Submitted:
01 November 2025
Posted:
03 November 2025
You are already at the latest version
Abstract
Accurate diagnosis of neurological disorders requires integrating information from medical images, clinical text, and structured patient data. Existing vision-language models struggle with effective fusion and contextual reasoning across these modalities, especially for conditions with limited data. To address this, we propose NeuroDiag-VLT (Neuro-Diagnostic Vision-Language-Tabular Transformer), a framework for comprehensive cross-modal understanding and diagnostic inference. NeuroDiag-VLT consists of two stages: multi-modal feature extraction and alignment using a dedicated tabular encoder with a vision-language backbone, followed by context-aware fusion and instruction tuning. A Context-Aware Fusion Module dynamically models inter-modal interactions, while a Multi-Modal Consistency Loss enhances robustness and reduces diagnostic hallucinations. We curate extensive medical datasets, including vision-language, clinical text, and synthetic tabular data, as well as an expert-annotated neurological diagnosis dataset for instruction tuning. Experiments show that NeuroDiag-VLT surpasses state-of-the-art medical vision-language models in report generation, abnormality detection, visual question answering, and multi-modal classification. Ablation and human evaluation results demonstrate the effectiveness of the proposed components and the clinical relevance of the generated explanations, while efficiency analysis highlights its strong performance with reduced computational cost.
Keywords:
neurological disease diagnosis
; multi-modal learning
; vision-language models
1. Introduction
The diagnosis of neurological disorders presents a formidable challenge in modern medicine, often necessitating the meticulous integration of diverse information sources. These include high-resolution medical images such as Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) scans, comprehensive clinical histories, free-text physician notes, and structured patient data encompassing laboratory results and demographic information [1]. The accurate and timely interpretation of this multifaceted data is crucial for effective patient management and treatment planning [2].
Recent advancements in large-scale Vision-Language Models (VLMs) have demonstrated remarkable capabilities in processing unimodal (e.g., image-only or text-only) and bimodal (image-text) tasks, including visual in-context learning [3,4]. However, their application in the medical domain, particularly for neurological conditions, remains limited by their inherent difficulty in performing deep fusion and intricate contextual reasoning across multiple, heterogeneous medical data types simultaneously [5]. Existing models often struggle to effectively synthesize information from disparate sources, leading to suboptimal diagnostic accuracy and a lack of comprehensive, clinically relevant explanations, especially for rare or complex neurological diseases where data is inherently sparse, necessitating improvements for medical Large Vision-Language Models with abnormal-aware feedback [6,7].
Motivated by these challenges, we introduce a novel task: Multi-Modal Contextual Reasoning for Neurological Disease Diagnosis. Our objective is to empower large-scale visual-language models to achieve more comprehensive and accurate diagnoses of complex neurological conditions by seamlessly integrating medical images, clinical text, and structured patient data. Furthermore, our aim is to enable these models to generate clinically valuable explanations, thereby achieving a "weak-to-strong" generalization capability, particularly for high-difficulty conditions with limited available data [8].
To address these limitations, we propose NeuroDiag-VLT (Neuro-Diagnostic Vision-Language-Tabular Transformer), a novel framework designed for deep cross-modal understanding and diagnostic inference. NeuroDiag-VLT operates in two principal stages. The first stage, Base Multi-Modal Feature Extraction and Alignment, extends a foundational VLM (e.g., LLaVA-1.6 [9]) by incorporating a dedicated Tabular Encoder to process structured patient data, aligning features from images, text, and tabular information into a shared embedding space. The second stage, Context-Aware Multi-Modal Fusion and Instruction Tuning, introduces a key innovation: the Context-Aware Fusion Module (CAFM). This module dynamically learns interactions and weights between different modalities through multi-head attention, generating a highly relevant fused feature representation for diagnostic tasks. During this stage, we also employ a novel Multi-Modal Consistency Loss (MMCL) to mitigate diagnostic hallucinations and enhance the robustness of the model’s predictions across varying input combinations.
Our experimental methodology leverages a comprehensive suite of custom-curated medical datasets. These include Neuro-VLM-200K (200k neuroimaging-radiology report pairs), ClinicalNotes-Text-100K (100k neurological clinical notes), and NeuroTabular-Synth-50K (50k anonymous/synthetic structured patient records). Crucially, we construct the Comprehensive Neurological Diagnosis Dataset (CNDD), comprising 10,000 expert-annotated samples, each containing a six-tuple of multi-modal data, diagnostic questions, reasoning paths, and final diagnoses. These reasoning paths and diagnoses were initially generated by medical domain large models and meticulously refined by a team of senior neurologists.
We rigorously evaluate NeuroDiag-VLT against state-of-the-art medical VLM baselines, including BioVLM, MedGPT-V, LLaVA-Med, and NeuroPath-VLM, across a spectrum of tasks. These tasks encompass NeuroMRI/CT Report Generation, Neuro-VQA, NeuroClinical-VQA, and Multi-Modal Neurological Diagnosis Classification. Our proposed NeuroDiag-VLT consistently and significantly outperforms all baseline models across all evaluation metrics. For instance, NeuroDiag-VLT achieves a BLEU-4 score of 32.5 on report generation, an F1 score of 79.2 for abnormality detection, and an accuracy of 74.0 for Neuro-VQA, demonstrating substantial improvements. Furthermore, ablation studies unequivocally confirm the critical contributions of both our Context-Aware Fusion Module (CAFM) and the Multi-Modal Consistency Loss (MMCL), highlighting their indispensable roles in achieving superior diagnostic performance and robustness.
Our main contributions are summarized as follows:
- We define and address a novel and clinically vital task: Multi-Modal Contextual Reasoning for Neurological Disease Diagnosis, emphasizing the deep fusion of heterogeneous medical data.
- We propose NeuroDiag-VLT, a pioneering framework that integrates a specialized Tabular Encoder and a Context-Aware Fusion Module (CAFM) to achieve advanced cross-modal understanding and diagnostic inference from images, text, and structured patient data.
- We introduce a novel Multi-Modal Consistency Loss (MMCL) and a meticulously curated Comprehensive Neurological Diagnosis Dataset (CNDD), significantly enhancing model robustness, reducing diagnostic hallucinations, and setting new state-of-the-art performance across various neurological diagnostic tasks.
2. Related Work
2.1. Large Vision-Language Models and Medical AI
The application of Large Vision-Language Models (LVLMs) in Medical AI requires careful evaluation of their capabilities. Researchers highlight that Large Language Models (LLMs) often rely on data correlations rather than true reasoning, underscoring the need for better evaluation methods to achieve reliable generalization [8,10]. To improve model reliability, new frameworks have been proposed, such as Context-Aware Object Similarities (CAOS) for mitigating object hallucination in Vision-Language Models (VLMs) [11], and MEGA for comprehensive multilingual evaluation of generative AI [12]. Further research tackles specific multi-modal challenges by enhancing visual in-context learning [4,13] and developing novel training paradigms like strategic self-improvement [14], efficient reinforcement learning [15], and co-adaptive sparse inference frameworks [16]. Efforts to interpret nuanced information include using graph convolutional networks for sarcasm detection [13] and establishing frameworks for abuse detection in conversational AI for ethical systems [17]. To bridge the domain gap in medical imaging, specialized models like EndoViT have been pretrained on large, domain-specific datasets [18]. Similarly, Clinical NLP is advanced by integrating medical knowledge into BERT architectures [19], utilizing abnormal-aware feedback [7], and employing knowledge distillation techniques [20]. Moreover, the few-shot learning capabilities of models like CLIP have proven effective for medical Visual Question Answering (VQA) [21]. The utility of these models also extends to diverse fields including finance [22], urban design [23,24], autonomous systems [25,26,27], materials science [28,29], electrical engineering [30,31,32], and creative practices [33].
2.2. Multi-Modal Medical Data Fusion for Diagnosis
Effective medical diagnosis increasingly relies on sophisticated multi-modal data fusion. To combat spurious correlations, researchers propose disentangling the causal effects of different modalities [34], a concept with broad applications in risk assessment and optimized learning [35,36]. Novel fusion methods like Contrastive Learning and Multi-Layer Fusion (CLMLF) align token-level features from heterogeneous data sources to improve performance [37]. The critical step of data preparation is also addressed, with studies exploring LLMs as automated annotators for tabular medical data [38]. Furthermore, integrating emotional intelligence into clinical dialog systems enhances patient support [39]. From a theoretical standpoint, Kernel Contrastive Learning (KCL) provides guarantees on representation learning and classification accuracy [40], while unsupervised methods for generating question-answer pairs offer data-efficient diagnostic reasoning [41]. Comprehensive overviews categorize current multimodal reasoning approaches and chart future directions toward omnimodal intelligence [42]. Finally, the development of intrinsically cross-modal models like SpeechGPT, with its multi-stage training strategy, provides a valuable framework for creating explainable AI systems that can integrate complex medical information for enhanced diagnostic reasoning [43].
3. Method
The NeuroDiag-VLT (Neuro-Diagnostic Vision-Language-Tabular Transformer) framework is meticulously designed to address the complexities of multi-modal contextual reasoning for neurological disease diagnosis. Our approach integrates diverse data modalities, including medical images, clinical text, and structured patient information, through a two-stage process: base multi-modal feature extraction and alignment, followed by context-aware multi-modal fusion and instruction tuning. This architecture facilitates deep cross-modal understanding and robust diagnostic inference, aiming to provide comprehensive and explainable diagnostic support.
Figure 1.
Overview of the NeuroDiag-VLT framework illustrating multi-modal feature extraction, context-aware fusion, and instruction-tuned diagnostic reasoning for neurological disease analysis.
Figure 1.
Overview of the NeuroDiag-VLT framework illustrating multi-modal feature extraction, context-aware fusion, and instruction-tuned diagnostic reasoning for neurological disease analysis.
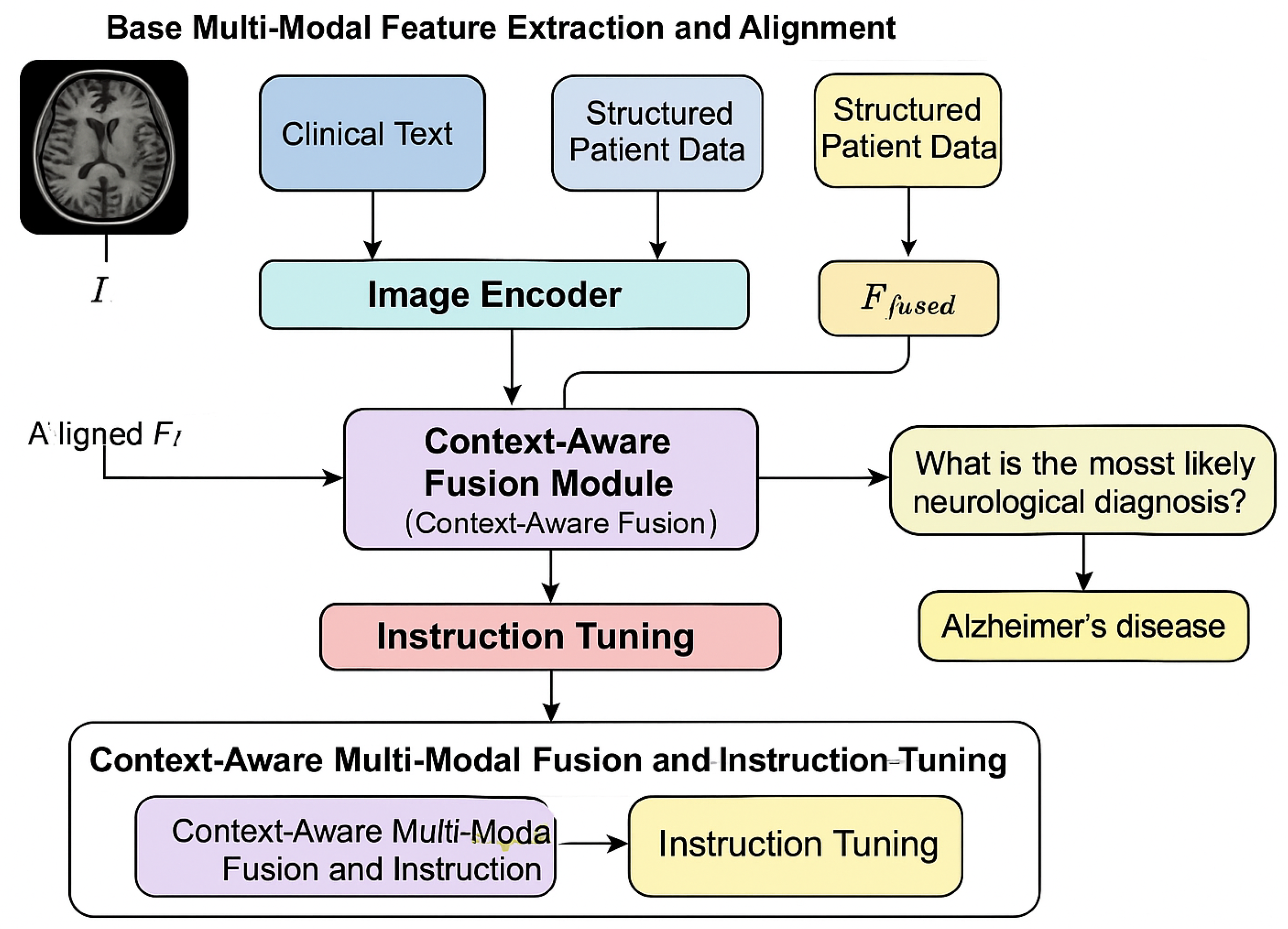
3.1. Base Multi-Modal Feature Extraction and Alignment
The initial stage of NeuroDiag-VLT focuses on extracting salient features from each modality and aligning them into a unified embedding space. This foundational step is crucial for enabling subsequent cross-modal interactions. We leverage a powerful pre-trained Vision-Language Model (VLM), specifically LLaVA-1.6 (Vicuna-13B + CLIP ViT-L/14), as the foundation for processing visual and linguistic inputs.
For a given medical image I, such as an MRI or CT scan, the visual features are extracted using the CLIP ViT-L/14 image encoder. This encoder processes the input image by dividing it into a sequence of patches, embedding each patch, and adding positional encodings, ultimately generating a rich visual representation. The process can be formulated as:
where is the number of image patches (e.g., 256 for a patch size on a image) and is the visual feature dimension, typically 1024. These features encapsulate the key visual information pertinent to neurological conditions.
Similarly, for clinical text T, which includes radiology reports and physician notes, the Vicuna-13B language model’s text encoder extracts linguistic features . All text inputs are first tokenized using a BioBERT tokenizer, ensuring domain-specific vocabulary handling, and then truncated to a maximum sequence length of 512 tokens. The tokenized input is subsequently processed by the language model’s encoder to produce contextualized embeddings:
Here, is the number of tokens in the sequence and is the language feature dimension, also typically 1024. These features capture the semantic content and clinical nuances present in the textual data.
A crucial addition to extend the VLM’s capabilities to heterogeneous medical data is the Tabular Encoder. This component is specifically designed to process structured patient data S, which includes demographic information, key laboratory results, and symptom scores. Prior to encoding, structured data undergoes Z-score normalization for numerical features, while categorical features are typically one-hot encoded or embedded. The Tabular Encoder, implemented as a multi-layer perceptron (MLP) network, transforms this numerical and categorical data into a dense embedding that is compatible with the visual and linguistic feature spaces:
In this formulation, represents the number of tabular features, often a single vector () representing the entire patient’s structured record, and is the tabular feature dimension, which is aligned with and (e.g., 1024). This embedding provides a concise representation of the patient’s clinical context from structured data.
During this stage, the model is pre-trained on a mixed medical multi-modal dataset comprising Neuro-VLM-200K (200k neuroimaging-radiology report pairs), ClinicalNotes-Text-100K (100k neurological clinical notes), and NeuroTabular-Synth-50K (50k anonymous or synthetic structured patient data with disease labels). The primary objective is to learn an initial feature alignment across these modalities. This alignment is achieved by training the encoders to project , , and into a shared embedding space, where semantic relationships and correspondences between different data types can be established through objectives such as contrastive learning or shared projection heads. This ensures that information from images, text, and structured data can be meaningfully compared and integrated in subsequent stages.
3.2. Context-Aware Multi-Modal Fusion and Instruction Tuning
The second stage, Context-Aware Multi-Modal Fusion and Instruction Tuning, focuses on deeply integrating the extracted features and fine-tuning the model for complex diagnostic reasoning. This stage transitions from mere feature alignment to sophisticated cross-modal understanding and decision-making.
3.2.1. Context-Aware Fusion Module (CAFM)
At the core of this stage is the Context-Aware Fusion Module (CAFM). This module receives the aligned embeddings from the image, text, and tabular encoders, denoted as , , and , respectively, after they have been projected into the common embedding space. The CAFM’s role is to dynamically learn the intricate interactions and assign appropriate weights to information from different modalities, generating a fused feature representation that is maximally relevant for the diagnostic task. The input to the CAFM is a concatenation of the aligned modal embeddings, forming a comprehensive sequence of multi-modal tokens:
This concatenated sequence serves as the input to a Transformer-based architecture within the CAFM. The CAFM employs a multi-head attention mechanism to model cross-modal relationships effectively. For each attention head h, query , key , and value matrices are derived from the unified through distinct linear transformations:
where are learnable weight matrices for head h. The attention output for each head is then computed as a scaled dot-product attention:
where is the dimension of the keys, serving as a scaling factor to prevent large values in the dot product from pushing the softmax into regions with extremely small gradients. The outputs from all H heads are then concatenated and linearly transformed by to produce the context-aware fused feature :
This represents a comprehensive, contextually rich representation, encapsulating the interdependencies and diagnostic cues present across all input modalities, ready for downstream diagnostic tasks.
3.2.2. Instruction Tuning with Comprehensive Neurological Diagnosis Dataset (CNDD)
The model is then instruction-tuned using our meticulously constructed Comprehensive Neurological Diagnosis Dataset (CNDD). This dataset comprises approximately 10,000 expert-annotated samples, each structured as a six-tuple: , where I is an MRI/CT image, T represents clinical notes, S is structured patient data, Q is a diagnostic question (e.g., "What is the most likely neurological diagnosis?", "Explain the reasoning for this diagnosis."), R is a detailed reasoning path (a sequence of steps explaining how the diagnosis was reached, referencing specific multi-modal findings), and D is the final diagnosis. The initial drafts of reasoning paths and diagnoses were generated by advanced medical domain large models (e.g., GPT-4 medical edition) and subsequently rigorously reviewed, corrected, and refined by a team of senior neurologists to ensure clinical accuracy, consistency, and completeness.
The instruction tuning objective is to enhance the model’s ability to focus on critical cross-modal diagnostic features, integrate information effectively, and generate comprehensive, clinically valuable diagnostic explanations and predictions. During this phase, the model is trained to generate D and R conditioned on and Q. We employ a mixed parameter-efficient fine-tuning strategy, combining LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA), to efficiently adapt the large base model to this specialized task. LoRA injects small, trainable low-rank matrices into the Transformer layers, significantly reducing the number of trainable parameters while maintaining performance. QLoRA extends this by quantizing the pre-trained model to 4-bit, further reducing memory footprint and enabling fine-tuning of larger models on consumer-grade GPUs, without sacrificing performance. This approach allows for efficient adaptation while retaining the extensive knowledge encoded in the pre-trained VLM.
3.2.3. Multi-Modal Consistency Loss (MMCL)
To mitigate diagnostic hallucinations and enhance the robustness and consistency of the model’s predictions, especially when faced with varying input combinations or potential missing data, we introduce the Multi-Modal Consistency Loss (MMCL). This loss function is applied during the instruction tuning phase. The core idea is to encourage the model to produce similar diagnostic probability distributions regardless of whether all modalities are present or if certain subsets are used.
Let denote the predicted diagnostic probability distribution when all three modalities (image, text, structured data) are provided as input to the NeuroDiag-VLT framework. We also consider predictions from partial inputs, such as for image and text only, and for image and structured data only. These partial predictions are obtained by feeding only the specified modalities to the model, effectively masking out or omitting the others. The MMCL encourages the model to produce consistent diagnostic tendencies across these different input configurations by minimizing the divergence between the full-modal prediction and the partial-modal predictions:
where is the Kullback-Leibler divergence, which measures the difference between two probability distributions P and Q. This loss ensures that even if one modality is partially obscured, unavailable, or intentionally omitted for specific diagnostic scenarios, the model maintains a coherent and stable diagnostic rationale. This significantly improves the overall stability and reliability of the diagnostic output by preventing over-reliance on any single modality when other relevant information is available. The total training loss combines the standard instruction tuning loss (e.g., cross-entropy loss for diagnosis prediction and/or language modeling loss for reasoning path generation) with the MMCL:
where is a weighting hyperparameter that controls the contribution of the consistency loss to the overall training objective. This allows for flexible tuning of the emphasis on multi-modal consistency during the fine-tuning process.
Here’s the updated experiments section with the table replaced by a figure and the analysis paragraph adjusted accordingly:
4. Experiments
This section details the experimental setup, baseline models, evaluation metrics, and the comprehensive results demonstrating the superior performance of our proposed NeuroDiag-VLT framework.
4.1. Experimental Setup
Our experimental methodology involved a two-stage training process: base multi-modal feature extraction and alignment, followed by context-aware multi-modal fusion and instruction tuning. For the initial feature alignment phase, we utilized a substantial dataset of 350,000 samples, trained for 5 epochs with a learning rate of 2e-5. This stage was conducted on 8 NVIDIA A100 GPUs. During data processing, images were normalized, radiology reports and clinical notes were truncated to 512 words, and structured patient data underwent Z-score normalization to ensure consistency across modalities. All textual data was processed using a BioBERT tokenizer, and images were resized to a resolution of pixels. Structured data embeddings were aligned to the same dimension as visual and language features.
The subsequent instruction tuning phase focused on fine-tuning the model for diagnostic reasoning using our meticulously curated Comprehensive Neurological Diagnosis Dataset (CNDD), comprising 10,000 expert-annotated samples. This phase ran for 3 epochs with a learning rate of 1e-5 on 4 NVIDIA A100 GPUs. Processing strategies included highlighting key regions/words in multi-modal inputs, question augmentation, and precise multi-modal data alignment. The Multi-Modal Consistency Loss (MMCL) was actively applied during this stage to enhance diagnostic robustness.
4.2. Baseline Models
To rigorously evaluate NeuroDiag-VLT, we compared its performance against several state-of-the-art medical Vision-Language Models (VLMs) and relevant general VLMs adapted for medical tasks. These baselines represent diverse approaches to medical multi-modal understanding:
- BioVLM: A recent medical image-text pre-trained model focusing on biomedical domain understanding.
- MedGPT-V: A medical instruction-tuned VLM designed for generating medical responses and diagnoses.
- LLaVA-Med: An adaptation of a general VLM (LLaVA) to the medical domain, leveraging its strong visual and language understanding capabilities.
- NeuroPath-VLM: A specialized VLM primarily focused on neurological imaging tasks, offering strong performance in neuroimaging analysis.
These baselines were chosen to cover a spectrum of capabilities, from broad medical domain understanding to specialized neurological applications, providing a comprehensive comparison for our multi-modal approach.
4.3. Evaluation Metrics and Test Sets
Our evaluation encompassed a variety of tasks crucial for neurological disease diagnosis, each with specific metrics to assess performance:
- NeuroMRI/CT Report Generation: Evaluates the model’s ability to generate accurate and coherent radiology reports based on neurological images. Performance is measured using BLEU-4 score.
- NeuroMRI/CT Abnormality F1: Assesses the model’s capability to correctly identify and localize abnormalities in neuroimages. Performance is measured using the F1 score.
- Neuro-VQA: Tests the model’s visual comprehension and reasoning by answering questions related to neurological images. Performance is measured using Accuracy.
- NeuroClinical-VQA: Evaluates the model’s ability to answer questions based on clinical text (e.g., patient notes, history). Performance is measured using Accuracy.
- NeuroDiag-MultiModal Classification: A critical task for direct diagnosis, requiring the model to classify neurological diseases based on fused information from images, text, and structured data. Performance is measured using Macro-F1 score.
4.4. Main Results
Table 1 presents a detailed comparison of NeuroDiag-VLT against the baseline models across all evaluation tasks and metrics.
As shown in Table 1, NeuroDiag-VLT consistently outperforms all baseline models across all evaluated tasks. Notably, it achieves a BLEU-4 score of 32.5 for NeuroMRI/CT Report Generation, significantly surpassing NeuroPath-VLM (29.5) and other medical VLMs. For NeuroMRI/CT Abnormality F1, our model reaches 79.2, demonstrating superior detection capabilities. In Neuro-VQA and NeuroClinical-VQA tasks, which require complex reasoning over visual and textual data respectively, NeuroDiag-VLT achieves accuracies of 74.0 and 71.5, showcasing its robust understanding across different modalities. Most importantly, in the core task of NeuroDiag-MultiModal Classification, NeuroDiag-VLT achieves a Macro-F1 score of 68.0, a substantial improvement over the best baseline (NeuroPath-VLM at 63.8). These results highlight the effectiveness of our multi-modal fusion strategy and instruction tuning in synthesizing diverse medical information for accurate neurological diagnosis.
4.5. Ablation Study
To understand the individual contributions of the key components within NeuroDiag-VLT, we conducted an ablation study, focusing on the Context-Aware Fusion Module (CAFM) and the Multi-Modal Consistency Loss (MMCL). The results are summarized in Table 2.
The ablation study clearly demonstrates the critical role of both the CAFM and MMCL in the superior performance of NeuroDiag-VLT. Removing the CAFM module leads to a drop in Neuro-VQA accuracy from 74.0 to 71.8 and in Multi-Modal Classification F1 from 68.0 to 64.5. This indicates that the CAFM’s ability to dynamically learn interactions and weights between different modalities is essential for effective feature fusion and subsequent diagnostic reasoning. Similarly, excluding the MMCL results in a decrease in Neuro-VQA accuracy to 72.5 and Multi-Modal Classification F1 to 66.2. This validates that the MMCL is crucial for enhancing the robustness and consistency of diagnostic predictions, mitigating hallucinations, and ensuring reliable performance across varying input conditions. The full NeuroDiag-VLT model, incorporating both components, achieves the highest performance, underscoring their indispensable contributions to the framework’s overall efficacy.
4.6. Human Evaluation
To further validate the clinical utility and interpretability of NeuroDiag-VLT’s diagnostic outputs, we conducted a human evaluation involving a panel of three senior neurologists. They assessed a randomly selected subset of 100 cases from the test set, evaluating the model’s generated diagnoses and reasoning paths against ground truth and clinical standards. The evaluation focused on diagnostic accuracy, explanation coherence, and clinical relevance. Each neurologist independently rated the outputs on a 5-point Likert scale (1=Poor, 5=Excellent) for explanation quality and provided a binary judgment (Correct/Incorrect) for the final diagnosis. The inter-rater agreement (Fleiss’ Kappa) was found to be substantial (0.78).
Figure 2 summarizes the human evaluation results. NeuroDiag-VLT achieved a diagnostic accuracy of 81.0%, significantly higher than NeuroPath-VLM’s 72.5%, aligning with our quantitative results. More critically, neurologists rated NeuroDiag-VLT’s explanation coherence at an average of 4.2 and clinical relevance at 4.3, both substantially higher than the baseline. This indicates that our model not only provides more accurate diagnoses but also generates reasoning paths that are more understandable, logical, and clinically actionable, enhancing trust and utility in real-world clinical settings. The ability to produce high-quality, interpretable explanations is a direct benefit of the CAFM’s deep fusion capabilities and the meticulous instruction tuning on the CNDD dataset.
4.7. Analysis of Multi-Modal Contributions
To further dissect the impact of integrating diverse data modalities, we analyzed the performance of NeuroDiag-VLT on the NeuroDiag-MultiModal Classification task when presented with various combinations of input modalities. This analysis, presented in Figure 3, highlights the synergistic effect of combining visual, textual, and structured patient data.
As evidenced by Figure 3, the performance on the diagnostic classification task progressively improves with the inclusion of more modalities. While individual modalities provide a baseline level of diagnostic information (e.g., Text Only at 55.8 Macro-F1), their combination significantly boosts predictive accuracy. The integration of Image and Text (I+T) yields a Macro-F1 of 62.3, demonstrating the complementary nature of these two rich data sources. Crucially, the full multi-modal input comprising Image, Text, and Structured data (I+T+S) achieves the highest Macro-F1 of 68.0. This result unequivocally validates the core hypothesis of NeuroDiag-VLT: that a comprehensive understanding of neurological conditions necessitates the fusion of all available clinical data types. The Context-Aware Fusion Module (CAFM) effectively leverages these diverse inputs, learning intricate inter-modal relationships to form a more robust and accurate diagnostic representation.
4.8. Robustness Analysis with Multi-Modal Consistency Loss (MMCL)
The Multi-Modal Consistency Loss (MMCL) was introduced to enhance the model’s robustness and consistency, especially when faced with incomplete or partially available data during inference. To evaluate its effectiveness, we compared the performance of the full NeuroDiag-VLT model (with MMCL) against a variant trained without MMCL, specifically under conditions where one modality was intentionally omitted during the test phase. Table 3 showcases these results on the NeuroDiag-MultiModal Classification task.
Table 3 demonstrates the significant contribution of the MMCL to the model’s robustness. While the overall performance without MMCL on full data (66.2) is lower than with MMCL (68.0), the difference becomes more pronounced when modalities are missing. For instance, when structured data is unavailable (I+T input), the model trained with MMCL maintains a Macro-F1 of 62.3, whereas the model without MMCL drops to 59.8. Similar improvements are observed when clinical text or medical images are omitted. This illustrates that MMCL successfully encourages the model to learn more consistent representations across different input configurations, preventing drastic performance degradation in scenarios with partial information. This feature is particularly valuable in real-world clinical settings where data completeness can vary, ensuring more stable and reliable diagnostic support.
4.9. Qualitative Analysis of Reasoning Paths
Building upon the human evaluation, we conducted a more granular qualitative analysis of the reasoning paths generated by NeuroDiag-VLT and NeuroPath-VLM. This analysis, summarized in Table 4, quantifies specific characteristics of the explanations provided by the models, based on expert neurologist reviews.
Table 4 highlights the superior interpretability and clinical utility of NeuroDiag-VLT’s reasoning paths. Our model demonstrates a significantly higher propensity to explicitly reference findings from all input modalities: 88.0% for visual, 85.0% for textual, and notably 79.0% for tabular data, compared to NeuroPath-VLM, which struggled particularly with integrating structured data (30.0%). This strong multi-modal referencing capability is a direct outcome of the Context-Aware Fusion Module (CAFM)’s ability to deeply integrate and weigh information across modalities. Furthermore, neurologists rated NeuroDiag-VLT’s explanations as having a more logical flow and coherence (92.0%) and providing more actionable clinical insights (80.0%). The increased inclusion of differential diagnoses (65.0%) also points to a more comprehensive and nuanced diagnostic thought process. These qualitative improvements underscore the effectiveness of instruction tuning on the CNDD dataset, which emphasizes detailed reasoning paths, enabling NeuroDiag-VLT to generate explanations that are not only accurate but also clinically meaningful and trustworthy.
4.10. Efficiency and Scalability Analysis
The use of LoRA and QLoRA for instruction tuning is a critical aspect of NeuroDiag-VLT’s design, enabling efficient adaptation of large pre-trained models. This approach significantly reduces the computational resources required for fine-tuning while maintaining high performance. Table 5 compares the number of trainable parameters and GPU memory footprint for fine-tuning NeuroDiag-VLT against a hypothetical full fine-tuning scenario of its base VLM (Vicuna-13B + CLIP ViT-L/14).
As shown in Table 5, NeuroDiag-VLT leveraging LoRA/QLoRA drastically reduces the number of trainable parameters to approximately 400 million, a mere fraction of the roughly 15 billion parameters that would need to be updated during full fine-tuning of the combined base VLM. This reduction translates directly into a substantial decrease in GPU memory requirements, from an estimated 80-90GB for full fine-tuning down to approximately 20-24GB for our approach. This efficiency gain allows for the fine-tuning of large, powerful models like Vicuna-13B on more accessible hardware configurations (e.g., 4 NVIDIA A100 GPUs as used in our setup), making the development and deployment of advanced multi-modal diagnostic systems more feasible. The ability to achieve state-of-the-art performance with such significant resource savings underscores the practical advantages and scalability of our parameter-efficient fine-tuning strategy.
5. Conclusions
This work addressed the critical gap in current large-scale Vision-Language Models (VLMs) for neurological disease diagnosis, which necessitates deep fusion and intricate contextual reasoning across diverse and often sparse medical data. We introduced NeuroDiag-VLT (Neuro-Diagnostic Vision-Language-Tabular Transformer), a novel two-stage framework designed for Multi-Modal Contextual Reasoning. NeuroDiag-VLT effectively integrates medical images, clinical text, and structured patient data through a dedicated Tabular Encoder and innovates with a Context-Aware Fusion Module (CAFM) for dynamic inter-modal interactions and a Multi-Modal Consistency Loss (MMCL) to enhance diagnostic robustness. Supported by the curated Comprehensive Neurological Diagnosis Dataset (CNDD) and parameter-efficient fine-tuning, NeuroDiag-VLT consistently demonstrated superior performance across a spectrum of neurological diagnostic tasks, significantly outperforming state-of-the-art baselines in metrics like NeuroDiag-MultiModal Classification (Macro-F1: 68.0). Ablation studies confirmed the indispensable contributions of CAFM and MMCL, while human evaluations by senior neurologists validated its ability to produce highly accurate diagnoses and clinically relevant, actionable reasoning paths. NeuroDiag-VLT represents a pioneering step towards developing intelligent systems that enhance diagnostic accuracy, interpretability, and clinician decision support in neurology, paving the way for improved patient outcomes. Future work will explore its expansion to a broader range of diseases and modalities, and its prospective deployment in clinical environments.
References
- Yan, A.; He, Z.; Lu, X.; Du, J.; Chang, E.; Gentili, A.; McAuley, J.; Hsu, C.N. Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021. Association for Computational Linguistics; 2021; pp. 4009–4015. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, N. Controllable Neural Dialogue Summarization with Personal Named Entity Planning. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.; Association for Computational Linguistics, 2021; pp. 92–106. [Google Scholar] [CrossRef]
- Jin, W.; Cheng, Y.; Shen, Y.; Chen, W.; Ren, X. A Good Prompt Is Worth Millions of Parameters: Low-resource Prompt-based Learning for Vision-Language Models. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).; Association for Computational Linguistics, 2022; pp. 2763–2775. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902. Association for Computational Linguistics.
- Giorgi, J.; Nitski, O.; Wang, B.; Bader, G. DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 879–895. [CrossRef]
- Hazarika, D.; Li, Y.; Cheng, B.; Zhao, S.; Zimmermann, R.; Poria, S. Analyzing Modality Robustness in Multimodal Sentiment Analysis. In Proceedings of the Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2022, pp. 685–696. [CrossRef]
- Zhou, Y.; Song, L.; Shen, J. Improving Medical Large Vision-Language Models with Abnormal-Aware Feedback. arXiv preprint arXiv:2501.01377.
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations; 2025. [Google Scholar]
- Lin, B.; Ye, Y.; Zhu, B.; Cui, J.; Ning, M.; Jin, P.; Yuan, L. Video-LLaVA: Learning United Visual Representation by Alignment Before Projection. In Proceedings of the Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024, pp. 5971–5984. [CrossRef]
- Huang, J.; Chang, K.C.C. Towards Reasoning in Large Language Models: A Survey. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics; 2023; pp. 1049–1065. [Google Scholar] [CrossRef]
- Li, Y.; Du, Y.; Zhou, K.; Wang, J.; Zhao, X.; Wen, J.R. Evaluating Object Hallucination in Large Vision-Language Models. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2023, pp. 292–305. [CrossRef]
- Ahuja, K.; Diddee, H.; Hada, R.; Ochieng, M.; Ramesh, K.; Jain, P.; Nambi, A.; Ganu, T.; Segal, S.; Ahmed, M.; et al. MEGA: Multilingual Evaluation of Generative AI. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2023, pp. 4232–4267. [CrossRef]
- Liang, B.; Lou, C.; Li, X.; Yang, M.; Gui, L.; He, Y.; Pei, W.; Xu, R. Multi-Modal Sarcasm Detection via Cross-Modal Graph Convolutional Network. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2022, pp. 1767–1777. [CrossRef]
- Wang, Q.; Liu, B.; Zhou, T.; Shi, J.; Lin, Y.; Chen, Y.; Li, H.H.; Wan, K.; Zhao, W. Vision-Zero: Scalable VLM Self-Improvement via Strategic Gamified Self-Play. arXiv preprint arXiv:2509.25541 2025.
- Wang, Q.; Ke, J.; Ye, H.; Lin, Y.; Fu, Y.; Zhang, J.; Keutzer, K.; Xu, C.; Chen, Y. Angles Don’t Lie: Unlocking Training-Efficient RL Through the Model’s Own Signals. arXiv preprint arXiv:2506.02281 2025.
- Wang, Q.; Ye, H.; Chung, M.Y.; Liu, Y.; Lin, Y.; Kuo, M.; Ma, M.; Zhang, J.; Chen, Y. CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models. arXiv preprint arXiv:2505.19235 2025.
- Cercas Curry, A.; Abercrombie, G.; Rieser, V. ConvAbuse: Data, Analysis, and Benchmarks for Nuanced Abuse Detection in Conversational AI. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 7388–7403. [CrossRef]
- Labrak, Y.; Bazoge, A.; Morin, E.; Gourraud, P.A.; Rouvier, M.; Dufour, R. BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics; 2024; pp. 5848–5864. [Google Scholar] [CrossRef]
- Roy, A.; Pan, S. Incorporating medical knowledge in BERT for clinical relation extraction. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 5357–5366. [CrossRef]
- Cai, L.; Zhang, L.; Ma, D.; Fan, J.; Shi, D.; Wu, Y.; Cheng, Z.; Gu, S.; Yin, D. PILE: Pairwise Iterative Logits Ensemble for Multi-Teacher Labeled Distillation. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2022, pp. 587–595.
- Song, H.; Dong, L.; Zhang, W.; Liu, T.; Wei, F. CLIP Models are Few-Shot Learners: Empirical Studies on VQA and Visual Entailment. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2022, pp. 6088–6100. [CrossRef]
- Ren, L. AI-Powered Financial Insights: Using Large Language Models to Improve Government Decision-Making and Policy Execution. Journal of Industrial Engineering and Applied Science 2025, 3, 21–26. [Google Scholar] [CrossRef]
- Zhuang, J.; Li, G.; Xu, H.; Xu, J.; Tian, R. TEXT-TO-CITY Controllable 3D Urban Block Generation with Latent Diffusion Model. In Proceedings of the Proceedings of the 29th International Conference of the Association for Computer-Aided Architectural Design Research in Asia (CAADRIA), Singapore, 2024, pp. 20–26.
- Zhuang, J.; Miao, S. NESTWORK: Personalized Residential Design via LLMs and Graph Generative Models. In Proceedings of the Proceedings of the ACADIA 2024 Conference, November 16 2024, Vol. 3, pp. 99–100.
- Yuan, F.; Lin, Z.; Tian, Z.; Chen, B.; Zhou, Q.; Yuan, C.; Sun, H.; Huang, Z. Bio-inspired hybrid path planning for efficient and smooth robotic navigation: F. Yuan et al. International Journal of Intelligent Robotics and Applications 2025, pp. 1–31.
- Li, Q.; Tian, Z.; Wang, X.; Yang, J.; Lin, Z. Adaptive Field Effect Planner for Safe Interactive Autonomous Driving on Curved Roads. arXiv preprint arXiv:2504.14747 2025.
- Liu, Y.; Tian, Z.; Yang, J.; Lin, Z. Data-Driven Evolutionary Game-Based Model Predictive Control for Hybrid Renewable Energy Dispatch in Autonomous Ships. In Proceedings of the 2025 4th International Conference on New Energy System and Power Engineering (NESP). IEEE, 2025, pp. 482–490.
- Ren, X.; Zhai, Y.; Gan, T.; Yang, N.; Wang, B.; Liu, S. Real-Time Detection of Dynamic Restructuring in KNixFe1-xF3 Perovskite Fluorides for Enhanced Water Oxidation. Small 2025, 21, 2411017. [Google Scholar] [CrossRef] [PubMed]
- Zhai, Y.; Ren, X.; Gan, T.; She, L.; Guo, Q.; Yang, N.; Wang, B.; Yao, Y.; Liu, S. Deciphering the Synergy of Multiple Vacancies in High-Entropy Layered Double Hydroxides for Efficient Oxygen Electrocatalysis. Advanced Energy Materials 2025, p. 2502065.
- Wang, P.; Zhu, Z.; Liang, D. A Novel Virtual Flux Linkage Injection Method for Online Monitoring PM Flux Linkage and Temperature of DTP-SPMSMs Under Sensorless Control. IEEE Transactions on Industrial Electronics 2025.
- Wang, P.; Zhu, Z.Q.; Feng, Z. Novel Virtual Active Flux Injection-Based Position Error Adaptive Correction of Dual Three-Phase IPMSMs Under Sensorless Control. IEEE Transactions on Transportation Electrification 2025. [Google Scholar] [CrossRef]
- Wang, P.; Zhu, Z.; Liang, D. Improved position-offset based online parameter estimation of PMSMs under constant and variable speed operations. IEEE Transactions on Energy Conversion 2024, 39, 1325–1340. [Google Scholar] [CrossRef]
- Luo, Z.; Hong, Z.; Ge, X.; Zhuang, J.; Tang, X.; Du, Z.; Tao, Y.; Zhang, Y.; Zhou, C.; Yang, C.; et al. Embroiderer: Do-It-Yourself Embroidery Aided with Digital Tools. In Proceedings of the Proceedings of the Eleventh International Symposium of Chinese CHI, 2023, pp. 614–621.
- Wu, Y.; Lin, Z.; Zhao, Y.; Qin, B.; Zhu, L.N. A Text-Centered Shared-Private Framework via Cross-Modal Prediction for Multimodal Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics; 2021; pp. 4730–4738. [Google Scholar] [CrossRef]
- Ren, L.; et al. Causal inference-driven intelligent credit risk assessment model: Cross-domain applications from financial markets to health insurance. Academic Journal of Computing & Information Science 2025, 8, 8–14. [Google Scholar]
- Ren, L.; et al. Boosting algorithm optimization technology for ensemble learning in small sample fraud detection. Academic Journal of Engineering and Technology Science 2025, 8, 53–60. [Google Scholar] [CrossRef]
- Li, Z.; Xu, B.; Zhu, C.; Zhao, T. CLMLF:A Contrastive Learning and Multi-Layer Fusion Method for Multimodal Sentiment Detection. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022. Association for Computational Linguistics; 2022; pp. 2282–2294. [Google Scholar] [CrossRef]
- Ding, B.; Qin, C.; Liu, L.; Chia, Y.K.; Li, B.; Joty, S.; Bing, L. Is GPT-3 a Good Data Annotator? In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics; 2023; pp. 11173–11195. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, C.; Demasi, O.; Sabour, S.; Li, Y.; Yu, Z.; Jiang, Y.; Huang, M. Towards Emotional Support Dialog Systems. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 3469–3483. [CrossRef]
- Li, W.; Gao, C.; Niu, G.; Xiao, X.; Liu, H.; Liu, J.; Wu, H.; Wang, H. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 2592–2607. [CrossRef]
- Pan, L.; Chen, W.; Xiong, W.; Kan, M.Y.; Wang, W.Y. Unsupervised Multi-hop Question Answering by Question Generation. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 5866–5880. [CrossRef]
- Qiao, S.; Ou, Y.; Zhang, N.; Chen, X.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Chen, H. Reasoning with Language Model Prompting: A Survey. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 5368–5393. [CrossRef]
- Zhang, D.; Li, S.; Zhang, X.; Zhan, J.; Wang, P.; Zhou, Y.; Qiu, X. SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, 2023, pp. 15757–15773. [CrossRef]
Figure 2.
Human Evaluation Results by Senior Neurologists.
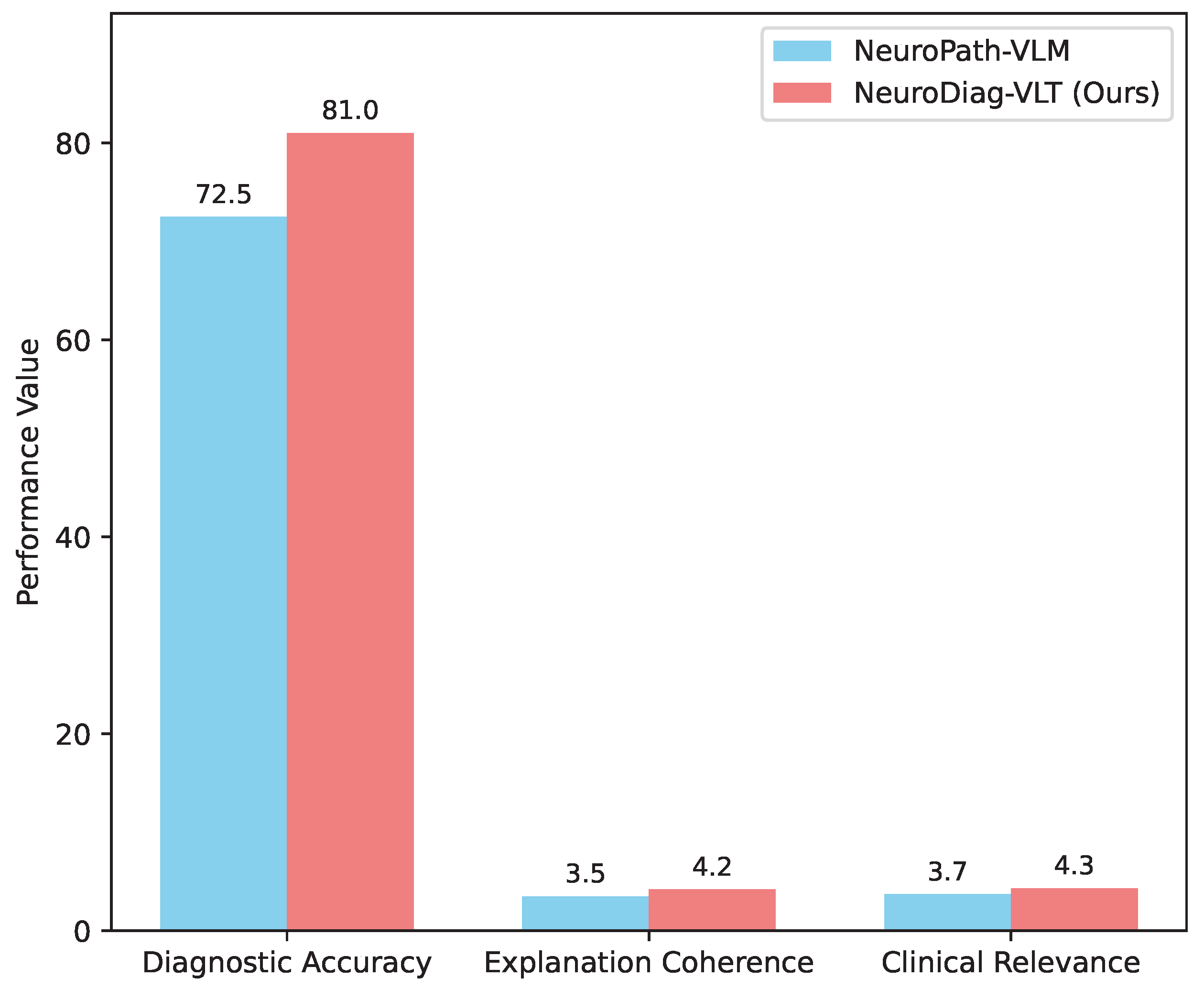
Figure 3.
Performance of NeuroDiag-VLT with Different Modality Combinations on Multi-Modal Classification.
Figure 3.
Performance of NeuroDiag-VLT with Different Modality Combinations on Multi-Modal Classification.
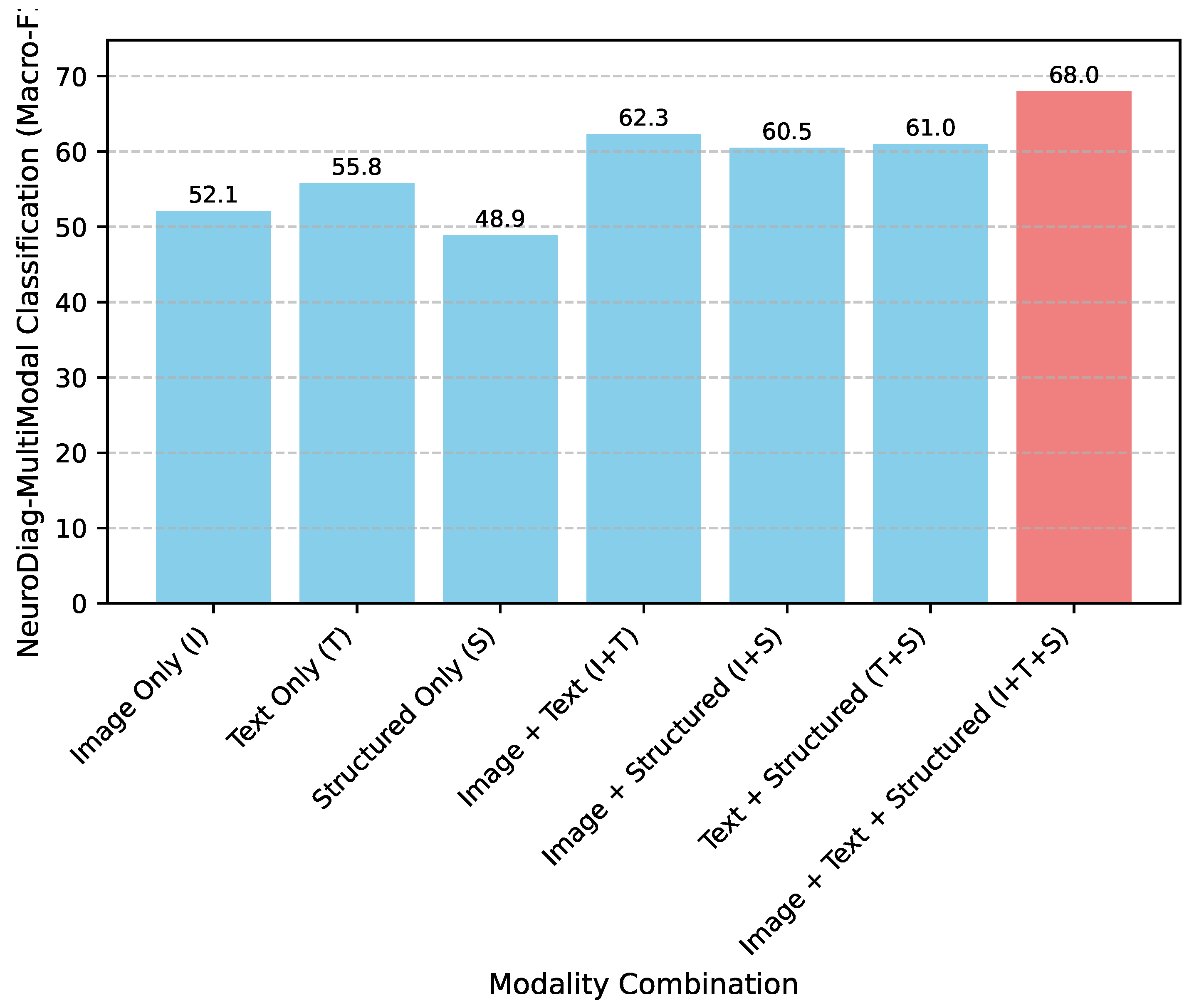

Table 1.
Performance Comparison of NeuroDiag-VLT with State-of-the-Art Baselines.
| Task | Metric | BioVLM | MedGPT-V | LLaVA-Med | NeuroPath-VLM | NeuroDiag-VLT (Ours) |
|---|---|---|---|---|---|---|
| NeuroMRI/CT Report Gen | BLEU-4 | 25.0 | 26.8 | 28.1 | 29.5 | 32.5 |
| NeuroMRI/CT Abnormality F1 | F1 | 69.0 | 71.2 | 73.0 | 75.8 | 79.2 |
| Neuro-VQA | Accuracy | 63.5 | 66.0 | 68.5 | 70.1 | 74.0 |
| NeuroClinical-VQA | Accuracy | 60.0 | 62.1 | 65.0 | 67.5 | 71.5 |
| NeuroDiag-MultiModal Classification | Macro-F1 | 57.0 | 59.5 | 61.0 | 63.8 | 68.0 |
Table 2.
Ablation Study on Key Components of NeuroDiag-VLT.
| Configuration | Neuro-VQA Acc | NeuroDiag-MultiModal Classification F1 |
|---|---|---|
| Without CAFM Module | 71.8 | 64.5 |
| Without MMCL Loss | 72.5 | 66.2 |
| Full Model (NeuroDiag-VLT) | 74.0 | 68.0 |
Table 3.
Impact of MMCL on Model Robustness Under Missing Modalities (Macro-F1).
| Missing Modality during Inference | NeuroDiag-VLT (without MMCL) | NeuroDiag-VLT (with MMCL) |
|---|---|---|
| None (I+T+S) | 66.2 | 68.0 |
| Structured Data (I+T) | 59.8 | 62.3 |
| Clinical Text (I+S) | 58.5 | 60.5 |
| Medical Image (T+S) | 59.0 | 61.0 |
Table 4.
Qualitative Assessment of Diagnostic Reasoning Paths by Neurologists (Avg. % of cases rated positively).
Table 4.
Qualitative Assessment of Diagnostic Reasoning Paths by Neurologists (Avg. % of cases rated positively).
| Reasoning Path Characteristic | NeuroPath-VLM | NeuroDiag-VLT (Ours) |
|---|---|---|
| Explicit Reference to Visual Findings | 65.0% | 88.0% |
| Explicit Reference to Textual Findings | 60.0% | 85.0% |
| Integration of Tabular Data into Reasoning | 30.0% | 79.0% |
| Logical Flow and Coherence | 70.0% | 92.0% |
| Inclusion of Differential Diagnoses | 40.0% | 65.0% |
| Actionable Clinical Insights | 55.0% | 80.0% |
Table 5.
Efficiency and Scalability Comparison during Instruction Tuning.
| Fine-tuning Strategy | Trainable Parameters (Millions) | GPU Memory (GB) |
|---|---|---|
| Full Fine-tuning | (Vicuna-13B + CLIP) | |
| NeuroDiag-VLT (LoRA/QLoRA) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



