
Submitted:
07 December 2025
Posted:
08 December 2025
You are already at the latest version
Abstract
Complex networks model the structure and function of critical technological, biological, and communication systems. Network dismantling, the targeted removal of nodes to fragment a network, is essential for analyzing and improving system robustness. Existing dismantling methods suffer from key limitations: they depend on global structural knowledge, exhibit slow running times on large networks, and overlook the network’s latent geometry, a key feature known to govern the dynamics of complex systems. Motivated by these findings, we introduce Latent Geometry-Driven Network Automata (LGD-NA), a novel framework that leverages local network automata rules to approximate effective link distances between interacting nodes. LGD-NA is able to identify critical nodes and capture latent manifold information of a network for effective and efficient dismantling. We show that this latent geometry-driven approach outperforms all existing dismantling algorithms, including spectral Laplacian-based methods and machine learning ones such as graph neural networks and . We also find that a simple common-neighbor-based network automata rule achieves near state-of-the-art performance, highlighting the effectiveness of minimal local information for dismantling. LGD-NA is extensively validated on the largest and most diverse collection of real-world networks to date (1,475 real-world networks across 32 complex systems domains) and scales efficiently to large networks via GPU acceleration. Finally, we leverage the explainability of our common-neighbor approach to engineer network robustness, substantially increasing the resilience of real-world networks. We validate LGD-NA's practical utility on domain-specific functional metrics, spanning neuronal firing rates in the Drosophila Connectome, transport efficiency in flight maps, outbreak sizes in contact networks, and communication pathways in terrorist cells. Our results confirm latent geometry as a fundamental principle for understanding the robustness of real-world systems, adding dismantling to the growing set of processes that network geometry can explain.
Keywords:
network robustness
; network dismantling
; network geometry
; network science
; complex systems
; network automata
; graphs
; network topology
1. Introduction
Complex networks are the backbone of our modern world, from the biological pathways within a cell to global financial and transportation systems (Newman 2003). While the interconnected nature of these systems is often a source of efficiency and strength, it also introduces profound vulnerabilities. A localized failure can be absorbed, or it can trigger a cascade of disruptions leading to a systemic collapse. Understanding this fragility is crucial, as the consequences are far-reaching: targeted disruptions can compromise cellular function in metabolic networks, dictate the spread of a virus through a social fabric, or cause catastrophic blackouts in power grids and failures in financial markets (Albert et al. 2000; Artime et al. 2024). The formal study of these vulnerabilities is known as network dismantling. It addresses a fundamental question: what is the most efficient way to fragment a network by removing a minimal set of nodes or links, to disrupt its structural integrity and functional capacity? Answering this question is essential not only for predicting the impact of malicious attacks but, more importantly, for designing robust and resilient systems that can withstand them. The task of dismantling serves a dual purpose. It determines whether a system is robust and how to reinforce desirable networks, for example preventing system failure in a flight network or security compromises in internet infrastructure. Conversely, it reveals how to disrupt undesirable systems, severing communications in terrorist cells or halting the spread of an epidemic. Efficient network dismantling is challenging because identifying the minimal set of nodes for optimal disruption is an NP-hard problem: no known algorithm can solve it efficiently for large networks (Artime et al. 2024), forcing the field to rely on heuristic approximations. This difficulty arises not only from the prohibitively large solution space but also from the structural complexity of real-world networks, which exhibit heterogeneous, fat-tailed connectivity (Barabási & Albert 1999; Broido & Clauset 2019; Serafino et al. 2021; Voitalov et al. 2019), modular and community structures (Newman 2012), hierarchies (Clauset et al. 2008; Ravasz & Barabási 2003), higher-order structures (Battiston et al. 2021; Lambiotte et al. 2019), and a latent geometry (Boguñá et al. 2021; Krioukov et al. 2010; Muscoloni et al. 2017; Serrano et al. 2008; Wu et al. 2015).
Node Betweenness Centrality (NBC) is a network centrality measure (Freeman 1977) that quantifies the importance of a node in terms of the fraction of the shortest paths that pass through it. NBC-based attack, where nodes are removed in order of their betweenness centrality, is considered one of, if not the best, method for network dismantling (Engsig et al. 2024; Holme et al. 2002; Motter & Lai 2002; Servedio et al. 2025). However, like many other dismantling techniques, it requires global knowledge of the entire network topology, and its high computational cost limits its scalability to large networks. These limitations are shared by many other state-of-the-art dismantling methods, which additionally rely on black-box machine learning models, and are rarely validated across large, diverse sets of real-world networks (see Table 1, Table A4, and Table A3).
Latent geometry has been recognized as a key principle for understanding the structure and complexity of real-world networks. Recent works in network science suggest that the latent geometry of complex networks could explain critical network characteristics such as small-worldness, degree heterogeneity, clustering, and navigability, and drives critical processes like efficient information flow (Boguñá et al. 2009, 2021; Kleinberg 2000; Krioukov et al. 2010; Muscoloni & Cannistraci 2018a, 2019; Serrano et al. 2008; Wu et al. 2015). Work by Muscoloni et al. (2017) revealed that betweenness centrality is a global latent geometry estimator: it approximates node distances in an underlying geometric space. They also introduced Repulsion-Attraction network automata rule 2 (RA2), a local latent geometry estimator that uses only first-neighbor connectivity. RA2 performed comparably to NBC in tasks such as network embedding and community detection, despite relying solely on local information. This raises the first question: can latent geometry, whether estimated globally or locally, guide effective network dismantling? If complex systems run on a latent manifold, estimating it may offer a more efficient way to disrupt connectivity. The second question concerns efficiency. While both NBC and RA2 have complexity (N as the number of nodes and m the number of links), RA2 is significantly faster in practice because its local computations avoid NBC’s large computational overhead. This motivates exploring whether local latent geometry estimators can match the dismantling performance of global methods like NBC while offering lower running time.
Motivated by these questions, we introduce the Latent Geometry-Driven Network Automata (LGD-NA) framework. Our first and primary contribution is the principle of (1) Latent Geometry-Driven (LGD) dismantling, where methods estimate effective node distances on a network’s latent manifold to expose critical structural information. Specifically, our (2) LGD-NA framework uses local network automata rules to approximate these geometric distances; a node’s summed distance to its neighbors estimates how critical it is for dismantling. Within this framework, we discovered that a (3) simple common neighbors-based rule, which we term Common Neighbor Dissimilarity (CND), is highly effective, achieving performance close to the state-of-the-art method, NBC. We prove the effectiveness of our approach through (4) comprehensive experimental validation on an ATLAS of 1,475 real-world networks across 32 complex systems domains, the largest and most diverse collection to date, showing that LGD-NA consistently outperforms all other existing dismantling algorithms, including machine learning and spectral Laplacian-based methods. To enable dismantling at large scales, we implement (5) GPU-acceleration for LGD-NA, yielding remarkable running time advantages over methods like NBC. Finally, using the explainability of our CND measure, we introduce a new method for (6) engineering network robustness, substantially reducing the effectiveness of the best dismantling methods. We further validate the practical utility of our dismantling framework and robustness engineering method by demonstrating their impact on domain-specific functional metrics, including neuronal firing rates in the Drosophila Connectome, flight map efficiency, epidemic sizes, and communication reachability in terrorist cells.
2. Related Work
- Latent Geometry of Complex Networks.
Many real-world networks are shaped by latent geometric manifolds of the complex systems that govern their topology and dynamics. These hidden geometries explain essential structural features such as small-worldness, degree heterogeneity, clustering, and community structure (Boguñá et al. 2021; Muscoloni & Cannistraci 2018a, 2018b; Muscoloni et al. 2017; Serrano et al. 2008; Wu et al. 2015; Zuev et al. 2015). The underlying metric space is not only descriptive but functional: it facilitates efficient routing and navigation with limited global knowledge (Boguñá et al. 2009; Kleinberg 2000; Krioukov et al. 2010; Muscoloni & Cannistraci 2019). Such properties emerge consistently across diverse systems, including biological, social, technological, and socio-ecological networks (Boguñá et al. 2021; Wu et al. 2015). Latent geometries also enable predictive modeling of dynamical processes such as network growth (Muscoloni & Cannistraci 2018a, 2018b; Papadopoulos et al. 2012), and epidemic spreading (Brockmann & Helbing 2013).
- Latent Geometry Estimators.
Latent geometry estimators assign edge weights to approximate linked nodes’ pairwise distances in the hidden geometric manifold. Among them, network automata rules based on the Repulsion-Attraction (RA) criterion use only local topological information to infer proximity in the latent space (Muscoloni et al. 2017). RA is grounded in the theory of network navigability (Boguñá et al. 2009), which posits that nodes with many non-overlapping neighbors tend to occupy distant regions in the latent space. Edges between such nodes receive higher dissimilarity scores due to strong repulsion, while those with many common neighbors are scored lower due to attraction. RA1 and RA2 are network automata rules for approximating linked nodes’ pairwise distances on the latent manifold of a complex network. These rules are categorized as network automata because they adopt only local information to infer the score of a link in the network without the need for pre-training of the rule. Note that RA1 and RA2 are predictive network automata that differ from generative network automata, which are rules created to generate artificial networks (Barabási & Albert 1999; Muscoloni & Cannistraci 2018b; Papadopoulos et al. 2012). They were introduced to serve as pre-weighting strategies for approximating angular distances associated with node similarities in hyperbolic network embeddings. RA2 performed slightly better than RA1, so for this reason we will only consider RA2 in this study. RA2 defines dissimilarity between nodes i and j as:
where is the number of common neighbors of nodes i and j, and and are the external degrees of i and j, representing the count of neighbors of i and j that are not involved in the common neighbors interactions. In the same work, Muscoloni et al. also showed that betweenness centrality is a global latent geometry estimator. By comparing it with RA2, they demonstrated that both global (betweenness centrality) and local (RA) estimators can effectively capture latent geometry, achieving strong results in network embedding and community detection. See Table A1 for a comparison of estimators and Figure A1 for illustrative examples. See also Appendix C, where we validate the ability of these latent-geometry estimators in identifying node importance and estimate link distances in networks with a known geometry.
- Topological centrality measures.
Degree, betweenness centrality, and their variants have all been used in the majority of dismantling studies (Artime et al. 2024), with betweenness centrality having been found to be the most effective strategy when applying dynamic dismantling, meaning the scores are recomputed after every step. Degree centrality ranks nodes by their number of neighbors, and betweenness centrality (Freeman 1977) counts how frequently a node lies on shortest paths. Other centrality variants include eigenvector centrality (Bonacich 1972), which gives higher scores to nodes connected to other influential nodes. PageRank (Page et al. 1999), based on a random walk model, favors nodes that receive many and high-quality links. Beyond these classical measures, several centrality indices have been developed specifically to capture aspects of network resilience. Fitness centrality (Servedio et al. 2025), adapted from economic complexity theory, evaluates node importance through the capabilities of neighbors while penalizing connections to weak nodes. DomiRank (Engsig et al. 2024) centrality models a competitive dynamic in which nodes gain or lose dominance, or importance, based on the relative strength of their neighbors. Resilience centrality (Zhang et al. 2020), derived from a dynamical systems reduction, quantifies how a node’s removal alters the system’s resilience. See Table A3 for more information.
- Statistical and Machine Learning Network Dismantling.
We focus on network dismantling for targeted attacks, where the goal is to fragment a network as efficiently as possible by removing selected nodes. Message passing-based methods such as Belief Propagation-guided Decimation (BPD) (Mugisha & Zhou 2016) and Min-Sum (MS) (Braunstein et al. 2016) use message-passing algorithms to decycle the network and then fragment the resulting forest with a tree-breaker algorithm, while CoreHD (Zdeborová et al. 2016) achieves decycling by iteratively removing the highest-degree nodes from the 2-core of the network and also includes a tree-breaker algorithm. Decycling and dismantling are, in fact, closely related tasks, as a tree (or a forest) can be dismantled almost optimally (Braunstein et al. 2016). Generalized Network Dismantling (GND) (Ren et al. 2019) targets nodes that maximize an approximated spectral partitioning. Collective Influence (CI) (Morone et al. 2016) targets nodes with maximal influence on their neighborhoods, and Explosive Immunization (EI) (Clusella et al. 2016), uses explosive percolation dynamics. Machine learning-based methods include Graph Dismantling with Machine Learning (GDM) (Grassia et al. 2021), which trains graph neural networks to predict optimal attack strategies in a supervised manner. FINDER (Fan et al. 2020b) uses reinforcement learning instead to autonomously learn dismantling strategies without needing labeled data. CoreGDM (Grassia & Mangioni 2023) combines ideas from CoreHD and GDM as it attacks the 2-core of the network but uses machine learning models trained on optimal dismantling solutions to guide node removal. See Table A4 for more information.
3. Latent Geometry-Driven Network Automata
We introduce the Latent Geometry-Driven Network Automata (LGD-NA) framework. LGD-NA adopts a parameter-free network automaton rule, such as RA2, to estimate latent geometric linked node pairwise distances and to assign edge weights based on these geometric distances. Then, it computes for each node its network centrality as a sum of the weights of adjacent edges. The higher this sum, the more a node dominates numerous and far-apart regions of the network, becoming a prioritized candidate for a targeted attack in the network dismantling process. This prioritized node is then removed from the network, and the procedure is iteratively repeated until the network is dismantled. See Figure 1 for a full breakdown of the LGD-NA framework.
3.1. Latent Geometry-Driven Dismantling
Our first contribution is Latent Geometry-Driven (LGD) dismantling, where any function can be used to estimate edge weights that represent effective distances between nodes, capturing the network’s underlying latent geometry. These inferred weights are used to construct a dissimilarity-weighted network, encoding a hidden geometric structure beneath the observable topology and allowing the dismantling process to prioritize nodes according to their geometric centrality in the latent manifold. Latent geometric structures have been shown not only to explain key properties of complex networks, but also to support the understanding of dynamical processes such as navigation, routing, and epidemic spreading. Building on the idea that network geometry captures essential structural and dynamical properties of complex systems, LGD dismantling is guided by a geometric intuition about how nodes connect distant regions in the latent space. If two nodes are connected to many different nodes but have little overlap in their neighborhoods, they are likely to be far apart in the network’s latent space. An edge between them, therefore, connects distant regions of the network. A node that has many such edges is central to holding the network together, as it links otherwise separate areas. We propose that removing those geometrically central nodes is an effective way to fragment the network. Muscoloni et al. (2017) also offered evidence that betweenness centrality can be used as a latent geometry estimator, hence, NBC is a global topology centrality measure which can be used for latent geometry-driven dismantling.
3.2. LGD Network Automata
Our second contribution is the introduction of a parameter-free network automaton framework for LGD dismantling. In this framework, node importance is estimated by aggregating edge geometric weights into node strengths, and the network is dismantled iteratively by removing the nodes with the highest strength and all their edges. The underlying intuition is that nodes that connect to many external, non-overlapping regions are geometrically central and thus more structurally important, leading to higher strength values. Formally, we begin with an undirected, unweighted network without isolated components. A network automaton rule, such as RA2, that is able to adopt local topology to estimate latent geometry, is applied to assign a weight to the edge between node i and node j, representing the estimated geometric distance between the two nodes. We get a dissimilarity-weighted network from these edge weights. The strength of node i is then calculated by summing the geometric weights of all its edges, that is, the weights to all its neighbors in the set :
In this paper, we adopt three types of LGD network automata rules. The first rule is RA2, which was proposed by Muscoloni et al. (2017) for hyperbolic network embedding purposes. The second rule is proposed in this study as an ablation test of the RA2 rule. It is the denominator of the RA2, which we call common neighbors dissimilarity (CND), defined as:
where is the number of common neighbors between nodes i and j. Here, the lower the number of common neighbors two interacting nodes have, the more geometrically distant they are, and thus a higher edge weight is assigned between these two nodes. The rationale for proposing a network automaton rule based only on the common neighbors denominator term of RA2 is to account for the mere attraction between a node and its neighbors. Neglecting the repulsion part associated with the external links (the numerator of RA2) makes sense in a dismantling task because any time we compute the common neighbors of a seed node with one of its neighbors, we indirectly account for the exclusion of nodes that are not in the topological neighborhood of the seed node. For completeness, we also investigate a third rule as an ablation test of RA2 in which we consider only the external links term in the RA2 numerator, expecting that the mere RA2 numerator should also work, but not as well as the common neighbor-based denominator. Indeed, a previous study offers evidence that common neighbors are among the topological features most associated with community organization and mesoscale network geometry (Bianconi et al. 2014).
4. Experiments
4.1. Evaluation Procedure
We evaluate all dismantling methods using a widely accepted procedure in the field of network dismantling (Artime et al. 2024). For each method, nodes are removed sequentially according to the order it defines. After each removal, we track the normalized size of the Largest Connected Component (LCC), defined as the ratio , where is the total number of nodes in the original network and is the number of nodes in the largest component after x removals. This process continues until the LCC falls below a predefined threshold. A commonly accepted threshold in dismantling studies is 10% of the original network size. To quantify dismantling effectiveness, we compute the Area Under the Curve (AUC) of the LCC trajectory throughout the removal process, which records the normalized LCC size at each step. A lower AUC indicates a more efficient dismantling, as it reflects an earlier and sharper disruption of network connectivity. The AUC is computed using Simpson’s rule. See Figure A2, Figure A6, Figure A10, and Figure A15 for visual illustrations of the LCC curve.
4.2. Optional Reinsertion Step
After reaching the dismantling threshold, we optionally perform a reinsertion step to reduce the dismantling cost, defined as the number of removals. Nodes are sequentially reinserted back into the network, one at a time, until the LCC of the remaining network just meets or exceeds the predetermined dismantling threshold. Reinsertion can significantly improve dismantling performance; recent work shows that simple heuristics with reinsertion can match or outperform complex algorithms that include reinsertion by default (Fan et al. 2020a). As a result, we enforce two constraints to ensure the reinsertion step does not override the original dismantling method: (1) reinsertion cannot reinsert all nodes to recompute a new dismantling order, and (2) reinsertion must use the reverse dismantling order as a tiebreak. If a method includes reinsertion by default, we also evaluate its performance without reinsertion for a fair comparison. See Table A5 for more information.
4.3. ATLAS Dataset
Our fourth contribution is the breadth and diversity of real-world networks tested in our experiments, demonstrating the generality and robustness of LGD-NA across domains and scales. We build an ATLAS of 1,475 real-world networks across 32 complex systems domains, which is the largest and most diverse collection of real-world networks to date used for testing in network dismantling studies. We first test all methods across networks of up to 5,000 nodes and 205,000 edges without reinsertion (), and 38,000 edges with reinsertion (). To assess the practical running time of the best performing methods, we evaluate NBC and RA2 on even larger networks of up to 23,000 nodes and 507,000 edges (). Current state-of-the-art dismantling algorithms have been evaluated on no more than 57 real-world networks (see Table 1), with most algorithms tested on fewer than a dozen. Our experiments cover 1,475 networks, representing a substantial expansion. A key aspect of our ATLAS dataset is the diversity of network types (see Table 2). We test across 32 different complex systems domains, ranging from protein-protein interaction (PPI) to power grids, international trade, terrorist activity, ecological food webs, internet systems, brain connectomes, and road maps. Since fields vary in both the number of networks and their characteristics, we evaluate dismantling methods using a mean field approach, ensuring that fields with more networks do not dominate the overall evaluation. Also, because dismantling performance varies in scale across fields, we compute a mean field ranking to make results comparable across domains.
4.4. LGD-NA Performance and Comparison to Other Methods
We compare our LGD-NA framework against the best-performing dismantling algorithms in the literature. Main results are visualized in Figure 2, and full quantitative results, including side-by-side comparisons of absolute AUC and mean-field ranks for all methods and fields, are reported in Table A21 through Table A33 in the Appendix.
First, we find that all latent geometry network automata, NBC, RA2, and its variants, achieve top dismantling performance, both with and without reinsertion. These findings show that estimating the latent geometry of a network effectively reveals critical nodes for dismantling, confirming our first contribution. For each method, we evaluate three reinsertion strategies and report the best result. We show in Figure A5 that using different reinsertion methods does not change the mean field ranking of the dismantling methods, and in Figure A7 and Figure A8 that the improvement in performance varies across fields and reinsertion methods (see Figure A6 for an illustrative example). We also adopt a dynamic dismantling process for the network automata rules and all centrality measures, where we recompute the scores after each dismantling step, as it consistently outperforms the static variant (see Figure A9 for an example of the improvements for CND and Figure A10 for an illustrative example). Second, we find that local network automata rules RA2, CND, and , which adopt only the local network topology around a node, are highly effective. In particular, RA2 and its variants consistently outperform all other non-latent geometry-driven dismantling algorithms, including those relying on global topological measures or machine learning. This confirms our second contribution. See Figure A2 for illustrative examples where the local network automata rules outperform NBC. In addition, Appendix C validates the ability of our latent-geometry-based network automata rules in identifying node importance and estimating latent geometric distances. Third, we find that the simplest RA2 variant, based solely on inverse common neighbors, which we refer to as common neighbor dissimilarity (CND), achieves the best performance among all local network automata rules. This is our third contribution and demonstrates that even minimal local topology-based information can effectively approximate latent geometry useful for effective dismantling. NBC strictly dominates as the top-ranking method across all fields. However, among the second-best performers, the LGD-NA methods lead in the majority of domains: CND ranks second in Internet networks, RA2 in Biomolecular and Brain networks, and RA2num in Covert networks. The only fields where non-LGD-NA methods rank second are Foodweb (Fitness Centrality), Infrastructure (GDM), and Social networks (GND). LGD-NA consistently outperforms all other non-latent geometry-driven dismantling algorithms, including those relying on spectral Laplacian-based methods and machine learning. The only measure that still outperforms LGD-NA is the NBC metric (which is also latent-geometry-driven), applied to dynamic dismantling. These results strongly demonstrate the practical reliability of our latent geometry-driven dismantling framework, LGD-NA.
4.5. GPU Acceleration of LGD-NA for Large-Scale Dismantling
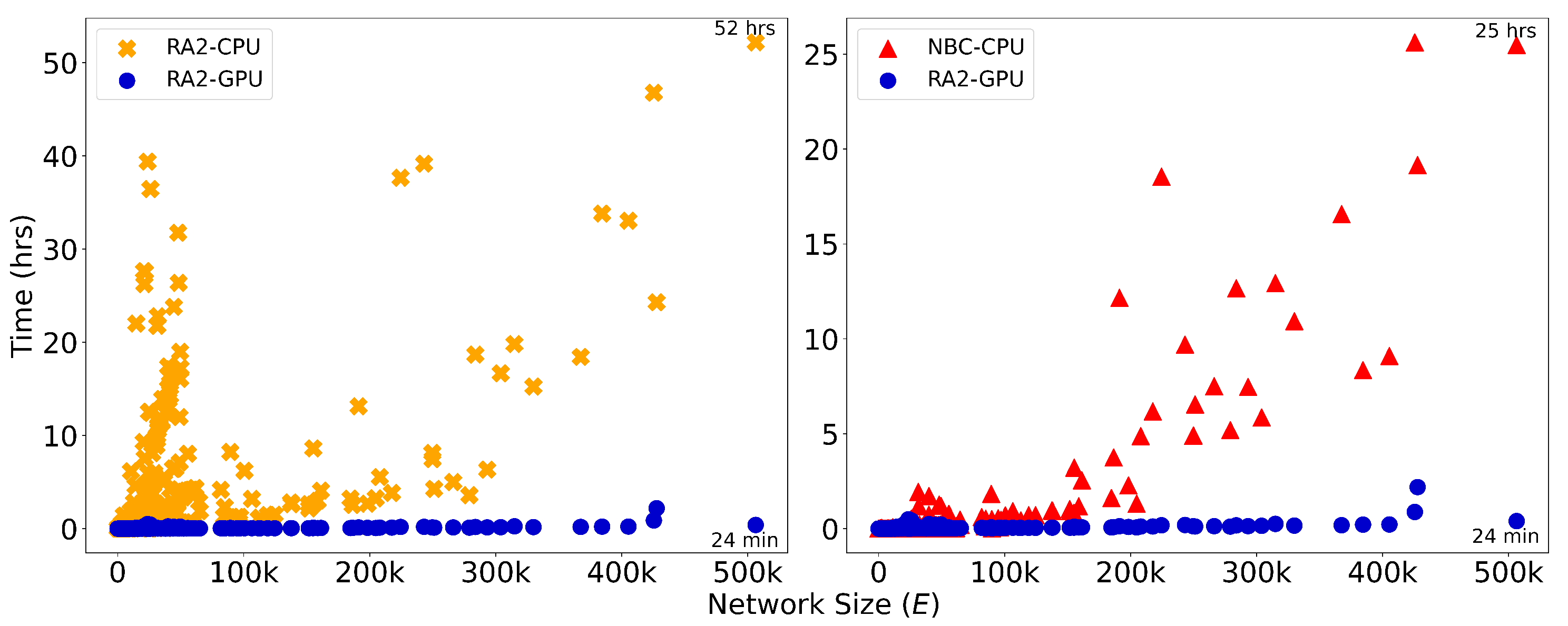
We implement GPU acceleration for all three LGD-NA variants by reformulating the required computations as matrix operations. On large networks, this enables a significant speedup in running time. When comparing RA2 and NBC, on the largest network, GPU-accelerated RA2 is 130 times faster than its CPU counterpart, highlighting the inefficiency of matrix multiplication on CPU. It is also over 63 times faster than NBC running on CPU, thanks to our GPU-optimized implementation. Note that NBC on CPU remains faster than RA2 on CPU, again due to the limitations of CPU-based matrix operations. We report only the CPU running time for NBC, as its GPU implementation did not yield any speedup (see Table A13). While some studies report GPU implementations of NBC with improved performance (Bernaschi et al. 2016; Fan et al. 2017; McLaughlin & Bader 2018; Pande & Bader 2011; Sariyüce et al. 2013; Shi & Zhang 2011), these are often limited by hardware-specific optimizations, data-specific assumptions (e.g., small-world, social, or biological networks), and the use of heuristics that are tailored to specific settings rather than offering general solutions. Moreover, publicly available code is rare, making these approaches difficult to reproduce or integrate. Overall, NBC is not naturally suited for GPU implementation, as it does not rely on matrix multiplication, but is based on computing shortest path counts between all node pairs. Overall, while NBC achieves better dismantling performance, its high computational cost makes it impractical for large-scale use. In contrast, thanks to our GPU-optimized implementation, our local latent geometry estimators based on network automata rules are the only viable option for efficient dismantling at scale. Here, we look at the details of our matrix operations for the LGD-NA measures. First, the common neighbors matrix is computed as
where is the adjacency matrix and ∘ denotes element-wise multiplication. Here, counts the number of paths of length two (i.e., common neighbors) between all node pairs. The Hadamard product with ensures that values are only retained for existing edges. Next, we compute the number of external links a node has relative to each of its neighbors. Given the degree matrix , the external degree matrix is:
Each entry of represents the external degree of node i with respect to node j: the number of neighbors of i that are neither connected to j nor directly connected to j itself. Non-edges are zeroed out. These matrices allow efficient construction of RA2 and its variants using only matrix operations. The time complexity is , with the common neighbor matrix being the dominant operation, for dense graphs, and for sparse graphs, N being the number of nodes and m the number of links. On CPU, matrix multiplication is typically memory-bound and limited by sequential operations. GPUs, however, are optimized for matrix operations, leveraging thousands of parallel threads. This results in a substantial speedup when implementing the GPU version. Finally, we show in Appendix J that in controlled settings with nPSO networks the GPU advantage becomes apparent when networks exceed 1,000 nodes or 100,000 edges.
Figure 3.
Runtime (in hours) is plotted against network size, measured by the number of edges, E, for dynamic dismantling. The annotated time indicates the runtime for the largest network. Evaluated on networks of up to 23,000 nodes and 507,000 edges ().
Figure 3.
Runtime (in hours) is plotted against network size, measured by the number of edges, E, for dynamic dismantling. The annotated time indicates the runtime for the largest network. Evaluated on networks of up to 23,000 nodes and 507,000 edges ().
4.6. Leveraging CND Explainability to Engineer Network Robustness
A key advantage of our LGD-NA framework is its explainability. Indeed, we can directly explain why any of our network-automata-based and latent-geometry-driven measures prioritize specific nodes for dismantling. CND, our most performant network automata rule for dismantling, makes this explainability even more straightforward and shows that the vulnerability of a node is strongly related to the number of links its neighbors share with one another. The higher this number, the more common neighbors exist between the adjacent nodes of a vulnerable target node. This means that, to enhance the robustness of the network to the failure of a critical node, we should simply increase the number of links between its adjacent nodes. The strategy is as follows. First, identify the nodes with the highest dismantling scores according to a given measure. Here, we consider NBC, a global shortest-path count-based measure, and CND, a local topology common-neighbor-based network automata measure, because they use different rationales to estimate critical nodes and are the two best-performing measures in this study. Second, for these critical nodes, add new links between their adjacent nodes that are not already connected to each other. Robustness is defined as the ability of a system to continue functioning when subjected to perturbations (Artime et al. 2024). In this initial context, we define attack tolerance, quantified by the LCC AUC, as a robustness measure itself, representing the system’s structural integrity under dismantling attacks. We validate our reinforcement strategy in Table A10 and Figure A11. We clearly show that adding links between the adjacent nodes of the most critical nodes significantly increases the AUC—and therefore the robustness—by 36% to 95% for 1% of added links, and by 59% to 259% for 10% of added links. Remarkably, by reinforcing only the top 1% of nodes, we increase network robustness regardless of the dismantling method used—whether it is our CND or NBC.
4.7. Real-World Applications: Fault Tolerance, Security, and Communications
To demonstrate the practical utility of LGD-NA, we evaluate its performance on four distinct real-world systems using domain-specific functional metrics. First, we use the Drosophila Connectome (Shiu et al. 2024) (Fault Tolerance), where we utilize a Spiking Neural Network (SNN) model of the sugar-sensing circuit. The metric is the sensory neuron firing rate required to trigger the proboscis extension response. Second, the Terrorist Cell (Gutfraind & Genkin 2017) (Security & Communications), where we analyze the network responsible for the 2015 Paris and 2016 Brussels attacks. The metric is Commander Reach, defined as the percentage of operatives able to communicate with at least one of the three key commanders. Third, the Flight Map (Cardillo et al. 2013) (Fault Tolerance), where we measure Global Efficiency (). Fourth, a School Contact Network (Mastrandrea et al. 2015) (Security/Epidemics), where we simulate an epidemic using an SEIR model (Anderson & May 1991). The metric is the Final Outbreak Size. Our results in Figure 4 show that dismantling strategies effectively degrade the functional performance across all four systems. In the Drosophila Connectome and Terrorist Cell, we observe particularly sharp drops in performance metrics after removing only a small fraction of nodes ( 5%). We observe a more gradual deterioration in the global efficiency of the Flight Map and the viral spread within the School Contact network. This functional collapse is particularly significant for the two adversarial scenarios (Terrorist Cell and School Contact Network): it confirms that LGD-NA is effective for security and communication disruption, efficiently suppressing epidemic outbreaks and isolating hostile leadership with minimal intervention. We subsequently applied our strategy for engineering network robustness to these four scenarios, demonstrating its effectiveness. As shown in Table A11, the reinforced networks are significantly harder to dismantle, achieving robustness gains of up to 363%. This increased resilience is evident across both our original topological metric (LCC AUC) and the domain-specific functional metrics defined for each case. For the Drosophila Connectome, this analysis informs the resilient and redundant design of fault-tolerant neuromorphic circuits by mimicking its biological wiring (Ham et al. 2021; Suárez et al. 2021). In the Flight Map, it identifies specific hubs where reinforcement prevents systemic failure. Finally, for adversarial networks, our robustness analysis serves a diagnostic purpose when faced with incomplete data. Since social networks, and especially covert ones, often contain unobserved links (e.g., dormant ties or unreported contacts), calculating an empirical robustness ceiling allows us to estimate the margin of error required for successful security operations with partial observability.
5. Conclusion
The first limitation is that hardware constraints precluded testing on extremely large networks, though our results are validated across 1,475 real-world networks across a vast range of disciplines. Second, while practical runtimes could deviate from theoretical expectations, all methods were executed under identical hardware and optimization settings to ensure fair comparison. In addition, we acknowledge the dual-use potential of this research, as understanding network vulnerabilities is critical for both designing targeted attacks and engineering robust defensive strategies. To mitigate this, we proactively demonstrate a constructive application for enhancing network robustness and believe the societal benefit of openly publishing these defensive tools outweighs the risk of misuse. In summary, we introduced Latent Geometry-Driven Network Automata (LGD-NA), a framework that achieves state-of-the-art network dismantling using only local topological information. By applying simple network automata rules to estimate a network’s latent geometry, LGD-NA identifies critical nodes with significant speed advantages over global methods like Node Betweenness Centrality (NBC). Across 1,475 real-world networks and 32 complex systems domains, it consistently outperforms all other dismantling algorithms, including those based on machine learning (e.g., Graph Neural Networks) and spectral Laplacian-based ones. Notably, our minimalistic Common Neighbor Dissimilarity (CND) measure matches NBC’s efficacy while being orders of magnitude faster. Leveraging the explainability of CND, we introduce a novel strategy to engineer network robustness. Crucially, we demonstrate the practical utility of our framework across diverse domains, from informing the design of neuromorphic circuits and reinforcing transport hubs, to disrupting terrorist cells. This work establishes latent geometry as a powerful and efficient principle for both explaining vulnerabilities and engineering stronger networks.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Acknowledgments
This work was supported by the Zhou Yahui Chair Professorship award of Tsinghua University (to CVC), the National High-Level Talent Program of the Ministry of Science and Technology of China (grant number 20241710001, to CVC).
Appendix A. Latent Geometry Estimators
Figure A1.
Illustration of how RA2 measures are computed on two toy networks. Seed nodes are shown in black; common neighbors (CN) are shown in white with a black border, and external nodes are white with a grey border. The dashed line is the edge that is being assigned a weight. External links e denote the number of edges connecting a node to nodes outside its CN set, here in red. In black, the links to common neighbors. For the link in the top network, , , and . For the link in the bottom network, , , and .
Figure A1.
Illustration of how RA2 measures are computed on two toy networks. Seed nodes are shown in black; common neighbors (CN) are shown in white with a black border, and external nodes are white with a grey border. The dashed line is the edge that is being assigned a weight. External links e denote the number of edges connecting a node to nodes outside its CN set, here in red. In black, the links to common neighbors. For the link in the top network, , , and . For the link in the bottom network, , , and .
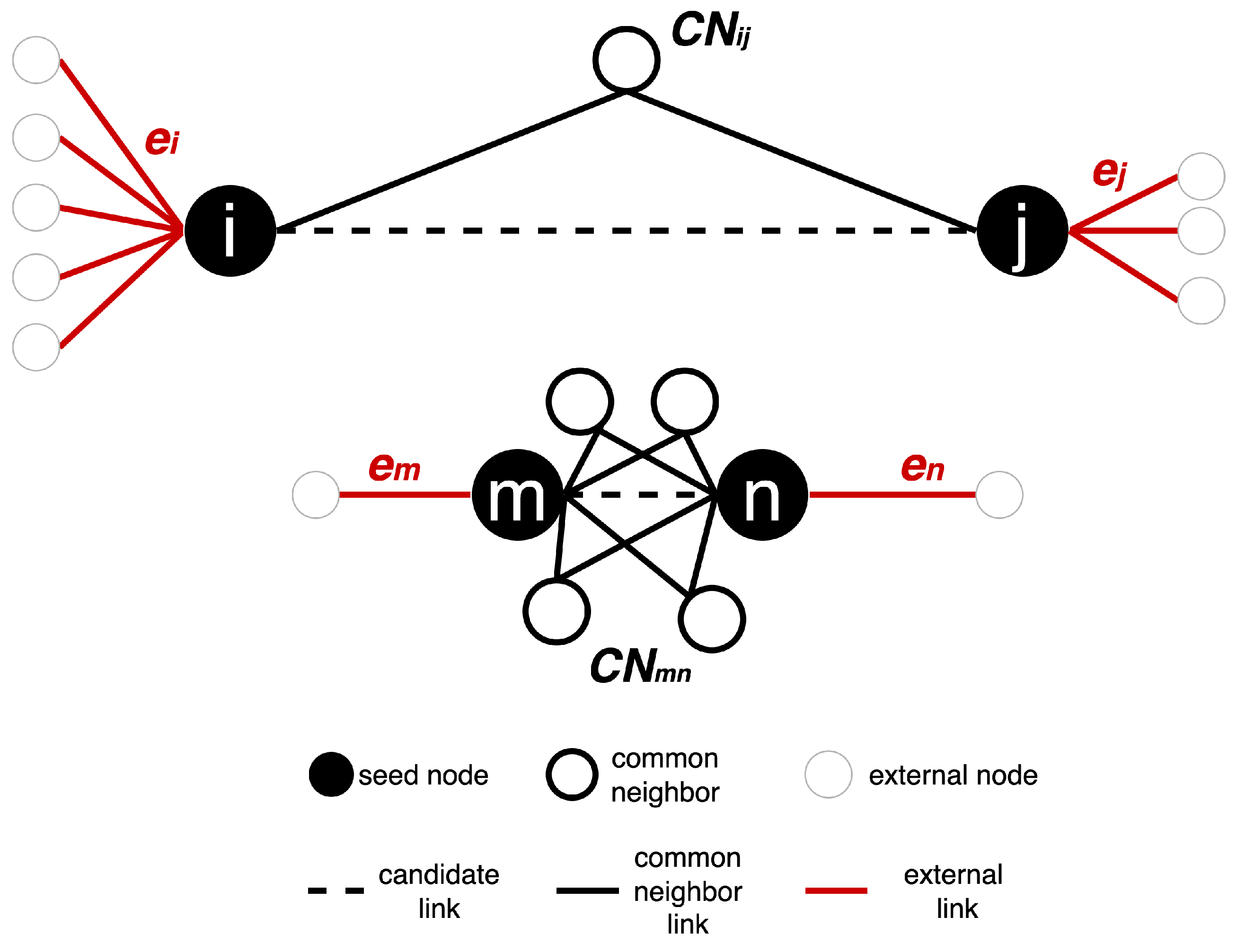

Table A1.
Comparison of latent geometry estimators and their variants. is the weight of the link between nodes i and j; and denote the number of external links of nodes i and j, respectively; is the number of common neighbors shared by i and j. Information Locality denotes the type of structural information required to assign a score to each node for dismantling. Time Complexity denotes the time complexity for dynamic dismantling using each estimator on sparse graphs, without reinsertion. N: number of nodes. m: number of links.
Table A1.
Comparison of latent geometry estimators and their variants. is the weight of the link between nodes i and j; and denote the number of external links of nodes i and j, respectively; is the number of common neighbors shared by i and j. Information Locality denotes the type of structural information required to assign a score to each node for dismantling. Time Complexity denotes the time complexity for dynamic dismantling using each estimator on sparse graphs, without reinsertion. N: number of nodes. m: number of links.
| Estimator | Author | Year | Formula | Information Locality | Time Complexity |
|---|---|---|---|---|---|
| Repulsion Attraction 2 | Muscoloni et al. (2017) | 2017 | Local | ||
| RA2 denominator-ablation (CND) | Ours | 2025 | Local | ||
| RA2 numerator-ablation | Ours | 2025 | Local |
- Latent Geometry-Driven Network Automata rule.
Figure A1 illustrates how RA2-based network automata rules assign edge weights by estimating geometric distances using only local topological features. The two toy subnetworks demonstrate how the RA2 rule and its variants distinguish between geometrically distant and close node pairs. In the top subnetwork, nodes i and j have only one common neighbor and are each connected to many external nodes (, ), indicating a weak integration in a local community and stronger connectivity to distinct parts of the network. According to the Repulsion-Attraction rule, this suggests a larger latent distance due to high repulsion and low attraction. In contrast, in the bottom subnetwork, nodes m and n share four common neighbors and have only one external link each (, ). This pattern indicates a stronger local community and a higher likelihood that the nodes are geometrically close in the latent space, with a lower dissimilarity score. These examples highlight how latent geometry-driven RA2-based network automata rules estimate hidden distances: fewer common neighbors and more external links suggest geometrical separation, while many common neighbors and few external links imply proximity in the latent manifold.
- Why is RA2 a latent geometry estimator?
In geometric networks, nearby nodes form dense, closed neighborhoods: they share many common neighbors (high ) and have few “external” links (small e). Distant node pairs show the opposite pattern. The Repulsion-Attraction rule 2 (RA2) captures these patterns in their formulation: any RA variant that decreases with and increases with external connectivity, e is therefore monotonic with latent distance: small values indicate proximity; large values indicate separation. Crucially, this relies on topological proximity, not a specific geometric space, so it applies across hyperbolic, Euclidean, or elliptic latent geometries. The only assumption to apply this estimator of underlying geometry is that the topology displays:
- node heterogeneity (meaning that the node degree distribution displays a standard deviation different from zero).
- homophily (similar nodes link together), for instance geometric proximity in latent space causes nodes that are geometrically close have overlapping neighborhoods.
We can aggregate RA2 to score node criticality by summing its pairwise RA2 to neighbors. This turns local edge-level “distance” into a node-level bridging load:
- Few adjacent nodes (neighbors) with mostly short links yields a small RA2. This node is peripheral and non-critical; removal has little global effect.
- Many neighbors with mostly short links still yields a modest RA2 (short links contribute little). The node is locally redundant; removal is buffered by community structure.
- Many neighbors with a mix of short and long links yields a large RA2 because long links carry high RA2. The node simultaneously anchors a local community and bridges distant regions; removing it is likely to disconnect communities and degrade global connectivity.
- Few neighbors with many long links (rare under geometric attachment) still yields a large RA2; such nodes are likewise critical inter-community hubs.
As a result, RA2 encodes latent separation from purely local topology. Summing RA2 over a node’s incident edges ranks nodes by how much long-range connectivity they support. Dismantling the highest-scoring nodes precisely targets those bridges whose removal most effectively fragments the network.
- Time Complexity.
We analyze the time complexity for the full dynamic dismantling process (excluding reinsertion) for the latent geometry-driven network automata rules in Table A1, where dynamic means recomputing the dismantling measure after each node removal. For RA2 and its variants, the dominant operation is the computation of the common neighbor (CN) matrix. This operation has a time complexity of for dense graphs and for sparse graphs, where N is the number of nodes and m is the number of links. Assuming N dismantling steps in the worst-case scenario, the overall time complexity becomes for sparse graphs. The assumption of N dismantling steps applies to all the time complexity analyses of dynamic dismantling methods.
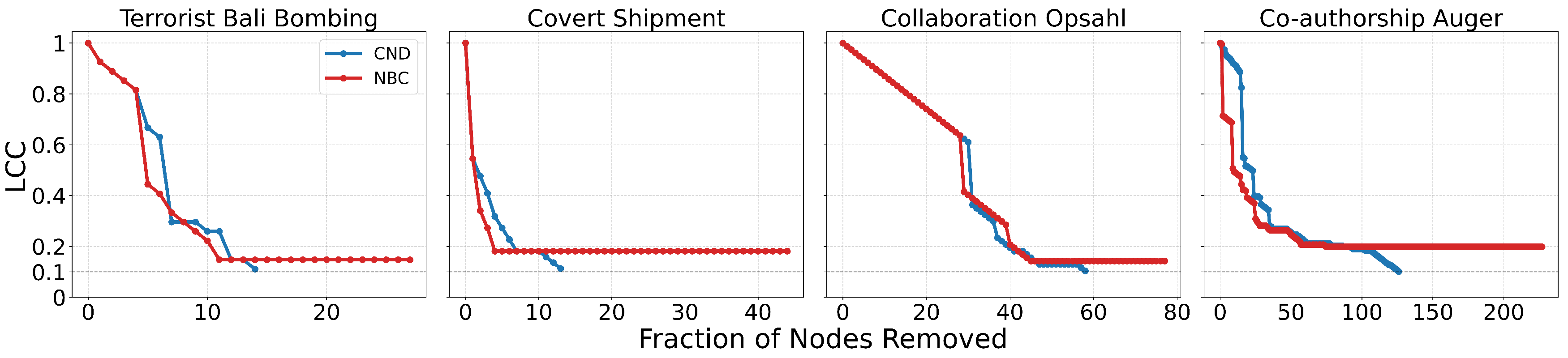
Figure A2.
Dynamic dismantling process on example networks comparing local network automata rule RA2 and its variants versus NBC, when the former outperforms NBC in terms of AUC. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. The final evaluation metric is the Area Under the Curve (AUC) of the LCC trajectory.
Figure A2.
Dynamic dismantling process on example networks comparing local network automata rule RA2 and its variants versus NBC, when the former outperforms NBC in terms of AUC. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. The final evaluation metric is the Area Under the Curve (AUC) of the LCC trajectory.
Appendix B. Theoretical Distinctions Between Graph Metrics and Latent Manifolds
To avoid ambiguity regarding the use of manifold theory in complex systems, we clarify the distinction between topological descriptors and latent geometric spaces. In this work, we define the latent manifold as the hidden, lower-dimensional structure that captures the essential configuration of the system.
To infer the latent manifold from high-dimensional data, a range of general dimensionality reduction and manifold learning techniques can be applied. These approaches seek to map the data points into a continuous, lower-dimensional space where geometric proximity reflects similarity in the original space. They can be broadly categorized as methods preserving local structure (e.g., t-SNE, UMAP, and Minimum Curvilinear Embedding (MCE)), methods based on calculating intrinsic distances (e.g., Isomap (ISO) and its variants), spectral methods (e.g., Laplacian eigenmaps and Diffusion Maps), and deep learning techniques (e.g., Autoencoders and VAEs) that learn the latent code necessary for data reconstruction. Finally, specialized manifold learning approaches in dynamical systems (e.g., Koopman operator theory) can transform complex, nonlinear dynamics into simpler, linear representations within a manifold.
When data is organized as a complex network, the latent manifold is typically inferred using network embedding techniques specifically designed to preserve the network’s topology. These methods fall into three broad categories: spectral methods (e.g., spectral clustering) which use the algebraic properties of the graph matrices; deep learning approaches (e.g., DeepWalk, Node2Vec, and Graph Autoencoders (GAE)) which learn representations using neural networks trained on structural information like random walks, while Graph Neural Networks (GNNs) have emerged as the state-of-the-art for learning task-specific embeddings using topology and node/edge features; and geometric approaches such as Hyperbolic network embeddings. These geometric methods (e.g., Poincaré embeddings, Hypermap) utilize non-Euclidean geometries, such as negative curvature, to efficiently capture the hierarchical and scale-free properties of complex networks. Specific algorithms like LPCS generate node coordinates by analyzing and ordering the network’s community structure.
We distinguish this latent manifold from graph metrics. For example, standard topological graph descriptors such as small-worldness, community structure, and degree heterogeneity are not direct descriptors of the manifold themselves. However, since the network is sampled from a specific latent space, these observed properties are influenced by the manifold’s geometry. Consequently, these topological metrics do characterize the topology of a network that is embedded in a specific latent space: for instance, small-worldness suggests short geodesic distances, community structure can imply stratification or clustering, and degree heterogeneity may reflect features such as local curvature or singularities. Our approach uses the topology of the observable network to infer the geometric distance between nodes within the network’s latent manifold, thereby allowing us to exploit the manifold’s geometric properties for dismantling.
Note that we include a GNN-based dismantling algorithm, Graph Dismantling with Machine learning (GDM) (Grassia et al. 2021), in our experiments. GDM is a GNN that is trained on optimally dismantled networks, and is considered a state-of-the-art dismantling algorithm (Artime et al. 2024; Grassia et al. 2021) that can implicitly capture features of the underlying latent geometry of the target network. The fact that our LGD-NA methods consistently outperform GDM in all situations suggests that our estimators might be yielding a more accurate estimation of the target network’s latent geometry.”
Appendix C. Geometric Validation of Latent Geometry Estimators
To provide visual and empirical validation for our latent-geometry estimators, we analyze the ability of our latent-geometry estimators to identify node importance and estimate link distances using synthetically generated networks with a known geometry. As previously mentioned, the RA measures were introduced to serve as pre-weighting strategies for approximating angular distances associated with node similarities in hyperbolic network embeddings (Muscoloni et al. 2017).
To investigate this, we synthetically generate networks using the non-uniform Popularity-Similarity Optimization (nPSO) model (Muscoloni & Cannistraci 2018b). The nPSO model is built on the principle that radial coordinates represent hierarchy (popularity) while angular coordinates represent similarity. It produces networks that are both scale-free (characterized by a power-law degree distribution, meaning a network has a few highly connected hubs while the majority of nodes have few links) and clustered with distinct communities, closely mimicking the structure of many real-world complex systems. We utilize the nPSO network model specifically for this task because these networks are generated with known node coordinates and a known underlying hyperbolic geometry, making them highly suitable for validating geometry-related measures in network science.
We generate various nPSO networks keeping the number of nodes () and communities () fixed. We test different network topologies by varying:
- The power-law exponent represents common bounds for real-world scale-free networks. With , fewer high-degree hubs exist, creating less hierarchy (seen through the radial coordinates) and reduced network hyperbolicity (meaning that they become more similar to a Erdos-Renyi random graph compared to when ).
- The number of nodes a new node will connect to when being added to the network, . This value represents approximately half of the average node degree, making the network more or less connected. This results in networks with three different density levels .
- The temperature controls clustering, where lower temperatures produce stronger clustering. Higher temperatures reduce clustering (seen through the angular coordinates) and increase the randomness of connectivity, thus reducing the generated network’s hyperbolicity (nodes connect more by random rather than following the underlying hyperbolic geometry).
Figure A3.
nPSO model networks visualized in the hyperbolic space. Fixed parameters are the number of nodes, N=500, and the number of communities, C=5. Nodes are colored according to their CND measure, where red represents higher CND scores and blue lower ones. Ranges of CND values are reported in the color bar and are different for each density level. Node sizes are positively correlated with their degree.
Figure A3.
nPSO model networks visualized in the hyperbolic space. Fixed parameters are the number of nodes, N=500, and the number of communities, C=5. Nodes are colored according to their CND measure, where red represents higher CND scores and blue lower ones. Ranges of CND values are reported in the color bar and are different for each density level. Node sizes are positively correlated with their degree.
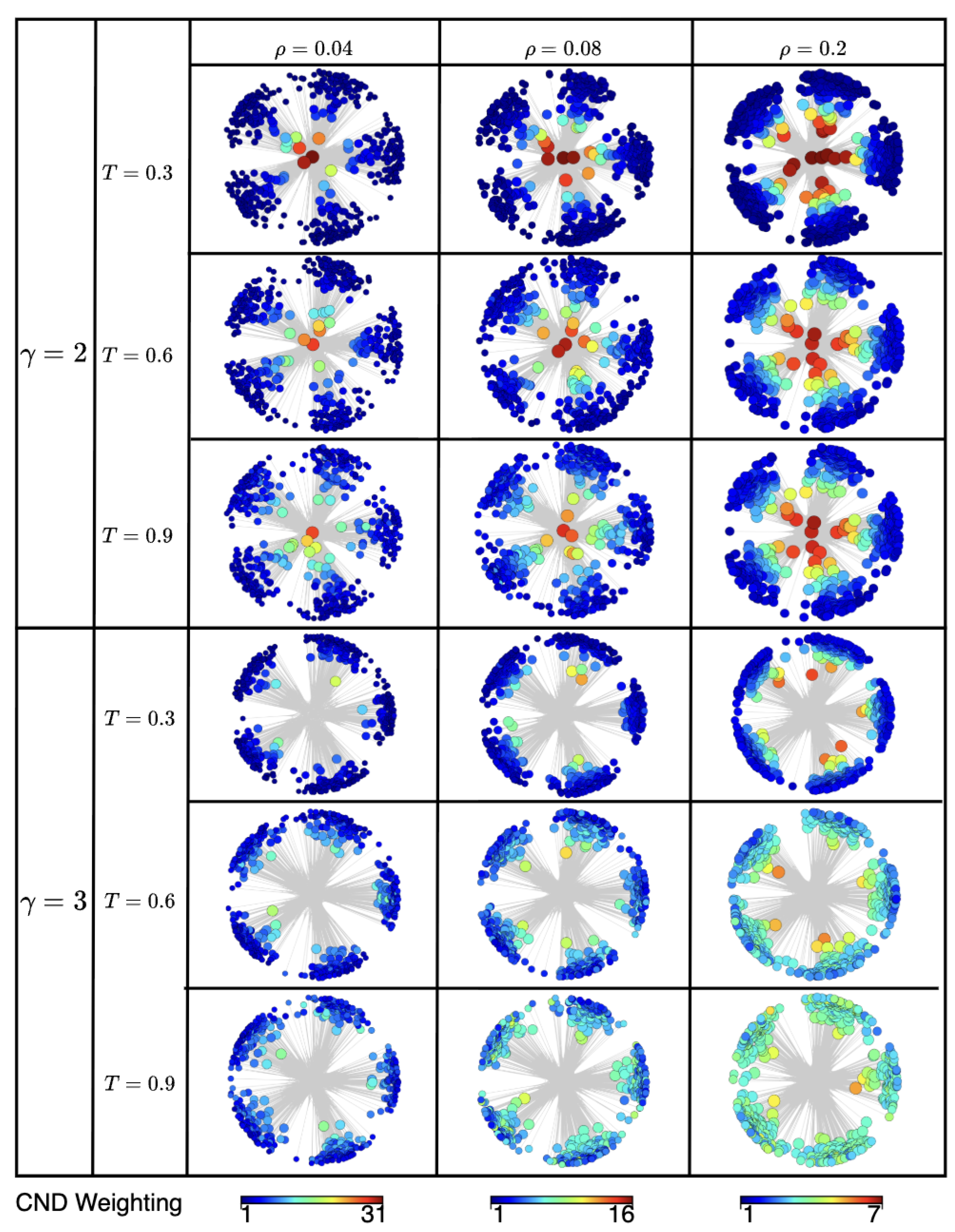
Figure A3 visualizes synthetic nPSO networks with nodes colored by CND score (red: high, blue: low) and sized by degree. The visualization clearly shows that high CND scores correspond to nodes with highcentrality, hubs located near the center of the hyperbolic disk. This relationship is most evident for , where the skewed degree distribution creates a clear distinction between central hubs and peripheral nodes. For , the trend persists but is less pronounced due to fewer super-hubs, consistent with the network’s reduced hyperbolicity. These results provide strong visual evidence that CND effectively identifies structurally important nodes in the hyperbolic latent space.
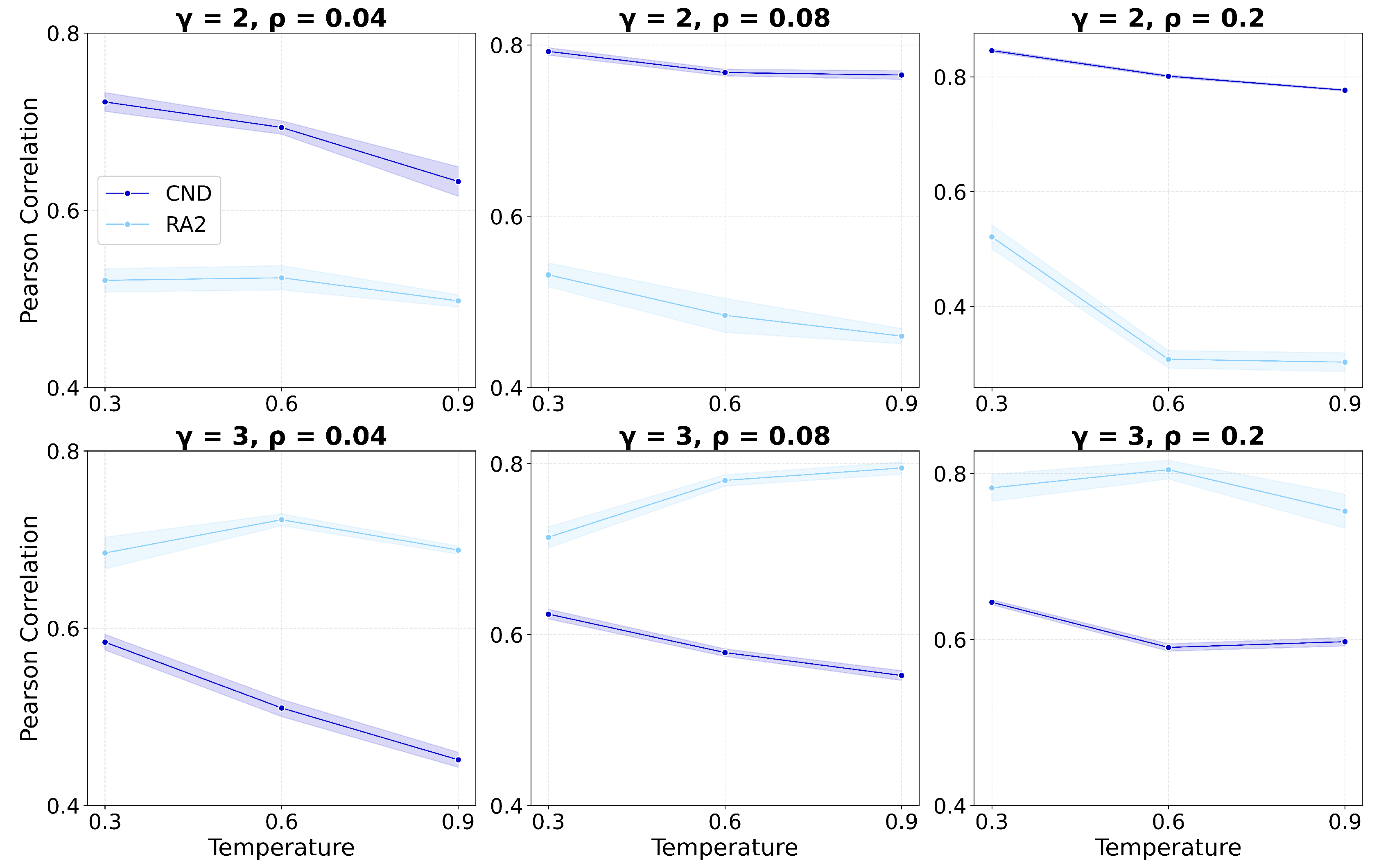
To quantitatively support our claim, we evaluate how well the latent geometry estimators approximate the true hyperbolic distances. We use the hyperbolic distance correlation (HD-correlation) metric, the Pearson correlation between all pairwise geometrical shortest path distances in the networks’ original hyperbolic space and the weighted shortest path distances using the latent-geometry estimators as edge weights (Muscoloni et al. 2017). The higher this correlation, the better the latent-geometry estimator is able to recover the geometrical distances between pairs of nodes in a network’s underlying geometry.
Figure Table A2 shows a high HD-correlation for both CND and RA2 across all tested nPSO configurations, confirming that these measures used in our dismantling framework are effective latent geometry estimators. This is further supported by the statistical significance reported in Table A18.
The Pearson correlation is visualized in Figure A4 for different parameters, visualizing how well the distance approximation changes as the network becomes less hyperbolic. As expected, for , the correlation decreases for both estimators with increasing temperature (i.e., reduced clustering and hyperbolicity). For the less hyperbolic networks, this decreasing trend persists for CND but not for RA2. This suggests that CND remains a robust estimator of the latent geometry even when hyperbolic structure is less pronounced, whereas RA2’s performance is more dependent on strongly hyperbolic conditions, consistent with our dismantling experiments.
We also conducted experiments considering only existing links, correlating their estimated weights with the true geometrical shortest path distances in the hyperbolic space (Figures Table A19 and Table A20). The results confirm that both CND and RA2 are effective latent geometry estimators, as the link weights strongly correlate with the true distances.
This visual and quantitative evidence demonstrates our LGD-NA measures’ ability to accurately estimate the geometric distance between nodes. Consequently, the node aggregation step in our LGD-NA framework can successfully identify nodes that connect distant regions in the latent space.
Table A2.
Pearson correlation between all the pairwise geometrical shortest path distances of the network nodes in the original nPSO model and in the reconstructed hyperbolic space (HD-correlation) (Muscoloni et al. 2017). Mean values over 10 seeds are reported, with a color gradient where green corresponds to values approaching 1 and red to values approaching -1. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. The temperature T controls the level of clustering (lower temperatures yield stronger clustering). Fixed parameters are the number of nodes, , and the number of communities, . Standard Error of the Mean (SEM) and Fisher p-value are found in Table A18.
Table A2.
Pearson correlation between all the pairwise geometrical shortest path distances of the network nodes in the original nPSO model and in the reconstructed hyperbolic space (HD-correlation) (Muscoloni et al. 2017). Mean values over 10 seeds are reported, with a color gradient where green corresponds to values approaching 1 and red to values approaching -1. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. The temperature T controls the level of clustering (lower temperatures yield stronger clustering). Fixed parameters are the number of nodes, , and the number of communities, . Standard Error of the Mean (SEM) and Fisher p-value are found in Table A18.
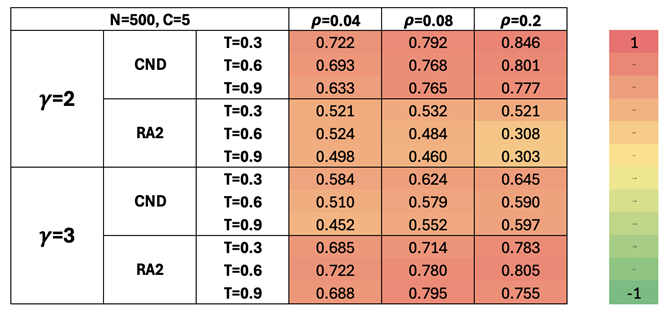
Figure A4.
Pearson correlation between all the pairwise geometrical shortest path distances of the network nodes in the original nPSO model and in the reconstructed hyperbolic space (HD-correlation) (Muscoloni et al. 2017). Mean values over 10 seeds are reported, with the shaded area the Standard Error of the Mean (SEM). The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks.The temperature T controls the level of clustering (lower temperatures yield stronger clustering). Fixed parameters are the number of nodes, , and the number of communities, .
Figure A4.
Pearson correlation between all the pairwise geometrical shortest path distances of the network nodes in the original nPSO model and in the reconstructed hyperbolic space (HD-correlation) (Muscoloni et al. 2017). Mean values over 10 seeds are reported, with the shaded area the Standard Error of the Mean (SEM). The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks.The temperature T controls the level of clustering (lower temperatures yield stronger clustering). Fixed parameters are the number of nodes, , and the number of communities, .
Appendix D. Topological Centrality Measures
Table A3.
Comparison of topological centrality measures and the associated time complexity for dynamic dismantling using each centrality measure. Information Locality denotes the type of structural information required to assign a score to each node. Time Complexity denotes the time complexity for dynamic dismantling using each centrality measure on sparse graphs, without reinsertion. N: number of nodes. m: number of links.
Table A3.
Comparison of topological centrality measures and the associated time complexity for dynamic dismantling using each centrality measure. Information Locality denotes the type of structural information required to assign a score to each node. Time Complexity denotes the time complexity for dynamic dismantling using each centrality measure on sparse graphs, without reinsertion. N: number of nodes. m: number of links.
| Measure | Author | Year | Type | Information Locality | Time Complexity |
|---|---|---|---|---|---|
| Degree | Degree-based | Local | |||
| Eigenvector | Bonacich (1972) | 1972 | Walks-based | Global | |
| Node Betweenness (NBC) | Freeman (1977) | 1977 | Shortest path-based | Global | |
| PageRank (PR) | Page et al. (1999) | 1999 | Random walk-based | Global | |
| Resilience | Zhang et al. (2020) | 2020 | Resilience-based | Global | |
| Domirank | Engsig et al. (2024) | 2024 | Fitness-based | Global | |
| Fitness | Servedio et al. (2025) | 2025 | Fitness-based | Global |
- Time Complexity.
We analyze the time complexity of dynamic dismantling (excluding reinsertion) for the topological centrality measures used in our experiments, summarized in Table A3. As before, the analysis assumes N dismantling steps in the worst-case scenario. For degree, the score update after each removal is local and can be done in time using a binary heap. For NBC, we use Brandes’ algorithm (Brandes 2001), which computes betweenness centrality in time per step for unweighted networks. Eigenvector, PageRank, Resilience, Domirank, and Fitness all rely on matrix-vector multiplications, which has a time complexity of . We also add the term N, which represents the overhead of looping over nodes to update or normalize the resulting vector at each iteration. This leads to a total per-step cost of . We also omit the constant k for Eigenvector, PageRank, and Fitness centrality, which represents the number of iterations these methods perform. In practice, reaching full convergence to a single optimal solution is often computationally infeasible; this is why a fixed number of k iterations is typically defined.
Appendix E. Statistical and Machine Learning Network Dismantling
Table A4.
Comparison of dismantling algorithms (Artime et al. 2024). Information Locality denotes the type of structural information required to assign a score to each node. Dynamicity indicates whether scores are recomputed after each removal. Reinsertion specifies whether the algorithm includes a reinsertion step after dismantling. Time Complexity denotes the time complexity of the method on sparse graphs, without reinsertion. N: number of nodes. m: number of links. h: number of attention heads. T: maximal diameter of the trees in the forest for BPD and MS. is a small constant used in spectral partitioning operations. Included states whether the method was run in our experiments; if not, a brief reason is provided.
Table A4.
Comparison of dismantling algorithms (Artime et al. 2024). Information Locality denotes the type of structural information required to assign a score to each node. Dynamicity indicates whether scores are recomputed after each removal. Reinsertion specifies whether the algorithm includes a reinsertion step after dismantling. Time Complexity denotes the time complexity of the method on sparse graphs, without reinsertion. N: number of nodes. m: number of links. h: number of attention heads. T: maximal diameter of the trees in the forest for BPD and MS. is a small constant used in spectral partitioning operations. Included states whether the method was run in our experiments; if not, a brief reason is provided.
| Algorithm | Type | Author | Year | Information Locality | Dynamicity | Reinsertion | Time Complexity | Included |
|---|---|---|---|---|---|---|---|---|
| Collective Influence (CI) | Influence maximization | Morone et al. (2016) | 2016 | Local | Dynamic | Yes | Yes | |
| Belief propagation-guided decimation (BPD) | Message passing-based decycling | Mugisha & Zhou (2016) | 2016 | Global | Dynamic | Optional | No - Code missing | |
| Min-Sum (MS) | Message passing-based decycling | Braunstein et al. (2016) | 2016 | Global | Dynamic | Yes | Yes | |
| Generalized Network Dismantling (GND) | Spectral partitioning | Ren et al. (2019) | 2019 | Global | Dynamic | Optional | Yes | |
| CoreHD | Degree-based decycling | Zdeborová et al. (2016) | 2016 | Global | Dynamic | Yes | Yes | |
| Explosive Immunization (EI) | Explosive percolation | Clusella et al. (2016) | 2016 | Global | Dynamic | No | Yes | |
| FINDER | Machine learning | Fan et al. (2020b) | 2020 | Global | Dynamic | Optional | No - Code outdated | |
| Graph Dismantling Machine (GDM) | Machine learning | Grassia et al. (2021) | 2021 | Global | Static | Optional | Yes | |
| CoreGDM | Machine learning | Grassia & Mangioni (2023) | 2023 | Global | Static | Yes | Yes |
Table A4 is adapted and extended from Table 1 of Artime et al. (Artime et al. 2024), a recent and comprehensive review which has become a key reference in the field of network dismantling. The majority of these algorithms were included in our experiments, with the exception of BPD and FINDER due to unavailable or outdated code, respectively.
Figure A5.
Mean field ranking for a subset of the best-performing methods from each category with each reinsertion method (R1, R2, R3) (). Methods based on latent geometry are shown in red. All LGD and topological centrality measures use dynamic dismantling. Error bars indicate the standard error of the mean (SEM). Method acronyms are defined in Table A1, Table A3, and Table A4.
Figure A5.
Mean field ranking for a subset of the best-performing methods from each category with each reinsertion method (R1, R2, R3) (). Methods based on latent geometry are shown in red. All LGD and topological centrality measures use dynamic dismantling. Error bars indicate the standard error of the mean (SEM). Method acronyms are defined in Table A1, Table A3, and Table A4.
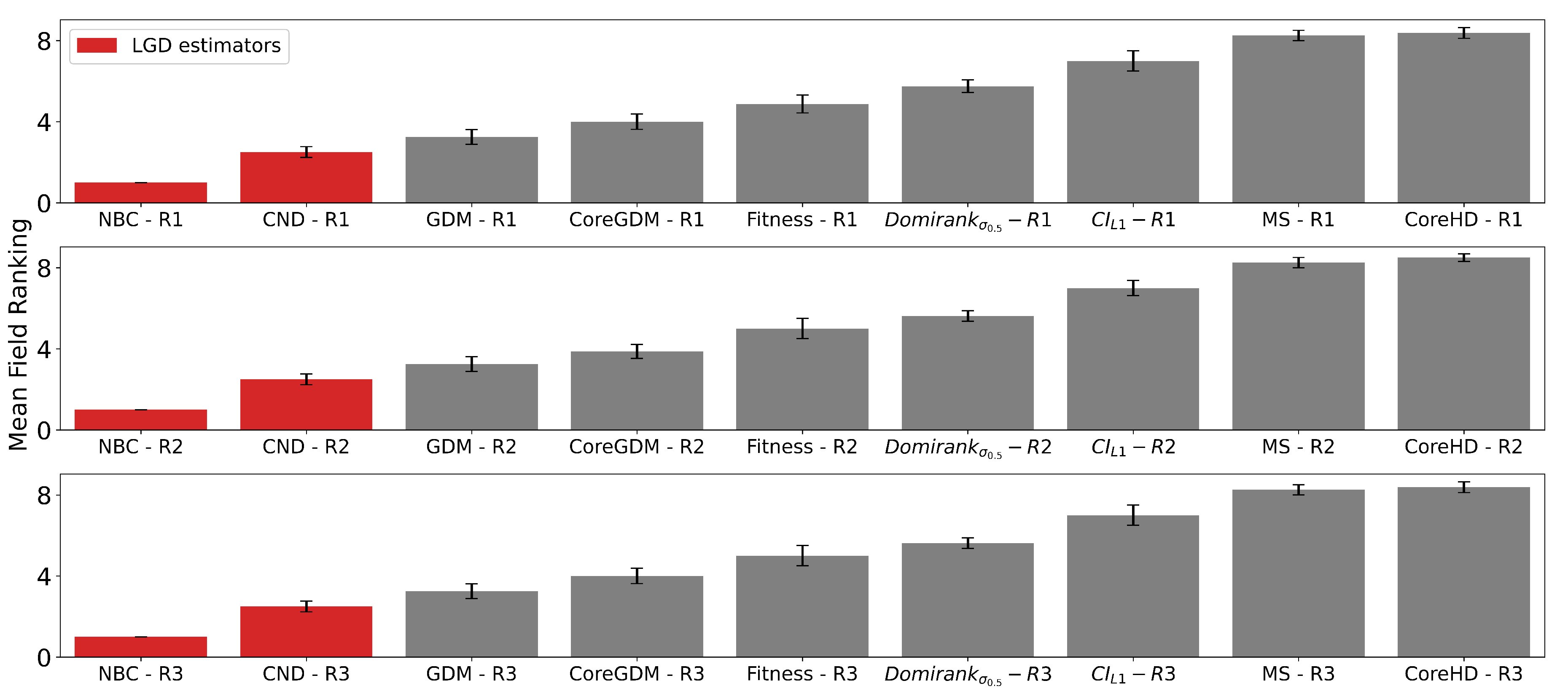
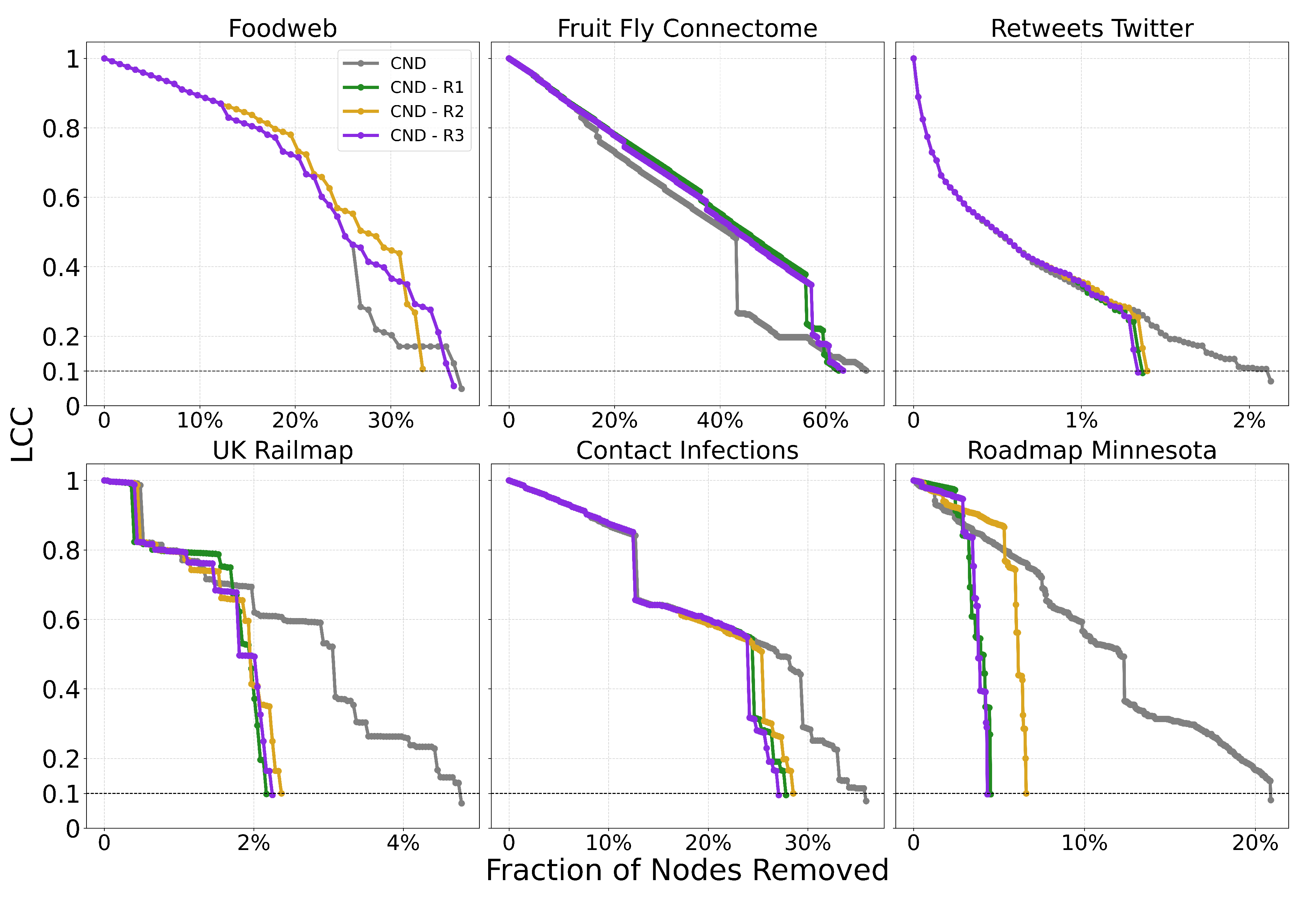
Figure A6.
Dynamic dismantling process on example networks comparing CND with and without reinsertion. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. The final evaluation metric is the Area Under the Curve (AUC) of the LCC trajectory.
Figure A6.
Dynamic dismantling process on example networks comparing CND with and without reinsertion. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. The final evaluation metric is the Area Under the Curve (AUC) of the LCC trajectory.
Appendix F. Reinsertion Methods
Reinsertion was originally introduced in the context of immunization as a reverse process: starting from a fully dismantled network, nodes are reinserted one by one, each time selecting the node whose addition causes the smallest increase in the largest connected component (LCC) (Schneider et al. 2012). This reversed sequence then defines an effective dismantling order. In subsequent studies, reinsertion has been used as a post-processing step to improve dismantling outcomes (Artime et al. 2024): the network is first dismantled by a given method, and nodes are reinserted until the LCC reaches the dismantling threshold. This reduces the dismantling cost while preserving the original attack target.
In this work, dismantling cost is defined as the number of nodes removed from the network. The reinsertion step aims to directly minimize this cost by reintroducing nodes that were initially removed but found to be unnecessary for achieving the dismantling objective. It’s important to note that while reinsertion reduces the number of physical removals, it does introduce a higher computational cost as it’s a post-processing step performed after the initial dismantling. However, the primary objective is to minimize this physical intervention, as in many real-world scenarios, the logistical and financial implications of physically removing network components (e.g., infrastructure) far outweigh the computational resources expended during the optimization phase. This is why we compare all methods with and without the reinsertion step.
Several reinsertion criteria have been proposed: Braunstein et al. (2016) select the node that ends up in the smallest resulting component after reinsertion; Morone et al. (2016) choose the node that reconnects the fewest components; Mugisha & Zhou (2016) select the node that causes the smallest LCC increase. See Table A5 for a full comparison.
Reinsertion can greatly enhance dismantling performance. However, recent work shows that this step can overpower the dismantling algorithm itself, allowing weak methods to appear effective when paired with reinsertion (Fan et al. 2020a). To address this, we enforce two constraints to ensure fair comparisons and prevent reinsertion from dominating the dismantling process:
- Reinsertion must stop once the LCC exceeds the dismantling threshold. Recomputing a new dismantling order by reinserting all nodes is not allowed.
- Ties in the reinsertion criterion must be broken by reversing the dismantling order: nodes removed later are prioritized.
These rules ensure that reinsertion complements rather than overrides the dismantling process, preserving the integrity of the original method.
In our experiments, we implement three reinsertion methods, adapted from prior work, here we explain which part of their method we change for our experiments. Those changes are marked with an asterisk (*) in Table A5.:
- R1 (Braunstein et al. 2016): We replace their original tiebreak (smallest node index) with reverse dismantling order.
- R2 (Morone et al. 2016): We apply the LCC stopping condition. Originally, all nodes are reinserted to compute a new dismantling sequence.
- R3 (Mugisha & Zhou 2016): We apply reverse dismantling order as the tiebreak, as no rule is defined in their paper, and their code is unavailable.
R3 is the most similar to the reverse immunization method proposed by Schneider et al. (2012), where nodes are added back one by one based on minimal LCC growth. In their original method, ties are broken by selecting the node with the fewest connections to already reinserted nodes; if multiple candidates remain, one is chosen at random.
We note that reinsertion typically reduces the number of removals but does not always lead to a lower AUC. Since the trajectory of the LCC changes with reinsertion, the dismantling process may reach the threshold faster, improving AUC. However, this is not guaranteed, as we see in the first two subplots of Figure A6 for the Foodweb and Fruit Fly Connectome networks. The methods with reinsertion arrive at the dismantling threshold in fewer number of removals, but the change in the LCC curve results in a worse final AUC.
We also see that the reduction in AUC is not proportional to the reduction in the number of removals, as seen in Figure A7 and Figure A8 for CND. Indeed, reinsertion, by definition, reinserts nodes that were ultimately unnecessary for the dismantling process to reach its target.
A significant limitation in previous literature is the lack of differentiation between algorithms that inherently include reinsertion and those that do not, leading to inconsistent comparisons. To ensure a strictly fair evaluation, we standardized two critical control variables across all experiments: the tie-breaking mechanism for the order of reinsertion and the stopping criteria. Furthermore, rather than arbitrarily assigning a reinsertion strategy, we evaluated every method under the three reinsertion methods. We report the best performance for each method, ensuring that the results reflect the maximum potential of the dismantling strategy rather than an inconsistent application of reinsertion.
- Ranking Stability.
Across all tested reinsertion methods, the mean-field ranking remains the same: NBC consistently outranks CND, which in turn outranks GDM. This order holds true both when comparing specific fixed reinsertion methods and when selecting the best-performing method for each dismantling method. However, we observe a nuanced interaction between the dismantling algorithms and their best reinsertion strategy: the optimal reinsertion method varies (R2 is optimal for NBC, R3 for CND, and R1 for GDM). For all other algorithms, though, R1 is the most effective reinsertion strategy.”
- Time Complexity.
We report the total time complexity of each reinsertion method over the full reinsertion process in Table A5, assuming all dismantled nodes are considered for reinsertion for every step and that all nodes are reinserted. Candidates for reinsertion are denoted as r. As a result, we multiply the per-step cost of updating for each method by the total number of reinsertion candidates. is the maximum number of components a node can connect to, equal to the maximum degree in the original graph, and is the maximum size of any connected component during the reinsertion phase. For R1, the candidate node that ends up in the smallest resulting component is selected. Reinserting a node may merge up to components, each of size at most , requiring an update of at most nodes. These updates are tracked in a binary heap of size r, where at maximum nodes have to be updated, giving a cost of per update. The per-step cost is therefore . R2 selects the node that connects the fewest existing components. Unlike R1, it requires inspecting not only the components merged by the candidate node, but also the neighbors of the affected neighbors. This increases the complexity by a factor of , resulting in a per-step time complexity of . R3 evaluates each candidate by explicitly computing the resulting LCC size after reinsertion. Each evaluation requires a graph traversal to recompute connected components, which takes time on sparse graphs. This has to be done for each reinsertion candidate, at every step, so ,
Table A5.
Comparison of reinsertion methods. Criteria defines the criterion for selecting which node to reinsert. Tiebreak specifies how ties are resolved. LCC Condition indicates whether all dismantled nodes are reinserted or if reinsertion stops once the predefined LCC threshold is reached. Time Complexity denotes the time complexity of each reinsertion method on sparse graphs, for the whole reinsertion process. N: number of nodes. m: number of links. r: set of reinsertion candidates. : maximum degree in the original graph G. : maximum size of any connected component during the reinsertion phase. Used In lists the methods that use each method, in bold, the dismantling method that originally proposed that reinsertion method. An asterisk (*) marks components of the reinsertion method that were modified in our study, as detailed in Appendix F.
Table A5.
Comparison of reinsertion methods. Criteria defines the criterion for selecting which node to reinsert. Tiebreak specifies how ties are resolved. LCC Condition indicates whether all dismantled nodes are reinserted or if reinsertion stops once the predefined LCC threshold is reached. Time Complexity denotes the time complexity of each reinsertion method on sparse graphs, for the whole reinsertion process. N: number of nodes. m: number of links. r: set of reinsertion candidates. : maximum degree in the original graph G. : maximum size of any connected component during the reinsertion phase. Used In lists the methods that use each method, in bold, the dismantling method that originally proposed that reinsertion method. An asterisk (*) marks components of the reinsertion method that were modified in our study, as detailed in Appendix F.
| Name | Author | Year | Criteria | Tiebreak | LCC Condition | Time Complexity | Used In |
|---|---|---|---|---|---|---|---|
| R1 | Braunstein et al. (2016) | 2016 | Node that ends up in the smallest component | Reverse dismantling order* | Yes | MS, CoreGDM, CoreHD, GDM, GND | |
| R2 | Morone et al. (2016) | 2016 | Node that connects to the fewest clusters | Reverse dismantling order | Yes* | CI | |
| R3 | Mugisha & Zhou (2016) | 2016 | Node that causes the smallest increase in LCC size | Reverse dismantling order* | Yes | BPD |
Figure A7.
Mean AUC and number of removals by field for CND without reinsertion and with each reinsertion method (R1, R2, R3) ( for all methods). Error bars represent the standard error of the mean (SEM). Red text indicates the percentage improvement achieved by using the best-performing reinsertion method for each field. Quantitative results for the AUC and removals improvement from each reinsertion methods are reported in Table A6.
Figure A7.
Mean AUC and number of removals by field for CND without reinsertion and with each reinsertion method (R1, R2, R3) ( for all methods). Error bars represent the standard error of the mean (SEM). Red text indicates the percentage improvement achieved by using the best-performing reinsertion method for each field. Quantitative results for the AUC and removals improvement from each reinsertion methods are reported in Table A6.
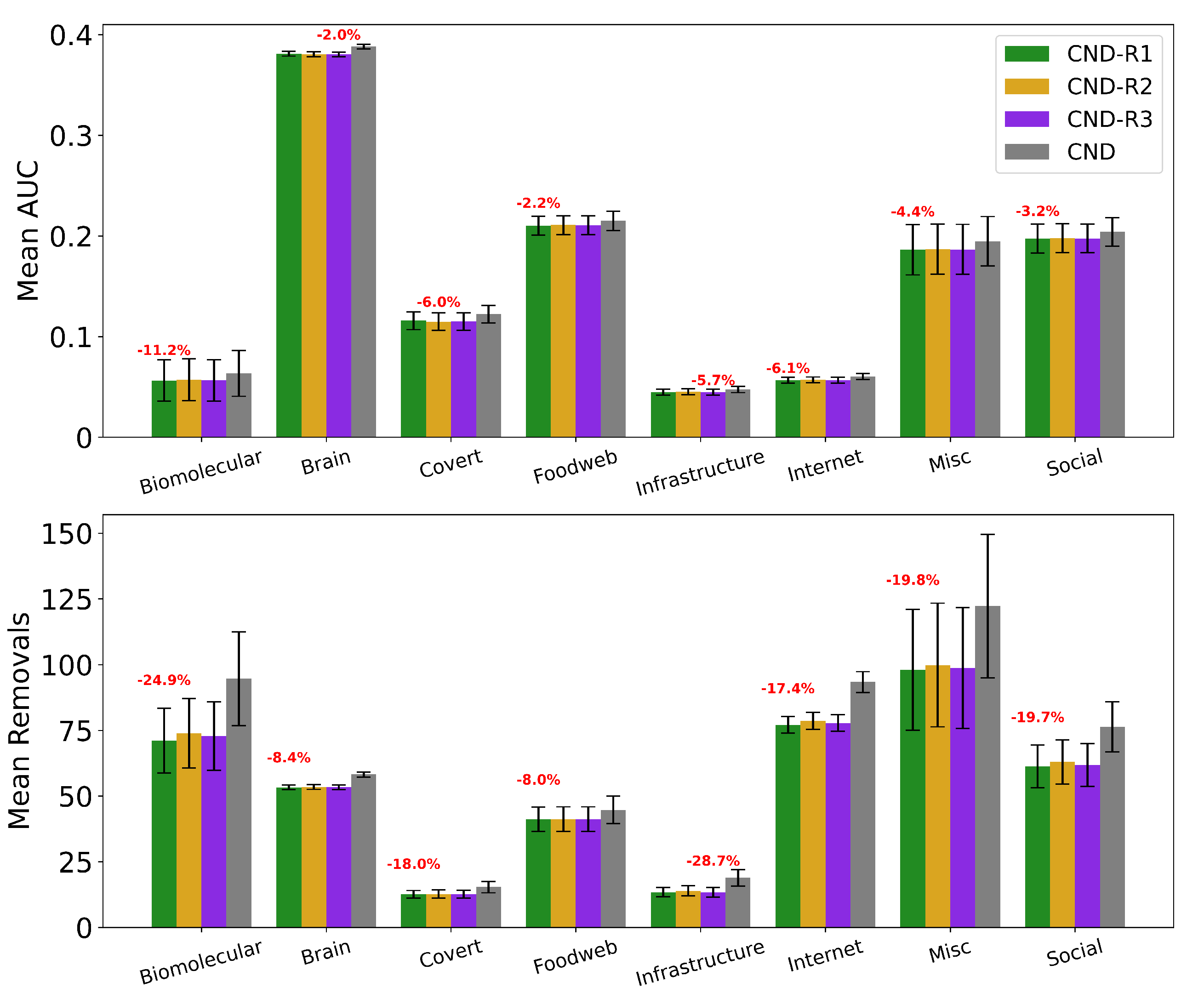
Figure A8.
Mean AUC and number of removals by field for RA2 without reinsertion and with each reinsertion method (R1, R2, R3) ( for all methods). Error bars represent the standard error of the mean (SEM). Red text indicates the percentage improvement achieved by using the best-performing reinsertion method for each field. Quantitative results for the AUC and removals improvement from each reinsertion methods are reported in Table A6.
Figure A8.
Mean AUC and number of removals by field for RA2 without reinsertion and with each reinsertion method (R1, R2, R3) ( for all methods). Error bars represent the standard error of the mean (SEM). Red text indicates the percentage improvement achieved by using the best-performing reinsertion method for each field. Quantitative results for the AUC and removals improvement from each reinsertion methods are reported in Table A6.
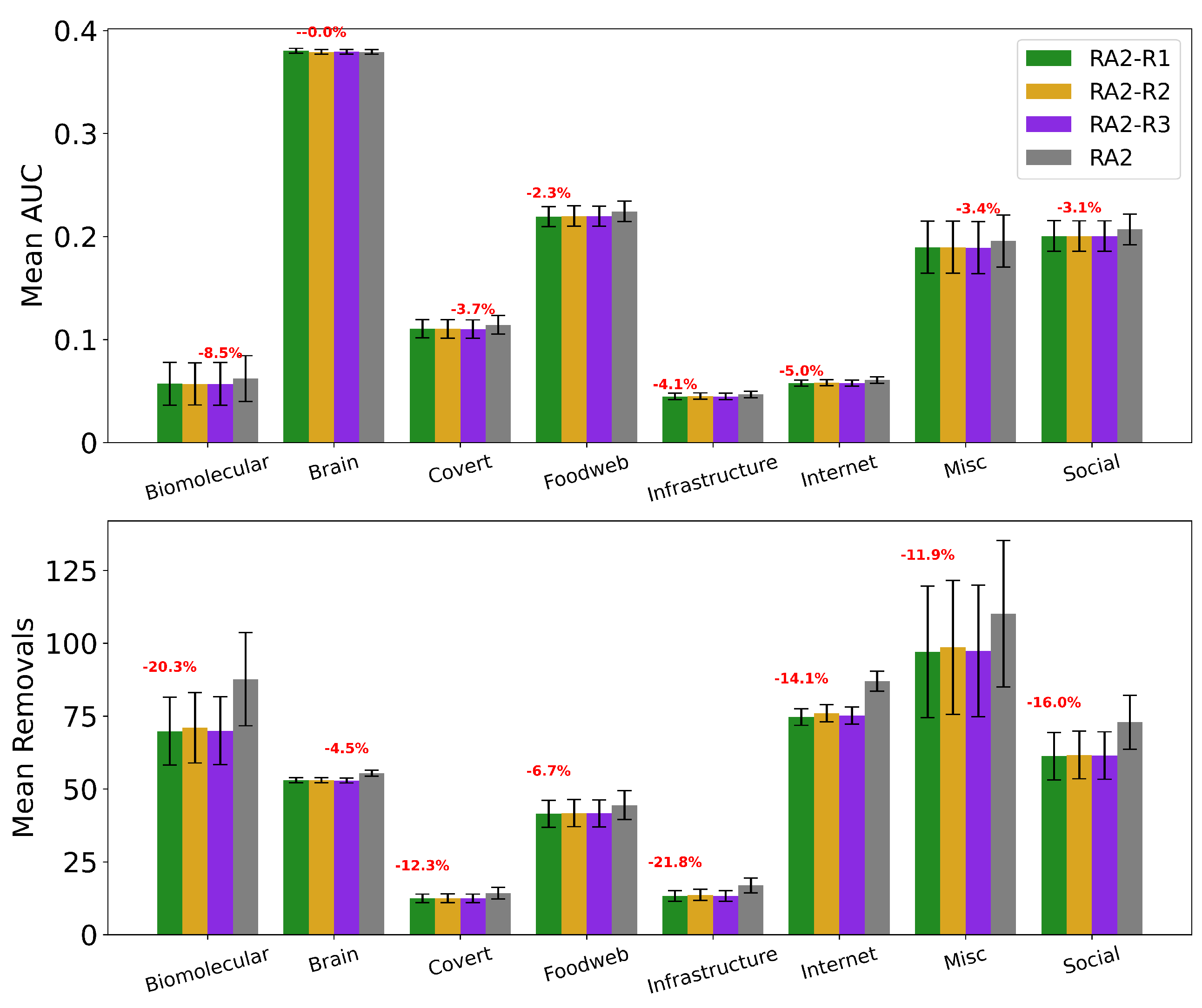
Table A6.
Percentage improvement for the mean AUC and mean number of removals for each reinsertion method over the baseline for CND and RA2 (). In bold the method that improves the baseline the most, by field.
Table A6.
Percentage improvement for the mean AUC and mean number of removals for each reinsertion method over the baseline for CND and RA2 (). In bold the method that improves the baseline the most, by field.
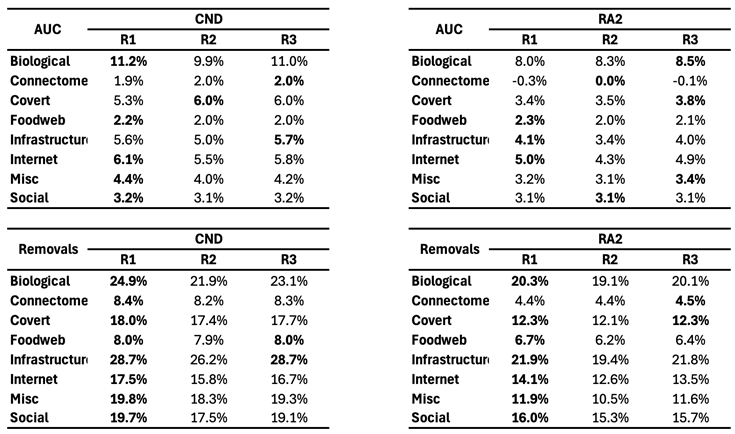
Table A7.
Full summary statistics of the ATLAS networks used in this study, averaged by field: number of subfields and networks, average number of nodes , number of edges , density , mean degree , characteristic path length , assortativity (Newman 2002), transitivity , mean local clustering coefficient , maximum k-core , average k-core , LCP-corr (Cannistraci et al. 2013), and modularity (Newman 2004)
Table A7.
Full summary statistics of the ATLAS networks used in this study, averaged by field: number of subfields and networks, average number of nodes , number of edges , density , mean degree , characteristic path length , assortativity (Newman 2002), transitivity , mean local clustering coefficient , maximum k-core , average k-core , LCP-corr (Cannistraci et al. 2013), and modularity (Newman 2004)
| Field | Biomolecular | Brain | Covert | Foodweb | Infrastructure | Internet | Misc | Social | Total |
| Subfields | 5 | 1 | 2 | 1 | 7 | 1 | 8 | 7 | 32 |
| Networks | 27 | 529 | 89 | 71 | 314 | 206 | 38 | 201 | 1,475 |
| 2,997 | 97 | 107 | 117 | 664 | 5,708 | 2,880 | 3,267 | ||
| 11,855 | 1,535 | 266 | 1,087 | 1,332 | 19,601 | 19,921 | 53,977 | ||
| 0.01 | 0.34 | 0.17 | 0.16 | 0.07 | 0.01 | 0.07 | 0.11 | ||
| 6.7 | 28.3 | 5.7 | 15.2 | 4.9 | 7.5 | 14.1 | 26.9 | ||
| 4.4 | 1.7 | 3 | 2.2 | 9.9 | 3.4 | 3.5 | 3.5 | ||
| -0.21 | -0.03 | -0.15 | -0.28 | -0.52 | -0.22 | -0.07 | -0.05 | ||
| 0.06 | 0.55 | 0.39 | 0.19 | 0.06 | 0.11 | 0.22 | 0.29 | ||
| 0.13 | 0.63 | 0.46 | 0.22 | 0.11 | 0.31 | 0.34 | 0.36 | ||
| 10.6 | 20.1 | 5.9 | 12.8 | 4.9 | 25 | 21.6 | 25.7 | ||
| 3.6 | 17.5 | 4.2 | 9.2 | 3 | 4 | 8.3 | 15.4 | ||
| 0.66 | 0.97 | 0.76 | 0.67 | 0.15 | 0.94 | 0.85 | 0.77 | ||
| 0.59 | 0.25 | 0.48 | 0.26 | 0.46 | 0.5 | 0.49 | 0.5 |
Table A8.
Number and size of real-world networks tested by dismantling algorithms. N denotes the number of nodes, E the number of edges.
Table A8.
Number and size of real-world networks tested by dismantling algorithms. N denotes the number of nodes, E the number of edges.
| Algorithm | Year | Networks | ||
|---|---|---|---|---|
| Collective Influence (CI) (Morone et al. 2016) | 2016 | 2 | 14M | 51M |
| CoreHD (Zdeborová et al. 2016) | 2016 | 12 | 1.7M | 11M |
| Explosive Immunization (EI) (Clusella et al. 2016) | 2016 | 5 | 50K | 344K |
| Min-Sum (MS) (Braunstein et al. 2016) | 2016 | 2 | 1.1M | 2.9M |
| Generalized Network Dismantling (GND) (Ren et al. 2019) | 2019 | 10 | 5K | 17K |
| Resilience Centrality (Zhang et al. 2020) | 2020 | 4 | 1K | 14K |
| Graph Dismantling Machine (GDM) (Grassia et al. 2021) | 2021 | 57 | 1.4M | 2.8M |
| CoreGDM (Grassia & Mangioni 2023) | 2023 | 15 | 79K | 468K |
| Domirank Centrality (Engsig et al. 2024) | 2024 | 6 | 24M | 58M |
| Fitness Centrality (Servedio et al. 2025) | 2025 | 5 | 297 | 4K |
| LGD-NA | 2025 | 1,475 | 23K | 507K |
Appendix G. Dynamic & Static Dismantling
In static dismantling, node scores are computed once at the beginning and are then removed in descending order of importance until the dismantling threshold is reached. In contrast, dynamic dismantling recomputes the scores after each removal. As shown in Figure A9, with CND given as an example, dynamic dismantling consistently outperforms static dismantling across all fields. Dynamic variants achieve lower AUC and fewer removals in every case, confirming the advantage of score recomputation.
Figure A9.
Mean AUC and number of removals for dynamic and static CND (. Error bars represent the standard error of the mean (SEM). Red text indicates the percentage improvement achieved by using dynamic over static variants.
Figure A9.
Mean AUC and number of removals for dynamic and static CND (. Error bars represent the standard error of the mean (SEM). Red text indicates the percentage improvement achieved by using dynamic over static variants.
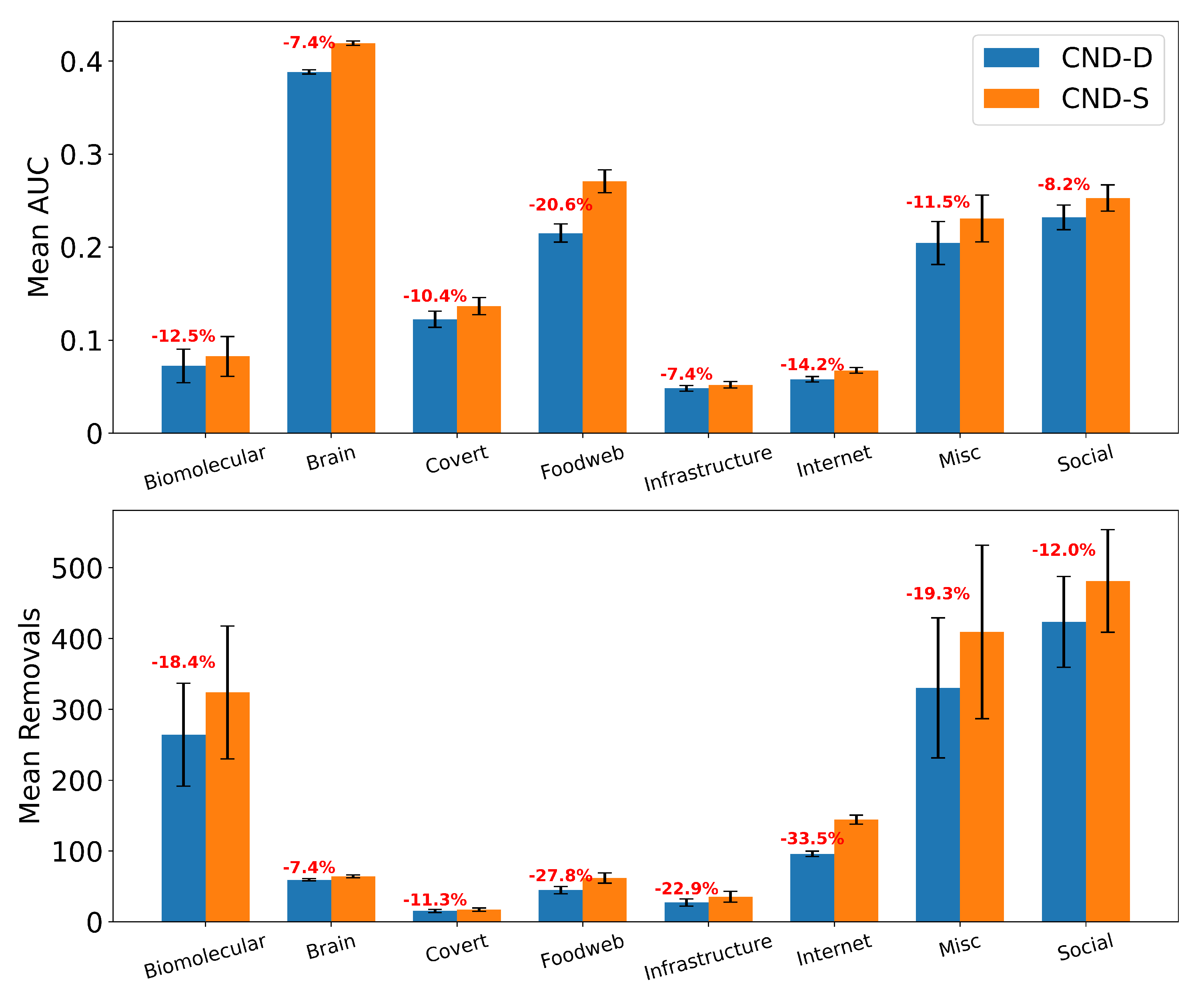
Table A9.
Percentage improvement for the mean AUC and mean number of removals for dynamic CND over static CND (), by field.
Table A9.
Percentage improvement for the mean AUC and mean number of removals for dynamic CND over static CND (), by field.
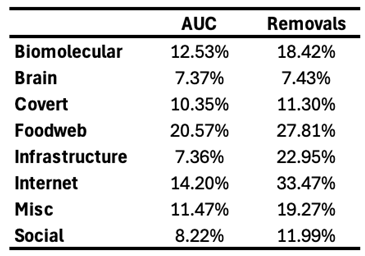
Figure A10.
Dismantling process on example networks comparing dynamic and static CND. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. Performance is evaluated using the Area Under the Curve (AUC) of the LCC trajectory.
Figure A10.
Dismantling process on example networks comparing dynamic and static CND. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. Performance is evaluated using the Area Under the Curve (AUC) of the LCC trajectory.
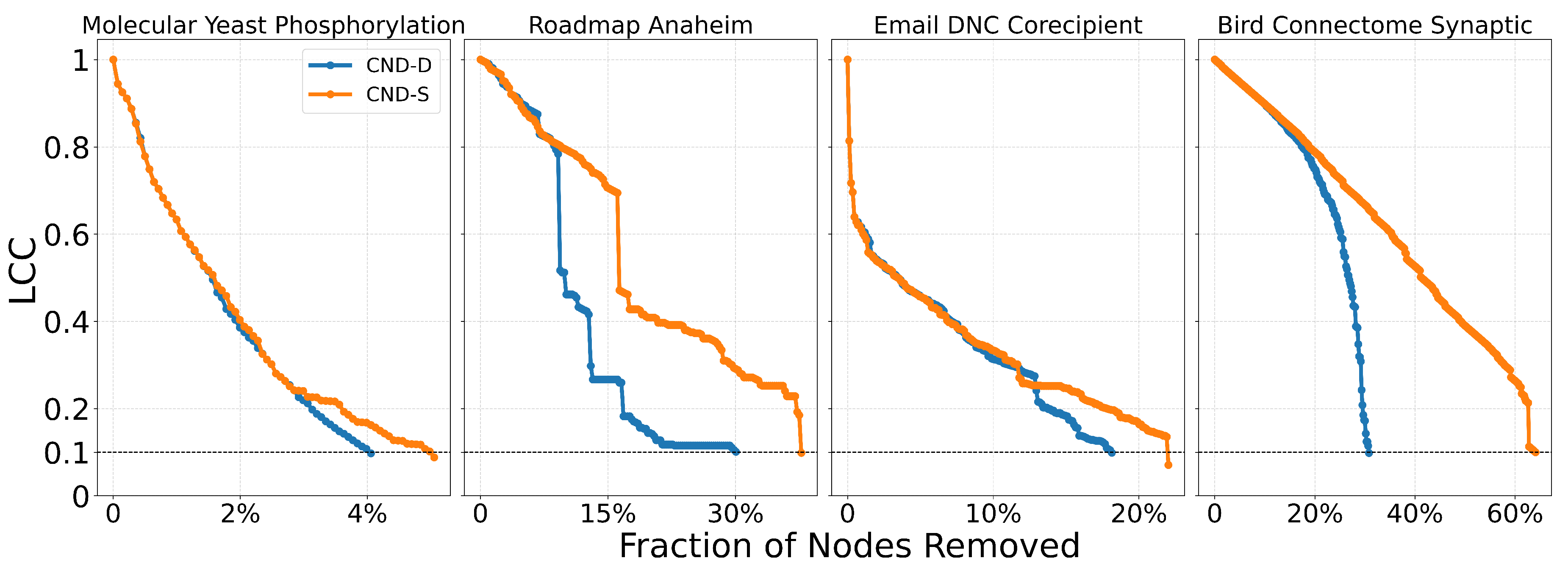
Appendix H. Engineering Network Robustness
Here, we would like to comment on the feasibility of our suggested network modifications in practical scenarios. In the case of PPI networks, recent advances in structural modeling of molecules using AlphaFold 3 (AF3) (Abramson et al. 2024) have reduced the longstanding limitations in testing and engineering arbitrary proteins. Coupling our dismantling predictions with AF3 could impact drug repositioning and drug design. For example, in the case of antibiotic-resistant bacteria, knowledge of how to dismantle the bacterial PPI network could be used to identify which proteins to target with repositioned, modified, or newly designed antibiotics. Meanwhile, to minimize side effects of newly designed drugs that target critical proteins in bacterial PPI networks, our reinforcement strategy based on common-neighbor generation could be applied to predict which protective bindings to promote in the human PPI network, thereby reducing the destructive impact of a drug on a critical human protein whose impairment could cause side effects. Finally, the application of the proposed common-neighbor reinforcement strategy to increase the robustness of flight and shipping networks is straightforward, as it can indicate which critical nodes should be reinforced by adding links between their adjacent nodes.
We validate our reinforcement strategy explained in Section 4.6 on three types of real-world networks considered critical: a human PPI network (biological), a flight map network (transportation with social and geographic constraints), and a shipping trade network (transportation with economic and geographic constraints). We select the top 1% of highest-scoring nodes according to the chosen measure (NBC or CND) and randomly add either 1% or 10% of the potential links between their respective adjacent nodes, thereby modifying the network topology according to the explainable rule discovered via CND.
Table A10.
Area Under the dismantling Curve (AUC) for NBC and CND on the original network and "reinforced" networks, by adding 1% and 10% of the links between common neighbors of the top 1% of nodes. In parentheses the increase in the AUC compared to the original network, representing the reduction in the dismantling effectiveness.
Table A10.
Area Under the dismantling Curve (AUC) for NBC and CND on the original network and "reinforced" networks, by adding 1% and 10% of the links between common neighbors of the top 1% of nodes. In parentheses the increase in the AUC compared to the original network, representing the reduction in the dismantling effectiveness.
| Human PPI | 0% Links | 1% Links | 10% Links | |
| NBC-baseline | 0.051 | |||
| NBC-reinforced | 0.093 (+84%) | 0.159 (+214%) | ||
| CND-baseline | 0.055 | |||
| CND-reinforced | 0.098 ((+79%)) | 0.198 ((+259%)) | ||
| Flight Map US | 0% Links | 1% Links | 10% Links | |
| NBC-baseline | 0.042 | |||
| NBC-reinforced | 0.067 (+61%) | 0.122 (+193%) | ||
| CND-baseline | 0.055 | |||
| CND-reinforced | 0.098 ((+95%)) | 0.172 ((+241%)) | ||
| Trade Shipping | 0% Links | 1% Links | 10% Links | |
| NBC-baseline | 0.138 | |||
| NBC-reinforced | 0.236 (+71%) | 0.240 (+74%) | ||
| CND-baseline | 0.220 | |||
| CND-reinforced | 0.298 ((+36%)) | 0.350 ((+59%)) |
Figure A11.
Dismantling curve on the original (solid) and reinforced networks (dashed). The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. Performance is evaluated using the Area Under the Curve (AUC) of the LCC trajectory.
Figure A11.
Dismantling curve on the original (solid) and reinforced networks (dashed). The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%. Performance is evaluated using the Area Under the Curve (AUC) of the LCC trajectory.
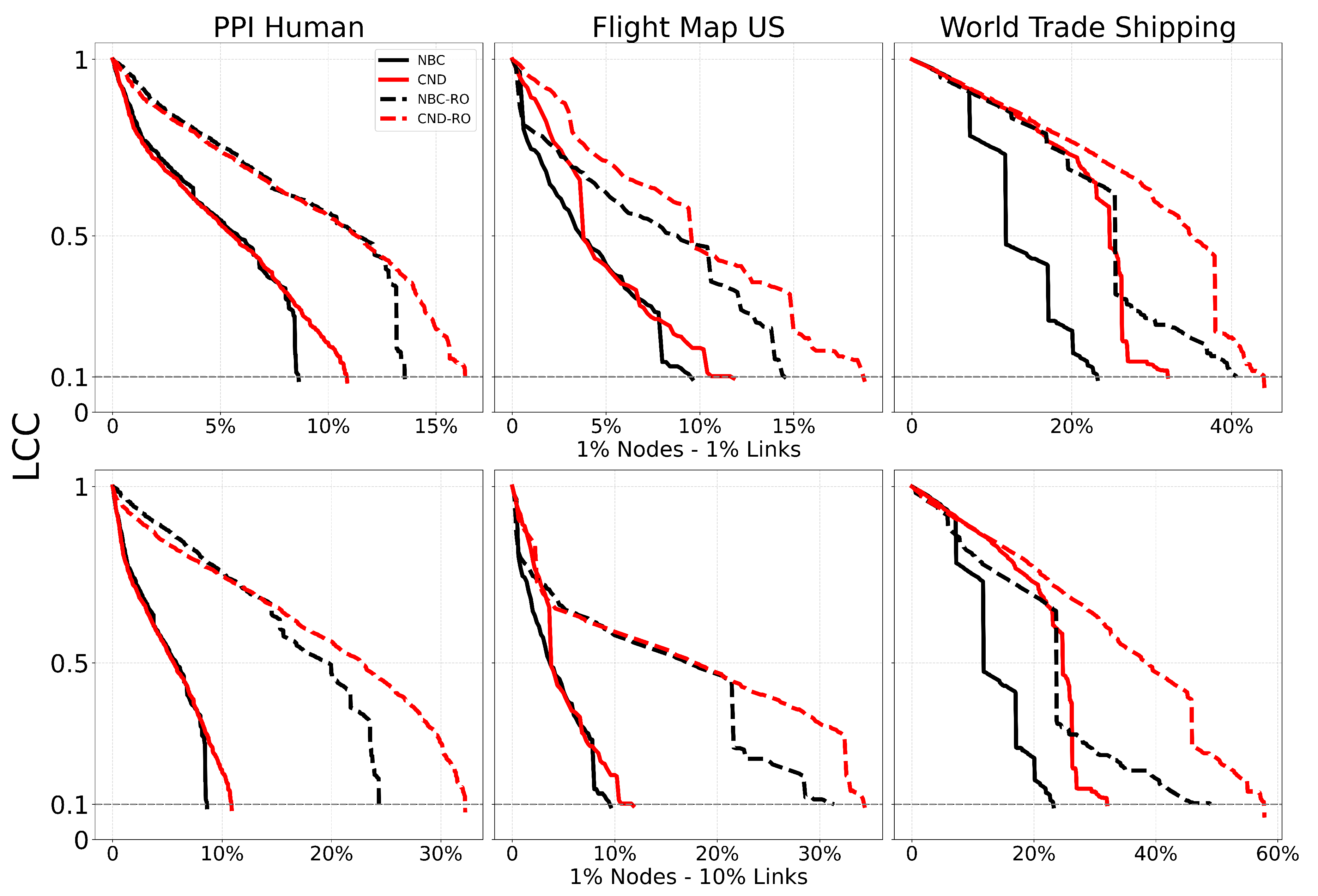
Our results in Figure 4 and Table A11 also confirm that engineering robustness translates into functional gains across the four real networks studied. Regarding Fault Tolerance, in the Drosophila Connectome and Flight Map, the analysis informs the design of fault-tolerant neuromorphic circuits and identifies critical hubs where reinforcement prevents systemic transport failure. For Security and Communications, in the adversarial systems (Terrorist Cell and School Contact Network), we can calculate the theoretical robustness ceiling, by accounting for unobserved links (e.g., dormant ties in covert networks) and quantify the margin of error required to successfully disrupt communications or secure the network against epidemics despite incomplete data.
Appendix I. Functional Metrics and Real-World Application Details
Table A11.
Network-specific evaluation metric and the original LCC AUC performance metric for four real-world networks, for NCB, CND, and RA2. N denotes the number of nodes, E the number of edges. Reinforced are the those reinforced by adding 10% of the links between common neighbors of the top 5% of nodes according to each method, as detailed in Appendix H. In red the improvement in robustness compared ot thhe baseline network, assuming that a higher value indicates worse dismantling performance, meaning the network is more robust. Specific functional metrics are detailed in Appendix I. In bold the best method for each metric and network.
Table A11.
Network-specific evaluation metric and the original LCC AUC performance metric for four real-world networks, for NCB, CND, and RA2. N denotes the number of nodes, E the number of edges. Reinforced are the those reinforced by adding 10% of the links between common neighbors of the top 5% of nodes according to each method, as detailed in Appendix H. In red the improvement in robustness compared ot thhe baseline network, assuming that a higher value indicates worse dismantling performance, meaning the network is more robust. Specific functional metrics are detailed in Appendix I. In bold the best method for each metric and network.
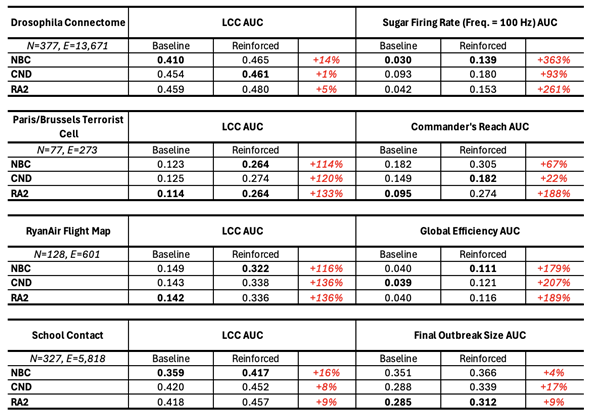
We now provide the specific experimental setup for the real-world functional experiments described in Appendix I. Unlike topological metrics (e.g., LCC size), these experiments measure the functional performance of the systems under dismantling.
- Drosophila Connectome:
We utilize the central brain connectome of Drosophila melanogaster (FlyWire), comprising over 125,000 neurons and 50 million synaptic connections. To assess functional performance, we employ a Leaky Integrate-and-Fire (LIF) spiking computational model, as established by Shiu et al. (2024). We focus on the sugar-sensing gustatory circuit (which results in a smaller subnetwork of 377 nodes and 13,671 edges), a critical pathway for feeding initiation. We simulate the activation of sugar-sensing Gustatory Receptor Neurons (GRNs), with a stimulation frequency of 100 Hz. We use the default parameters provided by Shiu et al. (2024), with the trial duration adjusted to 100 ms for the sake of time. The performance metric is the Motor Neuron Firing Rate, MN9. A dismantling attack is considered successful if the removal of specific interneurons prevents the propagation of the signal from the sensory GRNs to the motor neurons, causing the firing rate to drop.
- Paris/Brussels Terrorist Cell
We analyze the network of the terrorist cell responsible for the November 2015 Paris attacks and the 2016 Brussels bombings (Gutfraind & Genkin 2017), with 77 nodes and 271 edges. In adversarial networks, the ability of the leadership to communicate with the rest of the operational network, and vice versa, is crucial. As a result, we define Commander Reach as the percentage of network operatives (nodes) that retain a valid communication path to at least one of the three identified cell commanders.
- Ryanair Flight Map:
This network represents the flight routes of Ryanair in Europe (Cardillo et al. 2013), with 128 nodes and 601 edges. Nodes represent airports, and edges represent direct flight connections. We measure the functional integrity of the transport system using Global Efficiency (), rather than the Average Shortest Path Length (), because: is mathematically undefined (or diverges to infinity) when a network fragments into disconnected components, which inevitably occurs during dismantling. Global Efficiency avoids this divergence by averaging the inverse geodesic distances.
Where N is the number of airports and is the shortest path length between airport i and j. If no path exists, . This metric correctly quantifies the remaining communication capacity of a fragmented network.
- School Contact Network:
We utilize a contact network collected from a French high school (Mastrandrea et al. 2015), with 327 nodes and 5,818 edges, where nodes represent students and edges represent close-proximity physical contacts capable of disease transmission. We simulate the spread of an infectious disease using a classic Susceptible-Exposed-Infectious-Recovered (SEIR) compartmental model (Anderson & May 1991). Unlike basic SIR models, SEIR includes an "Exposed" state to account for the latency period typical of real-world pathogens. The simulation begins with 5% of nodes infected; over 200 discrete time steps, individuals progress from Susceptible (S) to Exposed (E) (based on contact with infected neighbors and rate ), then to Infected (I) (based on latency rate ), and finally to Recovered R (based on recovery rate ). These uniform parameters were selected to establish a generic baseline, ensuring that observed variations in outbreak size are attributable to network topology rather than pathogen-specific characteristics. We average the results of 50 independent simulations. The functional integrity of the network is measured by the Final Outbreak Size, defined as the total percentage of the population that was infected and subsequently recovered. The size is normalized with the size of the largest connected component, from which the epidemic starts from.
- Engineering Network Robustness Protocol:
To validate our method for "engineering robustness", we also reinforce these networks as defined in Section 4.7, choosing the top 5% of nodes and adding 10% of links, and rerun the dismantling process under the exact same conditions.
Table A11 shows the quantitative results for our original dismantling metric, LCC AUC, alongside the functional metrics defined above. Notably, both metrics yield highly similar rankings of the top methods, further validating our choice of LCC AUC as a robust evaluation standard.”
Appendix J. GPU Acceleration
Figure A12.
Running time (in seconds) comparison between CND on GPU and NBC on CPU on synthetic nPSO networks, as a function of network size in terms of edges. Experiments were conducted with network sizes ranging from 10 to 2,499,500 edges with densities () of 4%, 8%, and 20%, using fixed temperature and community counts scaled by network size ( for , for , for ). See Figure Table A35 for quantitative results.
Figure A12.
Running time (in seconds) comparison between CND on GPU and NBC on CPU on synthetic nPSO networks, as a function of network size in terms of edges. Experiments were conducted with network sizes ranging from 10 to 2,499,500 edges with densities () of 4%, 8%, and 20%, using fixed temperature and community counts scaled by network size ( for , for , for ). See Figure Table A35 for quantitative results.
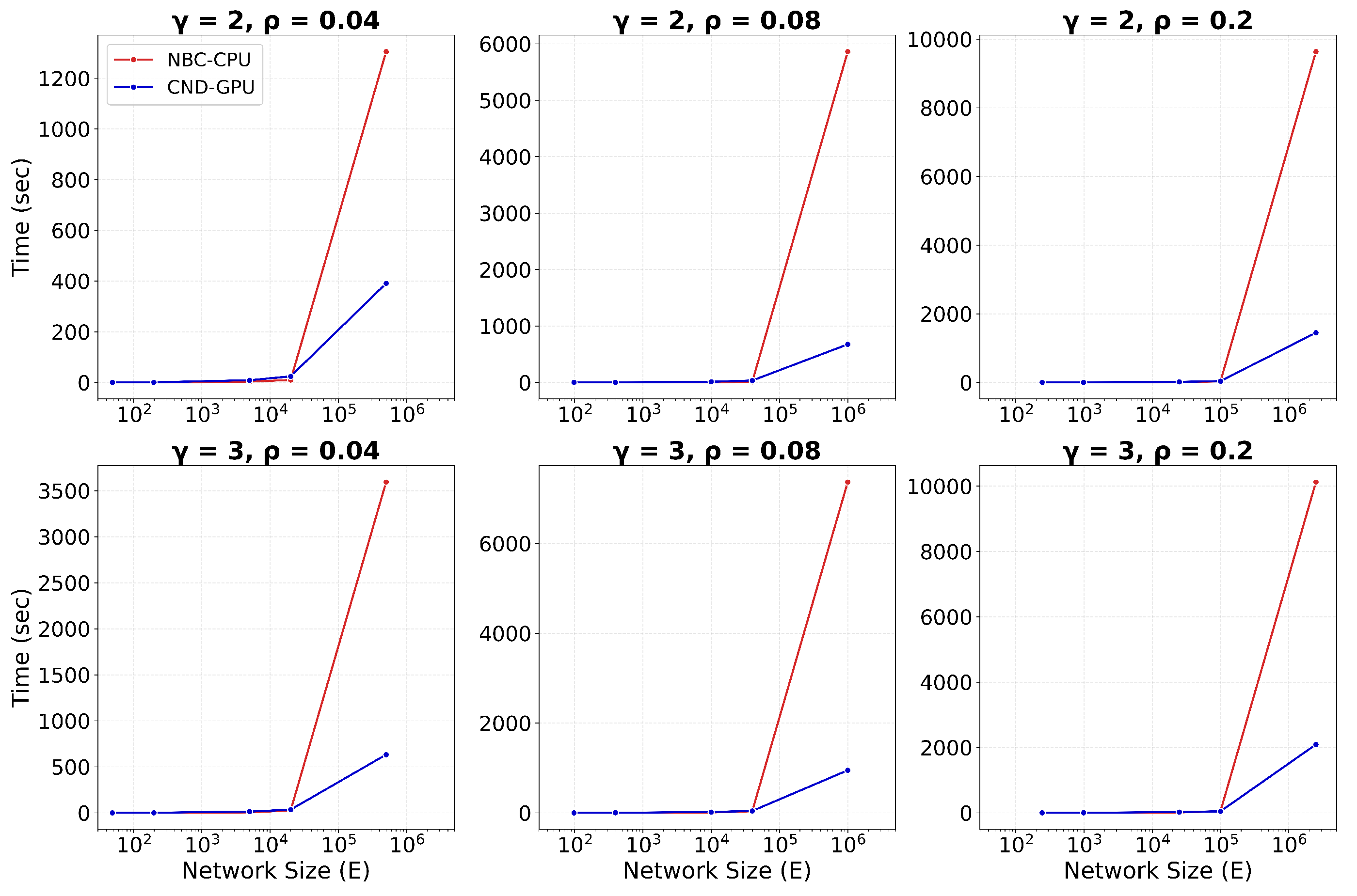
Figure A13.
Running time (in seconds) comparison between CND on GPU and NBC on CPU on synthetic nPSO networks, as a function of network size in terms of nodes. Experiments were conducted with network sizes ranging from 10 to 5,000 nodes with densities () of 4%, 8%, and 20%, using fixed temperature and community counts scaled by network size ( for , for , for ). See Figure Table A35 for quantitative results.
Figure A13.
Running time (in seconds) comparison between CND on GPU and NBC on CPU on synthetic nPSO networks, as a function of network size in terms of nodes. Experiments were conducted with network sizes ranging from 10 to 5,000 nodes with densities () of 4%, 8%, and 20%, using fixed temperature and community counts scaled by network size ( for , for , for ). See Figure Table A35 for quantitative results.
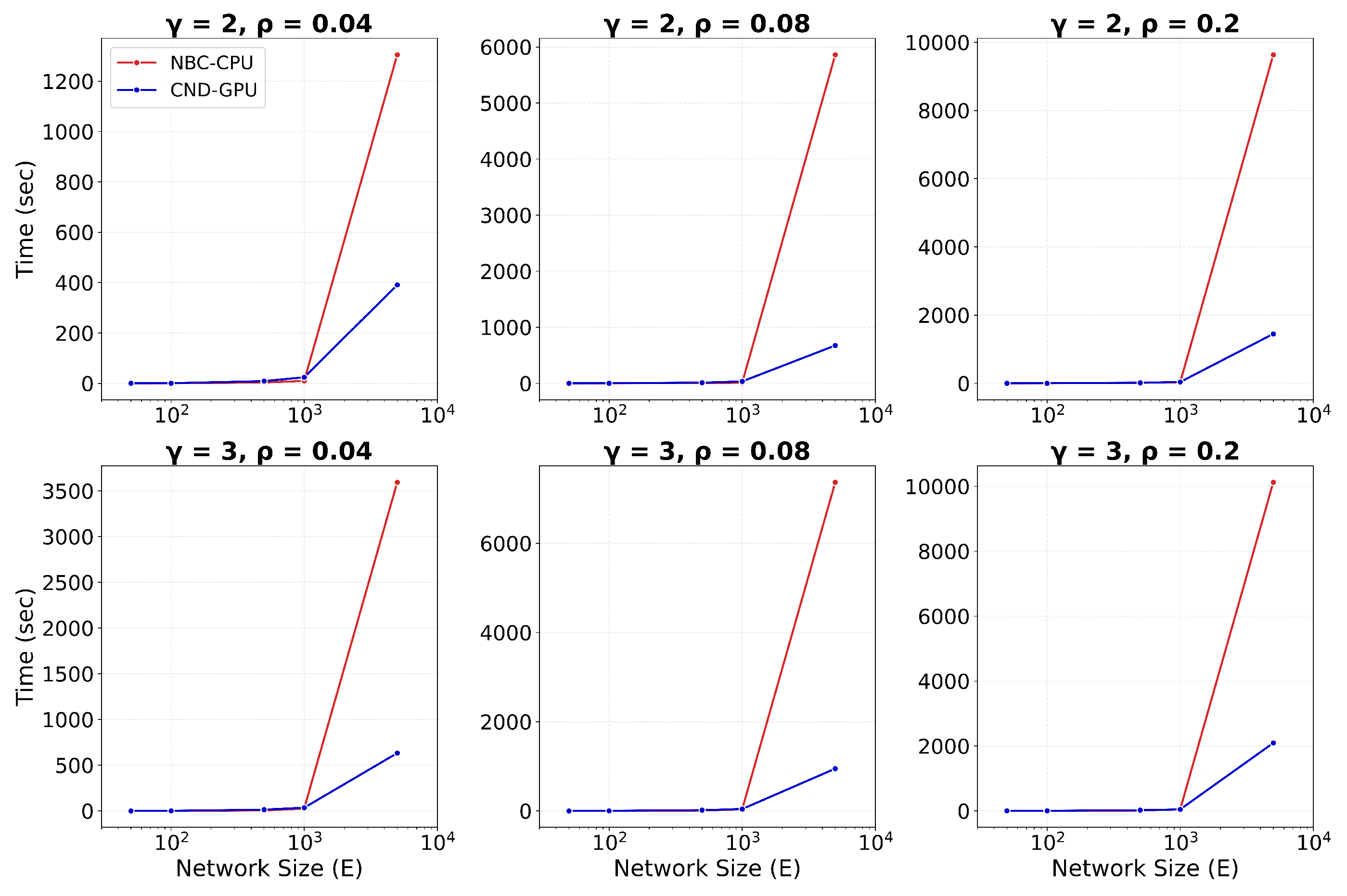
Figure A14.
Runtime (in hours) is plotted against network size, measured by the number of edges, E, for dynamic dismantling. The annotated time indicates the runtime for the largest network. Evaluated on networks of up to 23,000 nodes and 507,000 edges (). See Figure Table A12 for quantitative results.
Figure A14.
Runtime (in hours) is plotted against network size, measured by the number of edges, E, for dynamic dismantling. The annotated time indicates the runtime for the largest network. Evaluated on networks of up to 23,000 nodes and 507,000 edges (). See Figure Table A12 for quantitative results.
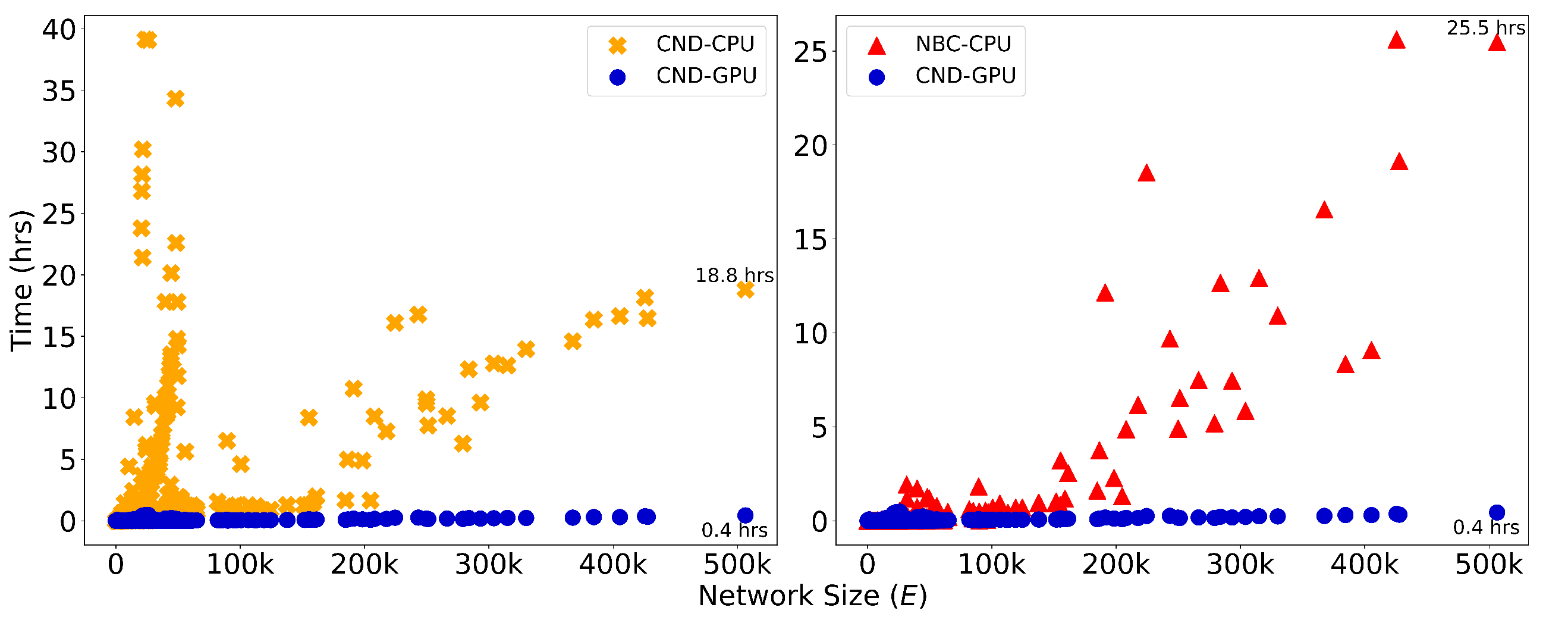
Table A12.
Average runtime (in seconds) and standard error of the mean (SEM) by field and method for dynamic dismantling. Evaluated on networks of up to 23,000 nodes and 507,000 edges (). In bold the fastest method per field. denotes average number of nodes and number of edges.
Table A12.
Average runtime (in seconds) and standard error of the mean (SEM) by field and method for dynamic dismantling. Evaluated on networks of up to 23,000 nodes and 507,000 edges (). In bold the fastest method per field. denotes average number of nodes and number of edges.
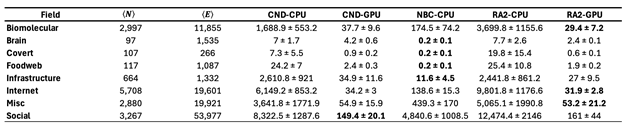
Table A13.
Runtime (in seconds) for NBC run on CPU (graph-tool) and GPU (cuGraph) on a subset of networks. N denotes the number of nodes and E the number of edges.
Table A13.
Runtime (in seconds) for NBC run on CPU (graph-tool) and GPU (cuGraph) on a subset of networks. N denotes the number of nodes and E the number of edges.
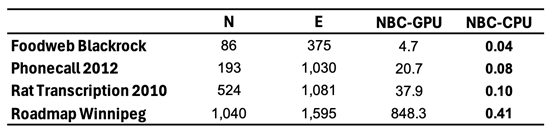
Since the difference in running time between the three LGD-NA methods is not relevant, neither for CPU nor GPU, we report the running time of the original RA2 in the main text (Figure 3) and the CND in the Appendix (Figure A14). When comparing CND and NBC, on the largest network, GPU-accelerated CND is over 46 times faster than its CPU counterpart and also over 63 times faster than NBC running on CPU.
To empirically validate these runtime advantages in a controlled setting, we conducted additional experiments using the nPSO model (Muscoloni & Cannistraci 2018b) with network sizes ranging from 10 to 5,000 nodes, and 10 to 2,499,500 edges, with densities of 4%, 8%, and 20%. We keep the temperature (lower temperature yields higher clustering) fixed () and adjust the number of communities to suit the size of the network ( for , for , for ). Our results demonstrate that GPU-accelerated LGD-NA methods begin to show running time advantages over NBC-CPU when networks exceed approximately 1,000 nodes (see Figure A13) or 100,000 edges (see Figure A12). This threshold aligns with our observations in real-world networks (see Figure 3 and Figure 3, and Table A12), where GPU methods achieve superior running times for larger-scale networks such as biomolecular, internet, and social networks, while offering no runtime benefit for smaller networks where CPU implementations remain efficient.
Section 4.5 details how we implement the RA-based measures for GPU, using matrix multiplication. We end up with the following formula for RA2:
and for CND:
In our experiments, the CPU-based RA2 and CND implementation uses Python’s NumPy (implemented in C) while the GPU implementation uses Python’s CuPy (implemented in C++/CUDA).
As mentioned earlier, we report only the CPU running time for NBC, as its GPU implementation did not yield any speedup. While some studies report GPU implementations of NBC with improved performance (Bernaschi et al. 2016; Fan et al. 2017; McLaughlin & Bader 2018; Pande & Bader 2011; Sariyüce et al. 2013; Shi & Zhang 2011), these are often limited by hardware-specific optimizations, data-specific assumptions (e.g., small-world, social, or biological networks), and using heuristics that are tailored to specific settings rather than offering general solutions. Moreover, publicly available code is rare, making these approaches difficult to reproduce or integrate. Overall, NBC is not naturally suited for GPU implementation, as it does not rely on matrix multiplication, but is based on computing shortest path counts between all node pairs. In our experiments, the CPU-based NBC implementation from Python’s graph_tool (implemented in C++), based on Brandes’ algorithm (Brandes 2001) with time complexity for unweighted graphs, outperformed the GPU version from Python’s cuGraph (implemented for C++/CUDA).
It is important to note that our LGD-NA implementation inherently utilizes a hybrid workflow: the sequential dismantling logic is managed by the CPU, while the expensive latent geometry estimations (relying on matrix multiplication) are offloaded to the GPU. This architecture is highly effective for LGD-NA but is not applicable to NBC. For NBC, the core computational burden is the calculation of all-pairs shortest paths, a task that does not lend itself well to GPU computations, meaning a hybrid pipeline yields no significant performance gain, and thus solely runs on CPU.
Appendix K. NBC Approximators
Table A14.
Average runtime (in seconds), AUC, and number of removals with their associated standard error of the mean (SEM) by field and method for dynamic dismantling. Evaluated where , , , , (). In bold the best method per field, by runtime, AUC, and number of removals. denotes average number of nodes and number of edges.
Table A14.
Average runtime (in seconds), AUC, and number of removals with their associated standard error of the mean (SEM) by field and method for dynamic dismantling. Evaluated where , , , , (). In bold the best method per field, by runtime, AUC, and number of removals. denotes average number of nodes and number of edges.
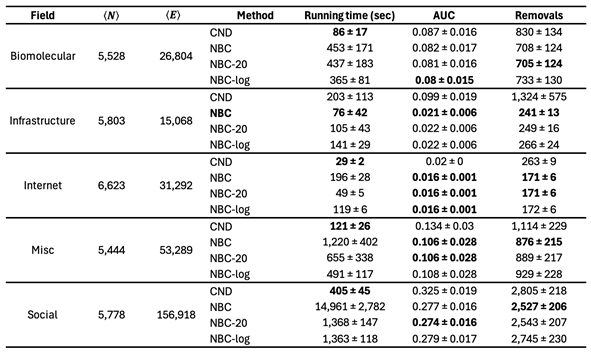
While the high computational cost of Node Betweenness Centrality (NBC) has motivated the development of numerous approximators (Bader et al. 2007; Bergamini & Meyerhenke 2015; Haghir Chehreghani 2013; Riondato & Kornaropoulos 2014), comparing against them is challenging due to the scarcity of standardized, publicly available code and the complexity of their sampling algorithms, which are often performant only for specific domains or incompatible with disconnected graph structures.
To address this, we implemented two standard randomized pivoting strategies for approximation. NBC-20 estimates betweenness centrality using a random sample of 20% of the nodes. NBC-log uses a random sample of nodes. NBC-20 prioritizes accuracy by always scanning a fixed slice of the network (20%), whereas NBC-log prioritizes speed by scanning a much smaller, logarithmically scaled subset that grows very slowly as the network gets larger. We evaluated these baselines against the exact NBC and our CND method on a subset of 157 networks selected for their size, where exact NBC calculation begins to become computationally expensive.
Table A14 reports the dismantling performance (AUC) and total runtime, averaged by field. First, we see that the NBC approximators perform comparably to the exact NBC, even occasionally outperforming it. However, this performance increase of NBC approximators should not be overstated due to the smaller sample size of this experiment. Second, while NBC approximators are significantly faster than exact NBC, CND remains faster than both approximation methods in almost all domains. A notable exception occurs in the Infrastructure field. Here, the usually slowest method NBC is actually the fastest in terms of total runtime because it takes a significantly lower number of removals to dismantle the network. Consequently, even though CND is faster per step, the NBC-based methods result in a lower total runtime simply because the dismantling threshold is reached much earlier.
Finally, it is critical to distinguish the theoretical foundations of these approaches. Existing NBC approximators focus on accelerating the estimation of a global metric. In contrast, LGD-NA leverages purely local topological information to directly estimate pairwise distances in the latent metric space. This distinction allows LGD-NA to bypass the need for global knowledge or more complex sampling strategies. Although approximation techniques improve NBC’s speed, their reliance on sampling global paths is inherently less efficient than our strictly local approach, as we validate in Table A14. Furthermore, sampling global information remains vulnerable to missing data and adversarial noise. The strength of LGD-NA, therefore, lies in its ability to achieve high dismantling performance by directly utilizing local geometric insights, rather than attempting to approximate a computationally intensive global metric.
Appendix L. Application to Directed Networks
While network dismantling has primarily targeted undirected networks Artime et al. (2024), many critical real-world systems, such as neural circuits, social media platforms, and financial transaction systems, are inherently directed. Although our LGD-NA framework is designed for undirected network, we explore its applicability to directed graphs. Research on directed network dismantling is relatively underexplored. Directed Node Entanglement (DNE) (Wu et al. 2025) generalizes the network density matrix to specifically capture and disrupt directed information flow within a system. Ma et al. (2022) utilizes the non-backtracking matrix to identify and remove the minimum set of nodes connecting distinct edge modules. Dismantling on Signed Networks based on Evolutionary Deep Reinforcement Learning (DSEDR) (Ou et al. 2024) is an evolutionary deep reinforcement learning approach designed to dismantle signed networks by optimizing a novel objective function. Embedding-based Signed Network Dismantling (ESND) (Xie et al. 2025) combines giant component detection, network embedding, and node clustering to identify critical nodes.
We evaluate our LGD-NA framework on directed graphs using two approaches: applying the original method (treating the graph as undirected) and a directed variant where node scores are computed aggregating only outgoing links. For comparison, we implement Directed Node Entanglement (DNE) as a baseline specific to directed networks. We exclude other methods—such as the set-based approach of Ma et al. (2022) and the complex, multi-step frameworks of DSEDR and ESND—to maintain a focused comparison on computationally efficient, node-ranking strategies.
Table A15.
LCC AUC for the three LGD-NA estimators treating a directed network as undirected, their directed variant, and DNE, a specific directed network dismantling method. In bold the best performing method per network. N denotes the number of nodes and E the number of edges.
Table A15.
LCC AUC for the three LGD-NA estimators treating a directed network as undirected, their directed variant, and DNE, a specific directed network dismantling method. In bold the best performing method per network. N denotes the number of nodes and E the number of edges.
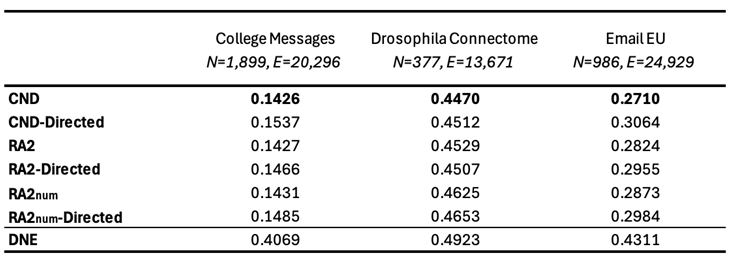
We focus on three directed networks from different fields. College Messages (Social) (Panzarasa et al. 2009) represents private messages on a social network at UC Irvine (1,899 nodes, 20,296 edges). Drosophila Connectome (Brain) (Shiu et al. 2024), focuses on the sugar-sensing gustatory circuit (377 nodes, 13,671 edges). Email EU (Social)(Paranjape et al. 2017) are anonymized internal emails from a European research institution (986 nodes, 24,929 edges).
Table A15 shows two key results. First, for our LGD-NA framework, treating directed networks as undirected yields superior dismantling performance over our directed variant. Second, even when applied in this undirected way, LGD-NA outperforms the directed-specific DNE baseline, demonstrating its effectiveness on directed networks.
Finally, our framework is predicated on the association between network topology and a latent geometry. For directed networks, this relationship is less established, with only preliminary studies (Allard et al. 2024). Therefore, designing asymmetric network measures that account for directional flow remains an open challenge, yet a promising direction for future research.
Appendix M. Experimental Setup
- Baseline Topological Centrality Measures.
We selected centrality measures to cover diverse categories: shortest path-based (NBC), degree-based (degree), walk-based (eigenvector), random walk-based (PageRank), resilience-based (Resilience), and fitness-based (Domirank and Fitness centrality). We also tested closeness and load centrality, but both performed worse than NBC and rely on the same shortest-path principle; thus, we retained NBC. Similarly, Katz centrality underperformed compared to eigenvector centrality and is also based on spectral properties of the adjacency matrix. For DomiRank, we tested three values for the numerator in the parameter formula: 0.1, 0.5, and 0.9. While the original study sometimes performs a grid search to find the optimal per network, this is not feasible for our large-scale evaluation. Instead, we selected a representative range and found that yielded the best performance, and we report that value. The parameter controls the balance between local degree-based dominance and global network-structure-based competition. As , the scores approximate degree centrality. As increases, nodes are evaluated in increasingly competitive environments, where centrality depends more on non-local structural dominance than individual connectivity. For Fitness centrality, we capped the number of iterations at . Without this cap, the method took a prohibitively long time to converge, especially on large networks.
- Baseline Dismantling Methods.
We selected the best-performing and most widely adopted dismantling algorithms from the literature (Artime et al. 2024). As mentioned earlier, we did not include BPD and FINDER in our experiments due to unavailable and outdated code, respectively. For Collective Influence (CI), we tested values , where ℓ defines the radius of a ball centered at node i, and is the frontier at distance ℓ (i.e., nodes exactly ℓ hops away). We found that performed best across our benchmarks and report this setting, while performed the worst. For Explosive Immunization (EI), we evaluated both scores and . The score targets high-connectivity nodes to rapidly fragment the network early on. The score aims to prevent large cluster merges near the percolation threshold by avoiding the connection of separate components. We found that consistently outperformed , and thus we use it in our final experiments. For eigenvector centrality, we capped the number of power iterations at to avoid long or unbounded runtimes, since convergence can be very slow in large networks. For PageRank, we used a convergence tolerance of , as the algorithm runs until the change in scores falls below this threshold.
- LGD-NA Measures.
Our analysis of pure win rates (draws are excluded) in Table A16 reveals distinct domain-specific strengths. CND achieves the highest win rate in Biomolecular, Foodweb, Infrastructure, Internet, and Social networks. In contrast, RA2 is the preferred method for Brain and Covert networks. Notably, RA2num does not emerge as the top-performing method in any of the tested domains.
Table A16.
Pure win rate (draws excluded), for LGD-NA measures, without reinsertion (). In bold the method with the highest win rate per field.
Table A16.
Pure win rate (draws excluded), for LGD-NA measures, without reinsertion (). In bold the method with the highest win rate per field.
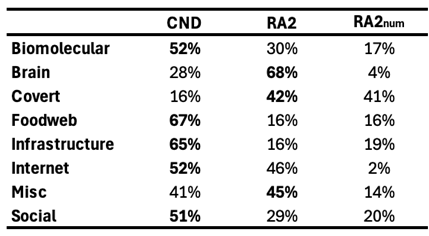
- Robustness to Threshold Variations.
As shown in Table A17, the mean field rankings of the methods are broadly consistent across removal thresholds of 10%, 25%, and 50%. While permutations occur, the dominance of NBC and CND is consistent across different thresholds, confirming that our conclusions are not artifacts of the 10% threshold.
Table A17.
Mean field ranking with standard error of the mean (SEM), for different threshold levels (). In bold the best method per threshold.
Table A17.
Mean field ranking with standard error of the mean (SEM), for different threshold levels (). In bold the best method per threshold.
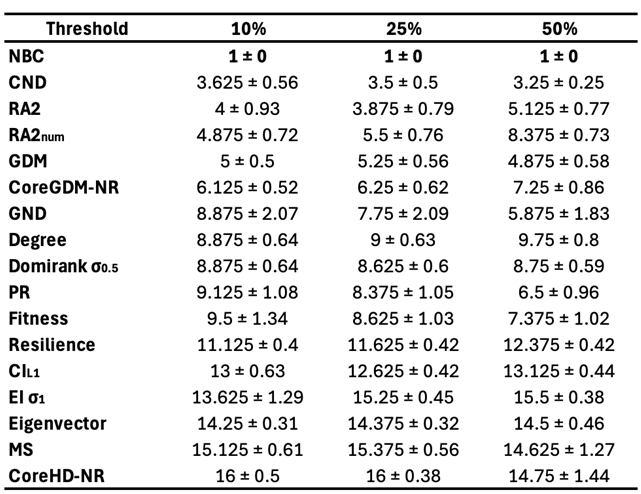
- Note on Reinsertion.
We did not apply reinsertion techniques on all networks included in the initial dismantling experiments. In some cases, certain methods performed so poorly that applying reinsertion became prohibitively slow. To ensure consistency, we excluded these networks from the reinsertion analysis for all methods. Specifically, we imposed a cutoff: networks were excluded if any method required more than 800 node removals to reach the dismantling threshold. Based on this criterion, 59 networks were excluded.
- LCC AUC as the evaluation metric.
We employ LCC AUC as our primary evaluation metric because it provides a unified standard for comparing methods across 32 distinct complex system domains. As the established standard in the vast majority of dismantling studies (Artime et al., 2024), it allows for direct comparisons between diverse networks from disparate fields and different dismantling algorithms. While dynamical metrics offer specific insights, simulating ’live’ system dynamics for every network is computationally unfeasible and conceptually inconsistent given the broad scope of domains. Crucially, our functional analysis in Section 4.7 demonstrates that rankings based on LCC AUC align closely with domain-specific functional metrics, validating LCC fragmentation as a reliable proxy for functional disruption. Note that a lower number of removals does not always imply a lower AUC. Our AUC metric rewards methods that fragment the network early, even if they require more steps to reach the dismantling threshold. As shown in Figure A15, we show cases where a method that reaches the threshold with more removals can still achieve a lower AUC, due to earlier damage to the network structure.
Figure A15.
Dynamic dismantling process on example networks comparing CND, RA2 and , showing a lower removal number does not necessarily mean a lower Area Under the Curve (AUC) of the LCC trajectory. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%.
Figure A15.
Dynamic dismantling process on example networks comparing CND, RA2 and , showing a lower removal number does not necessarily mean a lower Area Under the Curve (AUC) of the LCC trajectory. The plot shows the normalized size of the largest connected component (LCC) as a function of the fraction of nodes removed, with a target LCC threshold of 10%.
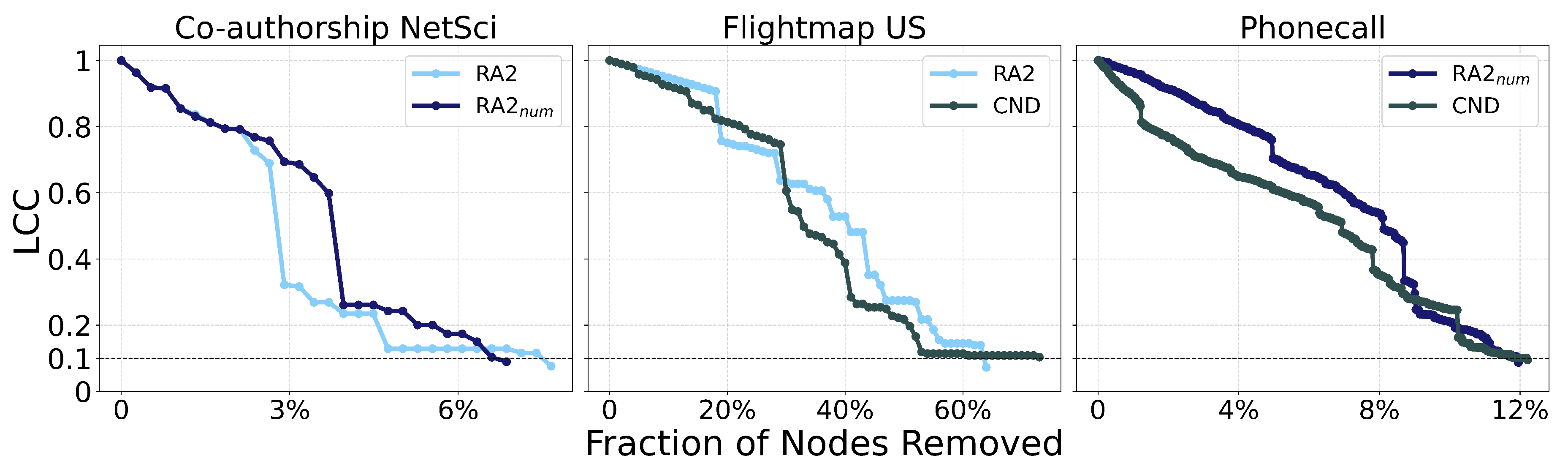
Appendix N. Technical Implementation and Reproducibility
- Code.
All our methods are implemented in our codebase, available in the supplementary material. We implement RA2, RA2num, CND, NBC, as well as degree and eigenvector centrality. We also adapt and integrate the original implementations of Domirank centrality and Fitness centrality. Since no code was available for Resilience centrality, we implemented it ourselves based on the original description in the paper. Instructions for running these methods and reproducing the experiments are included in the supplementary material. We also provide a representative network from the ATLAS dataset for testing purposes. For GDM, CoreGDM, GND, CI, EI, MS, and CoreHD, we use the publicly available code from Artime et al. (2024)’s review.
- Computational Resources.
All experiments were conducted on a machine equipped with an AMD Ryzen Threadripper PRO 3995WX CPU (64 cores), 251 GiB of RAM, and a single NVIDIA RTX A4000 GPU with 16 GiB of memory. All code was implemented in Python, with dependencies and library versions specified in the supplementary material to ensure full reproducibility.
- Quantitative Results.
Appendix O. Discussion, Limitations, and Future Work
- Missing or Manipulated Data.
The robustness of our LGD-NA methods to missing or manipulated information, such as missing neighbor data or adversarial modifications to neighborhood structure, is a crucial question for practical applications of any network analysis method, especially those relying on local information. Our LGD-NA methods, by design, are inherently more robust to global missing or manipulated information compared to methods that require a complete global view of the network (e.g., exact NBC). Since our methods rely solely on local neighborhood information, random missing data across the network would primarily affect only the scores of directly impacted nodes, rather than propagating errors throughout the entire graph. Similarly, adversarial modifications would need to target specific local neighborhoods to significantly alter a node’s dismantling score, making large-scale, coordinated attacks more challenging than for global metrics. However, we acknowledge that direct adversarial manipulation of a node’s immediate neighborhood could indeed impact its calculated score.
- Weighted Networks.
While many real-world systems, such as citation networks, neural synaptic connections, transportation and trade networks, contain directed interactions, our LGD-NA measures focus on unweighted topologies for two key reasons. First, in practical dismantling contexts, weight data is often dynamic, temporal, or unavailable, whereas topology is more robust. Second, current state-of-the-art dismantling algorithms focus on unweighted graphs (Artime et al. 2024), making fair comparisons impossible. Consequently, we consider the extension of latent-geometry approaches to weighted graphs as a promising avenue for future work.
- Limitations.
A limitation of this study is the mismatch between theoretical and observed runtimes, which can vary across methods. These differences stem from factors such as the programming language used, hardware acceleration, and implementation-level optimizations. However, all experiments were run on the same CPU and GPU to ensure a fair comparison, and we made a strong effort to optimize all methods both in terms of runtime and dismantling performance. For example, we tested different parameters for Domirank, CI, and EI, and evaluated multiple variants of shortest path-based and spectral partitioning-based centrality measures. Furthermore, we were unable to test on extremely large networks due to hardware constraints and the high computational cost of running a broad set of dismantling methods. However, we are confident that our results would generalize to larger networks, given the diversity of the 1,475 networks tested, spanning a wide range of domains and sizes from very small to large. Another limitation relates to the parameter tuning required by some baseline methods, especially machine learning-based approaches and Domirank. Due to the scale of our experimental setup—both in the number and size of networks—we were unable to perform extensive tuning. Although targeted tuning could enhance performance for specific methods on individual networks, it would compromise consistency across the wide range of complex systems domains considered. In contrast, LGD-NA requires no parameter tuning and consistently achieves strong, generalizable performance across all tested networks.
- Future Work.
Future research could further explore latent geometry, particularly how to effectively combine local and global information in dismantling strategies. Improving the scalability of matrix-based computations, especially for very large and sparse networks, is another important direction. There is also a need for more cost-efficient dynamic dismantling strategies that reduce the overhead of recomputing scores after every node removal without significantly sacrificing performance. In addition, edge dismantling remains a relatively underexplored area compared to node-based dismantling, and it would be valuable to investigate whether latent geometry-driven principles can also guide the efficient removal of links in complex networks. Targeting edges can be just as important as targeting nodes, and in many real-world systems, such as transportation networks (railroads, roads, subways, or shipping trade routes), edge removal may represent the more realistic and sensible threat scenario, making it highly relevant for dismantling strategies. Finally, our work can also be of interest to Explainable AI (XAI) for models like GNNs and Reservoir Computers (RC). By identifying critical (dismantling) or unimportant (percolation) nodes in a network, we can conduct "perturbation experiments" to assess their impact on an ML model’s performance. This process reveals which parts of the graph are most crucial for the model’s predictions or computations, effectively opening the model’s “black box” and providing crucial insights into its internal decision-making, robustness, and vulnerabilities.
Appendix P. Ethics Statement
The research on network dismantling presented in this paper has a potential for dual use. The techniques developed to identify and exploit network vulnerabilities could theoretically be used to design targeted attacks on critical systems, such as communication, transportation, or power grid networks. However, it can also be used for defensive strategies. A thorough understanding of network vulnerabilities is a prerequisite for designing robust systems. To directly address the dual-use concern, we demonstrate the constructive potential of our work by presenting a novel technique for proactively engineering network robustness using our latent geometry-based methods (see Section 4.6). This application moves beyond vulnerability analysis to provide an explainable framework for modifying a network to enhance its resilience. Finally, by openly publishing our theoretical foundations, source code, and comprehensive evaluations, we aim to ensure that the benefits of this research, namely the ability to secure critical networks, are accessible to all. We believe the societal benefit of advancing defensive capabilities significantly outweighs the risk of potential misuse.
Appendix Q. Reproducibility Statement
To ensure full reproducibility, we have made our source code publicly available, including detailed instructions on how to replicate all experiments. The codebase includes an implementation of our LGD-NA framework (illustrated in Figure 1), the exact formulas used (detailed in Appendix A), and an example network for demonstration. The code is compatible with both CPU and GPU environments and also provides the necessary tools to engineer network robustness as described in this work. The baseline methods were implemented using the code from the review by Artime et al. (2024). The exact topological measures of all networks used in our study are provided in Appendix Table A7. Further details regarding the experimental setup, including hardware specifications, are described in Appendix M and Appendix N.
Appendix R. Claim of the LLM Usage
We used LLM-based tools to improve the language and flow; the principles, core logic, and innovations are entirely the authors’.
Supplementary Material
Table A18.
Pearson correlation between between all the pairwise hyperbolic distances of the network nodes in the original nPSO model and in the reconstructed hyperbolic space (HD-correlation) (Muscoloni et al. 2017). Mean values over 10 seeds and Standard Error of the Mean (SEM) are reported, and the Fisher p-value in parentheses. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. Fixed parameters are the number of nodes, , and the number of communities, . The temperature T controls the level of clustering (lower temperatures yield stronger clustering).
Table A18.
Pearson correlation between between all the pairwise hyperbolic distances of the network nodes in the original nPSO model and in the reconstructed hyperbolic space (HD-correlation) (Muscoloni et al. 2017). Mean values over 10 seeds and Standard Error of the Mean (SEM) are reported, and the Fisher p-value in parentheses. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. Fixed parameters are the number of nodes, , and the number of communities, . The temperature T controls the level of clustering (lower temperatures yield stronger clustering).
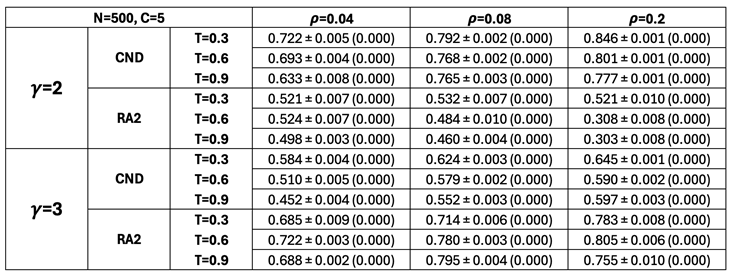
Table A19.
Pearson correlation between estimated link weights from CND and RA2 versus true geometric distances in nPSO networks. Mean values over 10 seeds are reported, with a color gradient where green corresponds to values approaching 1 and red to values approaching -1. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. The temperature T controls the level of clustering (lower temperatures yield stronger clustering). Fixed parameters are the number of nodes, , and the number of communities, . Standard Error of the Mean (SEM) and Fisher p-value are found in Table A20.
Table A19.
Pearson correlation between estimated link weights from CND and RA2 versus true geometric distances in nPSO networks. Mean values over 10 seeds are reported, with a color gradient where green corresponds to values approaching 1 and red to values approaching -1. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. The temperature T controls the level of clustering (lower temperatures yield stronger clustering). Fixed parameters are the number of nodes, , and the number of communities, . Standard Error of the Mean (SEM) and Fisher p-value are found in Table A20.
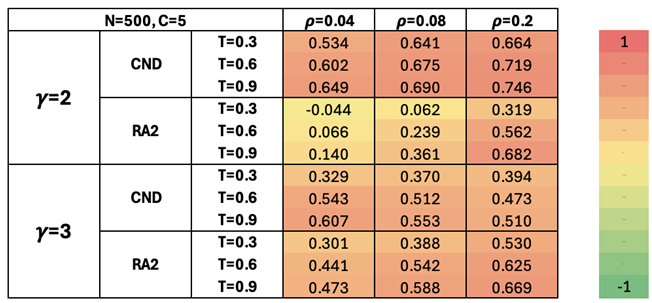
Table A20.
Pearson correlation between estimated link weights from CND and RA2 versus true geometric distances in nPSO networks. Mean values over 10 seeds is reported and Standard Error of the Mean (SEM) are reported, and the Fisher p-value in parentheses. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. Fixed parameters are the number of nodes, , and the number of communities, . The temperature T controls the level of clustering (lower temperatures yield stronger clustering).
Table A20.
Pearson correlation between estimated link weights from CND and RA2 versus true geometric distances in nPSO networks. Mean values over 10 seeds is reported and Standard Error of the Mean (SEM) are reported, and the Fisher p-value in parentheses. The power-law exponent represents the scale-freeness found in real-world networks. networks. is the density of the networks. Fixed parameters are the number of nodes, , and the number of communities, . The temperature T controls the level of clustering (lower temperatures yield stronger clustering).
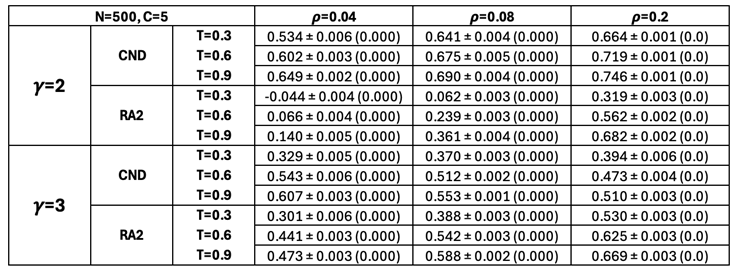
Table A21.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method (). In bold the best method per field.
Table A21.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method (). In bold the best method per field.
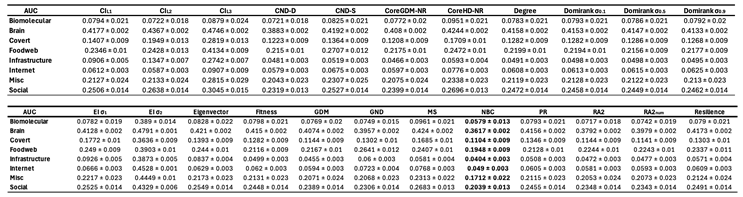
Table A22.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method (). In bold the best method per field.
Table A22.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method (). In bold the best method per field.
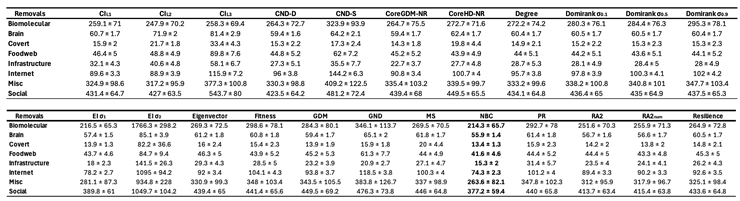
Table A23.
Ranking per field for selected dismantling method (). In bold the best method per field.

Table A24.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method, for reinsertion method R1, (). In bold the best method per field.
Table A24.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method, for reinsertion method R1, (). In bold the best method per field.

Table A25.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method, for reinsertion method R1, ().In bold the best method per field.
Table A25.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method, for reinsertion method R1, ().In bold the best method per field.

Table A26.
Ranking per field for selected dismantling method, for reinsertion method R1, (). In bold the best method per field.
Table A26.
Ranking per field for selected dismantling method, for reinsertion method R1, (). In bold the best method per field.

Table A27.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method, for reinsertion method R2, (). In bold the best method per field.
Table A27.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method, for reinsertion method R2, (). In bold the best method per field.

Table A28.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method, for reinsertion method R2, (). In bold the best method per field.
Table A28.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method, for reinsertion method R2, (). In bold the best method per field.

Table A29.
Ranking per field for selected dismantling method, for reinsertion method R2, (). In bold the best method per field.
Table A29.
Ranking per field for selected dismantling method, for reinsertion method R2, (). In bold the best method per field.

Table A30.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method, for reinsertion method R3, (). In bold the best method per field.
Table A30.
Mean and standard error of the mean (SEM) for the AUC per field, by dismantling method, for reinsertion method R3, (). In bold the best method per field.

Table A31.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method, for reinsertion method R3, (). In bold the best method per field.
Table A31.
Mean and standard error of the mean (SEM) for the number of removals per field, by dismantling method, for reinsertion method R3, (). In bold the best method per field.

Table A32.
Ranking per field for selected dismantling method, for reinsertion method R3, (). In bold the best method per field.
Table A32.
Ranking per field for selected dismantling method, for reinsertion method R3, (). In bold the best method per field.

Table A33.
Ranking per field for selected dismantling method with their best-performing reinsertion method (). In bold the best method per field.
Table A33.
Ranking per field for selected dismantling method with their best-performing reinsertion method (). In bold the best method per field.

Table A34.
Average AUC by field for top two performing methods: NBC and CND, under different reinsertion methods () and without reinsertion (). In bold the best method per field and reinsertion method.
Table A34.
Average AUC by field for top two performing methods: NBC and CND, under different reinsertion methods () and without reinsertion (). In bold the best method per field and reinsertion method.
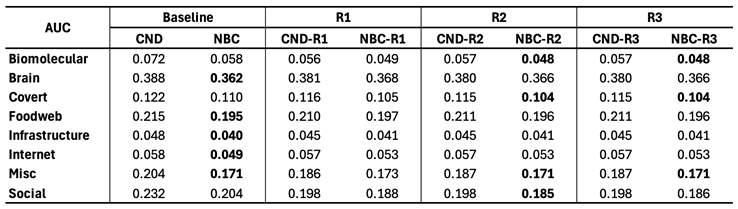
Table A35.
Running time (in seconds) comparison between CND on GPU and NBC on CPU on synthetic nPSO networks. Experiments were conducted with network sizes ranging from 10 to 5,000 nodes and densities () of 4%, 8%, and 20%, using fixed temperature and community counts scaled by network size ( for , for , for ). In bold the fastest method per network. N denotes number of nodes and E number of edges.
Table A35.
Running time (in seconds) comparison between CND on GPU and NBC on CPU on synthetic nPSO networks. Experiments were conducted with network sizes ranging from 10 to 5,000 nodes and densities () of 4%, 8%, and 20%, using fixed temperature and community counts scaled by network size ( for , for , for ). In bold the fastest method per network. N denotes number of nodes and E number of edges.
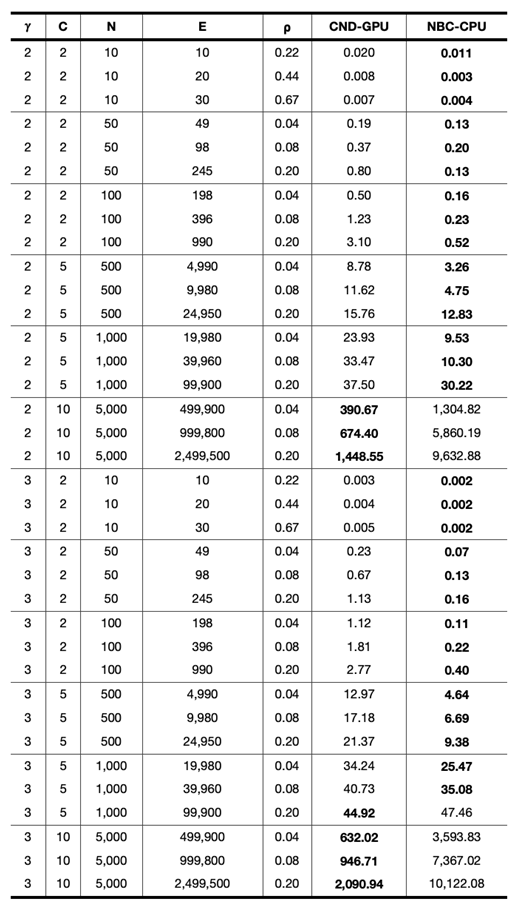
References
- Josh Abramson, Jonas Adler, Jack Dunger, Richard Evans, Tim Green, Alexander Pritzel, Olaf Ronneberger, Lindsay Willmore, Andrew J. Ballard, Joshua Bambrick, Sebastian W. Bodenstein, David A. Evans, Chia-Chun Hung, Michael O’Neill, David Reiman, Kathryn Tunyasuvunakool, Zachary Wu, Akvilė Žemgulytė, Eirini Arvaniti, Charles Beattie, Ottavia Bertolli, Alex Bridgland, Alexey Cherepanov, Miles Congreve, Alexander I. Cowen-Rivers, Andrew Cowie, Michael Figurnov, Fabian B. Fuchs, Hannah Gladman, Rishub Jain, Yousuf A. Khan, Caroline M. R. Low, Kuba Perlin, Anna Potapenko, Pascal Savy, Sukhdeep Singh, Adrian Stecula, Ashok Thillaisundaram, Catherine Tong, Sergei Yakneen, Ellen D. Zhong, Michal Zielinski, Augustin Žídek, Victor Bapst, Pushmeet Kohli, Max Jaderberg, Demis Hassabis, and John M. Jumper. Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature, 630(8016):493–500, June 2024. ISSN 1476-4687. doi: 10.1038/s41586-024-07487-w. URL . [CrossRef]
- Réka Albert, Hawoong Jeong, and Albert-László Barabási. Error and attack tolerance of complex networks. Nature, 406(6794):378–382, Jul 2000. ISSN 1476-4687 . [CrossRef]
- Antoine Allard, M. Ángeles Serrano, and Marián Boguñá. Geometric description of clustering in directed networks. Nature Physics, 20(1):150–156, 2024. ISSN 1745-2481. [CrossRef]
- Roy M. Anderson and Robert M. May. Infectious diseases of humans: Dynamics and control. Oxford University Press, 1991.
- Oriol Artime, Marco Grassia, Manlio De Domenico, James P. Gleeson, Hernán A. Makse, Giuseppe Mangioni, Matjaž Perc, and Filippo Radicchi. Robustness and resilience of complex networks. Nature Reviews Physics, 6(2), 2024. ISSN 2522-5820. [CrossRef]
- David A. Bader, Shiva Kintali, Kamesh Madduri, and Milena Mihail. Approximating betweenness centrality. In Anthony Bonato and Fan R. K. Chung (eds.), Algorithms and Models for the Web-Graph, pp. 124–137, Berlin, Heidelberg, 2007. Springer Berlin Heidelberg. ISBN 978-3-540-77004-6.
- Albert-László Barabási and Réka Albert. Emergence of scaling in random networks. Science, 286(5439):509–512, 1999. URL https://www.science.org/doi/abs/10.1126/science.286.5439.509. [CrossRef]
- Federico Battiston, Enrico Amico, Alain Barrat, Ginestra Bianconi, Guilherme Ferraz de Arruda, Benedetta Franceschiello, Iacopo Iacopini, Sonia Kéfi, Vito Latora, Yamir Moreno, Micah M. Murray, Tiago P. Peixoto, Francesco Vaccarino, and Giovanni Petri. The physics of higher-order interactions in complex systems. Nature Physics, 17(10):1093–1098, Oct 2021. ISSN 1745-2481. [CrossRef]
- Elisabetta Bergamini and Henning Meyerhenke. Fully-dynamic approximation of betweenness centrality. In Nikhil Bansal and Irene Finocchi (eds.), Algorithms - ESA 2015, pp. 155–166, Berlin, Heidelberg, 2015. Springer Berlin Heidelberg. ISBN 978-3-662-48350-3.
- Massimo Bernaschi, Giancarlo Carbone, and Flavio Vella. Scalable betweenness centrality on multi-gpu systems. In Proceedings of the ACM International Conference on Computing Frontiers, CF ’16, pp. 29–36, New York, NY, USA, 2016. Association for Computing Machinery. ISBN 9781450341288. [CrossRef]
- Ginestra Bianconi, Richard K. Darst, Jacopo Iacovacci, and Santo Fortunato. Triadic closure as a basic generating mechanism of communities in complex networks. Phys. Rev. E, 90:042806, Oct 2014. https://link.aps.org/doi/10.1103/PhysRevE.90.042806.
- Marián Boguñá, Dmitri Krioukov, and K. C. Claffy. Navigability of complex networks. Nature Physics, 5(1), 2009. ISSN 1745-2481. [CrossRef]
- Marián Boguñá, Ivan Bonamassa, Manlio De Domenico, Shlomo Havlin, Dmitri Krioukov, and M. Ángeles Serrano. Network geometry. Nature Reviews Physics, 3(2), 2021. ISSN 2522-5820. [CrossRef]
- Phillip Bonacich. Factoring and weighting approaches to status scores and clique identification. The Journal of Mathematical Sociology, 2(1):113–120, 1972. [CrossRef]
- Ulrik Brandes. A faster algorithm for betweenness centrality*. The Journal of Mathematical Sociology, 25(2):163–177, 2001. [CrossRef]
- Alfredo Braunstein, Luca Dall’Asta, Guilhem Semerjian, and Lenka Zdeborová. Network dismantling. Proceedings of the National Academy of Sciences, 113(44):12368–12373, 2016. URL https://www.pnas.org/doi/abs/10.1073/pnas.1605083113. [CrossRef]
- Dirk Brockmann and Dirk Helbing. The hidden geometry of complex, network-driven contagion phenomena. Science, 342(6164):1337–1342, 2013. URL https://www.science.org/doi/abs/10.1126/science.1245200.
- Anna D. Broido and Aaron Clauset. Scale-free networks are rare. Nature Communications, 10(1):1017, Mar 2019. ISSN 2041-1723. [CrossRef]
- Carlo Vittorio Cannistraci, Gregorio Alanis-Lobato, and Timothy Ravasi. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Scientific Reports, 3(1):1613, Apr 2013. ISSN 2045-2322. [CrossRef]
- Alessio Cardillo, Jesús Gómez-Gardeñes, Massimiliano Zanin, Miguel Romance, David Papo, Francisco del Pozo, and Stefano Boccaletti. Emergence of network features from multiplexity. Scientific Reports, 3(1):1344, 2013. ISSN 2045-2322. [CrossRef]
- Aaron Clauset, Cristopher Moore, and M. E. J. Newman. Hierarchical structure and the prediction of missing links in networks. Nature, 453(7191):98–101, May 2008. ISSN 1476-4687. [CrossRef]
- Pau Clusella, Peter Grassberger, Francisco J. Pérez-Reche, and Antonio Politi. Immunization and targeted destruction of networks using explosive percolation. Phys. Rev. Lett., 117:208301, Nov 2016. https://link.aps.org/doi/10.1103/PhysRevLett.117.208301.
- Marcus Engsig, Alejandro Tejedor, Yamir Moreno, Efi Foufoula-Georgiou, and Chaouki Kasmi. Domirank centrality reveals structural fragility of complex networks via node dominance. Nature Communications, 15(1):56, Jan 2024. ISSN 2041-1723. [CrossRef]
- Changjun Fan, Li Zeng, Yanghe Feng, Baoxin Xiu, Jincai Huang, and Zhong Liu. Revisiting the power of reinsertion for optimal targets of network attack. Journal of Cloud Computing, 9(1), 2020a. ISSN 2192-113X.
- Changjun Fan, Li Zeng, Yizhou Sun, and Yang-Yu Liu. Finding key players in complex networks through deep reinforcement learning. Nature Machine Intelligence, 2(6):317–324, Jun 2020b. ISSN 2522-5839. [CrossRef]
- Rui Fan, Ke Xu, and Jichang Zhao. A gpu-based solution for fast calculation of the betweenness centrality in large weighted networks. PeerJ Computer Science, 3:e140, 2017. [CrossRef]
- Linton C. Freeman. A set of measures of centrality based on betweenness. Sociometry, 40(1):35–41, 1977. ISSN 00380431, 23257938. URL http://www.jstor.org/stable/3033543.
- Marco Grassia and Giuseppe Mangioni. Coregdm: Geometric deep learning network decycling and dismantling. In Andreia Sofia Teixeira, Federico Botta, José Fernando Mendes, Ronaldo Menezes, and Giuseppe Mangioni (eds.), Complex Networks XIV, pp. 86–94, Cham, 2023. Springer Nature Switzerland. ISBN 978-3-031-28276-8.
- Marco Grassia, Manlio De Domenico, and Giuseppe Mangioni. Machine learning dismantling and early-warning signals of disintegration in complex systems. Nature Communications, 12(1), 2021. ISSN 2041-1723. [CrossRef]
- Alexander Gutfraind and Michael Genkin. A graph database framework for covert network analysis: An application to the islamic state network in europe. Social Networks, 51:178–188, 2017. ISSN 0378-8733. URL https://www.sciencedirect.com/science/article/pii/S0378873316302428 . [CrossRef]
- Mostafa Haghir Chehreghani. An efficient algorithm for approximate betweenness centrality computation. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, CIKM ’13, pp. 1489–1492, New York, NY, USA, 2013. Association for Computing Machinery. ISBN 9781450322638. [CrossRef]
- Donhee Ham, Hongkun Park, Sungwoo Hwang, and Kinam Kim. Neuromorphic electronics based on copying and pasting the brain. Nature Electronics, 4(9):635–644, 2021. ISSN 2520-1131. [CrossRef]
- Petter Holme, Beom Jun Kim, Chang No Yoon, and Seung Kee Han. Attack vulnerability of complex networks. Phys. Rev. E, 65:056109, May 2002. URL https://link.aps.org/doi/10.1103/PhysRevE.65.056109. [CrossRef]
- Jon M. Kleinberg. Navigation in a small world. Nature, 406(6798), 2000. ISSN 1476-4687. [CrossRef]
- Dmitri Krioukov, Fragkiskos Papadopoulos, Maksim Kitsak, Amin Vahdat, and Marián Boguñá. Hyperbolic geometry of complex networks. Phys. Rev. E, 82:036106, Sep 2010. URL https://link.aps.org/doi/10.1103/PhysRevE.82.036106. [CrossRef]
- Renaud Lambiotte, Martin Rosvall, and Ingo Scholtes. From networks to optimal higher-order models of complex systems. Nature Physics, 15(4):313–320, Apr 2019. ISSN 1745-2481. [CrossRef]
- Jinlong Ma, Peng Wang, and Huijia Li. Directed network disassembly method based on non-backtracking matrix. Applied Sciences, 12(23), 2022. ISSN 2076-3417. URL https://www.mdpi.com/2076-3417/12/23/12047. [CrossRef]
- Rossana Mastrandrea, Julie Fournet, and Alain Barrat. Contact patterns in a high school: A comparison between data collected using wearable sensors, contact diaries and friendship surveys. PLOS ONE, 10(9):1–26, 09 2015. [CrossRef]
- Adam McLaughlin and David A. Bader. Accelerating gpu betweenness centrality. Commun. ACM, 61(8):85–92, July 2018. ISSN 0001-0782. [CrossRef]
- Flaviano Morone, Byungjoon Min, Lin Bo, Romain Mari, and Hernán A. Makse. Collective influence algorithm to find influencers via optimal percolation in massively large social media. Scientific Reports, 6(1), 2016. ISSN 2045-2322. [CrossRef]
- Adilson E. Motter and Ying-Cheng Lai. Cascade-based attacks on complex networks. Phys. Rev. E, 66:065102, Dec 2002. URL https://link.aps.org/doi/10.1103/PhysRevE.66.065102. [CrossRef]
- Salomon Mugisha and Hai-Jun Zhou. Identifying optimal targets of network attack by belief propagation. Phys. Rev. E, 94:012305, Jul 2016. URL https://link.aps.org/doi/10.1103/PhysRevE.94.012305. [CrossRef]
- Alessandro Muscoloni and Carlo Vittorio Cannistraci. Leveraging the nonuniform pso network model as a benchmark for performance evaluation in community detection and link prediction. New Journal of Physics, 20(6):063022, jun 2018a. URL https://dx.doi.org/10.1088/1367-2630/aac6f9. [CrossRef]
- Alessandro Muscoloni and Carlo Vittorio Cannistraci. A nonuniform popularity-similarity optimization (npso) model to efficiently generate realistic complex networks with communities. New Journal of Physics, 20(5):052002, may 2018b. URL https://dx.doi.org/10.1088/1367-2630/aac06f. [CrossRef]
- Alessandro Muscoloni and Carlo Vittorio Cannistraci. Navigability evaluation of complex networks by greedy routing efficiency. Proceedings of the National Academy of Sciences, 116(5):1468–1469, 2019. URL https://www.pnas.org/doi/abs/10.1073/pnas.1817880116. [CrossRef]
- Alessandro Muscoloni, Josephine Maria Thomas, Sara Ciucci, Ginestra Bianconi, and Carlo Vittorio Cannistraci. Machine learning meets complex networks via coalescent embedding in the hyperbolic space. Nature Communications, 8(1), 2017. ISSN 2041-1723. [CrossRef]
- M. E. J. Newman. Assortative mixing in networks. Phys. Rev. Lett., 89:208701, Oct 2002. URL https://link.aps.org/doi/10.1103/PhysRevLett.89.208701. [CrossRef]
- M. E. J. Newman. The structure and function of complex networks. SIAM Review, 45(2):167–256, 2003. [CrossRef]
- M. E. J. Newman. Detecting community structure in networks. The European Physical Journal B, 38(2):321–330, Mar 2004. ISSN 1434-6036. [CrossRef]
- M. E. J. Newman. Communities, modules and large-scale structure in networks. Nature Physics, 8(1):25–31, Jan 2012. ISSN 1745-2481. [CrossRef]
- Yuxuan Ou, Fujing Xiong, Hairong Zhang, and Huijia Li. Network dismantling on signed network by evolutionary deep reinforcement learning. Sensors, 24(24), 2024. ISSN 1424-8220. URL https://www.mdpi.com/1424-8220/24/24/8026. [CrossRef]
- Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The pagerank citation ranking: Bringing order to the web. Technical Report 1999-66, Stanford InfoLab, November 1999. URL http://ilpubs.stanford.edu:8090/422/. Previous number = SIDL-WP-1999-0120.
- Prasanna Pande and David A. Bader. Computing betweenness centrality for small world networks on a gpu. In Proceedings of the 15th Annual High Performance Embedded Computing Workshop (HPEC), September 2011.
- Pietro Panzarasa, Tore Opsahl, and Kathleen M. Carley. Patterns and dynamics of users’ behavior and interaction: Network analysis of an online community. Journal of the American Society for Information Science and Technology, 60(5):911–932, 2009. URL https://asistdl.onlinelibrary.wiley.com/doi/abs/10.1002/asi.21015 . [CrossRef]
- Fragkiskos Papadopoulos, Maksim Kitsak, M. Ángeles Serrano, Marián Boguñá, and Dmitri Krioukov. Popularity versus similarity in growing networks. Nature, 489(7417):537–540, Sep 2012. ISSN 1476-4687. [CrossRef]
- Ashwin Paranjape, Austin R. Benson, and Jure Leskovec. Motifs in temporal networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, WSDM ’17, pp. 601–610, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450346757. [CrossRef]
- Erzsébet Ravasz and Albert-László Barabási. Hierarchical organization in complex networks. Phys. Rev. E, 67:026112, Feb 2003. URL https://link.aps.org/doi/10.1103/PhysRevE.67.026112. [CrossRef]
- Xiao-Long Ren, Niels Gleinig, Dirk Helbing, and Nino Antulov-Fantulin. Generalized network dismantling. Proceedings of the National Academy of Sciences, 116(14):6554–6559, 2019. URL https://www.pnas.org/doi/abs/10.1073/pnas.1806108116. [CrossRef]
- Matteo Riondato and Evgenios M. Kornaropoulos. Fast approximation of betweenness centrality through sampling. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, WSDM ’14, pp. 413–422, New York, NY, USA, 2014. Association for Computing Machinery. ISBN 9781450323512. [CrossRef]
- Ahmet Erdem Sariyüce, Kamer Kaya, Erik Saule, and Ümit V. Çatalyürek. Betweenness centrality on gpus and heterogeneous architectures. In Proceedings of the 6th Workshop on General Purpose Processor Using Graphics Processing Units, GPGPU-6, pp. 76–85, New York, NY, USA, 2013. Association for Computing Machinery. ISBN 9781450320177. [CrossRef]
- C. M. Schneider, T. Mihaljev, and H. J. Herrmann. Inverse targeting —an effective immunization strategy. Europhysics Letters, 98(4):46002, may 2012. URL https://dx.doi.org/10.1209/0295-5075/98/46002. [CrossRef]
- Matteo Serafino, Giulio Cimini, Amos Maritan, Andrea Rinaldo, Samir Suweis, Jayanth R. Banavar, and Guido Caldarelli. True scale-free networks hidden by finite size effects. Proceedings of the National Academy of Sciences, 118(2):e2013825118, 2021. URL https://www.pnas.org/doi/abs/10.1073/pnas.2013825118. [CrossRef]
- M. Ángeles Serrano, Dmitri Krioukov, and Marián Boguñá. Self-similarity of complex networks and hidden metric spaces. Phys. Rev. Lett., 100:078701, Feb 2008. URL https://link.aps.org/doi/10.1103/PhysRevLett.100.078701. [CrossRef]
- Vito D P Servedio, Alessandro Bellina, Emanuele Calò, and Giordano De Marzo. Fitness centrality: a non-linear centrality measure for complex networks. Journal of Physics: Complexity, 6(1):015002, jan 2025. URL https://dx.doi.org/10.1088/2632-072X/ada845. [CrossRef]
- Zhiao Shi and Bing Zhang. Fast network centrality analysis using gpus. BMC Bioinformatics, 12(1):149, May 2011. ISSN 1471-2105. [CrossRef]
- Philip K. Shiu, Gabriella R. Sterne, Nico Spiller, Romain Franconville, Andrea Sandoval, Joie Zhou, Neha Simha, Chan Hyuk Kang, Seongbong Yu, Jinseop S. Kim, Sven Dorkenwald, Arie Matsliah, Philipp Schlegel, Szi-chieh Yu, Claire E. McKellar, Amy Sterling, Marta Costa, Katharina Eichler, Alexander Shakeel Bates, Nils Eckstein, Jan Funke, Gregory S. X. E. Jefferis, Mala Murthy, Salil S. Bidaye, Stefanie Hampel, Andrew M. Seeds, and Kristin Scott. A drosophila computational brain model reveals sensorimotor processing. Nature, 634(8032):210–219, 2024. ISSN 1476-4687. [CrossRef]
- Laura E. Suárez, Blake A. Richards, Guillaume Lajoie, and Bratislav Misic. Learning function from structure in neuromorphic networks. Nature Machine Intelligence, 3(9):771–786, 2021. ISSN 2522-5839. [CrossRef]
- Ivan Voitalov, Pim van der Hoorn, Remco van der Hofstad, and Dmitri Krioukov. Scale-free networks well done. Phys. Rev. Res., 1:033034, Oct 2019. URL https://link.aps.org/doi/10.1103/PhysRevResearch.1.033034. [CrossRef]
- Min Wu, Jianhong Mou, Bitao Dai, Suoyi Tan, and Xin Lu. Dismantling directed networks: A multi-temporal information field approach. Chaos, Solitons & Fractals, 196:116404, 2025. ISSN 0960-0779. URL https://www.sciencedirect.com/science/article/pii/S0960077925004175. [CrossRef]
- Zhihao Wu, Giulia Menichetti, Christoph Rahmede, and Ginestra Bianconi. Emergent complex network geometry. Scientific Reports, 5(1):10073, May 2015. ISSN 2045-2322. [CrossRef]
- Chenwei Xie, Chuang Liu, Cong Li, Xiu-Xiu Zhan, and Xiang Li. Esnd: An embedding-based framework for signed network dismantling. Expert Systems with Applications, 289:128346, 2025. ISSN 0957-4174. URL https://www.sciencedirect.com/science/article/pii/S0957417425019657 . [CrossRef]
- Lenka Zdeborová, Pan Zhang, and Hai-Jun Zhou. Fast and simple decycling and dismantling of networks. Scientific Reports, 6(1), 2016. ISSN 2045-2322. [CrossRef]
- Yongtao Zhang, Cunqi Shao, Shibo He, and Jianxi Gao. Resilience centrality in complex networks. Phys. Rev. E, 101:022304, Feb 2020. URL https://link.aps.org/doi/10.1103/PhysRevE.101.022304. [CrossRef]
- Konstantin Zuev, Marián Boguñá, Ginestra Bianconi, and Dmitri Krioukov. Emergence of soft communities from geometric preferential attachment. Scientific Reports, 5(1):9421, Apr 2015. ISSN 2045-2322. [CrossRef]
Figure 1.
Overview of the LGD Network Automata framework. A: Begin with an unweighted and undirected network. B: Estimate latent geometry by assigning a weight to each edge between nodes i and j using local latent geometry estimators. C: Construct a dissimilarity-weighted network based on these weights. D: Compute node strength as the sum of geometric weights to all neighbors in :E–F: Perform dynamic dismantling by iteratively computing node strengths, removing the node with the highest and its edges, and checking whether the normalized size of the largest connected component (LCC) has dropped below a threshold. G–H (optional): Reinsert dismantled nodes using a selected reinsertion method.
Figure 1.
Overview of the LGD Network Automata framework. A: Begin with an unweighted and undirected network. B: Estimate latent geometry by assigning a weight to each edge between nodes i and j using local latent geometry estimators. C: Construct a dissimilarity-weighted network based on these weights. D: Compute node strength as the sum of geometric weights to all neighbors in :E–F: Perform dynamic dismantling by iteratively computing node strengths, removing the node with the highest and its edges, and checking whether the normalized size of the largest connected component (LCC) has dropped below a threshold. G–H (optional): Reinsert dismantled nodes using a selected reinsertion method.
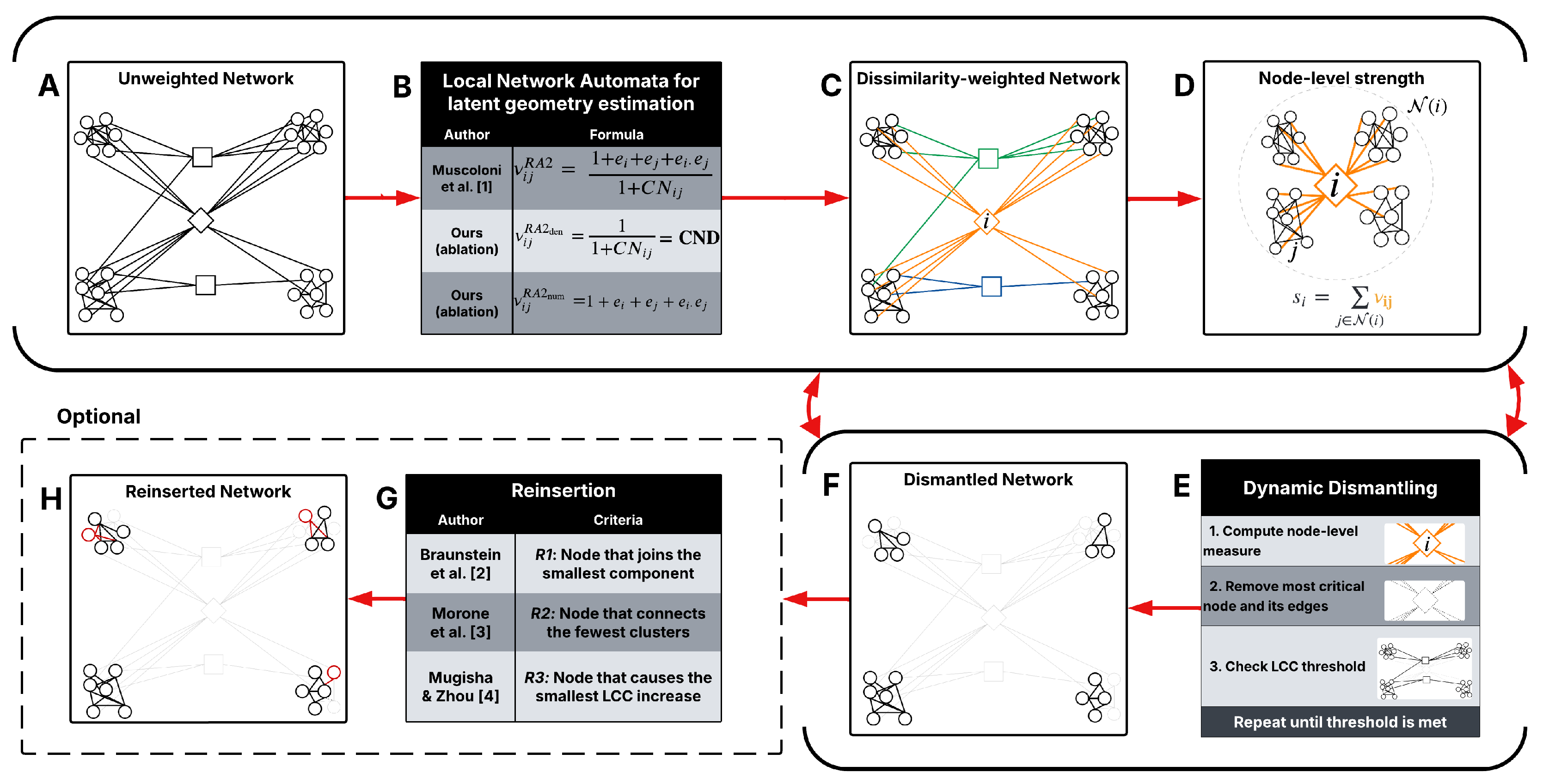
Figure 2.
Mean field ranking for each dismantling method without reinsertion (; upper panel) and with reinsertion (; lower panel), for dynamic dismantling. In the lower panel, a subset of the best-performing methods from each category is paired with their respective best-performing reinsertion strategy. Methods based on latent geometry are shown in red. denotes variants where the original reinsertion step was disabled. Error bars indicate the standard error of the mean (SEM).
Figure 2.
Mean field ranking for each dismantling method without reinsertion (; upper panel) and with reinsertion (; lower panel), for dynamic dismantling. In the lower panel, a subset of the best-performing methods from each category is paired with their respective best-performing reinsertion strategy. Methods based on latent geometry are shown in red. denotes variants where the original reinsertion step was disabled. Error bars indicate the standard error of the mean (SEM).
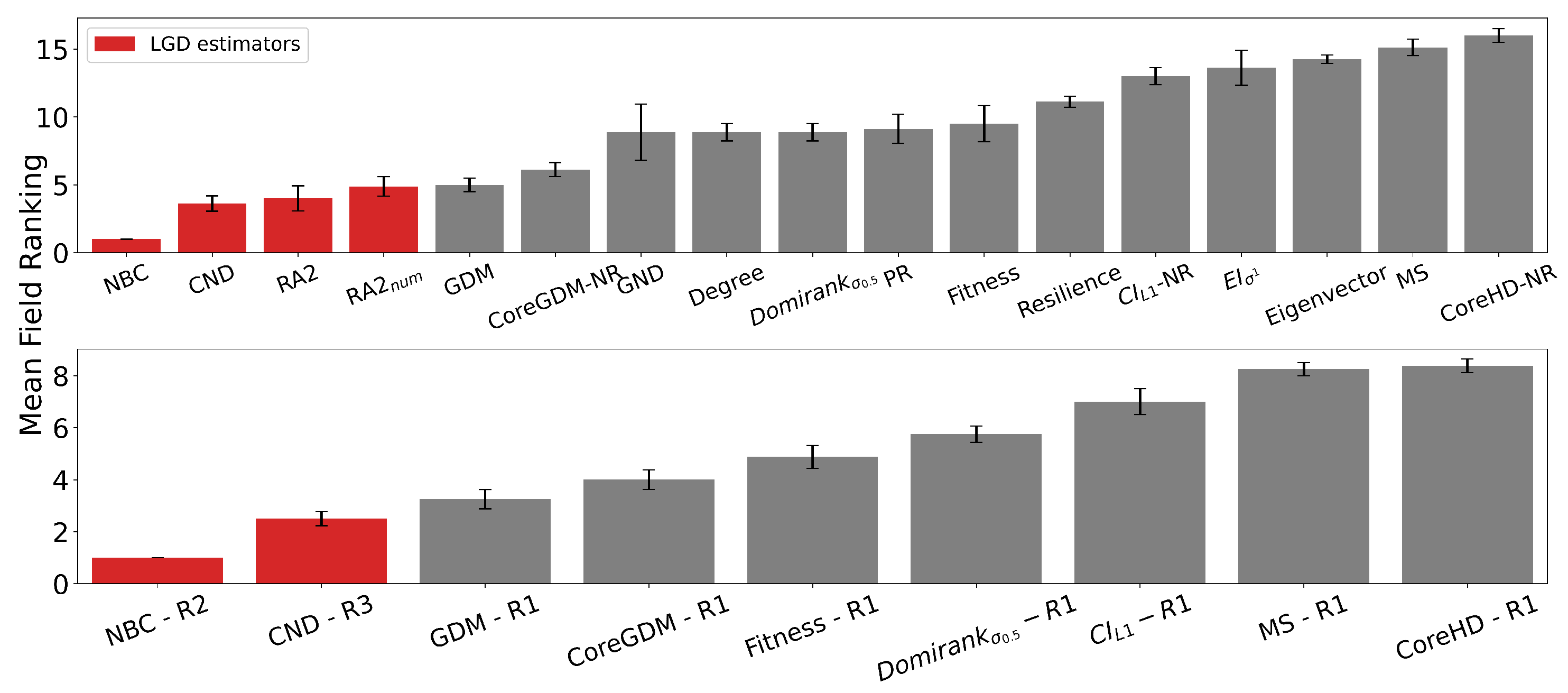
Figure 4.
Dynamic dismantling process for four real-world networks with field-spceifc functional metrics, for NBC, CND, and RA2. The final evaluation metric is the Area Under the Curve (AUC). Dashed line represents the dynamic dismantling process for reinforced networks. See Figure Table A11 for full quantitative results.
Figure 4.
Dynamic dismantling process for four real-world networks with field-spceifc functional metrics, for NBC, CND, and RA2. The final evaluation metric is the Area Under the Curve (AUC). Dashed line represents the dynamic dismantling process for reinforced networks. See Figure Table A11 for full quantitative results.
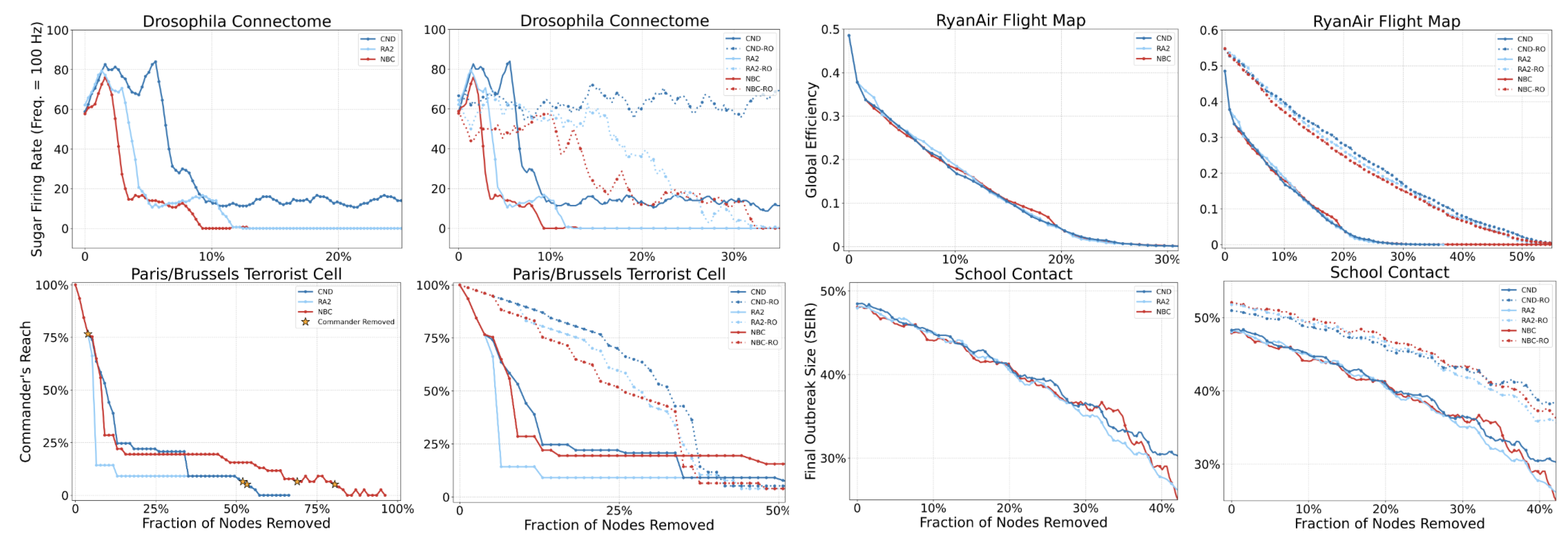
Table 1.
Number of real-world networks tested by dismantling algorithms, see Table A8 for more information.
Table 1.
Number of real-world networks tested by dismantling algorithms, see Table A8 for more information.
| Algorithm | Year | Networks | Ref. |
|---|---|---|---|
| Collective Influence (CI) | 2016 | 2 | Morone et al. (2016) |
| CoreHD | 2016 | 12 | Zdeborová et al. (2016) |
| Explosive Immunization (EI) | 2016 | 5 | Clusella et al. (2016) |
| Min-Sum (MS) | 2016 | 2 | Braunstein et al. (2016) |
| GND | 2019 | 10 | Ren et al. (2019) |
| Resilience Centrality | 2020 | 4 | Zhang et al. (2020) |
| GDM | 2021 | 57 | Grassia et al. (2021) |
| CoreGDM | 2023 | 15 | Grassia & Mangioni (2023) |
| Domirank Centrality | 2024 | 6 | Engsig et al. (2024) |
| Fitness Centrality | 2025 | 5 | Servedio et al. (2025) |
| LGD-NA | 2025 | 1,475 | Ours |
Table 2.
Summary of real-world networks tested in this paper, see Table A7 for more information.
Table 2.
Summary of real-world networks tested in this paper, see Table A7 for more information.
| Field | Subfields | Types | Networks |
|---|---|---|---|
| Biomolecular | 5 | PPI, Genetic, Metabolic, Molecular, Transcription | 27 |
| Brain | 1 | Connectome | 529 |
| Covert | 2 | Covert, Terrorist | 89 |
| Foodweb | 1 | Foodweb | 71 |
| Infrastructure | 7 | Flight, Nautical, Power grid, Rail, Road, Subway, Trade | 314 |
| Internet | 1 | Internet | 206 |
| Misc | 8 | Citation, Copurchasing, Game, Hiring, Lexical, Phone call, Software, Vote | 38 |
| Social | 7 | Coauthorship, Collaboration, Contact, Email, Friendship, Social network, Trust | 201 |
| Total | 32 | 1,475 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



