
Submitted:
19 May 2025
Posted:
20 May 2025
You are already at the latest version
Abstract
This study investigates the perception of AI-driven job displacement among computing students. Using a machine learning approach with psychometric data, the analysis identified key factors influencing students’ fear of replacement, including academic program, semester, learning strategies, and proficiency in using LLMs. Results show that students with less exposure to AI and those relying on memorization report higher anxiety, while those trained to develop and critically engage with GenAI tools exhibit more confidence. This work highlights the importance of curriculum design, AI literacy, and ethical reflection to prepare students for an AI-driven future.
Keywords:
Machine Learning
; AI
; GenAI
; AI technology anxiety
; neuroscience
; cognitive neuroscience
1. Introduction
Generative Artificial Intelligence (GenAI) has transformed the educational landscape, promoting significant changes both in teaching methodologies and in students’ learning experiences [Adewale et al. 2024]. One of AI’s main objectives in education is to provide personalized learning, adapting to each student’s knowledge level, difficulties, and study style [Hwang et al. 2020]. Much of the research in this area focuses on optimizing teaching and learning processes, while the impacts of GenAI on students’ academic performance have still received less attention [Adewale et al. 2024].
Among the most impactful innovations are Large Language Models (LLMs), which, through their integration in various domains, have revolutionized the AI field [Jošt et al. 2024]. They are redefining natural language processing, content generation, and text comprehension, paving the way for promising innovations and significantly impacting various areas of knowledge [Ferreira 2024]. LLMs are trained with an enormous amount of textual data and possess advanced natural language comprehension capabilities, allowing the resolution of complex tasks autonomously [Zhao et al. 2023]. In software development, these models have demonstrated their effectiveness by assisting with tasks such as identifying errors, proposing enhancements, and generating code snippets, thereby boosting productivity and minimizing human mistakes [Guo et al., 2024].
However, the growing influence of LLMs in the educational environment also raises concerns. A study conducted by Hernandez et al. [2023] demonstrated that adaptive technologies, adjusting to students’ learning styles and paces, can increase their confidence and enhance their ability to master content at their own pace. Nevertheless, excessive reliance on GenAI in the learning process can compromise the development of problem-solving skills and reduce students’ sense of autonomy. Consequently, some students have displayed anxiety, questioning their own abilities and feeling inferior compared to AI-based technologies [Asio and Suero 2024].
This insecurity related to GenAI is not limited to the academic environment but also extends to students’ professional future. With the growing adoption of this technology in various fields, many students fear that the careers they are preparing for may become obsolete [Chan and Hu 2023]. Moreover, its increasing use may raise recruitment standards. In this context, the ability to successfully enter the job market may depend not only on formal qualifications but also on AI literacy—an area where students from disadvantaged and international backgrounds are often at a disadvantage due to the persistent digital divide.
As highlighted by Zhou, Fang, and Rajaram [2025], disparities in digital literacy, access to institutional support, and familiarity with technological tools tend to widen over the course of undergraduate studies, limiting students’ capacity to engage in digital learning environments and to develop the competencies increasingly demanded by employers. From a connectivist perspective, this unequal access to digital networks and resources not only hinders educational progress but also places certain students at a disadvantage when transitioning into digitally driven professional contexts.
In light of these widening disparities, recent discussions around educational policy have emphasized the importance of fostering AI literacy among students. The Artificial Intelligence Literacy Act of 2023 (H.R.6791), introduced in the U.S. Congress, defines AI literacy as the skills associated with the ability to comprehend the basic principles, concepts, and applications of artificial intelligence, as well as the implications, limitations, and ethical considerations associated with the use of artificial intelligence. According to the bill, maintaining technological leadership in AI is a matter of economic and national security, which demands a workforce that combines both technical experts (e.g., engineers and data scientists) and nontechnical professionals who understand the capabilities and consequences of AI.
However, despite these policy efforts to promote AI literacy, many students still feel unprepared to navigate a job market increasingly shaped by generative AI technologies. The rapid evolution of these tools introduces an additional layer of concern for students—not only as a technological challenge, but as a perceived threat to their future employability. Among the main concerns of students is the potential of GenAI to replace human labor, increasing the risk of large-scale unemployment. For students in training, the exponential advance of this technology represents a concrete threat, increasing uncertainty about the job market and amplifying concerns about unemployment [Wang et al. 2022].
1.1. Objectives
Based on the previous discussion, this study aims to identify which groups of students show greater concern regarding replacement by GenAI in the job market. In addition, it seeks to map the characteristics of these students, analyzing factors such as time in the program, learning strategies, AI technology anxiety and difficulties in using LLMs for comprehension and problem-solving. By outlining the profile of students most susceptible to this fear, the intention is to contribute to a better understanding of the impacts of GenAI on academic training and on the professional expectations of computing students.
1.2. Related Works
Recent studies have explored the complexities surrounding students’ and professionals’ perceptions of GenAI integration in educational and occupational contexts. Nkedishu and Okonta [2024], for instance, found contrasting attitudes between students from different academic backgrounds: while those in Computer Science generally viewed AI as an opportunity, students in the humanities expressed deeper concerns regarding social implications, job displacement, and the need for ongoing retraining.
Pinto et al. [2023] conducted an empirical investigation with computer science students to explore the relationship between frequent interaction with LLMs and rising anxiety about AI-driven changes in the job market. The study employed validated psychometric scales to assess emotional and cognitive responses. While familiarity with these tools can enhance academic productivity, it may also heighten fears of professional obsolescence. Their findings underscore the importance of developing metacognition, highlighting the role of emerging skills such as prompt engineering and advanced digital literacy.
Further contributing to this debate, da Silva et al. [2024] conducted a mixed-methods survey focused on ethics and responsibility among students in computing-related programs. Their results reveal that while many students acknowledge the benefits of generative AI tools, a significant proportion also express ethical concerns about privacy, algorithmic transparency, and dependency. The lack of formal instruction on AI ethics in many curricula further exacerbates this tension, pointing to an urgent need for structured ethical education.
Carvalho et al. [2024] broaden the conversation by surveying attitudes toward AI across sectors including education, healthcare, and creative industries. Employing the ATAI scale and ensuring psychometric quality in their measurements, the study found moderate trust in AI, high perceived benefits, and relatively low fear, yet a persistent concern about job displacement — especially in Latin American contexts. Many participants were unaware of how AI already influenced their daily lives, which underscores the need for increased AI literacy and awareness in both public and educational spheres.
Most recently, Delello et al. [2025] surveyed over 330 educators from around the world, focusing on AI’s integration in classrooms, its perceived benefits, and its impacts on both teaching and mental health. While educators acknowledged AI’s potential for increasing efficiency, personalization, and student motivation, many also raised concerns about reduced interpersonal interaction, increased technostress, and the absence of institutional policies to guide ethical AI use. The study also identified a pressing need for professional development, particularly training on ethical usage, privacy, and strategies for mental health support in AI-mediated educational environments.
2. Methodology
2.1. Procedures and Participants
The dataset used in this study was retrieved from Kaggle, where it was made publicly available by Pinto [2025] for future analysis and research reuse. This dataset is notable for its richness, comprising both detailed sociodemographic information and responses to five psychometric scales that have been previously validated for use in Brazil. The data were originally collected through a probability-based survey conducted in 2023, using Google Forms. A total of 178 students participated in the survey, with a gender distribution of 143 male respondents (80.3%) and 35 female respondents (19.7%). In terms of academic background, the majority were undergraduate students enrolled in Computer Science and related programs.
2.2. Instruments
The dataset includes five psychometric scales, all of which have been previously validated for use in the Brazilian context [Pinto et al., 2023]. These instruments assess a range of constructs relevant to students' experiences with GenAI. Each item was rated on a 7-point Likert scale, with response options ranging from “Strongly Disagree” to “Strongly Agree” and from “Never” to “Always,” depending on the construct being measured. This format allows for a nuanced assessment of participants’ positions across multiple dimensions.
However, rather than applying a traditional psychometric framework based on pre-established factors or constructs, the authors adopted a Machine Learning (ML) based exploratory approach. The goal was to identify latent patterns and associations between items across different scales without the rigidity typically associated with confirmatory psychometric analysis. This strategy enabled a more flexible and data-driven investigation of the psychological and educational dynamics involved in students’ interactions with GenAI tools.
2.3. Data Analysis
The dataset were analyzed with the aim of identifying patterns among students, using the unsupervised learning algorithm K-means, listed among the 10 most frequently used clustering algorithms for data analysis [Ahmed et al. 2020]. Two distinct clusterings were carried out. The first clustering used the variables “I worry that programmers will be replaced by artificial intelligence models” and “I feel as if I cannot keep up with the changes brought about by artificial intelligence models”. The second clustering considered the variables “I worry that programmers will be replaced by artificial intelligence models” and “I am afraid that artificial intelligence models will make the content I learned in college obsolete”.
The K-means algorithm requires the prior definition of the number of clusters, which determines how many groups are formed in data segmentation [Hamerly and Elkan 2003]. For this analysis, the number of clusters was set to 4 in both clusterings, using the Elbow Method, which identifies the optimal point of intra-cluster inertia reduction to determine the ideal number of groups. In the first clustering, although four clusters were generated, only three were considered relevant for the study and were selected for the final dataset: students concerned about AI replacement, students who do not exhibit this concern, and students who find it difficult to keep up with the technological changes brought about by GenAI. In the second clustering, two main profiles were selected: students concerned about GenAI replacement and students who do not exhibit concern about this replacement.
To consolidate the results, a final dataset was created by combining the five identified groups and removing possible duplicate samples. Bar charts were then generated to identify characteristics associated with students who are most apprehensive about being replaced by GenAI in the job market. All analyses were conducted using the Python language and open-source libraries, including pandas [McKinney 2010], matplotlib [Hunter 2007], and scikit-learn [Pedregosa et al. 2011].
2.4. GenAI Usage Statement
The translation of this article into English was carried out with the assistance of ChatGPT-4o, ensuring accuracy and fidelity to the original content. The authors remain fully responsible for the integrity, interpretation, and originality of the content presented.
3. Results
3.1. Proportion of Students by Program
Students’ awareness of GenAI’s impact on the job market varies among the Computer Science, Computer Engineering, and Data Science and Artificial Intelligence programs. The bar chart inFigure 1 illustrates the proportion of students who express concern about being replaced by this technology.
A higher concern about replacement by GenAI appears among Computer Engineering students, where 42.9% convey this fear. In contrast, Data Science and Artificial Intelligence students exhibit the lowest rate of concern, at only 13.9%. Knowledge levels about LLMs also differ among these programs. Figure 2 demonstrates that Data Science and Artificial Intelligence students possess a stronger command of these technologies, whereas those in Computer Engineering show a considerably lower level of knowledge.
3.2. Proportion of Students by Semester
Time spent in the program and the concern about GenAI replacement may reveal interesting patterns in students’ perceptions during their academic journey. Figure 3 presents the proportion of students who express this fear across different stages of the program — up to 25% completed, between 25% and 50%, between 50% and 75%, and over 75%.
Most students who fear being replaced by GenAI in the job market are concentrated in the first half of the program. Concern increases in the final semesters, where 25% of students express this fear, in contrast to only 5.6% among those who have completed between 50% and 75% of the program.
3.3. Memorizing Content
Ways of assimilating knowledge can influence how students perceive the impact of GenAI in the job market. Some focus on memorizing content, while others pursue a deeper, more meaningful grasp of the material studied in college. Figure 4 displays how these distinct learning profiles relate to the fear of being replaced by LLMs.
A clear association emerges between the learning approach and apprehension about GenAI replacement. Students who merely memorize content and report this fear appear at a rate 2.11 times higher than those who truly learn the concepts.
3.4. Ability to Find Errors in LLMs-Generated Code
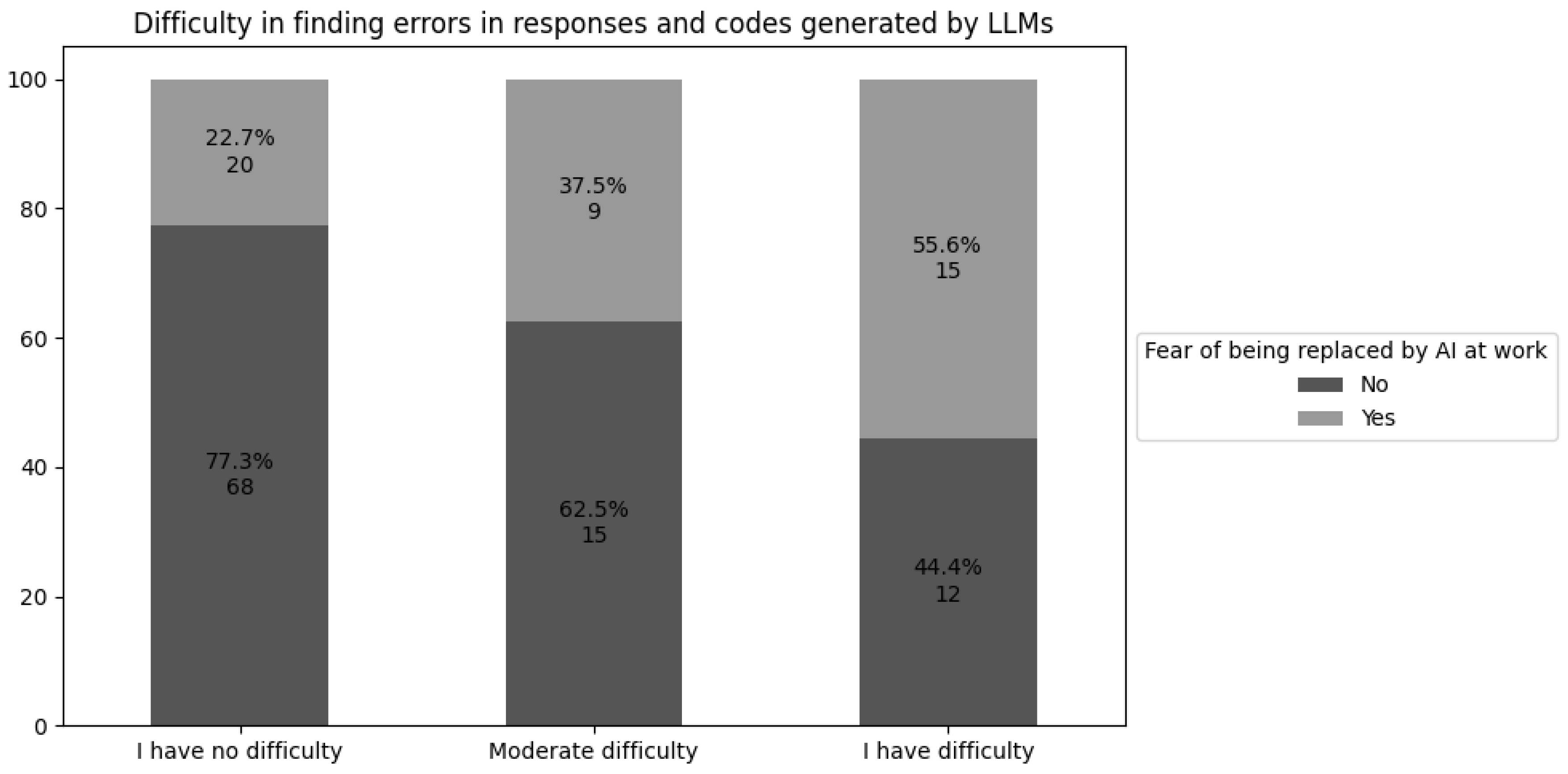
Students’ capacity to identify errors in LLM-generated code may reveal how they view GenAI as a tool. Figure 5 depicts the proportion of students who harbor this fear, segmented by different skill levels.
A notable connection exists between difficulty in spotting errors in LLM-generated code and anxiety about replacement by GenAI. More than half of the students who struggle in this area voice concerns about their job prospects upon graduation.
4. Discussion
4.1. AI as Threat or Ally? The Impact of Educational Trajectories on Students’ Confidence Toward AI Integration
Analyses point to intriguing patterns about information technology students who experience apprehension regarding GenAI’s impact on their careers. Computer Engineering students express the highest concern about being supplanted by these systems, whereas individuals in Data Science and Artificial Intelligence report comparatively lower unease.
One explanation for this difference lies in the curriculum structures of each program. The Computer Engineering course includes only one mandatory subject focusing on AI — Introduction to Artificial Intelligence, administered in the 8th semester. Meanwhile, Data Science and Artificial Intelligence offers three compulsory courses — Introduction to Artificial Intelligence (4th semester), Machine Learning (5th semester), and Deep Learning (6th semester) — and one elective: Natural Language Processing (7th semester). The Computer Science course features two mandatory AI-related classes — Introduction to Artificial Intelligence (4th semester) and ML Paradigms (6th semester) — and two electives: Applied Artificial Intelligence in Health (5th semester) and Deep Learning (7th semester).
This difference in training directly influences the students’ level of familiarity with AI [Marrone et al. 2024]. Since the Computer Engineering program offers only one required course in the field, and even that in a later semester, it is natural for its students to have less contact with AI concepts and applications throughout the program. This limited involvement results in a narrower understanding of LLMs, which, in turn, increases insecurity regarding these technologies’ impact on the job market [Chan and Hu 2023]. On the other hand, students in Data Science and Artificial Intelligence, in addition to having greater exposure to the topic during the program, are trained to develop these technologies, contributing to a more positive perception of AI as an allied tool rather than a threat [Chan and Hu 2023].
Furthermore, it is observed that most of the students who express this fear are in the initial semesters of their program, particularly in the first half of the course. This is directly related to the fact that, over time, students become more capable and gain familiarity with the technologies and tools they will use in their careers [Marrone et al. 2024]. However, this concern rises again in the final semesters, since, at the time of the questionnaire, the soon-to-graduate students had little contact with this technology. The lack of familiarity generates insecurity about how GenAI will affect their job opportunities, as they do not fully understand its potential and limitations [Tu et al. 2024].
Another relevant aspect concerns the depth of learning and the development of critical technical skills. Data suggest that students who rely primarily on memorization — possibly focusing only on passing exams — tend to experience significantly greater fear of being replaced by GenAI in the job market. This pattern reflects lower levels of mastery and self-confidence in using technologies required in professional settings, making these students more vulnerable to uncertainty and automation threats [Chan and Hu, 2023].
A specific example of this can be seen in the difficulty some students have in identifying errors in code generated by LLMs. This difficulty suggests a superficial understanding of programming logic, which directly impacts their perceived competence. As a result, over half of these students report concern about their future careers. In contrast, students who are able to detect and correct such errors tend to perceive GenAI not as a replacement, but as a collaborative tool that can enhance the software development process [Tu et al. 2024; Marrone et al. 2024].
4.2. Rethinking Evidence: Machine Learning and the Replicability Challenge in Cognitive and Behavioral Neuroscience
The increasing integration of ML algorithms into psychometric and educational research has expanded the analytical scope of these fields, enabling the identification of latent patterns in complex, multifactorial datasets [Sarker 2021]. In this study, such an approach was applied to a dataset composed of previously validated psychometric scales, aiming to investigate the psychological impact of GenAI, such as technology anxiety. Rather than relying solely on traditional confirmatory statistical methods, the unsupervised learning algorithm K-means was used — a widely adopted technique for data segmentation [Ahmed et al. 2020].
This methodological choice reflects a paradigm shift: instead of testing predefined hypotheses based on rigid constructs, the use of K-means enabled a flexible, data-driven organization of students’ responses. This approach uncovered emergent psychological profiles based on patterns of technological anxiety, learning strategies, and familiarity with LLMs. Thus, the algorithm served as an alternative to traditional factor analysis, exploring how students internally structure their experiences within AI-mediated learning environments.
Nonetheless, as extensively discussed in the cognitive neuroscience and psychological sciences literature, the adoption of ML techniques is not without challenges — particularly with respect to reproducibility, statistical validity, and overfitting risks [McDermott et al. 2019; Szucs & Ioannidis 2017; Cumming 2008]. ML models such as K-means can be highly sensitive to input parameters — including the predefined number of clusters — and may be influenced by sample biases. To mitigate these issues, the present study employed the Elbow Method to determine the optimal number of clusters, offering a practical way to reduce intra-cluster inertia and promote more stable findings.
Furthermore, the convergence of ML and cognitive-behavioral modeling opens new avenues for building predictive systems that are not only statistically robust but also theoretically grounded and ethically interpretable [Franco 2021]. As this study shows, ML does not replace classical psychometrics but complements it. When applied with theoretical rigor, ethical oversight, and methodological transparency, ML can enhance the precision, generalizability, and depth of educational and psychological research [Franco 2021; Orrù et al. 2020].
5. Conclusion
This study highlights how students' perceptions of AI are shaped by their academic pathways, learning strategies, and levels of exposure to generative technologies. Fear of replacement is more common among students with limited curricular contact with AI and those who rely on memorization, while students with deeper engagement and technical confidence tend to view AI as a supportive tool rather than a threat. These findings reinforce the importance of curriculum design that fosters not only technical proficiency but also confidence and autonomy in the use of AI. Addressing students’ concerns about employability in an AI-driven market requires early and consistent integration of AI literacy, critical thinking, and hands-on experience across computing education.
References
- Adewale, M. D. , Azeta, A., Abayomi-Alli, A., & Sambo-Magaji, A. (2024). “Impact of artificial intelligence adoption on students' academic performance in open and distance learning: A systematic literature review”, Heliyon, v. 10, n. 22, e40025. [CrossRef]
- Ahmed, M. , Seraj, R., & Islam, S. M. S. (2020). “The k-means Algorithm: A Comprehensive Survey and Performance Evaluation,” Electronics, v. 9, n. 8, p. 1295. [CrossRef]
- Asio, J. M. R. , & Suero, A. N. (2024). “Artificial Intelligence Anxiety, Self-Efficacy, and Self-Competence among Students: Implications to Higher Education Institutions”, Education Policy and Development, v. 2, n. 2, p. 82-93.
- Carvalho, D. , Ferro, M., Corrêa, F., Faria, V., Lima, L., Souza, A., & Gromato, M. (2024). “Um Estudo Sobre a Percepção e Atitude dos Usuários de Sistemas Computacionais em Relação à Inteligência Artificial”, In Anais do V Workshop sobre as Implicações da Computação na Sociedade, pp. 13-23. Porto Alegre: SBC. [CrossRef]
- Chan, C. K. Y. , & Hu, W. (2023). “Students’ voices on generative AI: perceptions, benefits, and challenges in higher education”, International Journal of Educational Technology in Higher Education, v. 20, p. 43. [CrossRef]
- Cumming, G. (2008). “Replication and P intervals: P values predict the future only vaguely, but confidence intervals do much better”, Perspect. Psychol. Sci. 3, 286–300. [CrossRef]
- Ferreira, R. , Freitas, E., Cabral, L., Dawn, F., Rodrigues, L., Rakovic, M., Raniel, J., & Gašević, D. (2024). “Words of Wisdom: A Journey through the Realm of NLP for Learning Analytics – A Systematic Literature Review”, Journal of Learning Analytics, v. 11, n. 3, p. 82–105. [CrossRef]
- Franco, V. R. (2021). “Aprendizado de Máquina e Psicometria: Inovações Analíticas na Avaliação Psicológica”, Avaliação Psicológica, 20(3), a-c. [CrossRef]
- Guo, D. , Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y., Li, Y. K., Luo, F., Xiong, Y., & Liang, W. (2024). “DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence”, ArXiv. [CrossRef]
- Hamerly, G., & Elkan, C. (2003). “Learning the k in k-means,” In Proceedings of the 17th International Conference on Neural Information Processing Systems (NIPS'03), v. 17, p. 281–288.
- Hunter, J. D. (2007). Matplotlib: A 2D Graphics Environment. Computing in Science & Engineering, 9(3), 90–95. [CrossRef]
- Hwang, G.-J. , Xie, H., Wah, B. W., & Gašević, D. (2020). “Vision, challenges, roles and research issues of Artificial Intelligence in Education”, Computers and Education: Artificial Intelligence, v. 1, 100001. [CrossRef]
- Jošt, G. , Taneski, V., & Karakatič, S. (2024). “The impact of Large Language Models on programming education and student learning outcomes,” Applied Sciences, v. 14, n. 10, p. 4115. [CrossRef]
- McDermott, M. B. A. , Wang, S., Marinsek, N., Ranganath, R., Ghassemi, M., Foschin, L., et al. (2019). “Reproducibility in machine learning for health”, ArXiv. [CrossRef]
- McKinney, W. (2010). “Data Structures for Statistical Computing in Python. Proceedings of the 9th Python in Science Conference”, 51–56. [CrossRef]
- Marrone, R. , Zamecnik, A., Joksimovic, S. et al. (2024). “Understanding Student Perceptions of Artificial Intelligence as a Teammate. Tech Know Learn”. [CrossRef]
- Nkedishu, V. C. , & Okonta, V. (2024). “Unpacking Optimism versus Concern: Tertiary Students' Multidimensional Views on the Rise of Artificial Intelligence (AI),” International Research Journal of Multidisciplinary Scope, v. 5, p. 362-377.
- Orrù, G. , Monaro, M., Conversano, C., Gemignani, A., & Sartori, G. (2020). “Machine learning in psychometrics and psychological research”, Frontiers in Psychology, 10. [CrossRef]
- Pedregosa, F. , Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O.,... & Duchesnay, É. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825–2830.
- Pinto, P. H. R. , Araujo, V. M. U. D., Ferreira Junior, C. D. S., Goulart, L. L., Aguiar, G. S., Beltrão, J. V. C., Lira, P. D. D., Mendes, S. J. F., Monteiro, F. D. L. V., & Avelino, E. L. (2023). “Assessing the Psychological Impact of Generative AI on Computer and Data Science Education: An Exploratory Study”, Preprints. [CrossRef]
- Pinto, P. H. R. (2025). LLMs Dataset UFPB [Data set]. Kaggle. [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN COMPUT. SCI. 2, 160 (2021). [CrossRef]
- Szucs, D. , and Ioannidis, J. P. A. (2017). “Empirical assessment of published effect sizes and power in the recent cognitive neuroscience and psychology literature”, PLoS Biol. 15:e2000797. [CrossRef]
- Silva, M. , Seixas, E., Ferro, M., Viterbo, J., Seixas, F., & Salgado, L. (2024). “Ética e Responsabilidade na Era da Inteligência Artificial: Um Survey com Estudantes de Computação”, In Anais do XXXII Workshop sobre Educação em Computação, (pp. 854-865). Porto Alegre: SBC. [CrossRef]
- Tu, Xinming, et al. “What Should Data Science Education Do with Large Language Models?” Harvard Data Science Review, vol. 6, no. 1, 19 Jan. 2024. [CrossRef]
- United States Congress. (2023). “Artificial Intelligence Literacy Act of 2023 (H.R.6791),” Bill introduced in the U.S. House of Representatives, 118th Congress, 1st Session. Available at: https://www.congress.gov/bill/118th-congress/house-bill/6791/text.
- Velastegui-Hernandez, D. C. , Rodriguez-Pérez, M. L., & Salazar-Garcés, L. F. (2023). “Impact of Artificial Intelligence on learning behaviors and psychological well-being of college students”, Salud, Ciencia y Tecnología - Serie de Conferencias, v. 2, p. 582. [CrossRef]
- Wang, Y.-M. , Wei, C.-L., Lin, H.-H., Wang, S.-C., & Wang, Y.-S. (2022). “What drives students’ AI learning behavior: a perspective of AI anxiety,” Interactive Learning Environments, v. 32, n. 6, p. 2584–2600. [CrossRef]
- Zhao, W. X. , Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., Liu, P., Nie, J.-Y., & Wen, J.-R. (2024). arXiv:2303.18223v15 [cs.CL]. [CrossRef]
- Zhou, X. , Fang, L., & Rajaram, K. (2025). “Exploring the digital divide among students of diverse demographic backgrounds: A survey of UK undergraduates”, Journal of Applied Learning & Teaching, 8(1). [CrossRef]
Figure 1.
Proportion of Students by Program.
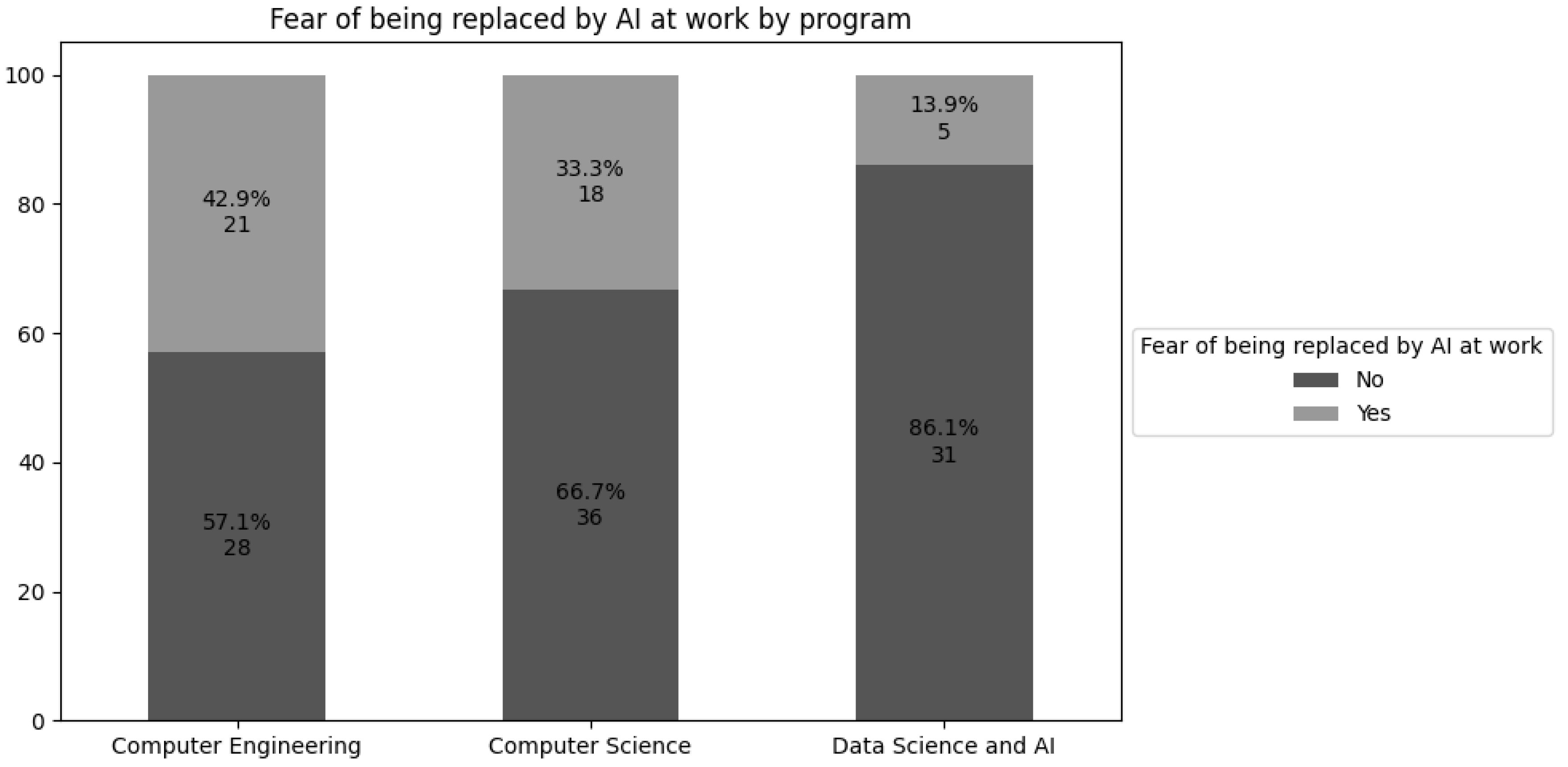
Figure 2.
Level of Knowledge about LLMs by Program.
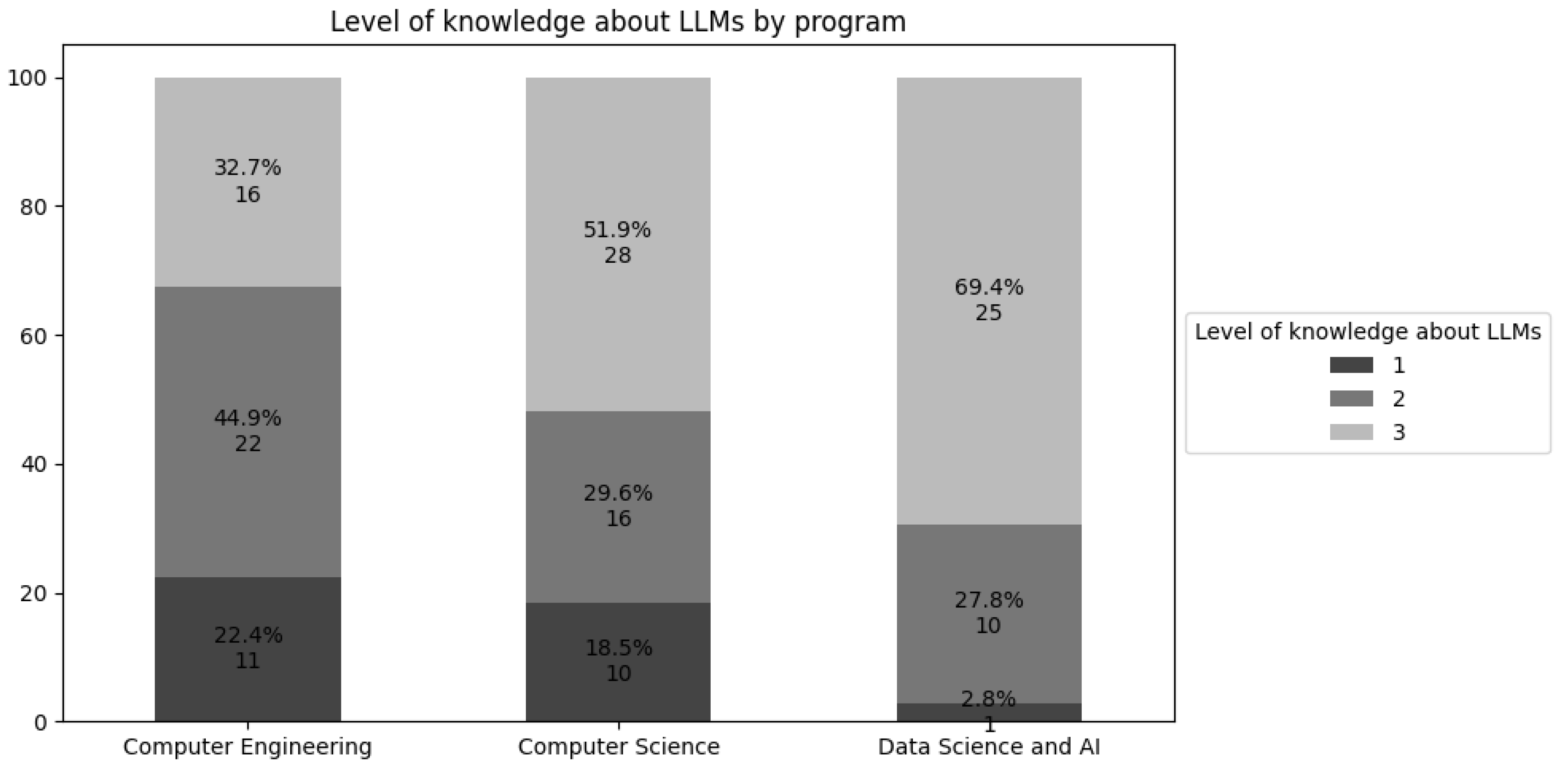
Figure 3.
Proportion of Students by Semester.
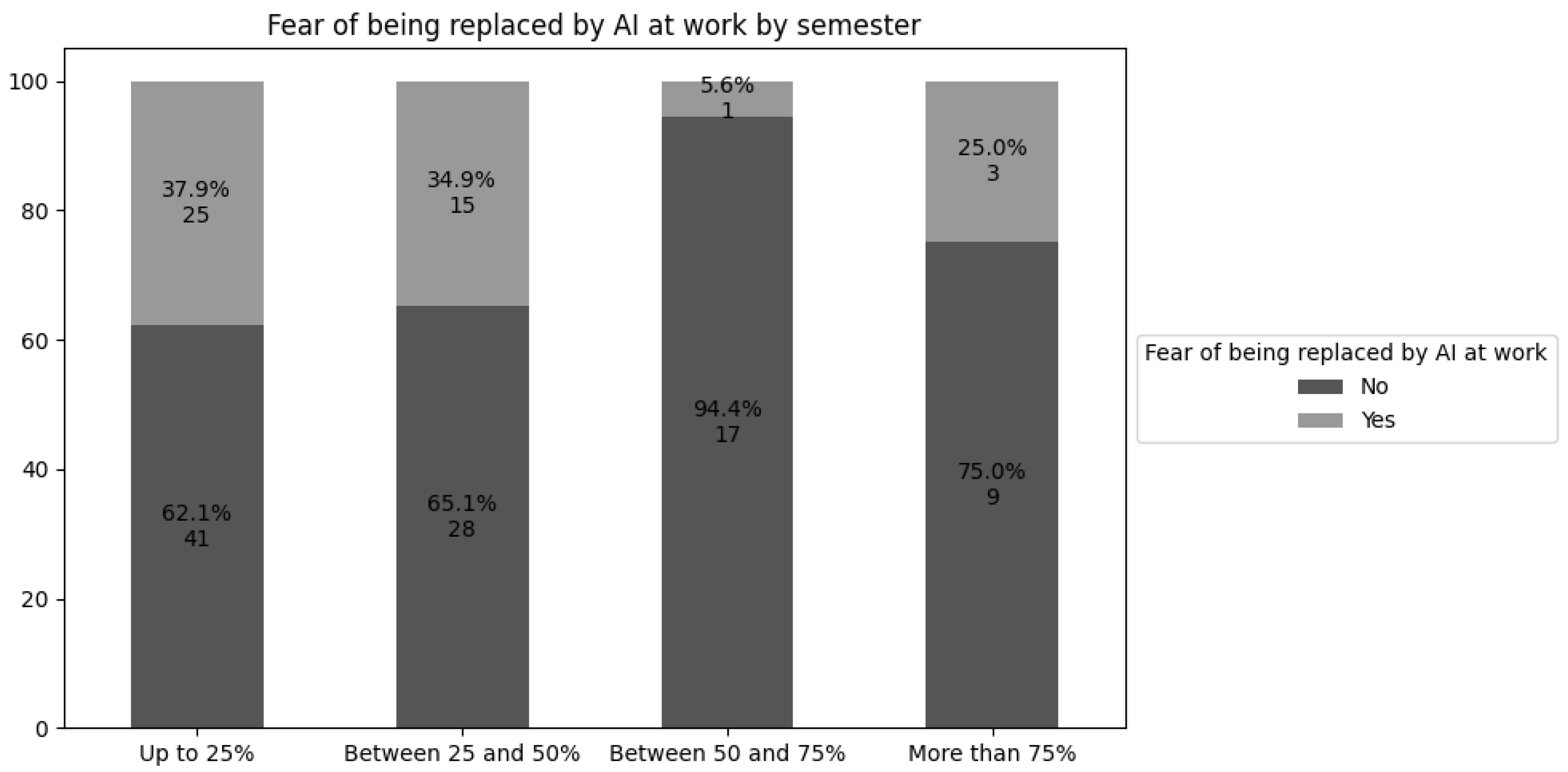
Figure 4.
Memorizing Content.
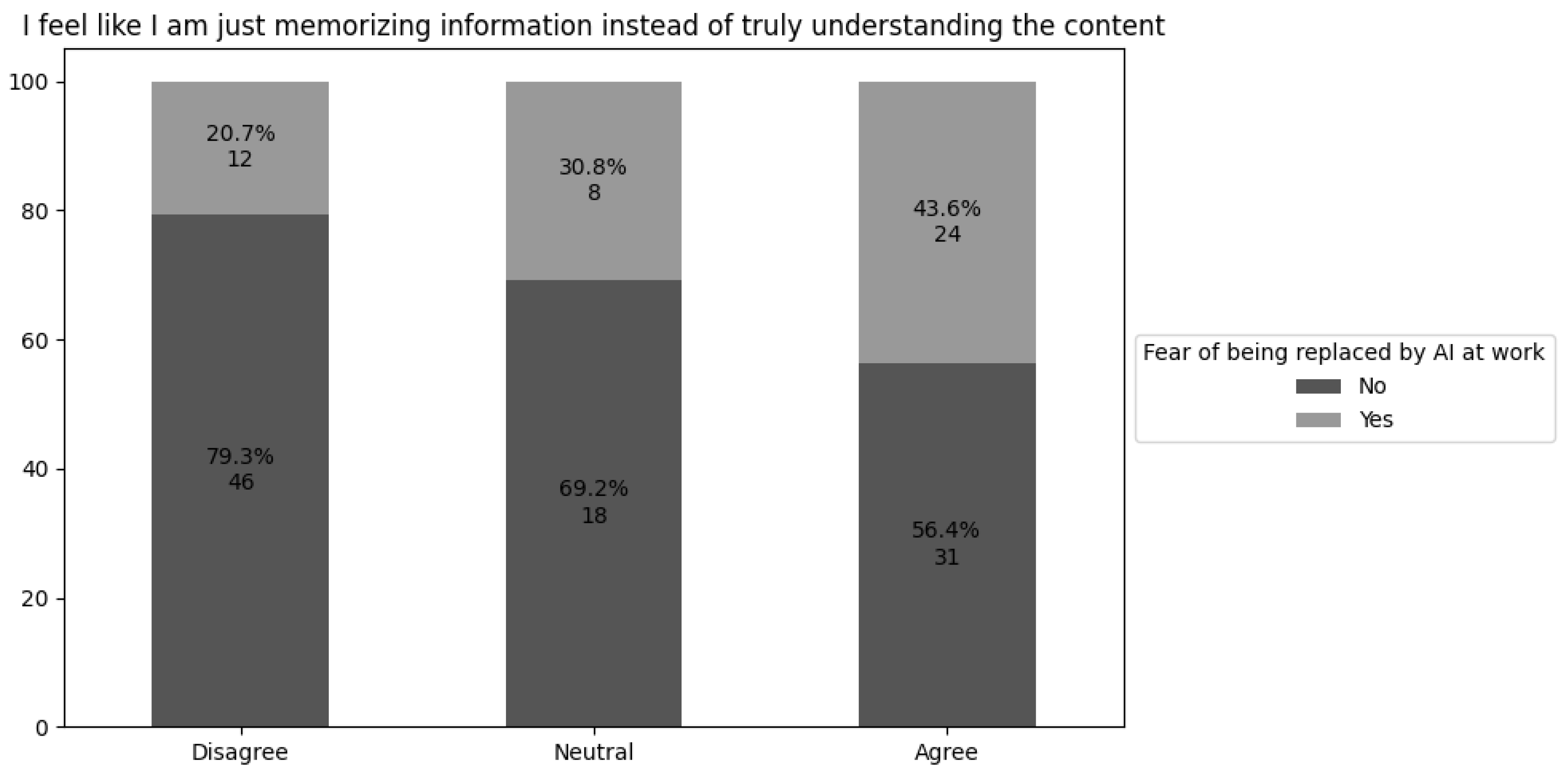
Figure 5.
Ability to Find Errors in LLMs-Generated Code.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



