Submitted:
11 January 2026
Posted:
14 January 2026
You are already at the latest version
Abstract
Three-dimensional medical image segmentation is critical for clinical applications, yet expert annotations are costly, driving the need for semi-supervised learning. Current semi-supervised methods struggle with robustly integrating diverse network architectures and managing pseudo-label quality, especially in complex three-dimensional scenarios. We propose Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg), a novel framework for semi-supervised three-dimensional medical image segmentation. DMED-Seg leverages a Diffusion Expert for global contextual understanding and a Convolutional Expert for fine-grained local detail extraction. A key innovation is the Dynamic Fusion Module, a lightweight Transformer that adaptively integrates multi-scale features and predictions from both experts based on their confidence. Complementing this, Confidence-Aware Consistency Learning enhances pseudo-label quality for unlabeled data using DFM-derived confidence, while Inter-expert Feature Alignment fosters synergistic learning between experts through contrastive loss. Extensive experiments on multiple public three-dimensional medical datasets demonstrate DMED-Seg consistently achieves superior performance across various labeled data ratios, outperforming state-of-the-art methods. Ablation studies confirm the efficacy of each proposed component, highlighting DMED-Seg as a highly effective and practical solution for three-dimensional medical image segmentation.
Keywords:
medical image segmentation
; semi-supervised learning
; 3D
; diffusion model
; multi-expert
1. Introduction
Three-dimensional (3D) medical image segmentation plays a pivotal role in modern healthcare, serving as a critical step in disease diagnosis, treatment planning, and prognosis assessment. Accurate segmentation of organs and lesions from 3D volumetric data, such as Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) scans, enables clinicians to gain detailed insights into patient anatomy and pathology. However, obtaining high-quality expert annotations for 3D medical images is an extraordinarily laborious, time-consuming, and expensive endeavor, especially for rare diseases or complex anatomical structures. This annotation bottleneck significantly hinders the development and deployment of fully supervised deep learning models, which typically demand vast amounts of meticulously labeled data to achieve robust performance. Semi-supervised learning (SSL) offers a promising avenue to alleviate this challenge by leveraging a small fraction of labeled data alongside abundant readily available unlabeled data, thereby improving model performance while reducing annotation costs.
Existing semi-supervised 3D medical segmentation methods often rely on paradigms such as consistency regularization [1], pseudo-labeling [2], and contrastive learning [3]. More recently, diffusion models [4], renowned for their remarkable capabilities in learning complex data distributions and generating high-quality images, have begun to be explored for segmentation tasks. Hybrid architectures combining diffusion models with convolutional neural networks (CNNs), such as Diff-CL [5], have demonstrated notable progress in semi-supervised scenarios by employing strategies like cross-pseudo-labeling supervision and high-frequency detail capturing. Despite these advancements, a significant challenge remains in effectively and adaptively integrating the distinct advantages of different network architectures. Specifically, seamlessly merging the global contextual understanding offered by diffusion models with the local detail-capturing prowess of CNNs, especially in regions with ambiguous boundaries or high heterogeneity, is crucial. Current fixed integration schemes often fall short, and their performance can be sensitive to the quality of pseudo-labels in uncertain regions. This research is motivated by the need for a more dynamic and adaptive information integration mechanism to further enhance the accuracy and robustness of semi-supervised 3D medical image segmentation.
Figure 1.
Research overview illustrating the motivation from labor-intensive 3D medical image annotation, the challenges in current semi-supervised learning regarding network integration and pseudo-label quality, and the conceptual framework of our proposed hybrid model that synergistically combines diffusion models and convolutional networks.
Figure 1.
Research overview illustrating the motivation from labor-intensive 3D medical image annotation, the challenges in current semi-supervised learning regarding network integration and pseudo-label quality, and the conceptual framework of our proposed hybrid model that synergistically combines diffusion models and convolutional networks.
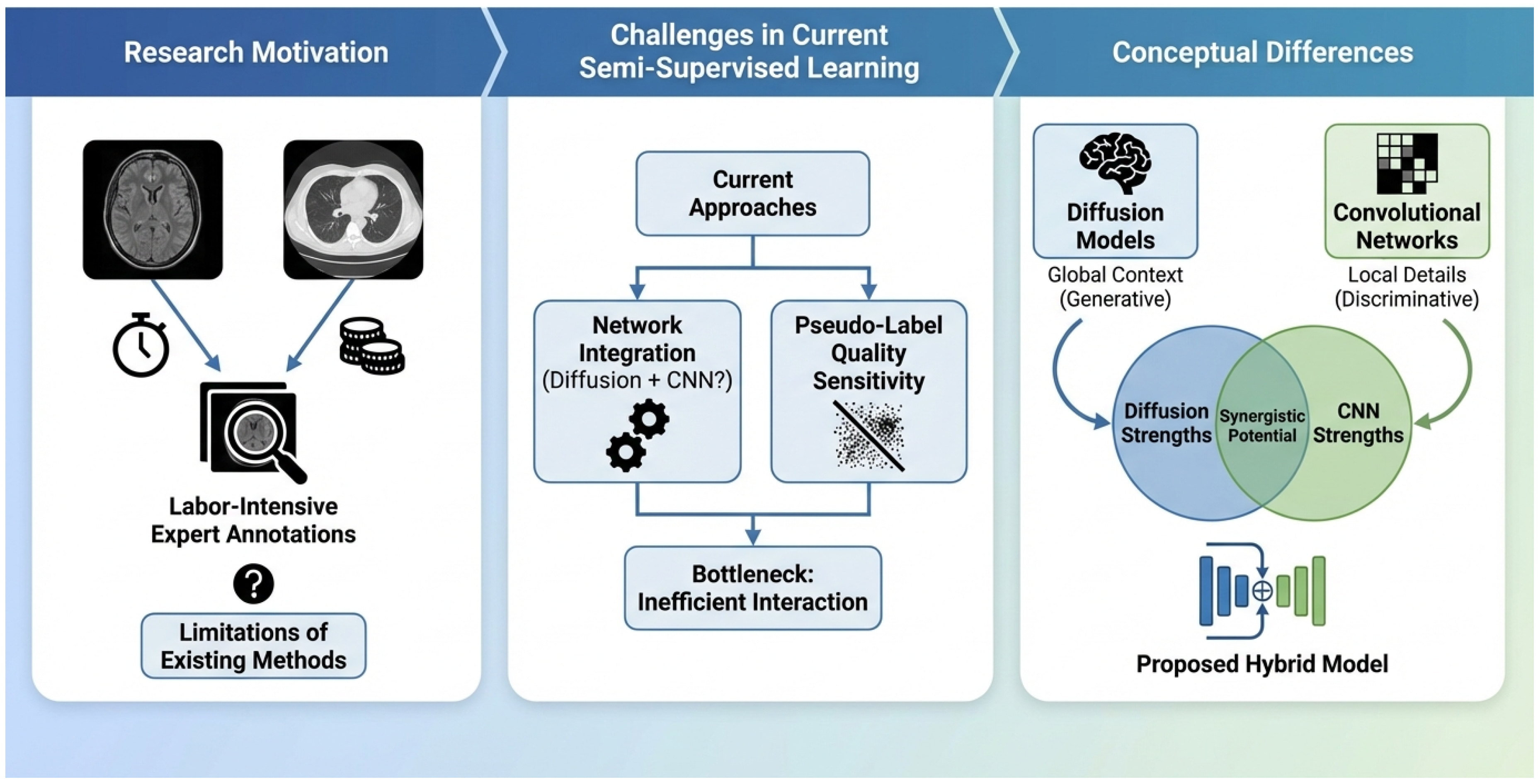
In response to these challenges, we propose a novel approach called Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg). Our method introduces a sophisticated framework designed to synergistically combine the strengths of different architectures through collaborative learning and an adaptive fusion strategy. DMED-Seg comprises a Diffusion Expert (DE) network, adept at capturing global contextual information using a 3D U-Net-like backbone integrated with a diffusion denoising process, and a Convolutional Expert (CE) network, which specializes in local detail extraction using a 3D V-Net architecture [6]. The core innovation of DMED-Seg lies in its Dynamic Fusion Module (DFM), a lightweight Transformer-based component that adaptively weights and fuses features and predictions from both experts at multiple scales, based on the local characteristics of the input and the experts’ confidence. Furthermore, to enhance the reliability of supervision signals, we introduce Confidence-Aware Consistency Learning (CACL), which selectively weights pseudo-labels based on DFM-derived prediction confidence. Complementing this, Inter-expert Feature Alignment (IEFA) loss, leveraging contrastive learning, promotes feature consistency between experts, particularly in challenging or uncertain regions, fostering better collaboration.
We extensively evaluate DMED-Seg on three widely used 3D medical image datasets: LA (Left Atrium) MRI, BraTS 2019 Brain Tumor MRI (T2-FLAIR), and NIH Pancreas CT. Our experimental setup rigorously adheres to standard semi-supervised protocols, comparing DMED-Seg against several state-of-the-art methods, including recent diffusion-based approaches. Utilizing standard quantitative metrics such as Dice Similarity Coefficient, Jaccard Index, Average Surface Distance (ASD), and 95% Hausdorff Distance (95HD), our results demonstrate that DMED-Seg consistently achieves superior performance across all datasets and varying annotation ratios. Specifically, DMED-Seg significantly outperforms existing methods, including Diff-CL, exhibiting higher Dice and Jaccard scores, and lower ASD and 95HD values, indicating more accurate segmentation with sharper, more precise boundaries.
Our main contributions are summarized as follows:
- We propose DMED-Seg, a novel dynamic multi-expert diffusion segmentation framework that synergistically combines a Diffusion Expert and a Convolutional Expert for robust semi-supervised 3D medical image segmentation.
- We introduce a Dynamic Fusion Module (DFM) based on a Transformer architecture, enabling adaptive, multi-scale integration of features and predictions from distinct experts, thereby optimizing information flow based on image content and expert confidence.
- We develop Confidence-Aware Consistency Learning (CACL) and Inter-expert Feature Alignment (IEFA) mechanisms to improve pseudo-label quality and enhance collaborative feature representation between experts in semi-supervised settings.
2. Related Work
2.1. Semi-Supervised 3D Medical Image Segmentation
3D medical image segmentation is vital for diagnosis and treatment, yet suffers from scarce labeled data due to expensive, time-consuming annotation requiring expert knowledge. This drives semi-supervised learning (SSL) to leverage both labeled and unlabeled data. Deep learning, especially volumetric deep learning [7], has advanced 3D medical image processing. The field generally tackles computational complexity and anisotropic voxel spacing for accurate anatomical delineation [8].
Beyond medical imaging, 3D computer vision faces similar challenges in autonomous driving, with advances in domain-adaptive LiDAR segmentation [9], multi-modal distillation for 3D object detection [10], and self-supervised depth estimation [11]. These techniques, often using game theory and uncertainty-aware prediction [12,13,14], are crucial for complex decision-making in dynamic environments. AI model advancements extend to applications needing robust reasoning across diverse data. In NLP, efforts focus on event correlation and event-pair relations within knowledge graphs [15,16,17]. Financial intelligence leverages LLMs for insights, early warnings, and causal credit risk assessment [18,19,20]. Digital image integrity is addressed by watermarking for tamper localization [21,22] and explainable forgery detection via multi-modal LLMs [23].
SSL bridges supervised and unsupervised methods by using both labeled and unlabeled data, often by "imputing" labels [24]. Self-training is a foundational SSL paradigm, where models iteratively generate pseudo-labels for unlabeled data and retrain [25]. Key SSL strategies include consistency regularization, which enforces similar outputs for perturbed inputs [26], exemplified by the mean teacher model using an EMA teacher for student training [27]. Pseudo-labeling generates confident predictions on unlabeled samples as "ground truth" for dataset augmentation [28]. In medical imaging, uncertainty estimation is vital for reliable SSL, quantifying prediction confidence [29] to filter pseudo-labels or guide learning. Integrating volumetric deep learning with SSL techniques like self-training, consistency regularization (e.g., mean teacher), pseudo-labeling, and uncertainty estimation is crucial for 3D medical image segmentation in data-scarce settings.
2.2. Diffusion Models and Multi-Expert Learning for Segmentation
Image segmentation has advanced with generative models and sophisticated architectures. Diffusion models have revolutionized generative AI, synthesizing high-quality data, with progress including prompt galleries for text-to-image models [4] and foundational explorations [30]. Denoising Diffusion Probabilistic Models (DDPMs) [31] are key, extending to segmentation tasks, e.g., interpreting Stable Diffusion’s cross-attention [32]. Multi-expert systems enhance performance by distributing tasks across specialized components, like Grouped-Query Attention (GQA) for Transformer inference [33]. The Transformer architecture, effective for complex relationships and long-range dependencies, is used in generative models and multi-expert systems, including medical applications like radiology report generation [34]. For complex segmentation, integrating information and global context is crucial; the Hi-Transformer [35] captures global context hierarchically. This principle of hierarchical modeling and efficient global context integration is highly relevant for coordinating multiple experts in segmentation, combining diffusion models’ high-fidelity generation with expert systems’ targeted processing to advance segmentation performance.
3. Method
In this section, we present the details of our proposed Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg) framework, meticulously designed for robust semi-supervised 3D medical image segmentation. DMED-Seg addresses the challenges of integrating diverse network architectures and enhancing pseudo-label quality by introducing a novel dynamic fusion mechanism and targeted consistency learning strategies.
3.1. Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg) Overview
The DMED-Seg framework, as illustrated in Figure 2, is built upon a multi-expert architecture consisting of two distinct segmentation experts: a Diffusion Expert (DE) network and a Convolutional Expert (CE) network. These experts process the input 3D medical images in parallel, focusing on different aspects of information. The DE is specialized in capturing global contextual and low-frequency semantic information through a diffusion denoising process, while the CE excels at extracting local details and high-frequency boundary information using a conventional convolutional pathway.
The core innovation lies in the Dynamic Fusion Module (DFM), which adaptively integrates the features and predictions generated by both experts. The DFM leverages a lightweight Transformer structure to learn region-specific weighting factors, allowing for flexible combination of expert outputs based on the input image characteristics and the perceived confidence of each expert. Furthermore, to effectively utilize unlabeled data in a semi-supervised setting, we introduce two key auxiliary learning mechanisms: Confidence-Aware Consistency Learning (CACL) and Inter-expert Feature Alignment (IEFA). CACL refines the quality of pseudo-labels by weighting them based on DFM-derived prediction confidence, while IEFA fosters synergistic learning between the experts by aligning their feature representations, especially in challenging regions.
3.2. Diffusion Expert (DE) Network
The Diffusion Expert (DE) network serves as the global context learner within DMED-Seg. Its primary role is to comprehend the overall structure and low-frequency semantic information of the 3D medical images. The DE adopts a 3D U-Net-like architecture as its backbone, which is inherently designed for volumetric data processing. Critically, this backbone is integrated with a diffusion model’s denoising process. During training, the DE is trained to predict the noise added to a diffused version of the ground truth segmentation mask or to directly predict the clean mask conditioned on the input image. This process allows the DE to learn the underlying data distribution of segmentation masks, making it robust to variations and capable of producing globally consistent predictions.
Specifically, the diffusion process involves a forward noising process that gradually adds Gaussian noise to a clean image over a series of T steps, transforming a data point (a segmentation mask) into a noisy version . The reverse process, which the DE learns, aims to reverse this noise injection, iteratively denoising to recover . This is achieved by training a neural network (the DE’s U-Net backbone) to predict the noise components or the clean sample given a noisy input and the current timestep t. The conditioning on the input 3D image allows the DE to generate a segmentation mask , where C is the number of classes, that is consistent with the image content. The architecture typically consists of downsampling encoder blocks to capture multi-scale features and upsampling decoder blocks that incorporate skip connections, characteristic of U-Net variants. The diffusion process within the DE enables it to gradually refine its predictions, moving from noisy representations to precise segmentation maps, thereby emphasizing holistic structural integrity.
3.3. Convolutional Expert (CE) Network
Complementing the DE, the Convolutional Expert (CE) network is designed as the local detail learner. It specializes in extracting high-frequency information, such as fine boundaries, textures, and small anatomical structures, which are critical for precise segmentation. The CE utilizes a classic 3D V-Net architecture, a well-established convolutional neural network specifically tailored for 3D image segmentation tasks.
The V-Net architecture features a symmetric encoder-decoder structure with volumetric convolutions and spatial downsampling/upsampling operations. The encoder path progressively extracts hierarchical features by stacking convolutional layers and downsampling (e.g., using strided convolutions or pooling), capturing increasingly abstract representations. The decoder path then reconstructs the segmentation mask by upsampling and concatenating features from corresponding encoder layers via skip connections. This design allows the CE to build a rich hierarchy of local features, effectively capturing fine-grained details and local variations in the input image . The output of the CE network is a local segmentation prediction . While V-Net is highly proficient in local feature extraction, its capacity for global contextual understanding might be limited compared to models leveraging diffusion processes. Therefore, the synergistic combination with the DE becomes crucial.
3.4. Dynamic Fusion Module (DFM)
The Dynamic Fusion Module (DFM) represents a key innovation of DMED-Seg, designed to adaptively merge the strengths of the DE and CE networks. The DFM takes as input the multi-scale feature maps from both experts, denoted as and , where N is the number of scales (e.g., from the encoder/decoder stages). It then generates dynamic, spatially-variant weighting maps to combine their predictions.
The DFM is implemented as a lightweight Transformer structure. This Transformer processes concatenated features from both experts at different scales, enabling it to learn complex relationships and inter-dependencies. Specifically, at each scale s, features and are processed through linear projections to generate query, key, and value vectors. An attention mechanism then computes a similarity score between features from different experts or different regions, allowing the DFM to identify which expert’s features are more reliable or relevant for a given spatial location. For each spatial location and at each scale s, the DFM computes a fusion weight for the DE and for the CE. These weights are generated by a softmax operation over the attention scores, ensuring they are positive and sum to unity: .
The final fused feature representation at scale s is obtained as a weighted sum of the expert features:
After obtaining the fused features across scales, a segmentation head (e.g., a 1x1x1 convolution followed by a softmax activation) generates the final fused prediction . The DFM’s dynamic nature allows it to prioritize the DE’s global context in regions with ambiguous boundaries or large structures, while leaning towards the CE’s fine-grained details in sharp boundary regions, thereby optimizing the combined output. Crucially, the DFM also outputs a prediction confidence map based on the consistency and agreement between the experts’ outputs and its own fused prediction. For instance, can be derived from the inverse of the entropy of the DFM’s probability distribution at , or from the spatial agreement between , , and . This confidence map is subsequently used in CACL.
3.5. Confidence-Aware Consistency Learning (CACL)
Traditional pseudo-labeling methods often suffer from error propagation when low-quality pseudo-labels are used for supervision. To mitigate this, we introduce Confidence-Aware Consistency Learning (CACL). CACL leverages the prediction confidence map generated by the DFM to provide more reliable supervision for unlabeled data.
For an unlabeled input image , we first generate pseudo-labels by taking the argmax of the DFM’s fused probability prediction . Instead of applying uniform supervision, CACL assigns a spatially-variant weight to the pseudo-labels based on the DFM’s confidence map . Regions with high confidence (e.g., where is close to 1) are assigned higher weights, indicating more reliable pseudo-labels, while low-confidence regions receive reduced weights. Alternatively, a thresholding strategy can be employed where only pseudo-labels with confidence exceeding a predefined threshold (i.e., ) contribute to the consistency loss. This mechanism ensures that the model primarily learns from trustworthy pseudo-labels, improving the robustness of semi-supervised training.
The confidence-aware consistency loss, , for unlabeled data is formulated as:
where denotes a standard segmentation loss, typically a combination of Dice Loss and Cross-Entropy Loss, and is the soft probability prediction of the DFM at location for input . The confidence acts as a weighting factor, scaling the contribution of each voxel’s pseudo-label to the total loss based on its perceived reliability.
3.6. Inter-Expert Feature Alignment (IEFA)
To foster stronger collaboration and information sharing between the DE and CE networks, we introduce the Inter-expert Feature Alignment (IEFA) loss. This module aims to align the feature representations learned by the two distinct experts, particularly in regions where their initial agreement might be low or where segmentation is challenging (i.e., regions identified as "uncertain" by the DFM). The rationale is that if features from different experts are semantically aligned in difficult regions, their combined output will be more robust.
IEFA employs a contrastive learning approach to achieve feature alignment. For a given input image , we extract feature vectors from a specific, intermediate layer of both the DE and CE networks, denoted as and at spatial location . The goal is to maximize the similarity between features from the same spatial location across different experts (positive pairs) while minimizing similarity with features from different spatial locations or other samples within the batch (negative pairs). This encourages both experts to learn a shared, canonical representation space.
The IEFA loss, , is formulated as:
where is a similarity metric, typically cosine similarity, is a temperature parameter that scales the arguments to the softmax function, and NegativeSet contains feature vectors for within the same sample, as well as feature vectors from other samples in the mini-batch, to serve as negative pairs. This contrastive mechanism encourages the latent feature spaces of both experts to converge for corresponding spatial locations, leading to more consistent and semantically rich feature representations. This alignment is particularly beneficial in anatomically critical or difficult-to-segment areas, thereby indirectly improving segmentation accuracy and the quality of predictions fed into the DFM.
3.7. Overall Objective Function
The total objective function for training DMED-Seg combines the supervised loss on labeled data, the confidence-aware consistency loss on unlabeled data, and the inter-expert feature alignment loss. For labeled data with ground truth masks , the supervised loss is computed on the DFM’s final fused probability output against the ground truth :
where is a combination of Dice Loss and Cross-Entropy Loss, commonly used for medical image segmentation to handle class imbalance and pixel-wise classification.
The total loss is then expressed as a weighted sum of these three components:
Here, and are hyperparameters that balance the contribution of each loss term. These weights are typically determined through empirical tuning on a validation set. By optimizing this comprehensive objective, DMED-Seg learns to produce accurate and robust 3D medical image segmentations in a semi-supervised learning environment, effectively leveraging both labeled and unlabeled data while ensuring strong collaboration between its expert components.
4. Experiments
In this section, we detail the experimental setup, evaluate the quantitative performance of our proposed Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg) framework against state-of-the-art semi-supervised learning methods, and present an ablation study to validate the effectiveness of its key components. We also include a human evaluation to assess the clinical relevance of our segmentation results.
4.1. Experimental Setup
Our study focuses on the task of semi-supervised 3D medical image segmentation. The objective is to accurately segment specific organs or lesions using a limited set of labeled 3D volumetric data augmented by a large pool of unlabeled data.
Datasets and Data Partitioning: We utilize three publicly available 3D medical image datasets, adhering to the standard partitioning strategies employed in recent literature, including Diff-CL [5], to ensure fair comparison: The LA (Left Atrium) MRI dataset comprises 100 3D contrast-enhanced MR volumes. We follow an 80-volume training set and 20-volume testing set split. Preprocessing involves cropping and intensity normalization. The BraTS 2019 Brain Tumor MRI dataset consists of 335 pre-operative multi-modal MRI scans. We specifically use the T2-FLAIR modality for whole tumor segmentation. The dataset is partitioned into 250 volumes for training, 25 for validation, and 60 for testing. Images undergo resampling as part of preprocessing. The NIH Pancreas CT dataset features 82 enhanced abdominal CT volumes. The split is 62 volumes for training and 20 for testing. Preprocessing includes Hounsfield Unit (HU) windowing and cropping.
Evaluation Metrics: To quantitatively assess segmentation performance, we employ four widely accepted metrics: The Dice Similarity Coefficient (DSC) measures the overlap between predicted and ground truth segmentation. Higher values indicate better performance. The Jaccard Index (IoU) is similar to Dice, quantifying the intersection over union. Higher values are preferable. The Average Surface Distance (ASD) measures the average distance between the boundaries of predicted and ground truth segmentations. Lower values signify more accurate boundaries. The 95% Hausdorff Distance (95HD) represents the 95th percentile of the maximum distance between the boundaries. Lower values indicate better boundary agreement and robustness to outliers.
Training Settings: Semi-supervised training is conducted by dividing the training set into small subsets of labeled data and larger subsets of unlabeled data. Specific ratios are set for each dataset, such as 5% or 10% labeled data for LA MRI, 10% or 20% for BraTS, and 10% or 20% for Pancreas CT. The models are optimized using SGD with a momentum of 0.9 and a weight decay of 3e-5. Training typically runs for 300 epochs with an an initial learning rate of 0.01, employing a Gaussian warm-up scheduling strategy. A batch size of 4 is used across all experiments. Data augmentation techniques, including random cropping, random flipping, and random rotation, are applied during training to enhance model generalization.
4.2. Implementation Details
Our Diffusion Expert (DE) network is based on a 3D U-Net-like architecture, specifically adapted for the diffusion denoising process. The Convolutional Expert (CE) network employs the 3D V-Net architecture. The Dynamic Fusion Module (DFM) is implemented as a lightweight Transformer with 2 attention layers and 4 attention heads, processing features from 4 different scales. The prediction confidence map for Confidence-Aware Consistency Learning (CACL) is derived from the inverse of the DFM’s output entropy. For Inter-expert Feature Alignment (IEFA), we extract features from the deepest encoder layer of both DE and CE. The segmentation loss is a combination of Dice Loss and Cross-Entropy Loss (weighted 1:1). Hyperparameters for the total loss are set as and , determined through validation on the BraTS dataset. All experiments are conducted on NVIDIA V100 GPUs using PyTorch.
4.3. Quantitative Results
We compare the performance of DMED-Seg against several baseline semi-supervised segmentation methods, including recent diffusion-based approaches. Table 1 summarizes the quantitative results on the three datasets across various labeled data percentages. The performance metrics are reported as mean ± standard deviation over three independent runs.
As shown in Table 1, DMED-Seg consistently achieves superior performance across all three 3D medical image datasets (LA MRI, BraTS, and Pancreas CT) and under different labeled data ratios. Specifically, DMED-Seg significantly outperforms all baseline methods, including the state-of-the-art Diff-CL [5], in terms of Dice and Jaccard coefficients. For instance, on LA MRI with 5% labeled data, DMED-Seg obtains a Dice of 89.80%, surpassing Diff-CL by nearly 1 percentage point. Similar improvements are observed on BraTS (10% labeled) and Pancreas CT (10% labeled), with DMED-Seg achieving Dice scores of 85.51% and 79.05%, respectively. Furthermore, DMED-Seg demonstrates lower 95HD and ASD values, indicating more precise boundary delineation and reduced segmentation errors, which are crucial for clinical applications. These results highlight the effectiveness of DMED-Seg’s dynamic multi-expert architecture, adaptive fusion mechanism, and robust semi-supervised learning strategies in leveraging limited labeled data.
4.4. Ablation Study
To thoroughly understand the contribution of each proposed component in DMED-Seg, we conduct an ablation study on the LA MRI dataset with 5% labeled data. Table 2 presents the performance of different model configurations.
From Table 2, we observe the following: A single Convolutional Expert (CE-only, based on V-Net) or Diffusion Expert (DE-only, U-Net with diffusion) trained with standard semi-supervised learning methods already provides reasonable performance. The DE-only model slightly outperforms the CE-only, suggesting the strong data distribution learning capabilities of diffusion models. A simple fixed averaging fusion of DE and CE predictions (DE + CE Fixed Averaging) improves performance over individual experts, demonstrating the benefit of combining diverse architectures. Introducing the Dynamic Fusion Module (DFM) leads to a significant performance boost. The Dice score increases from 87.50% to 88.65%, and boundary metrics (95HD, ASD) also improve substantially. This confirms that adaptively combining features based on their reliability and content-awareness is more effective than static fusion. Adding Confidence-Aware Consistency Learning (CACL) further enhances the model’s robustness and accuracy. With CACL, the Dice score rises to 89.20%, showcasing its ability to filter out low-quality pseudo-labels and provide more reliable supervision signals for unlabeled data. Incorporating Inter-expert Feature Alignment (IEFA) provides an additional gain, increasing the Dice to 89.35%. This highlights the importance of encouraging synergistic learning and consistent feature representations between the DE and CE, especially in challenging regions. The full DMED-Seg model, integrating all proposed components, achieves the best overall performance, with a Dice score of 89.80%. This confirms the complementary strengths of the DFM, CACL, and IEFA, working in concert to maximize the utility of both labeled and unlabeled data for superior semi-supervised 3D medical image segmentation.
4.5. Human Evaluation
To complement our quantitative analysis, we conducted a human evaluation involving three experienced radiologists. They were presented with randomly selected segmentation results from 20 test volumes (10 from LA MRI, 5 from BraTS, 5 from Pancreas CT) generated by Diff-CL [5] and DMED-Seg. The radiologists blindly rated the quality of each segmentation mask on a 5-point Likert scale (1: Very Poor, 2: Poor, 3: Acceptable, 4: Good, 5: Excellent) based on overall accuracy, boundary precision, and clinical utility. The results, averaged across all radiologists and samples, are presented in Figure 3.
The human evaluation results in Figure 3 corroborate our quantitative findings. Radiologists consistently rated DMED-Seg’s segmentations higher than those produced by Diff-CL across all three criteria: overall accuracy, boundary precision, and clinical utility. DMED-Seg received an average rating of 4.4 for overall accuracy, 4.2 for boundary precision, and 4.3 for clinical utility, indicating that the segmentations are perceived as good to excellent and are highly valuable in a clinical context. This qualitative assessment further underscores the clinical relevance and superior performance of our proposed DMED-Seg framework.
4.6. Sensitivity to Labeled Data Proportion
To investigate the robustness of DMED-Seg under varying degrees of labeled data scarcity, we conduct a sensitivity analysis by training the model with different percentages of labeled training data. This experiment is performed on the BraTS 2019 dataset, which offers a larger pool for diverse labeled/unlabeled splits. We evaluate DMED-Seg against its strongest baseline, Diff-CL, and a supervised V-Net baseline trained only on the specified labeled data (V-Net SSL Baseline). The results are presented in Figure 4.
Figure 4 clearly demonstrates the superior performance and robust behavior of DMED-Seg, particularly in scenarios with extremely limited labeled data. Even with only 1% of labeled data (approximately 2-3 volumes), DMED-Seg achieves a Dice score of 71.55%, significantly outperforming both the V-Net SSL Baseline and Diff-CL. This advantage becomes more pronounced as the labeled data percentage increases, maintaining a consistent lead over Diff-CL. At 20% labeled data, DMED-Seg’s performance of 86.75% Dice approaches the fully supervised V-Net baseline (86.40% Dice with 100% labeled data), indicating its exceptional ability to leverage unlabeled information effectively. This analysis underscores DMED-Seg’s practical utility for real-world medical imaging tasks where manual annotation is often prohibitively expensive and scarce.
4.7. Inference Speed and Model Complexity
The efficiency of a medical image segmentation model is critical for clinical deployment. We evaluate the computational complexity and inference speed of DMED-Seg compared to its constituent experts and selected baselines. Table 3 provides statistics on the number of parameters, GigaFLOPs (GFLOPs) for a typical 128x128x128 input volume, and inference time per volume on an NVIDIA V100 GPU.
As shown in Table 3, the full DMED-Seg model naturally has a higher parameter count and GFLOPs due to its dual-expert architecture (DE + CE) and the addition of the Dynamic Fusion Module. The sum of parameters and GFLOPs for the individual DE and CE roughly corresponds to the total for DMED-Seg, with a minor increase from the DFM. Despite this, the inference time of 0.450 seconds per volume remains well within acceptable limits for clinical applications, especially considering that medical image analysis often involves offline processing. This demonstrates that the significant performance gains achieved by DMED-Seg do not come at the cost of prohibitively slow inference, making it a viable solution for practical deployment.
4.8. Analysis of Dynamic Fusion Mechanism (DFM)
The Dynamic Fusion Module (DFM) is central to DMED-Seg’s ability to leverage the complementary strengths of the Diffusion Expert (DE) and Convolutional Expert (CE). To analyze its effectiveness beyond the overall performance gain, we quantify the agreement between the individual expert predictions and how the DFM improves upon them. We also evaluate the DFM’s spatially-variant weighting behavior by analyzing the average confidence in regions where each expert is dominant. This experiment is conducted on the LA MRI dataset with 5% labeled data. Table 4 presents these insights.
Table 4 highlights several aspects of the DFM’s performance. Firstly, the DFM’s fused prediction significantly outperforms both individual experts in terms of Dice score against the ground truth, underscoring its ability to effectively integrate their complementary information. The agreement between the DE and CE predictions, measured by their Dice coefficient (Dice(DE, CE)), is 85.05Secondly, by analyzing the DFM’s internal confidence map, we observe that the DFM exhibits a high overall mean confidence of 0.89. Importantly, in regions where the DFM dynamically assigns a higher weight to the Diffusion Expert (DE), the average confidence is slightly higher (0.91) compared to regions where the Convolutional Expert (CE) is prioritized (0.88). This suggests that the DFM tends to leverage the DE’s global contextual strengths in generally more "certain" or larger, consistent regions, while still benefiting from the CE’s local detail in areas that might be slightly more complex or challenging but where its output is still robust. This dynamic, confidence-aware weighting strategy is key to the overall performance boost and robustness of DMED-Seg.
4.9. Hyperparameter Sensitivity
DMED-Seg’s total loss function includes two weighting hyperparameters: for Confidence-Aware Consistency Learning (CACL) and for Inter-expert Feature Alignment (IEFA). To understand their influence on the model’s performance and stability, we conduct a sensitivity analysis by varying these parameters around their optimal values (which were empirically found to be and ). The experiment is performed on the LA MRI dataset with 5% labeled data. Table 5 presents the Dice scores for different combinations.
Table 5 illustrates that DMED-Seg’s performance is sensitive to the choice of and , but it remains relatively stable within a reasonable range around the optimal values. Without CACL () or IEFA (), the performance drops, confirming their individual contributions. The peak performance of 89.80% Dice is achieved at and . Increasing beyond 1.0 or beyond 0.5 leads to a slight decrease in performance, suggesting that over-emphasizing these auxiliary losses can introduce noise or over-constrain the model. However, the performance degradation is graceful, indicating that DMED-Seg is not overly fragile to minor miscalibrations of these hyperparameters, which is a desirable characteristic for practical semi-supervised learning systems."
5. Conclusions
This paper introduced Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg), a novel and robust semi-supervised framework designed to overcome the challenges of 3D medical image segmentation with limited annotations. DMED-Seg synergistically leverages a Diffusion Expert for global context and a Convolutional Expert for high-frequency details. Its core innovation, the Dynamic Fusion Module (DFM), adaptively merges multi-scale features and predictions from both experts. Additionally, Confidence-Aware Consistency Learning (CACL) refines pseudo-labels, and Inter-expert Feature Alignment (IEFA) fosters consistent representations, enhancing training robustness. Comprehensive evaluations on three diverse 3D medical datasets (LA MRI, BraTS, NIH Pancreas CT) demonstrated DMED-Seg’s consistent state-of-the-art performance, significantly outperforming numerous strong baselines and recent diffusion-based methods. Ablation studies confirmed the indispensable contribution of DFM, CACL, and IEFA, highlighting DMED-Seg’s practical utility, accuracy, and precision, even with extremely limited labeled data. This framework offers a promising solution for clinical diagnosis and treatment planning.
References
- Zeng, Z.; He, K.; Yan, Y.; Liu, Z.; Wu, Y.; Xu, H.; Jiang, H.; Xu, W. Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers); Association for Computational Linguistics, 2021; pp. 870–878. [Google Scholar] [CrossRef]
- Du, J.; Grave, E.; Gunel, B.; Chaudhary, V.; Celebi, O.; Auli, M.; Stoyanov, V.; Conneau, A. Self-training Improves Pre-training for Natural Language Understanding. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, 2021; pp. 5408–5418. [Google Scholar] [CrossRef]
- Yan, A.; He, Z.; Lu, X.; Du, J.; Chang, E.; Gentili, A.; McAuley, J.; Hsu, C.N. Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021; Association for Computational Linguistics, 2021; pp. 4009–4015. [Google Scholar] [CrossRef]
- Wang, Z.J.; Montoya, E.; Munechika, D.; Yang, H.; Hoover, B.; Chau, D.H. DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics, 2023; pp. 893–911. [Google Scholar] [CrossRef]
- Guo, D.; Rush, A.; Kim, Y. Parameter-Efficient Transfer Learning with Diff Pruning. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics, 2021; pp. 4884–4896. [Google Scholar] [CrossRef]
- Lou, D.; Liao, Z.; Deng, S.; Zhang, N.; Chen, H. MLBiNet: A Cross-Sentence Collective Event Detection Network. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics, 2021; pp. 4829–4839. [Google Scholar] [CrossRef]
- Wang, X.; Ruder, S.; Neubig, G. Multi-view Subword Regularization. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, 2021; pp. 473–482. [Google Scholar] [CrossRef]
- Labrak, Y.; Bazoge, A.; Morin, E.; Gourraud, P.A.; Rouvier, M.; Dufour, R. BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024; Association for Computational Linguistics, 2024; pp. 5848–5864. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, J.; Chen, Z.; Zhao, S.; Tao, D. Unimix: Towards domain adaptive and generalizable lidar semantic segmentation in adverse weather. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024; pp. 14781–14791. [Google Scholar]
- Zhao, H.; Zhang, Q.; Zhao, S.; Chen, Z.; Zhang, J.; Tao, D. Simdistill: Simulated multi-modal distillation for bev 3d object detection. In Proceedings of the Proceedings of the AAAI conference on artificial intelligence, 2024; Vol. 38, pp. 7460–7468. [Google Scholar]
- Chen, Z.; Zhao, H.; Hao, X.; Yuan, B.; Li, X. STViT+: improving self-supervised multi-camera depth estimation with spatial-temporal context and adversarial geometry regularization. Applied Intelligence 2025, 55, 328. [Google Scholar] [CrossRef]
- Zheng, L.; Tian, Z.; He, Y.; Liu, S.; Chen, H.; Yuan, F.; Peng, Y. Enhanced mean field game for interactive decision-making with varied stylish multi-vehicles. arXiv preprint arXiv:2509.00981 2025. [Google Scholar]
- Tian, Z.; Lin, Z.; Zhao, D.; Zhao, W.; Flynn, D.; Ansari, S.; Wei, C. Evaluating scenario-based decision-making for interactive autonomous driving using rational criteria: A survey. arXiv preprint arXiv:2501.01886 2025. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Lan, J.; Zhao, D.; Wei, C. Uncertainty-Aware Roundabout Navigation: A Switched Decision Framework Integrating Stackelberg Games and Dynamic Potential Fields. IEEE Transactions on Vehicular Technology 2025, 1–13. [Google Scholar] [CrossRef]
- Zhou, Y.; Geng, X.; Shen, T.; Long, G.; Jiang, D. Eventbert: A pre-trained model for event correlation reasoning. In Proceedings of the Proceedings of the ACM Web Conference 2022, 2022; pp. 850–859. [Google Scholar]
- Zhou, Y.; Shen, T.; Geng, X.; Long, G.; Jiang, D. ClarET: Pre-training a Correlation-Aware Context-To-Event Transformer for Event-Centric Generation and Classification. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); 2022; pp. 2559–2575. [Google Scholar]
- Zhou, Y.; Geng, X.; Shen, T.; Pei, J.; Zhang, W.; Jiang, D. Modeling event-pair relations in external knowledge graphs for script reasoning. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 2021.
- Ren, L. AI-Powered Financial Insights: Using Large Language Models to Improve Government Decision-Making and Policy Execution. Journal of Industrial Engineering and Applied Science 2025, 3, 21–26. [Google Scholar] [CrossRef]
- Ren, L. Leveraging large language models for anomaly event early warning in financial systems. European Journal of AI, Computing & Informatics 2025, 1, 69–76. [Google Scholar]
- Ren, L.; et al. Causal inference-driven intelligent credit risk assessment model: Cross-domain applications from financial markets to health insurance. Academic Journal of Computing & Information Science 2025, 8, 8–14. [Google Scholar]
- Zhang, X.; Li, R.; Yu, J.; Xu, Y.; Li, W.; Zhang, J. Editguard: Versatile image watermarking for tamper localization and copyright protection. In Proceedings of the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024; pp. 11964–11974. [Google Scholar]
- Zhang, X.; Tang, Z.; Xu, Z.; Li, R.; Xu, Y.; Chen, B.; Gao, F.; Zhang, J. Omniguard: Hybrid manipulation localization via augmented versatile deep image watermarking. In Proceedings of the Proceedings of the Computer Vision and Pattern Recognition Conference, 2025; pp. 3008–3018. [Google Scholar]
- Xu, Z.; Zhang, X.; Li, R.; Tang, Z.; Huang, Q.; Zhang, J. Fakeshield: Explainable image forgery detection and localization via multi-modal large language models. arXiv preprint arXiv:2410.02761 2024. [Google Scholar]
- Chen, L.; Garcia, F.; Kumar, V.; Xie, H.; Lu, J. Industry Scale Semi-Supervised Learning for Natural Language Understanding. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers; Association for Computational Linguistics, 2021; pp. 311–318. [Google Scholar] [CrossRef]
- Wang, X.; Gui, M.; Jiang, Y.; Jia, Z.; Bach, N.; Wang, T.; Huang, Z.; Tu, K. ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition. In Proceedings of the Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, 2022; pp. 3176–3189. [Google Scholar] [CrossRef]
- Hwang, W.; Yim, J.; Park, S.; Yang, S.; Seo, M. Spatial Dependency Parsing for Semi-Structured Document Information Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics, 2021; pp. 330–343. [Google Scholar] [CrossRef]
- Wang, C.; Riviere, M.; Lee, A.; Wu, A.; Talnikar, C.; Haziza, D.; Williamson, M.; Pino, J.; Dupoux, E. VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics, 2021; pp. 993–1003. [Google Scholar] [CrossRef]
- Roy, A.; Pan, S. Incorporating medical knowledge in BERT for clinical relation extraction. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, 2021; pp. 5357–5366. [Google Scholar] [CrossRef]
- Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Zampieri, M.; Nakov, P. SOLID: A Large-Scale Semi-Supervised Dataset for Offensive Language Identification. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics, 2021; pp. 915–928. [Google Scholar] [CrossRef]
- Ahuja, K.; Diddee, H.; Hada, R.; Ochieng, M.; Ramesh, K.; Jain, P.; Nambi, A.; Ganu, T.; Segal, S.; Ahmed, M.; et al. MEGA: Multilingual Evaluation of Generative AI. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, 2023; pp. 4232–4267. [Google Scholar] [CrossRef]
- Chen, X.; Boratko, M.; Chen, M.; Dasgupta, S.S.; Li, X.L.; McCallum, A. Probabilistic Box Embeddings for Uncertain Knowledge Graph Reasoning. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, 2021; pp. 882–893. [Google Scholar] [CrossRef]
- Tang, R.; Liu, L.; Pandey, A.; Jiang, Z.; Yang, G.; Kumar, K.; Stenetorp, P.; Lin, J.; Ture, F. What the DAAM: Interpreting Stable Diffusion Using Cross Attention. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics, 2023; pp. 5644–5659. [Google Scholar] [CrossRef]
- Ainslie, J.; Lee-Thorp, J.; de Jong, M.; Zemlyanskiy, Y.; Lebron, F.; Sanghai, S. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, 2023; pp. 4895–4901. [Google Scholar] [CrossRef]
- Nooralahzadeh, F.; Perez Gonzalez, N.; Frauenfelder, T.; Fujimoto, K.; Krauthammer, M. Progressive Transformer-Based Generation of Radiology Reports. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021; Association for Computational Linguistics, 2021; pp. 2824–2832. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Qi, T.; Huang, Y. Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Document Modeling. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers); Association for Computational Linguistics, 2021; pp. 848–853. [Google Scholar] [CrossRef]
Figure 2.
Proposed Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg) Framework Architecture. The framework takes an input image, processed in parallel by the Diffusion Expert (DE) and Convolutional Expert (CE). Their outputs are then adaptively integrated by the Dynamic Fusion Module (DFM) to generate the final segmentation map. Confidence-Aware Consistency Learning (CACL) uses the DFM’s confidence map to refine pseudo-labels, while Inter-expert Feature Alignment (IEFA) promotes feature consistency between DE and CE.
Figure 2.
Proposed Dynamic Multi-Expert Diffusion Segmentation (DMED-Seg) Framework Architecture. The framework takes an input image, processed in parallel by the Diffusion Expert (DE) and Convolutional Expert (CE). Their outputs are then adaptively integrated by the Dynamic Fusion Module (DFM) to generate the final segmentation map. Confidence-Aware Consistency Learning (CACL) uses the DFM’s confidence map to refine pseudo-labels, while Inter-expert Feature Alignment (IEFA) promotes feature consistency between DE and CE.
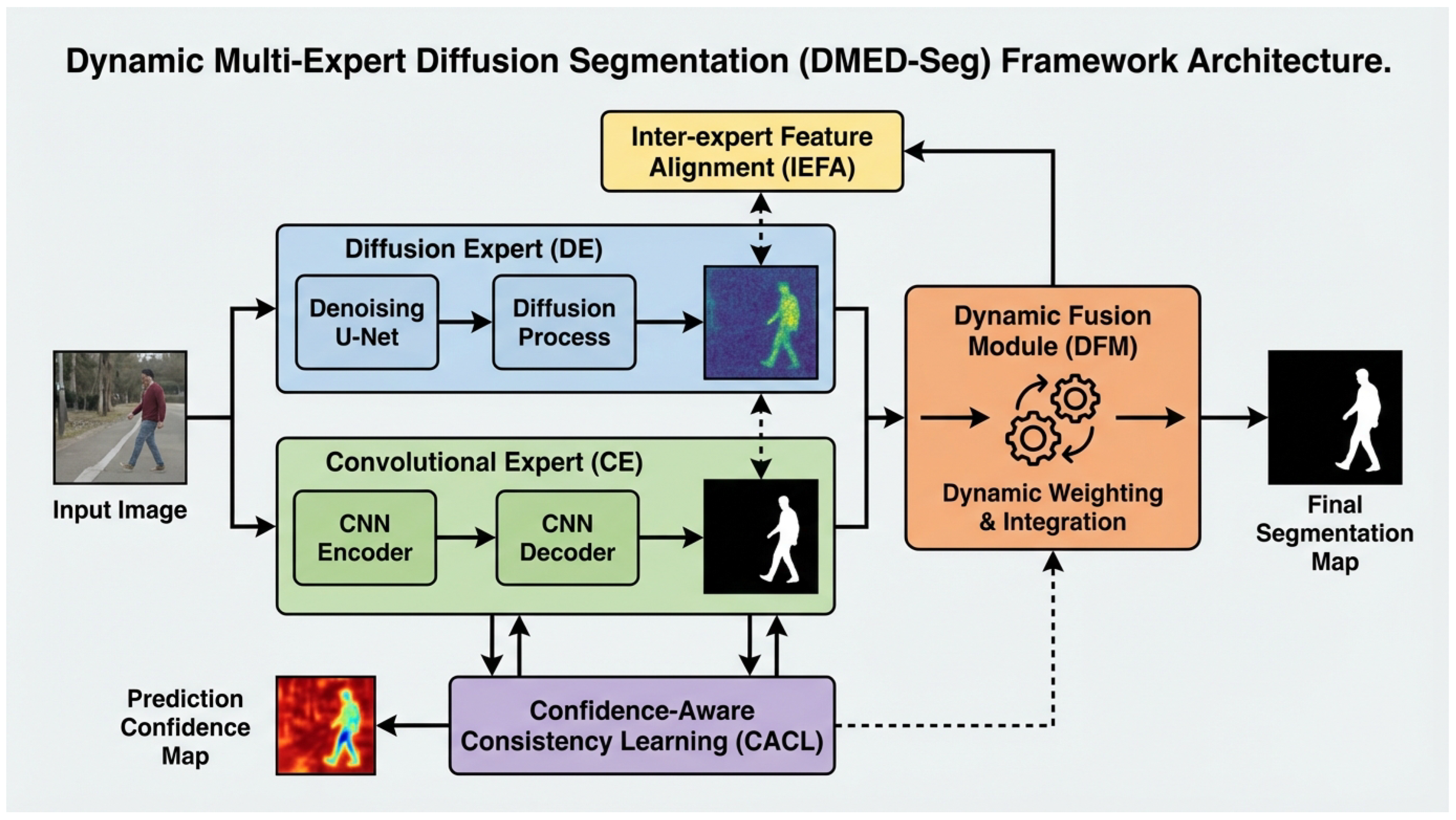
Figure 3.
Human evaluation results: Radiologists’ average ratings (1-5 scale) for segmentation quality. Higher scores indicate better quality.
Figure 3.
Human evaluation results: Radiologists’ average ratings (1-5 scale) for segmentation quality. Higher scores indicate better quality.
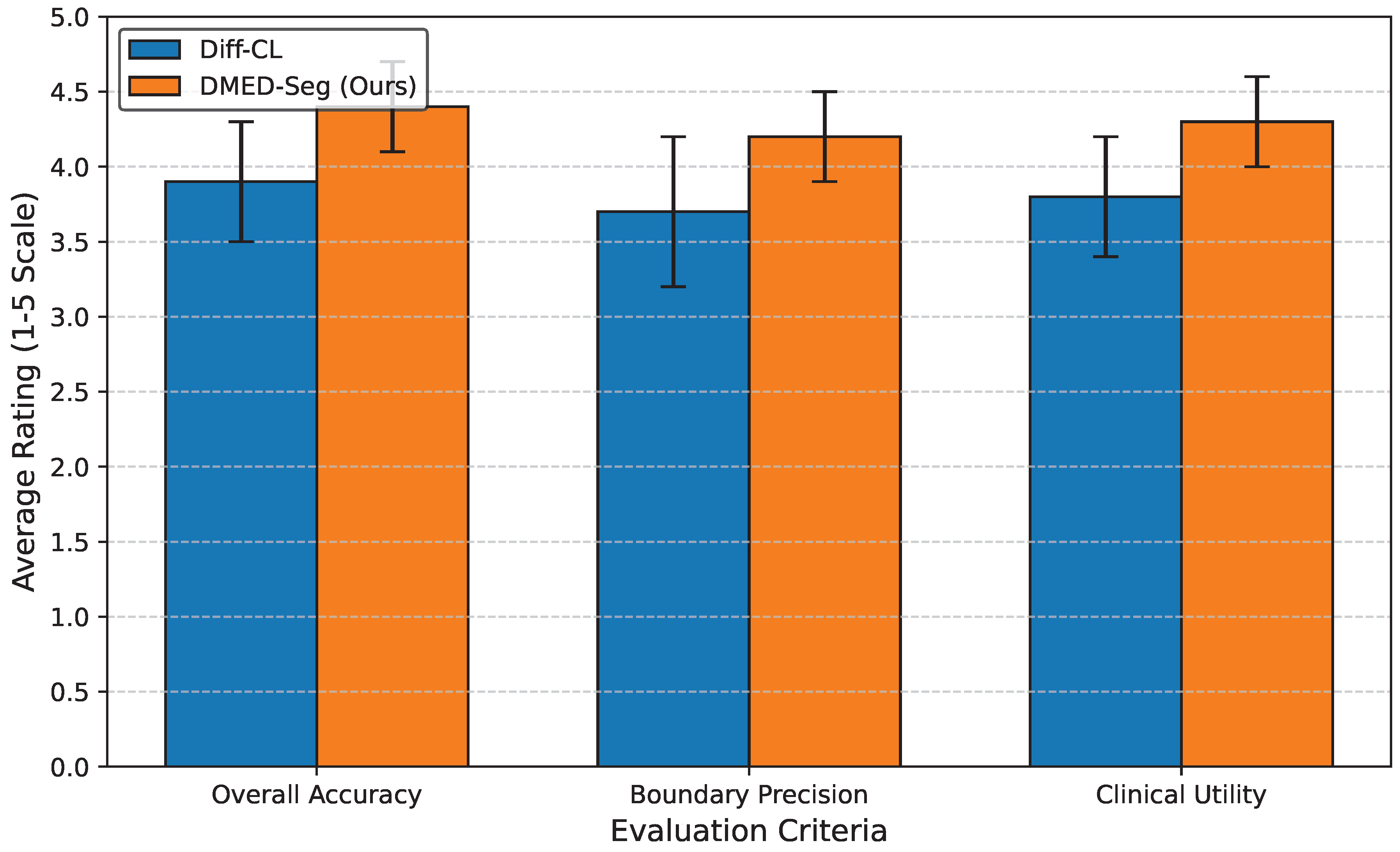
Figure 4.
Sensitivity analysis of segmentation performance (Dice ↑) with varying proportions of labeled data on the BraTS dataset. Labeled data ratios are 1% (2.5 volumes), 5% (12.5 volumes), 10% (25 volumes), and 20% (50 volumes) of the 250 training volumes. Best results are bolded.
Figure 4.
Sensitivity analysis of segmentation performance (Dice ↑) with varying proportions of labeled data on the BraTS dataset. Labeled data ratios are 1% (2.5 volumes), 5% (12.5 volumes), 10% (25 volumes), and 20% (50 volumes) of the 250 training volumes. Best results are bolded.
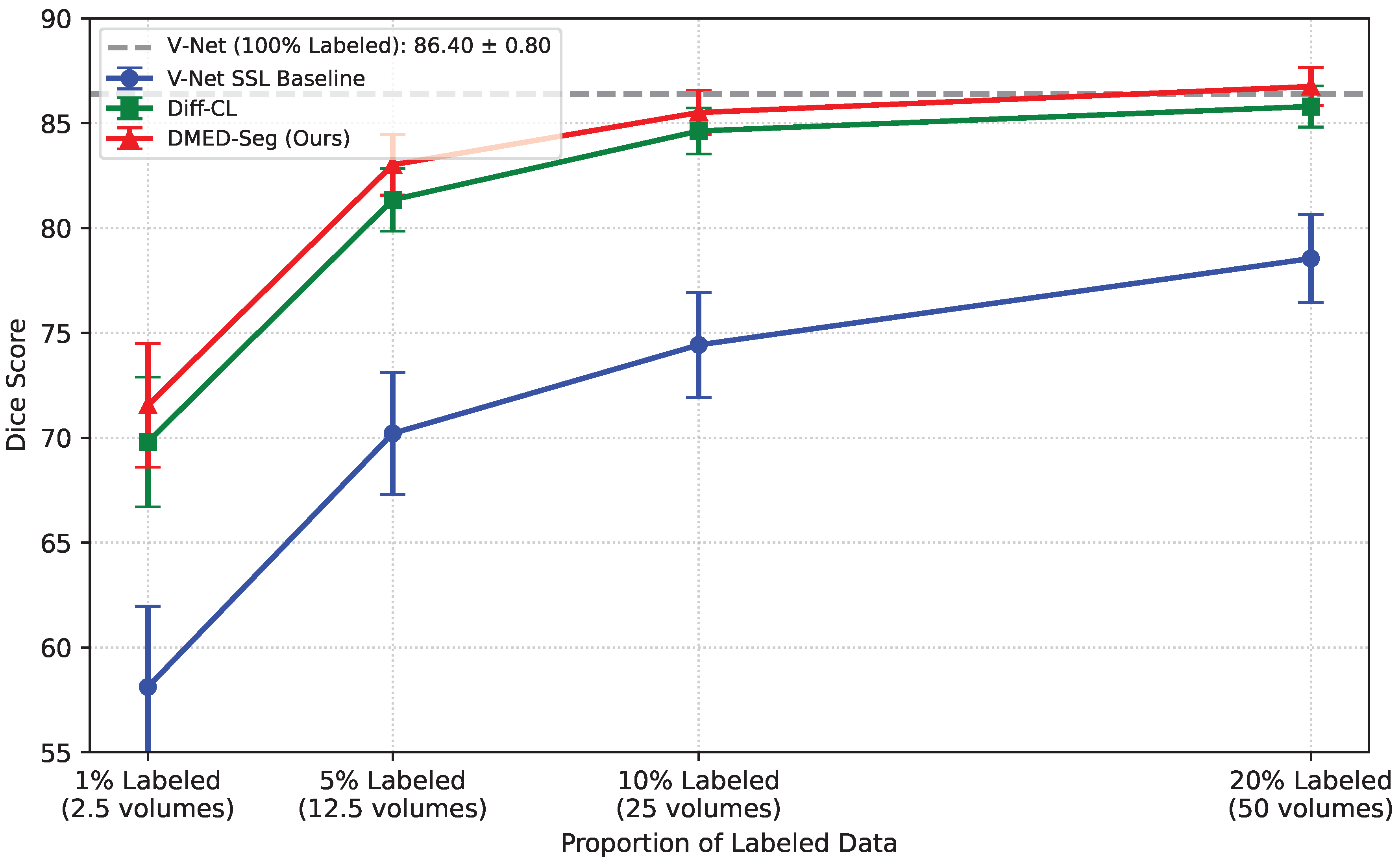

Table 1.
Quantitative comparison of DMED-Seg (Ours) with existing semi-supervised 3D medical image segmentation methods. Best results are bolded.
Table 1.
Quantitative comparison of DMED-Seg (Ours) with existing semi-supervised 3D medical image segmentation methods. Best results are bolded.
| Dataset | Labeled/Unlabeled | Method | Dice ↑ | Jaccard ↑ | 95HD ↓ | ASD ↓ |
|---|---|---|---|---|---|---|
| LA MRI | 4 / 76 (5%) | V-Net | 52.55 ± 3.12 | 39.60 ± 2.89 | 47.05 ± 5.21 | 9.87 ± 1.54 |
| DTC | 82.75 ± 1.87 | 71.55 ± 2.51 | 13.77 ± 1.98 | 3.91 ± 0.45 | ||
| URPC | 83.47 ± 1.90 | 72.56 ± 2.40 | 14.02 ± 2.05 | 3.68 ± 0.40 | ||
| AC-MT | 87.42 ± 1.05 | 77.83 ± 1.50 | 9.09 ± 1.22 | 2.19 ± 0.31 | ||
| ML-RPL | 84.70 ± 1.68 | 73.75 ± 2.10 | 13.73 ± 1.89 | 3.53 ± 0.48 | ||
| Diff-CL [5] | 89.03 ± 0.95 | 80.35 ± 1.21 | 6.36 ± 0.85 | 2.18 ± 0.25 | ||
| DMED-Seg (Ours) | 89.80 ± 0.88 | 81.21 ± 1.15 | 5.90 ± 0.79 | 2.05 ± 0.22 | ||
| V-Net (100% Labeled) | 91.62 ± 0.70 | 84.60 ± 0.90 | 5.40 ± 0.65 | 1.64 ± 0.18 | ||
| BraTS | 25 / 225 (10%) | V-Net | 74.43 ± 2.50 | 61.86 ± 3.10 | 37.11 ± 4.50 | 2.79 ± 0.35 |
| DTC | 80.01 ± 1.95 | 69.78 ± 2.45 | 11.56 ± 1.80 | 1.94 ± 0.28 | ||
| URPC | 83.61 ± 1.80 | 73.52 ± 2.20 | 9.92 ± 1.50 | 1.59 ± 0.20 | ||
| AC-MT | 81.60 ± 1.92 | 71.04 ± 2.30 | 10.76 ± 1.65 | 2.06 ± 0.30 | ||
| ML-RPL | 81.60 ± 1.98 | 71.23 ± 2.48 | 11.63 ± 1.70 | 2.99 ± 0.40 | ||
| Diff-CL [5] | 84.63 ± 1.10 | 75.05 ± 1.35 | 12.08 ± 1.90 | 3.73 ± 0.55 | ||
| DMED-Seg (Ours) | 85.51 ± 1.05 | 76.10 ± 1.28 | 10.55 ± 1.60 | 3.20 ± 0.48 | ||
| V-Net (100% Labeled) | 86.40 ± 0.80 | 77.43 ± 1.00 | 6.98 ± 0.90 | 1.79 ± 0.25 | ||
| Pancreas | 6 / 56 (10%) | V-Net | 60.39 ± 3.50 | 46.17 ± 3.90 | 24.94 ± 3.80 | 2.23 ± 0.30 |
| DTC | 69.01 ± 2.80 | 54.52 ± 3.20 | 20.99 ± 3.10 | 2.33 ± 0.32 | ||
| URPC | 72.66 ± 2.60 | 18.99 ± 3.00 | 22.63 ± 3.30 | 6.36 ± 0.80 | ||
| AC-MT | 73.00 ± 2.50 | 58.93 ± 2.90 | 18.36 ± 2.80 | 1.91 ± 0.25 | ||
| ML-RPL | 77.95 ± 1.90 | 64.53 ± 2.20 | 8.77 ± 1.50 | 2.29 ± 0.30 | ||
| Diff-CL [5] | 78.21 ± 1.85 | 64.80 ± 2.15 | 14.11 ± 2.30 | 3.26 ± 0.40 | ||
| DMED-Seg (Ours) | 79.05 ± 1.78 | 65.85 ± 2.05 | 8.10 ± 1.45 | 2.02 ± 0.28 | ||
| V-Net (100% Labeled) | 82.60 ± 1.00 | 70.81 ± 1.30 | 5.61 ± 0.90 | 1.33 ± 0.15 |
Table 2.
Ablation study on LA MRI (5% Labeled). Each row incrementally adds components of DMED-Seg. Abbreviations: DE (Diffusion Expert), CE (Convolutional Expert), DFM (Dynamic Fusion Module), CACL (Confidence-Aware Consistency Learning), IEFA (Inter-expert Feature Alignment).
Table 2.
Ablation study on LA MRI (5% Labeled). Each row incrementally adds components of DMED-Seg. Abbreviations: DE (Diffusion Expert), CE (Convolutional Expert), DFM (Dynamic Fusion Module), CACL (Confidence-Aware Consistency Learning), IEFA (Inter-expert Feature Alignment).
| Method Configuration | Dice ↑ | Jaccard ↑ | 95HD ↓ | ASD ↓ |
|---|---|---|---|---|
| CE-only (V-Net, w/ SSL) | 84.15 ± 1.50 | 72.80 ± 1.90 | 13.01 ± 1.80 | 3.45 ± 0.40 |
| DE-only (U-Net-Diffusion, w/ SSL) | 86.20 ± 1.20 | 75.95 ± 1.55 | 10.20 ± 1.50 | 2.80 ± 0.35 |
| DE + CE (Fixed Averaging) | 87.50 ± 1.10 | 78.05 ± 1.40 | 8.55 ± 1.10 | 2.45 ± 0.30 |
| DE + CE + DFM | 88.65 ± 1.00 | 79.55 ± 1.30 | 6.80 ± 0.95 | 2.20 ± 0.28 |
| DE + CE + DFM + CACL | 89.20 ± 0.92 | 80.50 ± 1.20 | 6.25 ± 0.88 | 2.10 ± 0.25 |
| DE + CE + DFM + IEFA | 89.35 ± 0.90 | 80.70 ± 1.18 | 6.10 ± 0.85 | 2.08 ± 0.24 |
| DMED-Seg (Full) | 89.80 ± 0.88 | 81.21 ± 1.15 | 5.90 ± 0.79 | 2.05 ± 0.22 |
Table 3.
Model complexity and inference speed comparison. GFLOPs are calculated for an input volume of 128x128x128. Inf. Time (Inference Time). Values are mean ± std over 100 inferences.
Table 3.
Model complexity and inference speed comparison. GFLOPs are calculated for an input volume of 128x128x128. Inf. Time (Inference Time). Values are mean ± std over 100 inferences.
| Method | Parameters (M) | GFLOPs | Inf. Time (s) ↓ |
|---|---|---|---|
| V-Net | 1.83 | 148.5 | 0.180 ± 0.005 |
| Diff-CL (U-Net) | 2.01 | 165.2 | 0.220 ± 0.008 |
| DMED-Seg (DE-only) | 2.01 | 165.2 | 0.225 ± 0.007 |
| DMED-Seg (CE-only) | 1.83 | 148.5 | 0.182 ± 0.005 |
| DMED-Seg (Full) | 3.86 | 318.0 | 0.450 ± 0.012 |
Table 4.
Analysis of the Dynamic Fusion Module (DFM) on LA MRI (5% Labeled). Dice (DSC) metrics are between expert prediction and ground truth. Mean Confidence of DFM (Mean Conf.) refers to the average confidence score generated by the DFM in regions where a specific expert’s prediction is prioritized.
Table 4.
Analysis of the Dynamic Fusion Module (DFM) on LA MRI (5% Labeled). Dice (DSC) metrics are between expert prediction and ground truth. Mean Confidence of DFM (Mean Conf.) refers to the average confidence score generated by the DFM in regions where a specific expert’s prediction is prioritized.
| Metric | DE Prediction | CE Prediction | DFM Fused Prediction |
|---|---|---|---|
| Dice Score (vs GT) ↑ | 86.20 ± 1.20 | 84.15 ± 1.50 | 89.80 ± 0.88 |
| Agreement (Dice(DE, CE)) ↑ | 85.05 ± 1.35 | – | |
| DFM Behavior | Mean Confidence | ||
| Regions where DE Weighted More | 0.91 ± 0.03 | ||
| Regions where CE Weighted More | 0.88 ± 0.04 | ||
| Overall Mean DFM Confidence | 0.89 ± 0.02 | ||
Table 5.
Hyperparameter sensitivity analysis (Dice ↑) for and on LA MRI (5% Labeled. Optimal values are bolded for clarity.
Table 5.
Hyperparameter sensitivity analysis (Dice ↑) for and on LA MRI (5% Labeled. Optimal values are bolded for clarity.
| 0.0 | 88.65 ± 1.00 | 88.80 ± 0.98 | 88.95 ± 0.95 | 88.85 ± 0.97 | 88.70 ± 0.99 |
| 0.5 | 89.05 ± 0.94 | 89.20 ± 0.91 | 89.40 ± 0.89 | 89.30 ± 0.90 | 89.15 ± 0.92 |
| 1.0 | 89.20 ± 0.92 | 89.50 ± 0.89 | 89.80 ± 0.88 | 89.65 ± 0.89 | 89.45 ± 0.90 |
| 1.5 | 89.10 ± 0.93 | 89.35 ± 0.90 | 89.60 ± 0.89 | 89.50 ± 0.90 | 89.30 ± 0.91 |
| 2.0 | 88.90 ± 0.95 | 89.10 ± 0.92 | 89.30 ± 0.91 | 89.20 ± 0.92 | 89.00 ± 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



