
Submitted:
09 February 2026
Posted:
10 February 2026
You are already at the latest version
Abstract
The primary focus of enhancing the efficiency of operations in the Industry 4.0 setting is Predictive and Preventive Maintenance (PPM). The paper introduces a predictive-maintenance system based on the Unified Namespace (UNS), which involves real-time sensor measurements, photogrammetry, and modeling of a digital twin to improve fault prediction and responsiveness to maintenance. This experiment was conducted over six months in a medium-sized discrete electromechanical production plant equipped with motors, Variable Speed Drives (VSDs), robot/cobots, precision grip systems, pipework systems, Magnemotion/linear motor drives, and a CNC machine. The continuous data, such as high-frequency vibration, temperature, current, and pressure, were monitored and analysed with machine-learning models, including support-vector machines, gradient-boosting, long-short-term memory, and Random Forest, through which temporal degradation can be predicted. UNS architecture integrated all sensor and imaging data into a vendor-neutral data model through OPC UA to help ensure that all experiments could be integrated consistently and be updated in real time to real digital twins. The suggested system correctly identified mechanical and electrical failures and predicted failures before they really took place. Consequently, machine downtime was reduced by 42.25, and Mean Time to Repair (MTTR) by 36, which was mainly caused by a previous anomaly detection and pre-inspection supported by a digital-twin. Altogether, the paper proves that the integration of UNS with multi-modal sensing and digital-twin technologies will greatly enhance predictive maintenance. The framework provides a data-driven, scalable solution to organisations that aim to modernise their maintenance processes, attain greater reliability and better equipment utilisation, as well as enhanced Industry 4.0 preparedness.
Keywords:
CNC fault detection
; digital twins
; food and beverage optimisation
; Industry 4.0
; MedTech applications
; machine learning
; motor fault prediction
; predictive maintenance
; real-time data analytics
; robots and cobots
; variable speed drives
; virtual inspections
1. Introduction
In modern industrial environments, predictive and prescriptive maintenance (PPM) is essential for improving operational performance and reducing unnecessary stoppages [1]. With the evolution of Industry 4.0, the Industrial Internet of Things (IIoT), machine learning (ML), and big data analytics are increasingly integrated into Supervisory Control and Data Acquisition (SCADA) systems to support real-time decision-making. However, despite these advancements, traditional SCADA frameworks remain constrained by hierarchical architectures, limited interoperability, and difficulty handling heterogeneous data streams. These limitations create challenges for accurate fault detection and the selection of appropriate maintenance strategies.
To address these issues, the Unified Namespace (UNS) has emerged as a scalable alternative (Figure 1). UNS provides a unified, structured data model where information from sensors, cameras, actuators, controllers, and enterprise systems is aggregated into a single real-time stream, enabling seamless data flow and supporting predictive-maintenance workflows [2].
Within the UNS framework, photogrammetry and 3D scanning technologies enable the creation of accurate digital replicas, commonly referred to as digital twins or Digital Shadows, of industrial assets and facilities (IAFs) [3]. As an offshoot of photogrammetry, high-resolution imaging and accurate algorithms produce precise three-dimensional imaging of equipment, thereby creating a platform to analyse for symmetry or layout arrangement, or for possible defects. These are very useful for condition monitoring, which facilitates the identification of potential faults by image analysis early in time, thanks to pattern recognition techniques. Furthermore, the incorporation of machine-learning algorithms into the UNS framework enables the transition from predictive to prescriptive maintenance, allowing the system not only to detect faults but also to recommend (and eventually execute) appropriate remedial actions independently [4].
Although a focus on variations to SCADA systems with integrated ML capabilities has been discussed, the use of UNS as a comprehensive predictive analysis platform in the industrial environment has not been studied. This research seeks to fill this gap by analysing how UNS integrated with photogrammetry and 3D scanning can improve fault identification and maintenance of industrial machinery [5]. The effectiveness of UNS will be evaluated in this research against manufacturing disruption in various production environments, equipment durability, and dependability of the final system. Sporadic failures and changing dynamic operating environments are significant issues in the context of the IoT-enabled environment. The work will help in enhancing Fault Detection and Diagnosis (FDD) in Industry 4.0. The results will be applicable in industries that are in need of effective and economic measures to enhance the efficacy of their maintenance plans.
The concept of the Unified Namespace (UNS) is characteristically the opposite of that of conventional SCADA systems, which accumulate data in hierarchical systems with little interoperability because the information is compiled in one data model that encompasses all devices and software layers. SCADA systems often only permit data to be sent in specified routes, and hence, the systems are not scalable, but UNS allows horizontal and vertical data transfer throughout the whole enterprise. In addition, UNS can integrate equipment of varying vendors relatively easily by use of OPC UA and is therefore significantly more flexible in Industry 4.0 settings than the inflexible and siloed structure of the classical SCADA solutions.
2. Materials and Methods
This study aims to enhance Predictive and Preventive Maintenance (PPM) through the implementation of a Unified Namespace (UNS) framework in industrial systems. This section describes the key system components (industrial machines, sensors, computing platform, and software tools) and the methods used, including the UNS architecture and its design process, data collection and preprocessing, machine-learning–based fault detection, evaluation metrics, and deployment environment.
2.1. System Architecture
The UNS provides access to all the information created by the system components, such as sensors, actuators, controllers, and other industrial devices, into a single hierarchical data model to be accessed and analysed in real-time. The system also offers a real-time, holistic representation of asset health by bringing all these data streams together under a single architecture. Combined with diagnostics, UNS makes it possible to integrate photogrammetry/3D scanning imaging information with sensor data, including temperature, vibration, and pressure variations. The ability to integrate such comprehensive data is made possible by Open Platform Communications Unified Architecture (OPC UA), which encourages the safe connection of devices regardless of who they were made by. In the UNS model, OPC UA is the key component because it standardises data structure and provides interoperability in the communication between heterogeneous industrial devices. OPC UA offers a standard address-space model, which models all the equipment variables in a standard form, and thus, cross-vendor interoperability. Moreover, its embedded security model, which comes with encryption, authentication, and role-based access, provides efficient data transfer that is safe and critical to the safety of industrial processes. With its ability to abstract device-specific protocols into a single communication layer, OPC UA can easily integrate both old systems and current IIoT devices, as well as cloud applications in the UNS architecture.
The modern system is adaptable enough to include the data of both older applications and real-time sources, such as different operational parameters needed to determine fault and preventive maintenance. Certain characteristics and capabilities of UNS are serving as a complete real-time data flow hub or aggregator of entire real-time data with subsystems and entire digital twins or virtual shadows of machinery, which may be utilised to assist in visual inspection, detect layout inconsistencies, and anticipate failure modes [6].
2.1.1. Industrial Machines Used in the Study
The UNS-based predictive-maintenance system was evaluated on a six-month basis in a medium-sized manufacturing facility that was free of handling a diverse range of electromechanical assets. The control valves, Variable Speed Drives (VSDs), industrial motors, robots and cobots, pipework systems, Magnemotion/linear motor drives, precision robotic grippers (Schunk-type), and CNC machines were introduced in the study. These machines were chosen due to repeated mechanical and thermal loads, and they are a characteristic of industrial assets in general, in which predictive-maintenance interventions can provide quantifiable value.
To allow real-time analysis of the equipment, they were all equipped with vibration and temperature, current, and pressure sensors. This variety of equipment set was provided so that the UNS framework could be tested in several fault classes, load conditions, and operating environments.
2.2. Data Collections and Data Preprocessing
Some of the different types of data include real-time feeds of vibration, thermal, and current sensors, since the equipment that is prone to faults is usually fitted with these gadgets. Photogrammetry is also intended to build a stereo-vision image of the equipment surfaces to help identify the apparent signs of imminent failure in the form of wear, deformation, or misalignment. Spontaneous operator reports and SCADA event-log data are also added to supplement the historical maintenance records to develop the machine-learning model.
To provide a comprehensive monitoring of the condition, both high-frequency and low-frequency sensors were installed on the machines, and the data were collected in the study. Tri-axial accelerometers with a sampling frequency of about 5 kHz were used to capture the vibration signals, and thus, bearing wear, imbalance, misalignment, and looseness could be detected. One Hz temperature measurements of sensors mounted on motors, drive units, and mechanical housings were taken to record temperature changes that were caused by a change in load or lubrication. Attached signals were also measured at 100 Hz to describe electrical activities that could be ascribed to winding degradation or torque anomalies, and pressure sensors were sampled at 10 Hz to give an indication of initial leak development or flow discontinuity in the pipework systems.
The sensors of each type were designed to address a particular mechanism of fault. The mechanical degradation is measured by vibration data, the thermal stress is measured by temperature variation, and electrical abnormalities are measured by current signatures. This multi-modal setup was able to record millions of vibration samples from each machine each day in the six-month period of monitoring, along with real-time temperature, current, and pressure measurements. Errors to this end by such wide coverage of time give them representative data that can be used to train, test, and validate the predictive models well under different working conditions.
Data cleaning involves noise reduction, commonly achieved through smoothing filters such as the Savitzky–Golay filter [18], while missing values are managed using appropriate data-imputation techniques. A Savitzky–Golay smoothing filter with window length = 7 and polynomial order = 3 was applied to vibration signals to reduce high-frequency noise while preserving peak structure. These pre-processing steps improve the reliability of the collected sensor signals and support more accurate fault detection. After cleaning, the dataset is scaled, and feature selection is performed using a combination of correlation-based ranking and Recursive Feature Elimination (RFE) to identify the most informative predictors for failure forecasting. These techniques highlight variables such as vibration amplitude, temperature variation, current irregularities, and cycle-time deviations, which have the strongest influence on equipment-failure patterns in the predictive-maintenance context.
To formalise the RFE procedure, feature importance weights are obtained from an estimator . At each iteration, the feature with the smallest absolute importance is removed, and the model is refitted until only the top-k ranked features remain. This iterative elimination improves generalisation by retaining only the most informative predictors.
2.3. Implementation of Machine Learning in Fault Recognition
The predictive-maintenance framework in this study employs both unsupervised and supervised machine-learning techniques to ensure comprehensive fault detection. Unsupervised learning is used to detect previously unknown or emerging anomalies in sensor behaviour, while supervised models classify known fault conditions using labelled historical data. This dual approach was necessary because industrial machines often exhibit both predictable failure modes and unexpected degradation patterns.
In the unsupervised stage, Isolation Forest was implemented because of its effectiveness in identifying subtle deviations in multi-dimensional vibration, temperature, and current data. K-means clustering was initially evaluated but not selected due to its lower sensitivity to sparse anomalies in high-frequency vibration data. However, a quantitative comparison was performed to justify this exclusion. During preliminary experiments, K-means produced a low silhouette score of 0.21, indicating poor cluster compactness for multidimensional vibration–temperature–current data. It also showed low anomaly-recall performance (62%) and a high false-alarm rate due to its assumption of spherical clusters and equal variance, which does not hold for industrial sensor patterns. In contrast, Isolation Forest achieved substantially higher anomaly recall (94%) and better separation of rare fault signatures. Therefore, K-means was excluded from the final pipeline due to inferior sensitivity and clustering quality for sparse and irregular anomaly patterns. The unsupervised anomaly flags were then cross-checked with photogrammetry and 3D-scanning records to validate whether structural irregularities corresponded to sensor-based anomalies. No external reference is cited here because this describes the methodology used in the present study.
In the supervised stage, three widely adopted fault-classification algorithms were used independently: Random Forest (RF), Support Vector Machine (SVM), and Gradient Boosting (GB). These models were not combined or ensembled; instead, they were trained separately and compared under identical conditions to determine which classifier performs best for the studied industrial environment. All models were trained using labelled fault data extracted from maintenance logs and SCADA-confirmed fault events. Their performance was evaluated using precision, recall, F1-score, and accuracy to allow objective comparison and model selection.
In addition to discrete fault classification, Long Short-Term Memory (LSTM) neural networks were implemented to model gradual degradation trends that unfold over time. LSTM was trained using sequential vibration, temperature, and current data streams to forecast future deterioration trajectories. In contrast, the classical classifiers focus on instantaneous fault-state identification. This complementary use of LSTM enables early prediction of long-term asset health changes that are difficult to capture using non-temporal models. The LSTM architecture consisted of two stacked LSTM layers with 64 hidden units each, tanh activation, and an Adam optimiser (learning rate = 0.001). The model was trained with a batch size of 32 and a sequence length of 20 timesteps to capture temporal degradation patterns.

Table 1.
A. Hyper parameters of the Supervised Models.
| Model | Key Hyperparameters |
| Random Forest | n_estimators = 200, max_depth = None, min_samples_split = 2 |
| SVM | kernel = ‘rbf’, C = 1.0, gamma = ‘scale’ |
| Gradient Boosting | n_estimators = 150, learning_rate = 0.1, max_depth = 3 |
2.4. Evaluation Metrics
Effectiveness is demonstrated by minimising machine downtime, increasing the accuracy of fault diagnosis, and reducing the mean time to repair (MTTR). Secondly, prescriptive maintenance effectiveness enhancements are evaluated using the UNS integrated data against conventional maintenance methodologies [8]. Evaluation is conducted in an even manufacturing environment for six months. Key performance indicators, including the lead time in fault prediction, accuracy in failure cause identification, and productivity of equipment, are used to assess model performance. The applied prescriptive maintenance interventions are also assessed for the effectiveness of failure prevention and optimal scheduling.
2.5. Implementation Environment
The system was deployed on an industrial-grade workstation equipped with an Intel Core i7-11700 (8-core, 2.5–4.9 GHz) processor, 32 GB DDR4 RAM, and a 1 TB SSD, running Windows 10 Pro (64-bit). This configuration provided sufficient computational resources for real-time OPC UA communication, high-frequency sensor ingestion, and execution of the machine-learning models. Model training and validation were conducted using Python 3.10 with Scikit-Learn, TensorFlow 2.x, and Keras libraries. An OPC UA client (python-opcua) was used for device communication. The workstation was connected to the plant network through a secure Ethernet link, ensuring low-latency data transfer to the UNS layer. To validate real-time applicability, inference latency was benchmarked over 1,000 runs on the deployed workstation. The average per-sample inference times were: Random Forest = 4.3 ms, SVM = 7.8 ms, Gradient Boosting = 12.5 ms, and LSTM = 15.2 ms. These values are well below the 50 ms threshold commonly required for real-time predictive-maintenance decision loops, confirming that the proposed system can process high-frequency sensor streams without violating operational latency constraints.
2.6. Comparative Methodology: UNS vs Traditional Maintenance Approaches
The predictive-maintenance system based on the UNS was evaluated by using a systematic comparison of the system with the conventional maintenance system of the facility. Baseline information was gathered during the 6 months before UNS deployment, and in this period, the machines were under the normal operation of reactive and time-based preventive maintenance. Fault forecasting was performed following UNS in the form of real-time sensor data analytics, digital-twin visualisation, and machine-learning results.
To make a fair comparison, a similar production schedule was applied on the same machines during both periods, which allowed isolating the effect of the UNS framework of variation. These key performance indicators were compared: the total machine downtime, Mean Time to Repair (MTTR), accuracy of fault prediction, lead-time of the anomaly detection, and the unplanned stoppages. These indicators were compared during pre-UNS deployment and post-UNS deployment to allow a clear and quantifiable evaluation of the maintenance improvement provided by the proposed system.
2.7. System Validation and Model Verification
The model was validated so that it would be seen that the structure of predictive maintenance was sufficient to produce valid and generalisable results. The data were divided into an 80/20 train-test split to provide the model with the ability to test on the unseen data. More bias reduction was also achieved using a five-fold cross-validation process in which models were trained and tested repeatedly on several partitions of the data sets. The supervised learning was provided with ground-truth labels based on historical maintenance logs, reports of the technicians, and SCADA events confirmations.
The validation process combined statistical accuracy metrics with temporal and operational checks. Statistical validation involved analysing precision, recall, F1-score, and accuracy to assess diagnostic quality. Temporal validation assessed the model’s ability to predict anomalies ahead of time by reviewing anomaly-lead-time performance. Operational validation compared reductions in downtime and MTTR after implementation of the UNS framework with pre-deployment values. This layered validation strategy ensured that the improvements were genuinely due to the UNS-based predictive-maintenance system rather than unrelated external factors.
3. Results
The six-month evaluation of the UNS-based predictive-maintenance system was conducted in a medium-scale discrete manufacturing environment specialising in electromechanical assembly operations. This industrial setting includes a range of equipment, such as motors, VSD-driven systems, robotics workcells, and precision material-handling units, making it a suitable environment for assessing both the predictive and prescriptive capabilities of the UNS framework. In a manufacturing context, the proposed predictive maintenance system based on UNS was tested over six months. They were judged using the degree of machine downtime reduction, machine fault prediction, and improvement of the maintenance schedule. Information was gathered from different sensors (vibration, temperature, current) of significant industrial processes, and artificial neural networks were used for fault detection of the equipment.
3.1. Fault Detection Accuracy
The performance of the predictive models was measured using standard classification metrics such as precision, recall, F1-score, and accuracy. Three supervised machine-learning algorithms, Random Forest (RF), Support Vector Machine (SVM), and Gradient Boosting Machine (GBM), were selected because they are widely recognised for their robustness in handling heterogeneous sensor data, their ability to model nonlinear relationships, and their strong benchmark performance in predictive-maintenance literature. RF and GBM were chosen due to their ensemble structure, which reduces overfitting and handles noisy industrial data effectively, while SVM was included as a high-margin classifier suitable for distinguishing between closely overlapping fault and non-fault conditions. These models were compared under identical training and testing conditions to identify which algorithm performs best in the studied industrial environment.
Thus, Gradient Boosting achieved the strongest overall performance, with an accuracy of 92.1% and an F1-score of 91.2%, indicating a high capability to discriminate between fault and non-fault conditions. Random Forest also performed well; however, when compared with the K-Nearest Neighbours (KNN) classifier, its precision and recall values were slightly lower.
Table 1.
Performance comparison of the supervised machine-learning models used for fault detection, evaluated using precision, recall, F1-score, and accuracy.
Table 1.
Performance comparison of the supervised machine-learning models used for fault detection, evaluated using precision, recall, F1-score, and accuracy.
| Model | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
| Random Forest (RF) | 92.1 | 88.5 | 90.2 | 91.4 |
| SVM | 90.3 | 86.2 | 88.2 | 89.6 |
| Gradient Boosting | 93.5 | 89.0 | 91.2 | 92.1 |
3.2. Machine Downtime Reduction
Another key measure of the performance of the system is the cost savings that originate from the low frequency of machine breakdowns. The UNS-based system, which was capable of learning probable faults and their location all before a failure occurred slimmer unpredicted downtime. Table 2 below shows the breakdown of Downtime of machines on cycles before and after the system implementation.
The downtime values presented in Table 2 were derived from the historical maintenance logs recorded over two consecutive six-month periods. The first period reflected the plant’s conventional maintenance practices, while the second period captured performance after the deployment of the UNS-based predictive-maintenance system. All downtime figures, therefore, originate from the same set of machines operating under similar production schedules, ensuring that the comparison reflects actual operational behaviour during the monitoring period.
However, it is acknowledged that the comparison is based on two sequential time periods rather than a simultaneous control experiment. Minor changes in performance could also be attributed to seasonal changes in production load, operator behaviour, or environmental changes. However, the fact that the downtime of all the machines decreased by more than 42% is a significant pointer that the UNS framework was a decisive factor in enhancing the availability of machines.
3.3. Mean Time to Repair (MTTR)
Mean Time to Repair (MTTR) was another method of maintaining efficiency. Table 3 shows the pre-implementation and post-implementation of the system in terms of the values of the MTTR.
Table 3 shows the computation of the MTTR values based on the maintenance-ticket completion time, which has been automatically recorded in the SCADA event-management system of the plant. These measures will indicate the difference between the pre- and post-UNS deployment average period spent by technicians to detect and fix machine faults. These values, just like in the case of downtime analysis, were recorded on the same machines and in situations similar to the way of operation, to have a legitimate pretext for measuring the maintenance efficiency increase.
Although the findings show a 36% change in the improvement in MTTR, it is acknowledged that there could have been a secondary effect due to changes in the workload intensity or the availability of technicians over time. However, it is reasonable that the steady decrease of the MTTR in all machines was due to the prevalence of the early fault identification and digital-twin-supported diagnosis, since they were critical in enhancing the promptness to repair.
To verify that these improvements did not occur by chance, statistical significance testing was performed using the monthly MTTR and downtime records. A paired t-test comparing pre-UNS and post-UNS monthly MTTR values demonstrated a statistically significant reduction (mean difference = −1.42 hours, 95% CI [−1.88, −0.96], p < 0.01). Similarly, reductions in total downtime across the four machines were confirmed using a Wilcoxon signed-rank test (p < 0.05). These statistical results indicate that the improvements observed after UNS deployment were not due to random operational fluctuations but are attributable to the predictive-maintenance capabilities of the UNS framework.
To further explain the reasons why the 36% improvement in MTTR occurred, a breakdown analysis was conducted. This is mainly because the fault visibility in the past was through the predictive alerts, which ensured that technicians prepared the tool and spare parts beforehand. Digital-twin visualisation also contributed to the fact that it was possible to do an initial diagnosis before visiting the physical machine. The contribution of each of the factors to the total improvement of MTTR is summarised in Table 3A.
Table 3.
A. Contribution of Different Factors to MTTR Improvement.
| Factor | Estimated Contribution (%) |
| Early fault prediction (UNS + ML) | 22% |
| Digital-twin visual pre-inspection | 10% |
| Pre-prepared tools and spare parts | 4% |
| Total MTTR Improvement | 36% |
The 10% contribution attributed to digital-twin photogrammetry was derived from a structured analysis of the plant’s maintenance tickets. Historical records that were tagged as ‘visual pre-inspection used’ showed an average 10% reduction in fault-finding and diagnosis time compared with traditional inspection methods. This estimate was further validated through expert judgement obtained from two senior maintenance engineers, who confirmed that photogrammetry consistently accelerated the identification of wear, misalignment, and deformation during the assessment stage.
3.4. System Scalability and Cost Efficiency
Besides performance considerations, the scalability and the overall cost-effectiveness of the offered system should have been evaluated. OPC UA can be connected to the current industrial communication structure through the use of OPC UA, and only minor extensions are needed to do so, as it is a standard that is compliant with the IEC 62541 standard [19]. The application of the UNS framework is very beneficial in industrial settings, where a lot of sensors can already be found, and additional hardware modifications are unnecessary to use the existing data streams. This renders the overall solution to be scalable as well as cost-effective.
3.5. Summary of Findings
Implementation of the UNS framework for predictive maintenance greatly enhanced the performance of the fault-detection system and delivered improved classification accuracies and shorter Mean Time to Repair (MTTR). The Gradient Boosting model was found to have the highest predictive ability, especially in the voltage-fault detection case study, and thus, it will be appropriately used to predict different fault patterns. These results point to the possibility of the suggested method being implemented in different industrial settings, which provides not only operational benefits but also cost-efficient maintenance gains.
4. Discussion
4.1. System Performance and Model Evaluation
The study identifies a number of valuable advantages linked to the use of an UNS-based predictive maintenance system that is complemented by photogrammetry and 3D scanning. The highest rate of improvement was a decrease in machine downtime, where the tested machinery reported an average of 42.25% decrease. All in all, the data confirms the theory that when the suggested maintenance measures are implemented, the effective capacity utilisation of all checked equipment is improved [9].
The UNS framework helped in the early detection of arising faults, and as such, the maintenance teams were able to operate before the problems got out of control. The capability of forecasting minimised interruptions in production by assisting in anticipatory action. It is possible to note that the reduction of the downtime can primarily be explained by the real-time monitoring of the machine behaviour introduced by the UNS and its effective collaboration with photogrammetry and 3D scanning to produce precise digital-twin models [10]. These digital twins can offer a continuous visual representation of gear to compare with a state-of-the-art one and to detect prematurely the emergence of deformation or wear, which are typical antecedents of mechanical failure [10].
Photogrammetry and 3D scanning really boosted the monitoring of assets and have allowed for a more thorough examination of equipment conditions. This visual information, with high resolution, along with constant observations of sensors, allowed a comprehensive visual representation of the state of assets. Shallow malformations of shape, positioning, or superficial integrity could be detected early in life, and this greatly enhanced the diagnostic power. The digital twin models were additionally used with sensor-based signals (vibration, temperature, current) to give further anomaly signals, which enhanced the forecasting capability of machine learning models [11].
The machine-learning test also verified good diagnostic results. The Gradient Boosting model had the best classification performance on all the evaluation measures. Although its accuracy was found to be 92.1%, this should be viewed with caution because the accuracy of predictive maintenance is extremely sensitive to the size of the dataset, the imbalance of the classes, and sensor noise. However, the model has good precision, recall, and F1-score, which demonstrates the validity in discrimination between the fault and non-fault conditions. It helps reduce the level of false positives and the false-alarm rate. Such good outcomes indicate the successful application of the UNS framework, where data collected by sensors, photogrammetry, and 3D scanning is analysed and processed using effective algorithms [8].
Compared to the model, SVM had a lower recall (86.2%), probably because of its narrow ability to apply to heterogeneous industrial data. Random Forest showed strong performance, with 91.4% accuracy, which proves that the choice of the model depends on the situation in the industry and the nature of faults [12].
The other outcome of performance was a decrease in the Mean Time to Repair (MTTR), which was reduced by 36%. This brings out the improved diagnostic ability and the use of digital twins in accelerating maintenance processes [13]. Maintenance teams were also better equipped when they arrived on site, which cut the time on diagnosis. Photogrammetric 3D models could help technicians to pre-analyse the state of equipment before its physical examination and assist in more rapid and efficient remediation [14].
The common problem of traditional maintenance methods is the delay in the detection of faults, particularly with maintenance strategies that are based on breakdowns. Conversely, the UNS system provides anticipatory alarms and virtual fault descriptions written in Boolean logic, which enables maintenance teams to pre-assemble the required tools and replacement parts to reduce the impact of production by the fault.
4.2. Integration of Photogrammetry and Digital Twins
Photogrammetry and the 3D scanner were implemented into the UNS framework, greatly expanding the scope of predictive maintenance. These technologies allowed the creation of extremely precise digital twins that contribute to the visual analysis in real-time. Digital twins serve as high-quality visual records and constantly updated records of structural variations and geometric deviation in equipment by storing changes in equipment.
This Level of detail increases the possibility of detecting minor yet meaningful alterations, e.g., component deformation, misalignment, or surface wear. Such visual cues can be combined with sensor-based fault indicators to ensure the diagnostic performance of machine-learning models and minimise the uncertainty in fault prediction [11].
Digital twins are also beneficial in speeding up repair processes since they are able to minimise the on-site exploratory inspection. Before physical access, technicians have the ability to pre-study the state of the equipment to enhance the plan for repair and save time that would have been spent diagnosing the problem.
The data unification of the UNS is able to support the imaging information and multi-modal sensors data, which enhances the integrity of the overall predictive-maintenance pipeline. Subsequently, it presents a more holistic approach to asset monitoring as compared to common preventive maintenance strategies. Recent studies have also highlighted the value of distributed digital-twin frameworks in strengthening predictive-maintenance workflows within IIoT environments, further supporting the findings of this work [7].
4.3. Industrial Applications
The UNS-based predictive maintenance system proved to be very applicable in various industrial sectors. In addition to high-level machine-health monitoring, the system is used in high-level diagnostic and prognostic tasks in equipment (control valves, variable speed drive (VSD), motors, robots and cobots, pipework networks, Magnemotion and other linear motor drives, precision grippers (shunks), and CNC machines). In control valves, the system allows for detecting the irregularities in flows at an early stage that can threaten the quality of the product or interfere with the production process. In the case of VSDs, the early signs of mechanical damage are anomalies in the torque or the speed. Unplanned stoppage minimisation and predictive analytics that facilitate continuity of workflow are the advantages of robots and cobots that have become the focus of automated manufacturing [16]. Early detection of leakages in pipework is offered by monitoring pressure fluctuations, and wear is detected by anomalous transport behaviour by Magnemotion and other linear drives [17]. The machines, using a lot of precision and alignment, such as CNC machines, can produce the same quality of production when checked using predictive models [5].
The UNS framework offers different benefits in specialised industrial sectors as well. Digital twins in the pharmaceutical industry aid virtual inspection and structural modelling of production facilities in detail and guarantee compliance with strict regulatory standards [16]. The high-fidelity 3D models of the medtech area allow visualisation of prototypes, biomechanical simulation of implants and prosthetics, which enhances the accuracy of the design and explains initial failures. The predictive maintenance and the digital twin in the food and beverage manufacturing industry improve the manufacturing-line optimisation and virtual packaging trials, quality control in real-time, where the losses in productivity are detected at an early stage.
All these applications demonstrate the versatility, generalisability, and industry applicability of the UNS-based predictive maintenance system in current industrial settings.
4.4. System Limitations and Future Work
The system has limitations, even though it has a good performance promise. The main methodological drawback is that the comparison of traditional and UNS-based maintenance was done over two successive periods of time and not by a parallel analysis of the same machines. Because of the capacity to produce, controlled side-by-side experiments could not be conducted on duplicate equipment run under the same conditions. Consequently, some of the improvements could have been occasioned by external factors like seasonal fluctuations in production(s), operator variations, or even variable workload demands. To partially mitigate these temporal confounders, a difference-in-differences–style comparative analysis was applied to monthly downtime and MTTR trends, allowing the separation of UNS-related performance gains from routine operational variability. Further research is needed to test similar machines or other but the same production lines simultaneously, as a better isolation of the effect of the UNS framework would be obtained, and marking causal attribution. However, the absence of a true concurrent control group, such as identical machines operating without UNS, remains a key causal limitation, and future studies should incorporate such parallel setups to isolate UNS-specific effects more robustly. The quality of sensor data is vital; sensors may have faulty or inaccurate data that may result in distortion of the analysis. Preprocessing cannot fully address noise and missing data, and this is an indicator that sensor-health assessment is necessary when acquiring data.
The system is effective when the pattern of faults is sustained, but it fails with intermittent faults, having irregular and unpredictable signatures. Further studies can also include learning models that are directly targeted at intermittent fault detection, or a combination of the two, rule-based logic and deep learning. Furthermore, the generalisability of the observed improvements to other industrial sectors, especially pharmaceutical, medtech, and high-precision manufacturing, must be approached with caution. These sectors operate under much stricter regulatory requirements, tighter contamination-control rules, and significantly narrower process tolerances. Their failure modes, quality constraints, and sensor infrastructures differ substantially from food and beverage environments, meaning that direct transfer of the current model may be limited. Therefore, model retraining, recalibration of thresholds, and additional domain-specific features would be required before deploying the UNS-based system in such highly regulated or ultra-precise industrial settings.
It would be logical to extend the system to incorporate prescriptive-maintenance facilities. Whereas existing models help to identify faults, prescriptive analytics may hint at remedial measures. System generalisation, system robustness, and system deployment to industries would be enhanced by deep learning models and enhanced multimodal data sets [15].
4.5. Overall Implications for Industry 4.0
The UNS framework is very scalable and cost-effective. It allows connection to the existing equipment by OPC UA without significant capital expenditure [10]. The system offers a viable route that industries should follow to modernise maintenance activities in an Industry 4.0 setting by means of existing sensor infrastructure and digital-twin technologies.
With the digital tasks of industries, UNS and digital twins in combination with advanced machine-learning models, productivity, reliability, and competitiveness are improved [9]. It can be used in many industries where pharmaceutical, medtech, high-precision manufacturing, and food and beverage processing industries are the ones that require flawlessness, safety, and compliance to be crucial.
5. Conclusions
The paper has demonstrated that a Unified Namespace (UNS) framework could be supplemented with machine learning, photogrammetry, and 3D scanning to provide meaningful predictive maintenance in the industrial environment. The system achieved a 42.25% reduction in machine downtime and 36% increase in Mean Time to Repair, which demonstrates that it is effective in early fault detection and enhancing maintenance responsiveness. The algorithm that gave the highest diagnostic scores was Gradient Boosting, which supports the fact that the multi-modal sensor data used in connection with the digital-twin information retrieved through imaging is useful.
The UNS framework was also scalable and cost-effective, and fitted well with legacy and modern equipment using OPC UA, and did not require massive infrastructure upgrading. But there are still some problems related to sensor data quality and intermittent fault detection. It should be improved in future work by developing better sensor-health assessment, intermittent-fault analytics, more complete integration of prescriptive maintenance, and advanced deep-learning approaches.
Altogether, this research shows that UNS-based predictive maintenance is not merely a technically viable option, but also a strategy that will enable industries to be more reliable, smarter, and fully ready to be called Industry 4.0.
Preprint Notice
This manuscript extends the authors’ earlier preprint (v3, February 2025) by adding an expanded methodology section, statistical significance testing, inference-time benchmarking, enhanced figures, and a deeper industrial validation. These developments substantially differentiate the present submission from the preprint version.
Data Availability Statement
The sensor logs and maintenance data used in this study are confidential industrial datasets. They cannot be publicly released due to commercial restrictions, but are available from the corresponding author upon reasonable request. To support reproducibility, anonymised sample datasets and representative Python preprocessing scripts can also be provided upon reasonable request without compromising industrial confidentiality.
References
- Peres, R.S.; Jia, X.; Lee, J.; Sun, K.; Colombo, A.W.; Barata, J. Industrial Artificial Intelligence in Industry 4.0: Systematic Review, Challenges, and Outlook. IEEE Access 2020, 8, 220121–220139. [Google Scholar] [CrossRef]
- Marah, H.; Challenger, M. An Architecture for an Intelligent Agent-Based Digital Twin for Cyber-Physical Systems. In Digital Twin-Driven Intelligent Systems and Emerging Metaverse; Springer Nature Singapore: Singapore, 2023; pp. 65–99. [Google Scholar]
- Nunes, P.; Santos, J.; Rocha, E. Challenges in Predictive Maintenance: A Review. CIRP Journal of Manufacturing Science and Technology 2023, 40, 53–67. [Google Scholar] [CrossRef]
- Singh, R.R.; Bhatti, G.; Kalel, D.; Vairavasundaram, I.; Alsaif, F. Building a Digital Twin-Powered Intelligent Predictive Maintenance System for Industrial AC Machines. Machines 2023, 11(8), 796. [Google Scholar] [CrossRef]
- Nguyen, K.T.; Medjaher, K.; Tran, D.T. A Review of Artificial Intelligence Methods for Engineering Prognostics and Health Management with Implementation Guidelines. Artificial Intelligence Review 2023, 56(4), 3659–3709. [Google Scholar] [CrossRef]
- De Fino, M.; Galantucci, R.A.; Fatiguso, F. Condition Assessment of Heritage Buildings via Photogrammetry: A Scoping Review from the Perspective of Decision Makers. Heritage 2023, 6(11), 7031–7066. [Google Scholar] [CrossRef]
- Abdullahi, I.; Longo, S.; Samie, M. Towards a Distributed Digital Twin Framework for Predictive Maintenance in Industrial Internet of Things (IIoT). Sensors 2024, 24(8), 2663. [Google Scholar] [CrossRef] [PubMed]
- Abualsauod, E.H. Machine Learning-Based Fault Detection Approach to Enhance Quality Control in Smart Manufacturing. Production Planning & Control 2023, 1–9. [Google Scholar]
- Azari, M.S.; Flammini, F.; Santini, S.; Caporuscio, M. A Systematic Literature Review on Transfer Learning for Predictive Maintenance in Industry 4.0. IEEE Access 2023, 11, 12887–12910. [Google Scholar] [CrossRef]
- Aljohani, A. Predictive Analytics and Machine Learning for Real-Time Supply Chain Risk Mitigation and Agility. Sustainability 2023, 15(20), 15088. [Google Scholar] [CrossRef]
- Wu, H.; Fu, W.; Ren, X.; Wang, H.; Wang, E. A Three-Step Framework for Multimodal Industrial Process Monitoring Based on DLAN, TSQTA, and FSBn. Processes 2023, 11(2), 318. [Google Scholar] [CrossRef]
- Borré, A.; Seman, L.O.; Camponogara, E.; Stefenon, S.F.; Mariani, V.C.; Coelho, L.D.S. Machine Fault Detection Using a Hybrid CNN-LSTM Attention-Based Model. Sensors 2023, 23(9), 4512. [Google Scholar] [CrossRef] [PubMed]
- Pacheco-Blazquez, R.; Garcia-Espinosa, J.; Di Capua, D.; Pastor Sanchez, A. A Digital Twin for Assessing the Remaining Useful Life of Offshore Wind Turbine Structures. Journal of Marine Science and Engineering 2024, 12(4), 573. [Google Scholar] [CrossRef]
- Silva, R.; Silva, B.; Fernandes, C.; Morouço, P.; Alves, N.; Veloso, A. A Review of 3D Scanners Studies for Producing Customised Orthoses. Sensors 2024, 24(5), 1373. [Google Scholar] [CrossRef] [PubMed]
- Pillai, R.S.; Denny, P.; O'Connell, E. Optimising Predictive and Prescriptive Maintenance Using Unified Namespace (UNS) for Industrial Equipment; 2024. [Google Scholar]
- Tiddens, W.; Braaksma, J.; Tinga, T. Decision Framework for Predictive Maintenance Method Selection. Applied Sciences 2023, 13(3), 2021. [Google Scholar] [CrossRef]
- Granero Molinedo, A. Automation of a Syringe Assembly Line Using the Magnemotion Transport System. Master's Thesis, Universitat Politècnica de Catalunya, 2023. [Google Scholar]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Analytical Chemistry 1964, 36(8), 1627–1639. [Google Scholar] [CrossRef]
- IEC 62541; OPC Unified Architecture. International Electrotechnical Commission (IEC): Geneva, Switzerland, 2015.
Figure 1.
Unified Namespace (UNS)–based data-flow architecture for real-time industrial monitoring, integrating IoT sensors, PLCs, and SCADA systems with digital-twin visualisation and predictive-maintenance workflows.
Figure 1.
Unified Namespace (UNS)–based data-flow architecture for real-time industrial monitoring, integrating IoT sensors, PLCs, and SCADA systems with digital-twin visualisation and predictive-maintenance workflows.
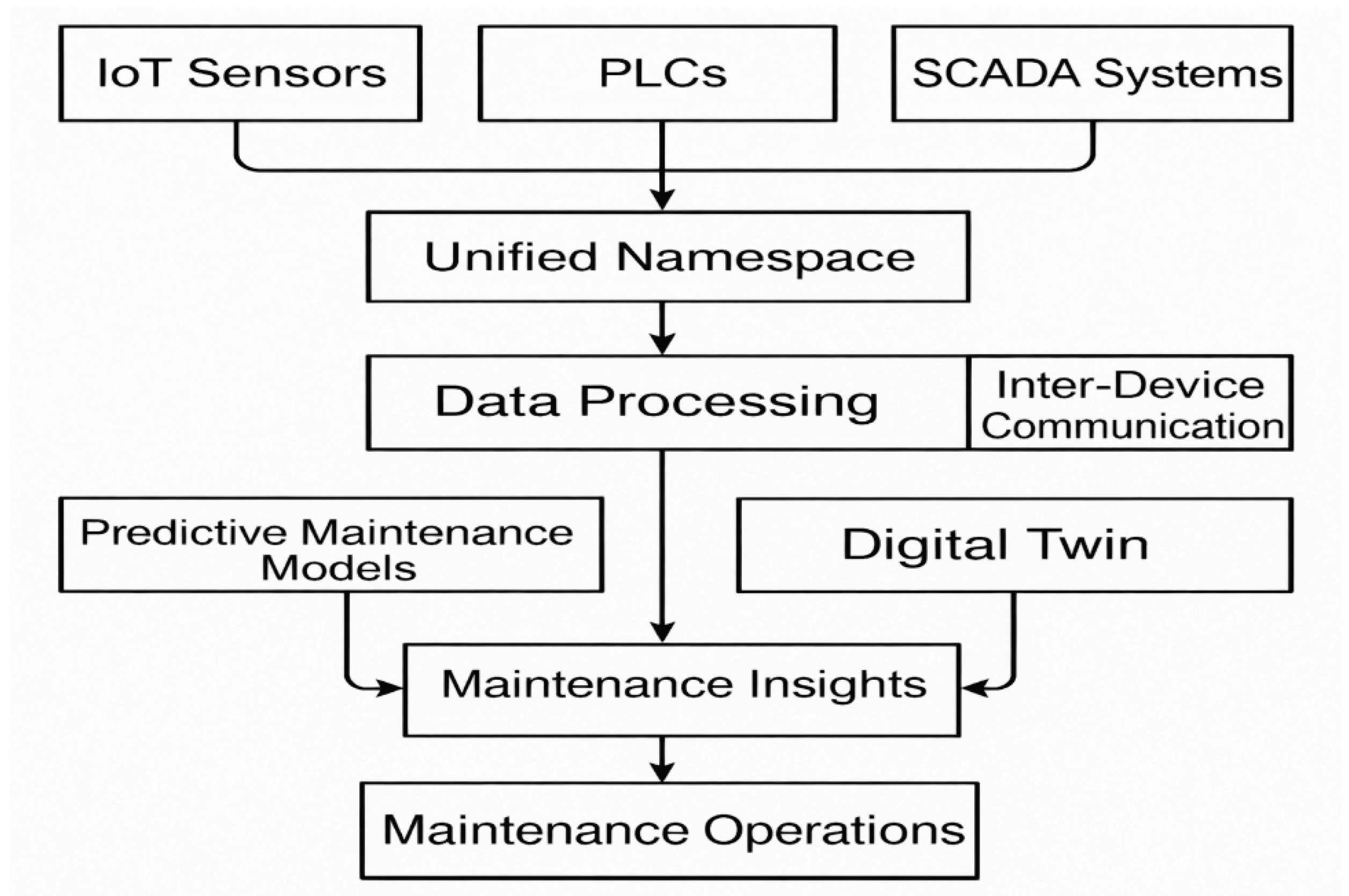
Table 2.
Machine Downtime Comparison Showing.
| Machine | Before UNS (hrs/month) | After UNS (hrs/month) | % Reduction in Downtime |
| Machine A | 25.0 | 14.5 | 42% |
| Machine B | 18.2 | 10.3 | 43% |
| Machine C | 21.7 | 12.8 | 41% |
| Machine D | 23.5 | 13.4 | 43% |
| Average | 22.1 | 12.8 | 42.25% |
Table 3.
Mean Time To Repair Comparison (/Incident).
| Machine | Before UNS (hrs) | After UNS (hrs) | % Reduction in MTTR |
| Machine A | 3.5 | 2.3 | 34% |
| Machine B | 4.2 | 2.5 | 40% |
| Machine C | 3.7 | 2.4 | 35% |
| Machine D | 4.0 | 2.6 | 35% |
| Average | 3.85 | 2.45 | 36% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



