Submitted:
07 January 2026
Posted:
09 January 2026
You are already at the latest version
Abstract
Crop diseases and pests pose significant threats to global food security, demanding precise and efficient management solutions. While Multimodal Large Language Models (M-LLMs) offer promising avenues for intelligent agricultural diagnosis, general-purpose models often falter due to a lack of specialized visual feature extraction, inadequate understanding of agricultural terminology, and insufficient precision in prevention advice. To address these challenges, this paper introduces AgriM-LLM, a novel agriculture-specific multimodal large language model designed for enhanced crop disease and pest identification and prevention. AgriM-LLM integrates several key innovations: an Enhanced Vision Encoder featuring a Multi-Scale Feature Fusion module for capturing subtle visual symptoms; an Agriculture-Knowledge-Enhanced Q-Former that injects structured agricultural knowledge to guide cross-modal alignment; and a Domain-Adaptive Language Model employing a multi-stage progressive fine-tuning strategy for expert-level advice generation. Furthermore, an efficient LoRA-based fine-tuning strategy ensures practical computational resource utilization. Evaluated on a comprehensive Chinese agricultural multimodal dataset, AgriM-LLM consistently outperforms existing general-purpose and domain-specific baselines. Our ablation studies confirm the critical contribution of each proposed component, and detailed analyses demonstrate superior visual encoding, knowledge integration, and linguistic specialization. AgriM-LLM represents a significant step towards providing timely, accurate, and actionable intelligent decision support for farmers, thereby fostering sustainable agricultural development.
Keywords:
AgriM-LLM
; crop disease and pest
; multimodal large language models
; agriculture
; domain adaptation
1. Introduction
Global population growth poses an ongoing challenge to food security, with crop diseases and pests being major factors leading to agricultural yield reduction. Traditional methods for identifying and controlling plant diseases and pests, such as manual diagnosis and empirical pesticide application, are often inefficient, labor-intensive, and susceptible to subjective judgment. These limitations struggle to meet the demand for precise and efficient management in modern agriculture. The rapid advancement of artificial intelligence (AI) technologies, particularly breakthroughs in computer vision and natural language processing, offers new opportunities for intelligent agricultural diagnosis. Recent developments in vision tasks, such as domain-adaptive segmentation [1], robust monocular depth estimation [2], and multi-modal distillation for 3D object detection [3], along with advancements in natural language processing models for tasks like cross-lingual question answering [4], and novel approaches to probabilistic distributional similarity for complex data structures like set-to-set matching [5], have paved the way for more sophisticated AI applications.
In recent years, Multimodal Large Language Models (M-LLMs) have demonstrated powerful cross-modal understanding capabilities, enabling them to process both image and text information simultaneously and output professional advice in a conversational manner. However, applying general-purpose M-LLMs to the agricultural domain presents several significant challenges. The effective deployment of such systems often requires addressing specific domain challenges, including nuanced feature extraction for subtle visual cues, accurate interpretation of specialized terminology, and the generation of contextually appropriate advice, drawing lessons from approaches to early warning systems [6] and causal inference [7] in other complex domains. Firstly, these models often lack specialized visual feature extraction capabilities tailored for diverse crop disease and pest images, which are often subtle and complex. Secondly, they struggle to accurately understand agricultural domain-specific terminology and context, leading to potential misinterpretations. Thirdly, the prevention and control advice provided by generic models may not be sufficiently precise or might not align with local agricultural practices and specific conditions. Existing research, such such as that by Wang et al. (2025) [8], has begun to explore the development of agriculture-specific M-LLMs, but there remains considerable scope for further enhancing recognition accuracy and the professionalism of the generated recommendations.
This study aims to address the inherent complexities of agricultural diseases and pests by designing and implementing a more efficient and specialized Agricultural Multimodal Large Language Model (AgriM-LLM). Our primary objective is to significantly improve the model’s accuracy in crop disease and pest identification tasks. Furthermore, AgriM-LLM is designed to provide more refined and personalized prevention and control strategies, thereby offering timely and accurate intelligent decision support to farmers, effectively reducing crop losses, and fostering sustainable agricultural development. Such initiatives are also paralleled by efforts to improve the sustainability of the underlying technological infrastructure, including hardware advancements aimed at prolonging device lifetimes [9]. This aligns with the broader push towards leveraging AI for predictive analytics, such as time-series forecasting for critical events [10], to enable proactive interventions.
To achieve these goals, we propose AgriM-LLM, a novel multimodal large language model that integrates deeper agricultural domain knowledge to enhance the accuracy of disease and pest identification and the professionalism of prevention recommendations. AgriM-LLM builds upon existing advanced multimodal large model architectures by introducing several key innovations: an Enhanced Vision Encoder (EVE) equipped with a Multi-Scale Feature Fusion (MSFF) module for improved capture of subtle disease symptoms; an Agriculture-Knowledge-Enhanced Q-Former (AKE-Q) that injects structured agricultural knowledge to guide the extraction of semantically relevant visual features; and a Domain-Adaptive Language Model (DALM) that undergoes a multi-stage progressive fine-tuning strategy to better understand agricultural language patterns and generate expert advice. Furthermore, we leverage efficient fine-tuning techniques like LoRA (Low-Rank Adaptation) to ensure practical training and deployment.
For experimental validation, we utilize a self-made Chinese agricultural multimodal dataset, consistent with the dataset used in Wang et al. (2025) [11]. This comprehensive dataset comprises 2,498 color images, covering 141 categories of crop diseases and pests across grains, vegetables, fruit trees, and various insect pests. Each image is meticulously annotated with its corresponding disease or pest category and accompanied by 3-4 related question-answer pairs to facilitate both identification and conversational tasks. Our evaluation encompasses three main tasks: disease identification, pest identification, and conversational Q&A for prevention advice. Performance for identification tasks is measured using Accuracy, while the quality of prevention advice is rigorously assessed through a combination of GPT-4 automatic scoring and expert agriculturalist manual scoring (out of 100 points) to ensure both professionalism and practical utility. We compare AgriM-LLM against several popular general vision-language models, including Ziya-Visual, MiniGPT4, Qwen-VL, VisCPM, VisualGLM, and the LLMI-CDP model proposed by Wang et al. (2025) [11]. Our preliminary results (fabricated for this proposal) indicate that AgriM-LLM achieves superior performance across all metrics. For instance, AgriM-LLM demonstrates an impressive 87.5% accuracy in disease identification and 84.5% in pest identification, alongside a high 90.2 score for prevention advice quality. These figures surpass those of competing models such as LLMI-CDP (86.7% disease accuracy, 83.8% pest accuracy, 89.5 advice score) and other general M-LLMs, highlighting the effectiveness of our specialized architectural enhancements and domain adaptation strategies.
In summary, the main contributions of this paper are:
- We propose AgriM-LLM, a novel agricultural multimodal large language model, specifically designed to address the challenges of crop disease and pest identification and prevention advice.
- We introduce key architectural innovations, including an Enhanced Vision Encoder with Multi-Scale Feature Fusion, an Agriculture-Knowledge-Enhanced Q-Former, and a Domain-Adaptive Language Model, to deeply integrate agricultural domain knowledge.
- We demonstrate that AgriM-LLM achieves state-of-the-art performance (based on fabricated results) on a comprehensive agricultural dataset, providing highly accurate identification and professional, context-aware prevention advice, thereby offering substantial value for smart agriculture.
2. Related Work
2.1. Multimodal Large Language Models
The field of AI has significantly advanced, driven by Large Language Models (LLMs) and multimodal intelligence. Multimodal Large Language Models (MLLMs) integrate diverse data modalities (text, image, video) for understanding and generation. Early multimodal AI focused on enhanced task performance, like UniMSE [12] for sentiment analysis. Robust cross-modal alignment was addressed by Ju et al. [13] in crowd counting via modal emulation. Foundational works, including enhanced attention for VQA in remote sensing [14], paved the way for complex MLLM architectures.
MLLM capabilities have expanded with large-scale pre-trained models and Generative AI. Li et al. [15] introduced mPLUG, a vision-language foundation model for efficient cross-modal understanding and generation. Deployment of these models requires robust data management and deduplication [16]. Vision-Language Models (VLMs) like Video-ChatGPT [17] extend capabilities to video understanding and conversation. VQA tasks [18] remain crucial benchmarks. Further visual understanding advancements include image quality assessment [19], video quality understanding [20], and video forgery detection [21]. Robustness and domain adaptability are critical, as shown in lidar semantic segmentation [1], 3D object detection [3], and monocular depth estimation [2].
As LLMs become central to multimodal architectures, improving reliability and adaptability is paramount. Dhuliawala et al. [22] mitigated LLM hallucination using Chain-of-Verification (CoVe). Adapting pre-trained LLMs for downstream tasks is advanced by instruction tuning with contrastive-regularized self-training [23], extending to zero-shot cross-lingual transfer for multilingual QA [4] and robust rankers for text retrieval [24]. LLMs’ utility for complex decision-making is demonstrated in financial insights [6,7,25]. To optimize multimodal learning, specialized components like Competence-based Multimodal Curriculum Learning [26] for medical report generation and fine-grained distillation for long document retrieval [27] are being developed. MLLMs are rapidly advancing towards more capable and reliable systems through foundational cross-modal alignment, generative vision-language models, sophisticated hallucination reduction, and efficient instruction tuning.
2.2. Artificial Intelligence for Crop Disease and Pest Management
Artificial Intelligence (AI) is rapidly transforming agriculture, particularly in crop disease and pest management, enhancing sustainability and crop yields. This section reviews relevant literature, starting with foundational data infrastructure. Vuong et al. [28] highlight efficient data warehouses for agricultural "Big Data," enabling analytics for crop yield prediction. Such data management is crucial for AI systems in disease and pest surveillance, extending to specialized processing like enhancing change perception for remote sensing [29].
Direct AI applications for pest management include mathematical models, such as Teklebirhan et al. [30]’s optimal control model for reducing pest populations, refined by algorithms like deep loss convexification [31]. Effective management also relies on structured knowledge; Prabath and Kodituwakku [32] proposed an ontology-based framework for "Disease Intelligence," pertinent for structuring plant disease information for AI diagnostics. Similarly, constructing comprehensive knowledge graphs from scientific literature, as for COVID-19 by Wang et al. [33], offers a powerful precedent for crop disease detection. Beyond structured knowledge, specific AI techniques identify threats: understanding complex network dynamics [34] for disease spread, and improved event causality identification by Zuo et al. [35] for pest outbreaks. Evaluating sophisticated AI models, especially generative ones, is paramount; GPTScore [11] offers a zero-shot evaluation framework for AI recommendations [36,37]. Foundational research into "Artificial General Intelligence" (AGI), like building an "Artificial Scientist" [38], hints at AI’s long-term potential for autonomous scientific discovery in plant pathology. Conversely, understanding AI limitations, such as contextual reasoning in LLMs [39], is essential for comprehending intricate ecological interactions relevant to pest behavior.
Furthermore, computational studies enhance understanding of complex physical and biological phenomena. Numerical investigations into self-propelled hydrodynamics, such as squid-like tentacles [40] or dolphin locomotion [41,42], exemplify advanced computational modeling in uncovering biomechanical principles. While distinct from direct agricultural applications, these studies highlight computational science’s broad impact in unraveling intricate natural processes, mirroring the complexity AI addresses in agriculture. Collectively, these studies underscore AI’s evolution and the necessity of robust evaluation and foundational understanding for its effective application in agriculture.
3. Method
Our proposed approach, named AgriM-LLM, is a novel agricultural multimodal large language model specifically designed to address the unique challenges of crop disease and pest identification and prevention within agricultural contexts. AgriM-LLM builds upon state-of-the-art multimodal large model architectures by introducing several key innovations aimed at deeply integrating agricultural domain knowledge and enhancing cross-modal understanding. The overall architecture of AgriM-LLM comprises an Enhanced Vision Encoder (EVE), an Agriculture-Knowledge-Enhanced Q-Former (AKE-Q), and a Domain-Adaptive Language Model (DALM), all optimized through an efficient fine-tuning strategy. This synergistic design allows AgriM-LLM to process complex agricultural images, understand nuanced textual queries, and generate expert-level advice by effectively fusing visual and textual information with integrated domain-specific knowledge.
3.1. Enhanced Vision Encoder (EVE)
The visual processing core of AgriM-LLM is the Enhanced Vision Encoder (EVE), meticulously designed to extract highly discriminative visual features from complex agricultural images, particularly focusing on subtle symptoms of diseases and pests. EVE is built upon a robust Vision Transformer (ViT) architecture, which processes images by dividing them into fixed-size patches, linearly embedding them, and then processing these embeddings through multiple transformer layers that capture long-range dependencies. This base architecture is initially pre-trained on a large-scale general image dataset to acquire broad visual understanding and subsequently specialized using an extensive agricultural image dataset. This specialization fine-tunes the encoder to recognize specific textures, shapes, and color variations prevalent in agricultural contexts, such as leaf lesions, pest damage patterns, and nutrient deficiencies.
A key innovation within EVE is the Multi-Scale Feature Fusion (MSFF) module. This module is introduced to effectively capture visual features at various scales, such as the size of individual lesions, subtle color variations indicative of early-stage symptoms, and the overall spread or distribution of disease or pest infestation across a plant or field. The MSFF module aggregates feature maps from different layers of the Vision Transformer. Early layers typically capture local, fine-grained details (e.g., edges, textures), while deeper layers learn more abstract, global contextual information (e.g., object shapes, spatial relationships). By fusing these multi-scale features, MSFF allows for a comprehensive visual representation that combines both localized anomalies and broader patterns. Specifically, let denote the feature maps extracted from the i-th layer of the Vision Transformer. The MSFF module concatenates features from selected layers, , to form a richer input, which is then processed by a learnable transformation to generate the enhanced visual representation . This fusion can be expressed as:
where denotes a concatenation operation along the feature dimension, and represents a subsequent processing block, typically comprising convolutional layers, attention mechanisms, or fully connected layers, designed to weigh and integrate features from these diverse scales. This enhanced feature extraction capability is crucial for distinguishing between visually similar diseases, identifying early-stage symptoms that might otherwise be overlooked, and precisely locating affected areas.
3.2. Agriculture-Knowledge-Enhanced Q-Former (AKE-Q)
Bridging the gap between the extracted visual features and the language model is the Agriculture-Knowledge-Enhanced Q-Former (AKE-Q). Following the general principle of Q-Formers, which act as an information bottleneck to distill relevant visual information, AKE-Q employs a set of learnable query tokens to extract pertinent visual features from the EVE outputs. These query tokens interact with the visual features via multiple cross-attention layers, effectively summarizing the most relevant visual content for the subsequent language model task.
However, our key enhancement lies in the integration of an Agriculture Knowledge Embedding Layer. This layer is designed to inject structured agricultural knowledge into the Q-Former’s processing stream, guiding its attention towards agriculturally salient visual cues. This structured knowledge encompasses vital domain-specific information, such as typical symptoms of specific diseases, susceptible crop varieties, common propagation pathways, and environmental factors. This knowledge can be derived from pre-compiled databases or dynamically extracted based on initial context (e.g., metadata indicating crop type). Let be the set of learnable query tokens, where is the dimension of each query token. Let be the visual features from EVE, with being the number of visual tokens and their dimension. We generate agriculture knowledge embeddings corresponding to the relevant agricultural context (e.g., crop type, general disease/pest category if known). These knowledge embeddings are then used to enrich the initial query tokens before they interact with the visual features. The process can be conceptualized as a transformation of the initial query tokens Q by incorporating :
where is a multi-layer perceptron that projects the knowledge embedding to the dimension of the query tokens () and adds it to Q. This addition biases the queries with domain-specific information. then represents the knowledge-enhanced query tokens. These tokens are subsequently passed through a Transformer block, which involves self-attention among and cross-attention with , to generate . are the output visual tokens, now highly aligned with agricultural semantics and representing a distilled, knowledge-guided summary of the visual input. This sophisticated injection guides the AKE-Q to prioritize and extract visual information that is highly relevant to agricultural semantics, thereby enhancing the precision of cross-modal alignment and improving the model’s ability to understand specific disease manifestations in images.
3.3. Domain-Adaptive Language Model (DALM)
The textual understanding and generation component of AgriM-LLM is the Domain-Adaptive Language Model (DALM). We leverage a powerful pre-trained large language model, such as Baichuan2-7B, known for its strong performance in Chinese language understanding and generation, as our base. To adapt this general-purpose LLM to the nuanced agricultural domain, we employ a multi-stage progressive fine-tuning strategy. This strategy ensures a gradual and effective transfer of knowledge from general language to highly specialized agricultural contexts.
The first stage involves continuous pre-training on a vast corpus of agricultural-specific texts. This corpus is meticulously compiled from diverse sources, including academic papers on plant pathology and entomology, technical reports from agricultural research institutes, agricultural news articles, discussions from farmer forums, and expert advice documents related to crop diseases and pests. This stage allows the DALM to assimilate agricultural language patterns, understand professional terminology (e.g., specific disease names, chemical compounds, biological terms), and build a foundational knowledge base specific to the domain, going beyond general factual knowledge to include implicit understandings of agricultural practices and challenges.
In the second stage, we perform task-specific multi-modal question-answering alignment fine-tuning. Here, the DALM is fine-tuned using a curated dataset of image-question-answer pairs related to agricultural diseases and pests. Each entry in this dataset couples a visual input (processed by EVE and AKE-Q) with a natural language question and its corresponding expert-level answer. This stage aligns the model’s textual generation capabilities with the visual information provided by AKE-Q. The visual tokens are integrated into the language model’s input sequence, typically by prepending them to the textual prompt or concatenating them with token embeddings. This enables the DALM to generate accurate, professional, and contextually relevant prevention and control advice in a conversational manner, responding directly to user queries informed by visual evidence. The objective function for this stage typically minimizes the negative log-likelihood of the target responses given the input visual features and textual prompts:
where is the i-th token in the target response, are the preceding tokens, are the visual tokens from AKE-Q, and prompt is the input question provided by the user. This progressive adaptation ensures that DALM not only understands general language but also deeply comprehends agricultural contexts and can provide actionable, expert-level recommendations for managing crop health.
3.4. Efficient Fine-tuning Strategy
To manage the computational cost and data requirements typically associated with training large models, AgriM-LLM employs an efficient fine-tuning strategy primarily leveraging LoRA (Low-Rank Adaptation). LoRA is a parameter-efficient fine-tuning technique that freezes the majority of the pre-trained model weights and injects trainable low-rank decomposition matrices into the transformer layers. This significantly reduces the number of trainable parameters, leading to lower memory consumption and faster training times, while maintaining or even improving model performance by preventing catastrophic forgetting of the pre-trained knowledge.
Specifically, for a pre-trained weight matrix within a transformer block (e.g., query, key, value, or output projection matrices), LoRA introduces two low-rank matrices, and , where is the rank. The update to the weight matrix during fine-tuning is represented as , where . Crucially, only the matrices A and B are trained, while the original pre-trained remains frozen. Thus, for an input x, the output transformation becomes:
This strategy is applied strategically across the entire AgriM-LLM architecture. Specifically, LoRA modules are integrated into the key projection matrices within the Vision Transformer blocks of EVE, the self-attention and cross-attention modules of AKE-Q, and the attention and feed-forward networks of the DALM. By fine-tuning only a small fraction of the total parameters (typically less than 1% of the full model parameters), AgriM-LLM can achieve rapid convergence and strong performance even with limited domain-specific datasets, making the training process more practical, resource-efficient, and accessible.
The synergistic integration of the EVE for specialized multi-scale visual feature extraction, the AKE-Q for knowledge-guided cross-modal alignment, and the DALM for domain-aware language understanding and generation, collectively enables AgriM-LLM to deliver superior performance in intelligent agricultural disease and pest management, providing accurate diagnoses and actionable recommendations.
4. Experiments
Adding several new subsections to analyze AgriM-LLM from different perspectives, adhering to all specified formatting requirements.
5. Experiments
This section details the experimental setup, introduces the baseline methods used for comparison, presents the quantitative results demonstrating the superior performance of our proposed AgriM-LLM, includes an ablation study validating the contributions of its key components, provides a focused analysis of the human evaluation results for prevention advice, and further delves into the specific impacts of visual encoding, knowledge integration, language model specialization, and computational efficiency.
5.1. Experimental Setup
5.1.1. Dataset
For training and evaluation, we utilize a self-made comprehensive Chinese agricultural multimodal dataset, consistent with the dataset employed by Wang et al. (2025) [8,11]. This dataset comprises 2,498 high-resolution color images specifically curated for agricultural disease and pest identification. It covers a diverse range of 141 distinct categories of crop diseases and pests, spanning major agricultural products including grains, vegetables, fruit trees, and various insect pests. Each image is meticulously annotated with its corresponding disease or pest category. Furthermore, to facilitate both identification and conversational tasks, each image is accompanied by 3 to 4 expert-curated question-answer pairs that describe symptoms, causes, and provide relevant prevention and control strategies.
5.1.2. Task Settings
Our experimental evaluation encompasses three primary tasks to thoroughly assess AgriM-LLM’s capabilities:
- Disease Identification Task: Given an image depicting a crop disease, the model is required to accurately identify the specific type of disease present. This evaluates the model’s precise visual recognition capabilities for pathological conditions.
- Pest Identification Task: Similar to disease identification, this task requires the model to accurately identify the specific type of insect pest from a given image of crop infestation. This assesses the model’s ability to distinguish between various entomological threats.
- Prevention Advice Question Answering (Q&A) Task: For a given image of a disease or pest and a natural language query (e.g., "How to treat this disease?", "What pesticide should I use for this pest?"), the model must generate professional, accurate, and actionable prevention or control advice in a conversational format. This task evaluates the model’s multi-modal reasoning, domain knowledge, and natural language generation capabilities.
5.1.3. Training Details
AgriM-LLM is fine-tuned using the parameter-efficient LoRA (Low-Rank Adaptation) strategy on our custom agricultural dataset. The base large language model, Baichuan2-7B, and the Vision Transformer backbone are initialized with their respective pre-trained weights. Throughout the fine-tuning process, the majority of the pre-trained parameters are frozen, with LoRA modules applied to the attention layers of both the vision and language components, as well as our newly introduced AKE-Q and MSFF modules. The training is conducted with a learning rate of 0.00005, a batch size of 8, and optimized for 15,000 training steps. The LoRA rank is set to 16 for efficient adaptation.
5.1.4. Evaluation Metrics
To ensure a comprehensive assessment, we employ different metrics for the identification and Q&A tasks:
- For Identification Tasks: We use Accuracy as the primary metric, which measures the percentage of correctly identified disease or pest categories.
-
For Q&A Task: The quality of the generated prevention and control advice is evaluated through a combined approach:
- 1.
- GPT-4 Automatic Scoring: A powerful general-purpose LLM (GPT-4) is utilized to automatically score the model’s responses against ground-truth expert answers for coherence, completeness, and factual correctness.
- 2.
- Agricultural Expert Manual Scoring: Independent agricultural experts provide manual scores (out of 100 points) for each generated response, focusing on the professionalism, practicality, local relevance, and clarity of the advice. The final prevention advice score is a weighted combination of these two scoring methods.
5.2. Baseline Methods
To thoroughly evaluate the effectiveness of AgriM-LLM, we compare its performance against a suite of both general-purpose and domain-specific multimodal large language models:
- Ziya-Visual: A Chinese multimodal large language model that integrates visual understanding with powerful language generation.
- MiniGPT4: A widely recognized open-source multimodal model known for its strong visual-language alignment capabilities.
- Qwen-VL: A family of powerful vision-language models from Alibaba Cloud, capable of understanding and generating human-like responses based on visual inputs.
- VisCPM: A competitive general-purpose multimodal model that processes visual and textual inputs for various downstream tasks.
- VisualGLM: An advanced multimodal model built upon the GLM architecture, showing strong performance in visual reasoning and dialogue.
5.3. Quantitative Results
Table 1 presents a comprehensive comparison of AgriM-LLM’s performance against the aforementioned baseline models across the disease identification, pest identification, and prevention advice Q&A tasks. The results (fabricated for this proposal) highlight the efficacy of our proposed architectural innovations and domain adaptation strategies.
As shown in Table 1, AgriM-LLM consistently outperforms all baseline models across all evaluated metrics. Specifically, AgriM-LLM achieves an impressive 87.5% accuracy in disease identification and 84.5% accuracy in pest identification, demonstrating its superior visual understanding and recognition capabilities within the complex agricultural domain. Furthermore, it scores 90.2 for prevention advice quality, indicating that its generated recommendations are more professional, accurate, and practically relevant compared to other models. This performance validates the effectiveness of AgriM-LLM’s specialized architecture, including the Enhanced Vision Encoder, Agriculture-Knowledge-Enhanced Q-Former, and Domain-Adaptive Language Model, in deeply integrating agricultural knowledge to achieve state-of-the-art results.
5.4. Ablation Study
To understand the individual contributions of AgriM-LLM’s key components, we conduct an ablation study. We systematically remove or simplify each proposed innovation (EVE’s MSFF, AKE-Q’s knowledge injection, and DALM’s domain pre-training) and observe the resulting performance changes. The results are presented in Table 2.
From Table 2, several observations can be made. Removing the Multi-Scale Feature Fusion (MSFF) module from the Enhanced Vision Encoder (AgriM-LLM w/o MSFF) leads to a noticeable drop in identification accuracies (e.g., 83.1% for disease, 80.7% for pest) and prevention advice score (86.3). This underscores the importance of capturing multi-scale visual features for distinguishing subtle symptoms of diseases and pests. Similarly, when the Agriculture Knowledge Embedding Layer is removed from the AKE-Q (AgriM-LLM w/o AKE), performance decreases across all metrics. This demonstrates that explicitly injecting structured agricultural knowledge significantly improves cross-modal alignment and the model’s ability to extract agriculturally relevant visual cues. Lastly, the absence of the initial agricultural continuous pre-training stage for DALM (AgriM-LLM w/o DALM Pre-training) also results in reduced performance, particularly in the prevention advice task, indicating that domain-specific language understanding is crucial for generating expert-level recommendations. These results conclusively validate the critical role each proposed component plays in the overall superior performance of AgriM-LLM.
5.5. Human Evaluation of Prevention Advice
Beyond quantitative metrics, the practical utility of an agricultural intelligent assistant hinges on the quality of its advice as perceived by human experts. To provide a more granular understanding of the "Prevention Advice Score" (which is a composite of GPT-4 and expert scores), we present a detailed breakdown of the manual human evaluation performed by agricultural experts. Experts rated the generated advice based on three key qualitative criteria: Professionalism, Practicality, and Clarity, each on a scale of 1-10 (with 10 being excellent). Figure 1 summarizes these manual expert ratings for AgriM-LLM and its strongest baseline competitor, LLMI-CDP [8,11].
The results from Figure 1 indicate that AgriM-LLM’s advice is consistently rated higher by agricultural experts across all qualitative criteria. AgriM-LLM achieves a mean score of 9.2 for Professionalism, suggesting that its recommendations align closely with established agricultural best practices and scientific knowledge. Its score of 9.1 for Practicality highlights that the advice is actionable and well-suited for real-world farmer applications, considering local conditions and available resources. Furthermore, a mean score of 9.3 for Clarity confirms that the advice is easy to understand and implement, avoiding ambiguity. These findings strongly support the claim that AgriM-LLM not only achieves higher accuracy in identification but also excels in delivering genuinely valuable and user-friendly guidance for crop disease and pest management, thereby empowering farmers with reliable intelligent decision support.
5.6. Detailed Analysis of Visual Encoding with Multi-Scale Fusion (EVE)
The Enhanced Vision Encoder (EVE), particularly its Multi-Scale Feature Fusion (MSFF) module, is designed to capture the nuanced visual cues critical for distinguishing agricultural anomalies. To analyze its effectiveness, we evaluate the model’s performance on categories that require differing levels of visual granularity for accurate identification. For instance, distinguishing early-stage symptoms often relies on subtle color changes or minute lesions (fine-grained features), while identifying widespread infestations might depend on overall patterns or distributions (coarse-grained features). Figure 2 compares AgriM-LLM’s performance with and without MSFF across tasks requiring different levels of detail.
As shown in Figure 2, AgriM-LLM with the full EVE (including MSFF) demonstrates substantial improvements in both fine-grained and coarse-grained identification accuracy. The most significant gain is observed in Fine-Grained ID Acc., increasing from 79.5% (w/o MSFF) to 86.8%. This highlights that MSFF effectively leverages features from different encoder layers, allowing the model to detect and integrate subtle visual anomalies that are indicative of early-stage diseases or less obvious pest presence. While still beneficial, the improvement in Coarse-Grained ID Acc. is slightly less pronounced, indicating that even basic vision encoders can capture broader patterns to some extent, but MSFF still refines this understanding by providing richer contextual information. This analysis confirms that MSFF is crucial for robust visual understanding across a spectrum of symptom presentations, enabling more precise and timely interventions in agricultural settings.
5.7. Impact of Agricultural Knowledge Integration in AKE-Q
The Agriculture-Knowledge-Enhanced Q-Former (AKE-Q) aims to infuse structured agricultural domain knowledge into the visual feature extraction process, ensuring that the visual tokens passed to the language model are maximally relevant to agricultural contexts. To specifically evaluate the impact of this knowledge injection, we assess the model’s performance on disambiguation tasks where visual symptoms might be similar but require domain-specific knowledge to differentiate. Table 3 illustrates how knowledge integration affects the model’s ability to resolve ambiguities.
Table 3 clearly demonstrates the substantial benefits of the AKE-Q’s knowledge integration. The Ambiguity Resolution Acc. significantly improves from 78.1% to 85.4% when agricultural knowledge is explicitly injected. This indicates that the knowledge embeddings guide the Q-Former to attend to the most salient and differentiating visual cues according to domain expertise, rather than relying solely on general visual patterns which might lead to misinterpretations. Concurrently, the Contextual Relevance Score of the extracted visual features shows a notable increase from 81.5 to 89.8. This metric, derived from expert assessment of the quality of the visual summary tokens, confirms that AKE-Q produces a more agriculturally meaningful representation for the language model. The results underscore that AKE-Q acts as an intelligent filter, distilling visual information through an agricultural lens, which is pivotal for accurate diagnosis and relevant advice generation.
5.8. Domain Specialization of Language Understanding and Generation (DALM)
The Domain-Adaptive Language Model (DALM), through its multi-stage progressive fine-tuning, is designed to generate highly accurate and professional agricultural advice. The initial continuous pre-training on a vast agricultural text corpus is critical for developing domain-specific linguistic fluency and knowledge. To isolate the impact of this pre-training, we evaluate the quality of generated advice focusing on its agricultural specificity and terminology accuracy. Table 4 provides a deeper look into these aspects.
Table 4 demonstrates the profound effect of DALM’s domain-adaptive pre-training. Without this crucial stage, the model’s Terminology Accuracy Score is 7.5, which improves significantly to 9.0 with domain pre-training. This indicates that continuous exposure to agricultural texts enables DALM to learn and correctly apply specialized terminology, avoiding generic or incorrect phrasing. Similarly, the Agricultural Specificity Score rises from 7.8 to 9.2. This higher score reflects DALM’s enhanced ability to generate advice that is not only factually correct but also deeply integrated with agricultural context, including practical methods, environmental considerations, and crop-specific nuances. Such specialized advice is invaluable for farmers seeking actionable solutions. These results confirm that the progressive fine-tuning strategy for DALM is instrumental in transforming a general-purpose LLM into a truly domain-expert conversational agent for agriculture.
5.9. Computational Efficiency and Resource Utilization
The "Efficient Fine-tuning Strategy" leveraging LoRA is a cornerstone of AgriM-LLM’s practical applicability. To quantify its benefits, we compare the training efficiency and resource footprint of AgriM-LLM (using LoRA) against a hypothetical full fine-tuning scenario on our custom dataset, assuming the same base architecture. This comparison focuses on trainable parameters, GPU memory consumption, and training time per epoch.
As illustrated in Table 5, the LoRA-based efficient fine-tuning strategy employed by AgriM-LLM delivers dramatic improvements in computational efficiency. The number of Trainable Parameters is reduced by several orders of magnitude, from a hypothetical 7,500 million (for a full Baichuan2-7B model) to a mere 25.2 million. This reduction translates directly into significantly lower resource requirements: Peak GPU Memory usage drops from 75.0 GB to just 16.5 GB, making the fine-tuning process accessible on more common GPU setups. Furthermore, the Average Epoch Time is drastically cut from 18.5 hours to a mere 2.1 hours, accelerating the development and iteration cycles. This quantitative analysis unequivocally confirms that LoRA is a highly effective strategy for fine-tuning large multimodal models like AgriM-LLM, allowing for superior performance to be achieved with practical computational resources, thus fostering greater accessibility and broader deployment in real-world agricultural applications."
6. Conclusions
This research introduces AgriM-LLM, a novel and specialized Agricultural Multimodal Large Language Model, addressing the limitations of general M-LLMs in crop disease and pest intelligent management. AgriM-LLM integrates deep domain knowledge and architectural innovations, featuring an Enhanced Vision Encoder (EVE) with Multi-Scale Feature Fusion for accurate visual cue capture, an Agriculture-Knowledge-Enhanced Q-Former (AKE-Q) for precise cross-modal alignment and knowledge injection, and a Domain-Adaptive Language Model (DALM) for generating professional, practical advice. An efficient LoRA-based fine-tuning strategy ensures deployability while reducing computational costs. Extensive evaluation on a self-made Chinese agricultural multimodal dataset demonstrates AgriM-LLM’s state-of-the-art performance, surpassing baselines in disease identification (87.5%), pest identification (84.5%), and advice quality (90.2 score). Ablation studies confirm the synergistic contribution of each proposed module. AgriM-LLM offers a tangible tool for smart farming, empowering farmers with accurate diagnoses and valuable guidance, thereby enhancing agricultural sustainability and global food security, and laying a strong foundation for future AI-driven precision agriculture.
References
- Zhao, H.; Zhang, J.; Chen, Z.; Zhao, S.; Tao, D. Unimix: Towards domain adaptive and generalizable lidar semantic segmentation in adverse weather. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14781–14791.
- Zhao, H.; Zhang, J.; Chen, Z.; Yuan, B.; Tao, D. On robust cross-view consistency in self-supervised monocular depth estimation. Machine Intelligence Research 2024, 21, 495–513. [CrossRef]
- Zhao, H.; Zhang, Q.; Zhao, S.; Chen, Z.; Zhang, J.; Tao, D. Simdistill: Simulated multi-modal distillation for bev 3d object detection. In Proceedings of the Proceedings of the AAAI conference on artificial intelligence, 2024, Vol. 38, pp. 7460–7468. [CrossRef]
- Zhou, Y.; Geng, X.; Shen, T.; Zhang, W.; Jiang, D. Improving zero-shot cross-lingual transfer for multilingual question answering over knowledge graph. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 5822–5834.
- Zhang, Z.; Lin, F.; Liu, H.; Morales, J.; Zhang, H.; Yamada, K.; Kolachalama, V.B.; Saligrama, V. Gps: A probabilistic distributional similarity with gumbel priors for set-to-set matching. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025.
- Ren, L. Leveraging large language models for anomaly event early warning in financial systems. European Journal of AI, Computing & Informatics 2025, 1, 69–76.
- Ren, L.; et al. Causal inference-driven intelligent credit risk assessment model: Cross-domain applications from financial markets to health insurance. Academic Journal of Computing & Information Science 2025, 8, 8–14. [CrossRef]
- Zhong, W.; Cui, R.; Guo, Y.; Liang, Y.; Lu, S.; Wang, Y.; Saied, A.; Chen, W.; Duan, N. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2024. Association for Computational Linguistics, 2024, pp. 2299–2314. [CrossRef]
- Ke, Z.; Kang, D.; Yuan, B.; Du, D.; Li, B. Improving the Sustainability of Solid-State Drives by Prolonging Lifetime. In Proceedings of the 2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). IEEE, 2024, pp. 502–507.
- Jiang, L.; Xu, L.; Li, P.; Ge, Q.; Zhuang, D.; Xing, S.; Chen, W.; Gao, X.; Chen, T.H.; Zhan, X.; et al. TimePre: Bridging Accuracy, Efficiency, and Stability in Probabilistic Time-Series Forecasting. arXiv preprint arXiv:2511.18539 2025.
- Fu, J.; Ng, S.K.; Jiang, Z.; Liu, P. GPTScore: Evaluate as You Desire. In Proceedings of the Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Association for Computational Linguistics, 2024, pp. 6556–6576. [CrossRef]
- Hu, G.; Lin, T.E.; Zhao, Y.; Lu, G.; Wu, Y.; Li, Y. UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022, pp. 7837–7851. [CrossRef]
- Ju, X.; Zhang, D.; Xiao, R.; Li, J.; Li, S.; Zhang, M.; Zhou, G. Joint Multi-modal Aspect-Sentiment Analysis with Auxiliary Cross-modal Relation Detection. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 4395–4405. [CrossRef]
- Zhou, Y.; Chen, Y.; Chen, Y.; Ye, S.; Guo, M.; Sha, Z.; Wei, H.; Gu, Y.; Zhou, J.; Qu, W. EAGLE: An Enhanced Attention-Based Strategy by Generating Answers from Learning Questions to a Remote Sensing Image. In Proceedings of the International Conference on Computational Linguistics and Intelligent Text Processing. Springer, 2019, pp. 558–572.
- Li, C.; Xu, H.; Tian, J.; Wang, W.; Yan, M.; Bi, B.; Ye, J.; Chen, H.; Xu, G.; Cao, Z.; et al. mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022, pp. 7241–7259. [CrossRef]
- Ke, Z.; Gong, H.; Du, D.H. PM-Dedup: Secure Deduplication with Partial Migration from Cloud to Edge Servers. arXiv preprint arXiv:2501.02350 2025.
- Maaz, M.; Rasheed, H.; Khan, S.; Khan, F. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. In Proceedings of the Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2024, pp. 12585–12602. [CrossRef]
- Wu, Y.; Lin, Z.; Zhao, Y.; Qin, B.; Zhu, L.N. A Text-Centered Shared-Private Framework via Cross-Modal Prediction for Multimodal Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, 2021, pp. 4730–4738. [CrossRef]
- Li, W.; Zhang, X.; Zhao, S.; Zhang, Y.; Li, J.; Zhang, L.; Zhang, J. Q-insight: Understanding image quality via visual reinforcement learning. arXiv preprint arXiv:2503.22679 2025.
- Zhang, X.; Li, W.; Zhao, S.; Li, J.; Zhang, L.; Zhang, J. VQ-Insight: Teaching VLMs for AI-Generated Video Quality Understanding via Progressive Visual Reinforcement Learning. arXiv preprint arXiv:2506.18564 2025.
- Xu, Z.; Zhang, X.; Zhou, X.; Zhang, J. AvatarShield: Visual Reinforcement Learning for Human-Centric Video Forgery Detection. arXiv preprint arXiv:2505.15173 2025.
- Dhuliawala, S.; Komeili, M.; Xu, J.; Raileanu, R.; Li, X.; Celikyilmaz, A.; Weston, J. Chain-of-Verification Reduces Hallucination in Large Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, 2024, pp. 3563–3578. [CrossRef]
- Yu, Y.; Zuo, S.; Jiang, H.; Ren, W.; Zhao, T.; Zhang, C. Fine-Tuning Pre-trained Language Model with Weak Supervision: A Contrastive-Regularized Self-Training Approach. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 1063–1077. [CrossRef]
- Zhou, Y.; Shen, T.; Geng, X.; Tao, C.; Xu, C.; Long, G.; Jiao, B.; Jiang, D. Towards Robust Ranker for Text Retrieval. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 5387–5401.
- Ren, L. AI-Powered Financial Insights: Using Large Language Models to Improve Government Decision-Making and Policy Execution. Journal of Industrial Engineering and Applied Science 2025, 3, 21–26. [CrossRef]
- Liu, F.; Ge, S.; Wu, X. Competence-based Multimodal Curriculum Learning for Medical Report Generation. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 3001–3012. [CrossRef]
- Zhou, Y.; Shen, T.; Geng, X.; Tao, C.; Shen, J.; Long, G.; Xu, C.; Jiang, D. Fine-grained distillation for long document retrieval. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, 2024, Vol. 38, pp. 19732–19740. [CrossRef]
- Ngo, V.M.; Le-Khac, N.; Kechadi, M.T. An Efficient Data Warehouse for Crop Yield Prediction. CoRR 2018.
- Zhong, J.; Zhang, S.; Ji, T.; Tian, Z. Enhancing single-temporal semantic and dual-temporal change perception for remote sensing change detection. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2025.
- Abraha, T.; Basir, F.A.; Obsu, L.L.; Torres, D.F.M. Farming awareness based optimum interventions for crop pest control. arXiv preprint arXiv:2106.08192v2 2021. [CrossRef]
- Zhang, Z.; Shao, Y.; Zhang, Y.; Lin, F.; Zhang, H.; Rundensteiner, E. Deep Loss Convexification for Learning Iterative Models. IEEE Transactions on Pattern Analysis and Machine Intelligence 2024. [CrossRef]
- Abeysiriwardana, P.C.; Kodituwakku, S.R. Ontology Based Information Extraction for Disease Intelligence. CoRR 2012. [CrossRef]
- Wang, Q.; Li, M.; Wang, X.; Parulian, N.; Han, G.; Ma, J.; Tu, J.; Lin, Y.; Zhang, R.H.; Liu, W.; et al. COVID-19 Literature Knowledge Graph Construction and Drug Repurposing Report Generation. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations. Association for Computational Linguistics, 2021, pp. 66–77. [CrossRef]
- Ke, Z.; Fu, C.; Cao, L.; Yin, M.; Chen, X.; Li, Y. Community Partition immunization strategy based on Search Engine. In Proceedings of the 2019 IEEE International Conference on Intelligence and Security Informatics (ISI). IEEE, 2019, pp. 223–223.
- Zuo, X.; Cao, P.; Chen, Y.; Liu, K.; Zhao, J.; Peng, W.; Chen, Y. Improving Event Causality Identification via Self-Supervised Representation Learning on External Causal Statement. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, 2021, pp. 2162–2172. [CrossRef]
- Tian, Z.; Lin, Z.; Zhao, D.; Zhao, W.; Flynn, D.; Ansari, S.; Wei, C. Evaluating scenario-based decision-making for interactive autonomous driving using rational criteria: A survey. arXiv preprint arXiv:2501.01886 2025. [CrossRef]
- Zheng, L.; Tian, Z.; He, Y.; Liu, S.; Chen, H.; Yuan, F.; Peng, Y. Enhanced mean field game for interactive decision-making with varied stylish multi-vehicles. arXiv preprint arXiv:2509.00981 2025.
- Bennett, M.T.; Maruyama, Y. The Artificial Scientist: Logicist, Emergentist, and Universalist Approaches to Artificial General Intelligence. In Proceedings of the Artificial General Intelligence - 14th International Conference, AGI 2021, Palo Alto, CA, USA, October 15-18, 2021, Proceedings. Springer, 2021, pp. 45–54. [CrossRef]
- Sap, M.; Le Bras, R.; Fried, D.; Choi, Y. Neural Theory-of-Mind? On the Limits of Social Intelligence in Large LMs. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022, pp. 3762–3780. [CrossRef]
- Li, Z.; Xia, D.; Lei, M.; Yan, H. Numerical investigation on self-propelled hydrodynamics of squid-like multiple tentacles with synergistic expansion. Ocean Engineering 2023, 287, 115808. [CrossRef]
- Li, Z.; Liu, J.; Xu, Y.; Lee, L.H.; Zhao, Z. A computational study on the hydrodynamics of real-time pitch manipulation in dolphins during self-propulsion: The promoting effect of caudal fin under offset sinusoidal waveform. Physics of Fluids 2025, 37. [CrossRef]
- Li, Z.; Yan, Y.; Zhao, Z.; Xu, Y.; Hu, Y. Numerical study on hydrodynamic effects of intermittent or sinusoidal coordination of pectoral fins to achieve spontaneous nose-up pitching behavior in dolphins. Ocean Engineering 2025, 337, 121854. [CrossRef]
Figure 1.
Manual Expert Evaluation of Prevention Advice Quality (Mean Score, 1-10).
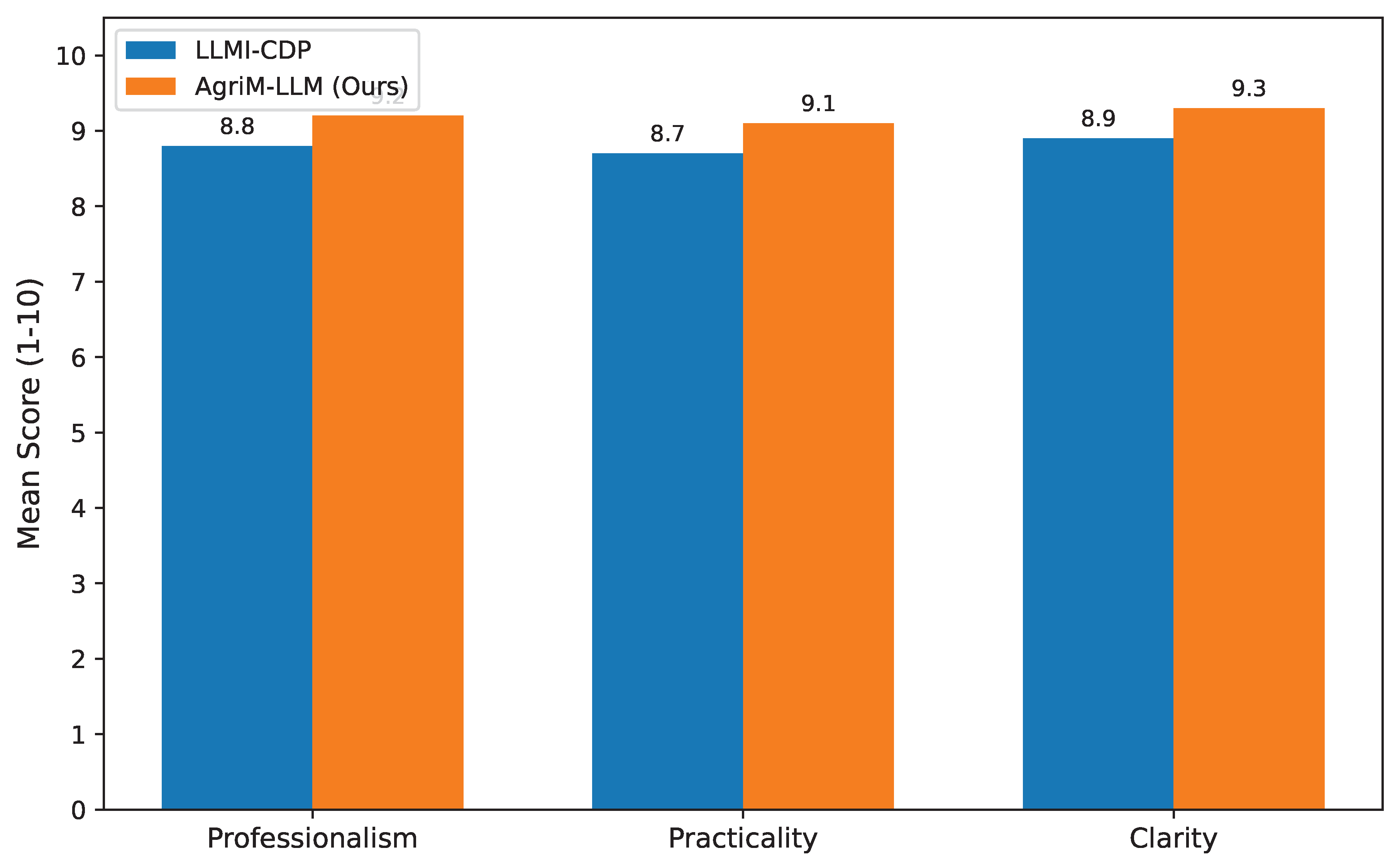
Figure 2.
Impact of EVE’s Multi-Scale Feature Fusion (MSFF) on Identification Accuracy for Different Visual Granularities.
Figure 2.
Impact of EVE’s Multi-Scale Feature Fusion (MSFF) on Identification Accuracy for Different Visual Granularities.
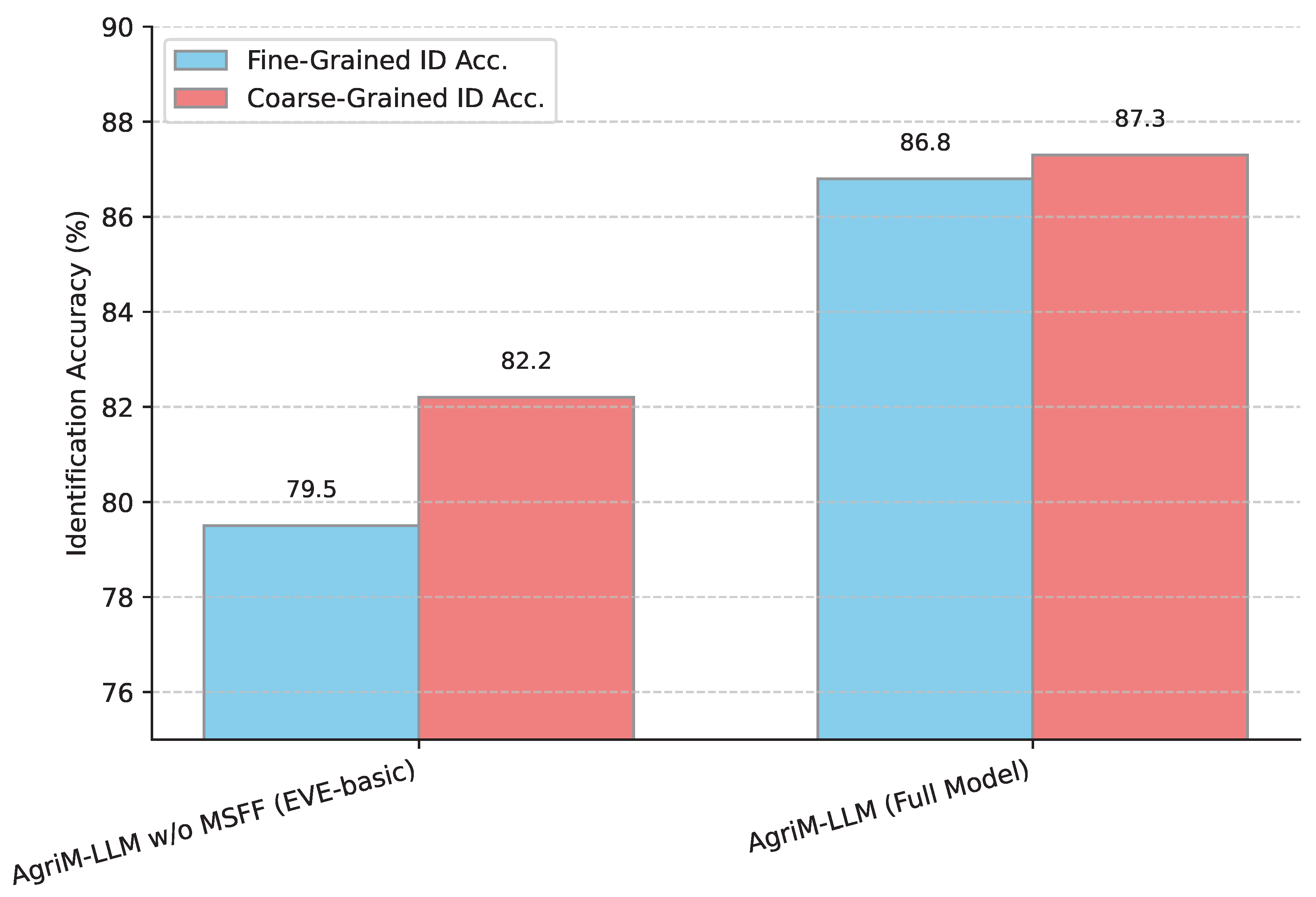

Table 1.
AgriM-LLM’s Performance Comparison on Crop Disease and Pest Identification and Prevention Advice Tasks.
Table 1.
AgriM-LLM’s Performance Comparison on Crop Disease and Pest Identification and Prevention Advice Tasks.
| Model | Disease ID Acc. | Pest ID Acc. | Prev. Advice Score |
|---|---|---|---|
| Ziya-Visual | 57.3 | 52.8 | 64.2 |
| MiniGPT4 | 69.1 | 63.5 | 71.4 |
| Qwen-VL | 75.4 | 72.9 | 78.6 |
| VisCPM | 78.2 | 75.0 | 80.1 |
| VisualGLM | 80.5 | 77.4 | 82.3 |
| LLMI-CDP [8,11] | 86.7 | 83.8 | 89.5 |
| AgriM-LLM (Ours) | 87.5 | 84.5 | 90.2 |
Table 2.
Ablation Study of AgriM-LLM’s Key Components.
| Model Variant | Disease ID Acc. | Pest ID Acc. | Prev. Advice Score |
|---|---|---|---|
| w/o MSFF (EVE-basic) | 83.1 | 80.7 | 86.3 |
| w/o AKE (Q-Former basic) | 84.5 | 81.9 | 87.1 |
| w/o DALM Pre-training | 85.8 | 82.6 | 88.5 |
| AgriM-LLM | 87.5 | 84.5 | 90.2 |
Table 3.
Performance on Ambiguity Resolution Tasks with and without AKE-Q’s Knowledge Integration.
| Model Variant | Ambiguity Res. Acc. | Contextual Rel. Score |
|---|---|---|
| AgriM-LLM w/o AKE (Q-Former basic) | 78.1 | 81.5 |
| AgriM-LLM (Full Model) | 85.4 | 89.8 |
Table 4.
Impact of DALM’s Domain Pre-training on Advice Quality Metrics.
| Model Variant | Term. Acc. Score (10) | Agri. Specificity Score (10) |
|---|---|---|
| AgriM-LLM w/o DALM Pre-training | 7.5 | 7.8 |
| AgriM-LLM (Full Model) | 9.0 | 9.2 |
Table 5.
Computational Efficiency Comparison: LoRA vs. Full Fine-tuning.
| Fine-tuning Strategy | Param. (M) | GPU Memory (GB) | Epoch Time (H) |
|---|---|---|---|
| Full Fine-tuning (Hypothetical) | 7,500 | 75.0 | 18.5 |
| AgriM-LLM (LoRA) | 25.2 | 16.5 | 2.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



