Submitted:
25 January 2026
Posted:
05 February 2026
You are already at the latest version
Abstract
This study develops an adaptive optimal tracking control law using neural network (NN)-based reinforcement learning (RL) for high-order partially unknown nonlinear systems. By designing a cost function associated with the sliding mode surface (SMS), the original tracking control problem is equivalently transformed into solving the optimal control problem related to the tracking Hamilton-Jacobi-Bellman (HJB) equation. Since the analytical solution of the HJB equation is generally intractable, we employ a policy iteration algorithm derived from the HJB equation, where both the partial derivative of the optimal tracking cost function and the optimal control law are approximated by NNs. The proposed RL framework achieves simplification through actor-critic training laws derived under the condition that a simple function is zero. Finally, two simulative examples are provided to demonstrate the effectiveness and advantages of the proposed adaptive optimal tracking control method.
Keywords:
optimal tracking control
; reinforcement learning
; actor-critic architecture
; partially unknown nonlinear system
1. Introduction
In recent decades, optimal tracking control for nonlinear systems has remained one of the most significant research topics in control theory, with extensive applications in industrial manufacturing [1], aerospace [2], and robotics [3,4]. However, the majority of existing controller designs fail to incorporate formal optimization frameworks for performance cost functions, despite energy/time efficiency being critical in practical engineering. This study addresses this gap by developing an optimal tracking control law for partially unknown continuous-time nonlinear systems. Using an actor-critic reinforcement learning strategy derived from the HJB equation, the proposed method enables system states to achieve asymptotic tracking of desired reference trajectory with guaranteed convergence.
Nonlinear tracking control problems can be effectively addressed through nonlinear control techniques including feedback linearization[5,6], backstepping approach [7,8,9,10], and sliding mode control(SMC) [3,11,12,13], among others. Feedback linearization, a mature methodology in nonlinear control theory, transforms nonlinear systems into partially or fully linear equivalents through coordinated nonlinear state feedback and coordinate transformations (including dynamic compensation). This enables the application of established linear control design methods. Unlike feedback linearization, the backstepping approach provides an alternative framework for nonlinear systems unbounded by linear constraints. This methodology synthesizes feedback control laws through an iterative recursive procedure. Its principal advantage lies in preserving beneficial nonlinearities while guaranteeing asymptotic stability for regulation and tracking tasks. However, these methods are mainly applicable to strictly feedback nonlinear systems. To enhance transient response performance, SMC has garnered significant research attention. As a robust control strategy, SMC’s distinctive feature lies in its adaptive control structure switching based on state-dependent sliding surfaces. Its multiple variants have been developed, including terminal SMC [11], integral SMC [3,12], and hierarchical SMC [13]. Recent years have witnessed increasingly in-depth research on adaptive optimal control integrated with sliding mode surface (SMS). Zhang et al. addressed the problem of SMS-based adaptive optimal control for a class of switched continuous-time nonlinear systems with average dwell time by employing an actor-critic RL strategy [14]. Zhao et al. investigated the SMS-based approximate optimal control problem in the context of nonlinear multi-player Stackelberg-Nash games [15]. Furthermore, Zhang et al. studied the adaptive optimal control scheme based on a hierarchical SMS for a class of switched continuous-time nonlinear systems subject to unknown disturbances, utilizing an actor-critic NNs architecture [16]. However, all of these are aimed at the problem of optimal regulation.
Designing optimal control laws for nonlinear systems typically requires solving HJB equation. However, the inherent nonlinearity of HJB equation makes analytical solutions challenging to derive via conventional methods. To address this, RL algorithms have been integrated into the optimal control framework, enabling feasible solutions. As a machine learning paradigm, RL allows agents to learn optimal policies through environmental interactions [17,20]. This RL-based function approximation approach has successfully enabled adaptive optimal control, emerging as a prominent methodology for complex nonlinear control in recent decades.
Current research extensively explores optimal tracking for nonlinear systems using adaptive dynamic programming (ADP) [18,19]. This method combines dynamic programming (DP) and RL. Notably, Modares et al. proposed a novel integral RL formulation for continuous-time nonlinear systems [20]. This approach adapts methodologies originally developed for optimal regulation problems to address optimal tracking control. Recent advancements in RL-based tracking control have demonstrated significant progress across diverse nonlinear systems. Wen et al. developed an optimized tracking control framework employing neural network-based actor-critic reinforcement learning for a class of nonlinear dynamic systems [21]. Wang et al. subsequently proposed a novel actor-critic RL scheme to achieve optimal tracking control for unmanned surface vehicles, explicitly addressing complex unknowns including dead-zone input nonlinearities, uncertain system dynamics, and external disturbances [22]. Further innovations include fuzzy integral RL-based fault-tolerant control algorithm, which integrates RL techniques with fuzzy-augmented models to handle partially unknown systems with actuator faults [23]. Specialized applications have been demonstrated, including robust online tracking control for space manipulators and nearly optimal trajectory tracking of autonomous surface vehicles [24,25]. While the backstepping technique has been widely applied in optimal tracking control of strict-feedback nonlinear systems [26,27,28,29], the same problem for high-order canonical nonlinear systems remains largely unexplored.
Motivated by the above discussions, this paper addresses a class of canonical form high-order nonlinear system by proposing a novel adaptive optimal tracking control scheme. The main contributions are in three aspects. First, an adaptive optimal tracking control scheme is proposed via a SMS for high-order canonical nonlinear systems. By constructing a cost function specifically related to the SMS, the original control problem is equivalently transformed into one that seeks an optimal control strategy. The designed SMS constrains the states of the error dynamic system, thereby forcing the tracking error to converge to zero with predefined dynamics. Second, in most of the existing literature, such as [19,20,21,22], the requirement of persistent excitation is necessary for training the RL optimal control with adaptive parameters. The proposed optimization method can avoid this requirement. Third, an adaptive optimal tracking law is developed using an actor-critic NNs RL framework. Compared with the [30] method, our method achieves higher tracking accuracy and computational efficiency with fewer conditional constraint.
The rest of this paper is organized as follows: Section 2 describes the optimal tracking control problem of a class of canonical form high-order nonlinear system. In Section 3, we present a SMS-based adaptive optimal tracking control using actor-critic RL. Based on Lyapunov theory, it is proved that the error signals are semi-globally uniformly ultimately bounded (SGUUB), and the tracking error can be steered into a small neighborhood of zero in Section 4. Simulation are given to demonstrate the effectiveness of the proposed method in Section 5. Finally, the conclusion summarized in Section 6.
2. Problem Description
A canonical form nonlinear system with relative degree n is given by [31]
where is the system state vector, is the control input, is the unknown and bounded nonlinear dynamic function, and is the known control gain constant.
Assumption A1.
The system (1) is stabilizable, meaning there exists an admissible control policy that ensures global stability of the closed-loop system.
Assumption A2.
The reference trajectory and its i-th order derivatives are assumed to be bounded.
Definition 1
([32]). For a nonlinear system , the solution is called SGUUB if for any initial state , where Ω is a compact set, there exist constants and such that for all .
The control objective of this paper is to design an optimized tracking controller for partially unknown nonlinear dynamic system (1) using a NN-based actor-critic RL strategy. The proposed control law not only ensures all closed-loop error signals are SGUUB, but also guarantees that the output state and its derivative signals rapidly track the reference trajectory and its corresponding derivatives, respectively.
3. Optimal Tracking Control Design
3.1. Tracking HJB Equation
The tracking errors are defined as . Based on the dynamic model (1) and the above tracking error definitions, the error dynamical system is derived as follows:
where , and .
Based on the tracking errors, the SMS [33] is constructed as
where , , and are design parameters.
Taking the time derivative of along the error dynamical system (2) yields
where .
The design parameters are chosen such that the polynomial is Hurwitz, i.e., all its roots lie in the open left-half plane. Note that when the tracking errors are constrained to the SMS , they will converge to a small neighborhood of zero.
Define an infinite-horizon cost function with respect to the SMS s as follow
where denotes the utility function.
Definition 2.
The optimal control objective for the error dynamical system (2) is to find an admissible control law that minimizes the cost function (5) over an infinite horizon, thus achieving the desired control task. Accordingly, the optimal cost function is defined as
where and denote the optimal cost function and optimal control law, respectively, and represents the set of admissible controls over the domain .
By calculating the time derivative of the cost function (6) along the sliding mode dynamic (4) and applying the optimality condition, the following HJB equation is derived:
where denotes the partial derivative of with respect to s.
Assuming the solution of (7) exists and is unique, the optimal control can be obtained by applying the stationarity condition as
The partial derivative can be obtained by solving the HJB equation (9). The optimal control protocol can then be derived by combining the result with (8). However, solving (9) analytically is difficult due to the inherent system nonlinearity. Furthermore, the lack of complete knowledge about the system dynamics further complicates the solution of (9). To overcome these challenges, this paper employs a reinforcement learning method with an actor-critic architecture.
3.2. NNs Approximation in Actor-Critic RL
To achieve the optimal tracking control, the term in (9) is decomposed as
where is the designed parameter and is the unknown function in this dual architecture.
Remark 1.
In (10), the terms and are designed to ensure the boundedness and stability of the system signals.
According to the Weierstrass approximation theorem [34], the continuous function can be approximated by weighted sum of basis functions. Given the relationship between s and , the approximation takes the form as
where is the ideal weight vector and bounded by a positive constant such that . Moreover, and are, respectively, activation function vector and the approximation error. With the number of neurons in the hidden layer , the NN approximation error .
Putting (11) into (10) yields
since the ideal weight vector is unknown, (12) is approximated by critic NN as
where denotes the current estimate of . The weight estimation error is then defined as .
According to (8) and (13), the optimal control to the system is approximated by an additional actor NN as
where is the current estimate of . The actor NN weight estimation error is defined as .
The critic and actor adaptive training laws are designed as
where and are the learning rates for the critic and actor networks, respectively. Here, is a regularization parameter, and denotes the identity matrix.
The Bellman residual error E is introduced, with its expression as
According to the previous analysis and the optimal control theory, the approximate optimized control should ensure . If the condition is met and has a unique solution, it is equivalent to
To make (19) hold, construct the following function such that
Obviously, ensures that (19) holds. When the weight vectors of both networks are trained to satisfy , equations (13) and (14) fulfill the relation (8), and the control action approaches the optimal solution.
Theorem 1.
Proof.
The partial derivatives of with respect to the weight estimates are
The time derivative of along the trajectories of the system is
Noting that , the expression in (23) can be rewritten as a function of itself. Since the matrix is positive definite, it follows that
where is the minimum eigenvalue of the positive definite matrix .
This inequality, , implies that converges to zero exponentially. □
Remark 2.
Remark 3.
As demonstrated in this subsection, the proposed RL approach not only features a simple structure but also eliminates the need for explicit knowledge of the system dynamic when solving the optimal control problem.
4. Main Results
Lemma 1
([35]). is a positive continuous function and has the bounded initial value . If the inequality holds, where and are constants, then
Theorem 2.
Consider the partially unknown nonlinear system (1) under Assumptions 1 and 2, with a bounded initial state. The optimal control law is derived from the actor-critic RL framework, where the critic and actor are updated according to (13) and (14), using the learning rules given in (15) and (16), respectively. If the parameters satisfy , and , then all estimation errors are SGUUB. Moreover, the tracking errors converge to an arbitrarily small neighborhood of zero.
Proof.
Choose the Lyapunov candidate function as
It follows from and that
and
From Cauchy-Schwartz and Young’s inequalities, we obtain
Under these inequalities, (30) reduces to
From the definition , the following equation can be derived
Moreover, the following inequality can be derived according to Young’s inequality,
According to the above equation (33) and inequality (34), the following inequality can be derived from (32)
This inequality (35) can be simplified to
where can be bounded by a constant , i.e., .
Let , then (36) can be rewritten as
Applying Lemma 1, we rigorously obtain the following inequality:
The above inequality implies that the signals , , and are SGUUB. Moreover, by selecting the design parameters to make sufficiently large, the tracking errors can be made to converge to an arbitrarily small neighborhood of zero. This completes the proof. □
5. Simulation Experiment
In this section, the effectiveness and advantages of the proposed adaptive optimal tracking control method are demonstrated through two simulation examples.
Example 1: Consider a second-order nonlinear dynamic model as presented in [30]:
where and are the system states, u is the control input, and is the control gain, with initial conditions and .
Based on the reference trajectory , the tracking errors can be obtained
The error dynamics derived in (39) are
Following from (3), the SMS is designed as
The critic and actor network weight vectors are defined as and , respectively. The activation function vector is given by . The learning rates and regularization parameters for the training laws of both the critic and actor (15) and (16) are set to , , and . The weight vectors are initialized to and .
The simulation results are presented in Figure 1–fg4. Specifically, Figure 1 shows that the states and closely follow the reference trajectories and its derivative , respectively. The corresponding tracking errors and , shown in Figure 2, converge to zero. Furthermore, the neural network weights for the actor and critic remain bounded, as illustrated in Figure 3. Finally, the evolution of the utility function is depicted in Figure 4. Compared with the simulation results in [30], the method proposed in this paper achieves superior tracking performance.
Remark 4.
The purpose of presenting Example 1 is to compare the performance of our proposed algorithm with that of Algorithm in [30]. To further verify its adaptability, we select a higher-order problem as Example 2.
Example 2: This example considers a third-order system. The system dynamics are described as follows:
The control gain is , and the initial states are , , .
Given the reference trajectory , the tracking errors can be calculated
The error dynamics derived in (43) are
Based on (3), the SMS is designed as
The activation function vector is given by . The weight vectors are initialized to and . The parameters are set to , , , and .
The simulation results of Example 2 are presented in Figure 5, Figure 6, Figure 7 and Figure 8. As shown in Figure 5, the states , and closely follow the reference trajectories and its first- and second-order derivatives and , respectively. The corresponding tracking errors , , and depicted in Figure 6, converge to a small neighborhood of zero. Furthermore, Figure 7 demonstrates that the neural network weights for both the actor and critic remain bounded. Finally, the evolution of the utility function is shown in Figure 8. These results demonstrate that the proposed high-order tracking control scheme for canonical nonlinear systems maintains the boundedness of the error signal while ensuring accurate tracking of each system state to its corresponding reference signal.
6. Conclusions
This paper proposes a SMS-based adaptive optimal tracking control scheme, utilizing an NN-based RL approach, for a class of high-order nonlinear systems with partial unknowns. A cost function defined in terms of the SMS is constructed to derive the optimal control law. Accordingly, the HJB equation is addressed within an actor-critic NN framework. Leveraging the inherent relationship between the SMS and the tracking errors significantly simplifies the computational process. Under the premise of ensuring the stability of the closed-loop system, the update law of the actor-critic network is indirectly derived under the condition that a simple function is zero, without the need for persistence excitation condition. Furthermore, the proposed design requires no prior knowledge of the internal system dynamics. Meanwhile, the proposed method offers a significant advantage over [30] by eliminating the need for a Riccati-like equation. Comparative simulation results demonstrate the superior tracking performance of the proposed scheme over existing methods. Finally, future work will extend this framework to tackle the inverse optimal tracking problem, addressing the challenge of manual cost function specification.
Author Contributions
D.X.: investigation, methodology, writing-review; X.L.: investigation, software; F.L.: formal analysis; J.T.: conceptualization, writing-original draft preparation; All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China under Grant No. 61463002 and the Doctoral Foundation of Guangxi University of Science and Technology Grant No. Xiaokebo 22Z04.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are already in the article. For further consultation, please contact the corresponding author.
Acknowledgments
The authors thank the journal editors and reviewers for their valuable suggestions and opinions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, P; Duan, G; Zhang, B; et al. High-Order Fully Actuated Approach for Output Tracking Control of Flexible Servo Systems Subject to Uncertainties and Disturbances[J]. IEEE Transactions on Industrial Electronics, 2025. [Google Scholar]
- Bu, X; Qi, Q. Fuzzy optimal tracking control of hypersonic flight vehicles via single-network adaptive critic design[J]. IEEE Transactions on Fuzzy Systems 2020, 30(1), 270–278. [Google Scholar] [CrossRef]
- Lee, J; Chang, P H; Jin, M. Adaptive integral sliding mode control with time-delay estimation for robot manipulators[J]. IEEE Transactions on Industrial Electronics 2017, 64(8), 6796–6804. [Google Scholar] [CrossRef]
- Wang, C; Liu, Z; Sun, S; et al. Trajectory tracking of a mobile robot in underground roadways based on hierarchical model predictive control. Actuators 2026, 15(1), 47. [Google Scholar] [CrossRef]
- Voos, H. Nonlinear control of a quadrotor micro-UAV using feedback-linearization[C]//2009 IEEE International Conference on Mechatronics; IEEE, 2009; pp. 1–6. [Google Scholar]
- Bonna, R; Camino, J F. Trajectory tracking control of a quadrotor using feedback linearization[C]//International Symposium on Dynamic Problems of Mechanics; University of Campinas: Sao Paulo, Brazil, 2015; 9, p. 1. [Google Scholar]
- Yousefizadeh, S; Bendtsen, J D; Vafamand, N; et al. Tracking control for a DC microgrid feeding uncertain loads in more electric aircraft: Adaptive backstepping approach[J]. IEEE Transactions on Industrial Electronics 2018, 66(7), 5644–5652. [Google Scholar] [CrossRef]
- Zhao, K; Song, Y. Removing the feasibility conditions imposed on tracking control designs for state-constrained strict-feedback systems[J]. IEEE Transactions on Automatic Control 2018, 64(3), 1265–1272. [Google Scholar] [CrossRef]
- Yu, J; Ma, Y; Yu, H; et al. Adaptive fuzzy dynamic surface control for induction motors with iron losses in electric vehicle drive systems via backstepping[J]. Information Sciences 2017, 376, 172–189. [Google Scholar] [CrossRef]
- Song, Y D; Zhou, S. Tracking control of uncertain nonlinear systems with deferred asymmetric time-varying full state constraints[J]. Automatica 2018, 98, 314–322. [Google Scholar] [CrossRef]
- Wang, Y; Gu, L; Xu, Y; et al. Practical tracking control of robot manipulators with continuous fractional-order nonsingular terminal sliding mode[J]. IEEE Transactions on industrial electronics 2016, 63(10), 6194–6204. [Google Scholar] [CrossRef]
- Qiao, L; Zhang, W. Adaptive non-singular integral terminal sliding mode tracking control for autonomous underwater vehicles[J]. IET Control Theory & Applications 2017, 11(8), 1293–1306. [Google Scholar]
- Hwang, C L; Chiang, C C; Yeh, Y W. Adaptive fuzzy hierarchical sliding-mode control for the trajectory tracking of uncertain underactuated nonlinear dynamic systems[J]. IEEE Transactions on Fuzzy Systems 2013, 22(2), 286–299. [Google Scholar] [CrossRef]
- Zhang, H; Wang, H; Niu, B; et al. Sliding-mode surface-based adaptive actor-critic optimal control for switched nonlinear systems with average dwell time[J]. Information Sciences 2021, 580, 756–774. [Google Scholar] [CrossRef]
- Zhao, H; Zhao, N; Zong, G; et al. Sliding-mode surface-based approximate optimal control for nonlinear multiplayer Stackelberg-Nash games via adaptive dynamic programming[J]. Communications in Nonlinear Science and Numerical Simulation 2024, 132, 107928. [Google Scholar] [CrossRef]
- Zhang, H; Zhao, X; Wang, H; et al. Hierarchical sliding-mode surface-based adaptive actor–critic optimal control for switched nonlinear systems with unknown perturbation[J]. IEEE Transactions on Neural Networks and Learning Systems 2022, 35(2), 1559–1571. [Google Scholar] [CrossRef]
- Huang, J; Xu, D; Li, Y; et al. Inverse reinforcement learning for discrete-time linear systems based on inverse optimal control[J]. ISA transactions 2025, 163, 108–119. [Google Scholar] [CrossRef] [PubMed]
- Xu, D; Wang, Q; Li, Y. Optimal guaranteed cost tracking of uncertain nonlinear systems using adaptive dynamic programming with concurrent learning[J]. International Journal of Control, Automation and Systems 2020, 18(5), 1116–1127. [Google Scholar] [CrossRef]
- Na, J; Lv, Y; Zhang, K; et al. Adaptive identifier-critic-based optimal tracking control for nonlinear systems with experimental validation[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems 2020, 52(1), 459–472. [Google Scholar] [CrossRef]
- Modares, H; Lewis, F L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning[J]. Automatica 2014, 50(7), 1780–1792. [Google Scholar] [CrossRef]
- Wen, G; Chen, C L P; Ge, S S; et al. Optimized adaptive nonlinear tracking control using actor–critic reinforcement learning strategy[J]. IEEE transactions on industrial informatics 2019, 15(9), 4969–4977. [Google Scholar] [CrossRef]
- Wang, N; Gao, Y; Zhao, H; et al. Reinforcement learning-based optimal tracking control of an unknown unmanned surface vehicle[J]. IEEE Transactions on Neural Networks and Learning Systems 2020, 32(7), 3034–3045. [Google Scholar] [CrossRef]
- Zhang, H; Zhang, K; Cai, Y; et al. Adaptive fuzzy fault-tolerant tracking control for partially unknown systems with actuator faults via integral reinforcement learning method[J]. IEEE Transactions on Fuzzy Systems 2019, 27(10), 1986–1998. [Google Scholar] [CrossRef]
- Zhuang, H; Zhou, H; Shen, Q; et al. Optimal robust online tracking control for space manipulator in task space using off-policy reinforcement learning[J]. Aerospace Science and Technology 2024, 153, 109446. [Google Scholar] [CrossRef]
- Wu, T; Zhang, Y; Yang, X; et al. Predefined-time nearly optimal trajectory tracking control for autonomous surface vehicles with unknown dynamics[J]. Ocean Engineering 2025, 327, 121021. [Google Scholar] [CrossRef]
- Wen, G; Ge, S S; Tu, F. Optimized backstepping for tracking control of strict-feedback systems[J]. IEEE transactions on neural networks and learning systems 2018, 29(8), 3850–3862. [Google Scholar] [CrossRef]
- Liu, Y; Zhu, Q; Wen, G. Adaptive tracking control for perturbed strict-feedback nonlinear systems based on optimized backstepping technique[J]. IEEE Transactions on Neural Networks and Learning Systems 2020, 33(2), 853–865. [Google Scholar] [CrossRef]
- Huang, Z; Bai, W; Li, T; et al. Adaptive reinforcement learning optimal tracking control for strict-feedback nonlinear systems with prescribed performance[J]. Information Sciences 2023, 621, 407–423. [Google Scholar] [CrossRef]
- Yuan, H; Cao, L; Lin, W; et al. Learning-observer-based fixed-time optimal tracking control for robotic manipulators with full-state constraints[J]. Neurocomputing 2025, 130186. [Google Scholar] [CrossRef]
- Wen, G; Niu, B. Optimized tracking control based on reinforcement learning for a class of high-order unknown nonlinear dynamic systems[J]. Information Sciences 2022, 606, 368–379. [Google Scholar] [CrossRef]
- Song, Y; Wang, Y; Holloway, J; et al. Time-varying feedback for regulation of normal-form nonlinear systems in prescribed finite time[J]. Automatica 2017, 83, 243–251. [Google Scholar] [CrossRef]
- Zhu, J; Wen, G; Veluvolu, K C. Optimized backstepping consensus control using adaptive observer-critic–actor reinforcement learning for strict-feedback multi-agent systems[J]. Journal of the Franklin Institute 2024, 361(6), 106693. [Google Scholar] [CrossRef]
- Hušek, P. Adaptive sliding mode control with moving sliding surface[J]. Applied Soft Computing 2016, 42, 178–183. [Google Scholar] [CrossRef]
- Dao, P N; Phung, M H. Nonlinear robust integral based actor–critic reinforcement learning control for a perturbed three-wheeled mobile robot with mecanum wheels[J]. Computers and Electrical Engineering 2025, 121, 109870. [Google Scholar] [CrossRef]
- Lin, J; Wang, M; Yan, H; et al. Prescribed-Time Optimal Tracking Control for a Class of Stochastic Systems Using Reinforcement Learning[J]. Journal of the Franklin Institute 2025, 107881. [Google Scholar] [CrossRef]
Figure 1.
The tracking performances.
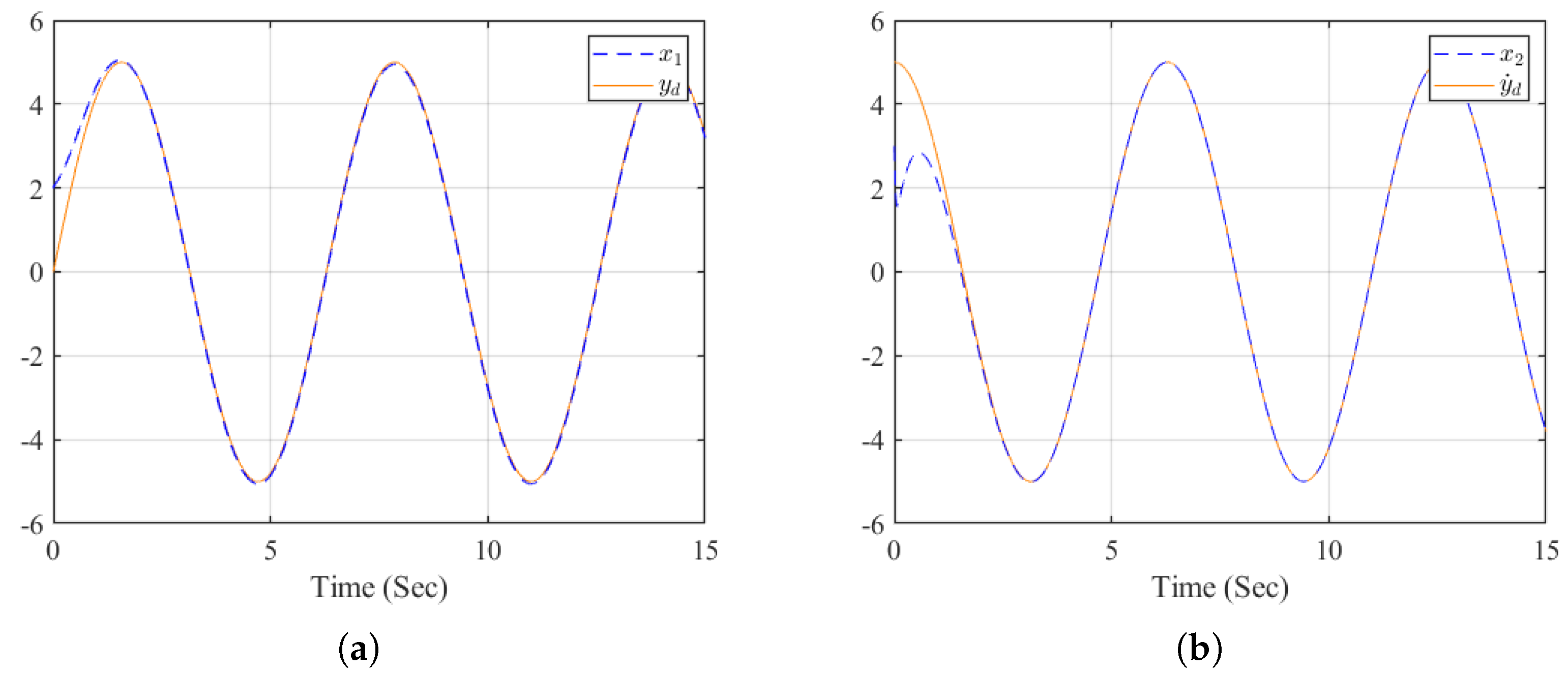
Figure 2.
The tracking errors.
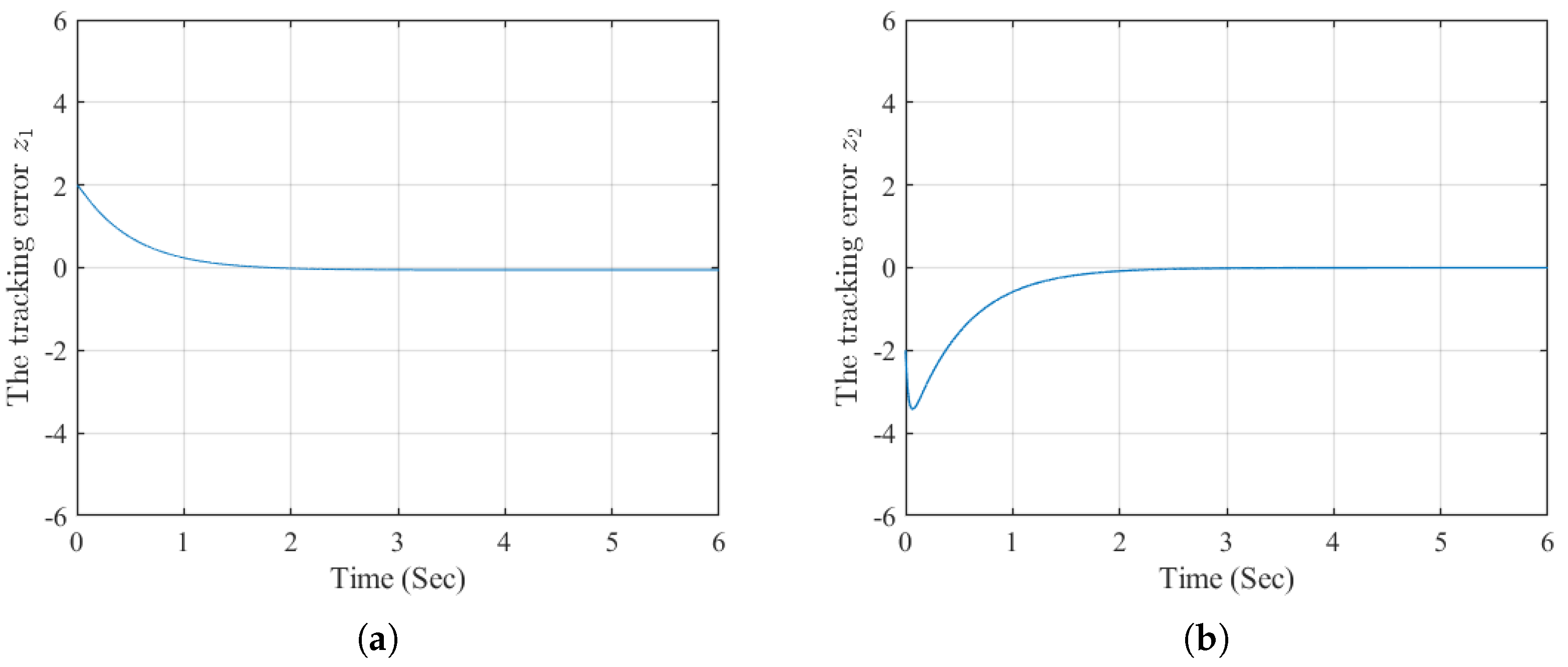
Figure 3.
The actor and critic network weights.
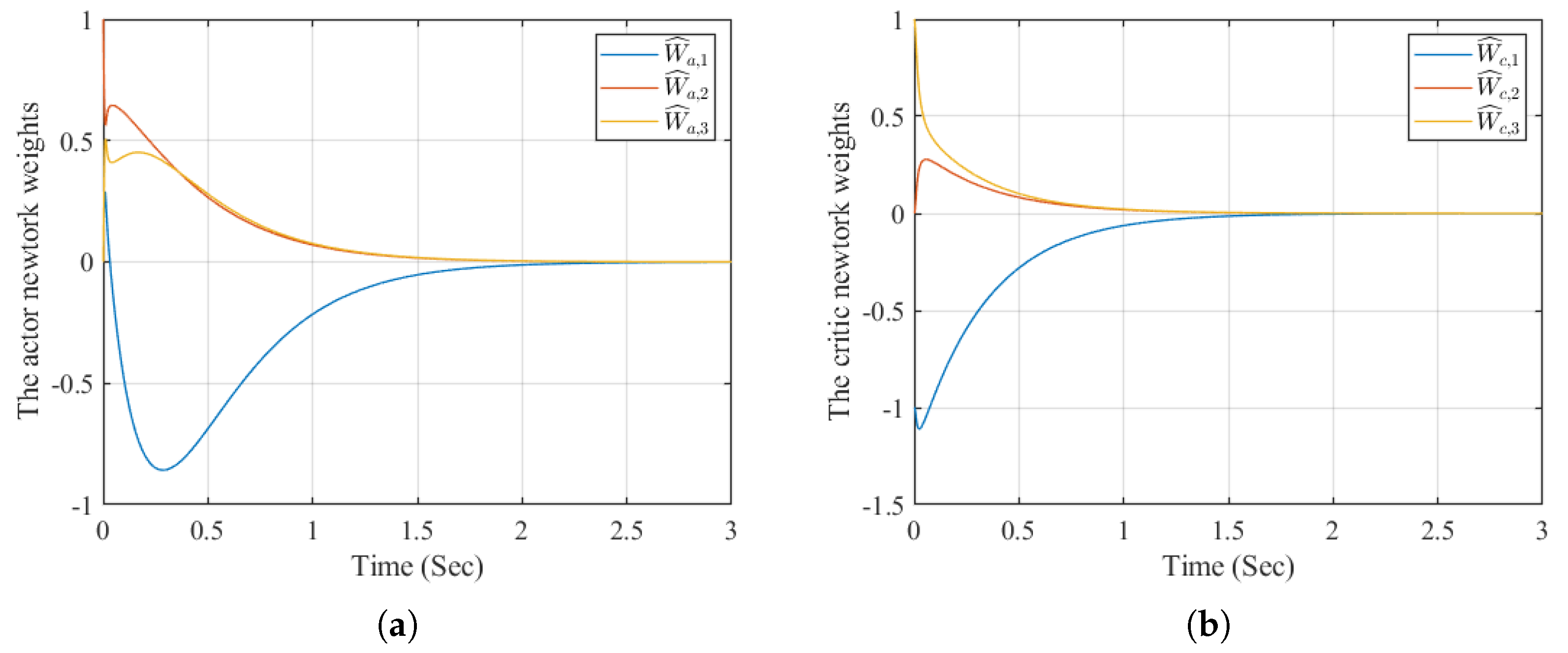
Figure 4.
The utility function.
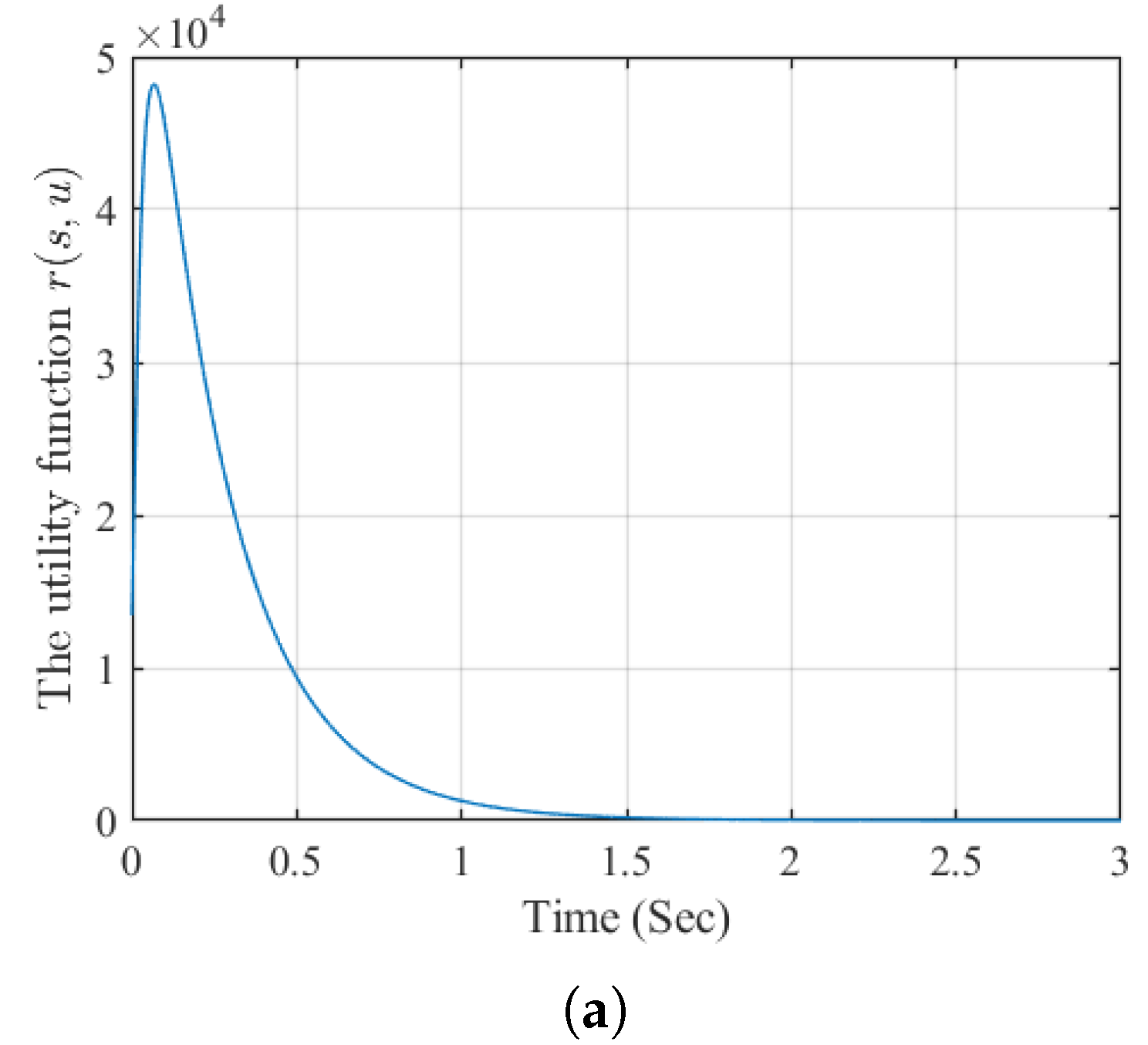
Figure 5.
The tracking performances.
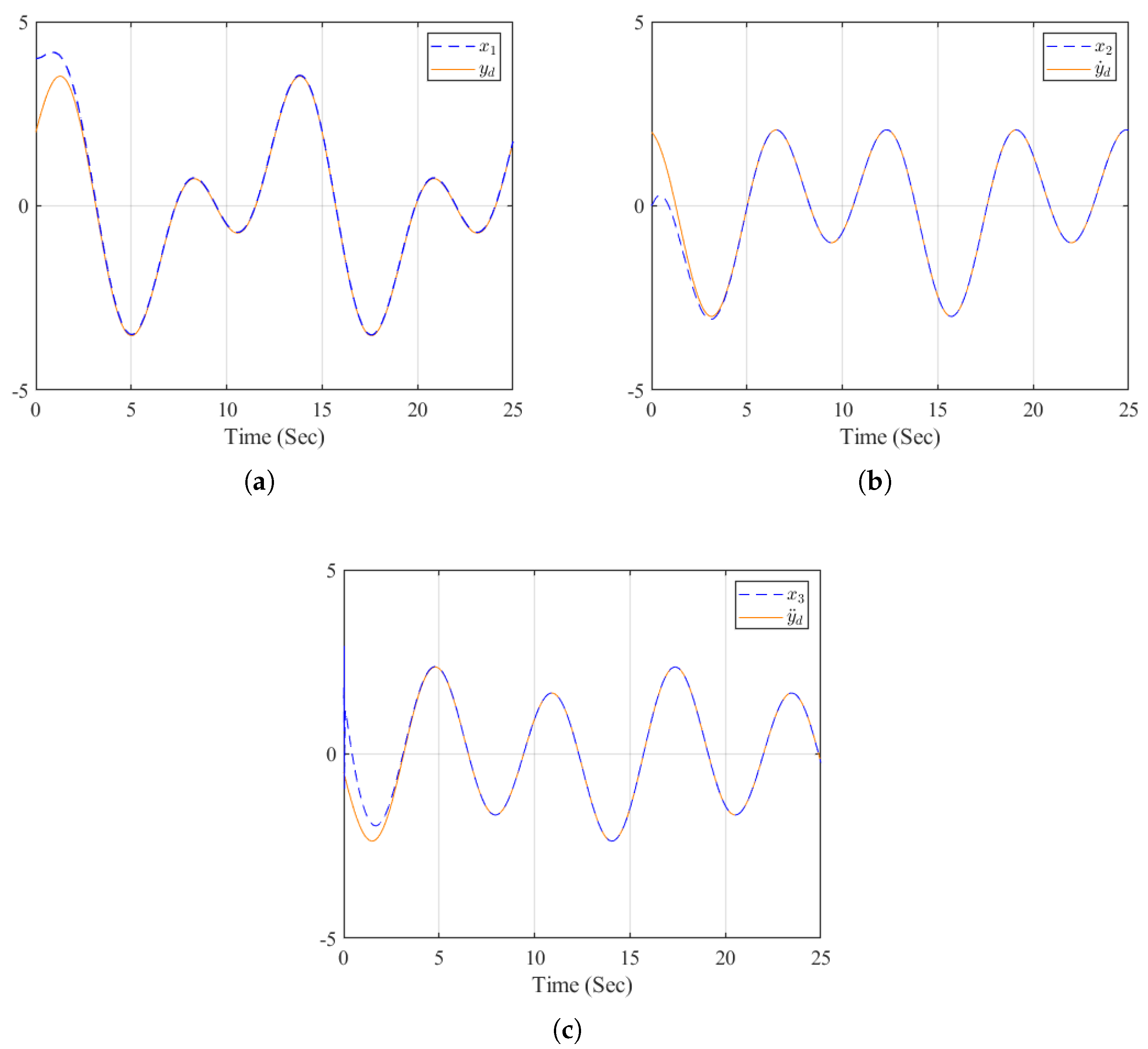
Figure 6.
The tracking errors.
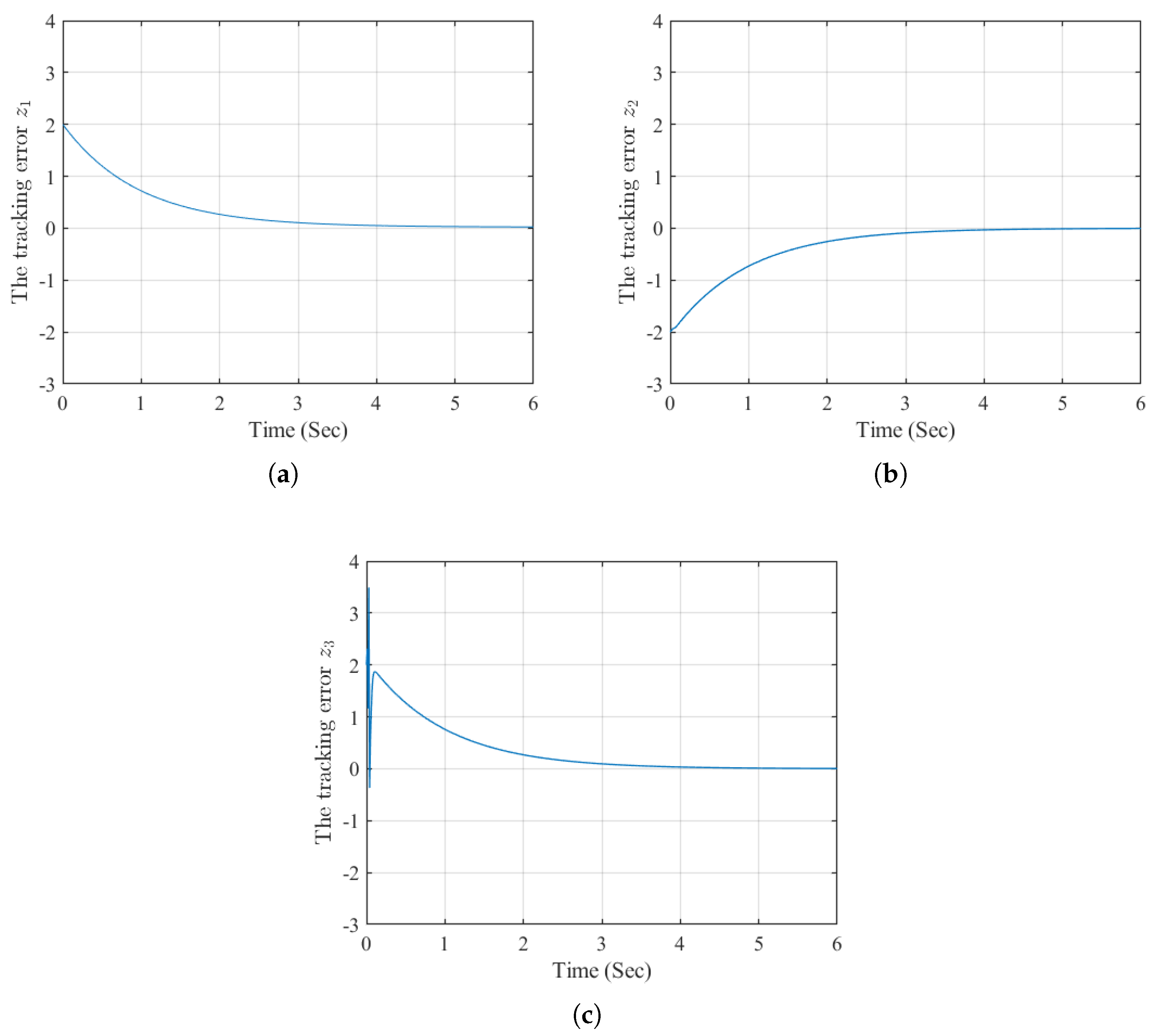
Figure 7.
The actor and critic network weights.
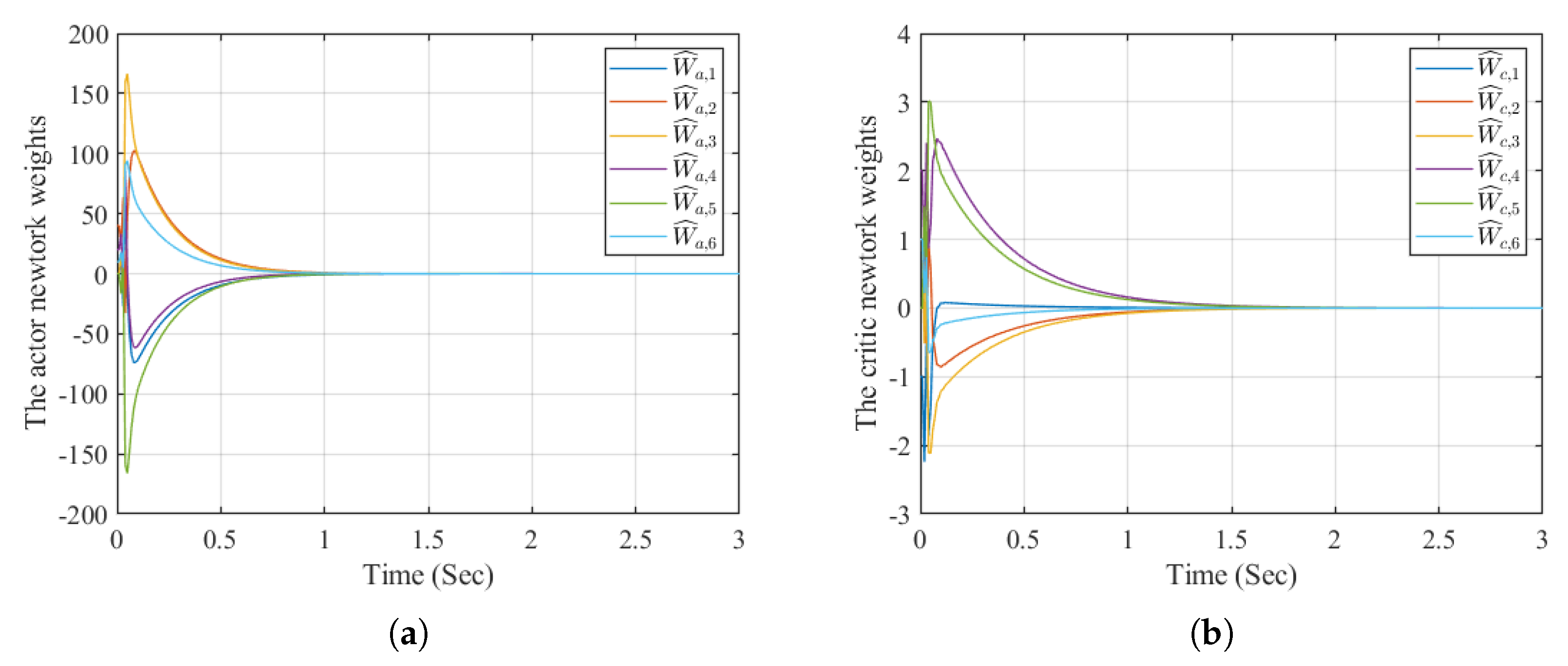
Figure 8.
The utility function.
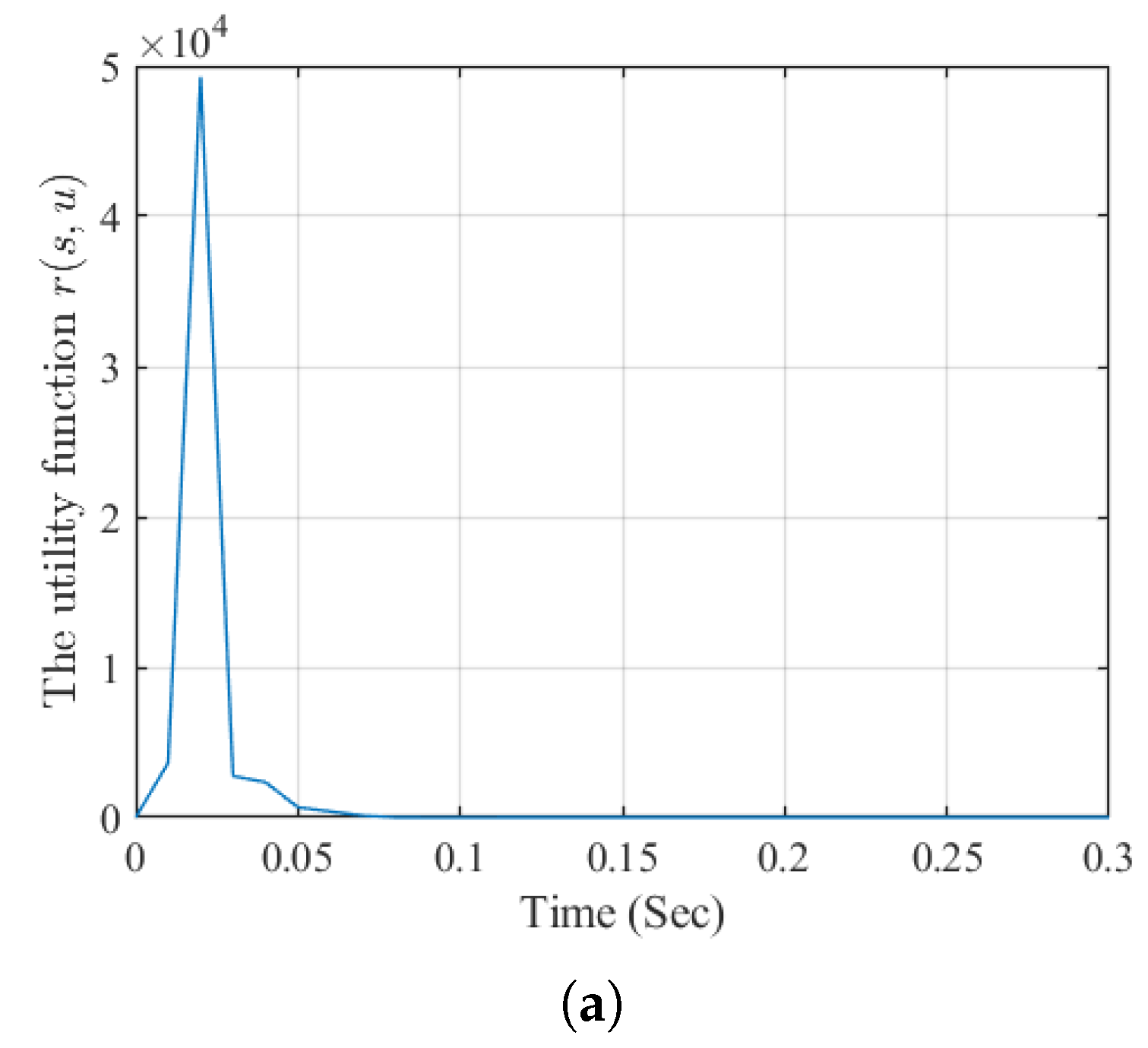
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



