
Submitted:
25 November 2025
Posted:
26 November 2025
You are already at the latest version
Abstract
How to quickly identify high-quality frontier topics from massive scientific research data to assist researchers in accurately carrying out scientific research work is of great importance. Traditional analysis methods have some bottlenecks, such as weak cross-domain adaptability, high resource consumption and low efficiency. In order to solve the above problems, a frontier topics mining method via AI-agent is proposed. A generative-verification dual-agents (D-Agents) architecture is innovatively constructed. Firstly, prompt engineering is used to construct generative agent (G-Agent), and the semantic understanding ability of large-scale pre-trained language models is used to realize the automatic generation of candidate frontier topics; Then, the verification agent (V-Agent) is introduced to establish a multi-dimensional evaluation system, and the candidate results are automatically verified from the dimensions of academic novelty, topic accuracy and completeness to identify frontier topics. The effectiveness of the proposed method is verified by constructing three labeled test dataset including computer vision (CV), natural language processing (NLP), and machine learning (ML). The experimental results show that D-Agents can be competent for frontier topics mining tasks in multiple domain at the same time. On three manually labeled datasets: CV-DataSet, NLP-DataSet and ML-DataSet, the accuracy rate of D-Agents exceeds 74% while maintaining the coverage rate of more than 85%. Compared with traditional bibliometric methods, the accuracy and coverage rate of frontier topics mining in three different fields: altitude sickness, recommendation system and oyster reef ecosystem have reached more than 67%. It can effectively alleviate the hallucination problem of G-Agent through the automatic generation and self-verification mechanism in D-Agents, and greatly improve the efficiency of frontier topics mining.
Keywords:
LLMs
; frontier topics
; prompt engineering
; D-Agents
; G-Agent
; V-Agent
; RAG
1. Introduction
The exponential proliferation of scientific and technological information resources necessitates the development of rigorous methodologies for efficiently extracting and identifying frontier topics from massive scholarly datasets. Systematically elucidating the developmental trajectory of disciplines, discerning pivotal research themes, and projecting future trends through comprehensive analysis of these resources constitutes a critical academic task. This analytical framework provides crucial theoretical guidance and practical references for optimizing research prioritization, and enhancing innovation efficiency in scientific exploration [1]. The task of mining frontier topics is essentially to conduct an in-depth analysis of the dynamic evolution of human knowledge system through advanced technology. It can not only provide strong support for scientific research decision-making, but more importantly, it can help human beings continuously expand their cognitive boundaries and accelerate the exploration of unknown areas. Figure 1 shows the general flow chart of traditional frontier topics mining method.
It can be seen from Figure 1 that the traditional frontier topic mining methods can generally only carry out frontier topic mining analysis for a certain discipline direction. Firstly, the corresponding domain experts are matched according to the set subject direction, and then the domain knowledge base and scientific literature database are collected. Then, different mining methods are combined to generate candidate frontier topics, and finally, the generated candidate frontier topics are manually reviewed by domain experts, and then the final frontier topics are output. Traditional methods are roughly divided into two categories because of different mining methods adopted. The first category is to combine bibliometric features, including word frequency analysis [2], literature citation [3], word co-occurrence analysis [4] and other statistical techniques to realize the mining of frontier topics. The second broad category is to identify frontier topics using topic models such as LDA [5] and BertTopic [6] in text mining. It is worth noting that although the frontier topics mined by traditional methods are highly readable and authoritative. However, this kind of method needs the support of domain experts, and relies on a large number of static scientific literature databases and high-quality domain knowledge bases. Therefore, traditional methods generally have the following shortcomings. ① Usually, it can only support a single discipline category, and cannot be compatible with frontier topic mining tasks of multiple disciplines at the same time. ② It takes a lot of manpower resources to collect and analyze literature data to achieve the goal of frontier topic mining, which is a typical low-efficiency and long-period method. ③ It is difficult to capture implicit semantic relevance information, which will affect its ability to deeply mine frontier topics. ④ Insufficient modeling of time series dynamics of unstructured data will lead to the problem of lag in frontier topic identification. ⑤ Because the frontier topics of emerging disciplines are usually sudden and uncertain, it is difficult for traditional methods to capture the early frontier topics of emerging disciplines in time.
Via deeply integration of artificial intelligence and scientific research, new opportunities have emerged in the field of frontier topics mining. The rapid development of large language models and AI agents provides the possibility of dynamic deep knowledge discovery. After the large language model or AI agent pre-trained and distills massive data in the general field, it can effectively overcome the shortcomings of traditional methods in the field of frontier topic mining based on feedback reinforcement learning and data dynamic update strategies combined with incremental learning. However, it is worth noting that this type of method also has an obvious shortcoming. Often due to the common "hallucination" problem of large language models, it is difficult to verify the authenticity of the excavated frontier topics. Considering that the large language models or AI agents need to provide multi-dimensional evidence chain support in frontier topic identification, existing methods do not have an automatic verification mechanism. Aiming at the above problems, inspired by references [7,8], Joint prompt engineering [9] proposed a frontier topics mining method via AI-agent (D-Agents). This method combines G-Agent and V-Agent at the same time to realize the automatic generation and verification of frontier topics. The G-Agent mainly responsible for mining potential frontier topics, while V-Agent is responsible for automatically verifying the mined frontier topics to ensure the accuracy and integrity of frontier topics. In addition, because the base of the AI agent is a general-purpose large language model, it has multi-domain adaptive learning capabilities and can be compatible with frontier topics in different fields to quickly mining tasks. The proposed method is via AI-agent automatic verification strategy to identify frontier topics, eliminating the need for domain experts to collect and process massive scientific and technological literature data, which can greatly improve the mining efficiency of frontier topics and the credibility of results. The core contributions of this paper are as follows:
① The generation-verification dual-agent architecture is innovatively constructed, it can be compatible with frontier topics mining task in multiple domain;
② The hallucination suppression mechanism was explored, in the task of automatic generation of frontier topics, an agent automatic verification mechanism was introduced to effectively alleviate the problem of generating "hallucination" and improve the reliability of frontier topics;
③ Have the ability to identify early frontier topics, the D-Agents method can greatly improve the efficiency of frontier topic mining based on a large language model and can combine retrieval-augmented generation technology to identify early frontier topics.
2. Related Works
Frontier topic refers to the latest knowledge system or research direction with development potential in a specific discipline or domain, usually involving high-tech or interdisciplinary integration. Frontier topics usually have three features: modernity, interdisciplinarity and application. Analyzing and mining frontier topics is of great significance for grasping the development trend of technology and the evolution of discipline context [10]. From the perspective of discipline division, it should be included in the research category of science. Due to differences in technical paths, the frontier topic analysis and mining methods are different. Bibliometrics and citation analysis, co-occurrence network and keyword analysis, interdisciplinary analysis, dynamic tracking, visualization and AI-driven analysis, and multi-source data collaborative verification belong to commonly methods.
Bibliometrics and citation analysis methods mainly explore frontier topics by combining literature features and citation network analysis. Gao Yunfeng [11] used bibliometric method combined with VOSviewer and CiteSpace visual analysis software to quantitatively analyze the literature related to mining ecological environment restoration published in CNKI from 2000 to 2018, and successfully excavated the top 5 frontier topics in this field as "Land reclamation", "Ecological compensation and deposit", "Phytoremediation of heavy metal pollution", "Geological disaster management", and "Green mine and mine park construction". Zhang Yali [12] conducted data mining and visualization of 3830 documents related to agricultural multispectral research published between 2002 and 2021 through citation analysis tools, and successfully got frontier topics and research institutions with the most published papers in this field as well as the most influential journals. Han Qi [13] visualized and analyzed 3018 anticancer network pharmacology research literatures published between January 2008 and May 2023, and successfully excavated frontier topics such as "Tumor microenvironment", "Anticancer drugs", "Traditional Chinese medicine", "Calycosin", "Molecular mechanism", "Molecular docking" and "Anticancer agents", which have been widely recognized by the industry.
Co-occurrence network and keyword analysis methods combined with keyword co-occurrence map and high-frequency word dynamic monitoring technology are widely used in frontier topics mining tasks. In order to comprehensively understand the research status in the field of big data, Zhang Niuniu [14] adopted technologies such as co-word analysis and social network analysis combined with SPSS and Gephi software to analyze and mine related articles published in Web of Science (WOS) databases between 2017 and 2019. The top 8 frontier topics in the field of big data have been successfully excavated as “Text mining”, “Data fusion”, “Distributed computing”, “Industry 4.0”, “Data privacy”, “Artificial intelligence”, “Energy big data”, “Bioinformatics”. Zhang B [15] took the literature about science and technology industry collected in CNKI database as the data source, and analyzed the research topics and development directions by using co-word analysis and social network analysis. Finally, the relevant frontier directions are summarized into four aspects: university science and technology industry, continuous innovation of science and technology industry, policy-oriented science and technology industry and evaluation system of science and technology industry.
Because of its advantages of multi-disciplinary cross-fusion, interdisciplinary analysis methods have the potential to identify early frontier topics of disciplines by combining multi-term combination retrieval and cross-domain data fusion technology. Dr. Nie Jia [16] focuses on altitude sickness, aiming at knowledge discovery, and jointly applies bibliometrics, knowledge graphs, data mining, network pharmacology and other methods to construct a multi-dimensional literature research model for altitude sickness. A comprehensive analysis was carried out on the research literature on altitude sickness published between 2006 and 2016. From the 31 research directions involved in altitude sickness, the top 6 research frontier topics in the world are "Altitude polycythemia", "Acute altitude sickness", "Chronic altitude sickness", "Apoptosis", "Altitude hypoxia" and "Pulmonary hypertension". Mi Lingyun [17] used CiteSpace as a bibliometric analysis tool, combined with cross-domain data fusion technology, systematically evaluated the development status of pro-environmental behavior (PEB) from macro, meso and micro levels, and summarized the frontier topic, trends and frontiers based on 4032 related articles in the Web of Science (WOS) database, which provided effective theoretical guidance for effectively promoting the sustainable development of society.
Dynamic tracking methods mainly use various academic literature publishing platforms to build dynamic tracking models according to time series to automatically predict frontier topics in the future. Li Bo [18] collected the literature data of more than 10 core journals including Chinese Management Science, Management World and Journal of Management Science by selecting important journals with high authority in the field of management science. Based on bibliometrics, this paper comprehensively analyzes the research features and dynamic development trend of management science, and establishes a dynamic tracking model combined with time series analysis, which reveals the frontier topics and dynamic evolution process of this field.
Visualization and AI-driven analysis methods are mainly based on knowledge graphs (KG) and semantic mining technology to automatically identify emerging concepts and visually display frontier topics and evolution paths. Xu Jia [19] collected 2882 literatures related to physiology teaching reform, and used bibliometrics and graph visualization methods to excavate the top 5 frontier topics in the field of physiology teaching reform as "Rehabilitation medicine", "Neuroscience", "Infectious diseases", "Pathogenesis of nervous system diseases" and "Treatment strategies of nervous system diseases", and revealed the close relationship between these frontier topics and brain research programs. Shao Bilin [20] took 5391 documents related to the topic of recommendation system from 2009 to 2018 and included in the Web of Science (WOS) core database as the research object, and analyzed them by combining bibliometric methods and semantic mining technologies. With the help of VOSviewer software, the knowledge graph is constructed, and valuable knowledge is intuitively discovered through visual approaches. Finally, according to the keyword concurrency graph, it is summarized that the top 7 frontier topics in the field of recommendation system are “Collaborative filtering and matrix factorization”, “Information technology and recommendation system”, “Recommendation algorithm and performance evaluation”, “User feature representation technology”, “Cold start and data sparsity”, “Personalized recommendation” and “privacy protection”. This discovery points out the scientific research direction for the development of recommendation system field.
Multi-source data collaborative verification methods can effectively verify the authenticity of frontier topics and reduce the bias of single data source through cross-comparison and topic correlation analysis. Cheng Jie [21] performed a visualization and cross-alignment analysis based on 1051 articles related to oyster reef ecosystems from 1981 to 2022. The top 3 frontier topics in this field between 2014 and 2022 were excavated as "Habitat protection and restoration", "Ecosystem services" and "Climate change", providing effective technical support for scholars and regulators concerned about oyster reef protection. Zhang Peng [22] screened 1305 articles on SA neuroimaging from January 1998 to December 2023 in Web of Science and Scopus, and successfully excavated the top 5 frontier topics in this field using multi-source data collaborative verification and topic correlation analysis technology are "Cognitive behavioral therapy", "Machine learning", "Transcranial direct current stimulation", "Depression", and "Brain imaging technology". The above results provide effective direction guidance for the research of SA brain mechanism.
Inspired by visualization and AI-driven analysis methods and multi-source data collaborative verification methods, combined with retrieval-augmented generation (RAG) technology [23], a frontier topics mining method via AI-agent is proposed in this paper. Our method can realize automatic generation and verification of frontier topics in multiple fields based on online search and local knowledge base, combining generative agents and verification agents at the same time, and can greatly improve the mining efficiency and generation quality of frontier topics.
3. Materials & Methods
3.1. Frontier Topic Mining Method via Generative Agent (G-Agent)
AI agents are intelligent systems that can autonomously perceive the environment, perform specific actions, and make decisions to achieve preset goals. Its essence is to combine artificial intelligence technology (such as large language models, reinforcement learning) and tool sets to form a set of programs that can run independently. An independent AI agent usually includes a brain, a memory module, planning module, an environment perception module, an execution module and a tool calling module. The above modules need to be deeply customized and designed and tuned in combination with prompt engineering and different business models in order to generate a complete AI agent. The trained AI agent generated have a clear goal, a set of executable action instructions and some optional tool sets. Figure 2 shows the architecture of G-Agent.
According to Figure 2, the G-Agent in addition to brain, memory module, planning module, environment perception module, execution module and tool calling module. It also includes a user input and feedback module and a result generation module. Learning and search instructions are added between the memory module and the planning module for optimizing performance. After in-depth analysis of the mining requirements of frontier topics, a high-quality G-Agent was deeply customized. Its goals, roles, brains, prompts and optional tool set are set up in Table 1.
According to the modules and instructions set in Table 1, the agent build platform [24] provided by Baidu is used to create a semi-supervised basic frontier topics automatically generated AI agent called G-Agent. The online platform supports efficient agent creation, editing, analysis, tuning, publishing, deleting, and online experience functions. After the agent is constructed and published based on the above platform, the user can automatically generate the corresponding candidate frontier topics list by constructing the mining instruction in the field according to the preset questioning mode and input it into the agent, and the structure of the list is , so as to obtain the candidate frontier topics in a specific field. K is an adjustable integer parameter that can be set by the user. The recommended value range is between , and the default value is . The generative agent brain in this article uses the completely free Baidu ERNIE 4.0 [25] large language model by default. For qualified users, other underlying large language model with better performance can also be used as the agent brain. Generative agent can achieve RAG goals through online search tools and local knowledge bases, and ensure the generation quality of frontier topics. The G-Agent contains retriever, generator, decoder, topic-generator four components. All core modules are calculated as follows:
where, in the retrieval component , is a dense representation of a document produced by a document encoder, and a query representation produced by a query encoder, also based on , Calculating , the list of k documents z with highest prior probability , in the generator component , we use pre-trained model and combination a local knowledge base , in the decoder component , we plug it as a standard decoder via combination a local knowledge base , in the topic-generator component , the top M documents are retrieved using the retriever, and then the generator produces a distribution via a local knowledge base for the next output topic for each document, before marginalizing, and repeating the process until output K-th topic.
3.2. Frontier Topics Mining Method via Dual Agents (D-Agents)
The frontier topic mining method of D-Agents belongs to a semi-supervised serial method with strict logical sequence. The entire method covers two different components: a generative AI agent (G-Agent) and a verification AI agent (V-Agent). The candidate frontier topic list output by the G-Agent is to be used as the input of V-Agent. The module name and instruction settings of the G-Agent are shown in Table 1. The core function of the V-Agent is to verify the novel, complete, accurate and authoritative of all elements in the input candidate frontier topic list. Then, all the frontier topics that pass the verification are returned to the user according to the specified format, so as to complete the verification of the whole frontier topics. The function of automatic verification is similar to the expert review step in traditional frontier topic mining method. It is worth noting that although the basic architecture of each module of the V-Agent is consistent with G-Agent. However, there are essential differences in their functions and goals, so there are great differences between the instructions and brain of each module in the V-Agent and the G-Agent. Figure 3 shows the overall architecture of D-Agents.
According to Figure 3, the D-Agents method is a semi-supervised serial method with strict logical sequence. The user first needs to call the G-Agent to output a list of candidate frontier topics, and then input this list into the V-Agent to complete the automatic verification and return of frontier topics. In order to achieve the above functions and goals, it is necessary to separately set corresponding instructions and brain for each module of the V-Agent. The detailed settings of the goal, role, brain, prompt instruction and optional tool set of the V-Agent are shown in Table 2.
According to the modules and instructions set in Table 2, the agent construction platform [24] provided by Baidu is used to create the V-Agent. The user inputs the candidate frontier topic list FHS according to the preset questioning mode and constructs frontier topic verification instructions and requirements and inputs them into the agent to automatically verify the novel, complete, accurate and authoritative of the candidate frontier topic and output the verified frontier topics according to the specified format, thereby completing the whole frontier topics mining task. Considering that there are differences in different large language model training corpus and underlying frameworks. In order to support the local knowledge base, ERNIE 3.5 [26] large language model was selected as the brain to build V-Agent. This design can effectively alleviate the "hallucination" problem of generating a single large language model. The V-Agent can achieve the goal of RAG through online search tools and local knowledge base, and ensure the generation quality of frontier topics. The V-Agent contains checker and aligner two core components. The formulas are calculated as follows:
where, in checker component , we use to check the novel & complete & accurate & authoritative (), length, independence and repeatability of each topic. In aligner component , at first, and are transformed into vectors of the same length using pre-trained model API, and then use cosine similarity to calculate the cosine distance between the current candidate topic and the topics in the local knowledge base
one by one, thus completing the automatic alignment of each topic. When the minimum cosine distance is less than the threshold (), the current candidate topic is replaced with the corresponding topic in the knowledge base, otherwise, the current candidate topic is maintained unchanged.
4. Data Sets and Evaluation Metrix
4.1. Dataset
For the performance evaluation of semi-supervised methods, it is a common way to use high-quality small-scale standard data sets for evaluation. Considering that there is currently a lack of standard high-quality evaluation data sets in the field of frontier topics mining. To objectively evaluate the comprehensive performance of the proposed method. It is based on three fields: computer vision, natural language processing and machine learning. By collecting the latest call for papers directions set by the international conferences corresponding to these three fields. Then, three high-quality small-scale frontier topics evaluation data sets are labeled after manual statistics and processing. An overview of the relevant evaluation datasets will show in Table 3, Table 4 and Table 5.
Table 3, Table 4 and Table 5 list the top 20 frontier topics at the current stage, which have high authority in the three fields of computer vision, natural language processing and machine learning. In the experimental will use these three data sets to complete the performance evaluation of the proposed method.
4.2. Evaluation Metrix
In order to objectively evaluate the comprehensive performance of the proposed method, accuracy and coverage rate (CR), are selected as performance evaluation criteria. The specific calculation formulas of accuracy and CR are as follows:
among them, is the frontier topics set contained in the labeled data set, is the frontier topics set mining by the proposed method, represents the number of common elements between the two sets (frontier topics implement semantic alignment), represents the total number of frontier topics set elements mining by the proposed method, and represents the total number of frontier topics set elements contained in the labeled data set.
5. Experimental and Results
5.1. Baseline Methods
In order to fully and objectively reveal the comprehensive performance of the proposed method, two groups of comparative experiments are set up in the experimental combined with different data sets to evaluate the performance of the method. In order to compare the differences between the G-Agent and the D-Agents, the first group of experiments carried out comparative experiments on three datasets: CV-DataSet, NLP-DataSet and ML-DataSet, and used Accuracy and RC to evaluate the performance of the methods. In order to evaluate the performance difference between the frontier topics mining method via D-Agents and the traditional method, the second group of experiments is compared with the interdisciplinary analysis method proposed in reference [16], the visualization and AI-driven analysis method proposed in reference [20] and the multi-source data collaborative verification method proposed in reference [21], and the performance of related methods is also evaluated by Accuracy and RC. It should be noted that the set of labeled frontier topics in the second group of experiments is directly extracted from the experimental results of the comparative reference, and is not labeled manually.
5.2. Results and Analysis
The experimental results of the comparison between the G-Agent and D-Agents carried out on CV-DataSet, NLP-DataSet and ML-DataSet data sets are shown in Table 6. Relevant indicators are calculated in combination with the top 20 frontier topics marked in Table 3, Table 4 and Table 5. The complete frontier topics generated by the G-Agent and D-Agents are shown in Figure A1, Figure A2 and Figure A3 in Appendix A.
It is worth noting that, in order to make the experimental results more directly compared, we extracted a small number of manually labeled frontier topics in the agent to construct a small-scale local knowledge base. The above knowledge base is mainly used to complete the generation style guidance and alignment guidance of frontier topics. According to the experimental results shown in Table 6 and Figure A1, Figure A1 and Figure A3 in the Appendix A, it can be seen that the comprehensive performance of the frontier topic mining method via D-Agents on three data sets is better than G-Agent. The accuracy of the D-Agents on the three datasets of CV-DataSet, NLP-DataSet and ML-DataSet reach 90%, 74% and 82%, respectively, which are 5%, 9% and 12% higher than the G-Agent, respectively. The coverage of the D-Agents on the three datasets reaches 95%, 85% and 90% respectively, which is 5%, 20% and 20% higher than G-Agent, respectively. The reason for the above results may be related to some high-quality planning strategies set in V-Agent. It can further verify the accuracy, completeness, novelty and authority of the results by combining different brain on the basis of G-Agent. Thus, filtering out some frontier topics that cannot pass verification. In addition, it can automatically expand some high-quality additional frontier topics that have not been discovered by G-Agent but are closely related to the field. The above strategies can effectively improve the comprehensive performance of D-Agents. From three different datasets, the D-Agents has the best comprehensive performance on the CV-DataSet dataset. The performance on the ML-DataSet dataset is second. The overall performance is the weakest on the NLP-DataSet dataset. According to the above results, it can be seen that there are certain fluctuations in the comprehensive performance of the proposed method in different fields, and the core reason may be related to the underlying brain performance. Although in the construction of agents, the Baidu ERNIE large language model in the general field is selected as the agent brain. However, there are certain differences in the training strategies and training corpus of large language models corresponding to different brains. This will directly lead to some deviations in the domain adaptability of the method. In order to further reveal the performance difference between the D-Agents and the traditional method. In order to further reveal the performance difference between the D-Agents method, the traditional expert mining method and the open source DeepSeek-R1-671B large language model [27], in addition to carrying out comparative experiments on the above three labeled datasets, the traditional mining methods proposed in references [16], references [20] and references [21] have carried out in-depth comparative experiments for three specific fields. The relevant experimental results are shown in Table 7.
According to the experimental results in Table 7, the comprehensive performance of D-Agents is excellent compared with the traditional baseline methods. It is worth noting that in order to better verify the effect of our method, a small number of frontier topics mined by these three traditional methods are also constructed into a local knowledge base. The above knowledge base is mainly used to complete the alignment guidance and the generation style guidance of frontier topics. In the comparative experiment of mining top 6 frontier topics in the field of altitude sickness from 2006 to 2016, except for the frontier topic of "apoptosis" has not been successfully identified, and all other frontier topics have been accurately generated, and additional two potential early frontier topics of “Preventive measures of altitude sickness” and “Pathogenesis of altitude sickness” have been generated, with accuracy and CR of 71% and 83% respectively, while DeepSeek only excavated two correct frontier topics of acute altitude sickness and altitude hypoxia. In the comparative experiment of Top 7 frontier topics mining in the field of recommendation systems from 2009 to 2018, except for the "recommendation algorithm and performance evaluation" topic that were not successfully identified, the rest of the topics were accurately generated, and an early potential topic of "AI recommendation system" was additionally generated, with both accuracy and CR were 86%, while DeepSeek only mined two correct frontier topics: cold start and data sparsity, privacy protection and federated learning. In the comparative experiment of top 3 frontier topics mining in the field of oyster reef ecosystem from 1981 to 2022, except for the "climate change" frontier topic that was not successfully excavated, the other topics were accurately generated, and an additional early potential frontier topic "Ecological diversity conservation" was generated, with both accuracy and CR of 67%, while DeepSeek only mined one correct frontier topic of ecosystem services. The results are analyzed from the aspects of comprehensive performance, efficiency and domain adaptability. The experimental results can fully show that the D-Agents has the ability to mining frontier topics in general field. Even in some fields, the comprehensive performance is close to the level of human experts. In terms of efficiency, because it is a semi-supervised method, it does not need to rely on domain experts to label data. Directly via agent, it can quickly complete a frontier topic mining task in a specified domain in a short period of time, which can greatly improve mining efficiency. In terms of domain adaptability, it uses large language models in general domains as the brain of the agent, which can simultaneously adapt to the mining requirements of frontier topics in multiple domains. The above results can fully illustrate that the DeepSeek model lacks high-quality prompt information and self-verification mechanism, as well as the style guidance and alignment guidance of the local knowledge base. Its comprehensive performance in frontier topic mining task has some gaps with the D-Agents method.
6. Discussion
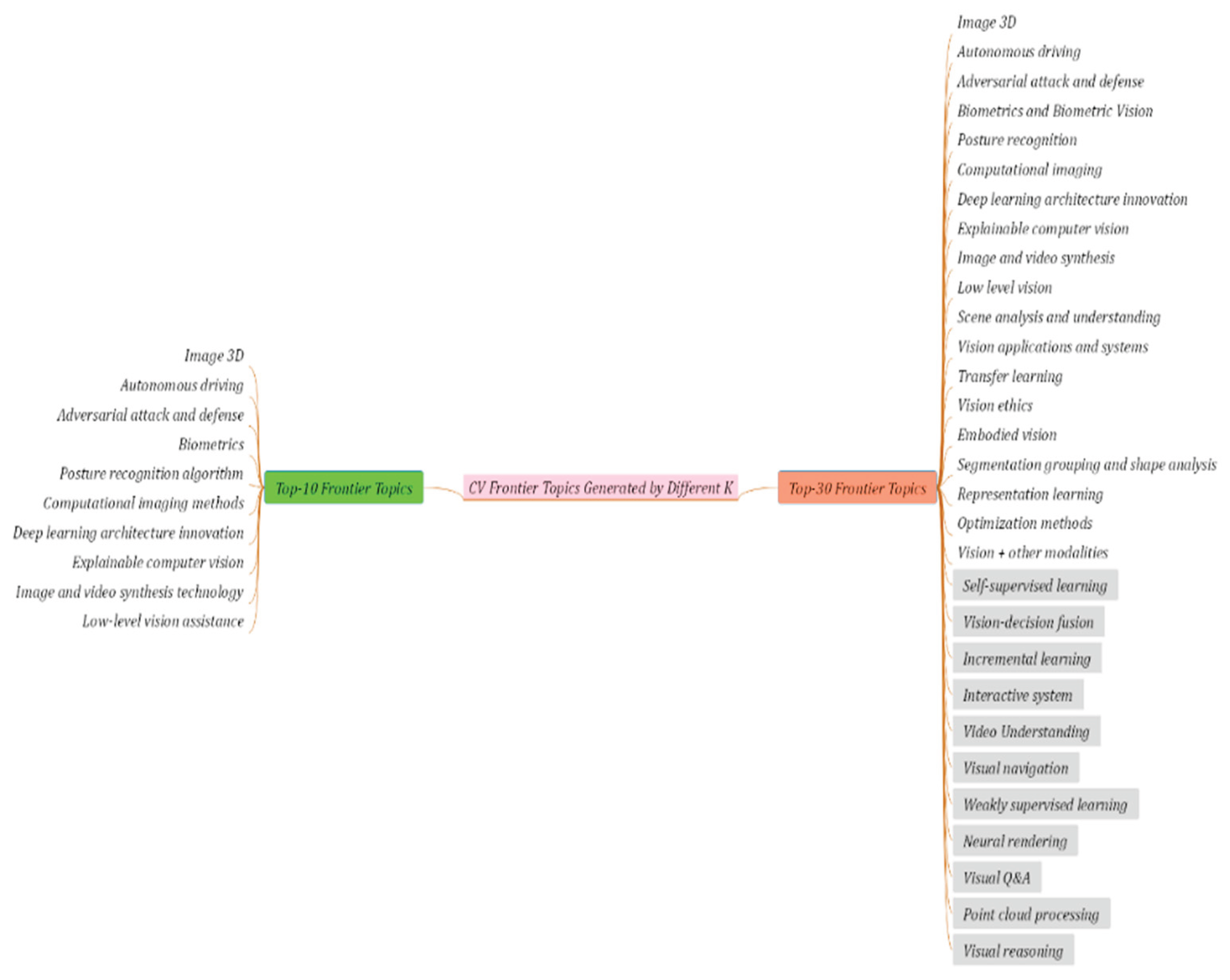
Although the D-Agents method has been proved to have better comprehensive performance and high mining efficiency in frontier topic mining experiments. But in the experimental process we found that it also has some points that can be continuously optimized. It can be summarized as follows: ① Before creating the agent, in-depth analysis according to the task requirements. Then, combined with the analysis results, setting clear task objectives and high-quality planning schemes for the agent, equipping some optional tool sets and selecting appropriate memory strategies will have a great impact on the overall performance of the agent. ② In terms of agent brain selection, the performance of the underlying large language model will have a direct impact on the performance of the agent. Due to different tasks, choosing a large language model that meets the task requirements as the agent brain will have better performance. It is recommended that qualified users consider using the large language model with better overall performance in subsequent task. In the experimental session, it was found that if the G-Agent and the V-Agent use the same large language model to build their respective brains, the frontier topic verification effect will decrease, and some frontier topics may be output without correct verification. This may be due to the same large language model does not have the ability to self-verify. In view of the above phenomenon, it is recommended that in subsequent frontier topics mining task, different agents should try their best to choose large language model with cross-validation capabilities as brains to verify frontier topics, which will have a better effect. ③ The overall performance of D-Agents is better than G-Agent. Because the D-Agents have prompt instructions to enhance execution functions. When the G-Agent performs poorly in executing a certain instruction, the generation quality of the model will be significantly improved after the secondary prompt of the D-Agents. In the experiment, it is found that this phenomenon will exist in the generation style and alignment instruction of frontier topics, which is called indirect reinforcement feedback learning, which is an emerging learning mechanism automatically realized by model without manual intervention. ④ The experiment shows that high-quality local knowledge base has an important influence on frontier topics generation. Because combining the local knowledge base can effectively guide the agent to generate frontier topics according to the user-specified style and complete automatic alignment. It is suggested that in the future task, according to the actual requirement of users, building a high-quality local knowledge base and integrating it into the agent can effectively improve the generation quality of frontier topics. ⑤ Setting the maximum K value of candidate frontier topics returned by G-Agent will also have a certain impact on the overall effect. For different fields, during multiple rounds of experiments, it was found that when the K value is set too small, important frontier topics may be missed. When the K value is set too large, some noisy topics may be generated, which will affect the generation quality. In the CV domain, the generation results of frontier topics corresponding to K = 10 and K = 30 are shown in Figure A4 in the Appendix A. Therefore, it is recommended to set the initialized K value to an integer between [3,30]. In the experiment, the initialized K value is set to 20 by default. It is recommended that users conduct in-depth analysis and multiple rounds of feedback fine-tuning according to the selected domain before determining the optimal K value, which will help to improve the quality of frontier topic generation. To sum up, D-Agents are fully competent for frontier topic mining tasks after multiple rounds of iterative optimization.
7. Conclusions
A frontier topic mining method via AI-agent is proposed by combining general large language model and prompt engineering technology. The automatic cross-validation mechanism of knowledge among different agents is explored, and the effectiveness of using AI-agent to automatically generate candidate frontier topics and automatically verify frontier topics is confirmed. Experiments show that the D-Agents method can be competent in mining frontier topics in multiple domain, and achieves good comprehensive performance on experimental datasets. It breaks through the limitation that traditional frontier topics mining methods need to rely too much on domain experts to collect and read massive literature. It opens up a new direction to automatically generate candidate frontier topics through G-Agent, and then use V-Agent to automatically verify frontier topics, providing an efficient solution for intelligently completing frontier topics mining task in multiple domain.
Although D-Agents method has achieved good comprehensive performance in the field of frontier topic mining. However, the proposed method has only been experimentally verified on agents with Baidu ERNIE large language model as the brain, and its universality needs to be verified on more agents with other large language models as the brain in the future. In addition, due to the diversity of the underlying large model, the agent generation results may cause slight changes in the generated frontier topics. Future work can focus on exploring the universality of the method and proposing high-quality knowledge base auxiliary agents in general domains to complete frontier topics alignment and generation style guidance, thereby further improving the mining quality of frontier topics.
Author Contributions
Conceptualization, Bin Ge and Chunhui He; methodology, Bin Ge and Chunhui He; software, Chunhui He; validation, Chunhui He and Jibing Wu; formal analysis, Chong Zhang; investigation, Bin Ge and Jibing Wu; resources, Chunhui He; data curation, Bin Ge and Qingqing Zhao; writing—original draft preparation, Chunhui He; writing—review and editing, Bin Ge, Chunhui He, Qingqing Zhao, Chong Zhang and Jibing Wu; visualization, Chong Zhang and Jibing Wu; supervision, Qingqing Zhao; project administration, Chong Zhang and Bin Ge; funding acquisition, Bin Ge. All authors have read and agreed to the published version of the manuscript.
Funding
This research received the support of National Natural Science Foundation of China (No. 72471237).
Data Availability Statement
The original third-party data can obtain by following links: CV-Dataset: CVPR-URL: https://cvpr.thecvf.com/Conferences/2025/CallForPapers. ICCV-URL: https://iccv.thecvf.com/Conferences/2025/CallForPapers. ECCV-URL: https://eccv2024.ecva.net/Conferences/2026/CallForPapers. NLP-Dataset: ACL-URL: https://2025.aclweb.org/calls/main_conference_papers/#acl-2025. EMNLP-URL: https://2025.emnlp.org/calls/main_conference_papers/. NAACL-URL: https://2025.naacl.org/calls/papers/#submission-topic. CoNLL-URL: https://www.conll.org. ML-Dataset: ICML-URL: https://icml.cc/Conferences/2025/CallForPapers. NeurIPS-URL: https://neurips.cc/Conferences/2025/CallForPapers. COLT-URL: https://learningtheory.org/colt2025/cfp.html.
Acknowledgments
Thanks to the agent online management platform provided by Baidu Company for helping to build relevant agents and complete experimental.
Conflicts of Interest
All authors declare that there are no financial or personal relationships with other people or organizations that could inappropriately influence (bias) their work. No competing interests exist in the conduct of this research or the preparation of this manuscript.
Appendix A
Figure A1.
Frontier topics generation results of G-Agent and D-Agents on CV-DataSet.
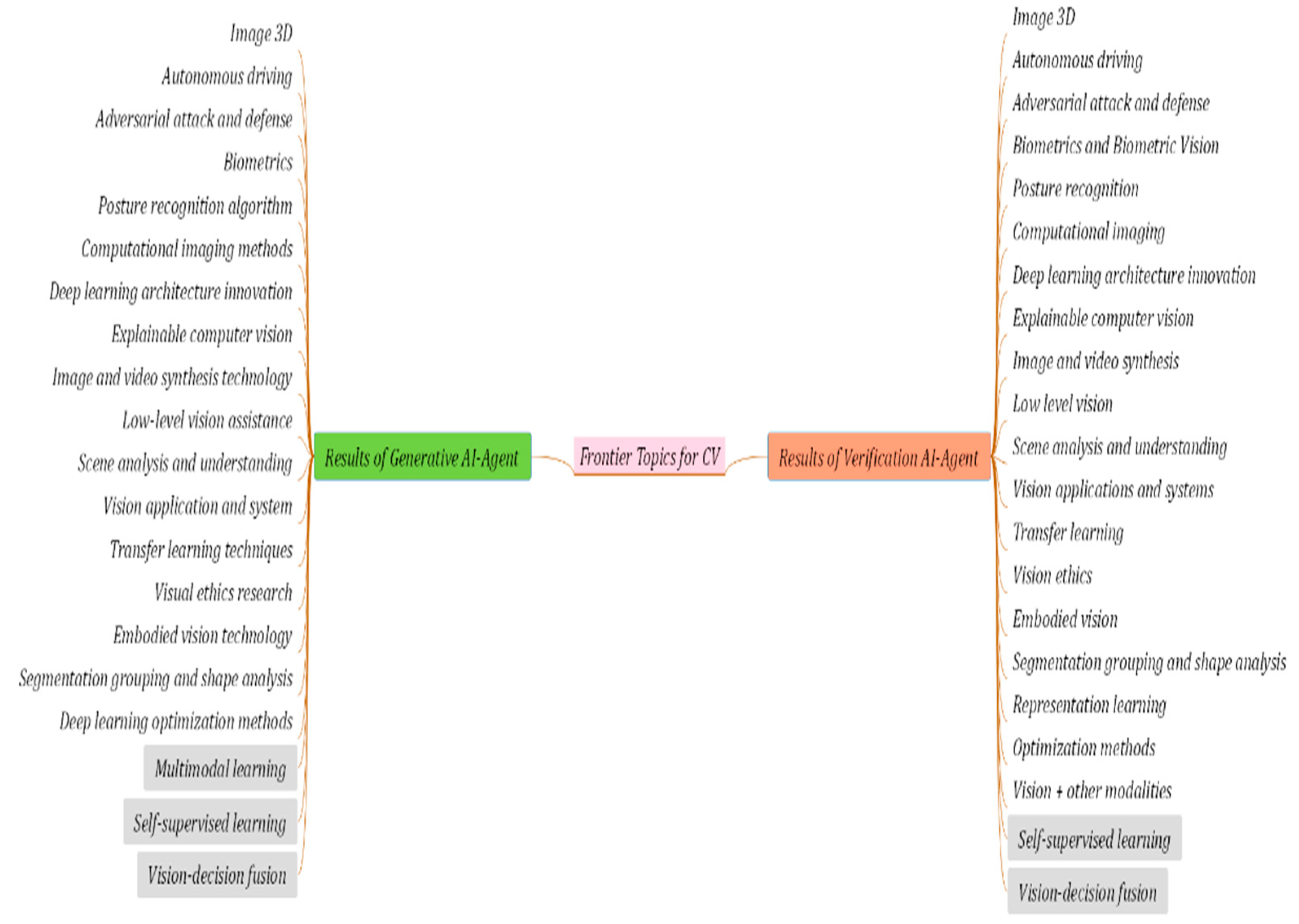
Figure A2.
Frontier topics generation results of G-Agent and D-Agents on NLP-DataSet.
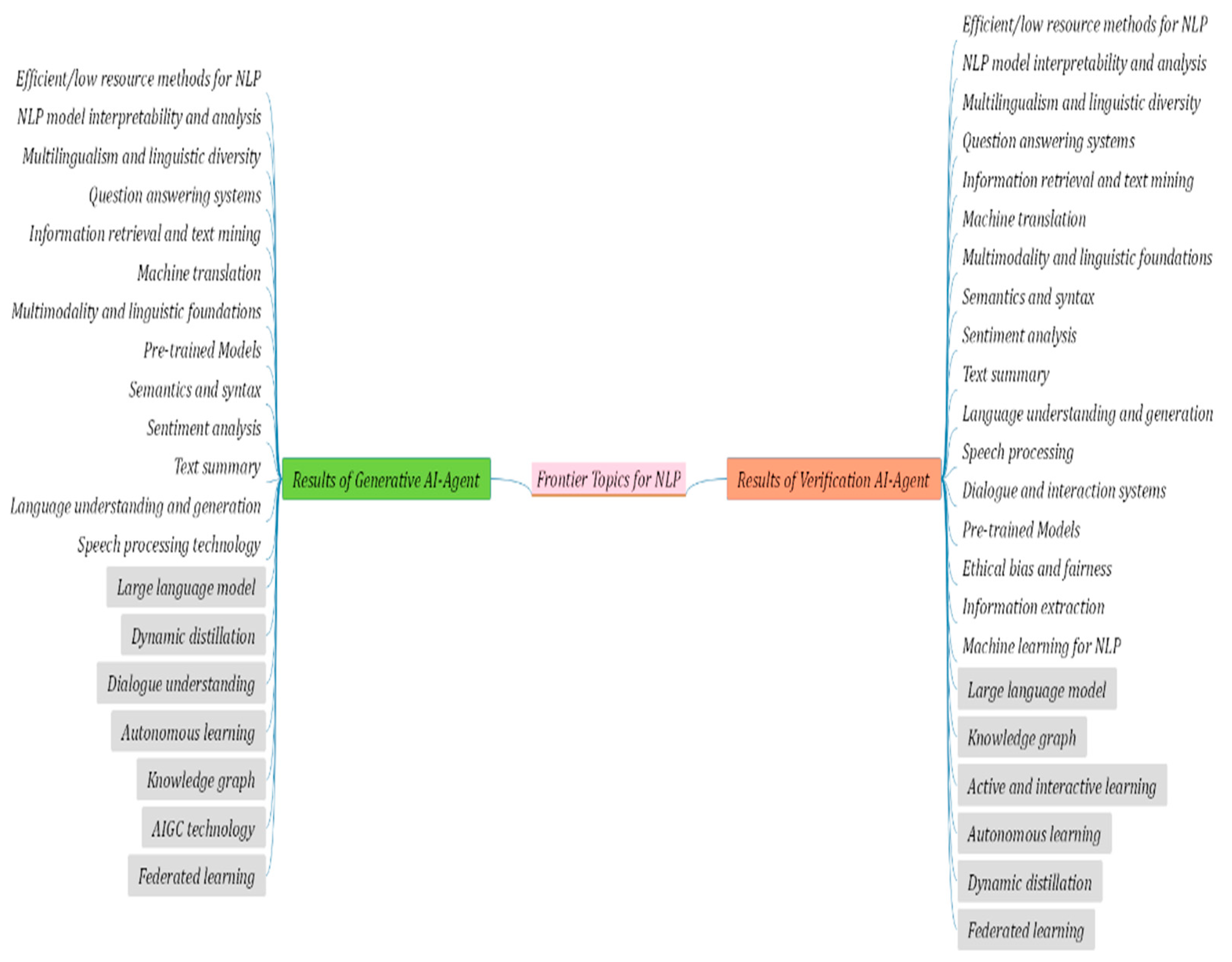
Figure A3.
Frontier topics generation results of G-Agent and D-Agents on ML-DataSet.
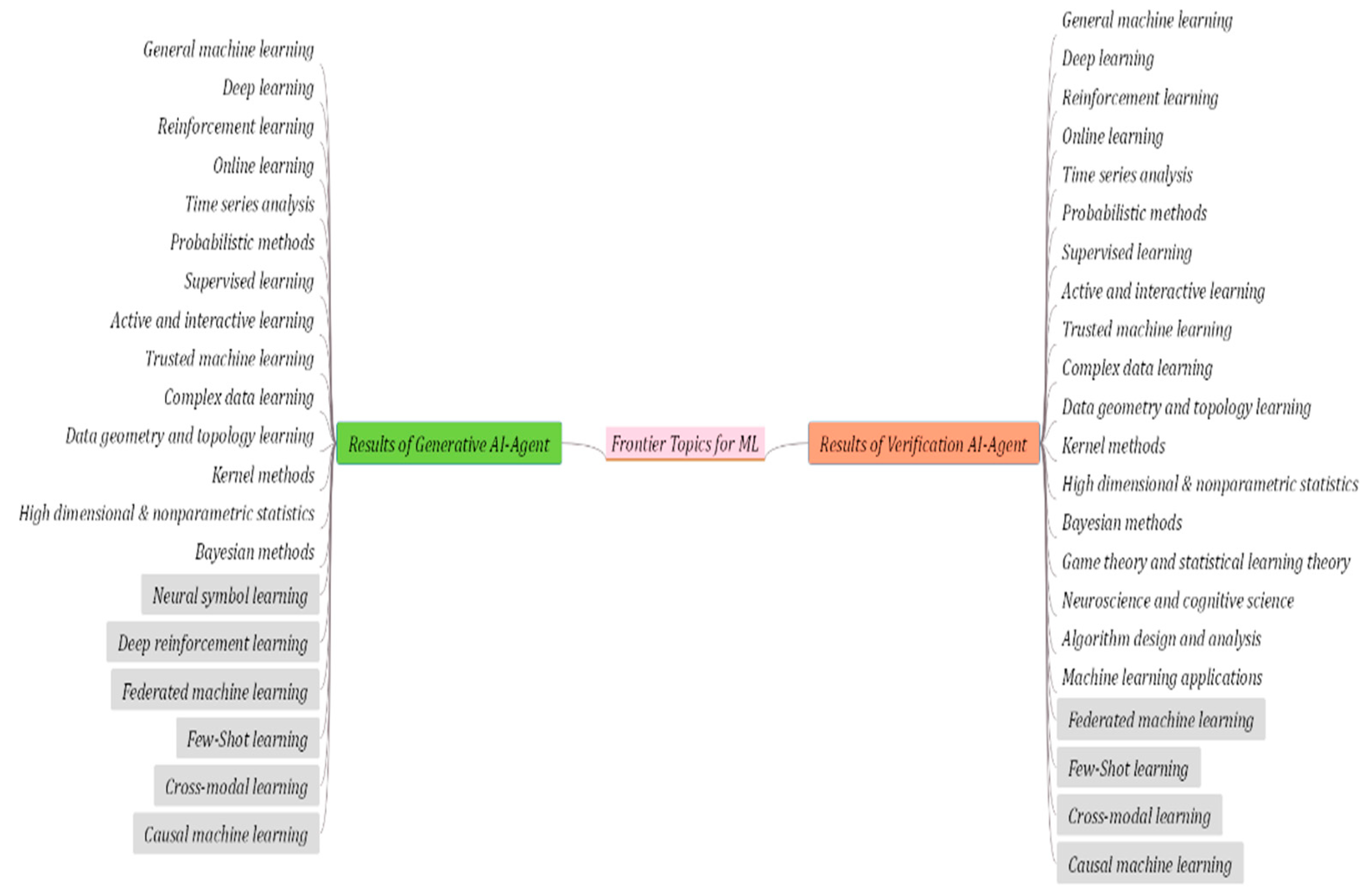
Figure A4.
Frontier topics generated by D-Agents in the CV domain according to different K.
References
- Zhang Hui,Yang Xiaoyan,Zhao Xujian, et al. Subject Frontiers Hot Spots Mining Based on Social Network Attention[J]. Journal of Zhengzhou University (Natural Science Edition), 2018, 50(03):46-52. https://link.oversea.cnki.net/doi/10.13705/j.issn.1671-6841.2017201.
- Prapobratanakul, Chariya. Frequency Analysis, Distribution, and Coverage of Academic Words in Materials Science Research Articles: A Corpus-Based Study [J]. LEARN Journal: Language Education and Acquisition Research Network 17.2, 2024: 793-813. [CrossRef]
- Kyebambe, Moses Ntanda, et al. Forecasting emerging technologies: A supervised learning approach through patent analysis [J]. Technological Forecasting and Social Change 125, 2017: 236-244. https://doi.org/10.1016/j.techfore.2017.08.002. [CrossRef]
- Klarin, Anton. How to conduct a bibliometric content analysis: Guidelines and contributions of content co-occurrence or co-word literature reviews [J]. International Journal of Consumer Studies 48.2, 2024: e13031. [CrossRef]
- Ge, Bin, et al. Chinese news hot subtopic discovery and recommendation method based on key phrase and the LDA model [J]. DEStech Transactions on Engineering and Technology Research, ECAR, 2018. [CrossRef]
- Lalk, Christopher, et al. Measuring alliance and symptom severity in psychotherapy transcripts using bert topic modeling [J]. Administration and Policy in Mental Health and Mental Health Services Research 51.4, 2024: 509-524. [CrossRef] [PubMed]
- He, Chunhui, Bin Ge, and Chong Zhang. Chinese Text Open Domain Tag Generation Method via Large Language Model [C].10th International Conference on Big Data and Information Analytics. IEEE, 2024, 183-188. [CrossRef]
- Jin, Yiqiao, et al. AGENTREVIEW: Exploring Peer Review Dynamics with LLM Agents [C]. //In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1208–1226, Miami, Florida, USA. Association for Computational Linguistics. [CrossRef]
- Giray, L. Prompt Engineering with ChatGPT: A Guide for Academic Writers [J]. Ann Biomed Eng 51, 2023, 2629–2633. [CrossRef] [PubMed]
- Hu H, Xue W, Jiang P, et al. Bibliometric analysis for ocean renewable energy: An comprehensive review for hotspots, frontiers, and emerging trends [J]. Renewable and Sustainable Energy Reviews. 2022, 167:112739. [CrossRef]
- Gao Y, XU Y, ZHU Y, et al. An analysis of the hotspot and frontier of mine eco-environment restoration doul big data visualization of VOSviewer and CiteSpace [J]. Geological Bulletin of China. 2018, 37(12):2144-53. http://dx.chinadoi.cn/10.12097/j.issn.1671-2552.2018.12.004.
- Zhang Y, Zhao D, Liu H, et al. Research hotspots and frontiers in agricultural multispectral technology: Bibliometrics and scientometrics analysis of the Web of Science [J]. Frontiers in Plant Science. 2022, 13:955340. [CrossRef] [PubMed]
- Han Q, Li Z, Fu Y, et al. Analyzing the research landscape: mapping frontiers and hot spots in anti-cancer research using bibliometric analysis and research network pharmacology [J]. Frontiers in Pharmacology. 2023, 14:1256188. [CrossRef] [PubMed]
- Zhang N, Feng G. Analysis of Big Data Research Hotspots Based on Keyword Co-occurrence [C]. In IEEE 9th International Conference on Data Science in Cyberspace, 2024, 464-471. [CrossRef]
- Zhang B, Zhang S. Analysis of the Sci-tech Industry Research Hot Spots Based on Keywords Co-occurrence Analysis and Social Network Analysis[J]. Science and Technology Management Research, 2016(20): 93-98. http://dx.chinadoi.cn/10.3969/j.issn.1000-7695.2016.20.018.
- Nie J. Study on the Law and Mechanism of Tibetan Medicine's Prevention and Treatment of Plateau Disease Based on Knowledge Discovery [D]. Chengdu University of Traditional Chinese Medicine, 2017.
- Mi L, Zhang W, Yu H, et al. Knowledge mapping analysis of pro-environmental behaviors: research hotspots, trends and frontiers [J]. Environment, Development and Sustainability. 2024:1-35. [CrossRef]
- Li B, Qin Y, Xu Z. Dynamic Tracking of Research Status and Frontiers in the Field of Management Science [J]. Chinese Journal of Management Science, 2023, 31(07):276-286. https://link.oversea.cnki.net/doi/10.16381/j.cnki.issn1003-207x.2021.1830.
- Xu J, Sun S, Zhao Y, et al. Knowledge domain, research hotspots and frontiers in physiology teaching reforms from 2012 to 2021: A bibliometric and knowledge-map analysis [J]. Frontiers in Medicine. 2023, 10:1031713. [CrossRef] [PubMed]
- Shao B, Li X, Bian G. A survey of research hotspots and frontier trends of recommendation systems from the perspective of knowledge graph [J]. Expert Systems with Applications. 2021, 165:113764. [CrossRef]
- Cheng J, Lu D, Sun L, et al. Development Trends, Current Hotspots, and Research Frontiers of Oyster Reefs: A Bibliometric Analysis Based on CiteSpace [J]. Water. 2023, 15(20):3619. [CrossRef]
- Zhang P, Zhang J, Wang M, et al. Research hotspots and trends of neuroimaging in social anxiety: a CiteSpace bibliometric analysis based on Web of Science and Scopus database [J]. Frontiers in Behavioral Neuroscience. 2024, 18:1448412. [CrossRef] [PubMed]
- Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in neural information processing systems, 2020, 33: 9459-9474.
- Baidu. Agent Builder [EB/OL]. https://agents.baidu.com/agent, 2024-04-19/2025-02-25.
- Baidu. ERNIE-4.0-8k [EB/OL]. https://cloud.baidu.com/doc/WENXINWORKSHOP/s/clntwmv7t, 2025-02-20/2025-02-25.
- Baidu.ERNIE-3.5-128k [EB/OL]. https://cloud.baidu.com/doc/WENXINWORKSHOP/s/dlw4ptsq7, 2025-02-21/20025-02-25.
- Deng Z, Ma W, Han Q L, et al. Exploring DeepSeek: A Survey on Advances, Applications, Challenges and Future Directions[J]. IEEE/CAA Journal of Automatica Sinica, 2025, 12(5): 872-893.
Figure 1.
Flow chart of traditional frontier topics analysis and mining method.
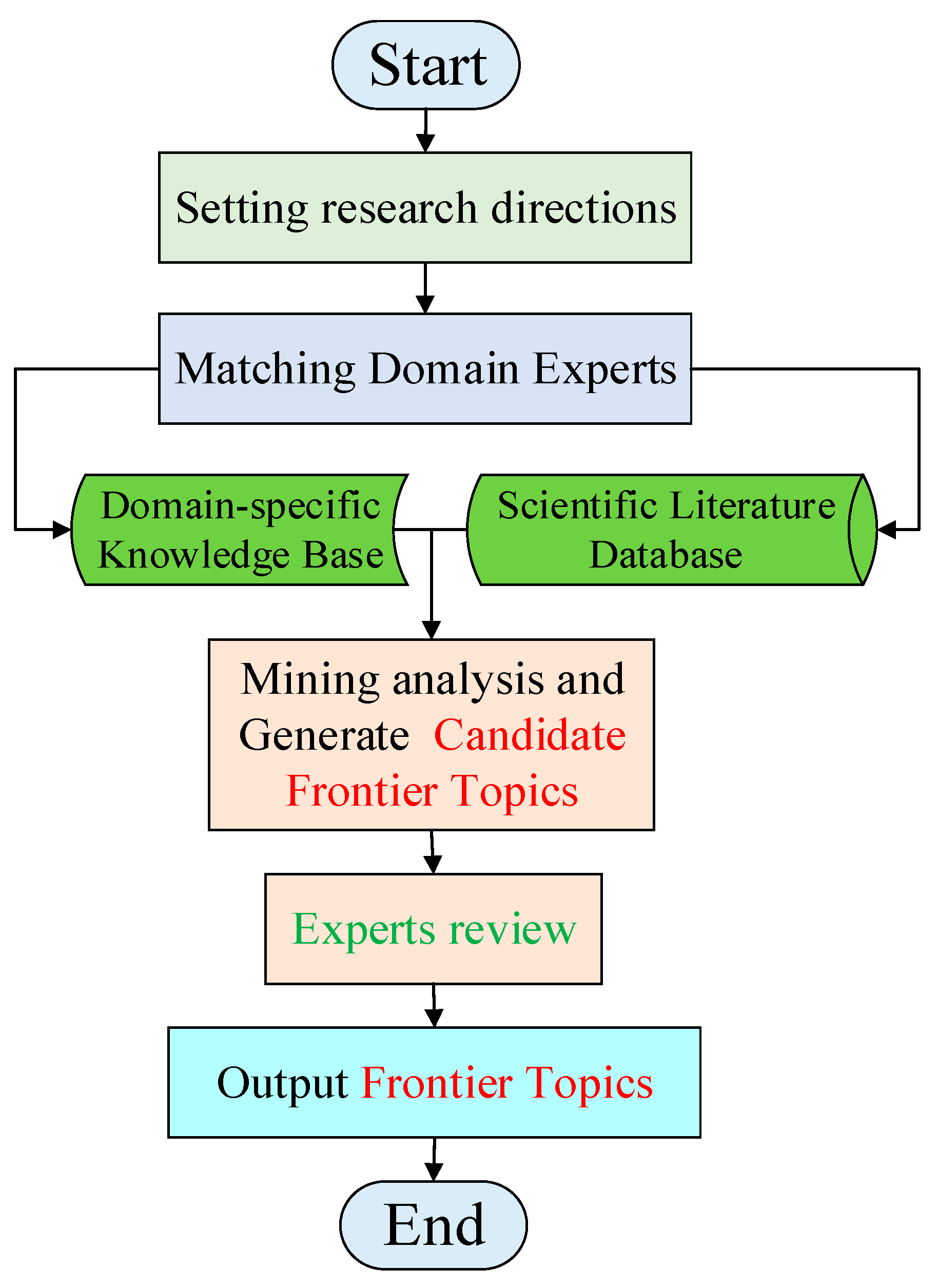
Figure 2.
Architecture design of G-Agent.
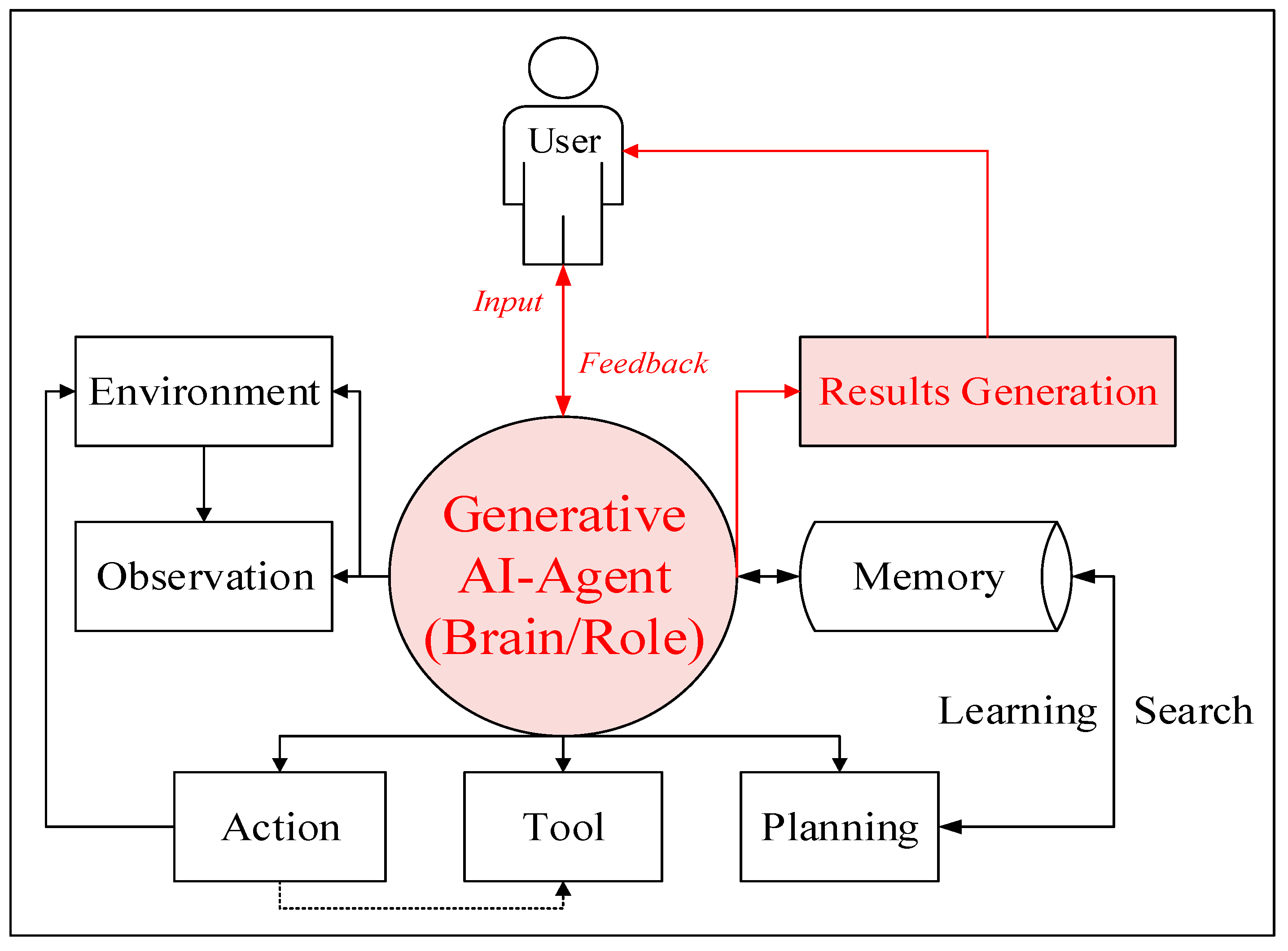
Figure 3.
Overall architecture of D-Agents.
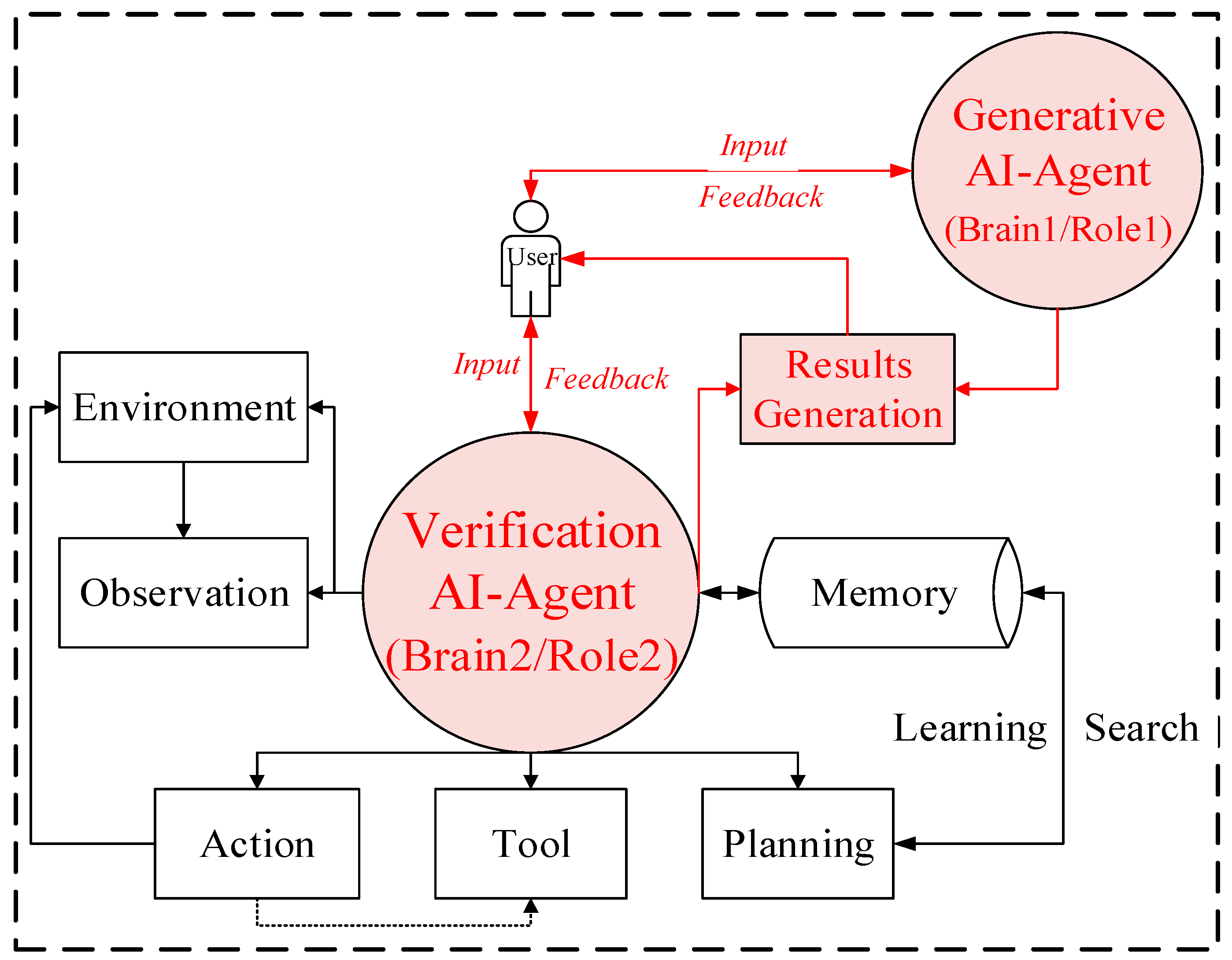

Table 1.
Module name and instruction settings of G-Agent.
| Agent module name | Module specific functions or corresponding instructions |
| User module | Guide users to enter frontier topic mining prompt instructions or give feedback instructions in specified fields. |
| Brain of the G-Agent | ERNIE 4.0 |
| Role of the G-Agent | Senior experts in the field of intelligence. |
| Perception of the G-Agent | Automatically capture domain frontier topic mining goals and requirements from user-input prompt instructions. |
| Memory of the G-Agent | Long-term memory |
| Action of the G-Agent | ① Default question ② Automatic questioning ③ Tool call ④ Feedback learning ⑤ Clear historical conversation |
| Planning of the G-Agent | ① Automatically complete the search and learning of knowledge according to memory and user feedback. ② Collect and interpret the corresponding authoritative literature according to the captured frontier topics mining goals and requirements. ③ Generate no more than K candidate frontier topics after in-depth interpretation of all data in chronological order. ④ The literature collected comes from published academic papers and patent documents, research reports, and conference call for papers. ⑤ Ensure that frontier topics are highly relevant and accurate to the field input by the user. ⑥ Ensure that the number of words in a single frontier topic is strictly prohibited from exceeding 10 words, and it is not repeated. ⑦ Only use the list form to return topics one by one, without any explanatory text. ⑧ The output format refers to the style of the knowledge base, and the output results are automatically aligned with the frontier topics in the knowledge base as much as possible. |
| Optional tool set for G-Agent | ① Online search ② Micro single domain knowledge base |
| Result generation of the G-Agent | Candidate frontier topics are returned to users one by one in strict accordance with the list format. |
Table 2.
Module names and instruction settings of V-Agent.
| Agent module name | Module specific functions or corresponding instructions |
| User module | Guide the user to input verification prompt instructions or give feedback instructions according to the candidate frontier topic list. |
| Brain of the V-Agent | ERNIE 3.5 |
| Role of the V-Agent | Senior experts in the field of intelligence. |
| Perception of the V-Agent | Automatically capture a list of candidate frontier topics and domains to which frontier topics belong from an input prompt instruction. |
| Memory of the V-Agent | Long-term memory |
| Action of the V-Agent | ① Default question ② Automatic questioning ③ Tool call ④ Feedback learning ⑤ Clear historical conversation |
| Planning of the V-Agent | ① Automatically complete the search and learning of knowledge according to memory and user feedback. ② Call knowledge to complete reasoning and verification according to the capture list, domain mining goals and requirements. ③ Strictly verify each frontier topics to make it novel, complete, accurate and authoritative. ④ Ensure that each verified frontier topic is independent and complete, with concise word count and strictly abiding by academic norms. ⑤ Ensure that the frontier topics that have passed the verification cannot be repeated, and automatically filter the frontier topics that have not passed the verification. ⑥ Allows to expand and supplement undiscovered but closely related and authentic frontier topics in the above list. ⑦ The output format strictly refers to the style of the local knowledge base, and the frontier topics covered by the knowledge base should be strictly consistent with it. ⑧ Ensure that the verified frontier topics are directly output one by one without explanatory text. |
| Optional tool set for V-Agent | ① Online search ② Large cross-domain knowledge base |
| Result generation of the V-Agent | The verified frontier topics are uniformly returned to the user in strict accordance with the specified format. |
Table 3.
Top 20 Frontier topics labeled data sets in the field of computer vision (CV).
| Dataset name | Data Source | Top 20 frontier topics |
| CV-DataSet | CVPR ICCV ECCV |
Image 3D, Autonomous driving, Adversarial attack and defense, Biometrics and Biometric Vision, Posture recognition, Computational imaging, Datasets and evaluation, Deep learning architecture innovation, Explainable computer vision, Image and video synthesis, Low level vision, Representation learning, Scene analysis and understanding, Optimization methods, Vision applications and systems, Vision + other modalities, Transfer learning, Vision ethics, Embodied vision, Segmentation grouping and shape analysis |
Table 4.
Top 20 Frontier topics labeled datasets in the field of natural language processing (NLP).
| Dataset name | Data Source | Top 20 frontier topics |
| NLP-DataSet | ACL EMNLP NAACL CoNLL |
Computational social sciences and sociolinguistics, Dialogue and interaction systems, Efficient/low resource methods for NLP, NLP model interpretability and analysis, Multilingualism and linguistic diversity, Question answering systems, Information retrieval and text mining, Machine translation, Machine learning for NLP, Multimodality and linguistic foundations, Ethical bias and fairness, Information extraction, Pre-trained Models, Resources and evaluation, Semantics and syntax, Sentiment analysis, Text summary, Language understanding and generation, Linguistic theory, Speech processing |
Table 5.
Top 20 Frontier topics labeled data sets in the field of machine learning (ML).
| Dataset name | Data source | Top 20 frontier topics |
| ML-DataSet | ICML NeurIPS COLT |
General machine learning, Game theory and statistical learning theory, Deep learning, Neuroscience and cognitive science, Large language models, Reinforcement learning, Online learning, Time series analysis, Optimization methods, Probabilistic methods, Algorithm design and analysis, Active and interactive learning, Data geometry and topology learning, Kernel methods, Complex data learning, Trusted machine learning, Machine learning applications, High dimensional & nonparametric statistics, Bayesian methods, Supervised learning |
Table 6.
Comparative experimental results of our method on three labeled datasets.
| Dataset name | Method | Accuracy | RC |
| CV-DataSet | G-Agent | ||
| D-Agents | |||
| NLP-DataSet | G-Agent | ||
| D-Agents | |||
| ML-DataSet | G-Agent | ||
| D-Agents |
Table 7.
Comparative experimental results of frontier topic mining with different methods in three specific fields (red indicates inconsistency with expert mining results).
Table 7.
Comparative experimental results of frontier topic mining with different methods in three specific fields (red indicates inconsistency with expert mining results).
| Domain Frontier Topic Mining |
Expert Mining Results |
DeepSeek-R1-671B Mining Results |
D-Agents Mining Results |
D-Agents Accuracy | D-Agents RC |
| Mining Top6 frontier topics in the Field of "Altitude Sickness" from 2006 to 2016 | Altitude polycythemia, Acute altitude sickness, Chronic altitude sickness, Apoptosis, Altitude hypoxia, Pulmonary hypertension [16] | Molecular mechanisms of altitude hypoxia adaptation, Characteristics and prevention of acute altitude sickness, Prevention and control of echinococcosis in high altitude areas, Altitude hypoxia, Altitude cardiovascular diseases, Altitude ecology and health | Altitude polycythemia, Acute altitude sickness, Chronic altitude sickness, Altitude hypoxia, Pulmonary hypertension, Preventive measures of altitude sickness, Pathogenesis of altitude sickness | ||
| Mining Top7 frontier topics in the field of "Recommendation System" from 2009 to 2018 | Collaborative filtering and matrix factorization, Information technology and recommendation system, Recommendation algorithm and performance evaluation, User feature representation technology, Cold start and data sparsity, Personalized recommendation, privacy protection [20] |
Explainable recommendation, Fairness & diversity, Reinforcement learning for recommendation system, Multi-modal recommendation, Cold start & data sparsity, Knowledge graph for recommendation system, Privacy & federated learning |
Collaborative filtering and matrix factorization, Information technology and recommendation system, User feature representation technology, Cold start and data sparsity, Personalized recommendation, privacy protection, AI recommendation system | ||
| Mining Top3 frontier topics in the field of "Oyster Reef Ecosystem" from 1981 to 2022 | Habitat protection and restoration, Ecosystem services, Climate change [21] | Ecosystem service, Ecological degradation and remediation techniques, Ecological conservation and policy support | Habitat protection and restoration, Ecosystem services, Ecological diversity conservation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



