Submitted:
15 June 2025
Posted:
16 June 2025
You are already at the latest version
Abstract
In Bangladesh, more tomatoes have been grown in the last few years. In addition to its health benefits, tomato farming is important for the work of many people. However, several illnesses that affect tomato leaves hinder tomato output. The goal of my study is to use convolutional neural networks (CNNs). This study looks into how to find diseases on tomato leaves. My study shows that CNNs have the revolutionary ability to change the way farming is done, which goes beyond their statistical successes. Because these models can find diseases quickly and correctly, they hold a lot of promise for long-term crop management and a big boost in food security around the world. Three types of tomato leaf diseases were looked at in this study, along with one healthy type. To test, 10% of the examples in each class were taken out. Only 20% was used for evaluation, and the other 70% was used for teaching. I look into five different designs in great detail, looking at their speed, processing efficiency, and social effects. These are ResNet50, DenseNet201, MobileNetV2, MobileNetV3, and VGG19. The system showed that it was correct 95.37% of the time. It is regarded as an easy- to-use technology that will assist vegetable farmers, particularly those who cultivate "tomatoes," in reducing pest suppression by detecting leaf illnesses and increasing production by creating additional options for professional marketing and researching various vegetable diseases.
Keywords:
Tomato Leaf Disease
; Convolutional Neural Network (CNN)
; Deep Learning
; Image Classification
; Data Augmentation
Introduction
Among the most widely grown and important crops in terms of trade abroad is the tomato. It’s a standard in many different recipes and offers a substantial addition to the farming sector. However, several diseases that affect different parts of the plant represent an ongoing threat to the health and output of tomato plants. Among these, illnesses that attack tomato plants can greatly affect the harvest's quality and amount. Almost 47.30 percent of the work force in Bangladesh is directly employed in agriculture, where more than 80% of people depend on it for their living (Mim et al., 2019). Vegetables are the second most popular food in our country, behind rice in the market. When compared to foods that grow all year round, special veggies are the most popular. Among them is the tomato. Tomatoes include beta-carotene, vitamin C, and vitamin E, the three most important antioxidants. They also contain a lot of potassium, which is a crucial vitamin for general health. According to “The Food and Agriculture Organization Corporate Statistical Database (FAOSTAT)”, Bangladesh uses, on average, 27,342 hectares of land to produce more than 380000 tons of tomatoes yearly (Al Mamun et al., 2020). Bangladesh uses an average of 27,342 hectares of land to grow more than 380000 tons of tomatoes yearly (Ahmad et al., 2020).
In our country, tomatoes are special fruit that are only grown in the winter. However, the tomato is now grown and sold year-round thanks to the Ministry of Agriculture's help and a couple of dedicated tomato growers. That's made possible for farms by technology. A major role in lowering poverty, the tomato is viewed as a source of income for farming families (Trivedi et al., 2021). However, raising tomatoes offers numerous challenges for farmers in our nation. Fighting off numerous leaf diseases in tomato plants is the most clear task. Bacterial spot, early blight, mosaic virus, and other common illnesses are a few examples. For efficient disease control and to avoid crop losses, illnesses in tomato plants must be found early and correctly. Conventional disease identification methods depend on skilled agronomists visually checking crops, which can be laborious and biased. Thanks to technology developments, especially in the areas of computer vision and machine learning, a chance appears to change the process of plant disease discovery radically. However, a good output might still be possible if the diseases can be predicted sooner.
CNNs have been demonstrated to work exceptionally well on picture classification tasks (Rashed & kakon., 2025) yet two major problems with CNN design and usage have been noticed. First, many CNN parameters must be calculated during the training phase; second, many input pictures are needed during the training phase. These deep-learning models are excellent at finding minor patterns and features in pictures, which makes them useful for studying plant diseases using leaf shots. Using CNNs to identify diseases in tomato leaves has the potential to greatly improve the testing process's speed, accuracy, and scale.
This work aims to explore and apply a CNN-based method for the automatic spotting of diseases affecting tomato plants. The suggested method includes using a collection of several shots of both healthy and broken tomato leaves to train the CNN model. This allows the network to find distinguishable traits related to different illnesses. The results of this study should help improve precision agriculture by giving farmers and agronomists a useful tool for quickly and correctly spotting tomato leaf diseases. I work to lessen the effects of illnesses on tomato products by adding technology into the agriculture sector, which finally supports healthy farming methods and promises food security.
Literature Review
Numerous works have already been finished. Numerous experts from all over the world have worked very hard on this bug problem because it has been there for a long time. However, it must be kept in mind that the weather changes throughout the country. Therefore, the disease's traits and dangerous bug species will vary. However, it might not be the same way. Not every study sticks to the same approach. Different types will offer different numbers and levels of accuracy. The most widely used classification methods for finding plant disease before the rise of deep learning were random forests, artificial neural networks (ANN), k-nearest neighbor (KNN), and support vector machines (SVM). Acknowledgment and usage of the previously mentioned methods for improved plant disease classification. These methods, however, rest on the selection and extraction of options for visible sickness. Numerous studies on machine- driven disease classification and recognition have been developed recently using deep learning methods.
(Jiachun et al., 2018) recommended using ten-layer CNN to group plant leaves. To identify the plant leaf in this method, a ten-layer CNN was created. The average accuracy was 87.92% based on results on a collection of Flavia leaves with 4,800 pictures and 32 types. Automatic feature extraction from neural networks allows 94–95% accuracy in sorting the input dataset's leaf picture into its proper separate classes.
(P. J. Herrera et al., 2014) used a fuzzy multicriteria decision-making method in conjunction with fuzzy decision making to identify weed types, and they were able to hit the best accuracy of 92.9%. (Suryawati et al., 2018) trained the model using Alexnet, GoogleNet, and VGGNet on picture examples of tomato leaves from the PlantVillage dataset. The model got test accuracy of 91.52%, 89.68%, and 95.25%, respectively. The same dataset is used by (Wang et al., 2017) to train and compare the results of the well-known CNN models, including VGG16, VGG19, Inception-V3, and ResNet50. They tested with many models both with and without transfer learning, and the VGG16 model gave the best test accuracy of 90.4%.
Finding a computationally sound answer for the core issue was the work's major goal. The writers claimed a 94% success rate using pictures from the PlanetVillage collection. (S. P. Mohanty et al., 2016) created models for the identification of tomato leaf diseases using the deep learning frameworks of GoogLeNet and AlexNet. To identify plant diseases such as bacterial speck, target spot, late blight, early blight, mosaic virus, and Septoria leaf spot, the writers of (S. Zhang et al., 2019) created a neural network-based method. With a three-channel convolution neural network, the suggested model achieved an accuracy of 89.29% total. (S. Zhang et al., 2017) mentioned using an automatic way to find illnesses in cucumber leaves. The system got 85.70% accuracy in segmentation using K-Means clustering. The study "Tomato Plant Diseases Detection System using Image Processing" was performed in 2018 by Santosh Adhikari, Bikesh Shrestha, Bibek Baiju, and Er. Saban Kumar K.C. Using the plant village dataset, the KEC Conference used CNN and achieved an average accuracy of 89% (Mohammed Brahimi et al., 2017). In their work, (P. Tm et al., 2018) showed a CNN model version called LeNet for the identification of several tomato leaf diseases. The model finally achieved an average accuracy of 94–95% and offered an automatic feature extraction way to ease the work of identifying several illnesses. The model applied categorical cross-entropy as the loss function and Adam as the planner. The full model used 30 epochs for training, with a batch size of 20. These days, machine learning is frequently utilized to identify different plant diseases. To spot diseases in tomato products, (Agarwal et al., 2020) built a CNN model with three convolution layers and max-pooling layers. Every layer held a different set of filters. There were also two fully joined layers in the model. For several groups, the model showed classification accuracy ranging from approximately 76% to 100%. The average accuracy achieved by the suggested model was 91.2%. While pre-trained models needed a storage capacity of approximately 100 MB, the suggested model only required 1.5 MB.
A plant disease monitoring method was described by the writers in (V. Singh & A. K. Misra., 2017). Features of shape and material were taken before classification. K-mean clustering and SVM are used to group illnesses based on the minimum distance measure. The accuracy of the system was 86.54%. A neural-network-based method was created by the authors in (S. Zhang et al., 2019) to identify plant diseases such as Septoria leaf spot, late blight, early blight, bacterial speck, and target spot. With a three-channel convolution neural network, the suggested model achieved an accuracy of 89.29% total.
| Author Name | Methodology | Description | Outcome |
| Mohammed Brahimi, & Abdelouahab Kamel Boukhalfa, Moussaoui | Deep Learning | Tomato Plant Diseases Detection System using Image Processing | 89% |
| Mim, T.T., Sheikh, M.H., Shampa, R.A., Reza, M.S. and Islam |
CNN and Transfer Learning | Leaves diseas detection of tomato using CNN | 87.92% |
| Rika Sustika, R. Sandra Yuwana, Agus Subekti, and Hilman F. Pardede | Convolutional Neural Networks (CNN) | Deep, Structured Convolutional Neural Network for Tomato Diseases Detection | 91.52% |
| Wang, Guan, Yu Sun, and Jianxin Wang | Deep Learning Approch | Automatic image-based plant disease severity estimation using deep learning | 90.4% |
| P. Tm, A. Pranathi, K. SaiAshritha, N. B. Chittaragi and S. G. Koolagudi | Convolutional Neural Networks (CNN) | Tomato Leaf Disease Detection Using Convolutional Neural Networks | 95% |
| Agarwal, Mohit & Singh, Abhishek & Arjaria, Siddhartha & Sinha, Amit & Gupta, Suneet | Convolutional Neural Network (CNN) model. | Tomato Leaf Disease Detection using Convolution Neural Network | 91.20% |
| Our proposed model | CNN with Transfer Learning | Detection Of Tomato's Leaves Disease Using CNN Deep Learning | 95.31% |
Materials and Methods
I will discuss the tools and methods we applied for measurement. I worked with a raw data file that included, exactly, 1624 photos. These were marked 1 through 4, marking the leaf's disease class. Here, sequential models have been used to teach a machine. The Python tools numpy, pandas, skit learn, matplotlib, seaborn, TensorFlow, keras, etc. were used with the Windows OS. Colab, a free Python package from Google built for use in information science and artificial intelligence tasks, was used for all development and review. To build a reliable tomato leaf disease detection system for Bangladeshi agriculture, this study uses CNN and ResNet50, MobileNetV2, DensNet201, MobileNetV3 and Vgg19 deep learning models. The following parts will cover model building, training, testing data, and analysis to help readers understand the study topic and tools.
Data Collection
To identify tomato leaf disease using CNNs, data collection was carefully planned. The study used secondary sources, getting pictures from various tomato farms using a cell phone in daylight. Initially, 400 pictures of four disease types were gathered, which were insufficient for training. To solve this, data expansion was performed, growing the collection to 1,626 pictures. This expanded sample helps the machine learn key disease traits more effectively. The goal is to help farmers in finding and learning different disease traits.
Figure 1.
Three Leaves Diseases and Healthy Leave.

This study offers statistical analysis to assess the performance of CNN models in identifying tomato leaf diseases. Key measures include accuracy, precision, and memory. I tried various architectures—CNN, MobileNetV2, MobileNetV3, ResNet50, DenseNet201, and VGG19—to improve accuracy. The collection includes 1,626 pictures across four classes: Bacterial Spot, Early Blight, Mosaic Virus, and Healthy. All photos were adjusted to 224×224 pixels. Data was split into 70% for training, 20% for testing, and 10% for confirmation.

Table 1.
Several photos and the class index for each of those 4 classes.
| Class Name | Class Index | No. of Image |
|---|---|---|
| Bacterial_spot | 1 | 407 |
| Early_blight | 2 | 406 |
| Mosaic_virus | 3 | 407 |
| Healthy | 4 | 406 |
Dataset Preparation
The method starts with the planning and collection of the "TomatoLeafDisease- 2023" dataset, which is representative and diverse. This dataset includes carefully chosen high-resolution pictures of tomato plants in both healthy and sick states. The named and tagged collection offers important ground truth data for CNN model training.
Data Augmentation Techniques
To improve the dataset's potential for extension, data expansion methods are used on it. Rotations flips, and zooms are some of these changes that add variance to the model, avoiding overfitting and improving its capacity to react to a variety of real- world events.
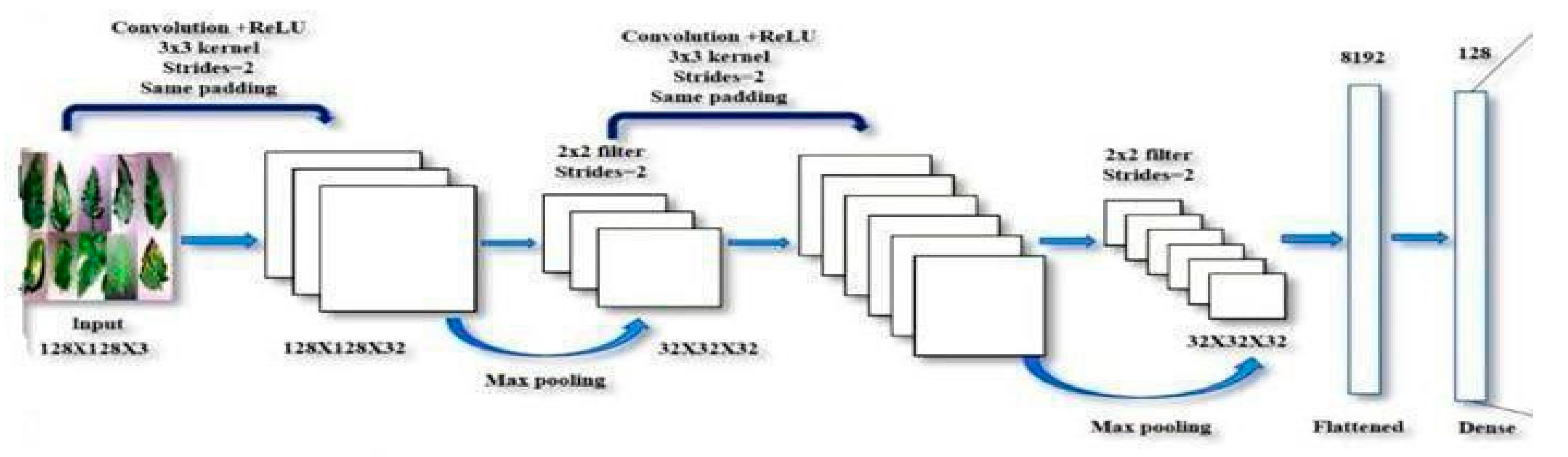
CNN Architecture Selection
A important first step is picking a good CNN design. Modern designs like ResNet, MobileNet, VGG19, DenseNet, and custom models are taken into consideration. The building design needs to show balance between complexity and effectiveness, fitting the subtleties of tomato leaf disease patterns.
Figure 2.
CNN Architecture Procedure.
Transfer Learning
The suggested method uses big datasets to leverage pre-trained CNN models, using transfer learning. This method expedites the training process and improves the model's ability to identify important traits from pictures of tomato leaves. Pre-trained models are changed to ensure that they are tailored to the goal of illness identification.
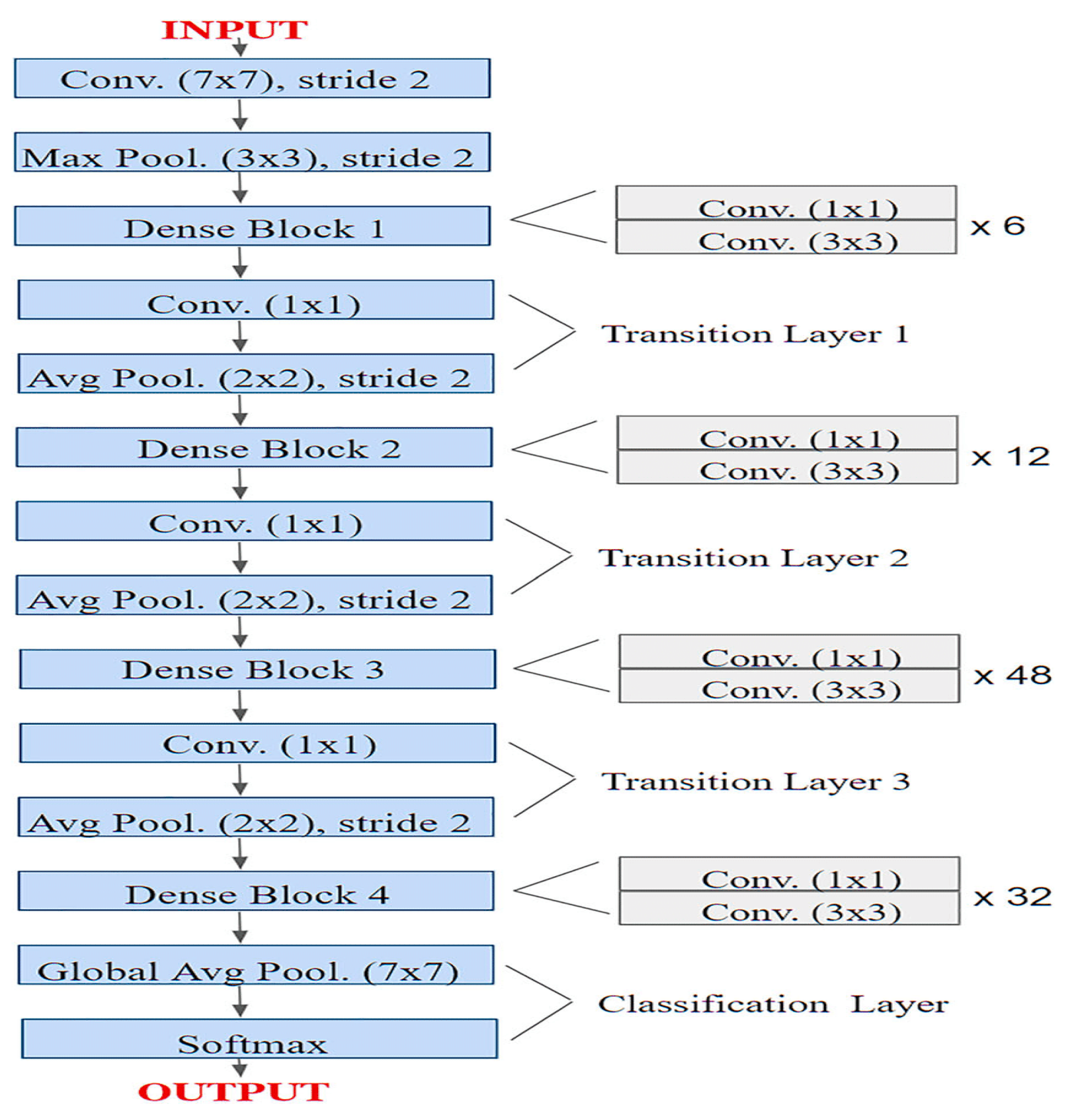
ResNet50
Convolutional neural networks (CNNs) like ResNet50 are part of the ResNet (Residual Network) family of neural networks. Its 50 levels of neural network design describe its depth. The number of layers, or "50" in ResNet50, suggests a significant depth that allows the model to pick up on complex features and trends in the data. The idea of residual learning, in which information can move straight between layers thanks to fast links, was first presented by ResNet designs. This helps to train very deep networks and lowers the problem of fading slopes.
Figure 3.
ResNet50 Layer Architecture.

DensNet201
DenseNet201 is a deep CNN model with 201 layers, known for its tightly connected design. Each layer gets information from all earlier layers, improving feature usage, gradient flow, and reducing the disappearing gradient problem. It works well in jobs like picture analysis and object recognition. Although computationally expensive, its design allows strong generalization and accurate pattern recognition, making it ideal for complex visual tasks.
Figure 4.
DensNet201 Layer Architecture.
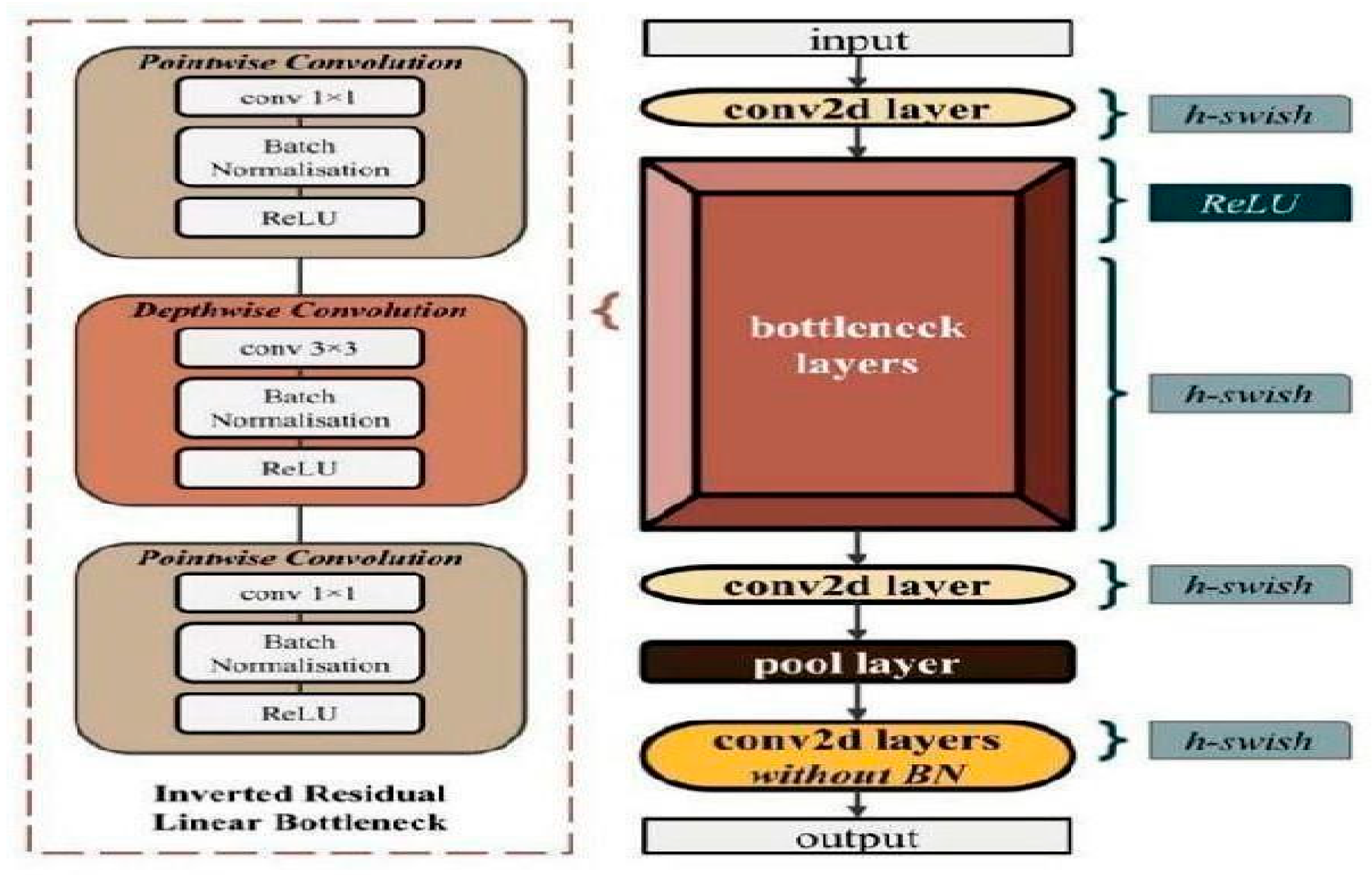
MobileNet V2
MobileNetV2 is a lightweight CNN framework intended for mobile and edge devices, combining speed and accuracy. It improves on the original MobileNet by using inverted residuals with linear limits to record fine-grained features. The model uses depth-wise separable convolutions and lowers dimensions to improve efficiency. Its adjustable design includes width and resolution boosters, improving freedom across various apps.
Figure 5.
MobileNetV2 Layer Architecture.
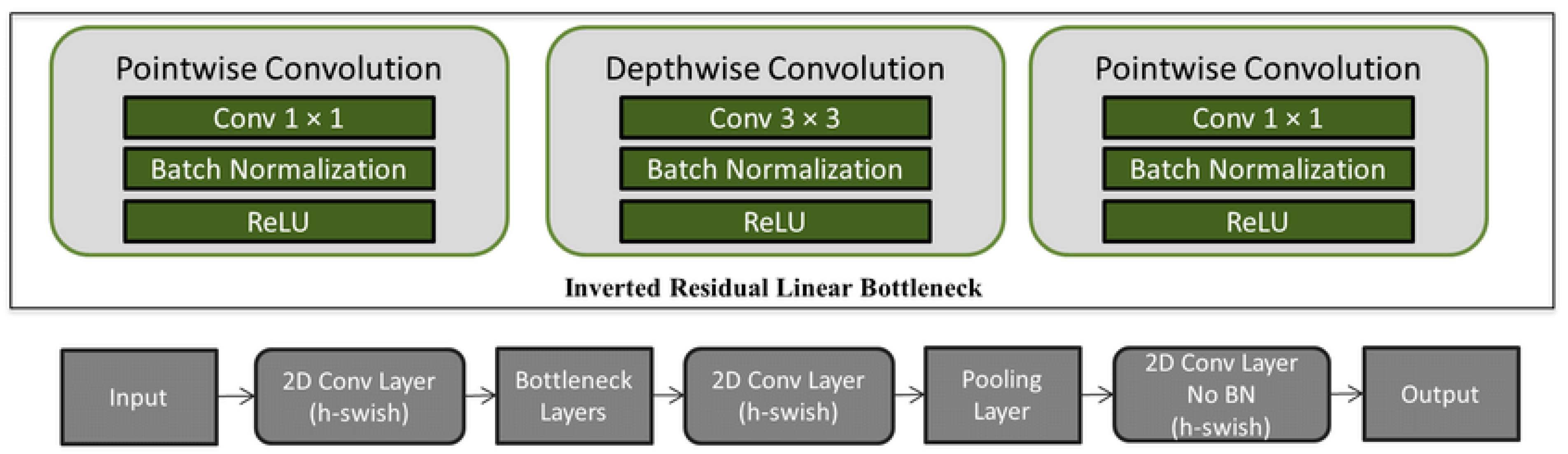
MobileNet V3
MobileNetV3 builds on the success of MobileNet and MobileNetV2, hoping to improve speed and accuracy for mobile and edge devices. It likely includes design changes, better cutting and compression methods, and task-specific tweaks for apps like picture classification and object recognition. MobileNetV3 also studies compression and improved activation functions to further improve efficiency. For the latest changes, checking current study and official sites is suggested.
Figure 6.
MobileNet V3 Architecture.
Model Training and Validation
A part of the prepared dataset is kept away for confirmation and used to train the CNN model. To reduce the loss function, training involves repeatedly changing the model's properties. By confirming the model's performance on data not noticed during training, validation guards against overfitting and ensures generalizability.
Performance Metrics and Evaluation
The prediction ability of the model is tested using a variety of performance measures, including precision, memory, accuracy, and F1 score. The accuracy is the number of correctly predicted photographs among all guesses. The following method shows accuracy.
Accuracy = Number of right guesses / Total number of predictions
The fraction of properly forecast truly positive results (TP) to all positive values (TP+FP) that the model expected is the accuracy measure. This leads to reduced accuracy because of the big amounts of FP. The exact value, which runs from 0 to 1, is determined in this way:
Precision = TP / TP + FP
The recall is used to measure the number of correct positive forecasts by comparing the number of true positive results (TP) to the total number of samples (TP+FN). The following method is used to find the recall:
Recall = TP / TP + FN
The F1-score, which is obtained from the harmonic mean of the precision and recall, is one measure used to check the model's correctness. It is defined as follows:
where the letters TP, FP, TN, FN, and FN, respectively, stand for True Positive, False Positive, True Negative, and False Negative.
F1 Score = 2 * Recall * Precision / Recall + Precision
Results and Discussion
This study shows a full review of CNN models for spotting tomato leaf diseases, showing great promise for precision agriculture. CNN was picked for its efficiency in picture analysis. The model showed steady improvement over ten training epochs, starting with 71% training and 84.38% validation accuracy, and hitting 98.80% training and 95.31% validation accuracy in the final epoch. These results show the model’s dependability. Training and evaluation accuracy/loss graphs were also used to track success throughout the process.
| Serial No. | Model | Test Accuracy |
| 1 | ResNet50 | 95.31% |
| 2 | MobileNetV3 | 89.06% |
| 3 | DenseNet201 | 88.28% |
| 4 | Vgg19 | 86.71% |
| 5 | MobileNetV2 | 84.37% |
| The table shows the test accuracy. | ||
Model Evolution
Thus, it is evident from the graphs above that ResNet50 is more stable than the other models.
Figure 7.
ResNet50 and MobileNetV3 Training & Validation Accuracy and Loss.
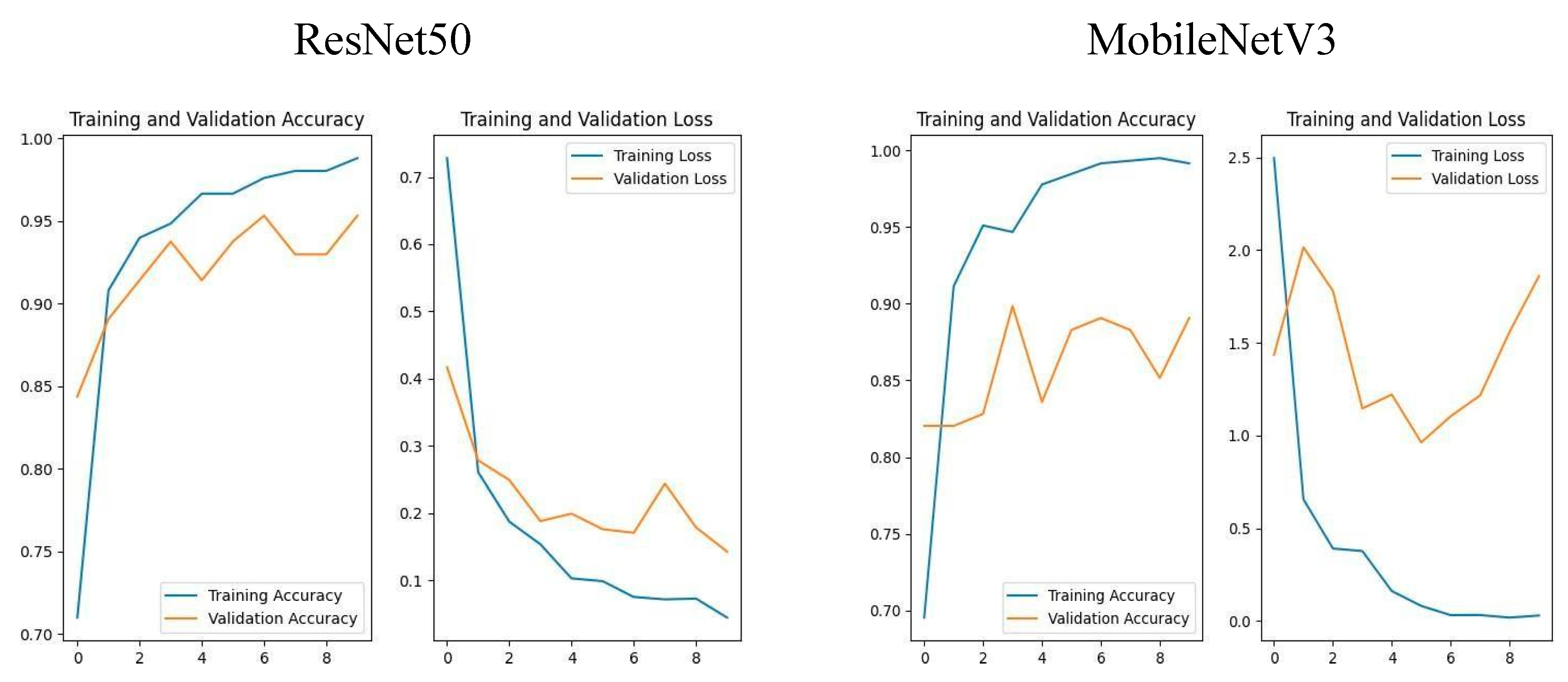
Figure 8.
DensNet201 and MobileNetV2 Training & Validation Accuracy and Loss.
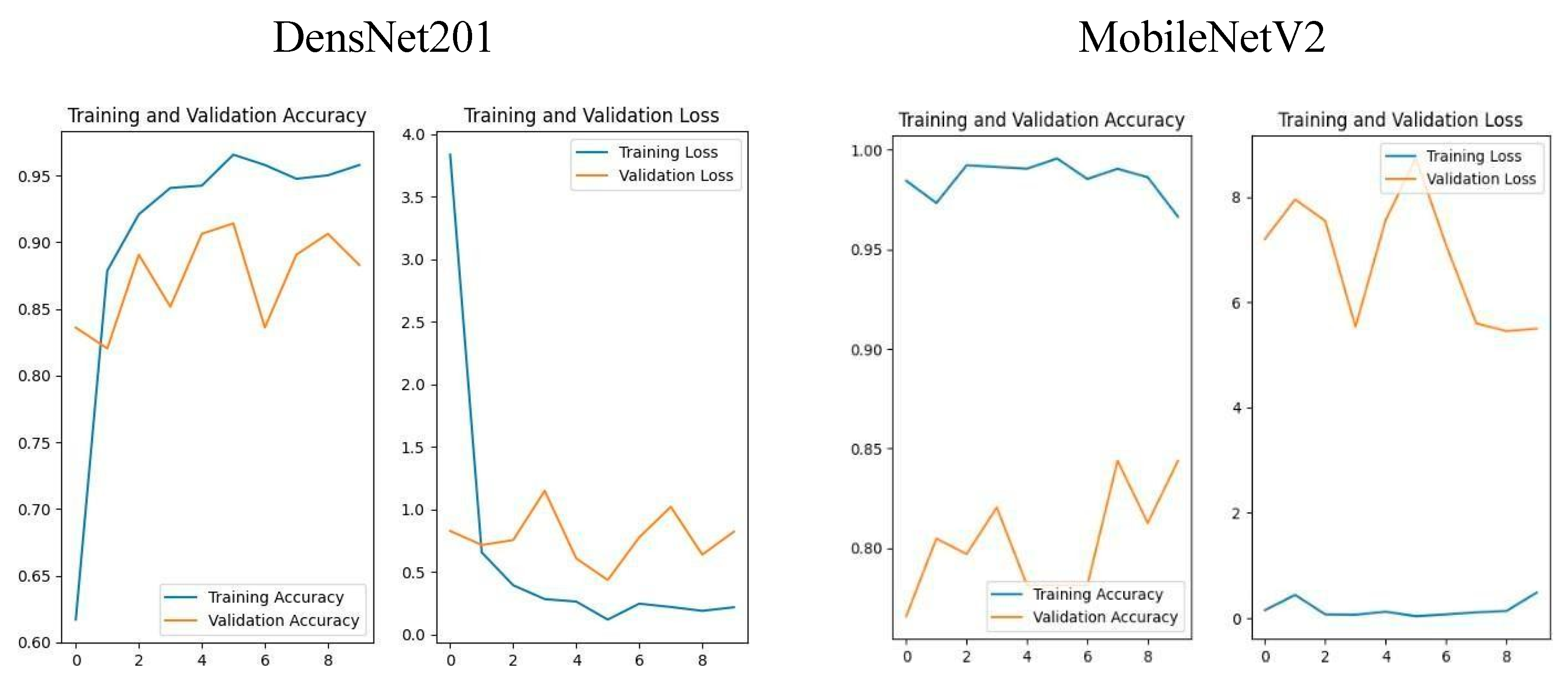
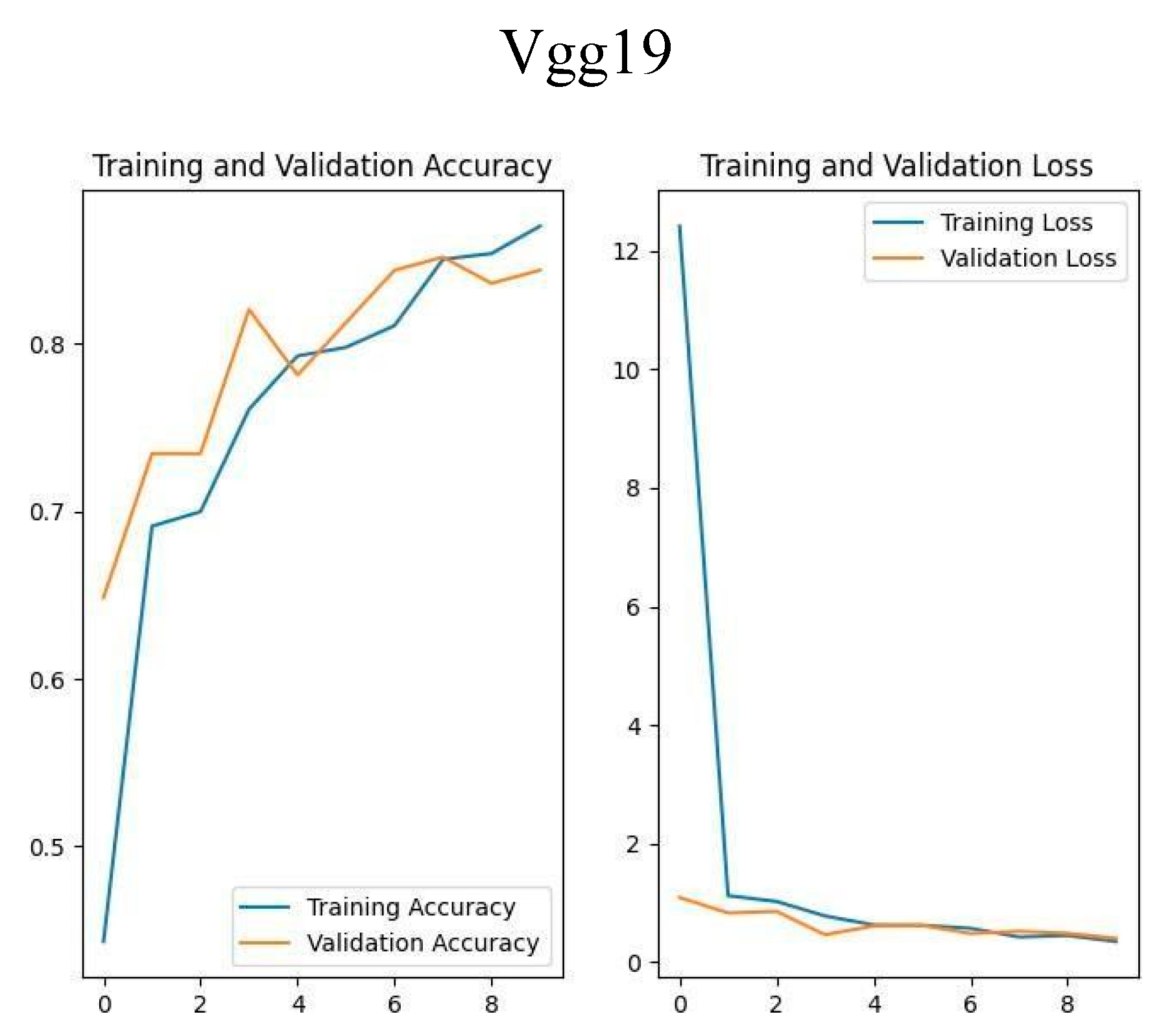
Figure 9.
Vgg19 Training & Validation Accuracy and Loss.
Confusion Metrix
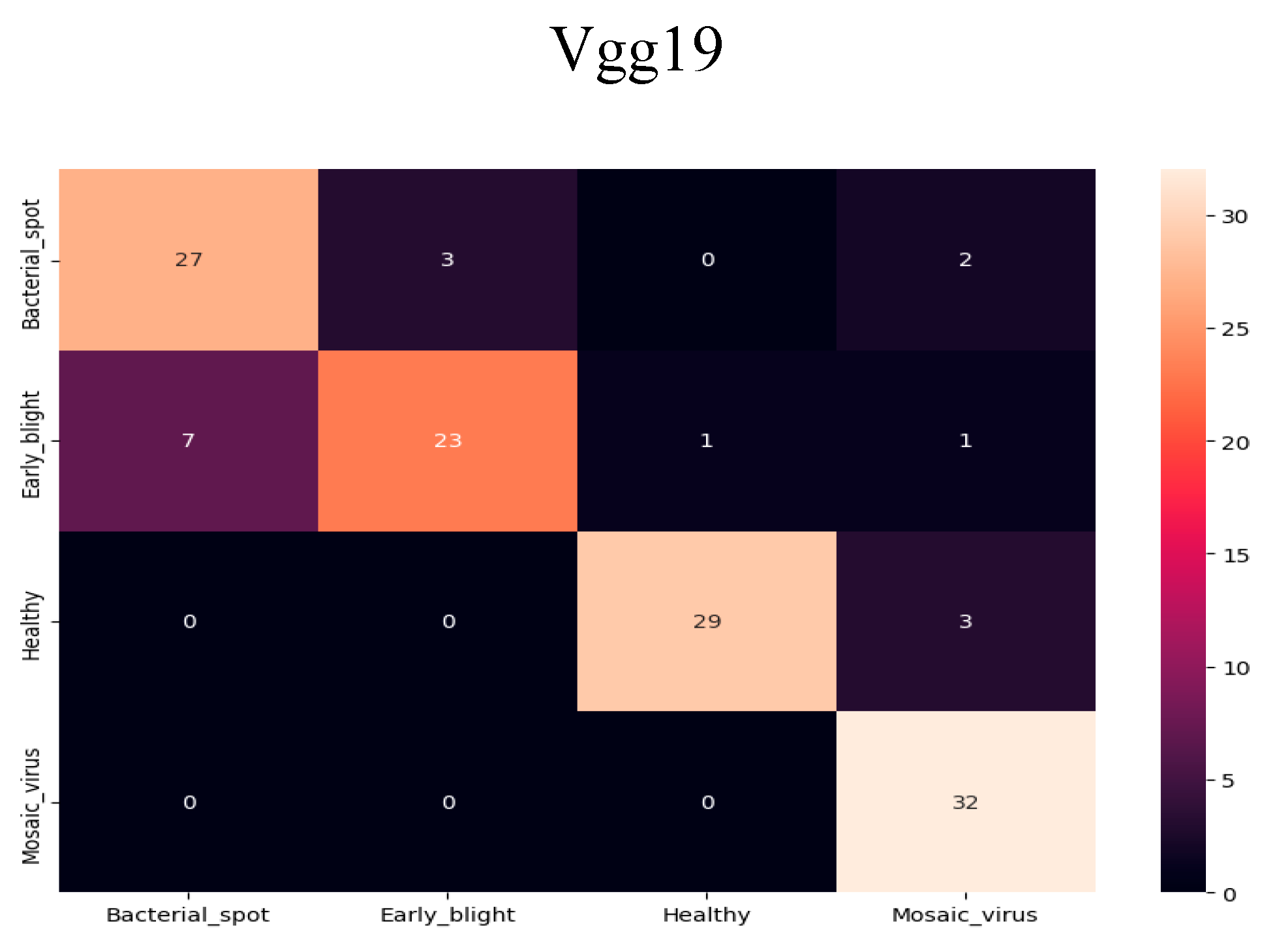
The confusion matrix can be used to gauge how well classification models are working. The amount of info that we properly and wrongly identify is obvious. Thus, the following is my five models' confusion matrix:
Figure 10.
ResNet50 and MobileNetV3 Confusion Metrix.
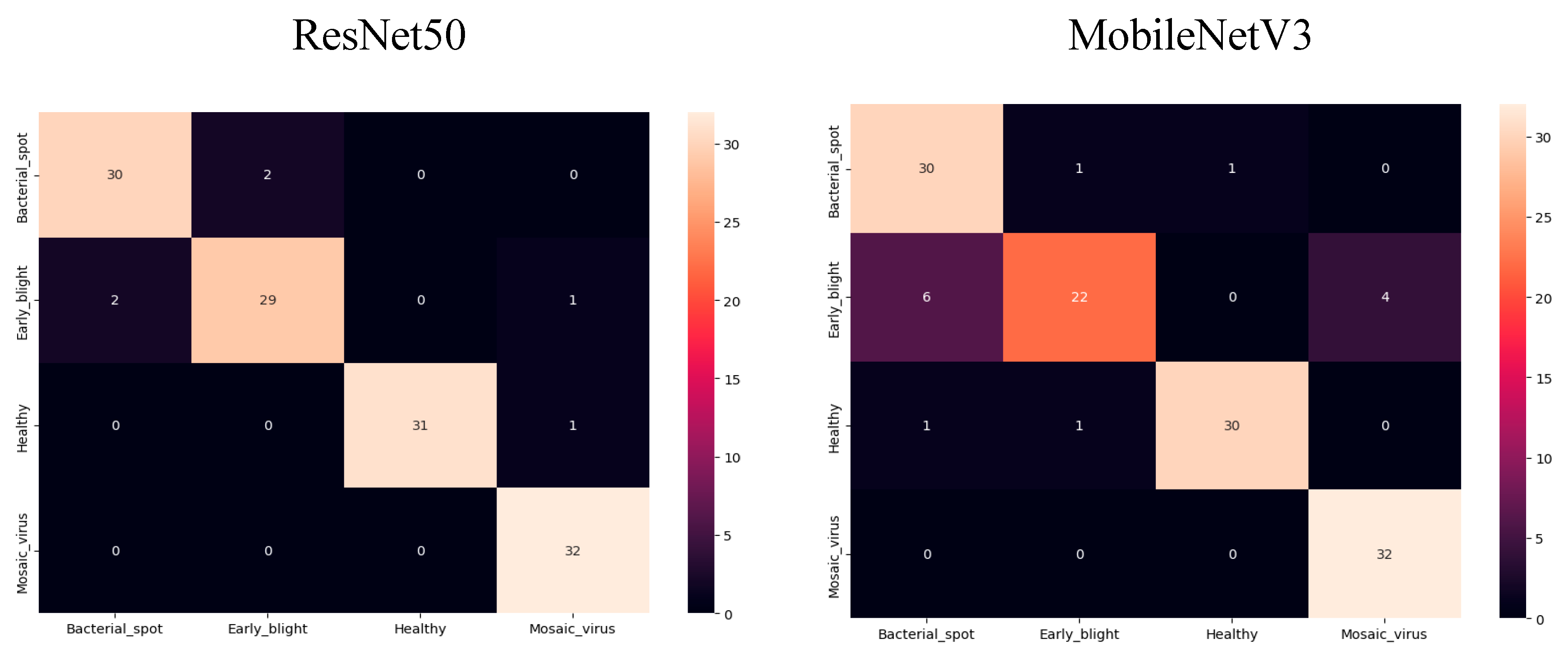
Figure 11.
DensNet201 and MobileNetV2 Confusion Metrix.
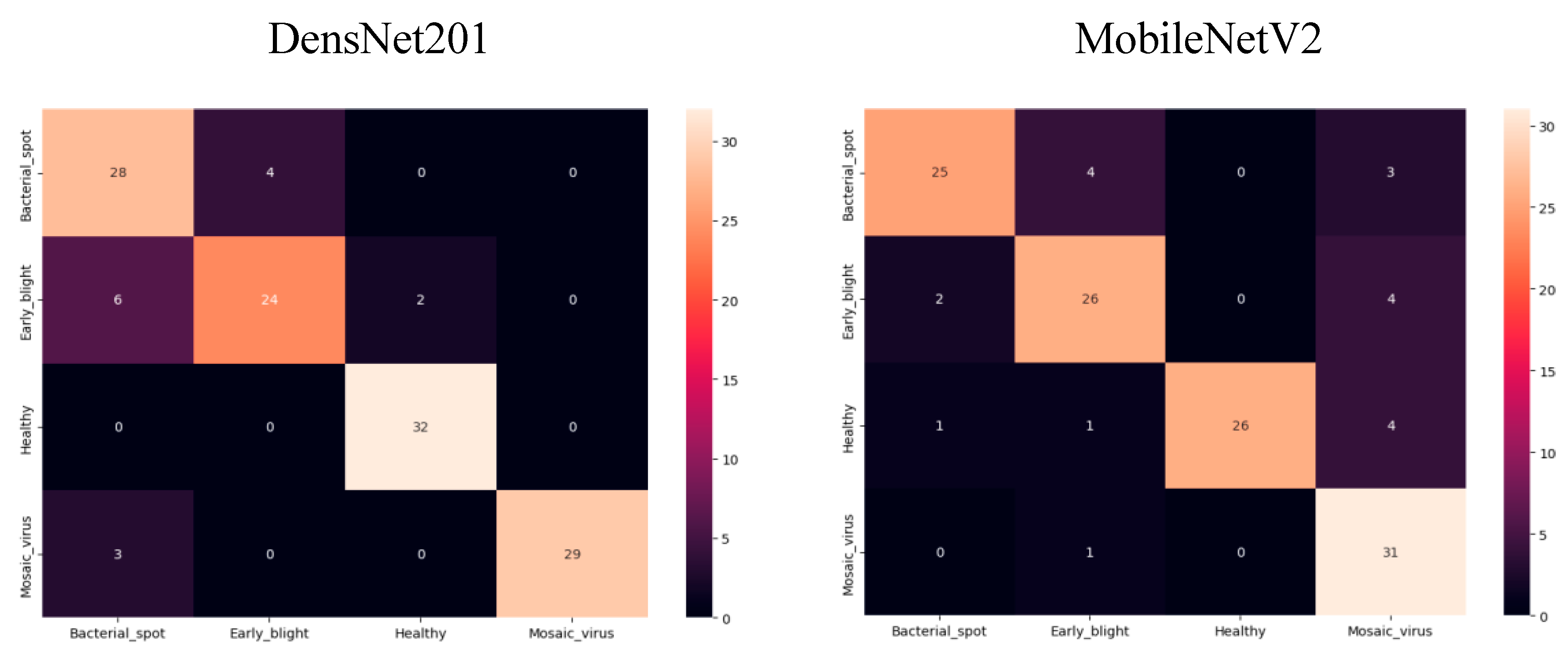
Figure 12.
Vgg19 Confusion Metrix.
In this table I show the 5 model result classification reports of tomato leaf diseases.
Table 2.
Result summary for ResNet50.
| Class Name | precision | recall | f1-score |
|---|---|---|---|
| Bacterial_Spot | 0.94 | 0.94 | 0.94 |
| Early_Blight | 0.94 | 0.91 | 0.92 |
| Healthy | 1.00 | 0.97 | 0.98 |
| Mosaic_Virus | 0.94 | 1.00 | 0.97 |
| Macro avg | 0.95 | 0.95 | 0.95 |
| Weighted avg | 0.95 | 0.95 | 0.95 |
Table 3.
Result summary for MobileNetV3.
| Class Name | precision | recall | f1-score |
|---|---|---|---|
| Bacterial_Spot | 0.81 | 0.94 | 0.87 |
| Early_Blight | 0.92 | 0.69 | 0.79 |
| Healthy | 0.97 | 0.94 | 0.95 |
| Mosaic_Virus | 0.89 | 1.00 | 0.94 |
| Macro avg | 0.90 | 0.89 | 0.89 |
| Weighted avg | 0.90 | 0.89 | 0.89 |
Table 4.
Result summary for DensNet201.
| Class Name | precision | recall | f1-score |
|---|---|---|---|
| Bacterial_Spot | 0.76 | 0.88 | 0.81 |
| Early_Blight | 0.86 | 0.75 | 0.80 |
| Healthy | 0.94 | 1.00 | 0.97 |
| Mosaic_Virus | 1.00 | 0.91 | 0.95 |
| Macro avg | 0.89 | 0.88 | 0.88 |
| Weighted avg | 0.89 | 0.88 | 0.88 |
Table 5.
Result summary for MobileNetV2.
| Class Name | precision | recall | f1-score |
|---|---|---|---|
| Bacterial_Spot | 0.89 | 0.78 | 0.83 |
| Early_Blight | 0.81 | 0.81 | 0.81 |
| Healthy | 1.00 | 0.81 | 0.90 |
| Mosaic_Virus | 0.74 | 0.97 | 0.84 |
| Macro avg | 0.86 | 0.84 | 0.85 |
| Weighted avg | 0.86 | 0.84 | 0.85 |
Table 6.
Result summary for Vgg19.
| Class Name | precision | recall | f1-score |
|---|---|---|---|
| Bacterial_Spot | 0.79 | 0.84 | 0.82 |
| Early_Blight | 0.88 | 0.72 | 0.79 |
| Healthy | 0.97 | 0.91 | 0.94 |
| Mosaic_Virus | 0.84 | 1.00 | 0.91 |
| Macro avg | 0.87 | 0.87 | 0.87 |
| Weighted avg | 0.87 | 0.87 | 0.87 |
Discussion
A discussion part that goes into the analysis of results, their importance, and the wider effects for farming and technological progress is included in my work on the application of CNN for tomato leaf disease detection. The variety of the information I worked with helped the accuracy of the classification models. I used the model to train it to recognize traits, distinguish between different groups, and consider the health of everyone. To build my program, I used 20% evaluation pictures of healthy and ill plants and 70% training photos. I found that ResNet50 has the best test accuracy of 95.31% percent using four classes of tomato datasets.
Limitations
This study is limited to three disease groups and one healthy class, which may affect generalizability. Real-world results may change due to environmental factors not present in the collection. High-end CNN models like DenseNet201 may be unsuitable for low-resource devices. The method relies heavily on high-quality pictures for efficient recognition. It lacks testing on constantly changing or mixed diseases in leaves. Ethical issues include limited reach for farmers with low digital skills.
Future Work
Future studies can include a wider range of tomato illnesses and mixed infections. Real-time testing in field settings will help prove the model’s reliability. Model improvement for mobile and edge devices can improve usability. Incorporating picture improvement methods may boost recognition accuracy. A user-friendly mobile app could support wider usage by local farms. Periodic retraining with new data will keep the system up to date.
Conclusion
In conclusion, a major scientific development in this subject is demonstrated by the application of CNN in agriculture to spot tomato leaf diseases. Driven by the pressing need to handle farming problems, the study successfully achieves its goal of building a CNN model. The model can correctly spot a variety of tomato leaf illnesses because of its strict approach, which puts a high value on ethics problems. Essentially, the study highlights CNNs' radical potential in tomato leaf disease identification and argues for their reasonable and sustainable integration into farming operations. Beyond identifying illnesses, the study greatly advances the talk of applying cutting-edge technologies to solve important problems in agriculture. This will serve as a guide for future attempts to balance technology with the complexity of the farming environment.
References
- Mim, T.T., Sheikh, M.H., Shampa, R.A., Reza, M.S. and Islam, M.S., 2019, November. Leaves diseases detection of tomato using image processing. In 2019 8th international conference system modeling and advancement in research trends (SMART) (pp. 244-249). IEEE.
- Al Mamun, M.A., Karim, D.Z., Pinku, S.N. and Bushra, T.A., 2020, December. Tlnet: A deep cnn model for prediction of tomato leaf diseases. In 2020 23rd International Conference on Computer and Information Technology (ICCIT) (pp. 1-6). IEEE.
- Ahmad, I., Hamid, M., Yousaf, S., Shah, S.T. and Ahmad, M.O., 2020. Optimizing pretrained convolutional neural networks for tomato leaf disease detection. Complexity, 2020, pp.1-6.
- Trivedi, N.K., Gautam, V., Anand, A., Aljahdali, H.M., Villar, S.G., Anand, D., Goyal, N. and Kadry, S., 2021. Early detection and classification of tomato leaf disease using high-performance deep neural network. Sensors, 21(23), p.7987.
- Rashed, M., & kakon, M. I. (2025). A Comparison of CNN Performance in Skin Cancer Detection. Preprints. [CrossRef]
- Jiachun Liu, Shuqin Yang, Yunling Cheng and Zhizhuang Song, “Plant Leaf Classification Based on Deep Learning.” Proceedings 2018 Chinese Automation Congress (CAC 2018), IEEE, pp.3165-3169, 2018.
- P. J. Herrera, J. Dorado, and A. Ribeiro, “A novel approach for ´ weed type classifcation based on shape descriptors and a fuzzy decision-making method,” Sensors, vol. 14, no. 8, pp. 15304– 15324, 2014.
- Suryawati, Endang, Rika Sustika, R. Sandra Yuwana, Agus Subekti, and Hilman F. Pardede.” Deep Structured Convolutional Neural Network for Tomato Diseases Detection.” In 2018 International Conference on Advanced Computer Science and Information Systems (ICACSIS), pp. 385-390. IEEE, 2018.
- Wang, Guan, Yu Sun, and Jianxin Wang.” Automatic image-based plant disease severity estimation using deep learning.” Computational intelligence and neuroscience 2017 (2017).
- S. P. Mohanty, D. P. Hughes, and M. Salath´e, “Using deep learning for image-based plant disease detection,” Frontiers in Plant Science, vol. 7, p. 1419, 2016.
- S. Zhang, W. Huang, and C. Zhang, "Three-channel convolutional neural networks for vegetable leaf disease recognition," Cognitive Systems Research, vol. 53, pp. 31-41,2019.
- S. Zhang, X. Wu, Z. You, and L. Zhang, "Leaf image-based cucumber disease recognition using sparse representation classification," Computers and electronics in agriculture, vol. 134, pp. 135-141,2017.
- Mohammed Brahimi, Kamel Boukhalfa & Abdelouahab Moussaoui (2017) Deep Learning for Tomato Diseases: Classification and Symptoms Visualization, Applied Artificial Intelligence, 31:4,299315. [CrossRef]
- P. Tm, A. Pranathi, K. SaiAshritha, N. B. Chittaragi and S. G. Koolagudi, "Tomato Leaf Disease Detection Using Convolutional Neural Networks," 2018 Eleventh International Conference on Contemporary Computing (IC3), Noida, 2018, pp. 1-5. [CrossRef]
- Agarwal, Mohit & Singh, Abhishek & Arjaria, Siddhartha & Sinha, Amit & Gupta, Suneet. (2020). ToLeD: Tomato Leaf Disease Detection using Convolution Neural Network. Procedia Computer Science. 167. 293-301. [CrossRef]
- V. Singh and A. K. Misra, "Detection of plant leaf diseases using image segmentation and soft computing techniques," Information processing in Agriculture, vol. 4, pp. 41-49, 2017.
- S. Zhang, W. Huang, and C. Zhang, "Three-channel convolutional neural networks for vegetable leaf disease recognition," Cognitive Systems Research, vol. 53, pp. 31-41,2019.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



