Submitted:
02 January 2026
Posted:
04 January 2026
You are already at the latest version
Abstract
Large Language Models (LLMs) have demonstrated remarkable abilities to solve problems requiring multiple reasoning steps, yet the internal mechanisms enabling such capabilities remain elusive. Unlike existing surveys that primarily focus on engineering methods to enhance performance, this survey provides a comprehensive overview of the mechanisms underlying LLM multi-step reasoning. We organize the survey around a conceptual framework comprising seven interconnected research questions, from how LLMs execute implicit multi-hop reasoning within hidden activations to how verbalized explicit reasoning remodels the internal computation. Finally, we highlight five research directions for future mechanistic studies.
Keywords:
large language models
; multi-step reasoning
; mechanistic interpretability
; literature review
1. Introduction
Large Language Models (LLMs) have demonstrated an impressive ability to carry out multi-step reasoning, which involves the process of drawing conclusions through a sequence of intermediate steps, where each step builds on the previous one. Multi-step reasoning has been widely regarded as one of the most fundamental forms of reasoning Guo et al. (2025); Hou et al. (2023a). It serves as the backbone of advanced tasks such as deep question answering, mathematical problem solving, logical deduction, code generation, and planning Chen et al. (2021); DeepSeek-AI et al. (2025); Dubey et al. (2024); Guo et al. (2024); OpenAI (2023); Wei et al. (2022); Yang et al. (2024).
Multi-step reasoning in LLMs generally takes on two distinct forms. Implicit reasoning involves performing multi-hop inference entirely within the model’s hidden activations, delivering a correct final answer without verbalizing intermediate steps. In contrast, explicit reasoning, exemplified by Chain-of-Thought (CoT) Wei et al. (2022), instructs the model to externalize the reasoning process into a sequence of natural language tokens. Remarkably, modern LLMs have exhibited strong performance in both paradigms Chen et al. (2025); Chu et al. (2024a); Li et al. (2025). Building on this empirical success, the internal mechanisms that enable such capabilities become scientifically intriguing. For implicit reasoning, a key puzzle is how multi-step reasoning capabilities emerge from simple next-token prediction training, and how LLMs internally carry out multi-step computations. For explicit CoT reasoning, critical questions persist about why CoT can elicit superior reasoning capabilities and whether the generated rationale faithfully reflects the model’s actual decision-making process. Understanding these mechanisms is not only a matter of scientific curiosity but also a prerequisite for building more reliable, controllable, and human-aligned reasoning systems.
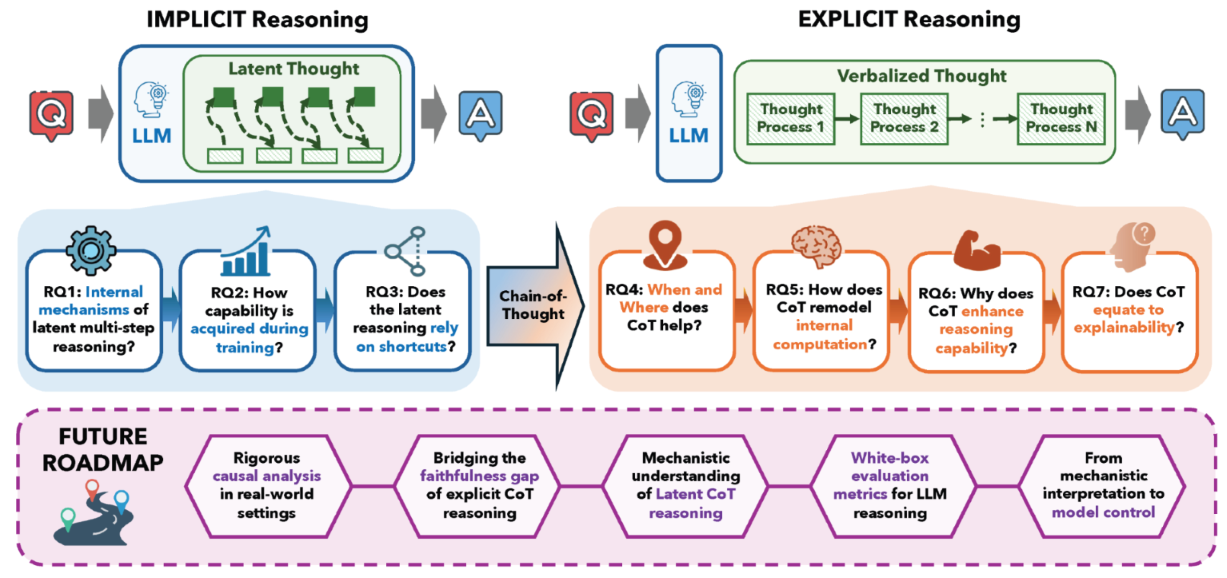
Although we still lack a unified mechanistic theory, a growing body of literature seeks to open the black box of LLM multi-step reasoning and has made significant progress. In this paper, we aim to provide a comprehensive overview of these works. Unlike existing surveys Chen et al. (2025); Chu et al. (2024b); Huang and Chang (2023) that primarily focus on enhancing reasoning (e.g., through tool use, retrieval augmentation, or self-correction), our survey explicitly focuses on understanding mechanisms, a perspective that has been largely overlooked in previous reviews. As illustrated in Figure 1, we identify seven pivotal, interconnected, and progressive research questions (RQs) to form the cognitive framework of our survey. These questions form a cohesive narrative, covering analytical methods and key findings from the hidden internal dynamics of latent reasoning to the visible mechanisms of explicit CoT reasoning. We end by pointing out five open research questions that remain under-explored but are essential for the future roadmap of mechanistic understanding.
2. Implicit Multi-Step Reasoning
Multi-hop implicit reasoning is the process of answering a question by combining multiple pieces of information across several steps. Unlike explicit reasoning, the intermediate links are not directly stated and must be inferred using background knowledge or context. Mechanistic study of multi-hop implicit reasoning is important because it reveals whether models truly perform step-by-step reasoning or rely on shallow shortcuts. Such understanding improves interpretability and trust in LLMs, and it guides the development of models that generalize more reliably.
2.1. What Are the Internal Mechanisms of Latent Multi-Step Reasoning?
Recent mechanistic studies have begun to unveil how LLMs carry out latent multi-hop computation entirely in their hidden states Biran et al. (2024); Brinkmann et al. (2024a); Yang et al. (2024). These studies employing causal probing, mechanistic tracing, and representational analysis have collectively revealed a staged internal process in which intermediate results are computed and transformed layer by layer, ultimately contributing to the final output. In essence, transformers appear to implement an internal chain-of-thought spread across their depth.
- Functional specialization of layers.
A major body of work explores layer specialization, aiming to identify the distinct computational roles each layer plays during multi-hop inference. Using Patchscopes Ghandeharioun et al. (2024) together with a novel intervention technique termed back-patching, Biran et al. (2024) uncovered a sequential computation pathway in which early layers identify the bridge entity, which is then propagated forward and exploited by later layers to complete the inference. Complementarily, Li et al. (2024) applied logit lens analysis nostalgebraist (2020) and found that implicit reasoning representations emerge in intermediate layers and have a causal influence on generating the final answer. Extending this perspective, Yu et al. (2025) traced logits through the network via a neuron-level logit flow method and observed that even a single-hop query is solved in multiple distinct stages—entity subject enrichment, entity attribute extraction, relation subject enrichment, and relation attribute extraction—each of which is localized to different layers. More recently, Yang et al. (2025) showed that this layer-wise reasoning also applies at the task level: for composite instructions, models execute different subtasks at different depths, forming a staged computation across layers. All the above studies provided evidence of functional specialization of transformer layers in multi-hop reasoning.
- Uncovering fine-grained reasoning structures.
Beyond layer specification, another line of work aims to recover more fine-grained implicit reasoning structures from model internals. MechanisticProbe Hou et al. (2023b) introduced an attention-probing technique to extract latent reasoning trees from transformer activations. They showed that on synthetic and natural tasks with GPT-2 and LLaMA, models often perform procedural reasoning layer by layer, with lower layers selecting statements and higher layers executing reasoning steps. Complementing these findings, Brinkmann et al. (2024b) analyzed a small transformer trained on a symbolic tree path-finding task, finding that it implements a backward chaining algorithm: deduction heads climb trees one level per layer, register tokens act as working memory for parallel subpaths, and a one-step lookahead heuristic compensates when chaining is insufficient. Together, these studies demonstrate that transformers can adopt structured, algorithm-like reasoning strategies beyond memorization, albeit within the limits of the model’s depth (to be discussed below).
- Layer depth as the primary bottleneck for implicit reasoning.
Theoretical and empirical studies indicate that the number of reasoning steps a model can perform implicitly is strictly limited by its depth. Merrill and Sabharwal (2024) theoretically demonstrated that a standard Transformer with constant depth cannot solve inherently serial problems that require computation scaling with input size, e.g., parity or graph connectivity. In practice, Yu (2025) and Guo
et al. (2025) found that specific multi-hop reasoning tasks require a minimum threshold of layers to resolve; if a model is too shallow, the “latent chain” is cut short, and the reasoning fails. Saunshi et al. (2025) formally established that an L-layer Transformer can simulate an m-step explicit reasoning process, provided L is sufficiently large to accommodate the iterative forward passes required. All these works revealed a close correlation between layer depth and the implicit reasoning capabilities of the model.
- Why implicit reasoning sometimes fails.
Identifying how and why implicit reasoning sometimes fails has also been illuminating. Biran et al.
(2024) discovered that many failures stem from delayed resolution of the first hop, and showed that rerunning computations via back-patching can correct these errors. Li et al. (2024) found that failures frequently arise from the improper generation or utilization of implicit reasoning results. To address this, they proposed CREME, a lightweight model-editing technique that patches specific multi-head self-attention modules, leading to improved compositional reasoning generalization with minimal disruption to unrelated predictions. In the context of two-hop queries (“’s ’s is ”), Yu et al. (2025) showed that errors often occur when high-layer features at the position overemphasize the intermediate entity , outweighing the logits for the correct final entity . This finding revealed that LLMs internally build and combine entity–relation representations in a staged manner, but positional interference can derail multi-hop reasoning. To fix this, they introduced a back-attention mechanism allowing lower layers to reuse higher-layer information from other positions, which substantially improved multi-hop accuracy. However, even with such interventions, certain transformers still struggle to reliably chain more than one reasoning step. For example, Yang et al. (2024) found that LLaMA-2 models, while reliably recalling a needed bridge entity, often fail to apply it to the second hop, highlighting limits in architecture that impede consistent multi-step chaining.

2.2. How Latent Multi-Step Reasoning Capability Is Acquired During Training?
Models do not possess latent reasoning capabilities at initialization. If multi-hop reasoning is implemented via specialized internal circuits discussed in Section 2.1, a critical question arises: how do these circuits emerge in the first place? Research into training dynamics reveals that implicit reasoning is an acquired behavior that emerges during the training process through distinct phase transitions.
- Grokking marks the shift from memorization to reasoning.
Recent studies Abramov et al. (2025); Wang et al. (2024); Ye et al. (2025); Zhang et al. (2025) suggested that LLMs do not learn multi-step reasoning gradually; instead, they often undergo phase transitions during training where reasoning capabilities appear suddenly rather than continuously. In other words, a model might spend many updates seemingly memorizing or floundering, then “grok” the underlying reasoning algorithm after a certain point. This phenomenon, known as “grokking”, was initially observed in deep networks trained on other tasks such as modular arithmetic, where generalization performance spikes long after training accuracy has saturated Power et al. (2022); Olsson et al. (2022); Wei et al. (2022).
In the context of multi-hop implicit reasoning, this phenomenon of transformers transitioning from early-stage memorization to later-stage generalization was first observed by Wang et al. (2024) through training transformers from scratch on symbolic reasoning tasks. They found that the multi-hop reasoning capability emerges only through grokking, where an early memorizing circuit is gradually replaced by a more efficient generalizing circuit due to optimization bias and weight decay. Ye et al. (2025) corroborated this phase transition, proposing a three-stage trajectory: (i) rapid memorization, (ii) delayed in-distribution generalization, and (iii) slower cross-distribution generalization, with persistent OOD bottlenecks at the second hop. Mechanistically, they employed cross-query semantic patching to localize the “bridge” entity and a cosine-based representational lens to reveal that generalization coincides with mid-layer clustering of intermediate entity representations.
- Factors influencing the emergence of reasoning.
The transition from memorization to generalization is not random; studies revealed that it is governed by specific properties. One of the primary determinants is the training data distribution. Wang et al. (2024) demonstrated that the speed of grokking correlates strongly with the ratio of inferred to atomic facts ϕ in training. A higher ratio of compositional examples forces the model to abandon inefficient memorization in favor of the generalizing circuit. Expanding this to real-world scenarios, Abramov et al. (2025) found that natural corpora often lack sufficient connectivity (low ) to trigger this transition, but data augmentation with synthetic inferred facts can artificially raise above the critical threshold required for circuit formation. Beyond data distribution, the scale of the training data also matters. Yao et al. (2025) revealed a scaling law: the data budget required to learn implicit k-hop reasoning grows exponentially with k, though curriculum learning can significantly mitigate this cost. From an optimization perspective, Zhang et al. (2025) identified complexity control parameters as crucial factors. They found that smaller initialization scales and stronger weight decay bias the optimization process toward low-complexity, rule-like solutions rather than high-complexity, memory-based mappings, thereby accelerating the emergence of reasoning capabilities. Finally, Li et al. (2025) observed that in large-scale pretraining, grokking is asynchronous and local; different domains and data groups undergo this memorization-to-generalization transition at different times depending on their inherent difficulty and distribution heterogeneity.

2.3. To What Extent Does Multi-Step Reasoning Rely on Shortcuts?
While the training dynamics discussed in Section 2.1 suggest that structured reasoning circuits can emerge, growing mechanistic evidence has also uncovered a more complex and often discouraging reality regarding model internals. Models frequently bypass genuine multi-step reasoning, relying instead on “shortcuts”—statistical correlations or surface-level heuristics that mimic reasoning without performing the underlying computation Elazar et al. (2024); Kang and Choi (2023); Yang et al. (2025a).
- Factual shortcuts bypass intermediate reasoning.
A primary form of shortcutting involves exploiting direct associations between the subject and the final answer, effectively skipping the intermediate steps. Ju et al. (2024) investigated this in the context of knowledge editing, finding that failures often stem from “shortcut neurons” that encode a direct link between the first and last entities, ignoring the multi-hop structure. Mechanistically, Yang et al. (2025b) used Patchscopes Ghandeharioun et al. (2024) to distinguish valid reasoning from shortcuts. They observed that genuine implicit reasoning coincides with the model constructing a hidden representation of the intermediate bridge entity. In contrast, shortcut-prone queries bypass this internal construction entirely. When these direct shortcuts are removed, model performance drops by nearly a factor of three, revealing that much of the perceived reasoning capability is illusory.
- Shortcuts based on surface-level pattern matching.
Beyond factual associations, models also latch onto structural regularities in the training data. Lin et al. (2025) analyzed implicit arithmetic reasoning and found that models often adopt a “bag-of-words” heuristic, treating operations as commutative even when they are not. While this shortcut works for fixed-template examples, performance collapses when premise order is randomized, proving the model had not learned the robust sequential logic. Similarly, Guo et al. (2025) found that in the presence of context distractors, pretrained models default to a heuristic of guessing based on surface plausibility. However, they also noted a positive trajectory: fine-tuning can force a phase transition where the model shifts from this shallow guessing behavior to a sequential query mechanism that explicitly retrieves intermediate entities.

3. Explicit Multi-Step Reasoning
Implicit reasoning operates entirely within the fixed computational budget of the model’s hidden states; therefore, it is bounded by the depth bottleneck and frequently falls prey to shortcuts. Explicit multi-step reasoning fundamentally alters this paradigm. By prompting an LLM to produce a step-by-step Chain-of-Thought (CoT), the reasoning process is externalized into a sequence of natural language tokens, effectively extending the computational capacity beyond the model’s layers. CoT has been shown to unlock significantly better performance on tasks that require reasoning. In this section, we dissect the mechanisms of this paradigm through four progressive research questions ( Section 3.1- Section 3.4).
3.1. Where and When Does CoT Help?
- On which tasks does CoT help?
To uncover this, Sprague et al. (2025) conducted a large-scale meta-analysis across 20 benchmarks and found that prompting with CoT yields large gains primarily on math and symbolic logic tasks, with far smaller or even negative gains on other domains. Suzgun et al. (2023) similarly showed that many BIG-Bench Hard tasks Srivastava et al. (2023), which had stumped standard few-shot prompts, become solvable with CoT. These were precisely tasks requiring multi-step reasoning, e.g., symbolic manipulation, compositional logic. However, for knowledge-heavy tasks like MMLU Hendrycks
et al. (2021) or commonsense reasoning, CoT often provides negligible improvement Sprague et al. (2025). In certain cases, CoT can even degrade accuracy. For example, Liu et al. (2024) examined cognitive-psychology tasks where additional deliberation harms human performance, e.g., certain trick riddles or intuitive judgment problems. They found that CoT substantially degraded accuracy on such tasks, and it tends to distract the model into over-complicating a problem that might have been solved via intuition. A complementary study on Blocksworld planning Stechly et al. (2024) found that CoT helps only when the prompt examples closely match the test distribution, and the gains quickly deteriorate if the test problem’s complexity exceeds that seen in the exemplars.
- What factors influence the efficacy of CoT?
Beyond task-level evaluations, empirical studies have shown that CoT performance can be dramatically influenced by many features of the CoT prompt. First, studies Ye and Durrett (2022); Madaan et al. (2023); Wang et al. (2023) reveal that the relevance and ordering of exemplars matter more than their semantics; models can still derive correct answers from invalid rationales if the prompt maintains a coherent structure. Second, the length of reasoning is another critical factor, with Jin et al. (2024) identifying that the number of reasoning steps significantly modulates model performance. Finally, CoT is surprisingly sensitive to phrasing; minor input perturbations can substantially bias models’ answers Turpin et al. (2023); Sadr et al. (2025).
- Why do these factors influence CoT efficacy?
To explain the mechanisms underlying these factors, recent research provided theoretical and mechanistic groundings. Tutunov et al. (2023) proposed that CoT efficacy stems from the model’s ability to approximate the true conditional distribution of reasoning, where structured exemplars help the model infer the task’s latent logic and reduce generation ambiguity. Prabhakar et al. (2024) refined this view through a controlled case study, characterizing CoT as a probabilistic process heavily modulated by output probability, task memorization in training data, and step-wise complexity. Mechanistically, Wu et al. (2023) revealed how specific components of the CoT prompt drive model generation via gradient-based feature attribution.

3.2. How Does Chain-of-Thought Remodel Internal Computation?
Chain-of-thought prompting does more than just alter an LLM’s output format. Growing evidence shows that it fundamentally changes the model’s internal computation into a “reasoning mode”, where the model retrieves and updates information in a stepwise fashion, leveraging the intermediate computational steps as external memory.
- The emergence of iteration heads.
First, Cabannes et al. (2024) identified the “iteration head” — an attention head that emerges during CoT. These heads explicitly focus on the model’s previously generated tokens to carry forward interim results. For example, in a loop counter task, an iteration head attends to the token “Step 4” to generate “Step 5”. This effectively allows the model to create a virtual recurrent neural network (RNN) where the hidden state is externalized as text. In another study of a Llama-2 model Touvron et al. (2023) solving multi-step ontology queries, Dutta et al. (2024) also identified early-layer attention heads that “move information along ontological relationships” in the contexts that are relevant to the current sub-problem. The emergence of iteration heads provides supporting evidence that CoT enables the model to internally utilize generated text as an external memory for sequential reasoning.
- Evidence of state maintenance and update.
Besides the access to external memory, studies show that LLMs with CoT can also maintain and update dynamic internal states to track the reasoning process. Zhang et al. (2025) found that when using CoT for state-tracking tasks, LLMs embed an implicit finite state automaton in their hidden layers. Specific feed-forward neurons in later layers were found to correspond directly to discrete problem states, forming a circuit that reliably updates with each new reasoning step. This internal state representation is highly robust and works correctly even with noisy or incomplete CoT steps, suggesting the model learns a resilient state-updating algorithm. By probing individual neurons of LLMs, Rai and Yao (2024) offered more granular evidence of state maintenance. They identified specific “reasoning neurons” in Llama-2’s feed-forward layers that activate to hold partial results, such as carried values during arithmetic. Their activation helps explain why including particular steps (e.g., an explicit breakdown of a sum) in the CoT prompt is effective: they reliably trigger the neurons responsible for maintaining the intermediate state.
- Computational depth matters more than token semantics.
Notably, the internal process of sequential reasoning appears to persist even when the CoT rationale lacks semantic meaning. For example, Pfau et al. (2024) replaced the meaningful CoT text with filler tokens (e.g., “...”). Surprisingly, models could still solve complex reasoning tasks simply by generating these dots. Similarly, Goyal et al. (2024) found that introducing a learnable “pause” token significantly boosts performance on tasks from QA to math. These findings suggest that the semantic content of reasoning steps may be secondary to the computational time they buy. The sheer act of generating extra tokens (regardless of their meaning) provides necessary computational depth; each token grants the model an additional forward pass through all its layers. This extra “think time” enables the model to implement complex reasoning algorithms that cannot be executed in a single pass. Bharadwaj (2024) reinforced this interpretation through a mechanistic study. They found that even when CoT steps are replaced by placeholders, the model’s deeper layers still encode the missing steps, which can be recovered to their correct semantic content via a logit lens probe.
- Parallelism and reasoning shortcuts.
Finally, although growing evidence reveals the sequential nature of CoT’s internal computation, other studies have found that LLMs often run multiple reasoning pathways in parallel during CoT, meaning that the model’s internal reasoning process is not strictly sequential. For example, Dutta et al. (2024) identified a “functional rift” where the model simultaneously tries to solve the problem directly from the question (“reasoning shortcuts”) while also following the step-by-step procedure, and these parallel approaches then converge in later layers. Nikankin et al. (2025) found that models perform arithmetic via a “bag of heuristics” (many simple feature detectors) rather than a single step-by-step algorithm. Arcuschin et al. (2025) observed that the models can still arrive at the correct answer, even if they might make a mistake in an early step internally. The above evidence on parallelism and shortcuts reveals that CoT’s internal workings are more complicated. It is a combination of sequential step-by-step reasoning, parallel associative shortcuts, and occasional after-the-fact rationalizations.

3.3. Why CoT Enhances Reasoning Abilities?
Empirically, explicit reasoning with CoT often solves complex tasks more accurately than implicit latent reasoning. Several reasons have been identified for why CoT prompting dramatically improves reasoning performance.
- CoT augments computational expressiveness.
Recent theoretical studies demonstrate that CoT enhances transformers’ expressiveness and computational capacity, enabling them to solve problems in higher complexity classes. A standard transformer decoder without CoT performs constant-depth computation per token, limiting it to the complexity class Merrill and Sabharwal (2023a, ); Chiang et al. (2023); Merrill and Sabharwal (2023a,b). Such models theoretically cannot solve inherently serial problems because the required computation depth grows with input size, while the model’s depth is fixed. CoT breaks this limit. By feeding the output back into the input, CoT allows the transformer to simulate an RNN or a Turing Machine. The effective depth of the computation becomes proportional to the length of the generated chain. This elevates the transformer’s expressiveness to Polynomial Time () Merrill and Sabharwal (2024), making inherently serial or recursive computations solvable where they otherwise are not Bavandpour et al. (2025); Feng et al. (2023); Kim and Suzuki (2025); Li et al. (2024).
- CoT introduces modularity that reduces sample complexity.
CoT decomposes complex tasks into granular, independent sub-problems. This modularity provides an inductive bias that matches the structure of complex, multi-step problems, enabling the model to master tasks with significantly less data. Through both experimental and theoretical evidence, Li et al. (2023) demonstrated that CoT decouples in-context learning into a “filtering” phase and a “learning” phase that significantly reduces the sample complexity required to learn compositional structures like MLPs. Extending this learnability perspective, Yang et al. (2025) demonstrated that CoT can render inherently “unlearnable” tasks efficiently learnable by reducing the sample complexity of the overall task to that of its hardest individual reasoning step. Wen et al. (2025) further identified that this efficiency stems from the sparse sequential dependencies among tokens. CoT induces interpretable, sparse attention patterns that enable polynomial sample complexity, whereas implicit reasoning requires exponentially many samples to disentangle dense dependencies.
- CoT enables more robust reasoning.
First, evidence has been found that CoT promotes robust generalization by encouraging models to learn generalizable solution patterns rather than overfitting to surface-level statistical shortcuts. For example, Yao et al. (2025) demonstrated that CoT-trained models induce a two-stage generalizing circuit that internalizes the reasoning process, leading to strong OOD generalization even in the presence of training noise. Complementing this, Li et al. (2025) provided a theoretical guarantee for CoT generalization, showing that CoT maintains high performance even when context examples are noisy or erroneous, as it relies on step-by-step pattern matching rather than fragile input-output mappings. Second, CoT helps reduce the propagation of errors during reasoning. Gan et al. (2025) identified a “snowball error effect” in implicit reasoning, where minor inaccuracies accumulate into significant failures. They demonstrated that CoT-based strategies mitigate this by expanding the reasoning search space, which effectively lowers the probability of cumulative information loss and prevents errors from cascading through the reasoning chain.

3.4. Does Chain-of-Thought Equate to Explainability?
Explicit reasoning appears to provide transparency, leading users to assume that CoT explanations accurately reveal how the model arrived at an answer. However, substantial evidence indicates that CoT outputs often do not faithfully reflect the model’s actual decision-making process Barez et al.
(2025); Chen et al. (2025); Lanham et al. (2023); Turpin et al. (2023), a phenomenon referred to as the unfaithfulness of CoT reasoning.
- Evidence of CoT unfaithfulness.
Recent studies reveal that CoT frequently functions as post-hoc rationalization rather than the causal driver of predictions Arcuschin et al. (2025); Kudo et al. (2024); Lewis-Lim et al. (2025). For instance, Turpin et al. (2023) demonstrated that models often alter their predictions based on spurious cues, such as the reordering of multiple-choice options. In such cases, the models still tend to confabulate logical-sounding CoT rationales that hide the actual spurious cause of their decision. Similarly, when correct answers are injected as hints, models often invent spurious derivations to support the injected answer without acknowledging the hint’s influence Chen et al. (2025). Furthermore, mechanistic analyses uncovered “silent error corrections”, where models internally correct mistakes without updating the CoT rationale Arcuschin et al. (2025). Unfaithfulness is also evident in sycophancy, where models prioritize agreement with user beliefs over truthfulness. Even when models possess the correct internal knowledge, they frequently concede to incorrect user premises and generate plausible rationales to justify these compliant responses Sharma et al. (2024). Collectively, these findings highlight a fundamental disconnect between verbalized rationales and internal computations, challenging the premise that CoT equates to explainability.
- Mechanistic understanding of CoT unfaithfulness.
Recent mechanistic analyses attribute this unfaithfulness to a fundamental mismatch between the distributed, parallel nature of transformer computation and the sequential nature of explicit reasoning. As discussed in Section 3.2, many works have revealed the distributed nature of LLMs’ internal reasoning; transformer-based LLMs frequently employ multiple redundant computational pathways to process information, e.g., simultaneously leveraging memorization, heuristics, and algorithmic circuits Dutta et al. (2024); McGrath et al. (2023); Nikankin et al. (2025). Consequently, CoT only acts as a “lossy projection” of high-dimensional internal states, often capturing only a fraction of the model’s actual decision process Dutta et al. (2024). Because computation is highly distributed, a single CoT rationale can capture at most one of many simultaneous causal pathways. As a result, CoTs typically omit influential factors and serve only as partial, post-hoc rationalisations of the model’s underlying distributed, superposed computation ez et al. (2025). This architectural dissonance makes unfaithfulness difficult to mitigate. Tanneru et al. (2024) demonstrated that even when training objectives explicitly penalize inconsistency, models still revert to plausible-but-not-causal explanations on complex tasks, highlighting the inherent difficulty in eliciting faithful CoT reasoning from LLMs.

4. Future Research Directions
- Rigorous causal analysis in real-world settings.
A fundamental challenge in current mechanistic research is the disparity between idealized experimental settings and the complexities of real-world reasoning. First, the reliance on toy models and synthetic data limits the generalizability of current findings. For example, while the “grokking” phenomenon has been identified as a potential pathway for the emergence of implicit multi-hop reasoning, most empirical evidence is derived from toy models trained from scratch on synthetic tasks ( Section 2.2). Consequently, it remains an open question whether the phase transitions observed in these controlled environments truly govern the development of reasoning capabilities in foundation models trained on large-scale, naturalistic corpora.
Second, the field should move beyond correlational analysis, which only proves information presence, to rigorous causal verification within these complex settings. Unlike clean synthetic environments, real-world data is ubiquitous with spurious cues, making it difficult to distinguish genuine reasoning circuits from robust shortcut heuristics ( Section 2.3). Therefore, causal interventions are crucial for proving that identified internal representations are truly drivers of correct inference in the wild. This understanding should ideally translate into robust training-time interventions that penalize such shortcuts, forcing models to learn generalizable algorithms despite the noisy data distribution. Ultimately, future work must aim to synthesize these insights into a unified theoretical framework that explains how diverse components, from memorization circuits to reasoning heads, interact within the massive scale of foundation models.
- Bridging the faithfulness gap of explicit CoT reasoning.
As discussed in Section 3.4, a critical bottleneck in current LLMs is the “functional rift” Dutta et al.
(2024) between the model’s internal, parallel processing and its sequential, explicit CoT reasoning. This structural mismatch forces models to compress high-dimensional, distributed latent states into a low-bandwidth stream of discrete tokens, often resulting in CoT that functions as a post-hoc rationalization rather than a causal driver. To address this, future research must explore white-box alignment methods that enforce a causal link between implicit and explicit reasoning. Promising avenues include developing training objectives that penalize discrepancies between the model’s hidden states (its true decision process) and its generated rationale Wang et al. (2025); Wang et al. (2025), imposing architectural constraints that compel the model to rely solely on the generated CoT for subsequent steps Viteri et al. (2024), as well as “self-explaining” dense internal representations into faithful natural language steps Sengupta and Rekik (2025). Further exploration of these directions is critical for aligning explicit outputs with internal dynamics, ensuring CoT serves as a valid window into the model’s computation.
- Mechanistic understanding of Latent CoT reasoning.
Beyond the dichotomy of implicit and explicit CoT, an emerging paradigm is latent CoT reasoning Chen et al. (2025); Li et al. (2025), where models are designed to simulate explicit reasoning trajectories entirely within hidden states. Unlike standard implicit reasoning, which relies on the fixed depth of a standard transformer, latent CoT architectures often introduce additional computational capacity via continuous “thought tokens”, iterative refinement, or recurrent state updates, frequently learning these behaviors by distilling explicit CoT data into latent representations. This approach theoretically offers the best of both worlds: it broadens the model’s expressive capacity and computational depth while eliminating the redundant decoding costs of natural language tokens.
While various latent CoT architectures have been proposed Hao et al. (2024); Mitra et al. (2024);
Shen et al. (2025), mechanistic interpretability has lagged significantly behind these innovations. While a vast body of work has explored the latent reasoning mechanisms of standard transformers ( Section 2.1), research into the internal dynamics of these novel latent CoT models remains limited Zhang and Viteri (2024); Wang et al. (2025); Zhang et al. (2025). Critical open questions remain: Does distilling explicit CoT truly force the model to internalize a sequential, step-by-step reasoning process, or does the model collapse the teacher’s rationale into high-dimensional statistical shortcuts? Therefore, gaining more mechanistic insights is crucial for designing next-generation latent CoT architectures and training objectives that effectively combine the interpretability of explicit reasoning with the efficiency of implicit computation.
- White-box evaluation metrics for LLM reasoning.
As we gain a deeper mechanistic understanding of multi-step reasoning, it should guide the development of evaluation protocols that go beyond simple end-task accuracy. Current black-box metrics (e.g., final accuracy) are increasingly insufficient, as models frequently arrive at correct answers via non-robust shortcuts, statistical heuristics, or “bag-of-words” processing ( Section 2.3). To rigorously distinguish genuine reasoning from sophisticated pattern matching, the field requires “white-box” evaluation metrics that integrate model internals into the evaluation protocol. Pioneering efforts have begun to explore this direction. For example, Cao et al. (2025) introduced a mechanism-interpretable metric (MUI) that quantifies the “effort” required to solve a task, defined as the proportion of activated neurons or features. A truly capable model should achieve higher performance with lower effort. While this area remains under-explored, developing metrics that not only score the final output but also verify the presence of necessary internal computational signatures, such as the formation of bridge entities in intermediate layers (Yang et al. 2025b), is a crucial future trend. By defining reasoning not just as the correct outcome but as the execution of a verified internal process, we can prevent the overestimation of model capabilities and ensure that improvements on leaderboards reflect true algorithmic generalization.
- From mechanistic interpretation to model control.
While current research has successfully identified various reasoning circuits, such as iteration heads or deduction heads, most work remains observational. A major frontier for future study is the shift towards Nanda et al. (2025, pragmatic interpretability); Nanda et al. (2025), moving from passively explaining mechanisms to actively leveraging them for model control and editing, a paradigm closely aligned with Wehner et al. (2025, Representation Engineering (RepE)). For example, if we can reliably identify the specific components responsible for multi-step logic, e.g., the state-maintenance neurons identified by (Rai and Yao 2024), we can potentially intervene in real-time to correct reasoning errors or suppress shortcut neurons (Ju et al. 2024). Such interventions enable the development of “self-correcting” architectures that actively monitor internal states to detect and resolve failures like “silent errors” on the fly. Ultimately, this enables a transition from interpretability as a passive analysis tool to an active, foundational component for robust and safe reasoning systems.
5. Conclusion
In this survey, we provided a comprehensive overview of the mechanisms underlying multi-step reasoning in large language models. We structured our analysis around two fundamentally distinct computational paradigms: implicit reasoning and explicit reasoning. Through a framework of seven interconnected research questions, we systematically explored the internal dynamics of latent inference, the emergence of reasoning capabilities, and the mechanistic impact of chain-of-thought prompting on model computation and expressiveness. Despite significant progress in opening the black box, critical challenges remain. Looking ahead, we outlined a roadmap for future research, emphasizing the necessary shift from passive observation to causal intervention and the need for rigorous verification in real-world settings to build more reliable reasoning systems.
Limitations
This survey concentrates strictly on the mechanistic understanding of multi-step reasoning within transformer-based LLMs. Consequently, we do not cover other aspects of reasoning, such as probabilistic inference, creative planning, or commonsense reasoning, which may operate under different mechanistic principles. Additionally, our scope is limited to the current paradigm of text-based transformers; we do not extensively address reasoning mechanisms in Multimodal LLMs (MLLMs), alternative architectures like Diffusion Language Models (DLMs), or neural networks that predate the modern era of large language models.
References
- Hou, Yifan, Jiaoda Li, Yu Fei, Alessandro Stolfo, Wangchunshu Zhou, Guangtao Zeng, Antoine Bosselut, and Mrinmaya Sachan. 2023. Towards a mechanistic interpretation of multi-step reasoning capabilities of language models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics, pp. 4902–4919. [Google Scholar]
- Huang, Jie, and Kevin Chen-Chuan Chang. 2023. Towards reasoning in large language models: A survey. In Findings of the Association for Computational Linguistics: ACL 2023. pp. 1049–1065. [Google Scholar]
- Jin, Mingyu, Qinkai Yu, Dong Shu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, and Mengnan Du. 2024. The impact of reasoning step length on large language models. In Findings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics: pp. 1830–1842. [Google Scholar]
- Ju, Tianjie, Yijin Chen, Xinwei Yuan, Zhuosheng Zhang, Wei Du, Yubin Zheng, and Gongshen Liu. 2024. Investigating multi-hop factual shortcuts in knowledge editing of large language models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL); Association for Computational Linguistics, pp. 8987–9001. [Google Scholar]
- Kang, Cheongwoong, and Jaesik Choi. 2023. Impact of co-occurrence on factual knowledge of large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics: pp. 7721–7735. [Google Scholar]
- Kim, Juno, and Taiji Suzuki. 2025. Transformers provably solve parity efficiently with chain of thought. Proceedings of the 13th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Kudo, Keito, Yoichi Aoki, Tatsuki Kuribayashi, Shusaku Sone, Masaya Taniguchi, Ana Brassard, Keisuke Sakaguchi, and Kentaro Inui. 2024. Think-to-talk or talk-to-think? when llms come up with an answer in multi-step reasoning. abs/2412.01113. [Google Scholar]
- Lanham, Tamera, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamile Lukosiute, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Maxwell, Timothy Telleen-Lawton, Tristan Hume, Zac Hatfield-Dodds, Jared Kaplan, Jan Brauner, Samuel R. Bowman, and Ethan Perez. 2023. Measuring faithfulness in chain-of-thought reasoning. abs/2307.13702. [Google Scholar]
- Lewis-Lim, Samuel, Xingwei Tan, Zhixue Zhao, and Nikolaos Aletras. 2025. Analysing chain of thought dynamics: Active guidance or unfaithful post-hoc rationalisation? CoRR abs/2508.19827.
- Li, Hongkang, Songtao Lu, Pin-Yu Chen, Xiaodong Cui, and Meng Wang. 2025. Training nonlinear transformers for chain-of-thought inference: A theoretical generalization analysis. Proceedings of the 13th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Li, Jindong, Yali Fu, Li Fan, Jiahong Liu, Yao Shu, Chengwei Qin, Menglin Yang, Irwin King, and Rex Ying. 2025. Implicit reasoning in large language models: A comprehensive survey. abs/2509.02350. [Google Scholar] [CrossRef]
- Li, Yingcong, Kartik Sreenivasan, Angeliki Giannou, Dimitris Papailiopoulos, and Samet Oymak. 2023. Dissecting chain-of-thought: Compositionality through in-context filtering and learning. Proceedings of the 2023 Annual Conference on Neural Information Processing Systems (NeurIPS). [Google Scholar]
- Li, Ziyue, Chenrui Fan, and Tianyi Zhou. 2025. Where to find grokking in LLM pretraining? monitor memorization-to-generalization without test. CoRR abs/2506.21551. [Google Scholar]
- Li, Zhaoyi, Gangwei Jiang, Hong Xie, Linqi Song, Defu Lian, and Ying Wei. 2024. Understanding and patching compositional reasoning in llms. In Findings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics: pp. 9668–9688. [Google Scholar]
- Li, Zhiyuan, Hong Liu, Denny Zhou, and Tengyu Ma. 2024. Chain of thought empowers transformers to solve inherently serial problems. Proceedings of the 12th International Conference on Learning Representations (ICLR). [Google Scholar]
- Lin, Tianhe, Jian Xie, Siyu Yuan, and Deqing Yang. 2025. Implicit reasoning in transformers is reasoning through shortcuts. In Findings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics: pp. 9470–9487. [Google Scholar]
- Liu, Ryan, Jiayi Geng, Addison J. Wu, Ilia Sucholutsky, Tania Lombrozo, and Thomas L. Griffiths. 2024. Mind your step (by step): Chain-of-thought can reduce performance on tasks where thinking makes humans worse. abs/2410.21333. [Google Scholar]
- Madaan, Aman, Katherine Hermann, and Amir Yazdanbakhsh. 2023. What makes chain-of-thought prompting effective? A counterfactual study. In Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics: pp. 1448–1535. [Google Scholar]
- McGrath, Thomas, Matthew Rahtz, János Kramár, Vladimir Mikulik, and Shane Legg. 2023. The hydra effect: Emergent self-repair in language model computations. abs/2307.15771. [Google Scholar] [CrossRef]
- Merrill, William, and Ashish Sabharwal. 2023a. A logic for expressing log-precision transformers. Proceedings of the 2023 Annual Conference on Neural Information Processing Systems (NeurIPS). [Google Scholar]
- Merrill, William, and Ashish Sabharwal. 2023b. The parallelism tradeoff: Limitations of log-precision transformers. Transactions of the Association for Computational Linguistics 11, 531–545. [Google Scholar] [CrossRef]
- Merrill, William, and Ashish Sabharwal. 2024. The expressive power of transformers with chain of thought. Proceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Mitra, Chancharik, Brandon Huang, Trevor Darrell, and Roei Herzig. 2024. Compositional chain-of-thought prompting for large multimodal models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024); IEEE, pp. 14420–14431. [Google Scholar]
- Nanda, Neel, Josh Engels, Arthur Conmy, Senthooran Rajamanoharan, Bilal Chughtai, Callum McDougall, János Kramár, and Lewis Smith. 2025. A pragmatic vision for interpretability. In AI Alignment Forum. [Google Scholar]
- Nanda, Neel, Josh Engels, Senthooran Rajamanoharan, Arthur Conmy, Bilal Chughtai, Callum McDougall, János Kramár, and Lewis Smith. 2025. How can interpretability researchers help AGI go well? LessWrong. [Google Scholar]
- Nikankin, Yaniv, Anja Reusch, Aaron Mueller, and Yonatan Belinkov. 2025. Arithmetic without algorithms: Language models solve math with a bag of heuristics. Proceedings of the 13th International Conference on Learning Representations (ICLR). [Google Scholar]
- nostalgebraist. 2020. interpreting GPT: the logit lens. August. Available online: https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens.
- Olsson, Catherine, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. 2022. In-context learning and induction heads. abs/2209.11895. [Google Scholar] [CrossRef]
- OpenAI. 2023. GPT-4 technical report. abs/2303.08774. [Google Scholar] [CrossRef]
- Pfau, Jacob, William Merrill, and Samuel R. Bowman. 2024. Let’s think dot by dot: Hidden computation in transformer language models. CoRR abs/2404.15758.
- Power, Alethea, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. 2022. Grokking: Generalization beyond overfitting on small algorithmic datasets. abs/2201.02177. [Google Scholar] [CrossRef]
- Prabhakar, Akshara, Thomas L. Griffiths, and R. Thomas McCoy. 2024. Deciphering the factors influencing the efficacy of chain-of-thought: Probability, memorization, and noisy reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics: pp. 3710–3724. [Google Scholar]
- Rai, Daking, and Ziyu Yao. 2024. An investigation of neuron activation as a unified lens to explain chain-of-thought eliciting arithmetic reasoning of llms. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL); pp. 7174–7193. [Google Scholar]
- Sadr, Nikta Gohari, Sangmitra Madhusudan, and Ali Emami. 2025. Think or step-by-step? unzipping the black box in zero-shot prompts. abs/2502.03418. [Google Scholar]
- Saunshi, Nikunj, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. 2025. Reasoning with latent thoughts: On the power of looped transformers. Proceedings of the 13th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Sengupta, Prajit, and Islem Rekik. 2025. X-node: Self-explanation is all we need. In Reconstruction and Imaging Motion Estimation, and Graphs in Biomedical Image Analysis - First International Workshop, RIME 2025, and 7th International Workshop, GRAIL 2025. Springer: Volume 16150, pp. 184–194. [Google Scholar]
- Sharma, Mrinank, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. 2024. Towards understanding sycophancy in language models. Proceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Shen, Zhenyi, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. 2025. CODI: compressing chain-of-thought into continuous space via self-distillation. CoRR abs/2502.21074.
- Sprague, Zayne Rea, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. 2025. To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning. Proceedings of the 13th International Conference on Learning Representations (ICLR). [Google Scholar]
- Srivastava, Aarohi, Abhinav Rastogi, Abhishek Rao, Abu Awal Shoeb Md, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amanda Askell, Amanda Dsouza, Ambrose Slone, Ameet Rahane, Anantharaman S. Iyer, Anders Andreassen, Andrea Madotto, Andrea Santilli, Andreas Stuhlmüller, Andrew M. Dai, Andrew La, Andrew K. Lampinen, Andy Zou, Angela Jiang, Angelica Chen, Anh Vuong, Animesh Gupta, Anna Gottardi, Antonio Norelli, Anu Venkatesh, Arash Gholamidavoodi, Arfa Tabassum, Arul Menezes, Arun Kirubarajan, Asher Mullokandov, Ashish Sabharwal, Austin Herrick, Avia Efrat, Aykut Erdem, Ayla Karakas, B. Ryan Roberts, Bao Sheng Loe, Barret Zoph, Bartlomiej Bojanowski, Batuhan Özyurt, Behnam Hedayatnia, Behnam Neyshabur, Benjamin Inden, Benno Stein, Berk Ekmekci, Bill Yuchen Lin, Blake Howald, Bryan Orinion, Cameron Diao, Cameron Dour, Catherine Stinson, Cedrick Argueta, Cèsar Ferri Ramírez, Chandan Singh, Charles Rathkopf, Chenlin Meng, Chitta Baral, Chiyu Wu, Chris Callison-Burch, Chris Waites, Christian Voigt, Christopher D. Manning, Christopher Potts, Cindy Ramirez, Clara E. Rivera, Clemencia Siro, Colin Raffel, Courtney Ashcraft, Cristina Garbacea, Damien Sileo, Dan Garrette, Dan Hendrycks, Dan Kilman, Dan Roth, Daniel Freeman, Daniel Khashabi, Daniel Levy, Daniel Moseguí González, Danielle Perszyk, Danny Hernandez, Danqi Chen, Daphne Ippolito, and Dar Gilboa. [PubMed]
- Stechly, Kaya, Karthik Valmeekam, and Subbarao Kambhampati. 2024. Chain of thoughtlessness? an analysis of cot in planning. Proceedings of the 2024 Annual Conference on Neural Information Processing Systems (NeurIPS). [Google Scholar]
- Suzgun, Mirac, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. 2023. Challenging big-bench tasks and whether chain-of-thought can solve them. Findings of the Association for Computational Linguistics: ACL 2023, 13003–13051. [Google Scholar]
- Tanneru, Sree Harsha, Dan Ley, Chirag Agarwal, and Himabindu Lakkaraju. 2024. On the hardness of faithful chain-of-thought reasoning in large language models. abs/2406.10625. [Google Scholar]
- Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and fine-tuned chat models. [Google Scholar] [CrossRef]
- Turpin, Miles, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS). [Google Scholar]
- Tutunov, Rasul, Antoine Grosnit, Juliusz Ziomek, Jun Wang, and Haitham Bou-Ammar. 2023. Why can large language models generate correct chain-of-thoughts? abs/2310.13571. [Google Scholar] [CrossRef]
- Viteri, Scott, Armand Lamparth, Pierre Chatain, and Clark Barrett. 2024. Markovian agents for informative language modeling. CoRR abs/2404.18988.
- Wang, Boshi, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. 2023. Towards understanding chain-of-thought prompting: An empirical study of what matters. Proceedings of the 61nd Annual Meeting of the Association for Computational Linguistics (ACL); pp. 2717–2739. [Google Scholar]
- Wang, Boshi, Xiang Yue, Yu Su, and Huan Sun. 2024. Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization. Proceedings of the 2024 Annual Conference on Neural Information Processing Systems (NeurIPS). [Google Scholar]
- Wang, Xiangqi, Yue Huang, Yujun Zhou, Xiaonan Luo, Kehan Guo, and Xiangliang Zhang. 2025. Causally-enhanced reinforcement policy optimization. CoRR abs/2509.23095.
- Wang, Yiming, Pei Zhang, Baosong Yang, Derek F. Wong, and Rui Wang. 2025. Latent space chain-of-embedding enables output-free LLM self-evaluation. Proceedings of the 13th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Wang, Zijian, Yanxiang Ma, and Chang Xu. 2025. Eliciting chain-of-thought in base llms via gradient-based representation optimization. [Google Scholar]
- Wehner, Jan, Sahar Abdelnabi, Daniel Tan, David Krueger, and Mario Fritz. 2025. Taxonomy, opportunities, and challenges of representation engineering for large language models. Transactions on Machine Learning Research (TMLR). [Google Scholar]
- Wei, Jason, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022. Emergent abilities of large language models. Transactions on Machine Learning Research (TMLR). [Google Scholar]
- Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS). [Google Scholar]
- Wen, Kaiyue, Huaqing Zhang, Hongzhou Lin, and Jingzhao Zhang. 2025. From sparse dependence to sparse attention: Unveiling how chain-of-thought enhances transformer sample efficiency. Proceedings of the 13th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Wu, Skyler, Eric Meng Shen, Charumathi Badrinath, Jiaqi Ma, and Himabindu Lakkaraju. 2023. Analyzing chain-of-thought prompting in large language models via gradient-based feature attributions. abs/2307.13339. [Google Scholar]
- Yang, An, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. 2024. Qwen2.5 technical report. CoRR abs/2412.15115.
- Yang, Chenxiao, Zhiyuan Li, and David Wipf. 2025. Chain-of-thought provably enables learning the (otherwise) unlearnable. Proceedings of the 13th International Conference on Learning Representations (ICLR). OpenReview.net. [Google Scholar]
- Yang, Sohee, Elena Gribovskaya, Nora Kassner, Mor Geva, and Sebastian Riedel. 2024. Do large language models latently perform multi-hop reasoning? Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL); Association for Computational Linguistics, pp. 10210–10229. [Google Scholar]
- Yang, Sohee, Nora Kassner, Elena Gribovskaya, Sebastian Riedel, and Mor Geva. 2025a. Do large language models perform latent multi-hop reasoning without exploiting shortcuts? Findings of the Association for Computational Linguistics: ACL 2025, 3971–3992. [Google Scholar]
- Yang, Sohee, Nora Kassner, Elena Gribovskaya, Sebastian Riedel, and Mor Geva. 2025b. Do large language models perform latent multi-hop reasoning without exploiting shortcuts? In Findings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics: pp. 3971–3992. [Google Scholar]
- Yang, Zhipeng, Junzhuo Li, Siyu Xia, and Xuming Hu. 2025. Internal chain-of-thought: Empirical evidence for layer-wise subtask scheduling in llms. CoRR abs/2505.14530.
- Yao, Xinhao, Ruifeng Ren, Yun Liao, and Yong Liu. 2025. Unveiling the mechanisms of explicit cot training: How chain-of-thought enhances reasoning generalization. abs/2502.04667. [Google Scholar]
- Yao, Yuekun, Yupei Du, Dawei Zhu, Michael Hahn, and Alexander Koller. 2025. Language models can learn implicit multi-hop reasoning, but only if they have lots of training data. CoRR abs/2505.17923.
- Ye, Jiaran, Zijun Yao, Zhidian Huang, Liangming Pan, Jinxin Liu, Yushi Bai, Amy Xin, Liu Weichuan, Xiaoyin Che, Lei Hou, and Juanzi Li. 2025. How does transformer learn implicit reasoning? Proceedings of the 2025 Annual Conference on Neural Information Processing Systems (NeurIPS 2025), San Diego, USA. [Google Scholar]
- Ye, Xi, and Greg Durrett. 2022. The unreliability of explanations in few-shot prompting for textual reasoning. Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS). [Google Scholar]
- Yu, Yijiong. 2025. Do llms really think step-by-step in implicit reasoning? CoRR abs/2411.15862.
- Yu, Zeping, Yonatan Belinkov, and Sophia Ananiadou. 2025. Back attention: Understanding and enhancing multi-hop reasoning in large language models. abs/2502.10835. [Google Scholar]
- Zhang, Jason, and Scott Viteri. 2024. Uncovering latent chain of thought vectors in language models. abs/2409.14026. [Google Scholar] [CrossRef]
- Zhang, Yifan, Wenyu Du, Dongming Jin, Jie Fu, and Zhi Jin. 2025. Finite state automata inside transformers with chain-of-thought: A mechanistic study on state tracking. Proceedings of the 63nd Annual Meeting of the Association for Computational Linguistics (ACL); Association for Computational Linguistics, pp. 13603–13621. [Google Scholar]
- Zhang, Yuyi, Boyu Tang, Tianjie Ju, Sufeng Duan, and Gongshen Liu. 2025. Do latent tokens think? a causal and adversarial analysis of chain-of-continuous-thought. abs/2512.21711. [Google Scholar] [CrossRef]
- Zhang, Zhongwang, Pengxiao Lin, Zhiwei Wang, Yaoyu Zhang, and Zhi-Qin John Xu. 2025. Complexity control facilitates reasoning-based compositional generalization in transformers. abs/2501.08537. [Google Scholar] [CrossRef]
Figure 1.
The cognitive framework and organizational structure of this survey. We explore the mechanisms of multi-step reasoning through two distinct paradigms: Implicit Reasoning and Explicit Reasoning, through seven interconnected Research Questions. The bottom panel highlights five strategic directions for future research.
Figure 1.
The cognitive framework and organizational structure of this survey. We explore the mechanisms of multi-step reasoning through two distinct paradigms: Implicit Reasoning and Explicit Reasoning, through seven interconnected Research Questions. The bottom panel highlights five strategic directions for future research.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



