Submitted:
10 July 2025
Posted:
10 July 2025
You are already at the latest version
Abstract
This paper proposes a deep discriminative model based on causal representation learning for the task of fraud detection in financial transactions. The method aims to enhance model stability and generalization in complex environments, such as distribution shifts and strategy changes, by modeling the underlying causal structures among transaction features. Specifically, the model first captures the generative process of transaction data using causal structural modeling. It introduces latent variables to represent causal dependencies among generative factors. Next, a causal encoder and reconstruction decoder are constructed within a variational autoencoder framework. This enables causally guided representation learning from the input data. Based on these representations, a classifier is designed to perform the fraud detection task. A domain discriminator is also introduced to enforce domain invariance in the latent space. This helps improve robustness under diverse fraud strategies. To validate the proposed method, experiments are conducted on a publicly available financial fraud dataset. The model is evaluated from multiple perspectives, including discrimination ability, stability, and cross-domain generalization. Results show that the proposed model outperforms representative existing methods across several metrics. It shows particularly strong performance in scenarios with noticeable strategy changes or significant feature perturbations. These findings further demonstrate the modeling advantage of causal mechanisms in fraud detection tasks. The overall framework enhances the extraction of key fraud-related features. It also provides theoretical and practical value for representation learning methods in high-risk environments.
Keywords:
fraudulent transaction identification
; causal representation learning
; robust classification
; domain invariance
I. Introduction
In the modern financial system, the prevalence of electronic payments and online transactions has led to a significant rise in both the frequency and complexity of financial fraud. Fraudulent transactions cause direct financial losses to individuals. They also disrupt the normal functioning of financial markets and weaken the credibility and risk management capacity of financial institutions[1]. As financial technology evolves, fraud techniques become more intelligent and concealed. Traditional rule-based or shallow machine learning methods are increasingly inadequate. There is an urgent need for more intelligent, efficient, and generalizable approaches. Detecting fraudulent transactions has become a core challenge in financial risk control, with great practical value and broad research potential[2].
In recent years, the wide application of artificial intelligence in finance has driven progress in fraud detection based on deep learning [3,4,5]. However, these methods still face many practical challenges. On one hand, the data suffer from serious class imbalance and rapid changes, causing models to overfit normal transaction patterns while missing potential fraud [6]. On the other hand, most models rely on statistical associations and lack a deep understanding of fraud mechanisms [7]. These "black-box" approaches struggle to adapt to evolving fraud strategies. They also face limitations in transferability and interpretability. Therefore, building fraud detection models with causal reasoning capabilities is a key path to overcoming current technological bottlenecks.
Causal representation learning is an emerging field that integrates causal inference with representation learning. It offers an effective way to understand and model the data generation process. Unlike traditional methods, it focuses not only on statistical dependencies but also on the underlying causal structures between variables[8,9]. These structures help models identify the key drivers of fraud, rather than relying only on surface-level feature co-occurrence [10]. In fraud detection, this provides clear advantages. It enhances the ability to detect unknown fraud patterns and supports better generalization when transaction environments change. Introducing causal representation learning into fraud detection can fundamentally improve model robustness and interpretability. This has significant theoretical and practical implications[11].
In addition, financial fraud is highly strategic and adversarial. Fraudsters often adjust their behavior based on known detection rules, making static models less effective over time. Causal representation learning, by focusing on generative mechanisms, provides greater resistance to adversarial changes. Even when fraudsters alter their surface behavior, the model may still detect underlying causal patterns. This makes more effective detection possible. Such a feature opens a new direction for building fraud-resistant risk control systems. It also highlights the strategic importance of causal representation learning in fraud detection tasks[12].
In conclusion, as financial fraud continues to evolve and financial environments grow more complex, traditional detection methods reveal critical limitations. These include poor generalization, weak interpretability, and vulnerability to adversarial manipulation. Causal representation learning brings new vitality to the field. It offers a mechanism-oriented approach to deep fraud detection. It may break the limitations of black-box models and improve adaptability in dynamic environments. Research on fraud detection based on causal representation learning supports theoretical innovation in financial risk control. It also holds wide application potential and societal value.
II. Method
This study constructs a fraudulent transaction identification framework grounded in causal representation learning. Drawing from Liu et al. [13], who emphasized the importance of structured reasoning in anomaly detection through knowledge graph integration, this framework focuses on uncovering and modeling the latent causal mechanisms underlying transaction data. By learning the mapping between these causal structures and observable transaction features, the model aims to improve its interpretability and robustness in dynamic environments.
Initially, the model adopts a generative approach where latent variables represent potential causal factors influencing transaction behaviors. Inspired by balancing data and enhancing generalization in imbalanced fraud datasets [14], the framework integrates a causal encoder-decoder architecture within a variational autoencoder setup. This design allows the model to reconstruct input transactions while preserving causal dependencies in the latent space.
In addition, a classifier is trained atop these causally-informed representations to discriminate fraudulent activities. To ensure resilience under changing fraud strategies, a domain discriminator is also incorporated, aligning with J. Liu’s [15] approach of enforcing invariance across temporal variations in anomaly detection tasks. This component enhances the model’s cross-domain generalization by mitigating the influence of domain-specific noise. The overall system architecture is illustrated in Figure 1.
Specifically, we first set a potential causal graph structure A, where nodes V represent different transaction features and edges E represent possible causal dependencies between features. The data generation process is modeled as a structured causal mechanism:
represents the i-th feature variable, represents its causal parent node set, is an independent noise term, and function captures the local generation mechanism. This modeling method provides structural guidance for subsequent learning, allowing the model to not only learn associations but also embed potential causal logic.
In order to achieve causal representation learning, we introduce the idea of variational reasoning to model the latent variable Z, build a causal encoder to extract causal invariant features and define a decoder to reconstruct the input. The overall optimization goal is based on the variational lower bound (Evidence Lower Bound, ELBO):
The first term is the reconstruction loss, and the second term is the KL divergence between the latent variable distribution and the prior , which is used to regularize the encoding space. This representation-learning process guides the model to learn representations with causal transferability while retaining the original information.
In the discriminative task, we introduce a binary classifier to predict fraudulent behavior of the latent causal representation and output label . The discriminative loss is modeled using the cross-entropy function:
By optimizing this objective function, the model encourages the learned causal representations to maintain strong discriminative power for fraud detection. To further enhance the robustness of these representations, especially in the face of diverse and evolving fraud patterns, we integrate domain invariance constraints into the training process.
Following the insights of Yao [16], who explored domain shifts in dynamic financial markets through nested reinforcement learning, we model fraud strategies as originating from multiple latent domains. To account for this, we define a domain discriminator that estimates the domain membership of latent representations. The objective is to minimize the discriminator’s ability to distinguish between domains through adversarial training, thus enforcing domain invariance in the causal feature space. This adversarial mechanism aligns with the value of integrating large language models with domain-robust components for early fraud warning systems [17]. Furthermore, Sha et al. [18] emphasized domain-aware feature learning using heterogeneous graph attention mechanisms, a concept echoed here through the disentangling of domain-specific noise from causal semantics. This ensures that the resulting representations generalize well across multiple fraud strategies and transaction types. The final training objective is formulated as follows:
Where D represents the domain label. By maximizing this loss, the domain classification ability is improved, thus forcing the main model to learn domain-insensitive causal features.
Finally, the total loss function of the model is a weighted combination of the above three items:
are adjustable hyperparameters used to control the balance between representation learning, discrimination accuracy, and causal robustness. By jointly optimizing this objective function, the model not only has a strong fraud identification ability but also has stronger generalization and explanation capabilities, which is suitable for the changing financial transaction environment.
III. Experimental Results
A. Dataset
This study uses the publicly available IEEE-CIS Fraud Detection Dataset as the primary experimental foundation. The dataset was jointly released by a financial services provider and a big data platform. It is widely used for algorithm evaluation in fraud detection research. The dataset simulates real-world online payment scenarios and contains around 12 million transaction records. Each transaction is labeled as fraudulent or not. The data include structured and semi-structured features such as timestamps, transaction amounts, device types, email domains, browser types, and address information.
The dataset is characterized by high feature dimensionality and a highly imbalanced distribution. Fraudulent transactions account for a small proportion of the total. It also contains complex cross-domain feature interactions. These characteristics place high demands on the generalization ability of detection models. Some features are anonymized, requiring models to automatically identify latent causal relationships. This supports the evaluation of causal representation learning methods in terms of effectiveness and adaptability.
In addition, the dataset includes both user identity features and transaction behavior features. This makes it suitable for building joint encoders to model fraudulent behavior. Because it closely simulates real-world scenarios and contains large-scale, high-dimensional data, this dataset has become a standard benchmark in fraud detection research. It is well-suited for testing the discrimination capabilities of advanced models in imbalanced, multimodal, and highly heterogeneous environments.
B. Experimental Results
First, this paper gives the comparative experimental results, as shown in Table 1.
Overall, the proposed fraud detection method based on causal representation learning outperforms mainstream models across multiple evaluation metrics. This demonstrates the significant performance improvement potential of causal structure modeling in financial risk control tasks. Compared with traditional deep learning methods, this approach not only learns statistical relationships among transaction features but also uncovers latent causal mechanisms. This enhances both discrimination ability and generalization capacity.
In comparison, models such as Transformer and TabNet show strong feature modeling capabilities. However, they still rely on surface-level statistical correlations. Their robustness to distribution shifts and strategy variations remains limited. By introducing a causal encoder and domain-invariance constraints, the proposed method reduces dependency on specific distributions. It maintains high stability and accuracy in complex or changing fraud environments.
In addition, causal representations improve the model's adaptability to class imbalance and cross-domain feature disturbances. While other methods are often affected by abnormal patterns, the proposed model tends to learn the underlying generative mechanisms of fraud. This leads to better discrimination on edge cases. Such capability is especially important for real-world financial systems where fraud is adversarial and rapidly evolving. In summary, the experimental results validate the effectiveness and feasibility of introducing causal reasoning into fraud detection models. Compared with existing approaches, the proposed method not only achieves superior accuracy but also offers unique advantages in robustness and interpretability. This aligns well with the dual demands for transparency and reliability in financial applications.
Furthermore, this paper also presents generalization performance evaluation experiments under different domain distributions. These experiments are designed to assess the model's ability to maintain consistent performance when applied to data from varying financial scenarios with distinct feature distributions. The evaluation aims to reflect how well the model adapts to domain shifts and handles distributional discrepancies, which are common in real-world fraud detection tasks. By conducting these experiments, the study provides a comprehensive examination of the model’s robustness across multiple environments. The corresponding experimental setup and outcomes are illustrated in Figure 2.
The results show that the proposed causal representation learning model demonstrates strong stability across various financial scenarios. In particular, it maintains high discrimination performance in typical settings such as E-Commerce, Banking, and Mobile Pay. This indicates that the transaction mechanisms captured by causal structures share a certain degree of commonality across different data distributions. As a result, the model exhibits cross-scenario generalization ability.
As the domain shifts, especially in settings like Crypto and Cross-Domain with significant distribution differences, model performance slightly declines but remains at a high level. This suggests that the model preserves key causal features under distribution drift or fraud strategy variation. It supports effective pattern recognition across domains. In contrast, traditional pattern-matching methods often fail in such cases. Causal representations offer stronger structural stability.
The experiments also reveal a clear trend in F1-Score variation. This suggests that even under extreme class imbalance, the model achieves a good balance between precision and recall. This is critical for financial risk control systems. It helps reduce false positives on legitimate users while identifying high-risk transactions.
Overall, the experiment confirms the effectiveness of causal representation learning in cross-domain fraud detection tasks. The model outperforms traditional deep models in environments with diverse transaction patterns and complex strategies. It provides a viable solution for large-scale real-world financial applications.
This paper further provides the experimental results of the model’s robustness evaluation conducted in a multi-strategy fraud simulation environment. The purpose of this experiment is to examine the model’s ability to maintain stable performance when facing various types of fraud strategies that differ in their behavioral patterns and levels of complexity. Such strategies are designed to simulate real-world scenarios where fraud tactics are dynamic, adaptive, and potentially adversarial. The experimental setup reflects the need for models to perform reliably under shifting strategic conditions, which is critical for practical deployment in financial systems. The details of this evaluation are presented in Figure 3.
The experimental results shown in the figure demonstrate the robustness of the proposed causal representation learning model under various simulated fraud strategies. It can be observed that the model maintains relatively stable performance across different evaluation metrics. This holds for rapid fraud, gradual fraud, and more deceptive or adversarial strategies. These results indicate that the modeled causal structure captures common generative mechanisms across strategies rather than relying on superficial feature differences.
In dynamic fraud environments, traditional methods often depend on handcrafted features or static distributions. As a result, their performance fluctuates significantly when strategies change. In contrast, the proposed method models latent causal factors through causal representation learning. This gives the model stronger adaptability to strategy variations. Such adaptability improves the model's responsiveness to evolving fraud behaviors and ensures greater stability in real-world deployment.
In particular, under complex strategies such as adversarial fraud, the model shows a slight performance decline but still maintains high usability. This indicates that the proposed method possesses a certain level of resistance to interference. The key advantage of causal mechanism modeling lies in its ability to remove misleading superficial features. It helps the model focus on more essential discriminative factors.
In summary, this experiment further confirms the practical adaptability of causal representation learning in the context of fraud detection. This adaptability is particularly important in financial environments characterized by high levels of strategic variability and complex behavioral patterns. The ability to handle such complexity is essential for developing reliable detection systems capable of responding to rapidly evolving fraud tactics. By incorporating domain invariance and structural robustness into the model design, the approach enables a transition from basic generalization to enhanced robustness. This ensures that the model remains effective across a wide range of fraud strategies and diverse operational scenarios.
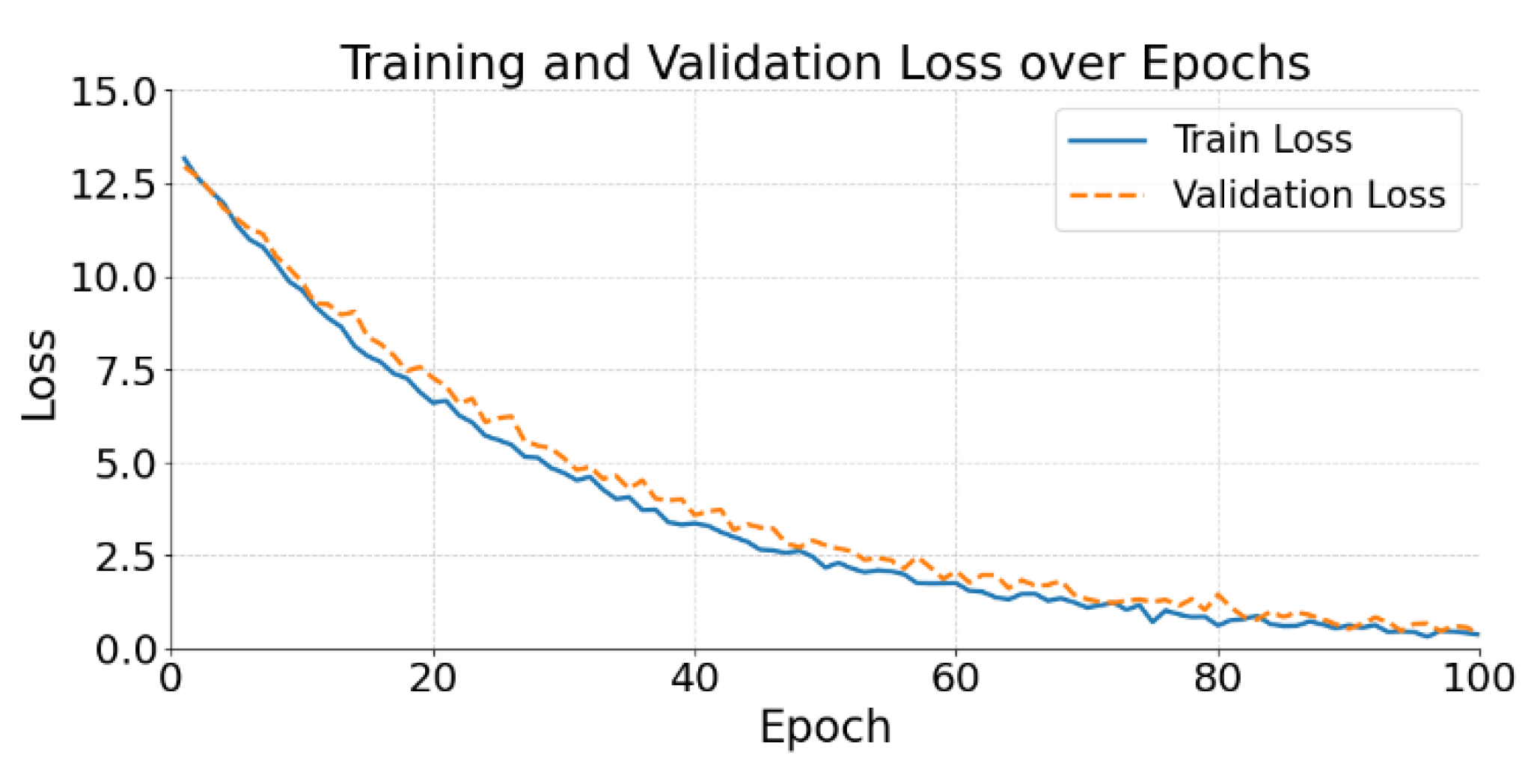
The figure shows that the loss function of the proposed model exhibits a stable and steadily decreasing trend during training. This indicates that the model progressively converges through iterations and effectively approaches the optimization objective. Both training loss and validation loss display strong consistency. This suggests that the model fits the training data well while maintaining good generalization on the validation set.
It is particularly noteworthy that both curves become stable in the middle and later stages. No significant oscillation or overfitting is observed. This indicates that the structural constraints and regularization mechanisms of causal representation learning play a key role during modeling. By introducing latent causal variables and domain-invariant discrimination mechanisms, the model reduces reconstruction error while preserving the stability of causal features.
In addition, the small gap between validation loss and training loss reflects the model’s adaptability to unseen data distributions. This confirms the robustness provided by the causal structure when facing strategy changes or domain differences. Such robustness supports risk control in complex transaction environments. It is especially important in real financial scenarios where fraud strategies change rapidly.
Overall, the loss curve validates the stability, convergence, and generalization ability of the proposed method during optimization. Through the structural advantages of causal modeling, the model not only learns feature representations efficiently but also effectively suppresses overfitting. This enhances its practical value and reliability in real-world fraud detection tasks.
IV. Conclusion
This paper focuses on the critical application of financial fraud detection and proposes a discriminative model based on causal representation learning. The goal is to enhance the model's ability to understand and identify the essence of fraudulent behavior. By introducing causal structure modeling and variational inference mechanisms, the model captures latent generative factors within high-dimensional and heterogeneous financial transaction data. This strengthens the stability and transferability of feature representations. Compared with traditional deep learning methods, the proposed approach not only achieves strong discrimination performance but also demonstrates notable robustness under distribution shifts and strategy perturbations. This capability is crucial for handling complex and diverse fraud strategies in real financial environments. In the experimental validation, the model is evaluated through multi-scenario simulations and cross-domain assessments. The results systematically show its advantages in stability, generalization, and structural robustness. In particular, under conditions of extreme class imbalance and strong adversarial strategies, the model effectively captures hidden fraudulent behavior by leveraging causal mechanisms. This improves the detection of covert fraud. At the same time, the use of causal representation learning helps alleviate the "black-box" nature of models. It offers greater interpretability and reliability for financial risk control systems and supports the development of transparent and controllable intelligent decision systems. At the methodological level, this study presents a unified framework that integrates representation learning and causal inference. It overcomes the limitations of existing financial risk control models that rely heavily on statistical correlations. This work advances the practical exploration of causal learning in high-risk decision-making tasks. The approach is also applicable to other areas such as credit scoring, anomaly detection, insurance risk management, and regulatory compliance. It shows strong adaptability across tasks and potential for real-world implementation. Furthermore, the method provides a practical perspective on embedding structural priors into complex real-world data to enhance model robustness. It offers both theoretical and practical insights into the intersection of machine learning and applied finance.
V. Future Work
Looking ahead, the further application of causal representation learning in high-frequency trading, real-time fraud prevention, and federated risk control systems deserves more attention. Improving model efficiency, response time, and cross-platform collaboration while maintaining causal interpretability will be key to large-scale industrial deployment. In addition, future directions include adaptive modeling of causal structures in dynamic environments, causal transfer across domains, and the development of causality-enhanced adversarial mechanisms. This work provides a new modeling paradigm for financial risk control and lays a foundation for the practical application of causal learning in critical tasks.
References
- J. Kim, H. Jung, and W. Kim, "Sequential pattern mining approach for personalized fraudulent transaction detection in online banking", Sustainability, vol. 14, no. 15, pp. 9791, 2022. [CrossRef]
- X. Li, Y. Peng, X. Sun, and others, "Unsupervised Detection of Fraudulent Transactions in E-commerce Using Contrastive Learning", arXiv preprint arXiv:2503.18841, 2025.
- D. Gao, "Deep Graph Modeling for Performance Risk Detection in Structured Data Queries", Journal of Computer Technology and Software, vol. 4, no. 5, 2025.
- X. Du, "Financial Text Analysis Using 1D-CNN: Risk Classification and Auditing Support", 2025.
- Q. Bao, J. Wang, H. Gong, Y. Zhang, X. Guo, and H. Feng, "A Deep Learning Approach to Anomaly Detection in High-Frequency Trading Data", Proceedings of the 2025 4th International Symposium on Computer Applications and Information Technology (ISCAIT), pp. 287–291, 2025.
- X. Liu, Y. Qin, Q. Xu, Z. Liu, X. Guo, and W. Xu, "Integrating Knowledge Graph Reasoning with Pretrained Language Models for Structured Anomaly Detection", 2025.
- Y. Wang, "A Data Balancing and Ensemble Learning Approach for Credit Card Fraud Detection", Proceedings of the 2025 4th International Symposium on Computer Applications and Information Technology (ISCAIT), pp. 386–390, 2025.
- Matloob, S. A. Khan, R. Rukaiya, and others, "A sequence mining-based novel architecture for detecting fraudulent transactions in healthcare systems", IEEE Access, vol. 10, pp. 48447–48463, 2022.
- Y. Sheng, "Temporal Dependency Modeling in Loan Default Prediction with Hybrid LSTM-GRU Architecture", Transactions on Computational and Scientific Methods, vol. 4, no. 8, 2024.
- F. Rahmani, C. Valmohammadi, and K. Fathi, "Detecting fraudulent transactions in banking cards using scale-free graphs", Concurrency and Computation: Practice and Experience, vol. 34, no. 19, pp. e7028, 2022. [CrossRef]
- D. K. Rakesh and P. K. Jana, "An improved differential evolution algorithm for quantifying fraudulent transactions", Pattern Recognition, vol. 141, pp. 109623, 2023. [CrossRef]
- D. Myalil, M. A. Rajan, M. Apte, and others, "Robust collaborative fraudulent transaction detection using federated learning", Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), pp. 373–378, 2021.
- X. Liu, Y. Qin, Q. Xu, Z. Liu, X. Guo, and W. Xu, "Integrating Knowledge Graph Reasoning with Pretrained Language Models for Structured Anomaly Detection", 2025.
- Y. Wang, "A Data Balancing and Ensemble Learning Approach for Credit Card Fraud Detection", Proceedings of the 2025 4th International Symposium on Computer Applications and Information Technology (ISCAIT), pp. 386–390, 2025.
- J. Liu, "Global Temporal Attention-Driven Transformer Model for Video Anomaly Detection", 2025.
- Y. Yao, "Time-Series Nested Reinforcement Learning for Dynamic Risk Control in Nonlinear Financial Markets", Transactions on Computational and Scientific Methods, vol. 5, no. 1, 2025.
- J. Gong, Y. Wang, W. Xu, and Y. Zhang, "A Deep Fusion Framework for Financial Fraud Detection and Early Warning Based on Large Language Models", Journal of Computer Science and Software Applications, vol. 4, no. 8, 2024.
- Q. Sha, T. Tang, X. Du, J. Liu, Y. Wang, and Y. Sheng, "Detecting Credit Card Fraud via Heterogeneous Graph Neural Networks with Graph Attention", arXiv preprint arXiv:2504.08183, 2025. arXiv:2504.08183, 2025.
- C. E. Rani and V. P. Raju, "Detecting Digital Financial Transaction Frauds Using CNN Model", Proceedings of the 2025 3rd International Conference on Device Intelligence, Computing and Communication Technologies (DICCT), pp. 164–169, 2025.
- Y. Chen and M. Du, "Financial Fraud Transaction Prediction Approach Based on Global Enhanced GCN and Bidirectional LSTM", Computational Economics, pp. 1–20, 2024. [CrossRef]
- J. Lin, X. Guo, Y. Zhu, and others, "FraudGT: A Simple, Effective, and Efficient Graph Transformer for Financial Fraud Detection", Proceedings of the 5th ACM International Conference on AI in Finance, pp. 292–300, 2024.
- S. Ö. Arik and T. Pfister, "Tabnet: Attentive interpretable tabular learning", Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 8, pp. 6679–6687, 2021.
Figure 1.
Overall model architecture diagram.
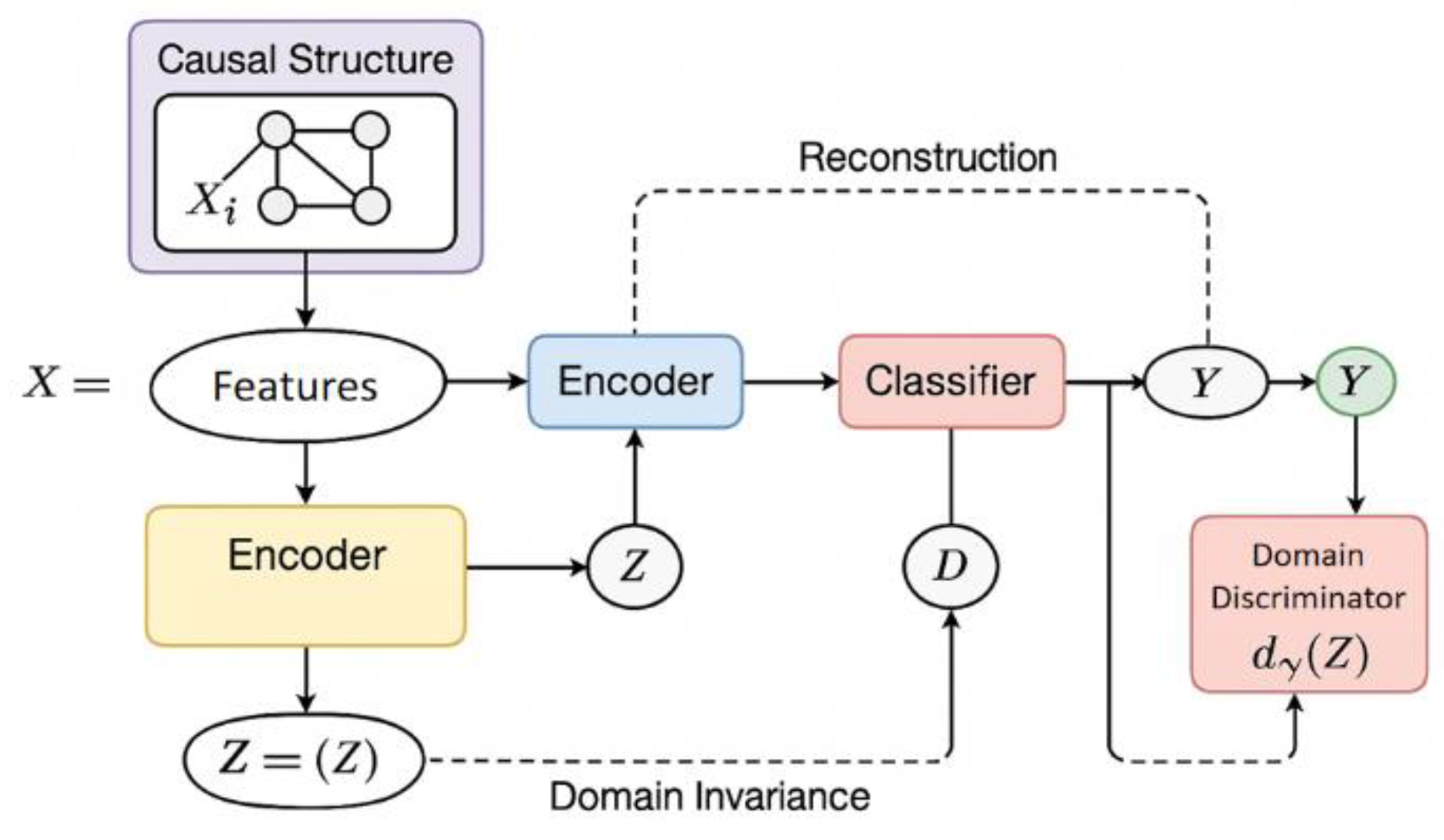
Figure 2.
Generalization performance evaluation experiment under different domain distributions.
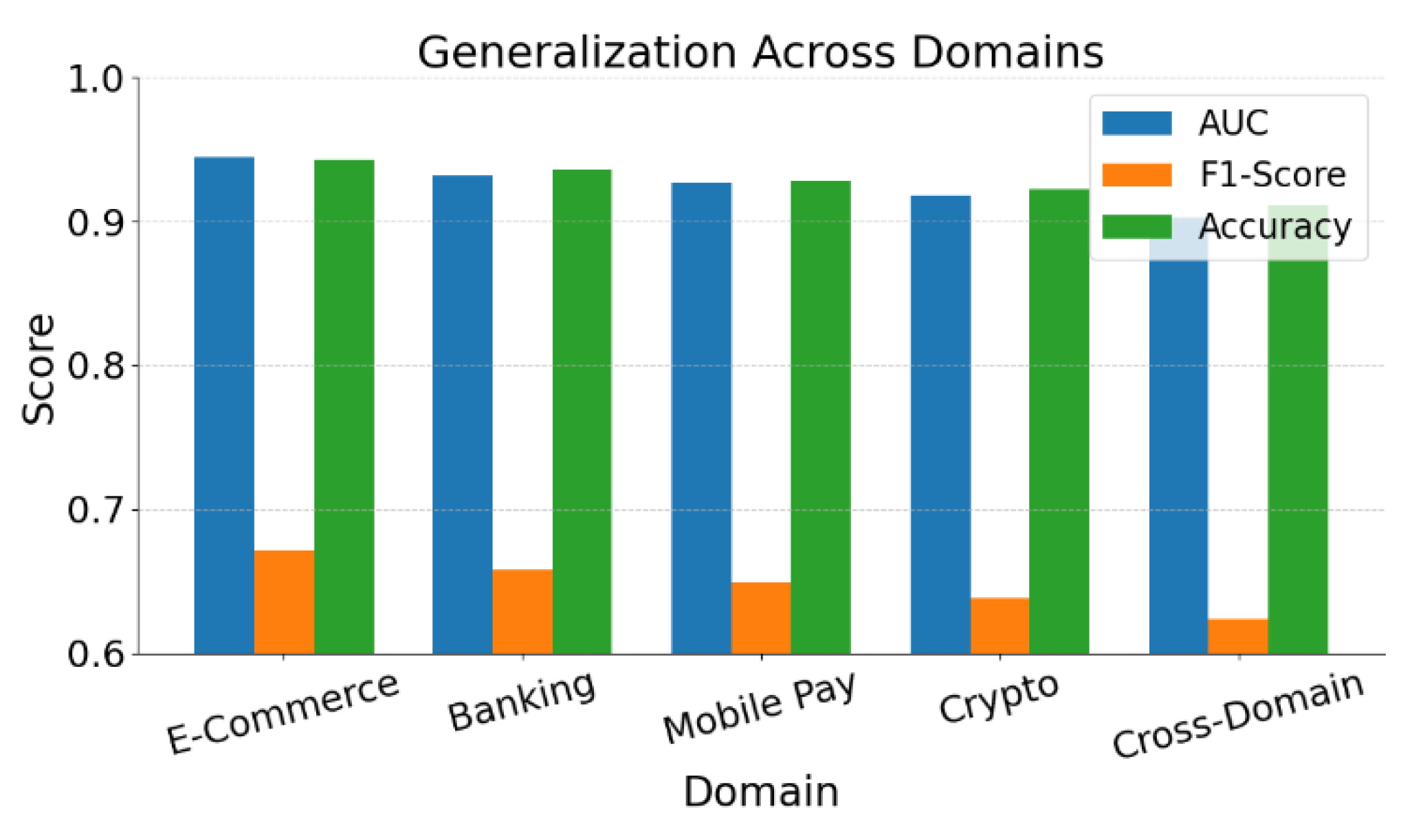
Figure 3.
Robustness experiment of the model in a multi-strategy fraud simulation environment.
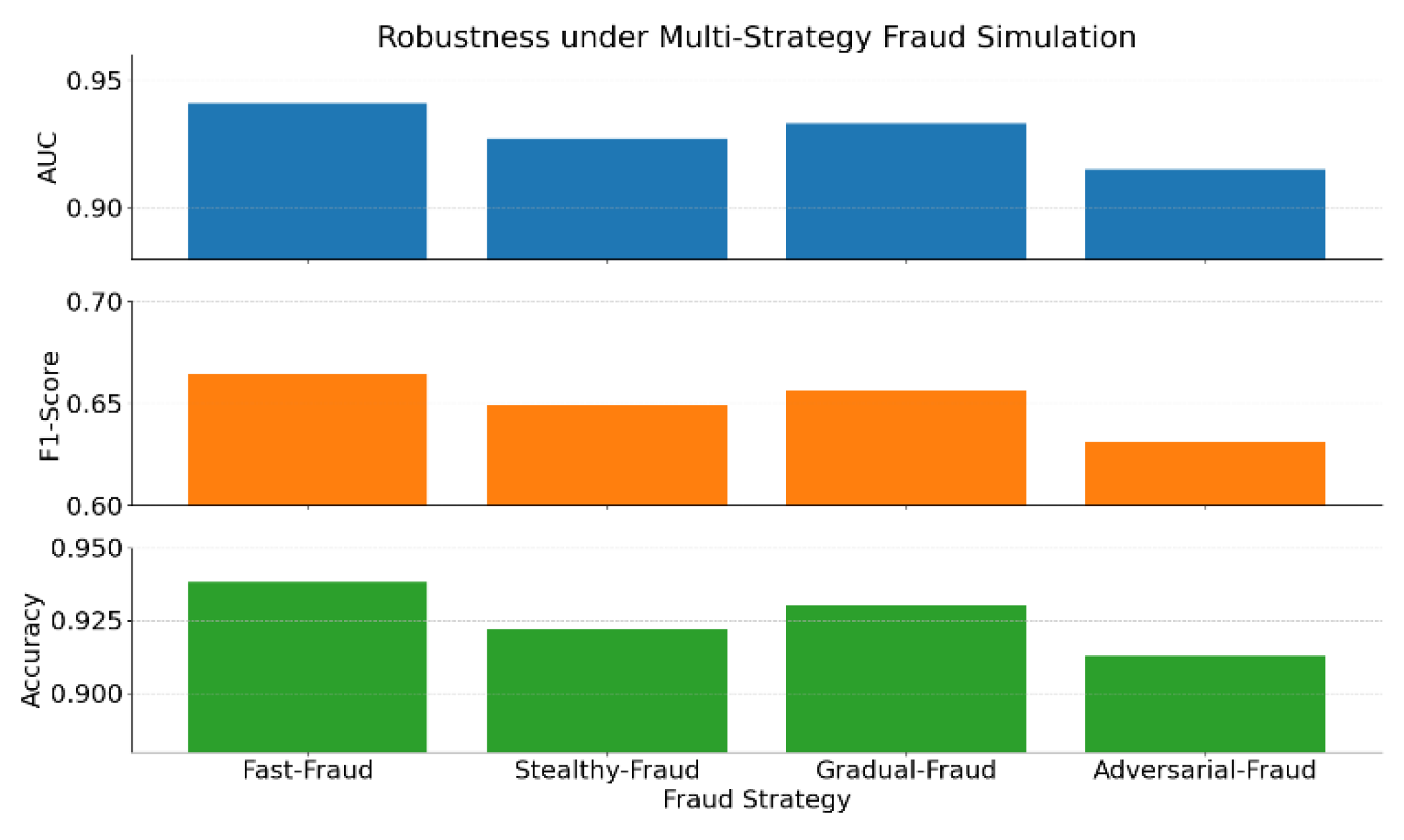
Figure 4.
Loss function changes with epoch.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



