
Submitted:
01 December 2025
Posted:
02 December 2025
You are already at the latest version
Abstract
In the era of ever-greater data produced and collected, public health research is often limited by the scarcity of data. To improve this, we propose a data sharing in the form of Data Spaces, which provide technical, business, and legal conditions for an easier and trustworthy data exchange for all the participants. The data must be described in a commonly understandable way, which can be assured by machine-readable ontologies. We compared the semantic interoperability technologies used in the European Data Spaces initiatives and adopted them in our use case of physical development in children and youth. We propose an ontology describing data from the Analysis of Children’s Development in Slovenia (ACDSi) study in the Resource Description Framework (RDF) format and a corresponding Next Generation Systems Interface-Linked Data (NGSI-LD) data model. For this purpose, we developed a tool to generate a NGSI-LD data model using information from an ontology in RDF format. The tool builds on the declaration from the standard that the NGSI-LD information model follows the graph structure of RDF, so that such translation is feasible. The source RDF ontology is analyzed using standardized SPARQL Protocol and RDF Query Language (SPARQL), specifically using Property Path queries. The NGSI-LD data model is generated from the definitions collected in the analysis. Multiple ancestries of classes are also supported, even over multiple or common ontologies. These features may equip the tool to be used more broadly in similar contexts.
Keywords:
semantic interoperability
; data spaces
; digital twin
; data model
; RDF
; NGSI-LD
1. Introduction
Several countries engage in collecting data about physical development in children and youth [1,2,3,4]. Studies in this field from the pre-big-data era describe problems arising from the scarcity of data needed to conduct such research [5,6]. Nowadays, the problem is still the same, at least with data from high-quality and representative surveys. These data are sensitive, and public sharing is sometimes not encouraged. Researchers are generally entitled to obtaining such data, but problems with technical incompatibility may hinder their usage.
To overcome these obstacles, we propose a solution initially developed in the manufacturing industry where various organizations and people decided to organize a regime of sharing their data, which would guarantee the rights of all involved entities, called Sovereign Data Sharing [7]. It has since been promoted by European institutions all over Europe and worldwide. It has been implemented in other branches of human activity, such as transportation, logistics, mobility, tourism, etc., and is intended to be used among different branches. It is embodied in Data Spaces [8,9]. This approach breaks “data silos” where data are constrained inside a single organization or a single branch. On the other hand, many existing data exchanges operate bilaterally, which, however, do not scale well, so novel approaches to multilateral associations of stakeholders are needed [10]. The technical, organizational, legal, and ethical aspects of data sharing are being addressed to overcome obstacles to data sharing [11]. Though the final goal is to have a single European Data Space, current steps are still made at the sectoral level. The ACDSi data could, based on the fact that they describe the developmental status of young people and are therefore personal data, be shared inside the European Health Data Space [12]. There, they would benefit of the same governance, protection and support as other, predominantly medical data.
In this work, we are interested in the technical aspect, which is called semantic interoperability. To achieve this goal, all the needed standards and technologies already exist. Therefore, the novelty of the Data Spaces approach is in the combination of means necessary to solve all the technical problems that may hinder efficient data sharing. The adoption process (e.g. selection of standards, protocols and tools) runs in parallel on the standardization level in formal bodies (e.g. in standardization institutes, like European Telecommunications Standardization Institute (ETSI)) and on the informal level, which means intense inclusion and well-steered collaboration of scientific, developer, and user communities. The output of this process are specifications of the necessary tools and procedures. The reference implementations of the tools are the software components, which cover the needs that have been identified in the specification phase and include at least the minimal required capabilities. They are being developed under open-source licenses to lower the barrier to acquiring the technologies. These implementations are often mature enough to be used in production, at least in less demanding environments (e.g. participants with small quantities of data). If needed, they can be adapted to the specific needs due to the openness of their source code.
To leverage the potential of the data, Europe has initiated a process of enabling participants to share their data in a trustworthy manner. This will encourage those entities in possession of the data (data providers), who are hesitant to share it due to concerns of giving away trade secrets or other sensitive information, to offer the data for the common good, benefitting them on one side and the consumers of the data on the other side and also the society as a whole. Data providers must know that data will be used in accordance to the conditions they set in advance and that all the relevant regulations will be respected. Data consumers on the other side must be assured that the data came from valid sources and its contents are trustworthy. This is also needed in our use case and in public health data in general. The data in these cases come from physical persons and are protected by important European and national legislation that both data providers and data consumers must abide by.
The trust is assured by providing common guidelines and trustworthy technical means for executing the data exchange. These guidelines and technical means will allow for automatic compliance with the conditions of data usage proscribed by the data provider without manual intervention. Such tools need to be certified as compliant with the Data Spaces specifications. Recently, two major European associations have undertaken to define the necessary specifications, and these will be briefly presented in this work. The first is the International Data Spaces Association (IDSA) [13] specification with the IDS Rulebook [14] and IDS Reference Architecture Model (IDS RAM) [15,16]. The second is the FIWARE [17] specification with the Generic Enablers for Data Spaces, combined with iSHARE security components [18,19]. These definitions currently have limitations as they were meant to demonstrate participants’ ability, initially in limited numbers, to share data. They have been later included in a definition process of the GAIA-X initiative [20], which currently works to adapt them into a broader infrastructure suitable for large-scale cloud deployments. Both associations are now, along with the GAIA-X initiative and the Big Data Value Association (BDVA) [21], founding members of the Data Spaces Business Alliance (DSBA), which steers these efforts further in a more strictly organized manner [22].
We are presenting two prevailing architectures of the data-sharing technologies developed by two associations: IDSA [8] and FIWARE [17]. The central component of the former is called the Connector, and the one of the latter is called the Context Broker. They offer similar features, but each may be more suitable for some use cases than others. In this work, we use Context Broker to verify the generated artifacts, as will be presented in later sections.
Two prevailing architectures of the data-sharing technologies are developed by two associations: IDSA [8] and FIWARE [17]. The central component of the former is called the Connector, and the one of the latter is called the Context Broker. They offer similar features, but each may be more suitable for some use cases than others. In this work, we use Context Broker to verify the generated artifacts, as will be presented in later sections.
Both architectures extend the access control mechanisms from the internal information systems inside organizations onto the World Wide Web scale. Data providers can define usage policies (simple or complex rules) that data consumers must follow. If agreed upon by both parties, the technologies involved in these architectures will enforce these policies on data usage without human intervention. Usage policies consist of usual access rights and more complex use cases (e.g., time limiting of the use, an obligation to delete data after use, logging or notifying about data use, etc.) [23]. Some policies are, at present, only executable on a contractual and juridical level as technical enforcement is not mature enough, or a combination of both measures is needed.
The technical enforcement of the policies is implemented as the capacity of the IDS Connector component to run a Data App – a certified application that can perform predefined operations on the data received from the Data Provider – inside the Data Consumer’s IDS Connector. Using this technique, it is possible to guarantee that unprocessed data never leaves the internal storage of the IDS Connector.
It has been shown that the Context Broker could play the role of a Data App in the data exchange managed by IDS Connectors. IDS Connectors on both sides of the data exchange would provide the necessary protection, whereas Context Broker would guarantee the semantic interoperability capabilities [18]. The original approach was later completed with a more scalable execution environment and additional security components [24]. A prototype combining IDS-compliant and FIWARE-provided components in the data exchange infrastructure was developed by the Engineering Ingegneria Informatica [25] and demonstrated in a Horizon 2020 project, PLATOON [26].
However, despite the protection of the IDS Connector, the data may still be vulnerable to so-called “Side Channel Attacks,” where the attacker can infer the protected data contents from specially crafted interactions with the computer components. A possible solution to this problem is the Trusted Hardware Enclave inside the main processing unit that only the predefined process could access, in our case, the IDS Connector. However, it has been shown that even this solution can be exploited by side-channel attacks. So, a cryptographic method called Oblivious Computing has been proposed to overcome this potential data exposure [27,28].
Enhancing the basic flow of data from the Data Provider to one or more Data Consumers, further ways of data exploitation are envisioned: Federated Learning, Secure Multi-Party Computation, and privacy-preserving techniques (homomorphic encryption, etc.) [29]. These techniques build upon the principle that the data does not need to leave the Data Provider to be analyzed. Instead, if there are multiple Data Providers, the algorithm is trained on each Data Provider’s part of data inside their infrastructure and then adjusted from learning on data from other Data Providers. Some algorithms can be decoupled to perform selected steps (preferably the first and the last) inside the Data Provider infrastructure. This approach is called Split Learning. According to the IDS architecture, these algorithms, or part of them, are built as Data Apps [30].
Data sharing principles of Data Spaces can also be implemented in scenarios where no specific data usage limitation is needed, like in publishing open data. Technologies otherwise used to protect and enforce the data usage policies can still be used. Still, the only policy enforced would be the simplest one: that everybody can access the data without limitations. This way, the security measures built into the technological components can protect the Data Space from malicious data alteration or deletion. Other infrastructure features like federated computing and Data Apps in general can also be utilized.
Currently, the Data Spaces components are in the early development stages and typically require expert knowledge to install and configure properly. To attract a wider audience to participate in data exchange through Data Spaces (e.g., Small and Medium Enterprises), the usability of these tools will need to be improved so that installation and configuration would only be as demanding as in an ordinary office application.
Besides the technologies that enable machines to communicate and transport the data between them, it is necessary for them and for people to have a common understanding of the data that is being shared. To achieve this, data models are being developed, which organize the data about real world entities, encompassing as many facets of the real world entity as possible or necessary. Like the software used in the data-sharing process, the data models are published openly.
A broader and more conceptual notion than data models are ontologies that are used to describe knowledge in terms of concepts and relations among them and are often defined inside a particular field of knowledge. Interesting efforts have been made to enable interoperability at the ontology level by formalizing the ontology-building process with a common set of principles and basic or reference ontologies as foundations. In the biosciences domain, the Open Biological and Biomedical Ontologies (OBO) Foundry has been developed [31]. Another known foundation is Dublin Core [32].
In the World Wide Web domain, the Semantic Web emerged [33]. It aims to specify additional notation elements in HTML for the machines to infer the semantics of data and their relationships (linked data) from the web pages themselves. Several well-known components have been developed that support this concept. The eXtensible Markup Language (XML) was defined earlier and allows to define custom tags that can supplement additional meaning to the document contents [34].
Resource Description Framework (RDF) is a model used to represent the contents by encoding it into statement-like structures (subject-predicate-object) called triplets [35]. This allows for any software to discern a meaning regardless of the particular data model that the software is based on. An ontology can be expressed as a set of statements, in this case RDF triples, that describe a given subject and relationships among its inner concepts. RDF can represent a graph structure where subjects and objects represent nodes in a graph and the predicates represent directed links among nodes. Such structure is called RDF graph. RDF Schema (RDFS) is an extension to RDF for describing classes and their relations and serves as a language to express data models [36]. Web Ontology Language (OWL) is a language for defining and instantiating Web ontologies and is more comprehensive than RDFS in expressing relations among classes and their other characteristics [37]. SPARQL is a query language for searching through the semantic web or databases containing triples [38]. Besides XML as the initial RDF serialization format, the JavaScript Object Notation-Linked Data (JSON-LD) [39] serialization has been developed, providing a more concise serialization of objects and their relationships compared to XML.
In order to facilitate finding particular data on the World Wide Web, special websites emerged that list available data and the associated metadata, called data catalogs. Several tools exist to define data catalogs. CKAN is a tool used to publish open-access data, predominantly by public institutions [40]. It allows for uploading or linking to datasets, which can then be consumed by downloading the file from the CKAN server or from the provided link. Using the DataStore extension, uploading the dataset to a relational database connected to the CKAN server is also possible. This extension allows the user to define a data dictionary describing individual data elements (e.g., columns in a table), which could be regarded as a data model. The data dictionary is also the control mechanism because new data can only be ingested if compliant with this dictionary. This extension is not mandatory, however. The Data Catalog Vocabulary (DCAT) is an RDF vocabulary designed to facilitate interoperability between data catalogs published on the Web [41]. It provides RDF classes and properties to allow datasets and data services to be described and included in a catalog. However, it defines the metadata to the level of datasets only; the individual data points (features) are not covered.
In the Telecommunications and Internet of Things domain, the research in context management (automatic alignment of data about the same subject from different sources) led to the standardization of Next Generation Systems Interface (NGSI) by Open Mobile Alliance and, in newer versions (extended with linked data capability, hence NGSI-LD), by ETSI and its Context Information Management (CIM) committee [42]. The FIWARE Foundation led the development of NGSI-LD under the European Commission’s support. It is now used in several projects and specifications (Connected Europe Facility, Living-in.eu project, IoT Big Data Framework Architecture by GSM Association, etc.). It has been proposed for use in the GAIA-X initiative [43]. The NGSI-LD API uses JSON-LD as a main serialization format, so the NGSI-LD data payloads are serialized as JSON-LD [44].
The ETSI standard GS CIM 006 defines NGSI-LD information model as a graph similar to an RDF graph, with a practical difference that in NGSI-LD, not only the entities (vertices) but also the relationships (edges, arcs) can have properties, which means that an RDF graph can be translated to an NGSI-LD one.
The use of data models differs in presented technologies. In the IDSA case, the data model is optional at the time of data provisioning, and a special component to host the model (called Vocabulary Provider) is needed [16]. In the FIWARE case, the data model is mandatory and has to be known in advance. The central component (Context Broker) needs the data model in advance, before the data contents are provided, so the Context Broker ensures that the data provided conform to the data model. Both the data and the model are structured according to the NGSI-LD standard and they are hosted in the Context Broker, so no additional component is needed [45]. In both the IDSA and the FIWARE cases, the model has to be known at the time of data consumption.
To better support the use of NGSI standard, FIWARE, and TM Forum have established, together with Indian Urban Data Exchange (IUDX) and Open and Agile Smart Cities (OASC), the Smart Data Models initiative [46], which aims to engage the community to develop and publish data models emanating from real use cases of data exchange. The process is agile and open and based on established standards.
Loebe [47] (Section 2.4) proposes a fundamental set of elements sufficient to express any ontology, consisting of categories and relations. NGSI-LD defines a similar concept framework where entities (acting as categories) have elementary properties describing them and properties describing relations with other entities.
Data models are a constituent part of Digital Twins (DT), which are comprehensive digital models of (physical or intangible) real-world objects. They add the real-time data to the data model, and so are an accurate digital representation of their physical or otherwise existing counterpart – the entity they describe. They were initially developed in the manufacturing industry to represent the products and the whole manufacturing processes [48]. The DT comprises both the real-world object’s structure and the data describing its state in the real or near-real time. This allows for an analysis of the real-world object’s current state and simulation and prediction of its future state. ETSI advocates the use of NGSI-LD property graphs as holistic Digital Twins [49]. They propose several use cases where the NGSI-LD specification is mature enough for use in DTs and provide recommendations for further NGSI-LD specification evolution. Recent research is demonstrating a feasibility of building complex DTs using the NGSI-LD specification [50].
In the recent years, a major breakthrough in the field of Artificial Intelligence was achieved with the development of Large Language Models (LLM) that are very successful at understanding and following instructions, perform various linguistic tasks (translation, summarization, paraphrasing, etc.), assisting developers at programming and many others. However, they struggle at performing complex reasoning tasks and in continuous improvement of their knowledge, among other problems. The current research proposes agentic systems to alleviate these problems. Among others, an Ontology Matching agentic system was proposed [51]. An important type of agents are memory agents that can manage the knowledge retained from the history of performed tasks and also the information obtained during these tasks from outside of these systems, called external knowledge [52]. An important source of external knowledge can be DT [53] and we are confident that also information about our use case could be exploited in such agentic systems as an external knowledge through the data models that we propose.
The main goal of this work is to present an automatic creation of a NGSI-LD data model from an existing RDF ontology. As no tool capable of authoring a NGSI-LD data model from scratch is known to us and a manual process is always error prone, we decided to use a tool (Protégé) to create a RDF ontology and then perform an automatic generation of a NGSI-LD data model.
There exists already a tool, similar to our proposal: SDMX to JSON-LD Parser [54]. However, it is only capable of transforming the data models compliant with STAT-DCAT-AP 1.0.1 specification. Consequently, it is not applicable to our case. Our approach also makes use of the SPARQL Property Path queries, whereas their tool uses different algorithm.
In the Materials and Methods section, we describe the necessary tools used in our work and the algorithm structure that has been developed. In the Results section, we demonstrate the products developed and the final result of published fictitious data. In the Discussion section, we present the current study’s limitations and envision possible directions for future work.
2. Materials and Methods
The set of tools used in this work consists of commonly used software systems and applications. The source ontology was developed in the Protégé tool, version 5.6.3 [55]. Next, the translation tool was developed in Python, version 3.10, using the package rdflib, version 7.0.0, and relied on the package pysmartdatamodels1, version 0.6.3 [56]. After the NGSI-LD data model was constructed, it was tested on the Context Broker that FIWARE recommends as a reference implementation, which is Orion-LD, version 1.4.0 [57].
2.1. Data Model for ACDSi Measurements
We propose a data model concerning the subset of the ACDSi data, containing the features assessed as important in the study [58]. These features are part of the EUROFIT [59] and SLOfit [60] test batteries.
The ontology describing the ACDSi data was conceived using the Protégé tool [55]. It consists of one root class named ACDSiMeasurement and two subordinate classes, EUROFIT and SLOfit, each containing measurements from their respective test batteries. The overall structure was conceived similarly to the Smart Applications REFerence ontology (SAREF) ontologies standardized by ETSI [61]. All the numerical data properties (features) were constrained to xsd:decimal datatype, except for the Age, which is assumed to be xsd:integer.
Next, we developed a tool that uses information from this ontology and creates a NGSI-LD data model in a format suitable for publication on the Smart Data Models repository. The publication process as described on the Smart Data Models web page [46] requires submitting five documents, from which three can be generated from the ontology (schema.json, notes_context.jsonld, and example-normalized.jsonld), and the rest are filled manually. As the ETSI standard GS CIM 006 explains, the NGSI-LD information model follows the graph structure of RDF, so it is feasible to translate the RDF graph to the NGSI-LD graph.
Initially, the RDF ontology was read into a set of triples using the rdflib package. The triples consist of three elements, subject, predicate, and object, in that order. The set of triples can be queried against using the rdflib triples() function with a triple pattern as an argument. In the pattern, any triple element can be unconstrained using the keyword “None”, fixed with a constant, or, for the predicate, constrained with a path pattern equivalent to the SPARQL 1.1 Property path operators [62].
The algorithm accepts an identification of the root class from the RDF ontology for which the data model will be generated as a parameter of type Internationalized Resource Identifier (IRI). This class constitutes the entity in the NGSI-LD terms. In our case, the root class is acdsi:ACDSiMeasurement and is defined as follows (in the Turtle syntax):
- acdsi:ACDSiMeasurement rdf:type owl:Class ;
- rdfs:comment “A set of measurements in an ACDSi campaign pertaining to a single person.”@en ;
- rdfs:label “ACDSi Measurement”@en .
Each line represents a triple and consists of three elements: subject, predicate, and object. Lines ending with semicolon are continued in the next line and all the following lines share the same subject with the first line, up to the line that ends with a dot. The first line declares that acdsi:ACDSiMeasurement is a class, the second line defines a class description and the third line defines a label, both in English language.
The first step in the translation process is to find all the data properties of the root class (these are defined on the “Data properties” tab in the Protégé editor). They are defined on the subordinate classes to the root class and are included in the NGSI-LD data model as properties of the entity. For example, acdsi:flamingoBalanceTest is one of the data properties and is defined as follows:
- acdsi:flamingoBalanceTest rdf:type owl:DatatypeProperty ;
- rdfs:range xsd:decimal ;
- rdfs:comment “Flamingo Balance Test description. Units: ‘second’“@en ;
- rdfs:label “Flamingo Balance Test”@en .
Again, the first line declares that acdsi:flamingoBalanceTest is a data property, the second line defines its data type, and the following two lines define the description and the label. This data property is associated with the root class via an intermediate class acdsi:EUROFIT and is defined as one of the properties of this intermediate class. Additionally, its data type is defined as a restriction:
- acdsi:EUROFIT rdf:type owl:Class ;
- rdfs:subClassOf acdsi:ACDSiMeasurement ,
- [ rdf:type owl:Restriction ;
- owl:onProperty acdsi:flamingoBalanceTest ;
- owl:allValuesFrom xsd:decimal
- ] ,
- ...
The ontology ACDSi is shown in Figure 1 as presented in the Protégé GUI. The left side shows the class hierarchy, where the base class ACDSi Measurement is divided into four subordinate classes: EUROFIT, SLOfit, Anthropometry, and Person. The right-hand side lists the EUROFIT class’s annotations on the top and its subordinate class structure at the bottom, which consists of the data properties and their restricted data types. The OntoGraf diagram depicting all four classes with their annotations and data properties is shown in Figure 2.
The data properties, which are subordinate classes to the root class, are found using the eval_path() function with a triple pattern as an argument. In the triple pattern, the object is fixed to the root class, and the path pattern consists of one or more concatenated rdfs:subClassOf predicates. The concatenation of predicates into variable-length paths is denoted as a combination of asterisk operator and the rdflib.paths.OneOrMore quantifier:
- rdflib.paths.eval_path(self.g, (None, RDFS.subClassOf * rdflib.paths.OneOrMore, self.objectRoot))
For example, the acdsi:flamingoBalanceTest data property is found because it is a subclass of acdsi:EUROFIT, which is in turn a subclass of the root class acdsi:ACDSiMeasurement. This method is flexible as such data property would be also found if it were nested deeper in the class hierarchy. Note that the intermediate classes (e.g. acdsi:EUROFIT) are not included in the results of this query. So they are not created as properties in NGSI-LD.
Next, the data properties connected to those classes are found as objects connected with the owl:onProperty predicate to the classes as subjects (see the acdsi:EUROFIT definition above):
- self.g.triples((l [2], OWL.onProperty, None))
Their data types are found through the restriction predicates owl:allValuesFrom or owl:someValuesFrom linked to the class as the subject. The allowed alternative predicates are denoted as separated with vertical bar:
- self.g.triples((l [2], (OWL.allValuesFrom | OWL.someValuesFrom), None))
If such a predicate is not found, the data type is found on the triple with rdfs:range predicate linked to the data property as the subject (see the acdsi:flamingoBalanceTest definition above):
- self.g.triples((pr [0][2], RDFS.range, None))
The root class’s object properties are mapped to NGSI-LD references. They are found as subclasses of the root class:
- rdflib.paths.eval_path(self.g, (self.objectRoot, RDFS.subClassOf * rdflib.paths.OneOrMore, None))
The object properties are found through the owl:onProperty or owl:maxCardinality predicate linked to the object property as the subject:
- self.g.triples((l [2], OWL.onProperty | OWL.maxCardinality, None))
There may be more than one object linked to an object property as the subject. They are found by searching through all the paths of various lengths containing the predicates owl:allValuesFrom, owl:unionOf, rdf:first, rdf:rest, or owl:maxCardinality:
- rdflib.paths.eval_path(self.g, (pr [0][0], (OWL.allValuesFrom | OWL.unionOf | RDF.first | RDF.rest | OWL.maxCardinality) * rdflib.paths.OneOrMore, None))
If the object found is of type URI, it is transformed into an NGSI-LD reference. If it is of the Literal type, it is transformed into a data property.
For the classes that have an annotation rdfs:isDefinedBy among their superclasses, this annotation points to another ontology. This ontology is then parsed similarly to the primary one, and the superclass’s data properties are included in the final data properties list.
All the data properties’ names, descriptions, and data types and references and their descriptions are then put into a flat list. They are then serialized into the allOf.properties field of the generated schema.json file as a dictionary structure. All the IRIs of the root class and all the data properties are written to the notes_context.jsonld file.
The third file, example-normalized.jsonld, is generated using the ngsi_ld_example_generator_str() function from the pysmartdatamodels package. The function takes the generated schema.json file contents and constructs a fictitious data structure conformant to the specification.
As the model had not yet been published on the smartdatamodels.org website, our local deployment had to provide the schema.json file as a locally served file. Additionally, a local context.jsonld file was needed. It was generated from the classes and data properties lists from the source RDF ontology in parallel and from the same data structure as the schema.json file.
The transformation output verification was performed on the SAREF ontologies published by ETSI. Some of these ontologies have been transformed and published on the smartdatamodels.org website in the past. We compared the output files from our transformation of selected ontologies (e.g., https://saref.etsi.org/saref4bldg/v1.1.2/) with the published corresponding Smart Data Models files (e.g., https://github.com/smart-data-models/dataModel.S4BLDG).
After all the files were generated and the necessary files published locally, the generated example payload was uploaded successfully to a locally deployed Orion-LD Context Broker using the POST command to the “/ngsi-ld/v1/entities” endpoint.
3. Results
Features that emerged as important in our previous studies about the ACDSi data and were modeled as data properties in the RDF ontology are listed in Table 1, along with their intermediate classes, data types, NGSI-LD data types after conversion, and recommended measurement units. Measurement unit “one” denotes the number of repetitions in the given time, conforming to the UNECE/CEFACT Trade Facilitation Recommendation No.20 [63]. Currently, no feature has a data type that would require the NGSI-LD date format.
The generated schema.json file is shown in Figure 3. Data properties of all ACDSi Measurement subclasses are converted to the properties inside the schema structure.
After the schema.json and the corresponding context.jsonld files were uploaded to the local web server, the fictitious data generated in the process were uploaded to the local Orion-LD Context Broker. Figure 4 shows the web browser with the query result obtained from this Context Broker. Querying using a common web browser is possible because no security measures and multitenancy features of the Context Broker were implemented in this simple deployment scenario.
In data sharing, all the participants must have a common understanding, in what measurement units the data is provided. Ontologies often do not provide any proposal or even constraint in this sense. The specification is deferred to the instantiation phase, where the provider can specify the units. In the SAREF ontologies, the measurement values that come from periodic measurements are specified as saref:Measurement object (and are object properties of classes) and the measurement unit can be given using the saref:isMeasuredIn predicate and saref:UnitOfMeasure object. Units are then specified using one of the known measurement unit ontologies [64]. The SAREF ontologies specify also other data about the given object that do not occur periodically. These are specified as data properties. In the NGSI-LD data model, the “unitCode” property is already defined in the API and can be specified together with the data value. The Smart Data Models initiative proposes to use the unit codes from the UNECE/CEFACT Trade Facilitation Recommendation No.20 [63]. The unit can also be specified as part of the description attribute of the properties in the schema.json file. In our case, we decided to model a single instance of all measurements for one person as one root object and so modeled the measured values as data properties. For simplicity, we did not model the measurement units similarly to the saref:Measurement object and proposed the expected units already in the data properties’ descriptions in the RDF ontology so that they are transferred unchanged to the NGSI-LD data model during translation. This implies that in the current version, the data provider has to ensure that data is published according to the proposed measurement units. In the future, we may improve the ACDSi RDF ontology to also provide capability similar to the saref:Measurement object.
The produced files are published openly. The RDF ontology ACDSi.ttl can be found in the repository https://github.com/fdrobnic/ontologies and the conversion algorithm including the generated NGSI-LD ACDSi data model files in the repository https://github.com/fdrobnic/rdf2sdm.
4. Discussion
As a possible measure to remediate the scarcity of high-quality data in the field of studies about physical development in children and youth, we engage the technologies originating in the Semantic Interoperability and Data Spaces initiatives. We developed an ontology to represent such data in the RDF format and conceived an algorithm and tool to generate an equivalent data model in the NGSI-LD format automatically. We successfully verified the NGSI-LD data model by installing the necessary software components, including the generated data model, and uploading fictitious data to this installation.
The developed ontology consists only of the features identified as most important from the ACDSi data in the previous machine learning studies. It is possible to improve this ontology further, which would necessitate the engagement of a broader community of experts in physical development in children and youth.
The conversion algorithm from RDF ontology to NGSI-LD data model can transform the SAREF ontologies and our relatively simple data model. It will be enhanced to transform a more diverse set of ontology variants in the future.
The NGSI-LD data model cannot be published formally on the Smart Data Models repository yet because the model is not currently being used in real data exchanges. In any case, the data models prepared with our tool can be used in the data sharing scenarios provided that they are published openly so that all the participants in the data sharing can access them and align their data and algorithms to them.
Author Contributions
Conceptualization, F.D. and G.S.; methodology, F.D.; software, F.D.; validation, G.S., G.J., and A.K.; formal analysis, F.D.; investigation, F.D. and G.S.; resources, F.D. and G.S.; data curation, F.D. and G.S.; writing—original draft preparation, F.D.; writing—review and editing, A.K. and M.P.; visualization, F.D.; supervision, A.K., G.J., and M.P.; project administration, A.K.; funding acquisition, A.K. and M.P. All authors have read and agreed to the published version of the manuscript.
Funding
This study was partly supported by the Slovenian Research and Innovation Agency within the research program P2-0425, “Decentralized solutions for the digitalization of industry and smart cities and communities”.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- ‘NATIONAL HEALTH AND NUTRITION EXAMINATION SURVEY III, Body Measurements (Anthropometry)’. Westat, Oct. 01, 1988. Accessed: June 23, 2018. [Online]. Available: https://www.cdc.gov/nchs/data/nhanes/nhanes3/cdrom/nchs/manuals/anthro.pdf.
- N. J. Wijnstok, T. Hoekstra, W. Van Mechelen, H. C. Kemper, and J. W. Twisk, ‘Cohort Profile: The Amsterdam Growth and Health Longitudinal Study’, Int. J. Epidemiol., vol. 42, no. 2, pp. 422–429, Apr. 2013. [CrossRef]
- G. Jurak, M. Kovač, and G. Starc, ‘The ACDSi 2013–The Analysis of Children’s Development in Slovenia 2013: Study protocol’, Anthropol. Noteb., vol. 19, pp. 123–143, Dec. 2013.
- G. Starc et al., ‘The ACDSi 2014–a decennial study on adolescents’ somatic, motor, psycho-social development and healthy lifestyle: Study protocol’, Anthropol. Noteb., vol. 21, pp. 107–123, Dec. 2015.
- T. J. Cole, ‘Establishing a standard definition for child overweight and obesity worldwide: international survey’, BMJ, vol. 320, no. 7244, pp. 1240–1240, May 2000. [CrossRef]
- T. J. Cole, K. M. Flegal, D. Nicholls, and A. A. Jackson, ‘Body mass index cut offs to define thinness in children and adolescents: international survey’, BMJ, vol. 335, no. 7612, p. 194, July 2007. [CrossRef]
- M. Jarke, B. Otto, and S. Ram, ‘Data Sovereignty and Data Space Ecosystems’, Bus. Inf. Syst. Eng., vol. 61, no. 5, pp. 549–550, Oct. 2019. [CrossRef]
- B. Otto, ‘A federated infrastructure for European data spaces’, Commun. ACM, vol. 65, no. 4, pp. 44–45, Mar. 2022. [CrossRef]
- E. Curry, S. Scerri, and T. Tuikka, Eds, Data Spaces: Design, Deployment and Future Directions. Cham: Springer, 2022.
- S. Dalmolen, H. J. M. Bastiaansen, M. Kollenstart, and M. Punter, ‘Infrastructural sovereignty over agreement and transaction data (‘metadata’) in an open network-model for multilateral sharing of sensitive data’, in 40th International Conference on Information Systems, ICIS 2019, Association for Information Systems, Jan. 2020. Accessed: Feb. 27, 2023. [Online]. Available: https://research.utwente.nl/en/publications/infrastructural-sovereignty-over-agreement-and-transaction-data-m.
- B. Otto, M. ten Hompel, and S. Wrobel, Eds, Designing Data Spaces: The Ecosystem Approach to Competitive Advantage. Cham: Springer International Publishing, 2022. [CrossRef]
- ‘European Health Data Space - European Commission’. Accessed: Mar. 01, 2025. [Online]. Available: https://health.ec.europa.eu/ehealth-digital-health-and-care/european-health-data-space_en.
- ‘International Data Spaces Association’, International Data Spaces Association. [Online]. Available: https://internationaldataspaces.org/.
- Steinbuss, Sebastian, ‘IDSA Rule Book’, Zenodo, Dec. 2020. [CrossRef]
- Otto, B., Steinbuss, S., Teuscher, A., and Lohmann, S., ‘IDS Reference Architecture Model’, Zenodo, Apr. 2019. [CrossRef]
- IDS RAM 4. (2022). International Data Spaces Association. Accessed: Mar. 29, 2023. [Online]. Available: https://github.com/International-Data-Spaces-Association/IDS-RAM_4_0.
- ‘FIWARE’. Accessed: June 06, 2023. [Online]. Available: https://www.fiware.org/.
- Á. Alonso, A. Pozo, J. Cantera, F. de la Vega, and J. Hierro, ‘Industrial Data Space Architecture Implementation Using FIWARE’, Sensors, vol. 18, no. 7, p. 2226, July 2018. [CrossRef]
- ‘Developers Catalogue – FIWARE’. Accessed: Mar. 19, 2023. [Online]. Available: https://www.fiware.org/catalogue/.
- ‘Gaia-X Framework’. Accessed: Mar. 19, 2023. [Online]. Available: https://docs.gaia-x.eu/framework/.
- ‘Big Data Value Association’. Accessed: June 06, 2023. [Online]. Available: https://www.bdva.eu/.
- ‘Data Spaces Business Alliance’. [Online]. Available: https://data-spaces-business-alliance.eu/.
- A. Eitel et al., ‘Usage Control in the International Data Spaces’, Zenodo, Mar. 2021. [CrossRef]
- A. Munoz-Arcentales, S. López-Pernas, A. Pozo, Á. Alonso, J. Salvachúa, and G. Huecas, ‘Data Usage and Access Control in Industrial Data Spaces: Implementation Using FIWARE’, Sustainability, vol. 12, no. 9, p. 3885, May 2020. [CrossRef]
- Engineering, FIWARE TRUE Connector. (2023). Accessed: June 06, 2023. [Online]. Available: https://github.com/Engineering-Research-and-Development/fiware-true-connector.
- Martino Maggio and Francesco Arigliano, ‘Deliverable D2.5 - PLATOON Reference Architecture (v2)’, ENG, Italy, Mar. 2021. Accessed: June 06, 2023. [Online]. Available: https://platoon-project.eu/wp-content/uploads/2023/02/D2.5-PLATOON-Reference-Architecture-v2.pdf.
- A. Dave, C. Leung, R. A. Popa, J. E. Gonzalez, and I. Stoica, ‘Oblivious coopetitive analytics using hardware enclaves’, in Proceedings of the Fifteenth European Conference on Computer Systems, Heraklion Greece: ACM, Apr. 2020, pp. 1–17. [CrossRef]
- A. Law et al., ‘Secure Collaborative Training and Inference for XGBoost’, 2020. [CrossRef]
- ‘Towards a Federation of AI Data Spaces’, NL AI Coallition, Nov. 2021. Accessed: Mar. 24, 2023. [Online]. Available: https://nlaic.com/wp-content/uploads/2022/02/Towards-a-Federation-of-AI-Data-Spaces.pdf.
- O. Arnon et al., ‘D4.2 Report on the implementation of deep learning algorithms on distributed frameworks’, 2022, [Online]. Available: https://www.trusts-data.eu/wp-content/uploads/2022/12/D4.2_Report-on-the-implementation-of-deep-learning-algorithms-on-distributed-frameworks.pdf.
- B. Smith, A. Kumar, and T. Bittner, Basic Formal Ontology for bioinformatics. IFOMIS Reports, 2005.
- ‘Dublin Core’. Accessed: Mar. 19, 2023. [Online]. Available: https://www.dublincore.org/resources/glossary/dublin_core/.
- T. Berners-Lee, J. Hendler, and O. Lassila, ‘The Semantic Web’, Sci. Am., vol. 284, no. 5, pp. 34–43, 2001.
- ‘XML Core Working Group Public Page’. Accessed: Feb. 26, 2025. [Online]. Available: https://www.w3.org/XML/Core/.
- ‘RDF - Semantic Web Standards’. Accessed: Feb. 24, 2025. [Online]. Available: https://www.w3.org/RDF/.
- ‘RDFS - W3C Wiki’. Accessed: Feb. 26, 2025. [Online]. Available: https://www.w3.org/wiki/RDFS.
- ‘OWL Web Ontology Language Guide’. Accessed: Feb. 26, 2025. [Online]. Available: https://www.w3.org/TR/owl-guide/.
- ‘SPARQL 1.1 Query Language’. Accessed: Feb. 26, 2025. [Online]. Available: https://www.w3.org/TR/sparql11-query/.
- ‘JSON-LD 1.1’. Accessed: Feb. 27, 2025. [Online]. Available: https://www.w3.org/TR/json-ld11/.
- ‘CKAN’. Accessed: Jan. 15, 2024. [Online]. Available: https://ckan.org/.
- ‘Data Catalog Vocabulary (DCAT)’. [Online]. Available: https://www.w3.org/TR/vocab-dcat-2/.
- ‘CIM’, ETSI. Accessed: Mar. 20, 2023. [Online]. Available: https://www.etsi.org/committee/cim.
- ‘GAIA-X’. Accessed: June 06, 2023. [Online]. Available: https://gaia-x.eu/.
- ‘GS CIM 006 - V1.2.1 - Context Information Management (CIM); NGSI-LD Information Model’. ETSI, June 2023. Accessed: Nov. 21, 2023. [Online]. Available: https://www.etsi.org/deliver/etsi_gs/CIM/001_099/006/01.02.01_60/gs_cim006v010201p.pdf.
- ‘Understanding @context - NGSI-LD Smart Farm Tutorials’. Accessed: Feb. 27, 2025. [Online]. Available: https://ngsi-ld-tutorials.readthedocs.io/en/latest/understanding-%40context.html.
- ‘Smart Data Models’. Accessed: June 07, 2023. [Online]. Available: https://smartdatamodels.org/.
- F. Loebe, H. Herre, and M. Grüninger, ‘Ontological Semantics’. 2015. [Online]. Available: https://nbn-resolving.org/urn:nbn:de:bsz:15-qucosa-166326.
- E. Negri, L. Fumagalli, and M. Macchi, ‘A Review of the Roles of Digital Twin in CPS-based Production Systems’, Procedia Manuf., vol. 11, pp. 939–948, Jan. 2017. [CrossRef]
- ‘GR CIM 017 - V1.1.1 - Context Information Management (CIM); Feasibility of NGSI-LD for Digital Twins’.
- C. Martella, A. Martella, and A. Longo, ‘Enabling secure and trusted digital twin federations with data spaces’, in Proceedings of the Twenty-sixth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Rice University Houston TX USA: ACM, Oct. 2025, pp. 418–427. [CrossRef]
- Z. Qiang, W. Wang, and K. Taylor, ‘Agent-OM: Leveraging LLM Agents for Ontology Matching’, Proc. VLDB Endow., vol. 18, no. 3, pp. 516–529, Nov. 2024. [CrossRef]
- Z. Zhang et al., ‘A Survey on the Memory Mechanism of Large Language Model-based Agents’, ACM Trans. Inf. Syst., vol. 43, no. 6, pp. 1–47, Nov. 2025. [CrossRef]
- A. Zahid, A. Ferraro, A. Petrillo, and F. De Felice, ‘Exploring the Role of Digital Twin and Industrial Metaverse Technologies in Enhancing Occupational Health and Safety in Manufacturing’, Appl. Sci., vol. 15, no. 15, p. 8268, July 2025. [CrossRef]
- ‘IoT Agent-Turtle/sdmx2jsonld at master · flopezag/IoTAgent-Turtle’. Accessed: Jan. 16, 2024. [Online]. Available: https://github.com/flopezag/IoTAgent-Turtle/tree/master/sdmx2jsonld.
- M. A. Musen, ‘The Protégé Project: A Look Back and a Look Forward.’, AI Matters, vol. 1, no. 4, pp. 4–12, June 2015. [CrossRef]
- ‘pysmartdatamodels - PyPI’. [Online]. Available: https://pypi.org/project/pysmartdatamodels/.
- ‘GitHub - FIWARE/context.Orion-LD’. [Online]. Available: https://github.com/fiware/context.orion-ld.
- F. Drobnič, G. Starc, G. Jurak, A. Kos, and M. Pustišek, ‘Explained Learning and Hyperparameter Optimization of Ensemble Estimator on the Bio-Psycho-Social Features of Children and Adolescents’, Electronics, vol. 12, no. 19, p. 4097, Sept. 2023. [CrossRef]
- COUNCIL OF EUROPE, COMMITTEE OF MINISTERS, ‘RECOMMENDATION No. R (87) 9’. COUNCIL OF EUROPE, May 19, 1987. Accessed: Jan. 05, 2023. [Online]. Available: https://rm.coe.int/09000016804f9d3d.
- G. Jurak et al., ‘SLOfit surveillance system of somatic and motor development of children and adolescents: Upgrading the Slovenian Sports Educational Chart’, AUC KINANTHROPOLOGICA, vol. 56, no. 1, pp. 28–40, June 2020. [CrossRef]
- ‘SAREF: the Smart Applications REFerence ontology’. Accessed: Jan. 26, 2024. [Online]. Available: https://saref.etsi.org/core/v3.1.1/.
- ‘rdflib package — rdflib 7.1.3 documentation’. Accessed: Feb. 27, 2025. [Online]. Available: https://rdflib.readthedocs.io/en/stable/apidocs/rdflib.html#rdflib.graph.Graph.triples.
- ‘UNCEFACT-Rec20, UNECE’. Accessed: Feb. 02, 2024. [Online]. Available: https://unece.org/trade/documents/2021/06/uncefact-rec20.
- J. M. Keil and S. Schindler, ‘Comparison and evaluation of ontologies for units of measurement’, Semantic Web, vol. 10, no. 1, pp. 33–51, Dec. 2018. [CrossRef]
| 1 | Note that, at the time of writing, the modifications to this package that were necessary to complete our work are still waiting to be incorporated into the official repository and are provisionally available at: https://github.com/fdrobnic/data-models
|
Figure 1.
The ACDSi ontology in the Protégé tool.
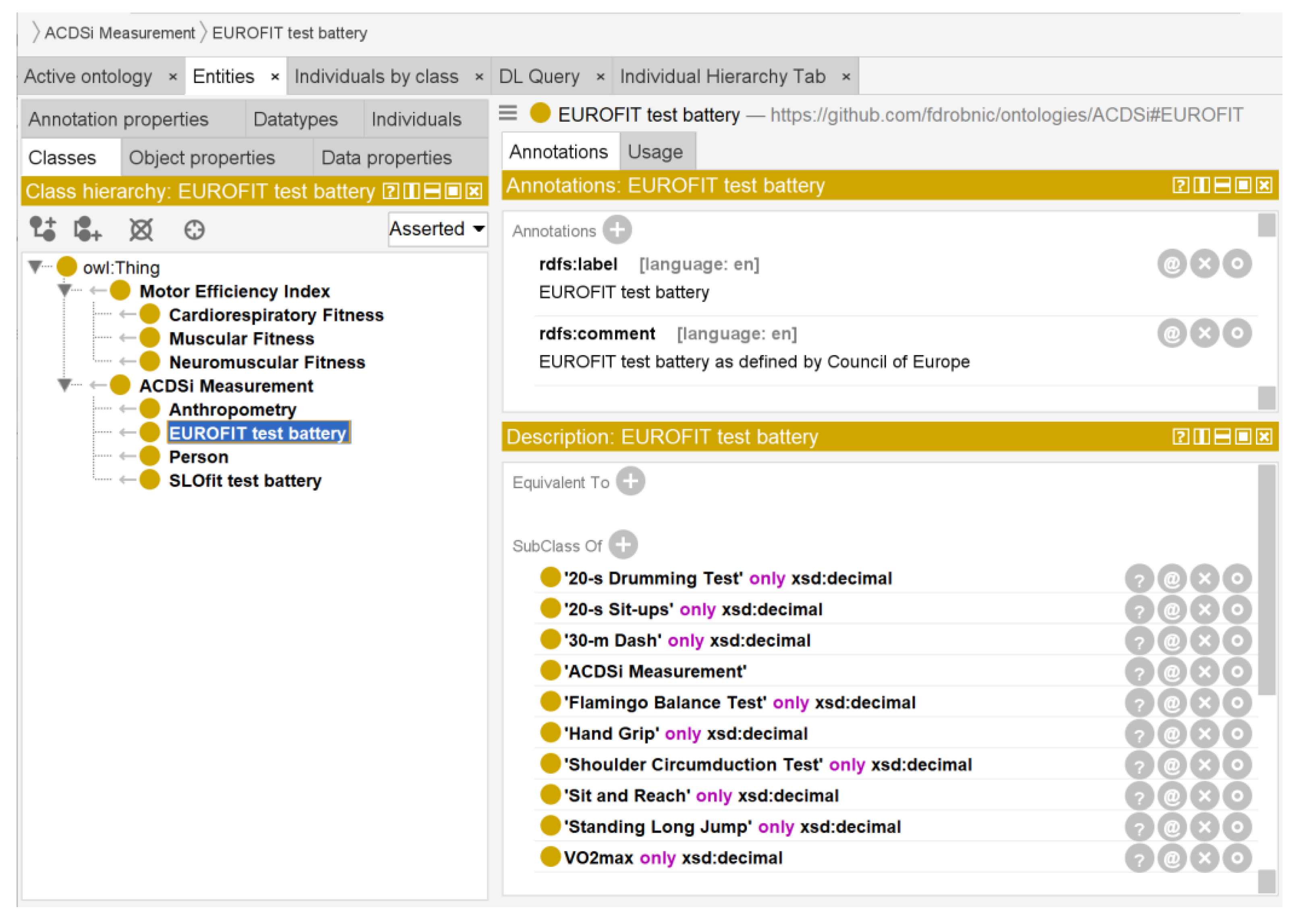
Figure 2.
The ACDSi ontology, as depicted in the OntoGraf window in the Protégé tool.
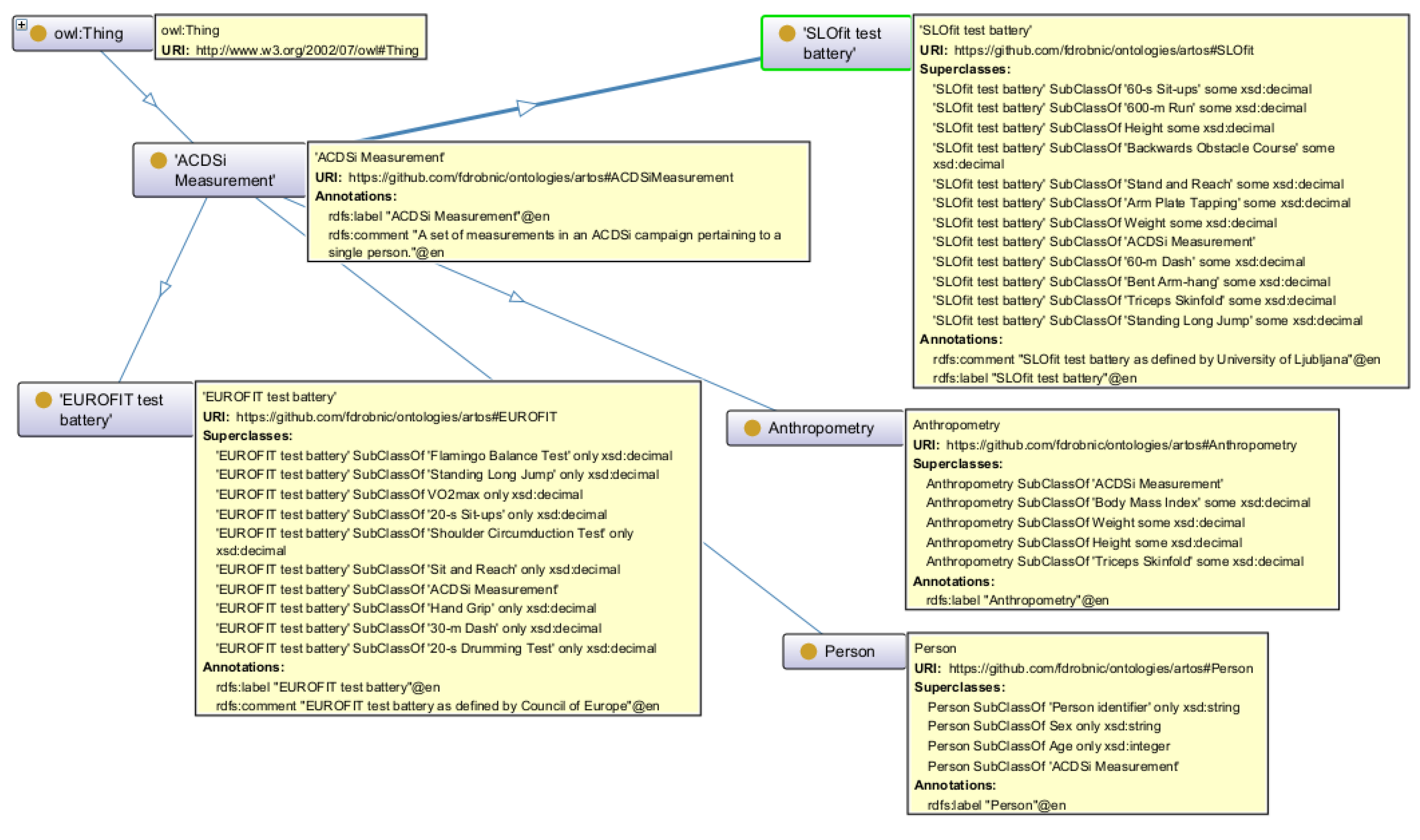
Figure 3.
Generated schema.json file.
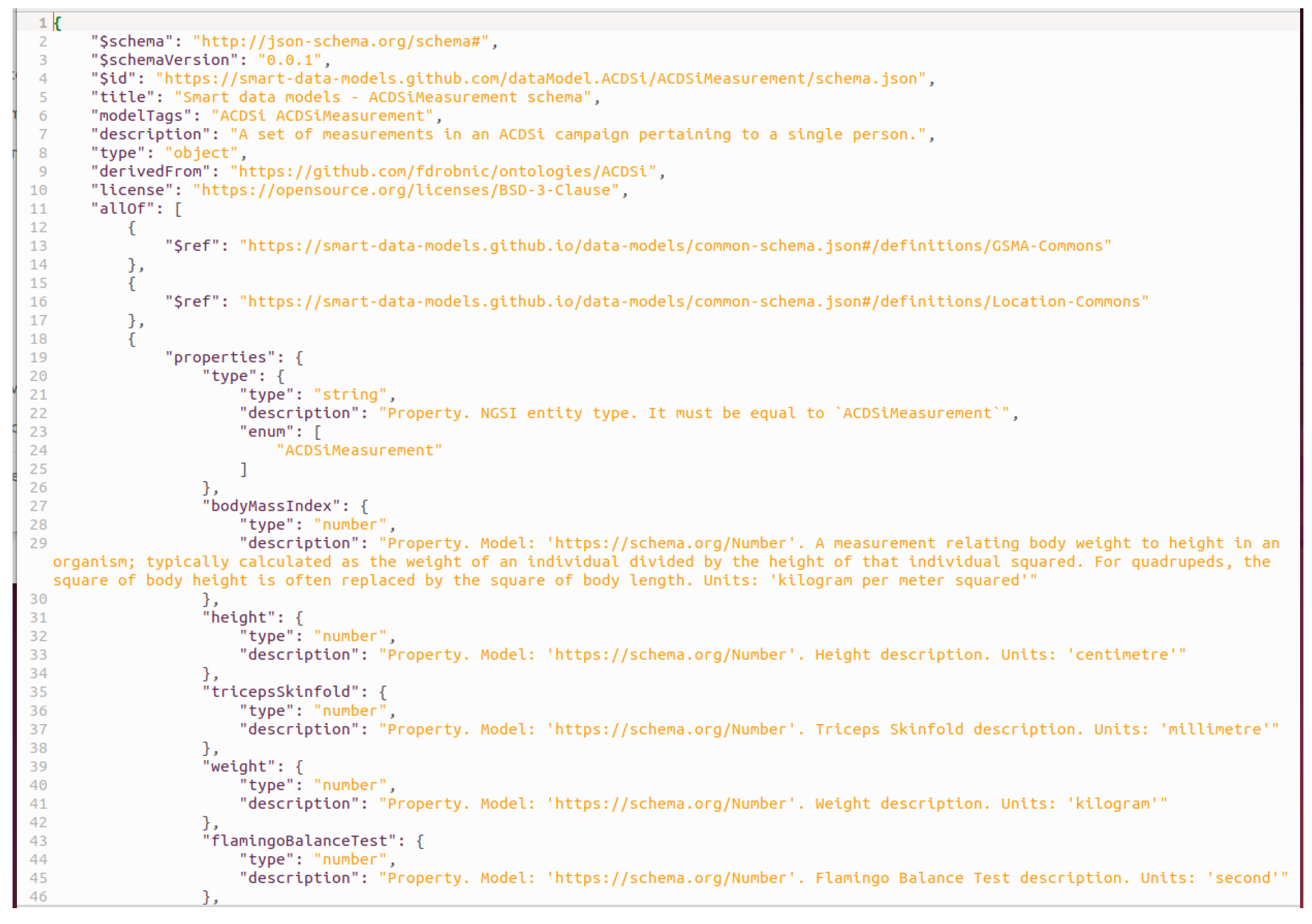
Figure 4.
Query result from the Orion-LD Context broker after the data upload.
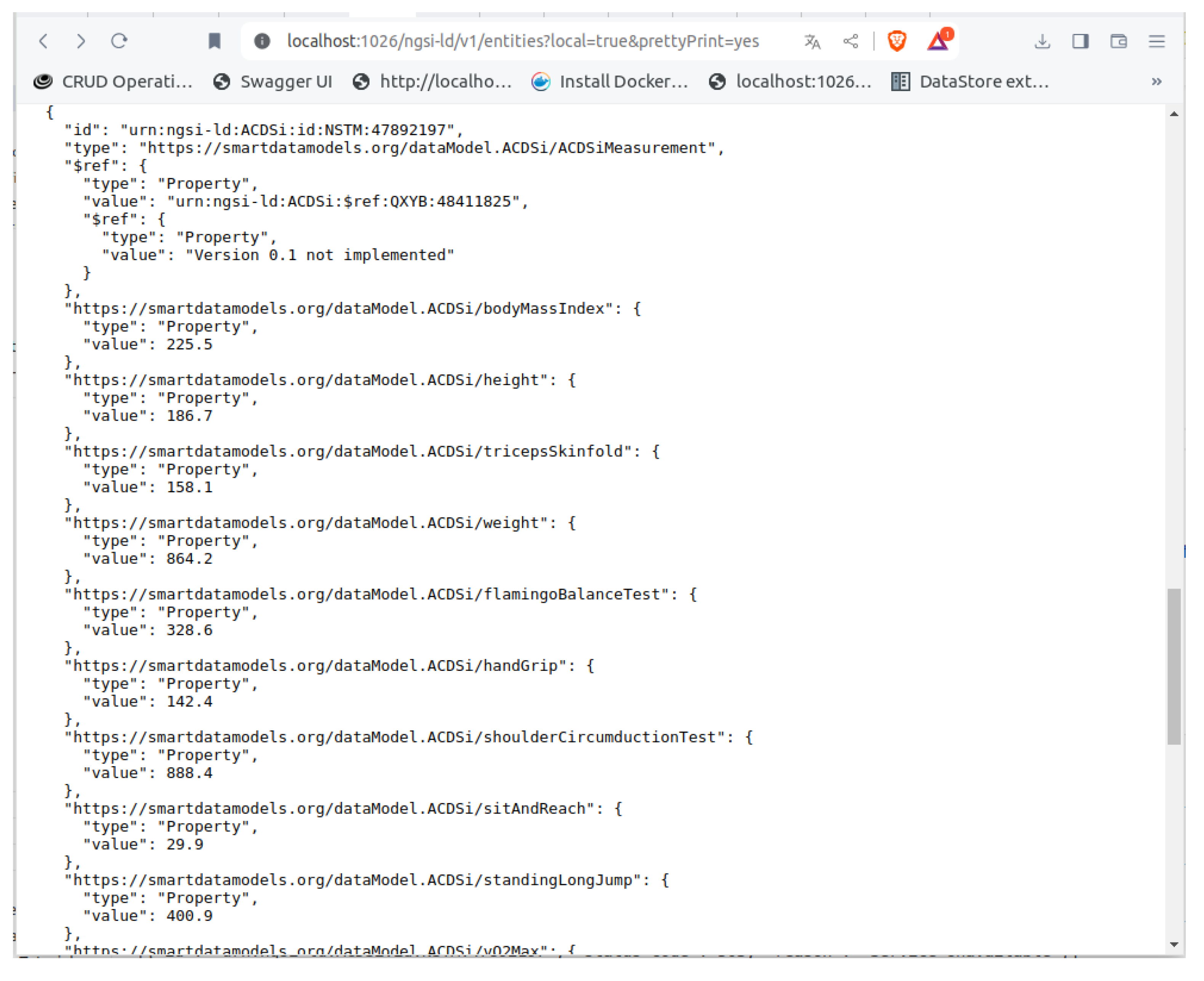

Table 1.
List of features, modeled as data properties, their RDF data types, converted NGSI-LD data types, and recommended measurement units.
Table 1.
List of features, modeled as data properties, their RDF data types, converted NGSI-LD data types, and recommended measurement units.
| Feature | Class | Data type | NGSI-LD data type | Measurement Unit |
|---|---|---|---|---|
| 20-sDrummingTest | EUROFIT | xsd:decimal | number | one |
| 20-sSit-ups | EUROFIT | xsd:decimal | number | one |
| 30-mDash | EUROFIT | xsd:decimal | number | s |
| 60-mDash | SLOfit | xsd:decimal | number | s |
| 60-sSit-ups | SLOfit | xsd:decimal | number | one |
| 600-mRun | SLOfit | xsd:decimal | number | s |
| armPlateTapping | SLOfit | xsd:decimal | number | one |
| backwardsObstacleCourse | SLOfit | xsd:decimal | number | s |
| bentArm-hang | SLOfit | xsd:decimal | number | s |
| flamingoBalanceTest | EUROFIT | xsd:decimal | number | s |
| handgrip | EUROFIT | xsd:decimal | number | kg |
| shoulderCircumductionTest | EUROFIT | xsd:decimal | number | cm |
| sitAndReach | EUROFIT | xsd:decimal | number | cm |
| standAndReach | SLOfit | xsd:decimal | number | cm |
| standingLongJump | EUROFIT, SLOfit | xsd:decimal | number | cm |
| vO2Max | EUROFIT | xsd:decimal | number | ml/kg/min |
| personIdentifier | Person | xsd:string | string | - |
| sex | Person | xsd:string | string | - |
| age | Person | xsd:integer | number | years |
| height | Anthropometry | xsd:decimal | number | cm |
| weight | Anthropometry | xsd:decimal | number | kg |
| tricepsSkinfold | Anthropometry | xsd:decimal | number | mm |
| bodyMassIndex | Anthropometry | xsd:decimal | number | kg/m2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



