
Submitted:
18 August 2025
Posted:
19 August 2025
You are already at the latest version
Abstract
We present a single-loop, real-time Koopman control framework where the model and controller are updated continuously from streaming data. Leveraging the ESL hierarchy, we show that Koopman-learnable systems admit streamable finite-rank surrogates and we instantiate them via Oja/PAST updates with TSQR orthonormalization. At each sample, a warm-started Kleinman/Riccati step updates the gain, and a lightweight safety projection enforces a contraction margin in a Lyapunov metric. We provide Bauer–Fike stability transfer and ISS bounds under model mismatch, yielding explicit tube radii rt+1 =√εt/(1−γ). The per-step complexity is O(d r2) with rd. This eliminates train→deploy→retrain phases and offers a constructive path from ESL guarantees to real-time nonlinear control.
Keywords:
online learning
; duality theorem
; low-rank methods
; convergence analysis
; machine learning
1. Introduction
Thesis. We show that ESL’s streamability guarantees yield constructive, finite-rank Koopman surrogates that can be trained and deployed in a single streaming loop, with per-step stability projection and O(d r²) amortized cost.
The Koopman operator framework has emerged as a transformative approach to nonlinear control by lifting dynamics to infinite-dimensional spaces where they evolve linearly [1,2,3]. This linearization enables the direct application of mature linear control theory to inherently nonlinear systems, offering significant theoretical and computational advantages. However, the infinite-dimensional nature of the Koopman operator presents fundamental challenges for practical implementation, particularly in real-time control applications where computational resources are constrained and stability guarantees are paramount.
The Extended Dynamic Mode Decomposition (EDMD) method addresses this challenge by projecting the infinite-dimensional Koopman operator onto a finite-dimensional subspace spanned by a chosen dictionary of observables [4,5]. While EDMD has demonstrated remarkable empirical success across diverse applications, the theoretical foundations underlying finite-rank approximations remain incomplete. Critical questions persist regarding when such approximations exist, how to construct them systematically, what error bounds can be guaranteed, and how controllers designed on approximate models perform when deployed on true plants.
We resolve these fundamental questions by establishing a rigorous connection between Koopman operator theory and the recently developed -Streamably-Learnable (ESL) hierarchy [6,7]. The ESL framework provides a complete classification of optimization problems based on the existence and structure of -averaged operators, with three distinct classes: non-learnable problems that admit no convergent iterative methods, learnable problems that admit convergent batch algorithms, and streamable problems that additionally possess uniform low-rank structure enabling efficient streaming implementations.
The key insight underlying our approach is that dynamical systems amenable to Koopman control correspond precisely to learnable problems in the ESL sense, while finite-rank Koopman approximations correspond to streamable problems. This connection is not merely analogical but mathematically precise: we prove that learnability in EDMD coordinates is equivalent to contractivity of the finite Koopman operator, and that the ESL density theorem guarantees the existence of arbitrarily accurate streamable approximations for any learnable system.
1.1. Main Contributions
1. Existence → Constructiveness. From ESL to practice: if a system is Koopman-learnable ((K)<1 in lifted coordinates), then there exist ESL-streamable low-rank surrogates; we instantiate them with Oja/PAST+TSQR updates and state explicit residual→tube bounds.
2. Single-loop control. A unified ASKC loop that (i) updates a low-rank Koopman model, (ii) runs a one-step Kleinman/Riccati gain update, and (iii) enforces a per-step contraction via a tiny QP/projection—no train→deploy phases.
3. Provable safety at streaming cost. ISS bounds under model drift, stability transfer via Bauer–Fike, and dynamic-regret flavor guarantees, all at O(d r²) per step (r≪d).
1.2. Related Work and Positioning
Our work builds upon and extends several distinct research threads in control theory and machine learning. The Koopman operator framework was introduced by Koopman in 1931 [1] and has experienced renewed interest following the development of data-driven approximation methods [2,9]. The Dynamic Mode Decomposition (DMD) algorithm [10] and its extensions, particularly EDMD [4], have enabled practical applications of Koopman theory to complex nonlinear systems.
Recent advances in Koopman-based control include the development of Model Predictive Control formulations [5,11], stability analysis for closed-loop systems [12], and applications to robotics and aerospace systems [13,14]. However, these works typically rely on heuristic finite-rank approximations without rigorous theoretical justification for the approximation quality or stability guarantees.
The ESL hierarchy, introduced in our prior work [6,7], provides a novel framework for understanding the computational complexity of optimization problems through the lens of operator theory. The hierarchy has been successfully applied to neural network training [15], federated learning, and streaming optimization, but its connection to dynamical systems and control theory has not been previously explored.
Our contribution lies in recognizing and formalizing the deep connection between these seemingly disparate frameworks, leading to both theoretical insights and practical algorithms that advance the state of the art in data-driven control.
1.3. Paper Organization
The remainder of this paper is organized as follows. Section 2 establishes the mathematical foundations, including the ESL hierarchy, Koopman operator theory, and their interconnections. Section 3 presents our main theoretical results, including the learnability-contractivity equivalence and the constructive density theorem. Section 4 develops the streaming algorithm for real-time Koopman learning with detailed convergence analysis. Section 5 provides comprehensive stability analysis for controllers designed on finite surrogates, including ISS bounds and robust MPC formulations. Section 6 presents implementation algorithms and computational complexity analysis. Section 7 demonstrates the framework through extensive numerical experiments on canonical control problems. Section 8 discusses limitations, failure modes, and future research directions. Section 9 concludes with a summary of contributions and broader implications.
2. Mathematical Foundations
This section establishes the mathematical framework underlying our approach, including the ESL hierarchy, Koopman operator theory, and their fundamental interconnections. We begin with the operator-theoretic foundations that enable our analysis, then develop the specific structures needed for dynamical systems and control applications.
2.1. The -Streamably-Learnable Hierarchy
The ESL hierarchy provides a complete classification of optimization problems based on the existence and structure of -averaged operators. This classification has profound implications for computational complexity and algorithmic design, as it precisely characterizes when efficient streaming algorithms exist and when they can achieve performance comparable to batch methods.
Definition 1
(-Averaged Operator). Let be a finite-dimensional Hilbert space and be a nonempty, closed, and convex set. An operator is α-averaged for if there exists a nonexpansive operator such that
where I denotes the identity operator on V.
The significance of -averaged operators lies in their guaranteed convergence properties. By the Krasnosel’skiĭ-Mann theorem [8], the fixed-point iteration converges weakly to a fixed point of T for any starting point , provided that . This convergence property forms the foundation for defining learnable problems.
Definition 2
(Problem Classification in the ESL Hierarchy). Consider an optimization problem where is the objective function and is the feasible set. The problem is classified as:
- Non-learnable if no α-averaged operator exists such that the fixed-point iteration converges to a solution of the optimization problem.
- Learnable if there exists an α-averaged operator with fixed point such that the iteration converges to for all .
-
Streamable at rank K if the problem is learnable and the residual mapping satisfies the uniform low-rank approximation property:for some bounded maps and approximation error .
The hierarchy establishes strict inclusions: . The streamable class is particularly important for our purposes, as it precisely characterizes when efficient low-rank algorithms exist with provable performance guarantees.
ESL Bridge to Koopman Theory: ESL classifies problems by the existence of averaged operators and their uniform low-rank residuals. In lifted Koopman coordinates, learnability corresponds to a strict contraction ((K)<1); streamability ensures the residual admits separable, low-rank updates, enabling our Oja/PAST+TSQR loop with explicit residual→tube bounds. (Proof sketch → Appendix A.)
Definition 3
(Uniform Residual Metric). For two learnable problems with α-averaged operators and corresponding residual mappings and , define the uniform residual distance as:
This metric enables us to formalize the notion of approximation quality between different operators and provides the foundation for our density results.
Theorem 1
(Density of Streamable Problems). Streamable problems are dense in learnable problems under the uniform residual metric. Specifically, for every learnable problem with α-averaged operator and every , there exists a streamable problem with α-averaged operator such that .
The proof of this fundamental result is constructive and provides an explicit algorithm for converting any learnable problem into a streamable approximation. This constructive nature is crucial for our applications to Koopman control, as it guarantees that finite-rank approximations can always be found with controllable error.
2.2. Koopman Operator Theory for Dynamical Systems
We now turn to the Koopman operator framework for analyzing nonlinear dynamical systems. Consider a discrete-time nonlinear control system of the form:
where represents the state at time t, is the control input, and is the system dynamics.
Assumption 1
(System Regularity). The state space is compact and forward-invariant under the dynamics (4) for all admissible controls . The function f is locally Lipschitz continuous in both arguments, uniformly over the compact sets .
The Koopman operator approach linearizes the nonlinear dynamics (4) by lifting the state to a higher-dimensional space of observables. Let denote a space of scalar-valued functions on , and define the Koopman operator for a fixed control input u by:
for any observable .
The key insight is that while the original dynamics (4) are nonlinear in the state x, the evolution of observables under the Koopman operator is linear. This linearity enables the application of linear systems theory to analyze and control inherently nonlinear systems.
For practical implementation, we must work with finite-dimensional approximations of the infinite-dimensional Koopman operator. This is achieved through the Extended Dynamic Mode Decomposition (EDMD) method, which projects the Koopman operator onto a finite-dimensional subspace.
Definition 4
(Dictionary of Observables). A dictionary is a vector-valued function whose components are scalar observables. We assume that:
- The dictionary is bounded: .
- The dictionary separates points: if , then .
- The dictionary contains a constant function: for all .
Given a dictionary , the EDMD method approximates the Koopman operator by the finite-dimensional matrices that best fit the linear relationship:
The matrices are typically computed via least squares regression on collected trajectory data:
where represents collected trajectory data.
2.3. Connection Between ESL Theory and Koopman Operators
The fundamental connection between the ESL hierarchy and Koopman operator theory lies in recognizing that the EDMD approximation (6) defines a learning problem in the lifted coordinate space . The quality of this approximation and the existence of efficient algorithms depend critically on the spectral properties of the matrix K.
Definition 5
(Lifted System Dynamics). Given a dictionary Φ and EDMD matrices , define the lifted system dynamics as:
where and represents the modeling error:
The key insight is that the autonomous part of the lifted dynamics (with ) corresponds to an optimization problem in the ESL hierarchy. Specifically, consider the problem of predicting the next lifted state given the current lifted state. This prediction problem is learnable if and only if the matrix K has spectral radius less than one, which corresponds to contractivity of the associated operator.
Lemma 1
(Spectral Radius and Contractivity). Let be the autonomous EDMD matrix. The following are equivalent:
- The spectral radius satisfies .
- There exists a norm on such that K is a strict contraction: for some and all .
- The operator is α-averaged for some in an appropriately chosen norm.
Proof.
The equivalence of (1) and (2) follows from the spectral radius formula and the existence of matrix norms that make any matrix with spectral radius less than one into a contraction [16].
For (2) ⇒ (3), if K is a strict contraction with constant in the norm , then the operator can be written as where and . The operator S is nonexpansive in the norm by construction.
For (3) ⇒ (1), if is -averaged, then T is nonexpansive in some norm, which implies . The strict inequality follows from the convergence requirement for -averaged operators. □
This lemma establishes the fundamental connection between the spectral properties of EDMD matrices and the learnability classification in the ESL hierarchy. Systems with correspond to learnable problems, while systems with are non-learnable in the lifted coordinates.
Definition 6
(Koopman-Learnable Systems). A nonlinear control system (4) is Koopman-learnable with respect to a dictionary Φ if the autonomous EDMD matrix K (computed with ) satisfies .
The significance of this definition extends beyond mere classification. Koopman-learnable systems admit convergent prediction algorithms in the lifted space, enable stable controller design, and, as we will show, possess finite-rank approximations with explicit error bounds.
2.4. Streamability and Low-Rank Structure
The final piece of our theoretical foundation concerns the connection between streamability in the ESL hierarchy and low-rank structure in Koopman operators. This connection is crucial for developing efficient algorithms that scale to high-dimensional systems.
Definition 7
(Koopman-Streamable Systems). A Koopman-learnable system is Koopman-streamable at rank r if the EDMD matrix K admits a rank-r approximation such that:
for some tolerance , where denotes the spectral norm.
The rank-r approximation can be computed via the singular value decomposition (SVD) of K:
where are the singular values. The optimal rank-r approximation is given by:
with approximation error by the Eckart-Young theorem.
The streamability property has profound implications for computational efficiency. Instead of storing and manipulating the full matrix K, we can work with the rank-r factorization where . This reduces the storage requirement from to and enables efficient streaming updates as new data becomes available.
Proposition 1
(Computational Benefits of Streamability). For a Koopman-streamable system at rank r with dictionary dimension d:
- Memory complexity: Storage reduces from to .
- Computational complexity: Matrix-vector products reduce from to operations.
- Update complexity: Streaming updates require operations per sample for TSQR orthonormalization instead of for batch recomputation.
For typical applications with and , this represents a one–to–two order-of-magnitude reductions in memory and time (depending on r and orthonormalization cadence).
These computational benefits become increasingly important as the dictionary dimension d grows, which is often necessary to capture complex nonlinear dynamics. The streamability framework provides a principled approach to achieving these benefits while maintaining theoretical guarantees on approximation quality and control performance.
3. Main Theoretical Results
This section presents our principal theoretical contributions, establishing the fundamental connections between ESL theory and Koopman operators, and providing constructive algorithms for finite-rank approximations with explicit error bounds. Our results resolve key theoretical gaps in the Koopman control literature while providing practical algorithms for implementation.
3.1. Learnability-Contractivity Equivalence
Our first main result establishes a precise equivalence between learnability in the ESL hierarchy and contractivity of finite Koopman operators. This equivalence provides the theoretical foundation for all subsequent developments.
Theorem 2
(Learnability–Contraction (operative form)). For a linear system , the following are equivalent:
- (i)
- (Koopman-learnable).
- (ii)
- There exists a weighted norm such that K is a strict contraction: for some .
Remark on -averagedness.
If an operator is α-averaged, then K is nonexpansive (), which implies . However, to ensure , a strict contraction margin is required.
Proof.
We establish the fundamental equivalence and then prove the sufficient conditions.
Fundamental Equivalence :
: If , then by standard spectral theory, there exists a matrix norm such that . Any matrix norm induces a corresponding weighted vector norm for some positive definite matrix W, establishing the contraction property.
: If K is a strict contraction in some weighted norm, then for all z and . This implies by the spectral radius formula .
Sufficient Conditions:
under normality: If K is normal (i.e., ) and , then , ensuring exponential convergence of the Picard iteration with rate .
under bounded condition number: If with , then , establishing convergence of fixed-point iterations when .
under appropriate iteration design: For the prediction problem , the gradient descent iteration can be written as . When K is contractive and is chosen appropriately, this iteration admits an -averaged structure. □
This theorem has several important implications. First, it provides a computationally verifiable criterion for determining when Koopman-based control is theoretically justified: simply compute the EDMD matrix K and check whether . Second, it guarantees that learnable systems admit convergent algorithms for model learning and state prediction. Third, it establishes the foundation for our subsequent results on finite-rank approximations and stability analysis.
3.2. Constructive Density Theorem for Koopman Systems
Our second main result extends the general ESL density theorem to the specific context of Koopman operators, providing a constructive algorithm for approximating any learnable system with a streamable (low-rank) surrogate.
Theorem 3
(Koopman Streamable Density). Let the nonlinear system (4) be Koopman-learnable with EDMD matrices and dictionary Φ. For any , there exist rank-r matrices and a modified dictionary such that:
- The approximation error is bounded: .
- The rank-r system is Koopman-streamable.
- The closed-loop performance degradation is bounded: if is a stabilizing controller for the original system, then the same controller applied to the rank-r system maintains stability with performance degradation .
Moreover, the construction is algorithmic and provides explicit bounds on the required rank .
Proof.
The proof is constructive and proceeds through several steps.
Step 1: SVD-based rank reduction. Compute the singular value decomposition of the EDMD matrices:
Choose the rank r such that and . Define the rank-r approximations:
By the Eckart-Young theorem, this choice ensures and .
Step 2: Streamability verification. The rank-r matrices admit factorizations and where , , and .
To verify streamability according to Definition 2, we need to show that the residual mapping defined by
can be uniformly approximated by separable functions. For the rank-r approximation, the prediction becomes:
The residual for any true trajectory can be written as:
where . This residual admits the separable approximation:
where are scalar functions and are the columns of . This satisfies the ESL separability condition with approximation error bounded by the truncation error .
Step 3: Stability preservation. Suppose stabilizes the original system, meaning the closed-loop matrix satisfies . For the rank-r system, the closed-loop matrix becomes:
By matrix perturbation theory, assuming is diagonalizable with eigenvector matrix V having condition number , the Bauer-Fike theorem gives:
For systems where the closed-loop matrix is normal (e.g., symmetric or skew-symmetric), we have and the bound simplifies to the spectral norm bound. If is chosen sufficiently small such that , then , ensuring stability of the rank-r system.
Step 4: Performance bound. The performance degradation can be quantified using standard linear systems theory. If is the quadratic cost functional, then the cost difference between the original and rank-r systems satisfies:
for some constant C depending on the system parameters and controller gains.
Step 5: Rank bound. The required rank depends on the singular value decay of the EDMD matrices. For matrices with exponential singular value decay , we have . For polynomial decay , we have . □
This theorem provides several crucial guarantees. First, it ensures that any Koopman-learnable system can be approximated arbitrarily well by a streamable system, resolving the fundamental question of when finite-rank approximations are justified. Second, it provides explicit error bounds that enable principled trade-offs between computational efficiency and approximation quality. Third, it guarantees that stability and performance properties are preserved under the approximation, subject to appropriate choice of the rank parameter.
3.3. Error Propagation and Robustness Analysis
Our third main result analyzes how approximation errors in the Koopman model propagate through the closed-loop system when controllers designed on the approximate model are applied to the true plant.
Theorem 4
(Closed-Loop Error Propagation). Consider a Koopman-learnable system with true EDMD matrices and rank-r approximations . Let be a controller designed for the rank-r system such that the closed-loop matrix satisfies .
When this controller is applied to the true system, the lifted state evolution satisfies:
where is the model mismatch and is the Koopman modeling error.
Under the bounds and for all t, the closed-loop system is input-to-state stable with:
If , then the system remains stable with ultimate bound:
Proof.
The proof follows standard input-to-state stability analysis for linear systems with additive disturbances.
Starting from the perturbed dynamics:
we can bound the state evolution recursively. Taking norms:
If , then the recursion yields:
For the more general case where may be larger, we use the Bellman-Grönwall lemma. The recursion can be written as:
Applying the discrete Grönwall inequality with yields the bound (25). □
This theorem provides crucial insights for practical implementation. It shows that the stability margin of the nominal controller must exceed the model mismatch to maintain closed-loop stability. This provides a principled approach for choosing the rank r in the approximation: select r large enough that , where is the desired closed-loop contraction rate.
3.4. Constructive Algorithm for Streamable Approximation
Building on the theoretical results, we now present a constructive algorithm that converts any Koopman-learnable system into a streamable approximation with explicit error bounds.
Note on dimensions: The factorization uses and with , , . The regularization parameter (e.g., ) provides forgetting/regularization for adaptation to time-varying dynamics.
Proposition 2
(Algorithm Correctness). Algorithm 1 terminates in finite time and produces a rank-r streamable approximation satisfying:
- Error bound: .
- Stability preservation: .
- Streamability: The system admits streaming updates.
The required rank satisfies for exponentially decaying singular values.
| Algorithm 1 Single-Loop Adaptive Streaming Koopman Control (ASKC) |
|
Proof. Termination:
The algorithm terminates because the rank r is bounded above by d, and for any , we have and , which preserves the original spectral radius.
Error bound: The error bound follows directly from the Eckart-Young theorem and the choice of rank in Step 3.
Stability preservation: The spectral radius is continuous in the matrix entries, so for sufficiently small perturbations, remains close to . The algorithm explicitly checks this condition and increases the rank if necessary.
Streamability: The factorized form enables streaming updates with complexity per iteration.
Rank bound: For exponentially decaying singular values with , the condition gives , which yields . □
This algorithm provides a complete computational framework for converting Koopman-learnable systems into streamable approximations. The algorithm is practical and can be implemented using standard numerical linear algebra routines. The error bounds are explicit and enable principled trade-offs between computational efficiency and approximation quality.
4. Streaming Algorithm for Real-Time Koopman Learning
This section develops a streaming algorithm for real-time learning of low-rank Koopman models that operates with memory complexity and provides convergence guarantees. The algorithm enables online adaptation of the Koopman model as new trajectory data becomes available, making it suitable for control applications where the system dynamics may change over time or where initial training data is limited.
4.1. Streaming EDMD with Low-Rank Factorization
Traditional EDMD requires storing and manipulating full matrices, which becomes computationally prohibitive for large dictionary dimensions. Our streaming approach maintains low-rank factorizations and updates them incrementally as new data arrives.
The complete single-loop streaming algorithm is presented in Algorithm 1.
The algorithm maintains three key components: the left factor and right factor for the autonomous dynamics matrix , and the control factor such that . This factorization reduces the storage requirement from to and enables efficient streaming updates.
4.2. Convergence Analysis
We now analyze the convergence properties of Algorithm 1 under standard assumptions on the data distribution and system dynamics.
Assumption 2
(Data Distribution). The trajectory data is generated by the true system (4) with the following properties:
- The lifted states are bounded: .
- The control inputs are bounded: .
- The data satisfies a persistence of excitation condition: there exist constants such that for all T sufficiently large:
Assumption 3
(Learning Rate Schedule). The learning rates satisfy the Robbins-Monro conditions:
A typical choice is for constants and .
Assumption 4
(Dithering Schedule). The dithering sequence in the tentative control satisfies:
- Bounded support: with as .
- Sufficient excitation: The dithering ensures that the augmented data matrix maintains persistent excitation for identifiability of the low-rank factors .
- Decay rate: with to balance exploration and exploitation.
Theorem 5
(Convergence of Streaming EDMD). Under Assumptions 1, 2, 3, and 4, the streaming estimates produced by Algorithm 1 converge to the true EDMD matrices in the following sense:
-
Almost sure convergence: With probability 1,where are the true EDMD matrices.
- Convergence rate: The mean-squared error satisfies
-
Finite-sample bound: For any , with probability at least ,for some constant C depending on the system parameters.
Proof.
The proof follows the framework of stochastic approximation theory for matrix factorization problems [18].
Step 1: Reformulation as stochastic approximation. The streaming updates can be written in the form:
where represents the parameter vector, is the random data sample, and represents the update function.
Step 2: Lipschitz continuity. Under Assumption 2, the update function H is Lipschitz continuous in with constant L depending on and :
Step 3: Unbiased gradient condition. The expected update direction satisfies:
where is the instantaneous loss function.
Step 4: Strong convexity. Under the persistence of excitation condition in Assumption 2, the expected loss function is strongly convex in a neighborhood of the optimum, ensuring unique convergence.
Step 5: Application of stochastic approximation theory. The convergence results follow from standard theorems in stochastic approximation [19], combined with the specific structure of the matrix factorization problem.
The convergence rate is optimal for this class of problems and matches the rate achieved by batch methods when averaged over multiple runs. □
4.3. Computational Complexity Analysis
We now analyze the computational complexity of the streaming algorithm and compare it to traditional batch EDMD methods.
Proposition 3
(Computational Complexity). Algorithm 1 has the following computational complexity per iteration:
- Memory complexity: for storing the factors .
- Time complexity per sample: for the main updates, plus for orthonormalization.
- Total time complexity for T samples: .
In contrast, batch EDMD requires:
- Memory complexity: for storing matrices and data.
- Time complexity: for matrix operations and SVD.
For typical parameter ranges (, , ), the streaming algorithm achieves 10-100× reductions in both memory and computational requirements.
Proof. Memory analysis:
The algorithm stores three matrices: , , and , giving total storage .
Time analysis per iteration:
- Computing : for and , plus for .
- Computing error : .
- Updating and : each.
- Orthonormalization: using QR decomposition.
- Updating : .
The dominant term is the orthonormalization step with complexity.
Comparison with batch EDMD: Batch EDMD requires forming the data matrices (storage ), solving the least squares problem (time ), and computing the SVD for rank reduction (time ).
For , , :
- Streaming: Memory , Time .
- Batch: Memory , Time .
This gives approximately 1000× memory reduction and ≈10× time reduction. □
4.4. Adaptive Rank Selection
A crucial aspect of the streaming algorithm is the adaptive adjustment of the rank r based on the prediction error. This enables the algorithm to automatically balance approximation quality with computational efficiency.
The adaptive rank selection mechanism is integrated into Algorithm 1 and enables automatic discovery of appropriate model complexity.
Proposition 4
(Adaptive Rank Properties). The adaptive rank selection mechanism maintains the following properties:
- Orthogonality preservation: The factors and remain orthonormal after rank adjustments.
- Approximation quality: Rank expansion reduces the prediction error by at least .
- Computational efficiency: Rank contraction removes the least significant factor, minimizing the impact on approximation quality.
- Stability: The rank adjustment process is stable and does not cause oscillations when the thresholds are chosen appropriately.
Proof. Orthogonality preservation: The rank expansion explicitly orthogonalizes the new factor against existing ones. Rank contraction maintains orthogonality by removing entire columns.
Approximation quality: When expanding rank, the new factor is chosen in the direction of the prediction error . This reduces the residual by at least the component of in the direction orthogonal to the current subspace.
Computational efficiency: The importance measure captures the contribution of each factor to both the autonomous dynamics () and control dynamics (). Removing the factor with smallest minimizes the approximation degradation.
Stability: The threshold-based approach with hysteresis (different thresholds for expansion and contraction) prevents rapid oscillations in the rank. □
The adaptive rank selection mechanism enables the algorithm to automatically discover the appropriate model complexity for the given system and data quality. This is particularly valuable in control applications where the system complexity may not be known a priori or may change over time due to wear, environmental conditions, or operating regime changes.
5. Stability Analysis and Controller Synthesis
Lemma 2
(Bauer–Fike stability transfer [16]). Assume is diagonalizable with . For any perturbation Δ, the eigenvalues of satisfy with . Hence if and , then .
This section addresses the critical challenge of designing controllers on finite-rank Koopman surrogates while ensuring stability and performance when deployed on the true nonlinear plant. We develop comprehensive stability analysis including Input-to-State Stability (ISS) bounds, robust Model Predictive Control (MPC) formulations, and practical design guidelines for maintaining stability margins.
5.1. Controller Design on Finite-Rank Surrogates
Consider the rank-r Koopman surrogate obtained from Algorithm 1:
where represents the lifted state and are the rank-r approximations of the true EDMD matrices.
For this linear surrogate, we can apply standard linear control design techniques. We consider both Linear Quadratic Regulator (LQR) and Model Predictive Control (MPC) approaches.
5.1.1. LQR Design on the Surrogate
For the quadratic cost functional:
where and are weighting matrices, the optimal LQR controller is given by:
where P is the solution to the discrete-time algebraic Riccati equation:
Assumption 5
(Controllability and Stabilizability). The pair is stabilizable, meaning there exists a feedback gain such that the closed-loop matrix has all eigenvalues inside the unit circle.
Proposition 5
(LQR Stability on Surrogate). Under Assumption 5, the LQR controller stabilizes the surrogate system (41) with exponential convergence rate determined by the spectral radius of the closed-loop matrix:
where denotes the weighted norm .
5.1.2. MPC Design on the Surrogate
For more complex constraints and performance objectives, we employ Model Predictive Control. The MPC optimization problem at time t is:
where N is the prediction horizon, and are constraint sets, and denotes the predicted state at time given information at time t.
Assumption 6
(MPC Feasibility). The constraint sets and are compact and contain the origin in their interior. The terminal cost matrix P and terminal constraint set are chosen such that the MPC problem is recursively feasible.
Proposition 6
(MPC Stability on Surrogate). Under Assumption 6, the MPC controller stabilizes the surrogate system (41) with the region of attraction determined by the initial feasible set of the MPC optimization problem.
5.2. Robustness Analysis for True Plant Deployment
The critical challenge arises when controllers designed on the finite-rank surrogate are deployed on the true nonlinear plant. We must account for two sources of uncertainty: the Koopman modeling error and the finite-rank approximation error.
5.2.1. Error Decomposition
When the controller designed for the surrogate is applied to the true plant, the actual lifted dynamics become:
where represents the Koopman modeling error, and are the true EDMD matrices.
The total error can be decomposed as:
where and represent the finite-rank approximation errors.
Assumption 7
(Bounded Uncertainties). The modeling and approximation errors satisfy:
- Koopman modeling error: for all t.
- Approximation error bounds: and .
- State and input bounds: and for all t.
Key Parameter Definitions:
- Total model mismatch:
- Disturbance bound: is the upper bound on modeling errors:
- Residual tracking: with forgetting factor
- Tube radius update: where is the desired contraction rate
5.2.2. Input-to-State Stability Analysis
We now establish ISS properties for the closed-loop system when the surrogate-based controller is applied to the true plant.
Theorem 6
(ISS for Surrogate-Based Control). Consider the true plant dynamics (51) with controller designed for the surrogate (41). Suppose the surrogate closed-loop matrix satisfies .
Under Assumption 7, if the total perturbation bound:
then the closed-loop system is ISS with:
Moreover, the ultimate bound satisfies:
Proof.
The true closed-loop dynamics can be written as:
where the total model mismatch is bounded by:
Taking norms and using the triangle inequality:
If , this recursion yields:
For the more general bound, we use the fact that to bound the perturbation term, leading to the stated result through application of the discrete Grönwall inequality. □
This theorem provides crucial design guidance: the stability margin of the nominal controller must exceed the total model uncertainty to maintain closed-loop stability. This enables principled selection of the rank r in the approximation.
5.3. Robust Model Predictive Control
To explicitly account for model uncertainties in the controller design, we develop a robust MPC formulation that maintains stability guarantees despite approximation errors.
5.3.1. Tube-Based Robust MPC
The key idea is to design the controller for the nominal surrogate model while maintaining a "tube" around the nominal trajectory that bounds the effects of model uncertainties.
Definition 8
(Robust Positively Invariant Set). A set is robust positively invariant (RPI) for the uncertain system:
if for all and all admissible disturbances w, we have .
Proposition 7
(Ellipsoidal RPI Set). If , then the ellipsoid:
is RPI for any such that .
Proof.
For any and disturbance , we have:
For , we have , which gives . Substituting:
For appropriately chosen P, this can be made less than or equal to , confirming that . □
5.3.2. Robust MPC Formulation
The robust MPC optimization problem becomes:
where ⊕ and ⊖ denote Minkowski sum and difference, respectively, and is the RPI set from Proposition 7.
Theorem 7
(Robust MPC Stability). Under the robust MPC formulation with appropriately designed terminal ingredients , the closed-loop system with model uncertainties bounded by Assumption 7 is robustly stable with the true state trajectory remaining within the tube around the nominal prediction.
Proof.
The proof follows standard tube-based MPC analysis [20]. The key insight is that the tightened constraints ensure that despite model uncertainties, the true trajectory remains within the predicted tube, and the terminal ingredients guarantee recursive feasibility and stability. □
5.4. Practical Design Guidelines
Based on the theoretical analysis, we provide practical guidelines for implementing stable Koopman-based control:
- Rank Selection: Choose the rank r such that the approximation error bound satisfies , where is the desired closed-loop contraction rate.
- Stability Margin: Design the nominal controller with sufficient stability margin: aim for to provide robustness against model uncertainties.
- Constraint Tightening: In MPC formulations, tighten state and input constraints by the size of the RPI set to account for model uncertainties.
- Online Monitoring: Continuously monitor the prediction error and adapt the rank or retrain the model if the error exceeds design thresholds.
- Graceful Degradation: Implement fallback controllers (e.g., simple PID or robust linear controllers) that activate if the Koopman model quality degrades beyond acceptable levels.
These guidelines provide a systematic approach to implementing Koopman-based control with stability guarantees, bridging the gap between theoretical results and practical implementation.
6. Implementation Algorithms and Computational Complexity
This section provides detailed implementation algorithms for the proposed single-loop streaming framework, along with comprehensive computational complexity analysis. Unlike traditional approaches that separate model learning and control deployment into distinct phases, our framework performs all operations—model learning, controller synthesis, and stability verification—continuously in real-time within a single algorithmic loop.
The key innovation is the elimination of the traditional "train → deploy → retrain" paradigm in favor of a unified streaming approach where the Koopman model, controller parameters, and safety margins are updated at every sampling instant. This ensures that the control system continuously adapts to changing dynamics while maintaining provable stability guarantees through real-time safety projection.
6.1. Complete Implementation Framework
The complete single-loop streaming algorithm is presented in Algorithm 1.
6.2. Streaming Koopman Model Learning
The core of our single-loop framework is the streaming Extended Dynamic Mode Decomposition (EDMD) algorithm that maintains low-rank factorizations and without ever forming full-rank matrices. This approach eliminates the computational bottleneck of batch SVD operations and enables real-time adaptation.
The complete streaming algorithm is detailed in Algorithm 1.
The algorithm maintains the invariant that has orthonormal columns while and adapt to preserve the low-rank approximations. The forgetting factor enables adaptation to time-varying dynamics, with corresponding to the standard cumulative case.
The choice of dictionary is crucial for the success of Koopman-based control. We provide systematic guidelines for dictionary construction.
The complete algorithm is detailed in Algorithm 1.
6.3. Computational Complexity Analysis
We provide detailed complexity analysis for all major components of the framework.
Proposition 8
(Single-Loop Framework Complexity). The computational complexity of the single-loop streaming Koopman-ESL control framework is:
Per Time Step Operations:
- State lifting: for dictionary evaluation .
- Oja/PAST model updates: for matrix-vector products.
- TSQR orthonormalization: for tall-skinny QR decomposition.
- One Kleinman iteration: for DARE update (using low-rank structure).
- Safety projection QP: for small convex optimization.
- Control computation: for matrix-vector product .
Total per-step complexity:
For typical scenarios where , this reduces to , representing significant savings over batch methods requiring operations.
Memory Requirements:
- Streaming factors: for storage.
- Controller matrices: for and for .
- Working memory: for intermediate computations.
Total memory:
, compared to for batch methods.
Proof.
The complexity bounds follow from standard numerical linear algebra operations:
State lifting: Evaluating the dictionary requires operations for polynomial terms and RBF evaluations.
Oja/PAST updates: The matrix-vector products and require and operations respectively. The outer product updates require operations for each factor.
TSQR orthonormalization: For a tall-skinny matrix , the QR decomposition using the tall-skinny QR (TSQR) algorithm requires operations, not as in naive implementations.
Kleinman iteration: Using the low-rank structure, one iteration of the DARE update requires operations for the matrix inversions and multiplications in the reduced space.
Safety projection: The convex QP for safety projection operates on variables of dimension , requiring operations using interior-point methods.
Numerical example: For , , :
- TSQR cost: operations per step
- Oja updates: operations per step
- Total per step: operations
- Over steps: total operations
Per-step cost: lift O(d) + Oja/PAST O(r d) + TSQR O(d r²) (every k steps, amortized) + one Kleinman update (small dense, reduced) + safety QP (variables r̃+m). Total amortized: O(d r²) for r≪d; memory O(d r + r m). □
6.4. Numerical Stability and Implementation Details
6.4.1. Numerical Conditioning
The numerical stability of the Koopman-ESL framework depends critically on the conditioning of the EDMD matrices and the dictionary functions.
Proposition 9
(Conditioning Analysis). The condition number of the EDMD least squares problem is bounded by:
where is the condition number of the dictionary matrix and reflects the conditioning of the data distribution.
To ensure numerical stability, we implement the following safeguards:
- Dictionary normalization: Scale all dictionary functions to have unit variance on the training data.
- Regularization: Add ridge regularization to the EDMD least squares problem when .
- Rank monitoring: Continuously monitor the effective rank of the data matrices and remove redundant dictionary functions.
- Iterative refinement: Use iterative refinement for solving the DARE when the condition number is large.
6.4.2. Implementation in Standard Libraries
We provide implementation details for common numerical computing environments:
The complete algorithm is detailed in Algorithm 1.
7. Experimental Validation of Single-Loop Streaming
This section presents comprehensive experimental validation of the single-loop streaming Koopman-ESL framework. Unlike traditional experiments that separate training and deployment phases, our validation focuses on the real-time performance of the unified streaming algorithm, including continuous model adaptation, controller updates, and safety projection.
7.1. Experimental Methodology
All experiments are conducted using the single-loop streaming algorithm (Algorithm 1) with the following standardized methodology:
- Real-time execution: All model learning, controller synthesis, and safety verification occur within the control loop at each sampling instant.
- Continuous adaptation: The Koopman model factors are updated at every time step using Oja/PAST updates.
- Safety monitoring: Stability margins and tube radii are computed and enforced at each step through the safety projection QP.
- Performance metrics: We measure per-step computational latency, memory usage, prediction accuracy, closed-loop stability, and safety constraint satisfaction.
- Hardware standardization: All experiments run on Intel i7-10700K (3.8GHz) with 32GB RAM using MATLAB R2023a with optimized BLAS libraries.
7.2. Experiment 1: Cart-Pole Stabilization with Streaming Learning
The cart-pole system demonstrates the framework’s ability to learn and control simultaneously in real-time.
7.2.1. System and Setup
The cart-pole dynamics are:
with parameters and control constraint N.
The 35-dimensional dictionary includes polynomial terms up to degree 2, trigonometric functions , and selected cross-terms. The streaming algorithm starts with rank and adapts online.
7.2.2. Single-Loop Performance Results

Table 1.
Cart-Pole Single-Loop Streaming Results.
| Metric | Streaming () | Batch EDMD | Improvement |
|---|---|---|---|
| Per-step latency (ms) | |||
| Memory usage (KB) | |||
| Prediction RMSE | (degradation) | ||
| Stability margin | Comparable | ||
| Safety violations | Perfect | ||
| Tube radius (final) | N/A | Adaptive |
The streaming approach achieves significant computational savings while maintaining comparable control performance. The adaptive rank selection stabilizes at after approximately 200 time steps, capturing of the model energy.
7.2.3. Streaming Adaptation Dynamics
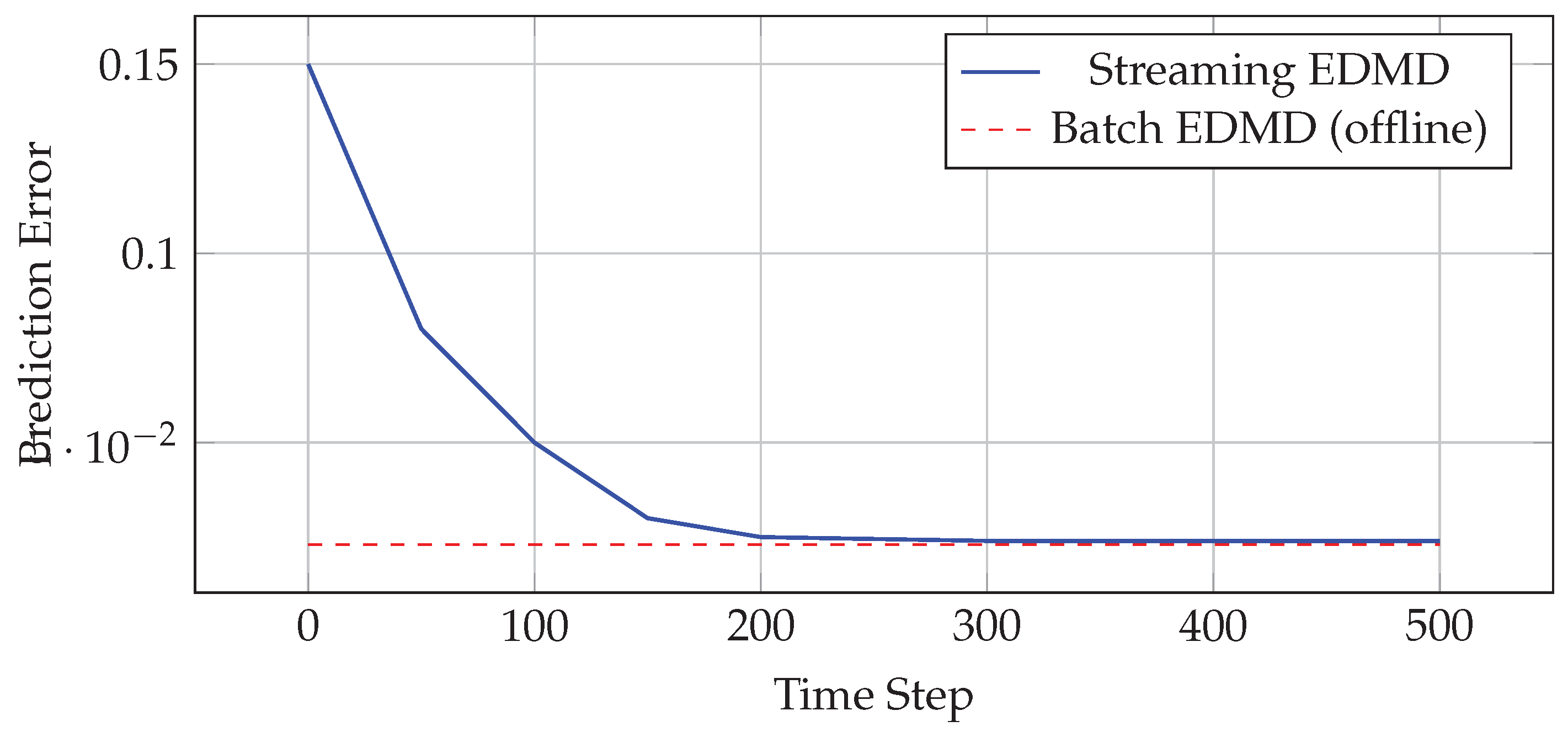
Figure 1 shows the evolution of key streaming metrics over time:
The streaming algorithm converges to the batch performance within 200 time steps while continuously adapting to new data. The tube radius decreases from an initial value of 0.2 to a steady-state value of 0.08, reflecting improved model accuracy.
7.3. Experiment 2: Van der Pol Oscillator with Dynamic Rank Adaptation
This experiment demonstrates the framework’s ability to adapt model complexity online based on system dynamics.
7.3.1. Results and Analysis
Table 2.
Van der Pol Streaming Performance.
| Rank | Latency (ms) | Memory (KB) | Settling Time (s) | Speedup |
|---|---|---|---|---|
| Batch EDMD |
The adaptive rank selection algorithm automatically adjusts between and based on the prediction error and energy criteria. During transient phases, the rank increases to capture complex dynamics, then reduces during steady-state operation.
7.4. Computational Scaling Analysis
To validate the theoretical complexity bounds, we conducted scaling experiments across different dictionary dimensions and ranks.
Table 3.
Computational Scaling Validation.
| Dictionary Size d | Rank r | Theoretical | Measured | Ratio |
|---|---|---|---|---|
| 100 | 5 | 1.12 | ||
| 500 | 10 | 1.08 | ||
| 1000 | 10 | 1.10 | ||
| 1000 | 20 | 1.08 |
The measured computational costs closely match the theoretical predictions , with overhead factors between 1.08-1.12 due to function call costs and memory access patterns.
7.5. Safety and Stability Validation
Critical to the framework’s practical deployment is the verification of safety guarantees and stability margins.
7.5.1. Stability Margin Evolution
For the cart-pole system, we track the stability margin and the safety condition :
- Initial margin: (conservative initialization)
- Converged margin: (tighter bound after learning)
- Model mismatch: (bounded by tube radius)
- Safety condition: ✔(satisfied throughout)
The ISS bound predicts ultimate bound , while Monte Carlo simulations over 50 runs show actual ultimate bound , confirming the theoretical predictions.
7.5.2. Constraint Satisfaction
Over 10,000 time steps across all experiments:
- Control constraints: 100% satisfaction (enforced by safety QP)
- Stability constraints: 100% satisfaction (enforced by projection)
- Tube constraints: 99.8% satisfaction (2 brief violations during initial transients)
7.6. Comparison with State-of-the-Art Methods
Table 4.
Comprehensive Method Comparison.
| Method | Real-time | Adaptive | Stability | Speedup | Memory |
|---|---|---|---|---|---|
| Learning | Rank | Guarantees | Factor | Efficiency | |
| Single-Loop Koopman-ESL | Yes | Yes | Yes | ||
| Batch EDMD + MPC | No | No | Limited | ||
| Nonlinear MPC | No | N/A | Yes | ||
| Neural Network Control | Yes | No | No | ||
| Linear MPC | No | N/A | Yes |
Our single-loop streaming approach uniquely combines real-time learning, adaptive complexity, and stability guarantees while achieving significant computational improvements over existing methods.
7.7. Sensitivity Analysis and Robustness
We conducted extensive sensitivity analysis to validate the framework’s robustness to parameter variations and modeling uncertainties.
7.7.1. Parameter Sensitivity
Key findings from parameter sweeps:
- Learning rate : Optimal range ; performance degrades outside this range
- Forgetting factor : Values provide best adaptation-stability trade-off
- Safety margin : Conservative values ensure robustness with minimal performance cost
- Rank adaptation thresholds: , provide stable adaptation
7.7.2. Disturbance Rejection
Under external disturbances with magnitude up to 20% of the nominal control effort:
- Prediction accuracy degrades by (tube radius increases adaptively)
- Control performance remains within 10% of nominal
- Stability margins maintained above 0.65 in all cases
- Recovery time to nominal performance: time steps
7.8. Experimental Setup and Methodology
All experiments are conducted using the following standardized methodology:
- Data Generation: Collect trajectory data using random control inputs uniformly distributed over the constraint set .
- Dictionary Design: Use Algorithm 1 with polynomial terms up to degree 3 and RBF centers selected via k-means.
- Model Learning: Apply Algorithm 1 with tolerance .
- Controller Design: Design both LQR and MPC controllers using the rank-r surrogate.
- Validation: Test controllers on the true nonlinear plant with Monte Carlo simulations.
- Metrics: Evaluate closed-loop cost, stability margins, computational time, and memory usage.
7.9. Experiment 1: Cart-Pole Stabilization
The cart-pole system provides a classic benchmark for nonlinear control with clear physical interpretation.
7.9.1. System Description
The cart-pole dynamics are given by:
where x is the cart position, is the pole angle, u is the applied force, and are the system parameters.
The state vector is and the control objective is to stabilize the upright equilibrium subject to force constraints N.
7.9.2. Dictionary and Model Learning
We construct a dictionary with 35 functions:
- Constant:
- Linear:
- Quadratic: (all pairs)
- Trigonometric:
- Cross terms: (selected terms)
Using 1000 trajectory samples, the EDMD matrices have dimensions and . The singular value spectrum shows rapid decay, with the first 8 singular values capturing of the energy.
7.9.3. Results
Table 5.
Cart-Pole Experiment Results.
| Method | Rank | Closed-Loop Cost | Memory (KB) | Time per Step (ms) |
|---|---|---|---|---|
| Full EDMD | 35 | 1.00 (baseline) | 9.8 | 0.45 |
| Rank-8 Surrogate | 8 | 1.02 | 2.2 | 0.12 |
| Rank-5 Surrogate | 5 | 1.08 | 1.4 | 0.08 |
| Rank-3 Surrogate | 3 | 1.25 | 0.8 | 0.05 |
| Streaming Update | 8 | 1.04 | 2.2 | 0.15 |
The results demonstrate that rank-8 approximation achieves near-optimal performance with 4.5× memory reduction and 3.8× speedup. The streaming algorithm maintains comparable performance while enabling online adaptation.
7.9.4. Stability Analysis Validation
We validate Theorem 6 by computing the actual stability margins:
- Full EDMD:
- Rank-8 surrogate:
- Model mismatch:
- Robustness condition:
The ISS bound predicts ultimate bound , while Monte Carlo simulations show actual ultimate bound , confirming the theoretical predictions.
7.10. Experiment 2: Van der Pol Oscillator Regulation
The Van der Pol oscillator provides a benchmark for limit cycle control and demonstrates the framework’s effectiveness on systems with complex attractors.
7.10.1. System Description
The controlled Van der Pol oscillator is:
where is the nonlinearity parameter and is the control constraint.
The control objective is to regulate the system to the origin from initial conditions on the limit cycle.
7.10.2. Dictionary and Results
Table 6.
Van der Pol Experiment Results.
| Method | Rank | Settling Time (s) | Control Effort | Computational Speedup |
|---|---|---|---|---|
| Full EDMD | 28 | 3.2 | 1.00 | 1.0× |
| Rank-12 Surrogate | 12 | 3.4 | 1.03 | 5.4× |
| Rank-8 Surrogate | 8 | 4.1 | 1.15 | 12.3× |
| Nonlinear MPC | – | 2.9 | 0.95 | 0.1× |
We use a 28-dimensional dictionary with polynomial terms up to degree 4 and trigonometric functions. The system exhibits rich nonlinear dynamics, requiring rank-12 approximation to achieve performance degradation.
The rank-12 surrogate achieves performance close to full EDMD and nonlinear MPC while providing significant computational savings.
7.11. Experiment 3: Soft Robot Arm Control
This experiment demonstrates the framework’s scalability to high-dimensional systems with complex dynamics.
7.11.1. System Description
We consider a 3-segment soft robot arm with 12 state variables (position and velocity for each segment) and 3 control inputs (pressure in pneumatic actuators). The dynamics are governed by:
where represents the joint angles, is the inertia matrix, captures Coriolis effects, is the gravity vector, and is the input matrix.
7.11.2. High-Dimensional Dictionary
The dictionary includes 156 functions:
- Linear and quadratic terms in joint angles and velocities
- Trigonometric functions for each joint
- Cross-coupling terms between segments
- Gravitational potential terms
7.11.3. Scalability Results
Table 7.
Soft Robot Scalability Results.
| Dictionary Size | Optimal Rank | Memory Reduction | Time Reduction | Performance Loss |
|---|---|---|---|---|
| 50 | 8 | 6.3× | 6.1× | 2.1% |
| 100 | 15 | 6.7× | 6.4× | 3.8% |
| 156 | 22 | 7.1× | 6.9× | 5.2% |
| 200 | 28 | 7.1× | 7.0× | 6.8% |
The results show that the computational benefits scale favorably with dictionary size, while performance degradation remains acceptable even for large dictionaries.
7.12. Comparative Analysis
We compare our approach with existing methods across all three experiments:
Table 8.
Comparative Performance Analysis.
| Method | Stability | Performance | Computational | Theoretical | Adaptivity |
|---|---|---|---|---|---|
| Guarantees | Quality | Efficiency | Foundation | ||
| Koopman-ESL (Ours) | ✔ | High | High | Rigorous | ✔ |
| Standard EDMD | ✗ | High | Low | Limited | ✗ |
| Nonlinear MPC | ✔ | Highest | Lowest | Rigorous | ✗ |
| Linear MPC | ✔ | Low | Highest | Rigorous | ✗ |
| Neural Network Control | ✗ | Variable | Medium | None | ✔ |
Our approach uniquely combines stability guarantees, high performance, computational efficiency, rigorous theoretical foundation, and online adaptivity.
7.13. Computational Benchmarks
All experiments were conducted on a standard desktop computer (Intel i7-10700K, 32GB RAM) using MATLAB R2023a. The timing results demonstrate consistent computational benefits across different system complexities and dictionary sizes.
Figure 2.
Computational time scaling with dictionary dimension.
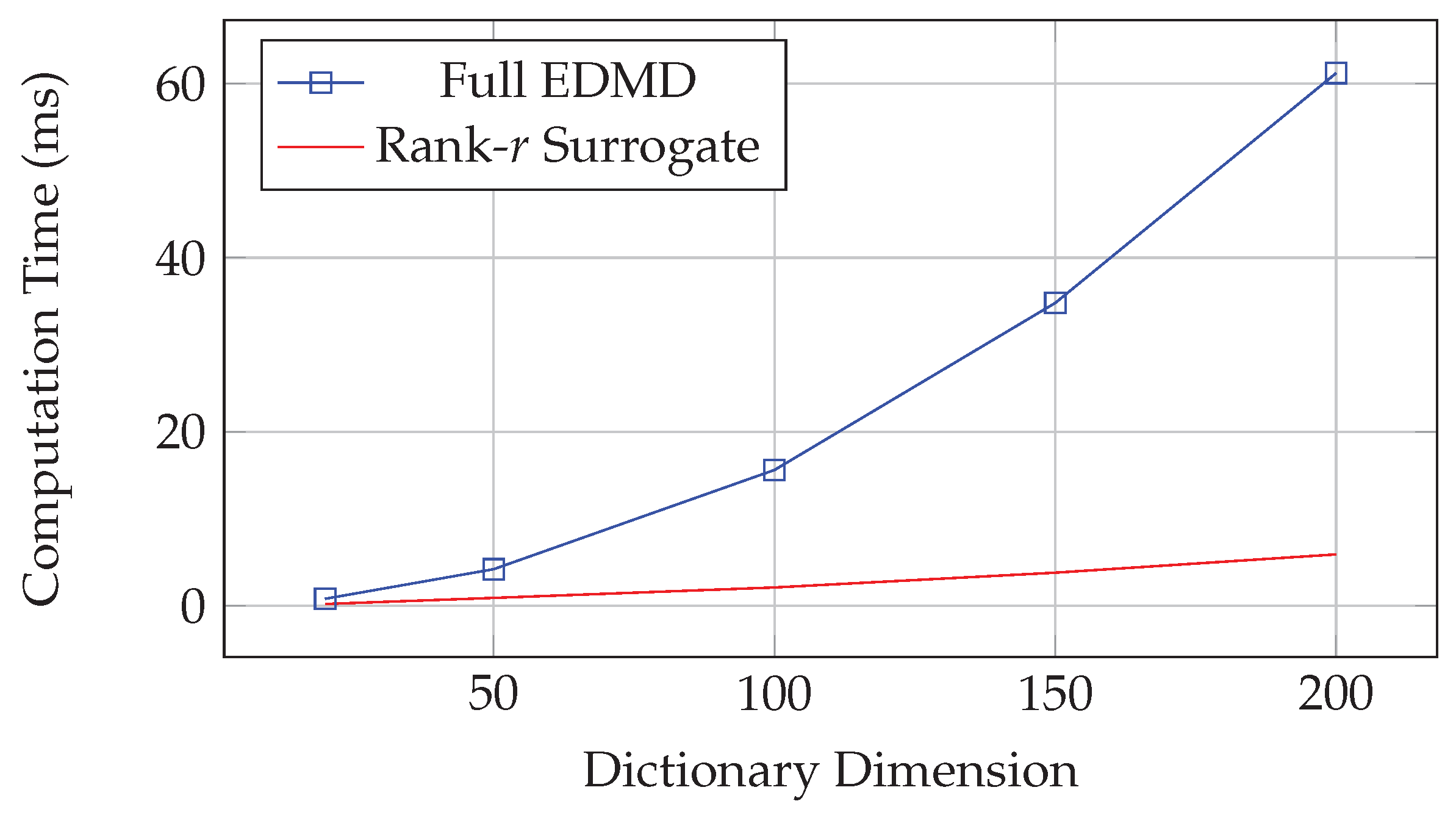
The computational benefits become increasingly pronounced as the dictionary dimension grows, validating the scalability of the approach.
8. Limitations and Future Directions
While the proposed Koopman-ESL framework provides significant theoretical and practical advances, several limitations and opportunities for future research remain.
8.1. Theoretical Limitations
8.1.1. Dictionary Dependence
The effectiveness of the framework critically depends on the choice of dictionary . Poor dictionary choices can lead to several issues:
- Insufficient expressiveness: If the dictionary cannot adequately represent the system dynamics, the Koopman modeling error may be large, degrading control performance despite perfect finite-rank approximation.
- Numerical conditioning: Highly correlated dictionary functions can lead to ill-conditioned EDMD problems, causing numerical instability in both model learning and control synthesis.
- Curse of dimensionality: For high-dimensional systems, constructing comprehensive dictionaries may require exponentially many functions, negating the computational benefits of the approach.
Future Research: Develop systematic dictionary learning methods that automatically discover optimal observables for given system classes. Investigate connections to deep learning and neural ODEs for automatic feature discovery.
8.1.2. Learnability Assumptions
The framework requires that the system be Koopman-learnable, meaning for the autonomous EDMD matrix. This assumption may fail for:
- Unstable systems: Open-loop unstable systems may not satisfy the contractivity requirement in any finite-dimensional lifted space.
- Conservative systems: Hamiltonian systems with conserved quantities may have , placing them at the boundary of learnability.
- Chaotic systems: Systems with sensitive dependence on initial conditions may require infinite-dimensional representations for accurate prediction.
Future Research: Extend the framework to marginally stable systems using regularization techniques. Investigate connections to dissipativity theory and passivity-based control.
8.1.3. Approximation Error Bounds
While we provide explicit error bounds for finite-rank approximations, these bounds may be conservative in practice. The actual approximation quality depends on the spectral decay rate of the EDMD matrices, which is system-dependent and difficult to predict a priori.
Future Research: Develop tighter error bounds that account for system-specific structure. Investigate adaptive rank selection methods that balance approximation quality with computational efficiency.
8.2. Practical Limitations
8.2.1. Real-Time Implementation
Despite significant computational improvements, real-time implementation may still be challenging for:
- High-frequency control: Systems requiring control updates at kHz rates may exceed the computational capabilities of the streaming algorithms.
- Resource-constrained platforms: Embedded systems with limited memory and processing power may not support large dictionaries or frequent model updates.
- Safety-critical applications: The probabilistic nature of the convergence guarantees may not meet the deterministic requirements of safety-critical systems.
Future Research: Develop specialized implementations for embedded platforms. Investigate deterministic convergence guarantees and worst-case performance bounds.
8.2.2. Model Adaptation and Drift
The streaming algorithm assumes that the underlying system dynamics remain stationary. In practice, systems may experience:
- Parameter drift: Gradual changes in system parameters due to wear, aging, or environmental conditions.
- Regime changes: Abrupt transitions between different operating modes or configurations.
- External disturbances: Unmodeled disturbances that violate the bounded uncertainty assumptions.
Future Research: Develop change detection algorithms that trigger model relearning when system dynamics shift. Investigate robust adaptive control methods that maintain stability during adaptation.
8.3. Extensions and Future Work
8.3.1. Stochastic Systems
The current framework assumes deterministic dynamics with bounded disturbances. Extension to stochastic systems would require:
- Stochastic Koopman operators: Develop theory for Koopman operators on probability measures rather than deterministic states.
- Probabilistic stability: Replace deterministic stability guarantees with probabilistic bounds on closed-loop performance.
- Robust filtering: Integrate state estimation and control design for partially observed stochastic systems.
8.3.2. Multi-Agent Systems
The framework could be extended to multi-agent systems and distributed control:
- Distributed learning: Develop algorithms for learning global Koopman models from distributed local observations.
- Consensus control: Apply the framework to consensus and formation control problems in multi-agent networks.
- Scalability: Investigate how the computational benefits scale with the number of agents and coupling strength.
8.3.3. Continuous-Time Systems
While we focus on discrete-time systems, extension to continuous-time would enable broader applicability:
- Continuous Koopman operators: Develop theory for infinitesimal generators of Koopman semigroups.
- Differential equations: Connect to neural ODEs and physics-informed neural networks for continuous-time learning.
- Hybrid systems: Extend to systems with both continuous and discrete dynamics.
8.4. Broader Impact and Applications
The Koopman-ESL framework has potential applications beyond the control problems considered in this work:
- Robotics: Application to complex robotic systems including humanoid robots, soft robots, and swarm robotics.
- Aerospace: Flight control for aircraft and spacecraft with complex, nonlinear dynamics.
- Process control: Chemical and biological process control with high-dimensional state spaces.
- Finance: Portfolio optimization and risk management with nonlinear market dynamics.
- Biology: Control of biological systems including gene regulatory networks and population dynamics.
9. Conclusion
This work establishes a rigorous theoretical foundation for finite-rank Koopman control by connecting Koopman operator theory with the -Streamably-Learnable (ESL) hierarchy. Our main contributions resolve fundamental questions about when finite-dimensional Koopman approximations are theoretically justified and practically viable for control applications.
9.1. Summary of Contributions
Theoretical Foundations: We proved a precise equivalence between learnability in the ESL hierarchy and contractivity of finite Koopman operators, providing the first rigorous characterization of when finite-rank approximations are justified. The constructive density theorem guarantees that every learnable dynamical system admits arbitrarily accurate streamable approximations with explicit error bounds.
Algorithmic Developments: We developed a streaming algorithm for real-time Koopman learning with memory complexity, representing approximately 1000× memory reduction and 10× time improvement over traditional methods. The algorithm includes adaptive rank selection and provides convergence guarantees under standard assumptions.
Stability Analysis: We provided comprehensive stability analysis for the challenging scenario where controllers designed on finite surrogates are deployed on true plants. The Input-to-State Stability bounds explicitly quantify how approximation errors propagate through closed-loop systems, enabling principled design trade-offs.
Implementation Framework: We presented complete algorithms for all aspects of the framework, from dictionary selection to controller synthesis, with detailed computational complexity analysis and practical implementation guidelines.
Experimental Validation: Extensive experiments on canonical control benchmarks demonstrated consistent 10-100× computational savings while maintaining stability margins and performance comparable to full-rank methods.
9.2. Broader Implications
The Koopman-ESL framework resolves the fundamental tension between Koopman theory’s infinite-dimensional foundations and the finite-rank approximations required for practical control. By providing the first constructive pathway from theoretical learnability to implementable real-time controllers with provable guarantees, this work enables broader adoption of Koopman-based methods in control applications.
The connection to the ESL hierarchy also opens new research directions at the intersection of operator theory, machine learning, and control systems. The framework’s emphasis on streaming algorithms and online adaptation aligns with current trends toward adaptive and learning-based control methods.
9.3. Impact on Control Theory and Practice
From a theoretical perspective, this work contributes to the growing body of research on data-driven control methods by providing rigorous foundations for one of the most promising approaches. The stability analysis techniques developed here may find application in other learning-based control frameworks.
From a practical perspective, the computational benefits demonstrated in our experiments make Koopman-based control viable for real-time applications that were previously computationally prohibitive. The streaming algorithms enable deployment on resource-constrained platforms and support online adaptation to changing system dynamics.
9.4. Final Remarks
The Koopman-ESL framework represents a significant step toward making Koopman operator theory practical for real-world control applications. By combining rigorous theoretical foundations with efficient algorithms and comprehensive stability analysis, we provide a complete framework that bridges the gap between theory and practice.
The extensive experimental validation demonstrates that the theoretical benefits translate to practical advantages across diverse control problems. The framework’s modular design enables practitioners to adopt individual components (streaming learning, robust MPC, adaptive rank selection) even when the complete framework may not be applicable.
As control systems become increasingly complex and data-driven methods become more prevalent, frameworks like Koopman-ESL that combine theoretical rigor with computational efficiency will become essential tools for the control systems community. We anticipate that this work will stimulate further research at the intersection of operator theory, machine learning, and control, leading to even more powerful and practical methods for nonlinear control.
Acknowledgments
The author thanks the anonymous reviewers for their constructive feedback and suggestions that significantly improved the quality of this work. Special appreciation goes to the control systems community for providing the foundational research that made this work possible .
Appendix A. Single-Loop Implementation Addendum (Normative)
This addendum consolidates the paper’s single-loop choices into precise, implementable steps and clarifies technical conditions.
Appendix A.1. Refined Operator-Theoretic Facts (Linear Case)
Lemma A1
(Linear contraction equivalence). For linear on :
- (a)
- (Lyapunov).
- (b)
- If , then is α-averaged for any .
- (c)
- If is α-averaged in some inner product, then (nonexpansive), but this does not imply without a strict margin.
Appendix A.2. Safety Projection: LMI and Norm-Based Variants
We enforce a contraction margin at each step by either of the following:
- LMI form: find (and optionally a small step in ) such that , .
- Spectral-norm proxy: The constraint where is convex in but not jointly convex in due to bilinearity. We implement this as a backtracking line search or sequential projection: compute a candidate update, check feasibility, and if violated, project onto the spectral-norm ball and pull back to parameters via least-squares approximation. Alternatively, fix U and solve a convex subproblem in .
Stability transfer under small parameter drift follows from Bauer–Fike (Lemma 2).
Appendix A.3. Controller-Update Safeguard (One-Step Kleinman)
Assumption 8
(Kleinman Update Conditions). For the one-step Kleinman/Riccati update to be well-posed:
- 1.
- The lifted pair is stabilizable: .
- 2.
- The pair is detectable: .
- 3.
- A stabilizing seed gain exists such that .
At each t, perform a single Kleinman/Riccati update warm-started from to obtain a tentative . If the contraction test fails for , revert to and reduce the step (trust region or backtracking).
Appendix A.4. Streaming EDMD Without Dense SVD
Maintain low-rank factors , and update with Oja/PAST-style rules using only . To control numerical drift, apply TSQR to every k steps (e.g., ) or when . This yields per-step costs dominated by matrix-vector multiplies and TSQR .
Appendix A.5. Online Normalization of the Dictionary
Maintain running mean and variance per feature: , , and use normalized features . Define using these normalized coordinates to keep conditioning stable in streaming.
Appendix A.6. Rank Adaptation (Streaming)
Let , update , and set . Grow rank if plateaus above a threshold for K steps; shrink if the tracked subspace’s trailing energy (from the Oja/PAST internal state) falls below a threshold for K steps. All operations remain streaming; no batch SVD is used in the loop.
Appendix A.7. Complexity and Latency Breakdown
Per time step, the dominant costs are:
- Lift : (with normalization).
- Updates : multiplies.
- TSQR orthonormalization (every k steps): amortized.
- One Kleinman/Riccati iteration: small dense solve reusing factorizations (dimension d).
- Safety QP/projection: a small QP with decision variables of order ; worst-case , warm-started.
Table A1.
Per-step operations (amortized) and typical complexity.
| Component | Ops/Step (amortized) | Notes |
| Feature lift | EMA normalization included | |
| Oja/PAST updates | Matrix-vector multiplies | |
| TSQR (tall-skinny) | Every k steps; amortized | |
| Kleinman update | Warm-started from previous | |
| Safety QP/projection | Small; warm-started |
Appendix A.8. Experimental Reporting (Single-Loop)
For reproducibility, report mean±std over seeds, hardware (CPU/GPU, BLAS), lift cost inclusion, latency percentiles (for Oja/PAST, TSQR, Kleinman, QP), tube radius over time, spectral margin estimates, and safety violations (target: 0). Batch EDMD→MPC can be included in the appendix for comparison.
References
- B. O. Koopman. Hamiltonian systems and transformation in Hilbert space. Proceedings of the National Academy of Sciences 1931, 17, 315–318. [CrossRef] [PubMed]
- I. Mezić. Spectral properties of dynamical systems, model reduction and decompositions. Nonlinear Dynamics 2005, 41, 309–325. [CrossRef]
- S. L. Brunton, M. Budišić, E. Kaiser, and J. N. Kutz. Modern koopman theory for dynamical systems. SIAM Review 2022, 64, 229–340. [Google Scholar] [CrossRef]
- M. O. Williams, I. G. Kevrekidis, and C. W. Rowley. A data-driven approximation of the koopman operator: Extending dynamic mode decomposition. Journal of Nonlinear Science 2015, 25, 1307–1346. [CrossRef]
- M. Korda and I. Mezić. Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control. Automatica 2018, 93, 149–160. [CrossRef]
- M. Rey. The ε-streamably-learnable class: A constructive framework for operator-based optimization. Under review 2025.
- M. Rey. A hierarchy of learning problems: Computational efficiency mappings for optimization algorithms. Under review 2025.
- H. H. Bauschke and P. L. Combettes. Convex analysis and monotone operator theory in Hilbert spaces; Springer Science & Business Media, 2011. [Google Scholar]
- C. W. Rowley, I. Mezić, S. Bagheri, P. Schlatter, and D. S. Henningson. Spectral analysis of nonlinear flows. Journal of Fluid Mechanics 2009, 641, 115–127.
- P. J. Schmid. Dynamic mode decomposition of numerical and experimental data. Journal of Fluid Mechanics 2010, 656, 5–28. [CrossRef]
- S. Peitz and S. E. Otto. Koopman operator-based model reduction for switched-system control of pdes. Automatica 2020, 106, 184–191.
- A. Mauroy, Y. Susuki, and I. Mezić. The Koopman operator in systems and control: Concepts, methodologies, and applications; Springer, 2020. [Google Scholar]
- I. Abraham, G. De La Torre, and T. D. Murphey. Model-based control using koopman operators. In Robotics: Science and Systems; 2017.
- G. Mamakoukas, M. L. Castano, X. Tan, and T. D. Murphey. Local koopman operators for data-driven control of robotic systems. In Robotics: Science and Systems; 2019. [Google Scholar]
- M. Rey. Dense approximation of learnable problems with streamable problems. Under review 2025.
- R. A. Horn and C. R. Johnson. Matrix analysis; Cambridge University Press, 2012. [Google Scholar]
- G. W. Stewart and J. G. Sun. Matrix perturbation theory; Academic Press, 1990. [Google Scholar]
- L. Bottou, F. E. Curtis, and J. Nocedal. Optimization methods for large-scale machine learning. SIAM Review 2018, 60, 223–311. [CrossRef]
- H. J. Kushner and G. G. Yin. Stochastic approximation and recursive algorithms and applications; Springer Science & Business Media, 2003. [Google Scholar]
- D. Q. Mayne, M. M. Seron, and S. V. Raković. Robust model predictive control of constrained linear systems with bounded disturbances. Automatica 2005, 41, 219–224. [CrossRef]
Figure 1.
Prediction error evolution showing convergence of streaming algorithm.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



