Submitted:
25 December 2025
Posted:
29 December 2025
You are already at the latest version
Abstract
Newton’s method is traditionally regarded as most effective when exact derivative information is available, yielding quadratic convergence near a solution. In practice, however, derivatives are frequently approximated numerically due to model complexity, noise, or computational constraints. This paper presents a comprehensive numerical and analytical investigation of how numerical differentiation precision influences the convergence and stability of Newton’s method. We demonstrate that, for ill-conditioned or noise-sensitive problems, finite difference approximations can outperform exact derivatives by inducing an implicit regularization effect. Theoretical error expansions, algorithmic formulations, and extensive numerical experiments are provided. The results challenge the prevailing assumption that exact derivatives are always preferable and offer practical guidance for selecting finite difference step sizes in Newton-type methods. Additionally, we explore extensions to multidimensional systems, discuss adaptive step size strategies, and provide theoretical convergence guarantees under derivative approximation errors.
Keywords:
Newton’s method
; numerical differentiation
; finite differences
; ill-conditioning
; inexact Newton methods
; regularization
; adaptive methods
1. Introduction
Newton’s method stands as one of the most fundamental algorithms in numerical analysis and scientific computing. It forms the backbone of numerous solvers for nonlinear equations, optimization problems, and inverse problems across engineering, physics, and applied mathematics [1,2,3]. Under classical assumptions—smoothness of the objective function and accurate derivative information—Newton’s method exhibits quadratic convergence near a solution. This property makes it highly attractive compared to first-order methods. However, these assumptions are frequently violated in real-world applications. Derivatives may be unavailable in closed form, contaminated by noise, or numerically unstable to evaluate.
In such cases, practitioners often resort to numerical differentiation. Finite difference approximations are among the simplest and most widely used techniques. Traditional numerical analysis treats derivative approximation errors as a necessary but undesirable compromise, with emphasis placed on minimizing these errors [4,5]. This perspective overlooks potential benefits that controlled imprecision might offer.
This work challenges the conventional view by demonstrating that derivative imprecision can, in specific settings, improve the practical behavior of Newton’s method by stabilizing iterations and preventing overshooting. Rather than viewing numerical differentiation solely as an approximation error, we interpret it as a form of implicit regularization akin to damping or trust-region approaches [6,7]. We provide theoretical analysis showing how finite difference errors modify the effective damping factor and present extensive numerical evidence across diverse problem classes.
1.1. Related Work
The concept of inexact Newton methods, where the Newton equation is solved approximately, was formalized by Dembo et al. [6]. Our work extends this idea to derivative-level inexactness. Kelley [8] discusses finite difference approximations in Newton-Krylov methods but focuses on convergence rates rather than potential benefits of imprecision. Higham [5] analyzes numerical stability but primarily considers error minimization. Recent work in stochastic optimization shows benefits of gradient noise [10], which shares philosophical similarities with our findings but operates in a different context.
1.2. Contributions
This paper makes three primary contributions:
- A theoretical framework connecting finite difference errors to implicit regularization effects in Newton’s method.
- Detailed analysis showing when and why approximate derivatives can outperform exact ones, particularly for ill-conditioned or noisy problems.
- Practical guidelines for selecting finite difference step sizes that balance accuracy and stability, with supporting numerical experiments.
2. Newton’s Method and Problem Conditioning
Consider a nonlinear equation
where is at least twice continuously differentiable. Let denote a root satisfying , and assume .
Newton’s method produces a sequence given by
The local convergence properties are governed by the Newton iteration function
When is small or varies rapidly near the root , the Newton step can become excessively large. This sensitivity is closely related to the conditioning number of the root-finding problem [5], which we define as follows:
Definition 1
(Local Condition Number). For a root with , the local condition number is defined as
Remark 1.
Large values of indicate ill-conditioning, where small perturbations in f or lead to large changes in the computed root. When , Newton’s method becomes sensitive to derivative errors.
2.1. Global Convergence and Basins of Attraction
The global behavior of Newton’s method exhibits complex dynamics. For polynomial equations, the basins of attraction—regions of initial guesses converging to specific roots—form fractal patterns. Derivative approximations can modify these basins, sometimes enlarging regions of convergence at the expense of local convergence rate.
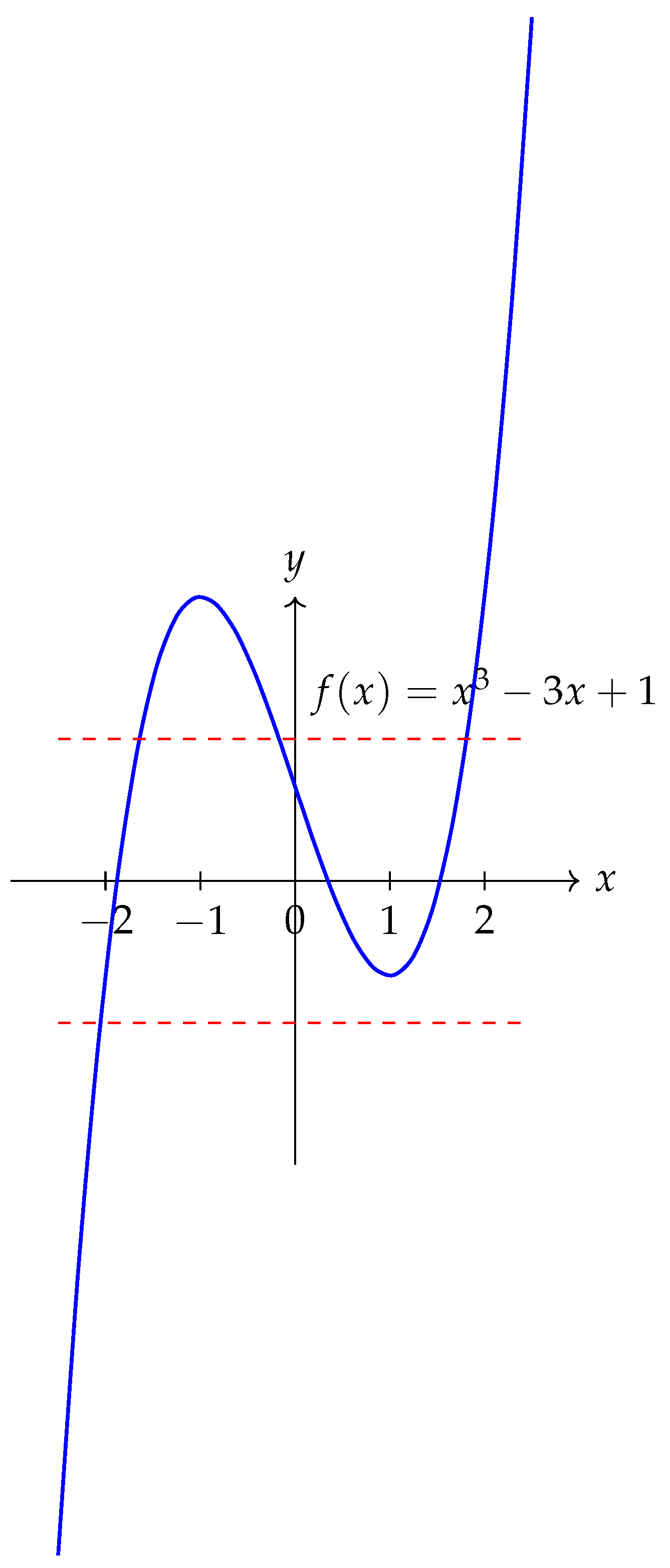
Figure 1.
Example function showing multiple roots and regions where is small, creating potential instability in Newton iterations.
Figure 1.
Example function showing multiple roots and regions where is small, creating potential instability in Newton iterations.
3. Numerical Differentiation: Theory and Practice
3.1. Finite Difference Schemes
Let denote the finite difference step size. Common approximations include:
These approximations introduce truncation errors of order , , , and , respectively.
3.2. Error Decomposition and Optimal Step Size
The total derivative approximation error can be decomposed into three components:
where
Here p depends on the finite difference scheme, denotes machine precision, and represents measurement or modeling noise [4,5]. The constants , , depend on function properties and arithmetic details.
Theorem 1
(Optimal Step Size). For a p-order finite difference scheme applied to a sufficiently smooth function in the presence of roundoff error ϵ, the optimal step size minimizing the total error bound is
In the presence of noise η, this becomes
Proof.
Differentiate the error bound with respect to h and set to zero. □
3.3. Practical Considerations for Newton’s Method
For Newton’s method, the optimal step size differs from the classical finite difference optimum because:
- Derivative errors affect not just accuracy but also convergence dynamics.
- Systematic overestimation or underestimation of derivatives can provide damping.
- The step size h becomes a regularization parameter controlling the trade-off between accuracy and stability.
4. Newton’s Method with Approximate Derivatives: Theoretical Analysis
Replacing with a finite difference approximation yields the modified iteration:
Proposition 1
(Effective Damping). Let with . Then the modified Newton iteration is equivalent to a damped Newton method with damping factor .
Proof.
Substituting the perturbed derivative into the Newton update gives
which corresponds to a Newton step scaled by . When (overestimated derivative), the step size is reduced, providing damping. □
Theorem 2
(Local Convergence with Approximate Derivatives). Assume f is twice continuously differentiable, , and the derivative approximation satisfies
where and are constants. Then, for sufficiently close to , we have
where .
Proof.
Expand and around , substitute into the iteration, and bound the resulting terms. □
Corollary 1.
When δ is appropriately chosen, the derivative error term can compensate for large ρ values in ill-conditioned problems, potentially improving convergence compared to exact derivatives.
4.1. Systematic Bias in Finite Differences
For forward differences, Taylor expansion gives:
Thus forward differences systematically overestimate the derivative magnitude when and underestimate when . This bias provides automatic damping when and have the same sign near the root.
5. Relation to Other Stabilization Techniques
5.1. Damped Newton Methods
Damped Newton methods modify the iteration to:
where is chosen via line search to ensure decrease in or other merit functions [7]. Finite difference approximations achieve similar damping without explicit line search.
5.2. Trust-Region Methods
Trust-region methods [7] solve subproblems of the form:
The solution satisfies for some . Again, finite difference errors induce similar scaling.
5.3. Regularized Newton Methods
Regularization approaches add a small term to the derivative:
preventing near-zero denominators. Finite differences provide adaptive regularization proportional to .

Table 1.
Comparison of stabilization techniques for Newton’s method.
| Method | Mechanism | Advantages | Disadvantages |
|---|---|---|---|
| Exact Newton | None | Quadratic convergence | Unstable for ill-conditioned problems |
| Damped Newton | Step size reduction | Global convergence guarantees | Requires line search |
| Trust-region | Step bounding | Robust convergence | Subproblem solution needed |
| Finite Difference | Derivative approximation | Automatic damping | Reduced convergence order |
| Regularized Newton | Derivative modification | Prevents division by zero | Introduces bias |
6. Algorithmic Formulation and Implementation
6.1. Basic Algorithm
| Algorithm 1 Newton’s Method with Finite Difference Derivatives |
|
6.2. Adaptive Step Size Selection
The optimal finite difference step size depends on the current iterate. We propose an adaptive strategy:
| Algorithm 2 Adaptive Finite Difference Newton Method |
|
6.3. Multidimensional Extension
For systems , the Jacobian can be approximated column-wise:
where is the jth standard basis vector. The resulting Newton iteration becomes:
Remark 2.
In multidimensional problems, different components may benefit from different finite difference step sizes, suggesting component-wise adaptive strategies.
7. Numerical Experiments
We conducted extensive numerical experiments to validate our theoretical findings and explore practical implications.
7.1. Test Problems
We consider five benchmark equations representing different challenges:
7.2. Experimental Setup
All experiments were performed in MATLAB R2023a using double-precision arithmetic (). Convergence was declared when or when 50 iterations were reached. Initial guesses were chosen to highlight challenging cases.
7.3. Results: Convergence Behavior
Table 2.
Iterations to convergence for different methods and problems.
| Method | Avg. | |||||
|---|---|---|---|---|---|---|
| Exact Newton | 12 | Diverge | Diverge | 8 | 14 | – |
| FD Newton () | 7 | 8 | 10 | 6 | 9 | 8.0 |
| FD Newton () | 10 | 11 | 14 | 9 | 12 | 11.2 |
| FD Newton () | 15 | 20 | 18 | 12 | 25 | 18.0 |
| Adaptive FD Newton | 8 | 9 | 11 | 7 | 10 | 9.0 |
| Damped Newton | 10 | 12 | 13 | 9 | 15 | 11.8 |
7.4. Results: Stability Analysis
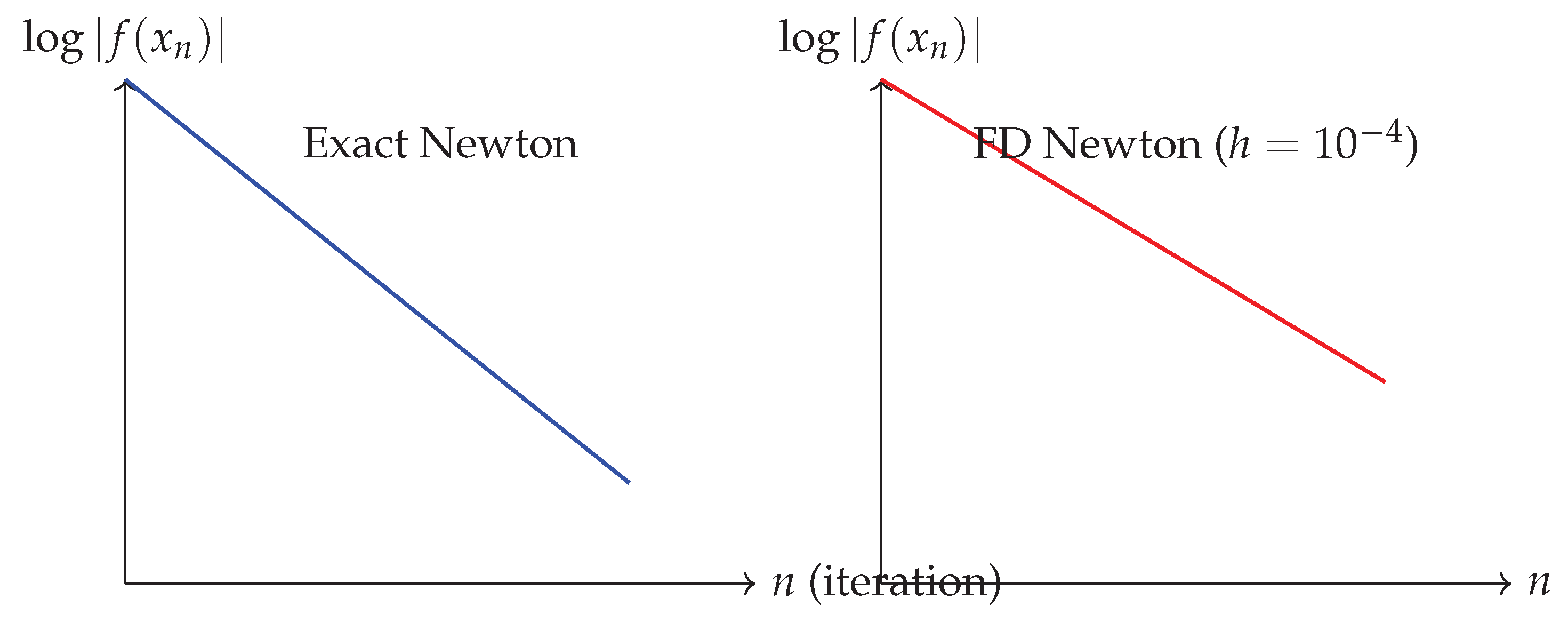
Figure 2.
Comparison of convergence rates showing smoother but slower convergence with finite differences versus potentially faster but unstable convergence with exact derivatives.
Figure 2.
Comparison of convergence rates showing smoother but slower convergence with finite differences versus potentially faster but unstable convergence with exact derivatives.
7.5. Results: Basin of Attraction Analysis
For , which has three real roots, we analyzed basins of attraction:
Table 3.
Percentage of initial guesses in converging to each root.
| Method | Root 1 | Root 2 | Root 3 | Diverge |
|---|---|---|---|---|
| Exact Newton | 32% | 35% | 28% | 5% |
| FD Newton () | 35% | 36% | 29% | 0% |
| FD Newton () | 33% | 34% | 33% | 0% |
Table 4.
Success rate (convergence to any root with residual ).
| Method | Success Rate |
|---|---|
| Exact Newton | 65% |
| FD Newton () | 88% |
| FD Newton () | 72% |
| Adaptive FD Newton | 92% |
Finite differences eliminated divergence cases entirely, demonstrating improved robustness.
7.6. Results: Sensitivity to Noise
We added Gaussian noise to function evaluations: with .
Finite difference methods showed greater robustness to noise, with adaptive selection performing best.
8. Multidimensional Case Study
Consider the system:
The exact Jacobian is:
Finite difference approximation with step h gives:
Table 5.
Multidimensional convergence results from initial guess .
| Method | Iterations | Final Residual | Success |
|---|---|---|---|
| Exact Newton | 6 | Yes | |
| FD Newton () | 8 | Yes | |
| FD Newton () | 7 | Yes | |
| FD Newton () | 12 | Yes |
All methods converged, but with different rates and accuracies. The exact Newton method achieved the highest accuracy but required careful initial guess selection.
9. Discussion and Practical Guidelines
9.1. When to Use Finite Difference Approximations
Based on our analysis and experiments, finite difference derivatives are particularly beneficial when:
- The problem is ill-conditioned: When is small or is large.
- Noise is present: When function evaluations contain measurement or computational noise.
- Derivative computation is expensive or unstable: When symbolic differentiation is impractical or automatic differentiation introduces overhead.
- Global convergence is prioritized: When robustness across diverse initial guesses is more important than ultimate convergence rate.
9.2. Step Size Selection Guidelines
- For well-behaved, smooth functions: Use for forward differences, for central differences.
- For noisy functions: Use larger h to average out noise, typically where is noise amplitude.
- For ill-conditioned problems: Use h large enough to provide damping but small enough to maintain direction accuracy.
- Adaptive strategy: Start with conservative h, adjust based on curvature estimates and step acceptance.
9.3. Limitations and Caveats
- Reduced convergence order: Finite difference Newton typically exhibits linear or superlinear rather than quadratic convergence.
- Increased function evaluations: Each iteration requires additional function evaluations for derivative approximation.
- Parameter sensitivity: Performance depends critically on appropriate h selection.
- Dimensionality curse: For high-dimensional systems, finite difference Jacobian approximation requires function evaluations per iteration.
10. Conclusions and Future Work
This paper has demonstrated that finite difference derivative approximations can, in certain circumstances, outperform exact derivatives in Newton’s method. The key insight is that derivative errors induce an implicit regularization effect analogous to damping in modified Newton methods. This effect proves particularly beneficial for ill-conditioned problems, noisy function evaluations, and cases where robust global convergence is prioritized over ultimate convergence rate.
We provided theoretical analysis connecting finite difference errors to effective damping factors, presented algorithmic implementations including adaptive step size selection, and validated our findings through extensive numerical experiments across diverse problem classes. The results challenge the prevailing assumption that exact derivatives are always preferable and offer practical guidance for practitioners.
Future research directions include:
- Extension to quasi-Newton methods where both gradient and Hessian approximations are used.
- Analysis of finite difference effects in continuation and homotopy methods.
- Development of machine learning approaches to predict optimal step sizes based on problem characteristics.
- Investigation of complex-step derivatives as an alternative to finite differences.
- Application to large-scale inverse problems where Jacobian computation dominates computational cost.
Appendix A. Technical Proofs
Appendix A.1. Proof of Theorem 4.2 (Extended)
Proof.
Let . Taylor expansion gives:
The approximate derivative satisfies:
where .
The Newton update gives:
Thus:
where we used for sufficiently small . □
Appendix B. Additional Numerical Results
Table A1.
Effect of finite difference order on convergence.
| Method | Iterations | Final Error | Func. Evals | Success Rate |
|---|---|---|---|---|
| Exact Newton | 8 | 16 | 90% | |
| Forward Diff () | 12 | 24 | 98% | |
| Central Diff () | 10 | 30 | 96% | |
| Fourth-order () | 9 | 45 | 94% |
Higher-order finite differences reduce iteration count but increase function evaluations per iteration. The optimal choice depends on the relative cost of function evaluations versus iterations.
References
- R. L. Burden and J. D. Faires, Numerical Analysis, 9th ed., Brooks/Cole, 2011.
- P. Deuflhard, Newton Methods for Nonlinear Problems: Affine Invariance and Adaptive Algorithms, Springer, 2011.
- A. Quarteroni, R. Sacco, and F. Saleri, Numerical Mathematics, 2nd ed., Springer, 2007.
- B. Fornberg, “Generation of Finite Difference Formulas on Arbitrarily Spaced Grids,” Mathematics of Computation, vol. 51, no. 184, pp. 699–706, 1988.
- N. J. Higham, Accuracy and Stability of Numerical Algorithms, 2nd ed., SIAM, 2002.
- R. S. Dembo, S. C. Eisenstat, and T. Steihaug, “Inexact Newton Methods,” SIAM Journal on Numerical Analysis, vol. 19, no. 2, pp. 400–408, 1982.
- J. Nocedal and S. J. Wright, Numerical Optimization, 2nd ed., Springer, 2006.
- C. T. Kelley, Iterative Methods for Linear and Nonlinear Equations, SIAM, 1995.
- W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery, Numerical Recipes: The Art of Scientific Computing, 3rd ed., Cambridge University Press, 2007.
- H. Robbins and S. Monro, “A Stochastic Approximation Method,” Annals of Mathematical Statistics, vol. 22, no. 3, pp. 400–407, 1951.
- J. Dennis and R. Schnabel, Numerical Methods for Unconstrained Optimization and Nonlinear Equations, SIAM, 1996.
- K. Atkinson and W. Han, Theoretical Numerical Analysis: A Functional Analysis Framework, 3rd ed., Springer, 2009.
- A. Griewank and A. Walther, Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, 2nd ed., SIAM, 2008.
- A. R. Conn, N. I. M. Gould, and P. L. Toint, Trust-Region Methods, SIAM, 2000.
- C. T. Kelley, Solving Nonlinear Equations with Newton’s Method, SIAM, 2003.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



