
Submitted:
09 July 2025
Posted:
11 July 2025
You are already at the latest version
Abstract
To address issues like haze, blurring, and color distortion in underwater images, this paper proposes an underwater image enhancement model called U-Vision Mamba, based on the Vision Mamba framework. The model first uses a U-shaped network encoder to extract multi-scale features. To aggregate these features, we introduce a novel multi-scale sparse attention fusion module into the network. The decoder then processes and refines the enhanced features to produce high-quality underwater images. Experimental results show that our algorithm effectively addresses image blurring and corrects color distortion. It performs well in both subjective and objective evaluations, demonstrating the model's effectiveness and robustness.
Keywords:
Image enhancement
; Vision Mamba
; Image defogging
1. Introduction
The image recognition technology used in underwater drones holds significant potential in fields such as aquatic exploration, resource surveying, and ecological monitoring. For instance, in pollution detection, underwater drones can capture images in contaminated water areas. Image recognition can differentiate between various pollutants, such as oil spills and plastic debris. Additionally, these drones can be used to monitor ecological changes in water bodies. By patrolling and identifying aquatic habitats, they can detect alterations in wildlife and habitats, enabling timely protective actions. However, as depth increases and factors like suspended particles, light absorption, and refraction in water come into play, images suffer from reduced contrast, color distortion, blurriness, and noise. These issues not only degrade the visual quality of underwater images but also hinder accurate analysis and recognition of underwater scenes.
Therefore, many scholars have carried out research on this. Underwater image enhancement techniques improve the clarity and contrast of images captured in complex underwater environments, making them more accurate representations of real-world conditions. These techniques provide clearer visual data, benefiting fields such as marine science, environmental conservation, and underwater robotic navigation. To address the aforementioned underwater image issues, there are currently three main categories of enhancement algorithms. The first category is based on physical models that use the principles of light propagation to correct and enhance underwater images. Typical models include the optical transmission model [1] and the underwater dark channel prior [2] et al. The second category is based on non-physical models, which directly enhance image quality by processing pixel values. Common techniques include histogram equalization [3], gamma correction [4], and white balance adjustment [5] et al.
The third category is deep learning-based image enhancement methods, which have recently gained prominence due to their powerful performance. The Deep learning based underwater image enhancement methods learn enhancement strategies from large datasets of training images. Using convolutional layers, they extract features from input images and pass them by progressively deeper layers, building a better understanding of the image’s content and structure, ultimately producing images with improved visual quality. As a result, many researchers have focused on deep learning approaches for underwater image enhancement, proposing various methods. As a result, many researchers have focused on deep learning approaches for underwater image enhancement, proposing various methods. Cao et al. [6] proposed a network model consisting of two fully convolutional networks, composed of five convolutional neural network layers and a multi-scale network. The model restores underwater images by estimating background light and scene depth. Liu et al. [7] introduced a deep residual-based method for underwater image enhancement. They incorporated a super-resolution reconstruction model into the enhancement process and proposed the UResNet residual learning model, improving color correction and image detail restoration. Chen et al. [8] proposed an improved Retinex algorithm. By combining it with a neural network and introducing an attention mechanism in the convolutional layer of the model, this method effectively enhances the reconstruction of the edge and texture details of the target image. Liu [9] et al. proposed a global feature multi-attention fusion method based on generative adversarial for underwater images with the presence of fog and uneven illumination. The improved global feature extraction utilizes a convolutional layer to continuously downsample the input image and introduces the residuals, which avoids the lack of local information when global feature extraction is performed and enables the image to recover more detailed information. Chen [10] et al. achieved effective removal of color deviation, blurring, etc. from underwater images by using fusion network to fuse the individual correlations of the images and introducing self-attention aggregation. Due to the outstanding performance of the Transformer framework, with its strong parallel processing and global context capabilities, Liu et al. [11] introduced it into the visual domain and proposed the Vision Transformer model. Using a hierarchical structure, it demonstrated advanced performance in visual tasks. Ren et al. [12] incorporated convolution into the Vision Transformer model to enhance channel and spatial attention. They embedded it into a U-Net architecture to improve the global feature capture ability, showcasing superior image enhancement performance.
2. Methodological Model
The network architecture consists of an encoder, decoder, and multi-scale sparse attention fusion module, with the encoder and decoder both based on a U-Vision Mamba [13], as shown in Figure 1. First, the raw underwater image is input into the Vision Mamba-based encoder, which performs preliminary feature extraction. The feature maps obtained before each down-sampling operation in the encoder are fed into the multi-scale sparse attention fusion module, where features at different scales are aggregated, attention is computed, and then input into the decoder. The decoder stitches the reconstructed features obtained from up-sampling with the aggregated features obtained from the multi-scale sparse attention fusion module. Finally, an enhanced underwater image is generated.
2.1. Vision Mamba
Mamba is a novel selective structured state-space model, and the Mamba block is a key feature of Vision Mamba. It marks image sequences using positional embeddings and compresses visual representations by a bidirectional state-space model. This method addresses the inherent location sensitivity of visual data. Vision Mamba has strong performance in capturing global context from images. Given a 2D input image , it transforms the image into flattened 2D patches , where, represents the dimensions of the input image, is the number of channels, and is the size of the image patches. Secondly, is linearly projected into a vector of size D, and positional embeddings are added, as shown in Equation 1.
where, represents the -th patch of image , and is a learnable projection matrix. The term refers to the use of a class token for the entire patch sequence. The token sequence is then fed into the -th layer of the Vision Manba encoder to obtain the output , as shown in Equation 2.
where, Vim block represents the standard Vision Mamba block. To improve feature extraction for underwater images, we normalize the image sequence before feeding it into the Vision Mamba encoder. This normalization allows for more effective multi-level feature extraction in the deep network and reduces the complexity of the input data, thereby reduces the computational burden on the Vision Mamba encoder. After processing by the Vision Mamba encoder, the output image patches are reassembled into a complete image. In order to enhance the model's ability to capture details in the image and to enhance the robustness of the model in capturing multi-scale or multi-level image information, while adjusting the number of channels of the feature map. we added two convolutional blocks at the end of the Vision Mamba block. The outputs of the convolutional blocks are summed to combine multiple feature image representations, as shown in Figure 2.
2.2. Multi-Scale Sparse Attention Fusion Module
The multi-scale sparse attention fusion module designed in this paper aims to aggregate the different scale features of U-Vision Mamba as an overall attention matrix and compute the attention sequentially. And by residual connections, the integrity of the input information is preserved, enabling the model to capture fine image details while understanding global contextual information during image enhancement. The network consists of multi-scale feature fusion combined with a sparse attention mechanism (Non-Local Sparse Attention) [14], as shown in Figure 3.
First, feature maps with 16, 32, and 64 channels are input sequentially. By three convolution blocks, the channel numbers are reduced to 4, 4, and 8, respectively, before being fed into the sparse attention module. In the sparse attention module, multiple hashing layers, set to 4 by default, compute sparse attention. Using locality-sensitive hashing (LSH), each pixel is assigned to a hash bucket, generating a hash code that allows the pixel features to be polymerization within the sparse attention process. By assigning features to different hash buckets, the sparse attention mechanism efficiently performs computations within localized regions, avoiding the high cost of global calculations. After assigning features to different hash buckets, padding is applied, and the features are concatenated with the original image data to ensure consistent image block size. Afterward, L2 normalization is performed, and calculation of unnormalized attention scores. These scores are normalized using the SoftMax function to compute the final attention weights. The attention weights are subsequently weighted and polymerized with the feature image after hash grouping and sorting using the Einstein summation convention method. Finally, the attention-weighted features are fused with the input to produce the final multi-scale features. We add three convolution blocks are added at the end of the module to restore the channel count of the features for decoding in the U-Vision Mamba decoder.
2.3. Loss Functions
In the field of deep learning, the selection and design of loss functions are indispensable. For this reason, many researchers have proposed many loss functions such as pixel-level mean square error (MSE), perceptual loss, adversarial loss and structural similarity loss (SSIM). In order to quantify the difference between the enhanced image and the reference image, better recover the effective information and to obtain high-quality underwater enhanced images. This paper constructs a multi-loss function structure composed of L1 loss function, L1 gradient loss function, and SSIM loss function as the loss function of the model in this paper. The L1 loss calculates the absolute difference at the pixel level between the enhanced image and the target image. It helps the model reduce this difference during training to obtain an enhanced image that is closer to the target image. The L1 loss is:
where is the total number of pixels in the image, is the value of the image generated after enhancement at the i-th pixel position, and is the value of the corresponding target image at the i-th pixel position.
The gradient loss calculates the L1 - norm of the gradient differences between the generated image and the target image in two directions. The gradient loss can guide the model to retain the details and edge information of the image as much as possible during the training process, and is very suitable for image enhancement tasks that maintain or restore the texture and edge information of the image. The gradient loss is:
where and are the horizontal and vertical gradients of the generated image at pixels, and and are the horizontal and vertical gradients of the target image at pixels, respectively.
Structural similarity (SSIM) is a measure of the quality of an optimized enhanced underwater image, which integrates the brightness, contrast and structural information of the image, and can effectively measure the structural similarity between the enhanced image and the reference image, and then guide the model to generate high-quality images more in line with the human visual perception. The calculation of the SSIM loss firstly relies on the SSIM index, which is calculated as shown in Eq. (5) is shown.
where and are the mean values of the enhanced image and the target image, respectively, and are denoted as the variance of the two, is the covariance of the two, and and are the regularization coefficients. Then the SSIM loss is defined as:
In summary, the total loss function in this paper is:
3. Experimentation and Analysis
3.1. Experimental Settings
In this paper, the publicly available UIEB [15] dataset is used, which contains 950 original underwater images, including those with color distortion and low contrast caused by different depths, turbidity, and lighting changes. The training set and the test set are allocated at a ratio of 9:1. The image size is uniformly set to 256×256, the number of epochs is 150, the learning rate is 0.0001, and the Adam optimizer is adopted.
3.2. Subjective Experimental Comparison
The UIEB dataset is often used to evaluate and compare different underwater image enhancement algorithms. In order to show the enhancement effect of the algorithm in this paper more intuitively, the algorithm in this paper is compared with the CLAHE algorithm [16], the DEHAZE algorithm [17], the FIVE_APLU algorithm [18], the U-Shape algorithm [19], the Shallow-UWnet algorithm [20], and the UWCNN algorithm [21], as shown in Figure 4, Where, INPUT is the original image. The DEHAZE algorithm exacerbates the effect of color bias, resulting in oversaturation of the image color and low overall image brightness. The CLAHE algorithm improves both the dark and bright areas of the image simultaneously, but the color saturation of the image is low and lacks color representation. The FIVE_APLU algorithm has improved color reproduction compared to the original image, making the difference between the object and the background more obvious, but the brightness and exposure of the image are not uniform, and the signage in the center area is too bright. The UWCNN algorithm has a certain degree of color bias when processing underwater images that are heavily color-biased and have low darkness, resulting in a degradation of the quality of the image. U-Shape algorithm and Shallow-UWnet in dealing with image fogging and blurring of this color bias, relative to the former performance are improved, and U-shape presents better color saturation, but there is still room for improvement in some of the brightness details of the image. The method proposed in this paper effectively removes the image blurring caused by fogging. The clarity of the image is significantly increased, the overall picture becomes more transparent, the colors are more distinct, the edges of objects are more natural, and clear underwater images are obtained. Judging from the comprehensive effect, the method in this paper performs excellently in multiple aspects such as defogging, color correction and global contrast, and is superior to other methods.
To further illustrate the effectiveness of this model for underwater image enhancement, we carried out underwater scene shooting in the Huajiang River Basin in Guilin and conducted enhancement experiment verification, as shown in Figure 5.
3.3. Objective Quality Assessment
Objective quality evaluation of image enhancement assesses the performance of algorithms through quantitative indicators to avoid the deviation of subjective evaluation. In this paper, four objective evaluation indicators, namely Peak Signal - to - Noise Ratio (PSNR) [22], Structural Similarity (SSIM) [22], Underwater Color Image Quality Evaluation (UCIQE) [23], and Underwater Image Quality Measurement (UIQM) [24], are used to conduct quantitative analysis and comparison on the enhanced image quality. The PSNR value is usually used to compare the difference between the original image and the enhanced image, the higher value indicates that the two are closer, with less distortion and better quality. SSIM responds to the structural similarity of images and takes into account the visual characteristics of the human eye. It uses the mean, standard deviation, and covariance as estimates of brightness, contrast, and structural similarity respectively. The closer the value is to 1, the more similar the structures of the two images are. UCIQE mainly evaluates the fidelity of image colors. UIQM is a comprehensive quality evaluation index. The higher the value, the better the enhancement effect. In this paper, different methods proposed in this paper are compared according to these four indexes, and the optimal values are highlighted in bold black, as shown in Table 1.
Experiments show that the UCIQE, PSNR, and SSIM indicators of the method in this paper are all superior to other methods, with values of 0.4986, 25.6562, and 0.9724 respectively. This indicates the balance of the algorithm in this paper in terms of image brightness, color, edge details, contrast, and saturation during underwater image enhancement. Although the UIQM index is slightly lower than that of the U-Shape algorithm, the algorithm in this paper is also at an above - average level with a mean value of 2.0543. Overall, the underwater images enhanced by the algorithm in this paper can better restore the color, contour, and texture of objects, making the objects distinct from the background and more in line with the visual perception of the human eye. It can be seen that the algorithm in this paper has the best effect.
3.4. Ablation Experiment
In order to verify the effectiveness of the Vision Mamba block and the multi-sparse attention fusion module in the algorithm of this paper, an ablation experiment was carried out, and the experimental results are shown in Table 2.
In experiment A, the Vision Mamba block in the network structure was removed, and the original Unet network convolution block was used for feature extraction and learning. In experiment B, the sparse - attention fusion module in the network structure was removed during the experiment, and the multi - scale features extracted by the Vision Mamba block were directly output through skip connections.
It can be seen that the PSNR and SSIM indicators in the experimental results that the performance of our method is the best when it is complete. Among them, the Vision Mamba block has strong context - reading performance, and combined with embedding and encoding operations, it extracts image information better. The multi - scale sparse - attention fusion module can aggregate different - scale features of the U-shaped network and calculate attention, which enhances the model's ability to extract multi - scale information and has a significant effect on image defogging and color correction, etc.
4. Conclusions
This paper proposes an underwater image enhancement network of U-Vision Mamba and designs a sparse - attention fusion module, which realizes the preservation of image details and the capture of global features, thus specifically solving the common problems in underwater images such as low contrast, color distortion and blurring. The underwater images enhanced by the algorithm in this paper obviously fix the common problems in the images such as green and blue color casts and blurring. The presented images have real colors, clear and natural content, and are more in line with human visual perception, and are superior to other algorithms in terms of PSNR and SSIM indicators. In view of the strong potential of the method in this paper for underwater image enhancement, in the future, we will explore ways to improve the model, realize the lightweight of the model and a more efficient attention calculation method for the convenience of practical deployment.
Author Contributions
Conceptualization, Y.W; methodology, Y.W. and Z.C.; software, Z.C.; validation, Y.W. and Z.T.; formal analysis, M.A.-B; investigation, Z.C. and Z.T.; resources, Y.W.; data curation, Y.W. and Z.C.; writing—original draft preparation, M.A.-B; writing—review and editing, Z.T.; visualization, Z.C.; supervision, Y.W.; project administration, Y.W.; funding acquisition, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Guangxi Science and Technology Plan Project (Grant No. AB25069501,No.AD22035141). Special Research Project on the Strategic Development of Distinctive Interdisciplinary Fields (GUAT Special Research Project on the Strategic Development of Distinctive Interdisciplinary Fields), Guilin University of Aerospace Technology (No. TS2024431).
Data Availability Statement
The original contributions presented in this study are included in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wen, Haocheng, et al. "Single underwater image enhancement with a new optical model." 2013 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2013.
- Drews, Paulo LJ, et al. "Underwater depth estimation and image restoration based on single images." IEEE computer graphics and applications 36.2 (2016): 24-35.
- Pizer, Stephen M. "Contrast-limited adaptive histogram equalization: Speed and effectiveness stephen m. pizer, r. eugene johnston, james p. ericksen, bonnie c. yankaskas, keith e. muller medical image display research group." Proceedings of the first conference on visualization in biomedical computing, Atlanta, Georgia. Vol. 337. 1990.
- Rizzi, Alessandro, Carlo Gatta, and Daniele Marini. "Color correction between gray world and white patch." Human Vision and Electronic Imaging VII. Vol. 4662. SPIE, 2002.
- Ancuti, Cosmin, et al. "Enhancing underwater images and videos by fusion." 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012.
- Cao, Keming, Yan-Tsung Peng, and Pamela C. Cosman. "Underwater image restoration using deep networks to estimate background light and scene depth." 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI). IEEE, 2018.
- Liu, Peng, et al. "Underwater image enhancement with a deep residual framework." IEEE access 7 (2019): 94614-94629.
- Chen, Xinyu, Jinjiang Li, and Zhen Hua. "Retinex low-light image enhancement network based on attention mechanism." Multimedia Tools and Applications 82.3 (2023): 4235-4255.
- Liu Xu, Lin Sen, and Tao Zhiyong. "Underwater Image Enhancement of Global - Feature Dual - Attention - Fusion Adversarial Network." Electro - Optics & Control, 29.07 (2022): 43 - 48.
- Chen Yan, et al. "Underwater Image Enhancement with Multi - path Fusion and Deep Aggregation Learning." Laser & Optoelectronics Progress, 1 - 17.
- Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
- Ren, Tingdi, et al. "Reinforced swin-convs transformer for simultaneous underwater sensing scene image enhancement and super-resolution." IEEE Transactions on Geoscience and Remote Sensing 60 (2022): 1-16.
- Zhu, Lianghui, et al. "Vision mamba: Efficient visual representation learning with bidirectional state space model." arXiv preprint arXiv:2401.09417 (2024).
- Mei, Yiqun, Yuchen Fan, and Yuqian Zhou. "Image super-resolution with non-local sparse attention." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
- Li, Chongyi, et al. "An underwater image enhancement benchmark dataset and beyond." IEEE transactions on image processing 29 (2019): 4376-4389.
- Wang, Hong, He Xiaohai, and Yang Xiaomin. "Adaptive Fog - Day Image Sharpening Algorithm Based on Fuzzy Theory and CLAHE." Microelectronics & Computer 29.1 (2012): 32 - 34.
- He, Kaiming, Jian Sun, and Xiaoou Tang. "Single image haze removal using dark channel prior." IEEE transactions on pattern analysis and machine intelligence 33.12 (2010): 2341-2353.
- Jiang, Jingxia, et al. "Five A $^{+} $ Network: You Only Need 9K Parameters for Underwater Image Enhancement." arXiv preprint arXiv:2305.08824 (2023).
- Fu, Zhenqi, et al. "Uncertainty inspired underwater image enhancement." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
- Naik, Ankita, Apurva Swarnakar, and Kartik Mittal. "Shallow-uwnet: Compressed model for underwater image enhancement (student abstract)." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 35. No. 18. 2021.
- Li, Chongyi, Saeed Anwar, and Fatih Porikli. "Underwater scene prior inspired deep underwater image and video enhancement." Pattern Recognition 98 (2020): 107038.
- Hore, Alain, and Djemel Ziou. "Image quality metrics: PSNR vs. SSIM." 2010 20th international conference on pattern recognition. IEEE, 2010.
- Yang, Miao, and Arcot Sowmya. "An underwater color image quality evaluation metric." IEEE Transactions on Image Processing 24.12 (2015): 6062-6071.
- Panetta, Karen, Chen Gao, and Sos Agaian. "Human-visual-system-inspired underwater image quality measures." IEEE Journal of Oceanic Engineering 41.3 (2015): 541-551.
Figure 1.
Geomagnetic sensor error correction schematic diagram.
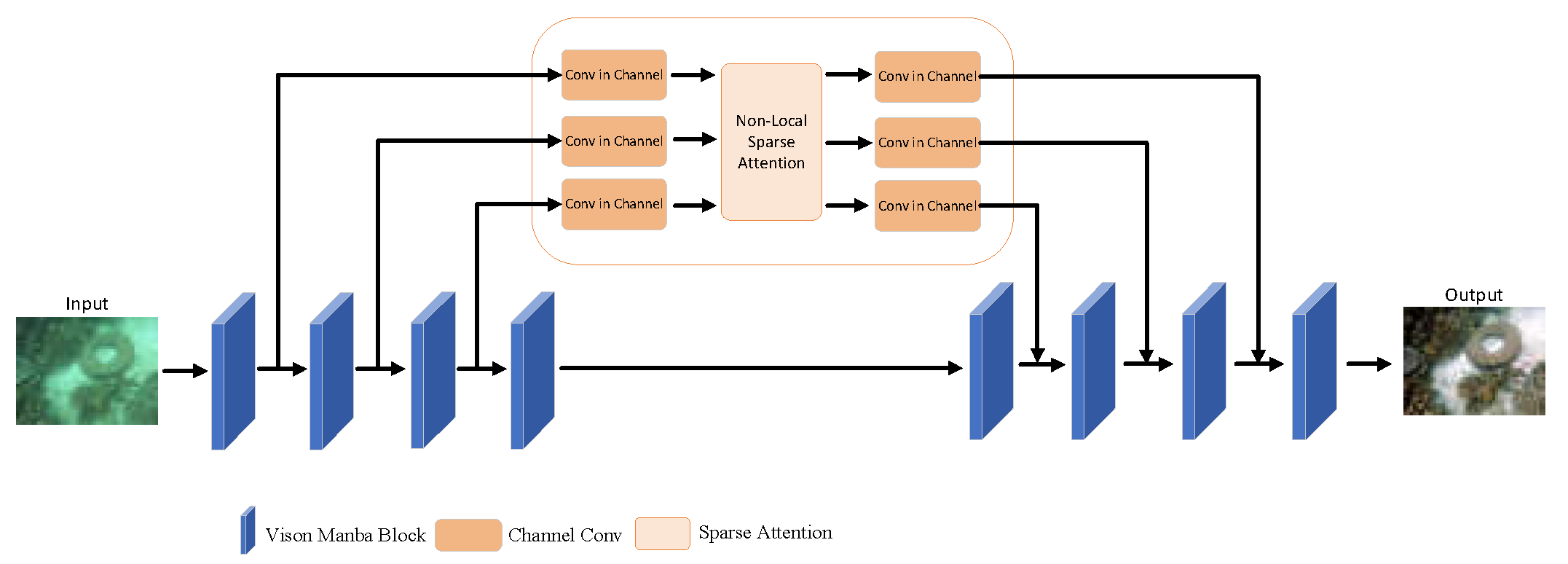
Figure 2.
Vision Mamba block.
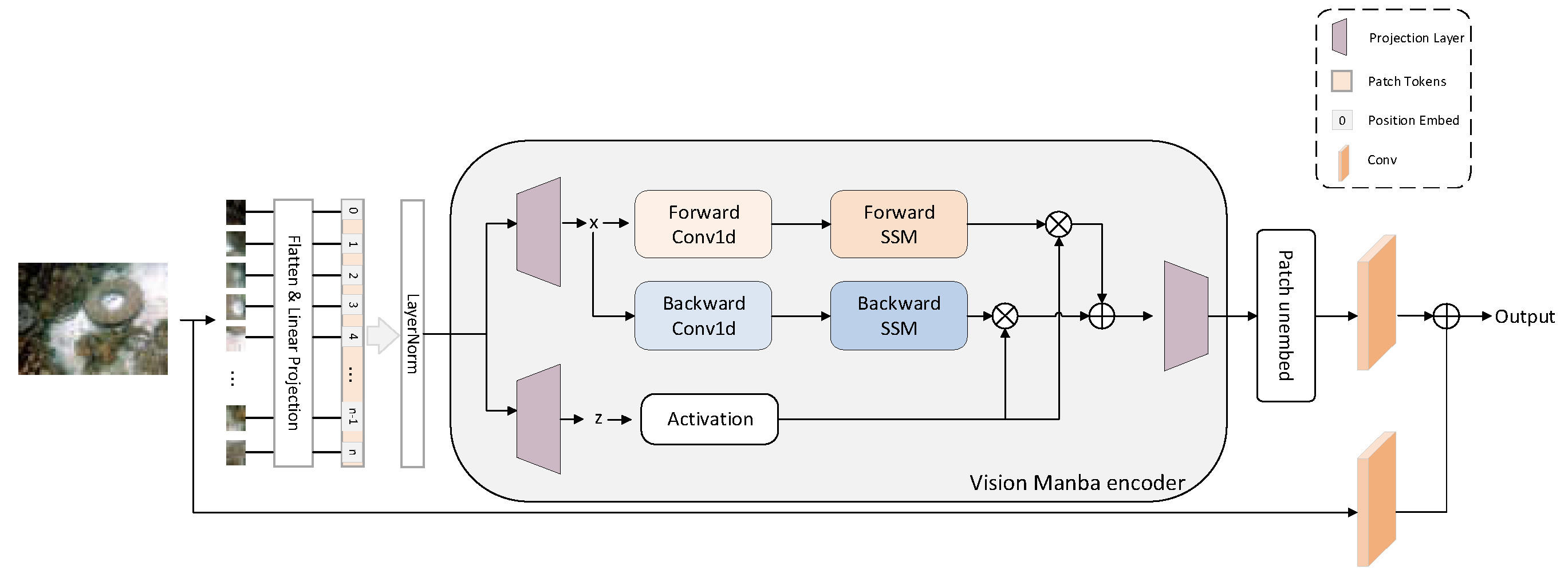
Figure 3.
Multi-scale sparse attention fusion module.
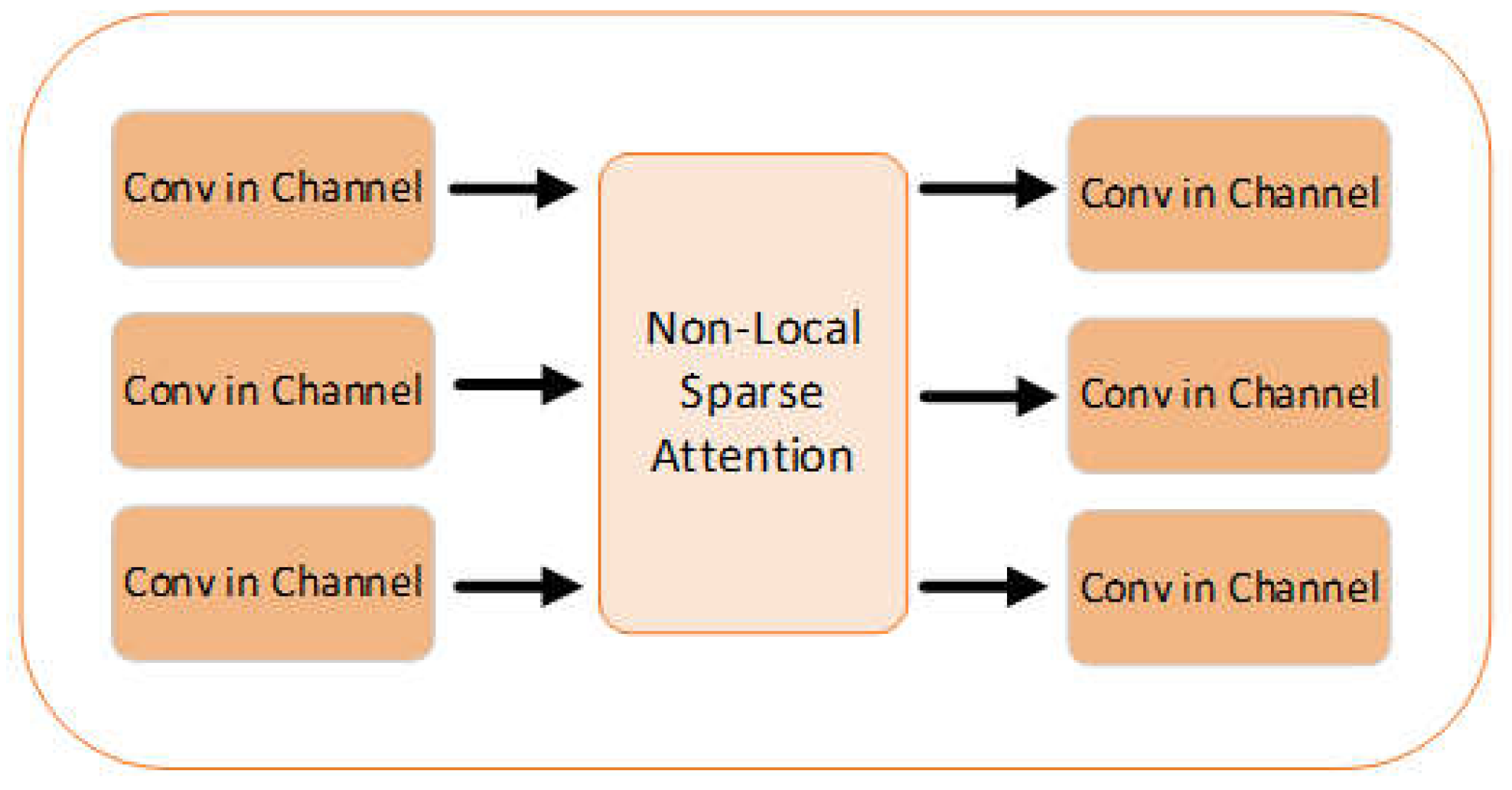
Figure 4.
Subjective comparison of underwater image enhancement algorithms on the UIEB dataset.

Figure 5.
Underwater image enhancement verification.


Table 1.
Evaluation indicators of different methods on UIEB dataset.
| Method | UIEB | |||
| UCIQE | UIQM | PSNR | SSIM | |
| CLAHE | 0.3395 | 2.0156 | 19.3283 | 0.8535 |
| DEHAZE | 0.4222 | 1.5273 | 14.3789 | 0.6514 |
| FIVE_APLU | 0.4154 | 2.2284 | 23.8334 | 0.9546 |
| UWCNN | 0.4504 | 2.3663 | 14.9460 | 0.7895 |
| U-Shape | 0.4943 | 2.5166 | 24.1623 | 0.9326 |
| Shallow-UWnet | 0.4908 | 2.4575 | 23.3061 | 0.9112 |
| Ours | 0.4986 | 2.4331 | 25.6562 | 0.9724 |
Table 2.
Ablation experiment.
| Module | PSNR | SSIM |
| A | 21.7286 | 0.9207 |
| B | 13.9768 | 0.8363 |
| Ours | 25.6562 | 0.9724 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



