Submitted:
03 June 2025
Posted:
03 June 2025
You are already at the latest version
Abstract
Herein, expanded Hidden Markov Models (HMMs) are considered as potential deep fake generation and detection tools. The most specific model is the HMM, while the most general is the pairwise Markov chain (PMC). In between, the Markov observation model (MOM) is proposed, where the observations form a Markov chain conditionally on the hidden state. An Expectation-Maximization (EM) analog to the Baum-Welch algorithm is developed to estimate the transition probabilities as well as the initial hidden-state-observation joint distribution for all such models considered. This new EM algorithm also includes a recursive log-likelihood equation so model selection can be performed (after parameter convergence). Once models have been learnt through the EM algorithm, deep fakes are generated through simulation, while they are detected using the log-likelihood. Our three models are compared empirically on generative and detective ability. PMC and MOM consistently produce the best deep fake generator and detector respectively.
Keywords:
Markov observation models
; hidden Markov model
; Baum-Welch algorithm
; expectation-maximization
; pairwise Markov chain
; deepfake
1. Introduction
Hidden Markov models (HMMs) were introduced in papers by Baum and Petrie [1] and Baum and Eagon [2]. Traditional HMMs have enjoyed tremendous modelling success in applications like computational finance (see e.g. Petropoulos et al. [34]), single-molecule kinetic analysis (see Nicolai [33]), animal tracking (see Sidrow et al. [39]), forecasting commodity futures (see Date et al. [13]) and protein folding (see Stigler et. al. [41]). The unobservable hidden HMM states are a discrete-time Markov chain and the observations process is some distorted, corrupted partial information or measurement of the current state of satisfying the condition
These emission probabilities, , have some conditional probability mass function .
Perhaps, the most common problems in HMM are calibrating the model, decoding the hidden sequence from the observation sequence, and real-time believe state propagation, i.e. filtering. The first problem is solved recursively in the HMM setting by the Baum-Welch re-estimation algorithm, which is an application of the Expectation-Maximization (EM) algorithm, predating the EM algorithm. The second, decoding problem is solved by the Viterbi algorithm (see Viterbi [44], Rabiner [37]), which is a dynamic programming type algorithm. The filtering problem is also solved effectively after calibration using a recursive algorithm that is similar to part of the Baum-Welch algorithm. In practice, there can be numeric problems like a multitude of local maxima to trap the Baum-Welch algorithm or inefficient matrix operations when the state size is large but the hidden state resides in a small subset most of the time. In these cases, it can be adviseable to use particle filters or other alternative methods, which are not the subject of this note (see instead Cappé et al. [7] for more information). The forward and backward propagation probabilities of the Baum-Welch algorithm also tend to get very small over time, the small number problem. While satisfactory results can sometimes be obtained by (often logarithmic) rescaling, this small number problem is still a severe limitation of the Baum-Welch algorithm. However, the independent emmission form of the observation modeling in HMM can be yet more foundamentally limiting.
The autoregressive HMM (AR-HMM) and, more generally, the pairwise Markov chain (PMC) were introduced to allow more extensive and practical observation models. For the AR-HMM the observations take the structure:
where are a (usually zero-mean Gaussian) i.i.d. sequence of random variables and the autoregressive coefficients are functions of the current hidden state . The AR-HMM has experienced strong success in applications like speech recognition (see Bryan and Levinson [6]), diagnosing blood infections (see Stanculescu et al. [40]) and the study of climate patterns (see Xuan [46]). One advantage of the AR-HMM is that the Baum-Welch algorithm can still be used (see Bryan and Levinson [6]).
The general PMC model from Pieczynski [35] only assumes that is jointly Markov. Derrode and Pieczynski [15], Derrode and Pieczynski [16] and Kuljus and J. Lember [28] explain the generality of PMC and give some interesting subclasses of this model. It is now well understood how to filter and decode PMCs. In fact, Kuljus and J. Lember [28] solves the decoding problem in great generality while Derrode and Pieczynski [16] uses Baum-Welch-like recursions to produce the filter. Both Derrode and Pieczynski [15] and Derrode and Pieczynski [16] assume reversibility of the PMCs and have the observations living in a continuous space. To our knowledge the Baum-Welch rate re-estimation algorithm has not been proven in general for PMCs. Our first goal is to develop and prove this Baum-Welch algorithm for PMCs while at the same time estimating hidden initial states and overcoming the small number problem mentioned above by using alternative variables in our forward and backward recursions. Our EM resulting algorithm will apply to many big data problems.
Our second goal is to show the applicability of HMM, PMC as well as a model, called the Markov Observation Model (MOM) here, part way in between HMM and PMC in deep fake detection and generation. The key to producing and detecting deep fakes is to bring in an element that is easily calculated yet often overlooked in HMM and PMC, the Likelihood. During training as well as detection, Likelihood can be used in place of the discriminator in a Generative Adversarial Network (GAN) while simulation plays the part of generator. Naturally, the expectation-maximization algorithm also plays a key role in this deep fake application as explained below.
Our third goal is subtler. Just because the PMC model is more general than the HMM and the Baum-Welch algorithm can be extended to learn either model does not mean one should pronounce the death of the HMM. The problem is that the additional generality leads in general to a more complicated likelihood with a multitude of maxima for the EM algorithm to get trapped in or choose from. It can become a virtually impossible task to learn a global, or even a useful, maximum. Hence, the performance of the PMC model as a hidden Markov structure can be sub-optimal compared to HMM or MOM as we shall show empirically. Alternatively, the global maximum of the PMC may not be what is wanted. For these reason, we promote the MOM model and, in fact, show it performs the best in a simple deep fake detection, while the PMC generates the best deep fakes.
The HMM and nonlinear filtering theory (NFT) can each be thought of as nonlinear generalization of the Kalman filter (see Kalman [20], Kalman and Bucy [21]). The recent analogues (see [25]) of the celebrated Fujisaki-Kallianpur-Kunita and the Duncan-Mortensen-Zakai equations (see [18,26,29,30,47] for some original and general results) of NFT to continuous-time Markov chain observations provide further evidence of the closeness of HMM and NFT. The hidden state, called signal in NFT, can be a general Markov process model and live in a general state space but there is no universal EM algorithm for identifying the model like the Baum-Welch algorithm nor dynamic programming algorithm for identifying a most likely hidden state path like the Viterbi algorithm. Rather the goals in NFT are usually to compute filters, predictors and smoothers, for which there are no exact closed form solutions, except in isolated cases (see [23]), and approximations have to be used. Like HMM, nonlinear filtering has enjoyed widespread application. For instance, the subfield of nonlinear particle filtering, also known as sequential Monte Carlo, has a number of powerful algorithms (see Pitt and Shephard [36], Del Moral et al. [14], Kouritzin [24], Chopin and Papaspiliopoulos [9]) and has been applied to numerous problems in areas like bioinformatics (Hajiramezanali et. al. [19]), economics and mathematical finance (Creal [10]), intracellular movement (Maroulas and Nebenführ [32]), fault detection (D’Amato et al. [12]), pharmacokinetics (Bonate [5]) and many other fields. Still, like HMM, the observations in nonlinear filter models are largely limited to distorted, corrupted, partial observations of the signal with very few limited exceptions like Crisan et al. [11]. NFT is used successfully in deepfake generation and detection in our sister paper [4]. However, the simplicity of the EM and likelihood algorithms for HMM, MOM and PMC are compelling advantages.
The layout of this note is as follows: In the next section, we explain the models, in particular the Markov Observation Models, and how they can be simulated. In Section 3 the filter and likelihood calculations are derived. In Section 4, EM techniques are used to derive an analog to the Baum-Welch algorithm for identifying the system (probability) parameters. In particular, joint recursive formulas for the hidden-state and observation transition probabilities as well as the initial hidden state-observation joint distribution are derived. Section 5 contains our deepfake application and results. Section 6 is devoted to connecting the limit points of the EM type algorithm to the maxima of the conditional likelihood given the observations.
2. Models and Simulation
Let be some final time. We first clarify the HMM assumption of independent emission probabilities.
Under the HMM model
where is a probability mass function for each x. Otherwise, HMM and PMC are explained elsewhere.
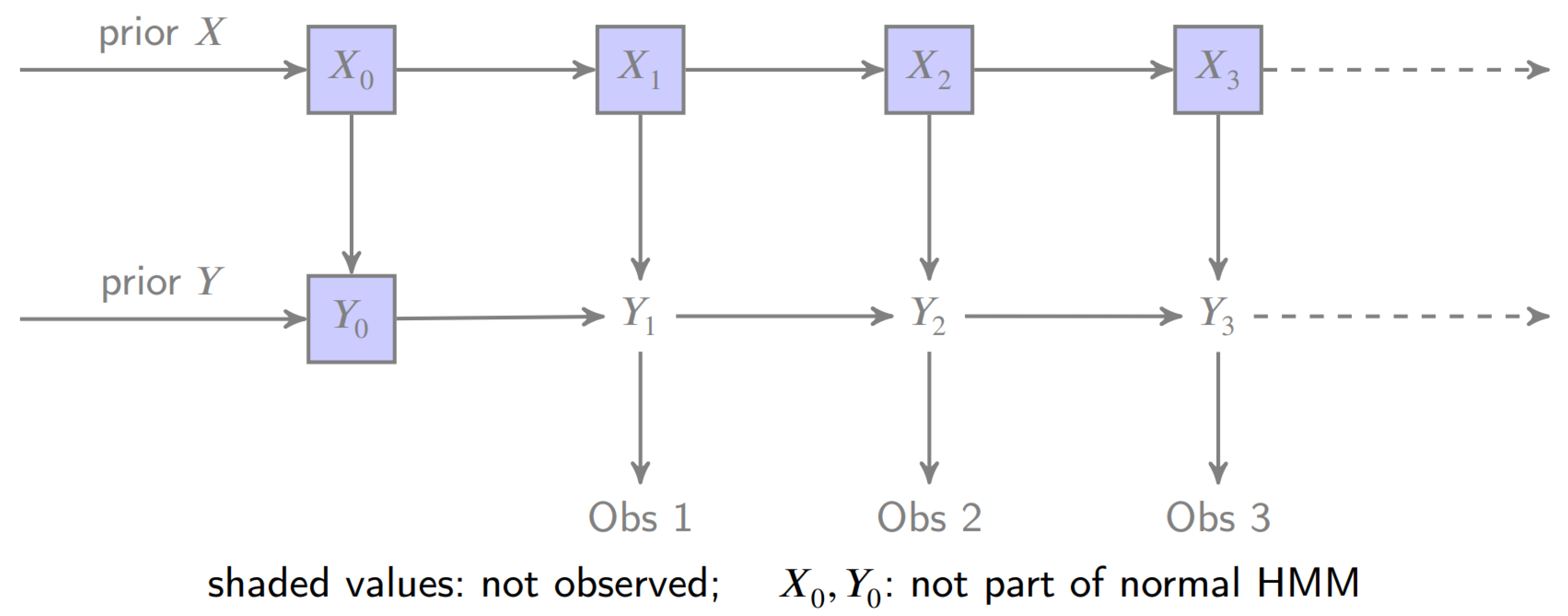
Next, we explain how MOM generalizes HMM and fits into PMC. Suppose is some discrete observation space. In MOM, like HMM, the hidden state is a homogeneous Markov chain on some discrete (finite or countable) state space with one step transition probabilities for . Contrary to HMM, MOM allows self-dependence in the observations. (This is illustrated by right arrows between the Y’s in Figure 1.) In particular, MOM observations Y are a (conditional) Markov chain given the hidden state with transitions probabilities
that do not affect the hidden state transitions in the sense
still. (3) implies that
i.e. that the new observation only depends upon the new hidden state (as well as the past observation). (3, 4) imply that the hidden state, observation pair is jointly Markov with joint one step transition probabilities
The joint Markov property then implies that
Notice that this generalizes the emisson probability to
so MOM generalizes HMM by just taking , a state dependent probability mass function. To see that MOM generalizes AR-HMM, we re-write (1) as
which, given the hidden state , gives an explicit formula for in terms of only and some independent noise . Hence, is obviously conditionally Markov and is a MOM.
A subtly that arises with MOM over HMM is that we need an enlarged initial distribution since we have a that is not observed (see Figure 1). Rather, we think of starting up the observation process at time 1 even though there were observations to be had prior to this time. Further, since we generally do not know the model parameters, we need a means to estimate this initial distribution
.
It is worth noting that MOM resembles the stationary PMC under Condition (H) in Pieczynski [35], which forces the Hidden state to be Markov by Proposition 2.2 of Pieczynski [35].
2.1. Simulation
Any PMC is characterized by an initial distribution on and a joint transition probability for its hidden state and observations. In particular,
for MOM and
for HMM. In any case, the marginal transitions are denoted
, p characterize a -PMC. The initial distribution gives the distribution of for MOM and PMC, while the initial distribution gives the distribution of for HMM by convention. This convention makes sense since MOM and PMC have observation history to model in some unknown . In the case of HMM an initial can then be drawn from .
The simulation of HMM, MOM and PMC observations is done in the same way: Begin by drawing ( for HMM) from , continue the simulation using and then finally throw out the hidden state X (as well as for MOM and PMC) to leave the observation process Y.
3. Likelihood, Filter and Predictor
A PMC is parameterized by its initial distribution and joint transition probability p for its hidden state and observations. Its ability to fit a given sequence of observations up to time n is naturally judged by its likelihood
Here is a probability measure where is -PMC. Therefore, given several PMC models, perhaps found by different runs of an expectation-maximization algorithm, as well as an observation data sequence, one can use the likelihoods to judge which model best fits the data. Each run of the EM algorithm would converge to a local maximum of the likelihood function and then the likelihood function could be used to determine which of these produces a higher maximum. Since MOM and HMM are PMCs (with specific p given in (8), (9)), this test extends to judging best MOM and best HMM.
In applications like filtering the hidden state has significance and estimating (the distribution of) it is important. The (optimal) filter is the (conditional) hidden-state probability mass function
We first work with the PMC and then extract MOM and HMM from these calculations. The likelihood and filter can computed together in real time using the forward probability
which is motivated from the Baum-Welch algorithm. Then, it follows from (12), (13) and (11) that
Moreover, we have by the joint Markov property and (13) that:
which can be solved recursively for , starting at
Recall is assigned differently. On a computer, we do not recurse due to risk of underflow (the small number problem), but rather revert back to the filter . Using (15), one finds the forward recursion for is:
which can be solved forward for , starting at
This immediately implies that and then by using (14), (17) and induction that
Thus, the filter and likelihood can be computed in real time (after initialization) via the recursions in (17) and (19).
Once the filter is computed, predictors can also be computed using Chapman-Kolmogorov type equations. For example, it follows by the multiplication rule and the Markov property that the one step predictor is
which reduces to
and
respectively in the cases of MOM and HMM.
In non-real-time applications, we strengthen our hidden-state estimates to include future observations via the joint path filter
which is a joint pmf for . To compute the joint path filter, we first let
and the normalized versions of
(Notice we include an extra variable y in . This is because we do not see the first observation so we have to consider all possibilities and treat it like another hidden state.) Then, by the Markov property, (19), (13) and (14)
so by (26,25,24)
for . This means there are two ways to compute the (marginal) path filter directly from (27):
for and
for . These all become computationally effective by a backward recursion for . It also follows from (24), the Markov property and our transition probabilities that:
so normalizing
which can be solved backward for starting from
The value for and become
to account for the fact we do not see as the data turns on at time 1. With in hand, we can estimate the joint distribution of , which are the remaining hidden variables. It follows from Bayes’ rule, (11) and (19)
for all , .
The pathspace filter and likelihood algorithm is given in Algorithm 1.
| Algorithm 1: Path Filter and Likelihood for PMC |
 |
The first part of Algorithm 1 up to the first set of outputs runs in real time, as the observations arrive, and provides the real-time filter and likelihood. For real time applications, one would stop there or else add predictors not included in Algorithm 1 but given as an example in (20). Otherwise, one can refine the estimates of the hidden states based upon future observations, which then provides the pathspace filters and is the key to learning a model. This is the second part of Algorithm 1 and is explained below. But first, we note that the recursions developed so far are easily tuned to MOM or HMM.
3.1. MOM Adjustments
For MOM, we use (8). We leave (13,14) and (19) unchanged so (17) and (18) become
for all , which can be solved forward for , starting at
The backward recursions change a little more, starting with (24) and (25), which change to
and the normalized versions
since
by Lemma 1 (to follow). Then, (27) becomes
for . This then implies the obvious simplifications of (28) and (29) to
and respectively. Then, (31) becomes
by (5), which is solved backwards starting from . The values at become
and
for all , .
3.2. HMM Adjustments
For HMM, we use (9). We have a MOM with the specific
that also starts at with instead of . This creates modest changes or simplifications for the filter startup:
But, otherwise (36) holds with just the substitution .
To handle the backward recursion, we first reduce the general definition of in (24) using (2) to
and the normalized versions
There are no , , nor variables for HMM. The HMM backward recursion simplifications are based upon the following result.
Lemma 1.
For the MOM and HMM models
Insomuch as the proofs replicate each other we merely prove the HMM case and indicate the changes required for MOM. In the HMM case, we need only show is a function of only. However, it follows from the multiplication rule, the tower property and (2) that
which establishes the desired dependence.
Moving to MOM, the right hand side of (50) becomes
Finally, the initial probability estimate becomes
4. Probability Estimation via EM Algorithm
In this section, we develop a recursive expectation-maximization algorithm that can be used to create convergent estimates for the transition and initial probabilities of our models. We leave the theoretical justification of convergence to Section 6.
| Algorithm 2: EM algorithm for PMC |
 |
The main goal of developing an EM algorithm is to find for all , and for all , . Noting every time step is considered to be a transition in a discrete-time Markov chain, we would ideally set:
which means we must compute , , and, using (23, 28), for all and for all to get this transition probability estimate. Now, by Bayes’ rule, (11,19), (24,25) and (13,14)
so
and so
and are computed recursively in (17,31) using the prior estimates of and .
| Algorithm 3: EM algorithm for MOM |
 |
Expectation-maximization algorithms use these types of formula and prior estimates to produce better estimates. We take estimates for , and and get new estimates for these quantities iteratively using (53), (54), (27), (35) and (28):
and using (35)
Remark 1.
1) Different iterations of will be used on the left and right hand sides of (57,58). The new estimates on the left are denoted .
2) Setting marginal or probability will result in it staying zero for all updates. This effectively removes this parameter from the EM optimization update and should be avoided unless it is known that one of these should be 0.
3) If there is no successive observations with and in the actual observation sequence, then all new estimates will either be set to 0 or close to it. They might not be exactly zero due to the first term in the numerator of (57) where we could have an estimate of and an observed .
We now have everything required for our EM algorithms, given for the PMC, MOM and HMM cases in Algorithms 2, 3 and 4 respectively.
| Algorithm 4: EM algorithm for HMM |
 |
These algorithms start with initial estimates , of , ; and refines them successively to new estimates , ; , ; etc. It is important to know that our estimates improve as .
Lemma 3 (below) will be used to ensure an initially positive estimate stays positive as k increases, which is important in our proofs in Section 6. The following lemma follows easily from (31,32,33), (17,18,), induction and the fact that . A sensible initialization of our EM algorithm would ensure the condition holds.
Lemma 2.
Suppose for all and . Then,
- for all and .
- for any such that .
- for all and if in addition for all .
- if .
The following result is the key to ensuring that our non-zero parameters stay non-zero. It follows from the prior lemma as well as (57,58,31).
Lemma 3.
Suppose , for all and . Then,
- if ; occurs; and for all .
- if and there exists such that .
5. Deep Fake Application
Motivated by [27] and [4], we consider our three hidden models in deep fake generation and detection. In particular, we use the models’ EM, simulation and Bayes’ factor capabilities to generate and detect deep fake real coin flip sequences and then compare them to determine which of the three is the best at each of generation and detection.
We first created 137 real sequences of 400 coin flips by generating independent fair Bernoulli trials. Another 137 hand fake sequences of 200 coin flips were created by students with knowledge of undergraduate probability. They were told to make them look real to try to fool both humans and machines. Note that we worked with coin flip sequences of length 200 except for the training with real sequences, where 400 was used so that length was not a defining factor of these real sequence. This added length of real sequences did not bias one of the HMM, MOM or PMC over the others as it was consistent for all.
We used HMM, MOM and PMC simulation with a single hidden state variable taking s possible values (henceforth referred to as s states) to generate deep fake sequences of 200 coin flips based upon the 137 real sequences. To do this, we first learnt each of the 137 real sequences using the EM algorithms with hidden states for each model, creating three collections of 137 parameter sets for each s. Then, we simulated a sequence from each set of parameters throwing the hidden states away, creating three collections of 137 observation coin flip sequences for each s. These are the deep fake sequences of type HMM, MOM and PMC. Note that we learnt from the 400 long real sequences (to remove noise from the parameters) but created 200 long deep fake sequences.
Once all the five sets of (real, fake and deep fake) data was collected, we ran 100 training and testing trials at each selected s and averaged over these trials. For each trial, we randomly and independently split each of 137 (hand) fake sequences into 110 training and 27 testing sequences, i.e. an 80 to 20 split. Conversely, we re-generated the 137 independent sets of real and three deep fake sequences using respectively independent random number and Markov chain simulation with their models, but still divided these sets into 110 training and 27 testing sequences. We then trained the HMM, MOM and PMC with s hidden states on each of these sets of 110 training sequences. Note that since the deep fake sequences were generated with hidden states the actual model generating these sequences could not be identified. At this point, we had 110 sets of HMM parameters (i.e. HMM models) for each of the real, hand fake, HMM, MOM and PMC different training sequences in that trial. Similarly, we had 550 sets of MOM and PMC parameters.
The detection on each testing sequence was done using all the models. In a trial, each of the 5 sets of 27 sequences was run against the 550 HMM, 550 MOM and 550 PMC models. A sequence was then predicted by HMM to be real, hand fake, HMM generated, MOM generated or PMC generated based upon HMM Likelihood with s hidden states. In particular, a sequence was predicted to be real if sum of the log Likelihood over the 110 real HMM models was higher than over the 110 hand fake, 110 HMM, 110 MOM and 110 PMC HMM models. In the same way, it was predicted to be hand fake, HMM, MOM or PMC by HMM. This same procedure was repeated for MOM and for PMC and then for the remaining 99 trials, using the regeneration method mentioned above. The results were averaged and put into Tables 1, 2 and 3 in the cases and 7 respectively.

Table 1.
Generative and Detection Ability with .
| Real(%) | Handfake(%) | HMM(%) | MOM(%) | PMC(%) | Overall(%) | |
|---|---|---|---|---|---|---|
| HMM Detection | 99.96 | 93.36 | 76.89 | 78.25 | 59.79 | 81.65 |
| Standard deviation | 0.357 | 3.590 | 25.343 | 9.841 | 27.386 | 10.076 |
| MOM Detection | 99.03 | 89.39 | 98.39 | 91.31 | 77.11 | 91.11 |
| Standard deviation | 2.250 | 0.612 | 2.347 | 9.370 | 5.129 | 2.148 |
| PMC Detection | 100 | 70.14 | 95.18 | 90.04 | 88.07 | 88.69 |
| Standard deviation | 0.0 | 2.243 | 1.990 | 3.491 | 5.519 | 1.402 |
| Overall Detection | 99.66 | 84.30 | 90.15 | 86.53 | 74.99 | 87.15 |
| Standard deviation | 0.759 | 1.425 | 8.510 | 4.677 | 9.343 | 3.466 |
Table 2.
Generative and Detection Ability with .
| Real(%) | Handfake(%) | HMM(%) | MOM(%) | PMC(%) | Overall(%) | |
|---|---|---|---|---|---|---|
| HMM Detection | 100 | 94.79 | 73.61 | 64.89 | 63.25 | 79.31 |
| Standard deviation | 0 | 3.383 | 27.013 | 24.905 | 19.987 | 11.739 |
| MOM Detection | 98.79 | 89.29 | 95.32 | 87.90 | 79.96 | 90.30 |
| Standard deviation | 2.101 | 0.001 | 3.685 | 11.203 | 9.868 | 3.040 |
| PMC Detection | 96.71 | 70.82 | 89.54 | 84.18 | 92.32 | 86.71 |
| Standard deviation | 2.470 | 1.688 | 1.917 | 3.526 | 4.607 | 1.218 |
| Overall Detection | 98.5 | 84.97 | 86.16 | 78.99 | 78.51 | 85.44 |
| Standard deviation | 1.081 | 1.260 | 9.110 | 9.179 | 7.587 | 4.062 |
Table 3.
Generative and Detection Ability with .
| Real(%) | Handfake(%) | HMM(%) | MOM(%) | PMC(%) | Overall(%) | |
|---|---|---|---|---|---|---|
| HMM Detection | 100 | 95.00 | 41.5 | 55.68 | 33.89 | 65.21 |
| Standard deviation | 0 | 3.003 | 29.270 | 28.099 | 22.608 | 12.141 |
| MOM Detection | 98.76 | 89.29 | 96.96 | 90.52 | 90.82 | 93.29 |
| Standard deviation | 2.166 | 0.001 | 3.419 | 12.049 | 7.998 | 2.531 |
| PMC Detection | 99.82 | 73.25 | 95.75 | 94.21 | 88.32 | 90.27 |
| Standard deviation | 0.782 | 2.298 | 1.736 | 2.723 | 5.464 | 1.230 |
| Overall Detection | 99.53 | 85.85 | 78.07 | 80.14 | 71.01 | 82.92 |
| Standard deviation | 0.768 | 1.260 | 9.989 | 10.231 | 8.198 | 4.154 |
6. Convergence of Probabilities
In this section, we establish the convergence properties of the transition probabilities and initial distribution that we derived in Section 4. Our method adapts the ideas of Baum et al. [3], Liporace [31] and Wu [45] to our setting.
We think of the transition probabilities and initial distribution as parameters, and let denote all of the non-zero transition and initial distribution probabilities in . Let and be the cardinalities of the hidden and observation spaces and set . Then, has a domain space of cardinality and has a domain space of cardinality . Combined this leads to parameters. However, we are removing the values that will be set to zero and adding sum to one constraints to consider a constrained optimization problem on for some . Removing these zero possibilities gives us necessary regularity for our re-estimation procedure. However, it was not enough to just remove them at the beginning. We had to ensure that zero parameters did not creep in during our interations or else we will be doing such things as taking logarithms of 0. Lemma 3 suggests estimates not initially set to zeros will not occur as zero in later iterations. In general, we will assume the following:
Definition 1.
A sequence of estimates is zero separating if:
- iff for all ,
- iff for all .
Here, iff stands for if and only if.
This means that we can potentially optimize over that we initially do not set to zero. Henceforth, we factor the zero out of , consider with and define the parameterized mass functions
in terms of the non-zero values only. The observable likelihood
is not changed by removing the zero values of and this removal allows us to define the re-estimation function
Note: Here and in the sequel, the summation in above are only over the non-zero combinations. We would not include an pair where nor an pair where . Hence, our parameter space is
Later, we will consider the extended parameter space
as limit points. Note: In both and K, is only over the and that are not just set to 0 (before limits).
Then, equating with to ease notation, one has that
The re-estimation function will be used to interpret the EM algorithm we derived earlier. We impose the following condition to ensure everything is well defined.
- (Zero)
- The EM estimates are zero separating.
The following result is motivated by Theorem 3 of Liporace [31].
Theorem 1.
We consider it as an optimization problem over the open set but with the constraint that we have mass functions so the values have to be in the set .
One has by (62) as well as the constraint that the maximum must satisfy
where is a Lagrange multiplier and means when . Multiplying by , summing over and then using (11, 35, 28) and then (19,14,25) one has that
Substituting (64) into (63) and repeating the argument in (64) but with (27) instead of (28), one has that
To explain the first term in the numerator in the last equality, we use multiplication rule and (24) to find
from which it will follow easily.
Finally, for a maximum one also requires
where is a Lagrange multiplier. Multiplying by and summing over , one has that
Now, we have established that the EM algorithm of Section 4 corresponds to the unique critical point of . Moreover, all mixed partial derivative of Q in the components of are 0, while
and
Hence, the Hessian matrix is diagonal with negative values along its axis and the critical point is a maximum.
The upshot of this result is that, if the EM algorithm produces parameters , then .
Now, we have the following result, based upon Theorem 2.1 of Baum et al. [3], that establishes the observable likelihood is also increasing i.e. .
Lemma 4.
Suppose (Zero) holds. implies . Moreover, implies .
for has convex inverse . Hence, by Jensen’s inequality
and the result follows.
The stationary points of P and Q are also related.
Lemma 5.
Suppose (Zero) holds. A point is a critical point of if and only if it is a fixed point of the re-estimation function, i.e. since Q is differentiable on in .
The following derivatives are equal:
which are defined since . Similarly,
We can rewrite (65,68) in recursive form with the values of and substituted in to find that
where M is a continuous function. Moreover, is continuous and satisfies from above. Now, we have established everything we need for the following result, which follows from the proof of Theorem 1 of Wu [45].
Theorem 2.
Suppose (Zero) holds. Then, is relatively compact, all its limit points (in K) are stationary points of P, producing the same likelihood say, and converges monotonically to .
Wu [45] has several interesting results in the context of general EM algorithms to guarantee convergence to local or global maxima under certain conditions. However, the point of this note is to introduce a new model and algorithms with just enough theory to justify the algorithms. Hence, we do not consider theory under any special cases here but rather refer the reader to Wu [45].
References
- L. E. Baum and T. Petrie. Statistical Inference for Probabilistic Functions of Finite State Markov Chains. The Annals of Mathematical Statistics. 37 (6): 1554-1563, 1966. [CrossRef]
- L. E. Baum and J. A. Eagon. An inequality with applications to statistical estimation for probabilistic functions of Markov processes and to a model for ecology. Bulletin of the American Mathematical Society. 73 (3): 360, 1967. [CrossRef]
- L. E. Baum, T. Petrie, G. Soules and N. Weiss. A Maximization Technique Occurring in Statistical Analysis of Probabilistic Functions in Markov Chains. The Annals of Mathematical Statistics, 41, 164-171, 1970. [CrossRef]
- J. Bhadana, M. A. Kouritzin, S. Park and I. Zhang. Markov Processes for Enhanced Deepfake Generation and Detection. arXiv 2411.07993 (2024). [CrossRef]
- P. Bonate Pharmacokinetic-Pharmacodynamic Modeling and Simulation. Berlin: Springer, 2011.
- J. D. Bryan and S. E. Levinson. Autoregressive Hidden Markov Model and the Speech Signal. Procedia Computer Science 61 328-333, 2015.
- O. Cappé, E. Moulines and T. Rydén. Inference in Hidden Markov Models. Springer, Berlin 2007.
- N. Chopin. Central Limit Theorem for Sequential Monte Carlo Methods and its Application to Bayesian Inference. The Annals of Statistics 32 (6), 2385–2411, 2004.
- N. Chopin and O. Papaspiliopoulos. An Introduction to Sequential Monte Carlo. Springer Nature, Switzerland AG 2020. [CrossRef]
- D. Creal. A Survey of Sequential Monte Carlo Methods for Economics and Finance. Econometric Reviews. 31 (2), 2012. [CrossRef]
- D. Crisan, M. A. Kouritzin and J. Xiong. Nonlinear filtering with signal dependent observation noise. Electronic Journal of Probability, 14 1863-1883, 2009. [CrossRef]
- E. D’Amato, I. Notaro, V. A. Nardi, and V. Scordamaglia. A Particle Filtering Approach for Fault Detection and Isolation of UAV IMU Sensors: Design, Implementation and Sensitivity Analysis. Sensors. 21 (9), 2021. [CrossRef]
- P. Date, R. Mamon and A. Tenyakov. Filtering and forecasting commodity futures prices under an HMM framework. Energy Economics, 40, 1001-1013, 2013. [CrossRef]
- P. Del Moral, M. A. Kouritzin and L. Miclo. On a class of discrete generation interacting particle systems. Electronic Journal of Probability 6 : Paper No. 16, 26 p., 2001.
- S. Derrode and W. Pieczynski. Unsupervised data classification using pairwise Markov chains with automatic copula selection. Computational statistics and data analysis 63: 81-98, 2013.
- S. Derrode and W. Pieczynski. Unsupervised classification using hidden Markov chain with unknown noise copulas and margins. Signal Processing 128: 8-17, 2016.
- J. Elfring, E. Torta and R. van de Molengraft. Particle Filters: A Hands-On Tutorial. Sensors (Basel) 21 (2):438, 2021. [CrossRef]
- M. Fujisaki, G. Kallianpur and H. Kunita. Stochastic differential equations for the nonlinear filtering problem. Osaka J. Math. 9, 19–40, 1972.
- E. Hajiramezanali, M. Imani, U. Braga-Neto, X. Qian and E. R. Dougherty. Scalable optimal Bayesian classification of single-cell trajectories under regulatory model uncertainty. BMC Genomics 20 (Suppl 6): 435, 2019. [CrossRef]
- R. E. Kalman. A New Approach to Linear Filtering and Prediction Problems. Journal of Basic Engineering. 82: 35-45, 1960. [CrossRef]
- R. E. Kalman and R. S. Bucy. New Results in Linear Filtering and Prediction Theory. ASME. J. Basic Eng. 83(1): 95-108, 1961. [CrossRef]
- T. Kloek and H. K. van Dijk. Bayesian Estimates of Equation System Parameters: An Application of Integration by Monte Carlo. Econometrica. 46 (1): 1-19, 1978. [CrossRef]
- M. A. Kouritzin. On exact filters for continuous signals with discrete observations, IEEE Transactions on Automatic Control, vol. 43, no. 5, pp. 709-715, 1998. [CrossRef]
- M. A. Kouritzin. Residual and Stratified Branching Particle Filters. Computational Statistics and Data Analysis 111, pp. 145-165, 2017. [CrossRef]
- M. A. Kouritzin. Sampling and filtering with Markov chains. Signal Processing 2251, ISSN 0165-1684, 2024. [CrossRef]
- M. A. Kouritzin and H. Long. On extending classical filtering equations. Statistics and Probability Letters. 78 3195-3202, 2008. [CrossRef]
- M.A. Kouritzin, F. Newton, S. Orsten, D.C. Wilson. On Detecting Fake Coin Flip Sequences, IMS Collections 4 Markov Processes and Related Topics: A Festschrift for Thomas G. Kurtz, pp. 107-122, 2008.
- K. Kuljus and J. Lember. Pairwise Markov Models and Hybrid Segmentation Approach. Methodol Comput Appl Probab 25, 67, 2023. [CrossRef]
- T. G. Kurtz and D. L. Ocone. Unique characterization of conditional distributions in nonlinear filtering. Ann. Probab. 16, 80–107, (1988).
- T. G. Kurtz, and G. Nappo. The Filtered Martingale Problem. in The Oxford Handbook of Nonlinear Filtering, Oxford University Press, 2010.
- L. A. Liporace. Maximum likelihood estimation for multivariate observations of Markov sources. IEEE Trans. Inf. Theory 28(5): 729-734, (1982).
- V. Maroulas and A. Nebenführ. Tracking Rapid Intracellular Movements: A Bayesian Random Set Approach. The Annals of Applied Statistics 9 (2): 926-949, 2015. [CrossRef]
- C. Nicolai. Solving ion channel kinetics with the QuB software. Biophysical Reviews and Letters 8 (3n04): 191-211, 2013 ). [CrossRef]
- A. Petropoulos, S. P. Chatzis and S. Xanthopoulos. A novel corporate credit rating system based on Student’s-t hidden Markov models. Expert Systems with Applications. 53: 87-105, 2016. [CrossRef]
- W. Pieczynski. Pairwise Markov chains. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25 (5), 634-639, (2003). [CrossRef]
- M. K. Pitt and N. Shephard. Filtering Via Simulation: Auxiliary Particle Filters. Journal of the American Statistical Association. 94 (446): 590-591, (1999). [CrossRef]
- L. R. Rabiner. A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE 77 (2): 257–286,1989. CiteSeerX 10.1.1.381.3454. [CrossRef]
- R. Shinghal and G. T. Toussaint. Experiments in text recognition with the modified Viterbi algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-l 184-193, 1979.
- E. Sidrow, N. Heckman, S. M. Fortune, A. W. Trites, I. Murphy and M. Auger-Méthé. Modelling multi-scale, state-switching functional data with hidden Markov models. Canadian Journal of Statistics, 50(1), 327-356, (2022).
- I. Stanculescu, C. K. I. Williams and Y. Freer. Autoregressive Hidden Markov Models for the Early Detection of Neonatal Sepsis. IEEE Journal of Biomedical and Health Informatics 18(5):1560-1570, 2014. DOI: 10.1109/JBHI.2013.2294692.
- J. Stigler, F. Ziegler, A. Gieseke, J. C. M. Gebhardt and M. Rief. The Complex Folding Network of Single Calmodulin Molecules. Science. 334 (6055): 512-516, 2011. Bibcode:2011Sci...334..512S. [CrossRef]
- H. K. van Dijk and T. Kloek. Experiments with some alternatives for simple importance sampling in Monte Carlo integration. In Bernardo, J. M.; DeGroot, M. H.; Lindley, D. V.; Smith, A. F. M. (eds.). Bayesian Statistics. Vol. II. Amsterdam: North Holland, 1984. ISBN 0-444-87746-0.
- P. J. Van Leeuwen, H. R. Künsch, L. Nerger, R. Potthast and S. Reich. Particle filters for high-dimensional geoscience applications: A review. Q. J. R. Meteorol Soc. 145: 2335–2365, 2019. [CrossRef]
- A. J. Viterbi. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Transactions on Information Theory. 13 (2): 260-269, 1967. [CrossRef]
- C. F. J. Wu. On the Convergence Properties of the EM Algorithm, Ann. Statist. 11(1): 95-103, 1983.
- T. Xuan. Autoregressive Hidden Markov Model with Application in an El Nino Study. MSc. Thesis, University of Saskatchewan, Saskatoon, 2004.
- M. Zakai. On the optimal filtering of diffusion processes. Z. Wahrsch. Verw. Gebiete 11, 230–243, (1969).
Figure 1.
Markov Observation Model Structure.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



