Submitted:
24 November 2025
Posted:
27 November 2025
You are already at the latest version
Abstract
Workplace safety and health remain a major global challenge, with work-related accidents and diseases still causing millions of deaths each year despite decades of regulatory, technical and organizational advances. In parallel, the digitalization of Industry 4.0/5.0 is generating unprecedented volumes of safety-relevant data and new opportunities to move from reactive analysis to proactive, data-driven prevention. This review maps how artificial intelligence (AI), with a specific focus on natural language processing (NLP) and large language models (LLMs), is being applied to occupational risk prevention across sectors. A structured search of the Web of Science Core Collection (2013– October 2025), combined OSH-related terms with AI, NLP and LLM terms. After screening and full-text assessment, 126 studies were discussed. Early work relied on text mining and traditional machine learning to classify accident types and causes, extract risk factors and support incident analysis from free-text narratives. More recent contributions use deep learning to predict injury severity, potential serious injuries and fatalities (PSIF) and field risk control program (FRCP) levels, and to fuse textual data with process, environmental and sensor information in multi-source risk models. The latest wave of studies deploys LLMs, retrieval-augmented generation and vision–language architectures to generate task-specific safety guidance, support accident investigation, map occupations and job tasks, and monitor personal protective equipment (PPE) compliance. Together, these developments show that AI-, NLP- and LLM-based systems can exploit unstructured OSH information to provide more granular, timely and predictive safety insights. However, the field is still constrained by data quality and bias, limited external validation, opacity, hallucinations and emerging regulatory and ethical requirements. In conclusion, AI and LLMs should be positioned as human-in-the-loop decision-support tools and outlines a research agenda centered on high-quality OSH datasets, hybrid models integrating domain knowledge and AI, and rigorous evaluation of fairness, robustness, explainability and governance.
Keywords:
safety management
; predictive safety strategies
; real-time risk mapping
; large language models
; accident prevention
1. Introduction
Occupational Safety and Health (OSH) is a major concern for all countries worldwide (Zhang et al., 2019), and its management is an ongoing challenge to protect the health and safety of workers and ensure a safe and healthy working environment. The latest International Labor Organization (ILO) estimates that nearly three million workers die each year from work-related accidents and diseases, an increase of more than 5 per cent compared to 2015 (ILO, 2023), denoting an urgent need for more action to prevent work-related accidents and diseases. Although the statistics remain alarming, working conditions have improved tremendously over the years (Badri et al., 2018). Advances in science and technology, such as engineering controls, safer machinery and processes, collective and individual protective equipment, and the implementation of regulations and labor inspections, have significantly reduced the incidence of occupational accidents and diseases associated with industrialization (Kim et al., 2016). In addition, the development of a preventive culture in organizational settings have been crucial in optimizing health and safety management. Industrial development began worldwide in the eighteenth century (Sharma & Singh, 2020) and has been characterized by a series of events that have triggered different revolutions over the years, as shown in Figure 1. These revolutions have been driven by technological transformations that have led to changes in the way industry operate and important social changes (Vinitha et al., 2020; Xu et al., 2018).
The First Industrial Revolution began with the introduction of the power loom in 1784 and was characterized by shifts towards the intensification of work activities. In this period, water power and the steam engine played a decisive role, both in their contributions to industry and transport (Sharma & Singh, 2020). In the 19th century, the Second Industrial Revolution was born with the invention of electricity production, innovations in development, the use of new materials (alloys, synthetic plastics), mass production and assembly lines (Zhang & Yang, 2020). With the appearance of the first programmable logic controller (PLC) in 1969, the transition from the invention and manufacture of analogue to digital electronic devices, automation, and the incorporation of information technologies (ICT) into industrial processes, the Third Industrial Revolution was born (Fonseca, 2018), which encouraged the glocalization of production and the relocation of jobs (Roberts, 2015).
The Fourth Industrial Revolution, or Industry 4.0 (early 21st century), is marked by technological developments with a certain autonomy and self-behavior, mainly focused on industrial automation robotic production through the integration of digital technology, information and communication technologies within an intelligent environment (Leesakul et al., 2022; Milea & Cioca, 2024; Gomez Miranda and Gonçalves, 2024). Specifically, this digital transformation is driven by technologies such as Blockchain, the Internet of Things, Big Data, Cyber-physical systems, Cobotics, Artificial Intelligence (AI), Natural Language Processing (NLP), Cloud Computing, Augmented Reality (AR) and Virtual Reality (VR), which aim to optimize production processes, increasing productivity and efficiency(Milea & Cioca, 2024). Finally, from 2021 onwards, the futuristic Fifth Industrial Revolution emerged, based on humans-robot collaboration to increase creativity and innovation by allowing robots to perform monotonous activities (Miraz et al., 2022).
On the other hand, the evolution in the field of OSH has always followed the different revolutionary advances in the industry (Badri et al., 2018) which has made it possible to react and propose effective solutions to be able to control occupational risks that may manifest themselves in the face of technological advances, innovations, changes in working methods, organization, work teams, processes, products, and workplace itself. Indeed, the nature of a changing work environment brings with it a series of OSH challenges and opportunities, which is why its management is essential to ensure workers' health, business sustainability and social stability (Wang et al., 2020)
Over the years, in most industrialized and developed countries, reactivity has given way to proactivity (Badri et al., 2018) which promotes a fully preventive approach to OSH that allows action from the source to eliminate risks. This allows the appropriate decisions to be made sufficiently in advance to anticipate possible undesirable events that could harm workers. To this end, the incorporation of digitalization is now beginning to offer new opportunities to innovate, improve and address new and emerging risks in the field of occupational risk prevention, through the incorporation of neurocognitive computing technologies, AI and NLP. Recent studies highlight the role of AI in the risk of occupational disease, analyzing workplace hazards, and enhancing safety measures (Garvin & Kimbleton, 2021; Howard & Schulte, 2024; Mollaei et al., 2023; Pishgar et al., 2021; Westhoven, 2022; Yimyam & Ketcham, 2022).
Thus, the evolution of occupational risk prevention has been characterized by a continuous expansion of its focus and methods. Initially focused on occupational health, it has transformed into a comprehensive approach that includes safety and health management and the early use of emerging technologies for the benefit of workers. This shift reflects a deeper understanding of workplace hazards, including chemical risks and psychosocial factors. The development of a preventive culture within organizational settings has been crucial in optimizing safety and health management systems. Recent strategies include dynamic risk assessment which helps organizations become better able to adapt to rapidly changing business or technological dynamics, putting them in a better position to respond to changes in business processes and their associated OSH risks (van Gulijk, 2021).
Today, this evolution is experiencing breakthrough, especially with the integration of AI and NLP. Recent studies highlight the role of AI in assessing the risk of occupational disease risk, analyzing workplace hazards, and enhancing safety measures (Garvin & Kimbleton, 2021; Mollaei et al., 2023; Pishgar et al., 2021; Westhoven, 2022; Yimyam & Ketcham, 2022) Specifically, NLP is demonstrating great potential in processing and interpreting large data sets for risk analysis. These technologies are central to the development of more efficient, accurate, and predictive occupational risk prevention strategies.
The objective of this study is to conduct a systematic review of the application of Artificial Intelligence (AI) models, particularly Large Language Models (LLMs) and Natural Language Processing (NLP), within the domain of occupational risk prevention. This review aims to elucidate how advanced technologies are being employed across various industrial sectors, including aviation, construction, the chemical industry, and transportation, to improve workplace safety and risk management. Specifically, the study will identify key technological applications such as real-time risk mapping, automated safety incident classification, and predictive modeling of occupational hazards. Furthermore, it seeks to address current challenges related to data quality, model transparency, and multilingual support while providing insights for future research to overcome these limitations and advance the efficacy of AI-driven occupational risk prevention strategies.
Recent work illustrates how AI and, in particular, large language models are reshaping occupational safety along the whole data–decision pipeline. At the level of risk assessment guidance, Baek et al. develop a retrieval-augmented LLM that mines 64,740 construction accident reports to automatically generate task- and equipment-specific safety risk management guidance, achieving quality comparable to experienced practitioners and reducing supervisors’ workload (Baek et al., 2025). Bernardi et al. extend this idea by combining RAG with explainable LLMs and layer-wise relevance propagation to produce job safety reports from unstructured aviation incident narratives, explicitly highlighting root causes to support human-centred, auditable decision-making (Bernardi et al., 2025).
A second cluster of studies focuses on structuring occupational information and safety data. Kim et al. fine-tune DistilKoBERT on nearly 100,000 survey responses to classify workers into 142 occupational codes with >84% accuracy, enabling large-scale, text-based occupational epidemiology (Kim et al., 2024). In parallel, Li et al. propose LLM4Jobs, an unsupervised framework that uses LLM-based summarization and embeddings to map noisy job descriptions to standard taxonomies such as ISCO/ESCO, outperforming prior unsupervised occupation coding methods (Li et al., 2025). Song et al. apply KoBERT to industrial accident descriptions to automatically classify occurrence types, mitigating subjectivity and inconsistency in manual coding and improving the quality of national accident statistics (Song et al., 2024).
Several contributions target predictive modelling of accident severity from textual or proactive safety data. Khairuddin et al. design an optimized Bi-LSTM architecture that fuses TF-IDF and GloVe embeddings of OSHA injury narratives, achieving up to 0.98 accuracy for amputation prediction and revealing salient causal keywords (Khairuddin et al., 2024). Using proactive Fatality Risk Control Programme data from an Indian steel plant, Sarker et al. combine NLP features with an ensemble of six classifiers in a soft-voting scheme to predict potential accident severity, supporting earlier and less biased interventions (Sarker et al., 2025). At the critical end of the severity spectrum, Parikh et al. integrate transformer-based text encoders with XGBoost to automatically flag incident reports involving potential serious injuries and fatalities (PSIF), using weak labelling and F2-optimised tuning to prioritise recall of high-risk cases (Parikh et al., 2024).
Finally, new multi-modal and reasoning-oriented architectures broaden the scope of AI-enabled prevention. Chen et al. introduce Clip2Safety, a zero-shot vision–language framework that recognises scenes, detects PPE and verifies fine-grained attributes across six workplace scenarios, improving accuracy and inference speed over prior VLM baselines (Chen et al., 2025). In general aviation, Liu et al. show that HFACS-guided chain-of-thought prompting (HFACS-CoT and HFACS-CoT+) markedly improves GPT-4o’s ability to infer pilots’ unsafe acts and preconditions from witness narratives, in some cases matching or surpassing human experts and exemplifying how domain knowledge can structure LLM-based accident investigation (Liu et al., 2025). Together, these studies demonstrate a shift from purely reactive analysis toward proactive, interpretable and context-aware AI systems for occupational risk prevention.
The present review occupies a specific niche at the intersection of occupational safety and health (OSH), natural language processing (NLP), large language models (LLMs) and, more broadly, AI-enabled safety analytics. Previous reviews have synthesized AI applications for industrial safety or Industry 4.0/5.0 more generally, but they have either focused on traditional machine-learning models, structured process data, or sector-specific issues (e.g. aviation, construction or healthcare) without systematically addressing text-centric and language-based approaches to occupational risk prevention. In contrast, this review concentrates on models that operate directly on unstructured OSH information—accident narratives, inspection reports, medical records, work-condition surveys or safety guidelines—and on how these models can be coupled with risk assessment and decision-support frameworks across sectors such as construction, mining, chemical and process industries, and healthcare.
In addition, this review extends the temporal scope to include the most recent wave of Gen-AI and LLM-based approaches that were not covered in earlier syntheses. These include ensemble learning models that map accident narratives to potential accident severity and Fatality Risk Control Programme (FRCP) levels (Sarker et al., 2025), coal-mine accident risk analysis frameworks that couple LLM reasoning with Bayesian networks (Du & Chen, 2025), improved topic-model–Bayesian-network pipelines for chemical safety risk identification (Zhou et al., 2025), multi-source data-driven risk assessment systems for coal-mine environments (Lu et al., 2024), and process-safety indicators derived from Industrial Internet data and LLM-assisted retrospective analysis (Ni et al., 2024). Furthermore, we incorporate recent developments in industrial accident type classification using KoBERT (Song et al., 2024), occupation and job-code classification with DistilKoBERT and LLMs (Kim et al., 2024; Li et al., 2025), multi-source heterogeneous data integration for incident likelihood analysis (Kamil et al., 2024), AHP-based studies of human error and environmental factors in mine accidents (Bekal et al., 2024), optimized deep-learning models for injury-severity prediction (Khairuddin et al., 2024), automatic identification of potential serious injuries and fatalities (PSIF) (Parikh et al., 2024), LLM-based accident-investigation reasoning guided by HFACS (Liu et al., 2025), RAG-enhanced large-language-model frameworks for safety guidance and job safety reports (Baek et al., 2025; Bernardi et al., 2025), and vision–language models for PPE-compliance monitoring (Chen et al., 2024). By integrating these very recent contributions, the review provides an updated and explicitly text-centric state-of-the-art on AI, NLP and LLMs for occupational risk prevention.
Several recent surveys focus on broad AI/OSH trends, risk management or Industry 4.0, but only tangentially cover text-based AI, natural language processing (NLP) and large language models (LLMs). For instance, Pishgar et al. (2021) provide the REDECA framework and a bibliometric mapping of AI in OSH, but do not systematically analyse the specific contribution of NLP and LLMs for processing unstructured safety narratives. Wang et al. (2020) map research domains in occupational health and safety management but treat AI only as one of many emerging themes. More recently, Gomes-Miranda and Gonçalves (2024) examine Industry 4.0 technologies and OHS, with AI appearing mostly as a component of digital transformation rather than as a dedicated methodological focus.
In contrast, the present review specifically targets text-centric AI methods, including classical NLP, deep learning architectures (e.g., CNNs, Bi-LSTM, BERT-type transformers) and, more recently, generative LLMs and retrieval-augmented generation (RAG)—as applied to accident reports, near-miss narratives, safety inspection records, occupational disease risk assessment and related OSH documentation
2. Methodology
This review explores how artificial intelligence (AI) models, especially natural language processing (NLP) techniques and large language model (LLM)–based approaches, are being applied to occupational risk prevention across industrial sectors. The aim is to map the breadth and characteristics of current applications. Accordingly, the methodology follows a structured approach, with four main stages: (i) identification of records through database and citation searches, (ii) screening and eligibility assessment based on predefined criteria, (iii) selection of studies for inclusion, and (iv) structured data extraction and narrative synthesis.
The review includes AI methods applied to text-centric or text-enriched safety data, accident and incident reports, near-miss and hazard observations, investigation narratives, work and exposure records, safety-management documentation, and, in some cases, multi-source frameworks that combine textual information with sensor, process or environmental data.
2.1. Data Sources and Search Strategy
The primary data source was the Web of Science Core Collection. Searches were conducted over all WoS collections and covered the period from 2013 to October 2025. This time window was chosen because it encompasses both the consolidation of machine-learning and deep-learning approaches in safety-critical domains and, from approximately 2020 onwards, the emergence and rapid expansion of transformer-based models and LLMs, highlighting the recent acceleration of LLM/NLP applications.
The search strategy was iterative and was refined in several steps. In an initial phase, we used topic searches combining core OSH phrases with AI-related terms. Specifically, we ran separate queries in which the OSH term set “occupational risk prevention”, “occupational safety”, and “workplace safety”, was combined using Boolean AND with the AI term set “artificial intelligence”, “machine learning”, “deep learning”, “natural language processing”, “large language models”, and “LLM”.
We then restricted the AI term set to “natural language processing”, “large language models” and “LLM” and repeated the queries with “occupational safety” and “workplace safety”. This step captured the subset of studies in which NLP or LLMs are explicitly mentioned, enabling a detailed analysis of their data sources, model architecture and safety-related tasks.
Because OSH terminology varies across disciplines and sectors, we expanded the OSH term set beyond the expressions above. We ran an additional broad query with Topic (OSH term set): “occupational risk prevention” OR “workplace safety” OR “hazard identification” OR “incident analysis” OR “risk management” OR “EHS” OR “health and safety”; AND Topic (AI term set): “artificial intelligence” OR “machine learning” OR “deep learning” OR “natural language processing” OR “large language models” OR “LLM”.
This broad query retrieved 4,897 records and was used to quantify the magnitude and diversification of recent AI/ML/NLP work in OSH-related domains. The subset of records involving text-centric methods, LLMs or multi-source data integration relevant to occupational risk prevention was then examined in detail during screening.
We complemented the Web of Science search with targeted Google Scholar queries and backward/forward citation chasing. Reference lists and citation networks of key recent AI/NLP/LLM safety studies were used to identify additional publications that met the eligibility criteria. All records identified through these complementary routes were subjected to the same screening and selection process as database-retrieved records.
No formal language restrictions were imposed at the search stage; however, the vast majority of included studies were published in English.
2.2. Eligibility Criteria
We primarily considered peer-reviewed journal articles indexed in Web of Science. In line with a scoping-review approach, we also allowed the inclusion of high-quality conference papers, book chapters and technical reports when they (i) introduced novel AI/NLP/LLM methods, data sets or pipelines, or (ii) provided industrial case studies directly relevant to occupational risk prevention.
Records published between 2013, and October 2025 were eligible. This period captures the progressive adoption of machine-learning and deep-learning methods in safety analytics and the more recent use of transformers and LLMs in OSH-relevant tasks.
Studies had to address occupational or process safety broadly understood. Works focused purely on clinical patient safety, general medical decision-making or other non-occupational risk domains were excluded unless an explicit occupational or workplace context was present.
Eligible studies had to employ at least one AI-related method, such as machine learning, deep learning, NLP, LLMs, topic modelling, embedding-based retrieval, computer vision, or vision–language models, to analyze or model safety-related data. Given the primary focus of this review, priority was given to studies where: (i) unstructured safety narratives or text fields (e.g., accident reports, incident descriptions, investigation narratives, job descriptions, safety observations) were the main data source; or (ii) textual data formed an explicit component of a multi-source or multimodal risk-assessment framework (e.g., combined with sensor, process, or environmental data).
A small number of influential AI-based safety reviews and multi-source frameworks without a dominant textual component were retained when they provided essential methodological context for the development and deployment of NLP and LLM approaches in occupational risk prevention.
To be included, studies had to provide sufficient methodological and contextual detail to support analysis of: data sources, AI/NLP/LLM methods used, safety-related tasks and outcomes, and at least a qualitative assessment of model performance, advantages and limitations. Opinion pieces, editorials, non-peer-reviewed summaries, purely conceptual papers without empirical or methodological content, and works relying solely on basic descriptive statistics or traditional regression models (without AI, ML, DL, NLP or LLM components) were excluded.
Applying these criteria ensured that the final corpus represented the diversity of AI-driven, and particularly text-centric, approaches to occupational risk prevention while maintaining a clear OSH focus.
2.3. Screening and Selection Process
All records retrieved were deduplicated. The subsequent screening and selection proceeded in two stages. Titles and abstracts were screened against the eligibility criteria to remove clearly irrelevant items. At this stage, we excluded, for example, clinical or patient-safety studies without occupational context, generic AI or computer-science papers with no explicit link to OSH or process safety, and articles where the analytical methods were limited to classical statistics or non-AI approaches.
The full texts of the remaining articles were examined to verify that an AI/ML/DL/NLP/LLM or vision/vision–language model was applied; the data analyzed were occupational, process-safety or workplace-related (e.g., accident or incident reports, near-miss databases, hazard observations, FRCP/PSIF datasets, occupational exposure or health records, job postings, safety-management documents, or multi-source safety data); and the study provided enough methodological and contextual information to allow extraction of sector, data type, model family, safety-related task, and main performance and implementation insights.
After duplication and full-text assessment, 126 primary studies met all eligibility criteria and were included in the review.
2.4. Data Extraction and Synthesis
A structured data-extraction template was developed to ensure consistency across studies. For each of the 126 records included, we extracted:
- Bibliographic and contextual information, such as first author, year of publication, country or region (when reported), publication venue and study type (methodological paper, empirical case study, review, or framework proposal), as well as industrial sector and setting: dominant sector(s) addressed (e.g., aviation, construction, mining, chemical and process industries, manufacturing, transportation, healthcare, public sector and other services) and any specific workplace or process characteristics relevant to OSH.
- Data sources and modalities, including type and origin of the safety-related data (e.g., free-text accident/incident reports, near-miss and hazard observations, PSIF/FRCP datasets, occupational injury or disease registries, compensation claims, exposure or environmental monitoring data, job descriptions, safety-inspection reports, training materials, video or image data for PPE/unsafe-condition detection, sensor and process data in multi-source frameworks). Particular attention was given to whether unstructured text was the primary data source or part of a multimodal pipeline.
- AI/NLP/LLM and vision methods: main model families employed (e.g., classical supervised machine learning; topic models and other unsupervised text-mining techniques; word and sentence embeddings; recurrent or convolutional neural networks; transformer-based NLP models; LLMs and retrieval-augmented generation pipelines; ensemble models; computer vision and vision–language architectures) and any domain adaptation, fine-tuning or strategies reported.
- Analytical objectives (e.g., automated classification of incident types or causes; extraction of causal chains and contributing factors; topic modelling of safety concerns; prediction of accident occurrence, likelihood or severity, including PSIF and FRCP levels; risk-index estimation; early warning and anomaly detection; generation of job- or task-specific safety guidance and reports; PPE compliance or unsafe-condition detection; monitoring of safety-culture or safety-climate indicators).
- Evaluation and performance metrics (e.g., accuracy, precision, recall, F1-score, AUC, confusion matrices) and/or qualitative assessments (e.g., expert validation, comparative analyses with baseline methods, user or practitioner feedback) used to evaluate model performance and practical utility.
- Advantages, limitations and implementation aspects, such as improved prediction accuracy, better handling of unstructured narratives, ability to integrate multi-source data, explainability and data quality, under-reporting, representativeness issues, transparency and explainability challenges.
Following extraction, studies were first grouped by industrial sector to reflect the domain-specific context in which AI, NLP and LLMs are currently being deployed for occupational risk prevention. Within each sector, we then organized the literature by methodological family (text-mining and ML, deep-learning NLP, multi-source data-integration frameworks, LLM-based and RAG-based systems, and vision/vision–language approaches). Thus, the structure of the Results section allows both: (i) sector-specific narratives that highlight how AI-driven text analytics and LLMs are being tailored to particular hazards, data infrastructures and regulatory environments; and (ii) a cross-cutting synthesis of methodological trends, gaps and challenges, and real-world implementation in safety-critical contexts.
3. Results
As pointed out by Zhao et al (2018), the benefits of using NLP methods in occupational risks prevention are multiple; for example, these approaches allow valuable information to be extracted and processed from large amounts of data. Future research directions include pattern recognition, in-situ identification of actual events, and fully automated methods (Zhao et al., 2018). More specifically, previous reviews have highlighted the high potential of AI, LLMs and NLP methods in different areas of occupational risk prevention, as summarized in Table 1, such as exploring the impact of NLP applications in the field of aviation safety (Yang & Huang, 2023; Kierszbaum & Lapasset, 2020), and in other safety-critical industries such as transport, medical and construction (Ricketts et al., 2023), as well as for occupational injury analysis (Khairuddin et al., 2022), unveiling the influential aspects of this field through descriptive and scient metric analyses (Sarkar & Maiti, 2020).
LLM and AI are demonstrating great potential for development in different areas of occupational risk prevention, in sectors such as aviation and construction, even in specific risks such as Fall from Height (FFH), and in the chemical industry, as well as in the transport system, including railway, in the nuclear power generation sector, and for the protection of mine workers and to avoid medical errors.
Among the advantages that we can find in the use of methodologies based on AI, LLM and NLP in the field of occupational risk prevention, some are particularly interesting due to their high general applicability to multiple sectors, such as the generation of risk maps in real-time. For example, the application of dynamic real-time analysis using multimodal data fusion to enhance occupational risks prevention through the development of risk maps for workplaces, using machine/deep learning techniques by analysing data from diverse sources such as images, videos, documents, mobile applications and sensors/IoT. Thus, the combination of computer vision, NLP techniques, and sensor data analysis enables automated root cause identification, damage prevention, and disaster recovery, dynamically updating risk assessments in real-time. (Dalal & Bassu, 2020).
It is also worth mentioning that an important part of the success of the application of LLM and NLP-based methods lies in their ability to extract and analyze information in an automated way from large datasets contained in reports (e.g., accident reports), where the information can be structured to address a variety of problems, such as the limitations of generic and static checklists, which often do not apply to specific workplace contexts (Westhoven & Jadid, 2023), or mor interestingly, the information may not have been previously structured.
Thus, in relation to the use of unstructured information, recent research highlights innovative integrations of AI, specifically through NLP and Machine Learning (ML), to refine safety and risk assessments. For example, Kamil et al. (2023) combine a variety of NLP and text mining techniques with fuzzy set theory to transform unstructured accident reports into useful data, a methodology that contrasts with others used by Hou et al. (2022), who rationalize incident classification using NLP techniques for text vectorization. On the other hand, Paraskevopoulos et al. (2022) extend the functionality of AI in safety management by introducing a multimodal architecture that synergizes textual and visual data, distinguishing it from other studies primarily focused on text. In addition, Zhao et al. (2020) and Macedo et al. (2023) extend text analysis in different ways, as Zhao focuses on summarizing accident reports, while Macedo aims to correct inaccuracies in report. Furthermore, Baker et al. (2020a) and G. Liu et al. (2021) both refine data extraction and prediction methods, but differ in their approaches, as Baker emphasizes predictive modelling for safety outcomes, while Liu explores causal relationships using clustering techniques. Similarly, Dorsey et al. (2020) and Ekramipooya et al. (2023) aim to improve data quality and analysis efficiency through the use of NLP and AI methods.
Next, a perspective is presented on the impact of methodologies based on AI, LLM and NLP on the advancement of occupational risk prevention in different industrial sectors is presented.
Beyond sector-specific applications, the recent literature reveals several cross-cutting methodological patterns in how AI, NLP and LLMs are being leveraged for occupational risk prevention. First, there is a clear movement from shallow text-mining and keyword-based approaches towards deep contextual representations and transformer-based models for accident and incident narratives. For example, Song et al. (2024) use the KoBERT model to classify occurrence types from Korean industrial accident cases and explicitly link these classes to prevention plans, while Khairuddin et al. (2024) develop an optimized deep-learning prediction model that contextualizes injury severity from occupational accident reports. In parallel, Kim et al. (2024) and Li et al. (2025) demonstrate how transformer-based language models can be used for occupation and job-code classification using working-conditions surveys and job postings, thereby enriching OSH risk assessments with standardized occupational information. At the risk-modeling level, ensemble-learning frameworks and multi-source data integration are becoming increasingly prominent, as illustrated by Sarker et al. (2025) in the context of potential accident severity and FRCP classification, by Kamil et al. (2024) in multi-source incident-likelihood analysis, and by Lu et al. (2024) in data-driven coal-mine environmental safety risk assessment systems.
Second, there is an emergent family of hybrid models that explicitly combine AI-based text analytics with established risk-assessment or safety-engineering frameworks. Recent examples include the use of improved LDA topic models coupled with Bayesian networks to identify and propagate chemical safety risk factors (Zhou et al., 2025), Analytical Hierarchy Process (AHP) studies that quantify the relative contribution of human error, environmental conditions and equipment failure to mine accidents (Bekal et al., 2024), and frameworks for process risk assessment that integrate prior hazard information into chunk-based text-mining models (Sahoo et al., 2024). At a more advanced level, LLMs are increasingly embedded within accident-investigation and safety-management workflows, as shown by Du and Chen (2025) in coal-mine accident risk analysis, Ni et al. (2024) in the development of Industrial-Internet-based process-accident indicators, Liu et al. (2025) in HFACS-guided Chain-of-Thought accident investigation for general aviation, and by Baek et al. (2025) and Bernardi et al. (2025) in retrieval-augmented LLM frameworks for construction safety guidance and job safety report generation. Complementing these text-centric approaches, vision–language models that detect PPE compliance and unsafe behaviors from images and video (Chen et al., 2024) illustrate how language models can be coupled with computer vision to provide a multimodal foundation for proactive occupational risk prevention.
3.1. Aviation
In the field of aviation safety, Miyamoto et al. (2022) and Dong et al. (2021) both used NLP techniques to analyze aviation safety reports. Miyamoto et al. focused on categorizing the causes of flight delay using clustering techniques, revealing maintenance issues as the primary cause. In contrast, Dong et al. combined NLP with deep learning models to automate the identification of primary factors in incident reports, demonstrating superior performance over traditional methods but limiting their scope to the most frequent incident categories. Moreover, Jiao et al. (2022) introduced a novel classification scheme using the XGBoost classifier and OC-POS vectorization to identify risk factors from Chinese aviation reports, indicating great potential for broader applications. Similarly, Kierszbaum et al. (2022) developed a compact, domain-specific language model, demonstrating that specialized pre-training can effectively address the scarcity of domain-specific data in aviation safety NLU tasks, highlighting a trend towards creating more specialized NLP and AI tools tailored to specific data challenges in aviation safety. In addition, Madeira et al. (2021) investigated human factors in aviation incidents, using a hybrid approach of semi-supervised and supervised learning to tackle the challenge of limited labelled data sets, a common issue in AI applications in safety analysis. This study aligns with the work of Rose et al. (2020), who also used NLP and clustering to categorize and visualize safety narratives, but with a focus on integrating numerical and text-based data to enhance accident investigation processes. Liu et al. (2025) have significantly accelerated and improved the efficiency of general aviation accident investigations by integrating the HFACS framework into chain-of-thought prompts using large language models (LLMs). Their HFACS-CoT+ approach outperforms basic prompting strategies and, in some cases, human experts. Bernardi et al. propose a novel RAG-based architecture in their work that generates occupational safety reports from unstructured accident descriptions. By evaluating multiple large language model (LLM) families and incorporating models into the Aviation Safety Reporting System (ASRS) dataset, the study provides robust empirical evidence in support of using domain-specific AI solutions to improve accident analysis and decision-making. These studies highlight a significant trend towards using advanced AI and NLP methods to dissect and understand large volumes of aviation safety data, as it is shown in Table 2.
3.2. Construction
Additionally, occupational risk prevention (ORP) in the construction industry has a wide range of research that incorporates AI advances in safety management, moving towards automated, accurate and effective methods, as resumed in Table 3 and discussed below. Despite methodological diversity, the literature reveals converging trends, allowing research to be grouped into four key areas: text mining and ML, knowledge representation, multimodal AI, and large-scale language model (LLM) applications. Collectively, these studies demonstrate a shift toward automated methods in management, accurate and effective for risk identification and security management, although shortcomings also exist, such as inconsistencies in preprocessing workflows, the unlimited use of unsupervised NLP methods, and the underutilization of machine learning models (Shayboun et al., 2025).
Text-mining and machine learning techniques have been widely applied to classify accidents and extract risk factors from incident narratives. Early studies highlighted the potential of AI for information retrieval from construction documents (Fan & Li, 2013; Tian et al., 2023), while ensemble classifiers improved precision in identifying accident causes and safety risks (Zhang et al., 2019; Wang et al., 2021). Deep learning approaches further enhanced predictive accuracy and interpretability: Baker et al. (2020) employed Convolutional Neural Networks (CNNs) and Hierarchical Attention Networks to analyze accident reports, enabling visual interpretation of model predictions to identify injury precursors. Furthermore, Fang et al. (2020) and Gadekar & Bugalia (2023) improved text classification in construction safety reports, focusing on the use of Bidirectional Transformers (BERT) for deep learning-based text classification and innovating with a semi-supervised model, respectively, achieving high accuracy with reduced dependence on pre-labelled data. Advanced NLP preprocessing combined with novel AI techniques has also improved the effectiveness of construction safety analyses (Cheng et al., 2020). In the domain of metro construction, Xu et al. (2021) applied text mining with an information entropy–weighted term frequency metric to extract safety risk factors, providing a quantitative tool for large-scale risk assessment.
Structured knowledge representation using ontologies, knowledge graphs, and named-entity recognition (NER) has emerged as a powerful approach for automating safety management. Thompson et al. (2020) proposed a construction-specific NER scheme to structure free-text safety data into actionable strategies. Shen et al. (2022) introduced an innovative integration of Building Information Modeling (BIM) with an ontology-based safety rule library and NLP, creating a dynamic safety rule-checking system capable of automatically identifying hazards on construction sites. Graph-based approaches have also shown advantages over deep learning for certain risk domains; for example, Ben Abbes et al. (2022) used NLP and knowledge graphs to analyze the DBkWik database (40,000 wikis) for Fall From Height (FFH) risk, efficiently extracting critical safety information and addressing some limitations of deep learning methods. These approaches enable systematic structuring of heterogeneous safety information, supporting proactive hazard mitigation and compliance monitoring.
Visual and multimodal AI extends hazard detection beyond textual narratives. Zhong et al. (2023) developed a ResNet101–LSTM attention model to translate video sequences into natural language descriptions of on-site activities, allowing automated identification of unsafe behaviors. Such multimodal approaches complement text-based methods and are critical for monitoring complex or large-scale worksites where conventional reporting is insufficient.
LLMs are rapidly being applied to accident classification, causal pattern extraction, summarization, and safety training. GPT-based models have been used to classify accident types, uncover latent hazard structures, and analyze OSHA narratives (Salles et al., 2024; Smetana et al., 2024; Yhoo et al., 2024), while the AIR Agent automates extraction of accident categories from subway reports (Zhang et al., 2025). Retrieval-augmented LLMs can generate safety guidance and training materials of comparable or superior quality to expert-authored documentation (Uhm et al., 2024; Baek et al., 2025). Embedding techniques, such as SBERT, allow analysis of discrepancies between inspection reports and actual incidents (Elizabeth et al., 2025), and scenario-based LLM platforms provide validated training environments to strengthen safety decision-making (Naderi & Shojaei, 2025).
In addition to improving classification and information-retrieval tasks, LLMs are beginning to automate the generation of construction safety guidance. Baek et al. (2025) presents an automated safety risk management guidance framework that combines a retrieval module with a large language model in a Retrieval-Augmented Generation (RAG) architecture. Their system retrieves relevant reference documents from a large database of 64,740 construction accident cases and associated safety materials and then uses an LLM to generate tailored safety risk management guidance for specific work activities and equipment. By performing domain adaptation and instruction-tuning, the authors demonstrate that the LLM can generate guidance that is consistent with construction safety experts while significantly reducing the time required to prepare task-specific job-hazard analyses. This work illustrates how LLMs, when combined with robust retrieval mechanisms and domain-specific corpora, can move beyond passive text analysis to actively support the design of prevention measures and the dissemination of context-aware safety information in construction projects.
3.3. Chemical, Mines and Other High-Risk Industrial Environments
The integration of AI and NLP in chemical industry safety has the potential to enhance occupational and environmental safety (see Table 4). Thus, Kamil et al. (2023) used NLP, Interpretive Structural Model (ISM), and probabilistic techniques to predict and analyze fire and explosion risks, leveraging accident databases for predictive accuracy in safety management practices. On the other hand, Kabir et al. (2023) improved the accuracy of flare system failure analyses in the oil and gas industry by integrating traditional Fault Tree Analysis (FTA) with Dynamic Bayesian Networks (DBNs). In contrast, Kumari et al. (2022) advanced incident prediction by means of Artificial Neural Networks (ANNs) for cause and sub-cause analysis, surpassing traditional models to offer causation clarity. Moreover, B. Wang & Zhao (2022) introduced a novel deep learning framework combining BERT, BiLSTM-CRF, and CNN models to automate the extraction and classification of risk factors from accident reports in confined spaces, addressing the manual labor-intensive and subjective traditional analysis. Additionally, Xu et al. (2022) and Jing et al. (2022) utilized deep learning for analyzing accident causes, applying a CNN model to classify causes and deploying a combination of LSTM and attention mechanisms to enhance text classification of chemical accidents, respectively.
Furthermore, X. Luo et al. (2023) explored the use of NLP to automate the analysis of chemical accidents, categorizing risk factors to support decision making in risk analysis. Also, Macêdo et al. (2022) used BERT models for text mining to enhance quantitative risk analysis in oil refineries. Lastly, Song and Suh (2019) innovated in the detection of anomalies in accident reports by applying a text mining-based method to examine the narratives of accident reports.
Recent work on data-driven safety and occupational risk prevention in the process industries converges on the integration of heterogeneous data sources, advanced text mining and probabilistic modelling to improve prediction, assessment and control of accidents. Thus, Kamil et al. propose a Safety 4.0 framework that combines natural language processing of CSB loss-of-containment narratives with operational sensor data to build multi-source likelihood models, showing that inadequate written procedures and management failures are highly sensitive drivers of LOC events (Kamil et al., 2024). In coal mining, Lu et al. (2025) develop a dynamic environmental safety risk assessment system that fuses expert judgements, online monitoring and subjective reporting through fuzzy linguistic transformation, multi-criteria weighting and grey clustering, enabling real-time risk status updates and critical risk identification. At the plant level, Ni et al. (2024) leverage Industrial Internet infrastructures to operationalise major accident indicators and, using STAMP and a large language model to retrospectively analyse 212 accident reports, demonstrate SMART-compliant indicators that are empirically linked to accident patterns. Text mining of safety reports is further extended by Sahoo et al. (2024), who encode prior hazard knowledge in rule-based chunking to extract fault-related phrases and then use unsupervised and semi-supervised learning to reconstruct chains of events and fault trees with high agreement with expert HSE assessments.
In parallel, several contributions focus on mining large accidents and hazard datasets to support preventive decision-making. Song et al. (2024) show that KoBERT-based models can automatically classify occurrence types in Korean industrial accidents with high accuracy, reducing subjectivity and noise in national statistics and strengthening the basis for prevention planning. Zhou et al. (2025) apply an improved LDA topic model to chemical accident reports, identifying key risk factors and then using association rules and Bayesian networks to map their causal structure and critical paths, overcoming the subjectivity and limited scalability of traditional expert-based analyses. At mine level, Kar et al. (2024) use the Analytic Hierarchy Process on a decade of Indian mining accidents to quantify the relative contribution of human error, environmental conditions and equipment faults, finding human error to be the dominant factor across accident types and transport machinery to be the most critical alternative. Finally, Du and Chen (2025) integrate large language models, Apriori association rule mining and Bayesian networks on coal mine accident reports, extracting a rich hierarchy of risk factors and primary drivers linked to on-site safety management, procedure execution and supervision, and argue for policy responses centred on enforcement, training and data-driven early-warning systems. Together, these studies illustrate a rapid shift from purely retrospective, expert-driven investigation towards AI-enabled, multi-source and probabilistic frameworks that support proactive, system-level occupational risk prevention.
3.4. Transport System
The application of NLP and AI has the potential to enhance the accuracy and efficiency of risk assessment and safety management in Transport Systems (see Table 5). Thus, Hughes et al. (2019) used an AI-based model to extract and categorize terms from multilingual incident reports through the application of NLP techniques, achieving a high accuracy rate in categorizing safety incidents in public transport. Also, Valcamonico et al. (2022) also enhanced road safety analysis by integrating Hierarchical Dirichlet Processes and Doc2Vec with machine learning classifiers, showing how combined models can better balance accuracy and explainability in automated report classification. Moreover, Jidkov et al. (2020) focused on maritime risk assessment, employing deep learning and various NLP techniques to capture, process, and analyze data related to maritime safety events such as piracy, hijackings, and smuggling, improving incident classification and information extraction. Meanwhile, Wang & Yin (2020) employed text mining and automatic association rules such as the FP-Growth algorithm to uncover key risk factors in China’s transport sector, providing insights into systemic issues affecting safety. Additionally, Zhang et al. (2021) introduced the use of NLP and deep learning to analyze aviation accident reports with predictive purposes and safety management in aviation. More recently, Ricketts et al. (2022) proposed the use of NLP, rule-based phrase matching and a trained NER model to enhance hazard identification in HAZOP studies of aircraft subsystems, approaching the continuous model refinement and more efficient safety actions.
Specifically, in relation to railway safety and risk prevention, NLP and AI techniques have recently been used to innovate in incident prediction and management. For example, Hughes et al. (2018) developed a semi-automated classification system for close call reports in the GB railway industry, using NLP to associate incident reports with bow-tie accident causation models, with practical applications in categorizing a vast array of unstructured safety-related text. In contrast, Figueres-Esteban et al. (2016) used visual text analysis to extract safety information from the GB railways' Close Call System, highlighting its potential to identify risks despite the linguistic variation different reporter groups. Also, Wu et al. (2020) introduced NLP methods to improve subway accident decision-making processes in metro accidents with high precision in retrieving relevant past cases and advancing automated accident response systems. Moreover, Heidarysafa et al. (2018) applied deep learning to enhance the accuracy of accident labelling in the US railway sector and advanced the automatic classification of accident causes from narrative texts. Also, Ebrahimi et al. (2023) used NLP and Random Forest to develop a machine learning model capable of predicting evacuation needs following hazardous materials incidents on railways, mapping causal evacuation factors to improve emergency management. Furthermore, Hua et al. (2019) and Liu & Yang (2022) used text mining to improve risk identification in railway safety, extracting accident risk factors from Chinese railway accident reports through convolutional neural networks, and using deep learning techniques to quantify risk relationships in British railway incidents, respectively.
Kim's study (2023) used textual network analysis to examine the main issues related to death from overwork reported in the Korean media over a 10-year period in the Big Kinds database. Four themes were identified through theme modelling using the NetMiner 4 programme. The results revealed that postal workers, civil servants and delivery drivers are particularly susceptible to death from overwork.
3.5. Healthcare and Assistive Services Systems
The integration of NLP and AI techniques in healthcare has demonstrated substantial potential for preventing medical errors, enhancing patient safety, and supporting occupational health in clinical environments (see Table 6). For example, Cohan et al. (2017) employed convolutional and recurrent neural networks with an attention mechanism to analyze complex clinicians’ narratives, effectively identifying and categorizing harmful events. This approach not only improved error detection in large datasets but also facilitated root cause analysis and resource allocation, thereby contributing to the prevention of patient harm.
Similarly, Denecke (2016) highlighted the utility of NLP for processing critical incident reports, which are often underutilized due to the time-consuming and complex nature of manual review. By mapping incident reports to the International Classification of Patient Safety (ICPS) and employing text mining techniques, the study enabled semantic annotation, faceted search, and automated event detection, thereby enhancing both patient safety and quality of care.
Recent advances have further improved anomaly detection in electronic health records (EHRs), enhancing both patient safety and data reliability. Niu et al. (2024) developed EHR-BERT, outperformed existing models by reducing false positives, improving detection accuracy, and minimizing information loss, demonstrating the value of advanced NLP models in safeguarding patient care.
Beyond patient-centered applications, NLP and AI have also contributed to predicting occupational health risks. Sen et al. (2024), for instance, developed ERG-AI, an AI/ML pipeline combining multi-sensor posture data, uncertainty estimation, and large language model-generated recommendations to predict long-term worker postures and communicate associated risks. Evaluated on the DigitalWorker Goldicare dataset (114 workers, 2913 hours), ERG-AI delivered accurate, uncertainty-aware predictions while maintaining low energy consumption, providing personalized and interpretable health recommendations.
Finally, the adoption and perception of AI tools among clinicians have been systematically assessed. Egli et al. (2025) conducted an anonymous survey of Swiss healthcare professionals, revealing that 32.8% reported frequent use of large language models (LLMs), particularly among younger, male, and research-active clinicians. The study identified administrative and analytical support as primary benefits, while ethical considerations and output reliability emerged as key challenges.
Taken together, these studies underscore the transformative role of NLP and AI in healthcare and assistive services, from improving patient safety and clinical decision-making to enhancing occupational health, while highlighting the importance of user engagement, transparency, and ethical considerations in AI deployment.
3.6. Other Sectors
As shown in Table 7, other sectors, such as nuclear energy and mining, also benefit from the integration of AI-based methods, particularly LLM and NLP. In relation to the application of NLP techniques to the nuclear power generation sector, Zhao et al. (2019; 2018) advanced the field by integrating NLP and multimodal data fusion to automatically identify causal relationships in event reports. They used arule-based expert system, the Causal Relationship Identification (CaRI), to effectively capture causal associations with a success rate of 86%. On the other hand, Dalal & Bassu (2020) explored the development of "risk maps" by applying machine learning models to analyze data from sensors and computer vision systems to achieve a dynamic real-time capability to identify risks and prevent workplace accidents. The combination of NLP and AI methods in the field of occupational risk prevention has also recently led to several studies related to mine safety. Thus, Ganguli et al. (2021) carried out automatic data analysis from Mine Health and Safety Management Systems (HSMS) using NLP and Machine Learning (ML), specifically through the development of nine Random Forest (RF) models, demonstrating high accuracy and improved incident categorization.
Recent work has also explored LLM-based decision support in more heterogeneous industrial environments. Bernardi et al. (2025) propose a Hum-AI/Gen-AI framework in which an LLM is combined with retrieval and explanation modules to generate job safety reports that summarize hazards, recommend preventive measures and document safety-critical activities. Their approach, implemented in an Information Systems Frontiers case study, retrieves relevant regulations, standards and prior incidents, and prompts the LLM to synthesize concise, context-specific safety recommendations while exposing the underlying evidence used to generate each suggestion. In the aviation domain, Liu et al. (2025) develop an HFACS-guided Chain-of-Thought (CoT) accident-investigation framework in which LLMs reason step-by-step through witness narratives and investigation texts to allocate causal factors to HFACS categories. The authors show that structuring prompts according to HFACS levels and requiring explicit CoT explanations substantially improves both accuracy and interpretability relative to direct-answer prompting, providing a promising template for LLM-assisted accident investigation in other high-hazard sectors.
In contrast, Shekhar and Agarwal (2021) applied text mining of fatality reports to enhance safety in Indian mines, identifying trends and patterns and highlighting the most vulnerable worker demographics and high-risk times periods. Furthermore, Qiu et al. (2021) combined text mining with complex network analysis to identify and quantify factors contributing to coal mine accidents, revealing complex interaction mechanisms and critical causal links, and providing a detailed map of accident causation pathways.
3.7. Severity, PSIF and proactive risk prediction
A growing body of work no longer treats AI and NLP as purely descriptive tools for analyzing past accidents, but rather as instruments for proactively estimating accident severity, identifying potential serious injuries and fatalities (PSIF), and supporting fatality-risk control programs. Khairuddin et al. (2024) introduce an optimized deep-learning prediction model that contextualizes injury severity based on free-text occupational accident reports. By combining deep neural networks with carefully engineered features derived from accident narratives, their model achieves improved performance over conventional classifiers in predicting severity classes, thereby enabling safety practitioners to prioritize high-risk cases for investigation and control. Complementing this case-based approach, Parikh et al. (2024) propose an automatic PSIF identification framework that flags incidents involving potential serious injuries and fatalities in large incident databases. Their study shows that focusing on PSIF-related incidents captures underlying exposure to fatal hazards more effectively than relying solely on historical fatality counts, and that automated PSIF classification can support a shift from reactive to proactive safety management.
At the level of structured safety programs, Sarker et al. (2025) develop an ensemble-learning framework that integrates NLP-derived features from accident narratives with structured safety data to predict potential accident severity and assign accidents to Fatality Risk Control Program (FRCP) levels. The authors combine multiple classifiers and assess feature importance via Leave-One-Covariate-Out (LOCO) analysis, demonstrating that narrative-based features and FRCP-specific indicators significantly improve predictive performance. Their results highlight how NLP-enhanced models can support FRCP implementation by providing early warnings and helping safety managers focus on high-impact events. Related ensemble and multi-source approaches also appear in process-safety contexts, where heterogeneous data (incident narratives, process parameters, environmental indicators) are combined to estimate incident likelihood and severity (Kamil et al., 2024; Lu et al., 2024; Sahoo et al., 2024).
Crucially, these severity-oriented models are emerging across multiple industrial domains. In steel manufacturing, Sarker et al. (2025) show that integrating narrative features with FRCP categories can anticipate severe events before they occur, whereas in mining, Du and Chen (2025) combine LLM-based extraction of causal factors from accident descriptions with Bayesian networks to estimate the probability of severe coal-mine accidents under different control measures. In the broader manufacturing context, Song et al. (2024) demonstrate that transformer-based occurrence-type classification supports the design of targeted prevention plans, implicitly influencing severity distribution by reducing the frequency of hazardous occurrence types. Taken together, these contributions illustrate an important shift towards AI- and NLP-enabled models that aim not only to understand past accidents, but also to predict their potential severity and embed these predictions into structured safety programs such as PSIF monitoring and FRCP implementation.
3.8. Text Mining, Topic Modelling and Hybrid Risk-Assessment Frameworks
Recent studies highlight the value of combining advanced text-mining and topic-modelling techniques with established risk-assessment and decision-analytic frameworks. Zhou et al. (2025) propose an improved Latent Dirichlet Allocation (LDA) topic model tailored to chemical safety incident data, which is subsequently coupled with a Bayesian network to quantify the probabilistic relationships between latent risk themes and observable accident outcomes. By incorporating domain knowledge into the topic modeling and using the inferred topics as nodes in the Bayesian network, their framework supports both identification of critical risk factors and scenario-based reasoning about the effect of preventive measures. Similarly, Du and Chen (2025) use LLMs to extract causal factors, unsafe conditions and contextual information from coal-mine accident reports, which are then encoded as nodes and conditional probabilities in a Bayesian network. This hybrid LLM–Bayesian approach enables coal-mine safety practitioners to perform “what-if” analyses and to assess the impact of different control strategies on accident likelihood and severity.
In process-safety and chemical-engineering settings, Kamil et al. (2024) introduce a multi-source heterogeneous data integration framework for incident likelihood analysis that combines NLP features from incident narratives with process-operation and environmental data. Their approach leverages representation learning to map heterogeneous inputs into a unified feature space, and then applies machine-learning models to estimate incident occurrence probabilities under varying operating conditions. Sahoo et al. (2024) similarly demonstrate how prior hazard information can be encoded into chunk-based text-mining models for process risk assessment, where domain-specific hazard concepts guide the segmentation and representation of textual data. These works exemplify how text mining can be systematically aligned with process-safety knowledge to produce risk indicators that are both data-driven and interpretable.
In the mining sector, Bekal et al. (2024) use the Analytical Hierarchy Process (AHP) to quantify the relative contribution of human error, environmental factors and equipment failure to mine accidents in India. Although their study does not rely on deep learning, it illustrates how structured expert judgments and hierarchical modeling can complement data-driven text mining by providing formal weights for different risk categories. Lu et al. (2024) extend the hybrid paradigm further by constructing a data-driven coal-mine environmental safety risk assessment system that integrates multi-source heterogeneous data, including environmental sensor readings and operational factors, into an objective, dynamic and real-time risk index. When viewed together with Zhou et al. (2025), Du and Chen (2025), Kamil et al. (2024) and Sahoo et al. (2024), these studies show how NLP and topic modelling can be tightly coupled with Bayesian networks, AHP and other decision-analytic tools to operationalize complex risk assessment in chemical and mining industries.
Finally, these hybrid frameworks are beginning to interact with LLM-based reasoning in more sophisticated ways. Ni et al. (2024) exploit Industrial-Internet data and retrospective accident analysis to develop major process-accident indicators, using LLMs to assist in the categorization and interpretation of accident factors under STAMP-inspired structures and SMART criteria. In a similar spirit, Bernardi et al. (2025) embed LLMs within a RAG pipeline that retrieves relevant regulations, safety guidelines and historical cases to generate job safety reports and risk-mitigation suggestions, while explicitly logging the retrieved evidence to maintain transparency. Taken together, these contributions suggest an emerging paradigm in which text mining, topic modelling, Bayesian reasoning and LLM-based generation are combined to support interpretable and context-aware risk assessment.
3.9. Vision and Vision–Language Models for PPE Compliance and Unsafe conditions
While most of the studies in this review operate on textual data, recent advances in multimodal AI show that integrating vision and language models can greatly enhance the detection of unsafe behaviors and conditions. Chen et al. (2024) propose a vision–language model for interpretable and fine-grained detection of safety compliance in diverse workplaces. Their model leverages a CLIP-style architecture to perform zero-shot detection of personal protective equipment (PPE) items and unsafe configurations by aligning visual features with text prompts describing compliant and non-compliant conditions. The authors demonstrate that the model can accurately identify missing PPE, improper usage and unsafe postures across different industrial settings without requiring extensive task-specific training data, while also providing textual rationales that explain why a given frame is flagged as compliant or not. By explicitly encoding safety concepts in natural language, this approach enables transparency and human-interpretable feedback on vision-based compliance assessments.
These developments naturally extend the text-analytic approaches reviewed in earlier sections. For instance, multimodal frameworks could link vision-based PPE-compliance observations with incident narratives and near-miss reports, enabling models to correlate observed unsafe behaviors with subsequent accidents and thereby refine proactive risk indicators. In addition, occupation- and job-task-classification models trained on working-condition surveys and job postings (Kim et al., 2024; Li et al., 2025) could be combined with vision–language PPE detectors to tailor compliance criteria and risk thresholds to specific occupations, tasks and work environments. Such integration would support adaptive, context-aware safety monitoring in which camera-based systems not only detect missing PPE but also understand which PPE is required for a given job and why its absence increases risk. Although practical deployment raises important privacy, ethical and regulatory questions (see Section 4), vision–language models hold substantial promise for scaling proactive detection of unsafe conditions in complex workplaces.
4. Conclusions
This scoping review shows that AI, NLP and LLMs are reshaping occupational risk prevention across a wide range of industrial sectors. Early applications of text mining and traditional machine learning have been complemented by more recent transformer-based and ensemble-learning approaches that operate directly on unstructured OSH data such as accident narratives, inspection reports, work-condition surveys and safety guidelines. Emerging models predict accident severity, PSIF status and FRCP levels (Parikh et al., 2024; Khairuddin et al., 2024; Sarker et al., 2025), integrate heterogeneous sources of process and environmental data for incident-likelihood analysis (Kamil et al., 2024; Lu et al., 2024; Sahoo et al., 2024), and embed LLMs and Bayesian networks within accident-investigation and risk-assessment pipelines (Zhou et al., 2025; Du & Chen, 2025; Ni et al., 2024). Parallel developments in occupation and occurrence-type classification (Song et al., 2024; Kim et al., 2024; Li et al., 2025) and in vision–language PPE-compliance monitoring (Chen et al., 2024) expand the scope of AI-driven safety analytics beyond post-hoc analysis to encompass proactive monitoring and worker-centered prevention strategies.
Despite these advances, several limitations and risks associated with the use of AI, NLP and LLMs in occupational risk prevention must be acknowledged. Many models are trained on historical accident reports or incident databases that reflect under-reporting, incomplete causal information and sector- or country-specific biases. As a result, predictions of severity, PSIF, FRCP level or incident likelihood may inherit and amplify these biases, particularly for under-represented worker groups, subcontractors or informal sectors. Ensemble-learning and multi-source frameworks such as those proposed by Kamil et al. (2024), Lu et al. (2024), Sahoo et al. (2024) and Sarker et al. (2025) partly mitigate these issues by integrating diverse data sources, but they still rely on the quality and representativeness of the underlying data. Similarly, topic-model–Bayesian-network approaches (Zhou et al., 2025; Du & Chen, 2025) and Industrial-Internet-based indicator systems (Ni et al., 2024) may be sensitive to modeling assumptions, discretization choices and expert-defined structures.
LLM-based systems introduce additional concerns related to opacity, hallucinated content, and alignment with domain regulations and ethical principles. In RAG-enhanced safety-guidance and job-safety-report frameworks (Baek et al., 2025; Bernardi et al., 2025), the quality of the retrieval step and the coverage of the underlying document repository critically determine whether the generated guidance is accurate and compliant with current legislation. HFACS-guided Chain-of-Thought prompting (Liu et al., 2025) and vision–language PPE detectors (Chen et al., 2024) improve interpretability by exposing intermediate reasoning or by aligning decisions with human-readable safety concepts, but they still depend on careful prompt engineering, safety-specific evaluation and continuous monitoring to prevent erroneous or unsafe recommendations. From a regulatory perspective, the deployment of such systems in real workplaces must comply with data-protection and surveillance regulations, worker-participation requirements, and emerging AI governance frameworks. This underscores the need for robust human-in-the-loop designs in which OSH professionals critically review AI outputs, validate them against established risk-assessment methods (e.g. FRCP, PSIF, AHP-based ranking) and retain ultimate responsibility for safety-critical decisions.
Recent developments show that deep learning models applied to accident narratives can accurately predict injury severity categories and near-miss potential, going beyond traditional coded data and rule-based systems. In particular, NLP-based classifiers have been used to infer detailed severity labels, PSIF events and FRCP-type control-strength scores directly from free-text descriptions, supporting the prioritization of investigations and reinforcement of critical controls. These approaches complement other narrative-driven models that detect injury precursors and evacuation decisions from textual and multi-modal safety data, thereby turning unstructured information into actionable leading indicators. However, most studies are still based on single-organization datasets with class imbalance and limited external validation, underscoring the need for cross-industry benchmarks, transparent performance reporting and closer collaboration with practitioners to calibrate decision thresholds and embed these predictions within existing risk control protocols.
In the process and chemical industries, recent works show that text mining and deep contextual language models (e.g., BERT-type architectures) substantially improve the extraction of causal and contextual risk factors from accident and near-miss reports, outperforming traditional bag-of-words approaches and enabling the discovery of latent hazard themes through topic modelling. In parallel, coal-mine safety studies illustrate how multi-source data, structured accident causation frameworks and multi-level indicator systems, often weighted through expert judgement and data-driven methods and combined with AHP or human-factor models, allow more nuanced quantification of environmental and human-error-related risks. Beyond mining, hybrid risk-prediction frameworks are emerging that fuse indicators derived from text (extracted risk factors) with process, equipment and environmental data using probabilistic or mixture models to anticipate accidents proactively. Overall, these contributions point to hybrid NLP plus probabilistic/multi-criteria approaches as a key future direction for occupational risk prevention, while also highlighting that current solutions remain largely at prototype stage and require tighter integration with operational safety management, including explicit treatment of uncertainty and sensitivity analysis.
Recent LLM- and RAG-based systems in OSH move beyond analysing incidents to generating concrete preventive guidance. By combining domain-adapted embedding models for retrieving similar accident and job-safety cases with generative LLMs, these tools can automatically produce job hazard analyses, structured safety reports and checklists tailored to specific tasks, and even highlight likely root causes. They are also being piloted in conversational formats (e.g., chatbots) to support workers directly. Together, these developments signal a shift towards prescriptive AI in occupational safety, while underscoring the need for transparent pipeline descriptions (retrieval, prompting, generation, human-in-the-loop validation), rigorous control of hallucinations and domain adaptation, and the systematic use of curated knowledge bases and mandatory expert review before any recommendations are implemented.
Advances in workplace monitoring are moving from isolated IoT and vision systems towards contrastive vision–language architectures that jointly encode images and textual safety prompts. Models of this type can recognise multiple PPE items and unsafe behaviours simultaneously from surveillance images and, thanks to their prompt-based design, allow safety managers to formulate new monitoring queries (e.g., specific unsafe actions) without retraining. They complement traditional computer-vision approaches for PPE or posture detection, but also introduce important challenges around privacy and surveillance, potential bias in detection performance, false alarms that may undermine trust, and the need to integrate alerts into existing safety workflows under emerging ethical and regulatory constraints.
Current AI and LLM applications in occupational risk prevention still face important limitations related to data quality, representativeness and bias, since most models are trained on historical records from single organisations with under-reporting and uneven coverage of vulnerable workers. They also present challenges of transparency and explainability, domain adaptation and concept drift, together with the persistence of hallucinations and the risk of over-reliance on generative outputs, which makes robust governance, continuous monitoring and human-in-the-loop validation indispensable. In parallel, the growing regulatory and ethical scrutiny of general-purpose AI underscores the need for transparency, accountability and human oversight when deploying these tools in safety-critical contexts. Explicitly recognising these constraints offers a more realistic view of the current maturity of AI/LLM systems in OSH and supports their positioning as decision-support tools rather than autonomous safety authorities.
Despite these advances, several limitations and risks associated with the use of AI, NLP and LLMs in occupational risk prevention must be acknowledged. Many models are trained on historical accident reports or incident databases that reflect under-reporting, incomplete causal information and sector- or country-specific biases. As a result, predictions of severity, PSIF, FRCP level or incident likelihood may inherit and amplify these biases, particularly for under-represented worker groups, subcontractors or informal sectors. Ensemble-learning and multi-source frameworks such as those proposed by Kamil et al. (2024), Lu et al. (2024), Sahoo et al. (2024) and Sarker et al. (2025) partly mitigate these issues by integrating diverse data sources, but they still rely on the quality and representativeness of the underlying data. Similarly, topic-model–Bayesian-network approaches (Zhou et al., 2025; Du & Chen, 2025) and Industrial-Internet-based indicator systems (Ni et al., 2024) may be sensitive to modelling assumptions, discretization choices and expert-defined structures.
LLM-based systems introduce additional concerns related to opacity, hallucinated content, and alignment with domain regulations and ethical principles. In RAG-enhanced safety-guidance and job-safety-report frameworks (Baek et al., 2025; Bernardi et al., 2025), the quality of the retrieval step and the coverage of the underlying document repository critically determine whether the generated guidance is accurate and compliant with current legislation. HFACS-guided Chain-of-Thought prompting (Liu et al., 2025) and vision–language PPE detectors (Chen et al., 2024) improve interpretability by exposing intermediate reasoning or by aligning decisions with human-readable safety concepts, but they still depend on careful prompt engineering, safety-specific evaluation and continuous monitoring to prevent erroneous or unsafe recommendations. From a regulatory perspective, the deployment of such systems in real workplaces must comply with data-protection and surveillance regulations, worker-participation requirements, and emerging AI governance frameworks. This underscores the need for robust human-in-the-loop designs in which OSH professionals critically review AI outputs, validate them against established risk-assessment methods (e.g. FRCP, PSIF, AHP-based ranking) and retain ultimate responsibility for safety-critical decisions.
Future research should therefore prioritize (i) the creation of high-quality, representative and ethically sourced OSH datasets that cover diverse sectors, worker populations and countries; (ii) the development of hybrid frameworks that combine domain-knowledge-driven models (e.g. Bayesian networks, AHP, FRCP, PSIF) with AI-based text, vision and multimodal analytics; and (iii) systematic evaluation protocols that assess not only predictive performance but also fairness, robustness, interpretability and regulatory compliance. Particular attention should be paid to longitudinal validation of severity and PSIF prediction models, cross-sector generalization of LLM-assisted accident investigation methods, and integration of occupation-classification and working-conditions data into risk-assessment pipelines (Kim et al., 2024; Li et al., 2025). Finally, multidisciplinary collaboration between AI researchers, OSH professionals, regulators and worker representatives will be crucial to ensure that AI-enabled safety tools are designed, validated and deployed in ways that effectively reduce occupational accidents and diseases while respecting workers’ rights, autonomy and well-being.
References
- Ahadh, A., Binish, G. V., & Srinivasan, R. (2021). Text mining of accident reports using semi-supervised keyword extraction and topic modeling. Process Safety and Environmental Protection, 155, 455-465. [CrossRef]
- Badri, A., Boudreau-Trudel, B., & Souissi, A. S. (2018). Occupational health and safety in the industry 4.0 era: A cause for major concern? Safety Science, 109, 403-411. [CrossRef]
- Baek, S., Park, C. Y., & Jung, W. (2025). Automated safety risk management guidance enhanced by retrieval-augmented large language model. Automation in Construction, 176, 106255. [CrossRef]
- Baker, H., Hallowell, M. R., & Tixier, A. J.-P. (2020). Automatically learning construction injury precursors from text. Automation in Construction, 118, 103145. [CrossRef]
- Ben Abbes, S., Temal, L., Arbod, G., Lanteri-Minet, P.-L., & Calvez, P. (2022). Combining Ontology and Natural Language Processing Methods for Prevention of Falls from Height. En B. Villazón-Terrazas, F. Ortiz-Rodriguez, S. Tiwari, M.-A. Sicilia, & D. Martín-Moncunill (Eds.), Knowledge Graphs and Semantic Web (pp. 47-61). Springer International Publishing. [CrossRef]
- Bernardi, M. L., Cimitile, M., Panella, G., Pecori, R., & Simoncelli, G. (2025). Automatic generation of job safety reports with explainable RAG-based LLMs. Information Systems Frontiers. [CrossRef]
- Chen, Z.; Chen, H.; Imani, M.; Chen, R. & Imani, F. (2025). Vision Language Model for Interpretable and Fine-Grained Detection of Safety Compliance in Diverse Workplaces. Expert Systems with Applications, 265, 125769. [CrossRef]
- Cheng, M.-Y., Kusoemo, D., & Gosno, R. A. (2020). Text mining-based construction site accident classification using hybrid supervised machine learning. Automation in Construction, 118, 103265. [CrossRef]
- Cohan, A., Fong, A., Ratwani, R. M., & Goharian, N. (2017). Identifying Harm Events in Clinical Care through Medical Narratives. Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology,and Health Informatics, 52-59. [CrossRef]
- Dalal, S., & Bassu, D. (2020). Deep analytics for workplace risk and disaster management. IBM Journal of Research and Development, 64(1/2), 14:1-14:9. IBM Journal of Research and Development. [CrossRef]
- de Vries, V. (2020). Classification of Aviation Safety Reports using Machine Learning. 2020 International Conference on Artificial Intelligence and Data Analytics for Air Transportation (AIDA-AT), 1-6. [CrossRef]
- Denecke, K. (2016). Automatic Analysis of Critical Incident Reports: Requirements and Use Cases. Studies in Health Technology and Informatics, 223, 85-92.
- Do, Q., Le, T., & Le, C. (2024). Uncovering critical causes of highway work zone accidents using unsupervised machine learning and social network analysis. Journal of Construction Engineering and Management, 150(5), 04024039. [CrossRef]
- Dong, T., Yang, Q., Ebadi, N., Luo, X. R., & Rad, P. (2021). Identifying Incident Causal Factors to Improve Aviation Transportation Safety: Proposing a Deep Learning Approach. Journal of Advanced Transportation, 2021, e5540046. [CrossRef]
- Du, G., & Chen, A. (2025). Coal Mine Accident Risk Analysis with Large Language Models and Bayesian Networks. Sustainability, 17, 1896. [CrossRef]
- Ebrahimi, H., Sattari, F., Lefsrud, L., & Macciotta, R. (2023). A machine learning and data analytics approach for predicting evacuation and identifying contributing factors during hazardous materials incidents on railways. Safety Science, 164, 106180. [CrossRef]
- Egli S. B., Apargaus A., Amacher S. A., Hunziker, S., & Bassti, S. (2025). Use, knowledge and perception of large language models in clinical practice: A cross-sectional mixed-methods survey among clinicians in Switzerland. BMJ Health Care Informatics, 32, e101470. [CrossRef]
- Elizabeth, R. M. C., Sattari, F., Lefsrud, L., & Gue, B. (2025). Visualizing what’s missing: Using deep learning and Bow Tie diagrams to identify and visualize missing leading indicators in industrial construction. Journal of Safety Research, 93, 1 11. [CrossRef]
- Fan, H., & Li, H. (2013). Retrieving similar cases for alternative dispute resolution in construction accidents using text mining techniques. Automation in Construction, 34, 85-91. [CrossRef]
- Fang, W., Luo, H., Xu, S., Love, P. E. D., Lu, Z., & Ye, C. (2020). Automated text classification of near-misses from safety reports: An improved deep learning approach. Advanced Engineering Informatics, 44, 101060. [CrossRef]
- Figueres-Esteban, M., Hughes, P., & van Gulijk, C. (2016). Visual analytics for text-based railway incident reports. Safety Science, 89, 72-76. [CrossRef]
- Fonseca, L. M. (2018). Industry 4.0 and the digital society: Concepts, dimensions and envisioned benefits. Proceedings of the International Conference on Business Excellence, 12(1), 386-397.
- Gadekar, H., & Bugalia, N. (2023). Automatic classification of construction safety reports using semi-supervised YAKE-Guided LDA approach. Advanced Engineering Informatics, 56, 101929. [CrossRef]
- Ganguli, R., Miller, P., & Pothina, R. (2021). Effectiveness of Natural Language Processing Based Machine Learning in Analyzing Incident Narratives at a Mine. Minerals, 11(7), 776. [CrossRef]
- Garvin, T., & Kimbleton, S. (2021). Artificial intelligence as ally in hazard analysis. Process Safety Progress, 40(3), 43-49. [CrossRef]
- Gomes-Miranda, L., & Gonçalvez, F. (2024). The impact of Industry 4.0 on occupational health and safety: A systematic literature review. Journal of Safety Research, 90, 254-271. [CrossRef]
- Hacker, P., Engel, A., & Mauer, M. (2023). Regulating ChatGPT and other large generative AI models. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (pp. 1112–1123). Association for Computing Machinery. [CrossRef]
- Heidarysafa, M., Kowsari, K., Barnes, L., & Brown, D. (2018). Analysis of Railway Accidents’ Narratives Using Deep Learning. 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), 1446-1453. [CrossRef]
- Howard, J., & Schulte, P. (2024). Managing workplace AI risks and the future of work. American Journal of Industrial Medicine, 67(11), 980–993. [CrossRef]
- Hua, L., Zheng, W., & Gao, S. (2019). Extraction and Analysis of Risk Factors from Chinese Railway Accident Reports. 2019 IEEE Intelligent Transportation Systems Conference (ITSC), 869-874. [CrossRef]
- Huber, J., Haslgrübler, M., Schobesberger, M., Ferscha, A., Malisa, V., & Effenberger, G. (2022). Addressing worker safety and accident prevention with AI. In Proceedings of the 11th International Conference on the Internet of Things (IoT '21) (pp. 150–157). Association for Computing Machinery. [CrossRef]
- Hughes, P., Robinson, R., Figueres-Esteban, M., & van Gulijk, C. (2019). Extracting safety information from multi-lingual accident reports using an ontology-based approach. Safety Science, 118, 288-297. [CrossRef]
- Hughes, P., Shipp, D., Figueres-Esteban, M., & van Gulijk, C. (2018). From free-text to structured safety management: Introduction of a semi-automated classification method of railway hazard reports to elements on a bow-tie diagram. Safety Science, 110, 11-19. [CrossRef]
- Hwang, J.-M., Won, J.-H., Jeong, H.-J., & Shin, S.-H. (2023). Identifying critical factors and trends leading to fatal accidents in small-scale construction sites in Korea. Buildings, 13(10), 2472. [CrossRef]
- ILO. (2023). A call for safer and healthier working environments—International Labour Organization. https://researchrepository.ilo.org/esploro/outputs/report/995343988202676.
- Jiao, Y., Dong, J., Han, J., & Sun, H. (2022). Classification and Causes Identification of Chinese Civil Aviation Incident Reports. Applied Sciences, 12(21). [CrossRef]
- Jidkov, V., Abielmona, R., Teske, A., & Petriu, E. (2020). Enabling Maritime Risk Assessment Using Natural Language Processing-based Deep Learning Techniques. 2020 IEEE Symposium Series on Computational Intelligence (SSCI), 2469-2476. [CrossRef]
- Jing, S., Liu, X., Gong, X., Tang, Y., Xiong, G., Liu, S., Xiang, Shuguang., & Bi, Rongshan. (2022). Correlation analysis and text classification of chemical accident cases based on word embedding. Process Safety and Environmental Protection, 158, 698-710. [CrossRef]
- Kabir, S., Taleb-Berrouane, M., & Papadopoulos, Y. (2023). Dynamic reliability assessment of flare systems by combining fault tree analysis and Bayesian networks. Energy Sources, Part A: Recovery, Utilization, and Environmental Effects, 45(2), 4305-4322. [CrossRef]
- Kamil, M. Z., Khan, F., Halim, S. Z., Amyotte, P., & Ahmed, S. (2023). A methodical approach for knowledge-based fire and explosion accident likelihood analysis. Process Safety and Environmental Protection, 170, 339-355. [CrossRef]
- Kamil, M. Z., Khan, F., Amyotte, P., & Ahmed, S. (2024). Multi-source heterogeneous data integration for incident likelihood analysis. Computers & Chemical Engineering, 185, 108677. [CrossRef]
- Kar, M. B., Aruna, M., & Kunar, B. M. (2024). An analytical hierarchy approach for studying the impact of human error, environmental factors, and equipment failure on mine accidents: A case study in India. International Journal of System Assurance Engineering and Management, 15, 2163–2169. [CrossRef]
- Khairuddin, M. Z. F., Hasikin, K., Abd Razak, N. A., Lai, K. W., Osman, M. Z., Aslan, M. F., Sabanci, K., Azizan, M. M., Satapathy, S. C., & Wu, X. (2022). Predicting occupational injury causal factors using text-based analytics: A systematic review. Frontiers in Public Health, 10, 984099. [CrossRef]
- Khairuddin, M.Z.F.; Sankaranarayanan, S.; Hasikin, K.; Abd Razak, N.A.; Omar, R. (2024). Contextualizing Injury Severity from Occupational Accident Reports Using an Optimized Deep Learning Prediction Model. PeerJ Computer Science, 10, e1985. [CrossRef]
- Kierszbaum, S., Klein, T., & Lapasset, L. (2022). ASRS-CMFS vs. RoBERTa: Comparing Two Pre-Trained Language Models to Predict Anomalies in Aviation Occurrence Reports with a Low Volume of In-Domain Data Available. Aerospace, 9(10). [CrossRef]
- Kierszbaum, S., & Lapasset, L. (2020). Applying Distilled BERT for Question Answering on ASRS Reports. In 2020 New Trends in Civil Aviation (NTCA), 33-38. [CrossRef]
- Kim, M. S. (2023). Topics model of overwork-related deaths in Korea and the implications of SDGs’ decent work perspective. Safety science, 166, 106239. [CrossRef]
- Kim, T.-Y.; Baek, S.-U.; Lim, M.-H.; Yun, B.; Paek, D.; Zoh, K.E.; Youn, K.; Lee, Y.K.; Kim, Y.; Kim, J.; et al. (2024) Occupation Classification Model Based on DistilKoBERT: Using the 5th and 6th Korean Working Condition Surveys. Annals of Occupational and Environmental Medicine, 36, e19. [CrossRef]
- Kim, Y., Park, J., & Park, M. (2016). Creating a Culture of Prevention in Occupational Safety and Health Practice. Safety and Health at Work, 7(2), 89-96. [CrossRef]
- Kuhn, K. D. (2018). Using structural topic modeling to identify latent topics and trends in aviation incident reports. Transportation Research Part C: Emerging Technologies, 87, 105-122. [CrossRef]
- Kumari, P., Wang, Q., Khan, F., & Kwon, J. S.-I. (2022). A unified causation prediction model for aboveground onshore oil and refined product pipeline incidents using artificial neural network. Chemical Engineering Research and Design, 187, 529-540. [CrossRef]
- Lee, W., & Lee, S. (2024). Development of a knowledge base for construction risk assessments using BERT and graph models. Buildings, 14(11), 3359. [CrossRef]
- Leesakul, N., Oostveen, A.-M., Eimontaite, I., Wilson, M. L., & Hyde, R. (2022). Workplace 4.0: Exploring the Implications of Technology Adoption in Digital Manufacturing on a Sustainable Workforce. Sustainability, 14(6), Article 6. [CrossRef]
- Leutz-Schmidt, P., Palm, V., Mathy, R. M., Grözinger, M., Kauczor, H.-U., Jang, H., & Sedaghat, S. (2025). Performance of large language models ChatGPT and Gemini on workplace management questions in radiology. Diagnostics, 15(4), 497. [CrossRef]
- Li, N.; Kang, B.; De Bie, T. (2025) LLM4Jobs: Unsupervised Occupation Extraction and Standardization Leveraging Large Language Models. Knowledge-Based Systems, 316, 113302. [CrossRef]
- Liu, C., & Yang, S. (2022). Using text mining to establish knowledge graph from accident/incident reports in risk assessment. Expert Systems with Applications, 207, 117991. [CrossRef]
- Liu, Q., Ding, Y., & Luo, X. (2025). Automated knowledge graph based risk assessment for fall from height accidents in construction. Automation in Construction, 158, 106482. [CrossRef]
- Liu, Q., Li, F., Ng, K. K. H., Han, J., & Feng, S. (2025). Accident investigation via LLMs reasoning: HFACS-guided Chain-of-Thoughts enhance general aviation safety. Expert Systems with Applications, 269, 126422. [CrossRef]
- Liu, Y., Wang, J., Tang, S., Zhang, J., & Wan, J. (2023). Integrating information entropy and latent Dirichlet allocation models for analysis of safety accidents in the construction industry. Buildings, 13(1831). [CrossRef]
- Lu, C., Li, S., Xu, K., & Zhang, Y. (2025). Research on data-driven coal mine environmental safety risk assessment system. Safety Science, 183, 106727. [CrossRef]
- Luo, X., Feng, X., Ji, X., Dang, Y., Zhou, L., Bi, K., & Dai, Y. (2023). Extraction and analysis of risk factors from Chinese chemical accident reports. Chinese Journal of Chemical Engineering, 61, 68-81. [CrossRef]
- Luo, Y., & Shi, H. (2019). Using lda2vec Topic Modeling to Identify Latent Topics in Aviation Safety Reports. In 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), 518-523. [CrossRef]
- Macêdo, J. B., das Chagas Moura, M., Aichele, D., & Lins, I. D. (2022). Identification of risk features using text mining and BERT-based models: Application to an oil refinery. Process Safety and Environmental Protection, 158, 382-399. [CrossRef]
- Madeira, T., Melício, R., Valério, D., & Santos, L. (2021). Machine Learning and Natural Language Processing for Prediction of Human Factors in Aviation Incident Reports. Aerospace, 8(2), Article 2. [CrossRef]
- Marev, K., & Georgiev, K. (2019). Automated Aviation Occurrences Categorization. In 2019 International Conference on Military Technologies (ICMT), 1-5. [CrossRef]
- Milea, A., & Cioca, L.-I. (2024). Work evolution and safety and health at work in Industry 4.0 / Industry 5.0. MATEC Web of Conferences, 389, 00074. [CrossRef]
- Miraz, M. H., Hasan, M. T., Sumi, F. R., Sarkar, S., & Hossain, M. A. (2022). Industry 5.0: The Integration of Modern Technologies. En Machine Vision for Industry 4.0. CRC Press.
- Miyamoto, A., Bendarkar, M. V., & Mavris, D. N. (2022). Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns. Aerospace, 9(8), Article 8. [CrossRef]
- Mollaei, N., Fujao, C., Rodrigues, J., Cepeda, C., & Gamboa, H. (2023). Occupational health knowledge discovery based on association rules applied to workers’ body parts protection: A case study in the automotive industry. Computer Methods in Biomechanics and Biomedical Engineering, 26(15), 1875-1888. [CrossRef]
- Naderi, H., & Shojaei, A. (2025). Large-language model (LLM)–Powered system for situated and game-based construction safety training. Expert Systems With Applications, 283, 127887. [CrossRef]
- Ni, Z., Wang, X., Zhang, Z., & Wang, L. (2024). Development of major process accident indicators based on Industrial Internet. Journal of Loss Prevention in the Process Industries, 92, 105418. [CrossRef]
- Niu, H., Omitaomu, O. A., Langston, M. A., Olama, M., Ozmen, O., Klasky, H. B., Laurio, A., Ward, M., & Nebeker, J. (2024). EHR-BERT: A BERT-based model for effective anomaly detection in electronic health records. Journal of Biomedical Informatics, 174, 104605. [CrossRef]
- Parikh, P.; Penfield, J.; Juaire, M. (2024) Automatic Identification of Incidents Involving Potential Serious Injuries and Fatalities (PSIF). Scientific Reports, 14, 8091. [CrossRef]
- Perboli, G., Gajetti, M., Fedorov, S., & Giudice, S. L. (2021). Natural Language Processing for the identification of Human factors in aviation accidents causes: An application to the SHEL methodology. Expert Systems with Applications, 186, 115694. [CrossRef]
- Pishgar, M., Issa, S. F., Sietsema, M., Pratap, P., & Darabi, H. (2021). REDECA: A Novel Framework to Review Artificial Intelligence and Its Applications in Occupational Safety and Health. International Journal of Environmental Research and Public Health, 18(13), Article 13. [CrossRef]
- Posse, C., Matzke, B., Anderson, C., Brothers, A., Matzke, M., & Ferryman, T. (2005). Extracting information from narratives: An application to aviation safety reports. In 2005 IEEE Aerospace Conference, 3678-3690. [CrossRef]
- Qiu, Z., Liu, Q., Li, X., Zhang, J., & Zhang, Y. (2021). Construction and analysis of a coal mine accident causation network based on text mining. Process Safety and Environmental Protection, 153, 320-328. [CrossRef]
- Ricketts, J., Barry, D., Guo, W., & Pelham, J. (2023). A Scoping Literature Review of Natural Language Processing Application to Safety Occurrence Reports. Safety, 9(2), Article 2. [CrossRef]
- Ricketts, J., Pelham, J., Barry, D., & Guo, W. (2022). An NLP framework for extracting causes, consequences, and hazards from occurrence reports to validate a HAZOP study. In 2022 IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), 1-8. [CrossRef]
- Roberts, B. (2015). The Third Industrial Revolution: Implications for Planning Cities and Regions. Workiing Paper Urban Frontiers, 1.
- Robinson, S. D. (2016). Visual representation of safety narratives. Safety Science, 88, 123-128. [CrossRef]
- Rose, R. L., Puranik, T. G., & Mavris, D. N. (2020). Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives. Aerospace, 7(10), Article 10. [CrossRef]
- Rybak, N., & Hassall, M. (2021). Deep Learning Unsupervised Text-Based Detection of Anomalies in U.S. Chemical Safety and Hazard Investigation Board Reports. 2021 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), 1-7. [CrossRef]
- Salles, L., Sukharev, I., & Khazanovich, L. (2024). Highway construction safety analysis using large language models. Applied Sciences, 14(4), 1352. [CrossRef]
- Sarkar, S., & Maiti, J. (2020). Machine learning in occupational accident analysis: A review using science mapping approach with citation network analysis. Safety Science, 131, 104900. [CrossRef]
- Sarker, B.; Barman, A.; Garg, A.; Maiti, J. (2025) Natural Language Processing-Based Ensemble Technique to Predict Potential Accident Severity. International Journal of System Assurance Engineering and Management, 16, 1975–1991. [CrossRef]
- Sen, S., Gonzalez, V., Husom, E. J., Tverdal, S., Tokas, S., & Tjøsvoll, S. O. (2024). ERG-AI: Enhancing occupational ergonomics with uncertainty-aware ML and LLM feedback. Applied Intelligence, 54, 12128–12155. [CrossRef]
- Sahoo, S., Mukane, P., Maiti, J., & Tewari, V. K. (2024). A framework for process risk assessment incorporating prior hazard information in text mining models using chunking. Process Safety and Environmental Protection, 189, 486–504. [CrossRef]
- Shayboun, M., Kifokeris, D., & Koch, C. (2025). A review of machine learning for analysing accident reports in the construction industry. Journal of Information Technology in Construction (ITcon), 30, 439–460. [CrossRef]
- Sharma, A., & Singh, B. J. (2020). Evolution of Industrial Revolutions: A Review. International Journal of Innovative Technology and Exploring Engineering, 9(11), 66-73. [CrossRef]
- Shekhar, H., & Agarwal, S. (2021). Automated Analysis through Natural Language Processing of DGMS Fatality Reports on Indian Non-Coal Mines. In 2021 5th International Conference on Information Systems and Computer Networks (ISCON), 1-6. [CrossRef]
- Shen, Q., Wu, S., Deng, Y., Deng, H., & Cheng, J. C. P. (2022). BIM-Based Dynamic Construction Safety Rule Checking Using Ontology and Natural Language Processing. Buildings, 12(5), Article 5. [CrossRef]
- Shi, D., Li, Z., Zurada, J., Manikas, A., Guan, J., & Weichbroth, P. (2024). Ontology-based text convolution neural network (TextCNN) for prediction of construction accidents. Knowledge and Information Systems, 66(4), 2651–2681. [CrossRef]
- Smetana, M., Salles de Salles, L., Sukharev, I., & Khazanovich, L. (2024). Highway construction safety analysis using large language models. Applied Sciences, 14(1352). [CrossRef]
- Song, B., & Suh, Y. (2019). Narrative texts-based anomaly detection using accident report documents: The case of chemical process safety. Journal of Loss Prevention in the Process Industries, 57, 47-54. [CrossRef]
- Song, J.-H., Shin, S.-H., Kang, S.-Y., Won, J.-H., & Yoo, K.-H. (2024). Occurrence type classification for establishing prevention plans based on industrial accident cases using the KoBERT model. Applied Sciences, 14, 9450. [CrossRef]
- Suh, Y. (2025). Identifying safety technology opportunities to mitigate safety-related issues on construction sites. Buildings, 15(6), 847. [CrossRef]
- Tanguy, L., Tulechki, N., Urieli, A., Hermann, E., & Raynal, C. (2016). Natural language processing for aviation safety reports: From classification to interactive analysis. Computers in Industry, 78, 80-95. [CrossRef]
- Thompson, P., Yates, T., Inan, E., & Ananiadou, S. (2020). Semantic Annotation for Improved Safety in Construction Work. In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 1990-1999). European Language Resources Association. https://aclanthology.org/2020.lrec-1.245.
- Tian, D., Li, M., Shen, Y., & Han, S. (2023). Intelligent mining of safety hazard information from construction documents using semantic similarity and information entropy. Engineering Applications of Artificial Intelligence, 119, 105742. [CrossRef]
- Uhm, M., Kim, J., Ahn, S., Jeong, H., & Kim, H. (2024). Effectiveness of retrieval augmented generation based large language models for generating construction safety information. Automation in Construction, 170, 105926. [CrossRef]
- Van Gulijk, C. (2021). El desarrollo de una evaluación de riesgos dinámica y sus implicaciones para la salud y seguridad en el trabajo. Agencia Europea para la Seguridad y la Salud en el Trabajo (EU-OSHA).
- Valcamonico, D., Baraldi, P., Amigoni, F., & Zio, E. (2022). A framework based on Natural Language Processing and Machine Learning for the classification of the severity of road accidents from reports. Proceedings of the Institution of Mechanical Engineers, Part O: Journal of Risk and Reliability, 1748006X221140196. [CrossRef]
- Vinitha, K., Ambrose Prabhu, R., Bhaskar, R., & Hariharan, R. (2020). Review on industrial mathematics and materials at Industry 1.0 to Industry 4.0. Materials Today: Proceedings, 33, 3956-3960. [CrossRef]
- Wang, B., & Zhao, J. (2022). Automatic frequency estimation of contributory factors for confined space accidents. Process Safety and Environmental Protection, 157, 193-207. [CrossRef]
- Wang, G., Liu, M., Cao, D., & Tan, D. (2021). Identifying high-frequency–low-severity construction safety risks: An empirical study based on official supervision reports in Shanghai. Engineering, Construction and Architectural Management, 29(2), 940-960. [CrossRef]
- Wang, Y., Chen, H., Liu, B., Yang, M., & Long, Q. (2020). A Systematic Review on the Research Progress and Evolving Trends of Occupational Health and Safety Management: A Bibliometric Analysis of Mapping Knowledge Domains. Frontiers in Public Health, 8. [CrossRef]
- Wang, Z., & Yin, J. (2020). Risk assessment of inland waterborne transportation using data mining. Maritime Policy & Management, 47(5), 633-648. [CrossRef]
- Westhoven, M. (2022). Requirements for AI Support in Occupational Safety Risk Analysis. Proceedings of Mensch und Computer 2022, 561-565. [CrossRef]
- Westhoven, M., & Jadid, A. (2023). Using Natural Language Processing to Generate Risk Assessment Checklists From Workplace Descriptions. Proceeding of the 33rd European Safety and Reliability Conference, 2636-2637. [CrossRef]
- Wu, H., Zhong, B., Medjdoub, B., Xing, X., & Jiao, L. (2020). An Ontological Metro Accident Case Retrieval Using CBR and NLP. Applied Sciences, 10(15), Article 15. [CrossRef]
- Wu, K., Zhang, J., Huang, Y., Wang, H., Li, H., & Chen, H. (2023). Research on safety risk transfer in subway shield construction based on text mining and complex networks. Buildings, 13(11), 2700. [CrossRef]
- Xu, H., Liu, Y., Shu, C.-M., Bai, M., Motalifu, M., He, Z., Wu, S., Zhou, P., & Li, B. (2022). Cause analysis of hot work accidents based on text mining and deep learning. Journal of Loss Prevention in the Process Industries, 76, 104747. [CrossRef]
- Xu, N., Ma, L., Liu, Q., Wang, L., & Deng, Y. (2021). An improved text mining approach to extract safety risk factors from construction accident reports. Safety Science, 138, 105216. [CrossRef]
- Yang, C., & Huang, C. (2023). Natural Language Processing (NLP) in Aviation Safety: Systematic Review of Research and Outlook into the Future. Aerospace, 10(7), Article 7. [CrossRef]
- Yang, Y., & Xiang, P. (2025). Knowledge graph for the vulnerability of construction safety system in megaprojects based on accident inversion. Engineering Applications of Artificial Intelligence, 150, 110630. [CrossRef]
- Yimyam, W., & Ketcham, M. (2022). Occupational Disease Risk Assessment System Using Artificial Intelligence System and Chatbot. 2022 International Conference on Cybernetics and Innovations (ICCI), 1-5. [CrossRef]
- Yoo, B., Kim, J., Park, S., Ahn, C. R., & Oh, T. (2024). Harnessing generative pre-trained transformers for construction accident prediction with saliency visualization. Applied Sciences, 14(2), 664. [CrossRef]
- Zhang, C., & Yang, J. (2020). Second Industrial Revolution. In C. Zhang & J. Yang (Eds.), A History of Mechanical Engineering (pp. 137-195). Springer. [CrossRef]
- Zhang, F., Fleyeh, H., Wang, X., & Lu, M. (2019). Construction site accident analysis using text mining and natural language processing techniques. Automation in Construction, 99, 238-248. [CrossRef]
- Zhang, L., Hou, Y., & Ren, F. (2025). AIR Agent—A GPT-based subway construction accident investigation report analysis chatbot. Buildings, 15(527). [CrossRef]
- Zhang, X., Srinivasan, P., & Mahadevan, S. (2021). Sequential deep learning from NTSB reports for aviation safety prognosis. Safety Science, 142, 105390. [CrossRef]
- Zhao, Y., Diao, X., Huang, J., & Smidts, C. (2019). Automated Identification of Causal Relationships in Nuclear Power Plant Event Reports. Nuclear Technology, 205(8), 1021-1034. [CrossRef]
- Zhao, Y., Diao, X., & Smidts, C. (2018, septiembre 1). Preliminary Study of Automated Analysis of Nuclear Power Plant Event Reports Based on Natural Language Processing Techniques.
- Zhong, B., Shen, L., Pan, X., & Lei, L. (2023). Visual attention framework for identifying semantic information from construction monitoring video. Safety Science, 163, 106122. [CrossRef]
- Zhou, Z., Guo, J., & Huang, J. (2025). Chemical safety risk identification and analysis based on improved LDA topic model and Bayesian networks. Applied Sciences, 15, 6197. [CrossRef]
Figure 1.
Evolution of industrial revolutions driven by technological transformations and increasing complexity.
Figure 1.
Evolution of industrial revolutions driven by technological transformations and increasing complexity.
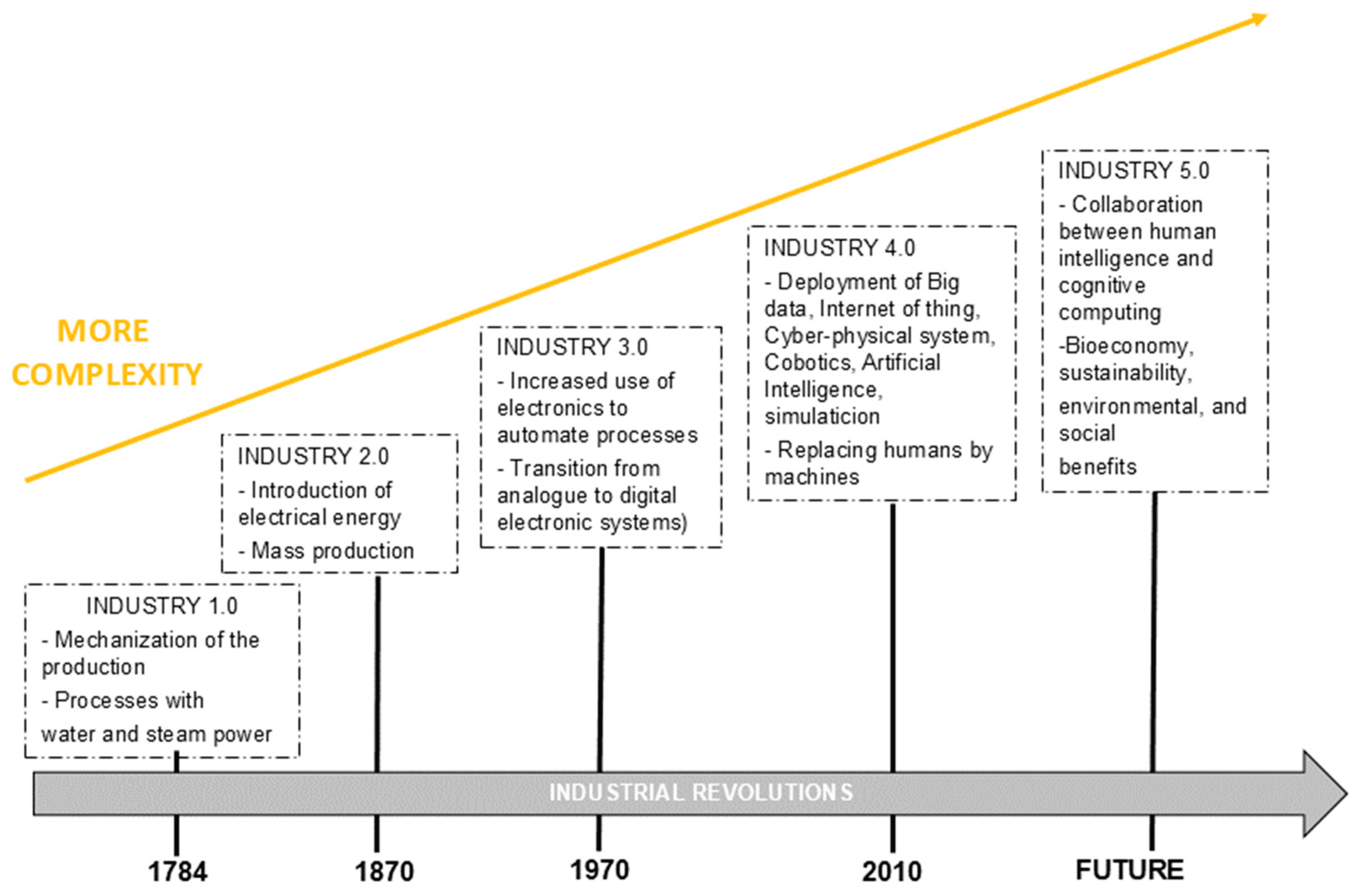

Table 1.
Application of artificial intelligence (AI) and natural language processing (NLP) in occupational risk prevention.
Table 1.
Application of artificial intelligence (AI) and natural language processing (NLP) in occupational risk prevention.
| Application | Model | Domain/Dataset | Advantages | Limitations | Years of review | Ref |
|---|---|---|---|---|---|---|
| Aviation Safety | NLP | Analysis of aviation incident/accident reports and air traffic control communications | 1. Enhance situational awareness 2. Reduce workload 3. Improve decision-making capabilities |
1. Ambiguity in language interpretation 2. Scarcity of adequate training data 3. Lack of multilingual support |
2010-2022 | (Yang & Huang, 2023) |
| Aviation safety | BERT | Aviation Safety Reporting System dataset | 1. About 70% accuracy in correctly answering the posed question 2. Uncovers information does not present in the dataset |
1. More questions are necessary to improve the model 2. Transparency of the model |
2011-2019 | (Kierszbaum & Lapasset, 2020) |
| Safety-critical industries | NPL | Safety occurrence reports | 1. Automatically classifies occurrence reports 2. Extract critical information 3. Allows semantic searches |
1. Limited availability of occurrence reporting databases 2. Data privacy restrictions |
2012-2022 | (Ricketts et al., 2023) |
| Occupational injury | NPL | Narratives from occupational injury reports | 1. Classify accident types 2. Identify causal factors 3. Predict occupational injuries |
1. Low quality and quantity of data 2. Unbalanced data distribution 3. Inconsistent terminologies |
2016-2021 | (Khairuddin et al., 2022) |
| Occupational injury | ML | Occupational accident analysis | 1. Prediction of incident outcomes 2. Extraction of rule-based patterns 3. Prediction of injury risk 4. Prediction of injury severity |
1. Review focused on citation network analysis, with no critical comments on limitations | 1995-2019 | (Sarkar & Maiti, 2020) |
Natural Language Processing (NLP); Bidirectional Encoder Representations from Transformers (BERT); Citation Network Analysis (CNA); Machine Learning (ML).
Table 2.
Applications of AI and NLP methodologies in the analysis of aviation safety data.
| Objective | Methodology | Results | Reference |
|---|---|---|---|
| Categorize and visualize the textual narratives from safety incident reports from the Aviation Safety Reporting System (ASRS) | NLP and clustering techniques, K Means clustering and t-distributed Stochastic Neighbor Embedding (t-SNE) | Seven major categories and 23 sub-clusters of flight delay causes were identified, revealing that maintenance issues, rather than weather conditions, are the main contributors to delays. | (Miyamoto et al., 2022) |
| Analysis of voluminous aviation incident reports to prevent occupational hazards | NLP techniques: Universal Language Model Fine-Tuning (ULMFiT) and Averaged Stochastic Gradient Descent Weight-Dropped LSTM (AWD-LSTM) for unsupervised language modelling and text classification. Deep recurrent neural networks and attention-based Long Short-Term Memory (LSTM) models. |
High accuracy in predicting multiple primary factors, providing a better understanding of incident factors, but limited to the six most common incident categories, with rarer categories not addressed due to insufficient data. | (Dong et al., 2021) |
| Classify and extract risk factors from Chinese civil aviation incident reports, which are traditionally underutilized due to their incoherence, large volume, and poor structure. | Machine learning: Extreme Gradient Boosting (XGBoost) classifier, combined with Occurrence Position (OC-POS) vectorization strategy. | Identification of incident causes from 25 empirically determined factors covering equipment, human, environmental, and organizational domains. | (Jiao et al., 2022) |
| Comparison of two language models in aviation safety: pre-trained ASRS-CMFS and RoBERTa model, without domain-specific pre-training. | Natural Language Understanding (NLU) and fine-tuning. | The RoBERTa model's size advantage does not outperform the ASRS-CMFS, which demonstrates greater computational efficiency. This highlights the advantage of pre-training compact models in scenarios where domain-specific data is limited. | (Kierszbaum et al., 2022) |
| Prediction of human factors in aviation safety incidents, identification and classification of human factor categories in aviation incident reports. | NLP for feature extraction, coupled with semi-supervised Label Spreading (LS) and supervised Support Vector Machine (SVM) techniques for data modelling. Use of TF-IDF models as an alternative to Doc2Vec (D2V), and Bayesian optimization to find near-optimal hyper-parameter combinations | The semi-supervised LS algorithm is particularly suitable for classification with fewer labels, while the supervised SVM is more reliable for larger and more uniformly labelled datasets. | (Madeira et al., 2021) |
| To enhance flight safety by analyzing aviation safety reports | NLP with preprocessing routines, in particular TF-IDF text representation model for document classification. Categorization and visualization of narratives through k-means clustering and t-distributed Stochastic Neighbor Embedding (t-SNE) and post-processing through metadata-based statistical analysis | Robust and repeatable framework for identifying class categories in aviation safety event narratives, capable of identifying 31 class categories for ASRS event narratives | (Rose et al., 2020) |
| Management and analysis aviation incident reports | Advanced NLP and text mining techniques, including algorithm design for active learning approaches, document content similarity methods, and topic modelling using TreeTagger and Gensim library | A range of developed tools to improve access to and analysis of aviation safety data | (Tanguy et al., 2016) |
| Overcome the difficulties of manually reviewing over 45,000 aviation reports. | Automatic text classification. Random forest algorithm for ICAO Occurrence Category | Text classification with an accuracy range of 80-93% | (de Vries, 2020) |
| Prevention of occupational hazards in aviation safety by efficiently extracting critical information from complex narratives | Common pattern specification language and normalized template expression matching in context | Overcome previous issues in these narratives, handle variants of multi-word expressions and improve accuracy. | (Posse et al., 2005) |
| Automated identification of human factors in aviation accidents | NLP techniques, Semantic Text Similarity approaches, Distributional Semantic theory, Vector Space Model (VSM), and document embeddings, integrated with the Software Hardware Environment Liveware (SHEL) accident causality model | Precision rate exceeding 86% and 30% reduction in time and cost compared to conventional methods | (Perboli et al., 2021) |
| Improve the analysis of accident reports, by overcoming the limitations of effective analysis of unstructured information | Automated, semi-supervised, domain-independent approach | User-defined classification topics and domain-specific literature, such as handbooks and glossaries, to autonomously identify and categorize domain-specific keywords with an average classification accuracy of 80%, rivalling traditional supervised learning methods | (Ahadh et al., 2021) |
| The critical issue in the analysis of aviation safety reports is the reliance on manually labelled datasets for traditional classification modelling, which has proven to be inadequate. | Latent Dirichlet Allocation (LDA) topic modelling to cluster aviation safety reports into meaningful sets for subsequent analysis. | Considerable reduction in dependence on aviation experts and improves in flexibility and efficiency | (Luo & Shi, 2019) |
| Delve into the vast repository of over a million confidential aviation safety incident reports within the Aviation Safety Reporting System (ASRS) to uncover latent structures and hidden trends. | NLP and structural topic modelling, demonstrating flexibility and reduced dependence on subject matter experts | Uncover previously unreported issues, such as fuel pump, tank, and landing gear problems, while underscoring the relative insignificance of smoke and fire incidents in private aircraft safety | (Kuhn, 2018) |
| Visualization of safety narratives to prevent occupational risks through the integration of NLP techniques | Latent semantic analysis (LSA) to uncover latent relationships and interpret meaning within safety narratives, followed by isometric mapping to project this information. | Primary safety problems at the different phases of flight were revealed | (Robinson, 2016) |
| Classification of aviation safety reports to avoid the time-consuming and resource-intensive process of manual categorization and classification narratives | NLP models with ULM-FiT procedures | Outperforming alternative models, increasing the F1 score from 0.484 to 0.663. | (Marev & Georgiev, 2019) |
| Evaluate the ability of LLMs to infer human errors in general aviation accidents and enhance their reasoning capabilities. | The development of two specialised prompts (HFACS-CoT and HFACS-CoT+) and the integration of knowledge into the HFACS 8.0 domain were completed. | Creation of a new General Aviation Accident Dataset (GAHFACS) and benchmarking using GPT-4o. | (Liu et al., 2025) |
| Design and evaluate an explainable RAG-based LLM framework that can automatically generate accurate and interpretable occupational safety reports from unstructured accident records. | Integration of BERT/SciBERT embeddings into an RAG pipeline; the evaluation of several LLMs; the use of the ASRS aviation dataset; the application of quantitative metrics; and the implementation of layer-wise analysis (LRP). | High-quality reports were generated with F1 scores of up to 0.909, and there was robust GLEU/METEOR performance. Domain-specific SciBERT embeddings consistently outperformed general-purpose ones. |
(Bernardi et al., 2025) |
Table 3.
Advances in occupational risk prevention in the construction industry through AI and NLP implementation.
Table 3.
Advances in occupational risk prevention in the construction industry through AI and NLP implementation.
| Objective | Methods | Results | Reference |
|---|---|---|---|
| Effective retrieval of relevant historical cases to prevent occupational risks in the construction industry. | Euclidean distance measure, cosine similarity measure, and the co-occurrence, and structured term vector model to represent unstructured textual cases. | Demonstration of the superior information retrieval of NLP-based models over traditional methods in a construction management information system | (Fan & Li, 2013) |
| Text mining and NLP techniques are used to classify accident causes and identify common hazardous objects from construction accident reports. | Five baseline models (Support Vector Machine, Linear Regression, K-Nearest Neighbor, Decision Tree, Naive Bayes) and an ensemble model, with the Sequential Quadratic Programming (SQP) algorithm to optimize the weights of classifiers within the ensemble | Optimized models in terms of average weighted F1 score, even with low support, enabling automatic extraction of common objects responsible for accidents. | (Zhang et al., 2019) |
| Identify injury precursors from construction accident reports to predict and prevent workplace injuries. | Convolutional Neural Networks (CNN) and Hierarchical Attention Networks (HAN), combined with Term Frequency-Inverse Document Frequency (TF-IDF) and Support Vector Machines (SVM) | Improve the understanding, prediction, and prevention of in the workplace injuries and provide tools that allow users to visualize and understand the predictions. | (Baker et al., 2020) |
| Effective management of occupational risks in the field of construction safety | NLP with a Named Entity Recognition (NER) scheme specifically designed for the construction safety domain | Effective and reliable annotator scheme with an agreement rate of 0.79 F-Score, overcoming previous limitations such as scope issues within hazard classification and the lack of coverage for specific construction activities, body parts injured, harmful consequences, and protective measures | (Thompson et al., 2020) |
| Analysis of near-miss reports to prevent potential accidents in the construction industry | Bidirectional Transformers for Language Understanding (BERT) for automatic classification of near-miss data | Outperforms the performance of other current state-of-the-art automatic text classification methods | (Fang et al., 2020) |
| More effective precautionary strategies and, consequently, improved safety assessments for construction projects. | Symbiotic Gated Recurrent Unit (SGRU) using NLP for text data preprocessing. | Improved classification accuracy and removal of human error in accident analysis and root cause identification. | (Cheng et al., 2020) |
| Identification of the critical causes of metro construction accidents in China | Development of a text mining strategy incorporating metric -information entropy weighted term frequency (TF − H) - metric to evaluate the importance of terms | Successful extraction of 37 safety risk factors from 221 metro construction accident reports, demonstrating effective distillation of important factors from accident reports regardless of their length | (Xu et al., 2021) |
| Extract and categorize safety risks from records, focusing on high-frequency but low-severity risks that are often missed by traditional methods. | Text mining Word2Vec models integrated with NLP. | 7 unsafe-act-related and nine unsafe-condition-related risks were uncovered, revealing predominant inappropriate human behaviors and the primary sources of safety hazards on-site | (Wang et al., 2021) |
| To establish an automatic inspection mechanism | Use of NLP to integrate Building Information Modeling (BIM) with a safety rule library. | Development of a safety rule-checking system for the construction process | (Shen et al., 2022) |
| Prevention of Fall From Height (FFH) accidents in the context of occupational safety. | NLP combined with knowledge graphs (KGs). | A robust approach to enhance occupational safety, using NLP and knowledge graphs, to mitigate FFH risks and improve prevention strategies. | (Ben Abbes et al., 2022) |
| Occupational risk prevention in the construction industry using NLP and semi-supervised machine learning techniques | Yet Another Keyword Extractor (YAKE) with Guided Latent Dirichlet Allocation (GLDA). | Effectiveness of the YAKE-GLDA approach, achieving an F1 score of 0.66 for OSHA injury narratives and an F1 score of 0.86 for specific categories, significantly reducing the need for manual intervention. | (Gadekar & Bugalia, 2023) |
| Mining of safety hazard information in construction documents presented in unstructured or semi-structured formats. | Term recognition models using semantic similarity and information correlation and term frequency-inverse document frequency methods (TF-IDF). | Automatic extraction and visualization of safety hazard information. | (Tian et al., 2023) |
| Extracting information from construction accident investigation reports in China to identify causes and see underlying patterns. | Text mining techniques and Dirichlet latent allocation (LDA) models were combined. | Delayed hazard identification and inadequate safety management on construction sites are the most frequent causal factors. | (Liu et al., 2023) |
| Analyze the causes and trends of industrial accidents at small-scale construction sites in South Korea to improve safety management and prevention strategies. | Statistical analysis, latent Dirichlet allocation (LDA) topic modeling, and network analysis were applied to KOSHA accident data from 2018–2022, focusing on small-scale construction sites. |
Scaffolding and working platforms were identified as the most critical cause of accidents, with falls being the predominant type; findings provide evidence to enhance safety culture and preventive measures for construction workers. | (Hwang et al., 2023) |
| Improve construction safety management by automatically extracting semantic information from on-site video data, enabling more effective monitoring of worker performance and safety conditions. |
A visual attention framework integrating frame extraction with interframe differences and a ResNet101–LSTM attention model was developed to generate natural language descriptions from construction video frames and validated on offline scene image datasets | The framework accurately captured objects, relationships, and attributes, enhancing automated safety monitoring, worker assessment, and video management. | (Zhong et al., 2023) |
| Identify critical safety risks and key transfer pathways in subway construction environments | Text mining, association rules, and complex network modeling were applied to incident reports to extract risk factors and map their interrelationships. | Key risks include inadequate safety management, unimplemented responsibilities, operational violations, and insufficient training; controlling these factors or disrupting transfer paths effectively mitigates accidents. | (Wu et al., 2023) |
| Improve accident analysis in highway construction by leveraging LLM to extract insights from textual injury reports and identify major causes of severe incidents. | OpenAI’s GPT-3.5 was applied to OSHA’s Severe Injury Reports (SIR) database, integrating natural language processing, dimensionality reduction, clustering algorithms, and LLM-based summarization to analyze and categorize accident narratives. | LLM-assisted cluster and causal analysis identified key accident types, demonstrating AI’s potential to support data-driven safety strategies and enhance accident prevention in construction. | (Salles et al., 2024) |
| Extracting useful information from road construction accident reports using LLM. | OpenAI’s GPT-3.5 was applied to OSHA Severe Injury Reports (SIR), integrating NLP techniques, dimensionality reduction, clustering algorithms, and LLM-based prompting to identify patterns and causes of major accidents. | The most significant types of accidents were identified, including those related to heat and pedestrian accidents, associating recurring factors in the cases, demonstrating the potential of AI analysis to support more effective accident prevention and intervention strategies. | (Smetana et al., 2024) |
| Elucidate the underlying causes of construction accidents in highway work zones—among the most hazardous environments in the transportation sector—to inform targeted safety interventions. | Employed advanced text mining and latent Dirichlet allocation (LDA) modeling on OSHA narrative reports, complemented by social network analysis (SNA) to quantify interrelationships and criticality among root causes. | Four dominant root causes—supervisory negligence, low safety awareness, poor work environments, and risk-taking behavior—were identified as critical to improving highway work zone safety. | (Do et al., 2024) |
| Develop an automated system to extract and manage construction safety knowledge, enhancing risk assessments and reducing reliance on individual expertise within the construction sector | Combined natural language processing (NLP) with graph-based models to extract predefined knowledge from unstructured construction data and construct an entity-relationship knowledge base, including entity-name recognition and keyword-extraction engines. | The proposed method efficiently and effectively generated a construction risk-assessment knowledge base, outperforming existing approaches and providing a foundation for automated knowledge management in construction safety. | (Lee & Lee, 2024) |
| Enhance accident prediction and safety management in the construction sector by integrating ontologies with deep learning models to leverage knowledge from construction accident reports. | Developed a construction safety ontology using domain word discovery and literature analysis, transformed accident reports into conceptual vectors via TransH, and implemented a TextCNN model, comparing performance against five traditional machine learning models. | The ontology-integrated TextCNN model outperformed all baseline models, achieving 88% accuracy and 0.92 AUC, demonstrating improved predictive performance and actionable insights for construction site safety management. | (Shi et al., 2024) |
| Evaluate the effectiveness of a Retrieval-Augmented Generation GPT (RAG-GPT) model for generating accurate and detailed construction safety information. | The RAG-GPT model was evaluated against four GPT variants, with responses assessed by researchers, safety experts, and construction workers using quantitative and qualitative metrics | RAG-GPT outperformed other models, providing more accurate and contextually relevant safety information, demonstrating the efficacy of retrieval-augmented strategies in construction safety management. | (Uhm et al., 2024) |
| Predict and prevent construction accidents by leveraging large language models to identify key accident types from textual reports. | Transfer learning was used with a precisely tuned, pre-trained generative transformer (GPT). | The generated model achieved 82% accuracy in predicting six types of accidents, enabling proactive safety interventions. | (Yhoo et al., 2024) |
| Strengthen safety risk management in the construction sector by automatically generating high-quality, activity-specific safety guidance using LLM. | A Retrieval-Augmented Generation framework was employed to retrieve pertinent information from 64,740 construction accident reports, integrating domain-adapted text embeddings with LLM based natural language generation to produce context-specific safety guidance. | The generated safety risk management guidance was found to be of equivalent or superior quality to those written by experienced practitioners through a double-blind peer review. |
(Baek et al., 2025) |
| Identify gaps in construction site safety inspections within the construction sector, highlighting which leading indicators fail to capture hazards associated with workplace incidents. | Natural language processing (NLP), text mining, and deep learning (SBERT) techniques were applied to generate embeddings from 633 incident reports and 9,681 inspection descriptions, followed by root cause analysis and visualization using bow-tie and Sankey diagrams. | High-risk hazards—working at heights (81%), equipment handling/storage (17%), and ergonomics (0.4%)—were inadequately captured during inspections, providing actionable insights to enhance predictive and proactive risk management in construction. | (Elizabeth et al., 2025) |
| Construct an automated framework to identify and quantify fall-from-height (FFH) risk factors in construction. | LLM generated a FFH knowledge graph from 1,097 accident reports, with clustering and network analysis applied for quantitative risk assessment. | GPT-4o achieved high extraction accuracy (F1 = 0.94; precision = 0.90), revealing key risk factors and unsafe behaviors, supporting enhanced construction site safety management. | (Lui et all, 2025) |
| Identify technological opportunities to prevent occupational incidents on construction sites by analyzing incidents and patent textual data. | Applied text mining and self-organizing maps to integrate incident reports and patent documents, categorizing potential safety technologies into five groups and performing gap analysis to assess feasibility. | The study revealed actionable technology solutions across machine tool work, high-place work, vehicle-related facilities, hydraulic machines, and miscellaneous tools, providing strategic guidance for enhancing workplace safety for business owners and safety managers. | Suh (2025) |
| Assess the ability LLM to support workplace management in the radiology healthcare sector | ChatGPT-3.5, ChatGPT-4.0, Gemini, and Gemini Advanced answered 31 workplace management questions; responses were scored for quality, clarity, and implementability. | ChatGPT-4.0 performed best across all metrics, followed by Gemini Advanced, showing that LLMs can aid workplace management in healthcare without specialized management training. | (Leutz-Schmidt et al., 2025) |
| Design a platform for training in construction safety. | The proposed system integrates a validated safety knowledge base, an LLM-driven scenario and feedback generator, game-based instructional elements, and a user interface. | The use of personalized and contextually realistic risk scenarios facilitated student decision-making, thereby enhancing the adoption of safe practices in workplace setting. | (Naderi & Shojaei, 2025) |
| Use Generative Pre-trained Transformer (GPT) models for the automated analysis of subway construction accident investigation reports, with the goal of improving the efficiency of accident identification and analysis |
Developed the AIR Agent, a GPT-based system with conversation, instruction, and knowledge modules, and validated it on 50 subway accident reports using ablation studies. | The AIR Agent achieved 80.32% accuracy in identifying accident types and extracting key details, demonstrating its capability to standardize, structure, and expedite accident investigation analysis. | (Zhang et al., 2025) |
| Examine the application of ML to construction accident report analysis, identifying methodological gaps and challenges in processing textual safety data. | A systematic literature review of ML-based studies was conducted, focusing on data preprocessing, algorithm selection, testing, and implementation. | Findings reveal underutilized unsupervised learning and NLP, inconsistent validation, and emphasize standardized pipelines, robust preprocessing, and LLM adoption to advance construction safety decision-making. | (Shayboun et al., 2025) |
Table 4.
Application of AI and NLP techniques to enhance safety management in the chemical industry.
Table 4.
Application of AI and NLP techniques to enhance safety management in the chemical industry.
| Objective | Methodology | Results | Reference |
|---|---|---|---|
| Analyse coal mine accident risks using LLMs and probabilistic modelling. | Use a large language model to extract risk factors from 700 coal mine accident investigation reports; apply Apriori association rule mining to derive strong association rules; build a 127-node Bayesian network and conduct sensitivity and critical path analyses. | Identify multiple layers of risk factors (direct, composite, specific) and seven primary drivers mainly related to on-site safety management, execution of operational procedures and safety supervision, providing a basis for data-driven early warning and policy design. | (Du & Chen, 2025) |
| Prioritise causes and types of mine accidents using a structured decision framework. | Apply the Analytic Hierarchy Process (AHP) to accident data (2011–2020) from the Indian mining industry, treating six accident types as alternatives and three criteria (human error, environmental factors, equipment faults); use expert-based pairwise comparisons implemented in R. | Show that transport machinery accidents have the highest priority, followed by ground movement and falls; human error emerges as the dominant causal factor across accident categories, guiding targeted prevention strategies in mines. | (Kar et al., 2024) |
| Integrate heterogeneous data sources for incident likelihood analysis in process industries. | Combine natural language processing-based feature extraction from CSB loss-of-containment narratives (2002–2021) via a co-occurrence network with operational parameters; perform scenario-based model verification and sensitivity analysis. | Develop a multi-source likelihood model that improves prediction of loss-of-containment events; reveal that inadequate written procedures and management/organisational failures have the highest sensitivity, supporting Safety 4.0 monitoring and control. | (Kamil et al., 2024) |
| Build a dynamic, data-driven coal mine environmental safety risk assessment system. | Construct an environmental safety indicator system and threshold rules; integrate expert judgments, sensor data and reported data; harmonise heterogeneous data via fuzzy linguistic transformation and range standardisation; fuse information using FAHP, CRITIC, grey clustering (GCL–RCV) and linear weighting models. | Achieve objective, real-time environmental risk assessment in coal mines; case studies demonstrate good accuracy and responsiveness, enabling identification and control of critical risks with strong industrial application potential. | (Lu et al., 2025) |
| Develop major process accident (MA) indicators supported by Industrial Internet data. | Use process safety management software linked to Industrial Internet infrastructures to define MA indicators; employ STAMP to map logical relationships between indicators and accidents; retrospectively analyse 212 accident reports with a large language model. | Produce SMART-compliant MA indicators empirically linked to accident patterns; show that the combination of STAMP and LLM-based analysis strengthens causal interpretation and practical usability of the indicator set. | (Ni et al., 2024) |
| Perform process risk assessment and fault diagnosis from safety reports using text mining. | Propose a hybrid framework that combines accident theory and prior hazard information with finite-state rule-based chunking of incident descriptions; apply an ensemble of unsupervised and semi-supervised models (clustering, logistic regression, association rules) to identify hazardous elements, chains of events and fault trees. | Identify 56 chains of events and 13 fault trees in Indian steel plant incident reports; achieve high agreement (~85%) with HSE expert assessments, demonstrating the effectiveness of chunking-based text mining for fault detection, diagnosis and accident modelling. | (Sahoo et al., 2024) |
| Objectively classify occurrence types in industrial accident cases to support prevention planning. | Develop and compare three AI models based on the KoBERT natural language processing architecture; implement a pipeline including sentence preprocessing, keyword replacement and morphological analysis tailored to Korean-language accident narratives. | Show that the best-performing model achieves 93.1% accuracy and allows up to three occurrence-type labels per case, reducing subjectivity and improving data quality for industrial accident prevention policies and strategies. | (Song et al., 2024) |
| Identify and analyse chemical safety risk factors from accident reports using modern AI. | Apply text mining and an improved LDA topic model to chemical safety accident cases to extract 33 main risk factors; use association rule mining and Bayesian network modelling to reveal correlations, causal relationships and critical accident development paths; perform sensitivity analysis of key nodes. | Demonstrate that the LDA–Bayesian network approach effectively extracts keywords, uncovers causal structures and critical paths in accident development, overcoming the subjectivity and limited scalability of traditional expert-based analyses. | (Zhou et al., 2025) |
| Predict adverse events by learning from experience in the chemical industry. | NLP combined with Interpretive Structural Model (ISM) in a probabilistic approach | Identify critical factors that contribute to fire and explosion incidents, mainly management issues and lack of procedures and training. | (Kamil et al., 2023) |
| Analyze and improve the understanding of flare system failures in the oil and gas industry. | Fault Tree Analysis (FTA) and Dynamic Bayesian Network (DBN) approaches | A comprehensive and accurate assessment of flare system reliability is provided. | (Kabir et al., 2023) |
| Predicting and preventing incidents in aboveground onshore oil and refined products pipeline | Artificial Neural Networks (ANNs) use models to predict root causes and sub-causes using 108 incidents relevant attributes. | 80-92% accuracy range in predicting incident causes and sub-causes for aboveground onshore oil and refined products pipelines. | (Kumari et al., 2022) |
| Reduce occupational risks associated with confined spaces work by automatically extracting and classifying contributory factors from accident reports. | BERT-BiLSTM-CRF and CNN models | Effective quantification and frequency estimation of the contributory factors contributing to risks associated with work in confined spaces | (Wang & Zhao, 2022) |
| Improve hot work accident prevention in the chemical industry through an automated system that can classify and predict the causes, overcoming the limitations of manual analysis of unstructured accident records. | AAI and LLM models, such as the Latent Dirichlet Allocation (LDA) model for topic extraction and Convolutional Neural Networks (CNN) for cause prediction | F1 score of 0.89 in predicting key causes of hot work accidents in the chemical industry | (Xu et al., 2022) |
| Extracting information from free text chemical accident reports to enhance the prevention of occupational risks. | NLP and AI techniques combine word embedding and bidirectional long-short-term memory (LSTM) models with attention mechanisms. | The classification of accident causes, including unsafe acts, behaviors, equipment, material conditions, and management strategies, with identification of common trends, characteristics, causes, and high-frequency types of chemical accidents, had an average precision (p) of 73.1% and recall (r) of 72.5%. | (Jing et al., 2022) |
| Accident prevention in the chemical industry, using NLP to construct a knowledge graph of chemical accidents. | The NLP model is named entity recognition (NER), and it uses SoftLexicon and BERT-Transformer-CRF to structure and store accident knowledge in a Neo4j graph database. | Automatic extraction and categorization of risk factors from 290 Chinese chemical accident reports, outperforming previous models. | (Luo et al., 2023) |
| Enhance the early stages of quantitative risk analysis (QRA) to prevent occupational risks associated with hazardous substances. | Text mining and fine-tuned trained bidirectional encoder representations from transformers (BERT) models. | Identified potential accident outcomes and ranked them by severity and probability, achieving mean accuracies of 97.42%, 86.44%, and 94.34%, respectively. User-friendly web-based app called HALO (hazard analysis based on language processing for oil refineries). | (Macêdo et al., 2022) |
| Detection of anomalous conditions in accidents by mining text information from accident report documents. | AI and NLP, with text mining-based Local Outlier Factor (LOF) algorithm | Four major types of anomaly accidents in chemical processes were identified, and risk keywords were extracted and compared to provide a comprehensive view of the anomalous conditions. | (Song & Suh, 2019) |
| NLP application for unsupervised anomaly detection and efficient evaluation of chemical accident risk factors. | A Variational Autoencoder (VAE) is used for unsupervised anomaly detection in industrial accident reports. Doc2Vec is utilized as the 'Vector Space Model'. | Quantitative risk factors are extracted from narrative-based accident reports using an outlier factor (OF) function. The six most anomalous accident reports were identified. |
(Rybak & Hassall, 2021) |
Table 5.
Enhancement of risk assessment and safety management in transport systems through AI and NLP applications.
Table 5.
Enhancement of risk assessment and safety management in transport systems through AI and NLP applications.
| Objective | Methodology | Results | Reference |
|---|---|---|---|
| Enhance occupational risk prevention in the transport system through the application of NLP and AI. | Text cleansing, tokenizing, tagging, and clustering, followed by analysis through NLP and a graph database to facilitate the querying of incident reports. | A true positive rate of 98.5% on a dataset of 5065 incident reports from the Swiss Federal Office of Transport, written in German, French, or Italian. | (Hughes et al., 2019) |
| Previous limitations in the expert interpretation of accident reports for road safety analysis have been overcome due to the voluminous nature of textual reports and the subjectivity of expert judgments. | NLP with textual report representations with Hierarchical Dirichlet Processes (HDPs) and Doc2vec, and ML-based classification by means of Artificial Neural Networks (ANNs), Decision Trees (DTs), and Random Forests (RFs), applied to a repository of road accident reports from the US National Highway Traffic Safety Administration | Accurate automatic extraction of the critical factors influencing road accident severity from accident reports. | (Valcamonico et al., 2022) |
| Development of a robust AI-based system capable of analyzing, categorizing, and extracting relevant information from unstructured maritime data sources, to assist in the prediction and prevention of maritime incidents. | DL and NLP are used to identify, classify and extract relevant maritime incident reports. NLP techniques include the bag-of-words approach, Named Entity Recognition (NER), and advanced word embeddings like Word2Vec, FastText, and BERT. ML models include convolutional neural networks (CNN), artificial neural networks (ANN), and long short-term memory (LSTM) networks optimized using Keras Tuner for hyperparameter tuning. | Accuracy up to 98.6% for binary incident classification. Incident date extraction achieved 61.8% accuracy | (Jidkov et al., 2020) |
| Assess and identify key risk factors in maritime accidents through text mining applied to accident reports. | Text mining and association rule mining using the FP-Growth algorithm | The main problems related to maritime accidents were unveiled, including overloading, poor navigational visibility, inadequate sailor competence, and insufficient government supervision of shipowners and shipping companies. Practical recommendations were made to government and regulatory bodies | (Wang & Yin, 2020) |
| Predict traffic accidents by learning from textual data describing event sequences. | Data labelling from the National Transportation Safety Board (NTSB) accident investigation reports and Long Short-term Memory (LSTM) neural networks to predict adverse events. |
Prototype query interface to predict and analyze traffic accidents from accident investigation reports. | (Zhang et al., 2021) |
| Automatic extraction of hazards, causes, and consequences from free-text occurrence reports to validate and refine safety measures for aircraft subsystems | NLP framework with rule-based phrase matching, combined with a spaCy Named Entity Recognition (NER) model. | Improved hazard identification system capable of reducing manual intervention to accurately determine causes, consequences, and hazards in HAZOP studies of aircraft transport systems. s. | (Ricketts et al., 2022) |
| Extraction of safety-related information from a large number of close call records in the GB railway industry, previously unfeasible for human analysis due to their sheer volume | NLP is applied to the analysis of free-text hazard reports and application to accident causation models, with categorization based on specific tokens. | Semi-automated technique for classifying close call reports in the GB railway industry. | (Hughes et al., 2018) |
| Extracting safety information from GB railways' Close Call System records, which accumulate over150,000 text-based archives that are unmanageable using traditional methods | Visual text analysis techniques to extract safety information from GB railways' Close Call System records. | The evaluation used 150 datasets covering incidents such as trespassing, slip/trip hazards, and level-crossing issues. It showed that the method worked well with small and controlled data groups of data but not with larger datasets from different groups of people describing things in many different ways. | (Figueres-Esteban et al., 2016) |
| Enhance the efficiency and accuracy decision making in metro accident response. | NLP techniques to automate the annotation of accident cases to facilitate information retrieval and Case-Based Reasoning (CBR) and Rule-Based Reasoning (RBR) to efficiently determine the most appropriate actions based on existing regulations and emergency plans | Average accuracy of 91%. | (Wu et al., 2020) |
| NLP application to the prevention of occupational risks avoiding railroad accidents in the United States. | NLP with advanced word embeddings like Word2Vec and GloVe. | Precise classification of accident causes from report narratives, with improved classification accuracy related to the increase in the number of reports analyzed. | (Heidarysafa et al., 2018) |
| Predicting the need for evacuation following railway incidents involving hazardous materials (hazmat) while simultaneously. | NLP and co-occurrence network analysis to scrutinize railway incident descriptions and supervised machine learning models, mainly Random Forest (RF), to evaluate the impact of different variables on evacuation prediction. | Elucidation of causal relationships through detailed network mapping of causes and contributing factors to emergencies in hazardous materials (hazmat) railway incidents. | (Ebrahimi et al., 2023) |
| Analyze Chinese railway accident reports to better prevent future accidents. | NLP and text mining techniques, specifically a multichannel convolutional neural network (M-CNN) and a conditional random field (CRF) model are used to extract critical accident risk factors from text data. | Efficient extraction and summarization of risk factors. | (Hua et al., 2019) |
| Improvement of occupational risk prevention in railway safety. | Hidden Markov model, conditional random field (CRF) algorithm, bidirectional long short-term memory (Bi-LSTM), and Bi-LSTM-CRF deep learning network for named entity recognition of the reports. Random forest (RF) algorithm to standardize entity classification. Knowledge graph (KG) for railway hazard identification and risk assessment with a visual representation of the relationships between hazards, incidents, and accidents in the railway system. | The visualization and quantification of potential risk factors is needed to provide more effective railway risk prevention measures for railways. | (Liu & Yang, 2022) |
| Identify the main issues related to deaths caused by overwork in Korea. | Use the Big Kinds database and model with the NetMiner 4 programme. It is used primarily in text network analysis. | Postal workers, civil servants and delivery drivers are at risk of dying from overwork. | (Kim, 2023) |
Table 6.
Applications of AI, LLM, and NLP in healthcare sector.
| Objective | Methodology | Results | Reference |
|---|---|---|---|
| Analyze complex narrative clinicians' reports to prevent medical errors and enhance patients' safety. | Convolutional and recurrent neural networks, coupled with an attention mechanism. NLP techniques to identify and categorize harm events in patient care narratives. | Improved medical error detection in large datasets, enhanced data analysis and root cause understanding, and better allocation of resources to address safety incidents have led to the prevention of patient’s harm. | (Cohan et al., 2017) |
| Explore potential applications of NLP methods in the analysis of critical incident reports in healthcare to enhance patient safety and quality of care. | Faceted search for intuitive report retrieval and text mining to uncover relationships between reported events. Mapping incident reports to the International Classification of Patient Safety (ICPS) to facilitate faceted searching and semantic annotation. | Requirements for automated processing include entity recognition, information categorization, event detection, and temporal analysis. | (Denecke, 2016) |
| Reduce musculoskeletal disorder (MSD) risks among home healthcare workers by leveraging a machine learning and large language model (LLM)-based AI system to predict long-term postures and deliver personalized ergonomic health recommendations | Developed ERG-AI, a sustainable machine IA pipeline that combines multi-sensor, uncertainty-aware posture prediction with LLM-driven natural language generation to communicate individualized ergonomic insights | Utilizing the DigitalWorker Goldicare dataset, ERG-AI demonstrated high predictive accuracy under uncertainty, low computational and environmental costs, and effective generation of clear, context-specific ergonomic guidance. | (Sen et al., 2024) |
| Improve anomaly detection in electronic health records (EHRs) to enhance patient safety and data reliability. | Developed EHR-BERT, a BERT-based framework using Sequential Masked Token Prediction to learn bidirectional clinical event sequences and identify anomalies. | Outperformed existing models on large multi-domain EHR datasets, reducing false positives, improving detection accuracy, and minimizing information loss. | (Niu et al., 2024) |
| Evaluate Swiss clinicians’ use, knowledge, and perceptions of large language models (LLMs) and identify factors associated with their adoption. |
An anonymous online survey was distributed through Swiss medical societies, assessing frequency of LLM use, with quantitative and qualitative analysis. | 32.8% reported frequent LLM use; younger, male, and research-active clinicians showed higher use and knowledge. Main benefits were administrative and analytical support, while key concerns involved ethics and output quality. | (Egli et al., 2025) |
Table 7.
Applications of AI, LLM, and NLP in enhancing safety across nuclear energy and mining sectors.
Table 7.
Applications of AI, LLM, and NLP in enhancing safety across nuclear energy and mining sectors.
| Objective | Methodology | Results | Reference |
|---|---|---|---|
| Enhance the safety and operation of nuclear power plants by automatically analyzing event reports, using NLP to efficiently extract and identify causal relationships. | The rule-based expert system, named Causal Relationship Identification (CaRI), has been augmented with a curated set of 11 keywords and 184 rules to identify causal relationships. | CaRI system successfully captures 86% of the causal relationships within the test data, surpassing inefficient manual procedures due to the immense volume and unstructured nature of these reports. | (Zhao et al., 2019) |
| Automated analysis of event reports from the nuclear power generation sector, specifically focusing on the US Nuclear Regulatory Commission Licensee Event Report database. | Manual keyword identification is followed using Stanford CoreNLP for automated analysis and the identification of causal relationships. | 85% success rate in identifying causal relationships. | (Zhao et al., 2018) |
| Automate the analysis of Mine Health and Safety Management Systems (HSMS) data. | NLP and ML methods, with 9 Random Forest (RF) models developed to classify narratives from the Mine Safety and Health Administration (MSHA) database into nine different accident types | Models dedicated to individual categories outperformed those designed for multiple categories. 96% Successful automated classification, as confirmed through manual evaluation. | (Ganguli et al., 2021) |
| Prevention of fatal and non-fatal injuries through the automated analysis of Directorate General Mines Safety (DGMS) fatality reports for non-coal mines in Indian. | Data Acquisition from annual reports, followed by TM and NLP applications with Python libraries (Pandas, NumPy, and Sci-Kit Learn) to format the data, followed by Regular expressions (RegEx) to detect patterns. Later, NLP techniques were applied, tokenization was used using the SpaCy library, and part-of-speech (POS) tagging was used using Python's NLTK library. Finally, Python's Matplotlib for data analysis, using Seaborn libraries, along with Tableau, for visualization. |
The most common accidents involve falling objects impacting workers aged between 28 and 32, specifically the 'mazdoor' (laborer) class. Most accidents occur between 10 AM and 2 PM. | (Shekhar & Agarwal, 2021) |
| Automatic identification and quantification of the contributing factors in coal mine accidents, overcoming the limitations of human analysis methods | Text mining, association rule extraction, and network theory. Text mining to extract key accident causes, reduce dimensionality, and classify factors within the risk model. A priori algorithm to identify associations between causes, revealing core causes and critical causal pathways. | Fifty-two root causes were identified and categorized. | (Qiu et al., 2021) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



