Submitted:
16 October 2025
Posted:
16 October 2025
You are already at the latest version
Abstract
This paper addresses key challenges in credit fraud detection, including small sample sizes, imbalanced data distribution, and rapidly changing fraud patterns. A meta-learning-based detection method is proposed to enhance the model's adaptability and detection efficiency in complex scenarios. The method adopts a two-level architecture consisting of a meta-learner and a task-learner. By extracting shared knowledge across multiple fraud detection tasks, the model can rapidly update its parameters. This allows it to maintain high detection performance when facing new types of fraud. In the method design, a task-level gradient update mechanism and a weighted loss strategy are introduced. These components help address the challenges caused by rare fraud samples and class imbalance. The proposed model is systematically evaluated through multiple experiments. These include different task quantities, varying degrees of data imbalance, and injected abnormal fraud patterns. The results confirm the model's effectiveness and robustness under diverse conditions. Experimental findings show that the proposed method outperforms traditional models in accuracy, precision, and recall. It also demonstrates better stability and generalization when facing dynamically changing fraud scenarios. This study highlights the application potential of meta-learning in credit fraud detection. It provides technical support for building more intelligent financial risk control models.
Keywords:
meta-learning
; credit risk identification
; small sample learning
; model robustness
I. Introduction
In the context of rapid digitalization and informatization, the service model of the financial industry is undergoing profound changes. In particular, online credit has become a mainstream trend in the field of credit services. However, the issue of credit fraud has also become increasingly prominent. It has emerged as a major challenge for financial institutions[1]. Credit fraud not only causes direct economic losses but also seriously affects the stability and fairness of the credit market. As fraudulent methods become more diverse and covert, traditional anti-fraud approaches are falling short in terms of accuracy and timeliness. Therefore, exploring more efficient and intelligent methods for credit fraud detection has become a key research focus in the field of financial technology[2].
Traditional credit fraud detection relies heavily on large amounts of historical data to build supervised learning models. These models perform well under conditions of stable data distribution and sufficient samples. However, in real-world scenarios, fraud behavior is highly dynamic and non-stationary. It often exhibits characteristics such as small sample size, class imbalance, and high heterogeneity[3]. As a result, traditional models struggle to generalize to new fraud patterns. Moreover, fraudsters constantly adjust their strategies in response to existing detection methods[4]. This causes a rapid decline in model performance. To address this issue, researchers are exploring ways to quickly adapt to new fraud scenarios using limited sample information. The goal is to improve the adaptability and robustness of detection models.
Against this background, meta-learning has emerged as an influential paradigm in machine learning, attracting growing research interest for its ability to “learn how to learn.” By abstracting and transferring knowledge from multiple prior tasks, meta-learning enables models to adapt rapidly to unseen problems and achieve efficient fast learning. This paradigm has been widely adopted across diverse areas such as large language models (LLMs) for efficient fine-tuning [5,6,7,8], computer systems and cloud services for resource optimization and fault prediction [9,10,11,12,13], and computer vision for few-shot recognition and domain adaptation [14,15,16,17].This capability is especially important for addressing the high task heterogeneity and small sample issues in credit fraud. Applying meta-learning to credit fraud detection is expected to significantly improve the speed and accuracy of responding to emerging fraud tactics. It offers financial institutions a more forward-looking and intelligent approach to risk control[18].
As data continues to grow and computing power improves, financial technology is moving toward an intelligent stage. This transformation is driving the upgrade of risk control systems. In this context, innovation in credit fraud detection methods can enhance risk prevention capabilities. It also helps allocate financial resources more effectively and improves the user experience. Building anti-fraud models with adaptive learning capabilities is an effective way to respond to fast-changing fraudulent behaviors. This contributes to the overall stability and security of the financial ecosystem. As a learning paradigm with strong generalization ability, meta-learning provides new technical support for credit fraud detection. It opens new directions for building intelligent risk control systems[19].
This study aims to explore the theoretical foundation and practical value of meta-learning in credit fraud detection. It seeks to clarify its advantages in dealing with complex fraud scenarios and promote the upgrade of traditional anti-fraud methods[20]. In a global financial environment that is increasingly complex and where fraud continues to evolve, developing intelligent algorithms with strong adaptability and fast response has become essential. Research on meta-learning–based credit fraud detection can provide strong support for building an efficient and secure credit system, while injecting new momentum into the evolution of financial technology. Beyond the financial domain, meta-learning also shows great potential to enhance the modeling and optimization of complex computational systems and to drive advances in other data-driven fields [21,22], such as large-scale distributed computing [23,24,25], intelligent cloud service orchestration[26,27,28], and adaptive analytics in diverse industrial applications.
II. Method
In this study, we apply the meta-learning paradigm to build a flexible credit fraud identification model, aiming to enhance adaptability and rapid learning under evolving fraud scenarios. The method is structured with two core modules: a meta-learner and a task learner. Drawing upon the methodological framework of Su [29], the meta-learner is designed to extract universal learning strategies by training on a broad set of historical fraud detection tasks, enabling the transfer of knowledge across diverse scenarios. In our training process, we incorporate simulation of various task environments, allowing the meta-learner to discover initial parameter settings that facilitate quick adaptation—a technique inspired by the structure-aware adaptation approach of Xin and Pan [30].
When facing new fraud patterns, the task learner utilizes the initialization provided by the meta-learner and can quickly converge with only a small amount of task-specific data and a few iterations. This not only accelerates the learning process but also addresses the common issue of limited labeled samples in credit fraud detection. Furthermore, we adopt contextual representation learning methods as proposed by Qin [31], which enhances the feature extraction capabilities of our model and improves its ability to distinguish between normal and fraudulent behaviors in complex financial environments. By integrating these methodological advances from prior works, our approach achieves stronger generalization and higher detection accuracy. The overall model architecture is illustrated in Figure 1.
In the task-level model training, a task set is set, and each task represents a credit fraud identification subtask, including a training set and a validation set . Under the initial parameter , the task learner updates once or several times through the gradient descent method to obtain the task-specific parameter . The updated formula is:
Among them, is the learning rate, and is the loss function on task , usually cross-entropy loss. After the task learner is updated, the loss is calculated on the validation set , and the meta-learner optimizes the initial parameter based on this. The optimization goal is:
This process is implemented through meta-gradient updates, where model parameters are optimized by back-propagating verification errors from a collection of simulated fraud detection tasks [32]. The core strategy is to adjust the model initialization based on aggregated feedback from multiple task environments, thus enhancing the system’s capacity for rapid adaptation to novel fraud patterns [33]. By integrating structured representation learning and graph-based relational modeling [34], the meta-gradient update procedure enables the model to capture complex dependencies in financial data and to robustly generalize across diverse transaction scenarios. This iterative update mechanism forms the foundation for efficient meta-adaptation and underpins the subsequent formulation of the optimization objective. The core idea is to adjust through back-propagation of verification errors of multiple tasks to improve the ability to quickly adapt to new tasks.
To enhance the robustness and generalization of the model, we incorporate a regularization mechanism directly into the meta-learning process. Specifically, the regularization term is designed to stabilize parameter updates and prevent overfitting, following hybrid deep learning strategies that integrate temporal and contextual patterns in financial data [35]. In addition, by drawing upon collaborative optimization ideas from federated learning [36], the regularization mechanism also enables the model to maintain consistent generalization when dealing with distributed or heterogeneous datasets. Furthermore, selective noise injection and feature scoring methods are utilized within the regularization framework to further suppress the effect of outliers and improve the reliability of meta-learned parameters [37]. Specifically, a regularization term is added to each meta-update to prevent the model from overfitting in a specific task, and the updated objective function becomes:
where is the category weight, and represent the true label and predicted probability respectively.
To improve information sharing across tasks, the parameter update strategy employs a model-agnostic meta-learning (MAML) structure, which is designed to retain first-order gradient information from the task learner’s initial parameters [38]. This allows the model to make rapid and informed adjustments to its architecture and weights when presented with previously unseen fraud scenarios, facilitating efficient adaptation and identification. The MAML framework is inherently model-agnostic, which enables seamless integration with various architectures and supports scalability for distributed or heterogeneous data environments [39]. Moreover, by incorporating cross-domain multi-task learning methods [40], the approach further strengthens knowledge sharing and transfer, ensuring the model maintains robust performance as task diversity increases. These features collectively establish a strong platform for future optimization and expansion.
III. Experimental Results
A. Dataset
This research utilizes the widely recognized Credit Card Fraud Detection dataset, which is publicly available and provided by a European financial institution. The dataset is extensively adopted in the credit fraud research community due to its grounding in real-world credit card transaction data. It comprises approximately 280,000 anonymized transaction records collected over a two-day period, within which only 492 transactions are labeled as fraudulent. This results in a highly imbalanced class distribution, accurately reflecting the rarity of fraudulent events in practical business contexts and presenting a realistic challenge for assessing model robustness and predictive accuracy. The dataset contains 30 distinct features, the majority of which are anonymized through Principal Component Analysis (PCA) to safeguard user privacy. Alongside these, three fields—"Time," "Amount," and "Class Label"—remain non-anonymized. The "Time" field indicates the elapsed seconds since the initial transaction, "Amount" represents the transaction value, and "Class Label" serves as a binary indicator, with 0 denoting legitimate transactions and 1 signifying fraud. This composition balances the need for privacy protection with the preservation of essential information required for effective modeling. Due to its structure, the dataset serves as a standard benchmark for tasks such as classification modeling, anomaly detection, and evaluation of model generalization capabilities—particularly under conditions of pronounced class imbalance. Leveraging this dataset enables a comprehensive examination of the effectiveness and adaptability of meta-learning approaches for credit fraud detection, offering both theoretical foundations and methodological support for the development of fraud prevention solutions in real-world financial systems.
B. Experimental Results
This paper first gives the results of the comparative experiment, as shown in Figure 1.

Table 1.
Comparative experimental results.
| Method | Acc | Precision | Recall |
|---|---|---|---|
| CNN[41] | 0.931 | 0.842 | 0.781 |
| Transformer[42] | 0.938 | 0.861 | 0.805 |
| LSTM+CNN[43] | 0.943 | 0.872 | 0.824 |
| LSTM+Transformer[44] | 0.948 | 0.886 | 0.837 |
| Ours | 0.957 | 0.903 | 0.855 |
The overall experimental results demonstrate that the proposed credit fraud detection framework based on meta-learning consistently achieves superior performance across key evaluation metrics, including accuracy, precision, and recall. Compared with a range of baseline and state-of-the-art methods, the meta-learning approach delivers significant improvements, indicating its stronger generalization capability and rapid adaptation to new fraud detection tasks. This performance gain suggests that meta-learning is particularly well-suited to address the intrinsic challenges of real-world financial data, such as severe class imbalance, scarcity of labeled fraudulent transactions, and the rapidly evolving nature of fraudulent behaviors. By effectively mitigating these issues, the proposed framework highlights its practical potential for deployment in complex and high-risk financial scenarios.When contrasted with traditional convolutional neural networks (CNNs) and sequence modeling approaches such as recurrent neural networks (RNNs) and their variants, the meta-learning framework preserves the deep models’ strong capacity for complex feature representation while substantially enhancing the ability to adapt quickly to new tasks and emerging fraud patterns. This structural advantage enables the model to rapidly recalibrate its internal representations when faced with novel or previously unseen fraud behaviors, maintaining high levels of detection accuracy even in non-stationary environments. Importantly, this adaptability translates into more stable recall rates, directly reducing the likelihood of missed fraudulent transactions—a critical factor for minimizing financial loss and maintaining trust in real-world credit systems.
Further comparative analysis with hybrid deep learning architectures, particularly those integrating long short-term memory (LSTM) networks and Transformer mechanisms, reveals additional insights. While such hybrid models excel at capturing sequential dependencies and attention-based feature relationships, they typically rely on large-scale labeled training datasets to achieve optimal performance. In small-sample scenarios—a common reality in credit fraud detection where fraudulent instances are rare and costly to label—these models often fail to generalize effectively. By incorporating meta-learning, the proposed method leverages knowledge transfer from historical tasks to new tasks, allowing it to achieve strong performance even under data-limited conditions. This transferability substantially improves both detection sensitivity and overall classification performance.
A comprehensive multi-metric evaluation highlights the robustness and versatility of the meta-learning approach in credit fraud detection. The primary advantage of this strategy is its ability to extract task-agnostic learning principles, which can be rapidly adapted to new environments, facilitating swift reconfiguration and precise identification of evolving fraudulent activities. This adaptability is particularly critical in dynamic, noisy, and adversarial financial environments, where fraud techniques are constantly changing to circumvent static detection models. By maintaining both stability and flexibility under such conditions, the proposed meta-learning method establishes a solid technical foundation for developing intelligent, adaptive, and forward-looking financial risk management systems. Beyond overall model performance assessment, this study also incorporates a sensitivity analysis focusing on the number of meta-training tasks, with the aim of understanding how task diversity impacts the effectiveness of the meta-learning process. As depicted in Figure 2, the experimental findings provide valuable insights into the relationship between the volume of training tasks and the model’s generalization ability, offering practical guidance for constructing meta-learning frameworks under varying data availability scenarios. The results shown in Figure 2 reveal that as the number of training tasks increases, the meta-learning-based model consistently improves in terms of accuracy, precision, and recall, demonstrating strong adaptability across diverse tasks. These findings indicate that the meta-learning framework effectively abstracts generalizable strategies from multiple fraud detection contexts, enhancing model performance when encountering new or previously unseen fraudulent behaviors. In scenarios where the number of meta-training tasks is limited, the model exhibits a degree of detection capability, but its generalization is constrained by insufficient exposure to varied tasks. As additional training tasks are introduced, the model accumulates broader cross-task knowledge, resulting in greater resilience and effectiveness when addressing diverse fraud patterns.
It is particularly noteworthy that, with the expansion of the task scale, all three performance metrics improve in a consistent trend. This reflects the model's ability to achieve coordinated optimization between detection accuracy and coverage. The synchronized improvement indicates that meta-learning not only enhances the model's sensitivity to fraudulent samples but also reduces false detection risk. This strengthens its feasibility for real-world deployment.
Overall, the experiment confirms the significant impact of task quantity on the effectiveness of meta-learning. It further validates the adaptability advantage of meta-learning in complex, imbalanced, and small-sample credit fraud detection settings. By increasing the number of training tasks, the model can better extract structural information across tasks. This provides a more efficient and intelligent solution for risk control in dynamic financial environments.
This paper also gives a model robustness test under data imbalance conditions, and the experimental results are shown in Figure 3.
The experimental results illustrated in the figure demonstrate a clear and consistent trend: as the class imbalance ratio increases, the overall performance of the proposed meta-learning model—measured by accuracy, precision, and recall—deteriorates to varying extents. This degradation highlights the substantial impact that skewed data distributions exert on meta-learning frameworks, particularly in domains where one class represents rare but critical events. In the context of financial fraud detection, where fraudulent transactions constitute only a very small fraction of the total data, this imbalance amplifies the learning challenge by restricting the model’s exposure to representative minority-class patterns during the training phase. Consequently, the ability of the model to generalize to unseen fraudulent samples diminishes as the imbalance grows more extreme. Among the three key performance indicators, recall shows the most significant decline when the conditions are severely imbalanced. This indicates that the model increasingly fails to recognize fraudulent samples as the minority class becomes less frequent, resulting in a higher false-negative rate. This phenomenon is not just a technical limitation but a critical risk factor in practical financial systems. Missing fraudulent transactions can directly lead to substantial monetary losses and security breaches. Therefore, maintaining a high recall rate under skewed distributions is crucial for ensuring the operational reliability of fraud detection systems and minimizing the risk exposure of financial institutions.
While precision and accuracy also follow a downward trajectory, their rate of decline is less steep compared to recall. This observation indicates that the model tends to overfit the majority (non-fraudulent) class, becoming overly confident in labeling transactions as legitimate. As a result, the classifier’s decision boundary drifts toward favoring the majority class, reducing its sensitivity to rare fraudulent patterns. This outcome underscores a fundamental limitation of employing basic meta-learning strategies in highly imbalanced contexts: although meta-learning improves adaptability across tasks, it does not inherently guarantee resilience against class skew without additional mechanisms to counterbalance the imbalance.
Overall, the results confirm that meta-learning confers a certain degree of robustness to moderate levels of data imbalance. However, when the imbalance becomes extreme, performance degradation remains inevitable, particularly in the minority class recall. From a practical perspective, this finding emphasizes the necessity of integrating advanced imbalance-handling techniques into the meta-learning framework before deployment in real-world financial environments. Potential strategies include resampling approaches (e.g., oversampling minority classes or undersampling the majority), cost-sensitive or weighted loss functions to penalize misclassification of rare fraud cases more heavily, and data augmentation methods, such as generative adversarial networks (GANs), to synthesize additional fraudulent samples and enrich minority-class representation. These enhancements can substantially improve the model’s robustness, ensuring both higher detection sensitivity and better generalization in production settings.
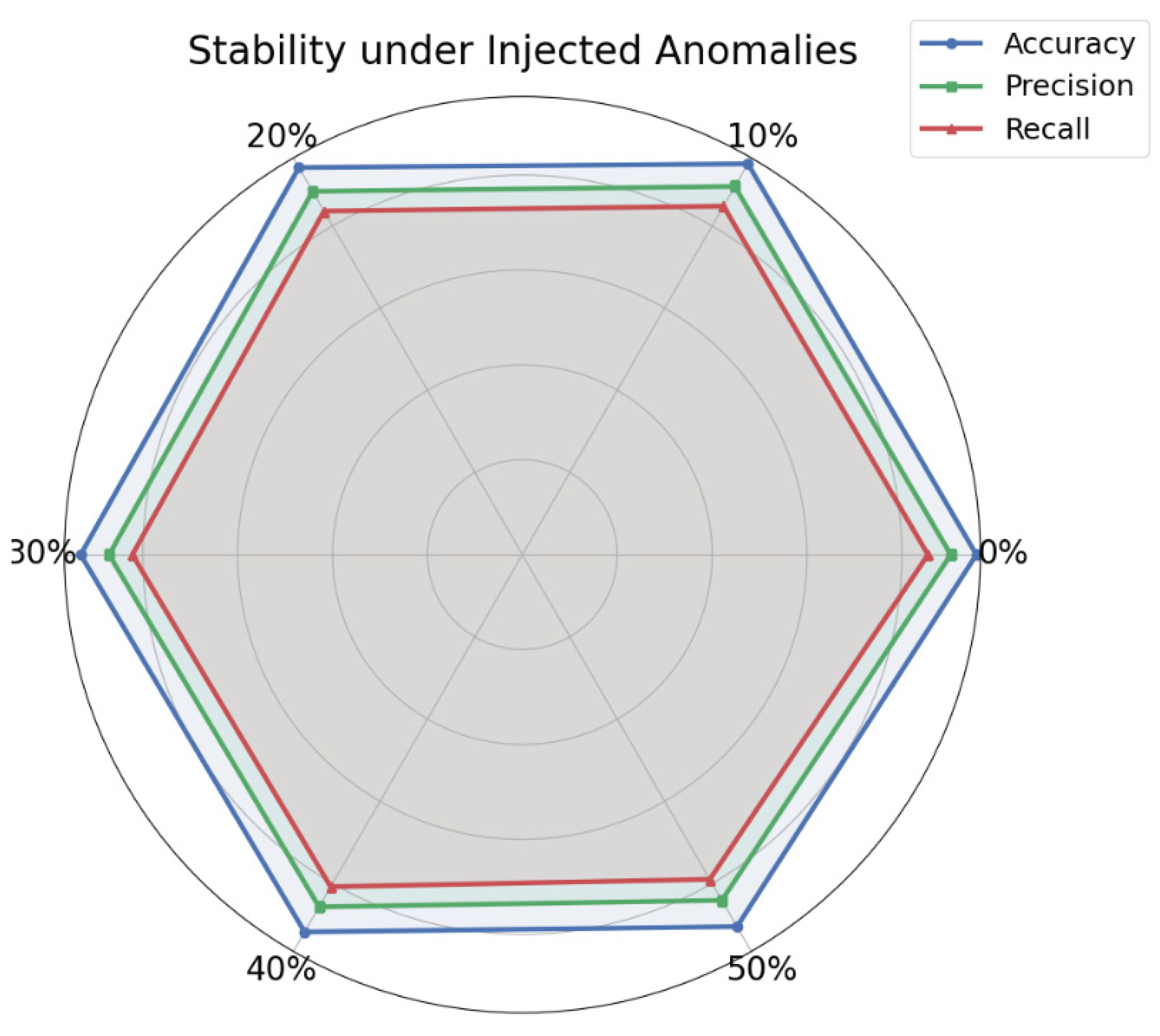
In addition to evaluating class imbalance, this study further investigates the model’s stability under dynamic fraud scenarios, where abnormal and previously unseen fraud patterns are injected into the test data. The results of this stability assessment, presented in Figure 4, provide additional insights into the model’s adaptability to evolving adversarial behaviors and its suitability for deployment in real-world fraud detection systems, where malicious actors continually modify strategies to evade detection.
The experimental results in the figure show that the model maintains relatively stable performance metrics when faced with continuously injected abnormal fraud patterns. This indicates that the proposed meta-learning method remains stable under anomalous disturbances. Such stability is critical in complex and dynamic credit fraud scenarios, especially in real-world applications where fraud behaviors are often unpredictable and highly heterogeneous.
As the proportion of abnormal samples increases, the model's performance shows a slight decline. However, the overall fluctuation remains small. This suggests that the model has strong noise resistance. This robustness reflects the generalization ability accumulated by the meta-learning mechanism during training across multiple tasks. Even when facing new and unknown fraud patterns, the model can still make relatively accurate predictions. This reduces the risk of performance collapse in high-risk environments.
It is noteworthy that the trends of all performance metrics remain consistent. This shows that the model does not experience a significant imbalance among metrics when exposed to abnormal disturbances. It confirms the structural coherence and the rationality of the optimization strategy. This characteristic allows the model to improve detection ability while balancing accuracy and coverage. It helps reduce both false positives and false negatives.
In summary, this experiment further confirms the applicability of the proposed algorithm in extreme or changing environments. Through abnormal fraud pattern injection testing, it is verified that the method can handle unstructured and irregular fraudulent behaviors. This provides greater stability and reliability for credit risk management systems.
IV. Conclusion
This study proposes a meta-learning-based model architecture for credit fraud detection. The goal is to improve the model's adaptability and detection ability in scenarios with limited samples, data imbalance, and dynamic changes. By introducing a meta-learning mechanism, the model can achieve efficient training under limited labeled data. It also can quickly adapt to emerging fraud behaviors. The method leverages common patterns from multiple fraud detection tasks for initialization. This significantly enhances the model's generalization capacity and deployment flexibility, offering a new technical breakthrough beyond traditional anti-fraud approaches. The proposed method is evaluated across multiple dimensions. These include the impact of training task quantity on learning performance, robustness under data imbalance, and stability under abnormal fraud pattern injection. The results show that the meta-learning approach outperforms traditional models in key metrics such as accuracy, precision, and recall. It also demonstrates strong stability. Compared to conventional supervised models, this method better accommodates the non-stationary and diverse characteristics of fraud behavior in the financial domain. It shows great potential for practical use.
This research contributes both theoretical innovation and practical value in financial technology. As the digital finance ecosystem continues to expand, fraud tactics are evolving. Traditional static models can no longer meet the demand for real-time response. Meta-learning offers a foundation for the next generation of intelligent risk control systems. It supports a shift from rule-based to data-driven methods, and from static modeling to dynamic adaptation. This provides financial institutions with more forward-looking and intelligent fraud prevention capabilities.
Future work can explore the integration of more advanced meta-learning structures with transfer learning strategies. This may enhance the model's ability to detect extremely rare fraud cases. The method can also be extended to broader financial application areas, such as consumer credit, supply chain finance, and cross-border payments, to test its general applicability and long-term performance. In addition, introducing explainability mechanisms and privacy-preserving computation will be key to improving the feasibility and compliance of meta-learning models in financial systems.
References
- Y. Zhang, X. Yang, F. Zhu, Y. Chen and Z. Li, "Distributed meta-learning for large-scale multi-institution credit default risk prediction", Proceedings of the International Conference on Database Systems for Advanced Applications, Springer Nature Singapore, pp. 313-326, 2024.
- P. Gambetti, F. Roccazzella and F. Vrins, "Meta-learning approaches for recovery rate prediction", Risks, vol. 10, no. 6, pp. 124, 2022. [CrossRef]
- J. Jeyalakshmi and C. Gowtham, "Adapting generative models with meta learning for financial applications", Generative AI in FinTech: Revolutionizing Finance Through Intelligent Algorithms, Springer Nature Switzerland, pp. 235-255, 2025.
- F. Zhou, X. Qi, C. Xiao, M. Li and J. Wang, "MetaRisk: Semi-supervised few-shot operational risk classification in banking industry", Information Sciences, vol. 552, pp. 1-16, 2021. [CrossRef]
- T. Yang, Y. Cheng, Y. Qi and M. Wei, "Distilling semantic knowledge via multi-level alignment in TinyBERT-based language models", Journal of Computer Technology and Software, vol. 4, no. 5, 2025.
- H. Zheng, Y. Ma, Y. Wang, G. Liu, Z. Qi and X. Yan, "Structuring low-rank adaptation with semantic guidance for model fine-tuning", 2025.
- Q. Wu, "Internal knowledge adaptation in LLMs with consistency-constrained dynamic routing", Transactions on Computational and Scientific Methods, vol. 4, no. 5, 2024.
- X. Quan, "Structured path guidance for logical coherence in large language model generation", Journal of Computer Technology and Software, vol. 3, no. 3, 2024.
- Y. Li, S. Han, S. Wang, M. Wang and R. Meng, "Collaborative evolution of intelligent agents in large-scale microservice systems", arXiv preprint arXiv:2508.20508, 2025.
- K. Aidi and D. Gao, "Temporal-spatial deep learning for memory usage forecasting in cloud servers", 2025.
- J. Zhan, "MobileNet compression and edge computing strategy for low-latency monitoring", Journal of Computer Science and Software Applications, vol. 4, no. 4, 2024. [CrossRef]
- M. Wei, "Federated meta-learning for node-level failure detection in heterogeneous distributed systems", Journal of Computer Technology and Software, vol. 3, no. 8, 2024.
- B. Fang and D. Gao, "Collaborative multi-agent reinforcement learning approach for elastic cloud resource scaling", arXiv preprint arXiv:2507.00550, 2025.
- W. Cui, "Vision-oriented multi-object tracking via transformer-based temporal and attention modeling", Transactions on Computational and Scientific Methods, vol. 4, no. 11, 2024. [CrossRef]
- T. Zhang, F. Shao, R. Zhang, Y. Zhuang and L. Yang, "DeepSORT-driven visual tracking approach for gesture recognition in interactive systems", arXiv preprint arXiv:2505.07110, 2025.
- X. Zhang and Q. Wang, "EEG anomaly detection using temporal graph attention for clinical applications", Journal of Computer Technology and Software, vol. 4, no. 7, 2025. [CrossRef]
- J. Zhan, "Single-device human activity recognition based on spatiotemporal feature learning networks", Transactions on Computational and Scientific Methods, vol. 5, no. 3, 2025.
- F. Roccazzella, P. Gambetti and F. D. Vrins, "Meta-learning approaches for recovery rate prediction", Available at SSRN 4067066,2022. [CrossRef]
- L. Wu, "A meta-learning network method for few-shot multi-class classification problems with numerical data", Complex & Intelligent Systems, vol. 10, no. 2, pp. 2639-2652, 2024. [CrossRef]
- G. Kavirathne, V. A. S. Perera, L. C. R. Karunathunge, S. Perera and A. Fernando, "A meta-learning approach to predict non-performing loans in Sri Lankan financial institutions", Proceedings of the 2022 13th International Conference on Computing Communication and Networking Technologies, pp. 1-6, 2022.
- M. Wei, H. Xin, Y. Qi, Y. Xing, Y. Ren and T. Yang, "Analyzing data augmentation techniques for contrastive learning in recommender models", 2025.
- H. Zheng, Y. Xing, L. Zhu, X. Han, J. Du and W. Cui, "Modeling multi-hop semantic paths for recommendation in heterogeneous information networks", arXiv preprint arXiv:2505.05989, 2025.
- W. Zhu, Q. Wu, T. Tang, R. Meng, S. Chai and X. Quan, "Graph neural network-based collaborative perception for adaptive scheduling in distributed systems", arXiv preprint arXiv:2505.16248, 2025.
- Y. Ren, "Strategic cache allocation via game-aware multi-agent reinforcement learning", Transactions on Computational and Scientific Methods, vol. 4, no. 8, 2024. [CrossRef]
- X. Zhang, X. Wang and X. Wang, "A reinforcement learning-driven task scheduling algorithm for multi-tenant distributed systems", arXiv preprint arXiv:2508.08525, 2025.
- G. Yao, H. Liu and L. Dai, "Multi-agent reinforcement learning for adaptive resource orchestration in cloud-native clusters", arXiv preprint arXiv:2508.10253, 2025.
- W. Zhu, "Adaptive container migration in cloud-native systems via deep Q-learning optimization", Journal of Computer Technology and Software, vol. 3, no. 5, 2024. [CrossRef]
- Y. Wang, H. Liu, G. Yao, N. Long and Y. Kang, "Topology-aware graph reinforcement learning for dynamic routing in cloud networks", arXiv preprint arXiv:2509.04973, 2025.
- X. Su, "Forecasting asset returns with structured text factors and dynamic time windows", Transactions on Computational and Scientific Methods, vol. 4, no. 6, 2024. [CrossRef]
- H. Xin and R. Pan, "Unsupervised anomaly detection in structured data using structure-aware diffusion mechanisms", Journal of Computer Science and Software Applications, vol. 5, no. 5, 2025. [CrossRef]
- Y. Qin, "Deep contextual risk classification in financial policy documents using transformer architecture", Journal of Computer Technology and Software, vol. 3, no. 8, 2024.
- Y. Wang, "Entity-aware graph neural modeling for structured information extraction in the financial domain", Transactions on Computational and Scientific Methods, vol. 4, no. 9, 2024.
- T. Tang, J. Yao, Y. Wang, Q. Sha, H. Feng and Z. Xu, "Application of deep generative models for anomaly detection in complex financial transactions", Proceedings of the 2025 4th International Conference on Artificial Intelligence, Internet and Digital Economy, pp. 133-137, 2025.
- Z. Liu and Z. Zhang, "Graph-based discovery of implicit corporate relationships using heterogeneous network learning", 2024.
- Q. Sha, "Hybrid deep learning for financial volatility forecasting: an LSTM-CNN-transformer model", Transactions on Computational and Scientific Methods, vol. 4, no. 11, 2024. [CrossRef]
- M. Wang, T. Kang, L. Dai, H. Yang, J. Du and C. Liu, "Scalable multi-party collaborative data mining based on federated learning", 2025.
- Y. Cheng, "Selective noise injection and feature scoring for unsupervised request anomaly detection", Journal of Computer Technology and Software, vol. 3, no. 9, 2024. [CrossRef]
- T. Kang, H. Yang, L. Dai, X. Hu and J. Du, "Privacy-enhanced federated learning for distributed heterogeneous data", 2025.
- Z. Liu and Z. Zhang, "Modeling audit workflow dynamics with deep Q-learning for intelligent decision-making", 2024.
- Y. Lin and P. Xue, "Multi-task learning for macroeconomic forecasting based on cross-domain data fusion", Journal of Computer Technology and Software, vol. 4, no. 6, 2025.
- B. Meng, J. Sun and B. Shi, "A novel URP-CNN model for bond credit risk evaluation of Chinese listed companies", Expert Systems with Applications, vol. 255, pp. 124861, 2024. [CrossRef]
- E. Siphuma and T. van Zyl, "Enhancing credit risk assessment through transformer-based machine learning models", Proceedings of the Southern African Conference for Artificial Intelligence Research, Springer Nature Switzerland, pp. 124-143, 2024.
- J. Li, C. Xu, B. Feng, W. Liu and Y. Zhao, "Credit risk prediction model for listed companies based on CNN-LSTM and attention mechanism", Electronics, vol. 12, no. 7, pp. 1643, 2023. [CrossRef]
- Y. Song, H. Du, T. Piao, M. Sun and X. Chen, "Research on financial risk intelligent monitoring and early warning model based on LSTM, transformer, and deep learning", Journal of Organizational and End User Computing, vol. 36, no. 1, pp. 1-24, 2024. [CrossRef]
Figure 1.
Overall model architecture diagram.
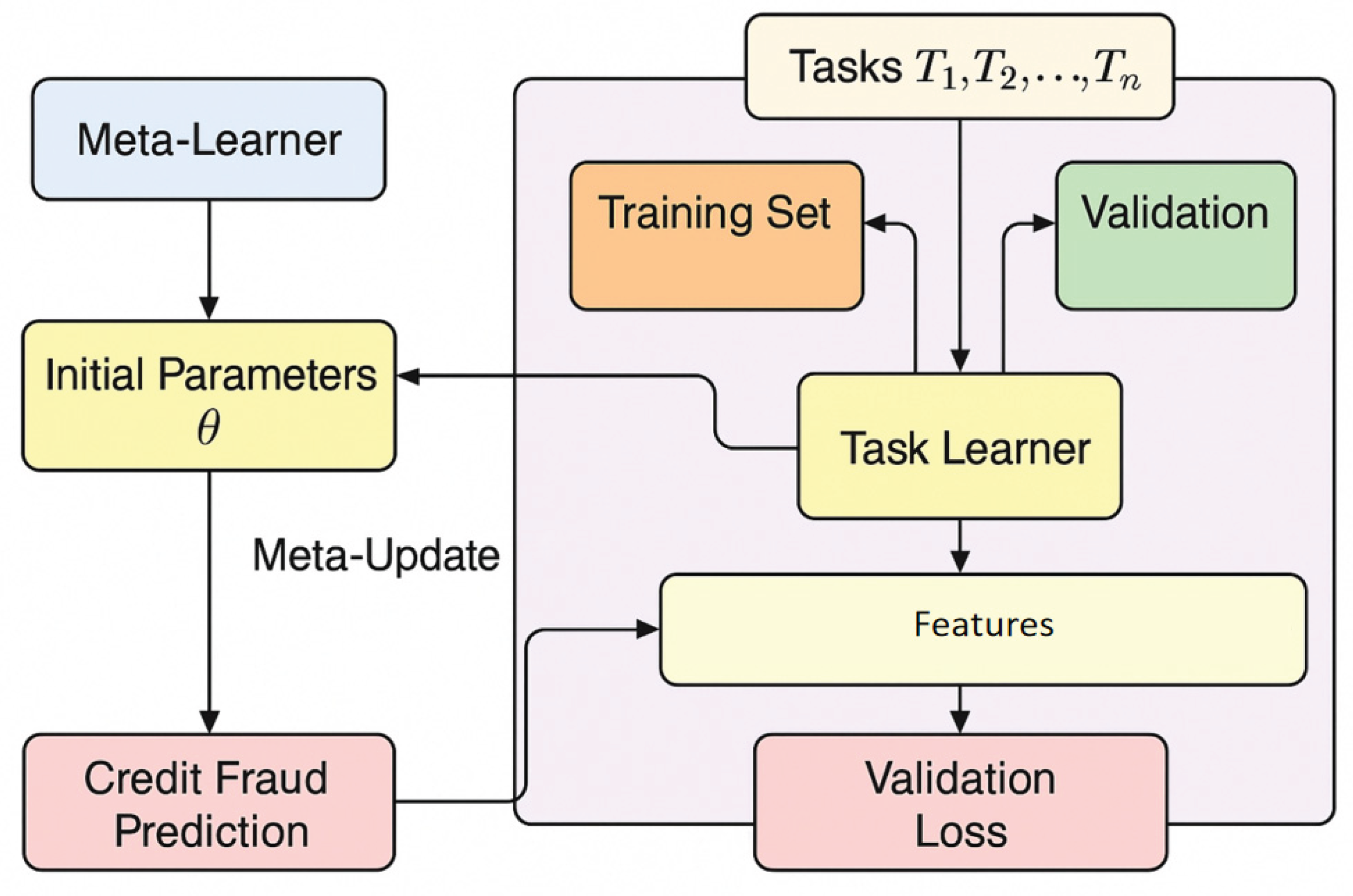
Figure 2.
Sensitivity experiment of the number of training tasks on meta-learning effect.
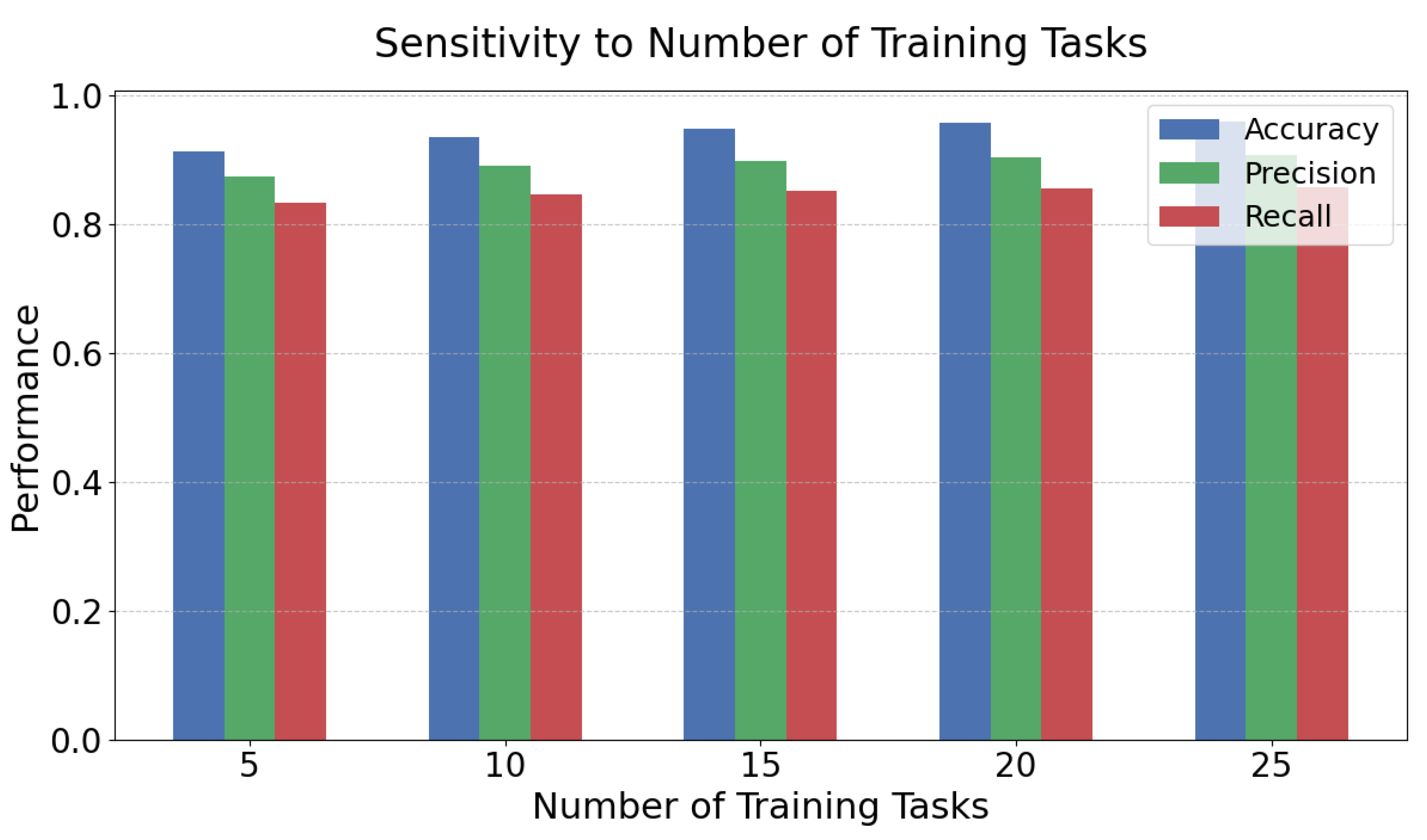
Figure 3.
Model robustness test under data imbalance conditions.
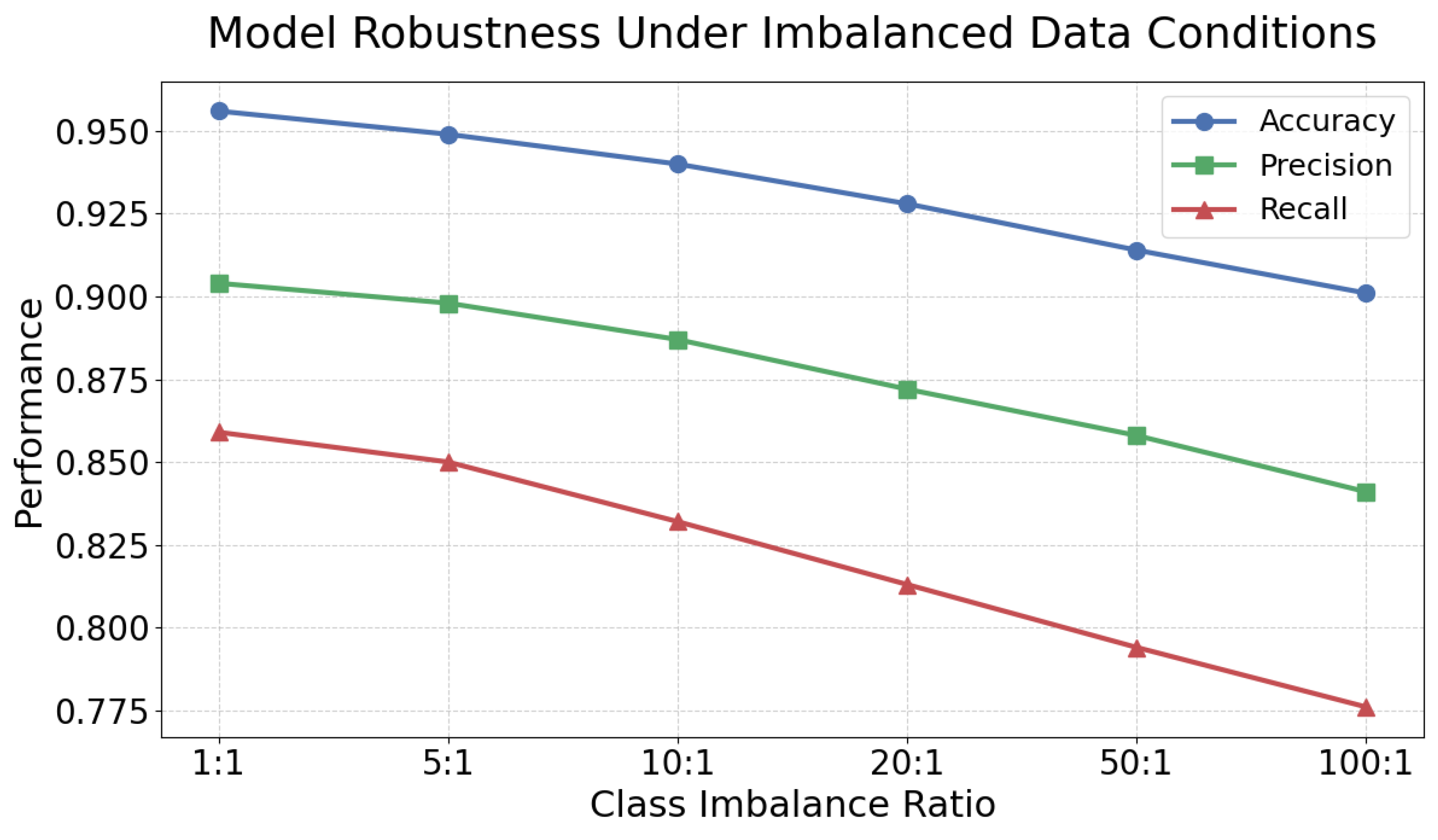
Figure 4.
Model stability experiment under abnormal fraud pattern injection.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



