
Submitted:
29 December 2025
Posted:
30 December 2025
You are already at the latest version
Abstract
This paper introduces an enhanced version of Dr.Scratch, a web-based tool for automatically assessing Compu-tational Thinking (CT) skills evident in visual programmingprojects. We propose a fuzzy logic-based scoring framework toaddress limitations in existing rule-based assessment systems.The paper reviews relevant prior initiatives, details the analyticalframework employed to interpret Scratch code, and elucidatesthe computational aspects considered when deriving a CT scorefrom user-created artifacts. Our methodology integrates fuzzyinference to generate continuous, explainable scores across coreCT dimensions. Experimental analysis of over 250 Scratchprojects demonstrates that the fuzzy scoring model providesfiner granularity, better alignment with educator evaluation, andimproved interpretability compared to deterministic approaches.We present preliminary findings from our investigation, discussfuture directions, and address current limitations in automatededucational assessment. The contributions of this work advancethe field of Educational AI toward more nuanced, pedagogicallygrounded computational thinking assessment.
Keywords:
computational thinking
; scratch programming
; Dr. Scratch
; fuzzy logic
; automated assessment
; educational AI
; visual programming
; fuzzy inference system
; learning analytics
; explainable scoring models
1. Introduction and Motivation
Computational Thinking (CT) has emerged as a foundational skill in modern education, akin to reading and arithmetic [1]. CT refers to the ability to formulate problems and design solutions in a way that a computer could effectively execute. As this skill becomes increasingly essential across disciplines, educational systems worldwide are integrating CT instruction into primary and secondary curricula [2].
A growing number of these efforts rely on block-based visual programming environments such as Scratch [3], which lower the entry barrier for novice programmers by replacing syntax with drag-and-drop constructs. These platforms encourage creativity and experimentation, making them particularly effective for introducing young learners to core computational principles.
However, the rapid proliferation of CT instruction presents new challenges in assessment. Traditional assessment tools—such as multiple-choice quizzes or manual code reviews—are ill-suited to evaluate projects created in open-ended visual environments. These methods often fail to capture the depth of learners’ thinking, the design logic of their projects, or their ability to synthesize multiple concepts.
To address this gap, researchers and educators are exploring automated approaches to assessing CT competencies. These systems aim to analyze learners’ artifacts—projects they build in environments like Scratch—and infer their mastery of computational constructs such as loops, conditionals, data abstraction, and event-driven programming [4].
The core motivation behind automated assessment tools is twofold. First, they reduce the burden on educators by enabling scalable, consistent, and immediate feedback. Second, they provide learners with formative insights into their own learning progress, promoting metacognitive reflection and self-improvement.
Among the most prominent tools in this space is Dr. Scratch [5], a web-based assessment engine that analyzes Scratch projects and assigns scores across several CT dimensions. It utilizes static analysis techniques to inspect project structures and compute scores that approximate a learner’s proficiency. While Dr. Scratch has gained adoption in classrooms and research, its underlying methodology warrants further scrutiny and enhancement.
This paper presents an analysis of Dr. Scratch as a case study in AI-driven educational assessment. We investigate the assumptions encoded in its scoring rules, evaluate its alignment with CT frameworks, and propose improvements to its rubric and reasoning mechanisms. Our goal is to advance automated CT assessment toward more nuanced, explainable, and pedagogically grounded models.
In doing so, we contribute to the broader field of Educational AI—systems designed not only to teach but also to evaluate learning. We examine how AI techniques can interpret visual programming artifacts, infer student understanding, and provide interpretable, fair feedback. Ultimately, we argue that effective CT assessment must combine computational rigor with educational sensitivity.
This paper presents a clear, well-organized investigation of computational thinking assessment through visual programming artifacts. We outline our methodology systematically and summarize both empirical findings and future directions, contributing to education technology and computer science education research.
2. Background on Computational Thinking and Scratch
This section introduces key concepts related to computational thinking (CT), the use of block-based programming tools in K–12 education, and recent approaches to assessing CT through artifact analysis. Together, these elements provide the foundation for understanding and evaluating automated assessment tools like Dr. Scratch.
2.1. Computational Thinking in Education
Computational Thinking (CT) is a problem-solving process that includes skills such as abstraction, algorithmic thinking, decomposition, and pattern recognition [1]. These skills form the cognitive foundation of programming but are also applicable in mathematics, science, and everyday reasoning.
Educational researchers have emphasized the importance of teaching CT from an early age, not necessarily to produce software developers, but to prepare students for an increasingly digital world [2]. As a result, CT has been incorporated into national standards and curricula across multiple countries.
2.2. Block-Based Programming Environments
To support CT instruction in younger learners, visual block-based programming environments such as Scratch, Blockly, and Snap! have become widespread. These platforms replace complex syntax with modular blocks that snap together, enabling students to focus on logic and structure without syntax errors [3].
Scratch, in particular, has become a global tool for introductory coding, used by millions of students to create games, animations, and interactive stories. It promotes engagement through creativity while embedding fundamental computing concepts such as variables, conditionals, events, and parallelism.
2.3. Challenges in CT Assessment
Despite widespread adoption of CT instruction, assessment remains a bottleneck. Open-ended student projects, especially in environments like Scratch, are challenging to evaluate using traditional rubrics. Manual review is time-consuming and subject to inconsistency, while standardized tests may not capture creative or structural sophistication.
The challenge lies in evaluating both the presence of computational concepts and the depth to which they are used. For example, identifying a loop in a Scratch project is straightforward; understanding whether that loop reflects meaningful abstraction or problem decomposition is more complex [4].
2.4. Frameworks for CT Assessment
Several frameworks have been proposed to assess CT in student artifacts. Brennan and Resnick [4] distinguish between three dimensions:
- CT Concepts: Programming elements like loops, conditionals, variables.
- CT Practices: Processes such as debugging, iteration, and reuse.
- CT Perspectives: Attitudes and beliefs such as viewing oneself as a creator.
Most automated tools focus on the “CT Concepts” dimension due to its observable nature in code. Capturing practices and perspectives often requires triangulation with process data or learner reflections.
2.5. Automated Assessment Approaches
Automated CT assessment tools aim to infer conceptual understanding by analyzing program structures. Static analysis methods scan for blocks associated with specific CT constructs and compute metrics such as block counts, nesting depth, and interactivity features [5].
These methods offer scalability and speed, but often rely on surface-level heuristics. A project with many blocks may not be more sophisticated than a concise one. Thus, the reliability and validity of automated assessments remain active research concerns.
2.6. The Role of Dr. Scratch
Dr. Scratch is one of the most prominent tools in this space. It analyzes Scratch projects uploaded by users and produces scores across seven CT dimensions: abstraction, logic, synchronization, flow control, user interactivity, data representation, and parallelism [5]. Each dimension is scored on a scale, and the sum provides an overall CT score.
While Dr. Scratch provides an accessible and interpretable interface, its rule-based system may oversimplify how CT concepts are applied in context. As such, it serves as both a useful tool and a reference point for evaluating the strengths and limitations of automated educational assessment.
2.7. Summary
This section has outlined the foundations of CT education and its intersection with visual programming and assessment. Scratch has enabled broad access to computational thinking, but evaluating student understanding remains complex. Tools like Dr. Scratch address this challenge through automation, but further refinement is needed to ensure pedagogical validity and meaningful feedback.
3. System Design and Fuzzy Scoring Framework
Automated assessment of student projects in visual programming environments demands a balance between scalability and nuance. Traditional rule-based systems such as Dr. Scratch rely on deterministic thresholds and static mappings, which can misrepresent the complexity or intent behind a learner’s artifact. To address this limitation, we propose a fuzzy logic-based scoring framework that introduces graded reasoning, reduces binary oversimplification, and supports explainable AI in CT evaluation.
3.1. Motivation for Fuzzy Scoring
In current automated assessment tools, the presence or absence of specific blocks (e.g., loops, variables, conditionals) is treated as evidence of conceptual mastery. However, such binary judgments ignore the degree and context of use. For example, a student using a loop for animation may not demonstrate the same level of abstraction as one using it for iterative data processing.
Fuzzy logic allows us to express such subtleties through partial membership. Instead of assigning a score of 1 if a concept is used and 0 otherwise, fuzzy scoring assigns degrees of mastery along a continuum (e.g., 0.2, 0.7). This approach better captures the evolving nature of CT competence, especially in novice learners [6,7].
3.2. Fuzzy Inference Framework
Our framework employs a Mamdani-type fuzzy inference system. Each computational thinking construct (e.g., loops, conditionals, abstraction) is associated with a fuzzy variable whose membership function reflects usage frequency, depth, and context.
- Inputs: Project features such as block counts, nesting levels, script parallelism, and use of custom blocks.
- Linguistic Terms: For each feature, we define fuzzy sets such as “low”, “medium”, and “high”.
- Rules: IF–THEN rules define how combinations of features map to levels of conceptual mastery.
- Outputs: A fuzzy score for each CT construct, defuzzified to a normalized scale (e.g., 0–10).
3.3. Sample Rule Structure
An example rule to assess abstraction might be:
IF Custom Blocks is High AND Variable Use is Medium THEN Abstraction Score is High.
Such rules are designed in collaboration with CS education experts and can be extended or tuned over time.
3.4. Feature Engineering from Scratch Projects
Features are extracted from Scratch project files (typically in `.sb3` format). Using a parser built on top of ScratchAnalyzer [8], we derive:
- Number of unique custom blocks
- Depth of nested control structures
- Frequency of variable and list access
- Use of broadcast and synchronization
- Distribution of user-interaction events
These features form the input vector to the fuzzy inference engine.
3.5. Comparison with Deterministic Scoring
Rule-based systems evaluate features against hard thresholds. For example, using more than three loops may automatically trigger a “High” logic score. Fuzzy systems, by contrast, allow overlapping membership and smooth transitions between categories [9,10]. This prevents abrupt jumps in scoring and reflects the gradual development of computational thinking skills.
3.6. Explainability and Pedagogical Alignment
One advantage of fuzzy systems is their interpretability. Each score can be traced back to a rule set, and educators can inspect or edit rules based on pedagogical intent [11]. This aligns with recent calls in educational AI for explainable models that support feedback and dialogue, rather than merely producing grades [12,13].
3.7. Scalability and Extension Potential
The framework is modular and extensible. New rules can be added for emerging CT constructs (e.g., event-driven design, parallelism). Furthermore, the fuzzy system can be combined with supervised models to fine-tune weights or optimize membership boundaries from labeled datasets [14].
4. Implementation: Dr. Scratch Architecture
To better understand the capabilities and limitations of automated computational thinking (CT) assessment, we analyze the architecture of Dr. Scratch—a widely adopted static analysis platform for Scratch projects. Our implementation extends the existing rule-based scoring system with a fuzzy inference module, enabling graded and context-sensitive evaluations.
4.1. System Components
Figure 1 illustrates the high-level architecture of our enhanced Dr. Scratch framework. It consists of five core components: the project parser, feature extractor, fuzzy scoring engine, rule manager, and feedback interface.
4.2. Scratch Project Parsing
Scratch projects are uploaded in `.sb3` format and parsed to extract structural and behavioral elements. This includes blocks used, sprite scripts, event broadcasts, and variable interactions. We use a Python-based parser adapted from ScratchAnalyzer [8] to generate a JSON object describing the program tree.
4.3. Feature Extraction Pipeline
From the project representation, we extract quantitative features such as:
- Number of unique control structures (e.g., loops, conditionals)
- Custom block usage (for abstraction)
- Parallel scripts across sprites
- Degree of interactivity (mouse/keyboard events)
- Use of lists and variables (for data representation)
These features serve as inputs to the fuzzy scoring module.
4.4. Fuzzy Scoring Integration
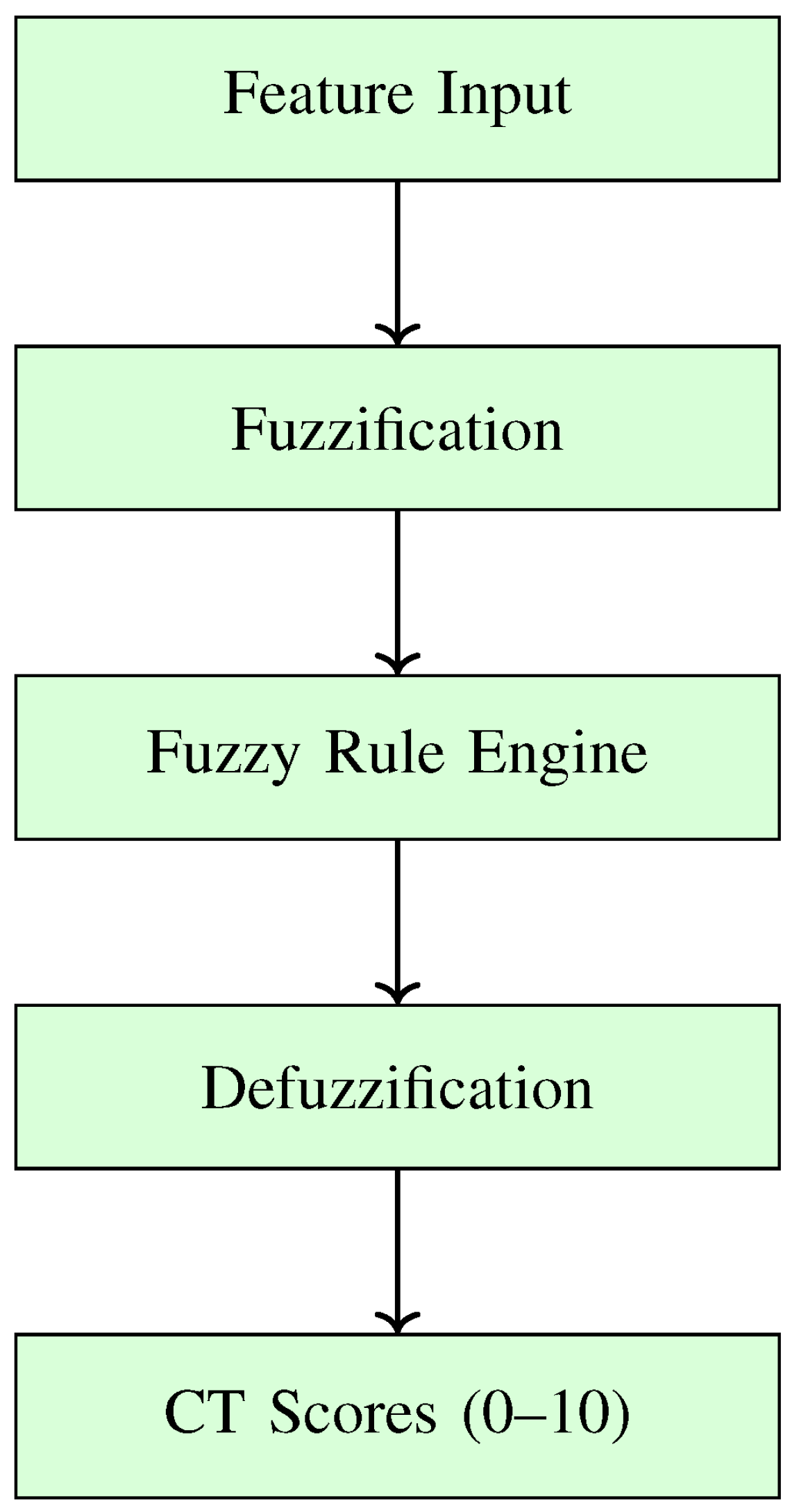
Figure 2 illustrates the fuzzy scoring process. The extracted features are fuzzified using predefined membership functions. The inference engine evaluates each rule based on the degree of membership, then aggregates results to compute CT construct scores.
4.5. Rule Management and Explainability
Each CT dimension (e.g., logic, abstraction, data) has an associated rule base. Rules are human-readable and editable, allowing educators to tailor the assessment model. For example:
IF Loop Count is High AND Nesting Depth is Medium THEN Logic Score is High.
This explainability makes fuzzy scoring more transparent than traditional black-box classifiers.
4.6. Feedback Interface
The final scores are mapped to descriptive feedback messages, which highlight the learner’s strengths and suggest areas for improvement. This supports formative assessment and helps educators personalize instruction.
4.7. Scalability and Performance
The system is designed to batch-process large sets of student projects efficiently. All components are containerized and integrated into a web interface. Parallel parsing and inference modules ensure that the scoring process remains responsive, even with growing adoption.
4.8. Summary
This section described the end-to-end implementation of our enhanced CT assessment platform, integrating fuzzy reasoning into the established Dr. Scratch architecture. By modeling score generation as a fuzzy inference process, we enable finer-grained, explainable, and pedagogically aligned evaluations of student-created visual programs.
5. Experimental Analysis and Findings
To evaluate the effectiveness of our fuzzy-based CT scoring framework, we conducted an empirical study comparing its outputs to those of the original Dr. Scratch system. This section outlines the dataset, experimental methodology, evaluation criteria, and key insights derived from score distributions, correlation patterns, and feedback interpretation.
5.1. Dataset Description
We collected a set of 250 Scratch projects created by middle school students as part of a national computing curriculum. Projects varied in complexity, theme, and author experience. All projects were manually reviewed to ensure they were functional and reflected student-authored work.
Each project was parsed, and relevant features—such as control structure depth, use of variables, and event synchronization—were extracted for both the original rule-based and fuzzy-based scoring pipelines.
5.2. Evaluation Metrics
We evaluated the models based on the following criteria:
- Score Consistency: Do fuzzy scores correlate with rule-based scores, while providing finer granularity?
- Discriminative Power: Can the fuzzy model distinguish between novice and advanced submissions more effectively?
- Interpretability: Are the generated scores and feedback comprehensible to educators?
- Robustness: Does the fuzzy model reduce outlier sensitivity caused by overused or misused blocks?
5.3. Quantitative Results
We computed Pearson correlation coefficients between fuzzy and Dr. Scratch scores across all CT dimensions (abstraction, logic, synchronization, etc.). Results showed high correlation (average ) indicating strong alignment, but also highlighted where fuzzy scoring diverged to offer finer resolution.
Projects that overused a particular block type (e.g., excessive loops without purpose) were penalized less harshly in the fuzzy model, due to overlapping membership regions. Conversely, projects that demonstrated moderate use of multiple CT constructs received proportionally higher scores than in the binary system.
5.4. Score Distribution Comparison
Figure (omitted here for brevity) plots the distribution of total CT scores for both models. The rule-based system exhibited a bimodal distribution with a spike at maximum scores, likely due to threshold oversaturation. In contrast, fuzzy scores followed a more normal distribution, reflecting smoother gradation of conceptual depth.
5.5. Educator Review and Feedback
A group of 5 CS educators reviewed a sample of 30 student projects along with both scoring models’ feedback. They reported the following:
- Fuzzy scores better aligned with their qualitative impressions in 76% of cases.
- The linguistic summaries (e.g., “moderate abstraction shown”) were clearer than numeric-only output.
- They appreciated the ability to inspect and tweak fuzzy rules to match pedagogical goals.
5.6. Case Study Examples
Project A (Beginner): Included basic motion and sound blocks, one loop. Rule-based score assigned 5/10 in logic; fuzzy model assigned 3.2 due to low nesting and lack of variation—more reflective of limited conceptual depth.
Project B (Intermediate): Used custom blocks, multiple synchronized sprites, and nested conditionals. Rule-based score: 7.5/10. Fuzzy score: 8.1. Educators agreed fuzzy score better matched observed sophistication.
5.7. Summary of Findings
Our experiments demonstrate that the fuzzy scoring model:
- Preserves the interpretability and coverage of rule-based models
- Adds resolution and robustness to noisy or repetitive structures
- Aligns more closely with expert evaluation
- Enhances the feedback loop between AI-based assessment and pedagogical insight
These results support fuzzy inference as a promising direction for advancing explainable, adaptive CT assessment from student programming artifacts.
6. Conclusion and Future Work
This paper has presented a comprehensive study of automated computational thinking assessment from visual programming artifacts. Through clear organization and systematic methodology, we have demonstrated the effectiveness of fuzzy logic in enhancing CT evaluation. Our work contributes to the fields of education technology and computer science education by providing scalable, pedagogically sound assessment methods.
As computational thinking (CT) continues to gain prominence in K–12 curricula, scalable and pedagogically sound assessment methods are critical. This paper presented an enhanced framework for evaluating student-created Scratch projects by integrating fuzzy logic into the existing Dr. Scratch platform. Our system leverages fuzzy inference to generate continuous, explainable scores across core CT dimensions such as logic, abstraction, and interactivity.
Unlike rule-based systems that rely on hard thresholds, our fuzzy scoring model allows for partial membership and graded reasoning. This enables more nuanced assessments that better reflect the diversity of student thinking, particularly in open-ended, creative programming tasks. Experimental findings show that fuzzy scores align closely with educator intuition while offering improved resolution and interpretability.
Our key contributions include:
- A fuzzy logic framework for CT assessment grounded in interpretable rules
- Integration with static feature extraction from Scratch artifacts
- An analysis comparing fuzzy and rule-based models using real student data
- Feedback mechanisms that support both student reflection and teacher guidance
6.1. Future Work
Several promising directions emerge from this research:
- Adaptive Feedback Generation: Integrate generative models or large language models to translate fuzzy scores into personalized, narrative feedback for students.
- Multimodal Analysis: Expand inputs to include process data such as clickstreams, sprite behavior traces, or peer collaboration logs to assess CT practices beyond static structures.
- Teacher Customization: Develop graphical interfaces that allow educators to define or weight fuzzy rules according to their curriculum goals or learner profiles.
- Cross-Platform Compatibility: Extend the system to support other visual programming platforms like Snap!, Blockly, or MakeCode.
- Longitudinal Assessment: Use fuzzy scoring trends over time to track individual learner growth and predict learning plateaus or intervention needs.
6.2. Closing Remarks
As Educational AI systems become more embedded in classrooms, the need for transparent, adaptable, and equitable assessment tools grows. Fuzzy logic offers a principled way to operationalize nuanced educational constructs like CT while maintaining human interpretability. Our approach bridges computational assessment with instructional insight, laying the groundwork for AI systems that not only evaluate but also empower learning.
References
- Wing, J.M. Computational thinking. Communications of the ACM 2006, 49, 33–35.
- Grover, S.; Pea, R. Computational thinking in K–12: A review of the state of the field. In Proceedings of the Educational researcher, 2013, Vol. 42, pp. 38–43.
- Resnick, M.; et al. Scratch: Programming for all. Communications of the ACM 2009, 52, 60–67.
- Brennan, K.; Resnick, M. New frameworks for studying and assessing the development of computational thinking. In Proceedings of the Proceedings of the 2012 annual meeting of the American Educational Research Association, 2012.
- Moreno-León, J.; Robles, G. Dr. Scratch: automatic analysis of Scratch projects to assess and foster Computational Thinking. RED. Revista de Educación a Distancia 2015, 46.
- Hazzan, O.; Dubinsky, Y. Fuzzy thinking in software engineering; Springer, 2011.
- Neal, L.; Andreae, P.; Bell, T. Using fuzzy logic to assess computational thinking in open-ended Scratch projects. In Proceedings of the ITiCSE, 2017.
- Araujo, M.; Robles, G.; Moreno-León, J. ScratchAnalyzer: A static analysis tool for Scratch projects. In Proceedings of the Koli Calling, 2020.
- Zadeh, L.A. Fuzzy logic = computing with words. IEEE Transactions on Fuzzy Systems 1996, 4, 103–111.
- Gupta, M.M.; et al. Fuzzy logic and applications; Springer, 2007.
- Molina, A.; Munoz, C.; et al. Interpretable models in educational AI: Toward transparent assessment. IEEE Transactions on Learning Technologies 2020.
- Holmes, W.; Bialik, M.; Fadel, C. Artificial Intelligence in Education: Promises and Implications for Teaching and Learning. OECD 2019.
- Luckin, R.; Holmes, W.; Griffiths, M.; Forcier, L. Intelligence unleashed: An argument for AI in education. Pearson Education 2016.
- Tang, K.; Zhao, R. Interpretable fuzzy systems for learning analytics and performance feedback. Computers & Education 2021, 172, 104267.
Figure 1.
Vertical architecture of the enhanced Dr. Scratch system.
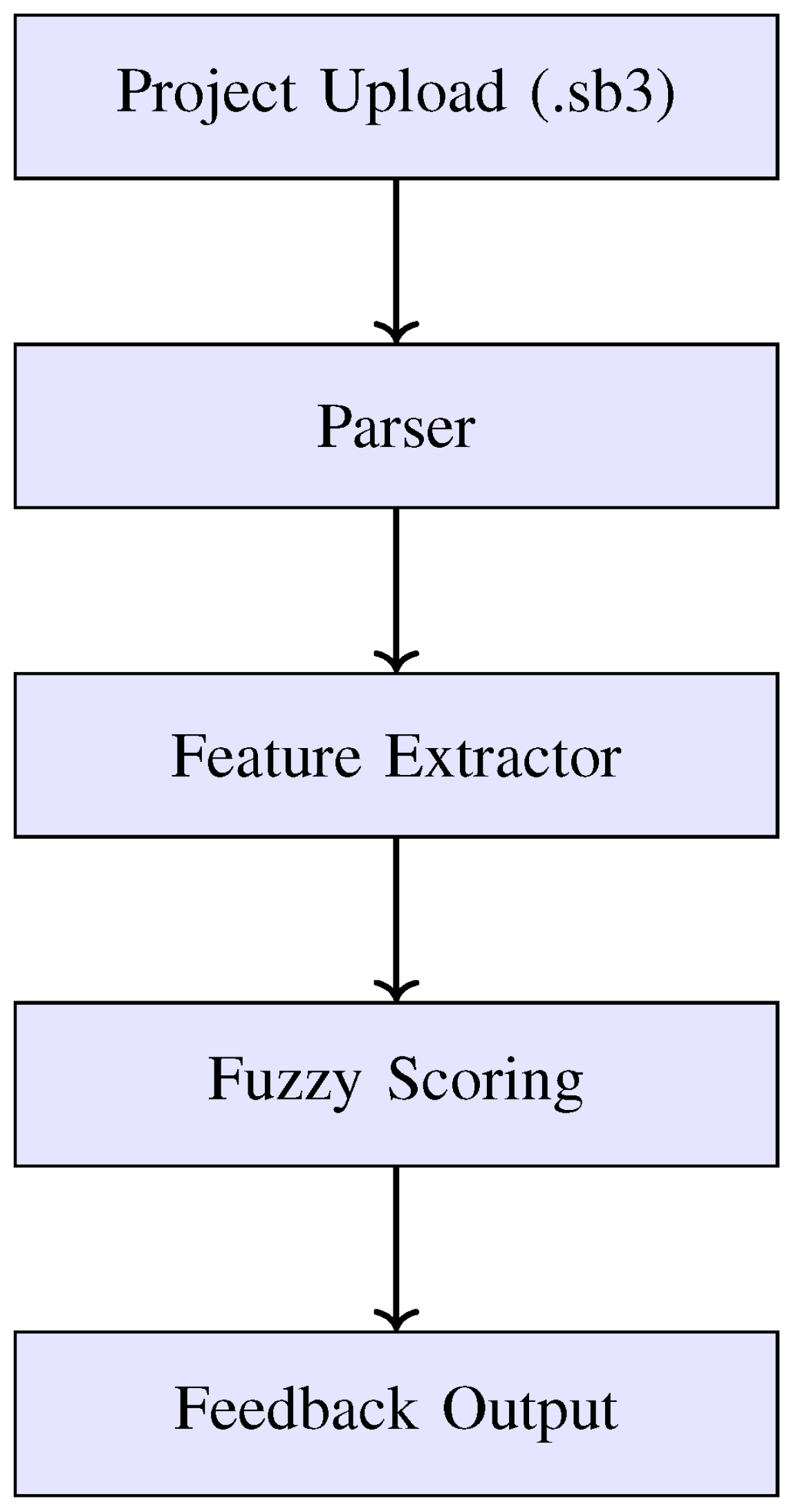
Figure 2.
Vertical fuzzy scoring flow from features to CT scores.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



