
Submitted:
26 September 2025
Posted:
30 September 2025
You are already at the latest version
Abstract
Transformers are the backbone of state-of-the-art systems across language, vision, and multimodal learning tasks, yet the relevance scale of their functional blocks (self-attention and feed-forward networks) is typically constant across inputs and depth. This static design neglects context-sensitive regulation of information flow through residual pathways. We introduce the \emph{contextual modulator}: a lightweight, input-aware mechanism that can scale the outputs of linear sublayers within a block or the entire block output at token- and channel-level granularity. The modulator is implemented via compact parametric functions and adds negligible parameter overhead. Building on this idea, we propose Transponder, which integrates contextual modulators throughout Transformer blocks to endow functional residual architectures with fine-grained, input-adaptive control. Transponder provides evident improvement over six other scaling or normalization methods across LLaMA backbones ranging from 60M to 250M parameters, yielding consistent perplexity reductions with $<1\%$ additional parameters. Analysis reveals depth-, module-, and token-specific scaling patterns, indicating that learned modulators act as input-adaptive regulators of residual information flow. Transponder provides a simple, general mechanism to augment Transformer-based models with context-sensitive modulators, providing robust and significant performance improvements without substantial architectural changes.
Keywords:
deep learning
; residual connection
; modulation training
; contextual scaling
1. Introduction
Transformer architectures deliver state-of-the-art performance across vision, language, and multimodal tasks [1,2,3,4]. In standard designs, information flows through a sequence of linear and nonlinear components—query/key/value projections, attention output projections, and the two feed-forward networks (FFN) linear maps—interleaved with residual connections. After training, the scaling by which these components contribute to the residual stream is effectively static for all the input tokens. Several mechanisms attempt to manipulate residual or path scaling via global reparameterizations (e.g., ReZero [5], DeepNorm/DeepNet [6]) or depth-aware normalization [7,8]. Yet these approaches assign fixed gains in spite of the current token, channel, or depth position.
These designs clash with the core goal of representation learning: the relevance of a component’s output is input-dependent. Rare tokens may call for amplifying specific heads; bursty channels may require attenuation; deeper layers may benefit from different mixing strengths than shallow ones. When scaling is static, the model must implicitly encode such selectivity inside the functional maps themselves—mixing representation (what to compute) with control (how much to pass through).
To address this limitation, we introduce Transponder, whose core principle is simple: pair each Transformer component with a contextual, input-aware modulator that explicitly controls its contribution at inference. Specifically, for a component with output , we attach a lightweight controller and compute . This decouples representation from control, turning residual mixing from a static heuristic into a principled, context-sensitive regulation mechanism.
We instantiate this principle with Transponder, designed to be minimally invasive and broadly compatible:
- Input-aware modulation. Modulators calculate the scales that multiply functional-path outputs at use time, yielding context-conditioned scaling factors for each component in Transformer.
- Granularity and placement. We systematically study where to modulate (projection- vs. path-level) and at what resolution (scalar vs. channel-wise), providing a comprehensive view of practical design.
- Low overhead, easy integration.Transponder adds parameters and integrates into standard Transformer blocks via a fused Triton kernel for each modulator to accelerate inference.
Across large-scale language-modeling benchmarks, Transponder delivers consistent gains on LLaMA backbones from 60M to 250M parameters, achieving up to 5.8–15.3% relative perplexity reductions over the LLaMA baselines. Extensive ablations spanning placement, granularity, hidden size, and component coverage (attention and FFN) show the robustness of the design. Analysis of learned modulator values uncover depth-, module-, and token-specific patterns that adapt layer-wise contributions to input semantics, providing direct evidence that residual functional transformations benefit from adaptive, context-aware scaling.
2. Related Work
2.1. Residual Connections and the Transformer Architecture
Residual connections [9] enable very deep models by adding a learned transformation to an identity shortcut, improving gradient flow, preserving signal, and allowing layers to refine rather than reconstruct representations. The Transformer [1] instantiates this principle with a persistent residual stream that carries token-wise state across layers while each block applies a functional path—multi-head self-attention (MHA) followed by a position-wise feed-forward network (FFN). Concretely, each block computes linear projections for queries, keys, and values and an attention output, then applies two FFN linear maps with nonlinearities; the results are mixed back into the residual stream through additive shortcuts. Layer normalization (LayerNorm) is interleaved with these sublayers: the original Post-LN normalizes after each sublayer [1], whereas Pre-LN normalizes before sublayers, improving optimization stability for deeper stacks [10]. This decomposition—identity carryover plus functional updates—yields strong gradient propagation and composability, but it also implicitly fixes the contribution of each subcomponent to the residual stream at inference, motivating methods that explicitly control (or scale) block updates relative to the identity path.
2.2. Scaling the Block: Static Reparameterizations and Normalization Placement
A substantial line of work manipulates the magnitude of each block’s update relative to the residual stream via static, input-agnostic mechanisms. ReZero [5] introduces a zero-initialized, learnable scalar per block that gates the residual branch, effectively starting from an identity mapping and allowing depth to emerge during training. DeepNorm/DeepNet [6] analytically rescales residual and sublayer outputs to maintain stability in very deep Transformers, enabling substantially deeper stacks without divergence. LAuReL [11] generalizes residual/functional mixing with learned coefficients (e.g., RW/LR/PA variants), providing a tunable trade-off between identity flow and the functional path. While these approaches improve training dynamics and depth, their coefficients are typically block-level and input-agnostic at inference time, leaving the strength of updates fixed for any given input.
2.3. Context-Conditioned Gating Methods
In convolutional networks, squeeze-and-excitation (SE) [12] introduces feature-wise, input-conditioned scaling by pooling global context and learning channel gates, improving representational efficiency and accuracy. The core idea—context-aware modulation of features—has influenced architectures beyond convolution. Within Transformers, SDPA-gated mechanisms [13] attach the gating mechanism to scaled dot-product attention, commonly parameterized at the head or channels. These gates selectively modulate attention behavior and can stabilize training, but they often incur heavy additional parameters and computation, and primarily target the attention pathway.
3. Transponder - Contextual Modulation Training
We formalize the Transponder by introducing the lightweight, input-conditioned modulators that scale the functional information flow inside Transformer blocks. The goal is to convert static functional compositions into context-aware modulation while preserving (i) the inductive bias of the base operator (attention/MLP), (ii) training stability, and (iii) negligible parameter/FLOP overhead. We show the main architecture of the Transponder in Figure 1.
3.1. Preliminaries: Residual Functional Composition in Transformers
Let denote the hidden states entering layer l (sequence length T, width d), and let denote a parameterized sublayer (self–attention or FFN). The standard residual formulation composes identity and functional streams additively:
While Equation (1) ensures stable signal and gradient propagation, the contribution of is typically static at inference time: once trained, the magnitude with which perturbs the skip path does not depend on the current token, channel, or context. Prior work improves optimization via block-wise scalars (e.g., ReZero [5]), depth-aware reparameterizations (e.g., DeepNorm [6]), or by mixing identity and functional streams with learned but input-agnostic coefficients (e.g., LAuReL [11]). Our aim is to endow Equation (1) with contextual modulators applied to, or inside, .
3.2. Definition: Transponder Scheme
A Modulator produces a contextual scaling signal that modulates a sublayer at its point of use. For a generic operator acting on ,
where ⊙ denotes broadcasted Hadamard multiplication. In a residual block,
- Modulator parameterization.
We parameterize the modulator with a compact bottleneck applied to each input activation , followed by a bounded nonlinearity:
where is the input width of the summary, matches the modulation resolution (one single scalar or channel-wise. is a pointwise nonlinearity (e.g., Sigmoid), and is a learnable curvature sigmoid,
The base gate maps to and interpolates between soft scaling (small ) and near-binary gating (large ). We use the calibrated gate so that , preserving the expected residual magnitude at initialization.
3.3. Granularity: Where and at What Resolution to Modulate?
We distinguish where the Modulator is applied (inter–layer) from how finely it is parameterized (intra–layer).
- Inter–layer granularity.
-
Projection–level modulation. Apply a modulator after each linear projection inside a functional path:This affords precise control (e.g., on and MLP up/down projections) with minimal additional computation.
- Path–level modulation. Modulate the entire functional path (e.g., self–attention or FFN):
- Intra–layer granularity.
Let be the dimension of ’s output at the modulation site. We instantiate:
- Layer–wise (scalar) modulation: via . A single scale uniformly modulates the sublayer; parameter and compute overheads are negligible.
- Channel–wise modulation: via , enabling feature–specific modulating with two low–rank matrices.
3.4. Fused Projection for Projection–Level Transponder
For each linear layer, the dominant cost is the matrix product . When the summary is token-wise, we also need . Instead of launching two kernels, we concatenate along the output dimension and perform a single tiled GEMM:
Here is the rank-r bottleneck, is the projection, B is batch size, and T is sequence length. After the fused GEMM, we compute the modulator logits and modulate in-register per tile:
Finally, we apply broadcasted modulation to the projected activations:
This fusion amortizes the summary computation into the main GEMM and keeps the modulator arithmetic on-chip, yielding precise projection-level control at minimal overhead.
4. Experiments
4.1. Setup
We evaluate Transponder on standard language modeling with LLaMA backbones [4] ranging from M to M parameters, trained on the C4 [14] and OpenWebText [15] corpus. All models are optimized with Adam and a base learning rate of for Openwebtext dataset and for C4 dataset. All the experiments are trained with bfloat16 for all the activations, weights, and optimization states. The hidden dimension of the contextual modulator is set to in the main comparisons to emphasize gains from contextual modulation rather than capacity. For fairness, we keep training data, tokenization, optimizer settings, and learning-rate schedules identical across baselines and Transponder. We report the perplexity (the lower the better) as the standard language-modeling metrics and measure parameter overhead relative to the corresponding backbone. We initialize of the Transponder with Kaiming uniform [16] and zero biases; set initially. Detailed hyperparameter settings can be found in Table A1.
4.2. Baselines
We compare against widely used residual/normalization designs and recent residual-scaling or layer-wise contextual control methods:
- DeepNorm/DeepNet [6]: rescales the residual branch with depth-dependent constants and tailored initialization to stabilize training of very deep Transformers.
- LayerNorm Scaling [8]: multiplies each layer’s normalized output by a depth-aware factor (e.g., ) to curb variance growth across residual connections.
- LAuREL [11]: learns a lightweight mixer that blends the skip and transformed paths (LR/PA variants), improving layer-wise signal routing with minimal extra parameters.
- SDPA-Gate [13]: applies a per-head sigmoid gate to the scaled dot-product attention output to modulate contribution and mitigate attention-sink effects.
To match SDPA-Gate’s mechanism more broadly, we also implement an ALL-Gate variant that applies the same gating scheme to all linear sublayers, including the MLP projections, providing a stronger control baseline.
4.3. Modulator Variants Validation
We instantiate five different variants of the contextual modulator in the framework of the Transponder to probe where and at what resolution modulation helps most:
- Modulator-path-scalar: a single scalar Modulator modulates the entire functional path (attention output or MLP output) per block.
- Modulator-path-channel: a channel-wise Modulator modulates the entire functional path (attention output or MLP output) output channels.
- Modulator-layer-scalar: a single scalar Modulator per linear projection.
- Modulator-layer-channel: a channel-wise Modulator per linear projection.
- Modulator-layer-channel-scalar (Transponder): a channel-wise Modulator per linear projection and a single scalar output Modulator per linear projection.
Table 1 shows two consistent trends across model scales. (i) The functional-path modulator does not aid training and can even destabilize optimization, whereas the layer-wise modulator consistently improves both training dynamics and final performance. (ii) With a layer-wise modulator in place, both channel-wise and scalar modulators further benefit Transponder: the scalar provides coarse, global control, while the channel-wise variant offers finer-grained adjustments. Using both together yields an additional, robust gain with only a modest parameter overhead.
Given its consistently best validation perplexity under comparable budgets and its favorable integration cost, we adopt Modulator–layer–channel–scalar as the default Transponder configuration for all subsequent comparisons against baseline methods.
4.4. Main Results for Language Modeling.
Table 2 compares validation perplexity (PPL; lower is better) across three LLaMA model scales. From the results, Transponder attains the best PPL wherever reported with only parameter overhead. Compared to the LLaMA baseline, Transponder reduces PPL on OpenWebText by 15.3% at 60M (26.56→22.50), 9.4% at 130M (19.27→17.45), and 13.6% at 250M (17.28→14.93); on C4 the reductions are 5.8% at 60M (30.31→28.55), 17.4% at 130M (26.73→22.09), and 14.6% at 250M (21.92→18.72). These gains persist through 250M under larger token budgets, indicating strong large-scale behavior.
Capacity-heavy gates (SDPA-Gate, ALL-Gate) improve PPL but require 15–80% extra parameters. In contrast, Transponder matches or exceeds these improvements with only overhead. Among minimal/zero-overhead baselines, LayerNorm Scaling is competitive yet still trails.
Several baselines that attempt to learn the mixing between the residual path and functional blocks exhibit instability at some scales (e.g., DeepNet and LAuReL-LR explode on C4-130M, 143.65 and 106.94 PPL; LAuReL-PA diverges on C4-130M with 1355 PPL and collapses on OpenWebText-250M to 257 PPL), whereas Transponder delivers consistent improvements across all reported settings.
Under comparable budgets, Transponder achieves state-of-the-art PPL with minimal overhead, strong large-scale behavior, and improved robustness, establishing it as our default configuration for subsequent comparisons.
4.5. Stability with Post-LayerNorm
Beyond the Pre-LN setting, we evaluate Transponder under the more delicate Post-LN regime. As shown in Table 3, vanilla LLaMA with Post-LN is unstable at scale: PPL explodes at 250M (1409.79), and even at 130M performance degrades to 26.95 in comparison to the Pre-LN LLaMA. In contrast, Transponder stabilizes training and improves accuracy in both cases, yielding a 4.6% PPL reduction at 130M (26.9525.71) and preventing divergence at 250M, where it achieves 20.28 PPL instead of catastrophic failure. While Post-LN remains slightly behind strong Pre-LN baselines at a similar scale, these results indicate that Transponder substantially enlarges the viable training regime for Post-LN models with only overhead, mitigating the well-known optimization fragility of Post-LN Transformers.
4.6. Ablations and Sensitivity Tests
- Contextual vs. Non-Contextual.
To assess the contribution of contextual modulation, we compare Transponder with and without contextual signals. In the non-contextual variant, for each layer l, we replace the contextual pathway with learnable parameters—a layer-wise scalar and a channel-wise vector —and set
where applies uniform scaling and provides per-channel modulation.
As shown in Table 4, the non-contextual variant already improves over the LLaMA baseline at certain scales, confirming the utility of the proposed modulator design. However, adding contextual control consistently delivers much larger gains across all model sizes, establishing it as the key driver of performance. This result directly supports our initial motivation: each component benefits from input-aware, contextual control rather than relying solely on static modulation.
- Sigmoid and Learnable Sigmoid.
A key innovation of Transponder is the introduction of a learnable sigmoid. This learnable non-linear modulation mechanism allows each modulator to dynamically adjust its sensitivity to the input, either amplifying or attenuating modulation strength as needed. As shown in Table 4, incorporating the learnable sigmoid consistently improves (except for 250M that is comparable)perplexity across model sizes, validating our design intuition that adaptive nonlinearity provides a crucial layer of flexibility for effective modulation.
- Hidden dimensions.
We further examine the effect of the hidden dimension r in the contextual modulator. Table 5 shows that even with an extremely compact setting (), Transponder already delivers large gains over the LLaMA baseline. Scaling up the hidden size from 8 to 32 provides marginal yet consistent improvements. These findings suggest that the modulator does not require a large intermediate capacity to capture input-dependent scaling, underscoring the efficiency of our design: lightweight modulators suffice to model contextual dependencies while adding negligible parameter overhead.
- Contribution of functional components.
We next investigate which functional modules benefit most from modulation by selectively applying the contextual modulators to individual subcomponents (Table 6). Applying modulators to either the self-attention or MLP block alone yields clear improvements, while restricting modulation to partial components (e.g., only_first, only_last, only_qk) provides only limited gains.
We further evaluate the effect of removing the up- and gate-projections. In the original LLaMA design, the gate projection serves as a channel-wise modulator to the up-projection, though implemented as a full-rank matrix. Interestingly, excluding these projections leads to strong performance, second only to the full “all” configuration. This suggests that the gate-projections already play a key role in channel-wise contextual modulation.
Overall, the best results are consistently achieved when all components are modulated jointly (“all”), yielding the lowest PPL on both LLaMA-60M and LLaMA-130M. This confirms that full-path functional modulation is necessary to provide comprehensive control over residual transformations, enabling robust and consistent improvements across scales.
5. Contextual Modulator Values Analysis
The results in Section 4 suggest that, beyond static architectural scaling (e.g., fixed layer-normalization schemes), context-/input-sensitive modulation is a powerful way to improve optimization and expressivity in deep language models. Transponder learns, for each token and sub-layer (self-attention and FFN), both a layer scalar and channel-wise modulation. The question is whether these modulators truly encode context rather than acting as static rescalers.
Figure 2 (layer-scalar, per module) shows clear depth- and module-specific structure with token-dependent variation. The traces for different tokens diverge at many layers, indicating context sensitivity. We observe systematic trends across modules: o_proj and down_proj steadily strengthen with depth, consistent with greater late-layer amplification; v_proj exhibits a pronounced surge in upper layers; up_proj follows a U-shaped pattern (early attenuation, late amplification); gate_proj remains in a tighter band with a mid-depth peak; and q_proj/k_proj show early suppression followed by recovery.
Figure A1 further confirms the effectiveness of the channel-wise modulation. Early layers are relatively flat, but mid–late layers develop structured ridges over both tokens and channels, with increasing contrast across depth. In particular, we observe a similar trend at some specific layers. For instance, at the 5th layer, one token exhibits very large modulator values across all channels, whereas in the 11th layer, one channel displays very large modulation values across the tokens.
Taken together, the two views indicate that Transponder learns structured, context-aware gains that evolve with depth and specialize by module and channel—precisely the behavior we would expect if the modulators were encoding useful contextual signals rather than acting as fixed, global scalars.
6. Conclusions
In this article, we proposed Transponder, a simple but effective way to modulate the sub-layers in Transformers context-aware. By pairing key projections and paths with compact modulators that produce scalar- and channel-wise gates, Transponder explicitly controls each component’s contribution at inference, separating representation from control. The design is minimally invasive— parameter overhead—and broadly compatible with standard decoder blocks. Empirically, Transponder consistently improves language modeling quality across LLaMA backbones (60M–250M) on OpenWebText and C4. Under comparable budgets, it surpasses stronger, capacity-heavy gating schemes while remaining far lighter, and it outperforms static depth-aware scaling methods. Ablations map a practical design space. We find (i) layer-wise placement is preferable to coarse functional-path-only control; (ii) combining channel-wise modulator with a single scalar modulator per layer yields the best accuracy-cost trade-off; (iii) modulating all the layers is crucial. Modulator value analyses further show structured, token- and depth-dependent behaviors, providing direct evidence that adaptive scaling learns semantically meaningful control. The limitation of this work can be found in Appendix B.
Appendix A.
Figure A1.
Channel-wise modulator values on down_proj across layers and tokens in a LLaMA-130M model trained with Transponder. The X and Y are the channel index and the token index, while the Z-axis are the channel-wise modulator values.
Figure A1.
Channel-wise modulator values on down_proj across layers and tokens in a LLaMA-130M model trained with Transponder. The X and Y are the channel index and the token index, while the Z-axis are the channel-wise modulator values.

Table A1.
Hyperparameters of LLaMA-60M, LLaMA-130M, and LLaMA-250M on OpenWebText and C4.
| Hyper-parameter | LLaMA-60M | LLaMA-130M | LLaMA-250M |
|---|---|---|---|
| Embedding Dimension | 512 | 768 | 1024 |
| Feed-forward Dimension | 1376 | 2048 | 2560 |
| Global Batch Size | 512 | 512 | 512 |
| Sequence Length | 256 | 256 | 256 |
| Training Steps | 10000 | 20000 | 40000 |
| Learning Rate | 3e-3 | 3e-3 (1e-3 for C4) | 3e-3 (1e-3 for C4) |
| Warmup Steps | 1000 | 2000 | 4000 |
| Learning rate Decay Method | noam | noam | noam |
| Optimizer | Adam | Adam | Adam |
| Layer Number | 8 | 12 | 24 |
| Head Number | 8 | 12 | 16 |
Appendix B. Limitation
Our study is compute-limited: we did not scale beyond ∼1B parameters or train for insufficient tokens because of the limits of the computational resources. In this regime, several zero-shot classification benchmarks yield Matthews correlation coefficient (MCC) scores near 0, which we attribute to undertraining rather than an inherent limitation of the current investigation of Transponder. Future work should evaluate Transponder at larger scales and with substantially longer training runs (more steps and tokens), and reassess zero-shot (and few-shot) generalization under those settings.
Appendix C. Claim of the LLM usage
We used LLM-based tools to improve the language and flow; the principles, core logic, and innovations are entirely the authors’.
Appendix D. Reporduction Statement
All experiments were conducted using the Hugging Face pretraining framework with data parallelism over NVIDIA A100 (40 GB) GPUs. For DeepNorm and LayerNorm scaling, we report the results from [8], as we adopt identical hyperparameter settings. To ensure reproducibility, we include our code and step-by-step instructions in the supplementary materials. Because LAuReL has not released its source code, we reimplemented the method based on our understanding of the paper. Detailed training hyperparameters are provided in Table A1.
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, .; Polosukhin, I. Attention is all you need. Advances in neural information processing systems 2017, 30.
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2019, [arXiv:cs.CL/1810.04805]. [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf, 2018.
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 2023. [CrossRef]
- Bachlechner, T.; Majumder, B.P.; Mao, H.; Cottrell, G.; McAuley, J. Rezero is all you need: Fast convergence at large depth. In Proceedings of the Uncertainty in Artificial Intelligence. PMLR, 2021, pp. 1352–1361.
- Wang, H.; Ma, S.; Dong, L.; Huang, S.; Zhang, D.; Wei, F. Deepnet: Scaling transformers to 1,000 layers. IEEE Transactions on Pattern Analysis and Machine Intelligence 2024. [CrossRef]
- Li, P.; Yin, L.; Liu, S. Mix-ln: Unleashing the power of deeper layers by combining pre-ln and post-ln. arXiv preprint arXiv:2412.13795 2024. [CrossRef]
- Sun, W.; Song, X.; Li, P.; Yin, L.; Zheng, Y.; Liu, S. The Curse of Depth in Large Language Models. arXiv preprint arXiv:2502.05795 2025. [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778. [CrossRef]
- Xiong, R.; Yang, Y.; He, D.; Zheng, K.; Zheng, S.; Xing, C.; Zhang, H.; Lan, Y.; Wang, L.; Liu, T.Y. On Layer Normalization in the Transformer Architecture, 2020, [arXiv:cs.LG/2002.04745]. [CrossRef]
- Menghani, G.; Kumar, R.; Kumar, S. LAUREL: Learned Augmented Residual Layer. arXiv preprint arXiv:2411.07501 2024. [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks, 2019, [arXiv:cs.CV/1709.01507]. [CrossRef]
- Qiu, Z.; Wang, Z.; Zheng, B.; Huang, Z.; Wen, K.; Yang, S.; Men, R.; Yu, L.; Huang, F.; Huang, S.; et al. Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free, 2025, [arXiv:cs.CL/2505.06708]. [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 2020, 21, 1–67.
- Gokaslan, A.; Cohen, V. OpenWebText Corpus. http://Skylion007.github.io/OpenWebTextCorpus, 2019.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, 2015, [arXiv:cs.CV/1502.01852]. [CrossRef]
Figure 1.
Illustration of theTranspondermechanism. The Figure shows a LLaMA decoder block, consisting of a self-attention module followed by a feed-forward network (FFN). Layer-Modulator (red) dynamically rescales the outputs of key linear transformations (e.g. Q, K, V, O) within both modules, while Path-Modulator (blue) modulates the functional paths directly (e.g. Self-attention, FFN). Each Modulator can operate in two modes: channel-wise control, where the output dimension matches the original feature dimension, and scalar-wise control, where a single scalar is used to regulate the entire function/layer.
Figure 1.
Illustration of theTranspondermechanism. The Figure shows a LLaMA decoder block, consisting of a self-attention module followed by a feed-forward network (FFN). Layer-Modulator (red) dynamically rescales the outputs of key linear transformations (e.g. Q, K, V, O) within both modules, while Path-Modulator (blue) modulates the functional paths directly (e.g. Self-attention, FFN). Each Modulator can operate in two modes: channel-wise control, where the output dimension matches the original feature dimension, and scalar-wise control, where a single scalar is used to regulate the entire function/layer.
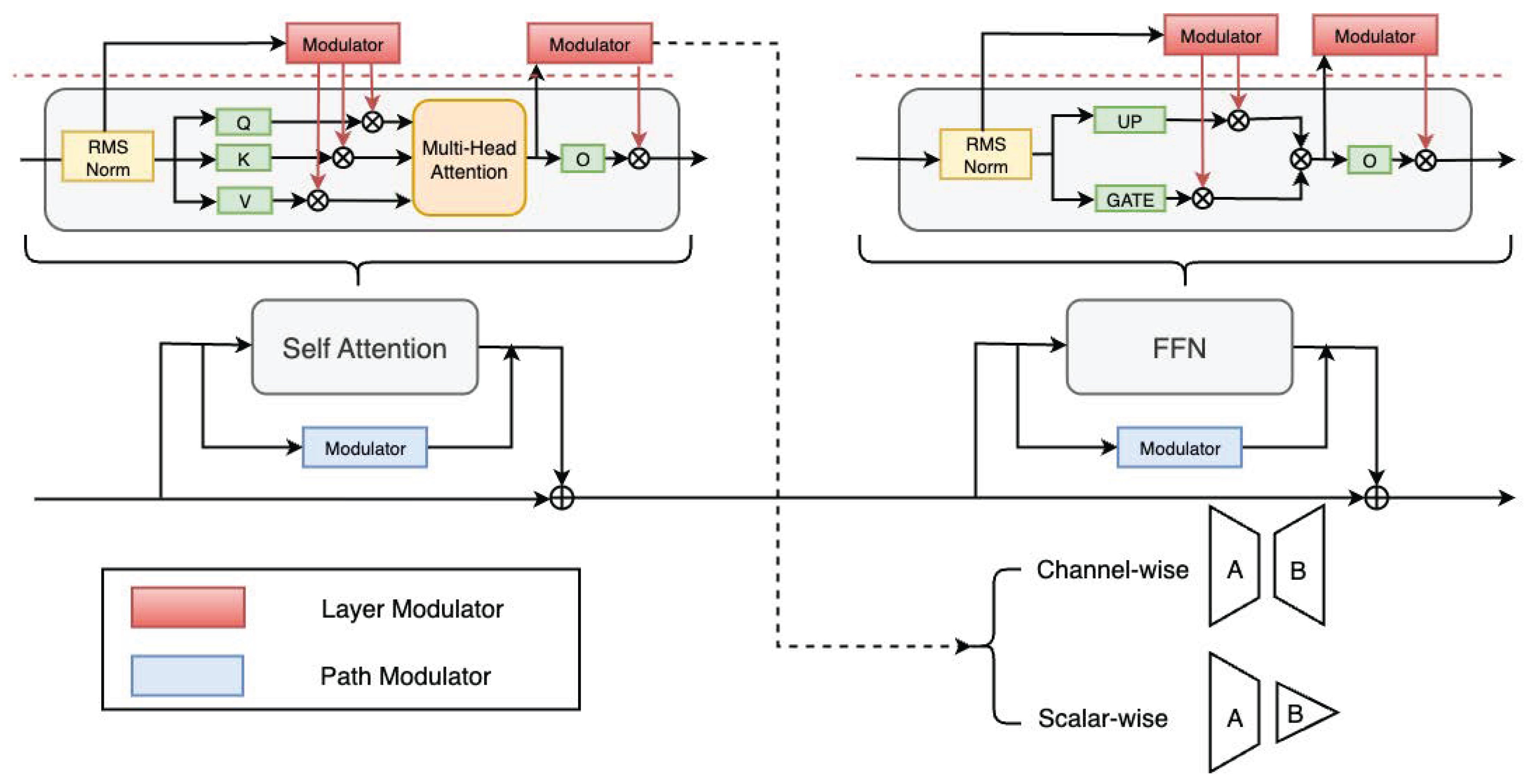
Figure 2.
Token-wise modulator values across layers and modules in a LLaMA-130M model trained with Transponder. We report the values of the scalar modulator as the representative. Each subplot corresponds to a specific linear projection of the decoder layer. The plotted curves represent different tokens from the input sequence.
Figure 2.
Token-wise modulator values across layers and modules in a LLaMA-130M model trained with Transponder. We report the values of the scalar modulator as the representative. Each subplot corresponds to a specific linear projection of the decoder layer. The plotted curves represent different tokens from the input sequence.
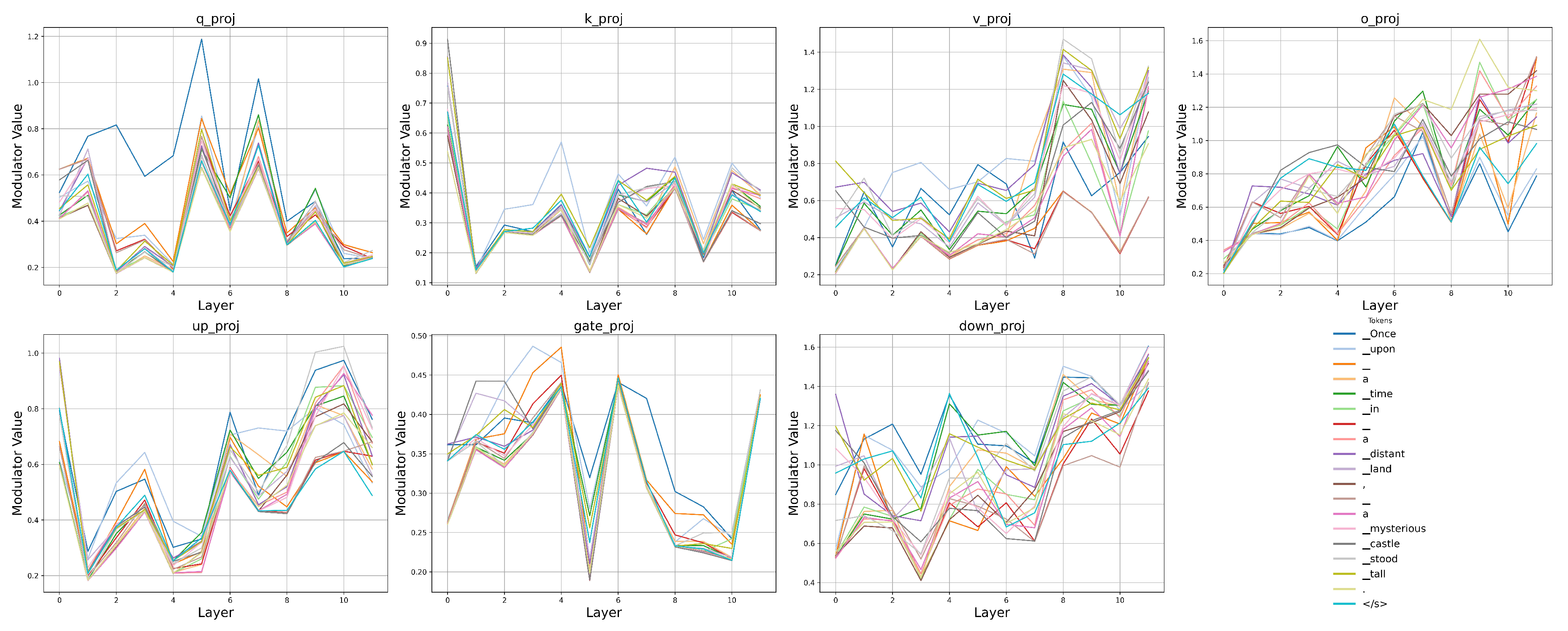
Table 1.
Validation perplexity (PPL, lower is better) of different variants of contextual modulators on Openwebtext. “Param ↑” denotes the relative parameter increase vs. LLaMA baseline. The best performance is highlighted in bold.
Table 1.
Validation perplexity (PPL, lower is better) of different variants of contextual modulators on Openwebtext. “Param ↑” denotes the relative parameter increase vs. LLaMA baseline. The best performance is highlighted in bold.
| 60M | 130M | 250M | ||||
| Model | PPL | Param ↑ | PPL | Param ↑ | PPL | Param ↑ |
| Modulator-path-scalar | 62.91 | % | 18.29 | % | 1088 | % |
| Modulator-path-channel | 23.25 | % | 18.91 | % | 16.14 | % |
| Modulator-layer-scalar | 23.15 | % | 17.76 | % | 15.21 | % |
| Modulator-layer-channel | 23.08 | 1% | 17.56 | 1% | 15.17 | 1% |
| Modulator-layer-channel-scalar | 22.50 | 1% | 17.45 | 1% | 14.93 | 1% |
Table 2.
Validation perplexity (PPL, lower is better) on C4 and Openwebtext. “Param ↑” denotes the relative parameter increase vs. LLaMA.
Table 2.
Validation perplexity (PPL, lower is better) on C4 and Openwebtext. “Param ↑” denotes the relative parameter increase vs. LLaMA.
| 60M | 130M | 250M | |||||
| Training tokens | 1.2B | 2.2B | 3.9B | ||||
| Dataset | Model | PPL | Param ↑ | PPL | Param ↑ | PPL | Param ↑ |
| Openwebtext | LLaMA (baseline) | 26.56 | - | 19.27 | - | 17.28 | - |
| DeepNet | 23.78 | % | 18.74 | % | 16.53 | % | |
| LAuReL-LR | 23.81 | % | 18.19 | % | 16.75 | % | |
| LAuReL-PA | 23.37 | % | 18.22 | % | 257 | % | |
| LayerNorm Scaling | 23.31 | 0% | 18.28 | 0% | 16.16 | 0% | |
| SDPA-Gate | 23.19 | 15% | 18.03 | 22% | 15.44 | 23% | |
| ALL-Gate | 22.96 | 44% | 17.91 | 65% | 14.97 | 80% | |
| Transponder | 22.50 | 1% | 17.45 | 1% | 14.93 | 1% | |
| C4 | LLaMA (baseline) | 30.31 | - | 26.73 | - | 21.92 | - |
| DeepNet | 30.18 | % | 143.65 | % | 21.72 | % | |
| LAuReL-LR | 30.05 | % | 106.94 | % | 39.14 | % | |
| LAuReL-PA | 29.50 | % | 1355 | % | 20.88 | % | |
| LayerNorm Scaling | 29.77 | 0% | 25.76 | 0% | 20.35 | 0% | |
| SDPA-Gate | 29.53 | 15% | 23.18 | 22% | 18.95 | 23% | |
| ALL-Gate | 28.98 | 44% | 22.92 | 65% | 18.82 | 80% | |
| Transponder | 28.55 | 1% | 22.09 | 1% | 18.72 | 1% | |
Table 3.
Validation perplexity of LLaMA 130M and 250M on C4 with Post-Layer Norm.
| 130M | 250M | |
| LLaMA w. Post-LN | 26.95 | 1409.79 |
| Transponder w. Post-LN | 25.71 | 20.28 |
Table 4.
Validation perplexity (PPL, lower is better) on Openwebtext comparing non-contextual and contextual variants.
Table 4.
Validation perplexity (PPL, lower is better) on Openwebtext comparing non-contextual and contextual variants.
| 60M | 130M | 250M | |
| Original LLaMA | 26.56 | 19.27 | 17.28 |
| Transponder w/o contextual control | 23.40 | 19.29 | 16.29 |
| Transponder w/o learnable sigmoid | 23.56 | 17.70 | 14.93 |
| Transponder | 22.50 | 17.45 | 14.93 |
Table 5.
Ablation study on the hidden dimension r of both the channel-wise and scalar-wise modulators for the Transponder on C4 dataset. The reported metric is Perplexity. The best performance is highlighted in bold.
Table 5.
Ablation study on the hidden dimension r of both the channel-wise and scalar-wise modulators for the Transponder on C4 dataset. The reported metric is Perplexity. The best performance is highlighted in bold.
| Hidden Size | LLaMA60M | LLaMA130M |
|---|---|---|
| Baseline | 30.31 | 26.07 |
| 2 | 28.91 | 23.01 |
| 4 | 28.65 | 22.64 |
| 8 | 28.55 | 22.09 |
| 16 | 28.41 | 22.12 |
| 32 | 28.73 | 22.07 |
Table 6.
Ablation study on modulators on different functional modules for the Transponder on C4 dataset. The reported metric is Perplexity. The best performance is highlighted in bold.
Table 6.
Ablation study on modulators on different functional modules for the Transponder on C4 dataset. The reported metric is Perplexity. The best performance is highlighted in bold.
| Modules | LLaMA60M | LLaMA130M |
|---|---|---|
| Baseline | 30.31 | 26.07 |
| self-attention | 29.04 | 23.21 |
| mlp | 29.43 | 23.36 |
| only_last | 29.88 | 23.97 |
| only_first | 29.91 | 24.11 |
| only_qk | 30.01 | 24.03 |
| w/o up and gate | 29.12 | 22.93 |
| all | 28.55 | 22.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



