
Submitted:
03 February 2026
Posted:
04 February 2026
You are already at the latest version
Abstract
To address the prevalent domain inadaptation issue in multi-source domain transfer fault diagnosis, this study proposes a novel model integrating graph embedding technology and adaptive classifiers. The framework combines multi-statistic multi-scale permutation entropy methods to simultaneously optimize projection and classifier performance, thereby enhancing generalization capabilities and diagnostic accuracy. During model construction, a weighted non-parametric maximum mean difference approach is employed to quantify and minimize differences in edge distributions and conditional distributions between source and target domains. Through similarity weight allocation, norm adjustment, and row sparsity learning strategies, the model effectively reduces interference from irrelevant samples. Additionally, by embedding category information and domain manifold structures, the model ensures classification validity of mapped features. Using labeled source domain data and unlabeled target domain data, the study develops a structure-aware adaptive classifier that narrows distribution differences while preserving manifold consistency, significantly improving diagnostic performance under variable operating conditions. Experimental results demonstrate that this multi-source domain transfer model achieves higher accuracy than single-domain approaches. Notably, in rotating machinery variable operating scenarios, the proposed method outperforms existing techniques in both precision and generalization capabilities.
Keywords:
multi-source domain transfer
; fault diagnosis
; graph embedding
; adaptive classifier
; domain distribution difference
1. Introduction
As the core equipment in industrial production, rotating machinery finds extensive application across diverse industries. Its operational state directly influences production efficiency and safety [1]. The accurate and timely diagnosis of rotating machinery faults is of great significance for minimizing downtime and reducing accident risks [2]. Nevertheless, with the increasing complexity of mechanical structures and the ever-changing operating conditions, traditional fault diagnosis methods face numerous challenges in practical applications [3]. Especially under conditions of data scarcity and domain inadaptability, the diagnostic accuracy and generalization ability of traditional methods decline significantly [4]. In complex real-world scenarios, fault diagnosis models trained under specific conditions often cannot be directly applied to other environments due to changes in working conditions, operational parameters, or equipment aging. This phenomenon is referred to as domain inadaptability [5]. For example, the characteristics of vibration signals of rotating machinery change significantly under different rotational speeds and load conditions, making diagnostic models trained under single conditions ineffective [6]. To tackle this problem, transfer learning techniques have been increasingly employed in fault diagnosis research [7]. Among them, multi-source domain transfer fault diagnosis has become a research focus [8]. This approach aims to integrate knowledge from multiple distinct yet related source domains to improve the fault diagnosis capabilities in the target domain [9]. The core challenge lies in effectively merging multi-source domain information, overcoming inter-domain distribution differences, and realizing efficient knowledge transfer [10].
In recent years, the swift advancement of Industry 4.0 and intelligent manufacturing has imposed more stringent requirements on the accuracy and real-time performance of fault diagnosis in rotating machinery [11,12,13]. Conventional fault diagnosis approaches are highly reliant on labeled data. Nevertheless, acquiring an adequate amount of high-quality labeled data proves to be extremely arduous when confronted with new operating conditions or equipment types [14,15,16]. The multi-source domain transfer fault diagnosis approach presents a novel solution by exploiting knowledge from multiple source domains to tackle data scarcity and domain incompatibility in target domains [17,18,19]. This research puts forward a multi-source domain transfer fault diagnosis model founded on graph embedding technology and adaptive classifiers. The model quantifies and minimizes the distribution disparities between source and target domains via graph embedding while maintaining the inherent manifold structure of the data, thereby enhancing its adaptability to complex operating conditions. Moreover, adaptive classifiers are incorporated to enhance diagnostic accuracy and generalization abilities under variable operating conditions. This model satisfies the requirements of intelligent and automated diagnostic technologies in the Industry 4.0 era, providing a new research perspective for fault diagnosis in complex industrial environments. Its remarkable performance in resolving domain incompatibility issues validates the substantial potential of transfer learning in fault diagnosis. With the continuous progress of technology and the expansion of application fields, multi-source domain transfer fault diagnosis methods are anticipated to play an increasingly crucial role in future industrial fault diagnosis.
The organizational framework of this study is delineated as follows. Section 2 conducts a comprehensive review of previous research. Section 3 elaborates on the proposed multi-source domain transfer fault diagnosis approach founded on graph embedding and adaptive classifiers. Section 4 introduces the experimental datasets and undertakes an analysis of the results. Section 5 summarizes the study and delineates future research orientations.
2. Related Work
The advent of multi-source domain transfer fault diagnosis technology is rooted in the need to surmount the limitations of traditional single-source domain transfer methods. Although early single-source approaches were capable of leveraging knowledge from a single source domain to facilitate target domain diagnostics, they were susceptible to negative transfer phenomena. This occurred when there were substantial disparities between the source and target domains or when the source domain contained noisy data, which severely undermined diagnostic performance. Pan et al., in their review on transfer learning, explicitly pointed out that industrial applications encounter difficulties in fulfilling single-source domain assumptions because of the complex data distributions across multiple operating conditions and equipment. Multi-source domain transfer learning substantially mitigates the potential risks induced by single-source domain biases through the integration of information from multiple related source domains [20]. For example, in the fault diagnosis of wind power equipment, the data collected from different wind farm environments form distinct source domains. Single-source domain transfer methods find it arduous to comprehensively encompass the characteristics of various operating conditions, while multi-source domain transfer technology capitalizes on the advantages of integrated wind farm data to improve the reliability of fault diagnosis [21].
In the realm of multi-source domain weight allocation mechanisms, scholars have put forward diverse adaptive fusion strategies. Chen et al. established a specialized open-set domain adaptation network leveraging multi-source domain data under varying operational conditions, thereby mitigating the “domain disparity” between the source and target domains. By incorporating a weight learning mechanism, they autonomously regulated the significance of “known classes” (fault categories common to both the source and target domains) and “unknown classes” (fault categories unique to the target domain) during feature distribution alignment, averting over-alignment of known classes that could potentially overlook the recognition of unknown classes [22]. Tian et al. proposed a dynamic similarity-guided multi-source domain adaptation network model. This model computes the similarity between source and target domain data based on features extracted from shared weight networks, dynamically adjusting the contribution of different source domain data to minimize distribution discrepancies [23]. Han et al. developed a progressive multi-stage alignment approach for multi-source domain adaptive fault diagnosis. The network integrates shared feature extractors, multiple domain-specific feature extractors, domain discriminators, and classifiers, adopting a multi-stage distribution adaptation strategy [24]. Li et al. presented a novel multi-source domain adaptive bearing fault diagnosis framework founded on adversarial networks and feature enhancement. This method diminishes feature distribution differences between the target and source domains via domain adversarial training, transferring fault diagnosis knowledge acquired from multiple labeled source domains to a single unlabeled target domain [25]. Other research endeavors employ deep subspace alignment techniques to map source and target domain data into shared subspaces, thus reducing distribution disparities [26]. In conventional methods, it is typically postulated that fault types in the target domain are entirely encompassed within the source domain. Nevertheless, in practical industrial applications, unknown faults are a frequent phenomenon. To tackle this problem, Yang et al. proposed an open-set multi-source domain diagnosis strategy based on multi-binary similarity screening. This strategy aims to filter source domain samples consistent with the target domain distribution while integrating an unknown fault detection module. In the application of wind turbine gearbox fault diagnosis, this method successfully achieved effective discrimination between known and unknown faults [27]. However, when confronted with a high proportion of unknown faults, the accuracy of this diagnostic method may display instability. To resolve this issue, Zhu et al. proposed a multi-antagonistic learning domain adaptation model for open-set cross-domain intelligent bearing fault diagnosis. The model acquires transferable features and target sample weights through adversarial learning: it introduces transfer weight conditions to adversarial networks to align joint feature-category distributions and obtain transferability indices; it utilizes recognizable prediction information from classifier outputs to further adjust and optimize the model; it achieves selective domain alignment through weighted adversarial learning networks while employing domain partitioning adversarial learning to precisely identify shared health states and unknown fault patterns [28].
Current research has made some headway in multi-source domain weight allocation and domain alignment techniques; however, several limitations still exist. Most existing approaches rely on static similarity calculations between source and target domains, rendering them inadequate for dealing with dynamic operational conditions. For example, in industrial production processes, equipment operating conditions change in real-time because of environmental factors, whereas static similarity calculation methods are unable to promptly adjust source domain weights and alignment strategies [29]. The conflict resolution mechanism among multi-source domains remains incomplete, making it vulnerable to interference from low-quality source domain data. Owing to the varying data quality across different source domains, some low-quality data may mislead diagnostic models, and existing methods lack effective mechanisms to identify and process such conflicting information [30]. The model developed in this study tackles these issues through a joint design of graph embedding and adaptive classifiers, with the aim of enhancing the accuracy and generalization ability of fault diagnosis for rotating machinery.
3. Theoretical Model of Multi-Source Domain Transfer Fault Diagnosis Based on Graph Embedding and Adaptive Classifiers
Based on a systematic review of the core challenges and research progress in multi-source domain transfer fault diagnosis, this section tackles the widespread problem of domain incompatibility in the cross-domain diagnosis of rotating machinery under variable operating conditions. We propose the Graph Embedding and Adaptive Classifier-based Multi-Source Domain Adaptation Fault Diagnosis Model (GE-AC-MSDA). This model realizes a substantial enhancement in cross-domain fault diagnosis performance through the synergistic design of four core modules, namely feature extraction, distribution alignment, manifold embedding, and classifier learning. Each module is closely integrated and complementary, accurately extracting feature representations that combine domain invariance and category discrimination from raw fault data. Subsequently, the adaptive classifier facilitates the precise identification of target-domain fault samples. The specific implementation mechanism and theoretical derivation are elaborated as follows.
3.1. Feature Extraction Module
Under diverse operating conditions, vibration signals associated with rotating machinery faults generally display non-stationary and nonlinear dynamic attributes. Traditional feature extraction methods that rely on single-scale or single-statistic techniques encounter difficulties in comprehensively capturing the inherent patterns of fault evolution. Consequently, these methods often yield inadequate discriminative capabilities and limited model generalization. To tackle this issue, our module utilizes the Multivariate Multiscale Permutation Entropy (MMPE) method for in-depth feature extraction. This enables a comprehensive and meticulous characterization of fault signals. The MMPE method was initially developed in our related study, which is currently under review (Shao et al., 2025, [Transactions of FAMENA]).
3.2. Distribution Alignment Module
The primary challenge in multi-source domain transfer fault diagnosis lies in the inter-domain distribution disparities. Owing to different operating conditions (such as rotational speed and load variations), distinct source domains and target domains display substantial deviations in feature distribution. This leads to a significant degradation of the performance of models trained on source domains when applied to target domains. To tackle this issue, this module presents the Weighted Multi-source Nonparametric Maximum Mean Discrepancy (WM-NMMD) method. This method quantifies and minimizes the distribution differences between multi-source and target domains, thereby enhancing the domain invariance of features.
Different from the Maximum Mean Discrepancy (MMD) method adopted in conventional single-source domain transfer, the WM-NMMD method first introduces a source domain similarity weight assignment mechanism to realize the differential measurement of the contribution degrees of different source domains. Let there be source domains and one target domain , where: denotes the feature matrix of the k-th source domain, denotes the number of samples in the -th source domain, and denotes the feature dimension; denotes the label matrix of the -th source domain, and denotes the number of fault categories; denotes the feature matrix of the target domain, and denotes the number of samples in the target domain. The cosine similarity is used to measure the distribution similarity between each source domain and the target domain, and the source domain weight assignment formulas are thus derived as shown in equations. (1) and (2).
where denotes the weight coefficient of the -th source domain (); represents the matrix cosine similarity function; denotes the matrix trace operation; and stands for the matrix Frobenius norm. The core advantage of this weight assignment mechanism lies in the fact that a source domain with a higher distribution similarity to the target domain is assigned a larger weight coefficient, thereby enhancing the information contribution of valid source domains. Conversely, a lower weight coefficient is assigned to the source domains with lower similarity, which weakens the interference of irrelevant source domains in model training and effectively avoids the negative transfer problem caused by the "equal treatment of all source domains" in conventional multi-source domain transfer.
On the basis of source domain weight assignment, the non-parametric MMD method is adopted to quantify the marginal distribution discrepancy between the weighted overall multi-source domains and the target domain. A projection matrix (where denotes the dimension of projected features) is defined, and the projected feature matrices of the source domain and the target domain are denoted as and , respectively. The derivation of the marginal distribution discrepancy between the weighted multi-source domains and the target domain is given in equation (3):
where represents the mapping function of the Reproducing Kernel Hilbert Space (RKHS); denotes the RKHS space; is the projected feature of the -th sample in the -th source domain; and stands for the projected feature of the -th sample in the target domain. Since it is difficult to directly calculate the distance in the RKHS space, the kernel trick is utilized to transform equation (3) into a computable kernel matrix form, as shown in equation (4):
where , and denote the inter-source-domain, intra-target-domain and source-target-domain kernel matrices, respectively; the Gaussian kernel is adopted as the kernel function (where is the kernel width parameter).
Aligning the marginal distribution alone is insufficient to completely eliminate the inter-domain discrepancy, and it is therefore necessary to further consider the conditional distribution discrepancy at the category level. Category prior information is introduced to quantify the conditional distribution discrepancy between each source domain and the target domain for the same fault category. Let the source domain sample set of the A-th fault category be denoted as B (with the number of samples being C), and the pseudo-labeled sample set of the A-th fault category in the target domain as D (with the number of samples being E). The derivation of the conditional distribution discrepancy is then given in equation (5):
Similarly, the kernel trick is utilized to transform equation (5) into a kernel matrix form for computation. The marginal distribution discrepancy and conditional distribution discrepancy are weighted and fused to construct the total distribution discrepancy loss function, as shown in equation (6):
where is the weight balance coefficient for marginal and conditional distribution discrepancies, which is used to adjust their contribution ratios to the total discrepancy loss. To avoid model overfitting and realize adaptive selection of projected feature dimensions, an L2 norm regularization and a row sparsity learning strategy are introduced in the distribution alignment process, and the regularization loss function is constructed as shown in equation (7):
where and are regularization coefficients; denotes the L2 norm term, which is used to constrain the overall scale of the projection matrix parameters and avoid overfitting; represents the row-sparsity L1 norm term, which adaptively eliminates redundant feature dimensions by penalizing the amplitude of row vectors in the projection matrix. By integrating the distribution discrepancy loss and the regularization loss, the optimization objective function of the distribution alignment module is constructed as shown in equation (8):
The gradient descent algorithm is adopted to minimize equation (8), and the optimal projection matrix is obtained via solution. The initial feature set is mapped through the optimal projection matrix to generate the distribution-aligned domain-invariant features and . This feature set effectively reduces the distribution discrepancy between the multi-source domains and the target domain; meanwhile, it achieves the dimensionality reduction of features through sparsity constraints, thus providing a more optimal input feature for the subsequent manifold embedding module.
3.3. Manifold Embedding Module
Although the distribution alignment module can effectively reduce the inter-domain distribution discrepancy, it may damage the intrinsic manifold structure of the original data during the projection process, leading to a decline in the class discriminability of features. To address this issue, this module introduces the Graph Embedding (GE) technique, which organically integrates category information and the domain manifold structure into the feature mapping process. This ensures that the mapped features simultaneously possess domain invariance and strong discriminability, while preserving the intrinsic manifold consistency of the data.
The core of manifold embedding is to construct a similarity graph that can reflect the intrinsic structure and category relationship of samples. First, all labeled samples from the source domains and unlabeled samples from the target domain are integrated to construct a unified sample set , where is the total number of samples. The Gaussian kernel function is adopted to calculate the similarity between any two samples and , as shown in equation (9):
where is the Gaussian kernel width parameter; denotes the similarity value between sample and sample . To highlight key connections and suppress noise interference, a similarity threshold is set to construct the adjacency matrix : if , then ; otherwise, .
Based on the constructed similarity graph, the degree matrix is defined as a diagonal matrix whose diagonal elements are , and the graph Laplacian matrix is thus denoted as . The objective function of graph embedding is realized through two core constraint terms: the locality-preserving constraint and the class-separability constraint, with the specific derivation given as follows.
- Locality-Preserving Constraint
This constraint ensures that adjacent samples in the manifold graph remain adjacent in the embedded feature space, thus preserving the local manifold structure of the data. A mapping matrix (where denotes the dimension of embedded features) is defined, and the embedded feature matrix is denoted as . The locality-preserving constraint term is then given in equation (10):
- 2.
- Class-Separability Constraint
This constraint ensures that samples of different categories are mutually separated in the embedded feature space, thus enhancing the class discriminability of features. A source domain category center matrix (where denotes the embedded feature center of the -th category samples and is the total number of the -th category samples) and a global feature center are defined. The class-separability constraint term is then given in equation (11):
In equation (11), is the class-separability matrix, where is an all-ones matrix and the outer product of a column vector with all ones and its transpose.
By integrating the locality-preserving constraint and the class-separability constraint, the final optimization objective of graph embedding is to maximize the ratio of the class-separability degree to the locality-preserving degree, i.e., to minimize its inverse ratio, as shown in equation (12):
The optimization problem shown in equation (12) can be transformed into a generalized eigenvalue solution problem: . By solving this generalized eigenvalue equation, the eigenvectors corresponding to the smallest eigenvalues are selected to form the optimal mapping matrix . The distribution-aligned features are mapped through the optimal mapping matrix to generate the final manifold-embedded features . These features not only inherit domain invariance but also preserve the intrinsic manifold structure and category discriminative information of the data, thus providing a higher-quality feature representation for the subsequent training of the classifier.
It is worth noting that the manifold embedding module effectively compensates for the structural damage problem that may be caused by the distribution alignment module by fusing category information with the manifold structure. The locality-preserving constraint ensures the manifold consistency of features, while the class-separability constraint enhances the discriminative ability of features. These two constraints act synergistically, making the embedded features more suitable for the task requirements of fault diagnosis.
3.4. Classifier Learning Module
The core objective of the classifier learning module is to learn a classifier that can adaptively match the data distribution of the target domain by using labeled data from the source domains and unlabeled data from the target domain, thus achieving accurate classification of fault samples in the target domain. Traditional classifiers are trained solely on labeled source domain data, making it difficult for them to adapt to the distribution shift of the target domain and leading to limited generalization performance. To address this issue, this module introduces the principle of Structural Risk Minimization (SRM) to construct an adaptive classifier with structural risk, realizing the joint optimization of empirical risk and structural risk.
The specific implementation process is as follows: First, the manifold-embedded features are taken as input to initialize a logistic regression classifier, which is preliminarily trained on labeled source domain samples to obtain the initial classifier parameters. To fully exploit the information of unlabeled target domain data, a semi-supervised learning strategy is introduced: the initial classifier is used to predict the category labels of unlabeled target domain samples to construct a pseudo-label set; a confidence screening mechanism is adopted to retain only the pseudo-labeled samples with prediction confidence higher than a preset threshold , and these samples are combined with labeled source domain samples to form an extended training set, which effectively reduces the impact of pseudo-label errors on model training.
The parameters of the adaptive classifier are defined as the weight matrix and the bias vector . The output of the classifier is the probability distribution of the sample belonging to each category, which is normalized by the softmax function, as shown in equation (13):
where is a normalization function that ensures the sum of the output probabilities is 1. The optimization objective of the classifier consists of two parts: an empirical risk term and a structural risk term, with the specific derivation given as follows.
- 3.
- Empirical Risk Term
The cross-entropy loss function is adopted for calculation based on the extended training set, which measures the deviation between the classifier's predicted results and the true labels (or high-confidence pseudo-labels), as shown in equation (14):
where is the number of samples in the extended training set; denotes the label of sample corresponding to the -th category; and is the probability of the -th category output by the classifier.
- 4.
- Structural Risk Term
It consists of a manifold regularization term and a domain-adaptive regularization term, which is used to constrain the classifier parameters and improve the generalization ability and target domain adaptability of the model.
Based on the similarity graph constructed by the manifold embedding module, this term ensures that the classifier output is consistent with the manifold structure of the data — i.e., adjacent samples in the manifold graph have similar classification outputs. Using the graph Laplacian matrix , the manifold regularization term is given in equation (15):
The Kullback-Leibler (KL) divergence is adopted to measure the distribution discrepancy between source and target domain samples in the classifier output space, and the adaptive adaptation of the classifier to the target domain is achieved by minimizing this discrepancy. The domain-adaptive regularization term is given in equation (16):
where is the mean value of the classification output probabilities of source domain samples; denotes the mean value of the classification output probabilities of target domain samples; and is the KL divergence, which is used to measure the degree of discrepancy between two probability distributions.
By integrating the empirical risk term and the structural risk term, the final optimization objective function of the adaptive classifier is given in equation (17):
where and are the weight coefficients of the structural risk term. The stochastic gradient descent (SGD) algorithm is adopted to minimize the above objective function, and the classifier parameters and are updated to obtain the final adaptive classifier. This classifier can fully exploit the structural information in the unlabeled target domain data while utilizing the labeled information of the source domain, achieving the simultaneous optimization of distribution discrepancy reduction and manifold structure consistency preservation, and ultimately improving the fault diagnosis performance under variable operating conditions.
4. Fault Diagnosis Process Based on GE-AC-MSDA
The overall framework of the GE-AC-MSDA model is shown in Figure 1.
The specific steps of the fault diagnosis method based on GE-AC-MSDA are as follows:
Step 1: Collect the multi-source domain fault vibration signals (with known fault category labels) and the target domain fault vibration signals (without category labels) of rotating machinery under different operating conditions, ensure that the signals cover all fault types to be diagnosed and the signals under normal operating conditions, define the transfer task for cross-domain diagnosis of the multi-source domain, and construct the multi-source domain dataset and the target domain dataset.
Step 2: MMPE is extracted as the fault feature from the vibration signals of the multi-source domain and the target domain, respectively, to obtain the high-dimensional sensitive initial feature sets of the multi-source domain and the target domain.
Step 3: All parameters of the GE-AC-MSDA model are initialized, including the maximum number of iterations , distribution weight balance coefficient , regularization coefficients and , structural risk weight coefficients and , and other related parameters.
Step 4: The WM-NMMD method is adopted to achieve distribution alignment between the multi-source domain and the target domain, and an optimal projection matrix is constructed. The initial feature sets are mapped through the optimal projection matrix, yielding the domain-invariant features of the multi-source domain and the domain-invariant features of the target domain.
Step 5: Graph embedding technology is employed to fuse category information with the manifold structure, thereby constructing a unified sample set and an optimal mapping matrix . The unified sample set is mapped via matrix , yielding the manifold-embedded features of the multi-source domain and the target domain.
Step 6: A logistic regression classifier is constructed on the basis of the initialized weight matrix and bias vector , and is preliminarily trained by using the manifold-embedded features and their corresponding labels of the multi-source domain. The initial classifier is applied to predict the categories of the manifold-embedded features of the target domain, and the high-confidence pseudo-labeled samples are screened according to the set confidence threshold .
Step 7: The high-confidence pseudo-labels are utilized to optimize the distribution alignment module and manifold embedding module in a reverse manner: the pseudo-labels are integrated into the calculation of the conditional distribution for distribution alignment to re-optimize the projection matrix; the pseudo-labels are incorporated into the construction of the category separation matrix for manifold embedding to re-optimize the mapping matrix. The initial features and domain-invariant features are mapped in sequence through the optimized matrices, yielding the optimal manifold-embedded features that simultaneously possess domain invariance, manifold compactness and category discriminability.
Step 8: The optimal manifold-embedded features of the multi-source domain are fused with the high-confidence pseudo-labeled samples of the target domain to construct an expanded training set. A comprehensive optimization objective containing empirical risk, manifold regularization risk and domain adaptation regularization risk is defined, and the SGD algorithm is adopted to iteratively update the weight matrix and bias vector of the classifier until the iteration termination condition is satisfied, thus obtaining the final adaptive classifier.
Step 9: The optimal manifold-embedded features of the target domain are input into the well-trained classifier, which outputs the category probability distribution of each sample. The category with the maximum probability is taken as the fault diagnosis result of the target domain samples.
5. Experimental Verification and Analysis
5.1. Description of the Experimental Dataset
The experimental data employed in this study consist of rolling bearing and gear datasets collected from the petrochemical unit simulation test rig of the Guangdong Provincial Key Laboratory of Intelligent Safety for Petrochemical Equipment. This research verifies the effectiveness and superiority of the proposed multi-source domain transfer diagnosis method, and conducts an in-depth analysis and discussion on the experimental results.
As shown in Figure 2, the petrochemical unit simulation test rig is composed of a five-stage centrifugal fan with a power of 11 kW, a gearbox, a torque sensor, a variable-frequency motor, a standard flat plate, as well as a series of components including faulty shafts, gears and bearings. This simulation test rig can simulate the single and composite fault modes of the multi-stage centrifugal fan unit by replacing different types of faulty gears, bearings, transmission shafts and other parts.
In this study, the vibration dataset of the petrochemical unit simulation test rig is selected as the experimental sample, which covers eight distinct mechanical states: normal state (NS), left bearing outer race wear (LOW), left bearing inner race wear (LIR), left bearing ball loss (LBL), large gear tooth loss (LGT), left bearing outer race wear-large gear tooth loss (LOW-LGT), left bearing inner race wear-large gear tooth loss (LIR-LGT), and left bearing ball loss-large gear tooth loss (LBL-LGT). These states correspond to four different operating conditions with rotational speeds of 600 r/min, 900 r/min, 1200 r/min and 1500 r/min, respectively. For each state, the dataset contains 200 samples, with each sample composed of 2000 sampling points. The detailed characteristic description of the dataset is presented in Table 1.
Within the transfer learning framework, the sample sets under two or three of these operating conditions are designated as the multi-source domain data in this study, while those under the remaining operating conditions serve as the target domain data. Based on this setup, a total of 16 transfer tasks are constructed, each involving knowledge transfer between the multi-source domain and the target domain. The specific configurations and parameters of the transfer tasks are detailed in Table 2.
5.2. Experimental Results and Analysis
The parameters of the GE-AC-MSDA model are set as follows in the experiments: (1) Feature extraction module: According to the characteristics of mechanical vibration signals, the scale factor of MMPE is set in the range of 1-10, with the time delay set to 1 and the embedding dimension set to 3; (2) Distribution alignment module: the weight balance coefficient for marginal and conditional distributions is set to 0.6, the regularization coefficients and , and the Gaussian kernel width ; (3) Manifold embedding module: the Gaussian kernel width , the similarity threshold , and the feature dimension after embedding ; (4) Classifier learning module: the structural risk weight coefficients and , the confidence threshold , the number of iterations , and the learning rate . To verify the superiority of the GE-AC-MSDA model, a comparative analysis is conducted with several state-of-the-art transfer learning models, including DANN[31], MDAN[32], MADN[33], and ADACL[34]. For the single-source domain transfer learning models among the compared methods, all labeled samples from the source domains are integrated into a single source domain for transfer learning with the target domain. To reduce random errors and verify the robustness of the proposed method, all experiments are repeated 20 times, and the mean and standard deviation of the diagnostic accuracy across the 20 repetitions are adopted as the evaluation metrics.
The experimental results are presented in Table 3 and Figure 3. In comparison with other models, the GE-AC-MSDA model achieves the highest diagnostic accuracy across all 16 transfer tasks, with an average diagnostic accuracy of 97.18%. For the three-source domain transfer tasks (T1, T5, T9, T13), the mean accuracy reaches 98.34% (T1: 98.15%, T5: 98.83%, T9: 99.02%, T13: 97.93%), which represents an improvement of 4.16% over ADACL (a model designed for multi-source domains, with a three-source domain mean accuracy of 94.18%) and 4.73% over MDAN (with a three-source domain mean accuracy of 93.61%). For the two-source domain transfer tasks (the remaining 12 tasks), the mean accuracy attains 96.79%, showing an increase of 2.90% compared with ADACL (with a two-source domain mean accuracy of 93.89%). In contrast, the performance improvement of traditional multi-source domain models (MDAN, MADN) in the three-source domain scenario is less than 1%. Notably, ADACL even exhibits lower accuracy in some three-source domain transfer tasks (e.g., T9) than in two-source domain transfer tasks. In contrast, the graph-embedded feature extraction mechanism of GE-AC-MSDA can dynamically aggregate the topological correlations of three-source domain features and avoid feature redundancy in the two-source domain scenario, thus achieving optimal performance across transfer tasks with different numbers of source domains. The overall standard deviation of GE-AC-MSDA is only 1.81%. For the three-source domain transfer tasks, the mean standard deviation is merely 1.36% (T1: 1.75%, T5: 0.96%, T9: 1.08%, T13: 1.62%), which is a reduction of 66.1% compared with ADACL (with a three-source domain mean standard deviation of 4.01%) and 74.6% compared with DANN (with a three-source domain mean standard deviation of 5.36%). For the two-source domain transfer tasks, the mean standard deviation is 1.95%, decreasing by 51.0% relative to ADACL (with a two-source domain mean standard deviation of 3.98%) and 66.8% relative to DANN (with a two-source domain mean standard deviation of 5.87%). Its dynamically adaptive classifier can adjust the decision boundary according to the number of source domains and rotational speed differences, effectively eliminating the interactive interference of multi-source features in the three-source domain scenario.
For transfer tasks combining three-source domains with large rotational speed differences (T1, T13), the GE-AC-MSDA model achieves a diagnostic accuracy of 97.93% and above, representing a performance improvement of more than 3.68% compared with ADACL, a multi-source domain-adaptive model. This result stems from the graph-embedded cross-domain topological modeling mechanism adopted by GE-AC-MSDA, which can break through the limitations of Euclidean space feature mapping and model the fault features under different rotational speed conditions of the three-source domains into a topological graph structure. By capturing the intrinsic correlations between each source domain and the target domain through weighted edges based on cross-domain feature similarity, it effectively aggregates the complementary features of the three-source domains and significantly alleviates the cross-domain feature shift problem caused by large rotational speed differences. For transfer tasks combining three-source domains with small rotational speed differences (T5, T9), the GE-AC-MSDA model achieves a high diagnostic accuracy of 98.83% to 99.02%, with an improvement range of 4.52% to 5.50% compared with ADACL. In this case, the graph-embedding mechanism can automatically simplify the topological structure and eliminate redundant information according to the characteristic of highly overlapping feature distributions under small rotational speed differences, which avoids the computational redundancy caused by excessive feature fusion in traditional multi-source domain models and makes the model performance approach the theoretical upper limit of fault diagnosis tasks. For transfer tasks combining two-source domains with varying rotational speed differences (the remaining tasks except T1, T5, T9, T13), the GE-AC-MSDA model maintains a diagnostic accuracy of 95.52% and above, with an improvement range of 2.31% to 3.05% compared with ADACL. This benefit from the dynamically adaptive classifier integrated into the model, which can real-time perceive the degree of rotational speed difference between the two-source domains and the target domain, dynamically adjust the calibration intensity and range of the decision boundary, thus accurately matching the adaptation requirements of the feature distributions of the two-source domains to the target domain and solving the problem of disconnection between the decision boundary and the actual feature distribution under the static calibration mode of traditional classifiers.
To further demonstrate the diagnostic accuracy of GE-AC-MSDA for each fault category, Figure 4 presents the diagnostic confusion matrices of GE-AC-MSDA across all 16 transfer tasks. The fault categories in the figure are defined as follows: 0: normal state (NS); 1: left bearing outer race wear (LOW); 2: left bearing inner race wear (LIR); 3: left bearing ball loss (LBL); 4: large gear tooth loss (LGT); 5: left bearing outer race wear-large gear tooth loss (LOW-LGT); 6: left bearing inner race wear-large gear tooth loss (LIR-LGT); 7: left bearing ball loss-large gear tooth loss (LBL-LGT). As can be seen from the figure, GE-AC-MSDA exhibits excellent reliability and robustness in cross-domain mechanical fault diagnosis tasks: the recognition accuracy of normal samples reaches 100% in 14 out of the 16 transfer tasks except T2 and T16. Even for T2 and T16, the misclassification rates of normal samples are only 0.20% and 0.10%, respectively, and all misclassified samples are attributed to the composite fault category of left bearing inner race wear combined with large gear tooth loss, which has the highest feature coupling degree. From the perspective of fault types, the average recognition accuracy of the model for single faults ranges from 96.45% to 99.75%, which is significantly higher than that for composite faults (83.05% to 98.55%). This accuracy stratification stems from the feature coupling effect of composite faults: the saliency of single fault sub-features contained in the vibration signals of composite faults is higher than that of coupling features, resulting in 70% of misclassifications being the misassignment of composite faults to single faults. Among them, the high-frequency misclassifications are "composite fault of LBL-LGT → single fault of LBL" and "composite fault of LIR-LGT → single fault of LIR", with the former exceeding a 5% misclassification rate in T2, T15 and T16. A further comparison of the misclassification distributions between high- and low-accuracy tasks reveals that errors in low-accuracy tasks (T2, T16) are concentrated in composite fault categories, while those in high-accuracy tasks (T5, T9) are more uniformly distributed. This difference indicates that the data distribution discrepancy between the source and target domains is the dominant factor affecting transfer performance, rather than limitations of the model architecture. The model performance can be further improved in future work through strategies such as composite fault coupling feature enhancement, domain adversarial training and sample balancing.
5.3. Parameter Sensitivity Analysis
To investigate the impact of parameter variations on the cross-domain diagnostic performance of the GE-AC-MSDA model, four key parameters of the model were analyzed for the specific experimental scenario of bearing and gear fault diagnosis, considering the distribution characteristics of rotating machinery fault data and the requirements of fault pattern recognition. These parameters include the weight balance coefficient for marginal and conditional distributions , Gaussian kernel width for distribution alignment , feature dimension after manifold embedding
Figure 3.
Diagnostic accuracy of the GE-AC-MSDA model under different parameter combinations.
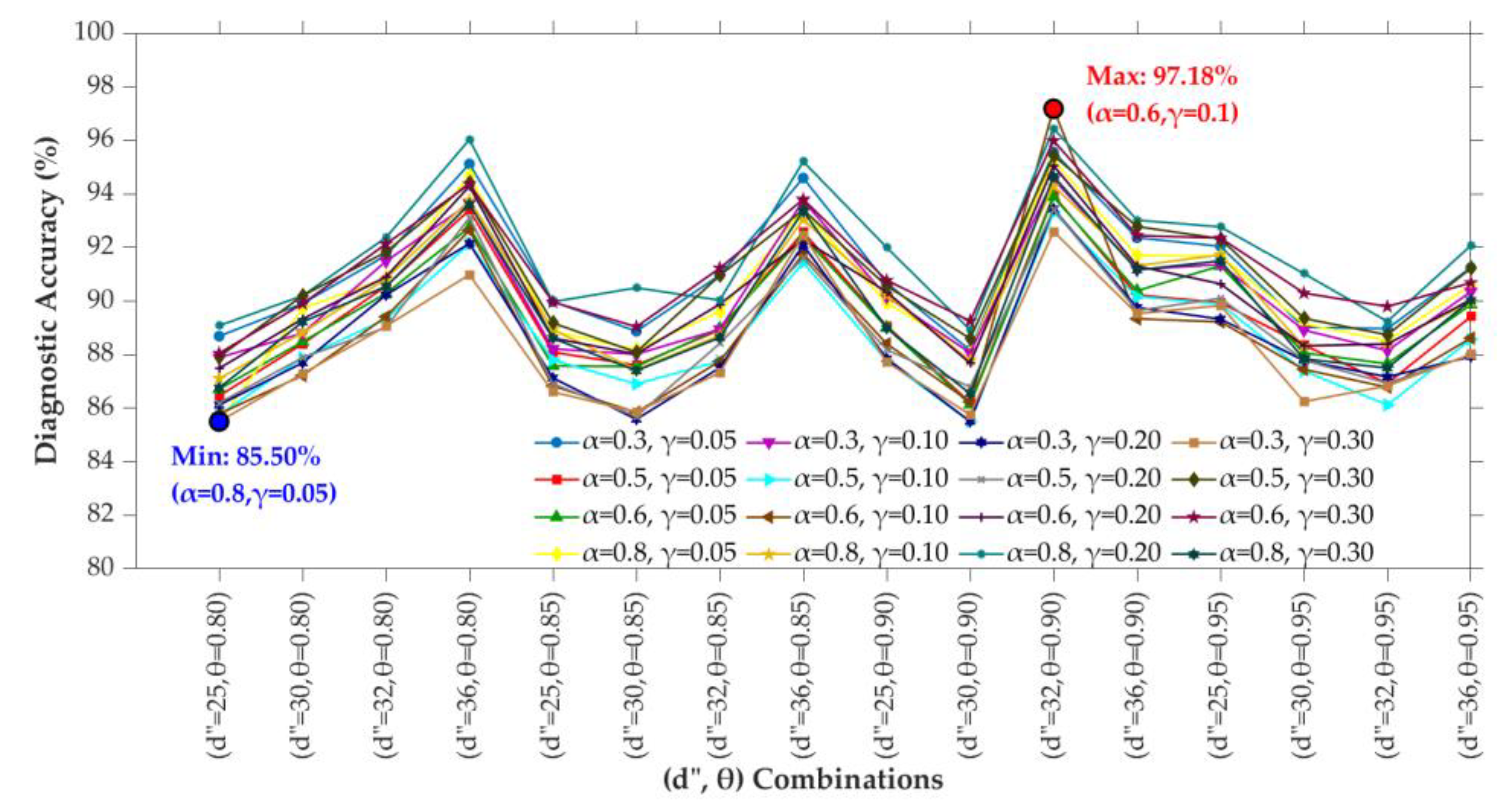
The experimental results demonstrate that the parameter combination yields the optimal diagnostic performance in this experiment. This result indicates that the weight balance coefficient for marginal and conditional distributions enables rational weight allocation across distinct feature spaces, while the Gaussian kernel width for distribution alignment adapts to the local structure of the data distribution. The combination of these two parameters maximizes the balance between distribution alignment and feature preservation. The feature dimension after manifold embedding retains sufficient discriminative information, and the pseudo-label confidence threshold effectively filters out low-confidence pseudo-labels; the combination of these two parameters exhibits strong fault tolerance to parameter fluctuations. The value of exerts a significant impact on performance: the model accuracy drops to 85.5% when , while the performance is consistently high when is close to 0.6. This is because an excessively large leads to an overbias toward a single feature space, resulting in an imbalance between distribution alignment and feature representation. The performance of is significantly superior to that of and , which illustrates that an excessively small causes over-localization of distribution alignment, whereas an excessively large value blurs the differences among samples, and represents a rational scale adapted to the data distribution. The performance of is significantly better than that of , and the performance of is superior to that of . This reveals that the sufficiency of the embedding dimension and the high-confidence screening of pseudo-labels are necessary conditions for improving diagnostic performance.
5.4. Ablation Experiments
To systematically verify the necessity and contribution of each core component of the GE-AC-MSDA model, this study conducts a quantitative analysis of the impacts of different ablation operations on the performance and robustness of multi-source domain fault diagnosis based on 20 independent repeated experiments. The parameters adopted by each model in the ablation experiments are consistent with those of the original model. The average diagnostic accuracy and standard deviation of the original model and its various ablation models on the experimental dataset are presented in Table 4 and Figure 6.
For the ablation model where the original MMPE features are replaced with MPE features [35], the average diagnostic accuracy drops to 84.62% with a relative decrease of 12.56%, and the experimental standard deviation rises to 2.14% with a relative increase of 18.2%. This result clearly demonstrates that MMPE can more accurately characterize the nonlinear and non-stationary dynamic characteristics of vibration signals from rotating machinery faults, and its fault pattern discrimination capability is significantly superior to that of traditional MPE. As the key feature foundation for the model to achieve high-performance diagnosis, the differences at the feature level directly limit the optimization upper limit of subsequent modules.
For the ablation model with average weight allocation and conditional distribution alignment removed, the average diagnostic accuracy decreases to 85.92% with a relative decrease of 11.26%, and the experimental standard deviation rises sharply to 4.52% with a relative increase of 149.7%—this represents the most significant degradation in stability among all ablation models. This phenomenon strongly verifies the synergistic mechanism of adaptive weight allocation-conditional distribution alignment: the former dynamically assigns domain weights based on the distribution similarity between source and target domains, which can effectively avoid redundant noise introduced by source domains with low matching degrees; the latter resolves the domain adaptation dilemma of "marginal distribution alignment but category feature confusion" by reducing category-level conditional distribution differences. The absence of both simultaneously impairs the domain invariance and category discriminability of features, ultimately leading to the dual degradation of model performance and robustness.
For the ablation model with local preservation and class separation constraints removed, its average diagnostic accuracy falls to 91.37% with a relative decrease of 5.81%, and the experimental standard deviation increases to 3.69% with a relative increase of 103.9%. Specifically, the local preservation constraint ensures the local agglomeration of homogeneous fault features by minimizing the feature distance of neighboring samples, while the class separation constraint enhances the global discrimination of fault patterns by maximizing the feature distance of heterogeneous samples. The absence of both causes the feature manifold structure to become loose, significantly increasing the sensitivity of the classifier's decision boundary to fluctuations in sample distribution. However, since the sample correlation modeling capability of the basic graph embedding is retained, the degree of performance degradation is weaker than that of the ablation models for the feature or domain adaptation modules.
For the ablation model with classifier structural risk optimization removed, the average diagnostic accuracy only decreases to 94.53% with a relative decrease of 2.65%, and the experimental standard deviation rises to 2.26% with a relative increase of 24.9%. This result indicates that the structural risk regularization of the classifier is an auxiliary optimization component, whose core functions are to suppress overfitting and fine-tune the decision boundary. However, it is not the core support for model performance and has a relatively limited impact on the overall diagnostic effect.
6. Conclusions
Aiming at the prevalent domain distribution mismatch problem in multi-source domain transfer fault diagnosis tasks, this study proposes a multi-source domain transfer fault diagnosis method based on graph embedding and an adaptive classifier, which provides an efficient and robust technical solution for the fault diagnosis of rotating machinery under complex working conditions. This method designs a weighted multi-source domain distribution alignment strategy, which realizes the dynamic allocation of source domain weights based on cosine similarity. By jointly minimizing the differences between marginal and conditional distributions, the distribution shift between multi-source and target domains is mitigated. Meanwhile, the L2 norm regularization and row sparsity learning mechanism are introduced to effectively suppress the negative impacts of irrelevant sample interference and redundant features, thus improving the accuracy and efficiency of distribution alignment. A collaborative optimization framework of graph embedding and an adaptive classifier is constructed: the graph embedding module deeply fuses category prior information with the sample manifold structure, endowing features with both domain invariance and category discriminability; the adaptive classifier, based on the structural risk minimization criterion, makes full use of labeled data from source domains and high-confidence pseudo-labeled data from the target domain to realize the joint optimization of empirical risk, manifold regularization risk and domain adaptation regularization risk, which significantly enhances the model's generalization ability on the target domain. Experimental verification results show that the proposed method exhibits excellent diagnostic accuracy, stability and generalization ability in the fault diagnosis tasks of rotating machinery under variable working conditions, providing a feasible technical approach for solving the multi-source domain transfer fault diagnosis problem in industrial scenarios.
Although phased achievements have been made in the field of multi-source domain transfer fault diagnosis in this study, there are still many directions for expansion and deepening. First, enhance the model's detection capability for unknown faults. The existing research assumes that the fault types in the target domain are completely included in the source domains, which is inconsistent with the actual industrial scenarios where unknown faults exist. In the follow-up, technologies such as open-set recognition and meta-learning can be combined to construct an integrated framework of accurate diagnosis of known faults - effective detection of unknown faults, breaking through the limitations of the closed-set assumption and improving the model's practicability in complex industrial scenarios. Second, expand the diagnostic paradigm of multi-modal data fusion. This study only uses vibration signals as the diagnostic data source; in the future, multi-modal industrial data such as temperature, sound pressure and current can be fused, and cross-modal attention mechanisms and feature fusion strategies can be designed to realize the complementarity and enhancement of multi-source heterogeneous information, further improving the diagnostic accuracy of complex composite faults. Third, promote the engineering application of theoretical achievements. Aiming at the fault diagnosis requirements of typical industrial equipment such as wind turbine gearboxes and high-speed train bearings, research on model lightweighting will be carried out to reduce computational complexity through technologies such as model compression and quantization, and an embedded fault diagnosis system will be developed to promote the transformation of the theoretical achievements of this study into engineering practice, providing technical support for the intelligent operation and maintenance of industrial equipment.
Author Contributions
L.S. conducted the experiment and drafted the manuscript. S.J. and J.X. provided academic guidance and ongoing support throughout the research process. A.Q. and Q.H. provided supervision and critically revised the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No. 62073090), the Natural Science Foundation of Guangdong Province (No. 2025A1515010837, 2024A1515010844, 2023A1515011423, 2024A1515012090, 2023A1515240020, 2024A1515011580), the Natural Science Foundation of Guangdong Province (No. U22A20221), the Chinese Academy of Sciences Science and Technology Service Network Program Huangpu special project (No. STS-HP-202202), the Key Laboratory of Marine Environmental Survey Technology and Application Ministry of Natural Resources P.R.China (No. MESTA-2022-B001), the Special Fund for Scientific and Technological Innovation Strategy of Guangdong Province (No. PDJH2023B0304, PDJH2024A225), the Project for Enhancing the Research Capacity of Key Construction Disciplines in Guangdong Province (No. 2024ZDJS021), the Guangdong Basic and Applied Basic Research Foundation (No. 2022A1515110650) and the Science and Technology Projects in Guangzhou (No. 2024A04J4760).
Data Availability Statement
The data presented in this study are available from the corresponding author upon reasonable request.
Acknowledgments
The authors would like to extend their appreciation to the Guangdong Provincial Key Laboratory of Intelligent Safety for Petrochemical Equipment.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhou, H.; Huang, X.; Wen, G.; Lei, Z.; Dong, S.; Zhang, P.; Chen, X. Construction of health indicators for condition monitoring of rotating machinery: A review of the research. Expert Systems with Application 2022, 203, 117297. [Google Scholar] [CrossRef]
- Kumar, S.; Raj, K.K.; Cirrincione, M.; Cirrincione, G.; Franzitta, V.; Kumar, R.R. A Comprehensive Review of Remaining Useful Life Estimation Approaches for Rotating Machinery. Energies 2024, 17, 5538. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, T.; Huang, X.; Cao, L.; Zhou, Q. Fault diagnosis of rotating machinery based on recurrent neural networks. Measurement 2021, 171, 108774. [Google Scholar] [CrossRef]
- Jia, S.X.; Wang, J.R.; Zhang, X.; Han, B.K. A Weighted Subdomain Adaptation Network for Partial Transfer Fault Diagnosis of Rotating Machinery. Entropy 2021, 23, 424. [Google Scholar] [CrossRef]
- Kim, M.; Ko, J.U.; Lee, J.; Youn, B.D.; Jung, J.H.; Sun, K.H. A Domain Adaptation with Semantic Clustering (DASC) method for fault diagnosis of rotating machinery. ISA Transactions 2021, 1, 120. [Google Scholar] [CrossRef] [PubMed]
- Tang, S.; Ma, J.; Yan, Z.; Zhu, Y.; Khoo, B.C. Deep transfer learning strategy in intelligent fault diagnosis of rotating machinery. Engineering Applications of Artificial Intelligence 2024, 134, 108678. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Wu, R.; Jiang, D. Deep transfer learning with limited data for machinery fault diagnosis. Applied Soft Computing 2021, 103, 107150. [Google Scholar] [CrossRef]
- Liu, S.W.; Jiang, H.K.; Wu, Z.H.; Yi, Z.C.; Wang, R.X. Intelligent fault diagnosis of rotating machinery using a multi-source domain adaptation network with adversarial discrepancy matching. Reliab. Eng. Syst. Saf. 2022, 231, 109036. [Google Scholar] [CrossRef]
- Zheng, X.R.; Nie, J.H.; He, Z.W.; Li, P.; Dong, Z.K.; Gao, M.Y. A fine-grained feature decoupling based multi-source domain adaptation network for rotating machinery fault diagnosis. Reliability engineering & system safety 2024, 243, 109892. [Google Scholar]
- Shang, Z.W.; Wu, C.C.; Liu, F.; Pan, C.L.; Cheng, H.C. Intelligent fault diagnosis of multi-source cross-machine bearings based on center-weighted optimal transport and class-level alignment domain adaptation. Measurement Science & Technology 2024, 35, 1–20. [Google Scholar]
- Kagermann, H.; Wahlster, W.; Helbig, J. Securing the future of German manufacturing industry: Recommendations for implementing the strategic initiative INDUSTRIE 4.0. Final report of the Industrie 4.0 Working Group 2015. pp. 1–84.
- Peng, J.Y.; Andreas, K.; Wang, D.K.; Niu, Z.B.; Fan, Z.; Wang, J.H.; Liu, X.F.; Jivka, O. A systematic review of data-driven approaches to fault diagnosis and early warning. Journal of Intelligent Manufacturing 2023, 34, 3277–3304. [Google Scholar]
- Xin, Y.C.; Zhu, J.N.; Cai, M.Y.; Zhao, P.Y.; Zuo, Q.Z. Machine learning based mechanical fault diagnosis and detection methods: a systematic review. Measurement Science and Technology 2025, 36, 012004. [Google Scholar] [CrossRef]
- Li, P.D. A Multi-scale Attention-Based Transfer Model for Cross-bearing Fault Diagnosis. International Journal of Computational Intelligence Systems 2024, 17, 1–11. [Google Scholar] [CrossRef]
- Huang, F.F.; Li, X.X.; Zhang, K.Z. A novel simulation-assisted transfer method for bearing unknown fault diagnosis. Measurement Science & Technology 2024, 35, 106127. [Google Scholar]
- Liu, W.B.; Gong, S.Y. Research on Mechanical Equipment Fault Diagnosis Method based on Transfer Learning. Scientific Journal of Intelligent Systems Research 2025, 7, 1–12. [Google Scholar] [CrossRef]
- Shi, Y.W.; Deng, A.D.; Ding, X.; Zhang, S.; Xu, S.; Li, J. Multisource domain factorization network for cross-domain fault diagnosis of rotating machinery: An unsupervised multisource domain adaptation method. Mechanical Systems and Signal Processing 2022, 164, 108219. [Google Scholar] [CrossRef]
- Su, Z.Q.; Jiang, W.L.; Chen, K.; Luo, M.L.; Feng, S.; Zhou, C. Multi-adversarial deep transfer network for multi-source open-set fault diagnosis of rotating machinery with category shift. Knowledge-based systems 2023, 282, 1–14. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, X.Z.; Xu, Y.B.; Fan, F. Intelligent fault diagnosis of rotating machinery using composite multivariate-based multi-scale symbolic dynamic entropy with multi-source monitoring data. Structural health monitoring 2023, 22, 56–77. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Transactions on Knowledge and Data Engineering 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Ji, J.C.; Ren, Z.H.; Ni, Q.; Wen, B.C. Multi-sensor open-set cross-domain intelligent diagnostics for rotating machinery under variable operating conditions. Mechanical Systems and Signal Processing 2023, 191, 110172. [Google Scholar] [CrossRef]
- Chen, Z. A Multi-Source Weighted Deep Transfer Network for Open-Set Fault Diagnosis of Rotary Machinery. IEEE Transactions on Cybernetics 2023, 53, 1982–1993. [Google Scholar] [CrossRef]
- Tian, J.; Zhang, S.; Xie, G.; Shi, H. A Multi-Source Domain Adaptation Method for Bearing Fault Diagnosis with Dynamically Similarity Guidance on Incomplete Data. ACTUATORS 2025, 14, 24. [Google Scholar] [CrossRef]
- Han, B.K.; Ge, R.K.; Wang, J.R.; Zhang, Z.Z.; Bao, H.Q.; Zhou, S.P. A multi-source domain adaptive bearing fault diagnosis method based on progressive multi-stage alignment guidance. Measurement Science & Technology 2025, 36, 056132. [Google Scholar]
- Li, Z.X.; Shen, S.Y.; Liu, Z.J.; Chen, Y. A Novel Multisource-Domain Adaptation Framework for Bearing Fault Diagnosis Based on Adversarial Network and Feature Enhancement. IEEE Transactions on Instrumentation and Measurement 2025, 74, 3510712. [Google Scholar] [CrossRef]
- Long, M.S.; Cao, Y.; Wang, J.M.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 7-9 July 2015; pp. 97–105. [Google Scholar]
- Yang, G.T.; Hu, S.L.; Wang, L.T. Multibinary similarity filtering-enabled multi-source domain open-set fault diagnosis for rotating machinery under cross conditions. IEEE Transactions on Instrumentation and Measurement 2025, 74, 1–14. [Google Scholar]
- Geng, Y.H.; Tang, G.; Wang, H.Y. Domain Adaptation With Multi-Adversarial Learning for Open-Set Cross-Domain Intelligent Bearing Fault Diagnosis. IEEE Transactions on Instrumentation and Measurement 2023, 72, 1–11. [Google Scholar]
- Fu, B.; Xu, L.; Quan, Y.; Li, C.S.; Zhao, X.L.; Zhu, Y.X. A cross domain processing deep transfer learning network for rotating machinery fault diagnosis. Measurement Science & Technology 2025, 36, 046132. [Google Scholar]
- Zhao, S.; Karimi; Yu, H.R.Y. Multi-Source Domain Adaptation for Fault Diagnosis: A Unified Framework for Feature and Relation Transfer. Signal, Image and Video Processing 2025, 19, 1–11. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial Training of Neural Networks. The journal of machine learning research 2016, 17, 2030–2096. [Google Scholar]
- Zhao, H.; Zhang, S.H.; Wu, G.H.; Costeria, J.P.; Moura, J.M.F.; Gordon, G.J. Adversarial Multiple Source Domain Adaptation. Neural Information Processing Systems 2018, 31, 8559–8570. [Google Scholar]
- Chai, Z.; Zhao, C.H. Deep Transfer Learning Based Multisource Adaptation Fault Diagnosis Network For Industrial Processes. IFAC-PapersOnLine 2021, 54, 49–54. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Ren, Z.H.; Zhou, S.H.; Yu, T.Z. Adversarial Domain Adaptation with Classifier Alignment for Cross-Domain Intelligent Fault Diagnosis of Multiple Source Domains. Measurement Science and Technology 2020, 32, 035102. [Google Scholar] [CrossRef]
- Wu, S.; Wu, P.H.; Wu, C.W.; Ding, J.J.; Wang, C.C. Bearing fault diagnosis based on multiscale permutation entropy and support vector machine. Entropy 2012, 14, 1343–1356. [Google Scholar] [CrossRef]
Figure 1.
Overall framework of the GE-AC-MSDA model.
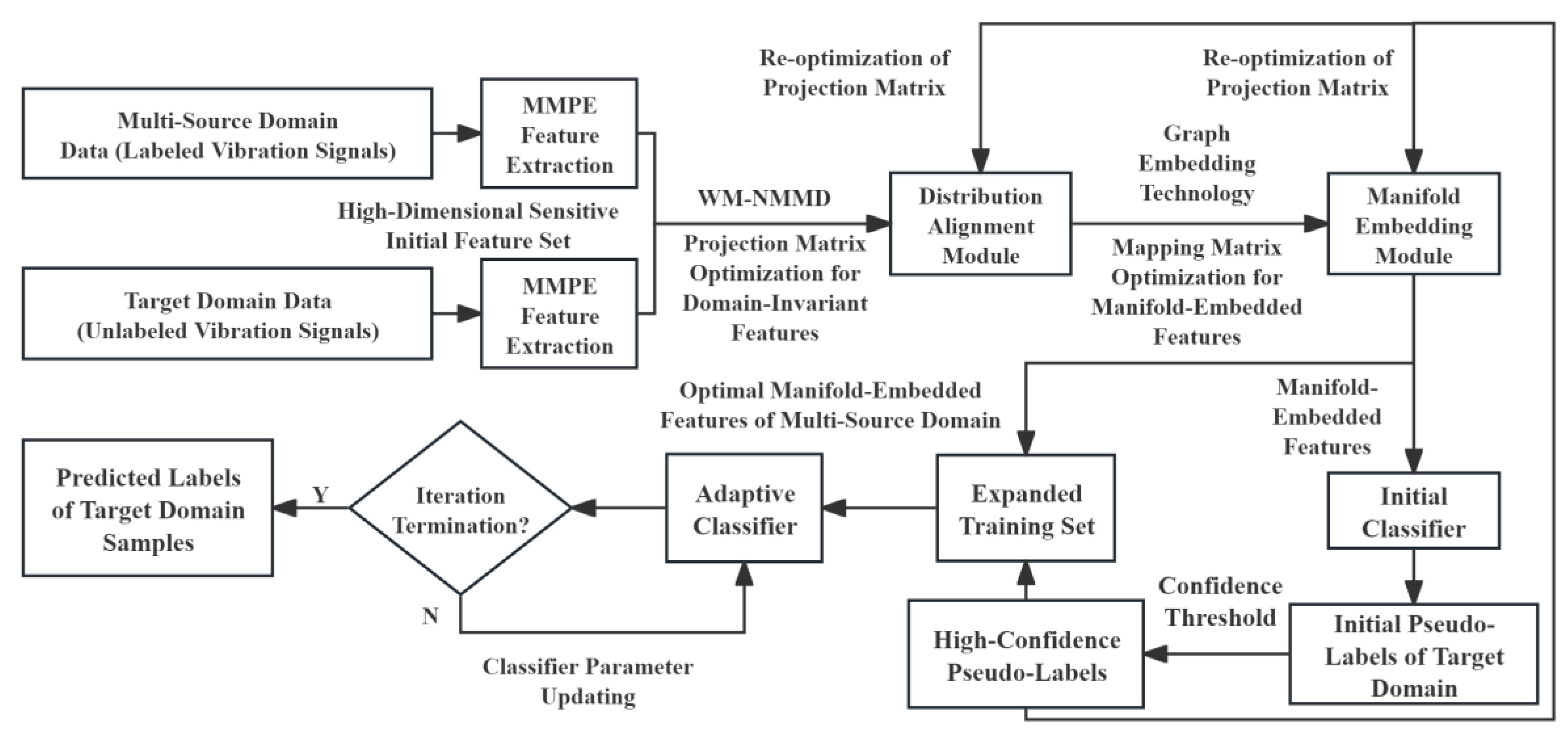
Figure 2.
Petrochemical Unit Simulation Test Rig.

Figure 1.
Comparison of diagnostic accuracy and standard deviation of each model under different transfer tasks.
Figure 1.
Comparison of diagnostic accuracy and standard deviation of each model under different transfer tasks.
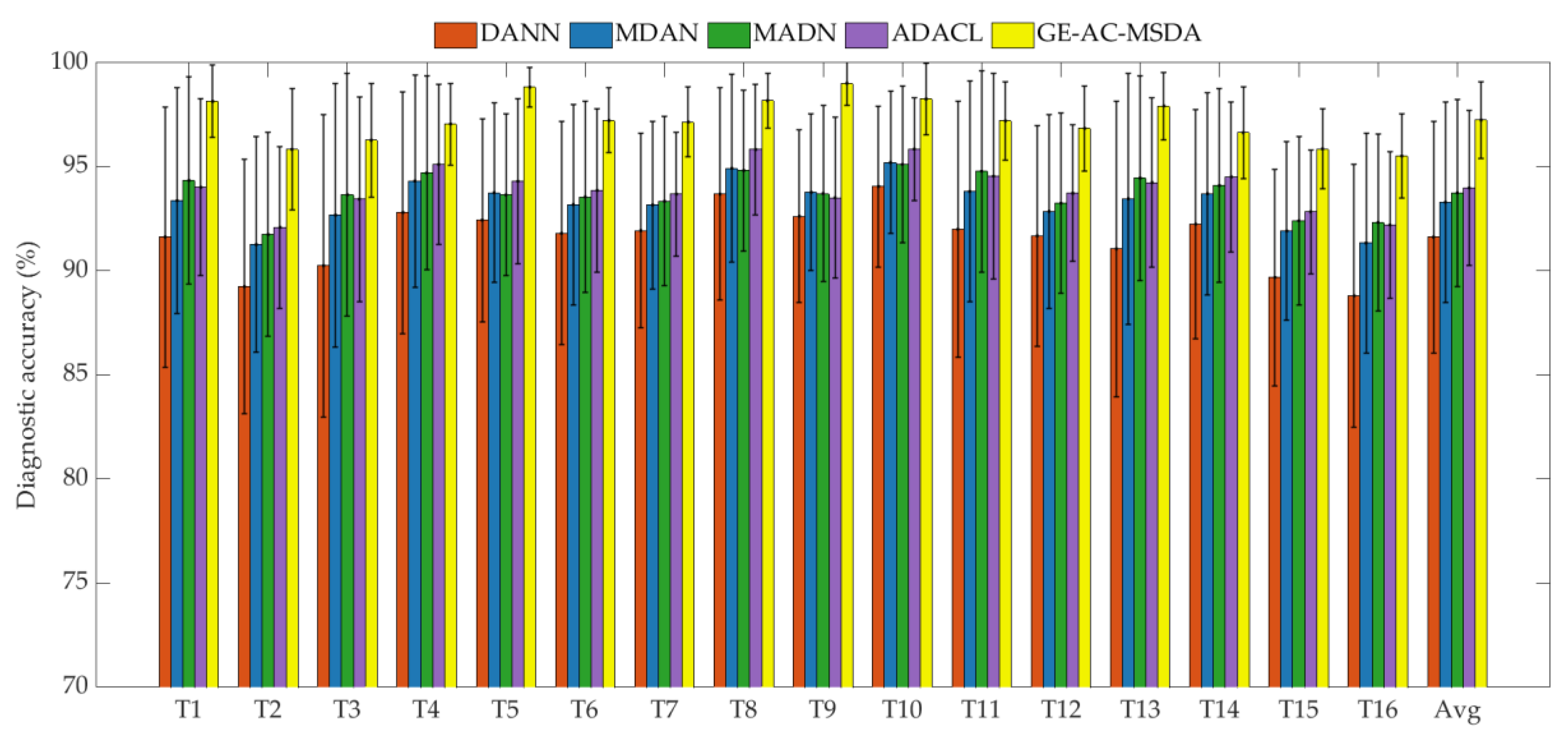
Figure 2.
Confusion matrices of the GE-AC-MSDA model for 16 transfer tasks.
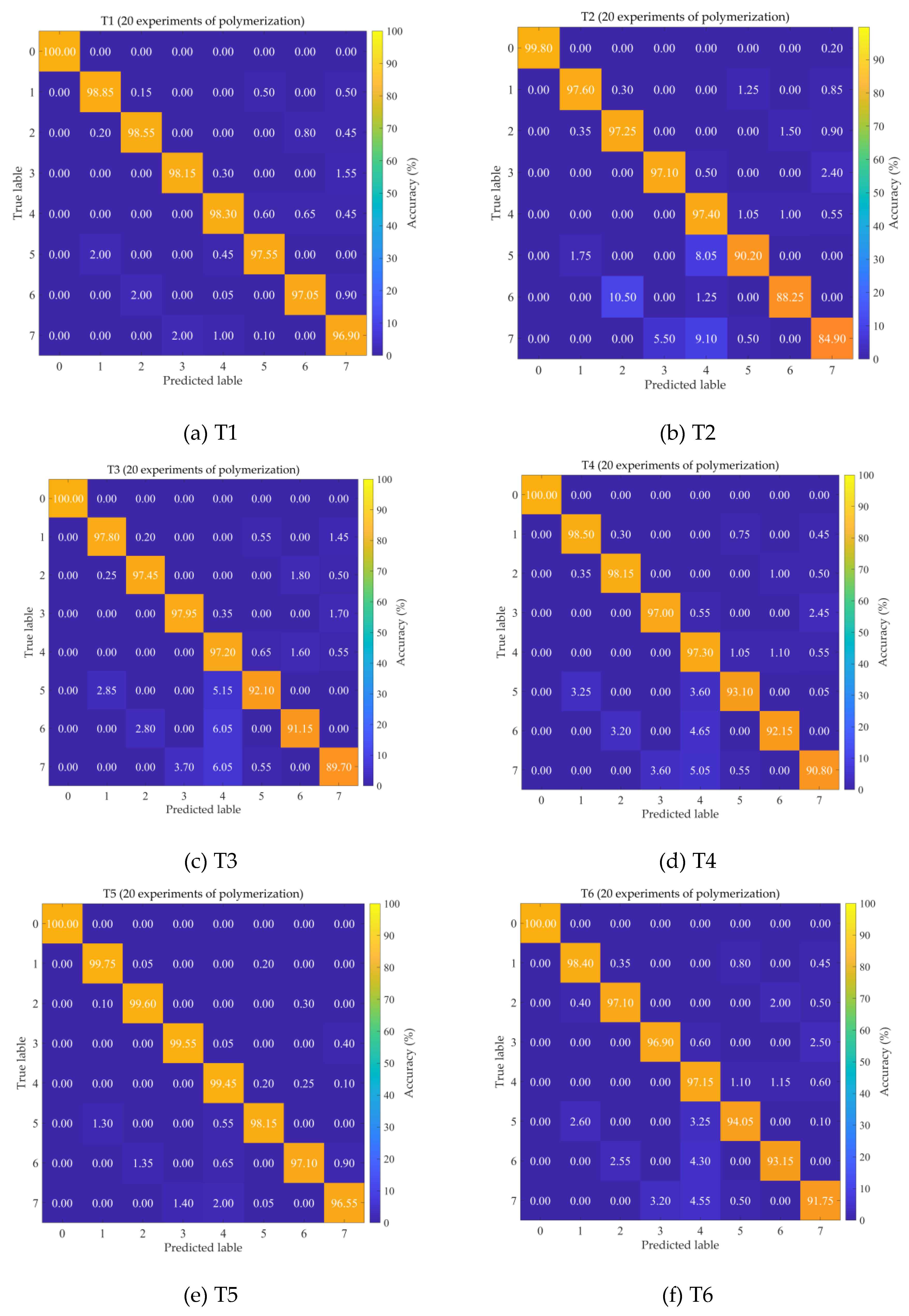
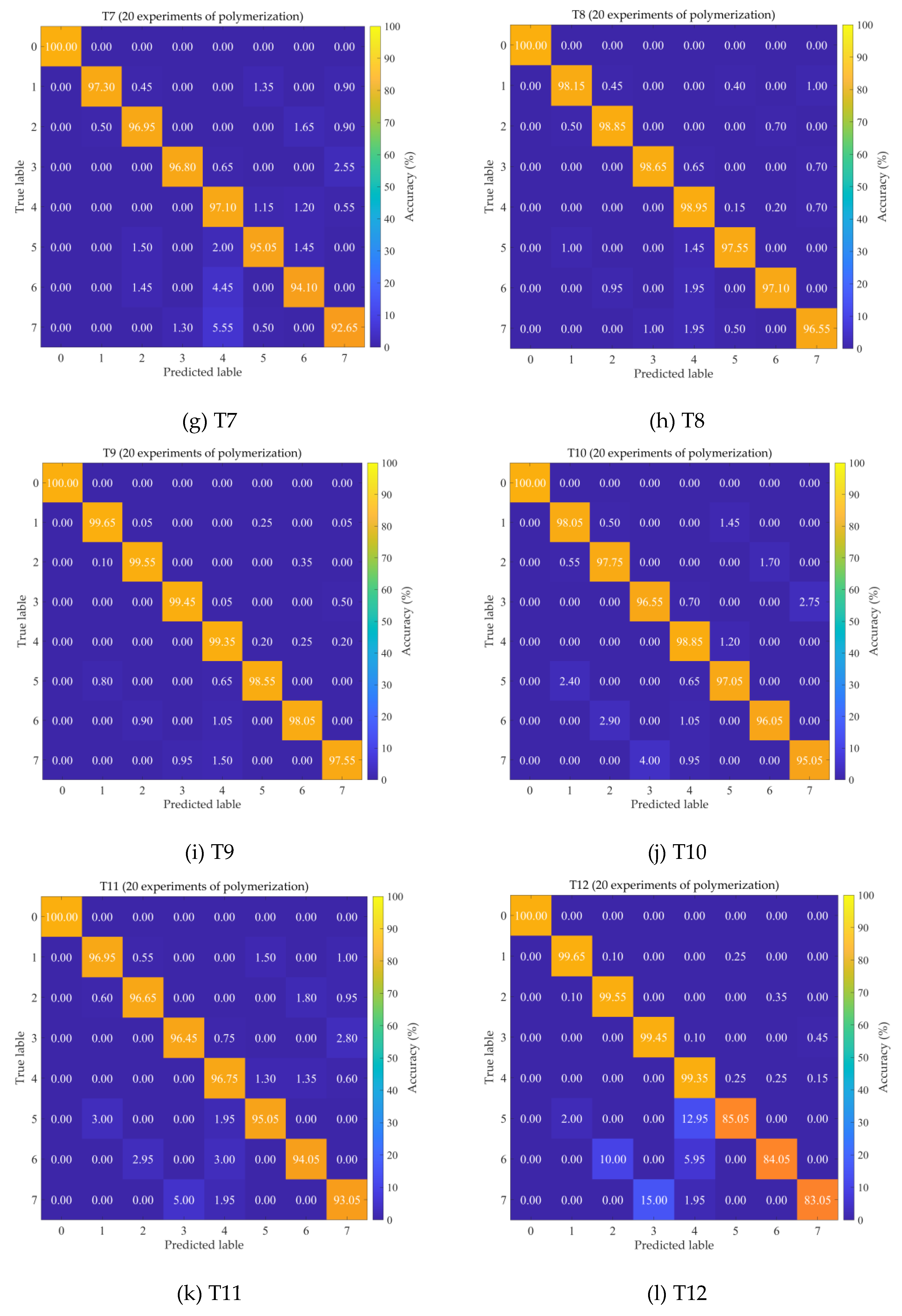
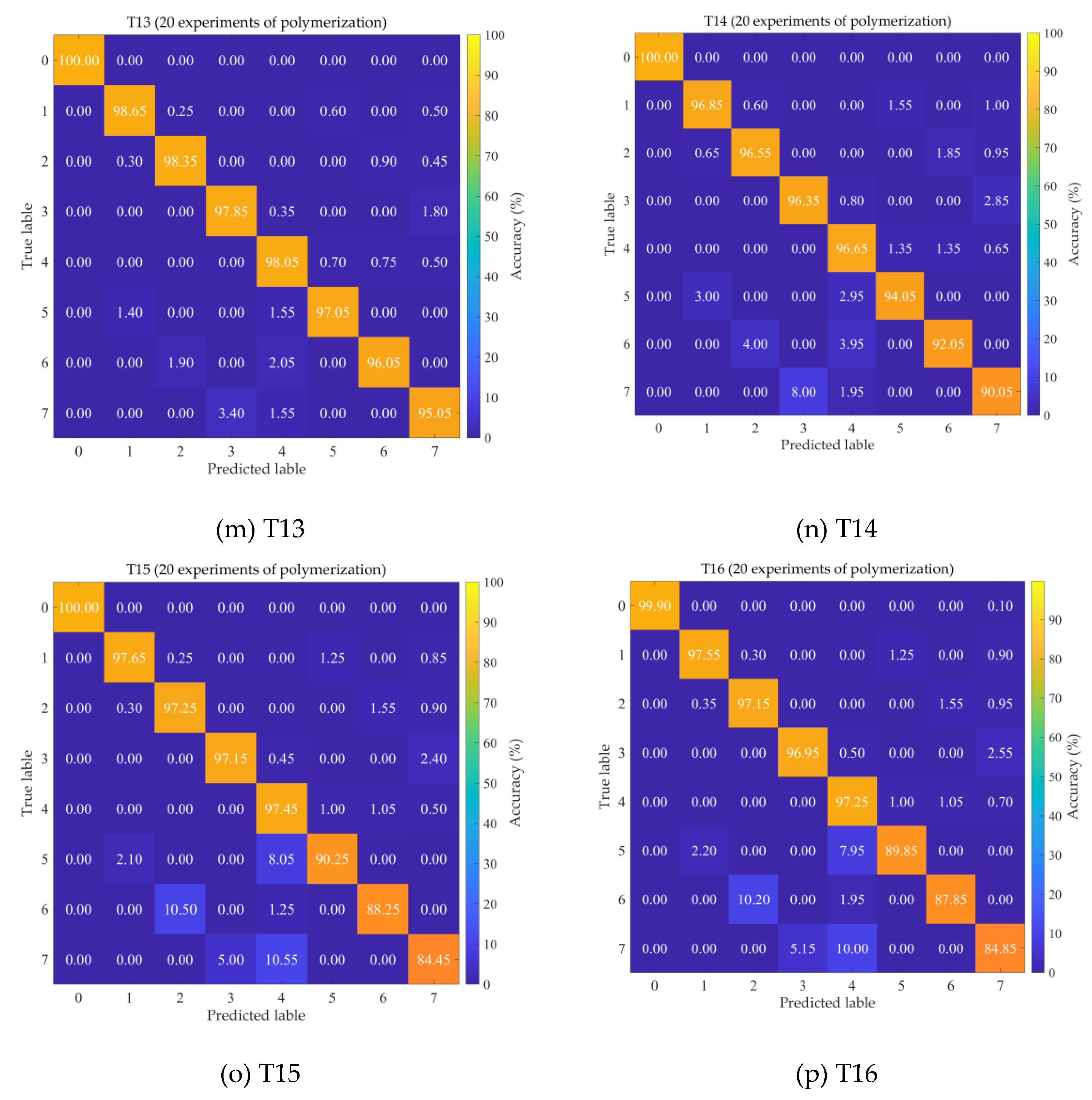
Figure 4.
Comparison of diagnostic performance between the original model and various ablation models.
Figure 4.
Comparison of diagnostic performance between the original model and various ablation models.
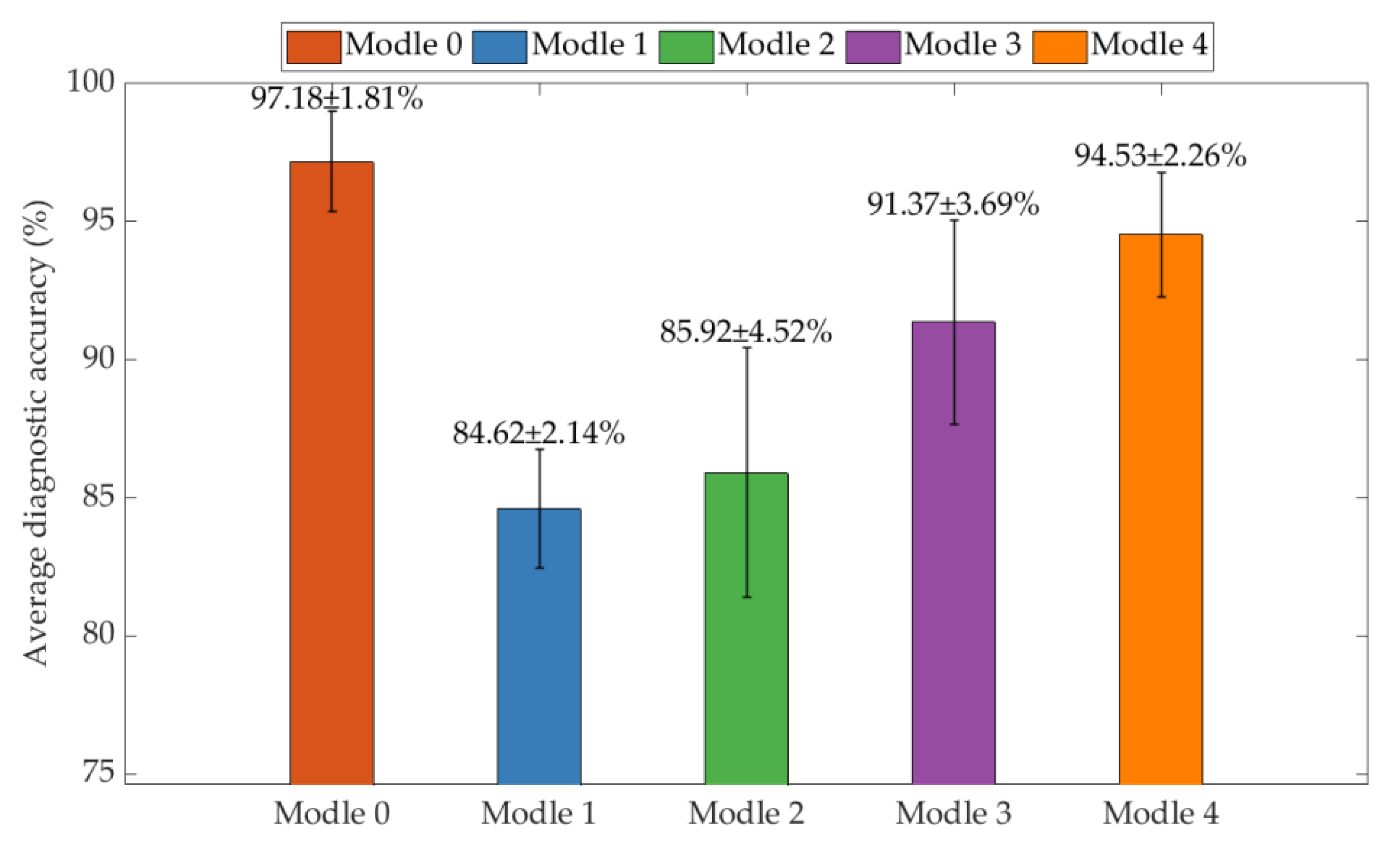

Table 1.
Detailed information of the measured dataset.
| Rotational speed | Operating states | Sample size |
|---|---|---|
| 600 r/min | NS, LOW, LIR, LBL, LGT, LOW-LGT, LIR-LGT, LBL-LGT | 1600 (200*8) |
| 900 r/min | 1600 (200*8) | |
| 1200 r/min | 1600 (200*8) | |
| 1500 r/min | 1600 (200*8) |
Table 1.
Detailed descriptions of sixteen transfer tasks based on the measured dataset.
| Transfer task | Source domain 1 | Source domain 2 | Source domain 3 | Target domain | Fault category |
|---|---|---|---|---|---|
| T1 | 600 r/min | 900 r/min | 1200 r/min | 1500 r/min | NS, LOW, LIR, LBL, LGT, LOW-LGT, LIR-LGT, LBL-LGT |
| T2 | 600 r/min | 900 r/min | / | 1500 r/min | |
| T3 | 600 r/min | 1200 r/min | / | 1500 r/min | |
| T4 | 900 r/min | 1200 r/min | / | 1500 r/min | |
| T5 | 600 r/min | 900 r/min | 1500 r/min | 1200 r/min | |
| T6 | 600 r/min | 900 r/min | / | 1200 r/min | |
| T7 | 600 r/min | 1500 r/min | / | 1200 r/min | |
| T8 | 900 r/min | 1500 r/min | / | 1200 r/min | |
| T9 | 600 r/min | 1200 r/min | 1500 r/min | 900 r/min | |
| T10 | 600 r/min | 1200 r/min | / | 900 r/min | |
| T11 | 600 r/min | 1500 r/min | / | 900 r/min | |
| T12 | 1200 r/min | 1500 r/min | / | 900 r/min | |
| T13 | 900 r/min | 1200 r/min | 1500 r/min | 600 r/min | |
| T14 | 900 r/min | 1200 r/min | / | 600 r/min | |
| T15 | 900 r/min | 1500 r/min | / | 600 r/min | |
| T16 | 1200 r/min | 1500 r/min | / | 600 r/min |
Table 2.
Diagnostic accuracy of different transfer learning models for multi-source domain fault diagnosis (%).
Table 2.
Diagnostic accuracy of different transfer learning models for multi-source domain fault diagnosis (%).
| Transfer task | Transfer learning models | Proposed model | |||
|---|---|---|---|---|---|
| DANN | MDAN | MADN | ADACL | GE-AC-MSDA | |
| T1 | 91.63±6.25 | 93.38±5.42 | 94.35±4.97 | 94.02±4.24 | 98.15±1.75 |
| T2 | 89.25±6.10 | 91.27±5.18 | 91.75±4.89 | 92.10±3.89 | 95.84±2.92 |
| T3 | 90.25±7.26 | 92.68±6.34 | 93.66±5.84 | 93.45±4.92 | 96.28±2.73 |
| T4 | 92.81±5.81 | 94.32±5.09 | 94.71±4.65 | 95.12±3.84 | 97.06±1.96 |
| T5 | 92.44±4.87 | 93.76±4.32 | 93.65±3.89 | 94.31±3.98 | 98.83±0.96 |
| T6 | 91.81±5.37 | 93.19±4.81 | 93.56±4.60 | 93.87±3.93 | 97.23±1.56 |
| T7 | 91.94±4.67 | 93.17±4.03 | 93.35±4.06 | 93.69±2.98 | 97.16±1.68 |
| T8 | 93.69±5.10 | 94.93±4.51 | 94.83±3.87 | 95.83±3.13 | 98.18±1.32 |
| T9 | 92.63±4.15 | 93.78±3.76 | 93.72±4.23 | 93.52±3.85 | 99.02±1.08 |
| T10 | 94.06±3.87 | 95.21±3.42 | 95.12±3.78 | 95.86±2.47 | 98.26±1.73 |
| T11 | 92.00±6.15 | 93.82±5.31 | 94.79±4.84 | 94.55±4.95 | 97.21±1.88 |
| T12 | 91.69±5.30 | 92.86±4.66 | 93.25±4.34 | 93.73±3.28 | 96.85±2.04 |
| T13 | 91.06±7.10 | 93.47±6.03 | 94.46±4.92 | 94.25±4.05 | 97.93±1.62 |
| T14 | 92.25±5.51 | 93.71±4.85 | 94.10±4.65 | 94.52±3.61 | 96.64±2.21 |
| T15 | 89.69±5.20 | 91.92±4.28 | 92.41±4.06 | 92.84±2.98 | 95.87±1.92 |
| T16 | 88.81±6.33 | 91.34±5.27 | 92.33±4.24 | 92.21±3.52 | 95.52±2.03 |
| Average accuracy | 91.34±5.78 | 93.34±4.95 | 93.68±4.53 | 93.97±4.01 | 97.18±1.81 |
Table 3.
Diagnostic accuracy and standard deviation of the original model and various ablation models.
Table 3.
Diagnostic accuracy and standard deviation of the original model and various ablation models.
| Ablation model number | Concrete operation | Average diagnostic accuracy(%) |
|---|---|---|
| 0 | Original model | 97.18±1.81 |
| 1 | Utilize the MPE feature set | 84.62±2.14 |
| 2 | With average weight allocation, conditional distribution alignment removed | 85.92±4.52 |
| 3 | Local Preservation and class separation constraints removed | 91.37±3.69 |
| 4 | Classifier structural risk optimization removed | 94.53±2.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



