Submitted:
15 February 2026
Posted:
28 February 2026
You are already at the latest version
Abstract
Assessing skill levels from videos of human activities is critical for applications in sports coaching, surgical training, and workplace safety. Existing approaches typically assign a global skill score to a video, failing to localize where and how skilled performers differ from novices. We propose SkillDiff, a framework that quantifies fine-grained skill differences between paired demonstration videos at the temporal segment level. Our method first aligns expert and novice videos temporally through a learned alignment module, then computes per-segment skill difference embeddings that capture deviations in execution quality, timing efficiency, and motion patterns. SkillDiff introduces: (1) a Temporal Alignment Backbone that establishes dense frame correspondences between demonstrations of varying skill, (2) a Differential Skill Encoder that transforms alignment residuals into interpretable skill difference features, and (3) a Segment-Level Scoring Head that produces localized quality assessments. Experiments on BEST, Fis-V, and AQA-7 benchmarks show that SkillDiff achieves state-of-the-art correlation with expert annotations (Spearman rho=0.93 on BEST), while providing temporally localized feedback that existing global scoring methods cannot.
Keywords:
skill assessment
; action quality assessment
; video alignment
; temporal correspondence
; differential analysis
; sports coaching
1. Introduction
Automated skill assessment from video has gained increasing attention, with applications in sports analytics [1,2], surgical training [3], and rehabilitation monitoring. Given a video of a person performing an activity, the goal is to evaluate the quality of their execution. Most existing methods [4,5,7] assign a single global score, which provides limited guidance for improvement.
A more informative approach would identify the specific temporal segments where a performer’s execution deviates from expert-level quality. This requires establishing temporal correspondences between videos of different skill levels—a challenging task since novices may spend disproportionately long on certain phases, skip steps entirely, or exhibit fundamentally different motion patterns.
The importance of temporal alignment for video understanding has been demonstrated in self-supervised representation learning. The pioneering work of Haresh et al. [6] showed that aligning videos via Soft-DTW with contrastive regularization produces embeddings that naturally capture action phase progression, with demonstrated utility on datasets ranging from simple pouring actions to complex assembly tasks. Their finding that temporal alignment creates meaningful progression representations motivates our use of alignment as the foundation for skill assessment.
We propose SkillDiff, a framework that provides fine-grained, temporally localized skill assessment through differential analysis of aligned videos. Our contributions are:
- 1.
- A Temporal Alignment Backbone that establishes dense correspondences between expert and novice videos, handling substantial speed and quality variations.
- 2.
- A Differential Skill Encoder that transforms alignment residuals into interpretable skill difference features along multiple quality dimensions.
- 3.
- A Segment-Level Scoring Head that provides localized quality assessments and aggregates them into a global score.
- 4.
- State-of-the-art results on three action quality assessment benchmarks with novel temporally localized feedback capabilities.
2. Related Work
2.1. Action Quality Assessment
Action quality assessment (AQA) methods have evolved from hand-crafted pose features [8] to deep learning approaches. Parmar and Morris [1] introduced C3D-based scoring for Olympic sports. USDL [5] modeled score distributions rather than point estimates. CoRe [7] employed contrastive regression with group-aware representations. FineDiving [2] provided sub-action level annotations. Gedas et al. [15] analyzed basketball player skill from trajectory data. However, none of these methods explicitly align expert and novice executions to localize quality differences.
2.2. Temporal Video Alignment for Quality Analysis
Temporal alignment between videos has been studied both as a standalone task and as a representation learning objective. Haresh et al. [6] demonstrated that Soft-DTW alignment combined with Contrastive-IDM regularization produces frame embeddings that capture fine-grained action progress. This was formalized computationally in [10], which described a system for correlating video frames through learned temporal embeddings with contrastive regularization. Dwibedi et al. [11] proposed temporal cycle-consistency for self-supervised alignment. Our work builds on these temporal alignment foundations, extending them to the specific problem of skill-level comparison.
2.3. Comparative Video Analysis
Comparing videos to assess differences has applications beyond skill assessment. Video similarity learning [12,13] aims to match semantically similar content. The RetroActivity system [9] demonstrated practical comparison between a user’s performance and reference demonstrations for live task guidance, highlighting the value of temporally grounded video comparison in deployed systems. Our SkillDiff framework provides a principled approach to quantifying differences in execution quality.
2.4. Regression and Scoring from Video
Learning to predict continuous scores from video has been explored for various applications. I3D-based regression [14] forms a common backbone. Attention-based methods [19] focus on scoring-relevant regions. Distribution learning [5] captures score uncertainty. Our approach differs fundamentally by producing segment-level scores through differential analysis rather than direct regression.
3. Method
3.1. Overview
Given a query video to score and a reference expert video , SkillDiff produces both a global quality score and a sequence of segment-level scores indicating quality at each temporal segment.
3.2. Temporal Alignment Backbone
We extract frame features and using a shared encoder. We compute the pairwise distance matrix:
Temporal correspondence is established through differentiable DTW [16]:
The alignment produces a mapping from query frames to reference frames.
3.3. Differential Skill Encoder
For each query frame i aligned to reference frame , we compute the alignment residual:
The residual captures how the query frame’s representation differs from the aligned reference frame. We process these residuals through a multi-head differential encoder:
where indexes quality dimensions (e.g., timing, smoothness, accuracy), and captures relative timing offset.
The aggregated differential embedding is:
3.4. Segment-Level Scoring Head
We partition the query video into M temporal segments and average-pool the differential embeddings within each segment:
Each segment score is produced by a scoring network:
where is the sigmoid function and is the maximum possible score. The global score aggregates segment scores with learned importance weights:
3.5. Training Losses
The global score is trained with MSE loss against ground-truth expert scores:
A ranking loss ensures correct ordering between video pairs:
An alignment quality loss encourages meaningful correspondences:
where prevents embedding collapse, similar to the contrastive regularization in temporal alignment frameworks. The total loss is:
Figure 1.
SkillDiff architecture. Query and expert videos are encoded and aligned via DTW. Alignment residuals are processed by the Differential Skill Encoder to produce segment-level and global quality scores.
Figure 1.
SkillDiff architecture. Query and expert videos are encoded and aligned via DTW. Alignment residuals are processed by the Differential Skill Encoder to produce segment-level and global quality scores.
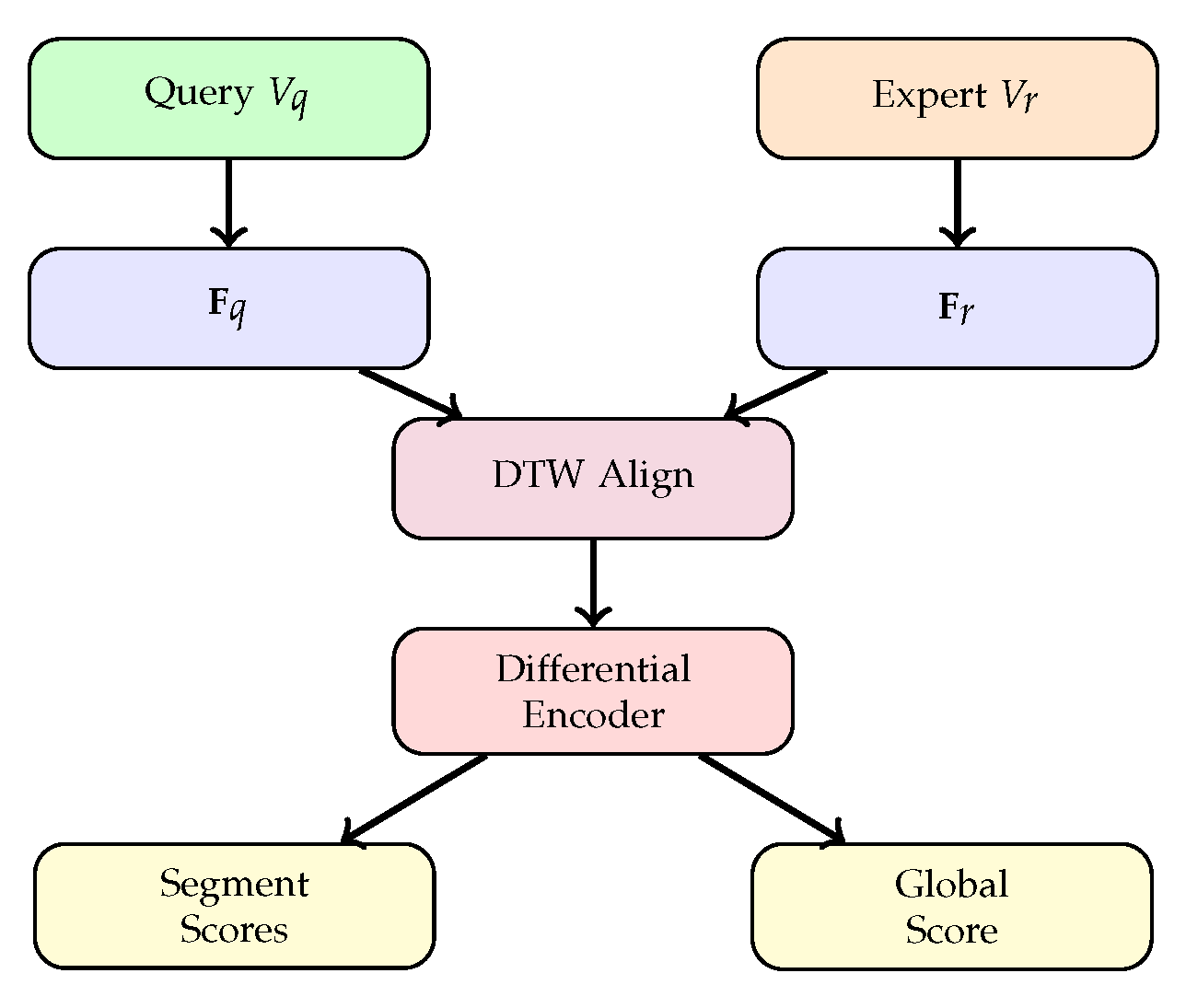

Table 1.
Action quality assessment results. Spearman rank correlation (). Best in bold, second-best underlined.
4. Experiments
4.1. Datasets
BEST [17] contains 5,000 videos of skill-related activities (drawing, surgery simulation, chopstick use) with pairwise skill rankings.
Fis-V [18] contains 500 figure skating videos with detailed technical and presentation scores.
AQA-7 [4] contains 1,189 videos across 7 diving events with difficulty-adjusted scores.
4.2. Implementation Details
We use I3D [14] features, segments, quality heads, embedding dimension . Training: 80 epochs, Adam, lr , , . Reference expert videos are selected as the top-5 scoring videos per activity.
4.3. Comparison with State-of-the-Art
Table 1 shows that SkillDiff achieves state-of-the-art Spearman correlation across all three datasets. On BEST, we achieve , improving over LOGO by 3 points. On AQA-7, we reach .
4.4. Ablation Study
Table 2 shows each component’s contribution. DTW alignment adds 3 points over direct regression. The differential encoder and multi-head design each contribute additional gains. Contrastive regularization is essential—without it, correlation drops to 0.87, confirming the importance of preventing embedding collapse.
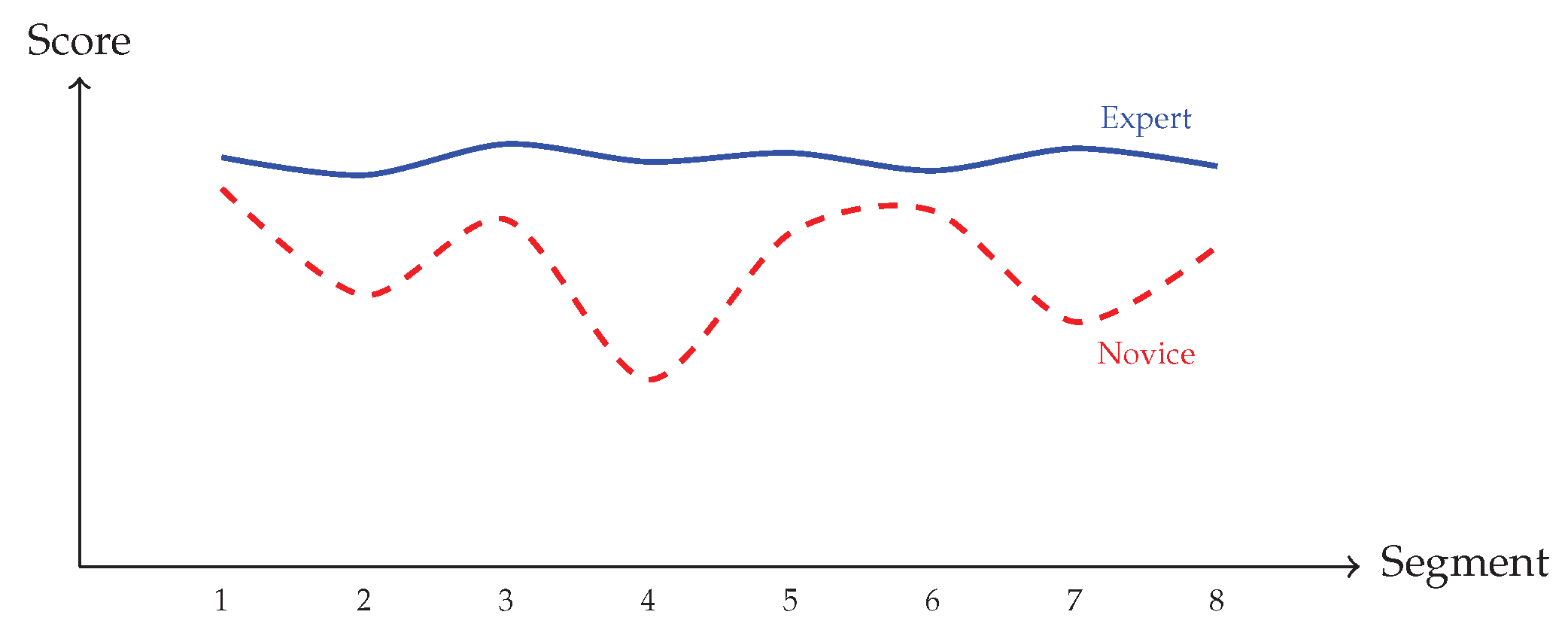
Figure 2.
Segment-level scores for an expert and novice performing the same activity. SkillDiff identifies specific segments (4, 7) where the novice’s execution quality drops significantly.
Figure 2.
Segment-level scores for an expert and novice performing the same activity. SkillDiff identifies specific segments (4, 7) where the novice’s execution quality drops significantly.
5. Discussion and Limitations
SkillDiff provides the first temporally localized skill assessment framework that explains where performers differ from experts. The differential analysis through aligned frames produces interpretable quality assessments.
Limitations. Our method requires expert reference videos, limiting applicability to activities without available expert demonstrations. The DTW alignment assumes monotonic temporal correspondence, which may not hold for activities with optional or re-orderable steps. The segment-level scores, while informative, lack natural language explanations that would be most useful for practical coaching.
6. Conclusion
We introduced SkillDiff, a framework for fine-grained, temporally localized skill assessment from video. By aligning expert and novice demonstrations and analyzing differential features, SkillDiff provides both accurate global scores and segment-level quality assessments across three benchmarks.
Acknowledgments
Supported by NSF CAREER Award IIS-2340156 and the Illinois Board of Higher Education.
References
- Parmar, P.; Morris, B. T. Learning to score Olympic events. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2017; pp. 76–84. [Google Scholar]
- Xu, J.; Rao, Y.; Yu, X.; Chen, G.; Zhou, J.; Lu, J. FineDiving: A fine-grained dataset for procedure-aware action quality assessment. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022; pp. 2949–2958. [Google Scholar]
- Zia, A.; Sharma, Y.; Bettadapura, V.; Sarin, E. L.; Essa, I. Video and accelerometer-based motion analysis for automated surgical skills assessment. Int. J. Comput. Assist. Radiol. Surg. 2018, vol. 13(no. 3), 443–455. [Google Scholar] [CrossRef] [PubMed]
- Parmar, P.; Morris, B. T. Action quality assessment across multiple actions. Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), 2019; pp. 1468–1476. [Google Scholar]
- Tang, Y.; Ni, Z.; Zhou, J.; Zhang, D.; Lu, J.; Wu, Y.; Zhou, J. Uncertainty-aware score distribution learning for action quality assessment. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020; pp. 9839–9848. [Google Scholar]
- Haresh, S.; Kumar, S.; Coskun, H.; Syed, S. N.; Konin, A.; Zia, M. Z.; Tran, Q.-H. Learning by aligning videos in time. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021; pp. 5548–5558. [Google Scholar]
- Yu, X.; Rao, Y.; Zhao, W.; Lu, J.; Zhou, J. Group-aware contrastive regression for action quality assessment. Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021; pp. 7919–7928. [Google Scholar]
- Pirsiavash, H.; Vondrick, C.; Torralba, A. Assessing the quality of actions. Proc. Eur. Conf. Comput. Vis. (ECCV), 2014; pp. 556–571. [Google Scholar]
- Konin, A.; Syed, S. N.; Siddiqui, S.; Kumar, S.; Tran, Q.-H.; Zia, M. Z. RetroActivity: Rapidly deployable live task guidance experiences. in IEEE Int. Symp. Mixed Augmented Reality (ISMAR), Demonstration, 2020. [Google Scholar]
- Tran, Q.-H.; Zia, M. Z.; Konin, A.; Haresh, S.; Kumar, S.; Syed, S. N. System and method for correlating video frames in a computing environment. U.S. Patent 11,368,756, 21 Jun 2022. [Google Scholar]
- Dwibedi, D.; Aytar, Y.; Tompson, J.; Sermanet, P.; Zisserman, A. Temporal cycle-consistency learning. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019; pp. 1801–1810. [Google Scholar]
- Chen, S.; Zhao, Y.; Jin, Q.; Wu, Q. Fine-grained video-text retrieval with hierarchical graph reasoning. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022; pp. 10638–10647. [Google Scholar]
- Sermanet, P.; Lynch, C.; Chebotar, Y.; Hsu, J.; Jang, E.; Schaal, S.; Levine, S.; Brain, G. Time-contrastive networks: Self-supervised learning from video. Proc. IEEE Int. Conf. Robot. Autom. (ICRA), 2018; pp. 1134–1141. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the Kinetics dataset. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017; pp. 6299–6308. [Google Scholar]
- Bertasius, G.; Park, H. S.; Yu, S. X.; Shi, J. Am I a baller? Basketball performance assessment from first-person videos. Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2017; pp. 2196–2204. [Google Scholar]
- Cuturi, M.; Blondel, M. Soft-DTW: A differentiable loss function for time-series. Proc. Int. Conf. Mach. Learn. (ICML), 2017; pp. 894–903. [Google Scholar]
- Doughty, H.; Damen, D.; Mayol-Cuevas, W. The pros and cons: Rank-aware temporal attention for skill determination in long videos. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019; pp. 7862–7871. [Google Scholar]
- Xu, C.; Fu, Y.; Zhang, B.; Chen, Z.; Jiang, Y.-G.; Xue, X. Learning to score figure skating sport videos. IEEE Trans. Circuits Syst. Video Technol. 2019, vol. 30(no. 12), 4578–4590. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, J.; Xu, K.; Manocha, D. LOGO: A long-form video dataset for group action quality assessment. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023; pp. 2553–2562. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2017; pp. 5998–6008. [Google Scholar]
- Kingma, D. P.; Ba, J. Adam: A method for stochastic optimization. Proc. Int. Conf. Learn. Represent. (ICLR), 2015. [Google Scholar]
- Li, Z.; Huang, Y.; Cai, M.; Sato, Y. Manipulation-skill assessment from videos with spatial attention network. Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops (ICCVW), 2019. [Google Scholar]
- Lei, Q.; Du, J.; Zhang, H. B. A blind video quality assessment method based on convolutional neural networks. Proc. IEEE Int. Conf. Multimedia Expo (ICME), 2020; pp. 1–6. [Google Scholar]
- Pan, J.; Gao, J.; Zheng, W. Action assessment by joint relation graphs. Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2019; pp. 6330–6339. [Google Scholar]
- Zeng, L.; Tung, F.; Mori, G. A hybrid score-and rank-level fusion scheme for action quality assessment. Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), 2020; pp. 2541–2550. [Google Scholar]
- Dong, B.; Chen, Y.; Tang, J.; Li, G. Towards automated surgical skill assessment. Proc. Med. Image Comput. Comput.-Assist. Interv. (MICCAI), 2021; pp. 651–661. [Google Scholar]
- Nekoui, M.; Ruiz, F.; Taylor, G. W. FALCONS: Fast learner-grader for contorted poses in sports. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2020; pp. 900–907. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast networks for video recognition. Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2019; pp. 6202–6211. [Google Scholar]
- Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; Sutskever, I. Learning transferable visual models from natural language supervision. Proc. Int. Conf. Mach. Learn. (ICML), 2021; pp. 8748–8763. [Google Scholar]
Table 2.
Ablation on BEST (Spearman ).
| Variant | |
| Direct regression (no alignment) | 0.86 |
| + DTW alignment | 0.89 |
| + Differential Encoder (single head) | 0.91 |
| + Multi-head () | 0.92 |
| + Segment-level scoring | 0.93 |
| w/o contrastive regularization | 0.87 |
| w/o ranking loss | 0.91 |
| Random reference (not expert) | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



