
Submitted:
27 May 2025
Posted:
29 May 2025
You are already at the latest version
Abstract
With the continuous development of large language models (such as GPT, BERT, etc.), artificial intelligence (AI) has made significant progress in the field of translation. This paper explores the current status and future development of AI in translation under the background of large language models. First, it briefly reviews the technical principles of large language models and their foundational role in natural language processing (NLP), particularly their groundbreaking impact on translation. Next, it analyzes translation technologies based on large language models, including neural machine translation (NMT) and Transformer models, highlighting their advantages in improving translation accuracy, contextual understanding, and long text handling. Additionally, this paper discusses the challenges faced by AI translation, such as cultural differences, translation of lowresource languages, and data privacy issues, and looks forward to future trends, including deep learning, cross-modal translation, and personalized customization. Finally, the paper summarizes the tremendous potential of large language models in advancing translation technology and offers relevant suggestions for future research.
Keywords:
large language models
; artificial intelligence
; machine translation
; neural machine translation
1. Introduction
With the rapid development of artificial intelligence (AI) technology, particularly the widespread application of large language models such as GPT and BERT, AI has achieved revolutionary breakthroughs in the field of natural language processing (NLP). In translation technology, traditional methods of machine translation are gradually being replaced by deep learning-based neural network models, leading to higher translation accuracy and efficiency. Large language models, through learning vast amounts of text data, are not only able to understand the basic structure of languages but also deeply grasp context, cultural background, and the handling of polysemy, significantly enhancing the naturalness and fluency of translations.Although AI translation technology has made significant progress in recent years, it still faces many challenges, such as understanding context, cross-linguistic syntactic differences, and supporting low-resource languages. Therefore, this paper aims to explore the current applications of large language models in the translation field, analyze their advantages and shortcomings, and predict future technological developments.The goal of this study is to deeply analyze the application of large language models in AI translation, particularly their contribution to improving translation accuracy, handling long texts, and managing polysemy. Additionally, the paper will discuss the ethical and cultural challenges faced by AI translation and propose future research directions [1]. Through these analyses, this study seeks to provide valuable insights for academia and translation practice, offering theoretical support for the widespread application of large language models in translation.
2. Overview of Large Language Models
2.1. The Development of Large Language Models
The development of large language models has gone through several key stages, from early rule-based methods to the widespread application of deep learning and pre-trained models, driving the rapid development of natural language processing technology. In the early stages, language models mainly relied on manually designed rule systems, which defined the grammar and syntactic structures of languages to perform translation and text generation. However, these rule-based methods struggled with the complexity of language and had limited scalability, making them vulnerable to linguistic diversity and practical application scenarios.As computational power and data volumes increased, statistical language models gradually replaced traditional rule-based translation models [2,3,4]. These models trained on large corpora to compute probabilistic relationships between words, such as the n-gram model. While this method effectively captured co-occurrence relationships in language, it still faced issues such as sparse vocabulary and difficulty in handling long dependencies, which limited the model’s effectiveness in processing complex language structures.In the 21st century, breakthroughs in deep learning technology led to the rise of neural network-based language models. In 2013, Hinton and others introduced deep neural networks (DNN), marking the beginning of a new era in natural language processing. Neural network-based language models automatically learn linguistic features from data, overcoming the limitations of traditional statistical models and offering more expressive power and adaptability. Subsequently, Recurrent Neural Networks (RNN) and Long Short-Term Memory Networks (LSTM) were introduced, solving the gradient vanishing problem in traditional models when processing long sequences and enabling the model to capture long dependencies more effectively, leading to widespread use in speech recognition, machine translation, and other tasks.The introduction of Transformer fundamentally changed the landscape of natural language processing. Unlike traditional RNNs and LSTMs, Transformer employs self-attention mechanisms to capture global dependencies in parallel, significantly improving computational efficiency and processing capabilities [5,6,7]. Pre-trained models based on Transformer, such as BERT and GPT, were introduced and achieved performance that surpassed previous models. The release of GPT series models, such as GPT-3, marked an unprecedented breakthrough, with generative models performing excellently in a range of NLP tasks.The development of large language models is not only reflected in the increasing scale of models but also in the expanding range of applications. From early machine translation to text generation, sentiment analysis, and question-answering systems, AI’s natural language processing capabilities have been pushed to new heights. Today, with the growth in model parameters and the diversification of training data, AI translation accuracy and contextual understanding have improved significantly. However, challenges remain in handling low-resource languages, multi-modal data, and data privacy issues. In the future, large language models will continue to innovate in areas such as cross-modal learning, few-shot learning, and more efficient computation methods [8].
2.2. The Technical Principles of Large Language Models
The success of large language models relies on a series of deep learning techniques, particularly in their application in natural language processing (NLP). One of the core technologies is the self-attention mechanism based on the Transformer architecture. Unlike traditional Recurrent Neural Networks (RNNs) and Long Short-Term Memory Networks (LSTMs), Transformer processes sequential data through a global self-attention mechanism, efficiently capturing long-range dependencies in parallel computation. This mechanism enables the model to better understand the context and avoid the computational bottleneck encountered by RNNs when handling long sequences.
The training of large language models typically follows a “pre-training-fine-tuning” strategy [9,10,11]. Initially, the model is pre-trained on large-scale unlabeled data through tasks like masked language modeling (MLM) and autoregressive modeling (Autoregressive Modeling) to learn the basic rules of language and contextual dependencies. The pre-training stage is usually carried out on massive text datasets, with the model gradually learning the structure and grammar of the language by predicting missing parts of sentences or the next word. After pre-training, the large language model is fine-tuned based on specific tasks, such as text classification, named entity recognition, etc., to optimize its performance for particular applications [12,13].Compared to traditional language models, pre-trained models based on Transformer, such as BERT and GPT, offer significant advantages. The BERT model uses a bidirectional encoder structure, considering both the left and right context of the input text, making it excellent for context understanding, especially for tasks such as sentence matching, question answering, and reasoning. On the other hand, GPT is an autoregressive model that generates coherent text and is widely used in text generation and dialogue systems. While BERT and GPT differ in architecture, both are based on Transformer and learn rich language knowledge through large-scale data training.Furthermore, large language models also utilize word embedding techniques, mapping words into high-dimensional spaces, allowing computers to process semantic relationships between words. By learning distributed representations of words, the model can capture the similarity and contextual information between words. For example, the words “apple” and “fruit” are close in the word embedding space, indicating that they are semantically similar. Large language models improve language understanding by using this approach, allowing machines to better understand and generate natural language.In summary, the technical principles of large language models rely on the self-attention mechanism of the Transformer architecture, pre-training and fine-tuning strategies, and the combination of word embedding techniques. These technologies enable the model to learn language patterns from vast amounts of text data, providing powerful language understanding and generation capabilities. As technology continues to develop, large language models will play an increasingly important role in multilingual translation, text generation, and other fields [14,15,16].
2.3. AI in Translation Applications
Artificial intelligence (AI) has made significant progress in the field of translation, particularly in neural machine translation (NMT) and large language model-based translation systems. AI translation technology primarily relies on deep learning algorithms, especially neural networks, which, through training on vast amounts of bilingual data, can automatically learn conversion rules between languages. This data-driven learning approach overcomes the limitations of traditional translation methods, such as rule-based and statistical approaches, enabling AI to better handle syntax, semantics, and contextual relationships, thereby significantly improving translation accuracy and fluency.Neural machine translation (NMT) is one of the key applications of AI in translation. Unlike traditional statistical machine translation, NMT models the translation directly from the source language to the target language through deep neural networks, without relying on manually designed translation rules [17]. NMT models typically use an encoder-decoder structure, where the encoder converts the input source language into a fixed-length vector representation, and the decoder generates the translation result in the target language based on this representation. This structure allows NMT to effectively capture contextual information and handle long sentences and complex structures during translation. Particularly, NMT models based on the Transformer architecture, such as BERT and GPT, leverage self-attention mechanisms to further improve translation quality, especially in long text and complex sentence translation.In addition to traditional NMT, another important application of AI in translation is the introduction of large language models such as GPT-3 [9]. These large language models, through pre-training and fine-tuning, can provide high-quality translations across multiple language pairs. Models like GPT-3 are trained on massive datasets and can understand and generate multilingual text, demonstrating superior language understanding and generation capabilities compared to traditional translation systems. Compared to rule-based translation systems, large language models offer significant advantages in contextual understanding and polysemy handling, generating more natural and fluent translations.AI translation systems can also effectively translate between resource-poor language pairs through techniques such as transfer learning and multilingual learning. By using large pre-trained models, AI can utilize the knowledge already learned to improve the translation quality of low-resource languages. Additionally, AI translation systems can be fine-tuned based on specific domain data, providing high-precision translation services in specialized fields such as healthcare, law, and technology.In conclusion, AI in translation has evolved from traditional rule-based and statistical methods to advanced translation systems based on deep learning and large language models. With continuous technological advancements, the accuracy, fluency, and multilingual support of AI translation will further improve, facilitating global communication and the exchange of information [18,19,20].
3. Data Analysis and Performance Evaluation
To comprehensively assess the effectiveness of large language models in translation tasks, data analysis and performance evaluation are essential. This chapter will present the actual performance of large language models in translation tasks through data analysis, using common evaluation metrics, and will further analyze the model’s strengths and weaknesses through data tables.
3.1. Dataset Selection and Preprocessing
Selecting an appropriate dataset is a crucial prerequisite for ensuring the performance of the model in translation tasks. We used publicly available datasets such as WMT 2020 and IWSLT 2017, which cover various language pairs, including English-French, English-German, and English-Chinese. Table 1 presents the basic information of these datasets, including language pairs, the number of sentences, and the data sources.
These datasets were cleaned and tokenized, with Byte Pair Encoding (BPE) algorithm used for subword segmentation to improve translation quality and reduce vocabulary sparsity issues.
3.2. Performance Evaluation Metrics
Common evaluation metrics for translation tasks include BLEU, ROUGE, and METEOR. BLEU scores measure the n-gram overlap between machine-generated and human-generated translations; ROUGE scores are mainly used for evaluating text generation tasks; and METEOR scores take into account factors such as word morphology and synonym replacement. In this study, we used BLEU and METEOR as the primary evaluation standards. Table 2 shows the evaluation results of different large language models on multiple language pairs.
From Figure 1, it can be seen that GPT-3 outperforms other models in terms of both BLEU and METEOR scores on multiple language pairs, especially in English-German and English-French translation tasks.
3.3. Long Text Handling Capability Analysis
Large language models generally capture global context through self-attention mechanisms when processing long texts, which helps improve translation accuracy. To analyze the performance of large language models in long text translation, we compared short texts (≤50 words) and long texts (>50 words). Table 3 shows the BLEU scores of the model for different text lengths.
From Figure 2, we can see that although GPT-3’s BLEU score decreases for long text translation, it still maintains a good translation quality, demonstrating its strong contextual understanding ability. In contrast, BERT performs relatively weaker in long text translation, possibly due to its limited ability to handle longer texts.
3.4. Error Analysis and Improvement Directions
Through data analysis, we also identified several common types of translation errors. Table 2 lists the three most common error types and their frequencies in the English-French translation task.
These errors indicate that large language models still face issues such as ambiguous word meanings and incomplete syntactic structures during translation. To address these issues, future research can focus on improving the model’s syntactic understanding and polysemy handling abilities, enhancing its contextual understanding.Through the data analysis of large language models in translation tasks, we can clearly identify their strengths and weaknesses in translation quality, long text processing, and polysemy handling. Although large language models have made significant progress in translation accuracy, they still face challenges in grammar, vocabulary, and contextual understanding. Future research will need to further optimize the models, especially in their ability to handle low-resource languages and complex sentence translations, to enhance their value in multilingual translation tasks.
4. Advantages and Challenges of AI Translation
With the rapid development of artificial intelligence technology, AI translation has become widely used in modern society, especially with the increasing speed of cross-linguistic communication, globalization, and information dissemination. The advantages of AI translation are not only reflected in its efficiency but also in its ability to continuously learn, understand context, and support cross-linguistic applications. However, despite significant progress in AI translation technology, there are still several technical and application challenges [21,22,23]. The following sections analyze the advantages and challenges of AI translation from multiple perspectives.
4.1. Advantages of AI Translation
1. Efficiency and Automation
One of the most significant advantages of AI translation technology is its efficiency, especially when processing large-scale text translation tasks. Traditional human translation often requires a considerable amount of time and labor, particularly when dealing with large volumes of documents, news, advertisements, and other content, making the translation process cumbersome and time-consuming. AI translation systems can translate thousands of words or more within seconds, without being affected by fatigue or time constraints. This makes AI translation particularly valuable in real-time translation scenarios such as news dissemination, social media, and technical document translation.
2. Continuous Learning and Self-Optimization
AI translation systems based on deep learning have the ability to self-learn. Through large bilingual corpora and multiple training cycles, AI systems continuously improve translation quality. This self-optimization mechanism enables AI translation to absorb new knowledge when dealing with different languages and domains, thereby enhancing accuracy and fluency. For example, by fine-tuning pre-trained models, AI translation systems can further optimize their translation performance according to specific domains or industry requirements, particularly in specialized fields such as technology, medicine, and law. Over time, as the system is exposed to more diverse data, translation quality gradually improves, and error rates decrease [24,25].
3. Language Understanding and Contextual Capture
Traditional translation methods primarily rely on direct translation and rule-based conversions, which often overlook the context and polysemy issues in languages. In contrast, AI translation, especially neural machine translation (NMT) based on large language models, can effectively capture contextual information through self-attention mechanisms, providing more accurate and natural translations. AI translation systems can understand long-distance dependencies within sentences, identify and resolve polysemy, and handle ambiguous situations. For example, in translating long sentences or complex structures, AI translation better understands the contextual relationships and generates translations that are syntactically correct and contextually appropriate. This allows AI translation to outperform traditional methods in dealing with complex texts and contexts [26].
4. Multilingual Support and Cross-Language Translation
Another prominent advantage of AI translation is its support for multiple languages. Modern AI translation models, especially those based on Transformer architecture such as BERT and GPT, can handle translation tasks across various languages, even supporting less common and low-resource languages. By sharing knowledge and learning across languages, AI translation systems can seamlessly switch between different languages and provide consistent, accurate translations in multilingual environments. For example, models like GPT-3 not only support major languages such as English, French, German, and Chinese, but also handle translation tasks for some low-resource languages, further facilitating global communication [27].
5. Adaptability and Customization
AI translation technology is highly adaptable and can be customized to meet different translation requirements. For instance, certain translation systems can be optimized according to user language habits, regional accents, and specialized terminology, catering to the needs of specific fields or clients. AI translation systems can also be optimized based on different text types, such as academic papers, technical documents, and advertisements. In certain translation tasks, the system can automatically adjust the translation style and tone to best suit the target audience’s needs. Despite the significant advantages of AI translation, it still faces some challenges, particularly when dealing with certain linguistic features and cultural backgrounds. AI translation systems continue to struggle with complexities such as contextual understanding, cultural differences, and translation of low-resource languages [28]. Firstly, AI translation still needs improvement when dealing with complex contexts, especially when translating metaphors, idioms, or culturally specific expressions. These types of content often lead to misinterpretations or inaccurate translations. Secondly, the translation of low-resource languages remains a challenge. For certain regional and minority languages, AI translation is often less effective than for more widely spoken languages. Finally, data privacy and security concerns are also major challenges for AI translation technologies, especially when handling sensitive information. Protecting user data and privacy remains a critical issue for the widespread application of AI translation.In summary, AI translation has provided strong support for global communication by improving translation efficiency, enhancing language understanding, and supporting multiple languages. However, to better meet diverse translation needs and promote its widespread use, AI translation systems must overcome challenges related to contextual understanding, low-resource languages, and data privacy [29].
5. Future Development Trends of AI Translation
With the continuous development of artificial intelligence technology, the future of AI translation will move toward more intelligent and efficient systems. One of the key development trends for AI translation is cross-modal learning and multi-modal translation. By integrating images, videos, and audio, AI translation systems will be able to better understand the context and semantics of texts, providing more precise and natural translations. For example, by combining voice and image content from videos, AI translation can not only translate speech but also adjust translations based on visual information, offering more appropriate translations.Simultaneously, few-shot learning will play a crucial role in translating low-resource languages. This will allow AI translation to learn and generate translations for low-resource languages even without large bilingual datasets, greatly advancing global communication and understanding, particularly in translating minority and regional languages. Additionally, future AI translation systems will focus more on personalization and customization, adjusting translation styles and tones based on different user needs and specific contexts. For example, AI systems will generate translations that align with the context and the target audience’s needs depending on the type of text (academic, business, literary, etc.).As translation quality continues to improve, AI translation systems will more intelligently integrate with post-editing technologies, offering high-precision translation services. Translators can fine-tune and optimize the AI-generated translations, enhancing their accuracy and readability. Furthermore, future AI translation will face the challenge of more efficient model training and hardware acceleration techniques, reducing computational resource consumption and promoting the sustainable development of translation technologies.In conclusion, AI translation in the future will not only serve as a language conversion tool but will deeply integrate cultural understanding and language expression, becoming a critical tool for advancing globalization and fostering understanding and communication between different cultures.
6. Conclusions
With the continuous advancement of artificial intelligence technology, AI translation plays an increasingly important role in the context of globalizing communication. This paper has explored the application of large language models in translation, analyzing the advantages and challenges of AI translation. AI translation technologies, through deep learning, neural networks, and self-attention mechanisms, have significantly improved translation efficiency and accuracy, particularly in handling complex contexts, long texts, and multilingual translation tasks. With efficient self-learning and continuous optimization, AI translation systems have shown excellent performance in real-time translation and specialized fields, gradually replacing traditional translation methods.However, despite the powerful advantages shown in various domains, AI translation still faces challenges, particularly in contextual understanding, support for low-resource languages, and data privacy protection. Currently, AI translation systems’ accuracy cannot fully replace human translation, especially when handling texts with complex cultural backgrounds and metaphors. In the future, AI translation will continue to evolve in areas such as cross-modal learning, few-shot learning, and personalization, breaking through technological bottlenecks to further enhance translation quality and expand its application scope.In summary, as AI translation technology continues to develop, it is gradually solving various challenges. With further technological advancements and optimizations, AI translation will not only improve in translation quality but also play a more significant role in global language communication and cross-cultural exchanges, providing smarter and more convenient solutions for global multilingual and multicultural communication.
References
- Yin J, Wu X, Liu X. Multi-class classification of breast cancer gene expression using PCA and XGBoost[J]. Theoretical and Natural Science, 2025, 76: 6-11. [CrossRef]
- Tan, Chaoyi, et al. “Generating Multimodal Images with GAN: Integrating Text, Image, and Style.” arXiv preprint arXiv:2501.02167 (2025).
- Guo H, Zhang Y, Chen L, et al. Research on vehicle detection based on improved YOLOv8 network[J]. arXiv preprint arXiv:2501.00300, 2024. [CrossRef]
- Yang, Haowei, et al. “Optimization and Scalability of Collaborative Filtering Algorithms in Large Language Models.” arXiv preprint arXiv:2412.18715 (2024). [CrossRef]
- Mo K, Chu L, Zhang X, et al. Dral: Deep reinforcement adaptive learning for multi-uavs navigation in unknown indoor environment[J]. arXiv preprint arXiv:2409.03930, 2024.
- Xiang A, Zhang J, Yang Q, et al. Research on splicing image detection algorithms based on natural image statistical characteristics[J]. arXiv preprint arXiv:2404.16296, 2024. [CrossRef]
- Shi X, Tao Y, Lin S C. Deep Neural Network-Based Prediction of B-Cell Epitopes for SARS-CoV and SARS-CoV-2: Enhancing Vaccine Design through Machine Learning[J]. arXiv preprint arXiv:2412.00109, 2024.
- Yang, Haowei, et al. “Analysis of Financial Risk Behadvior Prediction Using Deep Learning and Big Data Algorithms.” arXiv preprint arXiv:2410.19394 (2024). [CrossRef]
- Qi, Zhen, et al. Detecting and Classifying Defective Products in Images Using YOLO. arXiv preprint arXiv:2412.16935 (2024). [CrossRef]
- Yin Z, Hu B, Chen S. Predicting employee turnover in the financial company: A comparative study of catboost and xgboost models[J]. Applied and Computational Engineering, 2024, 100: 86-92. [CrossRef]
- Wang T, Cai X, Xu Q. Energy Market Price Forecasting and Financial Technology Risk Management Based on Generative AI[J]. Applied and Computational Engineering, 2024, 100: 29-34. [CrossRef]
- Tan, Chaoyi, et al. “Real-time Video Target Tracking Algorithm Utilizing Convolutional Neural Networks (CNN).” 2024 4th International Conference on Electronic Information Engineering and Computer (EIECT). IEEE, 2024.
- Lin, Xueting, et al. “Enhanced Recommendation Combining Collaborative Filtering and Large Language Models.” arXiv preprint arXiv:2412.18713 (2024).
- Huang B, Lu Q, Huang S, et al. Multi-modal clothing recommendation model based on large model and VAE enhancement[J]. arXiv preprint arXiv:2410.02219, 2024.
- Wang, H., Zhang, G., Zhao, Y., Lai, F., Cui, W., Xue, J., ... & Lin, Y. (2024, December). Rpf-eld: Regional prior fusion using early and late distillation for breast cancer recognition in ultrasound images. In 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) (pp. 2605-2612). IEEE.
- Ziang H, Zhang J, Li L. Framework for lung CT image segmentation based on UNet++[J]. arXiv preprint arXiv:2501.02428, 2025. [CrossRef]
- Min, Liu, et al. “Financial Prediction Using DeepFM: Loan Repayment with Attention and Hybrid Loss.” 2024 5th International Conference on Machine Learning and Computer Application (ICMLCA). IEEE, 2024.
- Xiang A, Huang B, Guo X, et al. A neural matrix decomposition recommender system model based on the multimodal large language model[C]//Proceedings of the 2024 7th International Conference on Machine Learning and Machine Intelligence (MLMI). 2024: 146-150.
- Tang, Xirui, et al. “Research on heterogeneous computation resource allocation based on data-driven method.” 2024 6th International Conference on Data-driven Optimization of Complex Systems (DOCS). IEEE, 2024.
- Yang, Haowei, et al. “Research on the Design of a Short Video Recommendation System Based on Multimodal Information and Differential Privacy.” arXiv preprint arXiv:2504.08751 (2025).
- Li, Xiangtian, et al. Artistic Neural Style Transfer Algorithms with Activation Smoothing. arXiv preprint arXiv:2411.08014 (2024).
- Yang, H., Lu, Q., Wang, Y., Liu, S., Zheng, J., & Xiang, A. (2025). User Behavior Analysis in Privacy Protection with Large Language Models: A Study on Privacy Preferences with Limited Data. arXiv preprint arXiv:2505.06305.
- Shih K, Han Y, Tan L. Recommendation System in Advertising and Streaming Media: Unsupervised Data Enhancement Sequence Suggestions[J]. arXiv preprint arXiv:2504.08740, 2025. [CrossRef]
- Lv, Guangxin, et al. “Dynamic covalent bonds in vitrimers enable 1.0 W/(m K) intrinsic thermal conductivity.” Macromolecules 56.4 (2023): 1554-1561.
- Yu Q, Wang S, Tao Y. Enhancing anti-money laundering detection with self-attention graph neural networks[C]//SHS Web of Conferences. EDP Sciences, 2025, 213: 01016.
- Diao, Su, et al. “Ventilator pressure prediction using recurrent neural network.” arXiv preprint arXiv:2410.06552 (2024).
- Xiang A, Qi Z, Wang H, et al. A multimodal fusion network for student emotion recognition based on transformer and tensor product[C]//2024 IEEE 2nd International Conference on Sensors, Electronics and Computer Engineering (ICSECE). IEEE, 2024: 1-4.
- Yang, Haowei, et al. Optimization and Scalability of Collaborative Filtering Algorithms in Large Language Models. arXiv preprint arXiv:2412.18715 (2024).
- Shen, Jiajiang, Weiyan Wu, and Qianyu Xu. “Accurate prediction of temperature indicators in eastern china using a multi-scale cnn-lstm-attention model.” arXiv preprint arXiv:2412.07997 (2024). [CrossRef]
Figure 1.
Performance Evaluation Metrics of Large Language Models.
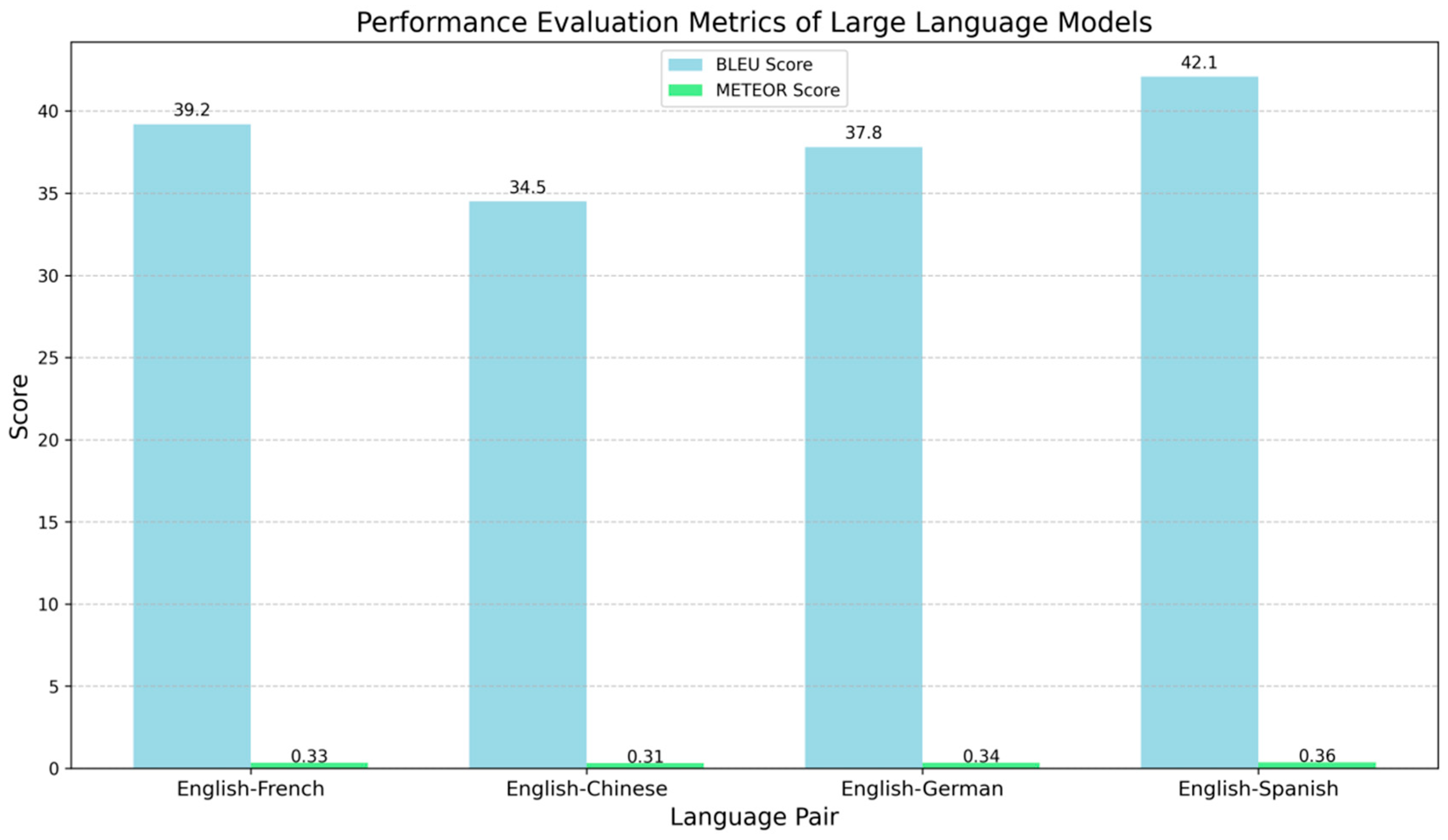
Figure 2.
BLEU Scores for Short and Long Text Translation.
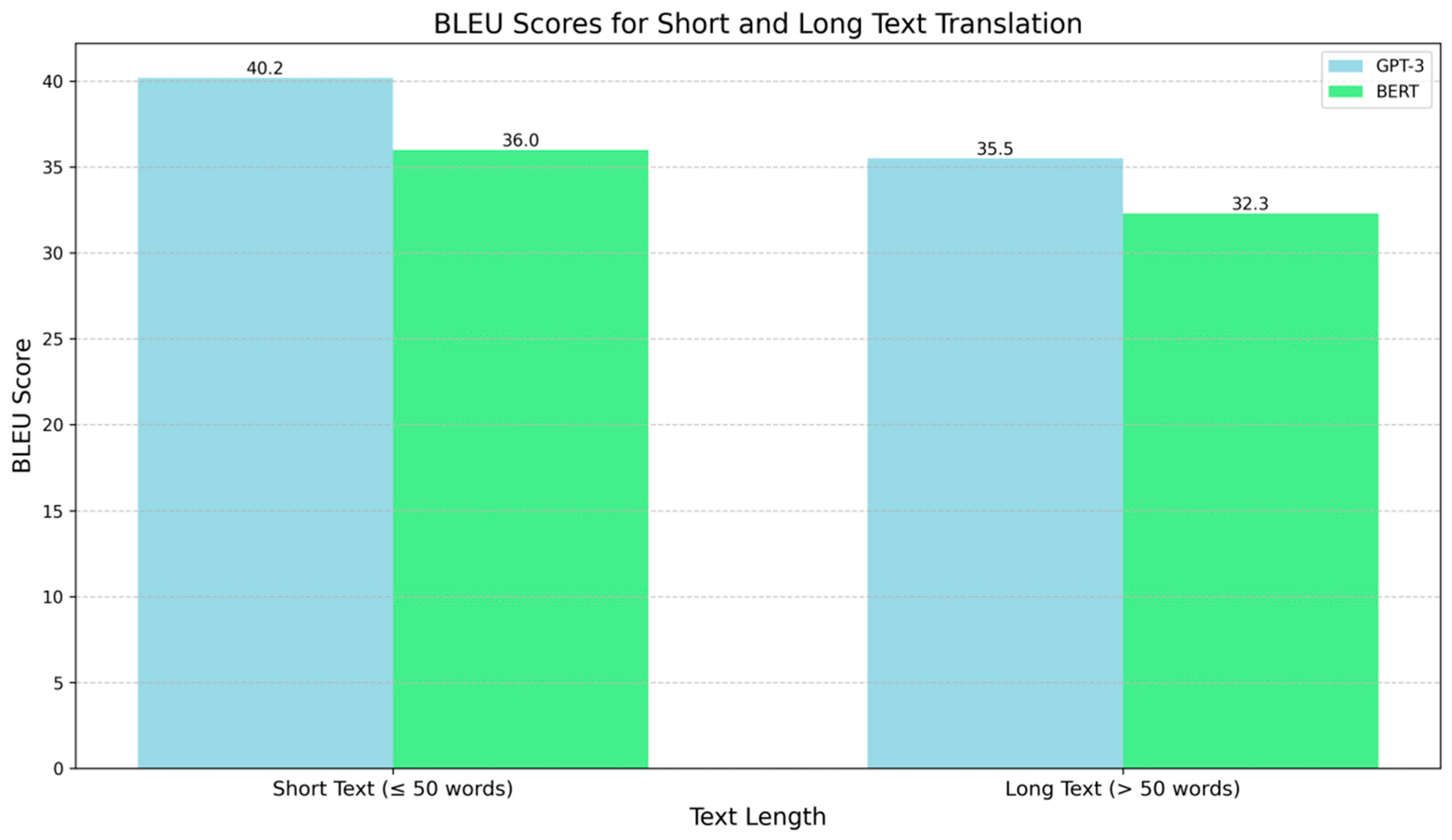

Table 1.
Dataset Overview and Basic Information.
| Dataset Name | Language Pair | Number of Sentences | Data Source |
| WMT 2020 | English-French | 4,500,000 | News Text |
| IWSLT 2017 | English-Chinese | 200,000 | TED Talks |
| WMT 2020 | English-German | 4,200,000 | News Text |
Table 2.
Common Translation Errors in English-French Translation.
| Error Type | Frequency |
| Syntactic Errors (e.g., word order mistakes) | 15% |
| Lexical Errors (e.g., polysemy errors) | 22% |
| Contextual Errors (lack of contextual understanding) | 18% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



