
Submitted:
09 December 2025
Posted:
10 December 2025
You are already at the latest version
Abstract
In this paper, we propose an alternative kernel estimator for the regression operator of a scalar response variable S given a functional random variable T that takes values in a semi-metric space. The new estimator is constructed through the minimization of the least absolute relative error (LARE). The latter is characterized by its ability to provide a more balanced and scale-invariant measure of prediction accuracy compared to traditional standard absolute or squared error criterion. The LARE is an appropriate tool for reducing the influence of extremely large or small response values, enhancing robustness against heteroscedasticity or/and outliers. This feature makes LARE suitable for functional or high-dimensional data, where variations in scale are common. The high feasibility and strong performance of the proposed estimator is theoretically supported by establishing its stochastic consistency. The latter is derived with precision of the converge rate under mild regularity conditions. The ease implementation and the stability of the estimator are justified by simulation studies and an empirical application to near-infrared (NIR) spectrometry data. Of course the to explore the functional architecture of this data, we employ random matrix theory (RMT) which is a principal analytical tool of econophysics.
Keywords:
functional data
; nonparametric regression
; stochastic consistency
; least absolute deviation
; relative error
; kernel method
; Bandwidth parameter
1. Introduction
Examining how a functional predictor co-varies with a scalar response variable is a fundamental issue in functional statistics. This relationship is commonly evaluated through regression models, which is estimated using the least squares loss function. In this paper, we adopt another smoothing approach based on the Least Absolute Relative Error (LARE). Undoubtedly, the LARE criterion improves the robustness and the accuracy of the standard regression approaches.
The general framework of this paper is the nonparametric prediction in functional statistics, which has attracted considerable interest due to numerous valuable contributions in recent years. The foundational work in this field was introduced by [1], who established the almost complete pointwise consistency of the kernel-type regression estimator under the assumption of independent and identically distributed (i.i.d.) observations. [2] proved the convergence of this estimator in the norm. [3] derived the exact asymptotic expression for the corresponding errors. The asymptotic normality of the same estimator in the strong mixing case was later demonstrated by [4]. In [5], the authors established a uniform version of the almost complete convergence rate in the i.i.d. framework. In addition to these classical kernel-based approaches, recent research has explored M-estimation techniques and/or local linear smoothing methods. Significant results in this field of nonparametric functional prediction were presented by [6,7,8,9]., which provide comprehensive references on this topics.
Alternatively, in this paper, we focus on relative error regression (RE-regression), a methodology in which the the relative error is used. The latter constitutes a performance measure in many practical applications. Despite its utility, the literature on nonparametric RE-regression remains limited. The most existing studies adopting parametric approaches. In this context, [9] were among the first to investigate the use of relative squared error in estimation. From a practical point of view, RE-regression has been applied in diverse fields, including medicine [10] and finance [11]. In [12], authors studied estimation via RE-regression in multiplicative regression models, while [13] extended this framework to nonparametric estimation, establishing the convergence of the local linear estimator derived from relative error loss.
In last decade, RE-regression has been explored extensively for dependent data. For instance, [14] considered quasi-associated time series, and [15] studied spatial processes. The functional nonparametric RE-regression was first introduced by [16], who established strong consistency and derived the asymptotic distribution of the RE-regression estimator. [17] extended the method to incomplete functional data, examining kernel smoothing techniques for truncated observations. The quasi-associated functional time series case was investigated by[18]. For a comprehensive overview of the latest progress on this topic, see [19,20].
While all the cited studies estimate the regression operator using the mean least squares relative error loss function, in the present contribution, we employ the absolute relative error loss function. This approach is combined with kernel-based local weighting techniques to develop a robust estimator for the nonparametric functional regression model. This alternative estimator offers substantial gains in robustness and accuracy compared to the earlier approach. Such an improvement is especially important in functional statistics, where data are typically noisy and high-dimensional. Specifically, in functional statistics, extreme values and rapid fluctuations are common, which can disproportionately influence least squares-based estimators. Unlike the Least Squares Relative Error (LSRE), the Absolute Relative Error (ARE) treats deviations proportionally, making it more robust to outliers. This robustness ensures a more reliable estimation of the underlying functional relationship, making ARE particularly suitable for high-frequency applications in many applied areas such as economics, finance, signal processing, and environmental monitoring. From a theoretical point of view, the manipulation of the LARE-regression model is more challenging than LSRE-regression. This difficulty is because the LSRE-regression can be explicitly expressed as the ratio of the first and second inverted conditional moments, whereas the LARE-regression lacks such an explicit form. Its asymptotic properties must be derived through its Bahadur representation. Despite this additional complexity, we have established the almost complete convergence of the proposed estimator with precision of the convergence rate. The latter is stated under standard assumptions in nonparametric functional statistics. The assumed conditions explore the functional nature of the model and the structure of the data. An additional advantage of the LARE-regression model is its broader scope of applicability compared to the LSRE-regression. Indeed, the LSRE-regression is limited to strictly positive response variables; in contrast, the LARE regression overcomes this restriction allowing it to extend its potential applicability. Furthermre, the practical usefulness of the proposed estimator is demonstrated through data-driven selection procedures for tuning parameters, as well as through simulation studies and real data applications, which confirm its robustness and superior performance in practice.
The paper is organized as follows. In Section 2, we introduce the proposed estimation algorithms. Section 3 presents the required assumptions and the main asymptotic results. In Section 4, we discuss methods for selecting the smoothing parameter and the metric using the random matrix theory from econophysics. The performance of the constructed estimator on simulated and real data is evaluated in Section 5. Finally, Section 6 is devoted to summarize some concluding remarks. The technical proofs are provided in the appendix’s Appendix A.
2. Functional LARE Regression and Its Estimation
As outlined in the introduction, our main objective is to evaluate the relationship between an exogenous functional variable T and a real-valued endogenous variable S. More precisely, the variables under consideration belong to the space . The set is a functional space endowed with an appropriate semi-norm N. Henceforth. we fix a point in and consider a neighborhood of within this functional space. In our earlier contributions ([16,18]), we modeled the underlying relationship between T and S using the LSRE regression defined by
The main feature of this loss function is its ability to provide an explicit definition of the predictor. Indeed, by simple differentiation with respect to , we can show that
Clearly, such an explicit definition of the model simplifies the analysis and derivation of its mathematical properties. Nevertheless, this approach is not without limitations. While the least squares relative error method reduces the effect of large outliers values, it can give excessive weight to large deviations which compromised its robustness against the very small values or highly dispersed observations. To address this limitation, we propose to proceed with the least absolute relative error (LARE) approach, which provides a more balanced treatment of both small and large deviations in the data. Formally, the LARE regression is defined as the estimator that minimizes
Evidently, this alternative loss function enhances the robustness of LSRE regression by treating all deviations proportionally in a linear manner, rather than using the traditional quadratic form. The LARE loss function evaluates the differences between predicted and true values more equitably, providing a more balanced, resilient, and reliable assessment of model performance. This advantage is particularly important in the presence of large deviations or extremely small observations, where the LSRE approach fails to handle. Overall, the LARE rule is more robust and effective, especially in datasets with irregular or heavy-tailed distributions.
For the estimation setup, we consider n independent and identically distributed (i.i.d.) pairs , sampled from the distribution of . The kernel estimator of is then given by
where M is a kernel function and (to simplify the notation) is a sequence of positive real numbers that goes to zero as n goes to infinity.
The primary objective of this paper is to establish the asymptotic properties of the estimator of , where the explanatory variable T takes values in a semi-metric space . To the best of our knowledge, this work is the first to employ this approach to construct an estimator of the regression operator, even in multivariate settings. Although the finite-dimensional case can be viewed as a special case of this framework, the infinite-dimensional case is especially interesting, both for its theoretical challenges and the variety of practical applications it supports. For further motivation and detailed discussions on this topic, we refer the reader to [21,22,23] and the references therein.
3. The Strong Consistency of the Kernel Estimator
Now, to investigate the almost complete convergence, we denote by C or strictly positive constants and put
We define the closed ball of radius r centered at as
and set
The following assumptions are imposed:
- (HM1)
- The small-ball probability satisfies for all , with
- (HM2)
- For all , the functions are of class (with respect to s ) and satisfy
- (HM3)
- The kernel M is measurable, supported on , and bounded: .
- (HM4)
- The small-ball probability satisfies
- (HM5)
- The response variable is bounded by inverse moments:
These assumptions are generally mild and consistent with those commonly adopted in the literature on functional mode estimation. The functional component is typically described by two main conditions. The first, (HM1), concerns the small-ball probability function, which captures the concentration of the probability measure of the functional regressor. The second, (HM2), addresses the time-series structure of the functional data, quantifying the local dependence among functional observations. Both of these conditions are standard in functional time series analysis (see [24] for detailed discussions and examples of functional data satisfying these assumptions). The nonparametric component is characterized by (Hy3), which is commonly used in nonparametric functional statistics and has appeared in several previous studies. Finally, assumptions (HM3)–(HM5) impose technical conditions that facilitate the proofs and ensure the validity of the asymptotic results.
Theorem 1.
Given assumptions (HM1)–(HM5), we obtain
The proof of this Theorem employs the Bahadur representation of the estimator. This representation is established through the following auxiliary results.
Lemma 1.
Let be a sequence of decreasing real-valued random functions and a real random sequence satisfying
for some constants . Then, for any real random sequence such that , we have
4. Smoothing Parameter Selection and Random Matrix Theory for Metric Approximation
The practical performance of the estimator depends crucially on the choice of parameters involved in its construction. In particular, the bandwidth parameter m plays a central role in the implementation of this regression method. Various strategies have been proposed in the nonparametric regression literature to address this issue. In this study, we adopt two widely used approaches from classical regression: the cross-validation rule and the bootstrap algorithm.
4.1. Leave-One-Out Cross-Validation Principle
In regression analysis, the leave-one-out cross-validation (LOOCV) criterion is based on minimizing the mean squared error. This criterion is highly effective for bandwidth selection because it directly optimizes for predictive accuracy. The LOOCV algorithm was successfully extended to the domain of functional statistics by [25] who demonstrated its particular efficacy and suitability for functional data. The main advantage of this approach is its flexibility; for instance, it can be readily adapted to our model for functional LARE regression as
where and denote the leave-one-out estimators of , respectively, computed without the i-th observation . The efficiency of these estimators depends on the choice of the subset , which determines the optimization of (4).
Concerning the subset , we point out that there are two primary strategies for choosing it. The local approach and the global one. In the local case, is determined by the number of neighborhoods around the location point. In the global case, is derived from the quantiles of the distance distribution between the functional regressors.
4.2. Bootstrap Approach
The bootstrap procedure is an alternative popular method to the cross-validation rule. Its principal feature is its data-driven nature, as it empirically approximates the sampling distribution of the estimator without external assumptions. This automatism analysis makes it particularly valuable in complex modeling scenarios, where asymptotic theory may be intractable or slow to converge. Furthermore, the bootstrap provides a direct and computationally feasible means to minimize a targeted loss function. This allows for a more adaptive for many loss functions. For the LARE- regression, we state the following algorithm :
- Step 1:
- Choose an arbitrary bandwidth and compute .
- Step 2:
- Compute the residual .
- Step 3:
- Generate a bootstrap residual using the distribution. , (d is dirac measure ).
- Step 4:
- Construct a bootstrap sample
- Step 5:
- Compute the estimators using the sample .
- Step 6:
- Repeat the steps 3-6 times and we put the estimator at the replication r.
- Step 7:
- Choose the optimal bandwidth m according to the following criterion
4.3. Random Matrix Metric
The principal task of functional data analysis is to move from comparing two curves directly to comparing them within the context of a larger, noisy system. In this context, Random Matrix Theory (RMT) is used to define a stable distance (without noise ) between any two curves by eliminating the noise of the entire system. The main idea is based on the use of RMT to clean the covariance matrix estimated from the data. The eigenvalues and eigenvectors of the noisy covariance matrix are a mixture of true signal and random noise. RMT provides a null model to identify which parts of the spectrum are likely to be signal and which are noise. To do that, we follow the following algorithm:
-
Step 1:Create the sample covariance matrixHere is assumed to have been column-centered. This matrix gives the observed covariances between all pairs of sampling points.
-
Step 2:The Marčenko-Pastur law describes the eigenvalue distribution for a random matrix. We compare the eigenvalue spectrum of our empirical to the spectrum predicted by the Marčenko-Pastur distribution for a random matrix with the same dimensions and variance.
- Perform the eigen-decomposition: , where is the diagonal matrix of eigenvalues .
- Identify the eigenvalues that are outside the support of the random distribution. These are considered as signal eigenvalues. The eigenvalues within the random bounds are considered noise.
-
Step 3:Create a cleaned covariance matrix by retaining only the signal components. A common method is to replace the noise eigenvalues with a constant value:where is a representative value for the noise eigenvalues .
-
Step 4:With the cleaned covariance matrix, we can define a stable metric. The Mahalanobis distance is a natural choice. For two curves represented as vectors and , the RMT-metric is:This metric is more stable and reliable than one calculated from the noisy covariance matrix , which is highly distorted by spurious correlations.In conclusion, RMT acts as a filter to denoise the covariance structure of the dataset. This cleaned structure increases the accurate metric for comparing any two individual curves within that dataset.
5. Data-Driven Analysis
5.1. A Simulated Data Case
This section is devoted to demonstrate the practical implementation of the proposed estimator through two illustrative examples. First, we assess the feasibility of both selection methods (LOOCV and Bootstrap selectors). Second, we illustrate the superior efficiency of the LARE regression over the LSRE approach. For this purpose, we generate two types of functional variables:
where is generated from a distribution and is drown from distribution. The curves are then discretized over a grid of points given by 100 equispaced measurements in . A visual comparison of the two functional samples is provided in (cf. Figure 1).
We model the scalar response Y using the following non-parametric regression
where the errors are assumed to be independent of . For the simulation study, we consider four error types of white noise generated from a normal mixture distribution, as follows:
Further details on normal mixture distributions can be found in [26]. Now, in order to compare the LOOCV to the Bootstrap selector, we optimize both rules over , the set of m such that the ball centered at with radius m contains exactly k neighbors of . Specifically, the number k is selected from the subset . Observe that the Bootstrap selector requires a pilot bandwidth which is chosen using the R- routine h.default from the R-package fda.usc. The two selection procedures performance are tested by comparing their averaged absolute errors ASE, where
The model performance also depends critically on using a metric N that is appropriate for the data type. The latter is related to the smoothness of the curves. Here, the shape of the curves (cf. Figure 1) confirms that the metric defined by the derivatives is adequate for the smooth curves,
where denotes the ith derivative of the curve . While for the rough curves we employ the PCA semi metric associated to the q-greatest eigenvalues.
While the simulation study investigated numerous values of i, q, and n, we report here only the results for , , and for brevity. A quadratic kernel on was used for this empirical analysis . Table 1 summarizes the obtained ASE-results for both selectors.
We observe that the LOOCV strategy yields superior results compared to the Bootstrap method. This advantage is pronounced in the case of Skewed Bimodal Distributions (S.B.D.), whereas for Contaminated Distributions (C.D.), the two methods perform nearly equivalently. Furthermore, both bandwidth selectors demonstrate relatively strong efficiency across the tested scenarios.
In the second part of this illustration, we examine the robustness of the proposed estimator by comparing it to the LSER-regression defined by
It is important to note that robustness can be assessed through various metrics, including the influence function, gross-error sensitivity, breakdown point, local shift sensitivity or bias/variance under contamination, among others (see [27] for a comprehensive overview). While some of these metrics are challenging to apply in the context of functional statistics, they all share the common goal of evaluating the stability of a statistical method and quantifying its sensitivity to deviations from model assumptions. In this experiment, we assess robustness by analyzing the variance under the contaminated data-generating process. Specifically, we construct a contamination model by taking it as a white noise, where
where is generated from S.N.D and is drown from C.D. Under this contamination, the empirical variance is defined by
In Figure 2 and Figure 3, we plot the function for both estimators in both cases (smooth and rough case).
Without surprising Figure 2 and Figure 3 confirm the robustness of compared to . It shows that the function of has a small variation compared to the variation in . This conclusion is confirmed by computing the range of , defined as
which serves as a measure of the function’s variability. This benchmark is computed over 50 discretized points in the interval (0,1). Specifically, in the smooth case, we obtained for the LARE-regression compared to for the LSRE-regression. The same statement for the rough case was observed, and RG =0.3 for the LARE-regressions against for the LSRE-regression case.
5.2. Real Data Application
This section presents a predictive analysis using the LARE-model. Specifically, we conduct a comparative study of several regression predictors. More precisely, we focus in this empirical analysis on prediction of the sulfone content in onion diets using Near-Infrared (NIR) spectral curves. Sulfones is organic compounds highly beneficial for human health. Their biomedical significance is well-documented in the literature, with studies indicating efficacy in treating conditions such as mucous-membrane inflammation and gastrointestinal disorders. Furthermore, research has highlighted their potential to suppress tumor initiation (see [28]). Our objective is to use the NIR spectrometry to quantify the relationship between onion consumption in a rodent model and subsequent sulfone levels in urine. The functional NIR data utilized in this analysis are available in the website http://www.models.life.ku.dk (accessed on 20 October 2025). The sample preparation involved a two-step chemical process: initial spectrometry processing, followed by spectral acquisition in the wavelength region of 9.6 to 0.3 ppm. The resulting dataset comprises 32 observations, which were recolored with sufficient replication. The spectral curves for these observations are plotted in Figure 4. Further details on this dataset are available in [28].
For the prediction task, we compare the performance of three regression estimators:
To ensure a fair comparison, common computational strategies were employed for the three estimators. This includes the use of the RMT-metric, an identical kernel function M and the application of the rule specified in Equation (4) for selecting the bandwidth parameter for the three methods.
To evaluate the robustness of these estimators, we introduced contamination by multiplying a subset of observations by a factor of 10. The impact of this contamination was assessed by controlling the variation in the Mean Absolute Error (MAE). Specifically, for a given contamination proportion , we multiplied observations (where denotes the integer part) and computed the variability of the prediction error function using
where denotes one of the three compared estimators. The resulting prediction errors are displayed in Figure 5.
The results indicate that while all three predictors have satisfactory performance under uncontaminated conditions(), the LARE approaches demonstrates a significant advantage. This advantage is particularly evident in the stability of the LARE estimator (), which exhibits lower variability in its MAE under contamination. The superior stability of the LARE method is quantitatively confirmed by examining the range of its error function. The range of the LARE-regression was observed to be between and , compared to a range of for the LSRE regression and for the standard nonparametric regression. This empirical finding aligns with the theoretical expectation that estimators based on absolute relative error (LARE) are more robust than those based on squared error (LSRE), due to the reduced influence of large residuals.
6. Conclusions and Prospects
This work introduces a robust framework for functional regression estimation by employing the least absolute relative error loss function. We construct a novel estimator and establish its asymptotic properties, specifically, proving its complete consistency. The functional structure is modeled using the small ball probability function that relates the topological structure of the probability measure of the functional explanatory variable. Furthermore, the employment of the LARE rule significantly increases the robustness of the model. The derived asymptotic results are obtained under general assumptions, ensuring their applicability to a broad class of functional data and continuous-time processes. Empirical analyses demonstrate the straightforward implementation of our estimator and confirm its superior robustness and predictive accuracy compared to alternative methods.
This contribution opens several promising questions for future research. A natural extension would be to develop a local linear version of this robust modal regression estimator. It is well-known that local linear modeling can improve the asymptotic convergence rate by reducing boundary bias. Establishing the asymptotic normality of the proposed robust estimator is another critical open question, as it is a prerequisite for constructing confidence intervals and conducting hypothesis tests. Other important directions include exploring linear or partially linear formulations of this regression. A particularly challenging task would be to extend these results to more complex data structures, such as censored data or functional time series. Clearly, the treatment of these complex structures requires new mathematical tools and developments that extend beyond the scope of the present work.
Author Contributions
The authors contributed approximately equally to this work. Formal analysis, M.R.; Writing—review & editing, I.A. and A. L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Deanship of Scientific Research and Graduate Studies at King Khalid University for funding this work through Research Groups under grant number RGP2/456/46.
Data Availability Statement
The data used in this study are available through the link http://www.models.life.ku.dk (accessed on 20 October 2025).
Acknowledgments
The authors thank and extend their appreciation to the funder of this work: Deanship of Scientific Research and Graduate Studies at King Khalid University for funding this work through Research Groups under grant number RGP2/456/46.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Proof of Lemma 1. The proof of this lemma adapts techniques employed by [29]. For an arbitrary positive constant , we decompose the probability by
and implying
Since , it remains to establish that
Utilizing the monotonicity of , we observe that
Thus, it suffices to demonstrate that
For the first term, we proceed with the following estimation,
The second term is bounded analogously by
Finally, selecting and invoking condition (ii) yields
Proof of Theorem 1. First, observe that through straightforward differentiation, we establish that satisfies the estimating equation,
The desired result follows from an application of Lemma 1 with the following identifications.
This gives the required Bahadur representation. From Equation (A1), we have . Thus, it remains to verify the conditions of Lemma. 1:
The claimed results are presented in the following Lemmas
Lemma A1.
Given assumptions (HM1)–(HM5), we obtain
Proof.
Define the centered random variables,
Then, the centered version of becomes
The proof of this lemma relies on the exponential inequality established in Corollary A.8(ii) of [24], which requires a bounding of the quantity . First, for any , we observe that
which implies
Moreover, we have
Applying the binomial theorem yields
Consequently,
We now apply the aforementioned exponential inequality with . For all ,
Selecting sufficiently large yields
Finally, we obtain
Further, we have
It follows that
□
Lemma A2.
Given assumptions (HM1)–(HM5), we obtain
Proof.
We split the proof in two parts: the dispersion term
and the bias term
where .
For (A6), we exploit the compactness of the interval , and construct a finite covering
For any , define . Then, we decompose the supremum as
Using the inequality , we bound the first term as
where
The random variables satisfy
Given the condition
we obtain
Now consider the middle term,
Define
where
The variables satisfy
Consequently, there exists such that
which completes the proof of (A6).
For the bias term (A7), we employ similar arguments. For all ,
Thus,
Therefore, the conditions of Lemma 1 are satisfied, yielding the Bahadur representation,
□
References
- Ferraty, F.; Vieu, P. The functional nonparametric model and application to spectrometric data. Computational Statistics 2002, 17(4), 545–564. [Google Scholar] [CrossRef]
- Dabo-Niang, S.; Rhomari, N. Estimation non paramétrique de la régression avec variable explicative dans un espace métrique. Comptes rendus. Mathématique 2003, 336(1), 75–80. [Google Scholar] [CrossRef]
- Delsol, L. Régression non-paramétrique fonctionnelle: Expressions asymptotiques des moments. Annales de l’ISUP 2007, 51(No. 3), 43–67. [Google Scholar]
- Masry, E. Nonparametric regression estimation for dependent functional data: asymptotic normality. Stochastic Processes and their Applications 2005, 115(1), 155–177. [Google Scholar] [CrossRef]
- Ferraty, F.; Laksaci, A.; Tadj, A.; Vieu, P. Rate of uniform consistency for nonparametric estimates with functional variables. Journal of Statistical planning and inference 2010, 140(2), 335–352. [Google Scholar] [CrossRef]
- Attouch, M.K.; Laksaci, A.; Saïd, E.O. Robust regression for functional time series data. Journal of the Japan Statistical Society 2013, 42(2), 125–143. [Google Scholar] [CrossRef]
- Barrientos-Marin, J.; Ferraty, F.; Vieu, P. Locally modelled regression and functional data. Journal of Nonparametric Statistics 2010, 22(5), 617–632. [Google Scholar] [CrossRef]
- Azzi, A.; Belguerna, A.; Laksaci, A.; Rachdi, M. The scalar-on-function modal regression for functional time series data. Journal of Nonparametric Statistics 2024, 36(2), 503–526. [Google Scholar] [CrossRef]
- Narula, S.C.; Wellington, J.F. Prediction, linear regression and the minimum sum of relative errors. Technometrics 1977, 19(2), 185–190. [Google Scholar] [CrossRef]
- Chatfield, C. The joys of consulting. Significance 2007, 4(1), 33–36. [Google Scholar] [CrossRef]
- Chen, K.; Guo, S.; Lin, Y.; Ying, Z. Least absolute relative error estimation. Journal of the American Statistical Association 2010, 105(491), 1104–1112. [Google Scholar] [CrossRef]
- Yang, Y.; Ye, F. General relative error criterion and M-estimation. Frontiers of Mathematics in China 2013, 8(3), 695–715. [Google Scholar] [CrossRef]
- Jones, M.C.; Park, H.; Shin, K.I.; Vines, S.K.; Jeong, S.O. Relative error prediction via kernel regression smoothers. Journal of Statistical Planning and Inference 2008, 138(10), 2887–2898. [Google Scholar] [CrossRef]
- Mechab, W.; Laksaci, A. Nonparametric relative regression for associated random variables. Metron 2016, 74(1), 75–97. [Google Scholar] [CrossRef]
- Attouch, M.; Laksaci, A.; Messabihi, N. Nonparametric relative error regression for spatial random variables. Statistical papers 2017, 58(4), 987–1008. [Google Scholar] [CrossRef]
- Demongeot, J.; Hamie, A.; Laksaci, A.; Rachdi, M. Relative-error prediction in nonparametric functional statistics: Theory and practice. Journal of Multivariate Analysis 2016, 146, 261–268. [Google Scholar] [CrossRef]
- Altendji, B.; Demongeot, J.; Laksaci, A.; Rachdi, M. Functional data analysis: estimation of the relative error in functional regression under random left-truncation model. Journal of Nonparametric Statistics 2018, 30(2), 472–490. [Google Scholar] [CrossRef]
- Chikr Elmezouar, Z.; Alshahrani, F.; Almanjahie, I.M.; Kaid, Z.; Laksaci, A.; Rachdi, M. Scalar-on-Function Relative Error Regression for Weak Dependent Case. Axioms 2023, 12(7), 613. [Google Scholar] [CrossRef]
- Benzamouche, S.; Ould Saïd, E.; Sadki, O. Nonparametric estimation of the relative error regression for twice censored and dependent data. Communications in Statistics-Theory and Methods 2025, 54(5), 1492–1525. [Google Scholar] [CrossRef]
- Xia, X.; Ming, H.; Li, J. Relative error model average for multiplicative models. Statistics and Computing 2026, 36(1), 18. [Google Scholar] [CrossRef]
- Wang, J.L.; Chiou, J.M.; Müller, H.G. Functional data analysis. Annual Review of Statistics and its application 2016, 3(1), 257–295. [Google Scholar] [CrossRef]
- New Trends in Functional Statistics and Related Fields; Aneiros, G., Bongiorno, E.G., Goia, A., Hušková, M., Eds.; Springer Nature, 2025. [Google Scholar]
- Ndiaye, M.; Dabo-Niang, S.; Ngom, P.; Thiam, N.; Brehmer, P.; El Vally, Y. Nonparametric prediction and supervised classification for spatial dependent functional data under fixed sampling design. In Nonlinear Analysis, Geometry and Applications: Proceedings of the Third NLAGA-BIRS Symposium, AIMS-Mbour, Senegal, 2024, May; Springer Nature Switzerland: Cham; pp. 69–100. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric functional data analysis: theory and practice; Springer New York: New York, NY, 2006. [Google Scholar]
- Rachdi, M.; Vieu, P. Nonparametric regression for functional data: automatic smoothing parameter selection. Journal of statistical planning and inference 2007, 137(9), 2784–2801. [Google Scholar] [CrossRef]
- Benaglia, T.; Chauveau, D.; Hunter, D.R.; Young, D.S. mixtools: an R package for analyzing mixture models. Journal of statistical software 2010, 32, 1–29. [Google Scholar]
- Huber, P. J.; Ronchetti, E. M. Robust Statistics, 2nd ed.; John Wiley & Sons, 2009. [Google Scholar]
- Clark, C. J.; et al. Dry matter and soluble solids in onion (Allium cepa L.): use of near-infrared spectroscopy as a screening tool. Journal of the Science of Food and Agriculture 2003, 83(5), 371–379. [Google Scholar]
- Koenker, R.; Zhao, Q. Conditional quantile estimation and inference for ARCH models. Econometric theory 1996, 12(5), 793–813. [Google Scholar] [CrossRef]
Figure 1.
A sample of 150 curves.
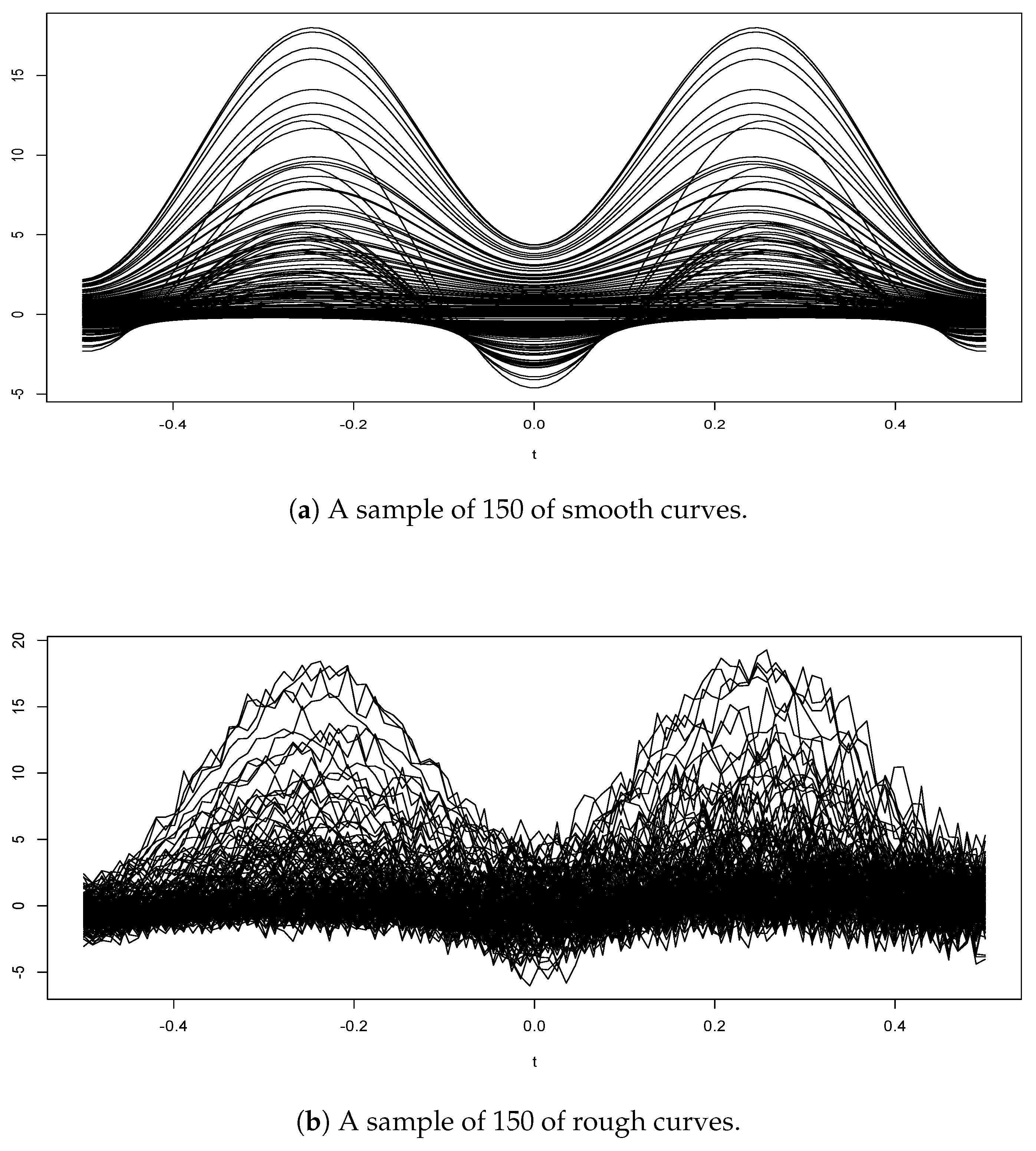
Figure 2.
Smooth case: The variability of the function over 50 point in .
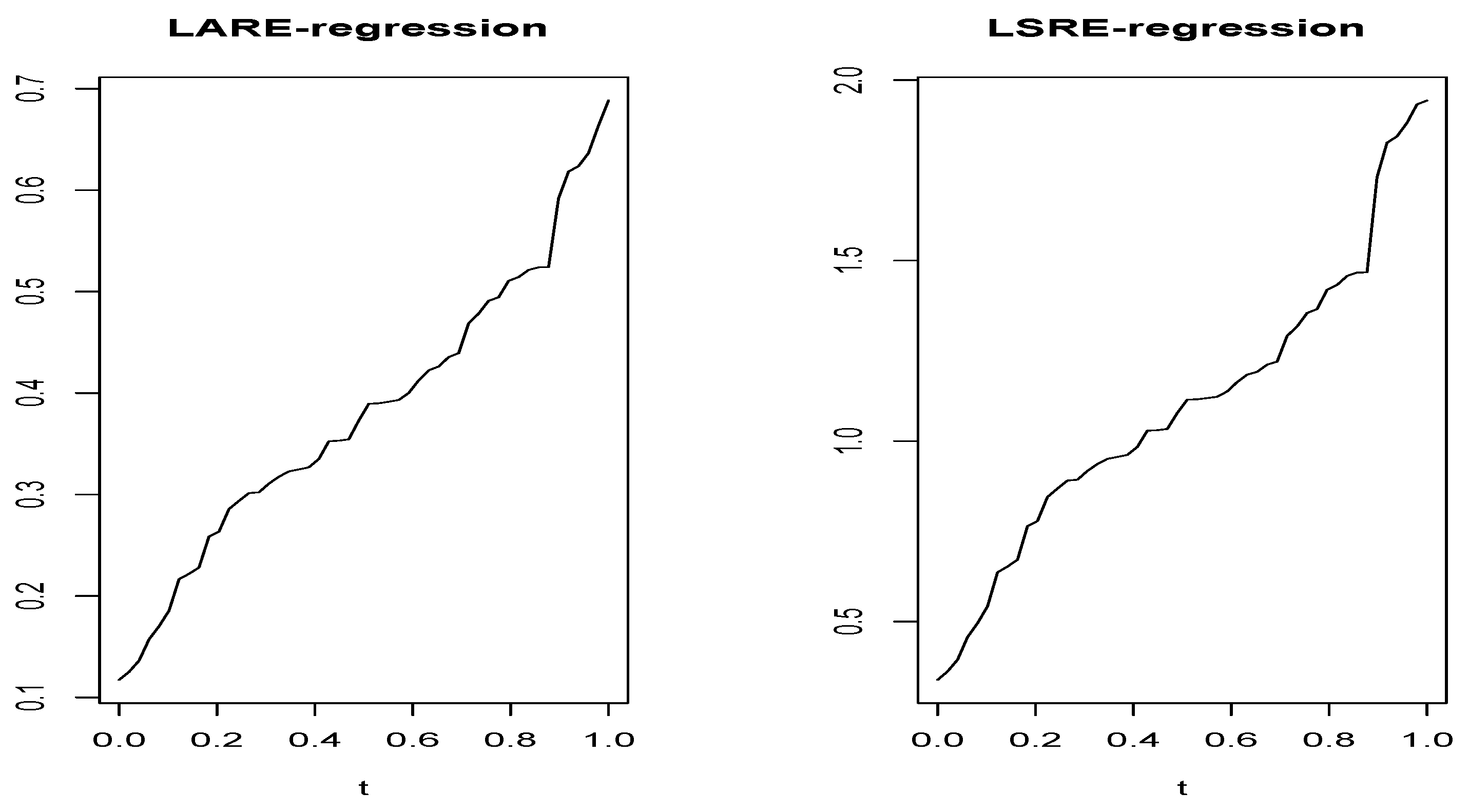
Figure 3.
Rough case: The variability of the function over 50 point in .
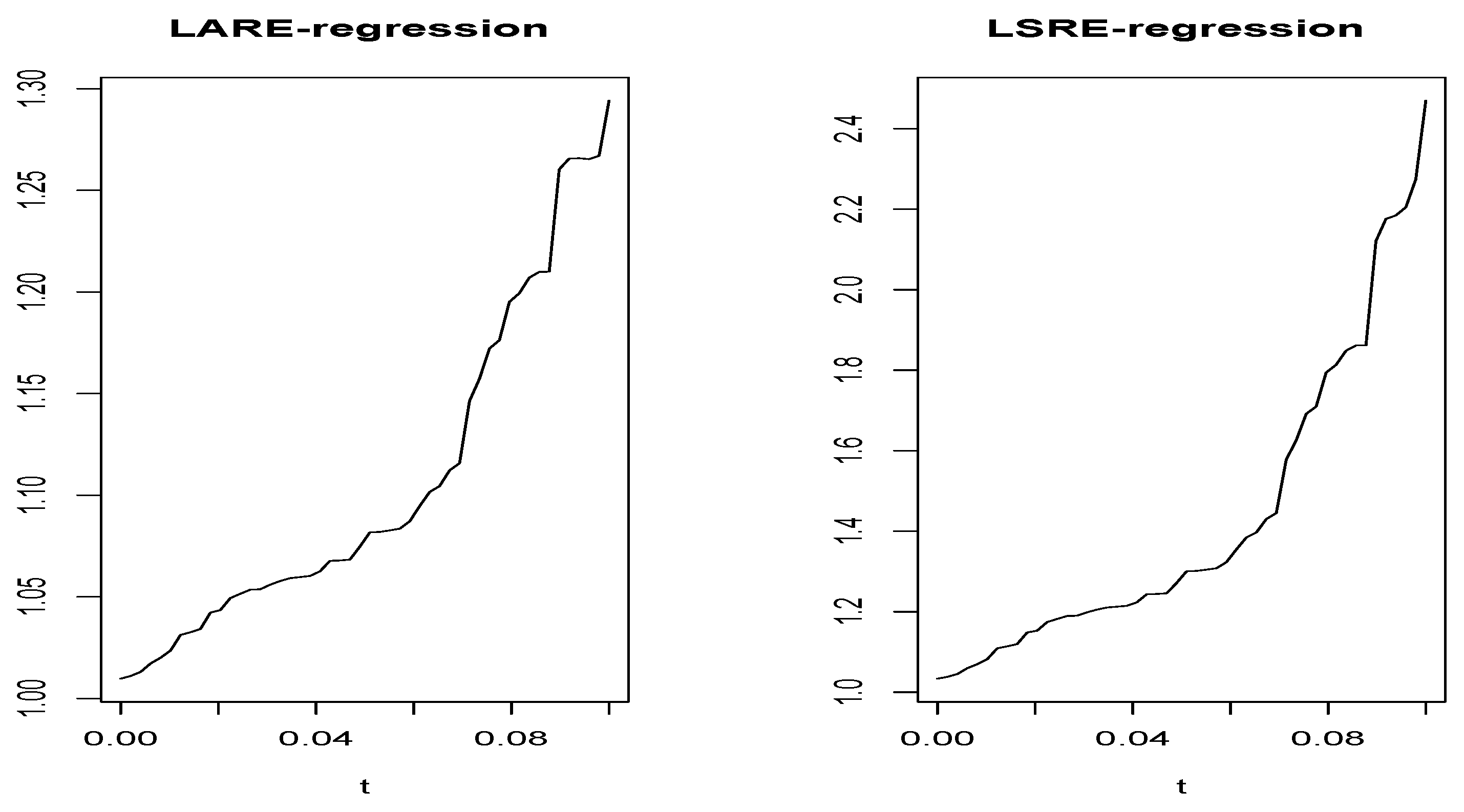
Figure 4.
The spectral curves of the NIR data.
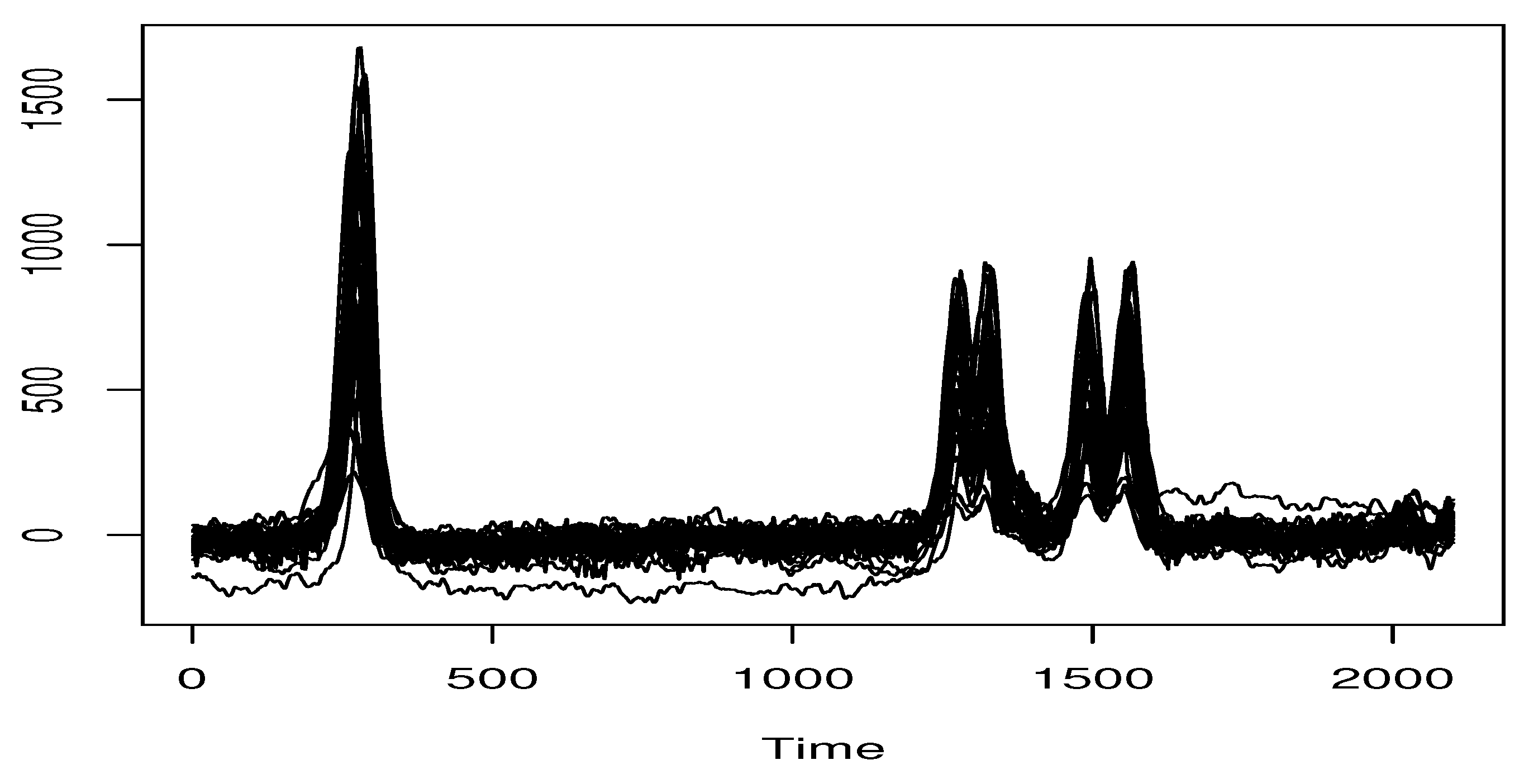
Figure 5.
Comparison of prediction errors across the three regression estimators under increasing data contamination.
Figure 5.
Comparison of prediction errors across the three regression estimators under increasing data contamination.
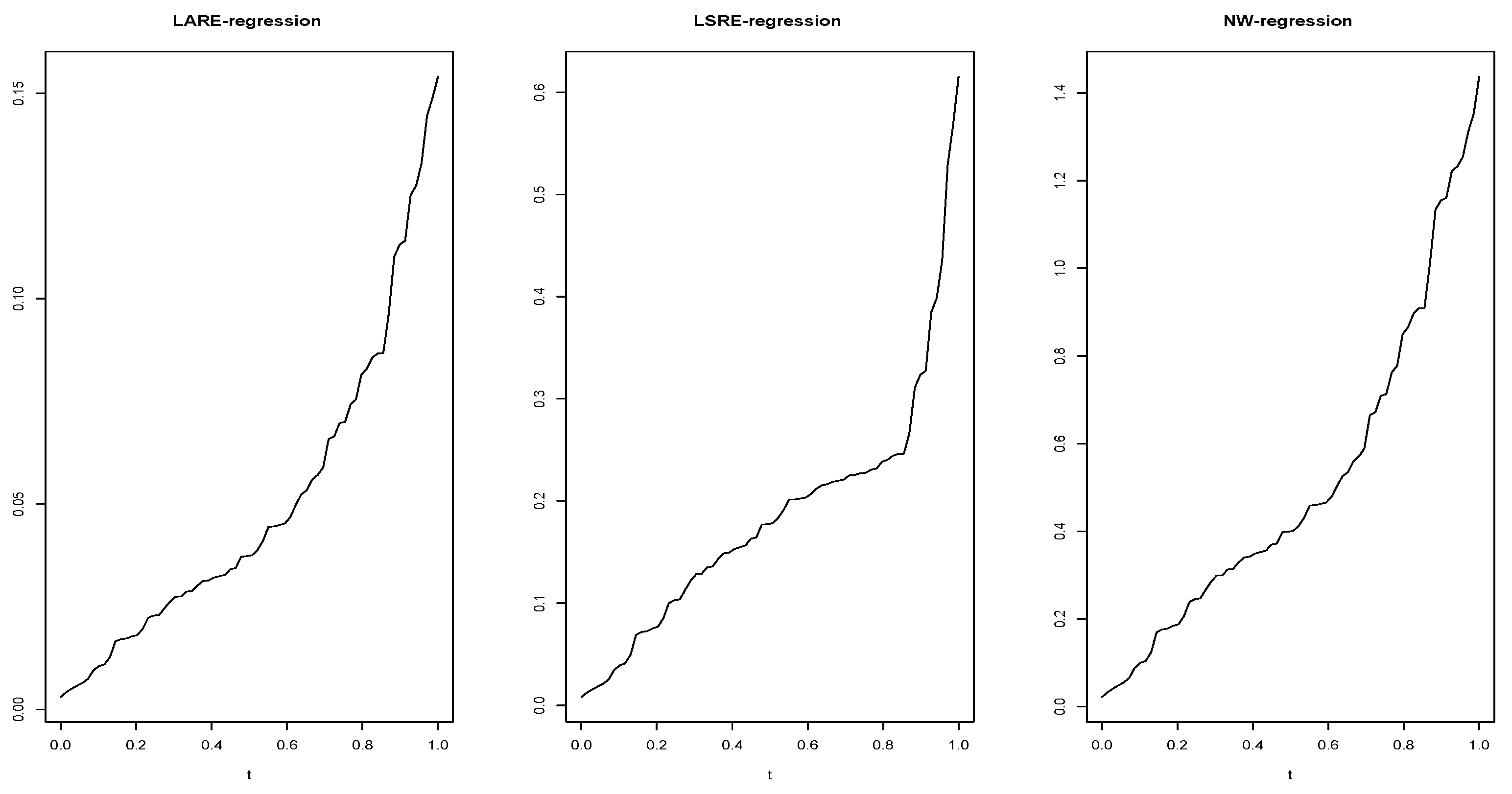

Table 1.
ASE results.
| Method | Distribution | LOOCV | Bootstrap | |
|---|---|---|---|---|
| Smooth curves selector | S.N.D. | 0.83 | 0.97 | |
| S.U.D. | 0.98 | 1.23 | ||
| S.B.D. | 1.12 | 1.37 | ||
| C.D. | 1.18 | 1.23 | ||
| Rough curves | S.N.D. | 1.17 | 1.84 | |
| S.U.D. | 1.26 | 1.74 | ||
| S.B.D. | 1.29 | 2.18 | ||
| C.D. | 1.52 | 1.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



