
Submitted:
07 November 2025
Posted:
20 November 2025
You are already at the latest version
Abstract
With the explosion of social networks, the amount of data produced by online users every day is huge. Sentiment Analysis (SA) serves as a powerful tool capable of extracting opinions and sentiments from textual data. SA tools analyze text to discern the author’s attitude towards a topic, providing insights into human emotions and opinions that guide decision-making across diverse domains. Developed by computer scientists, SA applications encompass product and marketing analysis, monitoring company strategies, financial forecasting, forecasting political movements, combating misinformation, health analysis, supporting education, and analyzing public opinions. Recent studies in SA focus on techniques or applied models. However, further research is needed to develop efficient and precise SA models customized for specific purposes. SA performance is influenced by data quality, feature selection, domain context, and the choice of classification algorithm. We employ the PRISMA methodology to narrow our search scope, focusing on 4,709 papers published by reputable sources such as Springer, Elsevier, IEEE, ACM, and others from 2020 to present. Through iterative review of titles, abstracts, and full texts, we selected 65 papers relevant to our topic, including 59 research papers and 6 survey papers, for in-depth analysis. Our survey provides a systematic, indepth understanding of advancements across domains, applications, datasets, techniques, and future development. It is a valuable resource for identifying knowledge gaps and suggesting potential domains of multidisciplinary application based on data content. Additionally, it offers insights into future research directions.
Keywords:
sentiment analysis
; machine learning
; applications
; datasets
; algorithms
1. Introduction
1.1. Background and Motivation
The explosion of data generated by users online is a result of the advancement of internet technology and the growth of social media [1]. This data, which includes text, images, sounds, videos, and more, is large, diverse, and comes from a variety of sources. Analyzing this structured and unstructured data has a significant impact on big data applications [2]. Machine learning, Deep Learning, Opinions mining, and Text mining techniques can be used to analyze this data for decision-making purposes. However, the sheer volume of data and the difficulty in extracting patterns make this a challenging task. Additionally, social platform services like Twitter, YouTube, Facebook, and blogs support various data formats, including those with and without proper grammar and short texts written without regard for grammatical rules. The vast amount of information (opinions) shared by users on these platforms can be used for a variety of purposes and SA has become an active research area according to an increasing number of published papers [1,3].
Today, companies handle large volumes of text data, including emails, customer support chat transcripts, social media comments, and reviews. SA tools can scan this text to automatically determine the author’s attitude towards a particular topic. The SA tools analyze digital text to classify the emotional tone of the message as positive, negative, or neutral, providing valuable insights into human emotions and opinions. This capability is instrumental in guiding decision-making processes, enhancing outcomes, and promoting better understanding and engagement across diverse domains. For instance, in product and marketing analysis, SA helps companies gauge consumer sentiment and tailor their strategies accordingly, leading to more effective campaigns and improved customer satisfaction. Similarly, in political movement and forecasting, SA enables policymakers to assess public sentiment, anticipate trends, and make informed decisions to better serve their constituents.
In the realm of financial forecasting, SA aids investors and analysts in understanding market sentiment, identifying potential risks, and making sound investment decisions. Moreover, SA plays a pivotal role in monitoring company strategies by analyzing customer feedback, social media sentiment, and market trends, empowering businesses to adapt and thrive in dynamic environments. Additionally, SA serves as a vital tool in combating misinformation by detecting fake news and hate speech, thereby safeguarding the integrity of online discourse and promoting responsible information dissemination.
Furthermore, SA contributes to health analysis by analyzing patient feedback, social media discussions, and medical literature to identify trends, assess public health concerns, and inform healthcare policies and interventions. In the education sector, SA can be utilized to analyze student feedback, sentiment in online learning environments, and educational content to enhance teaching methods, improve student engagement, and personalize learning experiences. Lastly, SA facilitates public opinions analysis by monitoring social media discussions, news articles, and public forums, enabling policymakers, researchers, and organizations to gain insights into public sentiment, concerns, and preferences, and make data-driven decisions that align with societal needs and interests. Overall, the ability of SA to analyze digital text and classify emotional tone has far-reaching implications across various fields, driving innovation, informing decision-making, and fostering positive societal impact
As mentioned earlier, there is a growing need for further research to explore methods for developing efficient and precise SA models tailored to specific purposes. Hence, a comprehensive survey will aim to identify and highlight research gaps in SA, particularly in cases of highly specific application needs. It also provides detailed insights into crucial factors, such as data quality, feature selection, domain context, and the choice of classification algorithm. These factors significantly impact the development of SA models for real-world applications.
1.2. Related Work
In a survey paper published in 2012 [4], the authors studied several papers and proposed that traditional rule-based approaches to SA often struggle to handle the vast and ever-growing volume of user-generated content on social media platforms. SA is commonly conducted at one of three levels: the document level, sentence level, or aspect level.
Recent survey papers [1,3,5,6,7] have highlighted that machine learning, deep learning, and hybrid techniques show promising results in automating the process of analyzing sentiments expressed in text data. Moreover, in some cases, supervised machine learning techniques are frequently the most widely used because of their ease of use and high accuracy. Rodrıguez-Ibanez et al. [1] conducted a review on the analysis of sentiment in social networks, highlighting marketing as the most scrutinized field, followed by politics, economics, and health. Furthermore, marketing and politics are identified as the most researched areas, primarily due to the convenience of accessing data through methods such as data extraction from Twitter or commercial websites.
Ezhilarasan et al. [6] conducted a survey on the Deep Learning approaches used in SA for product reviews. Similarly, Zhang et al. [7] also conducted a survey on Deep Learning approaches in SA. Bordoloi et al. [5], where the authors emphasized the significance of the keyword extraction algorithm in the success of a SA model. They highlighted that the use of generalized dictionaries may lead to inaccurate findings as they are not relevant to a specific domain. In [3], the Naive Bayes and Support Vector Machine functions are commonly used as benchmarks against which newly proposed approaches or models can be compared.
From recent surveys, there is no relevant comprehensive overview of SA datasets, models, techniques in each domains, the authors focused on either techniques or applied models. In [4], the authors only mentioned product review, and traditional rule-based approaches. Similarity, in [6], the authors chose a specific domain such as product review to make a survey. In [1,3], the authors did not discussed properties of dataset in each domains had an effect on accuracy of models. In [6], the authors discussed techniques, especially Deep Learning in SA, but not mention domains or datasets in SA. Although in [5], the authors discussed both domains and techniques in SA, but not mention detailed in applied models, future development of each domains. In contrast to existing survey papers, our survey aims to provide a comprehensive overview of SA domains, datasets, and techniques, with a specific emphasis on the application of machine learning, deep learning, and hybrid models. Notably, previous reviews have predominantly focused on papers published before 2020, while our review encompasses 59 papers, the majority of which were published between 2021 and 2024, offering a scoping review of the current SA literature.
1.3. Contribution
By exploring a diverse array of domains, tasks, methodologies, datasets, and the challenges encountered in current research papers, this paper aims to offer insights into the evolving landscape of Sentiment Analysis (SA). The contributions are outlined as follows:
- We offer a thorough examination of domains, datasets, and tasks specifically within the field of Sentiment Analysis (SA). Additionally, we provide insightful analyses derived from the compiled information.
- Our exploration both machine learning and deep learning algorithms, including Support Vector Machines (SVM), Naive Bayes (NB), Convolutional Neural Networks (CNNs), and Recurrent Neural Networks (RNNs), played crucial roles. Subsequently, we present a comprehensive analysis of the advantages and disadvantages associated with these approaches in the context of SA.
- We delve into the challenges confronting Sentiment Analysis (SA) models, addressing issues such as the dynamic nature of language, context-dependent interpretations, and the prospect of constructing a knowledge graph representation for semantic analytics or establishing sentiment scores for each entity.
- We draw from the findings in the SA research publication, we present and succinctly outline the essential steps involved in constructing a SA system.
1.4. Paper Structure
The remainder of this paper is organized as follows: in Section 2, we detail the methodology employed in selecting the papers from the literature. In Section 3, the current research in SA is presented and analysed under the following headings: SA application domains, datasets used, tasks addressed and analysis/modelling techniques applied. Section 4 contains a presentation and discussion of the main findings from the survey. Finally, Section 5 presents conclusions and discusses further research in this area.
2. Review Methodology
We focus on reviewing papers employing machine learning or deep learning models for sentiment analysis systems. Our overall methodology which is used to identify the relevant papers is based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA)1 [8]. The following criteria for research paper selection were used:
- Published from 01/01/2020 to 30/11/2024.
- Written in English, not discriminating by geographical area and dataset language.
- Title or keywords or abstract of each paper has keywords: ("Sentiment Analysis" OR "Opinion Mining") AND ("Machine Learning" OR "Deep Learning" OR Classification) AND (Datasets OR Applications). The keywords are used in the Boolean search query based on the form requirements of each library.
Ethical considerations together with relevance to the research topics, are crucial. These include ethical standards in research conduct, participant consent, data handling, and other pertinent ethical considerations. However, it’s important to clarify that the ethical assessment of the literature review falls outside the scope of our paper. As shown in Table 1, with search criteria in above, there are 4,709 downloaded papers through the advanced search functions of the publisher libraries. After reviewing the title and abstract of the papers, we identified 206 relevant papers. The precise count of papers for each publisher and year after the "downloading" and "reviewing title and abstract" phases is depicted in in Figure 1. We observed a year on year increase in the number of papers.
For each of these 206 papers, we continued to review the full text carefully, and selected 57 papers which are most relevant to the purpose of our paper. To avoid missing other relevant papers, we searched on Google Scholar and did not limit publisher or publication year of papers. This search led us to find an extra 8 relevant papers, resulting in a total of 65 relevant papers. This final set contained 59 research papers and 6 review papers in SA applications and methods. We presented and compared the 6 review papers [1,3,4,5,6,7], in Section 1. The subsequent sections will involve a detailed analysis, classification, and discussion of the 59 research papers.
3. Classification and Analysis
3.1. Overview
The 59 current research papers are classified and analysed in Table 2 and Table 3. In Table 2, these papers are presented in an order organised by publishers and categorized based on the domains of sentiment analysis (SA), the datasets used, the addressed SA tasks, and the applied models. Each paper is categorized under the respective publisher’s name, and the year of publication is specified. The domain and task of each research paper are also outlined. Lastly, the proposed models and their corresponding accuracies are provided.
3.2. Domains
Derived from an extensive dataset, the information shared by users offers significant potential for analyzing opinions across diverse domains, including financial predictions, product and marketing analysis, and health analysis, as presented in Table 2 and Table 3.
In recent years, text sentiment analysis and opinions mining have gained popularity in the finance [12,13,14,15,16,28,39,47,48,49,53,58] due to their ability to convey the thoughts and feelings of corporate stakeholders such as managers and investors including textual emotion in the forecasting of firm financial performance resulted in a significant improvement in performance. In [28], the authors suggested a new method build the relationship in financial texts to improve model accuracy. Elsewhere, in [58], the authors also suggested building a transformer learning in financial to improve effectiveness. Furthermore, in product and marketing analysis using social platforms, consumers can share their opinions and experiences. These platforms provide for product-related comments, which is a useful tool for any decision-making process. [23,24,34,35,36,37,42,43,54,55,56,57,59,63,64,65,66]. In addition, cross domains the authors mentioned in [63] by expanding experiments in another domains to learn more features which in current model proved dependency domain context. In field of health, research involves examining public opinions in order to provide in making decision with a better understanding of how the public views the disease [18,20,29,30,31,32,40,50,51,52,61].
Alternatively, users of online social media platforms use them for communication, sharing of life events, and expressing opinions about news and trending topics. Sometimes, interaction with online social network leads to out of control in arguments such as hate speech and abusive replies and here, SA applications focus on detecting fake news and the hate speech in the public forums [9,10,26,44,62,67]. In the education sector, topics such as services analysis [11,27,45,46,60] is common, it is significant in reputation management and educational marketing, similarly, it is also very important in monitoring the company strategies [18]. In political movements and political forecasting [21,33,41], on-line news portals are crucial to the information society, with discussion regarding technology of SA are presented in [19,22,38].

Table 3.
Domains, Datasets, Algorithms and Future Developments
| Study | Datasets | Algorithms | Future Developments | |
|---|---|---|---|---|
| Source | Name/Feature | |||
| Domain: Finance (12 papers) | ||||
| Nti et al. [12] | Self+NO | Ghana Stock ExchangeTwitter | IKN-ConvLSTM(acc: 0.9831) | Data argumentation techniques, autoencoders to enhance. |
| Colasanto, F et al. [13] | 3rd+O | Financial Time | FinBert, Monte Carlo method | N/A |
| Windsor et al. [14] | Self+NO | Twitter and Sina Weibo | MF-LSTM(R2: 0.9848) | Fusion strategies, modal structures, modality selections, etc. |
| Hajek et al. [15] | Self+NO | EarningsCast database | LSTM, feature: Emotion + FinBert(acc: 0.954) | N/A |
| Kaplan et al. [16] | Self+O | Dow Jones Newswires, Reuters, Bloomberg, Platts.Investing.com | CrudeBERT(acc: 0.98) | Trained on the full article content, extending economic models: inflation and interest rates. |
| Chen et al. [28] | 3rd+Self+O | Wind Financial TerminalPeople’s Daily, Xinhua News Agency, Global Times, Sina Finance, Tencent Finance, Autohome | SEN-LSTM(R2: 0.63) | Use of Knowledge Graph in building the relationships in financial texts, and improve forecasting effects. |
| Meera et al. [39] | Self+NO | financial news headlines | Word2Vec-TFIDF + SVM(acc: 0.82) | hybrid feature extraction techniques with deep learning and ensemble models. |
| Mishev et al. [47] | 3rd+O | LexisNexis databaseSemEval-2017 task | BART-Large(acc: 0.947) | Extend to Health, Legal, Business. |
| Ochilbek Rakhmanov [48] | Self+NO | Global PortalTwitter | DL-GuesS (price predict + sentiment analysis) | N/A |
| Ganglong et al. [53] | Self+NO | financial text | FinBERT + BiGRU + attention mechanism(acc: 0.95) | real-time retraining and error analysis. |
| Mishev et al. [49] | Self+NO | dataset pre-trained (328,326 tweets about crypto currencies and 140,000 tweets on the currency, stock and gold markets)dataset for sentiment (16452: 10631 from stock markets, 4821 headline about financial, 1000 crypto) | Keras Embeddings + LSTMKeras Embeddings + RNN(acc: 0.84) | N/A |
| Du et al. [58] | 3rd+O | SemEval 2017 Task 5FiQA Task 1 | RoBERTa + XLNet(R2: 0.71) | a new technique for knowledge embeddings, and the effectiveness of different transformer architecture. |
| Domain: Product (17 papers) | ||||
| Iddrisu et al. [23] | 3rd+O | Twitter, Kaggle | TF-IDF + optimized SVM(acc: 0.99) | N/A |
| Patel et al. [24] | 3rd+O | Airline reviews gathered from Kaggle | BERT(acc: 0.83) | BERT variants and many more can be used for future development. |
| Ahmed et al. [34] | 3rd+O | SemEval (6055 reviews Laptop, Restaurants)Product Review (1208 reviews on amazon)MAMS (Food and services) | Embedded CNN + BiLSTM(Acc: 0.83, F1: 0.81) | improve the accuracy |
| Ye et al. [35] | 3rd+O | Official website of Douban Books (reviews of 28 Douban education books and 8050 reviews) | LDA BERT | N/A |
| Atandoh et al. [36] | 3rd+O | IMDB, Amazon reviews | B-MLCNN(acc: 0.95) | Identify the explicit polarity based on the contextual position of the text. |
| Gunawan et al. [37] | Self+NO | TripAdvisor | SVM(acc: 0.79) | N/A |
| Source | Name/Feature | |||
| Domain: Finance (12 papers) | ||||
| Greeshma et al. [42] | 3rd+O | IMDb | BiGRU + GloVe + attention(acc: 0.98) | Addressing data biases. |
| Khushboo et al. [43] | 3rd+O | women’s clothing e-commerce reviews (23,486 rows and 10 feature variables) | DistilBERT (Acc: 0.96 for SC and 0.91 for PR) | spam detection, fraud detection, disease detection. |
| Kumar et al. [54] | Self+NO | amazon.com | DPTN + GSK (Acc: 0.95) | integrating self-attention representations. |
| Maroof et al. [55] | Self+NO | mobile app reviews | SVM, DL (Acc: 0.91, 0.92) | N/A. |
| Sherin et al. [56] | 3rd + O | Sentiment 140 dataset, T4SA dataset and Airline Twitter datasets | EAQ-FEE-enBi-LSTM-GRU (Acc: 0.95) | LLaMA’s capabilities in handling large-scale NLP tasks. |
| Rahman et al. [57] | Self + NO | Customer Surveys; Online Reviews; Chatbox Messages | BERT (Acc: 0.95) | N/A. |
| Perti et al. [59] | Self+NO | Twitter (14 Jan 2022 to 27 Dec 2022) of Mobile Phones, Laptops, and Electronic Devices | 4-Conv-NN-features+SVM(acc: 0.845) | Would be experimenting with BERT-based embeddings. |
| Gamal et al. [63] | 3rd+O | 4 datasets: IMDB, Cornell movies, Amazon and Twitter | NB, SGD, SVM, PA, ME, AdaBoost, MNB, BNB, RR and LR with two FE algorithms (n-gram and TF–IDF). Acc: 0.87-0.99 | making an experiemnt the detection of sarcasm and applying sentiment analysis to more domains and cross-domains. |
| Palak Baid et al. [64] | Self+NO | IMDB | NB, RF, K-NN (Acc: 0.81, 0.78, 0.55) | N/A |
| Ali et al. [65] | Self+NO | IMDB | MLP, CNN, LSTM, CNN-LSTM (Acc: 0.86, 0.87, 0.86, 0.89) | N/A |
| Nguyen et al. [66] | Self+NO | thegioididong.comvatgia.comtinhte.vn | Ontology | N/A |
| Domain: Health (11 papers) | ||||
| Bansal and Kumar [17] | Self+NO | Web scrapping 500 hospitals | Semantic method | N/A |
| Areeba and Elio [20] | 3rd+O | 10,000 tweets on COVID-19 vaccines from Kaggle | CT-BERT enhanced with convolutional layers (Acc: 0.875) | Integration with Diverse Data Sources, Real-Time Analysis, Enhanced Models |
| Colon-Ruiz et al. [29] | 3rd+O | Drugs.com | BERT embeddings + LSTM(F1: 0.947) | Explore new techniques in order to reduce the dependence on annotated corpora and the use of semantic features in order to improve the fine-tuning of these approaches. |
| Basiri et al. [30] | 3rd+OSelf+NO | Sentiment140 dataset for training8 datasets from 8 countries to classify (2020-01-24 to 2020-04-21) | Base learner (CNN, BiGRU, fastText, NBSVM, DistilBERT) + meta learner (XGBoost method)Acc: 0.858 | focusing on the opinions published by special communities or target societies to find its impact on the public sentiment and mood. |
| Meena et al. [31] | 3rd+O | Monkeypox Tweets (61379) | CNN-LSTM(acc: 0.94) | exlpore the more robust techniques. |
| Suhartono et al. [32] | 3rd+O | Drugs.com | GloVe + BERT (acc: 0.8487) | N/A |
| Valarmathi et al. [40] | 3rd+O | Kaggle: covid-19-tweets45 | NeatText, TextBlob API, LSTM (Acc: 0.96) | N/A |
| Han et al. [50] | 3rd+Self+NO | SentiDrugs | PM-DBiGRU(acc: 0.78) | Explore a more effective model of aspect-level sentiment classifcation in the medical background. |
| Source | Name/Feature | |||
| Domain: Health (11 papers) | ||||
| Sweidan et al. [51] | Self+NO | AskaPatient, WebMD, DrugBank, Twitter, n2c2 2018, TAC 2017 | Ontology-XLNet + BiLSTM(acc: 0.98) | explore multilingual models, and would be investigating the semi-automated methods for building ontology in the context of sentiment analysis |
| Bengesi et al. [52] | Self+O | Twitter(self-build 500,000 tweets, 103 languages with keyword #monkey pox) | TextBlob annotation, Lemmatization, CountVectorizer, and SVM(acc: 0.93) | Word embeddings (example: doc2Vec) and text labeling (example: Azure Machine Learning) to improve the model’s performance Deep Learning and transformer algorithms. |
| Muhammad et al. [61] | Self+NO | Drugs.com | Bi-GRU + Capsule + Text-Inception + K-Max (Acc: 0.99) | N/A |
| Domain: Detection (7 papers) | ||||
| Chakravarthi et al. [9] | Self+NO | YouTube | T5-Sentence + CNN(F1: 0.75) | A larger dataset with further fine-grained classification and content analysis. |
| Balshetwar et al. [10] | 3rd+O | ISOT, LIAR | TF-IDF + Naïve Bayes, passive-aggressive and Deep Neural Network(Acc: 0.98) | Test on other datasets. |
| Rosenberg et al. [25] | Self+O | Tweets using keywords | BERT(acc: 0.69) | N/A |
| Spinde et al. [26] | Self+O | adfontesmedia.comTwitter | fine-tuning XLNet(Acc: 0.95) | expand the dataset and analysis, including with additional concepts related to media bias. |
| Fazil et al. [44] | 3rd+O | 3 Twitter datasets DS-1 (80000 tweets: abusive, hateful, spam, normal) DS-2 (24802 tweets: offensive, or neither) DS-3 (20148 tweets: hateful, offensive, normal, or undecided) | Multi-Channel CNN-BiLSTM DS-1 (acc: 0.93)DS-2 (acc: 0.92, BERT acc: 0.94)DS-3 (acc: 0.86) | Proposed model over multilingual text, transformer-based language models. |
| Vadivu et al. [62] | 3rd+O | India twitter data; fakenews Net | fICS-DBN-DGCO (Acc: 0.89) | N/A |
| Hoang et al. [67] | 3rd+Self+O | amazon.comebay.com | knowledge-based Ontology(Acc: 0.90) | N/A |
| Domain: Education (5 papers) | ||||
| Dake et al. [11] | Self+NO | University of Education, Winneba, Ghana | SVM (acc: 0.63) | N/A |
| Rakhmanov [27] | Self+NO | University of Nigeria(52,571 comments) | TF-IDF+RF (acc: 0.968) TF-IDF+ANN (acc: 0.96) | bigrams or trigrams can be also tested. |
| Zhai et al. [45] | Self+NO3rd+O | Education and Restaurant | Multi-AFM(acc: 0.946) | develop transformer-based models and use multi-class sentiment analysis. |
| Rajagukguk et al. [46] | Self+NO | Students’ feedback | BiLSTM (Acc: 0.9275) | N/A |
| Dang et al. [60] | Self+NO | USAL-UTH (10,000 Vietnamese customer comments)UIT-VSFC (16,000 Vietnamese students’ feedback) | CNN, LSTM, and SVM(acc: 0.93) | combine with pre-trained language models, leveraging transfer learning and domain adaptation. |
| Domain: Technology (3 papers) | ||||
| Yan et al. [19] | 3rd+O | Lap2014 Rest2014, 2015, 2016 | AccuracyDE-CNN: 0.8489, O2-Bert: 0.8463 O2-Bert: 0.892, 0.8316, 0.8688 | Large Language Model and prompt engineering into TBSA tasks. |
| Muhamet et al. [22] | Self+NO | Collected 17.5 million tweets spanning 10 years (2012–2021) | BiLSTM with FastText (F1: 0.71) | Explore unsupervised and weakly supervised learning techniques. |
| Source | Name/Feature | |||
| Domain: Technology (3 papers) | ||||
| Vasanth et al. [38] | Self+NO | IMDB, Youtube | Bert | use clustering approaches to construct clusters in order to have a better idea |
| Domain: Politics (3 paper) | ||||
| Bola et al. [21] | Self+O | Dataset of 2,000 Canadian maritime court | CNN + LSTM (Acc: 0.925) | Extend the model to other domains of law.Integrate pre-trained word embeddings. |
| Baraniaka et al. [33] | Self+NO | 136.379 articles in English | BERT (Acc: 0.51) | Extending the size of the dataset. |
| Kevin et al. [41] | 3rd+O | SVM (Acc: 0.72)DeBERTa (Acc: 0.71) | N/A | |
| Domain: Management (1 paper) | ||||
| Capuano et al. [18] | Self+NO3rd+O | Analist Group Public datasets | HAN (Acc: 0.8) | integrated into a comprehensive CRM (customer relationship management). |
3.3. Tasks
Table 2 presents the four kinds of tasks: new model, comparison, improvement, experiment. For example, some new models are proposed in each domain such as Finance: IKN-ConvLSTM [12], MF-LSTM [14], LSTM feature: Emotion + FinBert [15], CrudeBERT [16], DL-GuesS [48], RoBERTa + XLNet [58]; Product: LDA BERT [35], B-MLCNN [36]. In [12], Nti et al. proposed a new framework called IKN-ConvLSTM, the model is built based on a hybrid approach, it is a combination of CNN and LSTM to predict stock price movements. This CNN model extracted sixty-two (62) features with an accuracy of 88.75%.
In [14], the data are input into a new MF-LSTM model (new model), where the abstract features obtained from the previous layer are fused by a common representation layer, and two parallel LSTM modules in the first layer learn from each modality of information. In experiments in [47], Mishev et al showed that the NLP transformers had superior performances compared to other evaluated approaches, the results can be applied in finance. In [49], Yekrangi et al developed optimized embeddings for improvement (impr), producing the best results across all models, the LSTM with the fine-tuned embedding layer added as the first layer is the best model. Consequently, the combination of fine-tuned embedding and LSTM performed better than any other model in the study with an accuracy of 83.9%. In [24], the authors ran a comparison (comp) of the performance of ML approaches and the BERT framework to perform sentiment analysis on the airline review dataset is done. The results demonstrate that BERT performs better than models like LSTM, Roberta, and Electra.
3.4. Models
Figure 2 provides a detailed overview of algorithms and the number of prior research papers within the applied model categories, including corpus-based/NLP, machine learning (ML)/deep learning (DL), and hybrid approaches. Combining with information about models and algorithms in Table 2 and Table 3, we will analyse the model categories and their respective algorithms below.
3.4.1. Corpus-Based/NLP
The corpus-based/NLP approach leverages syntactic patterns or co-occurring patterns in extensive corpora to expand the initial seed list of opinion terms. These methods demonstrate a notable accuracy in generating opinion words, as reported by studies such as [17]. Specifically, the ratio of positive to negative synonyms linked to an unknown word can determine its polarity, utilizing various semantic relationships provided by resources like WordNet.
In addition, researchers, as evidenced in [66,67], employ an ontological approach to compute entity scores. Subsequently, they conduct experiments to classify opinions or identify opinion spam based on these entity scores. This nuanced approach reflects the evolving strategies within the corpus-based/NLP methodology for sentiment analysis.
3.4.2. Machine Learning
Support Vector Machines (SVM), classified as a discriminative model, is often regarded as the optimal method for text classification. It operates as a statistical classification method. In a comparative study presented in [11], four models—Naive Bayes (NB), SVM, J48DT, and RF—were evaluated for the qualitative assessment of students’ responses. SVM emerged as the most effective model among the compared approaches. This methodology was also employed in [37] to analyze the emotions expressed in restaurant reviews.
Naive Bayes (NB), characterized by its simplicity and effectiveness, is a widely used algorithm for document classification. The fundamental concept involves estimating the probabilities of categories given a test document by leveraging the joint probabilities of words and categories. In a study by [64], various algorithms, including Naive Bayes, Random Forest, and k-Nearest Neighbour, were implemented. The Naive Bayes classifier yielded the most favorable results, showcasing its efficacy in the task at hand.
3.4.3. Deep Learning
Convolutional Neural Networks (CNNs) are powerful deep learning architectures widely applied in various computer vision tasks, such as image classification and object detection. Recently, CNNs have also been adapted for natural language processing (NLP) tasks, including sentiment analysis and hate speech detection. In these applications, textual data is treated as a one-dimensional sequence, and 1D convolutional layers are employed to extract localized features and patterns. By applying filters over the text sequences, the convolutional layer captures significant local dependencies and structural information. In [19], the author introduced a novel model and compared it with the standard CNN approach. The findings indicated that DE-CNN outperformed O2-BERT in terms of accuracy on the Lap2014 dataset.
A Recurrent Neural Network (RNN) is a type of artificial neural network used to analyze time series or sequential data. RNNs have the ability to retain the states or details of prior inputs for use in creating new outputs. For tasks like sentiment analysis, where precise prediction depends on the context and word order in a text, RNNs work well. An RNN type called Long Short-Term Memory (LSTM) deals with the vanishing gradient issue, which improves the network’s ability to detect long-range dependencies in sequential input. Similar to conventional RNNs, LSTMs can be used for sentiment analysis, but it has the advantage of reading lengthier texts and maintaining context over longer sequences. LSTM is able to comprehend the context and sentiment conveyed in a sentence by efficiently capturing the sequential connections between words. Word by word, the input text is processed by the LSTM, which records contextual information and word dependencies by updating its hidden state at each time step, and used in field of Finance [14,28], Education [46], Health [50]. Moreover, extra methods such as attention processes are integrated to improve the performance of LSTM and using hybrid model.
Transformer-based models have significantly changed in the field of NLP [19]. As these models can manage long-range relationships and analyze text in parallel, they have become the leading approach for many NLP tasks. They are better than conventional RNNs and CNNs in efficiency and scalability due to their parallel processing. Transformer-based models’ attention mechanism, which enables the model to concentrate on pertinent passages of the input text while producing predictions, is the fundamental idea behind them. Through the use of this attention mechanism, the model is able to take into account the contextual linkages that exist between each word and every other word in the sentence, so capturing a wealth of contextual information. Transformer-based models have shown promise in a variety of NLP tasks, such as a Robustly Optimized BERT Pre-training Approach (RoBERTa), Generative Pre-trained Transformer (GPT), and Bidirectional Encoder Representations from Transformers (BERT). These tasks include machine translation, question answering, named entity recognition, sentiment analysis, and other activities. These models can perform exceptionally better even with limited training data because they are usually pre-trained on large text corpora and then fine-tuned for certain downstream applications. Transformer models are very effective because of contextual awareness, bidirectional context, transfer learning, pre-training on big corpora, and the attention mechanism. These techniques make transformer models more effective for sentiment analysis tasks in field of Finance [13,16,47,58], Product [24,35], Detection [25], Technonology [38], Politics [33].
3.4.4. Hybrid Models
In addition to the models discussed above, hybrid models have also shown promise in the area of sentiment analysis. In work by Chakravarthi et. al. [9], the CNN was integrated with T5-Sentence to combine their strengths for speech detection tasks. Meena et. al. [31] proposed a CNN-LSTM framework for detecting sentiment polarities on monkey pox tweets. As a result, combinations allow the models to run better in capturing both local patterns and long-range dependencies in long textual opinions. Table 2 illustrates that the hybrid approach is categorized into two types: corpus + ML/DL and FE (ML/DL) + ML/DL under the column "Models".
In the combination of corpus-based and machine learning/deep learning approach, the output from the corpus-based component was used in the machine learning/deep learning component as training data to train the sentiment classifiers using ML/DL approach. Similar to the corpus + ML/DL approach, the feature extraction (FE) (ML/DL) + ML/DL approach has a difference from the first phase, where the ML/DL step is used as the feature extractor to generate input data for the subsequent layers of the ML/DL models. Then, the testing data (unlabeled data) was used to evaluate the performance of the sentiment classifiers.
The results of the hybrid approach suggest that combining a corpus-based or FE (ML/DL) approach with an ML/DL approach is more effective than an alternative approach.
3.4.5. Metrics of Sentiment Analysis
One of the key steps in constructing an effective model is the classification of sentiments as either positive or negative, followed by performance evaluation. In binary classification tasks, model performance is commonly assessed using a confusion matrix that includes four components: True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN).
Among various evaluation metrics, accuracy is the most widely used to assess the overall performance of a model. As illustrated in Equation 1, accuracy quantifies the ratio of correctly predicted instances (e.g., documents, sentences, or words) to the total number of instances analyzed by the sentiment analysis system.
In addition to accuracy, metrics such as precision and recall are commonly utilized in text classification tasks [5]. Precision, or positive predictive value, refers to the proportion of correctly predicted positive instances, while negative predictive value indicates the proportion of correctly identified negative instances. Recall (also known as sensitivity) measures the ratio of actual positives correctly predicted, whereas specificity—or negative recall—captures the proportion of actual negatives that the model classifies correctly. Equations 2 and 3 demonstrate the formulas for calculating these metrics.
Precision and recall are better indicators of the current system’s success than accuracy for an imbalanced binary classifier. Yet, in certain situations, a system may have high precision but poor recall, or vice versa. In this case, the f-measure allows you to articulate all issues with a single number. Once the precision and recall for a binary or multi-class classification task have been calculated, the two scores together form the f-measure in Equation 4.
The value, also known as the Coefficient of Determination or Goodness of Fit, is a context-independent metric employed in regression analysis. It serves as a relative indicator of the model’s ability to explain the variance in the dependent variable, essentially representing how closely the observed data align with the predicted regression line. As defined in Equation 5, is computed using the squared sum of residuals (SSR) and the squared sum around the mean (SSM).
3.5. Datasets
Table 3 serves as a comprehensive overview of two distinct types of data sources: Self (self-built by authors) and 3rd (third-party supplies). Beyond merely identifying the source, the table offers valuable insights into two critical properties of these data sources, namely NO (no Open for access) and O (Open for access). This classification provides an important context for understanding the availability and accessibility of the datasets used in the discussed sentiment analysis studies.
For a more detailed illustration, consider the case of [18], located at the bottom of Table 3, where Capuano et al. extensively discussed the dataset employed for training and testing their model. This dataset, comprising over 30,000 items, was constructed with approximately 40% sourced from the customer service of Analist Group4, showcasing the active involvement of the authors in creating a significant part of the dataset (Self). However, it’s noteworthy that access to this portion of the dataset is restricted, requiring authorization due to its confidential nature (NO).
Conversely, the remaining 60% of the dataset was obtained from third-party public sources (3rd), indicating external contributions. This portion of the dataset is accessible to the public (O), highlighting a more open and transparent approach to data sourcing. This nuanced exploration of data source types and access properties enhances our understanding of the sentiment analysis models discussed, underscoring the significance of transparency and accessibility in the realm of data-driven research.
From Table 3, one can see where authors built self datasets that were not made publicly available. These models generally exhibit low accuracy due to context of domains where experiments were carried out.
3.6. Future Developments
Potential developments of SA are presented in Table 3. In the financial sector, the researchers in [12] spent much time in integrating the six data sources as a single data, because they were of different formats and not in the same sequence. Therefore, developments could automate this process and introduce data argumentation techniques such as Generative Adversarial Networks (GANs), autoencoders to enhance the current framework. In [14], future studies can be conducted on various fusion strategies, optimization techniques, modal structures, modality selections. In [16], the authors mentioned a future model would be trained on the full article content, and extending economic models: inflation and interest rates. In [28], the authors suggested that using Knowledge Graph to capture the structured relationships in financial texts, make more effective use of text information, and improve forecasting effects. In [58], the authors mentioned alternative methods for knowledge embeddings, and the effectiveness of different transformer architecture.
For field of Product reviews, in [24], BERT variants and many more could be used for future development. In [36], the authors discussed about identify the explicit polarity based on the contextual position of the text for sentiment classification when subjected to multiple datasets. Moreover, in [59], the authors refer to their experimenting with BERT-based embeddings in developmental work.
In the realm of health analysis, the authors in [29] discussed the exploration of novel methods aimed at diminishing reliance on annotated corpora. In addition, the authors would explore the use of semantic features along with contextual ones in order to improve the fine-tuning of their approaches. An iterative method that employs the more robust techniques is mentioned in [31]. In [50,51], the authors suggested new models will be continuing to explore and develop in future. Beside, in [52], the authors showed improving the model’s performance Deep Learning and transformer algorithms, it also would be the future work.
For field of Detection, in [9], future researcher could make an experiment on a larger dataset with further fine-grained classification and content analysis. In [10,26], the authors discussed about using an other dataset, extending the dataset for their models. In [44], proposed models over multilingual text, transformer based language models is considered as developments in SA.
For field of Education, in [27], the authors mentioned an experiment of first step of hybrid using bi-grams or tri-grams techniques in their model. In [45], adopting transformer-based related models and using multi-class sentiment analysis are the specific future jobs. In NLP technology, the authors also mentioned Large Language Model and using clustering approaches to have a better data as promising potential approach.
In the Political sector, the authors suggested extending the size of dataset for their model. Additionally, in the field of management, future work could explore the integration if SA applications into a comprehensive CRM or existing information systems.
4. Results and Discussion
4.1. Process for Developing the SA System
The process for Sentiment Analysis as presented in Figure 3 shows the step by step approach for analyzing sentiment including Data Collection, Data Pre-processing, Sentiment Identification, Feature Selection, Sentiment Classification, and Sentiment Polarity, serving as a further measure of sentiment intensity, will be discussed below:
Data Collection: The first step is to collect a dataset of text or images that you want to analyze. This dataset can be collected from a variety of sources, such as social media, news articles, or customer reviews.
Data Pre-processing: Once the dataset is collected, it needs to be pre-processed. This may involve cleaning the data, removing noise, and converting it to a format that can be easily analyzed.
- Cleaning the Twitter RTs, @, #, and the links from the sentences;
- Stemming (flies -> fly), (is -> is) or lemmatization (is -> be);
- Converting the text to lower case;
- Cleaning all the non-letter characters, including numbers;
- Removing English stop words and punctuation;
- Eliminating extra white spaces;
- Decoding HTML to general text.
Sentiment Identification: The next step is to identify the opinion words or phrases in the dataset. These are words or phrases that express a positive, negative, or neutral sentiment. There are a number of ways to identify opinion words and phrases, such as using a corpus or using machine learning deep learning algorithms.
Feature Selection: Once the opinion words and phrases have been identified, they need to be selected for feature extraction. Feature selection is the process of selecting the most important features from a dataset for a given task. In the case of sentiment analysis, the features may include the presence of certain words or phrases, the word order, and the grammatical structure of the text.
Feature Extraction: Feature extraction is the process of converting the selected features into a numerical representation. This numerical representation can then be used by machine learning algorithms to classify the sentiment of the text.
Sentiment Classification: The final step is to classify the sentiment of the text. This can be done using a variety of machine learning/deep learning algorithms, such as SVM, NB, CNN, LSTM and BERT.
Sentiment Polarity: Once the sentiment of the text has been classified, it can be further analyzed to determine the sentiment polarity. Sentiment polarity is a measure of the intensity of the sentiment, such as whether the sentiment is strongly positive, weakly positive, strongly negative, or weakly negative.
4.2. Domains
Utilizing the data categorized in Table 2 and Table 3, we present a comprehensive statistical analysis depicting the evolution of sentiment analysis over recent years in Figure 4. Additionally, the application of sentiment analysis across various domains is illustrated in Figure 5. These visual representations offer valuable insights into the trends and the widespread implementation of sentiment analysis in different contexts.
Figure 4 shows the number of the research papers published increasing every year. Especially, SA is an essential research in 2023 and 2024 with approximately 59% of the selected research papers due to the rapidly growth of social medias and SA is a potential tool to discover and understand public sentiments. Figure 5 shows 8 different domains that researchers focused on in recent years, with the most popular being Product (approximately 29%), Finance (approximately 20%), Health (approximately 18%), Detection (approximately 12%).
4.3. Tasks
Figure 6 presents the breakdown of the type of task addressed in the selected papers from the literature. The tasks addressed focused on: (1) a proposed new model; (2) make an experiment on model in other domain; (3) comparison of models; and (4) improvement an existing model by tuning hyper-parameters or adding layers. The majority (approximately 46%) of the research analysed proposed new models. In terms of popularity, the remaining focused on experiment (approximately 22%), comparison (approximately 19%), and improvement (approximately 13%). One explanation of this breakdown can be increasing hybrid approaches and a proposed new model is better than previous other models.
4.4. Models and Algorithms
Figure 7 presents the breakdown of the analysis and modelling techniques proposed in the selected literature. The most popular model is Hybrid (approximately 54%). We also identified three major topics as: (1) noisy/imbalance nature of the data [12,16]; (2) the hybrid models used in almost domains such as Product Reviews [36,42,54,56,63], Health [29,30,31,40,61], Detection [9,10,26,44], Education and NLP [22,27,45,60], but Deep Learning models (approximately 34%) still be used in Finance [14,16,28,47,58], (3) the representation of the feature vector in the corpus, machine learning and deep learning models is the first step in Hybrid model [9,10,12,21,22,27,29,30,31,36,39,40,42,44,45,53,54,56,59,61,63]. Also, based on the short analysis of the dataset, getting them labelled from the experts or linguistics is important during dataset preparation, especially in field of Detection [10,26]. Next, we provided an overview of various models utilized in sentiment analysis of each domain. Our examination of the surveyed articles revealed that some researchers made attempts to categorize sentiment analysis. Table 3 also shows that while both hybrid and deep learning models have been deployed in Product Reviews, Health, Detection, Education, Finance, and they are also used in combination with new approaches such as: Knowledge graphs [28,31], Large Language Model [19], Semantic score together with context [29] remains more prevalent in research efforts.
4.5. Datasets
Figure 8 presents the breakdown of the datasets used in the selected papers from the literature. The majority (approximately 53%) of the papers used self-generated and closed data, which is not publicly available to the research community. A slightly smaller percentage (approximately 35%) of the literature used datasets that were generated from a third-party such as social media and subsequently made publicly available to the community. There are 21 open datasets created by third-parties. In that, 9 of them are in field of product, 5 of them are in health, 3 of them are in finance, 3 of them are in detection, and another is technology. Much smaller percentages of papers used datasets that were self-generated and then made available (approximately 11%) or which were generated by a third-party and kept private (approximately 2%).
4.6. Future Developments
From the survey, in the financial sector, the main challenges are around integrating multiple data sources as a single data source; various fusion strategies, optimization techniques, modal structures, and modality selections. Further development could be focused on the improvement of full article content using Knowledge Graph to capture the structural relationships in financial texts, and improve forecasting effects. For field of Product reviews, that is identify the explicit polarity based on the contextual position of the text for sentiment classification when subjected to multiple datasets. In field of Health analysis, the future development mentioned an exploring new methods in order to reduce the dependence on annotated corporafuture, alternative methods for knowledge embeddings, and the effectiveness of different transformer architecture. In addition, researchers should explore the use of both semantic and contextual features in order to improve the fine-tuning of their approaches. For field of Detection, a larger dataset with further fine-grained classification and content analysis could be used and also, the ability to extend the dataset for models. In the field of Education, a first experiment with hybrid using bi-grams or tri-grams techniques in the model could be explored. In NLP technology, Large Language Model and using clustering approaches could be used to obtain better data has promising potential approach. In the Political sector, the size of dataset for their model is highlighted while in field of management, future development could involve integrating SA applications into a comprehensive CRM or existing information systems
Moreover, we understand that in recent times, researchers have started to use transformer-based models for NLP tasks and deploy these models to classify sentiment in Finance [15,16,47,58], Product [24,35], Health [30,32], Detection [25,44], Politics [33]. The transformers create contextual embeddings by applying attention mechanisms to each word in a sentence, allowing them to model relationships and meaning based on word surroundings. These embeddings carry rich contextual signals that help in accurately capturing semantics. As a result, transformers have achieved state-of-the-art performance across numerous NLP tasks, including sentiment analysis, product reviews, finance, healthcare, speech detection, and general language understanding. Thanks to their powerful architecture, they have become the preferred model for many researchers and developers in real-time applications. However, there is still room for improvement in areas such as domain identification, understanding domain-specific context, multilingual datasets, and the open-source availability of code—particularly for languages other than English.
5. Conclusion
Due to the growth of social networks, a vast amount of data is generated daily by internet users. Sentiment analysis (SA) systems can automatically analyze this text to ascertain the author’s perspective on a given subject and provide insightful information about human feelings and viewpoints, impacting various fields by assisting in decision-making, enhancing results, and encouraging greater comprehension and involvement. We have provided a concise summary, classification, analysis, and discussion of the latest state-of-the-art in current SA research papers. This overview encompasses various aspects, including domains, tasks, datasets, developments, models and algorithms. Additionally, we have presented a generic process for developing an SA system.
Our investigation spans a broad spectrum of approaches and fields, showcasing the advancements in this pivotal area. The foundational insights obtained from scrutinizing traditional machine learning techniques such as SVM and NB have laid the groundwork for the development of increasingly intricate models. Since their inception, deep learning models like CNNs, RNNs, and transformer-based architectures such as BERT, particularly hybrid models, have demonstrated exceptional capabilities across diverse fields, including sentiment analysis in online content.
As we navigate the landscape of sentiment analysis, there are several promising research directions that can further propel the field. Exploring transfer learning approaches that harness knowledge from high-resource languages to enhance sentiment analysis in languages with limited resources is crucial. This avenue holds significant potential for advancing the effectiveness and applicability of sentiment analysis methodologies.
In future research, it is recommended that scholars investigate the integration of semantic graphs and knowledge graphs within hybrid modeling frameworks. Additionally, incorporating sentiment analysis techniques could further enhance the performance of NLP applications such as cyberbullying detection [68]. Finally, future work will also explore the integration of ontologies [69,70] and knowledge graphs [71,72] to enrich semantic representation and reasoning capabilities.
References
- Rodríguez-Ibánez, M.; Casánez-Ventura, A.; Castejón-Mateos, F.; Cuenca-Jiménez, P.M. A review on sentiment analysis from social media platforms. Expert Systems with Applications 2023, 223, 119862. [CrossRef]
- Hande, A.; Priyadharshini, R.; Chakravarthi, B.R. KanCMD: Kannada CodeMixed Dataset for Sentiment Analysis and Offensive Language Detection. In Proceedings of the Proceedings of the Third Workshop on Computational Modeling of People’s Opinions, Personality, and Emotion’s in Social Media, Barcelona, Spain (Online), 2020; pp. 54–63.
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A survey on sentiment analysis methods, applications, and challenges. Artificial Intelligence Review 2022, 55, 5731–5780. [CrossRef]
- G, V.; Chandrasekaran, D. Sentiment Analysis and Opinion Mining: A Survey. Int J Adv Res Comput Sci Technol 2012, 2.
- Bordoloi, M.; Biswas, S.K. Sentiment analysis: A survey on design framework, applications and future scopes. Artif Intell Rev 2023, pp. 1–56. [CrossRef]
- Ezhilarasan, M.; Govindasamy, V.; Akila, V.; Vadivelan, K. Sentiment Analysis On Product Review: A Survey. In Proceedings of the 2019 International Conference on Computation of Power, Energy, Information and Communication (ICCPEIC), 2019, pp. 180–192. [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis : A Survey. CoRR 2018, abs/1801.07883, [1801.07883].
- Ngo, V.M.; Thorpe, C.; Dang, C.N.; Mckeever, S. Investigation, Detection and Prevention of Online Child Sexual Abuse Materials: A Comprehensive Survey. In Proceedings of the 2022 RIVF International Conference on Computing and Communication Technologies (RIVF), 2022, pp. 707–713. [CrossRef]
- Chakravarthi, B.R. Hope speech detection in YouTube comments. Soc Netw Anal Min 2022, 12, 75. [CrossRef]
- Balshetwar, S.V.; Rs, A.; R, D.J. Fake news detection in social media based on sentiment analysis using classifier techniques. Multimed Tools Appl 2023, pp. 1–31. [CrossRef]
- Dake, D.K.; Gyimah, E. Using sentiment analysis to evaluate qualitative students’ responses. Educ Inf Technol (Dordr) 2023, 28, 4629–4647. [CrossRef]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A novel multi-source information-fusion predictive framework based on deep neural networks for accuracy enhancement in stock market prediction. Journal of Big Data 2021, 8. [CrossRef]
- Colasanto, F.; Grilli, L.; Santoro, D.; Villani, G. BERT’s sentiment score for portfolio optimization: a fine-tuned view in Black and Litterman model. Neural Comput Appl 2022, 34, 17507–17521. [CrossRef]
- Windsor, E.; Cao, W. Improving exchange rate forecasting via a new deep multimodal fusion model. Appl Intell (Dordr) 2022, 52, 16701–16717. [CrossRef]
- Hajek, P.; Munk, M. Speech emotion recognition and text sentiment analysis for financial distress prediction. Neural Computing and Applications 2023, 35, 21463–21477. [CrossRef]
- Kaplan, H.; Weichselbraun, A.; Brasoveanu, A.M.P. Integrating Economic Theory, Domain Knowledge, and Social Knowledge into Hybrid Sentiment Models for Predicting Crude Oil Markets. Cognit Comput 2023, pp. 1–17. [CrossRef]
- Bansal, A.; Kumar, N. Aspect-Based Sentiment Analysis Using Attribute Extraction of Hospital Reviews. New Gener Comput 2022, 40, 941–960. [CrossRef]
- Capuano, N.; Greco, L.; Ritrovato, P.; Vento, M. Sentiment analysis for customer relationship management: an incremental learning approach. Applied Intelligence 2020, 51, 3339–3352. [CrossRef]
- Yan, Y.; Zhang, B.W.; Ding, G.; Li, W.; Zhang, J.; Li, J.J.; Gao, W. O2-Bert: Two-Stage Target-Based Sentiment Analysis. Cognitive Computation 2023. [CrossRef]
- Umair, A.; Masciari, E. Sentiment Analysis Using Improved CT-BERT_CONVLayer Fusion Model for COVID-19 Vaccine Recommendation. SN Computer Science 2024, 5, 931. [CrossRef]
- Abimbola, B.; Tan, Q.; De La Cal Marín, E.A. Sentiment analysis of Canadian maritime case law: a sentiment case law and deep learning approach. International Journal of Information Technology 2024, 16, 3401–3409. [CrossRef]
- Kastrati, M.; Kastrati, Z.; Shariq Imran, A.; Biba, M. Leveraging distant supervision and deep learning for twitter sentiment and emotion classification. Journal of Intelligent Information Systems 2024, 62, 1045–1070. [CrossRef]
- Iddrisu, A.M.; Mensah, S.; Boafo, F.; Yeluripati, G.R.; Kudjo, P. A sentiment analysis framework to classify instances of sarcastic sentiments within the aviation sector. International Journal of Information Management Data Insights 2023, 3. [CrossRef]
- Patel, A.; Oza, P.; Agrawal, S. Sentiment Analysis of Customer Feedback and Reviews for Airline Services using Language Representation Model. Procedia Computer Science 2023, 218, 2459–2467. [CrossRef]
- Rosenberg, E.; Tarazona, C.; Mallor, F.; Eivazi, H.; Pastor-Escuredo, D.; Fuso-Nerini, F.; Vinuesa, R. Sentiment analysis on Twitter data towards climate action. Results in Engineering 2023, 19. [CrossRef]
- Spinde, T.; Richter, E.; Wessel, M.; Kulshrestha, J.; Donnay, K. What do Twitter comments tell about news article bias? Assessing the impact of news article bias on its perception on Twitter. Online Social Networks and Media 2023, 37-38. [CrossRef]
- Rakhmanov, O. A Comparative Study on Vectorization and Classification Techniques in Sentiment Analysis to Classify Student-Lecturer Comments. Procedia Computer Science 2020, 178, 194–204. 9th International Young Scientists Conference in Computational Science, YSC2020, 05-12 September 2020, . [CrossRef]
- Chen, L.; Kong, Y.; Lin, J. Trend Prediction Of Stock Industry Index Based On Financial Text. Procedia Computer Science 2022, 202, 105–110. International Conference on Identification, Information and Knowledge in the internet of Things, 2021, . [CrossRef]
- Colon-Ruiz, C.; Segura-Bedmar, I. Comparing deep learning architectures for sentiment analysis on drug reviews. J Biomed Inform 2020, 110, 103539. [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Asadi, S.; Acharrya, U.R. A novel fusion-based deep learning model for sentiment analysis of COVID-19 tweets. Knowl Based Syst 2021, 228, 107242. [CrossRef]
- Meena, G.; Mohbey, K.K.; Kumar, S.; Lokesh, K. A hybrid deep learning approach for detecting sentiment polarities and knowledge graph representation on monkeypox tweets. Decision Analytics Journal 2023, 7. [CrossRef]
- Suhartono, D.; Purwandari, K.; Jeremy, N.; Philip, S.; Arisaputra, P.; Parmonangan, I. Deep neural networks and weighted word embeddings for sentiment analysis of drug product reviews. Procedia Computer Science 2023, 216, 664–671. [CrossRef]
- Baraniak, K.; Sydow, M. A dataset for Sentiment analysis of Entities in News headlines (SEN). Procedia Computer Science 2021, 192, 3627–3636. [CrossRef]
- Ahmed, Z.; Wang, J. A fine-grained deep learning model using embedded-CNN with BiLSTM for exploiting product sentiments. Alexandria Engineering Journal 2023, 65, 731–747. [CrossRef]
- Ye, L.; Yimeng, Y.; Wei, C. Analyzing Public Perception of Educational Books via Text Mining of Online Reviews. Procedia Computer Science 2023, 221, 617–625. [CrossRef]
- Atandoh, P.; Zhang, F.; Adu-Gyamfi, D.; Atandoh, P.H.; Nuhoho, R.E. Integrated deep learning paradigm for document-based sentiment analysis. Journal of King Saud University - Computer and Information Sciences 2023, 35. [CrossRef]
- Gunawan, L.; Anggreainy, M.; Wihan, L.; Santy, Lesmana, G.; Yusuf, S. Support vector machine based emotional analysis of restaurant reviews. Procedia Computer Science 2023, 216, 479–484. [CrossRef]
- Vasanth, K.; P., S.; Shete, V.; Ravi, C.N.; P, V. Dynamic Fusion of Text, Video and Audio models for Sentiment Analysis. Procedia Computer Science 2022, 215, 211–219. [CrossRef]
- George, M.; Murugesan, R. Improving sentiment analysis of financial news headlines using hybrid Word2Vec-TFIDF feature extraction technique. Procedia Computer Science 2024, 244, 1–8. 6th International Conference on AI in Computational Linguistics, . [CrossRef]
- Valarmathi, B.; Gupta, N.S.; Karthick, V.; Chellatamilan, T.; Santhi, K.; Chalicheemala, D. Sentiment Analysis of Covid-19 Twitter Data using Deep Learning Algorithm. Procedia Computer Science 2024, 235, 3397–3407. International Conference on Machine Learning and Data Engineering (ICMLDE 2023), . [CrossRef]
- Tanoto, K.; Gunawan, A.A.S.; Suhartono, D.; Mursitama, T.N.; Rahayu, A.; Ariff, M.I.M. Investigation of challenges in aspect-based sentiment analysis enhanced using softmax function on twitter during the 2024 Indonesian presidential election. Procedia Computer Science 2024, 245, 989–997. 9th International Conference on Computer Science and Computational Intelligence 2024 (ICCSCI 2024), . [CrossRef]
- Greeshma, M.; Simon, P. Bidirectional Gated Recurrent Unit with Glove Embedding and Attention Mechanism for Movie Review Classification. Procedia Computer Science 2024, 233, 528–536. 5th International Conference on Innovative Data Communication Technologies and Application (ICIDCA 2024), . [CrossRef]
- Taneja, K.; Vashishtha, J.; Ratnoo, S. Transformer Based Unsupervised Learning Approach for Imbalanced Text Sentiment Analysis of E-Commerce Reviews. Procedia Computer Science 2024, 235, 2318–2331. International Conference on Machine Learning and Data Engineering (ICMLDE 2023), . [CrossRef]
- Fazil, M.; Khan, S.; Albahlal, B.M.; Alotaibi, R.M.; Siddiqui, T.; Shah, M.A. Attentional Multi-Channel Convolution With Bidirectional LSTM Cell Toward Hate Speech Prediction. IEEE Access 2023, 11, 16801–16811. [CrossRef]
- Zhai, G.; Yang, Y.; Wang, H.; Du, S. Multi-attention fusion modeling for sentiment analysis of educational big data. Big Data Mining and Analytics 2020, 3, 311–319. [CrossRef]
- Rajagukguk, S.A.; Prabowo, H.; Bandur, A.; Setiowati, R. Higher Educational Institution (HEI) Promotional Management Support System Through Sentiment Analysis for Student Intake Improvement. IEEE Access 2023, 11, 77779–77792. [CrossRef]
- Mishev, K.; Gjorgjevikj, A.; Vodenska, I.; Chitkushev, L.T.; Trajanov, D. Evaluation of Sentiment Analysis in Finance: From Lexicons to Transformers. IEEE Access 2020, 8, 131662–131682. [CrossRef]
- Parekh, R.; Patel, N.P.; Thakkar, N.; Gupta, R.; Tanwar, S.; Sharma, G.; Davidson, I.E.; Sharma, R. DL-GuesS: Deep Learning and Sentiment Analysis-Based Cryptocurrency Price Prediction. IEEE Access 2022, 10, 35398–35409. [CrossRef]
- Yekrangi, M.; Nikolov, N.S. Domain-Specific Sentiment Analysis: An Optimized Deep Learning Approach for the Financial Markets. IEEE Access 2023, 11, 70248–70262. [CrossRef]
- Han, Y.; Liu, M.; Jing, W. Aspect-Level Drug Reviews Sentiment Analysis Based on Double BiGRU and Knowledge Transfer. IEEE Access 2020, 8, 21314–21325. [CrossRef]
- Sweidan, A.H.; El-Bendary, N.; Al-Feel, H. Sentence-Level Aspect-Based Sentiment Analysis for Classifying Adverse Drug Reactions (ADRs) Using Hybrid Ontology-XLNet Transfer Learning. IEEE Access 2021, 9, 90828–90846. [CrossRef]
- Bengesi, S.; Oladunni, T.; Olusegun, R.; Audu, H. A Machine Learning-Sentiment Analysis on Monkeypox Outbreak: An Extensive Dataset to Show the Polarity of Public Opinion From Twitter Tweets. IEEE Access 2023, 11, 11811–11826. [CrossRef]
- Duan, G.; Yan, S.; Zhang, M. A Hybrid Neural Network Model for Sentiment Analysis of Financial Texts Using Topic Extraction, Pre-Trained Model, and Enhanced Attention Mechanism Methods. IEEE Access 2024, 12, 98207–98224. [CrossRef]
- Kumar, L.K.; Thatha, V.N.; Udayaraju, P.; Siri, D.; Kiran, G.U.; Jagadesh, B.N.; Vatambeti, R. Analyzing Public Sentiment on the Amazon Website: A GSK-Based Double Path Transformer Network Approach for Sentiment Analysis. IEEE Access 2024, 12, 28972–28987. [CrossRef]
- Maroof, A.; Wasi, S.; Jami, S.I.; Siddiqui, M.S. Aspect-Based Sentiment Analysis for Service Industry. IEEE Access 2024, 12, 109702–109713. [CrossRef]
- Sherin, A.; Jasmine Selvakumari Jeya, I.; Deepa, S.N. Enhanced Aquila Optimizer Combined Ensemble Bi-LSTM-GRU With Fuzzy Emotion Extractor for Tweet Sentiment Analysis and Classification. IEEE Access 2024, 12, 141932–141951. [CrossRef]
- Rahman, B.; Maryani. Optimizing Customer Satisfaction Through Sentiment Analysis: A BERT-Based Machine Learning Approach to Extract Insights. IEEE Access 2024, 12, 151476–151489. [CrossRef]
- Du, K.; Xing, F.; Cambria, E. Incorporating Multiple Knowledge Sources for Targeted Aspect-based Financial Sentiment Analysis. ACM Transactions on Management Information Systems 2023, 14, 1–24. [CrossRef]
- Perti, A.; Sinha, A.; Vidyarthi, A. Cognitive Hybrid Deep Learning-based Multi-modal Sentiment Analysis for Online Product Reviews. ACM Transactions on Asian and Low-Resource Language Information Processing 2023. [CrossRef]
- Dang, C.N.; Moreno-García, M.N.; De la Prieta, F.; Nguyen, K.V.; Ngo, V.M. Sentiment Analysis for Vietnamese – Based Hybrid Deep Learning Models 2023. pp. 293–303.
- Swaileh A. Alzaidi, M.; Alshammari, A.; Almanea, M.; Al-khawaja, H.A.; Al Sultan, H.; Alotaibi, S.; Almukadi, W. A Text-Inception-Based Natural Language Processing Model for Sentiment Analysis of Drug Experiences. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024. [CrossRef]
- Vadivu, S.V.; Nagaraj, P.; Murugan, B.S. Opinion Mining on Social Media Text Using Optimized Deep Belief Networks. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024. [CrossRef]
- Gamal, D.; Alfonse, M.; M. El-Horbaty, E.S.; M. Salem, A.B. Analysis of Machine Learning Algorithms for Opinion Mining in Different Domains. Machine Learning and Knowledge Extraction 2019, 1, 224–234. [CrossRef]
- Palak Baid, A.G.; Chaplot, N. Sentiment Analysis of Movie Reviews Using Machine Learning Techniques. International Journal of Computer Applications 2017.
- Nehal Mohamed Ali, M.; Youssif. Sentiment analysis for movies reviews dataset using deep learning models. International Journal of Data Mining and Knowledge Management Process 2019, 09, 19–27. [CrossRef]
- Nguyen, P.T.; Le, L.T.; Ngo, V.M.; Nguyen, P.M. Using Entity Relations for Opinion Mining of Vietnamese Comments. CoRR 2019, abs/1905.06647, [1905.06647].
- Nguyen, H.L.; Pham, H.T.N.; Ngo, V.M. Opinion Spam Recognition Method for Online Reviews using Ontological Features. CoRR 2018, abs/1807.11024, [1807.11024].
- Ngo, V.M.; Gajula, R.; Thorpe, C.; Mckeever, S. Discovering child sexual abuse material creators’ behaviors and preferences on the dark web. Child Abuse & Neglect 2024, 147, 106558. [CrossRef]
- Ngo, V.M.; Cao, T.H. Discovering Latent Concepts and Exploiting Ontological Features for Semantic Text Search. In Proceedings of the Proceedings of 5th International Joint Conference on Natural Language Processing, 2011, pp. 571–579.
- Cao, T.H.; Ngo, V.M. Semantic search by latent ontological features. New Generation Computing 2012, 30, 53–71. [CrossRef]
- Ngo, V.M.; Munnelly, G.; Orlandi, F.; Crooks, P. A Semantic Search Engine for Historical Handwritten Document Images. In Proceedings of the Linking Theory and Practice of Digital Libraries: 25th International Conference on Theory and Practice of Digital Libraries, TPDL 2021, Virtual Event, September 13–17, 2021, Proceedings. Springer Nature, 2021, Vol. 12866, p. 60. [CrossRef]
- Ngo, V.M.; Bolger, E.; Goodwin, S.; O’Sullivan, J.; Cuong, D.V.; Roantree, M. A Graph Based Raman Spectral Processing Technique for Exosome Classification. In Proceedings of the Artificial Intelligence in Medicine; Bellazzi, R.; et al., Eds. Springer, 2025, pp. 344–354. [CrossRef]
Figure 1.
Volume of literature by year
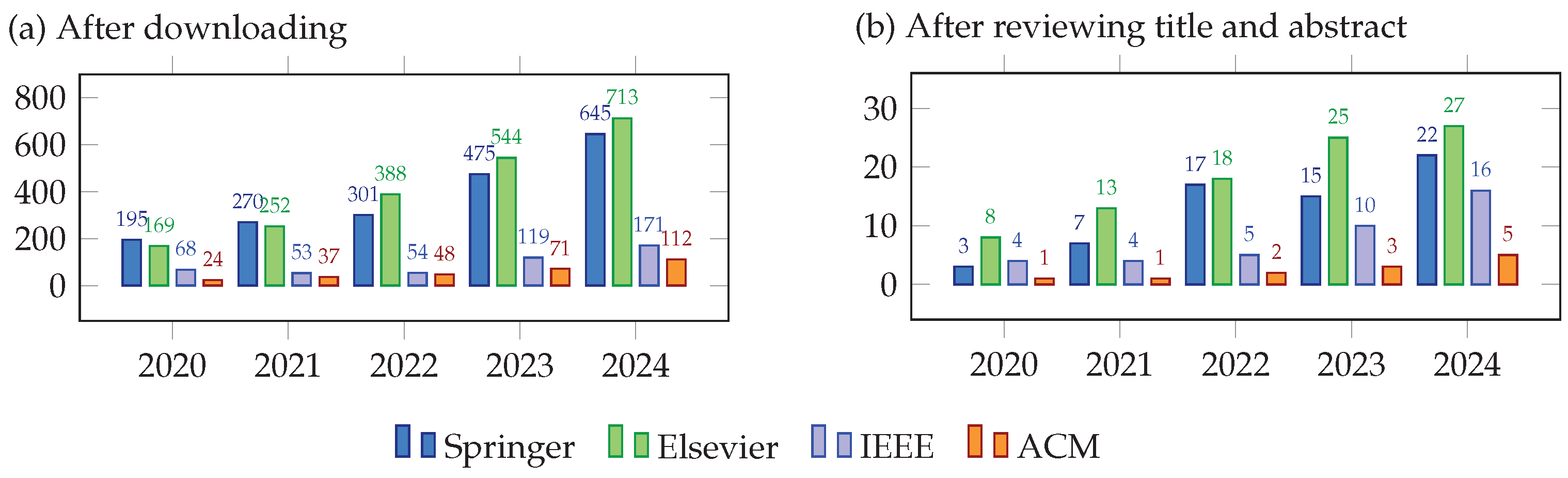
Figure 2.
Models and Algorithms of Sentiment Analysis
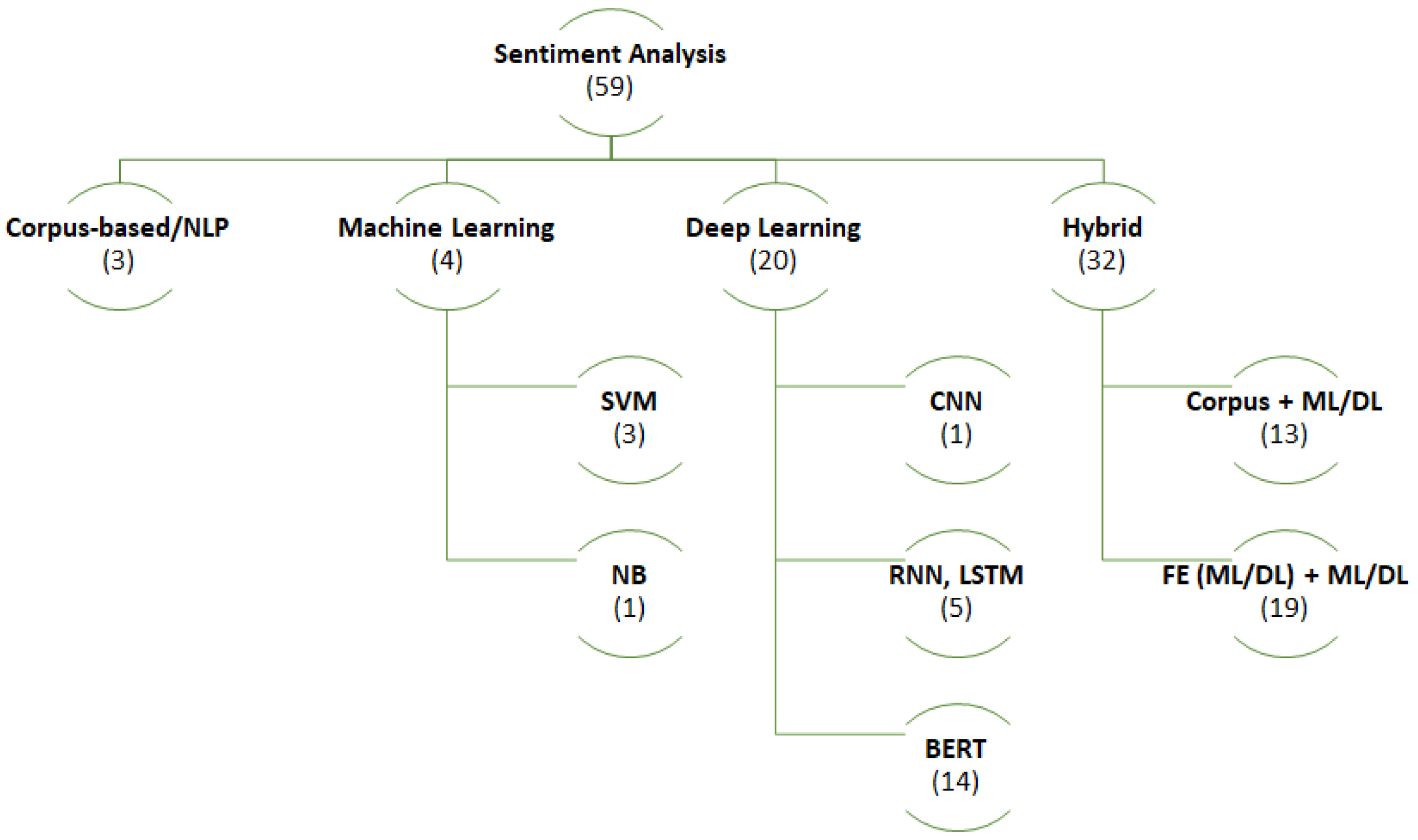
Figure 3.
Process of Sentiment Analysis

Figure 4.
Prior research publications categorized by year.
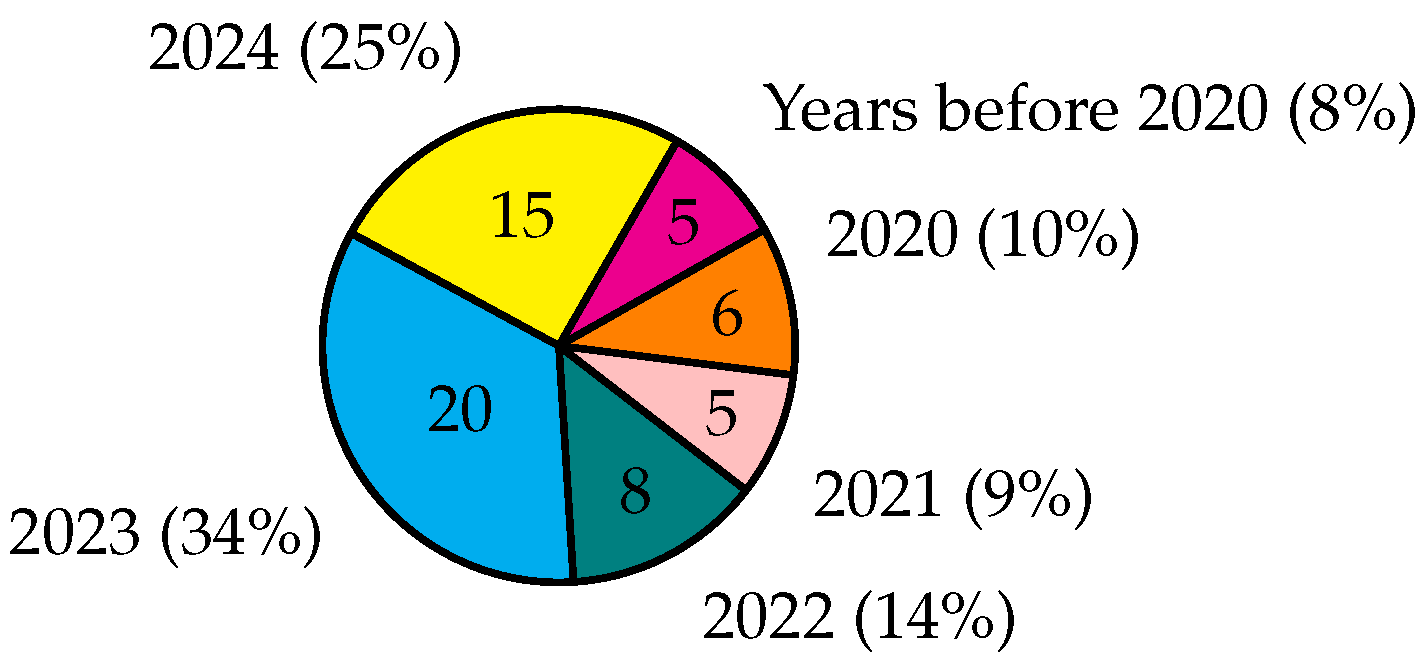
Figure 5.
Prior research classification based on domains.
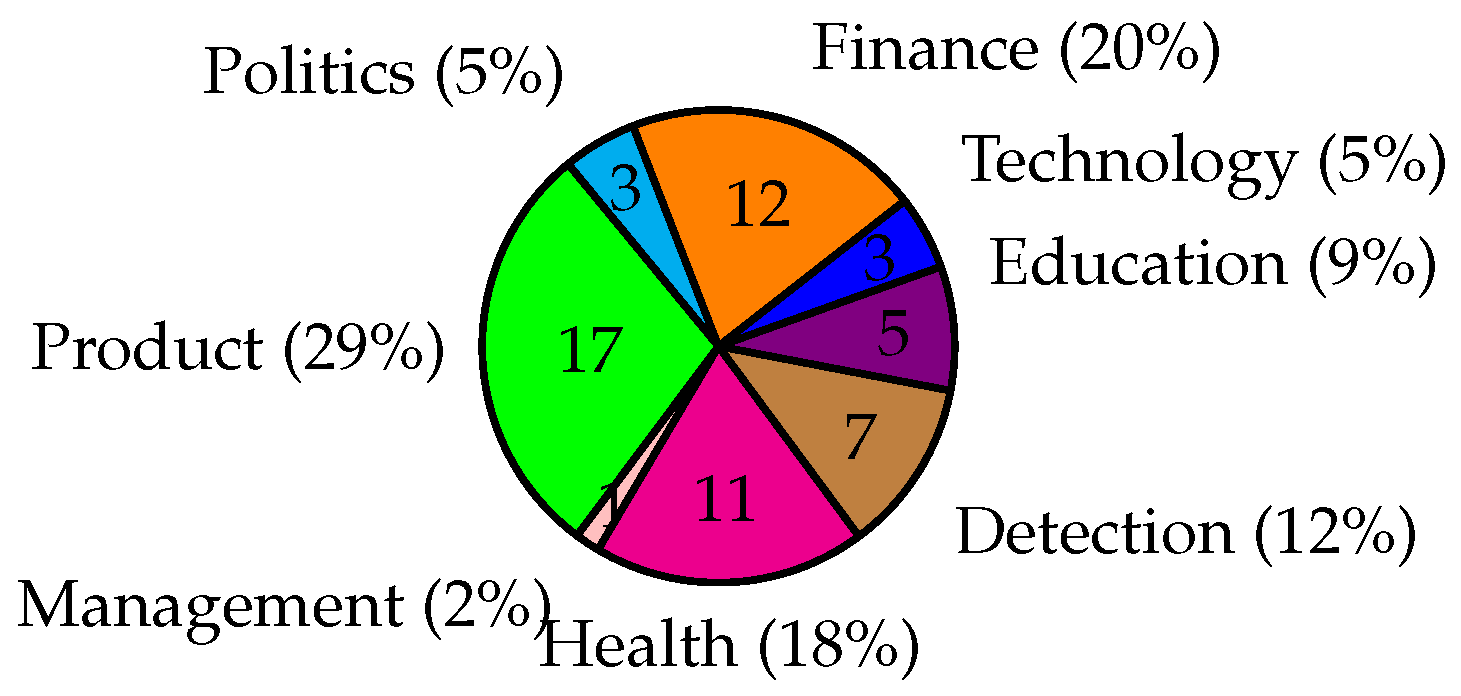
Figure 6.
Prior research classified using task-specific addresses.
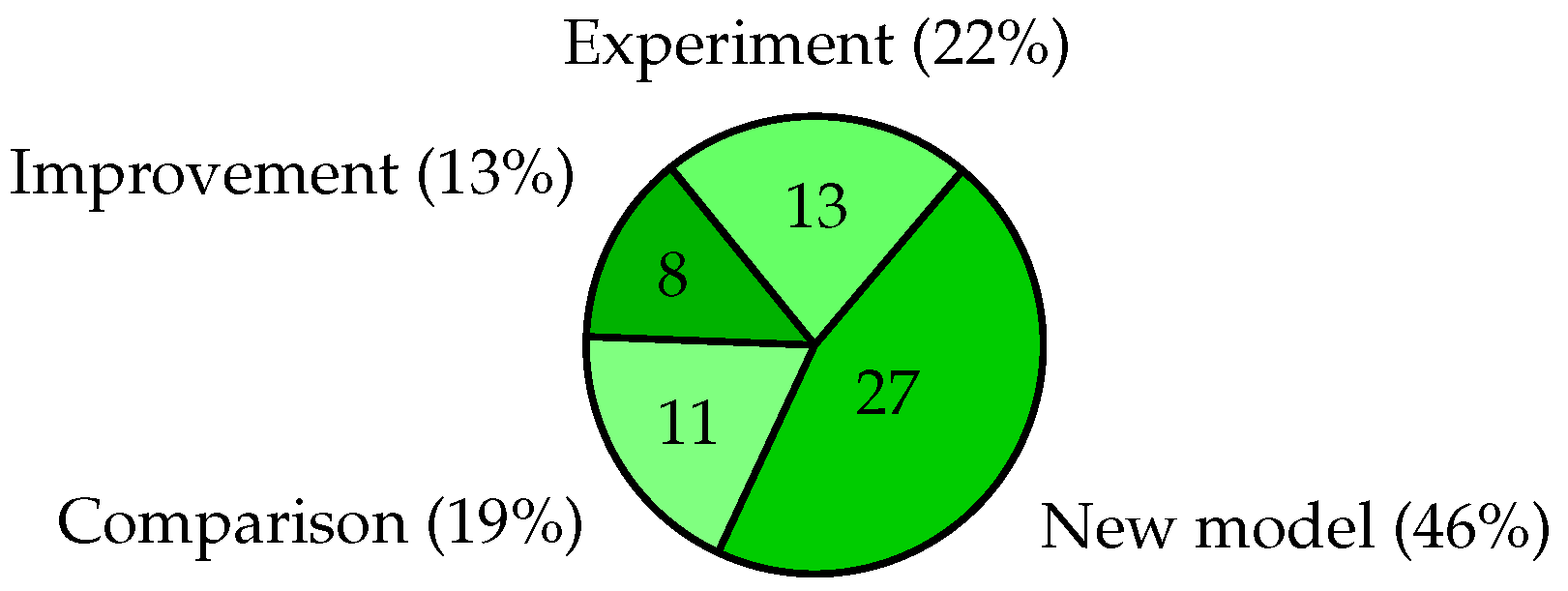
Figure 7.
Prior research categorized according to applied models and algorithms.
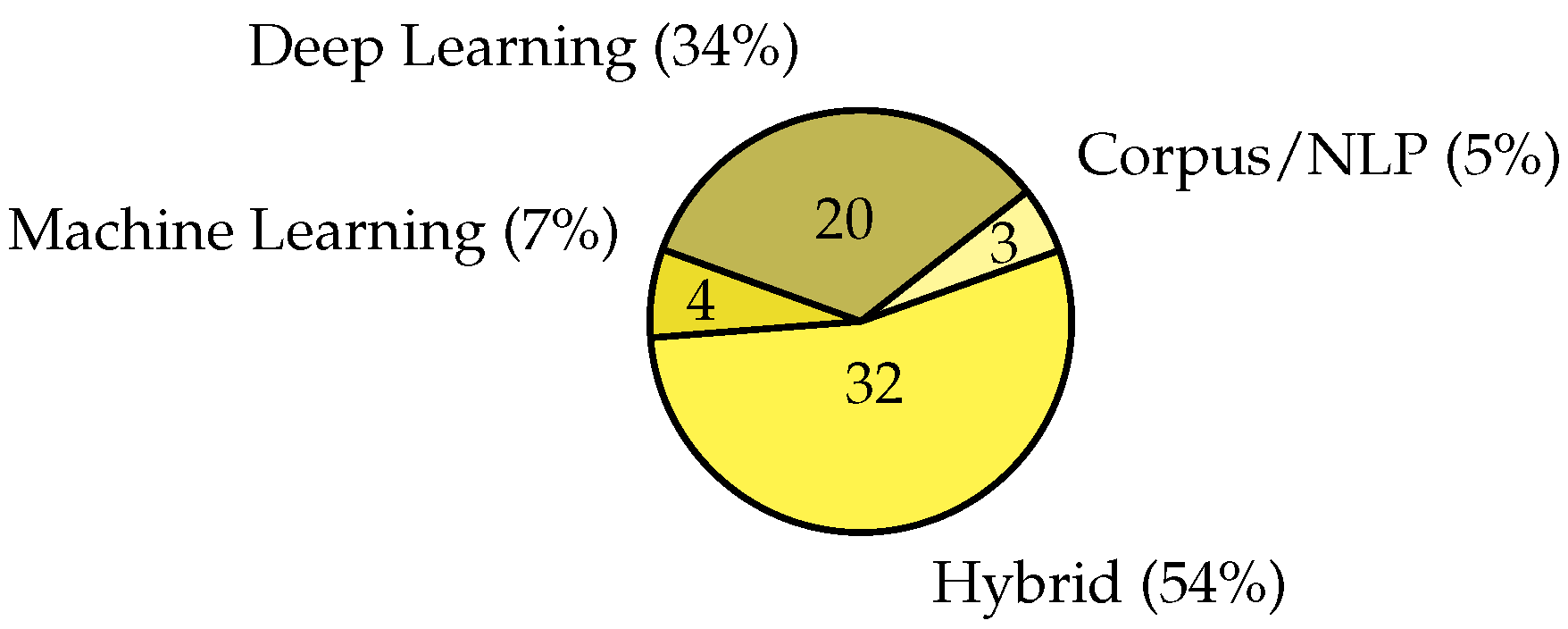
Figure 8.
Prior research is classified based on the utilized datasets.
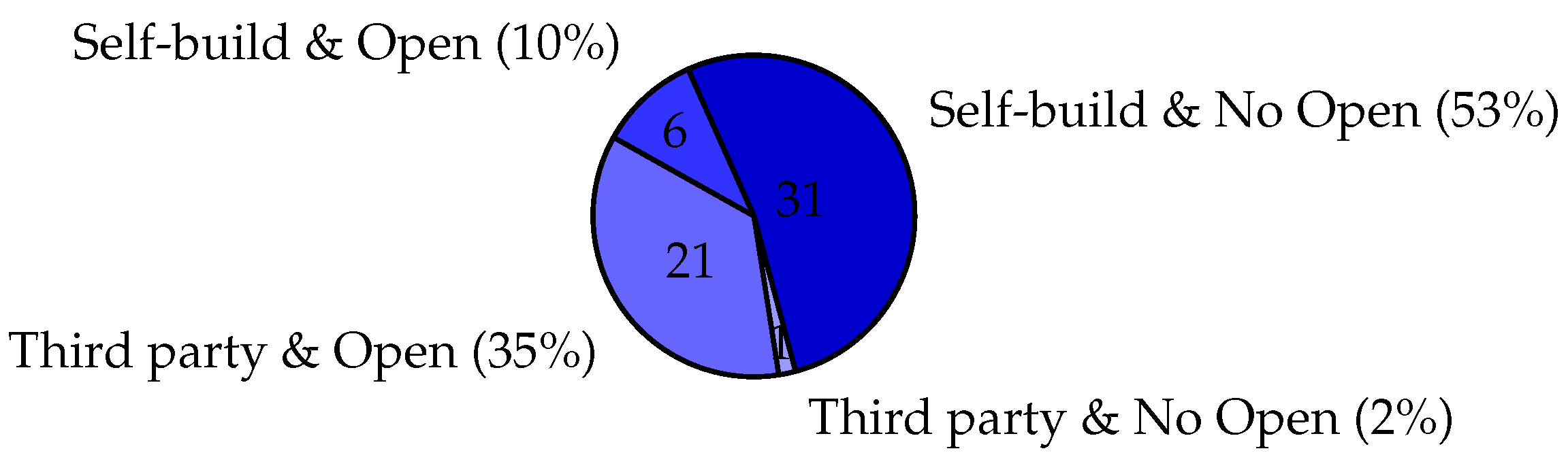
Table 1.
The number of related literatures in publishers
| Publisher | The number of literatures | ||
|---|---|---|---|
| with search | After | After reviewing | After reviewing |
| criteria | downloading | title and abstract | full text |
| Springer | 1,886 | 64 | 16 (Res1: 14, Sur2: 2) |
| Elsevier | 2,066 | 91 | 22 (Res: 21, Sur: 1) |
| IEEE | 465 | 39 | 14 (Res: 14, Sur: 0) |
| ACM | 292 | 12 | 5 (Res: 5, Sur: 0) |
| Total | 4,709 | 206 | 57 (Res: 54, Sur: 3) |
| Others with unlimited publisher and pub. year | 8 (Res: 5, Sur: 3) | ||
| Final Review | 65 (Res: 59, Sur: 6) | ||
1 Res: the number of research papers. 2 Sur: the number of survey papers.
Table 2.
Domains, Tasks and Models of the 59 current research
| No | Study | Domains | Year | Task1 | Models and Accuracy |
|---|---|---|---|---|---|
| Springer | |||||
| 1 | Chakravarthi et al. [9] | Detection | 2022 | new-m | Corpus+DL, F1: 0.75 |
| 2 | Balshetwar et al. [10] | Detection | 2023 | new-m | Corpus+ML, Acc: 0.98 |
| 3 | Dake et al. [11] | Education | 2022 | comp | ML, Acc: 0.63 |
| 4 | Nti et al. [12] | Finance | 2021 | new-m | FE (DL)+DL, Acc: 0.98 |
| 5 | Colasanto et al. [13] | Finance | 2022 | impr | DL |
| 6 | Windsor et al. [14] | Finance | 2022 | new-m | DL, R2: 0.9848 |
| 7 | Hajek et al. [15] | Finance | 2023 | new-m | FE (DL)+DL, Acc: 0.954 |
| 8 | Kaplan et al. [16] | Finance | 2023 | new-m | DL, Acc: 0.98 |
| 9 | Bansal et al. [17] | Health | 2021 | new-m | Corpus-based/NLP |
| 10 | Capuano et al. [18] | Management | 2020 | impr | DL, Acc: 0.8 |
| 11 | Yan et al. [19] | Technology | 2023 | new-m | DL, Acc: 0.89 |
| 12 | Areeba et al. [20] | Health | 2024 | impr | DL, Acc: 0.87 |
| 13 | Bola et al. [21] | Politics | 2024 | new-m | FE (DL)+DL, Acc: 0.92 |
| 14 | Muhamet et al. [22] | Technology | 2024 | new-m | Corpus+DL, F1: 0.71 |
| Elsevier | |||||
| 1 | Iddrisu et al. [23] | Product | 2023 | impr | Corpus+ML, Acc: 0.99 |
| 2 | Patel et al. [24] | Product | 2023 | comp | DL, Acc: 0.83 |
| 3 | Rosenberg et al. [25] | Detection | 2023 | expe | DL, Acc: 0.69 |
| 4 | Spinde et al. [26] | Detection | 2023 | expe | FE (DL)+DL, Acc: 0.95 |
| 5 | Rakhmanov [27] | Education | 2020 | expe | Corpus+ML, Acc: 0.96 |
| 6 | Chen et al. [28] | Finance | 2022 | expe | DL, R2: 0.63 |
| 7 | Colon-Ruiz et al. [29] | Health | 2020 | comp | FE (DL)+DL, F1: 0.947 |
| 8 | Basiri et al. [30] | Health | 2021 | new-m | FE (DL)+DL, Acc: 0.858 |
| 9 | Meena et al. [31] | Health | 2023 | expe | FE (DL)+DL, Acc: 0.94 |
| 10 | Suhartono et al. [32] | Health | 2023 | comp | Corpus+DL, Acc: 0.84 |
| 11 | Baraniak et al. [33] | Politics | 2021 | expe | DL, Acc: 0.51 |
| 12 | Ahmed et al. [34] | Product | 2022 | expe | FE (DL)+DL, Acc: 0.83 |
| 13 | Ye et al. [35] | Product | 2023 | new-m | DL |
| 14 | Atandoh et al. [36] | Product | 2023 | new-m | FE (DL)+DL, Acc: 0.95 |
| 15 | Gunawan et al. [37] | Product | 2023 | expe | ML, Acc: 0.79 |
| 16 | Vasanth et al. [38] | Technology | 2022 | new-m | DL |
| 17 | Meera et al. [39] | Finance | 2024 | impr | Corpus+ML, Acc: 0.82 |
| 18 | Valarmathi et al. [40] | Health | 2024 | impr | Corpus+DL, Acc: 0.96 |
| 19 | Valarmathi et al. [41] | Politics | 2024 | expe | ML(Acc: 0.72), DL(Acc: 0.71) |
| 20 | Greeshma et al. [42] | Product | 2024 | new-m | Corpus+DL, Acc: 0.98 |
| 21 | Khushboo et al. [43] | Product | 2024 | comp | DL, Acc: 0.96 |
| IEEE | |||||
| 1 | Fazil et al. [44] | Detection | 2023 | new-m | FE (DL)+DL, Acc: 0.94 |
| 2 | Zhai et al. [45] | Education | 2020 | new-m | FE (DL)+DL, Acc: 0.946 |
| 3 | Rajagukguk et al. [46] | Education | 2023 | expe | DL, Acc: 0.927 |
| 4 | Mishev et al. [47] | Finance | 2020 | expe | DL, 0.947 |
| 5 | Parekh et al. [48] | Finance | 2022 | new-m | Corpus+DL |
| 6 | Yekrangi et al. [49] | Finance | 2023 | impr | FE (DL)+DL, Acc: 0.84 |
| 7 | Han et al. [50] | Health | 2020 | comp | DL, Acc: 0.78 |
| IEEE | |||||
| 8 | Sweidan et al. [51] | Health | 2021 | new-m | Corpus+DL, Acc: 0.98 |
| 9 | Bengesi et al. [52] | Health | 2023 | expe | Corpus+ML, Acc: 0.93 |
| 10 | Ganglong et al. [53] | Finance | 2024 | impr | FE (DL)+DL, Acc: 0.95 |
| 11 | Kumar et al. [54] | Product | 2024 | new-m | Corpus+DL, Acc: 0.95 |
| 12 | Maroof et al. [55] | Product | 2024 | comp | ML(Acc: 0.91) DL(Acc: 0.92) |
| 13 | Sherin et al. [56] | Product | 2024 | new-m | FE (DL)+DL(Acc: 0.94) |
| 14 | Rahman et al. [57] | Product | 2024 | comp | DL(Acc: 0.95) |
| ACM | |||||
| 1 | Du et al. [58] | Finance | 2023 | new-m | DL, R2: 0.71 |
| 2 | Perti et al. [59] | Product | 2023 | expe | FE (DL)+ML, Acc: 0.845 |
| 3 | Dang et al. [60] | Education | 2023 | new-m | FE (DL)+ML, Acc: 0.93 |
| 4 | Muhammad et al. [61] | Health | 2024 | new-m | Corpus+DL, Acc: 0.99 |
| 5 | Vadivu et al. [62] | Detection | 2024 | new-m | DL, Acc: 0.89 |
| Others | |||||
| 1 | Gamal et al. [63] | Product | 2018 | comp | Corpus+ML, Acc: 0.87-0.99 |
| 2 | Palak Baid et al. [64] | Product | 2017 | comp | ML, Acc: 0.81 |
| 3 | Ali et al. [65] | Product | 2019 | comp | FE (DL)+DL, Acc: 0.89 |
| 4 | Nguyen et al. [66] | Product | 2019 | new-m | Corpus-based/NLP, Acc: 0.84 |
| 5 | Nguyen et al. [67] | Detection | 2019 | new-m | Corpus-based/NLP, Acc: 0.90 |
1 new-m = new model; comp = comparison; impr = improvement; expe = experiment
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



