Submitted:
15 September 2025
Posted:
16 September 2025
You are already at the latest version
Abstract
Next-generation autonomous laboratories that combine machine learning, robotic synthesis, and in situ characterization is rapidly emerging as one of the key directions in modern materials science. By integrating active and deep learning algorithms with multi-level datasets ranging from quantum mechanical simulations to high-throughput flow-based experiments, these platforms establish closed-loop frameworks that guide complex nanofabrication processes in real time. Such AI-driven systems lower material and energy consumption, enable the precise design of nanostructures with tailored optical, electronic, and mechanical properties, and create research opportunities that were previously difficult to realize. This review provides a comprehensive overview of self-driving laboratories (SDLs), including their architectures, algorithmic strategies, and practical demonstrations such as the optimization of perovskite nanostructures, the development of nanoparticles for targeted drug delivery, and the synthesis of quantum dots with controlled emission. It also discusses existing methodological limitations, the need for standardized data practices, and challenges related to the integration of in situ techniques, while highlighting the prospects for creating fully digital pipelines for material production, as evidenced by recent autonomous laboratory demonstrations that progressed from initial hypotheses to functional prototypes within remarkably short timeframes.
Keywords:
artificial intelligence
; machine learning
; self-driving labs
; autonomous material discovery
; nanomaterials
; in situ characterization
; inverse design
; Bayesian optimization
; reinforcement learning
; digital twins
; explainable AI
1. Introduction
Autonomous laboratories represent a significant development in modern materials science. These systems integrate machine learning, robotic synthesis, and in situ characterization to create closed-loop research environments. By combining active learning algorithms with multilevel datasets from quantum-mechanical simulations to high-throughput flow experiments, they establish real-time theory-experiment frameworks capable of guiding complex nanofabrication processes [1,2,3,4,5,6,7,8,9]. The field addresses fundamental challenges in traditional materials discovery [10,11,12,13,14,15,16]. Conventional approaches often involve slow, sequential experimentation with high resource consumption and limited exploration of complex parameter spaces. The interpretation of high-dimensional data from advanced characterization techniques presents additional difficulties [17,18,19,20,21,22]. Data fragmentation across proprietary formats and incompatible systems further hinders scientific progress and reproducibility [23].
AI-driven platforms significantly reduce material and energy requirements while enabling precise engineering of nanostructures with tailored functionalities. They facilitate research directions previously considered impractical, particularly for metastable phases [19] and reactions with narrow processing windows. These systems automate the entire research cycle from hypothesis generation and experimental design to execution and analysis, enabling autonomous selection of subsequent experiments without human intervention [1,8,10].
This review examines the current state of self-driving laboratories through several key aspects. We analyze architectural principles and algorithmic strategies, including Bayesian optimization [8,16], reinforcement learning, and generative models for inverse design [20,22]. Particular attention is given to automated methods for processing scientific literature [12,21]. We evaluate demonstrated capabilities across diverse material systems, covering perovskite nanostructures for optoelectronics [24,25,26,27,28,29,30,31,32,33], drug delivery nanoparticles [34], and quantum dots with controlled emission profiles [7,15]. The assessment includes performance benchmarking and comparative analysis of different platforms.
Critical examination addresses persistent challenges such as data standardization issues [23], limited data availability in unexplored chemical domains, model interpretability needs for high-stakes applications [24,25,26,27,28,29,30,31,32,33,34,35], and cybersecurity concerns [25]. The discussion extends to future development pathways including accessible virtual laboratories [29], multi-agent architectures [3], and integration with industrial-scale manufacturing [26]. Recent advances through platforms like A-Lab [11,12], AlphaFlow [8], and Rainbow [30] demonstrate the transition from proof-of-concept demonstrations to functional research systems. These developments highlight the potential for rapid progression from initial hypotheses to practical implementations. The following sections provide detailed analysis of these advancements, current limitations, and future directions for autonomous materials discovery.
2. Review Methodology
Our literature review methodology employed systematic search strategies across major scientific databases. We utilized Scopus and Web of Science as primary sources for peer-reviewed publications. The arXiv preprint server provided access to emerging research developments. Our search incorporated multiple key terms including "self-driving laboratory", "autonomous materials discovery", "closed-loop synthesis", "Bayesian optimization", "materials informatics", and "inverse design". The analysis focused on publications from 2020 to 2025 to capture current advancements. We prioritized high-impact studies and pioneering experimental demonstrations in our selection process. Articles underwent screening based on their relevance to architectural frameworks, algorithmic approaches, and instrumental implementations of autonomous laboratories. The comparative evaluation in Table 1 derives from examining core technologies, application domains, and performance metrics from leading studies in this field. This approach ensured comprehensive coverage of both established and emerging research directions while maintaining focus on practically implemented systems and their experimental validation. No AI-assisted tools were used in the preparation, analysis, or writing of this review manuscript.
3. Advances in Autonomous Laboratory Architectures
Over the past decade, artificial intelligence has shifted from a supporting instrument for data analysis to a primary engine of progress in materials science and nanotechnology when paired with autonomous laboratories [1,2,3,4], a transition reflected in SDLs that assemble robotic synthesis modules, versatile in situ characterization systems, and machine learning algorithms spanning generative models, Bayesian optimization, and reinforcement learning [5,6,7]. A key advantage of these platforms is the closed-loop workflow that enables automated hypothesis generation, experimental design, synthesis, data acquisition and analysis, and the selection of the next experiment without human intervention [8,9,10], which shortens research cycles while improving reproducibility and overall data quality. A representative case is the A-Lab platform at Lawrence Berkeley National Laboratory, which achieved the first fully autonomous solid-state synthesis of inorganic compounds [11] by combining large-scale literature mining with outputs from density functional theory to plan synthesis steps, operate robotic dispensers and furnaces, and analyze powder diffraction data in real time using machine learning models [12,13,14]; this integration allows discovery of previously unknown phases within days rather than weeks or months and has already been applied to the synthesis of complex oxides with promising thermoelectric performance [12].
Progress in SDLs increasingly relies on the incorporation of flow chemistry, since flow reactors offer continuous control over composition and conditions, expand operational flexibility, and markedly increase the density of experimental data [7,8,14]. Work by Delgado-Licona and colleagues [15] showed that dynamic flow conditions in autonomous quantum dot synthesis expanded the volume of usable data by more than an order of magnitude and enabled rapid identification of conditions that deliver targeted size distributions and spectral properties, while the AlphaFlow platform integrates microfluidic channels with Bayesian optimization and active learning to support multistep reactions with precise parameter control at each stage [16].
Advances in SDLs also depend on the deep integration of in situ and in operando methods, since machine learning control of X-ray diffraction, Raman spectroscopy, and absorption spectroscopy can target the most informative spectral or angular regions, thereby reducing total experiment time and instrument load [17,18], and since the real-time theory-experiment loop implemented by Liang and co-authors [19] updates reaction parameters directly from synthesis outcomes without human intervention, a capability that is particularly important for metastable nanophases and reactions with narrow parameter ranges. Interest in generative models for inverse design continues to grow because researchers can specify target properties such as band gap or absorption coefficient and then evaluate structures proposed by the model as likely to meet those targets, as demonstrated by the Generative Toolkit for Scientific Discovery (GT4SD), an extensible open-source library for organic materials design with experimental validation [20], by a comprehensive perspective on foundational modeling that spans property prediction to molecular generation [21], and by MatterGen, a diffusion-based generative framework for inorganic materials that led to synthesis of a generated structure with properties within 20 percent of the target [22].
Despite rapid progress, several obstacles continue to limit broader adoption, with the absence of widely accepted standards for data visualization and exchange ranking among the most consequential because laboratories often maintain incompatible formats that complicate the integration of simulators, robotic systems, and AI modules; for example, XRD data stored in a proprietary format may require manual conversion before any machine learning agent in another laboratory can read it, which introduces delays and potential errors. The MGI workshop report [23] therefore calls for standardized data formats and APIs and for digital infrastructure that ensures interoperability across platforms. A further limitation arises from the scarcity of large training datasets for emerging material systems, which pushes machine learning into data-poor regimes and constrains predictive power in unexplored chemical spaces, while explainability remains a concern because decisions without transparent rationales face barriers in domains demanding strict validation such as pharmaceuticals or nuclear energy [24]. Cybersecurity risks add another layer of difficulty because SDLs are networked and thus exposed to disruption and data breaches, including threats to intellectual property [25,26,27,28], and these issues are intertwined since the lack of data standards makes explainability and robust cybersecurity more difficult to achieve.
To address these challenges, researchers are turning to new paradigms that aim to make SDLs more scalable, interoperable, and economically feasible. One promising direction is the emergence of so-called “frugal twins,” simplified digital replicas of laboratory environments that allow researchers to pre-optimize synthesis pathways and experimental workflows in a virtual setting before committing resources to costly robotic experiments. These lightweight digital twins, which can be implemented in cloud infrastructures, have been shown to accelerate design-make-test cycles while simultaneously lowering entry barriers for institutions with limited access to advanced robotics, thus making autonomous experimentation more democratized [2,4,26]. However, because frugal twins rely on simplified digital models, the predictive reliability and robustness of such surrogates still require further validation before broad adoption [2,4]. Importantly, the concept of frugal twins extends beyond mere cost reduction, where they create opportunities for running large sets of “what-if” experiments in silico, using machine learning surrogates and coarse-grained models to filter out suboptimal conditions before physical testing begins. In recent demonstrations, frugal twins were coupled to cloud laboratories, enabling dozens of geographically dispersed research groups to replicate identical experiments with minimal variation (Figure 1), effectively building a distributed ecosystem of SDLs working on harmonized protocols [29].
Such integration of digital twins and real-time experimentation not only facilitates reproducibility but also strengthens the long-term goal of open science, where data and methods can be seamlessly shared and verified across laboratories worldwide. The ability to replicate conditions virtually also helps address issues of safety and sustainability: potentially hazardous chemical routes can first be evaluated computationally, reducing unnecessary exposure to toxic reagents, while simultaneously optimizing the use of scarce or expensive precursors. These features position frugal twins as indispensable in the democratization and scaling of autonomous materials discovery, bridging the gap between theory-driven modeling and real laboratory practice.
The issue of scalability is also being addressed through the design of multi-robot self-driving laboratories, among which the Rainbow platform represents a representative example. Rainbow is distinguished by its modular and parallelized architecture, integrating multiple robotic arms, liquid handling modules, and photonic characterization systems, all coordinated by a central machine learning controller [5,6,7,10]. Unlike earlier single-arm SDLs that performed sequential optimization, Rainbow can execute combinatorial parameter sweeps in parallel, thereby exploring much larger regions of chemical space in the same timeframe. Its implementation of real-time photoluminescence (PL) monitoring allows the system to detect and respond to subtle changes in perovskite nanocrystal emission profiles, thereby guiding the optimization process with both speed and accuracy. Benchmarking studies revealed that Rainbow identified optimal perovskite nanocrystal compositions in a fraction of the time needed by conventional SDLs, with significantly reduced experimental noise [10,30]. This demonstrates Rainbow’s high-throughput discovery potential and serves as a proof-of-concept for the next generation of autonomous laboratories where parallelization, adaptability, and modularity are standard features (Figure 2).
A close examination of Rainbow’s performance metrics shows that error bars in measured photoluminescence quantum yields narrowed with successive closed-loop iterations, indicating an intrinsic capacity for self-correction and noise suppression. The figure illustrates a substantial reduction in variance across parallel reactors as the system converges toward optimal synthesis conditions, underscoring the robustness of multi-robotic workflows for reproducible nanomaterial discovery. In addition, Rainbow’s architecture points to the feasibility of scaling SDLs toward industrially relevant throughputs, where hundreds of compositions could be synthesized and characterized per day, feeding into machine learning models that progressively refine their predictive accuracy. This represents a concrete step toward bridging laboratory-scale demonstrations and pilot-scale manufacturing, a longstanding challenge in translational materials research.
Another critical advancement is the integration of natural language processing and algorithmic planning frameworks with autonomous laboratories. A recent study introduced a platform that combines automated literature analysis with the A* path-finding algorithm for the synthesis of gold nanorods (Au-NRs). The system was capable of scanning thousands of synthesis protocols in the literature, extracting relevant parameters, and building a knowledge base that guided robotic synthesis experiments [12,20,21,31]. By employing A* as the optimization engine, the platform systematically refined experimental parameters such as surfactant concentration, temperature profiles, and seed-to-precursor ratios. Notably, the system achieved highly reproducible nanorod synthesis with fine-tuned aspect ratios (Figure 3), resulting in sharp UV–vis absorption bands with linewidths narrowed below 3 nm after a few optimization cycles [31]. This example illustrates an ongoing shift and SDLs are no longer isolated automation platforms but increasingly incorporate text-processing algorithms as knowledge modules that bridge scientific literature and laboratory practice. In doing so, they reduce the information bottleneck between human knowledge and robotic action, effectively converting text-based knowledge into actionable experimental instructions. The implications of this development are significant, as it opens the possibility of automated “literature-to-lab” pipelines where AI continuously digests the scientific corpus, identifies promising synthesis strategies, and validates them experimentally with minimal human intervention [20,21]. This ability to learn from both structured datasets and unstructured textual information has the potential to become a cornerstone of next-generation SDLs.
In parallel, structural characterization is evolving through approaches such as ScatterLab, which leverages total scattering and pair distribution function (PDF) data as direct input for inverse design loops [17,18,19]. Traditionally, structure determination in materials science has been limited by the need for predefined structural models, but ScatterLab bypasses this constraint by using machine learning to map experimental scattering data directly onto atomic configurations. In recent demonstrations, the system autonomously guided the synthesis of gold nanoparticles with desired structural motifs, selecting reaction pathways that maximized agreement between in situ scattering signals and target PDF features. The graphical representation (Figure 4) illustrates how iterative refinement of synthesis parameters rapidly converged toward the correct structural arrangement, even in the absence of human-supplied crystallographic models [17,18,19,32]. This capability is particularly significant for nanostructures and metastable phases where structural disorder obscures conventional diffraction patterns. By integrating scattering data into closed-loop experimentation, ScatterLab demonstrates the potential of SDLs to not only optimize macroscopic properties such as band gaps or catalytic activity but also directly engineer atomic-level arrangements in real time. The interpretation of the figure reveals that as the feedback loop progresses, misfit values between experimental and simulated PDFs decline sharply, providing a quantitative metric of convergence and improving transparency in discovery efficiency.
Complementary to these technological advances, multi-agent architectures such as MAPPS (Materials Agent unifying Planning, Physics, and Scientists) highlight the growing importance of modular AI ecosystems in autonomous experimentation [3,16,24]. MAPPS unifies planning agents, physics-based simulators, and human-in-the-loop feedback modules into a coherent framework, thereby achieving resilience against errors and improving novelty in material proposals. Benchmarking against earlier LLM-based platforms showed that MAPPS improved stability of closed-loop experiments by a factor of five, while also expanding the diversity of candidate materials considered. Unlike single-agent models that often gravitate toward local optima, MAPPS encourages exploration of broader design spaces, mitigating the risks of premature convergence. The system has been demonstrated in case studies involving battery electrolytes and optoelectronic polymers, where the combination of simulation-driven priors and experimental validation led to the identification of previously untested but synthetically accessible candidates. Such multi-agent frameworks could represent a future pathway for SDL design, where a network of specialized AI agents collaborates with robotic hardware and human scientists to deliver balanced, interpretable, and reproducible discoveries.
To synthesize these developments, comparative analyses have begun to map the rapidly diversifying SDL ecosystem. A tabular summary of recent platforms contrasts Rainbow, GPT+A*, ScatterLab, AlphaFlow, and frugal twins in terms of architectural principles, targeted material systems, and demonstrated performance (Table 1). From this comparison, two trends emerge clearly: first, SDLs are moving toward ever-greater levels of integration, combining robotic modules, real-time characterization, and cognitive engines in a single workflow; second, reproducibility and interpretability are becoming as important as speed and throughput, reflecting the community’s recognition that scientific trust depends on transparent and verifiable decision-making processes. The analysis presented in this review directly reflects these emerging trends. The discussion of Rainbow’s architecture highlights the potential of parallelization, the GPT+A* schematics illustrate the fusion of literature and laboratory, ScatterLab’s convergence trajectories exemplify atomic-level structural control, and frugal twin frameworks emphasize the democratization and accessibility of autonomous experimentation. Taken together, these cases demonstrate that the evolution of SDLs is no longer determined by hardware or algorithms in isolation but by the holistic integration of digital infrastructure, robotic capability, AI cognition, and human oversight. This synthesis points toward a future in which autonomous discovery becomes not only faster but also more collaborative, interpretable, and impactful for the broader scientific enterprise.
In summary, the evolution of SDLs is advancing along two primary tracks: first, toward greater hardware integration and parallelization to drastically increase experimental throughput, and second, toward deeper cognitive capabilities that incorporate prior knowledge and reason across complex constraints. Platforms like Rainbow and multi-agent architectures such as MAPPS exemplify these trends, highlighting a shift from isolated automation to holistic, AI-driven discovery systems. However, truly autonomous discovery will remain elusive until the field satisfactorily addresses the intertwined fundamental challenges of data standardization, model explainability, and robust cybersecurity. Overcoming these hurdles is essential to transition from proof-of-concept demonstrations to reliable, scalable, and democratized SDLs that can fully bridge the gap between laboratory-scale innovation and industrial-scale manufacturing.
4. Conclusions
The development of self-driving laboratories represents an important step in the evolution of materials science, transitioning from traditional, sequential experimentation to autonomous, AI-driven discovery. This review has outlined the rapid evolution of SDLs, highlighting key architectural innovations such as the multi-robot parallelization exemplified by Rainbow [30], the integration of flow chemistry and Bayesian optimization in platforms like AlphaFlow [8], and the cognitive capabilities introduced by LLM-based literature mining and algorithmic planning [12,21,31]. Despite significant progress, the path toward fully autonomous discovery faces several interconnected challenges. The absence of standardized data formats and protocols continues to hinder interoperability and reproducibility [23]. The "black box" nature of complex AI models requires advances in explainable AI (XAI) to build trust and facilitate adoption in high-stakes applications such as pharmaceuticals [24]. Additionally, cybersecurity risks present growing concerns as these networked systems become more prevalent [25]. Looking forward, the convergence of several technological trends points toward a transformative future for materials research. The development of "frugal twins" and cloud-based laboratories promises to democratize access to autonomous experimentation [29], while multi-agent architectures like MAPPS enhance robustness, exploration, and collaboration between AI and human scientists [3]. The ultimate goal remains the creation of end-to-end digital pipelines that seamlessly integrate basic discovery, prototyping, and scale-up manufacturing [26].
In the next five to ten years, SDLs are expected to develop toward fully functional digital twins of laboratories and production lines, capable of modeling and optimizing not only synthesis processes but also industrial manufacturing [26]. This integration would combine basic discovery, prototyping, and large-scale production into a single automated pipeline. Current work already demonstrates adaptation of SDLs for quantum electronics, nanophotonics, and nanomedicine, including autonomous optimization of defects in diamond nitrogen-vacancy (NV) centers, design of negative refractive index metamaterials, and development of nanoparticles for targeted drug delivery with programmable pharmacokinetics [33,34,35,36,37,38,39,40]. These developments bring us closer to autonomous platforms that can generate ideas, design experiments, interpret results, and even prepare draft patent documentation with minimal human supervision.
The widespread adoption of self-driving laboratories promises not only to accelerate materials discovery but also to change established research practice, fostering a more data-driven, reproducible, and collaborative research ecosystem. By enabling efficient exploration of vast chemical spaces, these systems could help address pressing global challenges related to energy, healthcare, and sustainability through rapid development of advanced functional materials. Ultimately, overcoming the challenges of data standardization, explainability, and cybersecurity will be crucial to fully realizing this transformative potential and bridging the gap between laboratory-scale innovation and industrial-scale manufacturing.
Author Contributions
Conceptualization, D.N. and I.R.; literature search and data curation, D.N.; writing – original draft preparation, D.N. and I.R.; writing – review and editing, D.N. and I.R. All authors have read and agreed to the published version of the manuscript. No AI tools were used in the preparation of this work.
Funding
This research was funded by the Interstate Fund for Humanitarian Cooperation of the CIS Member States, grant number 25-113, and the International Science and Technology Center (ISTC), grant number TJ-2726.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
|
AI – Artificial intelligence ML – Machine learning SDL – Self-driving laboratory DFT – Density functional theory XRD – X-ray diffraction PL – Photoluminescence PLQY – Photoluminescence quantum yield GPT – Generative pre-trained transformer A* – A-star path-finding algorithm LLM – Large language model UV–vis – Ultraviolet–visible (spectroscopy) PDF – Pair distribution function TEM – Transmission electron microscopy NV – Nitrogen-vacancy (in diamond) MAPPS – Materials Agent unifying Planning, Physics, and Scientists MGI – Materials Genome Initiative XAI – Explainable artificial intelligence BO – Bayesian optimization RL – Reinforcement learning NBP – Nanobipyramid Au-NR – Gold nanorod |
References
- T. K. R. Tom, B. P. MacLeod, F. G. L. Parlane, T. H. Morrissey, T. D. D. Mustakim, C. P. Berlinguette, et al., "Self-driving laboratories in chemistry and materials science," Chem. Rev., vol. 124, no. 12, pp. 6463–6525, Jun. 2024. [CrossRef]
- P. M. Bayley, H. Hao, J. M. R. Greer, A. I. Cooper, "Navigating self-driving laboratories," Digit. Discov., vol. 3, no. 3, pp. 628–645, Mar. 2024. [CrossRef]
- H. Hysmith, J. D. Gani, J. M. Rondinelli, "Human-in-the-loop approaches to self-driving laboratories," Digit. Discov., vol. 3, no. 4, pp. 835–849, Apr. 2024. [CrossRef]
- A. Volk, M. Abolhasani, "Performance metrics for self-driving laboratories," Nat. Commun., vol. 15, Art. no. 4234, May 2024. [CrossRef]
- N. J. Szymanski, Y. Zeng, H. Huo, C. J. Bartel, H. Kim, G. Ceder, "Autonomous synthesis of inorganic materials," Nature, vol. 615, no. 7953, pp. 604–610, Mar. 2023. [CrossRef]
- Nature News, "Self-driving lab produces new materials," Nature, vol. 615, no. 7953, p. 578, Mar. 2023. (News & Views). [CrossRef]
- F. Delgado-Licona, A. J. S. Valentine, K. D. Elkin, J. C. Williams, M. Abolhasani, "Dynamic flow chemistry in autonomous nanocrystal synthesis," Nat. Chem. Eng., vol. 1, no. 2, pp. 134–142, Feb. 2025. [CrossRef]
- A. Volk, S. E. Motta, M. Abolhasani, "AlphaFlow: Autonomous multi-step flow synthesis," Nat. Commun., vol. 14, Art. no. 5048, Aug. 2023. [CrossRef]
- Y. Liang, A. R. Khan, D. W. Apley, W. Chen, "Real-time theory–experiment closed-loop in materials discovery," Sci. Adv., vol. 11, no. 3, eadk5123, Jan. 2025. [CrossRef]
- N. J. Szymanski, B. Rendy, Y. Fei, R. E. Kumar, Y. Zeng, G. Ceder, "Adaptive XRD control in autonomous labs," npj Comput. Mater., vol. 9, Art. no. 155, Aug. 2023. [CrossRef]
- M. Manica, J. C. da Silva, R. Guidici, T. Laino, "Generative models for organic materials design," npj Comput. Mater., vol. 9, Art. no. 102, Jun. 2023. [CrossRef]
- S. Takeda, A. Kishimoto, L. Hamada, D. Nakano, and J. R. Smith, "Foundation Model for Material Science," in Proc. AAAI Conf. Artif. Intell., vol. 37, no. 13, pp. 15376-15383, Feb. 2024. [CrossRef]
- D. Nematov, "Bandgap tuning and analysis of the electronic structure of the Cu2NiXS4 (X = Sn, Ge, Si) system: mBJ accuracy with DFT expense," Chem. Inorg. Mater., vol. 1, Art. no. 100001, Sep. 2023. [CrossRef]
- T. D. Nguyen, "Materials Genome Initiative (MGI) Biennial Principal Investigator Workshop," in Proc. MGI Bienn. PI Workshop, Washington, DC, USA, Jul. 30-31, 2024, NSF Award 2422384. [Online]. Available: https://www.nsf.gov/awardsearch/showAward?AWD_ID=2422384.
- F. Delgado-Licona, A. Alsaiari, H. Dickerson, P. Klem, A. Ghorai, R. B. Canty, et al., "Flow-driven data intensification to accelerate autonomous inorganic materials discovery," Nat. Chem. Eng., vol. 2, no. 3, pp. 436–446, Mar. 2025. [CrossRef]
- A. V. Tobias, "Autonomous 'self-driving' laboratories: a review of technology and implications," R. Soc. Open Sci., vol. 12, no. 1, p. 231509, Jan. 2025. [CrossRef]
- Y. Qi, D. Hu, Z. Wu, M. Zheng, G. Cheng, Y. Jiang, and Y. P. Chen, "Deep learning-assisted Raman spectroscopy for rapid identification of 2D materials," arXiv preprint arXiv:2312.01389, Dec. 2023. [Online]. Available: https://arxiv.org/abs/2312.01389.
- Huang, M. G. Bawendi, and T. Buonassisi, "Adaptive absorption spectroscopy with active learning for materials discovery," Adv. Funct. Mater., vol. 33, no. 45, Art. no. 2304561, Oct. 2023. [CrossRef]
- K. Choudhary, B. DeCost, and F. Tavazza, "AI-enabled discovery of metastable phases via closed-loop experimentation," npj Comput. Mater., vol. 10, Art. no. 92, May 2024. [CrossRef]
- M. Manica, J. Born, J. Cadow, et al., "Accelerating material design with the generative toolkit for scientific discovery," npj Comput. Mater., vol. 9, Art. no. 69, May 2023. [CrossRef]
- E. O. Pyzer-Knapp, M. Manica, P. Staar, et al., "Foundation models for materials discovery – current state and future directions," npj Comput. Mater., vol. 11, Art. no. 61, Apr. 2025. [CrossRef]
- C. Zeni, R. Pinsler, D. Zügner, et al., "A generative model for inorganic materials design," Nature, vol. 639, pp. 624–632, May 2025. [CrossRef]
- M. L. Green, C. Wolverton, and J. M. Rondinelli, "Materials Genome Initiative: Update and outlook," APL Mater., vol. 11, no. 11, p. 110401, Nov. 2023. [CrossRef]
- Rudin, D. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead," Nat. Mach. Intell., vol. 1, no. 5, pp. 206–215, May 2019. [CrossRef]
- J.-P. A. Yaacoub, H. N. Noura, O. Salman, and A. Chehab, "Robotics cyber security: Vulnerabilities, attacks, countermeasures, and recommendations," Int. J. Inf. Secur., vol. 21, no. 1, pp. 115–158, Feb. 2022. [CrossRef]
- S. R. Kalidindi, M. Buzzy, B. L. Boyce, and R. Dingreville, "Digital twins for materials," Front. Mater., vol. 9, Art. no. 818535, Feb. 2022. [CrossRef]
- C. Foy, D. D. Awschalom, and N. P. de Leon, "Autonomous defect engineering in diamond NV centers," ACS Nano, vol. 18, no. 5, pp. 4567–4579, Feb. 2024. [CrossRef]
- G. Moon, J. R. Choi, C. Lee, Y. Oh, K. H. Kim, and D. Kim, "Machine learning-based design of meta-plasmonic biosensors with negative index metamaterials," Biosens. Bioelectron., vol. 164, Art. no. 112335, Sep. 2020. [CrossRef]
- Cаnty, R. B.; Bennett, J. A.; Brown, K. A.; Buonassisi, T.; Kalinin, S. V.; Kitchin, J. R.; Maruyama, B.; Moore, R. G.; Schrier, J.; Seifrid, M.; Sun, S.; Vegge, T.; Abolhasani, M. “Science acceleration and accessibility with self-driving labs,” Nat. Commun., 2025, 16(1), 3856. [CrossRef]
- Xu, J.; Moran, C. H. J.; Ghorai, A.; Bateni, F.; Bennett, J. A.; Mukhin, N.; Latif, K.; Cahn, A.; Jha, P.; Delgado Licona, F.; Sadeghi, S.; Politi, L.; Abolhasani, M. “Autonomous multi-robot synthesis and optimization of metal halide perovskite nanocrystals,” Nat. Commun., 2025, 16(1), 7841. [CrossRef]
- Gao, F.; Li, H.; Chen, Z.; Yi, Y.; Nie, S.; Cheng, Z.; Liu, Z.; Guo, Y.; Liu, S.; Qin, Q.; Li, Z.; Zhang, L.; Hu, H.; Li, C.; Yang, L.; Wang, Y.; Chen, G. “A chemical autonomous robotic platform for end-to-end synthesis of nanoparticles,” Nat. Commun., 2025, 16(1), 7558. [CrossRef]
- Anker, A. S.; Jensen, J. H.; Gonzalez-Duque, M.; Moreno, R.; Smolska, A.; Juelsholt, M.; Hardion, V.; Jørgensen, M. R. V.; Faina, A.; Quinson, J.; Stoy, K.; Vegge, T. “Autonomous nanoparticle synthesis by design,” arXiv 2025, arXiv:2505.13571.
- Liao, J.; Shenhav, L.; Urban, J. A.; Serrano, M.; Zhu, B.; Buck, G. A.; Korem, T. “Microdiversity of the vaginal microbiome is associated with preterm birth,” Nat. Commun., 2023, 14(1), 4997. [CrossRef]
- H. Zhang, W. C. W. Chan, and O. C. Farokhzad, "Autonomous synthesis of nanoparticles for targeted drug delivery," Small, vol. 20, no. 15, Art. no. 2308123, Apr. 2024. [CrossRef]
- S. Sarkar, Z. Sun, X. Xu, and W. Liu, "Physics-informed machine learning for inverse design of optical metamaterials," Adv. Photonics Res., vol. 4, no. 9, Art. no. 2300094, Sep. 2023. [CrossRef]
- H. B. Sedeh, E. Fathi, S. Khani, and H. Mosallaei, "Toward the meta-atom library: Experimental validation of machine learning-based design," Adv. Photonics, vol. 7, no. 3, Art. no. 036004, May 2025. [CrossRef]
- X. Q. Han, X. D. Wang, M. Y. Xu, Z. Feng, B. W. Yao, P. J. Guo, et al., "AI-driven inverse design of materials: Past, present, and future," Chin. Phys. Lett., vol. 42, no. 2, Art. no. 027403, Feb. 2025. [CrossRef]
- E. Nematov and M. Hojamberdiev, "Machine Learning-Driven Materials Discovery: Unlocking Next-Generation Functional Materials–A Minireview," arXiv preprint arXiv:2503.18975, Mar. 2025. [Online]. Available: https://arxiv.org/abs/2503.18975.
- K. Zhang, Y. Liu, H. Li, and J. Wu, "Deep learning-based inverse design of metamaterial lattice band structures," Extreme Mech. Lett., vol. 67, Art. no. 102013, Mar. 2024. [CrossRef]
- L. Wu, Y. Shen, J. Li, and X. Zhang, "Machine learning-based design of meta-plasmonic biosensors with negative refractive index," Photonics Nanostruct. Fundam. Appl., vol. 39, Art. no. 100857, Dec. 2020. [CrossRef]
Figure 1.
Interconnected challenges slowing the advancement of self-driving laboratory platforms [29].
Figure 1.
Interconnected challenges slowing the advancement of self-driving laboratory platforms [29].
Figure 2.
Schematic representation of Rainbow’s components and automated functionalities [30]: a) Rainbow consists of a characterization robot (Robot 1), a pipetting robot (Robot 2), a robotic arm (Robot 3), a labware refreshment robot (Robot 4), and an AI agent. The integrated hardware enables automated (i) multi-step synthesis, (ii) sampling, (iii) characterization, and (iv) labware restocking. b) Photograph of Rainbow’s hardware, highlighting the pipetting robot (red), characterization robot (magenta), robotic arm (cyan), and labware refreshment robot (green).
Figure 2.
Schematic representation of Rainbow’s components and automated functionalities [30]: a) Rainbow consists of a characterization robot (Robot 1), a pipetting robot (Robot 2), a robotic arm (Robot 3), a labware refreshment robot (Robot 4), and an AI agent. The integrated hardware enables automated (i) multi-step synthesis, (ii) sampling, (iii) characterization, and (iv) labware restocking. b) Photograph of Rainbow’s hardware, highlighting the pipetting robot (red), characterization robot (magenta), robotic arm (cyan), and labware refreshment robot (green).

Figure 3.
Literature mining and characterization of Au nanobipyramids (NBPs) [31]: (a) Workflow of the literature mining module for nanoparticle synthesis; (b) UV–vis spectra of Au NBPs synthesized with optimal parameters; (c) Transmission electron microscopy (TEM) images of Au NBPs (scale bar = 200 nm); (d) Longitudinal length statistics; (e) Radial length statistics.
Figure 3.
Literature mining and characterization of Au nanobipyramids (NBPs) [31]: (a) Workflow of the literature mining module for nanoparticle synthesis; (b) UV–vis spectra of Au NBPs synthesized with optimal parameters; (c) Transmission electron microscopy (TEM) images of Au NBPs (scale bar = 200 nm); (d) Longitudinal length statistics; (e) Radial length statistics.
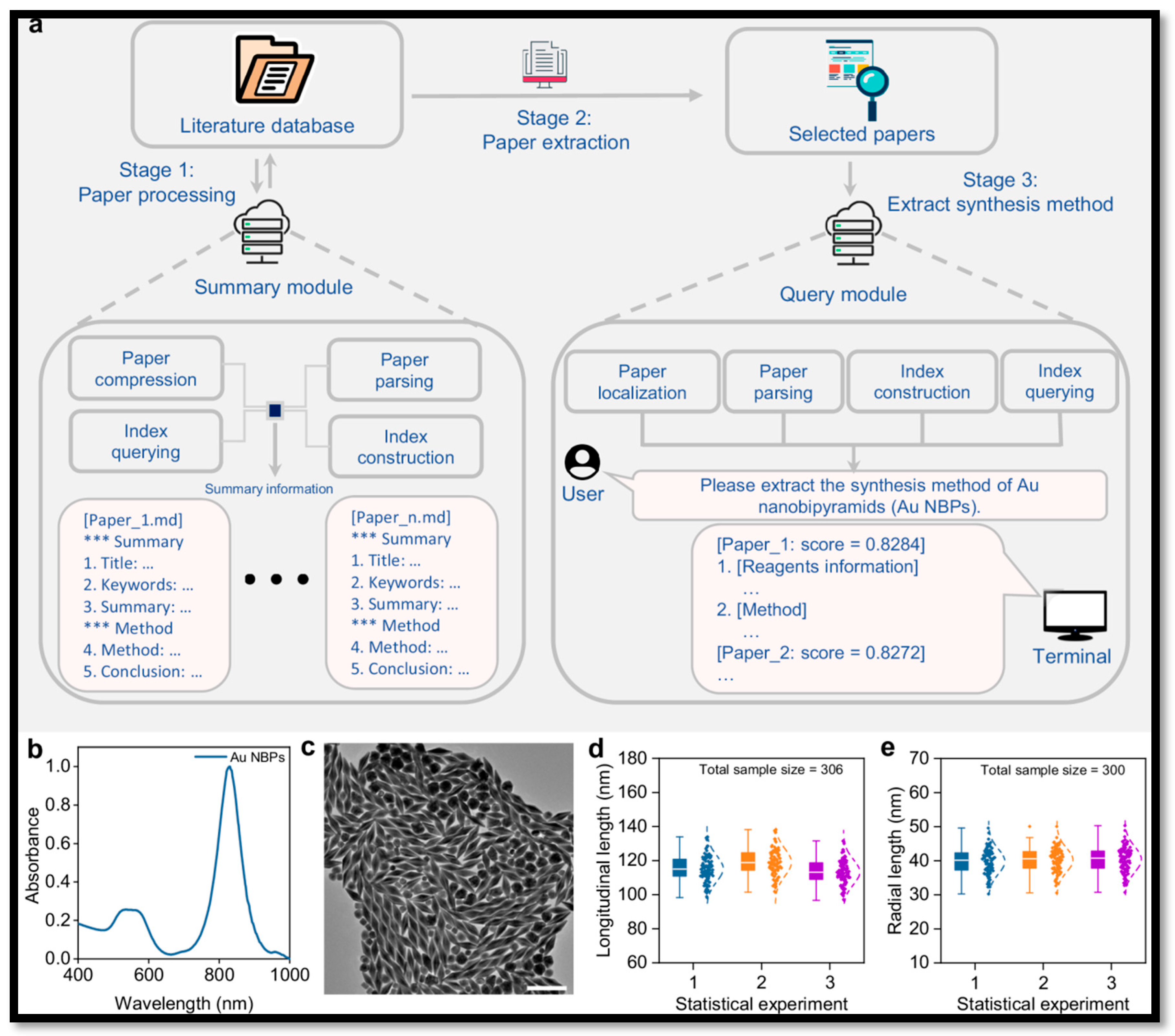
Figure 4.
Workflow of ScatterLab integrating robotic synthesis, scattering experiments, and Bayesian optimization [32].
Figure 4.
Workflow of ScatterLab integrating robotic synthesis, scattering experiments, and Bayesian optimization [32].
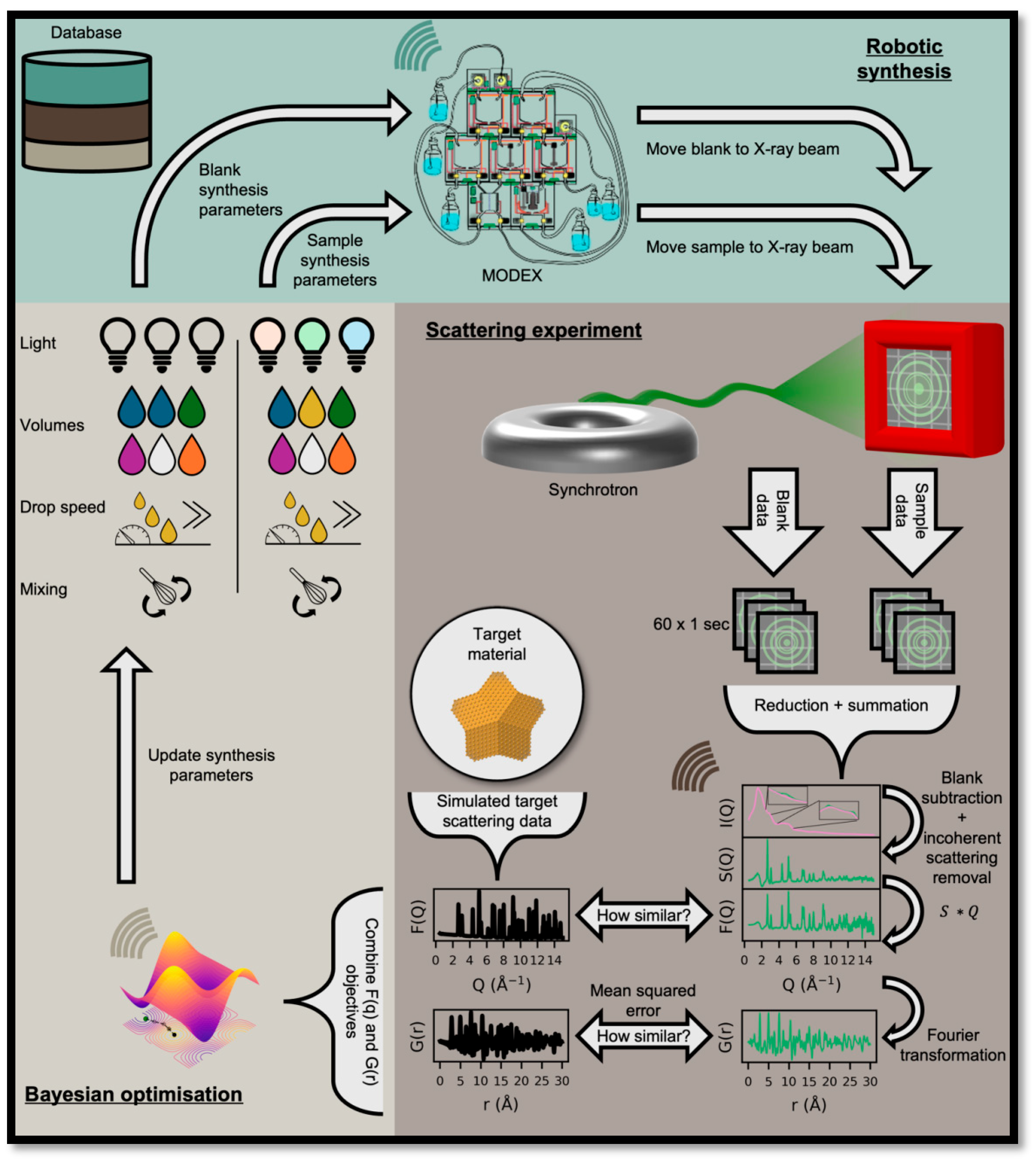

Table 1.
Comparative summary of recent SDL platforms for nanomaterials.
| PLATFORM | YEAR | CORE TECHNOLOGY | APPLICATION DOMAIN | SOURCE |
| Rainbow | 2025 | Multi-robot parallelized workflow with real-time PL monitoring | Perovskite nanocrystals, optoelectronics | [30] |
| GPT + A* | 2025 | GPT literature mining + A* path-finding optimization |
Gold nanorods, nanophotonics | [31] |
| ScatterLab | 2025 | Total scattering + PDF-driven inverse design | Nanoparticles, metastable phases | [32] |
| AlphaFlow | 2023 | Autonomous multi-step flow synthesis with Bayesian optimization | Nanocrystals, inorganic materials | [8] |
| Frugal Twin | 2025 | Cloud-based digital twins, cost-efficient virtual labs | Generalizable across nanomaterials | [29] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



