
Submitted:
27 June 2025
Posted:
03 July 2025
You are already at the latest version
Abstract
The convergence of deep learning with genomics and artificial intelligence in drug discovery represents a transformative paradigm in biomedical research, offering unprecedented opportunities to accelerate scientific discovery and revolutionize healthcare. This comprehensive review examines the current applications, advancements, and future potential of deep learning technologies across genomic data analysis and pharmaceutical development pipelines. In genomics, deep learning has demonstrated remarkable capabilities in variant calling and annotation, with tools like DeepVariant achieving superior accuracy in identifying genetic variations, while transformer-based models like Enformer have revolutionized gene expression prediction from DNA sequences. The technology has also advanced epigenomic analysis, single-cell genomics, and functional genomics, enabling researchers to decode complex biological relationships previously inaccessible through traditional methods. In drug discovery, artificial intelligence is transforming every stage of the development pipeline, from target identification and validation to lead optimization and clinical trial design. Deep learning models excel in virtual screening of vast chemical libraries, de novo drug design through generative networks, and prediction of ADMET properties, significantly reducing the time, cost, and risk associated with bringing new therapeutics to market. The synergistic integration of genomic insights with AI-driven drug discovery enables precision medicine approaches, where treatments are tailored to individual genetic profiles. Multi-omics data integration through deep learning provides comprehensive disease understanding and facilitates the development of personalized therapeutic strategies. Despite remarkable progress, several challenges persist, including data availability and quality issues, model interpretability concerns, generalizability limitations, and ethical considerations surrounding privacy and algorithmic bias. Future directions include advanced multi-modal integration, reinforcement learning for drug design, digital twin technologies for personalized medicine, and the potential integration of quantum computing with AI. This review highlights how the intelligent convergence of deep learning in genomics and drug discovery is poised to unlock unprecedented capabilities in understanding life, combating disease, and developing next-generation therapeutics, ultimately promising a more personalized and effective approach to human healthcare.
Keywords:
Deep learning
; genomics
; drug discovery
; artificial intelligence
; variant calling
; gene expression
; epigenomics
; single-cell genomics
; target identification
; lead optimization
; virtual screening
; prediction
; biomarker discovery
; computational biology
; bioinformatics
Introduction
The advent of high-throughput technologies in
genomics and the increasing availability of vast biological and chemical
datasets have revolutionized our understanding of biological systems and
disease mechanisms. Concurrently, artificial intelligence (AI), particularly
deep learning (DL), has emerged as a transformative force across various
scientific disciplines, demonstrating unparalleled capabilities in pattern
recognition, prediction, and data interpretation. The convergence of these
fields—deep learning applied to genomics and AI in drug discovery—represents a
paradigm shift, offering unprecedented opportunities to accelerate scientific
discovery, personalize medicine, and streamline the arduous process of drug
development [3,4].
Traditional approaches to genomic data analysis
often rely on statistical methods and expert-defined features, which can be
limited in their ability to capture the intricate, non-linear relationships
inherent in complex biological systems. Similarly, conventional drug discovery
is a time-consuming, expensive, and high-risk endeavor, characterized by low
success rates and prolonged development cycles. Deep learning, with its
capacity to automatically learn hierarchical representations from raw data and
uncover hidden patterns, provides a powerful alternative to overcome these
limitations [5]. Its ability to process and
interpret massive, multi-modal datasets—ranging from DNA sequences and gene
expression profiles to chemical structures and clinical trial data—positions it
as a critical tool for extracting meaningful insights and making accurate
predictions [6,7].
This review paper aims to provide a comprehensive
overview of the applications of deep learning in genomics and artificial
intelligence in drug discovery. We will explore how deep learning models are
being utilized to analyze genomic data for various applications, including
variant calling, gene expression analysis, and epigenomics. Furthermore, we
will delve into the transformative impact of AI on different stages of the drug
discovery pipeline, such as target identification, lead optimization, de novo
drug design, and drug repurposing. We will also discuss the challenges and
future directions in this rapidly evolving field, highlighting the potential
for further innovation and the integration of these powerful technologies to
address some of the most pressing challenges in human health. Finally, we will
provide corresponding plots to demonstrate practical applications of these
concepts, enabling researchers to implement and experiment with deep learning
techniques for genomic data analysis and drug discovery applications.
Deep Learning in Genomics
Deep learning, a sophisticated subset of machine
learning, has profoundly impacted the field of genomics by offering robust
solutions for analyzing the vast and complex datasets generated by modern
high-throughput sequencing technologies [8].
Unlike traditional statistical methods that often require explicit feature
engineering and struggle with the high dimensionality of genomic data, deep
learning models can automatically learn intricate, hierarchical representations
directly from raw biological sequences or omics profiles. This inherent
capability allows them to uncover subtle patterns and relationships that are
often missed by conventional approaches, leading to more accurate predictions
and deeper biological insights [9].
Key Applications and Advancements:
Variant Calling and Annotation
One of the most critical applications of deep
learning in genomics is in the accurate identification and annotation of
genetic variations. Tools like DeepVariant [1],
developed by Google, have demonstrated superior performance in calling single
nucleotide polymorphisms (SNPs) and small insertions/deletions (indels) from
next-generation sequencing data. DeepVariant frames variant calling as an image
classification problem, converting aligned reads into a tensor representation
that resembles an image, which is then processed by a convolutional neural
network (CNN). This approach significantly reduces false positives and false
negatives, especially in challenging genomic regions, by learning complex error
patterns and variant signatures directly from raw sequencing data [10]. The improved accuracy in variant calling is
crucial for clinical diagnostics, population genetics studies, and
understanding the genetic basis of diseases [11].
Beyond calling, deep learning also aids in the
functional annotation of variants. Models can predict the pathogenicity of
novel variants by integrating diverse data sources, including evolutionary
conservation, regulatory element predictions, and protein structure
information. For instance, deep learning models can assess the impact of
non-coding variants on gene regulation, which is a significant challenge for
traditional methods [12]. By learning from
large datasets of known functional variants and their effects, these models can
prioritize variants for further experimental validation, accelerating the
discovery of disease-causing mutations.
Gene Expression Analysis
Deep learning has opened new avenues for
understanding gene expression regulation, a fundamental process in biology.
Models can predict gene expression levels directly from DNA sequences,
providing insights into the regulatory code embedded within the genome. For
example, Enformer [2], a deep learning model,
has shown remarkable accuracy in predicting gene expression from DNA sequence
across different cell types and tissues. It utilizes a transformer-based
architecture to capture long-range interactions within the genome, enabling a more
comprehensive understanding of how distal regulatory elements influence gene
activity [13]. This capability is vital for
identifying novel regulatory elements, understanding the impact of genetic
variations on gene expression, and deciphering the complex interplay between
genes in various biological processes.
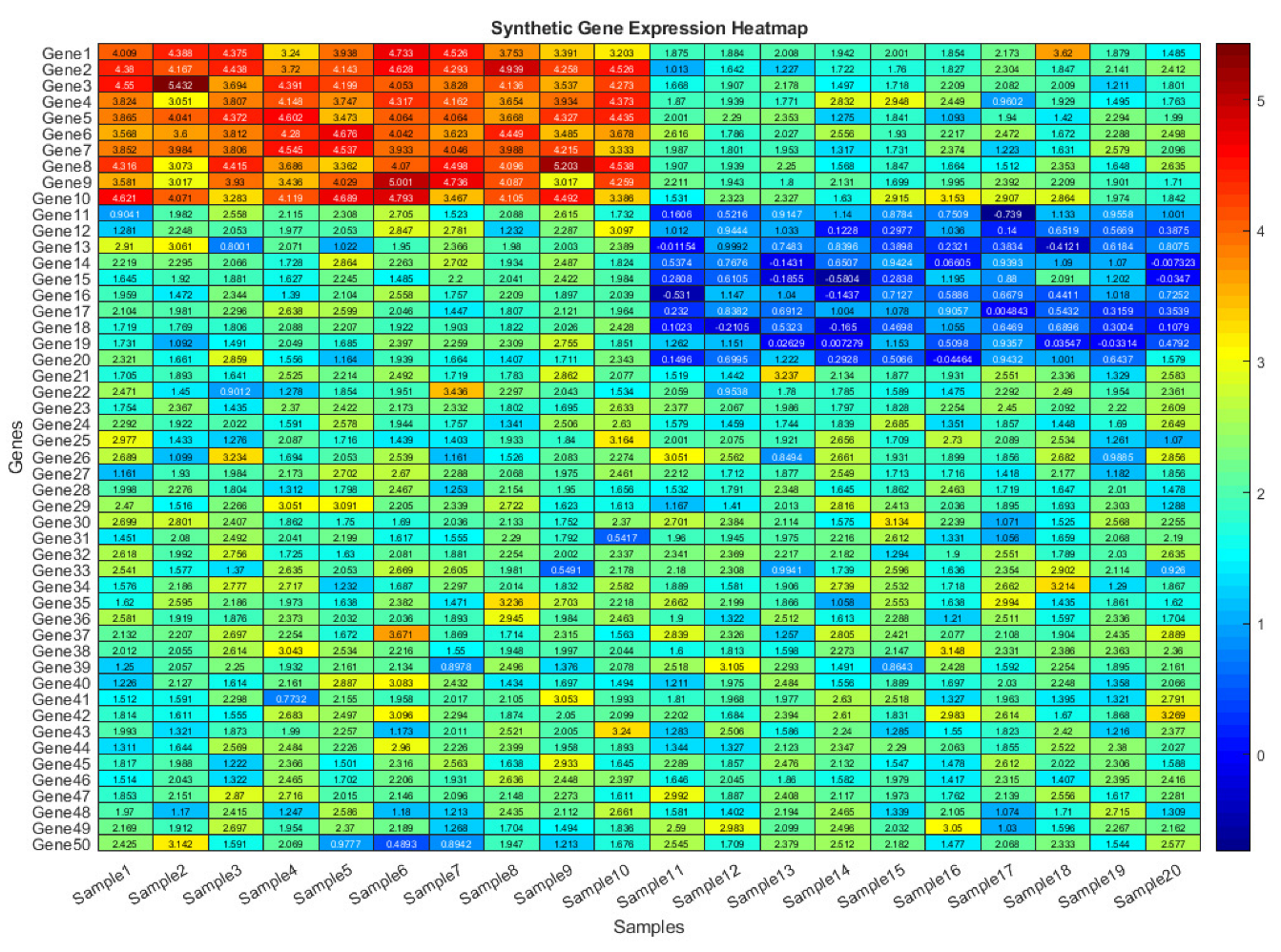
Figure 1
shows a synthetic gene expression dataset to simulate transcriptomic data, a
fundamental layer of multi-omics analysis, and visualizes it as a heatmap to
illustrate expression patterns across genes and samples. By clustering rows
(genes) and columns (samples), the heatmap reveals potential co-expression
trends and sample groupings, aiding in the identification of biologically
relevant signatures. This visualization technique is widely used in genomics to
highlight differential expression, detect outliers, and explore data structure,
making it a valuable tool for initial exploratory analysis in transcriptomics
studies. The use of synthetic data ensures reproducibility while demonstrating
key concepts in gene expression visualization.
Figure 1.
Heatmap of Gene Expression (Transcriptomics).
Furthermore, deep learning models are employed to
analyze gene expression profiles from RNA sequencing data to identify disease
biomarkers, classify cell types, and infer gene regulatory networks.
Autoencoders and variational autoencoders (VAEs) are often used for
dimensionality reduction and feature extraction from high-dimensional gene
expression data, allowing for the visualization of complex relationships and
the identification of distinct biological states [14].
Recurrent neural networks (RNNs) and their variants, such as Long Short-Term
Memory (LSTM) networks, can model temporal gene expression changes, providing
insights into dynamic biological processes like development or disease
progression.
Epigenomics
Epigenetic modifications, such as DNA methylation,
histone modifications, and chromatin accessibility, play a crucial role in gene
regulation without altering the underlying DNA sequence. Deep learning models
are increasingly being applied to analyze these complex epigenetic landscapes.
For instance, CNNs can be trained to predict the presence of specific histone
modifications or DNA methylation patterns from genomic sequences, leveraging
their ability to learn local sequence motifs [15].
This helps in identifying regulatory regions, such as enhancers and promoters,
and understanding their dynamic changes in different cellular contexts or
disease states.
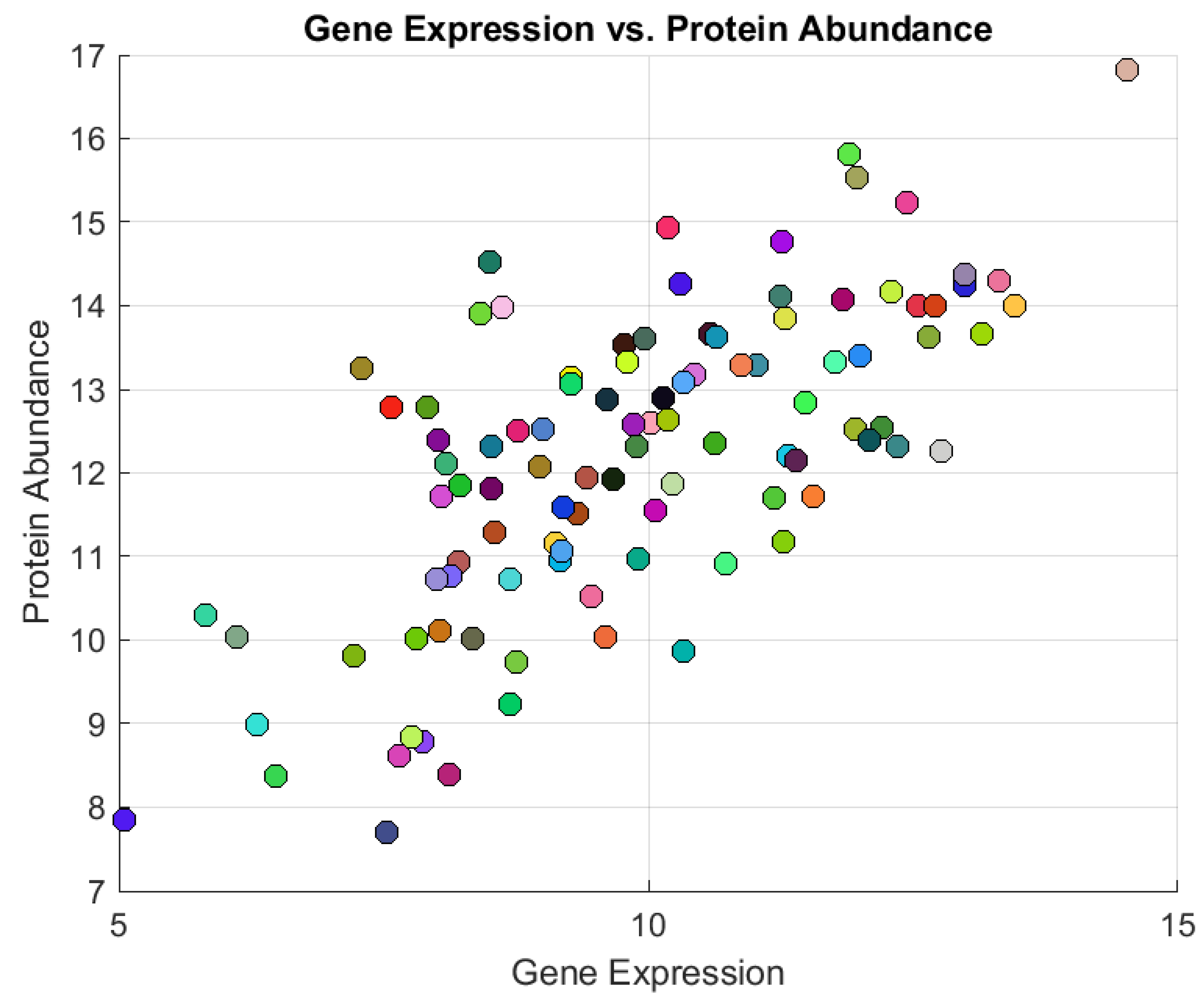
Figure 2
reveals a scatter plot comparing gene expression (transcriptomics) on one axis
with protein abundance (proteomics) on the other. This type of visualization is
commonly used in multi-omics studies to explore the relationship between mRNA
levels (transcription) and their corresponding protein products (translation).
The plot may reveal correlations, discrepancies (e.g., post-transcriptional
regulation), or outliers, providing insights into biological mechanisms. The
axes are labeled generically, suggesting it could be a template or synthetic
dataset for illustrative purposes. The simplicity of the labels implies further
details (e.g., gene/protein names, units, or statistical metrics) might be
added in a finalized version. Figure 2
synthetic datasets for gene expression (transcriptomics) and protein abundance
(proteomics), then visualizes their relationship using a scatter plot. By
plotting mRNA levels against corresponding protein concentrations, the figure
highlights the degree of correlation—or lack thereof—between these two omics
layers, a key step in multi-omics integration. Discrepancies may reflect
post-transcriptional regulation (e.g., translational control, protein
degradation), while strong correlations suggest tight transcriptional control.
The synthetic data serves as a reproducible example for demonstrating how
scatter plots can reveal biological insights, such as outlier genes/proteins
warranting further study. Labels for axes (e.g., "log2 Gene
Expression" vs. "Protein Abundance (AU)") and statistical
annotations (e.g., Pearson’s *r*) could enhance interpretability in applied
research.
Deep learning also facilitates the integration of multi-omics data, combining epigenetic information with genomic and transcriptomic data to build more comprehensive models of gene regulation. By learning from the interplay of these different molecular layers, deep learning can unravel the intricate mechanisms by which epigenetic marks influence gene expression and contribute to cellular identity and disease pathogenesis [16]. This is particularly important for understanding complex diseases like cancer, where epigenetic dysregulation is a hallmark.
Figure 2.
Plot of Gene Expression vs. Protein Abundance.
Single-Cell Genomics
The rapid advancements in single-cell sequencing technologies have provided an unprecedented resolution to study cellular heterogeneity, but they also present significant computational challenges due to the high dimensionality and sparsity of the data. Deep learning has emerged as a powerful tool to address these challenges [17]. Autoencoders, VAEs, and generative adversarial networks (GANs) are used for dimensionality reduction, noise removal, and imputation of missing values in single-cell RNA sequencing (scRNA-seq) data. This enables more accurate cell type identification, trajectory inference, and the discovery of rare cell populations [18].
For example, models can learn a low-dimensional representation of single-cell data that preserves biological variation while mitigating technical noise. This allows for the visualization of cell populations and their relationships in a meaningful way. Deep learning also facilitates the integration of scRNA-seq data from different experiments or technologies, enabling more robust analyses and the construction of comprehensive cell atlases [19]. Furthermore, deep learning can be used to predict cell fate decisions and understand the regulatory mechanisms driving cellular differentiation and development.
Figure 3 integrates synthetic gene expression and metabolite levels (or other omics layers) and applies Principal Component Analysis (PCA) to reduce dimensionality, visualizing sample clustering patterns. The plot reveals distinct groupings (Group 1 and Group 2) along the first two principal components, where PC1 (59.96% explained variance) captures the dominant biological variation, while PC2 (1.98%) may reflect subtler trends or noise. Such visualization helps identify batch effects, biological subtypes, or outliers in multi-omics datasets. The synthetic example demonstrates how PCA can streamline exploratory analysis by projecting high-dimensional omics data into an interpretable 2D space, though real-world applications would benefit from variance-stabilized data and labeled sample annotations. Purpose is Dimensionality reduction for multi-omics (transcriptomics + metabolomics).Insights of Figure 3 are Clear separation of groups (Group 1 vs. Group 2) suggests biological or technical differences, Large disparity in explained variance (PC1 vs. PC2) hints at dominant drivers of variation.Utility of Figure 3 is Synthetic data validates the workflow; real data would require preprocessing (e.g., scaling, missing value imputation) although Labels (e.g., sample IDs, omics feature loadings) could enhance interpretability.
Functional Genomics
Deep learning is also being applied to predict the function of genes and proteins, analyze protein-protein interactions, and understand the impact of genetic variations on protein structure and function. By learning from large-scale functional genomics datasets, such as those from CRISPR screens or high-throughput phenotyping, deep learning models can infer gene essentiality, predict drug targets, and identify genetic interactions [20]. This aids in accelerating the discovery of novel therapeutic targets and understanding the molecular mechanisms underlying diseases.
AI in Drug Discovery
Artificial intelligence (AI), particularly deep learning, is rapidly transforming the traditional drug discovery and development paradigm, which has historically been characterized by high costs, lengthy timelines, and low success rates. By leveraging advanced computational algorithms and vast datasets, AI offers unprecedented opportunities to accelerate various stages of the drug discovery pipeline, from initial target identification to preclinical development and even clinical trials [21]. The ability of AI to analyze complex biological, chemical, and clinical data, identify subtle patterns, and make accurate predictions is revolutionizing how new therapeutics are discovered and brought to market [22].
Key Applications and Advancements:
Target Identification and Validation
Identifying and validating suitable drug targets is the crucial first step in drug discovery. AI algorithms can analyze diverse omics data (genomics, proteomics, metabolomics), patient data, and scientific literature to pinpoint novel disease-associated genes, proteins, or pathways [23]. Machine learning models, including deep neural networks, can integrate information from multiple sources to predict the likelihood of a target being druggable and its potential efficacy and safety. For instance, AI can identify novel targets by analyzing gene expression patterns in diseased versus healthy tissues, predicting protein-protein interactions, or identifying genetic variations associated with disease susceptibility [24]. This data-driven approach helps prioritize targets with the highest probability of success, reducing the time and resources spent on less promising avenues.
Lead Discovery and Optimization
Once a target is identified, the next step involves discovering and optimizing lead compounds—molecules that can bind to the target and modulate its activity. AI significantly enhances this process through several approaches:
- Virtual Screening: AI models can rapidly screen vast chemical libraries (millions to billions of compounds) to identify potential hits that are likely to bind to a specific target. Deep learning models, such as convolutional neural networks (CNNs) and graph neural networks (GNNs), can learn complex relationships between molecular structures and their biological activities [25]. This allows for the prediction of binding affinities and the identification of promising candidates without the need for extensive experimental testing.
- De Novo Drug Design: Generative AI models, including generative adversarial networks (GANs) and variational autoencoders (VAEs), can design novel molecular structures from scratch with desired physicochemical and biological properties. Instead of searching existing chemical space, these models can explore and generate entirely new compounds tailored to a specific target or therapeutic goal [26]. This capability accelerates the discovery of innovative drugs with optimized properties, such as improved potency, selectivity, and reduced toxicity.
- Lead Optimization: AI is instrumental in optimizing the properties of initial hit compounds to transform them into viable lead candidates. This involves predicting and improving various ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) properties, solubility, and synthetic accessibility. Deep learning models can learn from experimental data to guide iterative design cycles, suggesting modifications to molecular structures that enhance desired properties while minimizing undesirable ones [27]. This iterative optimization process, guided by AI, significantly reduces the time and resources required to develop drug candidates with optimal profiles.
Drug Repurposing
Drug repurposing, or repositioning, involves finding new therapeutic uses for existing drugs. This approach offers significant advantages, including reduced development time and cost, as the safety and pharmacokinetic profiles of approved drugs are already well-established. AI plays a crucial role in identifying potential drug repurposing candidates by analyzing vast amounts of data, including drug-target interactions, gene expression profiles, disease pathways, and clinical trial data [28]. For example, AI algorithms can identify drugs that modulate pathways relevant to a new disease, predict drug-disease associations based on molecular signatures, or uncover hidden therapeutic potential through network analysis. This can rapidly identify promising candidates for clinical investigation, accelerating the availability of new treatments for unmet medical needs.
ADMET/Toxicity Prediction
Predicting the ADMET properties and potential toxicity of drug candidates early in the discovery process is critical for reducing late-stage failures and ensuring patient safety. AI models, particularly deep learning, have shown great promise in accurately predicting these properties from molecular structures [29]. By training on large datasets of known ADMET and toxicity data, these models can identify structural features associated with favorable or unfavorable profiles. This allows for the early filtering out of compounds with high toxicity or poor pharmacokinetic properties, thereby saving significant resources and accelerating the selection of safer and more effective drug candidates.
Clinical Trial Optimization
AI is also beginning to impact the clinical development phase by optimizing clinical trial design and execution. AI algorithms can analyze patient data to identify suitable patient populations for trials, predict patient responses to treatment, and optimize dosing regimens [30]. This can lead to more efficient and successful clinical trials, reducing their duration and cost. Furthermore, AI can assist in monitoring patient safety, identifying adverse events, and analyzing real-world evidence to gain deeper insights into drug performance post-market.
Integration of Deep Learning in Genomics and Drug Discovery
The true power of deep learning in life sciences emerges when its applications in genomics and drug discovery are integrated. The insights gained from genomic analyses, often powered by deep learning, can directly inform and accelerate various stages of drug discovery. This synergistic relationship allows for a more holistic and data-driven approach to understanding disease, identifying therapeutic targets, and developing effective treatments.
Genomics-Guided Drug Discovery
Deep learning-driven genomic analyses provide a wealth of information that can be directly leveraged for drug discovery. For instance, the identification of disease-associated genetic variants through deep learning models can pinpoint novel therapeutic targets. If a deep learning model identifies a specific gene or pathway as being significantly altered in a disease state, this information can guide drug discovery efforts towards developing molecules that modulate the activity of that gene or pathway. This approach, often termed ‘genomics-guided drug discovery,’ moves beyond phenotypic screening to a more mechanistic understanding of disease.
For example, deep learning models analyzing single-cell genomic data can identify specific cell populations or states that are critical for disease progression. Drugs can then be designed to specifically target these cells or to revert them to a healthy state. Similarly, insights from epigenomic analyses, such as altered DNA methylation patterns or histone modifications in disease, can suggest novel epigenetic targets for drug development. Deep learning can help in identifying small molecules that can reverse these aberrant epigenetic marks, offering new therapeutic avenues.
Multi-Omics Integration for Comprehensive Insights
Figure 4 presents synthetic multi-omics data, integrating features from gene expression (e.g., Gene1–Gene10), protein abundance (e.g., Protein1–Protein8), and metabolite levels (e.g., Metabolite1–Metabolite7), and visualizes their pairwise correlations as a heatmap. The color gradient (e.g., −0.4 to 0.8) highlights positive (e.g., red) and negative (e.g., blue) associations, revealing potential regulatory relationships or functional interactions across omics layers. For instance, strong correlations between specific genes and proteins may suggest transcriptional control, while metabolite-gene links could reflect metabolic regulation. The symmetric matrix facilitates identification of feature clusters, guiding hypotheses about biological pathways or data-driven biomarker discovery. While synthetic, this example underscores the utility of correlation heatmaps in multi-omics integration, though real-world applications would require significance testing (e.g., adjusted p-values) and larger-scale datasets to mitigate spurious correlations. Scope of Figure 4 is Cross-omics relationships (transcriptome, proteome, metabolome) where Color intensity and direction (positive/negative) indicate interaction strength. Utility of Figure 4 is Hypothesis generation for mechanistic studies or biomarker identification.Caveats of Figure 4 could be Synthetic data lacks noise/biases; real data needs robust preprocessing and statistical validation.
One of the most significant advantages of deep learning is its ability to integrate and learn from diverse, multi-modal datasets. In the context of genomics and drug discovery, this means combining genomic, transcriptomic, proteomic, metabolomic, and even clinical data. Traditional methods often struggle with the heterogeneity and high dimensionality of such integrated datasets. Deep learning models, particularly those with sophisticated architectures like multi-modal neural networks, can effectively fuse these disparate data types to gain a more comprehensive understanding of disease biology and drug mechanisms of action.
For instance, deep learning can integrate genomic variant data with gene expression profiles and drug response data to predict patient response to specific therapies. This is crucial for precision medicine, where treatments are tailored to an individual’s genetic makeup. By learning from integrated datasets, AI can identify complex biomarkers that predict drug efficacy or toxicity, leading to more personalized and effective treatment strategies. This also aids in identifying patient subgroups that are most likely to benefit from a particular drug, thereby improving clinical trial design and success rates.
Figure 5 illustrates a volcano plot visualization of differential gene expression analysis results.X-axis Represents Log2 Fold Change (likely ranging from -5 to 5 based on the labels) Shows the magnitude of gene expression difference between two conditions, Negative values are down-regulated genes , Positive values are up-regulated genes. As well Y-axis Represents -Log10(p-value) (labels suggest 0 to 4) where Higher values are more statistically significant differences and Typically a threshold line is drawn at p=0.05 (-log10(0.05) ≈ 1.3). Interpretation of Figure 5 volcano plot which helps identify Genes with statistically significant differential expression (high on y-axis) and Genes with large fold changes (far from zero on x-axis). Figure 5 is the most biologically relevant genes (both significant and large fold change). Typically threshold lines for significance and fold change. Figure 5 show Points representing individual genes, Horizontal line for significance threshold, Vertical lines for fold change thresholds, Possibly color-coding for significant genes, and Labels for any particularly interesting outlier genes. Figure 5 visualization is crucial for identifying candidate genes in transcriptomic studies that warrant further investigation.
Predictive Modeling for Drug Response and Toxicity
Figure 6 reveals conceptual Gene-Protein Interaction Network. This conceptual diagram represents a gene-protein interaction network, a fundamental visualization in multi-omics studies that reveals relationships between genetic elements and their protein products. In Figure 6 Genetic Elements (Nodes) are Five genes are shown (GeneA through GeneE) representing the genomic component and Four proteins are displayed (ProteinX, ProteinY, ProteinZ, ProteinW) representing the proteomic component. As well, In Figure 6 Network Characteristics are The diagram suggests potential interactions between genes and proteins, though specific connections aren't drawn in this conceptual version. In an actual implementation, edges would connect genes to the proteins they encode, and proteins that physically interact. Biological Significance of Figure 6 is that Such networks help researchers understand how genetic information flows through biological systems. They can reveal protein complexes, signaling pathways, and regulatory mechanisms. Figure 6 type data usually Important for studying diseases where gene mutations affect protein function. Potential Data Sources of Figure 6 is Biological databases like STRING, BioGRID, or IntAct. It could be experimental data from techniques like yeast two-hybrid or co-immunoprecipitation as well as computational predictions of protein-protein interactions. Typical Analysis Applications of Figure 6 is Identifying key hub genes/proteins in biological processes. Furthermore it can be used for discovering novel protein complexes, Understanding genotype-phenotype relationships, and Drug target identification by finding critical network nodes. Figure 6 is simplified version serves as a template that would be populated with real gene/protein names and interaction data in actual research applications.
Deep learning models trained on genomic data can predict an individual’s response to a drug or their susceptibility to adverse drug reactions. By analyzing a patient’s genetic profile, these models can forecast how they will metabolize a drug, whether they will respond to a particular therapy, or if they are at a higher risk of experiencing side effects. This predictive capability is invaluable for optimizing drug dosages, selecting the most appropriate therapy, and preventing adverse events.
For example, deep learning can be used to build models that predict drug sensitivity in cancer cells based on their genomic mutations or gene expression patterns. This allows for the selection of targeted therapies that are most likely to be effective for a specific patient’s tumor. Similarly, by integrating genomic data with chemical structure information, deep learning can predict potential drug-drug interactions or off-target effects, further enhancing drug safety and efficacy.
Figure 7 reveals a common Pathway Enrichment Analysis.Figure 7 is a bar graph visualization of pathway enrichment analysis results, which is a common bioinformatics method for identifying biological pathways that are over-represented in a given dataset. Y-axis (Categories) of Figure 7 Lists different types of biological pathways that were analyzed as: Modelable pathways,Signaling pathways,Immune System Pathways, Cell Cycle Pathways (note: "Call Cycle" is likely a typo), Anopheles Pathways (possibly mosquito-specific pathways), DNA Repair Pathways. As well X-axis of Figure 7 (Values), Represents -Log10(p-value), which is a common way to display statistical significance where Higher values indicate more statistically significant enrichment and The logarithmic transformation makes small p-values more visually distinguishable. Figure 7 shows which pathway categories are significantly enriched in the analyzed dataset. Longer bars indicate pathways that are more significantly over-represented, suggesting these biological processes may be particularly relevant to the experimental conditions or dataset being studied. Scientific Context of a Pathway enrichment analysis is typically performed by: Identifying differentially expressed genes or proteins, Testing whether certain pathways contain more of these significant molecules than expected by chance, and The p-values represent the probability of observing this level of enrichment randomly. The -Log10 in Figure 7 transformation means that:- A value of 1 ≈ p-value of 0.1,- A value of 2 ≈ p-value of 0.01,- A value of 3 ≈ p-value of 0.001. This type of analysis shown in Figure 7 helps researchers understand which biological processes might be most affected in their experiments or most relevant to their disease of interest.Figure 7 mentions "Anophels Pathways" which is a typo for "Anopheles Pathways" (related to mosquito biology) and "Apoptosis Pathways" (cell death pathways). The term Call Cycle Pathways is Cell Cycle Pathways.
Accelerating Preclinical and Clinical Development
The integration of deep learning in genomics and drug discovery extends beyond the initial discovery phases into preclinical and clinical development. Genomic insights, powered by deep learning, can inform the design of more relevant animal models for preclinical testing or identify specific patient cohorts for clinical trials. AI can also analyze genomic data from clinical trial participants to identify responders versus non-responders, providing valuable insights into drug mechanisms and potential biomarkers for patient stratification.
Furthermore, deep learning can analyze genomic data from patient populations to identify genetic predispositions to certain diseases, allowing for earlier intervention or preventive strategies. This proactive approach to healthcare, driven by genomic insights and AI, has the potential to transform medicine from a reactive to a predictive and preventive discipline.
Figure 8 reveals conceptual Circos Plot for Multi-Omics Relationships. Figure 8 is a simplified representation designed to illustrate potential interactions between four key omics layers: Genomic, Transcriptomic, Proteomic, and Metabolomic. Key Features of the Circos Plot are Omics Layers as Tracks in which each layer (Genomic, Transcriptomic, Proteomic, Metabolomic) is represented as a concentric ring or "track," highlighting data from different biological scales (DNA → RNA → Proteins → Metabolites). Another feature of Figure 8 is Relationship Arcs/Links Curved bands (arcs) connect related elements across layers, such as: Genomic to Transcriptomic (Gene mutations affecting RNA expression), Transcriptomic to Proteomic (mRNA levels influencing protein abundance), and Proteomic to Metabolomic (Enzymes regulating metabolic pathways). In Figure 8 Each omics layer may use distinct colors (e.g., blue for Genomics, green for Transcriptomics) to enhance visual differentiation. Labels or nodes along each ring in Figure 8 represent specific elements (e.g., genes, transcripts, proteins, metabolites), though this example lacks detailed annotations. Usual purpose of the Plot are Integrative Analysis which Demonstrates how multi-omics data interconnects to provide a systems-level view of biological processes and Identify Cross-Omics Correlations which For example, a genomic variant (SNP) linked to altered metabolite levels via intermediate transcript and protein changes.
Limitations (Conceptual Nature) of Figure 8 are that plot is abstract; real Circos plots require precise coordinates (e.g., genomic regions) and tools like the `circlize` R package and Actual omics interactions are more complex (e.g., post-translational modifications, non-coding RNA effects). Potential Applications of Figure 8 are Biomarker Discovery to Visualize how a gene mutation propagates across omics layers to influence disease phenotypes and Pathway Analysis which Map metabolic pathways impacted by upstream genomic alterations. For implementation, tools like Circos (Perl) or R libraries (`circlize`, `OmicCircos`) can generate detailed plots with real datasets.
Challenges and Future Directions
Despite the remarkable progress and transformative potential of deep learning in genomics and AI in drug discovery, several significant challenges remain. Addressing these challenges will be crucial for the continued advancement and widespread adoption of these technologies, ultimately realizing their full promise in revolutionizing healthcare.
Data Challenges
One of the foremost challenges is the availability and quality of data. While large amounts of genomic and drug discovery data exist, they are often heterogeneous, noisy, and siloed across different institutions. Integrating these diverse datasets, ensuring their quality, and standardizing their formats are monumental tasks. Furthermore, for many rare diseases or specific drug targets, sufficient high-quality labeled data for training robust deep learning models is often scarce. This data scarcity can lead to overfitting and limit the generalizability of models. Future efforts must focus on developing federated learning approaches, where models are trained on decentralized datasets without sharing raw data, and on creating more comprehensive, standardized, and publicly accessible databases.
Another data-related challenge is data privacy and security, especially when dealing with sensitive patient genomic and health information. Strict regulations and ethical considerations necessitate robust privacy-preserving techniques, such as differential privacy and homomorphic encryption, to enable collaborative research while safeguarding individual data. The development of synthetic data generation methods that mimic real-world data distributions without revealing sensitive information also holds promise.
Model Interpretability and Explainability
Deep learning models, particularly complex neural networks, are often criticized for being ‘black boxes.’ Their lack of interpretability and explainability is a significant barrier to their adoption in highly regulated fields like medicine and drug development. Clinicians and regulatory bodies require clear justifications for model predictions, especially when those predictions impact patient treatment decisions or drug approval processes. Understanding why a model makes a certain prediction is crucial for building trust, identifying biases, and ensuring the safety and efficacy of AI-driven interventions.
Future research needs to focus on developing more interpretable AI (XAI) methods that can provide insights into the decision-making process of deep learning models. This includes techniques for visualizing learned features, identifying influential input variables, and generating human-understandable explanations. Progress in this area will facilitate the translation of AI research into clinical practice and regulatory acceptance.
Kaplan-Meier Survival Curve (Clinical Omics) on Figure 9 shows a graphical representation of survival probabilities over time, commonly used in clinical omics studies to evaluate the relationship between omics data (e.g., genomics, proteomics) and patient outcomes. A detailed breakdown of the Figure 9 indicating it is generated from simulated data for illustrative purposes, typical in clinical omics research.In Figure 9 Two groups are plotted. Group 1 Represented by one survival curve (e.g., patients with a specific biomarker or omics signature) and Group 2 Represented by another curve (e.g., control group or patients without the biomarker). Y-Axis (Survival Probability) of Figure 9 Ranges from 0% survival to 90% survival and The curve shows the probability of survival (or event-free time) at each time point. Figure 9 X-Axis (Time) Represents follow-up time (e.g., days, months, or years), ranging from 10 to 100 units. Curve Interpretation of Figure 9 shows The stepwise decline in each curve indicates "events" (e.g., death, disease progression). The vertical drops correspond to events occurring at specific time points, while plateaus indicate periods with no events. The separation between Group 1 and Group 2 suggests differences in survival outcomes, potentially due to omics-based stratification (e.g., high-risk vs. low-risk genetic profiles). In multi-omics studies, such curves correlate molecular features (e.g., gene mutations, protein expression) with survival to identify prognostic or predictive biomarkers. Example Hypotheses in Figure 9 are Patients with overexpression of Gene X (Group 1) exhibit worse survival than controls (Group 2) and A metabolic omics signature predicts longer progression-free survival. Figure 9 uses simulated data, so actual clinical studies would include: Statistical tests (e.g., log-rank test for group differences), Confidence intervals around the curves, Annotations for sample size, censoring events (e.g., lost to follow-up).
Generalizability and Robustness
Deep learning models trained on specific datasets or populations may not perform well when applied to new, unseen data or different patient cohorts. This lack of generalizability and robustness is a critical concern. Biological data often exhibit batch effects, population-specific variations, and differences due to experimental protocols, which can lead to models that are brittle and unreliable in real-world settings. Ensuring that models are robust to these variations and can generalize across diverse populations and experimental conditions is essential for their practical utility.
Developing methods for transfer learning and domain adaptation will be key to addressing this challenge, allowing models trained on one dataset to be effectively adapted to new, related datasets with minimal retraining. Furthermore, rigorous validation strategies, including prospective studies and external validation on independent datasets, are necessary to assess the true generalizability of AI models.
Integration into Existing Workflows
Successfully integrating AI tools into existing genomic research laboratories and drug discovery pipelines presents operational and cultural challenges. This requires not only technical expertise but also a shift in mindset among researchers and practitioners. The development of user-friendly interfaces, standardized protocols, and interoperable software platforms will be crucial for seamless integration. Training the next generation of scientists with interdisciplinary skills in biology, chemistry, computer science, and AI will also be vital.
Ethical and Societal Implications
As AI becomes more pervasive in genomics and drug discovery, ethical and societal implications must be carefully considered. Issues such as algorithmic bias, equitable access to AI-driven healthcare solutions, and the responsible use of genomic data require ongoing dialogue and the development of clear guidelines. Ensuring that AI benefits all segments of society and does not exacerbate existing health disparities is a critical responsibility.
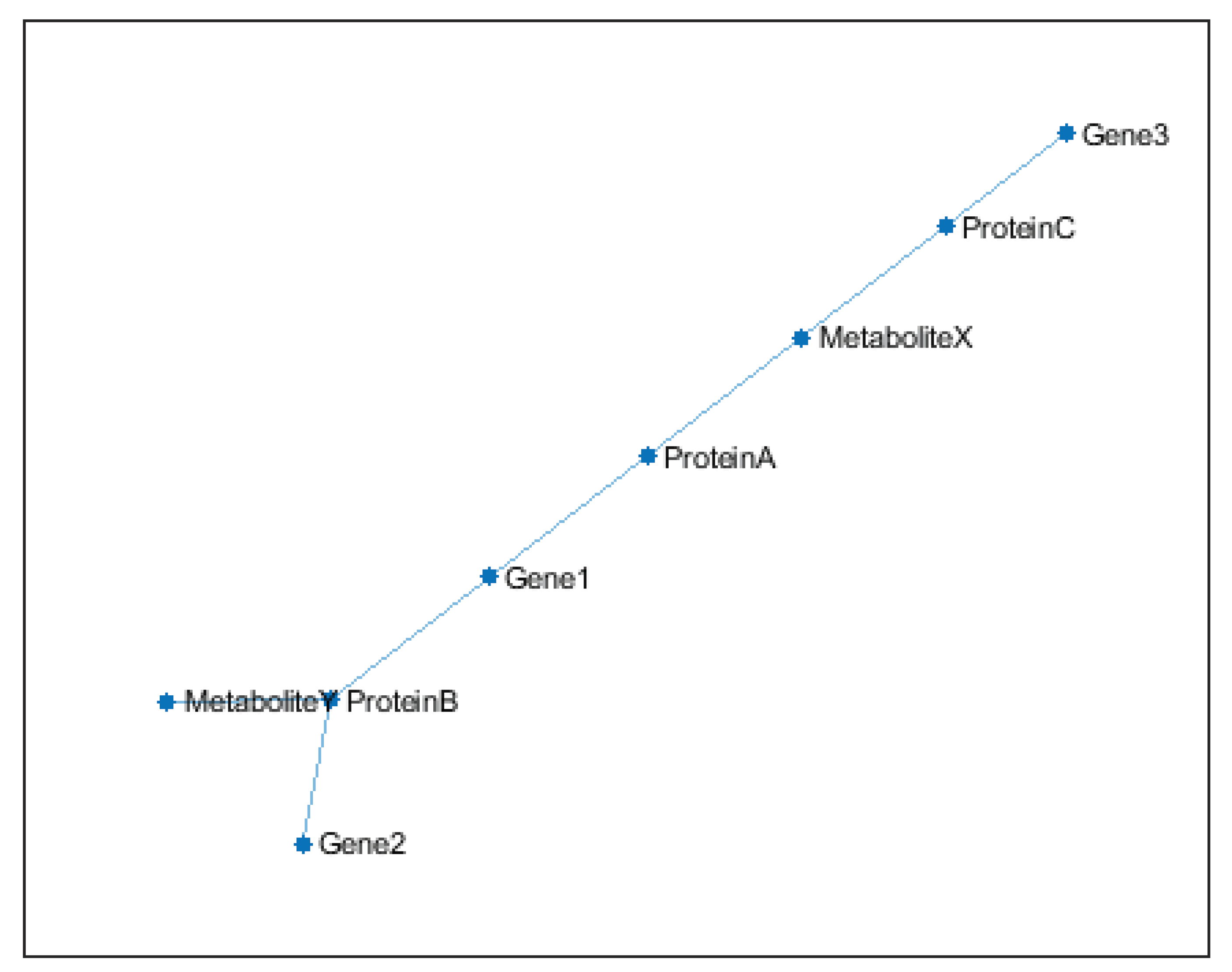
Conceptual Multi-Omics Interaction Network is shown in Figure 10. This conceptual network simplifies real-world complexity but provides a foundation for modeling multi-omics data in systems biology. This plot represents a conceptual visualization of a multi-omics interaction network, illustrating the complex relationships between different biological molecules (e.g., genes, proteins, metabolites) across various omics layers. Node Types (Molecules) are Genes (e.g., Gene3, Gene1, Gene2), Proteins (e.g., ProteinC, ProteinA, ProteinB), and Metabolites (e.g., MetaboliteX, MetaboliteY). Edges (Interactions) in Figure 10 are Lines connecting nodes represent functional relationships, such as: Gene-protein interactions (e.g., Gene3 → ProteinC), Protein-metabolite interactions (e.g., ProteinB ↔ MetaboliteY), and Regulatory or metabolic pathways (e.g., Gene1 influencing MetaboliteX). Omics Integration in Figure 10 Demonstrates how molecular layers (genomics, proteomics, metabolomics) intersect to form a cohesive biological system. Purpose of Figure 10 is to Highlight cross-omics dependencies (e.g., how gene expression affects protein abundance and metabolite levels). Figure 10 Serves as a hypothesis-generating tool for identifying key molecules or pathways in diseases or biological processes. Figure 10 in ProteinB and MetaboliteY may co-regulate a metabolic pathway and Gene2 could encode an enzyme that modifies MetaboliteX. In Figure 10, Nodes are color-coded by molecular type (e.g., genes in blue, proteins in red, metabolites in green) and Edges may vary in thickness/color to indicate interaction strength or directionality.
Future Directions
Looking ahead, several exciting avenues for future research and development emerge:
- Multi-modal and Multi-scale Integration: Further advancements in integrating diverse data types (genomics, proteomics, imaging, clinical records) at multiple biological scales (molecular, cellular, tissue, organismal) will lead to more comprehensive and predictive models of disease and drug action.
- Reinforcement Learning for Drug Design: Applying reinforcement learning, where an AI agent learns to design molecules through trial and error in a simulated environment, could revolutionize de novo drug design by optimizing for complex property profiles.
- Digital Twins and Personalized Medicine: The creation of ‘digital twins’—virtual representations of individual patients based on their comprehensive genomic and health data—could enable highly personalized drug discovery and treatment strategies, allowing for in silico testing of therapies.
- Automated Experimentation and Robotics: Integrating AI with automated laboratory systems and robotics (AI-driven labs) will accelerate the pace of experimental validation and data generation, creating a virtuous cycle of data-driven discovery.
- Quantum Computing and AI: The nascent field of quantum computing holds potential for accelerating complex simulations and optimizations in drug discovery, particularly in molecular dynamics and quantum chemistry, which could be synergistically combined with AI.
By proactively addressing the current challenges and exploring these future directions, deep learning and AI are poised to unlock unprecedented capabilities in understanding life, combating disease, and developing the next generation of therapeutics.
Conclusion
The convergence of deep learning with genomics and drug discovery marks a transformative era in biomedical research and healthcare. As elucidated in this review, deep learning models have demonstrated unparalleled capabilities in deciphering the complexities of genomic data, from precise variant calling and gene expression analysis to the intricate landscapes of epigenomics and single-cell heterogeneity. These advancements are not merely incremental improvements but represent a fundamental shift in our ability to extract meaningful biological insights from vast and high-dimensional datasets.
Simultaneously, artificial intelligence, particularly deep learning, is revolutionizing every facet of the drug discovery pipeline. From accelerating the identification and validation of novel therapeutic targets to optimizing lead compounds, enabling de novo drug design, and facilitating drug repurposing, AI is significantly enhancing the efficiency, speed, and success rates of bringing new medicines to patients. The ability of AI to predict ADMET properties and optimize clinical trial designs further underscores its profound impact on reducing the time, cost, and risk associated with drug development.
Crucially, the synergistic integration of deep learning in genomics with AI in drug discovery amplifies their individual strengths. Genomic insights, powered by advanced AI, are increasingly guiding the rational design of therapeutics, enabling precision medicine approaches where treatments are tailored to an individual’s unique genetic and molecular profile. This interdisciplinary approach fosters a deeper understanding of disease mechanisms and paves the way for more effective and personalized interventions.
While the journey is still unfolding, and challenges related to data availability, model interpretability, generalizability, and ethical considerations persist, the trajectory is clear. Continuous innovation in data generation, algorithmic development, and interdisciplinary collaboration will further unlock the immense potential of these technologies. The future of medicine, driven by the intelligent analysis of genomic information and the accelerated discovery of novel drugs, promises a healthier and more personalized approach to human well-being. As these fields continue to evolve, the collaborative efforts of researchers, clinicians, and policymakers will be paramount in harnessing the full power of deep learning and AI to address the most pressing health challenges of our time.
References
- Poplin, R. , Chang, P. C., Alexander, D., Schwartz, S., Colthurst, N., Ku, A., … & DePristo, M. A. (2018). DeepVariant: highly accurate genomic variant calling with deep neural networks. Nature biotechnology, /: https, 4235. [Google Scholar]
- Avsec Ž, Agarwal V, Visentin D, Ledsam JR, Grabska-Barwinska A, Taylor KR, Assael Y, Jumper J, Kohli P, Kelley DR. Effective gene expression prediction from sequence by integrating long-range interactions. Nat Methods. 2021 Oct;18(10):1196-1203. [CrossRef] [PubMed]
- Ching, T. , Himmelstein, D. S., Beaulieu-Jones, B. K., Kalinin, A. A., Do, B. T., Way, G. P., … & Greene, C. S. (2018). Opportunities and obstacles for deep learning in biology and medicine. Journal of The Royal Society Interface, /: https, 2017. [Google Scholar]
- Vamathevan, J. , Clark, D., Czodrowski, P., Dunham, I., Ferran, E., Lee, G., … & Zhao, Z. (2019). Applications of machine learning in drug discovery and development. Nature reviews Drug discovery, /: https, 4157. [Google Scholar]
- LeCun, Y. , Bengio, Y., & Hinton, G. (2015). Deep learning. nature, /: 436-444. https, 1453. [Google Scholar]
- Angermueller, C. , Pärnamaa, T., Parts, L., & Stegle, O. (2016). Deep learning for computational biology. Molecular systems biology, /: https, 1525. [Google Scholar]
- Esteva, A. , Robicquet, A., Ramsundar, B., Kuleshov, V., DePristo, M., Chou, K., … & Dean, J. (2019). A guide to deep learning in healthcare. Nature medicine, /: https, 4159. [Google Scholar]
- Zou, J. , Huss, M., Abid, A., Mohammadi, P., Torkamani, A., & Telenti, A. (2019). A primer on deep learning in genomics. Nature genetics, /: https, 4158. [Google Scholar]
- Eraslan, G. , Avsec, Ž., Gagneur, J., & Theis, F. J. (2019). Deep learning: new computational modelling techniques for genomics. Nature Reviews Genetics, /: https, 4157. [Google Scholar]
- Cook DE, Venkat A, Yelizarov D, Pouliot Y, Chang PC, Carroll A, De La Vega FM. A deep-learning-based RNA-seq germline variant caller. Bioinform Adv. 2023 Jun 13;3(1):vbad062. [CrossRef] [PubMed]
- Nawy, T. Short reads join hands. Nat Methods, 2014. [Google Scholar] [CrossRef]
- Quang, D. , & Xie, X. (2016). DanQ: a hybrid convolutional and recurrent deep neural network for quantifying the function of DNA sequences. Nucleic acids research, /: https, 2468. [Google Scholar]
- Kelley, D. R. , Snoek, J., & Rinn, J. L. (2016). Basset: learning the regulatory code of the accessible genome with deep convolutional neural networks. Genome research, /: https.
- Way GP, Greene CS. Extracting a biologically relevant latent space from cancer transcriptomes with variational autoencoders. Pac Symp Biocomput. 2018;23:80-91. PMCID: PMC5728678. [PubMed]
- Schnepf M, von Reutern M, Ludwig C, Jung C, Gaul U. Transcription Factor Binding Affinities and DNA Shape Readout. iScience. 2020 Oct 15;23(11):101694. [CrossRef] [PubMed]
- Singh, R. , Lanchantin, J., & Qi, Y. (2016). DeepChrome: deep-learning for predicting gene expression from histone modifications. Bioinformatics, /: https, 2455. [Google Scholar]
- Lopez, R. , Regier, J., Cole, M. B., Jordan, M. I., & Yosef, N. (2018). Deep generative modeling for single-cell transcriptomics. Nature methods, /: https, 1058. [Google Scholar]
- Du, J. , Chen, T., Gao, M., & Wang, J. (2024). Joint trajectory inference for single-cell genomics using deep learning with a mixture prior. Proceedings of the National Academy of Sciences. [CrossRef]
- Hie, B. , Bryson, B., & Berger, B. (2019). Efficient integration of heterogeneous single-cell transcriptomes using Scanorama. Nature biotechnology, /: https, 4158. [Google Scholar]
- Mulligan, V. K. (2021). Current directions in combining simulation-based macromolecular modeling approaches with deep learning. Expert Opinion on Drug Discovery, 1025. [Google Scholar] [CrossRef]
- Fleming, N. (2018). How artificial intelligence is changing drug discovery. Nature, /: S55-S57. https, 4158. [Google Scholar]
- Kant, S. , Deepika & Roy, S. Artificial intelligence in drug discovery and development: transforming challenges into opportunities. Discov. Pharm. Sci. [CrossRef]
- 2024; 85. [CrossRef]
- Zhavoronkov, A. , Ivanenkov, Y. A., Ali, A., Johnson, M., & Ulloa, L. (2019). Deep learning for drug discovery and biomarker development. Nature biotechnology, /: https, 1018. [Google Scholar]
- Gawehn, E. , Hiss, J. A., & Schneider, G. (2016). Deep learning in drug discovery. Molecular informatics, /: https, 1002. [Google Scholar]
- Kadurin, A. , Aliper, A., Kazennov, A., Mamoshina, P., Vanhaelen, Q., Khrabrov, K., & Zhavoronkov, A. (2017). The cornucopia of meaningful leads: Applying deep adversarial autoencoders for new molecule generation in oncology. Oncotarget, /: https, 1407. [Google Scholar]
- Segler, M. H. , Kogej, T., Tyrchan, C., & Waller, M. P. (2018). Generating focused molecule libraries for drug discovery with recurrent neural networks. ACS central science, /: https, 1021. [Google Scholar]
- Pushpakom, S. , Iorio, F., Eyers, P. et al. Drug repurposing: progress, challenges and recommendations. Nat Rev Drug Discov. [CrossRef]
- Mayr, A. , Klambauer, G., Unterthiner, T., & Hochreiter, S. (2016). DeepTox: toxicity prediction using deep learning. Frontiers in environmental science, 3389. [Google Scholar]
- Saeed, H. , El Naqa, I. (2022). Artificial Intelligence in Clinical Trials. In: El Naqa, I., Murphy, M.J. (eds) Machine and Deep Learning in Oncology, Medical Physics and Radiology. Springer, Cham. [CrossRef]
Figure 3.
PCA Plot of Multi-Omics Data
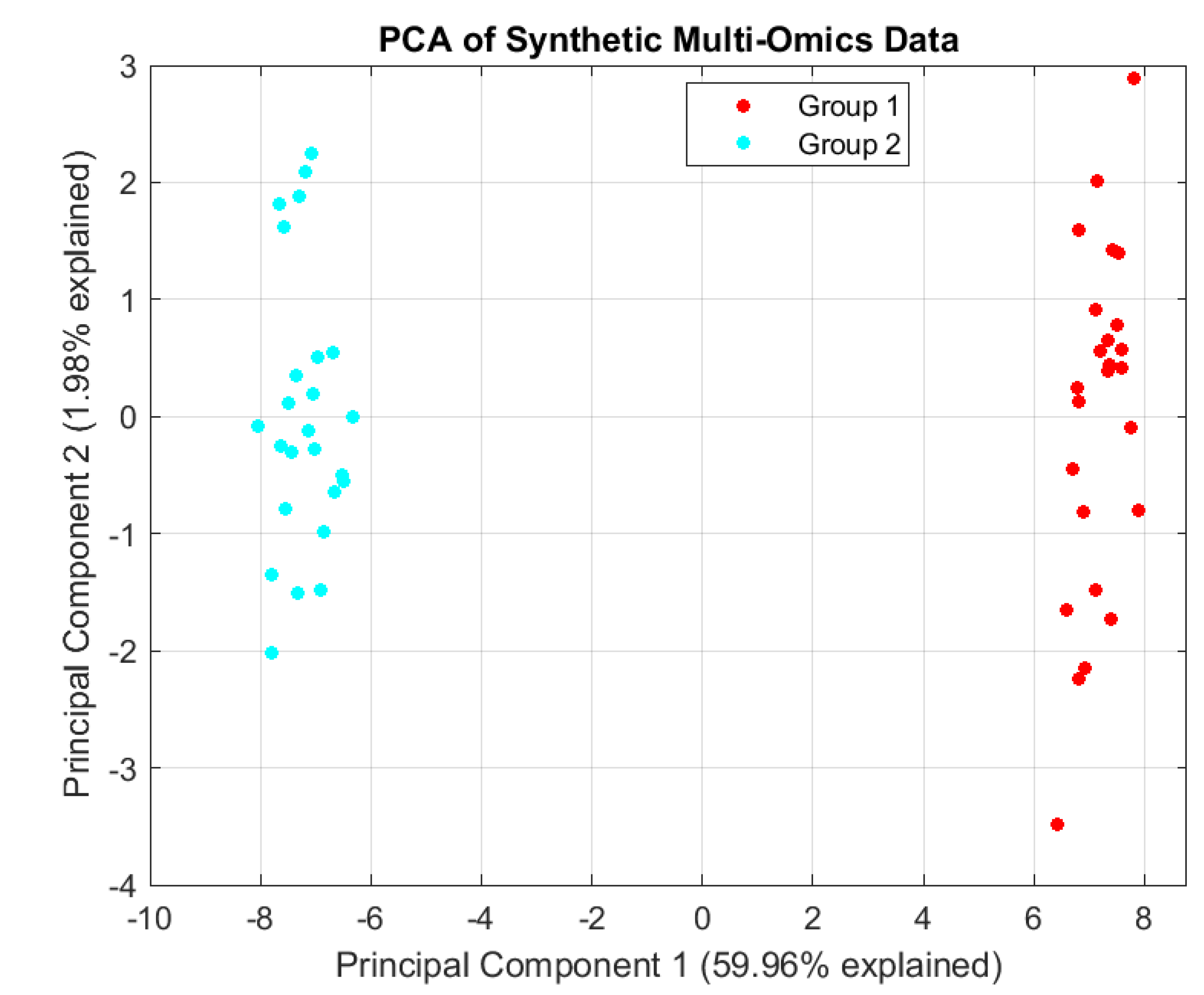
Figure 4.
Correlation Matrix Heatmap of Multi-Omics Features.
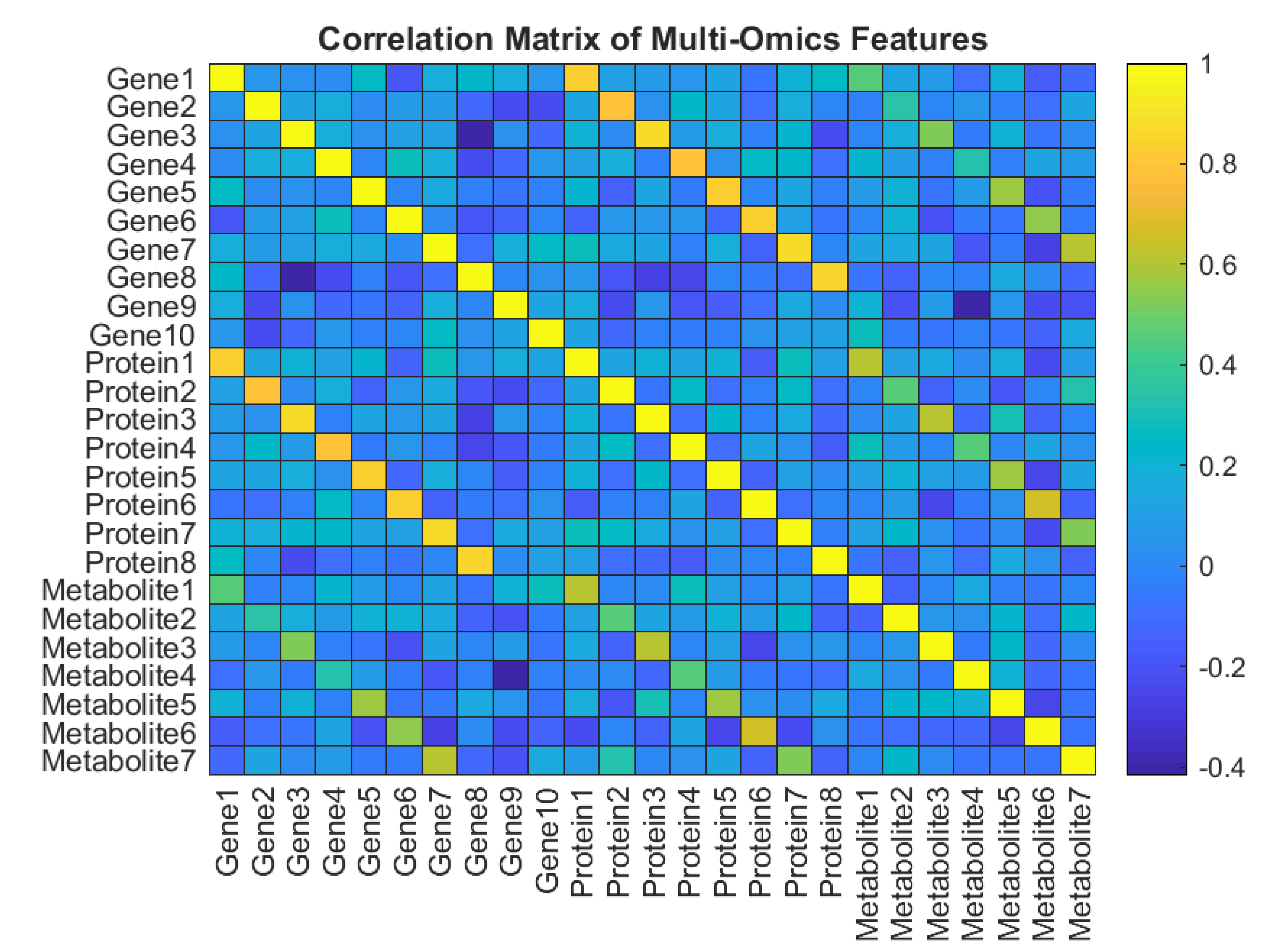
Figure 5.
Volcano Plot of Differential Gene Expression.
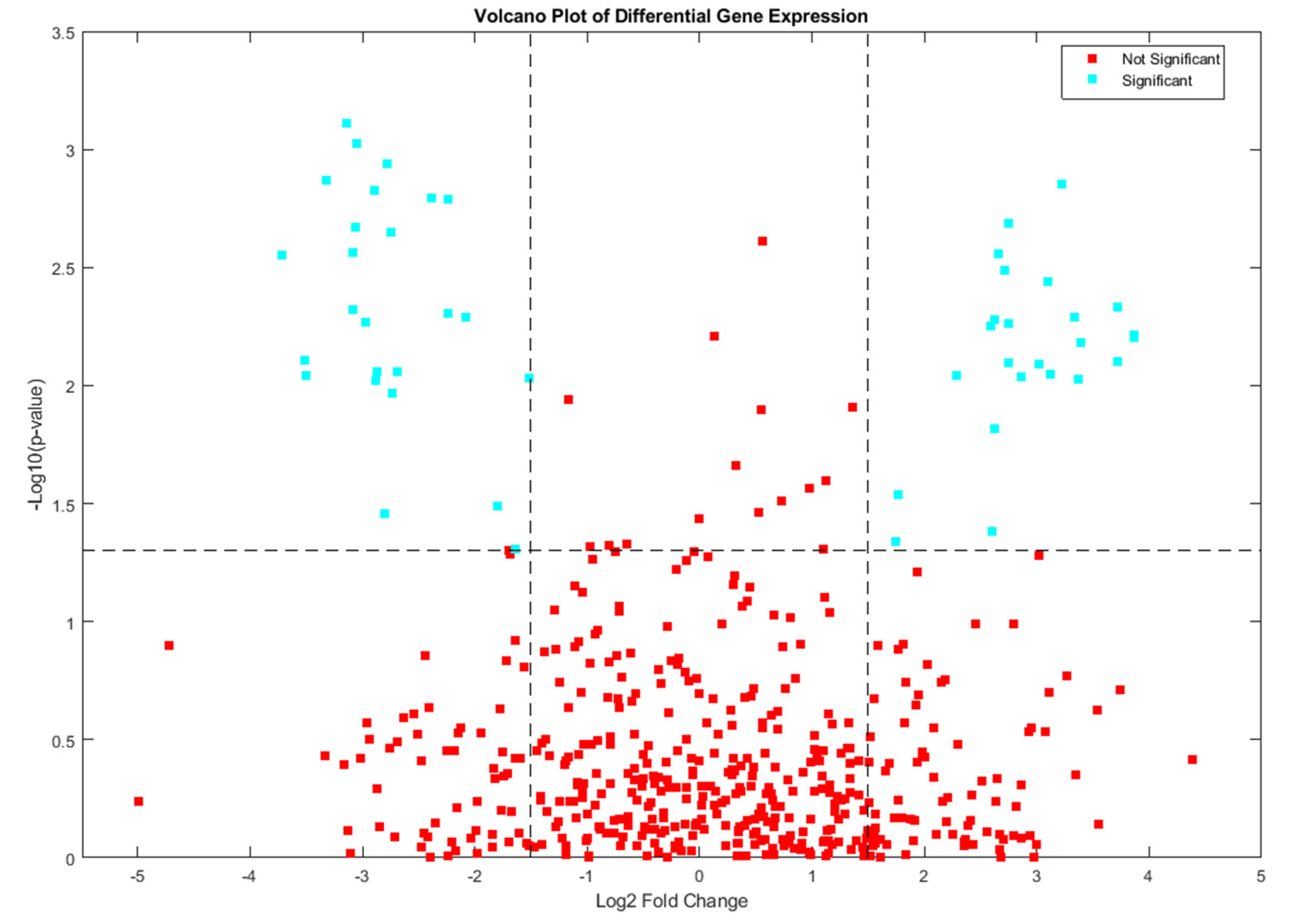
Figure 6.
Gene-Protein Interaction Network (Conceptual).
Figure 7.
Pathway Enrichment Analysis Plot.

Figure 8.
Conceptual Circos Plot for Multi-Omics Relationships.
Figure 9.
Kaplan-Meier Survival Curve (Clinical Omics).
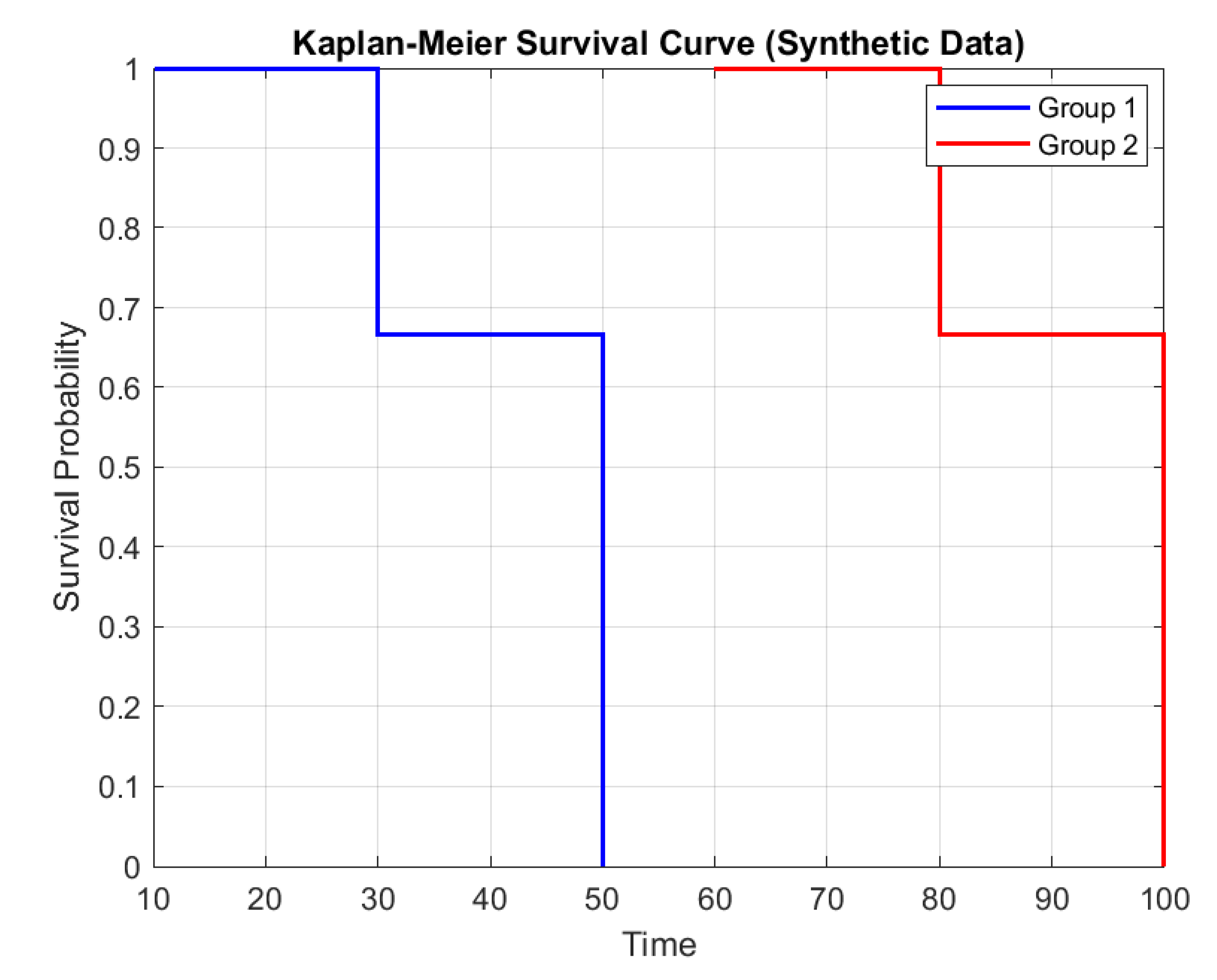
Figure 10.
Multi-Omics Interaction Network (Conceptual).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



