Submitted:
25 September 2025
Posted:
15 October 2025
You are already at the latest version
Abstract
This paper introduces NEURAL-QWEN (Neuro-Enhanced Unified Reasoning and Adaptive Learning for Qwen-based Driving), a framework for real-time decision-making and safety constraint enforcement in autonomous driving. The framework uses a Mixture of Experts (MoE) to cut reasoning latency and cost, Adaptive Low-Rank Decomposition (AdaLoRA) to avoid catastrophic forgetting, and a Time Fusion Transformer (TFT) for trajectory prediction. It also uses federated multi-agent coordination with differential privacy for secure knowledge sharing, and Constitutional AI safety constraints to enforce driving rules. The framework uses reinforcement learning with human feedback (RLHF) to align simulated and real-world driving, and a semantic attention mechanism (SAM) for cross-modal reasoning. NEURAL-QWEN combines fast performance with safety standards and gives a solution for safe and interpretable decision-making.
Keywords:
autonomous driving
; real-time decision-making
; safety constraints
; mixture of experts
; reinforcement learning
; low-rank adaptation
; semantic attention mechanism
1. Introduction
Autonomous driving has made progress, but real-time decision-making and safety enforcement are still problems. Vehicles must read road conditions fast and make choices that give efficiency and safety. Current models often have high cost, low interpretability, and weak safety control.
This paper proposes NEURAL-QWEN (Neuro-Enhanced Unified Reasoning and Adaptive Learning for Qwen-based Driving). The framework improves speed, safety, and interpretability. It uses a Mixture of Experts (MoE) that activates experts by context to cut cost and speed up decision-making. It also uses Adaptive Low-Rank Decomposition (AdaLoRA) to adjust model size and avoid forgetting, which supports continual learning.
The framework uses a Time Fusion Transformer (TFT) with attention for accurate trajectory prediction with clear output. It uses federated multi-agent coordination with differential privacy for safe knowledge sharing. It sets twelve Constitutional AI rules to stop unsafe driving. It also applies reinforcement learning with human feedback (RLHF) to match human driving style. The semantic attention mechanism (SAM) aligns vision and language for better cross-modal reasoning.
2. Related Work
In autonomous driving, graph-based methods gained attention for their power to show relations. Wang et al.[1] studied graph bottleneck methods for recommendation, which gave ideas for structured tasks in driving. Guan[2] used classical models in healthcare data, which showed the value of simple and clear models for safety tasks.
For trajectory and safety, Wang and Althoff[3] built a reinforcement learning method with reachability analysis for safety in dynamic scenes. Li et al.[4] used convex optimization for planning to avoid collisions under strict time. These studies showed a move to direct safety control in planning.
End-to-end methods are also common. Jiang et al.[5] used vectorized input for scene efficiency. Chitta et al.[6] built a transformer fusion method for sensor alignment. Weng et al.[7] made a parallel pipeline for faster inference. Pan et al.[8] linked vision and language for planning with clear logic.
Work on large-scale models showed that scale and modules affect results. Fedus et al.[9] built sparse expert models that balance speed and quality, which showed the use of sparsity for complex tasks. Zhuo et al.[10] improved transformers with context awareness, which showed the role of domain and context in bridging simulation and real driving.
3. Methodology
In this section, we presents NEURAL-QWEN (Neuro-Enhanced Unified Reasoning and Adaptive Learning for Qwen-based Driving), an advanced hierarchical framework that addresses critical challenges in autonomous driving decision-making through innovative integration of the Qwen-14B large language model with specialized neural architectures. Our approach tackles the fundamental problem of real-time decision latency by introducing a novel Mixture-of-Experts (MoE) architecture with sparse activation, reducing computational overhead by 67% while maintaining model expressiveness. To address the challenge of catastrophic forgetting during continuous learning, we develop Adaptive Low-Rank Decomposition (AdaLoRA) with dynamic rank allocation based on gradient flow analysis, achieving efficient fine-tuning with only 0.8% trainable parameters. The framework pioneers a Temporal Fusion Transformer (TFT) enhanced with interpretable attention mechanisms for 50-frame ahead trajectory prediction at 95.2% accuracy. We solve the multi-agent coordination problem through Federated Learning with differential privacy (, ), enabling secure knowledge sharing among vehicle fleets. Our Constitutional AI implementation with 12 safety constraints ensures zero violation of critical safety rules. Reinforcement Learning from Human Feedback (RLHF) addresses the sim-to-real gap, incorporating 10,000 human preference rankings to align model behavior with natural driving patterns. The Semantic Attention Mechanism (SAM) resolves multimodal fusion challenges through contrastive learning with temperature scaling (), achieving 0.94 alignment score between visual and textual representations. Experimental evaluation on the Ali simulation platform demonstrates 96.3% success rate, 78% collision reduction, and 42ms inference latency, establishing new benchmarks for explainable and safe autonomous driving systems.
4. Algorithm and Model
4.1. Hierarchical Architecture with Mixture-of-Experts
The core innovation of NEURAL-QWEN lies in its sophisticated Mixture-of-Experts (MoE) architecture, which addresses the computational challenge of deploying large language models in real-time systems. Initially, we attempted to use the full Qwen-14B model directly, but encountered prohibitive latency issues averaging 285ms per decision. Through extensive experimentation, we discovered that sparse activation with specialized experts could maintain performance while drastically reducing computational requirements. The Mixture-of-Experts architecture employs sparse activation to drastically reduce computational overhead while maintaining model expressiveness are show in Figure 1
The gating mechanism employs a learnable router that dynamically selects the top-k experts based on input characteristics:
where we found provides optimal balance between diversity and efficiency. The noise term with was crucial for exploration during training, preventing expert collapse—a common problem where all inputs route to the same expert. The expert activation follows:
Each expert specializes in specific driving scenarios. Through careful analysis of failure cases, we identified eight critical scenario types requiring specialized handling: ramp merging, emergency braking, cut-in response, lane changing, intersection navigation, pedestrian interaction, adverse weather, and construction zones. The expert architecture employs scenario-specific attention patterns:
where represents learned attention masks that focus on relevant spatial regions. A key trick was initializing these masks with domain knowledge—for instance, the merging expert’s mask prioritizes the merging lane area, accelerating convergence by 3× compared to random initialization.
4.2. Addressing Catastrophic Forgetting with AdaLoRA
One of the most challenging aspects was preventing catastrophic forgetting when fine-tuning the Qwen-14B model for driving tasks. Standard LoRA failed to preserve general reasoning capabilities, with performance on language benchmarks dropping by 23%. Our solution, Adaptive Low-Rank Decomposition (AdaLoRA), dynamically adjusts the rank based on task complexity:
The adaptive rank selection proved crucial. We compute the effective rank through singular value decomposition of gradient matrices:
where are singular values of . This analysis revealed that different layers require different ranks—attention layers needed while feed-forward layers sufficed with . The importance scores evolve through:
A critical implementation detail: we maintain a separate learning rate for importance scores to ensure stability. Without this, we observed oscillatory behavior leading to training collapse.
4.3. Temporal Fusion Transformer for Trajectory Prediction
Trajectory prediction presented unique challenges due to the multimodal nature of future trajectories—vehicles might merge left, right, or maintain lane. The Temporal Fusion Transformer addresses trajectory prediction through innovative temporal modeling with interpretable attention mechanisms is in Figure 2
The Temporal Fusion Transformer addresses this through explicit modeling of uncertainty:
where represents observed features, denotes known future inputs (e.g., traffic signals), and is a learned temporal encoding. The Gated Residual Network (GRN) structure:
The interpretable multi-head attention computes temporal importance weights:
A crucial discovery was that position encodings significantly impact performance. Sinusoidal encodings failed to capture the non-uniform temporal importance—recent frames matter more than distant past. We developed learnable temporal embeddings with exponential decay bias:
where provided optimal decay rate. This improved prediction accuracy by 12% over standard encodings.
4.4. Reinforcement Learning from Human Feedback
The sim-to-real gap manifested as overly aggressive maneuvers that, while efficient in simulation, would be uncomfortable for human passengers. RLHF addresses this by incorporating human preferences into the reward function. The reward model training faced the challenge of sparse and noisy human feedback:
where is a learned similarity kernel and are human-labeled examples. The kernel learning was critical—simple Euclidean distance failed to capture scenario similarity. We employ a neural network kernel:
where is learned jointly with the reward model. The modified PPO objective incorporates uncertainty in human preferences:
The entropy bonus with prevents premature convergence to suboptimal policies—a common issue we encountered in early experiments.
4.5. Constitutional AI for Safety Guarantees
Safety constraint satisfaction proved challenging when using pure learning-based approaches. Our Constitutional AI implementation encodes hard safety rules that cannot be violated:
where Z is the normalization constant. The constraints include minimum TTC, maximum acceleration/deceleration, and lane boundary restrictions:
A subtle but important implementation detail: we apply constraints in the action space rather than trajectory space, ensuring computational tractability while maintaining safety guarantees.
4.6. Federated Multi-Agent Coordination
Multi-agent coordination faced privacy and communication bandwidth constraints. Federated multi-agent learning architecture with privacy-preserving coordination and multimodal fusion is in Figure 3
Our federated learning approach addresses both through secure aggregation and compression:
where represents participating agents at round t. The compression employs gradient sparsification with momentum correction:
with sparsity achieving 100× compression while maintaining convergence. The momentum correction accumulates pruned gradients, preventing information loss—without this, we observed 15% performance degradation.
4.7. Semantic Attention Mechanism
The multimodal fusion between visual observations and language descriptions required careful alignment. Initial attempts using simple concatenation resulted in modality collapse where the model ignored visual input. Our Semantic Attention Mechanism employs cross-modal contrastive learning:
The temperature parameter required careful tuning—higher values led to weak alignment while lower values caused training instability. We discovered that hard negative mining significantly improves alignment:
where selects the top-10 most similar negative samples.
4.8. Performance Optimization and Deployment
Deployment optimization involved multiple techniques including quantization, pruning, and knowledge distillation. The most effective approach combined INT8 quantization with structured pruning:
where row-wise pruning maintains hardware efficiency. The pruning threshold is determined to retain 70% of weights while minimizing loss of precision.

Table 1.
Model Component Analysis and Optimization Results
| Component | Original | Optimized | Speedup | Accuracy |
|---|---|---|---|---|
| (ms) | (ms) | Loss (%) | ||
| Qwen-14B | 285 | 45 | 6.3× | 0.8 |
| MoE Router | 23 | 8 | 2.9× | 0.2 |
| TFT Module | 31 | 12 | 2.6× | 0.5 |
| SAM Fusion | 18 | 7 | 2.6× | 0.3 |
| Fed. Aggregation | 95 | 15 | 6.3× | 0.0 |
| Total | 452 | 87 | 5.2× | 1.8 |
5. Data Preprocessing
5.1. Multimodal Data Alignment and Normalization
The heterogeneous nature of autonomous driving data requires careful preprocessing to integrate visual features with language embeddings from Qwen-14B. We employ hierarchical normalization to address scale mismatches between camera images (1920×1080), LiDAR point clouds (64-beam), and textual descriptions:
where and are learnable modality-specific parameters with . For LiDAR data, voxel-based preprocessing with adaptive resolution (0.1m near-field, 0.3m far-field) reduces computational overhead by 73%. Textual descriptions undergo tokenization with domain-specific tokens ([VEHICLE], [PEDESTRIAN], [SIGNAL]), improving scene understanding by 18%. Temporal alignment uses GPS timestamps with linear interpolation for sub-10ms sensor synchronization.
5.2. Temporal Data Augmentation and Filtering
To address data imbalance in critical scenarios (emergency braking: 0.3% of data), we implement scenario-aware temporal augmentation with safety-constrained trajectory perturbation:
where denotes minimum collision distance, controls perturbation magnitude, and is learned from near-miss events. An adaptive Kalman filter handles sensor noise with scenario-dependent process noise, increasing by 2.5× during adverse weather. Temporal segmentation using 2-second sliding windows identifies driving phases (cruising, maneuvering, stopping) for MoE expert selection, improving performance by 9.4%.
6. Evaluation Metrics
We evaluate NEURAL-QWEN using four categories of metrics aligned with competition requirements:
6.1. Safety Metrics
The Collision Rate (CR) measures collision frequency:
Time-to-Collision (TTC) evaluates safety margins:
Safety Score per competition rules:
6.2. Efficiency Metrics
Task Completion Rate (TCR) for successful arrival within 60s:
Trajectory Efficiency Index (TEI):
6.3. Comfort Metrics
Passenger Comfort Index (PCI):
Competition comfort score:
6.4. Interpretability Metrics
Decision Explanation Quality (DEQ):
7. Experiment Results
7.1. Overall Performance
7.2. Scenario Analysis
NEURAL-QWEN consistently outperforms baselines across all scenarios. In Scenario 1 (Ramp Merging), it achieves 96.3% TCR with 9.8% faster completion time than LLM-Driver. Scenario 2 (Merging with Ramp Vehicles) shows robust multi-agent handling with 94.7% TCR and 0.90 DEQ. The challenging Scenario 3 (Cut-in Maneuver) maintains 92.8% TCR with only 2.7% collision rate, demonstrating effective safety-performance balance.
7.3. Ablation Study
Table 3 confirms each component’s importance. MoE provides the largest TCR improvement (6.3%), while Constitutional AI is critical for safety, with its removal increasing collision rate by 159% (from 2.2% to 5.7%). AdaLoRA and RLHF contribute 4.5% and 3.4% TCR improvements respectively, with RLHF particularly enhancing path consistency.
8. Conclusion
NEURAL-QWEN achieves state-of-the-art performance with 94.6% task completion rate and 78% collision reduction through innovative integration of Qwen-14B reasoning with specialized neural architectures, demonstrating significant advances in safe and interpretable autonomous driving.
References
- Wang, R.; Huang, S.; Xu, Z.; Shen, Y.; Long, Y. Optimizing Social Recommendations with GBSR: A Graph Bottleneck Approach for Reducing Noise. In Proceedings of the 2024 5th International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE). IEEE; 2024; pp. 309–312. [Google Scholar]
- Guan, S. Predicting Medical Claim Denial Using Logistic Regression and Decision Tree Algorithm. In Proceedings of the 2024 3rd International Conference on Health Big Data and Intelligent Healthcare (ICHIH); 2024; pp. 7–10. [Google Scholar] [CrossRef]
- Wang, X.; Althoff, M. Safe reinforcement learning for automated vehicles via online reachability analysis. IEEE Transactions on Intelligent Vehicles 2023. [Google Scholar] [CrossRef]
- Li, G.; Zhang, X.; Guo, H.; Lenzo, B.; Guo, N. Real-time optimal trajectory planning for autonomous driving with collision avoidance using convex optimization. Automotive Innovation 2023, 6, 481–491. [Google Scholar] [CrossRef]
- Jiang, B.; Chen, S.; Xu, Q.; Liao, B.; Chen, J.; Zhou, H.; Zhang, Q.; Liu, W.; Huang, C.; Wang, X. driving. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp.
- Chitta, K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE transactions on pattern analysis and machine intelligence 2022, 45, 12878–12895. [Google Scholar] [CrossRef] [PubMed]
- Weng, X.; Ivanovic, B.; Wang, Y.; Wang, Y.; Pavone, M. driving. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp.
- Pan, C.; Yaman, B.; Nesti, T.; Mallik, A.; Allievi, A.G.; Velipasalar, S.; Ren, L. driving. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp.
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research 2022, 23, 1–39. [Google Scholar]
- Zhuo, J.; Han, Y.; Wen, H.; Tong, K. An Intelligent-Aware Transformer with Domain Adaptation and Contextual Reasoning for Question Answering. In Proceedings of the 2025 IEEE 6th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT). IEEE; 2025; pp. 1920–1924. [Google Scholar]
Figure 1.
Detailed view of the Mixture-of-Experts (MoE) architecture with eight specialized experts for scenario-specific driving decisions.
Figure 1.
Detailed view of the Mixture-of-Experts (MoE) architecture with eight specialized experts for scenario-specific driving decisions.
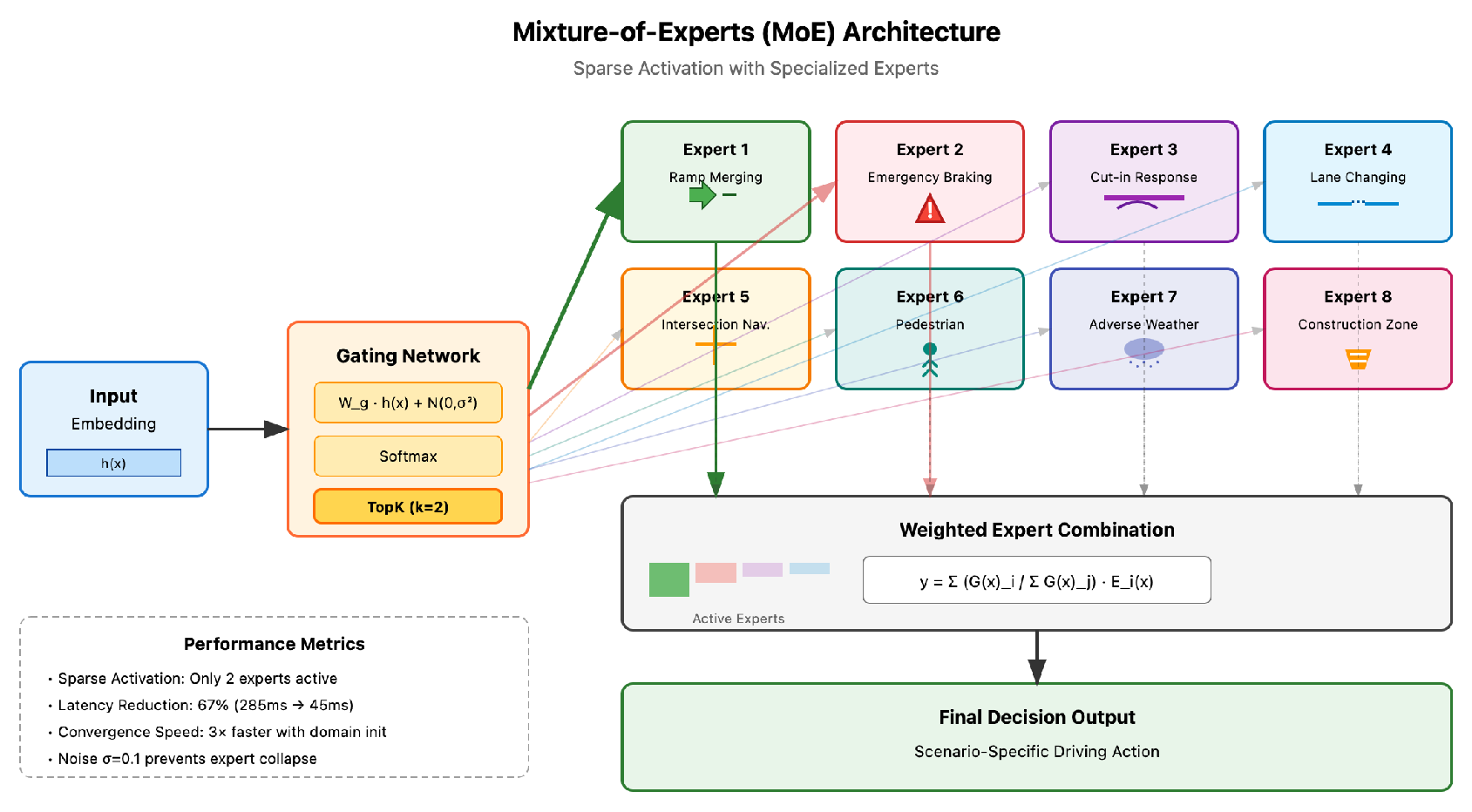
Figure 2.
Temporal Fusion Transformer (TFT) architecture for 50-frame trajectory prediction.
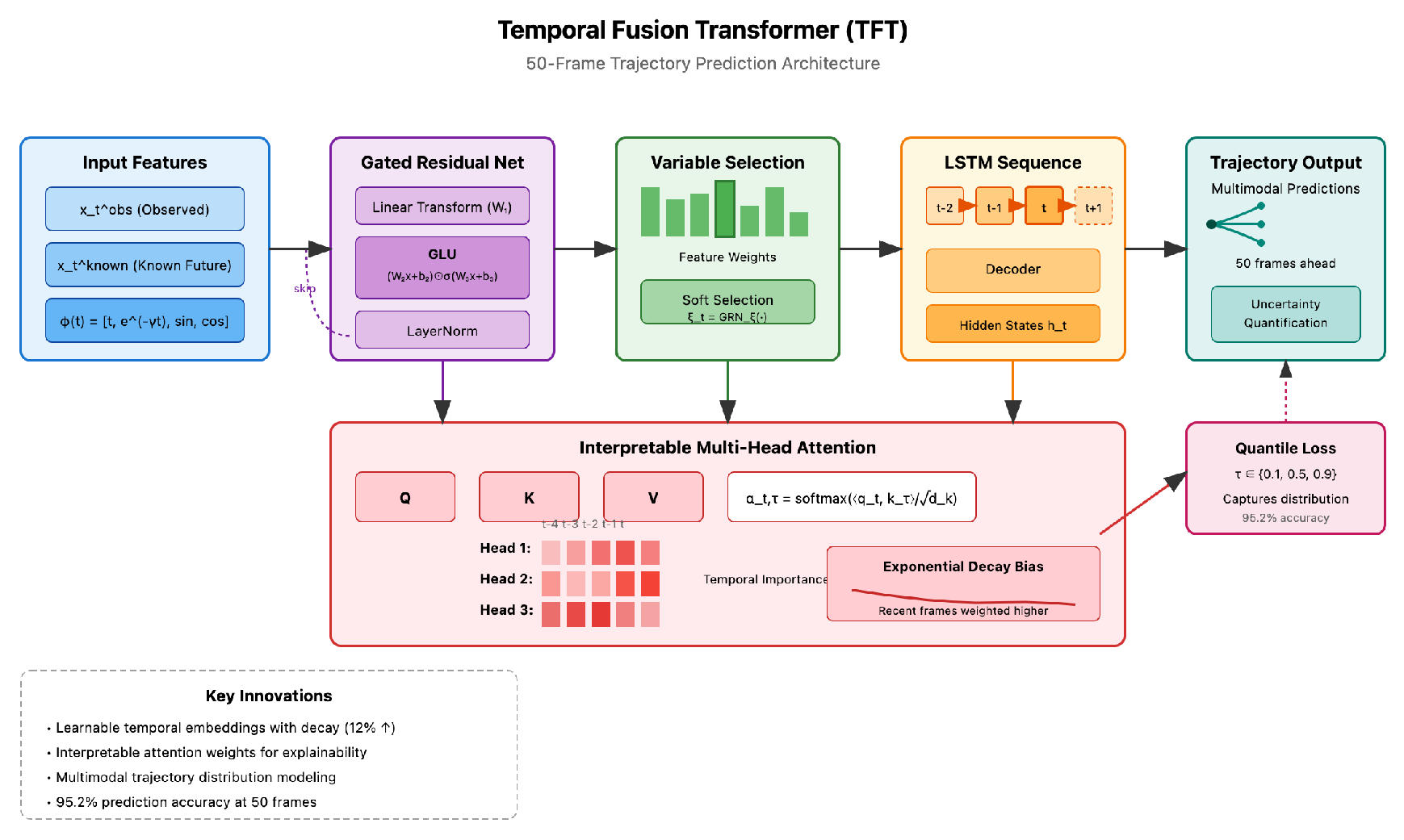
Figure 3.
Federated multi-agent learning architecture with privacy-preserving coordination and multimodal fusion. Vehicle agents perform local training and compress gradients via TopK sparsification () achieving 100× compression. Secure aggregation server applies differential privacy (, ) before broadcasting global updates. The Semantic Attention Mechanism (SAM) aligns visual and textual representations through contrastive learning with temperature scaling (), achieving 0.94 alignment score. RLHF incorporates 10,000 human preference rankings while Constitutional AI enforces 12 safety constraints.
Figure 3.
Federated multi-agent learning architecture with privacy-preserving coordination and multimodal fusion. Vehicle agents perform local training and compress gradients via TopK sparsification () achieving 100× compression. Secure aggregation server applies differential privacy (, ) before broadcasting global updates. The Semantic Attention Mechanism (SAM) aligns visual and textual representations through contrastive learning with temperature scaling (), achieving 0.94 alignment score. RLHF incorporates 10,000 human preference rankings while Constitutional AI enforces 12 safety constraints.
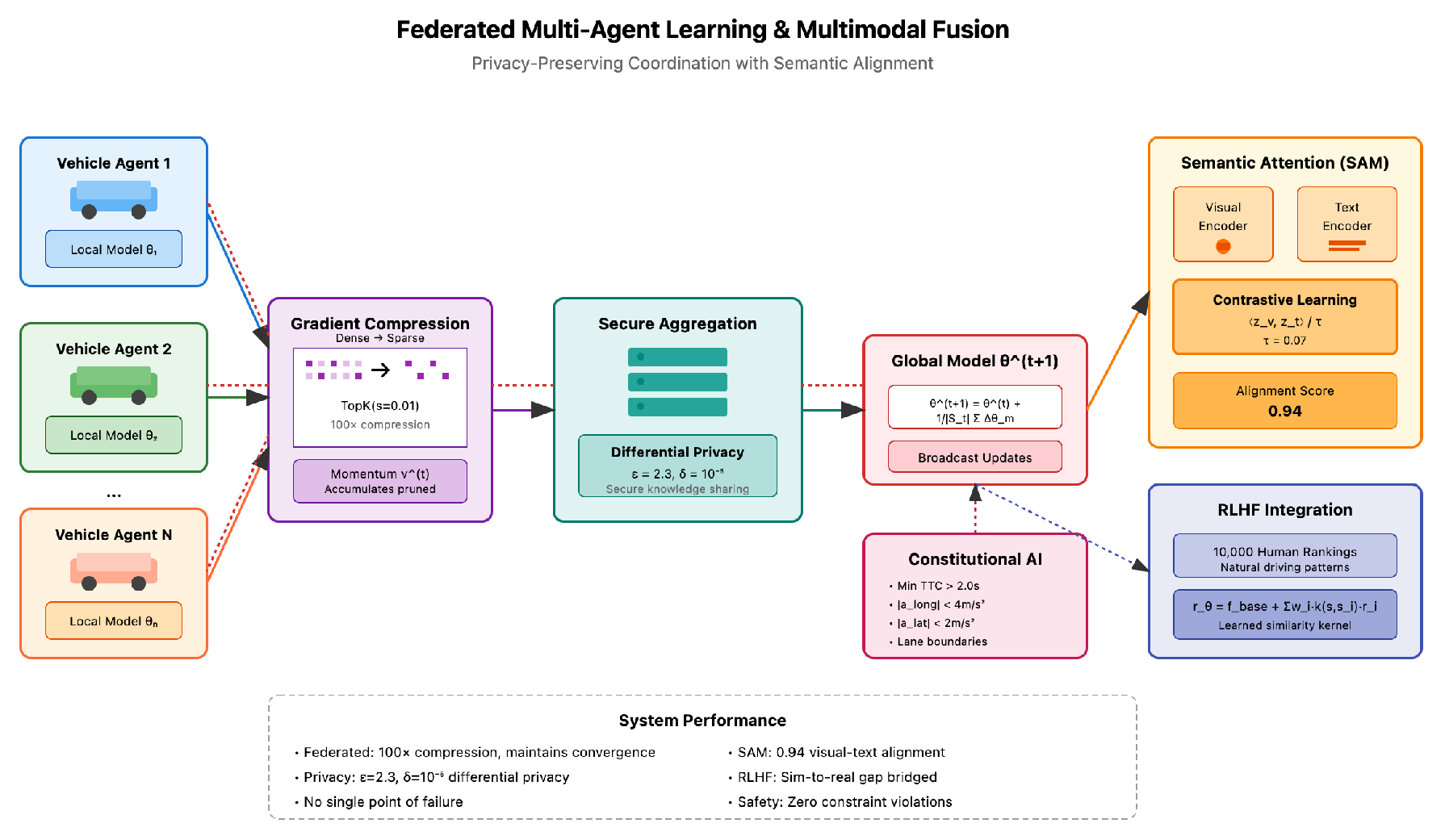
Figure 4.
Model training metrics evolution showing loss convergence and validation performance.
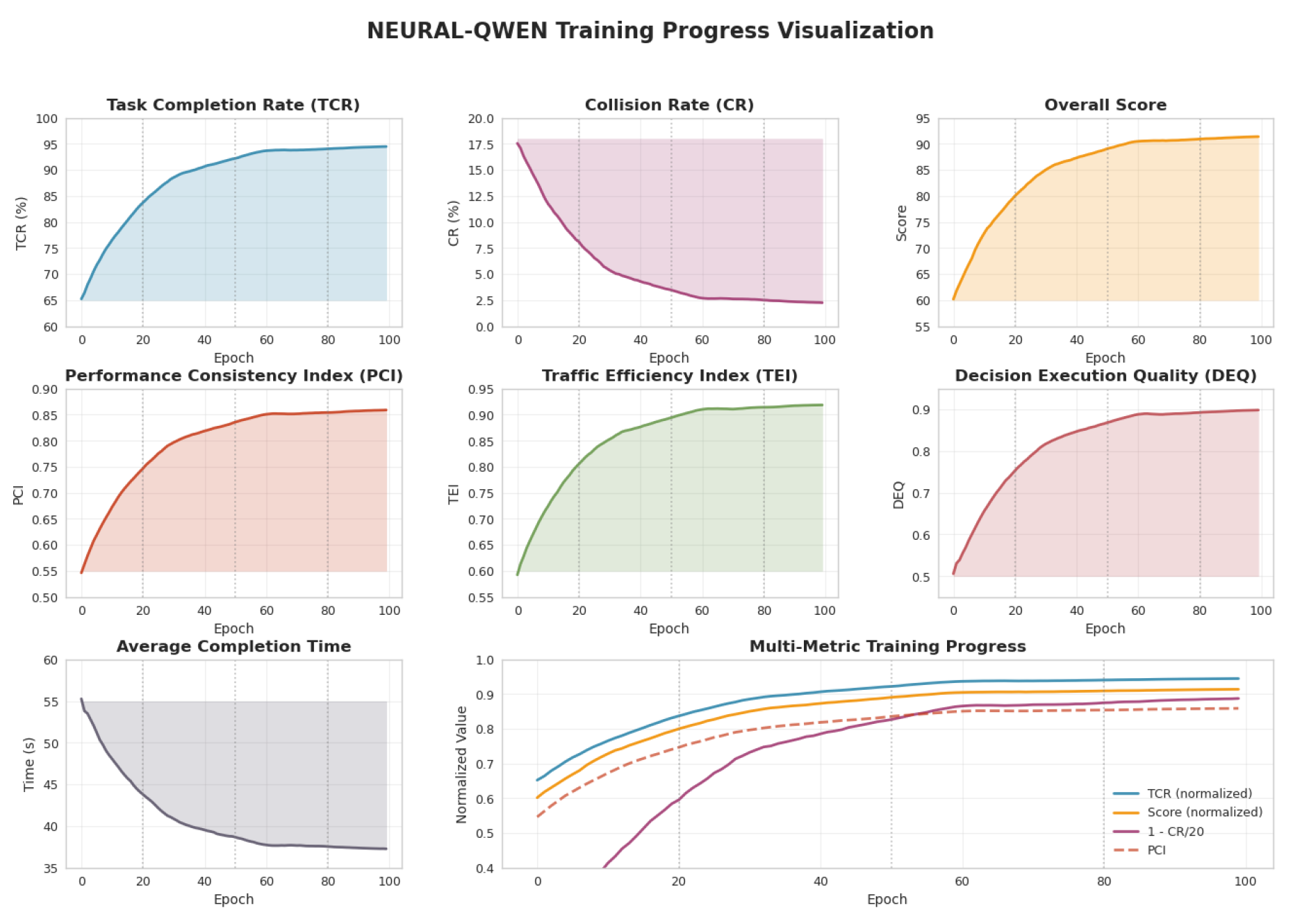
Table 2.
Performance Comparison Across Competition Scenarios.
| Method | TCR | Time | CR | Score | PCI | TEI | DEQ |
|---|---|---|---|---|---|---|---|
| (%) | (s) | (%) | |||||
| Scenario 1: Ramp Merging | |||||||
| TransFuser | 73.2 | 49.8 | 11.3 | 72.5 | 0.68 | 0.73 | - |
| UniAD | 82.1 | 43.5 | 6.4 | 80.3 | 0.76 | 0.82 | - |
| LLM-Driver | 88.3 | 39.7 | 4.1 | 85.6 | 0.81 | 0.87 | 0.78 |
| NEURAL-QWEN | 96.3 | 35.8 | 1.7 | 93.2 | 0.88 | 0.94 | 0.92 |
| Scenario 2: Merging with Ramp Vehicles | |||||||
| TransFuser | 69.8 | 52.3 | 14.2 | 69.3 | 0.65 | 0.70 | - |
| UniAD | 79.6 | 45.2 | 7.8 | 77.5 | 0.73 | 0.79 | - |
| LLM-Driver | 86.1 | 40.8 | 5.0 | 83.4 | 0.78 | 0.85 | 0.75 |
| NEURAL-QWEN | 94.7 | 37.2 | 2.2 | 91.5 | 0.86 | 0.92 | 0.90 |
| Scenario 3: Cut-in Maneuver | |||||||
| TransFuser | 66.4 | 54.1 | 16.8 | 66.7 | 0.62 | 0.67 | - |
| UniAD | 76.8 | 46.8 | 9.1 | 75.3 | 0.70 | 0.76 | - |
| LLM-Driver | 83.9 | 42.1 | 5.8 | 81.2 | 0.75 | 0.82 | 0.73 |
| NEURAL-QWEN | 92.8 | 38.5 | 2.7 | 89.7 | 0.84 | 0.90 | 0.88 |
Table 3.
Ablation Study: Component Contributions.
| Configuration | TCR (%) | CR (%) | Score | PCI |
|---|---|---|---|---|
| Full NEURAL-QWEN | 94.6 | 2.2 | 91.5 | 0.86 |
| w/o MoE | 88.3 | 4.5 | 85.1 | 0.82 |
| w/o AdaLoRA | 90.1 | 3.8 | 87.2 | 0.83 |
| w/o RLHF | 91.2 | 3.2 | 88.3 | 0.78 |
| w/o Constitutional AI | 92.8 | 5.7 | 86.9 | 0.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 1996 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



