Submitted:
19 February 2026
Posted:
13 March 2026
You are already at the latest version
Abstract
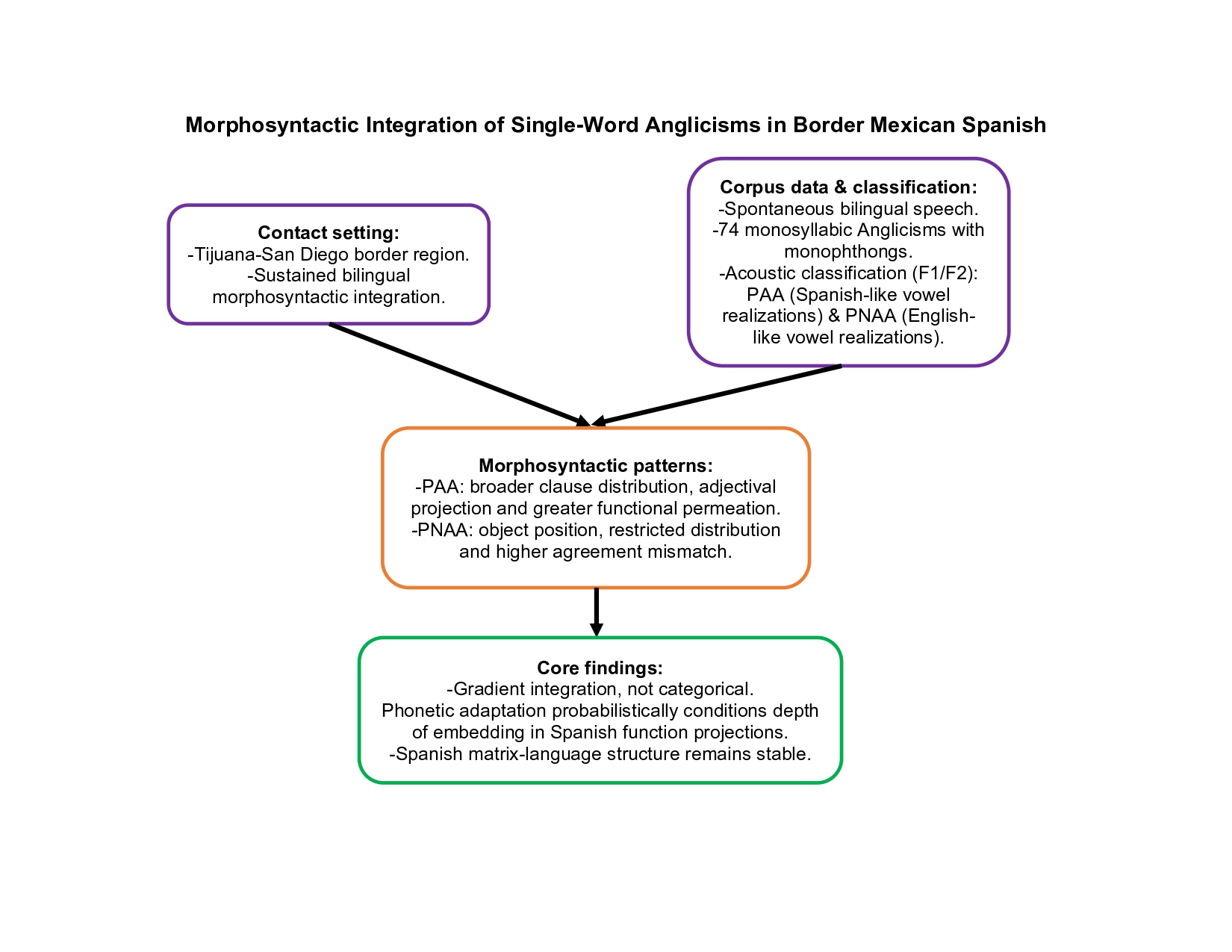
Loanword Research on Anglicisms has largely centered on lexical borrowing and phonological adaptation, with comparatively limited attention to morphosyntactic integration in recipient grammars. This study examines the syntactic behavior of single-word Anglicisms in Mexican Spanish, drawing on phonetically classified corpora of 131 monosyllabic Anglicisms with mon-ophthongs extracted from spontaneous speech by Spanish–English bilinguals in the Tijuana–San Diego border region. Building on prior acoustic analyses based on F1 and F2 vowel measure-ments, the study investigates the relationship between phonological adaptation and morphosyn-tactic integration. Results reveal a gradient pattern of incorporation. Anglicisms exhibiting Span-ish-like phonetic properties tend to occupy canonical syntactic positions and show greater com-patibility with Spanish functional morphology, whereas phonetically non-adapted forms more frequently resist morphological marking and display island-like behavior within otherwise Spanish clauses. The analysis examines distribution across nominal, adjectival, and prepositional domains, as well as object positions, enabling a fine-grained assessment of degrees of morpho-syntactic integration. The former is illustrated as follows: (1) Guardo cash ([kaʃ]) por si acaso (2) Si hacen match ([mæʧ]), puede funcionar Adopting a usage-based and contact-oriented perspective for syntactic borrowing (Bybee, 2015), the study is situated within the Matrix Language Frame model (Myers-Scotton, 1993; Muysken, 2000) and recent approaches to insertional borrowing (Poplack & Dion, 2012; Onysko & Win-ter-Froemel, 2011). A central contribution lies in establishing a principled link between morpho-syntactic behavior and an independently motivated phonetic classification, offering convergent evidence for the systematic integration of Anglicisms into Spanish grammar. At a broader ana-lytical level, the study advances debates on syntactic borrowing and contact-induced change by demonstrating that Anglicisms are subject to Spanish morphosyntactic constraints rather than functioning as unconstrained lexical insertions, and by developing an interface-based account of borrowing that captures the gradient nature of grammatical incorporation in contact settings and contributes a corpus-based, empirically grounded perspective to typologies of borrowing in Spanish contact linguistics.
Keywords:
language contact shift
; morphosyntax
; Anglicisms
; Mexican Spanish
1. Introduction
Language contact settings have been described as particularly revealing for understanding how grammatical systems respond to sustained cross-linguistic interaction (Myers-Scotton, 2002; Winford, 2017; Otheguy et al., 2015). In these settings, recurrent exposure to elements from another language facilitates not only lexical transfer but also the emergence of patterned linguistic behavior indicative of ongoing change rather than isolated code-switching events. In this respect, the continuous and multicontextual contact—social, cultural, economic and educational—between Mexican Spanish in Tijuana and American English from San Diego has normalized the circulation of Anglicisms as integral components of local speech practices and border dynamics (Escandón, 2019, p. 118; Lanz, 2022, p. 87; Toledo & Garcia, 2018, p. 106). Consequently, Tijuana constitutes an explanatory site for examining how contact-induced morphosyntactic change emerges and for observing incipient and gradient processes of grammatical integration (Peralta-Rivera et al., 2025). Despite the substantial body of research on Anglicisms (e.g., Bäumler, 2024; Calabrese & Wetzels, 2009; Franco, 2019; Onysko & Winter-Froemel, 2011; Paradis & LaCharité, 2008; Poplack & Dion, 2012, inter alia), prior scholarship has predominantly focused on lexical borrowing and phonological adaptation, leaving the morphosyntactic behavior of English-origin forms within recipient-language structures comparatively underexamined. From a morphosyntactic perspective, Anglicisms are often treated as structurally inert insertions or classified impressionistically, obscuring systematic variation in degrees of grammatical integration. In particular, relatively few studies have examined how phonetic realization interfaces with syntactic behavior (Otheguy et al., 2015; Winford, 2003), or whether differences in phonological adaptation correlate with participation in recipient-language morphosyntactic patterns (Myers-Scotton, 1993, 2002; Otheguy et al., 2015; Winford, 2017). This gap is especially consequential in high-contact language settings, where dense and repetitive exposure to borrowed forms fosters intermediate stages of integration and incipient grammaticalization. Addressing this limitation therefore requires moving beyond categorical treatments of borrowing and examining Anglicisms as dynamic elements whose morphosyntactic behavior unfolds along a continuum. For instance, in (1a) and (1b) borrowings such as cash /kæʃ/ and match /mæʧ/, despite sharing the same phonological English vowel source /æ/, exhibit two phonetic realizations in Spanish discourse.

These differences motivate questioning whether such divergences are reflected in their syntactic distribution and interaction with Spanish functional morphology. More specifically, it invites examination of whether phonetically more adapted forms show greater compatibility with canonical Spanish syntactic positions and morphological marking, while less adapted forms exhibit restricted distribution, reduced morphosyntactic integration, or island-like behavior within otherwise Spanish clauses. Framed in this way, the contrast between cash and match serves not as isolated anecdotal evidence, but as an empirical motivation for investigating how phonetic adaptation may condition gradient degrees of morphosyntactic incorporation in contact situations.
Therefore, to address the interface-related gap identified above, the present study adopts a contact-oriented, usage-based perspective in which morphosyntactic integration is treated as a gradient process shaped by frequency, entrenchment and structural compatibility with the recipient language. Grounded in established models of contact linguistics—specifically insertional borrowing (Muysken, 2000; Winford, 2003) and the Matrix Language Frame framework (Myers-Scotton, 1993, 2002)—and informed by usage-based approaches (Bybee, 1999, 2015) emphasizing probabilistic representation and gradual conventionalization, this study conceptualizes morphosyntactic integration as a gradient process rather than a categorical outcome. Within this framework, Anglicisms are not assumed to be uniformly integrated or excluded from Spanish grammar. Instead, their syntactic behavior is expected to vary as a function of phonological realization and usage patterns that allows an explicit phonology–morphosyntax interface account. Empirically, the study draws on a corpus of single-word Anglicisms phonetically classified through acoustic vowel F1/F2 measurements (Peralta-Rivera et al., 2025). This allows a replicable basis for examining grammatical behavior in a high-contact border setting.
Finally, the investigation aims: a) to examine whether and how degrees of phonetic adaptation condition the morphosyntactic integration of single-word Anglicisms, as reflected in their compatibility with canonical syntactic positions and Spanish functional morphology, and b) to analyze the clause-level distribution of Anglicisms in border Mexican Spanish in order to determine whether they pattern along a gradient continuum of morphosyntactic integration, from canonical incorporation to island-like behavior. The study advances an interface-based, usage-driven account of borrowing by establishing a principled link between independently motivated phonetic classifications and morphosyntactic patterns. It further demonstrates that English-origin forms are subject to Spanish morphosyntactic constraints to different degrees, contributing empirical and theoretical insights to broader typologies of contact-induced morphosyntactic change beyond the Mexico–US border region. Finally, this research answers the next question:
To what extent do degrees of phonetic adaptation, as established through acoustic vowel measurements (F1/F2), condition Anglicisms’ compatibility with Spanish functional morphology and canonical syntactic positions in a high-contact border setting?
2. Background and theoretical frameworks
Research on Spanish–English contact has extensively documented lexical borrowing, phonological accommodation and discourse-level convergence (Muysken, 200; Winford, 2003; Otheguy et al., 2015 inter alia). Nevertheless, comparatively less attention has been paid to the morphosyntactic behavior of borrowed lexical items once integrated in recipient-language clauses (Otheguy et al., 2015; Winford, 2003, 2017; Zenner & Backus, 2019). In many accounts, morphosyntax is implicitly treated as resistant to contact-induced influence, or Anglicisms are assumed to enter Spanish structures without systematically interacting with functional morphology. Consequently, their syntactic behavior is often described impressionistically rather than examined as a structured domain of contact-induced variation. From a morphosyntactic perspective, contact effects are particularly revealing in areas governed by functional structure—such as determiner selection, number marking and the licensing of syntactic positions—which are tightly constrained in Spanish and thus provide robust diagnostics for grammatical integration (Myers-Scotton, 1993, 2002; Otheguy & Zentella, 2012; Winford, 2003, 2017). High-contact border contexts are especially informative in this respect. In settings characterized by sustained bilingual interaction, borrowed forms circulate frequently and become routinized components of everyday speech. The Tijuana–San Diego border region exemplifies this dynamic, as sustained cross-border interaction has rendered English-origin lexical material a routine component of Mexican Spanish (Escandón, 2019, p. 118; Lanz, 2022, p. 87). Treating contexts as explanatory sites rather than exceptional cases shifts the examination from categorical outcomes to analyze gradient patterns. Specifically, a morphosyntactic integration under conditions of continuous contact (e.g., daily cross-border mobility). Anglicisms are understood here as English-origin lexical items that undergo adaptation across multiple linguistic levels within a recipient language (adapted from Gottlieb, 2005, p. 163). Traditional typologies of borrowings have emphasized lexical provenance, semantic specialization, pragmatic value and phonological accommodation (Calabrese & Wetzels, 2009; Gomez-Capuz, 1997; Görlach, 2003; Zenner & Backus, 2019). While these dimensions are essential for understanding borrowing processes, they often leave the morphosyntactic behavior of Anglicisms underexamined. In this regards, English-origin forms are frequently treated as structurally inert insertions whose grammatical behavior is assumed rather than empirically demonstrated. Therefore, both morphological and syntactic integrations must be distinguished to understand the Anglicisms nature of this study. Morphological integration can associate the extent to which a borrowed form participates in the inflectional and functional morphology of Spanish. For instance, gender assignment, number marking and determiner selection. Conversely, syntactic integration can refer to the distribution of borrowed forms in different phrase types and clause positions such as, occurrences within noun phrases, adjectival phrases, prepositional phrases or object positions. These dimensions do not mandatorily converge. A form may occupy syntactic positions licensed by Spanish grammar while resisting morphological marking, or it may show partial morphological adaptation while remaining distributionally restricted. Nevertheless, instances of convergence between morphology and syntax can occur, though this alignment is contingent and does not characterize all borrowed forms. Recent works in contact linguistics have increasingly rejected categorical distinctions between “integrated” and “non-integrated” borrowings (e.g., Bybee, 2015; Zenner & Backus, 2019; Otherguy et al., 2015). Instead, borrowings are conceptualized as a gradient process in which they exhibit varying degrees of structural accommodation depending on frequency, entrenchment and compatibility with recipient-language constraints (Peralta-Rivera et al., 2025). Under this view, Anglicisms do not form a homogeneous class. Rather, they pattern along a continuum ranging from forms that behave indistinguishably from native Spanish items to forms that display restricted distribution or island-like behavior within otherwise Spanish clauses. Differences in phonetic realizations, for example, may correlate with differences in morphosyntactic behavior. For instance, the borrowings bun and plus—both nouns with the same underlying vowel /ʌ/—differ in their morphosyntactic aspects. Bun realized as [bʌn] can occur with both definite el ‘the’ (2a) and definite articles un ‘an’ (2b), whereas plus realized as [plus] restricts its occurrence to un ‘an’ (2c), not evidenced with el ‘the’ (2d).

Accordingly, Anglicisms are best analyzed as dynamic elements which morphosyntactic integration and grammatical behavior is underlie by an ongoing interaction between phonetic-phonological adaptations and usage patterns that reflect a probabilistic and gradient process. This approach is grounded in the Matrix Language Framework (MLF) (Myers-Scotton, 1993, 2002). It is also complemented with insertional borrowing accounts (Muysken, 2000) and usage-based models of grammar (Bybee, 2015). Within the MLF, bilingual clauses are structured around a matrix language that provides the morphosyntactic frame of the clause—including functional morphology and syntactic ordering—where elements from an embedded language are inserted. In Spanish–English contact settings, Spanish functions as the matrix language that supplies determiners, agreement morphology and syntactic structures, while English borrowings provides embedded elements. A central prediction of the MLF is that such integrated items are constrained by the morphosyntactic requirements of the matrix language, even when they retain phonological or semantic properties associated with the donor language. This framework is particularly well-suited to the analysis of single-word Anglicisms in Spanish clauses, as it offers explicit diagnostics for assessing morphosyntactic integration. This includes compatibility with Spanish functional morphology, participation in canonical syntactic positions and alignment with Spanish word order. Crucially, the MLF allows for variability, recognizing that embedded elements may exhibit differing degrees of accommodation—grounded on phonetic basis—rather than uniform behavior. To account for this variability, the MLF and insertional borrowing approaches are integrated with a usage-based view of grammar. From this perspective, morphosyntactic integration emerges through frequency of use, entrenchment and repeated exposure in specific structural environments, rather than constituting a categorical property of borrowed forms. restricted. This integrated framework directly informs the empirical design of the study. A corpus-based methodology is employed to capture distributional tendencies in naturally occurring data, while independent operationalization of phonetic adaptations through acoustic analysis enable systematic examinations of phonology–morphosyntax correspondences. By combining the Matrix Language Framework with usage-based assumptions, the study advances an interface-based account of borrowing in which phonological and morphosyntactic adaptations are treated as interrelated dimensions of contact-induced change within this Spanish dialect in contact setting.
3. Materials and Methodology
This section describes the data source, the criteria for token selection and the analytical procedure adopted for the morphosyntactic analysis.
3.1. Data Source and Corpus Overview
The study draws on a corpus of 131 monosyllabic Anglicism tokens with monophthongal vowels extracted from spontaneous speech produced between the researcher and the Spanish–English bilinguals—individuals living in Tijuana (Mexico) with age range between 18-29 with diverse sociolinguistic aspects—in the Tijuana–San Diego border region (Peralta-Rivera et al., 2025). The data originates from a previously published acoustic-phonetic study that classified vowel adaptation patterns using formant measurements (F1/F2) (adapted from Ibid, p.16-20).1 The present analysis does not replicate the phonetic examination; rather, it reuses the resulting phonetic classifications as an independent basis for morphosyntactic analysis. This ensures a clear methodological distinction between phonetic and grammatical assessments.
3.2. Corpus Selection Criteria and Extraction
In order to maintain analytical rigor, the dataset is restricted to Anglicisms classified as Phonetically Adapted Anglicisms (PAA) and Phonetically Non-Adapted Anglicisms (PNAA). Tokens categorized as Ambiguous (forms exhibiting acoustic properties not clearly attributable to either English or Spanish) and Both (structures displaying mixed formant values, with F1 aligning with one language and F2 with the other) are excluded. This selection yields a final dataset of 74 Anglicism tokens in different syntactic contexts; for instance, noun phrases, adjective phrase, subordinate clauses, among others. The list of all 74 Anglicisms, their classification and their morphosyntactic contexts of occurrences is in Appendix A. This enabled a robust comparison of morphosyntactic behavior grounded in clearly defined phonetic profiles. Importantly, these phonetic categories were established independently of any morphosyntactic considerations: no syntactic position, morphological marking or grammatical context was considered during phonetic classification. Thus, phonetic adaptation functions as an external and autonomous variable, allowing subsequent morphosyntactic observations to be evaluated without analytical circularity.
3.3. Analytical Framework and Morphosyntactic Procedure
The primary contribution of the present study lies in its morphosyntactic analysis of Anglicisms, which takes independently established phonetic classifications as a point of departure for examining grammatical behavior in context. Each token was analyzed within its clausal environment with respect to its syntactic distribution, interaction with Spanish functional morphology and the degree of structural integration. Specifically, the analysis considered participation in canonical syntactic positions, compatibility with determiners and number marking and tendencies toward integrated versus island-like behavior. By comparing PAA and PNAA tokens, the study assesses whether degrees of phonetic adaptation correlate systematically with compatibility with Spanish morphosyntactic constraints. The analysis is situated within a usage-based and contact-oriented framework that conceptualizes borrowing as a potential morphosyntactic gradient process, drawing on the MLF framework and related insertional approaches. Within this model, phonetic adaptation is treated as a correlate—rather than a determinant—of lexical entrenchment and grammatical accommodation.
4. Results
This section presents the empirical results of the study, examining how phonetic classification relates to (4.1) the distribution of Anglicisms by phonetic profile, (4.2) their clause-level syntactic positions, (4.3) their compatibility with Spanish functional morphology, and (4.4) the gradient patterns of structural integration that emerge in the border contact context.
4.1. Distribution of Anglicisms by Phonetic Class
Of the total dataset, 33 tokens (44.6%) are classified as PAA and 41 tokens (55.4%) are classified as PNAA. This distribution indicates that both phonetic profiles are robustly represented in the corpus. It also provides a balanced empirical basis for subsequent morphosyntactic comparison. PAA tokens include items; such as, blend, cash, dark(s), nerd, plus, sad, shot(s), staff and top that exhibited vowel realizations aligned with Spanish phonological targets. PNAA tokens comprise forms; such as, boss, bun, bundle, core, crush, flush, fuck, mall(s), match, must and spot(s) which vowel realizations retain English-like acoustic properties. Importantly, both phonetic classes include nouns and adjectives. Both occur in Spanish-licensed syntactic environments. This confirms that phonetic accommodation is not a structural prerequisite for insertion into Spanish-licensed syntactic domains.
Similarly, the corpus findings reveal asymmetries across phonetic classes. PAA tokens account for all adjectival uses in the dataset (e.g., dark, nerd, sad, top), while PNAA tokens are restricted to nominal and verbal-complement uses. Both classes show instances of agreement convergence (e.g., darks, shots, malls) as well as agreement mismatch (e.g., nerd, top, boss, must), indicating that neither phonetic adaptation nor phonetic non-adaptation uniformly predicts morphological behavior. Because phonetic classification was established independently of syntactic position, morphological marking, or grammatical context, this baseline distribution provides a methodologically neutral point of departure for examining how morphosyntactic behavior varies across phonetic classes in the following sections.
4.2. Syntactic Distribution Across Clause-Level Contexts
Across the corpus, the syntactic distribution of Anglicisms emerges in multiple clause-level contexts. These include object position (OP), noun phrase (NP), prepositional phrase (PP) and adjectival phrase (AP). Object position emerges as the most frequent syntactic environment for both phonetic classes. PNAA tokens show a strong concentration in this context, often occurring as verbal complements in fixed or semi-fixed constructions (e.g., hacer match, tener crush), typically as bare forms with minimal interaction with Spanish functional structure. The confinement of these tokens to complement positions suggests insertion at the lexical level without extended projection into Spanish functional domains. PAA tokens also occur productively in object position, though they more frequently co-occur with determiners or plural marking. This indicates greater morphosyntactic accommodation in comparable contexts. Table 1 reviews the phonetic classification and morphosyntactic contexts of 33 PAA tokens (n = 33), while Table 2 presents the same information for 41 PNAA tokens (n = 41). The full token frequencies and proportional distributions for each phonetic class across the different syntactic environments are provided in Appendix A.
Occurrences within NP are robust for both phonetic classes. PAA items frequently appear in fully projected NPs with Spanish determiners and, in some cases, overt number marking (e.g., el cash, los darks, los shots), whereas PNAA items also occur in NP contexts but show more variable agreement convergence and a higher incidence of bare or weakly integrated forms (e.g., el boss, los must). Prepositional phrase environments are attested primarily with nominal Anglicisms in both classes (e.g., por el mall, de los servicios plus), though PAA tokens again display greater compatibility with surrounding functional material. Finally, AP contexts are comparatively limited and are restricted to PAA items such as dark, nerd, sad and top, which occur in canonical Spanish adjective positions and frequently co-occur with degree modifiers (e.g., bien dark, bien sad). The absence of adjectival PNAA tokens suggests that access to adjectival projection may require greater phonological accommodation or higher levels of lexical entrenchment within Spanish functional structure. Taken together, the distributional patterns indicate that while both PAA and PNAA Anglicisms occupy Spanish-licensed syntactic contexts, PAA forms exhibit broader dispersion across clause-level environments, whereas PNAA forms are more tightly concentrated in object position and nominal uses.
4.3. Interaction with Spanish Functional Morphology
For analytical clarity, patterns are classified as agreement convergence when Anglicisms align with both Spanish morphological determiners and numbers, and as agreement mismatch when surface forms fail to reflect Spanish agreement requirements. Therefore, the analysis examines determiner selection and number marking across PAA and PNAA, both of which occur in Spanish nominal and adjectival environments that license functional morphology. Across the corpus, convergent and mismatch patterns are attested in both classes, indicating variable correspondence between phonetic adaptation and morphosyntactic integration. Instances of agreement convergence are attested in forms such as darks and shots (PAA) and malls (PNAA), where plural marking aligns with Spanish functional requirements. Similarly, several English-origin items display agreement mismatch, including nerd and top (PAA) and boss and must (PNAA). The former can provide surface agreement mismatches between determiner and noun morphology. These patterns indicate that neither phonetic adaptation nor non-adaptation uniformly predicts agreement convergence. For the case of determiner selection, both definite and indefinite articles are attested across phonetic classes, though distributional asymmetries emerge at the lexical level. For example, nerd (PAA) consistently occurs with definite determiners but not with the Spanish indefinite article un, whereas plus (PAA) systematically appears without the definite article el. PNAA nouns such as bundle, crush and core occur with indefinite articles (un bundle, un crush), while others (e.g., must) appear with determiners that do not match their morphological form (los must). These tendencies suggest item-specific constraints rather than categorical class-based behavior. In adjectival contexts, functional interaction is further evidenced by the co-occurrence of Spanish degree modifiers, particularly bien (Spanish adverb), with PAA adjectives such as dark, nerd and sad. No comparable adjectival uses are attested for PNAA items. Importantly, across all nominal and adjectival uses, Anglicisms consistently conform to Spanish canonical word order (noun + adjective), with no instances of English-like adjective–noun ordering. In both phonetic classes, Anglicisms are consistently embedded within Spanish DP projections, with determiner licensing and canonical word order conforming to Spanish functional structure despite phonological variability. This pattern is consistent with models of contact in which functional projections are supplied by the matrix language, while lexical items may vary in degree of morphophonological adjustment (Myers-Scotton, 1993, 2002; Muysken, 2000; Winford, 2017). Table 3 summarizes patterns of determiner selection, number marking, and agreement convergence across the corpus. It is organized by phonetic class (PAA vs. PNAA). It also provides a qualitative overview of Anglicisms’ participation in Spanish functional morphology. Rather than presenting frequency counts, the table reports attested morphosyntactic patterns contrasted with Spanish functional requirements; agreement mismatches reflect surface realizations rather than categorical ungrammaticality.
Overall, the results show that English-origin items across both phonetic classes interact with Spanish functional morphology in gradient and variable ways. While PAA items display broader functional integration, PNAA items also occur in determiner and number-marking contexts, albeit less consistently. These patterns underpin the subsequent analysis of gradient integration and islandlike behavior.
4.4. Gradient Integration and Island-Like Behavior
The results exhibited varying degrees of structural integration within Spanish clauses, focusing on the distinction between integrated, restricted, and island-like patterns of behavior. Island-like behavior reflects restricted access to Spanish functional projections, whereby the Anglicism occupies a lexical position without consistently activating determiner licensing, number morphology, or adjectival agreement. Such tokens remain only partially embedded in Spanish DP or AP structure. Contrarily, integrated behavior entails systematic participation in Spanish functional projections, including determiner selection, agreement convergence, and canonical word order. The former results in full morphosyntactic incorporation. Hence, rather than treating integration as categorical, the analysis adopts a gradient perspective.
On the one hand, Phonetically Adapted Anglicisms (PAA) most frequently display integrated behavior, appearing in canonical syntactic positions and participating in Spanish functional morphology. These tokens embed smoothly within Spanish phrasal structures. For instance, PAA items such as cash or top are attested in contexts where they co-occur with Spanish functional material and align with expected syntactic distributions. In contrast, Phonetically Non-Adapted Anglicisms (PNAA) more often exhibit restricted or island-like behavior. Restricted patterns are characterized by limited syntactic distribution, such as a preference for object position or fixed verbal constructions, alongside reduced interaction with functional morphology. Island-like behavior is observed when Anglicisms appear as morphosyntactically insulated units within otherwise Spanish clauses, resisting determiner integration, inflectional marking, or further syntactic embedding. Tokens such as match or crush exemplify this pattern, frequently surfacing as bare forms in verbal complements without overt agreement convergence. Importantly, these patterns do not constitute rigid categories. Partial integration is attested in both phonetic classes, and individual items may vary depending on local syntactic context. The continuum observed in the corpus reflects varying degrees of activation of Spanish functional structure rather than a binary distinction between integrated and non-integrated forms. From this perspective, differences across phonetic classes reflect differential degrees of morphosyntactic embedding within matrix-language functional projections, rather than wholesale restructuring of clause architecture (Myers-Scotton, 1993, 2002; Winford, 2017).
Taken together, the corpus evidence indicates that Anglicisms in border Mexican Spanish display graded morphosyntactic integration. Although phonetic adaptation correlates with broader participation in Spanish functional structure, it does not deterministically predict grammatical incorporation. Rather, degrees of phonetic convergence condition morphosyntactic compatibility in a limited and probabilistic manner: greater alignment with Spanish phonological targets tends to co-occur with deeper engagement in Spanish functional projections, yet structural embedding remains possible even in the absence of phonological accommodation. The relationship is therefore gradient rather than categorical, reflecting varying depths of integration within a stable matrix-language framework in which phonological accommodation and morphosyntactic embedding operate as partially independent, though interacting, dimensions of contact-induced change.
5. Discussion
This section discusses the findings within morphosyntactic, matrix-language, and usage-based models of contact, examining the probabilistic role of phonetic adaptation, the stability of Spanish functional structure in a border context, and the gradient nature of morphosyntactic integration.
5.1. Phonetic Adaptation and Morphological Adaptation
The results demonstrate that phonetic accommodation and morphosyntactic embedding operate as partially independent dimensions in border Mexican Spanish. Although Phonetically Adapted Anglicisms (PAA) more frequently participate in Spanish functional morphology, phonetic alignment does not deterministically predict structural incorporation. Conversely, Phonetically Non-Adapted Anglicisms (PNAA) are not excluded from Spanish-licensed syntactic environments; rather, their participation is more restricted and variable. This asymmetry confirms that phonological convergence alone is insufficient as a diagnostic of grammatical integration. Instead, integration must be evaluated in relation to participation in functional projections and agreement systems. These findings challenge models that assume a linear progression from phonetic adaptation to full morphosyntactic incorporation. In the present corpus, structural embedding may occur even when lexical phonology retains English-like properties, underscoring the autonomy of morphosyntactic structure from surface phonetic realization.
5.2. Functional Structure Stability In a Border Contact Setting
A central finding of this study is the consistent embedding of Anglicisms within Spanish DP projections. Throughout both phonetic classes, determiner licensing, number morphology and canonical noun–adjective order conform to Spanish functional structure. Even in cases of agreement mismatch, the clause-level architecture remains Spanish. This pattern aligns with contact models in which functional projections are supplied by the matrix language (Myers-Scotton 1993, 2002), while lexical items may vary in their degree of morphophonological accommodation. The data indicate that Spanish functional heads—particularly within the DP domain—remain structurally stable in the Tijuana–San Diego border context. Rather than evidencing wholesale restructuring, the corpus reflects insertion of English-origin lexical material into an otherwise Spanish grammatical frame. In this respect, the contact ecology does not erode Spanish morphosyntactic architecture. Instead, it permits variable depth of lexical integration within a stable grammatical system, reflecting the routine coexistence of two languages in the sociocultural practices of this border community.
5.3. Gradient Integration as Depth of Functional Permeation
The distinction between integrated, restricted and island-like patterns is best understood as reflecting varying degrees of penetration into Spanish functional structure. Integrated tokens activate determiner licensing, agreement convergence and canonical projectional relations. Restricted forms participate in clause structure but exhibit limited interaction with functional morphology. Island-like items remain largely confined to lexical insertion sites, with minimal activation of agreement or determiner mechanisms. Importantly, these categories do not represent discrete types of borrowings but points along a continuum. Gradient integration thus reflects differences in the extent to which Anglicisms engage Spanish functional projections rather than a binary opposition between agreement convergence and agreement mismatch. From a usage-based perspective (Bybee, 2010, 2015), gradient integration may reflect differences in frequency and entrenchment across lexical items. Tokens that recur in diverse syntactic environments are more likely to become routinized within Spanish functional projections, whereas items confined to formulaic constructions may remain only partially embedded. Thus, the projection-based continuum identified here is compatible with emergent models of grammatical structure shaped through repeated use.
5.4. Implications for Contact-Induced Change
The findings contribute to broader debates in contact linguistics regarding the nature of grammatical integration. Traditional typologies often distinguish sharply between “integrated” and “non-integrated borrowings” (e.g., Gomez-Capuz, 1997; Görlach, 2003; Poplack et al., 1988;). The present analysis instead supports a gradient, interface-based model in which phonological accommodation and morphosyntactic embedding interact but do not collapse into a single trajectory. In the border context examined here, contact-induced change operates within a structurally stable Spanish clause architecture. Rather, it operates through differential activation of functional projections within a stable matrix-language frame. Such outcomes highlight the importance of examining functional domains—particularly DP structure and agreement systems—as diagnostic sites of integration in contact settings. As a whole, the findings provide a clear answer to the central research question. Degrees of phonetic adaptation, as established through acoustic vowel measurements, condition Anglicisms’ compatibility with Spanish functional morphology and canonical syntactic positions in a probabilistic and gradient manner. Greater phonological convergence tends to align with deeper engagement in Spanish functional projections. Nevertheless, structural syntactic integration remains possible even in the absence of phonetic accommodation. In the high-contact border setting examined here, morphosyntactic integration is thus shaped by—but not reducible to—phonetic adaptation, reflecting the resilience of matrix-language functional structure alongside variable depth of lexical incorporation.
6. Conclusions
The study has shown that the morphosyntactic integration of single-word Anglicisms in Mexican Spanish offers a privileged lens through which to examine how grammatical boundaries shift under sustained bilingual interaction. By combining independently established acoustic vowel classifications (F1/F2) with corpus-driven clause-level analysis, the study advances an interface-based account of borrowing in which phonetic and morphosyntactic behavior are analytically distinct yet dynamically interacting dimensions of language contact. Both PAA and PNAA insertion into Spanish-licensed syntactic environments confirms the structural resilience of Spanish functional architecture in this contact zone. Phonetic accommodation is not a prerequisite for structural embedding. However, asymmetries emerge in the depth of functional permeation: PAA forms display broader dispersion across clause-level domains—including adjectival projection—and more consistent participation in determiner licensing and number morphology, whereas PNAA items are more frequently confined to object position and fixed complement constructions, showing higher rates of agreement mismatch and more restricted activation of Spanish functional projections.
The relationship between phonological convergence and morphosyntactic incorporation is therefore probabilistic rather than deterministic. Greater phonetic alignment tends to correlate with deeper functional integration, yet English-like realization does not preclude structural embedding. Shifting grammatical boundaries in this contact zone thus manifest not as wholesale restructuring of clause architecture, but as gradient variation in lexical permeability within a stable matrix-language frame.
The findings refine predictions associated with the Matrix Language Frame model, (Myers-Scotton, 1993, 2002) extended insertional perspectives such as Typology of Code-Mixing (Muysken, 2000) and they are aligned with usage-based approaches including Usage-Based Phonology (Bybee, 1999, 2015). Methodologically, the study strengthens empirical claims about contact-induced change by operationalizing phonetic adaptation as an external diagnostic variable, thereby avoiding analytical circularity. Although limited to 74 monosyllabic tokens within a single contact ecology, the study underscores that Spanish morphosyntax in contact situations negotiates shifting grammar through constrained and gradient reconfiguration rather than structural destabilization.
Author Contributions
Conceptualization, R.R.P.-R.; methodology, R.R.P.-R.; software, R.R.P.-R.; validation, R.R.P.-R.; formal analysis, R.R.P.-R..; investigation, R.R.P.-R.; resources, R.R.P.-R.; data curation, R.R.P.-R.; writing —original draft preparation, R.R.P.-R.; writing—review and editing, R.R.P.-R.; visualization, R.R.P.-R..; supervision, R.R.P.-R.; project administration, R.R.P.-R; funding acquisition, R.R.P.-R. All authors have read and agreed to the published version of the manuscript.
Funding
The author is thankful to the Facultad de Idiomas Mexicali from Universidad Autónoma de Baja California for granting the time and liberty to conduct this research. This research received no external funding.
Institutional Review Board Statement
My colleagues and I informed about the anonymization and storage of the data to the subjects when we conducted the research in 2025; the participants were eventually informed about the scientific objectives of the study.
Informed Consent Statement
Verbal informed consent was originally obtained from the subjects. Verbal consent was obtained rather than written as a procedure approved by the Ethics Committee Board of Facultad de Idiomas Tijuana from Universidad Autónoma de Baja California in 2025. The authors committed themselves to follow legal stipulations by signing individually the confidentiality commitment letters submitted with the present study.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
This paper is a research extension from Peralta et al., 2025. This journal article expands upon that work with specific analyses and findings.
Conflicts of Interest
The author declared no conflicts of interest.
Appendix A
Appendix A.1
The appendix details the Anglicisms specifically selected due to their established empirically-based phonetic classifications—F1 and F2 proximity to either Spanish or English theoretical target vowels—as Phonetically Adapted Anglicisms (PAA) and Phonetically Non-Adapted Anglicisms (PNAA) (adapted from Peralta et al., 2025, p. 16-22). The information contains the focusing word in the first column, its classification in the second and the morphosyntactic context of occurrence in the third. English-origin items are repeated to reflect their frequency within the corpus.
| Anglicism |
Classificacion (PAA or PNAA) |
Morphosyntactic context of occurrence |
| Blend | PAA | Pues depende del blend que le pongas al chai |
| Blend | PAA | Agregas el blend a la comida |
| Blend | PAA | Un tipo de blend de esa cafe(tería) |
| Cash | PAA | Tengo suficiente cash para comprarlos |
| Cash | PAA | El cash es lo de menos para él |
| Cash | PAA | Guardo cash por si acaso |
| Dark(s) | PAA | Las peleas eran entre emos y darks |
| Dark(s) | PAA | Su vestimenta bien dark entre todos |
| Dark(s) | PAA | Tiene un giro dark la movie |
| Hack | PAA | Me hace hack la mente |
| Nerd | PAA | Anda de date con tipo súper nerd |
| Nerd | PAA | Anda bien nerd estudiando |
| Nerd | PAA | Súper inteligente es como nerd, acá |
| Nerd | PAA | Ellos todos nerd con esos pantalones |
| Plus | PAA | También me gusta ese plus de los servicios |
| Plus | PAA | Es un plus para nosotros |
| Plus | PAA | Te otorgan buen plus por todo |
| Plus | PAA | Es como un plus si obtiene ese nivel |
| Plus | PAA | Tiene un plus de reconocimiento internacional |
| Plus | PAA | Le agregas ese plus y te funciona |
| Sad | PAA | Así bien sad con otros |
| Sad | PAA | Anda medio sad para que le hables |
| Sad | PAA | Si estaba medio sad hasta hace unos meses |
| Sad | PAA | Se quedó bien sad, pero al rato se le quita |
| Sad | PAA | Un panorama sad ahí |
| Shot(s) | PAA | Llegamos y todos shots shots, o sea |
| Shot(s) | PAA | Sirvieron shots de varios sabores |
| Shot(s) | PAA | El shot de la otra vez |
| Staff | PAA | Yo atendía al equipo de staff, ¿no? |
| Staff | PAA | Había un staff enfadoso que no dejaba pasar |
| Top | PAA | Se convirtió en artista top por un buen tiempo |
| Top | PAA | Él es el top en el jale, es como el boss |
| Top | PAA | Neta que ese tipo es de los top en la clase |
| Boss | PNAA | Como boss en secreto |
| Boss | PNAA | Él es el top en el jale, es como el boss |
| Boss | PNAA | Son los boss del business |
| Boss | PNAA | El mero boss de los que estamos |
| Boss | PNAA | Tiene buena coordinación como boss en general |
| Bun | PNAA | Ese es el bun que te decía |
| Bun | PNAA | Depende del tipo de bun que te quieras hacer |
| Bun | PNAA | El bun de la tipa todo deforme jaja |
| Bun | PNAA | Traía un bun súper grande |
| Bundle | PNAA | Si, ese es un bundle así colocado |
| Bundle | PNAA | Con el PlayStation son bundles más variados |
| Bundle | PNAA | Agarras el bundle que te viene |
| Core | PNAA | Buscas el core de todo el cableado |
| Core | PNAA | El core de la empresa va conectado a otros sectores |
| Core | PNAA | Tiene un core super complejo el sistema |
| Core | PNAA | Construyen un core principal con base a las funciones |
| Crush | PNAA | Sabrás si hay crush o no |
| Crush | PNAA | Era como su crush |
| Crush | PNAA | Ese tipo tenía un crush por ella cañón |
| Crush | PNAA | Sentí el crush justo con él, me dijo |
| Flush | PNAA | Dos semanas para dejarla que haga flush, ¿sí? |
| Flush | PNAA | En el momento en que haga flush, es que ya está |
| Flush | PNAA | Hace como flush y se nota |
| Fuck | PNAA | Todo y digo fuck, o sea |
| Fuck | PNAA | Es como que llegué y fuck, no lo podía creer |
| Fuck | PNAA | Ah fuck, no sabía |
| Mall(s) | PNAA | Me gustó el mall, tiene fuente de colores toda sweet |
| Mall(s) | PNAA | Vas viendo el mall por todo el freeway |
| Mall(s) | PNAA | Pasas por el mall y giras a la izquierda |
| Mall(s) | PNAA | Para ese mall debes tomar otro camino |
| Mall(s) | PNAA | Son varios malls lo que ves |
| Match | PNAA | Siempre hacemos match para trabajar |
| Match | PNAA | Si hacen match, puede funcionar |
| Match | PNAA | Hay match esta noche |
| Must | PNAA | ¡Esa es una de las atracciones must de esa ciudad! |
| Must | PNAA | Viene siendo un must que debes considerar |
| Must | PNAA | Revisa los must que hay ahí |
| Spot(s) | PNAA | El mero spot es donde se junta la raza |
| Spot(s) | PNAA | Los buenos spots son en la quinta y la sexta |
| Spot(s) | PNAA | La clavan en un spot bien secreto |
| Spot(s) | PNAA | Era el spot preferido para skatear |
| 1 | The reference vowel formant values were obtained from established acoustic studies of Mexican Spanish (Grijalva et al., 2013, p. 4) and Californian English (Aiello, 2010, p. 301; Hagiwara, 1997, p. 656). Chicano English was deliberately excluded to ensure a relatively neutral representation of the Californian English dialect. |
References
- Aiello, A. (2010). A phonetic examination of California. [Master thesis, University of California, Santa Cruz]. SemanticScholar.
- Bybee, J. L. (1999). Usage-based Phonology. In M. Darnell, F. J. Newmeyer, M. noonman and E. A. Moravcsik (Eds.) Functionalism and Formalism in Linguistics, 1 (pp. 211-242). John Benjamins Publishing Company.
- Bybee, J. (2010). Language, usage and cognition. Cambridge University Press.
- Bybee, J. (2015). Language change. Cambridge University Press.
- Bäumler, L. (2024). Loanword Phonology of Spanish Anglicisms: New Insights from Corp Data. Languages, 9(9), 294, 1-18. https://doi.org/10.3390/languages9090294. (accessed on 19 January 2026). [CrossRef]
- Calabrese, A., and Wetzels, L. (2009). Loan Phonology: Issues and controversies. In A. Calabrese and L. Wetzels (Eds.) Loan Phonology (pp. 1-10). John Benjamins Publishing Company.
- Escandón, A. (2019). Linguistic practices and the linguistic landscape along the US-Mexico border: Translanguaging in Tijuana [Doctoral dissertation, University of Southampton]. ResearchGate. Available online: http://eprints.soton.ac.uk/id/eprint/438663. (accessed on 20 January 2026).
- Franco, D. (2019). Tipología descriptiva del galicismo y el anglicismo léxico: una aproximación a partir del signo li güístico. Lingüística Mexicana. Nueva Época, 1, (pp. 107-140).
- Gómez-Capuz, J. (1997). Towards a Typological Classification of Linguistic Borrowing(Illustrated with Anglicisms in Romance Languages). Revista Alicantina de Estudios Ingleses, 10, 81-94. (accessed on 10 January 2026) https://rua.ua.es/dspace/bitstream/10045/5997/1/RAEI_10_08.pdf. (accessed on 07 January 2026).
- Gottlieb, H. (2005). Anglicisms and Translation. In G. Anderman and M. Rogers (Eds.), In and Out of English: For Better, for Worse? (161-184). Multilingual Matters. https://doi.org/10.21832/9781853597893. (accessed on 14January 2026). [CrossRef]
- Grijalva C., Piccinini, E., and Arvaniti, A. (2013). The vowels spaces of southern Californian English and Mexican Spanish as produced by monolinguals and bilinguals. The Journal of the acoustical Society of America, 133(5), 1-9. https://doi.org./ 10.1121/1.4805638. (accessed on 17 January 2026). [CrossRef]
- Görlach, M. (2003). English Words Abroad. John Benjamin.
- Hagiwara, R. (1997). Dialect variation and formant frequency: The American English vowels revisited. The Journal of the Acoustical Society of America, 102(1), 655-658. https://doi.org/10.1121/1.419712. (accessed on 20 January 2026). [CrossRef]
- Lanz, L. (2022). Mixed feelings en Tijuana: Bilingüismo, sentimiento y consumo. McGraw Hill.
- Muysken, P. (2000). Bilingual speech: A typology of code-mixing. Cambridge University Press.
- Myers-Scotton, C. (1993). Duelling languages: Grammatical structure in codeswitching. Oxford University Press.
- Myers-Scotton, C. (2002). Contact linguistics: Bilingual encounters and grammatical outcomes. Oxford University Press.
- Paradis, C., and LaCharité, D. (2008). Apparent phonetic approximation: English loanwords in Old Quebec French. Journal of Linguistics, 44(1), 87-128. https://doi.org/10.1017/S0022226707004963. (accessed on 18 January 2026). [CrossRef]
- Onysko, A., y Winter-Froemel, E. (2011). Necessary loans-luxury loans? Exploring thepragmatic dimension of borrowing. Journal of Pragmatics, 43(6), 1550-1567. https://doi.org/10.1016/j.pragma.2010.12.004. [CrossRef]
- Otheguy, R., & Zentella, A. C. (2012). Spanish in New York: Language contact, dialectal leveling, and structural continuity.Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199737406.001.0001. (accessed on 18 January 2026). [CrossRef]
- Otheguy, R., García, O., & Reid, W. (2015). Clarifying translanguaging and deconstructing named languages: A perspective from linguistics. Applied Linguistics Review, 6(3), 281–307. https://doi.org/10.1515/applirev-2015-0014. (accessed on 02 February 2026). [CrossRef]
- Peralta-Rivera, R. R., Gil-Burgoin, C. I., & Valenzuela-Miranda, N. E. (2025). Phonetically Based Corpora for Anglicisms: A Tijuana-San Diego Contact Outcome. Languages, 10(6), 143. https://doi.org/10.3390/languages10060143. (accessed on 10 January 2026). [CrossRef]
- Poplack, S., & Dion, N. (2012). Myths and facts about loanword development. Language Variation and Change, 24(3), 279–315. https://doi.org/10.1017/S095439451200018X. (accessed on 17January 2026). [CrossRef]
- Poplack, S., Sankoff, D., & Miller, C. (1988). The social correlates and linguistic processes of lexical borrowing and assimilation. Linguistics, 26(1), 47–104. https://doi.org/10.1515/ling.1988.26.1.47. (accessed on 14 January 2026). [CrossRef]
- Toledo, D., and García, L. (2018). Escenarios lingüísticos emergentes en la frontera Tijuana-San Diego. Káñiña, Revista Artes y Letras-Universidad de Costa Rica, 42(2), 87-111. http://dx.doi.org/10.15517/rk.v42i2.34597. (accessed on 17 January 2026). [CrossRef]
- Winford, D. (2003). An introduction to contact linguistics. Blackwell.
- Winford, D. (2017). Borrowing and contact in creole genesis. In The Oxford handbook of language contact (pp. 51-74). Oxford University Press. https://doi.org/10.1093/oxfordhb/9780199945092.013.2. (accessed on 22 January 2026). [CrossRef]
- Zenner, E., & Backus, A. (2019). Loanwords in discourse: A study of Anglicisms in Dutch. John Benjamins.

Table 1.
Phonetically Adapted Anglicisms (PAA, n = 33).
| Anglicism | OP | NP | PP | AP |
|---|---|---|---|---|
| blend | ✓ | ✓ | — | — |
| cash | ✓ | ✓ | — | — |
| dark(s) | — | ✓ | — | ✓ |
| hack | ✓ | — | — | — |
| nerd | — | ✓ | — | ✓ |
| plus | ✓ | ✓ | ✓ | — |
| sad | — | ✓ | — | ✓ |
| shots(s) | ✓ | ✓ | — | — |
| staff | — | ✓ | ✓ | — |
| top | — | ✓ | — | ✓ |
✓ indicates attested occurrences; — implies unattested occurrences for all PAA
Table 2.
Phonetically Non-Adapted Anglicisms (PNA, n = 41).
| Anglicism | OP | NP | PP | AP |
|---|---|---|---|---|
| boss | ✓ | ✓ | — | — |
| bun | — | ✓ | — | — |
| bundle | ✓ | ✓ | — | — |
| core | — | ✓ | — | — |
| crush | ✓ | ✓ | — | — |
| flush | ✓ | — | — | — |
| fuck | ✓ | — | — | — |
| mall(s) | — | ✓ | ✓ | — |
| match | ✓ | — | — | — |
| must | — | ✓ | — | — |
| spot(s) | — | ✓ | ✓ | — |
✓ indicates attested occurrences; — implies unattested occurrences for all PNAA.
Table 3.
Interaction of Anglicisms with Spanish functional morphology by phonetic class.
| Phonetic class |
Determiner selection |
Number marking |
Agreement patterns |
Examples |
|---|---|---|---|---|
| PAA | Definite and indefinite determiners attested; item-specific constraints observed |
Plural marking frequently attested |
Both agreement convergence and agreement mismatch patterns |
-el cash -los darks -los shots -mismatch: nerd, top |
| PNAA | Determiners attested, often indefinite; greater variability |
Plural marking attested but less consistent |
Higher incidence of agreement mismatch |
-un bundle -un crush -los malls -mismatch: boss, must |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



