Submitted:
21 January 2026
Posted:
22 January 2026
You are already at the latest version
Abstract
To address the challenge of rapidly and accurately detecting male cones of Chinese Torreya at various stages of maturity in natural environments, the research team proposes a target detection algorithm, GFM-YOLOV8s, based on an improved YOLOv8s. By utilizing the YOLOv8s network model as the foundation, we replace the backbone feature extraction network with c2f-faster-ema to lighten the model and simultaneously enhance its ability to capture and express important image features. Additionally, the PAN-FPN feature extraction structure in the neck is substituted with a BiFPN structure. By removing less contributive nodes and adding cross-layer connections, the algorithm achieves better fusion and utilization of features at different scales. The WIoU loss function is introduced to mitigate the mismatch in orientation between the predicted and ground truth bounding boxes. Furthermore, a structured pruning strategy was applied to the optimized network, significantly reducing redundant parameters while preserving accuracy. Results: The improved GFM-YOLOV8 has a detection accuracy of 88.2% for Torreya male cones, the detection time of a single image is 8.3 ms, and the model size is 4.44 M, fps is 120 frames, parameters is 2.20´106. Compared with the original YOLOv8s algorithm, map50 and recall are increased by 2.0% and 2.0% respectively, and the model size and model parameters are reduced by 79.2% and 80.1% respectively. The refined lightweight model can swiftly and accurately detect male cones of Torreya at different stages of maturity in natural settings, providing technical support for the visual recognition system used in growth monitoring at Torreya bases.
Keywords:
1. Introduction
2. Materials and Methods
2.1. Experimental Datasets
2.1.1. Datasets
2.1.2. Classification of Maturity Levels of Torreya Male Cones
2.1.3. Data Generation
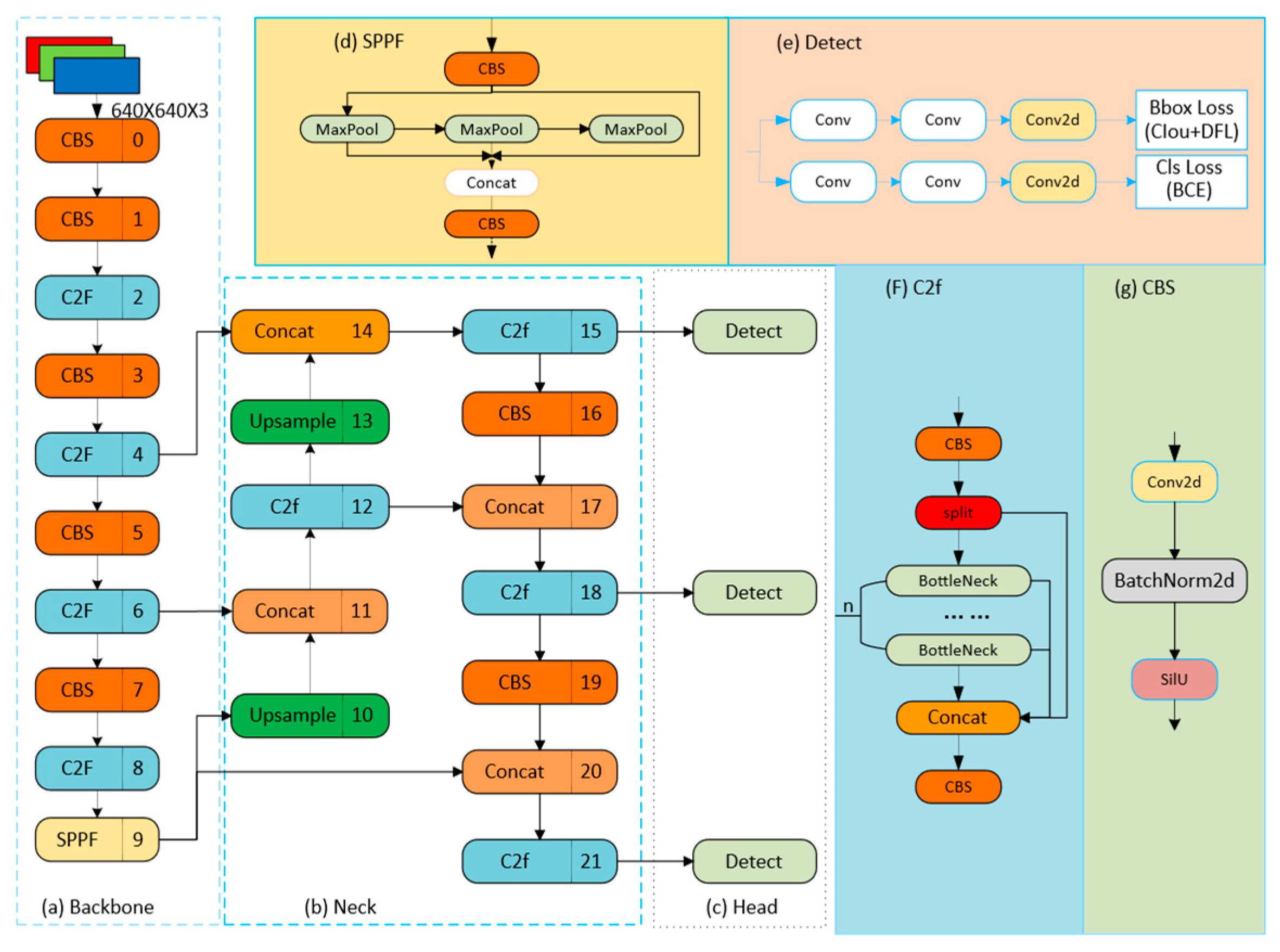
2.2. The YOLOv8 Network Architecture
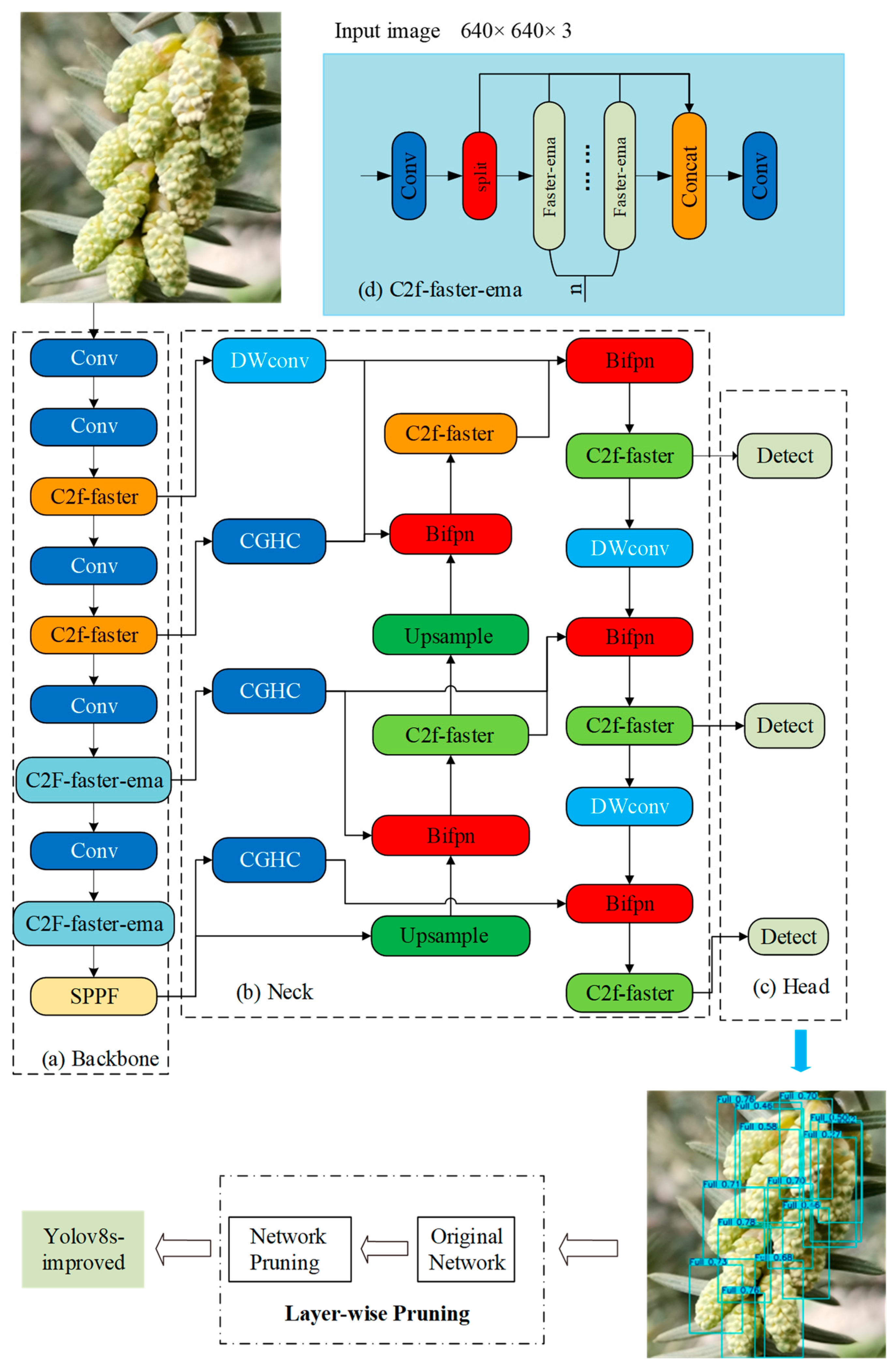
2.3. Improved Torreya Male Cone Maturity Detection Model
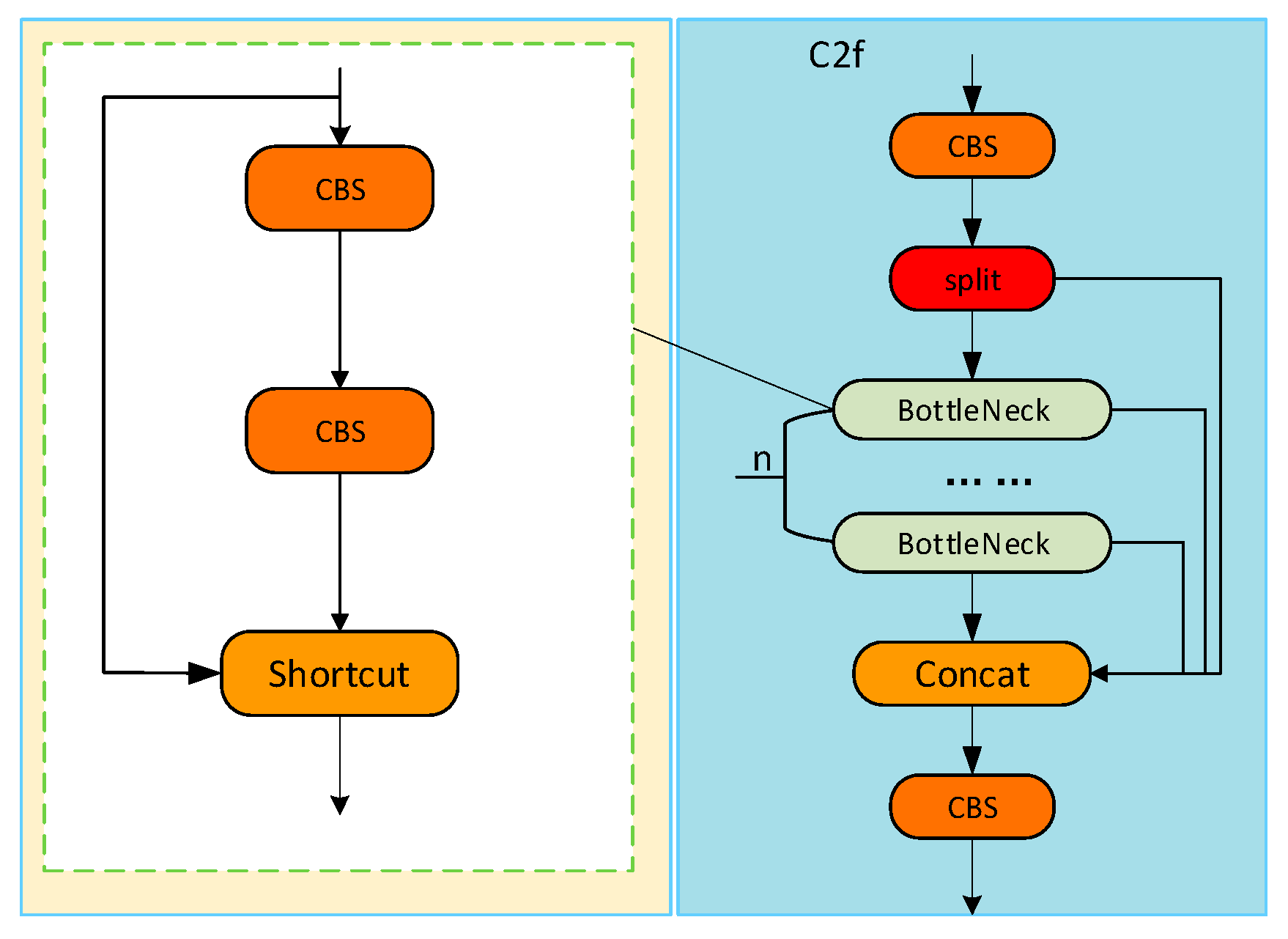
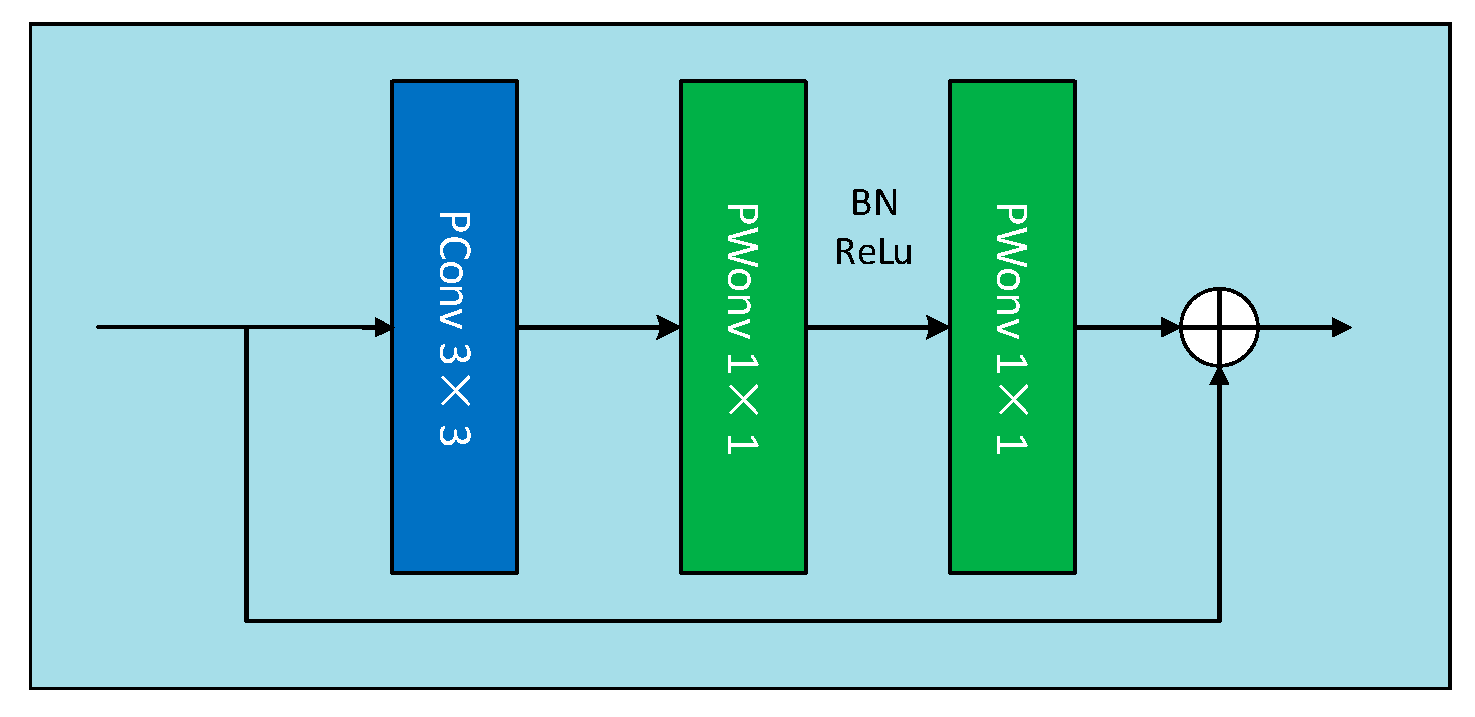
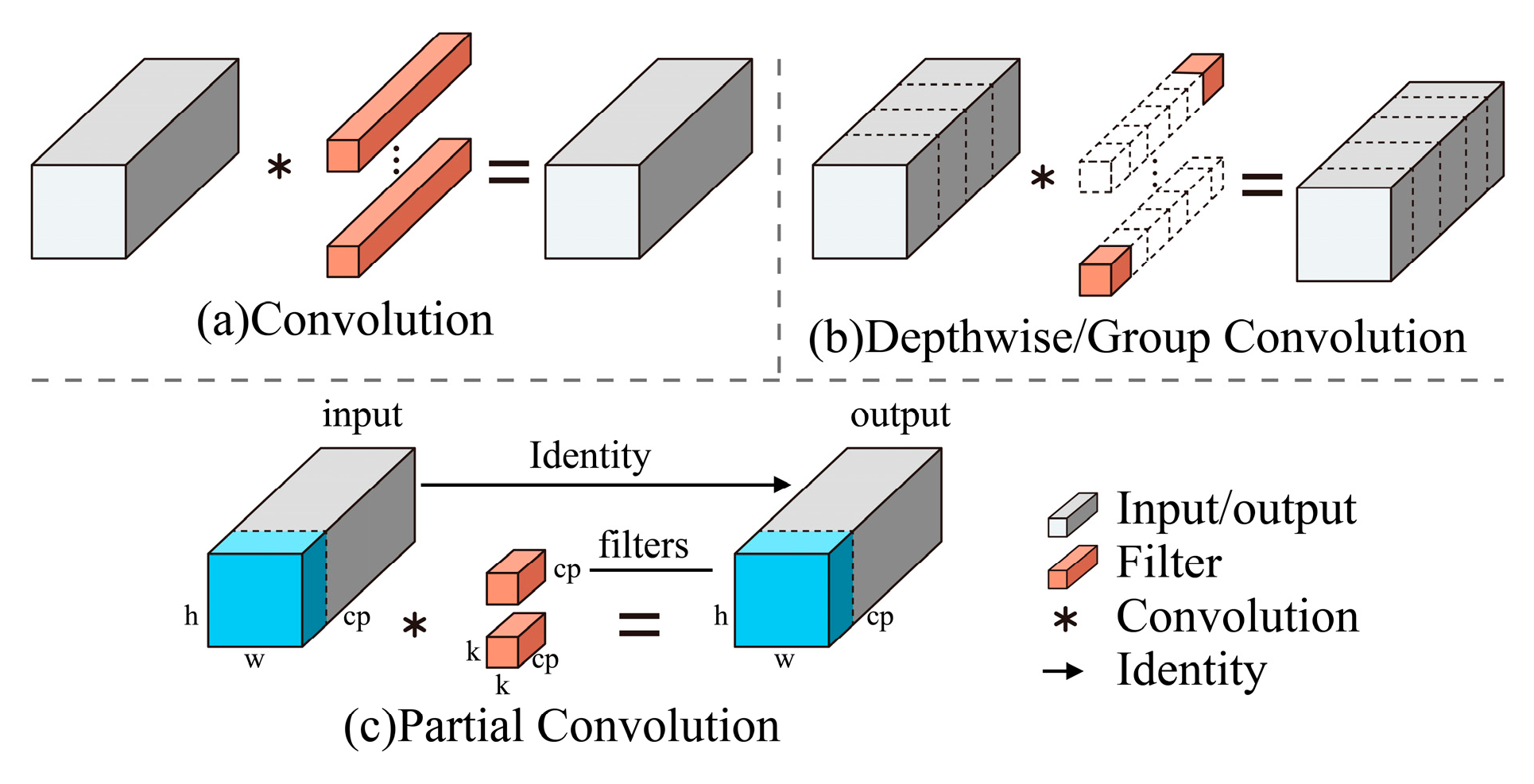
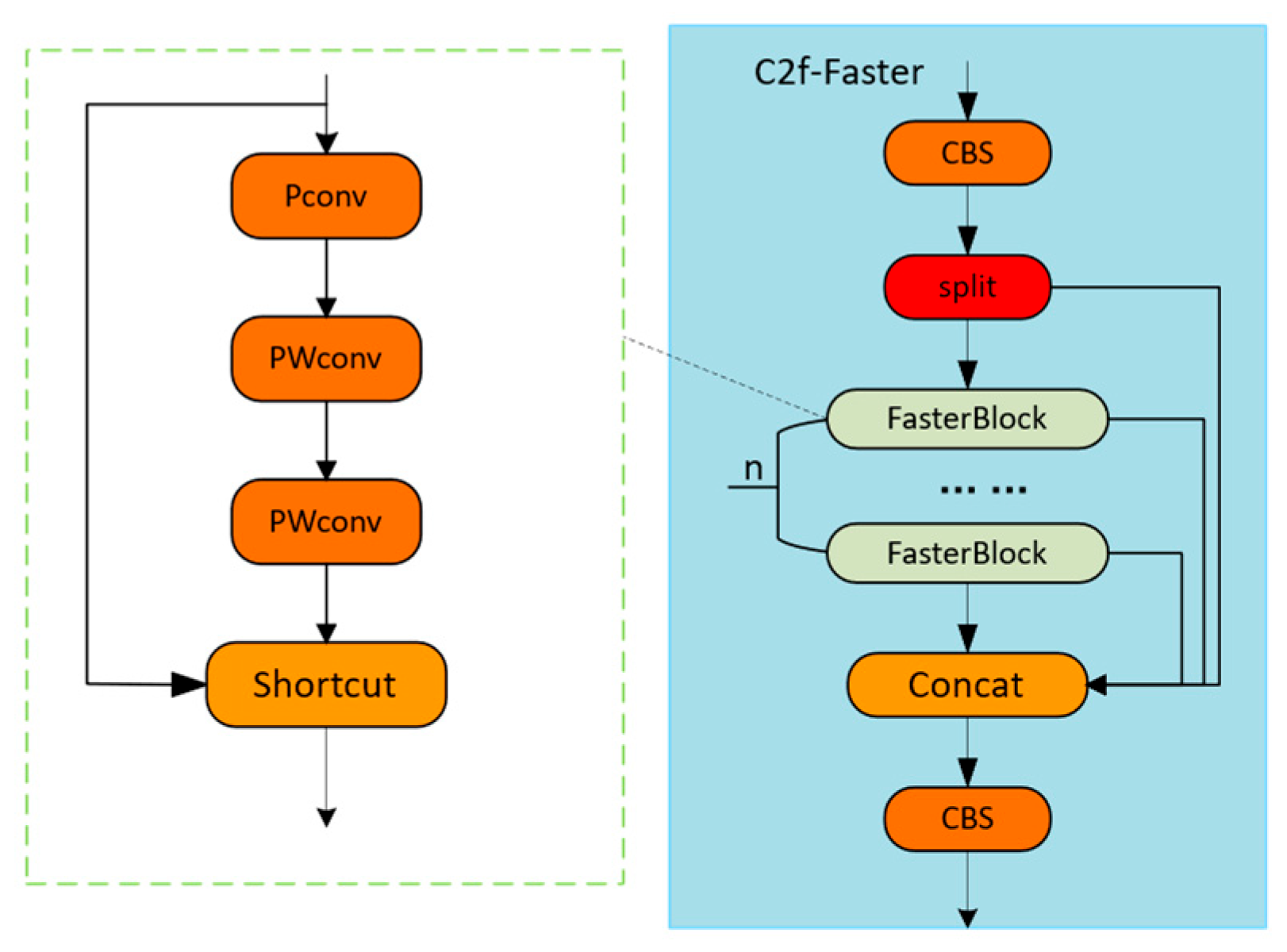
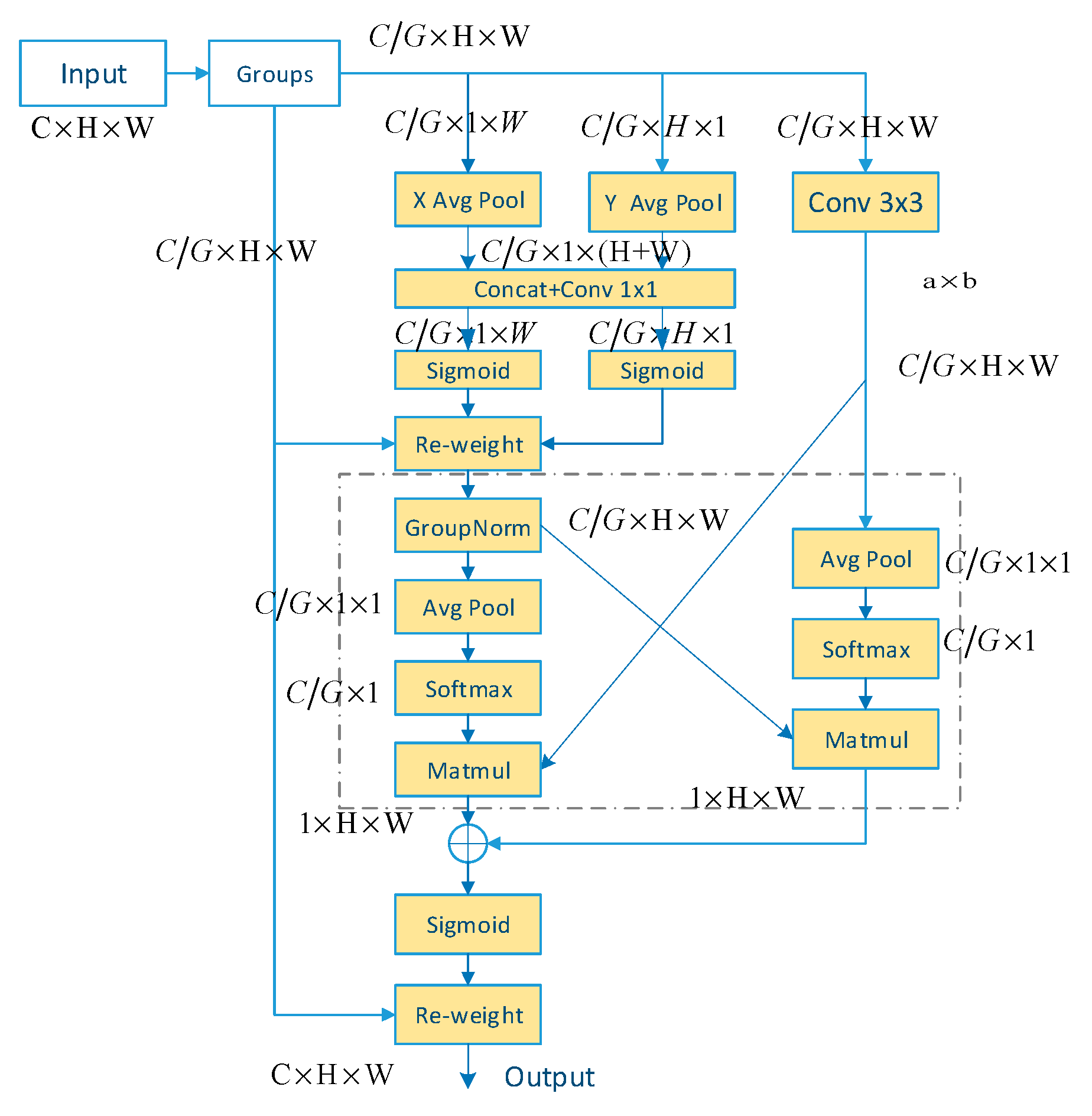
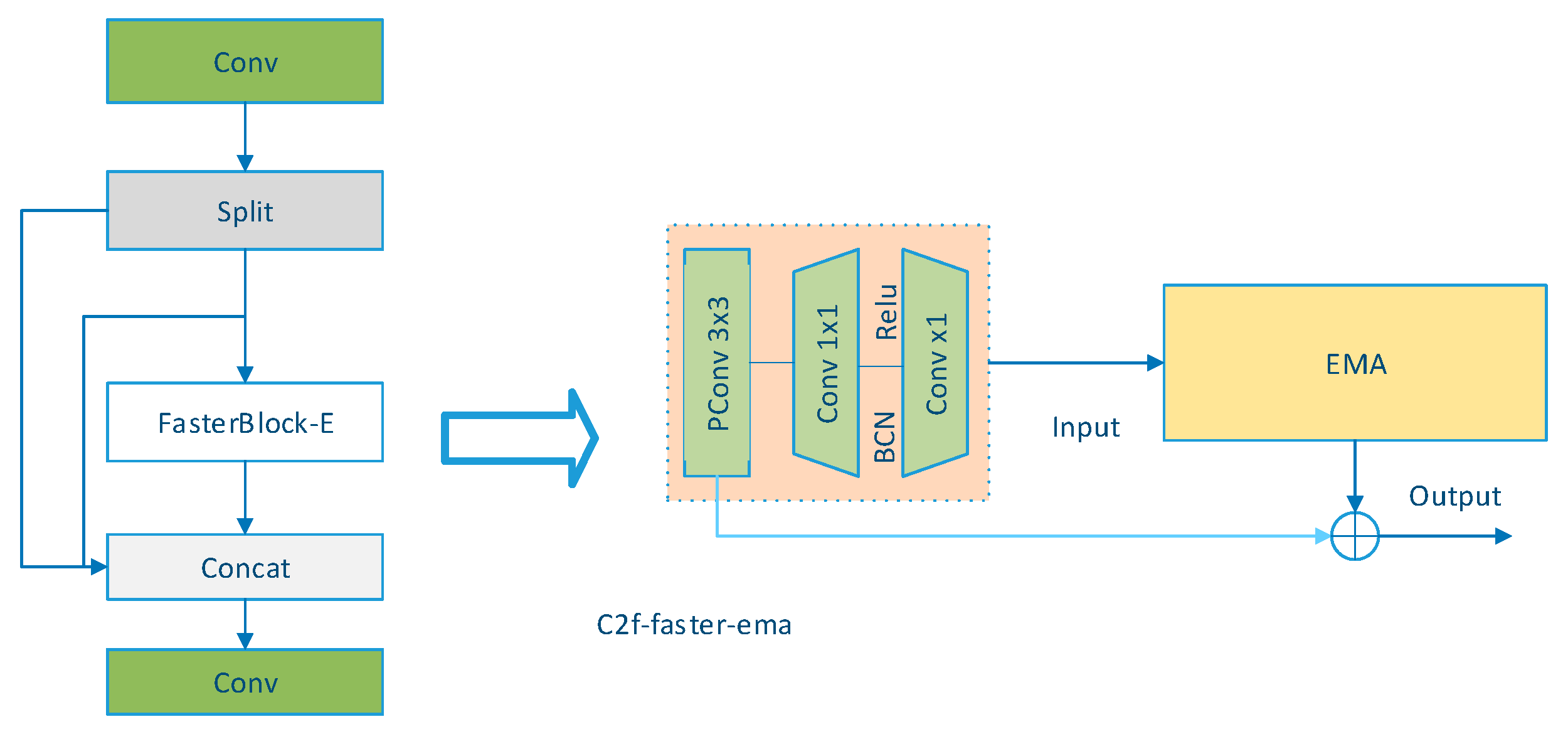
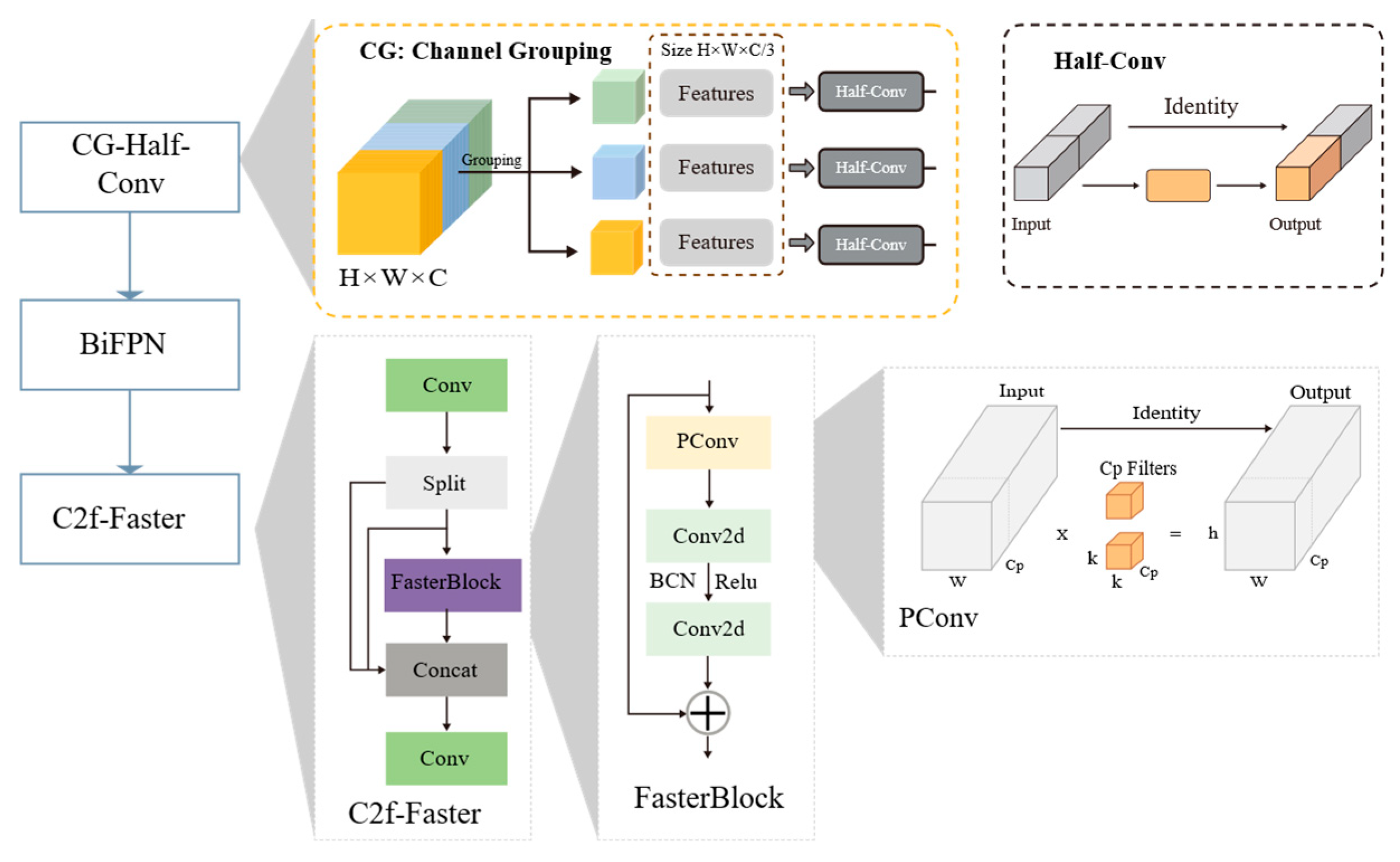
2.3.1. Architectural Optimization for Lightweight Detection
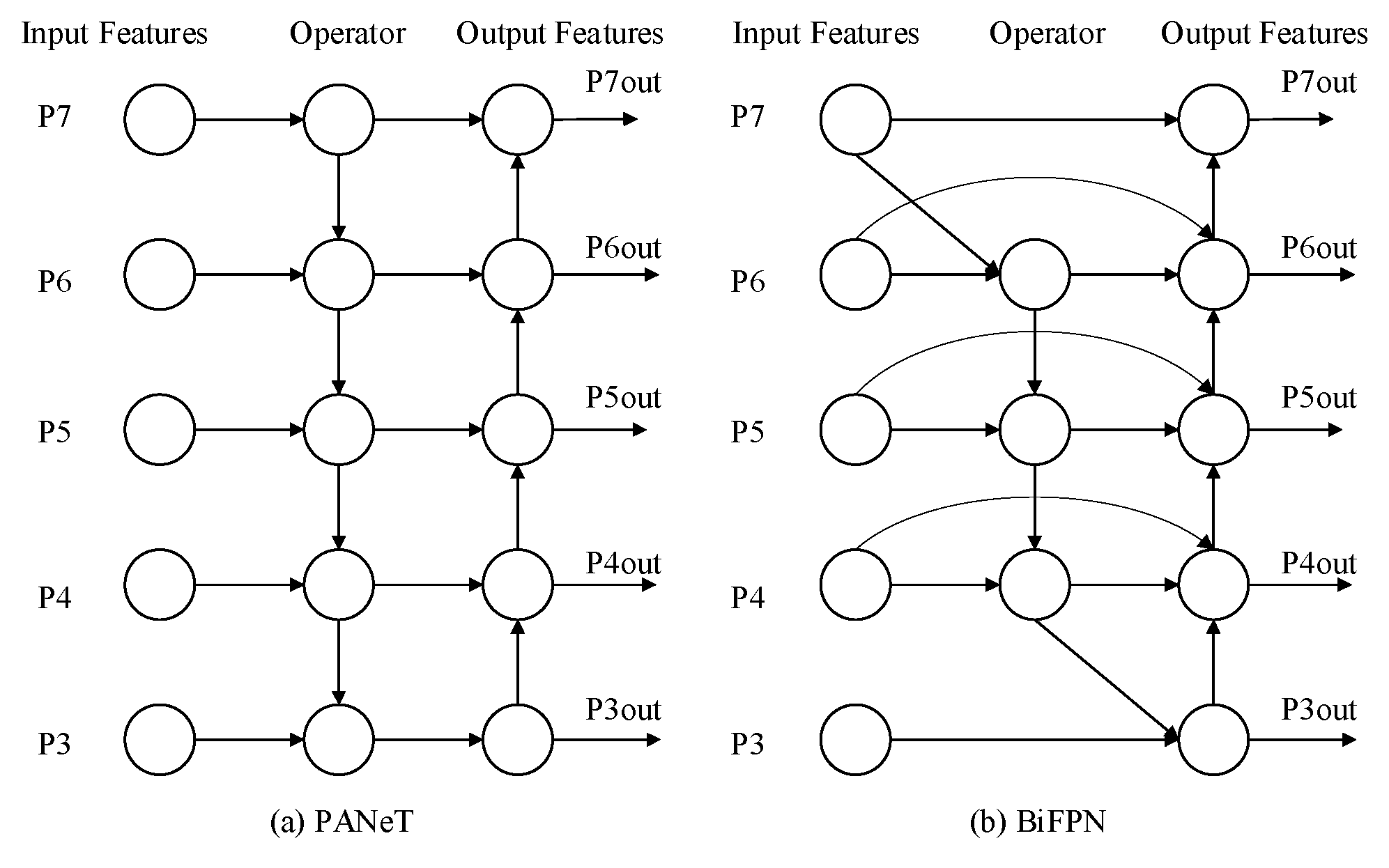
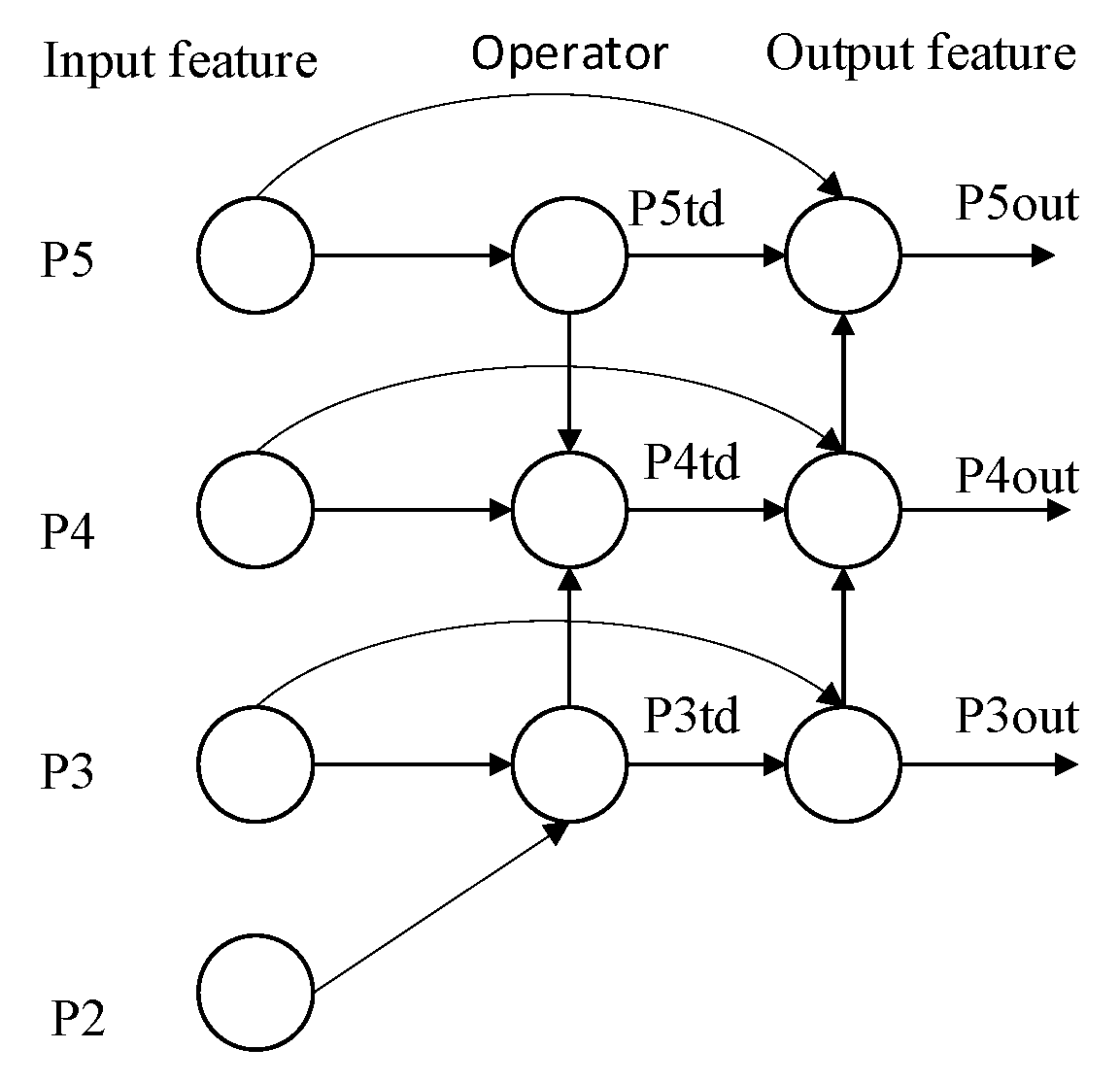
2.3.2. Enhancement of the Neck Network
2.3.3. Improve The Loss Function
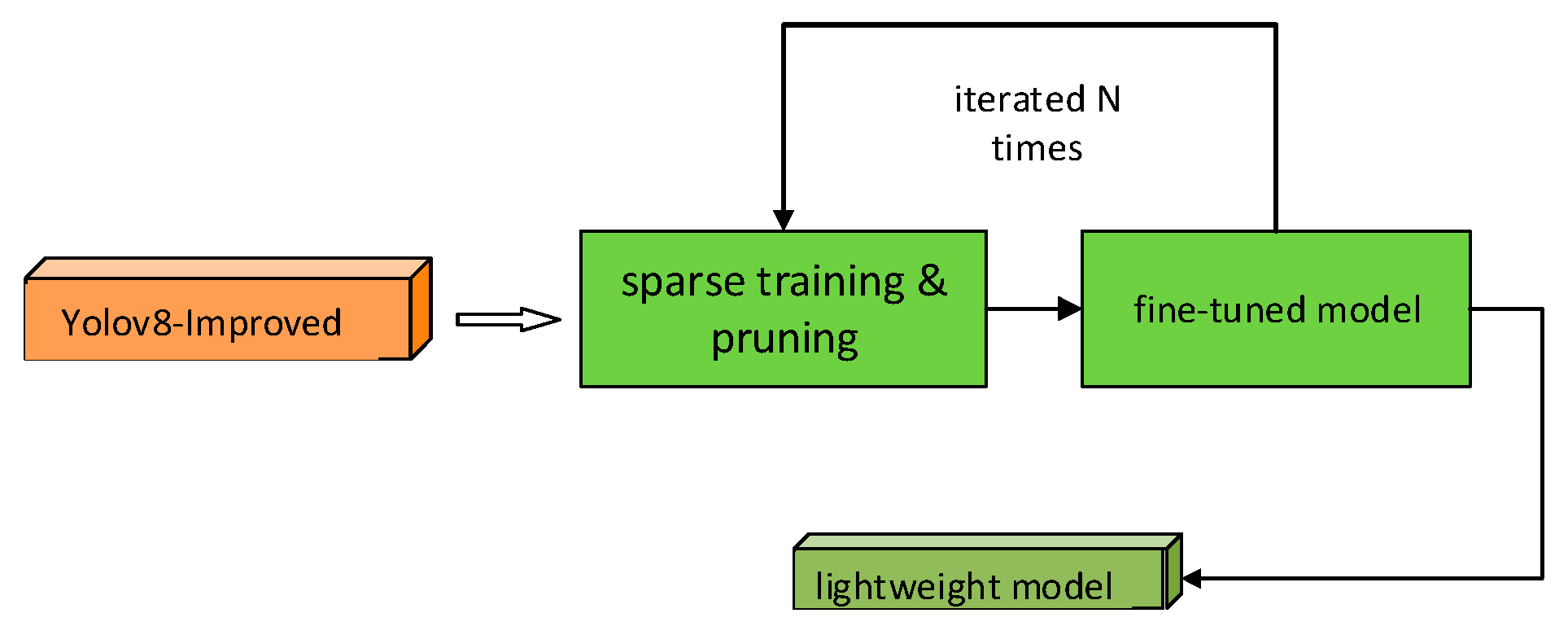
2.4. Pruning-Based Lightweighting Improvement
2.4.1. Model Pruning
2.4.2. YOLOv8s-Improved Pruning Algorithm Design
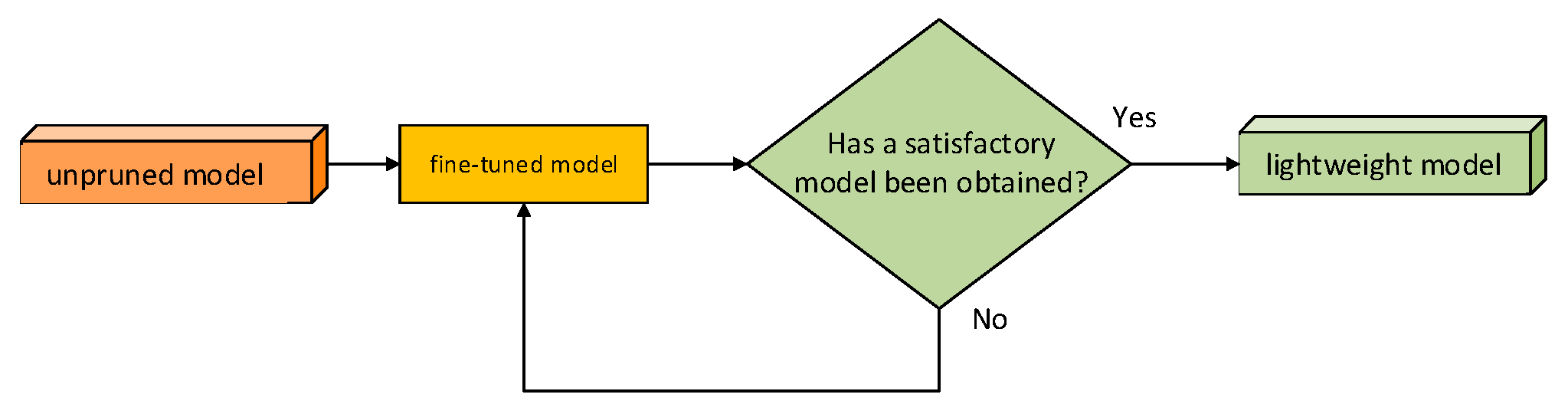
2.4.3. Pruning Model Fine-Tuning
2.5. Evaluation Metrics
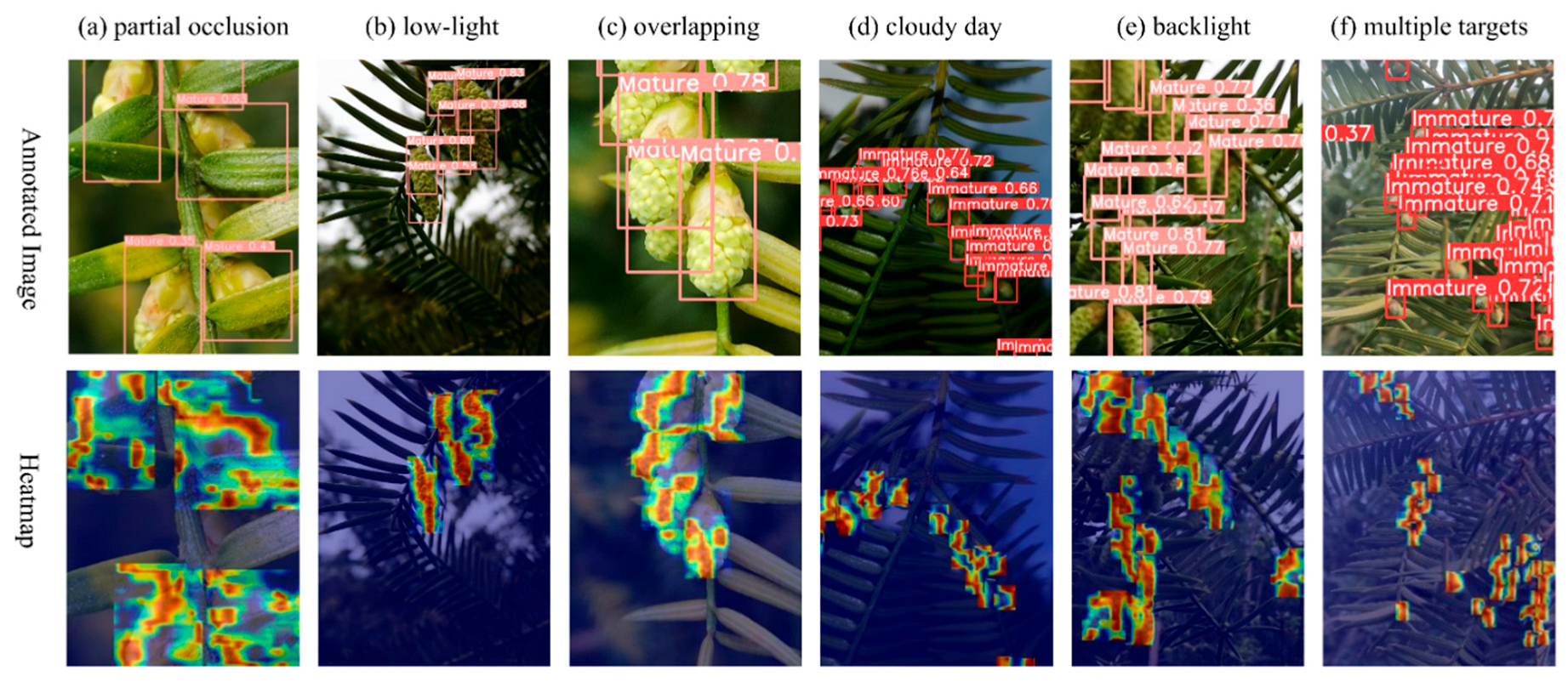
3. Results and Analysis
3.1. Experimental and Parameter Settings
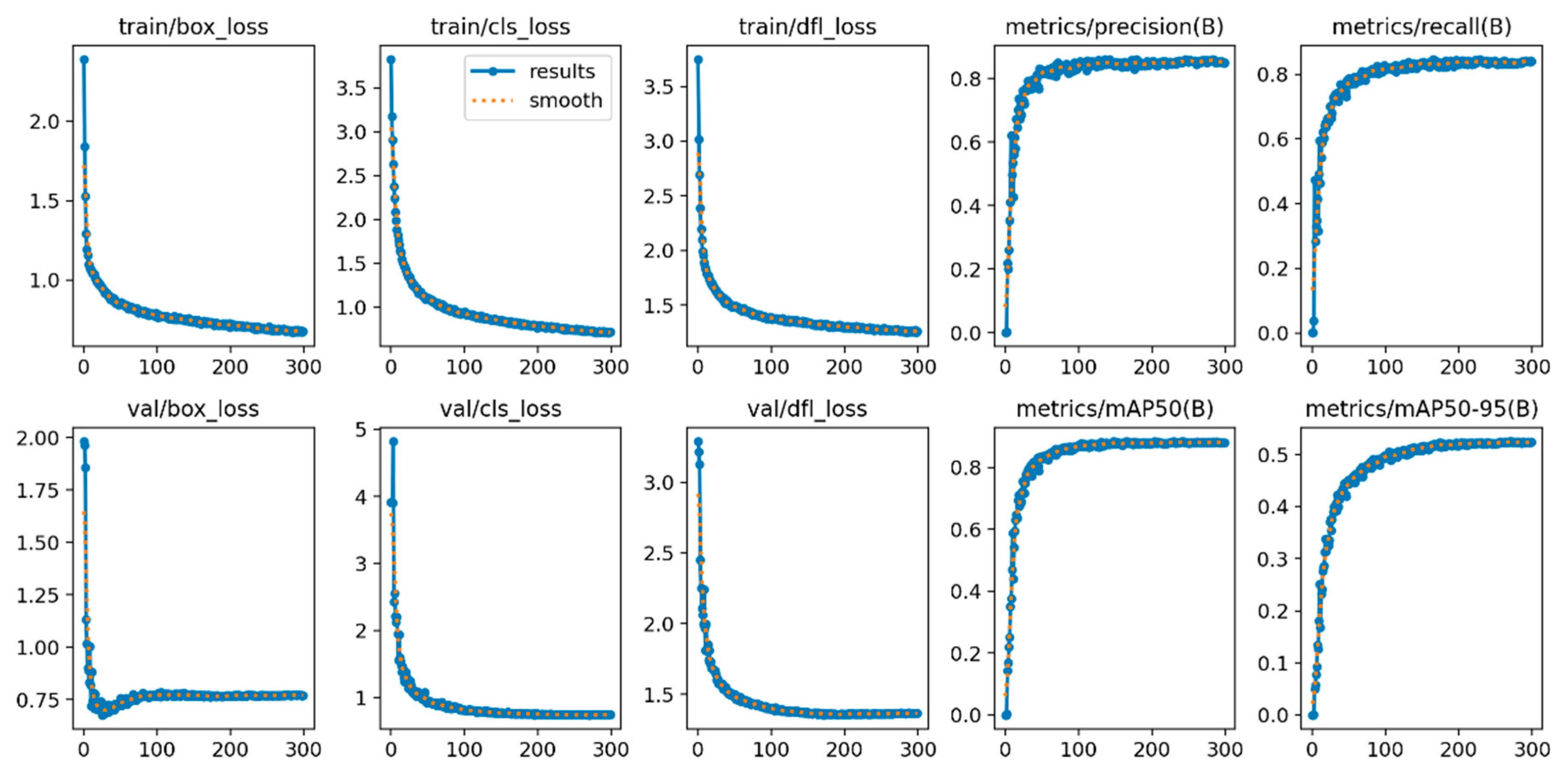
3.2. Analysis of Training Dynamics
3.3. Ablation Experiments
3.4. Comparison of Attention Mechanisms
3.5. Comparison of Loss Functions
3.6. Sparse Training Experimental Comparative Analysis
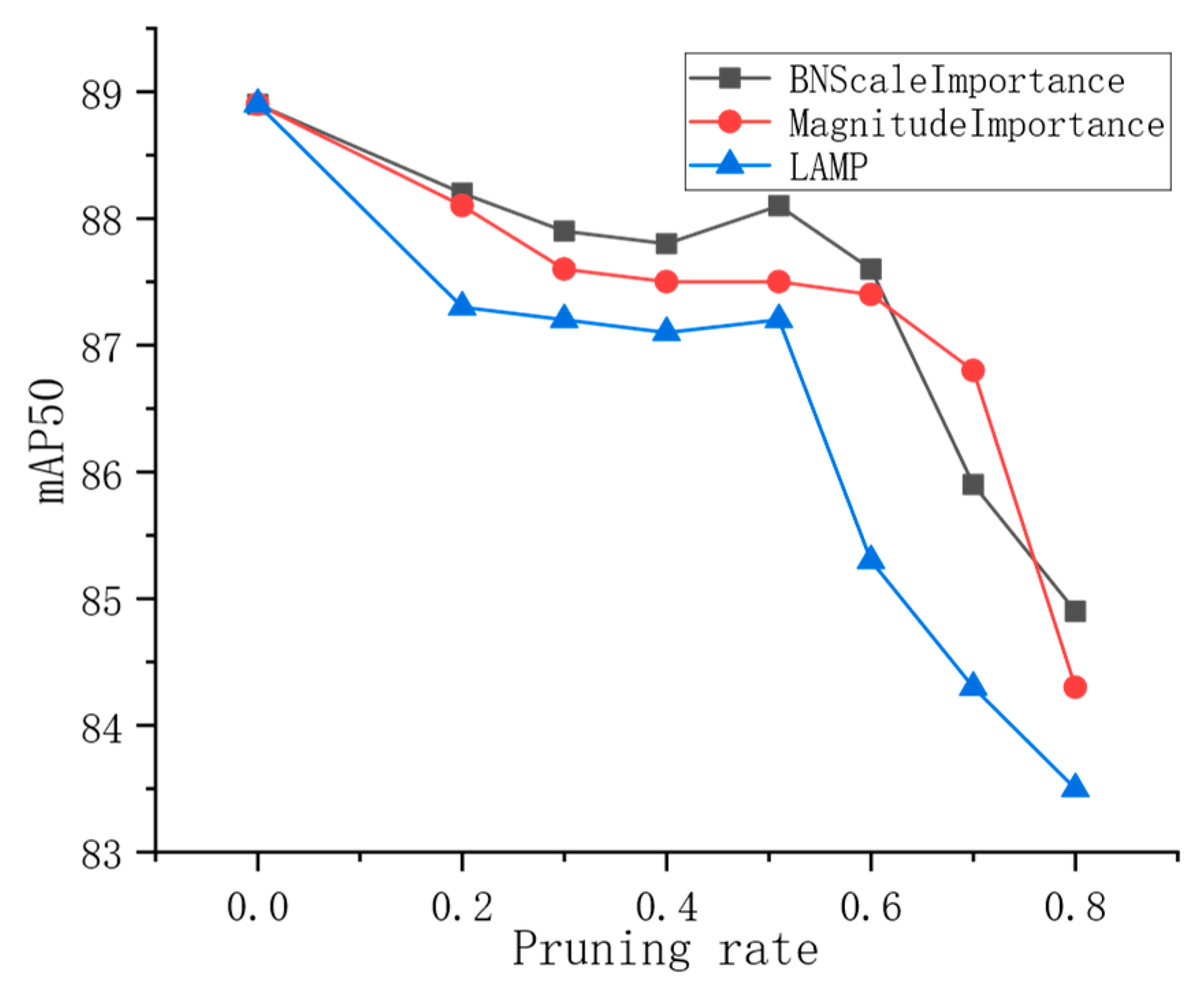
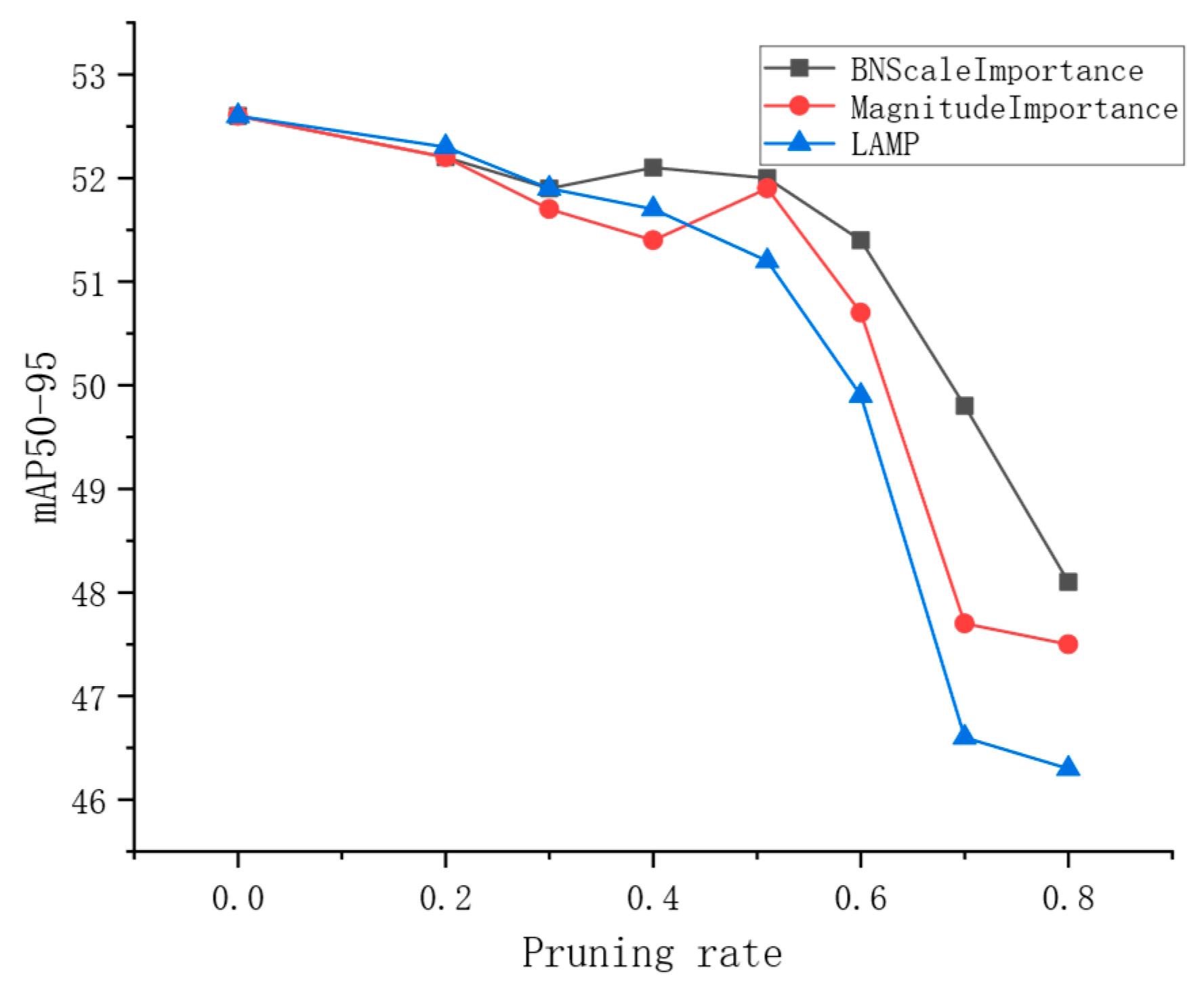
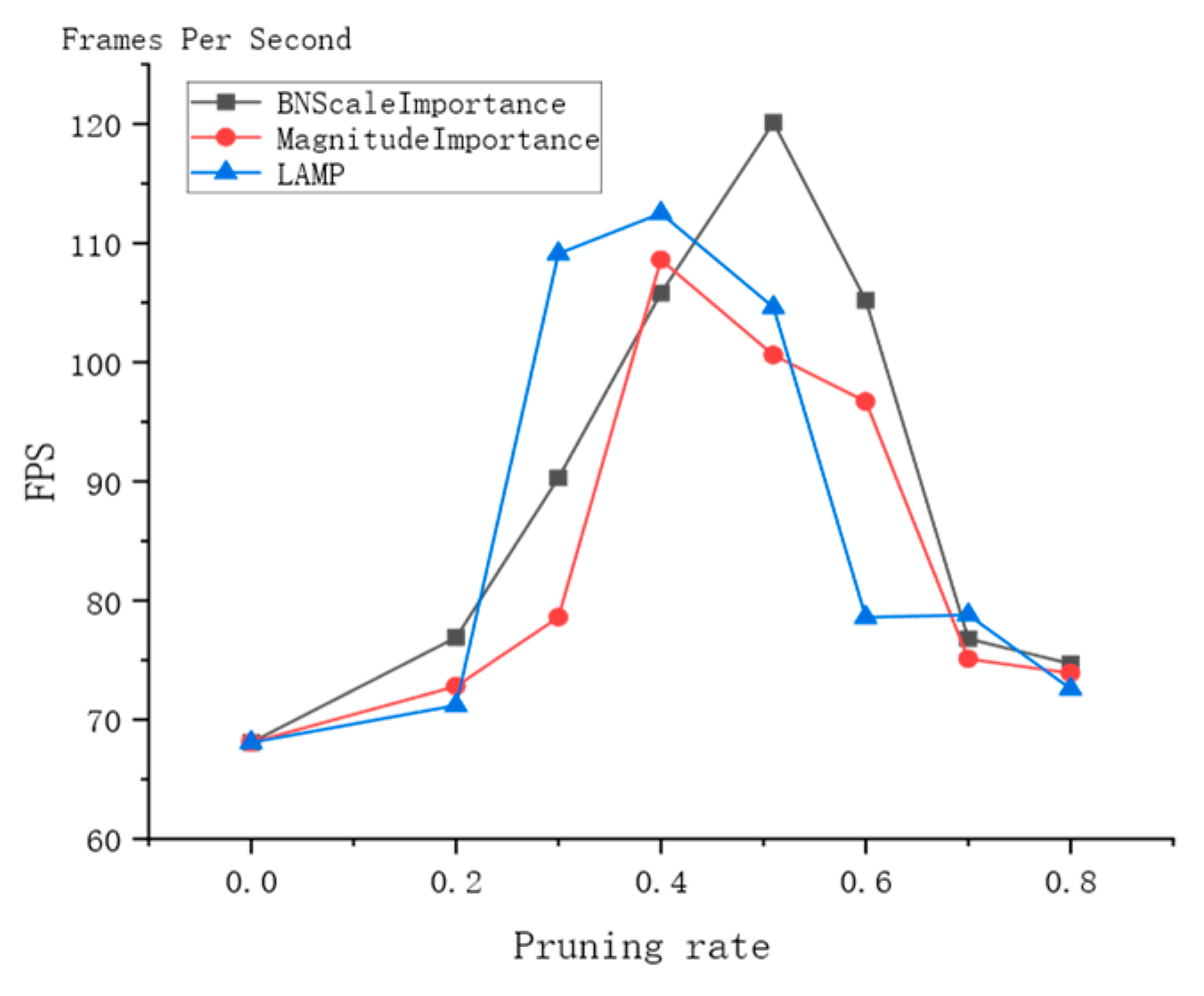
3.7. Model Pruning Experiment
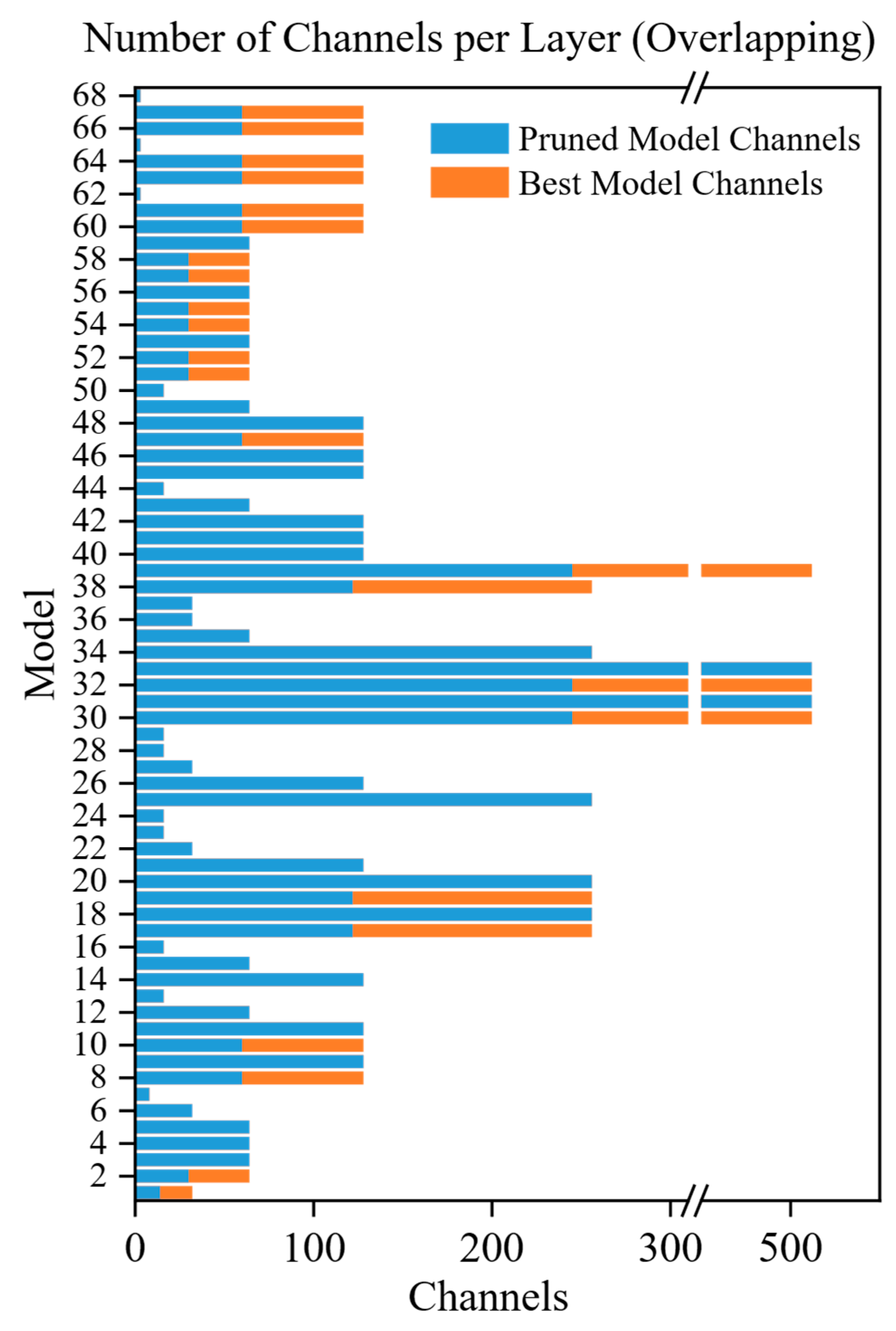
3.8. Analysis of Pruning Effects
3.9. Comparison of Different Advanced Detection Algorithms
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Li, Y.; Wang, R.; Ji, H.; Lu, C.; Su, X. Chinese Torreya Grandis Cv.Merrillii Seed Oil Affects Obesity through Accumulation of Sciadonic Acid and Altering the Composition of Gut Microbiota. Food Science and Human Wellness 2022, 11, 58–67.
- Chen, X.; Niu, J. Evaluating the Adaptation of Chinese Torreya Plantations to Climate Change. Atmosphere 2020, 11. [CrossRef]
- Chen; Jin Review of Cultivation and Development of Chinese Torreya in China. Forests, Trees and Livelihoods 2019, 28, 68–78.
- Hu, S.; Wang, C.; Zhang, R.; Gao, Y.; Li, K.; Shen, J. Optimizing Pollen Germination and Subcellular Dynamics in Pollen Tube of Torreya Grandis. Plant science : an international journal of experimental plant biology 2024, 348, 112227. [CrossRef]
- Chen, W.; Jiang, B.; Zeng, H.; Liu, Z.; Chen, W.; Zheng, S.; Wu, J.; Lou, H. Molecular Regulatory Mechanisms of Staminate Strobilus Development and Dehiscence in Torreya Grandis. Plant physiology 2024. [CrossRef]
- Liu, L.; Li, Z.; Lan, Y.; Shi, Y.; Cui, Y. Design of a Tomato Classifier Based on Machine Vision. PLoS ONE 2019, 14, e0219803–e0219803.
- Guo, Q.; Chen, Y.; Tang, Y.; Zhuang, J.; He, Y.; Hou, C.; Chu, X.; Zhong, Z.; Luo, S. Lychee Fruit Detection Based on Monocular Machine Vision in Orchard Environment. Sensors 2019, 19, 4091–4091. [CrossRef]
- Xiao, B.; Nguyen, M.; Yan, W.Q. Fruit Ripeness Identification Using YOLOv8 Model. Multimed Tools Appl 2023, 83, 28039–28056. [CrossRef]
- Cometa, L.M.A.; Garcia, R.K.T.; Latina, M.A.E. Real-Time Visual Identification System to Assess Maturity, Size, and Defects in Dragon Fruits. Engineering Proceedings 2025, 92. [CrossRef]
- Zhu, X.; Chen, F.; Zheng, Y.; Chen, C.; Peng, X. Detection of Camellia Oleifera Fruit Maturity in Orchards Based on Modified Lightweight YOLO. Computers and Electronics in Agriculture 2024, 226, 109471–109471.
- Trinh, T.H.; Nguyen, H.H.C. Implementation of YOLOv5 for Real-Time Maturity Detection and Identification of Pineapples. TS 2023, 40, 1445–1455. [CrossRef]
- Chen, Y.; Xu, H.; Chang, P.; Huang, Y.; Zhong, F.; Jia, Q.; Chen, L.; Zhong, H.; Liu, S. CES-YOLOv8: Strawberry Maturity Detection Based on the Improved YOLOv8. Agronomy 2024, 14, 1353–1353. [CrossRef]
- Sun, H.; Ren, R.; Zhang, S.; Tan, C.; Jing, J. Maturity Detection of ‘Huping’ Jujube Fruits in Natural Environment Using YOLO-FHLD. Smart Agricultural Technology 2024, 9, 100670–100670. [CrossRef]
- Chen, W.; Jiang, B.; Zeng, H.; Liu, Z.; Chen, W.; Zheng, S.; Wu, J.; Lou, H. Molecular Regulatory Mechanisms of Staminate Strobilus Development and Dehiscence in Torreya Grandis. Plant Physiology 2024, 195, 534–551. [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. CoRR 2015, abs/1506.02640.
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization 2015.
- Wang, C.-Y.; Mark Liao, H.-Y.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2020; pp. 1571–1580.
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection 2020.
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023; pp. 12021–12031.
- Lang, C.; Yu, X.; Rong, X. LSDNet: A Lightweight Ship Detection Network with Improved YOLOv7. Research Square 2023. [CrossRef]
- Liu, G.; Shih, K.J.; Wang, T.-C.; Reda, F.A.; Sapra, K.; Yu, Z.; Tao, A.; Catanzaro, B. Partial Convolution Based Padding 2018.
- Liu, G.; Dundar, A.; Shih, K.J.; Wang, T.-C.; Reda, F.A.; Sapra, K.; Yu, Z.; Yang, X.; Tao, A.; Catanzaro, B. Partial Convolution for Padding, Inpainting, and Image Synthesis. IEEE Transactions on Pattern Analysis and Machine Intelligence 2023, 45, 6096–6110. [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE, June 2023; pp. 1–5.
- Khalili, B.; Smyth, A.W. SOD-YOLOv8 -- Enhancing YOLOv8 for Small Object Detection in Traffic Scenes 2024.
- Sun, Y.; Jiang, M.; Guo, H.; Zhang, L.; Yao, J.; Wu, F.; Wu, G. Multiscale Tea Disease Detection with Channel–Spatial Attention. Sustainability 2024, 16. [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation 2018.
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection 2020.
- Liu, C.; Min, W.; Song, J.; Yang, Y.; Sheng, G.; Yao, T.; Wang, L.; Jiang, S. Channel Grouping Vision Transformer for Lightweight Fruit and Vegetable Recognition. Expert Systems with Applications 2025, 292, 128636. [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression 2019.
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv preprint arXiv:2301.10051 2023.
- Evci, U.; Gale, T.; Menick, J.; Castro, P.S.; Elsen, E. Rigging the Lottery: Making All Tickets Winners 2021.
- Lee, J.; Park, S.; Mo, S.; Ahn, S.; Shin, J. Layer-Adaptive Sparsity for the Magnitude-Based Pruning 2021.
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming 2017.
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets 2017.
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks 2020.
- Lee, Y.; Park, J. CenterMask : Real-Time Anchor-Free Instance Segmentation 2020.
- Lau, K.W.; Po, L.-M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN 2023.
- Xu, W.; Wan, Y. ELA: Efficient Local Attention for Deep Convolutional Neural Networks 2024.
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design 2021.
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection 2022.
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression 2022.
- Zhang, H.; Zhang, S. Shape-IoU: More Accurate Metric Considering Bounding Box Shape and Scale 2024.
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression 2019.
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression 2019.
- Ma, S.; Xu, Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression 2023.

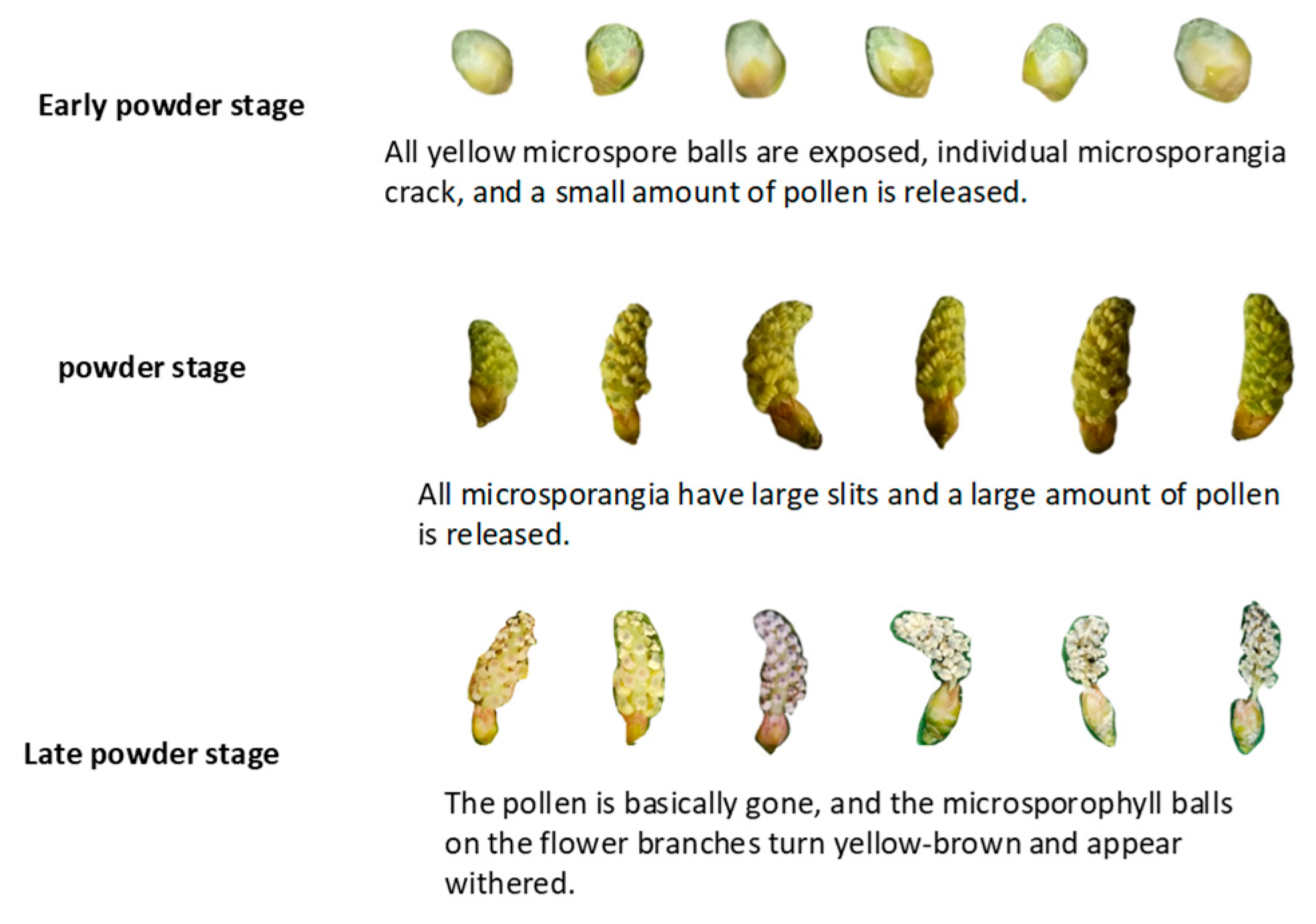


| Category | Train | Val | Test | Total |
|---|---|---|---|---|
| Early powder stage (immature) | 4808 | 601 | 601 | 6010 |
| Powder stage(mature) | 4984 | 623 | 623 | 6230 |
| Late powder stage(overripe) | 4835 | 604 | 604 | 6043 |
| Configuration Name | Version Information |
|---|---|
| CPU | CPU Xeon(R) Platinum 8362 14-core |
| GPU | NVIDIA GeForce RTX 4090 24G |
| Data Disk | 100G |
| Memory | 64G |
| Operating System | ubuntu22.04 |
| Development Language | Python3.8 |
| CUDA | 11.8 |
| PyTorch | 2.0.0 |
| Hyperparameter | Value |
|---|---|
| Epochs | 300 |
| Learning rate | 0.001 |
| Batch size | 16 |
| Input size | 640×640 |
| Optimizer | AdamW |
| Weight recay rate | 0.005 |
| Close_mosaic | 10 |
| Exp | NO | C2f-f | EMA | GSC-BiFPN | P(%) | R(%) | F1(%) | mAP50(%) | Weight | GFLOPs |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 1 | 85.1 | 81.5 | 83.26 | 86.3 | 22.5M | 28.8 | |||
| +C2f-f | 2 | √ | 84.9 | 84.3 | 84.60 | 88.3 | 16.9M | 21.4 | ||
| +EMA | 3 | √ | 84.1 | 84.7 | 84.40 | 88.1 | 22.9M | 29.6 | ||
| + GSC-BiFPN | 4 | √ | 85.6 | 82.5 | 84.02 | 88.3 | 15.1M | 25.2 | ||
| C2f-f +EMA | 5 | √ | √ | 85.7 | 84.4 | 85.04 | 88.9 | 17.0M | 22.0 | |
| C2f-f+ GSC-BiFPN | 6 | √ | √ | 85.6 | 84.4 | 85.00 | 88.5 | 10.34M | 17.5 | |
| EMA+ GSC-BiFPN | 7 | √ | √ | 84.5 | 83.6 | 84.04 | 88.4 | 15.4M | 25.8 | |
| All | 8 | √ | √ | √ | 85.5 | 84.9 | 85.20 | 88.9 | 10.32M | 17.5 |
| Attention | P(%) | R(%) | Map50(%) | mAP50-95(%) | InfTime@GPU | InfTime@CPU | Size/MB | Parameters |
|---|---|---|---|---|---|---|---|---|
| ECA [35] | 85.9 | 84.1 | 88.9 | 52.6 | 8.9 ms | 78 ms | 10.35 | 5754053 |
| EMA | 85.3 | 84.9 | 88.9 | 52.5 | 4.0 ms | 72.8 ms | 10.32 | 5295909 |
| ESE [36] | 84.6 | 84.9 | 88.3 | 52.3 | 9.7 ms | 76.1 ms | 11.0 | 5396165 |
| LSKA [37] | 84.2 | 84.7 | 88.5 | 52.6 | 4.7 ms | 75.8 ms | 11.0 | 5387973 |
| ELA [38] | 85.3 | 83.0 | 88.4 | 52.3 | 5.5 ms | 77.3 ms | 12.2 | 5978821 |
| CAA [39] | 85.7 | 83.7 | 88.9 | 52.8 | 4.7 ms | 71.4 ms | 11.3 | 5490213 |
| Loss | P(%) | R(%) | mAP50(%) | mAP50-95(%) |
|---|---|---|---|---|
| SIoU [41] | 85.4 | 84.2 | 88.3 | 52.4 |
| shape_iou [42] | 85.8 | 83.4 | 88.4 | 52.7 |
| GIoU [43] | 84.3 | 84.6 | 88.7 | 52.8 |
| DIoU [44] | 84.8 | 84.4 | 88.5 | 52.1 |
| MDPIOU [45] | 84.3 | 84.6 | 88.5 | 52.0 |
| CIoU [44] | 85.2 | 84.4 | 88.7 | 52.3 |
| Wiou | 85.3 | 84.9 | 88.9 | 52.5 |
| Network | experiment | λ | P(%) | R(%) | mAP50(%) | Weight | GFLOPs |
|---|---|---|---|---|---|---|---|
| GFM-YOLO | 1 | 0.0005 | 84.9 | 84.2 | 88.5 | 10.32M | 17.5 |
| 2 | 0.001 | 84.3 | 83.8 | 88.3 | 10.32M | 17.5 | |
| 3 | 0.005 | 84.8 | 83.8 | 88.4 | 10.32M | 17.5 | |
| 4 | 0.01 | 84.9 | 84.4 | 88.5 | 10.32M | 17.5 |
| Model name | P(%) | R(%) | mAP50(%) | mAP50-95(%) | Cpu (ms) |
Gpu (ms) |
Fps/Gpu | GFLOPs | Parameters | Model size |
|---|---|---|---|---|---|---|---|---|---|---|
| Yolov4-tiny | 73.2 | 58.8 | 62 | 26.3 | 12.2 | 5.40 | 184 | 69.5 | 60.5×106 | 22.49 M |
| Yolov4 | 79.4 | 89.2 | 85.1 | 38.3 | 124 | 11.3 | 87 | 60.5 | 64.4×106 | 244.4 M |
| Yolov5s | 85.8 | 81.2 | 85.6 | 51.7 | 39.1 | 6.60 | 152 | 16.0 | 15.8×106 | 14.4 M |
| ours | 84.7 | 83.5 | 88.2 | 51.5 | 55.3 | 8.30 | 120 | 8.7 | 2.20×106 | 4.44 M |
| Yolov7-tiny | 89.1 | 71.8 | 82.9 | 35.1 | 42.6 | 7.30 | 137 | 13.2 | 6.02×106 | 23.1 M |
| Yolov8s | 85.1 | 81.5 | 86.2 | 52.0 | 60.3 | 12.8 | 77.8 | 28.7 | 11.1×106 | 21.4 M |
| Yolov8s-c2f-faster | 85.5 | 84.3 | 88.9 | 52.5 | 43.7 | 15.1 | 66 | 17.5 | 5.29×106 | 10.32 M |
| Yolov8s-fasernet | 85.7 | 84.6 | 86.8 | 50.9 | 51.8 | 8.91 | 112 | 17.9 | 6.55×106 | 12.7 M |
| Yolov10s | 84.4 | 83.1 | 88.2 | 52.6 | 52.6 | 8.90 | 80 | 24.8 | 8.0×106 | 21.4 M |
| RT-DETR-l | 81.6 | 80.7 | 83.4 | 49.3 | 263 | 33.3 | 30 | 100.6 | 28.4×106 | 59.1 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



