge.
At the narrowest level are review-scoped vocabularies. These contain concepts that matter within a specific review, dataset, or analytical task. They support exploratory coding, temporary distinctions, and project-specific categories that may not persist beyond the study. In the present review, for example, workflow labels and internal coding terms were useful during extraction and analysis but were excluded from the VOSviewer keyword visualization because they did not represent substantive concepts in the literature.
The next level consists of group-scoped vocabularies. These include terms negotiated and reused across several projects by a research group, laboratory, or community of practice. They support continuity without requiring all concepts to become universal field terms. For example, a research group studying TTRPG-derived multimedia data may use stable internal categories for campaign continuity, player agency, platform trace, or semantic annotation across multiple reviews and datasets.
The third level consists of source-paper vocabulary. These preserve terminology coined, adapted, or operationalized by specific sources. This layer is important in TTRPG research because concepts such as bleed, immersion, fiction-first, safety, actual play, campaign, scenario, or mega-campaign may carry distinct meanings in different publications or communities. A source-paper vocabulary allows these meanings to remain connected to their original context before being mapped to broader vocabularies.
The broadest level consists of external named vocabularies and authority systems, including systems such as Library of Congress Subject Headings, Wikidata, CIDOC CRM, LRMoo, SKOS, PROV-O, and other disciplinary vocabularies or ontologies. These systems provide wider interoperability but should not overwrite local conceptual distinctions.
Together, these layers create a compositional semantic environment. A researcher working with a TTRPG dataset may use concepts from the review, the research group, specific source papers, and external authority systems at the same time. The value of the scope ladder is that it makes those layers visible. It allows researchers to ask not only what a concept means, but where it comes from, who uses it, how broadly it circulates, and how it has been mapped to adjacent concepts.
Figure 9 operationalizes this provenance-aware model as a scope ladder. The model shows how researchers can activate multiple vocabulary scopes simultaneously, preserving local interpretive context while supporting broader comparison, retrieval, and interoperability (see Figure 9)
The model organizes vocabularies across four activated scopes: review-scoped vocabularies, group-scoped vocabularies, source-paper vocabularies, and external named vocabularies or authority systems. The upward direction indicates increasing semantic authority and interoperability, while the downward direction indicates increasing contextual locality and exploratory flexibility.
In this model, the effective vocabulary used in analysis is not a single controlled list but the union of activated scopes. This process allows a researcher to preserve review-specific codes, group conventions, source-paper terminology, and external authority mappings without collapsing them into one hierarchy.
6.4. Implications for Knowledge Graphs, Annotation Systems, and AI-Assisted Analysis
The scope ladder has direct implications for knowledge graphs and annotation systems. In graph-based environments, an annotation should not only link a data fragment to a concept. It should also link that concept to its vocabulary scope, source, definition, and mapping status. Under this model, provenance becomes part of the semantic relation itself rather than secondary documentation added after analysis.
This structure would allow researchers to query both concepts and their histories of use. A graph could identify which concepts were introduced in a specific paper, which were adopted by a research group, which were mapped to external vocabularies, and which remained local to a single review. It could also reveal whether a term functions differently across educational research, computational modeling, cataloging, actual play studies, or TTRPG community discourse.
This model also supports AI-assisted analysis. Retrieval-augmented systems depend on the quality of the semantic context supplied to the model. If concepts, entities, and relations are not scoped, the system may retrieve superficially related but methodologically incompatible materials. Scope-aware knowledge graphs can reduce this risk by preserving distinctions between local codes, source-specific definitions, group vocabularies, and external authority terms. This model does not eliminate interpretation, but it makes interpretive conditions more explicit and auditable.
For TTRPG research, the broader implication is that future infrastructures should treat concepts as socially situated and historically traceable. This idea matters because TTRPG-derived data are not only heterogeneous in format. They are also heterogeneous in authorship, mediation, and interpretive purpose. A character sheet, Discord log, campaign recap, VTT trace, actual play recording, or structured game-state dataset may move across analytical contexts while retaining traces of player agency, rules mediation, platform affordance, and retrospective interpretation. A provenance-aware semantic infrastructure can help preserve these relations while still supporting comparison and reuse.
6.5. Methodological and Practical Implications
The findings suggest four implications for future multimedia research on TTRPGs. First, researchers should document the semantic scope of their analytical categories. Terms such as immersion, character, mechanic, scenario, and campaign should be defined not only conceptually but also operationally, with attention to the data type and analytical purpose involved.
Second, review and annotation systems should distinguish between local coding, source-derived terminology, group vocabularies, and external authority systems. This distinction would improve transparency and help avoid false equivalence between terms that appear similar but function differently across contexts.
Third, computational pipelines should preserve provenance as part of data modeling. This is especially important for AI-assisted analysis, where retrieval, annotation, and generation depend on structured contextual information. Without provenance, computational systems may treat contested or context-specific concepts as stable categories.
Fourth, researchers should report term-normalization decisions when conducting bibliometric, keyword, or semantic analyses. The VOSviewer analysis shows that keyword variation directly affects co-occurrence mapping. Reporting normalization decisions would improve reproducibility and help future researchers understand why particular terms were merged, excluded, or retained.
These implications are practical rather than purely theoretical. They affect how review teams build extraction matrices, how corpora are indexed, how annotations are validated, how datasets are reused, and how AI systems retrieve contextual information. They also support the article’s broader methodological contribution: the semantic atlas is not a universal ontology of role-playing games but a framework for coordinating plural, situated, and reusable knowledge about play-derived data.
6.6. Limitations and Future Research
This review has limitations. The corpus is shaped by database coverage, language restrictions, indexing practices, and the visibility of English-language and Dungeons and Dragons-centered research. Although supplementary searching and multivocal sources were included, the review cannot fully represent community practices, unpublished tools, non-English scholarship, or local archives that remain difficult to retrieve through conventional systems.
The review also maps methodological patterns rather than evaluating the effectiveness of specific tools, interventions, or computational models. As a result, the findings should be read as evidence of an emerging infrastructural problem rather than as a ranking of methods. The scope ladder and semantic atlas are proposed as conceptual and methodological contributions. They require further testing through implementation in review software, annotation systems, knowledge graphs, and AI-assisted retrieval workflows.
The keyword co-occurrence analysis should also be interpreted as diagnostic rather than exhaustive. It represents the semantic structure of the reviewed corpus, not the entire field of TTRPG studies. The normalization decisions made before visualization strengthened interpretability but also demonstrated that bibliometric analysis depends on prior semantic judgment. This representation reinforces, rather than resolves, the traceability problem identified in the review.
Future research should therefore focus on applied validation. One direction is to implement a prototype semantic atlas for a bounded TTRPG corpus and evaluate whether scope-aware annotation improves retrieval, comparison, and reuse. A second direction is to test how provenance-aware knowledge graphs affect AI-assisted analysis of session transcripts, character sheets, campaign notes, and platform traces. A third direction is to compare how different communities define and operationalize key TTRPG concepts across languages, systems, and publication ecosystems. A fourth direction is to test whether term-normalization protocols improve reproducibility in bibliometric and evidence-mapping studies of role-playing game research.
Taken together, the Discussion extends the Results by showing why methodological fragmentation cannot be solved by adding more tools alone. TTRPG research requires semantic infrastructures that can preserve interpretive plurality, document provenance, and support coordination across heterogeneous multimedia evidence.
7. Conclusions
This review examined how qualitative, computational, multimodal, multimedia, and knowledge-organization methods are being used to analyze play-derived data in tabletop role-playing game research. The findings show that TTRPG studies increasingly work with complex evidence ecologies composed of speech, gesture, character sheets, maps, rules references, platform traces, audiovisual records, structured game states, annotations, metadata, and retrospective documentation. These materials are not secondary records of play. They constitute Multimedia Play Data: layered, situated, collaborative, and technically mediated evidence that requires methods for interpretation, retrieval, comparison, and reuse.
The review found that the field has developed a broad methodological repertoire, including qualitative interpretation, discourse and conversation analysis, player-experience evaluation, structured datasets, named entity recognition, semantic annotation, AI-assisted generation, and controlled vocabulary work. However, these approaches remain unevenly coordinated across publication ecosystems, data modalities, vocabularies, and levels of formalization. The problem is therefore not a lack of methods, but the absence of shared infrastructure for connecting them.
The central contribution of this article is the proposal of a Polyvocal Semantic Infrastructure for organizing and analyzing TTRPG-derived Multimedia Play Data. The semantic atlas and scope ladder provide a way to preserve multiple vocabularies, interpretive strata, provenance records, and semantic mappings without imposing a single universal ontology on role-playing games. This contribution matters because TTRPG research depends on terms whose meanings shift across communities, systems, disciplines, and analytical purposes. A polyvocal infrastructure allows these differences to remain visible while still supporting comparison, retrieval, reuse, and AI-assisted analysis.
The need for this infrastructure is also practical. TTRPG research is distributed across academic fields, player communities, libraries, archives, software platforms, therapeutic practices, educational settings, and design cultures. These communities often produce related knowledge without shared vocabularies or mutual visibility. A single ontology would risk flattening this diversity by privileging one interpretive system over others. The Polyvocal Semantic Infrastructure instead provides a foundation for holding the field’s polysemy together: it makes divergent terms, meanings, and classifications traceable without forcing them into premature consensus.
A practical implication of this work is that metadata should be treated as analyzable data. Descriptions, classifications, mappings, extraction decisions, provenance records, and vocabulary choices are not merely administrative byproducts of review work. Once formalized, they can support conceptual auditing, methodological transparency, longitudinal comparison, and cumulative scholarship. This formalization turns the review from a one-time synthesis into an expandable infrastructure for future research.
This study has limitations. The corpus remains shaped by database coverage, language restrictions, publication visibility, and the dominance of English-language and Dungeons & Dragons-centered research. The review also maps methodological patterns rather than testing the performance of a fully implemented semantic atlas across multiple datasets.
Future work should validate the proposed infrastructure through applied prototypes, comparative annotation studies, AI-assisted retrieval workflows, and longitudinal review updates. Researchers should test whether scope-aware annotation improves retrieval, whether provenance-aware knowledge graphs strengthen AI-assisted analysis, and whether term-normalization protocols improve reproducibility in bibliometric and evidence-mapping studies. The broader task is clear: TTRPG research needs shared infrastructures that preserve plurality rather than erase it, making role-playing games a valuable site for advancing multimedia analysis, knowledge organization, human-AI collaboration, and semantic interoperability.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org, Database: DB1 CSV of 150 sources; DB2 RIS of 150 sources. Digital Ontologies: DBFR 1 TTL file of the semantic vocabulary; DBFR 2 JSON-LD file of the semantic vocabulary. Presentations: PPT1 PRISMA flowchart; PPT3: Atlas architecture; PPT2: Refracting Knowledge. Figures: S1 Polyvocal Semantic Infrastructure; S2 Triage queues report; S3 Group-verdict screening workflow; S4 Full-text retrieval and eligibility workflow; S5 PRISMA Flow; S6 SPIDER Extraction Matrix; S7 Research-Question Alignment Matrix; S8 VOSViewer co-ocurrence; S9 Scope ladder. Tables: T1. Compact Corpus; T2 Emerging Methodological; T3. Data Modalities; T4. Levels of Formalization; T5. Tensions Emerging; T6. Acronyms.
Author Contributions
For research articles with several authors, a short paragraph specifying their individual contributions must be provided. Cristo Leon, Ph.D. (First Author, Corresponding Author): Conceptualization, Methodology, Validation, Formal analysis, Investigation, Resources, Writing - Original Draft, Writing - Review & Editing, Visualization, Supervision, Project administration. Julian Marcone (Collaborating Author): Conceptualization, Software, Validation, Formal analysis, Investigation, Resources, Data Curation, Writing - Review & Editing, Visualization.
Funding
None.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data management plan associated with this research is publicly available through DMP Tool: Cristo Leon, Marcos O. Cabobianco, James Lipuma, Julian Marcone, Agustina Cinanni, and Romano Ponce-Díaz (2026), DMSP para “Narrativas Transmedia y Convergencia: Creando un Repositorio Digital Transnacional para los juegos de rol (JdR) de Mega-Campañas” [Data Management Plan], https://doi.org/10.48321/D12Q16. The OSF project associated with this work is available at https://osf.io/vs298/ under a CC BY-NC-ND 4.0 International license. The scoping review protocol, Mapeo de técnicas computacionales, multimodales y de organización del conocimiento para datos de juegos de rol de mesa: una revisión de alcance con mapeo de evidencia y productos basados en SKOS, was registered on OSF and is available at https://osf.io/2rm4q/. Data generated during the review process, including evidence tables and derived mappings, will be made available through the associated OSF project as permitted by copyright, licensing, and ethical constraints at https://osf.io/vs298/files/osfstorage. The machine-readable semantic vocabulary outputs associated with this study, including the TTL and JSON-LD files, are available through the OSF folder for digital ontologies within the associated project repository.
Acknowledgments
The authors would like to acknowledge the review, discussions, and conversations with Rodrigo Santamaría, Marcos O. Cabobianco, and Tamara Pandolfi, whose feedback and interdisciplinary perspectives contributed to the conceptual development of this work. The authors also acknowledge the librarians at the Robert W. Van Houten Library at the New Jersey Institute of Technology for their support in literature access, retrieval, and research consultation. During the preparation of this manuscript, the authors used ChatGPT for language refinement, structural drafting, and conceptual organization. The authors reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Acronym | Full name |
| ARPG | analog role-playing game |
| CIDOC CRM | International Committee for Documentation Conceptual Reference Model |
| CRPG | Computer Role-Playing Games |
| D&D | Dungeons and Dragons |
| Edu LARP | educational live-action role-playing games |
| GOLEM | Graphs and Ontologies for Literary Evolution Models |
| LARP | live-action role-playing games |
| LRMoo | Library Reference Model object-oriented formulation |
| MMORPG | massively multiplayer online role-playing game |
| PROV-O | Provenance Ontology |
| PSI | Polyvocal Semantic Infrastructure |
| RAG | Retrieval-Augmented Generation |
| RPG | role-playing game |
| SKOS | Simple Knowledge Organization System |
| SKOS-XL | Simple Knowledge Organization System eXtension for Labels |
| TRP | therapeutic role-play |
| TTRPG | Tabletop Role-Playing Games |
| TTRPG | table-top role-playing game |
| VTT | Virtual Tabletop |
| VTT | virtual tabletop |
| YAGO | Yet Another Great Ontology |
Appendix A. Evidence Matrix

Table S1.
Evidence Matrix Linking Major Findings to Primary Sources.
| Major finding | Primary evidence sources | Related output |
| F1. RPG/TTRPG research is distributed across multiple publication ecosystems rather than one disciplinary venue. | Shyne and Cooper (2025); Yuliawati et al. (2024); Sousa et al. (2023); Whittemore (2021); Smith (2024); Zhang et al. (2025); Maik (2026) | Table 1; Table 2 |
| F2. TTRPG-derived data are increasingly multimodal, multimedia, and platform-mediated. | Zhu et al. (2023); Whittemore (2021); Knoetze (2025); Niarchos et al. (2023); Kelly et al. (2023); Maik (2026) | Table 2; Table 3 |
| F3. Qualitative and interpretive methods remain central to the analysis of role-playing data. | Breland (2022); Hazlett et al. (2025); James (2023); Hobbi and Bololia (2026); Sezen et al. (2024); Whittemore (2021) | Table 1; Table 2 |
| F4. Computational, AI, NLP, and technical approaches are expanding in TTRPG research. | Kelly et al. (2023); Tang et al. (2023); Peiris and De Silva (2023); Weerasundara and De Silva (2023); Sivaganeshan and De Silva (2023); Zhu et al. (2023); Maik (2026); Owczarek et al. (2026); von Kacsoh et al. (2025); Zheng et al. (2025) | Table 1; Table 2; Figure 8 |
| F5. Knowledge-organization and formalization work is emerging but remains unevenly coordinated. | Smith (2024); Berggren et al. (2025); Peiris and De Silva (2023); Zhu et al. (2023); Owczarek et al. (2026); Knoetze (2025) | Table 2; Table 4; Figure 9 |
| F6. Terminological instability affects retrieval, comparison, and semantic traceability. | Smith (2024); Berggren et al. (2025); Shyne and Cooper (2025); Yuliawati et al. (2024); James (2023); Whittemore (2021) | Table 2; Figure 8 |
| F7. Analytical purposes cluster around facilitation, evaluation, learning, intervention, and generation. | Kelly et al. (2023); Tang et al. (2023); Liapis and Denisova (2023); Zhang et al. (2025); Yuliawati et al. (2024); Rosenblad et al. (2025); Owczarek et al. (2026); Maik (2026) | Table 2 |
| F8. Educational, therapeutic, psychological, and social-intervention studies represent a substantial applied research strand. | Zhang et al. (2025); Billieux et al. (2025); Yuliawati et al. (2024); Henning et al. (2024); Rosenblad et al. (2025); Atherton et al. (2025); Snodgrass et al. (2026); Hobbi and Bololia (2026); Brockway (2025) | Table 1; Table 2 |
| F9. Dungeons & Dragons-centered sources dominate the corpus, creating both methodological opportunity and representational bias. | Billieux et al. (2025); Kelly et al. (2023); Peiris and De Silva (2023); Weerasundara and De Silva (2023); Sivaganeshan and De Silva (2023); Zhu et al. (2023); Atherton et al. (2025); Rosenblad et al. (2025); Snodgrass et al. (2026) | Table 1; Table 5; Figure 8 |
| F10. The field requires provenance-aware semantic infrastructure to coordinate heterogeneous data, vocabularies, and analytical purposes. | Smith (2024); Berggren et al. (2025); Knoetze (2025); Zhu et al. (2023); Peiris and De Silva (2023); Owczarek et al. (2026); Shyne and Cooper (2025) | Table 4; Table 5; Figure 8; Figure 9 |
Note. Primary evidence sources are sources from the final included corpus that directly support the stated finding. Secondary or contextual sources provide additional support, boundary clarification, or examples. The broader RIS and CSV Zotero exports document the discovery and reference-management workflow, but the findings reported in the review are based on the final included corpus of 35 sources.
Appendix B. Source-Level Extraction Matrix

Appendix C. Source-Level Research-Question Alignment Matrix

References
- Berggren, Peter, Björn Johansson, and David Myrén. 2025. “Untangling Scenario Terminology to Improve Exercise Ontology Across Domains.” Paper presented at Proceedings of the International ISCRAM Conference. Proc. Int. ISCRAM Conf.
- Binding, Ceri. 2010. “Implementing Archaeological Time Periods Using CIDOC CRM and SKOS.” In The Semantic Web: Research and Applications, edited by Lora Aroyo, Grigoris Antoniou, Eero Hyvönen, et al. Springer. [CrossRef]
- Bowman, Sarah Lynne. 2018. “Immersion and Shared Imagination.” In Role-Playing Game Studies: Transmedia Foundations, 1st ed. Routledge. [CrossRef]
- Bowman, Sarah Lynne, Elektra Diakolambrianou, and Simon Brind, eds. 2025. Transformative Role-Playing Game Design. Acta Universitatis Upsaliensis. [CrossRef]
- Boyd, Zac, and Míša Hejná. 2025. “The ‘Critical Role’ of Voice Quality in Dungeons and Dragons: A Case Study of Non-Player Characters Voiced by Matthew Mercer.” Language in Society, May 8, 1–26. [CrossRef]
- Brata Winardy, Gary Collins, and Eva Septiana. 2023. “Role, Play, and Games: Comparison Between Role-Playing Games and Role-Play in Education.” Social Sciences & Humanities Open 8 (1): 100527. [CrossRef]
- Breland, Luke. 2021. “Pretense Awareness Context and Autism: Insights from Conversation Analysis.” Journal of Autism and Developmental Disorders, ahead of print, August. [CrossRef]
- Gade, Morten, Line Thorup, and Mikkel Sander, eds. 2003. As Larp Grows Up – Theory and Methods in Larp. 1st ed. Projektgruppen KP03. https://nordiclarp.org/w/images/c/c2/2003-As.Larp.Grows.Up.pdf.
- Grouling Cover, Jennifer. 2010. The Creation of Narrative in Tabletop Role-Playing Games. McFarland & Company.
- Haarman, Susan, ed. 2025. Education and Analog Role-Playing Games: Theory and Pedagogy, Volume 1. Vol. 1. CRC Press. [CrossRef]
- Haarman, Susan, ed. 2026. Education and Analog Role-Playing Games: TeachRPG – Tabletop Role-Playing Games in the Classroom, Volume II. Vol. 2. CRC Press. https://www.routledge.com/Education-and-Analog-Role-Playing-Games-TeachRPG---Tabletop-Role-Playing-Games-in-the-Classroom-Volume-II/Haarman/p/book/9781041076148.
- Hergenrader, Trent. 2018. Collaborative Worldbuilding for Writers and Gamers. Paperback. Bloomsbury Academic.
- Holst, Dirk, Keno Moenck, Julian Koch, Ole Schmedemann, and Thorsten Schüppstuhl. 2025. “Transparent Reporting of AI in Systematic Literature Reviews: Development of the PRISMA-trAIce Checklist.” Jmir Ai 4 (December): e80247. [CrossRef]
- Hope, Robyn. 2017. “Play, Performance, and Participation: Boundary Negotiation and Critical Role.” Masters, Concordia University. https://spectrum.library.concordia.ca/id/eprint/983446/.
- Jones, Shelly. 2021. Watch Us Roll: Essays on Actual Play and Performance in Tabletop Role-Playing Games. Studies in Gaming. McFarland & Company, Incorporated Publishers.
- Kelly, Jack, Michael Mateas, and Noah Wardrip-Fruin. 2023. “Towards Computational Support with Language Models for TTRPG Game Masters.” In Proceedings of the 18th International Conference on the Foundations of Digital Games, Fdg 2023, edited by P. Lopes, F. Luz, A. Liapis, and H. Engstrom. Assoc Computing Machinery. [CrossRef]
- Kneale, William, and Martha Kneale. 1985. The Development of Logic. Oxford.
- Knoetze, Frederik Willem Matthys. 2025. “Developing the Integrated Analysis Matrix (I-AM): A Data-Minding Approach for Better Ludonarrative Design-Based Research in Education.” International Journal of Qualitative Methods (Thousand Oaks) 24 (October): 16094069251390161. [CrossRef]
- Laws, Robin D. 2010a. Hamlet’s Hit Points: What Three Classics Narratives Tell Us About Roleplaying Games. Gameplaywright Press.
- Laws, Robin D. 2010b. Hamlet’s Hit Points: What Three Classics Narratives Tell Us About Roleplaying Games. Gameplaywright Press.
- León, Cristo. 2025. “Mapas, marcos y meta-comunicación: bases epistemológicas para una teoría del juego de rol de mesa en las industrias creativas / Maps, Frames, and Metacommunication: Epistemological Foundations for a Theory of Tabletop Role-Playing Games in the Creative Industries.” Brazilian Creative Industries Journal (Novo Hamburgo, Rio Grande do Sul, Brasil), Game Studies e as Indústrias Criativas, vol. 5 (2): 98–147. CLDM_Ds_Peer-reviewed, pp. 98–147. /Research/Cultural and Social Studies. 2. [CrossRef]
- Liapis, Antonios, and Alena Denisova. 2023. “The Challenge of Evaluating Player Experience in Tabletop Role-Playing Games.” Proceedings of the 18th International Conference on the Foundations of Digital Games (New York, NY, USA), FDG ’23, April 12, 1–10. [CrossRef]
- Litmaps. n.d. “Litmaps.” Accessed April 18, 2024. https://app.litmaps.com.
- Maik, Mikołaj. 2026. “Evaluating AI-Driven Game Masters: Adaptive Avatars for Personalized Tabletop Role-Playing.” Entertainment Computing 57. [CrossRef]
- Mak, Susanne, and Aliki Thomas. 2022. Steps for Conducting a Scoping Review. Journal of Graduate Medical Education. October 1. [CrossRef]
- Methley, Abigail M., Stephen Campbell, Carolyn Chew-Graham, Rosalind McNally, and Sudeh Cheraghi-Sohi. 2014. “PICO, PICOS and SPIDER: A Comparison Study of Specificity and Sensitivity in Three Search Tools for Qualitative Systematic Reviews.” BMC Health Services Research 14 (November): 579. [CrossRef]
- Mohapatra, Srikanta Kumar, Prakash Kumar Sarangi, Premananda Sahu, Santosh Kumar Sharma, and Ochin Sharma. 2023. “Game Data Visualization Using Artificial Intelligence Techniques.” In Proceedings of International Conference on Recent Trends in Computing, edited by Rajendra Prasad Mahapatra, Sateesh K. Peddoju, Sudip Roy, and Pritee Parwekar. Springer Nature. [CrossRef]
- Nguyen, C. Thi, and John R. Sageng, eds. 2025. The Routledge Handbook of Philosophy of Games. Routledge. [CrossRef]
- Owczarek, Wojciech, Julia Wróbel, and Damian Pęszor. 2026a. “Knowledge-Driven Generative Design of Role-Playing Game Scenarios.” Applied Sciences 16 (6): 2966. [CrossRef]
- Owczarek, Wojciech, Julia Wróbel, and Damian Pęszor. 2026b. “Knowledge-Driven Generative Design of Role-Playing Game Scenarios.” Applied Sciences 16 (6): 2966. [CrossRef]
- Page, Matthew J., Joanne E. McKenzie, Patrick M. Bossuyt, et al. 2021. “The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews.” BMJ, March 29, n71. [CrossRef]
- Peiris, A., and N. De Silva. 2023. “SHADE: Semantic Hypernym Annotator for Domain-Specific Entities - Dungeons and Dragons Domain Use Case.” 55–60. Scopus. [CrossRef]
- Peters, A., J. Woods, C. Aditijo, et al. 2025. “Safety, Connection, and Personal Growth: Experiences of Tabletop Role Play Game Groups Amongst Autistic Adolescents and Emerging Adults.” Autism in Adulthood, ahead of print. Scopus. [CrossRef]
- Pianzola, Federico, Luotong Cheng, Franziska Pannach, Xiaoyan Yang, and Luca Scotti. 2025. “The GOLEM Ontology for Narrative and Fiction.” Humanities 14 (10): 193. [CrossRef]
- Ribeiro, Felipe. 2025. Role Playing Game (RPG) Open Pedagogy. [CrossRef]
- Rosenblad, Sherry R., Tessa Wolford, Richard S. Brennan III, Josh Darnell, Challen Mabry, and Andrew Herrmann. 2025. “Mastering Your Dragons: Using Tabletop Role-Playing Games in Therapy.” Behavioral Sciences (Basel) 15 (4): 441. [CrossRef]
- Sacksteder, William. 1991. “Least Parts and Greatest Wholes Variations on a Theme in Spinoza.” International Studies in Philosophy 23 (1): 75–87. [CrossRef]
- Scheff, Thomas. 2011. “Parts and Wholes: Goffman and Cooley.” Sociological Forum 26 (3): 694–704.
- Shackelford, L. D., Megan Schoettler, Jax Kinniburgh, and David Halliwell. 2025. “Dungeons and Dialogues: A Collaborative Autoethnographic Account of Gender Performance in Tabletop RPGs.” Women & Language 48 (2). https://search.ebscohost.com/login.aspx?direct=true&profile=ehost&scope=site&authtype=crawler&jrnl=87554550&AN=191917810&h=dkzltmmAj0VyWzvPlLTjR4BfOe9ywlh%2B85xj83NPsTmzIa5B2VkQi7gGPW0qe2xCgotIOtY6ZaiI2ChznELvlg%3D%3D&crl=c.
- Shaker, Noor, Julian Togelius, and Mark J. Nelson. 2016. Procedural Content Generation in Games. Computational Synthesis and Creative Systems. Springer International Publishing. [CrossRef]
- Shyne, Fiona, and Seth Cooper. 2025. “Computational Tools for Table-Top Role-Playing Games: A Scoping Review.” Proceedings of the 20th International Conference on the Foundations of Digital Games (Graz, Austria), FDG ’25, May 9, 1–14. [CrossRef]
- Sivaganeshan, A., and N. De Silva. 2023. “Fine Tuning Named Entity Extraction Models for the Fantasy Domain.” 346–51. Scopus. [CrossRef]
- Smith, T. S. 2024. “A Dicey Situation: A Study of How Controlled Vocabularies Describe Tabletop Roleplaying Games.” Cataloging and Classification Quarterly 62 (2): 99–123. Scopus. 2. [CrossRef]
- Suchanek, Fabian M., Mehwish Alam, Thomas Bonald, Lihu Chen, Pierre-Henri Paris, and Jules Soria. 2024. “YAGO 4.5: A Large and Clean Knowledge Base with a Rich Taxonomy.” Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (New York, NY, USA), SIGIR ’24, July 11, 131–40. [CrossRef]
- Tricco, Andrea C., Jennifer Tetzlaff, and David Moher. 2011. “The Art and Science of Knowledge Synthesis.” Journal of Clinical Epidemiology 64 (1): 11–20. [CrossRef]
- Whittemore, Rhys Duncan. 2021. “Tabletop Role-Playing Games and the Actual Play Show: Author, Audience, and Adaptation.” Master’s Thesis, Virginia Tech. https://vtechworks.lib.vt.edu/handle/10919/103882.
- Wickramarathna, Nishan Chathuranga, and Gamage Upeksha Ganegoda. 2019. “Invoke Artificial Intelligence and Machine Learning for Strategic-Level Games and Interactive Simulations.” In Artificial Intelligence, edited by Jude Hemanth, Thushari Silva, and Asoka Karunananda. Springer. [CrossRef]
- Winnicott, D. W. 2021. Realidad y juego. GEDISA.
- Wolf, Mark J. P., ed. 2025. Navigating Imaginary Worlds: Wayfinding and Subcreation. Routledge. [CrossRef]
- Yannakakis, Georgios N., and Julian Togelius. 2025. Artificial Intelligence and Games. Springer Nature Switzerland. [CrossRef]
- Yuliawati, Livia, Putri Ayu Puspieta-Wardhani, and Joo Hou and Ng. 2024. “A Scoping Review of Tabletop Role-Playing Game (TTRPG) as Psychological Intervention: Potential Benefits and Future Directions.” Psychology Research and Behavior Management 17 (December): 2885–903. [CrossRef]
- Yuliawati, Livia, Putri Ayu Puspieta Wardhani, and Joo Hou Ng. 2024. “A Scoping Review of Tabletop Role-Playing Game (TTRPG) as Psychological Intervention: Potential Benefits and Future Directions.” Psychology Research and Behavior Management Volume 17 (August): 2885–903. [CrossRef]
- Zagal, José Pablo, and Sebastian Deterding, eds. 2018. Role-Playing Game Studies: A Transmedia Approach. 1st ed. Routledge.
- Zagal, José Pablo, and Sebastian Deterding. 2024. The Routledge Handbook of Role-Playing Game Studies. The Routledge Handbook of Role-Playing Game Studies. Taylor and Francis. Scopus. [CrossRef]
- Zhu, Andrew, Karmanya Aggarwal, Alexander Feng, Lara J. Martin, and Chris Callison-Burch. 2023. “FIREBALL: A Dataset of Dungeons and Dragons Actual-Play with Structured Game State Information.” In PROCEEDINGS OF THE 61ST ANNUAL MEETING OF THE ASSOCIATION FOR COMPUTATIONAL LINGUISTICS, ACL 2023, VOL 1, edited by A. Rogers, J. Boyd-Graber, and N. Okazaki. Assoc Computat Linguist; Cohere; Microsoft; Bloomberg; Google Res; Liveperson; Meta; Apple; IBM; Amazon Sci; Baidu; ByteDance; Google DeepMind; Flitto; Grammarly; Huawei; Kaust Artificial Intelligence Initiat; Megagon Labs; Dataocean AI; Ant Grp; Comcast; J P Morgan; NEC; Tencent; Aixplain; Alibaba Grp; Bosch; Duolingo; Translated; Adobe; Babelscape; Servicenow.
| 1 | Source: https://www.litmaps.com/ |
Figure 1.
Conceptual model of stratum-based semantic coordination for TTRPG-derived data.

Figure 6.
SPIDER Extraction Matrix for Coding Included Sources. Source: https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/extract.
Figure 6.
SPIDER Extraction Matrix for Coding Included Sources. Source: https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/extract.

Figure 7.
Research-Question Alignment Matrix for Included Sources. Source https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/align.
Figure 7.
Research-Question Alignment Matrix for Included Sources. Source https://akashic-ida.vercel.app/triage/tri-stratum-team_scoping_2026/align.

Figure 8.
The keyword co-occurrence network was generated with VOSviewer.

Figure 9.
Scope ladder for provenance-aware semantic coordination in TTRPG-derived data.

Table 1.
Compact Corpus Distribution of the Final Included Sources (n = 35).
| Category | n | % of corpus |
| Publication type | ||
| Conference paper | 16 | 45.70% |
| Journal article | 15 | 42.90% |
| Thesis | 2 | 5.70% |
| Book section | 2 | 5.70% |
| Subtotal | 35 | 100.00% |
| Publication year | ||
| 2021 | 2 | 5.70% |
| 2022 | 2 | 5.70% |
| 2023 | 11 | 31.40% |
| 2024 | 5 | 14.30% |
| 2025 | 11 | 31.40% |
| 2026 | 4 | 11.40% |
| Subtotal | 35 | 100.00% |
| Primary RPG scope | ||
| TTRPG/D&D-centered sources | 28 | 80.00% |
| LARP, analog, or tabletop-adjacent sources | 7 | 20.00% |
| Subtotal | 35 | 100.00% |
| Primary methodological/thematic focus | ||
| Computational, AI, NLP, or technical studies | 13 | 37.10% |
| Qualitative or interpretive studies | 12 | 34.30% |
| Knowledge-organization or formalization studies | 10 | 28.60% |
| Subtotal | 35 | 100.00% |
| Primary applied or evidentiary focus | ||
| Therapeutic, psychological, or social-intervention studies | 9 | 25.70% |
| Educational, learning, or pedagogy studies | 6 | 17.10% |
| Multimedia, multimodal, or platform-mediated studies | 6 | 17.10% |
| Review or synthesis studies | 3 | 8.60% |
| Other or undetermined | 11 | 31.40% |
| Subtotal | 35 | 100.00% |
Note. Categories are reported as compact descriptive groupings of the final corpus. Publication type, publication year, and primary RPG scope are mutually exclusive. Methodological/thematic and applied/evidentiary focus categories are reported according to the primary classification assigned during extraction.
Table 2.
Emerging Methodological Patterns.
| Sub question | Emerging Pattern | Typical Data Types | Dominant Methods/Tools | Representative Sources | Methodological Implication |
| a) Sources, formats, and publication channels | Research is distributed across interdisciplinary and multivocal publication ecosystems rather than a single disciplinary venue. | Conference proceedings, journal articles, theses, datasets, technical papers, platform documentation, actual play media | Scoping reviews, HCI prototyping, AI conference publications | Shyne & Cooper (2025); Whittemore (2021) | Retrieval requires multivocal and cross-disciplinary search strategies. |
| b) Types of analyzed data and evidence | Play-derived data are increasingly multimodal and platform-mediated. | Discord logs, transcripts, audiovisual recordings, character sheets, maps, structured game states, Avrae commands | Corpus extraction, multimodal analysis, structured dataset design | Zhu et al. (2023); Whittemore (2021) | TTRPG research is shifting from isolated narrative interpretation toward multimedia evidence ecosystems. |
| c) Methods, techniques, and analytical frameworks | Hybrid methodological infrastructures are emerging. | Textual, audiovisual, interactional, and structured state data | NLP, NER, semantic annotation, discourse analysis, conversation analysis, ethnography | Kelly et al. (2023); Sivaganeshan & De Silva (2023); Breland (2021) | Computational methods increasingly coexist with qualitative interpretation rather than replacing it. |
| d) Analytical purposes | Analytical goals cluster around facilitation, evaluation, learning, intervention, and generation. | NPC dialogue, player behavior, educational interactions, psychological outcomes, scenario structures | LLM support systems, player experience evaluation, integrated matrices, AI-assisted generation | Maik (2026); Knoetze (2025); Yuliawati et al. (2024) | The field is converging around applied multimedia interaction and co-creative support systems. |
| e) Concepts, descriptors, and terminology | Terminological instability persists across disciplines and systems. | RPG, TTRPG, TRPG, LARP, actual play, campaign, scenario, immersion, agency | Controlled vocabulary comparison, semantic analysis | Smith (2024); Berggren et al. (2025) | Vocabulary instability affects retrieval, interoperability, and corpus comparability. |
| f) Formalization and knowledge organization | Formalization efforts remain uneven but increasingly computational. | Entity lists, taxonomies, semantic hypernyms, structured datasets, scenario glossaries | NER, semantic annotation, ontology-oriented design, SKOS-compatible structures | Peiris and De Silva (2023); Smith (2024); Zhu et al. (2023) | Transitioning from descriptive categorization toward machine-readable knowledge structures. |
| g) Immersion, mechanics, and character | Characters and mechanics increasingly function as formalizable analytical units. | Character states, mechanics, role interaction, pacing, agency structures | Player experience frameworks, state modeling, narrative analysis | Liapis and Denisova (2023); Zhu et al. (2023); Whittemore (2021) | Role-playing systems are being treated simultaneously as narrative and procedural systems. |
| h) Gaps, biases, and limitations | The corpus is shaped by D&D dominance, English-language bias, and limited longitudinal work. | D&D-centered datasets, short-session analyses, Western publication venues | Scoping review synthesis | Shyne and Cooper (2025); Yuliawati et al. (2024) | Current infrastructures risk narrowing the field to highly visible and easily processable systems. |
Table 3.
Data Modalities and Associated Analytical Methods.
| Data modality | Examples | Common analytical methods | Computational potential |
|---|---|---|---|
| Spoken interaction | Session dialogue, GM narration | Conversation analysis, discourse analysis | Speech-to-text, NLP |
| Textual records | Campaign notes, transcripts | Narrative analysis, coding | NER, semantic extraction |
| Structured game states | HP, inventory, initiative | State modeling | Machine learning, prediction |
| Audiovisual media | Actual play recordings | Multimodal analysis | Video annotation |
| Material artifacts | Maps, dice, sheets | Ethnographic interpretation | Digitization pipelines |
| Platform traces | Discord logs, VTT actions | Interaction analysis, behavioral analytics | Log analysis, structured event extraction |
Table 4.
Levels of Formalization in the Corpus.
| Level | Description | Example |
|---|---|---|
| Informal descriptive | Narrative interpretation without explicit schema | Ethnographic session reports (Shackelford et al. 2025) |
| Semi-structured coding | Thematic or qualitative coding frameworks | Player experience studies (Haarman 2025) |
| Structured annotation | Entity tagging and semantic labeling | SHADE (Peiris and De Silva 2023) |
| Structured datasets | Machine-readable game-state datasets | FIREBALL (Zhu et al. 2023) |
| Ontological formalization | Controlled vocabularies and semantic relations | Smith (2024); SKOS-compatible structures |
| Generative integration | AI-assisted scenario generation using structured knowledge | Owczarek et al. (2026b) |
Table 5.
Tensions Emerging Across the Corpus.
| Tension | Description |
| Narrative richness vs computational structure | Formalization improves comparability but may flatten interpretive nuance. |
| Accessibility vs methodological rigor | Community-generated sources increase visibility but complicate validation. |
| Human improvisation vs AI assistance | AI systems support Game Masters but risk over-structuring play. |
| D&D availability vs representational diversity | D&D enables datasets but biases the field toward fantasy-centric systems. |
| Retrieval breadth vs terminological precision | Broader search terms improve recall but increase false positives and semantic noise. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



