
Submitted:
27 October 2025
Posted:
29 October 2025
You are already at the latest version
Abstract
This article defines an inverted Topp-Leone distribution. Several mathematical properties and maximum likelihood estimation of parameters of this distribution are considered. The shape of the distribution for different sets of parameters is discussed. Several mathematical properties such as the cumulative distribution function, mode, moment-generating function, survival function, hazard rate function, stress-strength reliability $R$, moments, R\'enyi entropy, Shannon entropy, Fisher information matrix, partial ordering associated with this distribution have been derived. Distributions of sum and quotient of two independent inverted Topp-Leone variables have also been obtained.
Keywords:
entropy
; fisher information matrix
; gauss hypergeometric function
; hazard rate function
; moments
; survival function
; Topp-Leone distribution
MSC: 62H15; 62E15
1. Introduction
A random variable X is said to have a Topp-Leone distribution, denoted by , if its pdf is given by
For , the distribution defined by the density (1) is referred to as the J-shaped distribution by Topp and Leone [38] because , and for all , where and are the first and the second derivatives, respectively, of . For , (1) attains different shapes depending on values of parameters (see Kotz and van Dorp [19]). This family has a close affinity to the family of beta distributions as the distribution of has a McDonald beta distribution (Kumaraswamy distribution with parameters 2 and ) and follows a standard beta distribution with parameters 1 and .
A number of studies addressing different facets of the univariate Topp-Leone distribution have surfaced in recent years, reflecting the revived interest in the Topp-Leone family of probability distributions. For example, see Nadarajah and Kotz [26], Kotz and van Dorp [19, Chapter 2], Kotz and Seier [21], Al-Zahrani [2], Al-Zahrani and Al-Shomrani [3], Bayoud [11,12,13], Genç [15], Ghitany, Kotz and Xie [16], MirMostafaee, Mahdizadeh, Aminzadeh [24], Vicari, Van Dorp and Kotz [39], and Zghoul [40,41].
The inverse gamma distribution is useful as a prior for positive parameters. This distribution has a heavy tail and keeps probability further from zero than the gamma distribution.
Traditionally, if a random variable follows a particular distribution then the distribution of the reciprocal of that random variable is known as inverted or inverse distribution. Meaningful inverted forms of several well know distributions have been derived and their properties have been studied extensively in the scientific literature. Inverted distributions have ample applications in all areas of science and engineering. One of the most widely used distributions and one that has been thoroughly examined in the scientific literature is the two-parameter beta distribution with the support in the unit interval . The inverted counterpart of this distribution is defined in a slightly different way than many other inverted distributions. If U has a two-parameter beta distribution, then, instead of , the form such as is considered more appropriate to derive inverted beta distribution with support in and useful to model positive data. Since has a Topp-Leone distribution with support in and has standard beta distribution with parameters 1 and , it will be interesting to examine the distribution of .
By using the transformation , , in (1), the inverted Topp-Leone density can be derived as
A notation to designate that Y has pdf (2) is . For , the two parameter inverted Topp-Leone distribution reduces to the standard ITL distribution.
Despite the fact that various aspects of Topp-Leone distribution and its variations have been developed and examined over the past 20 years, the inverted Topp-Leone distribution has not received much attention. In this article, we study mathematical properties of the inverted Topp-Leone distribution defined by the density (2). Section 2 deals with several results such as cumulative distribution function, mode, moment generating function, survival function, hazard rate function, etc. Results on expected values of functions of ITL variable are given in Section 3. Entropies such as Rényi and Shannon are derived in Section 6. Estimation of parameters and Fisher information matrix are discussed in Section 7. Results on partial ordering and sum and quotient distributions are presented in Section 8 and Section 9, respectively. Finally, simulation work is shown in Section 10.
2. Properties
This section deals with a number of properties of the inverted Topp-Leone distribution defined and derived in the previous section.
The first order derivative of with respect to y is
Setting the above equation to zero, we have
and the only positive solution which is the mode of this equation is for . Computing second order derivatives of , from (5), we have
Further, it can be verified that which indicates that the density attains its maximum at given by
Thus we conclude that is indeed the mode of the distribution.
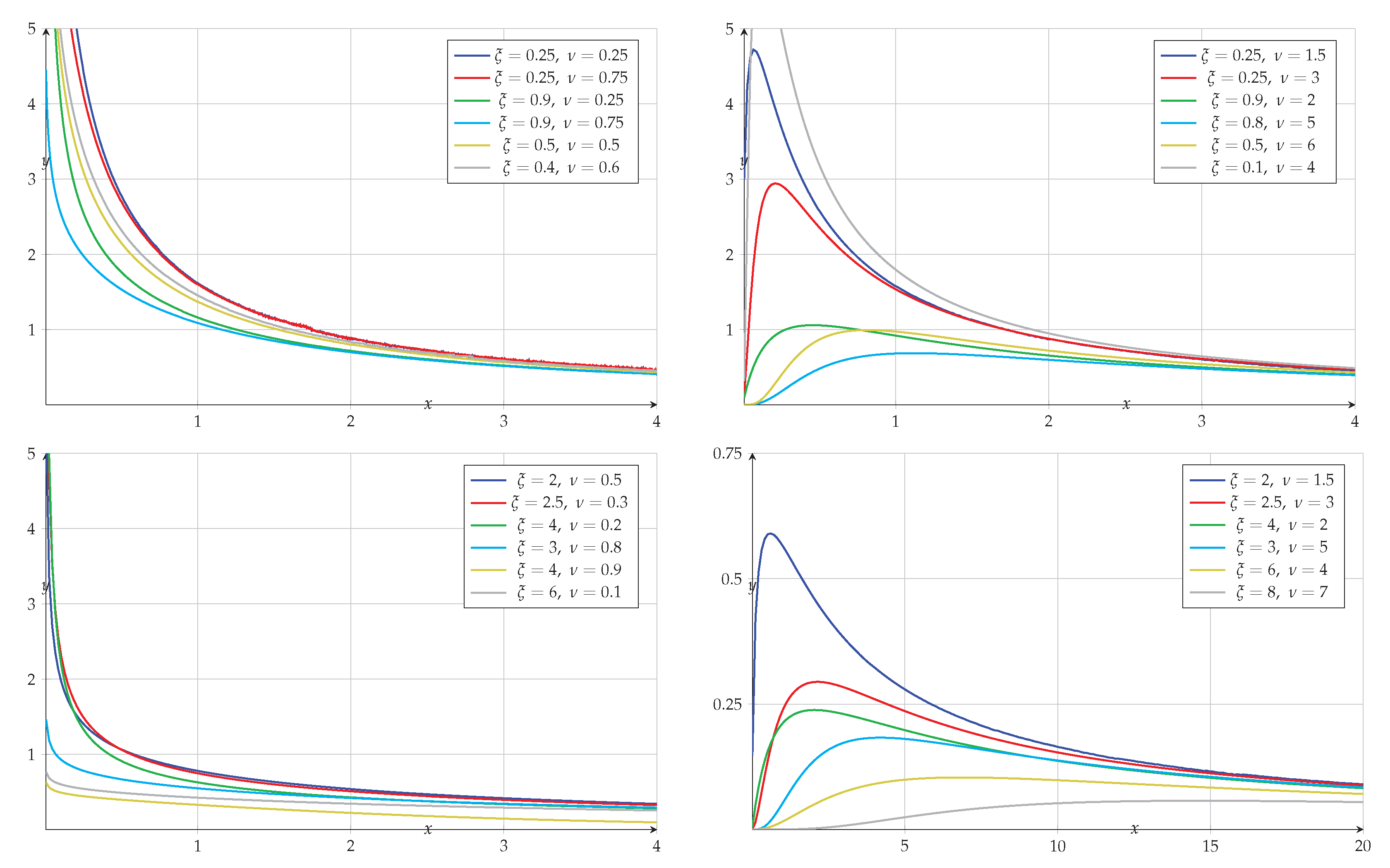
In continuation, we present a few graphs (Figure 1) of the density function defined by the expression (2) for a range of values of parameters and . Each plot contains four curves for selected values of and . Here one can appreciate the vast varieties of shapes that emerge from the inverted Topp-Leone distribution.
By using the transformation in (1), a different inverted Topp-Leone density can also be derived as
Observe that (3) can be obtained from (2) buy transforming with . This distribution, for , is defined and studied in Hassan, Elgarhy and Ragab [9]. For , the inverted Topp-Leone density slides to a Pareto distribution given by the density
By using (2), the CDF of Y is derived as
where we have used the substitution . The final result is obtained by substituting and evaluating the resulting expression obtaining
where .
By using (2) and (5), the truncated version of the inverted Topp-Loene distribution can be defined by the density
where
The quantile function is given by
The survival function (reliability function) and the hazard rate (failure rate) function of , by using the CDF of Y, can be obtained as
and
Figure 2.
Graphs of the hazard rate function (7) for different values of and .
Figure 2.
Graphs of the hazard rate function (7) for different values of and .
By using (2), the Laplace transform of Y, denoted by is derived as
where we have used the substitution . We will evaluate the above integral by using results on Laguerre polynomials.
The Laguerre polynomial of degree n is defined by the sum (for details see Nagar, Zarrazola and Sánchez [10]),
where is the binomial coefficient. The first few Laguerre polynomials are
The first order derivative of the the Laguerre polynomial is given by
where is the generalized Laguerre polynomial of degree n defined by the sum
The generating function for the Laguerre polynomials is given by
Replacing by its series expansion involving Laguerre polynomials (Miller [23, Eq.
3.4a, 3.4b]), namely,
in (8), we get
By integrating the above expression, we get the Laplace transform of Y.
Finally, we give the following theorems summering results given in Section 1 and this section.
Theorem 1.
If and , , then . Further, if then .
Theorem 2.
Let and . Then, U follows a Kumaraswamy distribution given by the density
and has a beta distribution with parameters 1 and ν.
Theorem 3.
Let and . Then, U follows a uniform distribution with support in . Further, and follow standard exponential distribution.
Proof.
Application of probability integral transformation yields the desired result. The second part follows by applying the transformation . □
3. Expected Values
Using Theorem 2, it is easy to see that
For a non-negative integer r and an arbitrary , the r-the moment of is derived as
where we have used the substitution with and the definition of the Gauss hypergeometric function. For , using the substitution in (11), one gets
The above result can also be obtained by using (7.3.7.9) of Prudnikov, Brychkov and Marichev [35, p.414].
Further, if , then by using Theorem 3 it is straightforward to show that
Theorem 4.
If , then then
where and .
Proof.
By definition
where we have used the substitution . Now, expanding using binomial theorem and substituting , we obtain
Finally, integrating z by using the definition of beta function, the desired result in obtained. □
Corollary 1.
If , then for ,
Substituting and in the above corollary and simplifying, one gets
Also, substituting in the above theorem and simplifying the resulting expression, we get
Similarly, one can easily derive the following theorem.
Theorem 5.
If , then
4. Stress-Strength Reliability Model
Inferences about , where X and Y are two independent random variables, is very common in reliability, statistical tolerance and biometry (Ali and Woo [1], Kotz, Lumelskii and Pensky [20]).
Let Y represents the random variable of a stress that a device will be subjected to in service and X represents the strength that varies from item to item in the population of devices. Then, the reliability, which is the probability that a randomly selected device functions successfully, denoted by R, is equal to .
Let Y and X be the stress and the strength random variables, independent of each other, and , then
5. Order Statistics
If be order statistics from an inverted Topp-Leone distribution, then the density of , denoted by , , is given by
It is interesting to note that and the density of is given by
The density of sample media when n is odd, say , can also be obtained by substituting in the density of .
6. Entropy
An entropy of a random variable of is a measure of variation of uncertainty. In this section we will derive two entropies know as Shannon and Rényi entropies for the inverted Topp-Leone distribution.
Denote by the well-known Shannon entropy introduced in Shannon [33]. It is define by
One of the main extensions of the Shannon entropy was defined by Rényi [32]. This generalized entropy measure is given by
where
The additional parameter is used to describe complex behavior in probability models and the associated process under study. Rényi entropy is monotonically decreasing in , while Shannon entropy (12) is obtained from (13) for . For details see Nadarajah and Zografos [30], Zografos and Nadarajah [43] and Zografos [42].
Theorem 6.
For the inverted Topp-Leone distribution defined by the pdf (2), the Rényi and the Shannon entropies are given by
and
respectively, where is the digamma function.
Proof.
For and , using the joint density of Y given by (2), we have
where the last line has been obtained by substituting . The final result is obtained by substituting and evaluating the resulting expression by using beta integrals,
Now, taking logarithm of and using (13) we get . The Shannon entropy is obtained from by taking and using L’Hopital’s rule. □
7. Estimation and Information matrix
Let be a random sample from the inverted Topp-Leone distribution defined by the density (2). The log-likelihood function, denoted by , is given by
>Now, differentiating w.r.t. , we get
Further, differentiating w.r.t , one gets
Thus, by solving numerically (16) and (17), the MLEs of the and can be obtained. As the MLEs are not in a closed form, an Python code is developed to get the estimates. However, if the parameter has a fixed value, say , then the MLE of can be given by
Note that we can write , where are independent random variables. Also, from Theorem 3, follows an exponential distribution with mean 1 and therefore is distributed as gamma with shape parameter n and scale parameter 1. Now, using results on gamma distribution, we get
from which the mean, the variance and the MSE of are calculated as , and , respectively. Further, the unbiased estimator has variance bigger than the Rao-Cramér lower bound which is . For a fixed value of , say , the statistic has a chi-square distribution with degrees of freedom and could be used to test the hypothesis .
Further differentiating (16) and (17) with respect to and , respectively, the second order derivatives are derived as
and
Keeping in mind that the expected value of a constant is the constant itself, and applying the results on expected values given in Section 3, one can see that
and
For a given observation y, the Fisher information matrix for the inverted Topp-Leone distribution given by the density (2) is defined as
8. Partial Ordering
A random variable X with distribution function can be said to be greater than another random variable Y with distribution function in a number of ways. There are several different concepts of partial ordering between random variables such as likelihood ratio ordering, hazard rate ordering, reverse hazard rate ordering, and stochastic ordering. A random variable X is stochastically greater than a random variable Y, written as , if (equivalently ) for all t. He, in this section, we denote the by and the density function and the survival function, respectively, of X. A random variable X is considered to be larger than a random variable Y in the hazard rate ordering (denoted by ), if
for all . The condition is equivalent to the condition that the function is non-decreasing in t. The random variable Y is said to be smaller than the random variable X in the reverse hazard rate order (written as ) if is non-decreasing in t. We state that X is larger than a random variable Y according to the likelihood ratio ordering (written as ) if is non-decreasing function of t.
It is well know that and . Clearly the likelihood ratio ordering is stronger than other orderings. For further reading on patrial ordering between random variables and related topics the reader is referred to Bapat and Kochar [5] Belzunce, Martínez-Riquelme and Mulero [6], Boland, Emad El-Neweihi and Proschan [7], Nanda and Shaked [31], and Shaked and Shanthikumar [36].
In case of the inverted Topp-Leone distribution defined by the density (2), the likelihood ratio is given by
where and . Now differentiating wrt t, we obtain
For , the derivative of is positive for all t indicating that is an increasing function of t and therefore likelihood ratio ordering is exhibited, i.e., . By using relationship between different orderings described above it is clear that the inverted Topp-Leone distribution also possess the stochastic ordering, the hazard rate ordering, and the reverse hazard rate ordering.
9. Sum and Quotient
In this section we will derive distributions of and where and are independent. Since is invariant under the transformation and , , we can take . The joint density of X and Y is given by
where and . Now, substituting and with the Jacobian in the above density, the joint density of R and S is obtained as
where and . Using
and
to re-write the joint density of R and S and integrating s, we have the density of R as
where the last line has been obtained by substituting with . Now, using the definition of the Lauricella’s hypergeometric function given in (A.4), the above integral is evaluated as
To derive the marginal density of S we first re-write the joint density of R and S by using (24) and
and then integrate wrt r to get
Our next step is the evaluation of the integral given in the above expression. Writing
and
and using the definition of the Lauricella’s hypergeometric function , the density of S is derived as
Similarly, if X has a standard ITL distribution with parameter and Y follows a standard inverted beta distribution with parameters and , then the density of R is
The density of S, in this case, is given by
10. Simulation
To generate random samples from the Inverted Topp-Leone (ITL) distribution, we employed the inverse transform method. This method relies on generating a uniform random variable and transforming it via the inverse cumulative distribution function (CDF) specific to the ITL distribution, as defined by equation (5).
Subsequently, the Maximum Likelihood Estimation (MLE) approach was utilized for estimating the parameters and , using the previously derived estimator (16) y (17).
In the context of estimating the parameters of a probability distribution via the method of maximum likelihood, it is often necessary to solve a system of nonlinear equations derived from the first-order conditions (score equations), typically of the form
where denotes the log-likelihood function and is the parameter vector. For this purpose, the numerical solution was obtained using the scipy.optimize.root function from the SciPy library, employing the `hybr’ method. The invocation is as follows:
sol = root(fun_grad,
x0,
method=’hybr’,
tol=tol,
options={’maxfev’: maxfev})
The `hybr’ method corresponds to the hybrid Powell method, implemented in MINPACK’s hybrd and hybrj routines. It is particularly well-suited for solving systems of nonlinear equations of the form , where is a smooth vector-valued function. The method combines features of the Newton-Raphson algorithm with trust-region techniques to improve stability and convergence properties, especially when derivatives are not explicitly provided or are difficult to compute.
In this specific application, the function fun_grad returns the score vector, i.e., the gradient of the log-likelihood function with respect to the parameters. The vector represents the initial guess for the parameter vector , which is essential for the local convergence properties of the algorithm.
The hybrid method proceeds by computing a quasi-Newton approximation of the Jacobian matrix when an analytical Jacobian is not supplied, which is then used to generate a sequence of iterations that approximate a solution. The method dynamically adjusts between Broyden’s update and finite-difference approximations, while also incorporating a Levenberg-Marquardt-type trust-region strategy. This allows for robust handling of ill-conditioned or nearly singular Jacobians-a frequent issue in likelihood estimation, particularly when the likelihood surface is flat or exhibits ridges.
The parameters tol and maxfev play a crucial role in the termination criteria of the solver. The former controls the stopping criterion based on the norm of the function value (i.e., how close the score vector is to zero), while the latter limits the maximum number of function evaluations to prevent infinite loops in the case of non-convergence. In practical terms, the chosen values should ensure a balance between computational efficiency and numerical precision, particularly when used in simulation-based estimation procedures or bootstrap replications.
The use of the hybr method within scipy.optimize.root is fully justified given the structure of the problem: solving a moderately sized system of nonlinear equations derived from differentiable functions, without requiring explicit specification of the Jacobian. Its robustness and efficiency, especially in problems involving maximum likelihood estimation, make it a reliable choice for statistical inference in the absence of closed-form solutions.
Table 1 and Table 2 summarize a comparative analysis between the true and estimated values of and across varying sample sizes:
The simulation study demonstrates the consistency and reliability of the maximum likelihood estimators for the parameters and of the Inverted Topp–Leone distribution. As the sample size n increases, the following trends are observed:
-
For parameter :
- -
- The bias decreases progressively, from at to at , indicating that the estimator becomes increasingly unbiased.
- -
- The Mean Squared Error (MSE) also declines significantly, from to , confirming improved accuracy.
- -
- The empirical confidence intervals become narrower with increasing n, reflecting higher estimator precision.
-
For parameter :
- -
- The bias remains very close to zero across all sample sizes, showing remarkable stability and suggesting that the estimator is nearly unbiased even for small samples.
- -
- The MSE diminishes notably, from at to at , indicating improved estimation accuracy with more data.
- -
- Similar to , the empirical confidence intervals for tighten as n grows, further supporting the consistency of the estimator.
Overall, the results confirm the desirable asymptotic properties of the maximum likelihood estimators, particularly their unbiasedness and efficiency, as both bias and MSE decrease with larger sample sizes. These findings support the applicability of the proposed estimation procedure for practical use, especially in contexts where moderate to large samples are available.
Materials and Methods
Competing Exponential and Weibull models are likewise fitted via MLE. Model selection uses AIC, BIC and HQIC. PP plots compare the empirical cumulative distribution against the theoretical CDF of the fitted model. Figure 3Figure 4 display the updated plots with the corrected quantile function.
Information criteria and their interpretation
- AIC.
-
Akaike Information Criterion: .Balances in-sample fit (LL) with a penalty for complexity. A lower AIC indicates better future predictive ability (in the Kullback–Leibler sense).
- BIC.
-
Bayesian Information Criterion (Schwarz): .Stronger penalty increasing with . Favors simpler models as n increases; it is consistent (selects the “true” model if it is among the candidates).
- HQIC.
-
Hannan–Quinn Information Criterion: .Intermediate penalty between AIC and BIC. Also consistent, but less strict than BIC for moderate sample sizes; useful when AIC overfits and BIC is too conservative.
Results
Dataset 1
The following data set represents Vinyl chloride data from clean up gradient ground-water monitoring wells in (g/L). This is data set was first recorded by Bhaumik et al. [8]:

Table 3.
Vinyl chloride concentrations (g/L).
| 5.1 | 1.2 | 1.3 | 0.6 | 0.5 | 2.4 | 0.5 | 1.1 | 8.0 | 0.8 | 0.4 | 0.6 |
| 0.9 | 0.4 | 2.0 | 0.5 | 5.3 | 3.2 | 2.7 | 2.9 | 2.5 | 2.3 | 1.0 | 0.2 |
| 0.1 | 0.1 | 1.8 | 0.9 | 2.0 | 4.0 | 6.8 | 1.2 | 0.4 | 0.2 |
Table 4 summarises the fits. The ITL distribution emerges as the preferred model according to the AIC criterion, outperforming both the Inverse Weibull and Inverse Gamma distributions. Specifically, ITL improves upon the Inverse Weibull by , and over the Inverse Gamma by . This indicates a substantially better fit, with ITL capturing the tail behavior more accurately (see Figure 3).
Dataset 2
The following data shows the time between failures for 30 repairable items and has been provided by Murthy et al. [25]. The data are listed as follows:
Table 5.
Time between failures for 30 repairable items.
| 1.43 | 0.11 | 0.71 | 0.77 | 2.63 | 1.49 | 3.46 | 2.46 | 0.59 | 0.74 | 1.23 | 0.94 |
| 4.36 | 0.40 | 1.74 | 4.73 | 2.23 | 0.45 | 0.70 | 1.06 | 1.46 | 0.30 | 1.82 | 2.37 |
| 0.63 | 1.23 | 1.24 | 1.97 | 1.86 | 1.17 |
Table 6 summarises the comparative goodness-of-fit results for Dataset 2. According to the AIC criterion, the ITL distribution provides the best fit, with the lowest AIC value of 115.08. It outperforms the Inverse Weibull distribution by a margin of , and the Inverse Gamma distribution by . These differences indicate that ITL captures the structure of the data more effectively, providing a better balance between fit quality and model complexity. Similar conclusions are supported by BIC, CAIC, and HQIC values. For a visual assessment, refer to Figure 4.
Probability-Probability (PP) plots are graphical tools used to assess the goodness-of-fit of a statistical model. They compare the empirical cumulative distribution function (ECDF) of the observed data against the theoretical cumulative distribution function (CDF) of the proposed model. In a P-P plot, each data point represents a pair . If the model fits the data well, the points will lie approximately along the 45-degree reference line, indicating that the empirical and theoretical distributions are closely aligned. Deviations from this line suggest discrepancies between the data and the fitted model, particularly in the tails or center, depending on the curvature and pattern of the deviation.
As can be observed in Figure 3 and Figure 4, the Inverted Topp-Leone (ITL) distribution provides a satisfactory fit to both datasets. The points in both PP plots remain close to the diagonal reference line, demonstrating that the ITL distribution adequately captures the empirical behavior of the data. This visual evidence complements the numerical results reported in Table 4 and Table 6, further supporting the suitability of the ITL model for these data sets.
11. Conclusion
By using classical method of transformation of variables, we have derived and defined an inverted Topp-Leone distribution (ITLD). This distribution has support on the positive real line and can be applied to lifetime data problems. By using standard definitions and results, several properties of this distribution the CDF, moments, and Fisher information matrix have been derived. Entropies and estimation of parameters associated with the inverted Topp-Leone distribution (ITLD) have also be consodered. The likelihood ratio ordering which also implies other orderings has been established. The mathematics involved in the derivation of results is tractable and therefore the model discussed in this article may serve an alternative to many existing distributions defined on positive real line.
The ITLD has proven to be a highly competitive alternative for modeling lifetime and reliability data. In particular, goodness-of-fit comparisons with classical distributions—such as the Inverse Weibull and Inverse Gamma—demonstrated that the ITLD provides superior performance across various datasets, as evidenced by lower values of AIC, BIC, CAIC, and HQIC, as well as better alignment with empirical distributions through PP-plots.
The Maximum Likelihood Estimation (MLE) procedure has been implemented to estimate the parameters and of the ITLD. Simulation studies confirmed the consistency and asymptotic normality of the estimators, while also allowing the computation of biases, mean squared errors, and empirical confidence intervals for different sample sizes.
The proposed methodology for ITLD parameter estimation and simulation provides a robust framework that can be extended to more complex models, including bivariate or regression-based generalizations.
A future work is to construct multivariate, matrix variate and complex variate generalizations of the proposed distribution. The construction of bivariate, multivariate, and matrix variate generalizations of the suggested distribution is a future project.
Acknowledgments
This research work was supported by the Sistema Universitario de Investigación, Universidad de Antioquia [project no. 2021-47390].
Appendix
The Pochhammer symbol is defined by for and . Further, for
The integral representation of the Gauss hypergeometric function is given as
where . Note that, by expanding , , in (A.1) and integrating t the series expansion for F can be obtained.
For properties and results the reader is referred to Luke [22].
The Lauricalla hypergeometric function has integral representation
where and , . For , the Lauricalla hypergeometric function is also known as Appell’s first hypergeometric function .
For further results and properties of these functions the reader is referred to Srivastava and Karlsson [37], and Prudnikov, Brychkov and Marichev[35, 7, Sec. 7.2.4].
Finally, we define the beta type 1 and beta type 2 distributions. These definitions can be found in Johnson, Kotz and Balakrishnan [18].
Definition A.1.
The random variable X is said to have a beta type 1 distribution with parameters , , , denoted as , if its pdf is given by , .
Definition A.2.
The random variable X is said to have a beta type 2 (inverted beta) distribution with parameters , denoted as , if its pdf is given by , , , .
References
- M. Masoom Ali and Jungsoo Woo, Inference on reliability P(Y < X) in a p-dimensional Rayleigh distribution, Mathematical and Computer Modelling 42 (2005), 367–373. [CrossRef]
- Bander Al-Zahrani, Goodness-of-fit for the Topp-Leone distribution with unknown parameters, Appl. Math. Sci. (Ruse), 6, (2012), no. 128, 6355–6363. [CrossRef]
- Bander Al-Zahrani, Ali A. Al-Shomrani, Inference on stress-strength reliability from Topp-Leone distributions, J. King Saud Univ. Sci., 24, (2011), no. 1, 73–88.
- N. Balakrishnan, Chin-Diew Lai, Continuous Bivariate Distributions, Second edition, Springer, Dordrecht, 2009.
- R. B. Bapat and Subhash C. Kochar, On likelihood-ratio ordering of order statistics, Linear Algebra Appl., 199 (1994), 281–291.
- Félix Belzunce, Carolina Martínez-Riquelme and Julio Mulero, An introduction to stochastic orders. Elsevier/Academic Press, Amsterdam, 2016.
- Philip, J. Boland, Emad El-Neweihi and Frank Proschan, Applications of the hazard rate ordering in reliability and order statistics, J. Appl. Probab., 31 (1994), no. 1, 180–192.
- Bhaumik, D. K, Kapur, K. C. Datta, T. K. and Gibbons, R. D. Testing parameters of a gamma distribution for small samples. Technometrics, 51(3), 2009, 326–334.
- Amal, S. Hassan, Mohammed Elgarhy and Randa Ragab, Statistical Properties and Estimation of Inverted Topp-Leone Distribution, J. Stat. Appl. Pro., 9, (2020), no. 2, 319–331.
- Daya, K. Nagar, Edwin Zarrazola and Luz Estela Sánchez, Entropies and Fisher information matrix for extended beta distribution, Applied Mathematical Sciences, 9 (2015), no. 80, 398–3994.
- Husam Awni Bayoud, Estimating the shape parameter of the Topp-Leone distribution based on type I censored samples, Appl. Math. (Warsaw), 42, (2015), no. 2–3,, 219–230.
- Husam Awni Bayoud, Admissible minimax estimators for the shape parameter of Topp- Leone distribution, Comm. Statist. Theory Methods, 45, (2016), no. 1, 71–82.
- Husam Awni Bayoud, Estimating the shape parameter of Topp-Leone distributed based on progressive type II censored samples, REVSTAT, 14, (2016), no. 4, 415–431.
- M. Elgarhy, N. Alsadat, A. S. Hassan, C. Chesneau and A.H. Abdel-Hamid, A New Asymmetric Modified Topp-Leone Distribution: Classical and Bayesian Estimations Under Progressive Type-II Censored Data with Applications, Symmetry, 15 (2023), 1396.
- Ali, I. Genç, Moments of order statistics of Topp-Leone distribution, Statist. Papers, 53, no. 1, (2012), 117–131.
- M. E. Ghitany, S. Kotz, M. Xie, On some reliability measures and their stochastic orderings for the Topp-Leone distribution, J. Appl. Stat., 32, (2005), no. 7, 715–722.
- A. K. Gupta, D. K. Nagar, Matrix Variate Distributions, Chapman & Hall/CRC, Boca Raton, 2000.
- N. L. Johnson, S. Kotz, N. Balakrishnan, Continuous Univariate Distributions-2, Second Edition, John Wiley & Sons, New York, 1994.
- Samuel Kotz, Johan René van Dorp, Beyond Beta. Other Continuous Families of Distributions with Bounded Support and Applications, World Scientific Publishing Co. Pte. Ltd., Hackensack, NJ, 2004.
- Samuel Kotz, Yan Lumelskii and Marianna Pensky, The stress-strength model and its generalizations. Theory and applications. World Scientific Publishing Co., Inc., River Edge, NJ, 2003.
- Samuel Kotz, Edith Seier, Kurtosis of the Topp-Leone distributions, Interstat, 2006, July, no 1.
- Y. L. Luke, The Special Functions and Their Approximations, Vol. 1, Academic Press, New York, 1969.
- Allen, R. Miller, Remarks on a generalized beta function, J. Comput. Appl. Math., 100 (1998), no. 1, 23–32.
- S. M. T. K. MirMostafaee, M. Mahdizadeh, Milad Aminzadeh, Bayesian inference for the Topp-Leone distribution based on lower k-record values, Jpn. J. Ind. Appl. Math., 33, (2016), no. 3, 637–669.
- D. N. P. Murthy, M. Xie, and R. Jiang. Weibull Models. John Wiley & Sons, Hoboken, NJ, 2004.
- Saralees Nadarajah, Samuel Kotz, Moments of some J-shaped distributions, J. Appl. Stat., 30, (2003), no. 3, 311–317.
- Saralees Nadarajah, Shou Hsing Shih, Daya K. Nagar, A new bivariate beta distribution, Statistics, 51, (2017), no. 2, 455–474.
- Daya, K. Nagar, S. Nadarajah and Idika E. Okorie, A new bivariate distribution with one marginal defined on the unit interval, Ann. Data Sci., 4, (2017), no. 3, 405–420.
- Daya, K. Nagar, Edwin Zarrazola, Santiago Echeverri-Valencia, Bivariate Topp-Leone family of distributions, International Journal of Mathematics and Computer Science, 17 (2022), no. 3, 1007–1024.
- S. Nadarajah and K. Zografos, Expressions for Rényi and Shannon entropies for bivariate distributions, Inform. Sci., 170 (2005), no. 2-4, 173–189.
- Asok, K. Nanda and Moshe Shaked, The hazard rate and the reversed hazard rate orders, with applications to order statistics, Ann. Inst. Statist. Math., 53 (2001), no. 4, 853–864.
- A. Rényi, On measures of entropy and information, in Proc. 4th Berkeley Sympos. Math. Statist. and Prob., Vol. I, Univ. California Press, Berkeley, Calif., pp. 547–561 (1961).
- C. E. Shannon, A mathematical theory of communication, Bell System Tech. J., 27 (1948), 379–423, 623–656.
- A. P. Prudnikov, Yu.A. Brychkov and O. I. Marichev, Integrals and Series. Elementary Functions, Vol. 1, Gordon and Breach, New York, 1986.
- A. P. Prudnikov, Yu.A. Brychkov and O. I. Marichev, Integrals and Series. More Special Functions, Vol. 3, Translated from the Russian by G. G. Gould. Gordon and Breach Science Publishers, New York, 1990.
- Moshe Shaked and J. George. Shanthikumar, Stochastic orders. Springer Series in Statistics. Springer, New York, 2007.
- H.M. Srivastava and P.W. Karlsson, Multiple Gaussian Hypergeometric Series, John Wiley & Sons, New York, USA (1985).
- Chester, W. Topp, Fred C. Leone, A family of J-shaped frequency functions, J. Amer. Statist. Assoc., 50, (1955), 209–219.
- Donatella Vicari, Johan Rene van Dorp, Samuel Kotz, Two-sided generalized Topp and Leone (TS-GTL) distributions, J. Appl. Stat., 35, (2008), no. 9-10, 1115–1129.
- A. A. Zghoul, Order statistics from a family of J-shaped distributions, Metron, 68, (2010), no. 2, 127–136.
- A. A. Zghoul, Record values from a family of J-shaped distributions, Statistica, 71, (2011), no. 3, 355–365.
- K. Zografos, On maximum entropy characterization of Pearson’s type II and VII multivariate distributions, J. Multivariate Anal., 71 (1999), no. 1, 67–75.
- K. Zografos and S. Nadarajah, Expressions for Rényi and Shannon entropies for multivariate distributions, Statist. Probab. Lett., 71 (2005), no. 1, 71–84.
Figure 1.
Graphs of the inverted Topp-Leone density for different values of and .
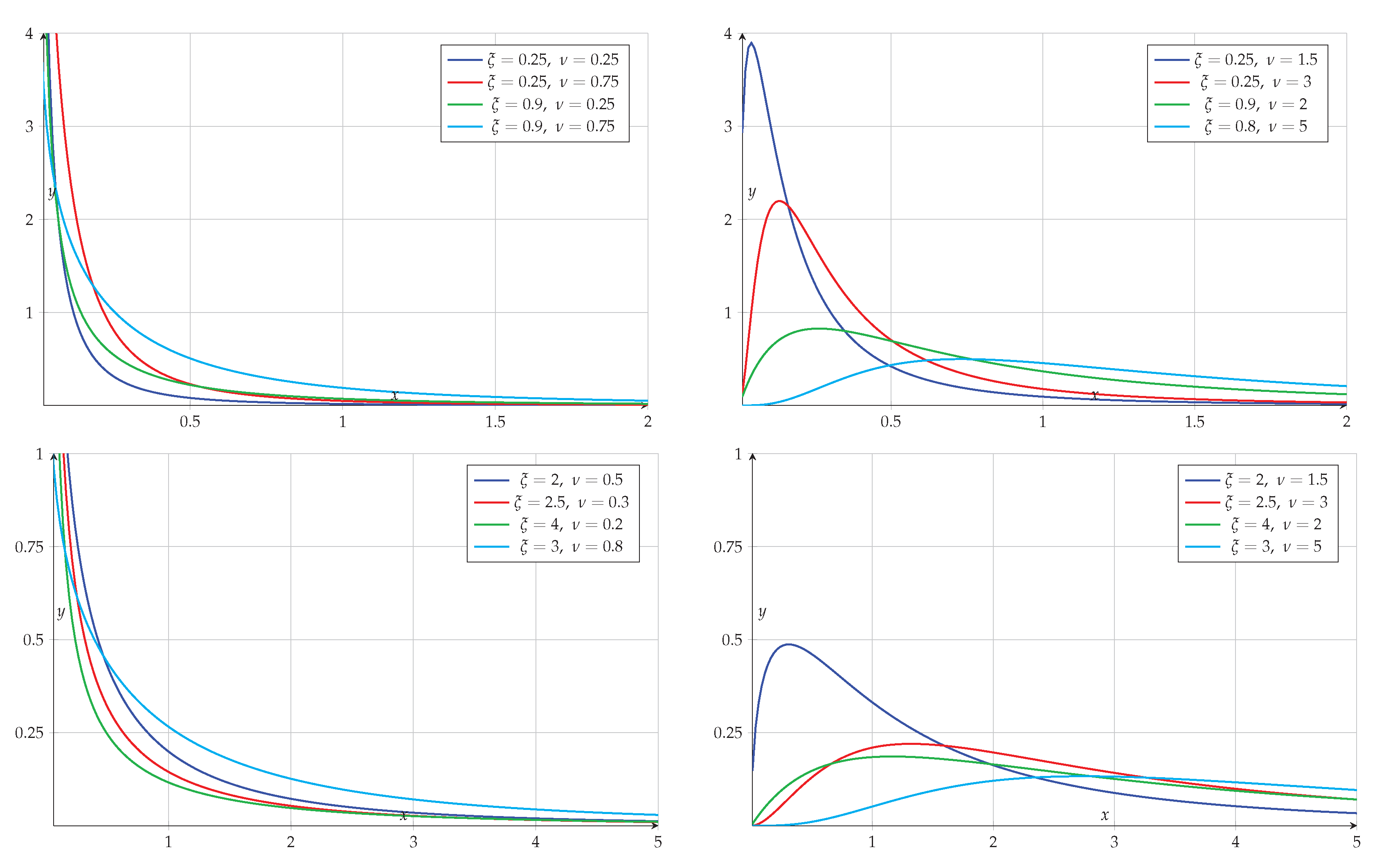
Figure 3.
PP-plot for ITL fit to Dataset 1.
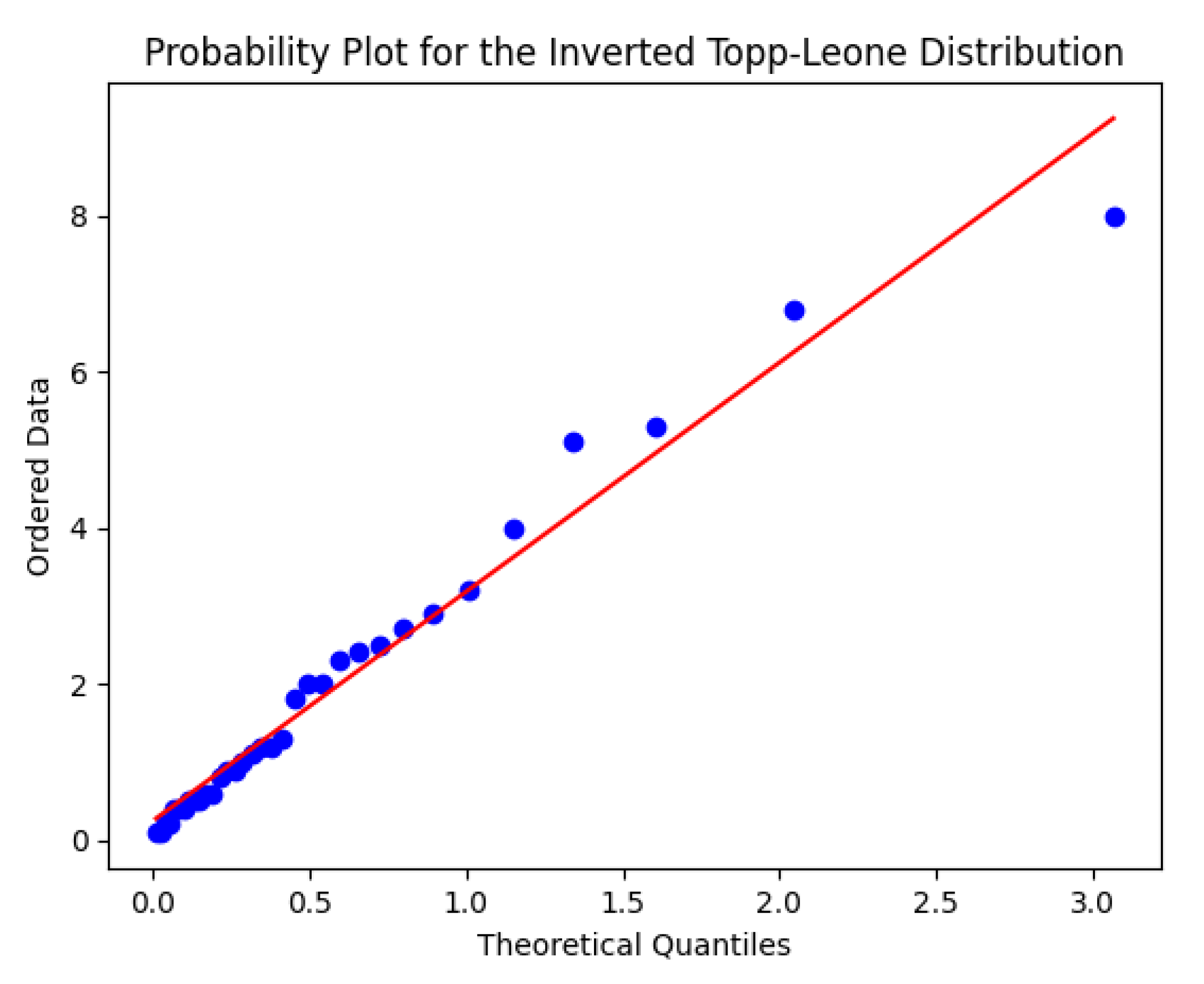
Figure 4.
PP–plot for ITL fit to Dataset 2.
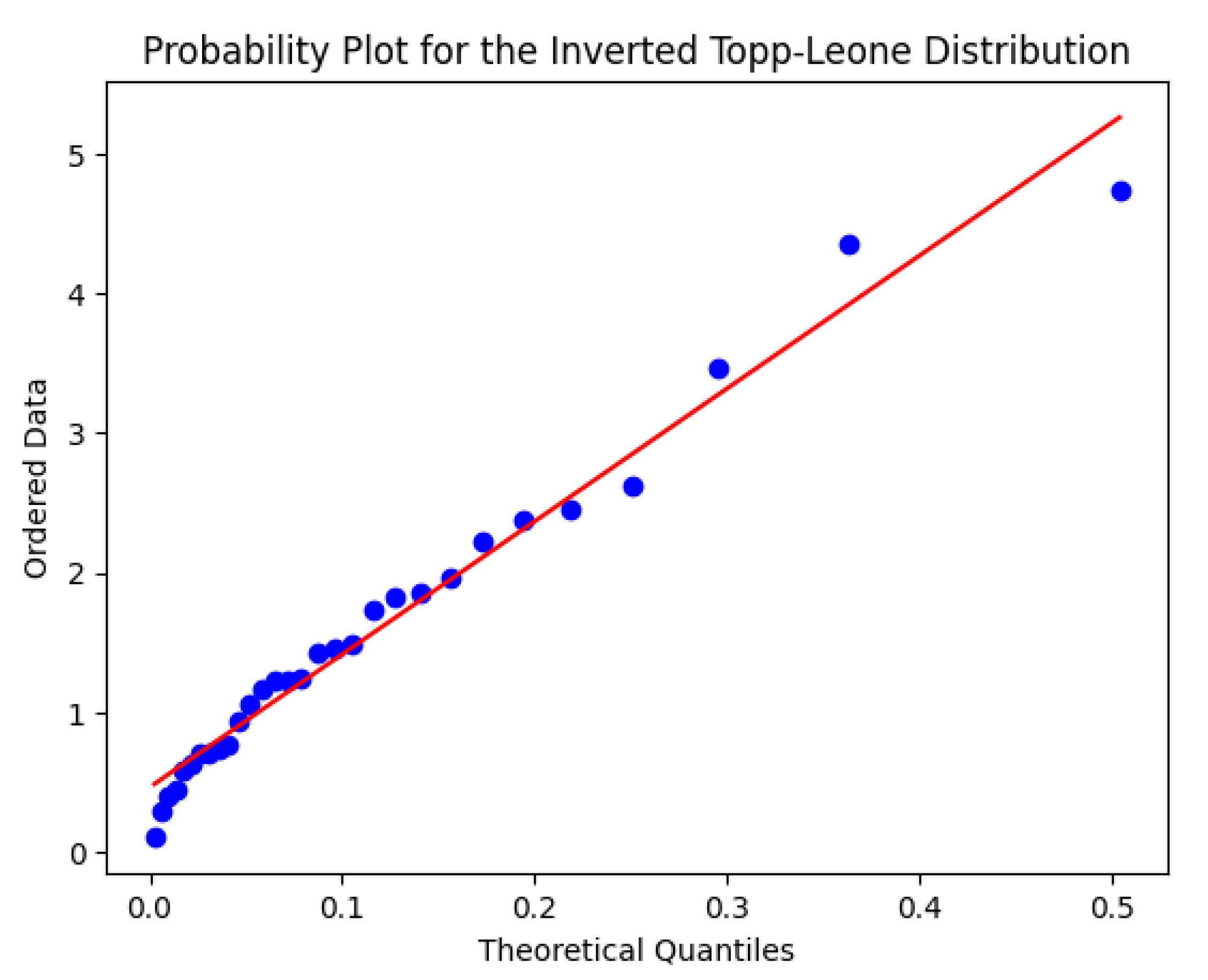
Table 1.
Comparison of True and Estimated Values for Parameter .
| n | Bias | MSE | CI lower | CI upper | |
|---|---|---|---|---|---|
| 100 | 2.145479 | 0.145479 | 0.285984 | 1.412837 | 3.395362 |
| 200 | 2.067830 | 0.067830 | 0.115006 | 1.543739 | 2.833557 |
| 500 | 2.026010 | 0.026010 | 0.040594 | 1.688080 | 2.464037 |
| 1000 | 2.012837 | 0.012837 | 0.019029 | 1.766096 | 2.305012 |
Table 2.
Comparison of True and Estimated Values for Parameter .
| n | Bias | MSE | CI lower | CI upper | |
|---|---|---|---|---|---|
| 100 | 0.993807 | -0.006193 | 0.057248 | 0.591871 | 1.531506 |
| 200 | 0.998264 | -0.001736 | 0.028667 | 0.701223 | 1.358450 |
| 500 | 0.999845 | -0.000155 | 0.011551 | 0.805474 | 1.228158 |
| 1000 | 0.999741 | -0.000259 | 0.005676 | 0.857869 | 1.154789 |
Table 4.
Comparison of Distributions (Dataset 1).
| Model | Log-Likelihood | AIC | BIC | CAIC | HQIC |
| ITL | -55.5384 | 115.0768 | 118.1295 | 120.1295 | 116.1179 |
| Inverse Weibull | -58.6266 | 121.2532 | 124.3059 | 126.3059 | 122.2942 |
| Inverse Gamma | -59.0659 | 122.1319 | 125.1846 | 127.1846 | 123.1793 |
Table 6.
Comparison of Distributions (Dataset 2).
| Model | Log-Likelihood | AIC | BIC | CAIC | HQIC |
| ITL | -55.5384 | 115.0768 | 118.1295 | 120.1295 | 116.1179 |
| Inverse Weibull | -58.6266 | 121.2532 | 124.3059 | 126.3059 | 122.2942 |
| Inverse Gamma | -59.0659 | 122.1319 | 125.1846 | 127.1846 | 123.1793 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



