Submitted:
07 November 2025
Posted:
10 November 2025
Read the latest preprint version here
Abstract
Code generation has emerged as a critical research area at the intersection of Software Engineering (SE) and Artificial Intelligence (AI), attracting significant attention from both academia and industry. Within this broader landscape, Verilog, as a representative hardware description language (HDL), plays a fundamental role in digital circuit design and verification, making its automated generation particularly significant for Electronic Design Automation (EDA). Consequently, recent research has increasingly focused on applying Large Language Models (LLMs) to Verilog code generation, particularly at the Register Transfer Level (RTL), exploring how these AI-driven techniques can be effectively integrated into hardware design workflows. Despite substantial research efforts have explored LLM applications in this domain, a comprehensive survey synthesizing these developments remains absent from the literature. This review fill addresses this gap by providing a systematic literature review of LLM-based methods for Verilog code generation, examining their effectiveness, limitations, and potential for advancing automated hardware design. The review encompasses research work from conferences and journals in the fields of SE, AI, and EDA, encompassing 70 papers published on venues, along with 32 high-quality preprint papers, bringing the total to 102 papers. By answering four key research questions, we aim to (1) identify the LLMs used for Verilog generation, (2) examine the datasets and metrics employed in evaluation, (3) categorize the techniques proposed for Verilog generation, and (4) analyze LLM alignment approaches for Verilog generation. Based on our findings, we have identified a series of limitations of existing studies. Finally, we have outlined a roadmap highlighting potential opportunities for future research endeavors in LLM-assisted hardware design.
Keywords:
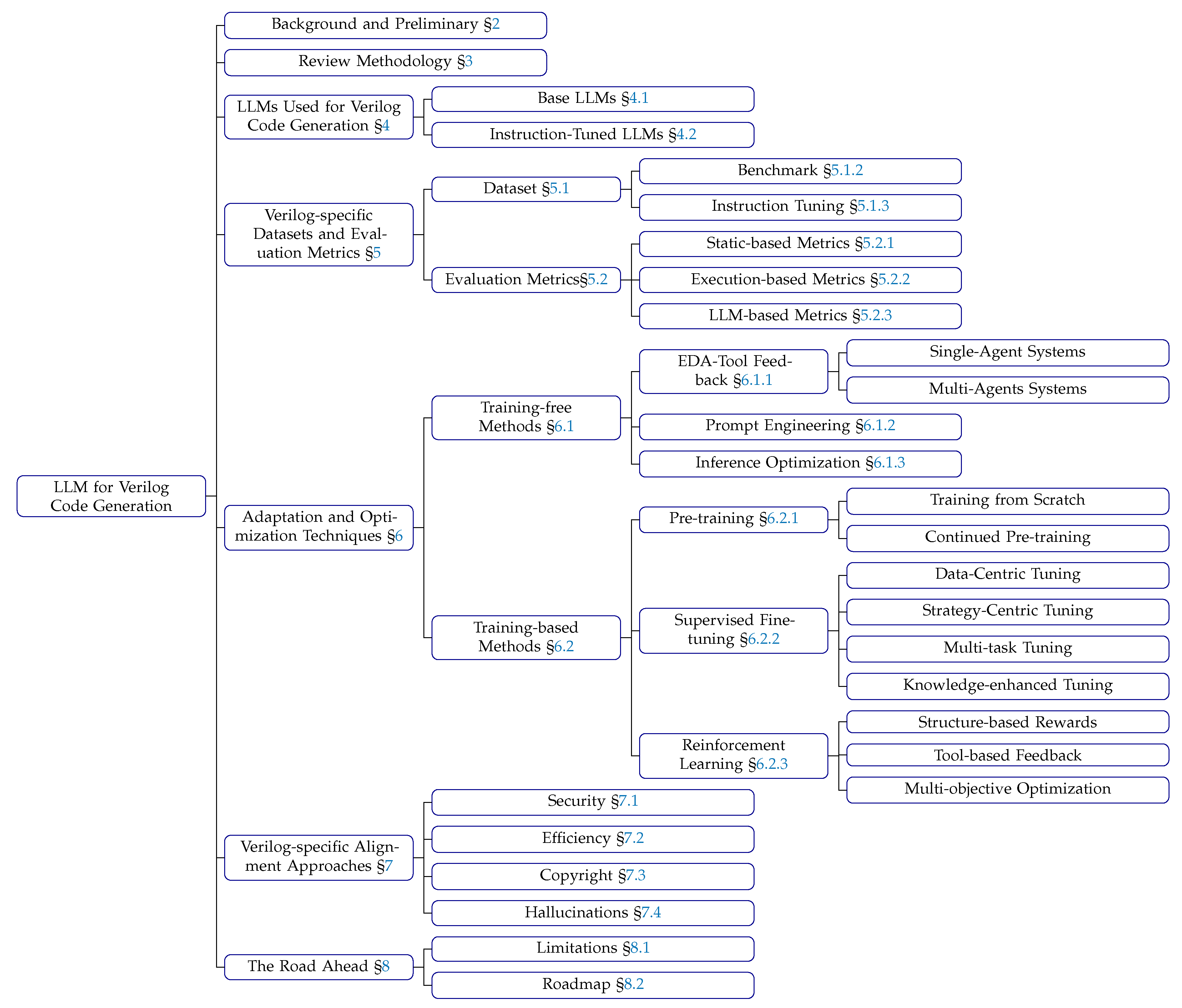
1. Introduction
- Concurrency: hardware systems are inherently parallel, requiring simultaneous consideration of multiple signal paths unlike sequential software execution;
- Timing constraints: designs must satisfy strict timing requirements including clock domains, setup/hold times, and propagation delays;
- Physical limitations: generated code must respect area, power, and routing constraints that directly impact manufacturing feasibility;
- Synthesizability: verification encompasses functional correctness, timing closure, and fabrication compliance beyond traditional software testing;
- Domain expertise: effective generation demands deep understanding of digital logic, computer architecture, and semiconductor physics.
- We present the first systematic literature review on LLM-based Verilog code generation, analyzing 102 papers (70 peer-reviewed, 32 high-quality preprints) spanning 2020-2025.
- We provide comprehensive taxonomy and trend analysis of LLMs for Verilog generation (RQ1), systematically analyze dataset construction and evaluation evolution across 27 benchmarks and 34 training datasets (RQ2), investigate adaptation and optimization techniques (RQ3), and examine alignment techniques addressing human-centric requirements including security, efficiency, copyright, and hallucinations (RQ4).
- We identify key research limitations and propose a comprehensive roadmap for future directions in LLM-assisted hardware design.
2. Background and Preliminaries
2.1. Large Language Models
2.2. Verilog Code Generation
3. Review Methodology
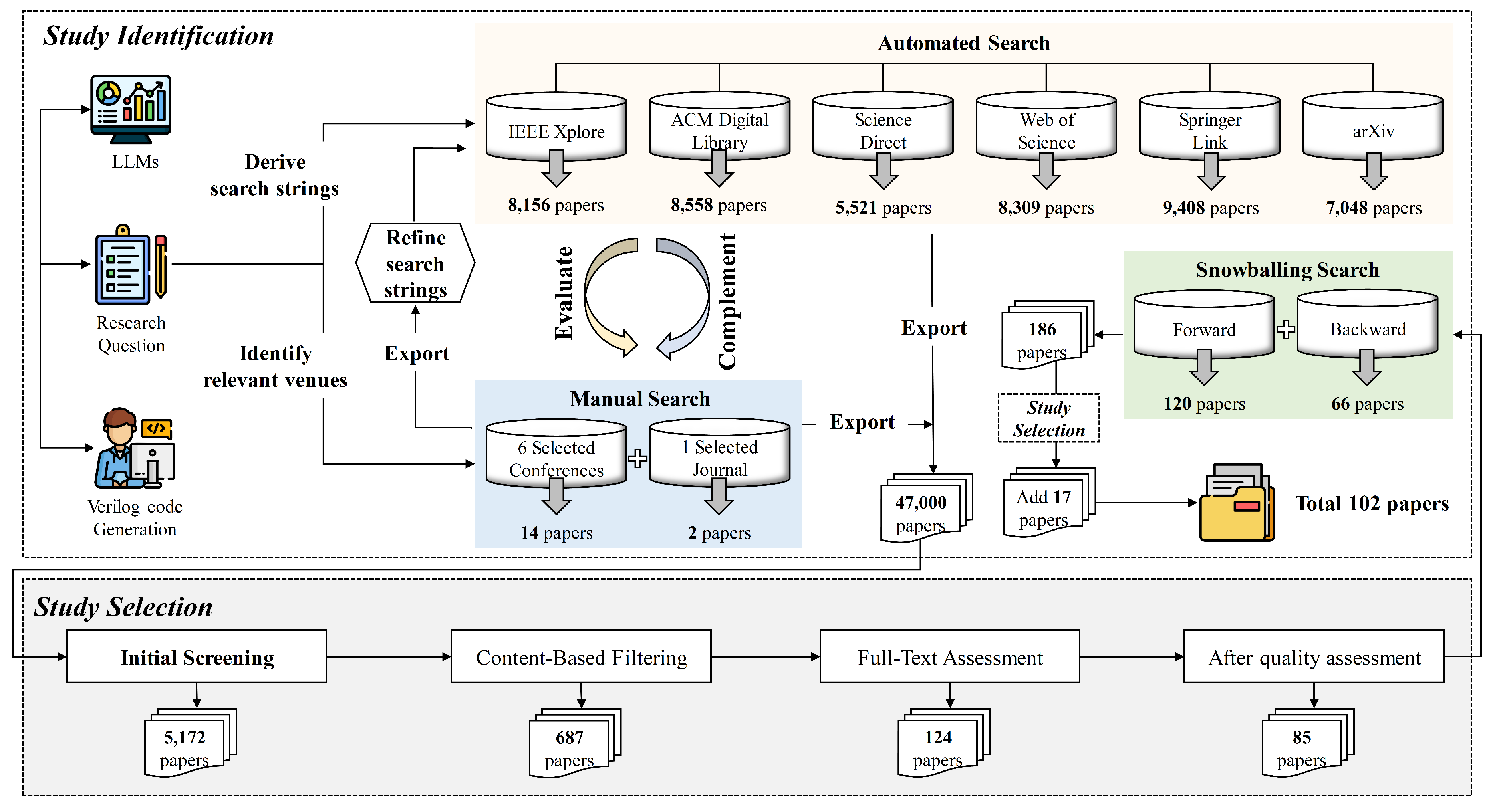
3.1. Research Question
3.2. Search Strategy
3.2.1. Search Items
- Keywords related to Verilog code generation (12 terms): Verilog, HDL, Hardware Description Language, RTL, Register Transfer Level, Digital Design, Hardware Design, Electronic Design Automation, EDA, Verilog Generation, FPGA, ASIC
- Keywords related to LLMs (13 terms): LLM, Large Language Model, Language Model, GPT, ChatGPT, Transformer, fine-tuning, prompt engineering, In-context learning, Natural Language Processing, NLP, Machine Learning, AI
3.2.2. Search Databases
3.3. Search Selection
3.3.1. Inclusion and Exclusion Criteria
3.3.2. Quality Assessment
3.3.3. Forward and Backward Snowballing
3.4. Data Extraction and Analysis
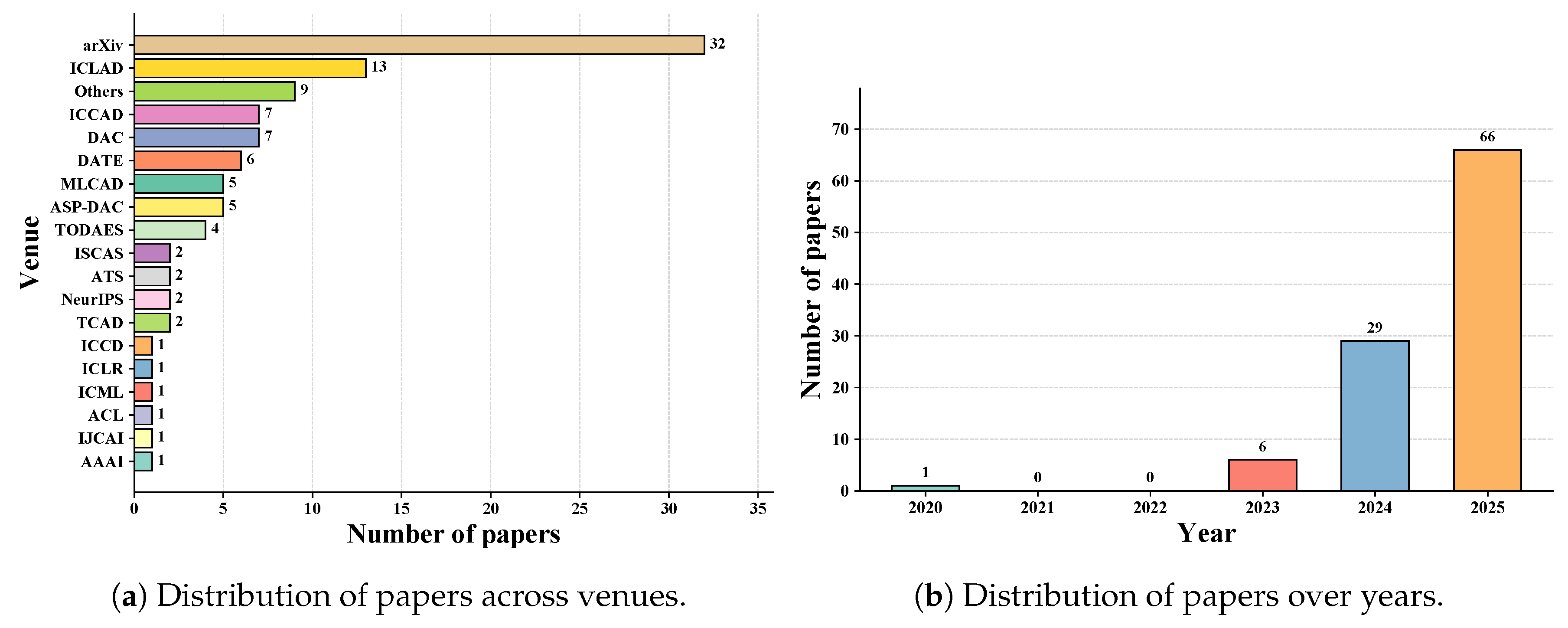
4. RQ1: LLMs Employed for Verilog Code Generation
4.1. Analysis of Base LLMs
4.1.1. Open-Source Base LLMs
(1) Llama Family Leadership
(2) DeepSeek Series Growth
(3) Qwen Series Growth
(4) Code-Oriented Models
(5) Other Models
4.1.2. Closed-Source Base LLMs
(1) GPT-series LLMs
(2) Other LLMs
4.1.3. Trends Analysis
(1) Open-Source vs. Closed-Source
-
Open-Source LLMs: Demonstrate accelerated growth (5 → 46 → 153 mentions) with 233% increase from 2024 to 2025. The evolution shows a clear shift from specialized code models to general-purpose foundation models:
- −
- 2023: Dominated by traditional code generation models (CodeGen: 3 mentions)
- −
- 2024: Transition to foundation families (Llama: 15, DeepSeek: 6, Qwen: 3 mentions)
- −
- 2025: Widespread adoption of latest foundation models (Llama: 49, DeepSeek: 48, Qwen: 25 mentions)
-
Closed-Source LLMs: Show steady expansion (7 → 51 → 121 mentions) with 137% growth rate, reflecting market diversification:
- −
- 2023: Exclusively OpenAI models (GPT-3.5, GPT-4: 7 mentions)
- −
- 2024: GPT dominance continues (42 mentions) while competitors emerge (Claude: 5 mentions, Gemini: 1 mention)
- −
- 2025: Market expansion with new reasoning models (GPT-o1/o3) and stronger competition from Claude 3.5 and Gemini
(2) Architectural Preferences
4.2. Analysis of IT LLMs
4.2.1. Foundation Model
- DeepSeek-Coder ecosystem: 32.4% market share (11 models) across variants (base, v2, R1-Distill), reflecting confidence in its code comprehension architecture
- Qwen coding series: 26.5% adoption (9 models) combining CodeQwen and Qwen2.5-Coder, demonstrating rapid integration of Alibaba’s latest developments
- CodeLlama variants: 23.5% usage (8 models), maintaining strong presence despite newer alternatives
4.2.2. Naming Patterns
4.2.3. Trends Analysis
4.3. Model Selection Insights

5. RQ2: Dataset and Evaluation Metrics for Verilog Code Generation
5.1. Dataset Construction
5.1.1. Overview
5.1.2. Benchmark Dataset Construction
(1) Data Sources
(2) Quality Assurance
5.1.3. Instruct-Tuning Dataset Construction
(1) Data Sources
(2) Quality Assurance
5.1.4. Trends Analysis
(1) Testbench availability
(2) Input modality
(3) Dataset scale
5.2. Evaluation Metrics
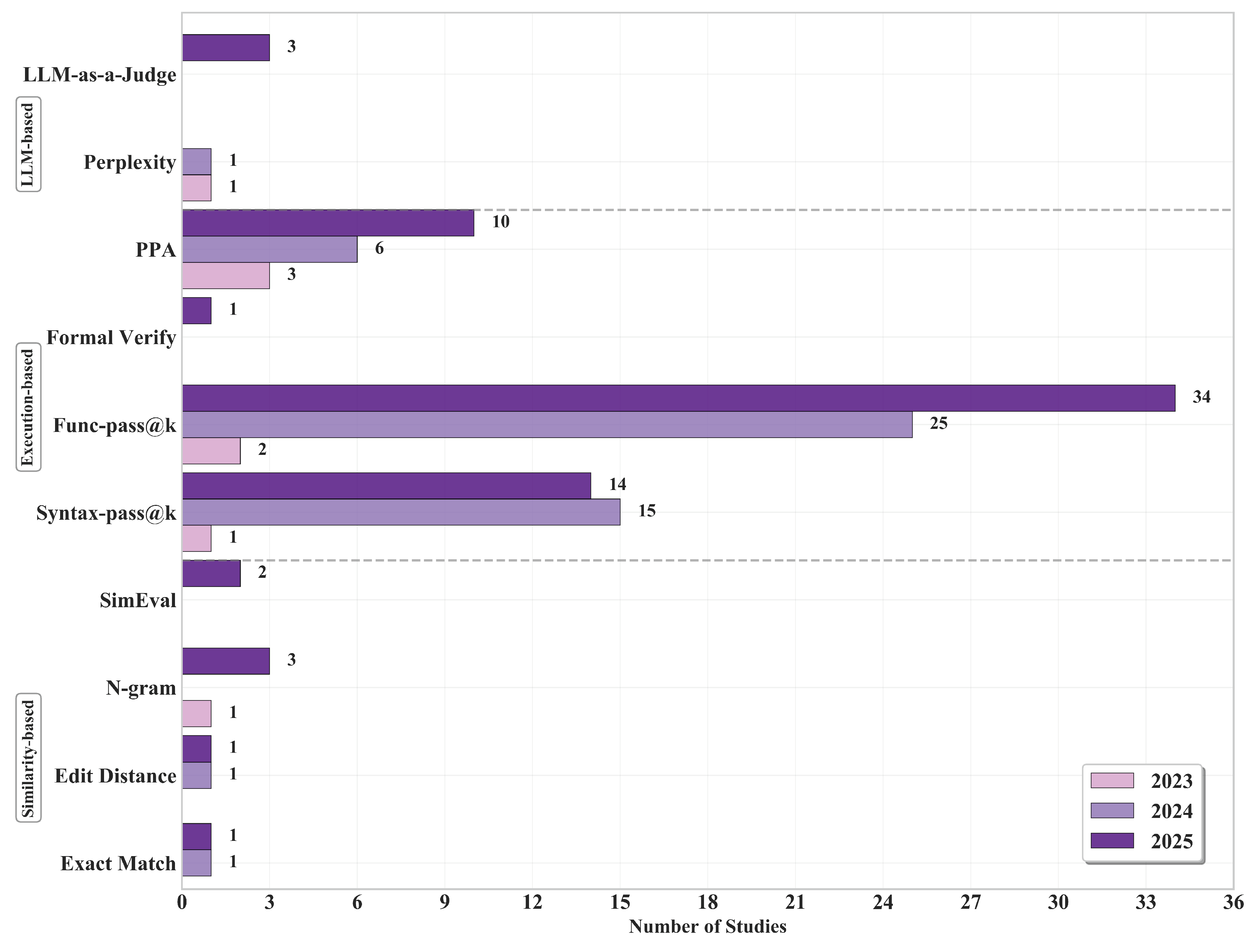
5.2.1. Similarity-based Metrics
(1) General-Purpose Metrics
(2) Verilog-Specific Metrics
5.2.2. Execution-based Metrics
(1) Correctness Assessment
- Syntax-pass@k: Quantifies the proportion of generated code samples that successfully compile without syntax errors across k attempts
- Functional-pass@k: Determines behavioral correctness by executing generated modules against standardized testbenches with predefined expected outputs
- Formal-Verification: Establishes equivalence between generated code and reference implementations using formal methods via "Yosys -equiv"
(2) Hardware Quality Metrics
- Power: Measures energy efficiency of synthesized designs
- Performance: Analyzes timing characteristics including maximum operating frequency, critical path delays, and latency metrics
- Area: Quantifies resource utilization efficiency in terms of logic gates, flip-flops, memory elements, and overall silicon footprint
5.2.3. LLM-based Metrics
(1) Model Confidence Metrics
(2) LLM-as-a-Judge
- VCD-RNK: Evaluates semantic consistency between natural language specifications and generated code implementations, implementing knowledge distillation techniques to develop efficient lightweight models capable of assessing functional [119]
- MetRex: Utilizes language models as expert evaluators to predict the PPA of generated Verilog code [115]
5.2.4. Metrics Trends Analysis
(1) Execution-based metrics
(2) Similarity-based metrics
(3) LLM-based metrics

6. RQ3: Adaptation and Optimization Techniques for Verilog Code Generation
6.1. Training-free Methods
6.1.1. EDA-Tool Feedback
(1) Single-Agent Systems
(2) Multi-Agent Systems
6.1.2. Prompt Engineering
6.1.3. Inference Optimization
6.2. Training-based Methods
6.2.1. Pre-training
(1) Training from Scratch:
(2) Continued Pre-training:
6.2.2. Supervised Fine-tuning
(1) Data-Centric Tuning
(2) Strategy-Centric Tuning
(3) Multi-task Tuning
(4) Knowledge-enhanced Tuning.
6.2.3. Reinforcement Learning
(1) Structure-based Rewards.
(2) Tool-based Feedback.
(3) Multi-objective Optimization.

7. RQ4: Alignment Approaches for Verilog Code Generation
- Security: Ensuring generated Verilog code is free from vulnerabilities, backdoors, or other security issues that could affect system security when implemented in hardware.
- Efficiency: Optimizing generated code for resource usage (e.g., Performance, Power, Area), as poorly designed implementations can lead to excessive energy consumption, slower operation, or inefficient use of silicon resources.
- Copyright: Addressing ownership concerns by verifying that generated Verilog code does not infringe on existing patents, licenses, or copy other’s designs without permission.
- Hallucinations: Reducing instances where LLMs produce code that appears correct but contains functional errors or logical inconsistencies that only become apparent during testing or implementation.
7.1. Security
(1) Current Methods
(2) Ongoing Challenges
(3) Promising Solutions
7.2. Efficiency
(1) Current Methods
(2) Ongoing Challenges
(3) Promising Solutions
7.3. Copyright
(1) Current Methods
(2) Ongoing Challenges
(3) Promising Solutions
7.4. Hallucinations
(1) Current Methods
(2) Ongoing Challenges
(3) Promising Solutions

8. The Road Ahead
8.1. Limitations
8.2. Roadmap
8.2.1. Established Pathways in Current Studies.
8.2.2. Path Forward.
- Opportunity 1: Hardware-Aware Foundation Models. While existing studies predominantly use general-purpose LLMs (RQ1), there is substantial opportunity to develop billion-scale Verilog-specific foundation models pretrained on curated hardware design corpora. These models should integrate EDA tool feedback during pretraining to develop intrinsic understanding of physical constraints, incorporate specialized architectural components for modeling concurrency and timing, and employ hardware-aware tokenization strategies capturing domain-specific patterns. Initial efforts like ChipGPT [70] demonstrate feasibility, but systematic development of specialized foundation models with reasoning capabilities remains largely unexplored.
- Opportunity 2: Comprehensive Benchmark Construction. Current benchmarks suffer from limited scale and coverage (RQ2). A critical opportunity exists to construct large-scale benchmarks exceeding 1,000 samples with graduated complexity from basic modules to industrial SoC designs. These benchmarks should include complete testbench suites with comprehensive coverage metrics, verified PPA ground truth from actual synthesis runs, standardized formats enabling consistent evaluation, and contamination prevention mechanisms ensuring fair assessment. Community-driven efforts maintaining living benchmarks through continuous expert-verified additions would provide reliable progress measurement.
- Opportunity 3: System-Level and Hierarchical Generation. Current approaches focus predominantly on module-level generation. Substantial opportunities exist for system-level (SoC to RTL) hierarchical generation capable of managing cross-module dependencies, interface protocol compliance, and design partitioning. This includes automatic design decomposition identifying appropriate module boundaries, hierarchical planning generating top-level architectures before detailed implementation, interface synthesis ensuring protocol compatibility across modules, and IP integration reusing verified components. Recent work on hierarchical benchmarks [100,103] provides foundations for this direction.
- Opportunity 4: Multimodal Verilog Generation. While most studies process text-only inputs, practical hardware design involves diverse artifacts including circuit diagrams, timing waveforms, block schematics, and datasheet specifications. Vision-language models adapted for hardware design could enable designers to sketch conceptual architectures and automatically generate RTL implementations. Initial explorations like ChipGPTV [97] and VGV [92] demonstrate feasibility, but systematic development of multimodal generation frameworks integrating visual specifications with textual descriptions remains largely unexplored.
- Opportunity 5: Closed-Loop PPA Optimization. As identified in RQ4, current PPA optimization approaches rely on expensive iterative feedback. Opportunities exist for developing reinforcement learning algorithms with reward functions derived directly from synthesis results, implementing efficient gradient-free optimization suitable for discrete hardware design spaces, and establishing automated refinement frameworks where initial generations undergo systematic improvement based on EDA tool feedback. Integration of synthesis tools (Yosys, Design Compiler) into generation loops could enable PPA-aware generation without manual iteration.
- Opportunity 6: Comprehensive Security Alignment. Security analysis (RQ4) reveals limited coverage of hardware-specific vulnerabilities. Opportunities include systematic construction of security-focused datasets covering full CWE hardware taxonomy, development of specialized detection models identifying timing-based vulnerabilities, side-channel weaknesses, and trojan insertion points, robust backdoor defense mechanisms protecting against training data poisoning, and automated security verification integrating formal methods and simulation-based validation. Frameworks like SecFSM [126] and SecV [127] provide initial foundations.
- Opportunity 7: Deployment-Ready Features. No current studies integrate solutions into industrial design workflows (RQ4). Critical opportunities exist for developing interactive design tools supporting human-in-the-loop refinement, implementing explainable generation providing transparent rationales for design decisions, creating seamless IDE integration enabling designers to leverage AI assistance within existing workflows, and establishing intelligent feedback mechanisms learning from designer corrections to align with project-specific requirements. Such features are essential for transitioning from research prototypes to production-ready tools.
- Once hardware-aware foundation models are developed, researchers can apply established fine-tuning or prompting techniques to enhance system-level hierarchical generation, then extend these models to support interactive designer collaboration through explainable interfaces and iterative refinement.
- With comprehensive benchmarks established, researchers can re-evaluate existing approaches to assess true progress beyond potentially contaminated datasets. Combining new benchmarks with standardized evaluation frameworks integrating PPA assessment and security analysis would enable fair cross-method comparison.
- Researchers can leverage multimodal generation capabilities with closed-loop PPA optimization, enabling designers to sketch high-level architectures that are automatically refined through synthesis feedback to meet timing and power constraints while maintaining visual correspondence with original specifications.
- Developing hierarchical generation frameworks using hardware-aware foundation models with integrated security alignment could produce system-level designs that are both architecturally sound and free from hardware vulnerabilities, verified through automated formal checking integrated into the generation pipeline.
9. THREATS TO VALIDITY
10. CONCLUSION
Acknowledgments
References
- Chen, M.; Tworek, J.; Jun, H.; et al. Evaluating large language models trained on code. arXiv 2021. [CrossRef]
- Roziere, B.; Gehring, J.; Gloeckle, F.; et al. Code llama: Open foundation models for code. arXiv 2023. [CrossRef]
- Peng, Q.; Chai, Y.; Li, X. HumanEval-XL: A Multilingual Code Generation Benchmark for Cross-lingual Natural Language Generalization. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024. 8383–8394.
- Zhao, Q.; Liu, F.; Long, X.; et al. On the Applicability of Code Language Models to Scientific Computing Programs. IEEE Transactions on Software Engineering 2025, 51, 1685–1701. [Google Scholar] [CrossRef]
- Gui, Y.; Li, Z.; Wan, Y.; et al. Webcode2m: A real-world dataset for code generation from webpage designs. In Proceedings of the ACM on Web Conference 2025, 2025, 1834–1845. [Google Scholar]
- Joel, S.; Wu, J.; Fard, F. A survey on llm-based code generation for low-resource and domain-specific programming languages. ACM Transactions on Software Engineering and Methodology, Online. 2025. [Google Scholar]
- Gu, X.; Chen, M.; Lin, Y.; et al. On the effectiveness of large language models in domain-specific code generation. ACM Transactions on Software Engineering and Methodology 2025, 34, 1–22. [Google Scholar] [CrossRef]
- Wu, N.; Xie, Y.; Hao, C. Ai-assisted synthesis in next generation eda: Promises, challenges, and prospects. In Proceedings of the 2022 IEEE 40th International Conference on Computer Design (ICCD); 2022. 207–214. [Google Scholar]
- Pearce, H.; Tan, B.; Karri, R. DAVE: Deriving Automatically Verilog from English. In Proceedings of the MLCAD ’20: 2020 ACM/IEEE Workshop on Machine Learning for CAD, Virtual Event, Iceland, 2020. 27–32.
- Kitchenham, B.A.; Madeyski, L.; Budgen, D. SEGRESS: Software Engineering Guidelines for REporting Secondary Studies. IEEE Transactions on Software Engineering 2022, 49, 1273–1298. [Google Scholar] [CrossRef]
- Zhang, H.; Babar, M.A.; Tell, P. Identifying relevant studies in software engineering. Inf. Softw. Technol. 2011, 53, 625–637. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, F.; Shen, J.; et al. A survey on large language models for code generation. arXiv 2024. [CrossRef]
- Chen, X.; Hu, X.; Huang, Y.; et al. Deep learning-based software engineering: progress, challenges, and opportunities. Science China Information Sciences 2025, 68, 111102. [Google Scholar] [CrossRef]
- Fang, W.; Wang, J.; Lu, Y.; et al. A survey of circuit foundation model: Foundation ai models for vlsi circuit design and eda. arXiv 2025.
- He, Z.; Yu, B. Large language models for eda: Future or mirage? In Proceedings of the 2024 International Symposium on Physical Design, 2024. 65–66.
- Chen, L.; Chen, Y.; Chu, Z.; et al. Large circuit models: opportunities and challenges. Science China Information Sciences 2024, 67, 200402. [Google Scholar] [CrossRef]
- Hou, X.; Zhao, Y.; Liu, Y.; et al. Large language models for software engineering: A systematic literature review. ACM Transactions on Software Engineering and Methodology 2024, 33, 1–79. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; et al. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, 2017. 5998–6008.
- Brown, T.; Mann, B.; Ryder, N.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, 2020. 1877–1901.
- Bai, Y.; Jones, A.; Ndousse, K.; et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv 2022. [CrossRef]
- Liu, S.; Lu, Y.; Fang, W.; et al. Openllm-rtl: Open dataset and benchmark for llm-aided design rtl generation. In Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024. 1–9.
- Hou, X.; Zhao, Y.; Liu, Y.; et al. Large Language Models for Software Engineering: A Systematic Literature Review. ACM Transactions on Software Engineering and Methodology 2024, 33, 1–79. [Google Scholar] [CrossRef]
- Zhou, X.; Cao, S.; Sun, X.; et al. Large Language Model for Vulnerability Detection and Repair: Literature Review and the Road Ahead. ACM Transactions on Software Engineering and Methodology 2025, 34, 1–31. [Google Scholar] [CrossRef]
- Hu, X.; Niu, F.; Chen, J.; et al. Assessing and Advancing Benchmarks for Evaluating Large Language Models in Software Engineering Tasks. arXiv 2025. [CrossRef]
- IEEE Xplore Database. https://ieeexplore.ieee.org.
- ACM Digital Library. https://dl.acm.org.
- ScienceDirect Database. https://www.sciencedirect.com.
- Web of Science Database. https://www.webofscience.com.
- SpringerLink Database. https://link.springer.com.
- arXiv Database. https://arxiv.org.
- Abdollahi, M.; Yeganli, S.F.; Baharloo, M.; et al. Hardware design and verification with large language models: A scoping review, challenges, and open issues. Electronics 2024, 14, 120. [Google Scholar] [CrossRef]
- Negri-Ribalta, C.; Geraud-Stewart, R.; Sergeeva, A.; et al. A systematic literature review on the impact of AI models on the security of code generation. Frontiers in Big Data 2024, 7, 1386720. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, H.; Shen, H.; et al. Quality Assessment in Systematic Literature Reviews: A Software Engineering Perspective. Information and Software Technology 2021, 130, 106397. [Google Scholar] [CrossRef]
- Wohlin, C. Guidelines for snowballing in systematic literature studies and a replication in software engineering. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering, 2014. 1–10.
- Touvron, H.; Lavril, T.; Izacard, G.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023. [CrossRef]
- Dubey, A.; Jauhri, A.; Pandey, A.; et al. The llama 3 herd of models. arXiv 2024. [CrossRef]
- Bi, X.; Chen, D.; Chen, G.; et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv 2024.
- Guo, D.; Zhu, Q.; Yang, D.; et al. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv 2024.
- Guo, D.; Yang, D.; Zhang, H.; et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature 2025, 645, 633–638. [Google Scholar] [CrossRef] [PubMed]
- Bai, J.; Bai, S.; Chu, Y.; et al. Qwen technical report. arXiv 2023. [PubMed]
- Hui, B.; Yang, J.; Cui, Z.; et al. Qwen2. 5-coder technical report. arXiv 2024.
- Nijkamp, E.; Pang, B.; Hayashi, H.; et al. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. In Proceedings of the International Conference on Learning Representations, 2023.
- Nijkamp, E.; Hayashi, H.; Xiong, C.; et al. CodeGen2: Lessons for Training LLMs on Programming and Natural Languages. arXiv 2023. [CrossRef]
- Li, R.; Zi, Y.; Muennighoff, N.; et al. StarCoder: may the source be with you! Transactions on Machine Learning Research, 2023.
- Lozhkov, A.; Li, R.; Allal, L.B.; et al. Starcoder 2 and the stack v2: The next generation. arXiv 2024. [CrossRef]
- CodeGemma, Team; Zhao, H.; Hui, J. CodeGemma Team; Zhao, H.; Hui, J.; et al. Codegemma: Open code models based on gemma. arXiv 2024. [Google Scholar]
- Wang, Y.; Le, H.; Gotmare, A.D.; et al. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. In Proceedings of the EMNLP 2023–2023 Conference on Empirical Methods in Natural Language Processing; 2023. 1069–1088. [Google Scholar]
- Gunasekar, S.; Zhang, Y.; Aneja, J.; et al. Textbooks are all you need. arXiv 2023.
- Li, Y.; Bubeck, S.; Eldan, R.; et al. Textbooks are all you need ii: phi-1.5 technical report. arXiv 2023. [CrossRef]
- Adler, B.; Agarwal, N.; Aithal, A.; et al. Nemotron-4 340b technical report. arXiv 2024. [CrossRef]
- OpenAI’s GPT series models. https://platform.openai.com/docs/models.
- Anthropic’s Claude series models. https://docs.claude.com/en/docs/about-claude/models/overview.
- Google’s Gemini series models. https://ai.google.dev/gemini-api/docs/models.
- Liu, H.; Li, C.; Wu, Q.; et al. Visual instruction tuning. In Proceedings of the Advances in Neural Information Processing Systems, 2023. 34892–34916.
- Gao, M.; Zhao, J.; Lin, Z.; et al. Autovcoder: A systematic framework for automated verilog code generation using llms. In Proceedings of the 2024 IEEE 42nd International Conference on Computer Design (ICCD), 2024. 162–169.
- Pei, Z.; Zhen, H.; Yuan, M.; et al. Betterv: Controlled verilog generation with discriminative guidance. In Proceedings of the International Conference on Machine Learning, 2024.
- Liu, M.; Pinckney, N.; Khailany, B.; et al. Verilogeval: Evaluating large language models for verilog code generation. In Proceedings of the 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), 2023. 1–8.
- Liu, M.; Tsai, Yu.; Zhou, W.; et al. CraftRTL: High-quality Synthetic Data Generation for Verilog Code Models with Correct-by-Construction Non-Textual Representations and Targeted Code Repair. In Proceedings of the International Conference on Learning Representations, 2025.
- Liu, Y.; Zhou, C.X.U.Y.; et al. DeepRTL: Bridging Verilog Understanding and Generation with a Unified Representation Model. In Proceedings of the International Conference on Learning Representations, 2025.
- Liu, Y.; Zhang, H.; Zhou, Y.; et al. DeepRTL2: A Versatile Model for RTL-Related Tasks. In Proceedings of the Findings of the Association for Computational Linguistics, 2025. 6485–6500.
- Bush, S.; DeLorenzo, M.; Tieu, P.; et al. Free and Fair Hardware: A Pathway to Copyright Infringement-Free Verilog Generation using LLMs. In Proceedings of the 2025 62nd ACM/IEEE Design Automation Conference (DAC), 2025. 1–7.
- Wu, P.; Guo, N.; Xiao, X.; et al. Itertl: An iterative framework for fine-tuning llms for rtl code generation. In Proceedings of the 2025 IEEE International Symposium on Circuits and Systems (ISCAS), 2025. 1–5.
- Nadimi, B.; Zheng, H. A multi-expert large language model architecture for verilog code generation. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), 2024. 1–5.
- Wang, J.; Wan, L.J.; Pingali, S.; et al. OpenRTLSet: A Fully Open-Source Dataset for Large Language Model-based Verilog Module Design. In Proceedings of the 2025 IEEE International Conference on LLM-Aided Design (ICLAD), 2025. 212–218.
- Nadimi, B.; Boutaib, G.O.; Zheng, H. Pyranet: A multi-layered hierarchical dataset for verilog. In Proceedings of the 2025 62nd ACM/IEEE Design Automation Conference (DAC), 2025. 1–7.
- Akyash, M.; Azar, K.; Kamali, H. RTL++: Graph-enhanced LLM for RTL Code Generation. In Proceedings of the 2025 IEEE International Conference on LLM-Aided Design (ICLAD), 2025. 44–50.
- Wu, P.; Guo, N.; Lv, J.; et al. RTLRepoCoder: Repository-Level RTL Code Completion through the Combination of Fine-Tuning and Retrieval Augmentation. arXiv 2025.
- Deng, C.; Tsai, Yu.; Liu, Gu.; et al. ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation. In Proceedings of the 2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD), 2025. 1–9.
- Roy, P.B.; Saha, A.; Alam, M.; et al. Veritas: Deterministic Verilog Code Synthesis from LLM-Generated Conjunctive Normal Form. arXiv 2025.
- Chang, K.; Wang, Y.; Ren, H.; et al. Chipgpt: How far are we from natural language hardware design. arXiv 2023. [CrossRef]
- Zhao, Y.; Huang, D.; Li, C.; et al. CodeV: Empowering LLMs with HDL Generation through Multi-Level Summarization. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025. Early Access.
- Zhu, Y.; Huang, D.; Lyu, H.; et al. CodeV-R1: Reasoning-Enhanced Verilog Generation. In Proceedings of the Advances in Neural Information Processing Systems, 2025. Accept.
- Zhang, G.; Zou, D.; Sun, K.; et al. GEMMV: An LLM-based Automated Performance-Aware Framework for GEMM Verilog Generation. IEEE Journal on Emerging and Selected Topics in Circuits and Systems 2025, 15, 325–336. [Google Scholar] [CrossRef]
- Fu, W.; Li, S.; Zhao, Y.; et al. Hardware phi-1.5 b: A large language model encodes hardware domain specific knowledge. In Proceedings of the 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), 2024. 349–354.
- Yang, Y.; Teng, F.; Liu, P.; et al. Haven: Hallucination-mitigated llm for verilog code generation aligned with hdl engineers. In Proceedings of the 2025 Design, Automation & Test in Europe Conference (DATE), 2025. 1–7.
- Zhang, Y.; Yu, Z.; Fu, Y.; et al. Mg-verilog: Multi-grained dataset towards enhanced llm-assisted verilog generation. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), 2024. 1–5.
- Goh, E.; Xiang, M.; Wey, I.; et al. From english to asic: Hardware implementation with large language model. arXiv 2024. [CrossRef]
- Cui, F.; Yin, C.; Zhou, K.; et al. Origen: Enhancing rtl code generation with code-to-code augmentation and self-reflection. In Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024. 1–9.
- Qin, H.; Xie, Z.; Li, J.; et al. ReasoningV: Efficient Verilog Code Generation with Adaptive Hybrid Reasoning Model. arXiv 2025. [CrossRef]
- Liu, S.; Fang, W.; Lu, Y.; et al. Rtlcoder: Fully open-source and efficient llm-assisted rtl code generation technique. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 2024. [Google Scholar] [CrossRef]
- Wei, A.; Tan, H.; Suresh, T.; et al. VeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation. arXiv 2025.
- Thakur, S.; Ahmad, B.; Pearce, H.; et al. Verigen: A large language model for verilog code generation. ACM Transactions on Design Automation of Electronic Systems 2024, 29, 1–31. [Google Scholar] [CrossRef]
- Min, K.; Park, S.; Park, H.; et al. Improving LLM-Based Verilog Code Generation with Data Augmentation and RL. In Proceedings of the 2025 Design, Automation & Test in Europe Conference (DATE), 2025. 1–7.
- Wang, N.; Yao, B.; Zhou, J.; et al. Insights from Verification: Training a Verilog Generation LLM with Reinforcement Learning with Testbench Feedback. arXiv 2025. [CrossRef]
- Wang, Y.; Sun, G.; Ye, W.; et al. VeriReason: Reinforcement Learning with Testbench Feedback for Reasoning-Enhanced Verilog Generation. arXiv 2025.
- Wang, N.; Yao, B.; Zhou, J.; et al. Large language model for verilog generation with code-structure-guided reinforcement learning. In Proceedings of the 2025 IEEE International Conference on LLM-Aided Design (ICLAD), 2025. 164–170.
- Yubeaton, P.; Nakkab, A.; Xiao, W.; et al. Verithoughts: Enabling automated verilog code generation using reasoning and formal verification. In Proceedings of the Advances in Neural Information Processing Systems, 2025. Accept.
- Thakur, S.; Ahmad, B.; Fan, Z.; et al. Benchmarking large language models for automated verilog rtl code generation. In Proceedings of the 2023 Design, Automation & Test in Europe Conference Exhibition (DATE), 2023. 1–6.
- Gupta, V.K.; Yadav, A.; Fujita, M.; et al. LLM-aided Front-End Design Framework For Early Development of Verified RTLs. In Proceedings of the 2024 IEEE 33rd Asian Test Symposium (ATS), 2024. 1–6.
- DeLorenzo, M.; Chowdhury, A.B.; Gohil, V.; et al. Make every move count: Llm-based high-quality rtl code generation using mcts. arXiv 2024.
- Vitolo, P.; Psaltakis, G.; Tomlinson, M.; et al. Natural Language to Verilog: Design of a Recurrent Spiking Neural Network using Large Language Models and ChatGPT. In Proceedings of the 2024 International Conference on Neuromorphic Systems (ICONS), 2024. 110–116.
- Wong, S.; Wan, G.; Liu, D.; et al. VGV: Verilog generation using visual capabilities of multi-modal large language models. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), 2024. 1–5.
- Li, C.; Chen, C.; Pan, Y.; et al. Autosilicon: Scaling up rtl design generation capability of large language models. ACM Transactions on Design Automation of Electronic Systems 2025, 30, 1–26. [Google Scholar] [CrossRef]
- Tang, J.; Qin, J.; Thorat, K.; et al. Hivegen–hierarchical llm-based verilog generation for scalable chip design. In Proceedings of the 2025 IEEE International Conference on LLM-Aided Design (ICLAD), 2025. 30–36.
- Ye, J.; Liu, T.; Tian, Q.; et al. ChatModel: Automating Reference Model Design and Verification with LLMs. arXiv 2025. [CrossRef]
- Thakur, S.; Blocklove, J.; Pearce, H.; et al. Autochip: Automating hdl generation using llm feedback. arXiv 2023. [CrossRef]
- Chang, K.; Chen, Z.; Zhou, Y.; et al. Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation. In Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024. 1–9.
- DeLorenzo, M.; Gohil, V.; Rajendran, J. Creativeval: Evaluating creativity of llm-based hardware code generation. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), 2024. 1–5.
- Blocklove, J.; Garg, S.; Karri, R.; et al. Evaluating llms for hardware design and test. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), 2024. 1–6.
- Nakkab, A.; Zhang, S.Q.; Karri, R.; et al. Rome was not built in a single step: Hierarchical prompting for llm-based chip design. In Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, 2024. 1–11.
- Lu, Y.; Liu, S.; Zhang, Q.; et al. Rtllm: An open-source benchmark for design rtl generation with large language model. In Proceedings of the 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), 2024. 722–727.
- Allam, A.; Shalan, M. Rtl-repo: A benchmark for evaluating llms on large-scale rtl design projects. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), 2024. 1–5.
- Purini, S.; Garg, S.; Gaur, M.; et al. ArchXBench: A Complex Digital Systems Benchmark Suite for LLM Driven RTL Synthesis. In Proceedings of the 2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD), 2025. 1–10.
- Pinckney, N.; Deng, C.; Ho, C.; et al. Comprehensive Verilog Design Problems: A Next-Generation Benchmark Dataset for Evaluating Large Language Models and Agents on RTL Design and Verification. arXiv 2025. [CrossRef]
- Wan, G.; Wang, Y.; Wong, S.; et al. GenBen: A Generative Benchmark for LLM-Aided Design. Arxiv 2025. [Google Scholar]
- Jin, P.; Huang, D.; Li, C.; et al. RealBench: Benchmarking Verilog Generation Models with Real-World IP Designs. arXiv 2025.
- Guo, C.; Zhao, T. ResBench: A Resource-Aware Benchmark for LLM-Generated FPGA Designs. In Proceedings of the 15th International Symposium on Highly Efficient Accelerators and Reconfigurable Technologies, 2025. 25–34.
- Pinckney, N.; Batten, C.; Liu, M.; et al. Revisiting verilogeval: A year of improvements in large-language models for hardware code generation. ACM Transactions on Design Automation of Electronic Systems 2025, 30, 1–20. [Google Scholar] [CrossRef]
- Calzada, P.E.; Ibnat, Z.; Rahman, T.; et al. VerilogDB: The Largest, Highest-Quality Dataset with a Preprocessing Framework for LLM-based RTL Generation. arXiv 2025.
- Chang, K.; Wang, K.; Yang, N.; et al. Data is all you need: Finetuning llms for chip design via an automated design-data augmentation framework. In Proceedings of the 61st ACM/IEEE Design Automation Conference, 2024. 1–6.
- Liu, S.; Fang, W.; Lu, Y.; et al. RTLCoder: Outperforming GPT-3.5 in Design RTL Generation with Our Open-Source Dataset and Lightweight Solution. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), 2024. 1–5.
- Li, Z.; Xu, C.; Shi, Z.; et al. DeepCircuitX: A Comprehensive Repository-Level Dataset for RTL Code Understanding, Generation, and PPA Analysis. In Proceedings of the 2025 IEEE International Conference on LLM-Aided Design (ICLAD), 2025. 204–211.
- Chen, X.; Yang, G.; Cui, Zh.; et al. Survey of State-of-the-art Automatic Code Comment Generation. Journal of Software 2021, 32, 2118. [Google Scholar]
- HDLBits Website. https://hdlbits.01xz.net/wiki/Main_Page.
- Abdelatty, M.; Ma, J.; Reda, S. MetRex: A Benchmark for Verilog Code Metric Reasoning Using LLMs. In Proceedings of the 30th Asia and South Pacific Design Automation Conference, 2025. 995–1001.
- OpenCores Website. https://opencores.org.
- Dehaerne, E.; Dey, B.; Halder, S.; et al. A deep learning framework for verilog autocompletion towards design and verification automation. arXiv 2023. [CrossRef]
- Akyash, M.; Kamali, H.M. Simeval: Investigating the similarity obstacle in llm-based hardware code generation. In Proceedings of the 30th Asia and South Pacific Design Automation Conference, 2025. 1002–1007.
- Yang, G.; Zheng, W.; Chen, X.; et al. The Cream Rises to the Top: Efficient Reranking Method for Verilog Code Generation. arXiv 2025. [CrossRef]
- DeLorenzo, M.; Tieu, K.; Jana, P.; et al. Abstraction-of-Thought: Intermediate Representations for LLM Reasoning in Hardware Design. arXiv 2025.
- Bai, K.; Yan, P.; Liu, L.; et al. VeriRAG: Design AI-Specific CPU Co-processor with RAG-Enhanced LLMs. In Proceedings of the 2025 International Symposium of Electronics Design Automation (ISEDA), 2025. 76–82.
- Ping, H.; Li, S.; Zhang, P.; et al. Hdlcore: A training-free framework for mitigating hallucinations in llm-generated hdl. arXiv 2025.
- Akyash, M.; Azar, K.; Kamali, H. DecoRTL: A Run-time Decoding Framework for RTL Code Generation with LLMs. arXiv 2025.
- Zhao, Z.; Qiu, R.; Lin, C.; et al. Vrank: Enhancing verilog code generation from large language models via self-consistency. In Proceedings of the 2025 26th International Symposium on Quality Electronic Design (ISQED), 2025. 1–7.
- Xu, C.; Liu, Y.; Zhou, Y.; et al. Speculative Decoding for Verilog: Speed and Quality, All in One. In Proceedings of the 62nd ACM/IEEE Design Automation Conference, DAC 2025, San Francisco, CA, USA, June 22–25, 2025, 2025. 1–7.
- Hu, Z.; Xia, Y.; Chen, X.; et al. SecFSM: Knowledge Graph-Guided Verilog Code Generation for Secure Finite State Machines in Systems-on-Chip. arXiv 2025.
- Fan, F.; Xia, Y.; Kuang, L. SecV: LLM-based Secure Verilog Generation with Clue-Guided Exploration on Hardware-CWE Knowledge Graph. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, 2025. 8049–8057.
- Mankali, L.L.; Bhandari, J.; Alam, M.; et al. Rtl-breaker: Assessing the security of llms against backdoor attacks on hdl code generation. In Proceedings of the 2025 Design, Automation & Test in Europe Conference (DATE), 2025. 1–7.
- Wang, Z.; Shao, M.; Bhandari, J.; et al. VeriContaminated: Assessing LLM-driven verilog coding for data contamination. arXiv 2025.
- Wang, Z.; Shao, M.; Karn, R.; et al. SALAD: Systematic Assessment of Machine Unlearing on LLM-Aided Hardware Design. arXiv 2025. [CrossRef]
- Tasnia, K.; Garcia, A.; Farheen, T.; et al. Veriopt: Ppa-aware high-quality verilog generation via multi-role llms. arXiv 2025.
- Chang, K.; Zhu, W.; Wang, K.; et al. A data-centric chip design agent framework for Verilog code generation. ACM Transactions on Design Automation of Electronic Systems 2025, 30, 1–27. [Google Scholar] [CrossRef]
- Thorat, K.; Zhao, J.; Liu, Y.; et al. LLM-VeriPPA: Power, Performance, and Area Optimization aware Verilog Code Generation with Large Language Models. In Proceedings of the 2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD), 2025. 1–7.
- Wang, B.; Xiong, Q.; Xiang, Z.; et al. Rtlsquad: Multi-agent based interpretable rtl design. arXiv 2025.
- Wang, K.; Chang, K.; Wang, M.; et al. Rtlmarker: Protecting llm-generated rtl copyright via a hardware watermarking framework. In Proceedings of the 30th Asia and South Pacific Design Automation Conference, 2025. 808–813.
- Zhang, J.; Liu, C.; Li, H. Understanding and Mitigating Errors of LLM-Generated RTL Code. arXiv 2025. [CrossRef]
- Sun, W.; Li, B.; Zhang, G.L.; et al. Paradigm-based automatic hdl code generation using llms. In Proceedings of the 2025 26th International Symposium on Quality Electronic Design (ISQED), 2025. 1–8.
- Huang, H.; Lin, Z.; Wang, Z.; et al. Towards llm-powered verilog rtl assistant: Self-verification and self-correction. arXiv 2024.
- Tsai, Y.; Liu, M.; Ren, H. RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Model. In Proceedings of the the 61st ACM/IEEE Design Automation Conference, 2024. 1–6.
- Guo, P.; Wang, Y.; Ye, W.; et al. EvoVerilog: Large Langugage Model Assisted Evolution of Verilog Code. arXiv 2025.
- Blocklove, J.; Thakur, S.; Tan, B.; et al. Automatically Improving LLM-based Verilog Generation using EDA Tool Feedback. ACM Transactions on Design Automation of Electronic Systems 2025, 30, 1–26. [Google Scholar] [CrossRef]
- Islam, M.u.; Sami, H.; Gaillardon, P.; et al. AIvril: AI-Driven RTL Generation With Verification In-The-Loop. arXiv 2024.
- Ranga, S.; Mao, R.; Bhattacharjee, D.; et al. RTL Agent: An Agent-Based Approach for Functionally Correct HDL Generation via LLMs. In Proceedings of the 2024 IEEE 33rd Asian Test Symposium (ATS), 2024. 1–6.
- Zhao, Y.; Zhang, H.; Huang, H.; et al. MAGE: A Multi-Agent Engine for Automated RTL Code Generation. In Proceedings of the 2025 62nd ACM/IEEE Design Automation Conference (DAC), 2025. 1–7.
- Ho, Ch.; Ren, H.; Khailany, B. VerilogCoder: Autonomous Verilog Coding Agents with Graph-based Planning and Abstract Syntax Tree (AST)-based Waveform Tracing Tool. In Proceedings of the the AAAI Conference on Artificial Intelligence, 2025. 300–307.
- Mi, Z.; Zheng, R.; Zhong, H.; et al. CoopetitiveV: Leveraging LLM-powered Coopetitive Multi-Agent Prompting for High-quality Verilog Generation. arXiv 2025.
- Sami, H.; Islam, M.u.; Charas, S.; et al. Nexus: A Lightweight and Scalable Multi-Agent Framework for Complex Tasks Automation. arXiv 2025. [CrossRef]
- Wei, Y.; Huang, Z.; Li, H.; et al. VFlow: Discovering Optimal Agentic Workflows for Verilog Generation. arXiv 2025.
- Nadimi, B.; Boutaib, G.O.; Zheng, H. VeriMind: Agentic LLM for Automated Verilog Generation with a Novel Evaluation Metric. arXiv 2025.
- Negri-Ribalta, C.; Geraud-Stewart, R.; Sergeeva, A.; et al. A systematic literature review on the impact of AI models on the security of code generation. Frontiers in Big Data 2024, 7, 1386720. [Google Scholar] [CrossRef] [PubMed]
- Zhuo, T.Y.; Vu, M.C.; Chim, J.; et al. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions. In Proceedings of the International Conference on Learning Representations, 2025.
- Liu, T.; Xu, C.; McAuley, J. RepoBench: A Benchmark for Repo-Level Code Generation. In Proceedings of the International Conference on Learning Representations, 2023.
- Jimenez, C.E.; Yang, J.; Wettig, A.; et al. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? In Proceedings of the International Conference on Learning Representations, 2024.
| 1 | For preprint papers released on arXiv, we performed manual quality assessments to determine their eligibility for inclusion based on methodological soundness and contribution relevance. |
| 2 | Due to page limitations, we place the full statistical results of other models on the project homepage. |
| 3 | |
| 4 |


| Survey | Year | Papers | Topics | Verilog Focus |
|---|---|---|---|---|
| General Code Generation Surveys | ||||
| Jiang et al. [12] | 2024 | 235 | General Programming Languages | ✗ |
| Joel et al. [6] | 2024 | 111 | Low-Resource and Domain-Specific Programming Languages | Partial |
| Chen et al. [13] | 2025 | 601 | Deep Learning-based Software Engineering | ✗ |
| EDA-focused Surveys | ||||
| Fang et al. [14] | 2025 | 250 | Layout/Netlists/HDL/Assertion Generation | Partial |
| He et al. [15] | 2024 | 211 | EDA Generation, Verification, and Debugging | Partial |
| Chen et al. [16] | 2024 | A Paradigm Shift from AI4EDA towards AI-rooted EDA (full-workflow AI4EDA) | Partial | |
| Our Verilog-specific Survey | ||||
| Our work | 2025 | 102 | Verilog Code Generation | |
| Acronym | Venues |
|---|---|
| AAAI | AAAI Conference on Artificial Intelligence |
| ACL | Annual Meeting of the Association for Computational Linguistics |
| ICML | International Conference on Machine Learning |
| ICLR | International Conference on Learning Representations |
| NeurIPS | Conference on Neural Information Processing Systems |
| DAC | Design Automation Conference |
| TCAD | IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems |
| Inclusion criteria | |
|---|---|
| 1) | The paper claims that an LLM is used. |
| 2) | The paper claims that the study involves to solve Verilog code generation. |
| 3) | The paper with accessible full text and must be written in English. |
| Exclusion criteria | |
| 1) | Short papers whose number of pages is less than 5. |
| 2) | Books, records, theses, tool demos papers, editorials, or venues not subject to a full peer-review process. |
| 3) | The paper is a literature review or survey. |
| 4) | The paper mentions LLMs only in future work or discussions rather than using LLMs in the approach. |
| 5) | The paper does not involve Verilog code generation. |
| 6) | Duplicate papers or similar studies authored by the same authors. |
| ID | Quality Assessment Criteria |
|---|---|
| QAC1 | Was the study published in a prestigious venue? |
| QAC2 | Does the study make a contribution to the academic or industrial community? |
| QAC3 | Does the study provide a clear description of the workflow and implementation of the proposed approach? |
| QAC4 | Are the experiment details, including datasets, baselines, and evaluation metrics, clearly outlined? |
| QAC5 | Do the findings from the experiments strongly support the main arguments presented in the study? |
| LLM Family | LLM Name | 2023 | 2024 | 2025 | Total |
|---|---|---|---|---|---|
| Llama Series | CodeLlama | 0 | 7 | 16 | 23 |
| Llama | 0 | 0 | 1 | 1 | |
| Llama2 | 0 | 2 | 5 | 7 | |
| Llama3 | 0 | 4 | 7 | 11 | |
| Llama3.1 | 0 | 0 | 18 | 18 | |
| Llama3.2 | 0 | 0 | 1 | 1 | |
| Llama3.3 | 0 | 0 | 1 | 1 | |
| LlaVa | 0 | 2 | 0 | 2 | |
| Subtotal | 0 | 15 | 49 | 64 | |
| DeepSeek Series | DeepSeek-Coder | 0 | 6 | 21 | 27 |
| DeepSeek-Coder-V2 | 0 | 0 | 5 | 5 | |
| DeepSeek-R1 | 0 | 0 | 8 | 8 | |
| DeepSeek-R1-Distill | 0 | 0 | 5 | 5 | |
| DeepSeek-V2 | 0 | 0 | 1 | 1 | |
| DeepSeek-V2.5 | 0 | 0 | 1 | 1 | |
| DeepSeek-V3 | 0 | 0 | 7 | 7 | |
| Subtotal | 0 | 6 | 48 | 54 | |
| Qwen Series | CodeQwen | 0 | 3 | 10 | 13 |
| Qwen2.5-Coder | 0 | 0 | 12 | 12 | |
| Qwen3 | 0 | 0 | 1 | 1 | |
| Qwen-vl | 0 | 0 | 1 | 1 | |
| QWQ | 0 | 0 | 1 | 1 | |
| Subtotal | 0 | 3 | 25 | 28 | |
| CodeGen Series | CodeGen | 3 | 2 | 0 | 5 |
| CodeGen2 | 0 | 4 | 1 | 5 | |
| CodeGen2.5 | 0 | 0 | 2 | 2 | |
| Subtotal | 3 | 6 | 3 | 12 | |
| StarCoder Series | StarCoder | 0 | 4 | 3 | 7 |
| StarCoder2 | 0 | 1 | 3 | 4 | |
| Subtotal | 0 | 5 | 6 | 11 | |
| Others | Various Models | 2 | 11 | 22 | 35 |
| Total Open-Source | 5 | 46 | 153 | 204 | |
| LLM Family | LLM Name | 2023 | 2024 | 2025 | Total |
|---|---|---|---|---|---|
| GPT Series | code-davinci-002 | 1 | 1 | 0 | 2 |
| GPT-3.5 | 3 | 16 | 24 | 43 | |
| GPT-4 | 3 | 20 | 29 | 52 | |
| GPT-4o | 0 | 4 | 31 | 35 | |
| GPT-4-turbo | 0 | 0 | 2 | 2 | |
| GPT-4V | 0 | 1 | 1 | 2 | |
| GPT-o1 | 0 | 0 | 6 | 6 | |
| GPT-o3 | 0 | 0 | 4 | 4 | |
| GPT-o4 | 0 | 0 | 3 | 3 | |
| Subtotal | 7 | 42 | 100 | 149 | |
| Claude Series | Claude 2 | 0 | 1 | 0 | 1 |
| Claude 3 | 0 | 2 | 2 | 4 | |
| Claude 3.5 | 0 | 2 | 6 | 8 | |
| Claude 3.7 | 0 | 0 | 5 | 5 | |
| Claude 4 | 0 | 0 | 1 | 1 | |
| Subtotal | 0 | 5 | 14 | 19 | |
| Gemini | Gemini | 0 | 1 | 4 | 5 |
| Others | Various Models | 0 | 3 | 3 | 6 |
| Total Closed-Source | 7 | 51 | 121 | 179 | |
| Verilog-Specific LLM | Foundation Model | Weight | URL |
|---|---|---|---|
| Closed-Source (Model Weights) | |||
| AutoVCoder [55] | CL/CQ/DS-Coder | Closed | - |
| BetterV [56] | CL/CQ/DS-Coder | Closed | - |
| CodeGen-Verilog [57] | CodeGen | Closed | - |
| CraftRTL [58] | CL/DS-Coder/StarCoder2 | Closed | - |
| DeepRTL [59] | CodeT5+ | Closed | - |
| DeepRTL2 [60] | Llama3.1/DS-Coder | Closed | - |
| FreeV [61] | Llama3.1 | Closed | - |
| ITERTL [62] | DS-Coder/DS-Coder-v2 | Closed | - |
| MEV-LLM [63] | CodeGen/Gemma | Closed | - |
| OpenRTLSet [64] | Qwen2.5 | Closed | - |
| PyraNet [65] | CL/DS-Coder | Closed | - |
| RTL++ [66] | CL | Closed | - |
| RTLRepoCoder [67] | DS-Coder | Closed | - |
| ScaleRTL [68] | DS-R1-Distill-Qwen | Closed | - |
| Veritas [69] | Llama-3.2 | Closed | - |
| Open-Source (Model Weights) | |||
| DAVE [9] | GPT-2 | Open | https://shorturl.asia/VWPTn |
| ChipGPT [70] | Llama2/Llama3 | Open | https://www.modelscope.cn/profile/changkaiyan |
| CodeV [71] | CQ/DS-Coder/QC | Open | https://huggingface.co/zhuyaoyu |
| CodeV-R1 [72] | QC | Open | https://huggingface.co/zhuyaoyu |
| GEMMV [73] | DS-R1-Distill-Qwen/Llama3.1 | Open | https://huggingface.co/bxsk2024 |
| Hardware Phi-1.5B [74] | Phi-1.5B | Open | https://huggingface.co/KSU-HW-SEC/Hardware_Phi_30k_version |
| HAVEN [75] | CL/DS-Coder/CQ | Open | https://huggingface.co/yangyiyao |
| MG-Verilog [76] | CL | Open | https://shorturl.asia/rDNSm |
| Mistral-Verilog [77] | Mistral | Open | https://huggingface.co/emilgoh/mistral-verilog |
| Origen [78] | DS-Coder | Open | https://huggingface.co/henryen/OriGen |
| ReasoningV [79] | QC | Open | https://modelscope.cn/models/GipsyAI/ReasoningV-7B |
| RTLCoder [80] | Mistral/DS-Coder | Open | https://github.com/hkust-zhiyao/RTL-Coder |
| VeriCoder [81] | QC | Open | https://huggingface.co/LLM4Code/VeriCoder_Qwen14B |
| VeriGen [82] | CodeGen | Open | https://huggingface.co/shailja |
| VeriLogos [83] | DS-Coder | Open | https://huggingface.co/97kjmin/VeriLogos |
| VeriPrefer [84] | Mistral/CL/DS-Coder/CQ/QC | Open | https://shorturl.asia/sMj3J |
| VeriReason [85] | QC/CL | Open | https://shorturl.asia/yaNkf |
| VeriSeek [86] | DS-Coder | Open | https://huggingface.co/LLM-EDA/VeriSeek |
| VeriThoughts [87] | QC | Open | https://shorturl.asia/81f2a |
| Dataset | Year | Input | Samples | Testbench | Available | URL |
|---|---|---|---|---|---|---|
| Closed-Source | ||||||
| DAVE_test [9] | 2020 | Text | 250 | No | Closed | - |
| LLM-aided [89] | 2024 | Text | 10 | Yes | Closed | - |
| MCTS [90] | 2024 | Text | 15 | Yes | Closed | - |
| NL2Verilog [91] | 2024 | Text | 8 | Yes | Closed | - |
| VGV [92] | 2024 | Text+Image | 20 | Yes | Closed | - |
| AutoSilicon_test [93] | 2025 | Text | 9 | Yes | Closed | - |
| GEMMV_test [73] | 2025 | Text | 10 | Yes | Closed | - |
| HiVeGen_test [94] | 2025 | Text | 4 | Yes | Closed | - |
| ModelEval_test [95] | 2025 | Text | 94 | Yes | Closed | - |
| Open-Source | ||||||
| ChipGPT [70] | 2023 | Text | 8 | Yes | Open | https://zenodo.org/records/7953725 |
| VeriGen_test [88] | 2023 | Text | 17 | Yes | Open | https://github.com/shailja-thakur/VGen |
| VerilogEval-v1 [57] | 2023 | Text | 156/143 | Yes | Open | https://github.com/NVlabs/verilog-eval/tree/release/1.0.0 |
| AutoChip [96] | 2024 | Text | 138 | Yes | Open | https://zenodo.org/records/10160723 |
| ChipGPTV [97] | 2024 | Text+Image | 30 | Yes | Open | https://github.com/aichipdesign/chipgptv |
| CreativEval [98] | 2024 | Text | 120 | Yes | Open | https://github.com/matthewdelorenzo/CreativEval |
| Evaluatie_LLMs [99] | 2024 | Text | 8 | Yes | Open | https://zenodo.org/records/10947127 |
| Hierarchical [100] | 2024 | Text | 10 | Yes | Open | https://github.com/ajn313/ROME-LLM |
| RTLLM-v1 [101] | 2024 | Text | 30 | Yes | Open | https://github.com/hkust-zhiyao/RTLLM/tree/v1.1 |
| RTLLM-v2 [21] | 2024 | Text | 50 | Yes | Open | https://github.com/hkust-zhiyao/RTLLM/tree/main |
| RTLRepo_test [102] | 2024 | Text+Code | 1.17k | No | Open | https://huggingface.co/datasets/ahmedallam/RTL-Repo |
| ArchXBench [103] | 2025 | Text | 51 | Yes | Open | https://github.com/sureshpurini/ArchXBench |
| CVDP [104] | 2025 | Text | 783 | Yes | Open | https://github.com/NVlabs/cvdp_benchmark |
| GenBen [105] | 2025 | Text+Image | 324 | Yes | Open | https://github.com/ChatDesignVerification/GenBen |
| RealBench [106] | 2025 | Text+Image | 60 | Yes | Open | https://github.com/IPRC-DIP/RealBench |
| ResBench [107] | 2025 | Text | 56 | Yes | Open | https://github.com/jultrishyyy/ResBench |
| VerilogEval-v2 [108] | 2025 | Text | 156 | Yes | Open | https://github.com/NVlabs/verilog-eval/tree/main/ |
| VeriThoughts [87] | 2025 | Text | 291 | No | Open | https://huggingface.co/datasets/wilyub/VeriThoughtsBenchmark |
| Dataset | Year | Input | Samples | Testbench | Available | URL |
|---|---|---|---|---|---|---|
| Closed-Source | ||||||
| DAVE_train [9] | 2020 | Text | 5k | No | Closed | - |
| VerilogEval_train [57] | 2023 | Text | 8.5k | No | Closed | - |
| BetterV [56] | 2024 | Text | Unknown | No | Closed | - |
| MEV-LLM [63] | 2024 | Text | 31k | No | Closed | - |
| CodeV [71] | 2025 | Text | 165k | No | Closed | - |
| CraftRTL [58] | 2025 | Text | 80K | No | Closed | - |
| DeepRTL [59] | 2025 | Text | 556k | No | Closed | - |
| DeepRTL2 [60] | 2025 | Text | 433k | No | Closed | - |
| GEMMV_train [73] | 2025 | Text | 12k | No | Closed | - |
| OpenRTLSet [64] | 2025 | Text | 98K | No | Closed | - |
| ScaleRTL [68] | 2025 | Text | 62k | No | Closed | - |
| VerilogDB [109] | 2025 | Text | 20k | No | Closed | - |
| Open-Source | ||||||
| VeriGen_train [88] | 2023 | Text | 109k | No | Open | https://huggingface.co/datasets/shailja/Verilog_GitHub |
| AutoVCoder-Data [55] | 2024 | Text | 1M | No | Open | https://github.com/sjtu-zhao-lab/AutoVCoder/tree/main/data |
| ChipGPT-FT-Data [110] | 2024 | Text | 124k | No | Open | https://modelscope.cn/datasets/changkaiyan/chipgptseries |
| MG-Verilog-Data [76] | 2024 | Text | 11k | No | Open | https://huggingface.co/datasets/GaTech-EIC/MG-Verilog |
| Origen-Data [78] | 2024 | Text | 222k | No | Open | https://huggingface.co/datasets/henryen/origen_dataset_instruction |
| RTLCoder-Data [80,111] | 2024 | Text | 27K | No | Open | https://github.com/hkust-zhiyao/RTL-Coder/tree/main/dataset |
| RTLRepo_train [102] | 2024 | Text+Code | 2.92k | No | Open | https://huggingface.co/datasets/ahmedallam/RTL-Repo |
| Verilog-dateset [77] | 2024 | Text | 68k | No | Open | https://huggingface.co/datasets/emilgoh/verilog-dataset-v2 |
| CodeV-R1-Data [72] | 2025 | Text | 3k | No | Open | https://huggingface.co/datasets/zhuyaoyu/CodeV-R1-dataset |
| DeepCircuitX [112] | 2025 | Text | 28k | No | Open | https://drive.google.com/file/d/1Y002eJQPMbrEX7IpmzXDpFRlGl0XgUFu |
| Haven-KL [75] | 2025 | Text | 62k | No | Open | https://huggingface.co/datasets/yangyiyao/HaVen-KL-Dataset |
| OpenCores [86] | 2025 | Text | 834 | No | Open | https://huggingface.co/datasets/LLM-EDA/opencores |
| PyraNet [65] | 2025 | Text | 692k | No | Open | https://huggingface.co/datasets/bnadimi/PyraNet-Verilog |
| ReasoningV-Data [79] | 2025 | Text | 5k | No | Open | https://huggingface.co/datasets/GipAI/ReaoningV |
| RTL++-Data [66] | 2025 | Text+Graph | 11.7k | No | Open | https://huggingface.co/datasets/makyash/RTL-PP |
| VeriCoder-Origen [81] | 2025 | Text | 126k | Yes | Open | https://huggingface.co/datasets/LLM4Code/expanded_origen_126k |
| VeriCoder-RTLCoder [81] | 2025 | Text | 12k | Yes | Open | https://huggingface.co/datasets/LLM4Code/expanded_rtlcoder_12k |
| VeriLogos-Data [83] | 2025 | Text | 10k | No | Open | https://huggingface.co/datasets/97kjmin/VeriLogos_Augmented_Dataset |
| VeriPrefer-Data [84] | 2025 | Text | 90k | No | Open | https://huggingface.co/datasets/LLM-EDA/pyra |
| VeriReason-Data [85] | 2025 | Text | 1k | Yes | Open | https://huggingface.co/Nellyw888/datasets |
| VeriThoughts-Data [87] | 2025 | Text | 20k | No | Open | https://huggingface.co/datasets/wilyub/VeriThoughtsTrainSet |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



