
Submitted:
17 May 2025
Posted:
19 May 2025
You are already at the latest version
Abstract
StudSar is a novel neural associative memory system engineered to emulate human-like mechanisms for forming, storing, and retrieving memories in artificial intelligence (AI), addressing critical limitations in existing memory models. Inspired by human learning strategies, StudSar processes extensive textual data through a structured workflow that segments inputs into semantically rich blocks, generating 384-dimensional embeddings using the ‘all-MiniLM-L6-v2’ model from the Sentence Transformers library. These embeddings serve as associative markers, enabling real-time knowledge integration and precise, similarity-based retrieval via a custom StudSarNeural network implemented in PyTorch. Through iterative refinements, StudSar has evolved to incorporate advanced features, including dynamic memory updates, enhanced contextual handling, and metadata integration, such as emotional tags (e.g., “curiosity”), reputation scores, and usage frequency; mimicking human memory dynamics where frequently accessed information is reinforced. Unlike conventional AI assistants, which struggle to accurately link to specific fragments within large inputs, particularly as data scales, StudSar excels at pinpointing exact information with context-aware precision, even in expansive corpora. This paper elucidates StudSar’s architecture, detailing its five-stage pipeline: text segmentation, embedding generation, marker creation, network integration, and query-driven retrieval. Experimental results demonstrate robust retrieval accuracy (e.g., cosine similarity scores of 0.6652–0.7981), persistent memory across sessions, and adaptability to new data, validated through tests on diverse queries and metadata-driven scenarios. StudSar’s scalability and modular design position it as a transformative contribution to next-generation AI systems, with applications in conversational agents, personalized learning platforms, and knowledge management. By bridging intuitive human memory processes with technical innovation, StudSar lays a foundation for advanced cognitive features, such as emotional state modeling and memory consolidation, paving the way for AI systems that more closely emulate human intelligence. This work offers a comprehensive analysis of StudSar’s implementation and potential, highlighting its role in advancing AI memory research.
Keywords:
Sparse retrieval
; StudSar
; Text segmentation
; Contextual retrieval
; Dynamic memory updates
; Metadata integration
; Cosine similarity
; Machine learning benchmarking
; Natural language processing
; Reinforcement learning
; Integrative AI
1. Introduction
Human intelligence is distinguished by its ability to retain and recall information over extended periods while preserving contextual meaning. In contrast, contemporary artificial intelligence (AI) systems often falter in maintaining long-term memory, losing causal relationships and semantic depth. This limitation inspired the development of StudSar, a neural associative memory system dedicated to Sara, a mentor whose effective study techniques formed the foundation of this research. The initial conceptualization of StudSar, captured in a handwritten sketch (see Figure 1), reflects a personal exploration of memory retention strategies adapted for AI.
The motivation for StudSar stems from the need to create a system that associates specific information with synthetic markers for robust, context-aware recall, surpassing simple keyword matching or summarization. The development of StudSar emerged from years of academic study and formal learning, rooted in deep engagement with university textbooks and specialized literature. The initial insight arose serendipitously during personal introspection: the rediscovery of the ability to recall complex concepts from old manuals after a single reading. This observation inspired the aspiration to mirror effective human learning strategies in an AI system, emphasizing detail-oriented memory capable of binding complex content contextually. The conceptual framework reflects the process of synthesizing information from multiple sources (e.g., seven textbooks) triggered by a single query, aiming to replicate this in AI through text segmentation and associative markers. StudSar further advances this vision by incorporating metadata to emulate human memory reinforcement and fading, enhancing its ability to adapt and prioritize information based on usage and feedback.
Through iterative development, StudSar has established mechanisms for text segmentation, embedding generation, and associative retrieval, addressing the shortcomings of traditional AI memory models. Further advancements have introduced enhanced persistence, dynamic updates, and infrastructure for incorporating feedback and usage patterns, drawing inspiration from how human memories are reinforced or faded based on experience. This paper details StudSar’s architecture, experimental results, and future directions, presenting it as a cohesive framework for advancing AI memory capabilities.
Figure 1.
Handwritten Sketch of Structured Workflow Mirroring Human Memory Formation (further described in the methodology section).
Figure 1.
Handwritten Sketch of Structured Workflow Mirroring Human Memory Formation (further described in the methodology section).

2. Background and Related Work
2.1. Background
Memory is a cornerstone of human cognition, enabling the storage, organization, and context-sensitive retrieval of information across diverse experiences and timescales. In artificial intelligence (AI), replicating such capabilities has been a persistent challenge, critical for advancing applications like conversational agents, knowledge management systems, and personalized learning platforms. The evolution of AI memory research reflects a progression from static representations to dynamic, context-aware architectures, each addressing distinct aspects of information retention and recall.
The foundations of modern AI memory were laid with distributed word embeddings, such as Word2Vec [Mikolov et al., 2013], which introduced efficient methods for capturing semantic relationships in text. By mapping words to high-dimensional vectors based on their co-occurrence patterns, Word2Vec enabled similarity-based retrieval, a precursor to more sophisticated memory systems. However, these embeddings were inherently static, lacking the ability to adapt to new contexts or retain sequential dependencies, limiting their utility for complex, long-term memory tasks.
The introduction of transformer architectures marked a paradigm shift in AI memory research [Vaswani et al., 2017]. By leveraging self-attention mechanisms, transformers could process entire sequences of text simultaneously, capturing intricate contextual relationships. This innovation underpinned models like BERT [Devlin et al., 2019], which achieved state-of-the-art performance in natural language understanding by pre-training on massive corpora and fine-tuning for specific tasks. BERT’s bidirectional context modeling improved semantic coherence, but its reliance on fixed-length inputs and high computational costs posed challenges for real-time memory updates and precise retrieval in large documents.
Concurrently, research into external memory-augmented neural networks sought to address these limitations by integrating trainable memory components. Neural Turing Machines (NTMs) [Graves et al., 2014] pioneered this approach, combining neural networks with an addressable memory matrix to emulate human-like read-write operations. Memory Networks [Weston et al., 2015] and their variants [Sukhbaatar et al., 2015; Kumar et al., 2016] further advanced this paradigm by enabling query-driven access to stored facts, supporting tasks like question answering and reasoning. These models introduced the concept of associative memory in AI, where information is retrieved based on content similarity rather than predefined indices.
The development of large-scale language models, such as GPT-3 [Brown et al., 2020], further expanded the scope of AI memory by leveraging vast pre-trained knowledge to generate contextually relevant responses. Supported by frameworks like Hugging Face’s Transformers [Wolf et al., 2020], these models excel in few-shot learning and generalization but often struggle with pinpointing specific information fragments in long-form texts, a critical requirement for human-like memory. Sentence embedding techniques, such as Sentence-BERT [Reimers & Gurevych, 2019], addressed this by optimizing transformers for semantic similarity, enabling efficient retrieval at the sentence level. However, these approaches lack mechanisms for dynamic updates or metadata integration, limiting their adaptability to evolving data.
StudSar builds on this rich history, drawing inspiration from human learning strategies to create a neural associative memory system that integrates real-time updates, metadata-driven retrieval, and scalable architecture. By synthesizing insights from word embeddings, transformers, and memory-augmented networks, StudSar aims to bridge the gap between static AI memory models and the dynamic, context-aware capabilities of human cognition [Bulla et al., 2025].
2.2. Related Work
AI memory research has produced a diverse array of paradigms, each contributing to the development of systems like StudSar. Below, we critically analyze the referenced works, highlighting their strengths, limitations, and relevance to StudSar’s design.
Word Embeddings and Semantic Representations
The work of Mikolov et al. [2013] on Word2Vec introduced distributed word embeddings, a foundational technique for capturing semantic relationships in text. By training on large corpora, Word2Vec generates dense vectors that encode word meanings based on their contextual usage, enabling efficient similarity searches. This approach revolutionized tasks like word analogy and text classification, providing a lightweight alternative to earlier bag-of-words models. However, Word2Vec’s static embeddings cannot adapt to new data without retraining, and its focus on individual words limits its ability to capture sentence-level or document-level semantics. StudSar leverages the principle of similarity-based retrieval from Word2Vec but extends it to sentence-level embeddings, using the ‘all-MiniLM-L6-v2’ model [Reimers & Gurevych, 2019] to ensure richer contextual representations.
Transformer Architectures and Contextual Modeling
The transformer model, introduced by Vaswani et al. [2017], transformed AI memory research with its self-attention mechanism, which allows simultaneous processing of entire text sequences. This innovation enabled models to capture long-range dependencies and contextual nuances, outperforming recurrent neural networks (RNNs) in tasks like machine translation. BERT [Devlin et al., 2019] built on this by introducing bidirectional pre-training, achieving state-of-the-art results in natural language understanding. BERT’s ability to encode contextual relationships makes it a powerful tool for semantic retrieval, but its high computational demands and fixed-length input constraints hinder real-time applications. StudSar adopts transformers’ contextual strength via the ‘all-MiniLM-L6-v2’ model, optimized for efficiency, and augments it with dynamic memory updates to overcome BERT’s static limitations [Bulla et al., 2025].
Sentence-BERT [Reimers & Gurevych, 2019] further refined transformer-based embeddings by fine-tuning BERT for sentence-level semantic similarity. Using a Siamese network architecture, Sentence-BERT produces 384-dimensional vectors that excel in tasks like semantic search and clustering. Its efficiency and robustness make it a cornerstone of StudSar’s embedding generation, as the ‘all-MiniLM-L6-v2’ model directly powers StudSar’s marker creation. However, Sentence-BERT lacks mechanisms for associating metadata or updating embeddings in real time, areas where StudSar innovates by integrating emotional tags, reputation scores, and usage frequency [Bulla et al., 2025].
2.2.1. Memory-Augmented Neural Networks
Neural Turing Machines (NTMs) [Graves et al., 2014] introduced a groundbreaking approach to AI memory by combining neural networks with an external memory matrix. NTMs use differentiable addressing to read and write data, enabling learning-driven memory operations akin to human cognition. This flexibility supports tasks like algorithmic reasoning, but NTMs’ computational complexity and training instability limit their scalability for large-scale text processing. StudSar draws inspiration from NTMs’ read-write paradigm but simplifies it with a CPU-based, dynamic memory structure, ensuring accessibility and scalability [Bulla et al., 2025].
Memory Networks [Weston et al., 2015] advanced this paradigm by storing facts in an external memory bank, accessed via query-driven attention. Designed for question answering, Memory Networks excel in retrieving relevant facts but require predefined memory structures, limiting adaptability to unstructured or evolving data. End-to-End Memory Networks [Sukhbaatar et al., 2015] addressed this by enabling fully trainable memory access, supporting multi-hop reasoning over stored facts. Dynamic Memory Networks [Kumar et al., 2016] further improved flexibility by integrating memory with question answering and visual tasks, allowing dynamic updates to memory content. Despite these advancements, these models lack mechanisms for real-time integration of new data or metadata-driven retrieval, challenges StudSar tackles through its StudSarNeural network and metadata infrastructure [Bulla et al., 2025].
2.2.2. Large-Scale Language Models and Frameworks
The development of GPT-3 [Brown et al., 2020] marked a milestone in AI memory research, leveraging vast pre-trained knowledge to generate contextually relevant responses across diverse tasks. GPT-3’s few-shot learning capabilities enable it to adapt to new prompts without fine-tuning, making it a powerful tool for conversational applications. However, its reliance on implicit knowledge encoded in parameters makes it less effective for precise retrieval of specific information fragments, particularly in long-form texts. StudSar addresses this by combining explicit memory storage with transformer-based embeddings, ensuring accurate, context-aware retrieval [Bulla et al., 2025].
The Hugging Face Transformers framework [Wolf et al., 2020] has democratized access to transformer-based models, providing tools like ‘all-MiniLM-L6-v2’ that power StudSar’s embedding generation. This framework supports rapid prototyping and deployment of state-of-the-art models, but its focus on pre-trained architectures limits its ability to handle dynamic memory tasks. StudSar extends the framework’s capabilities by integrating a custom neural module for real-time updates and metadata management, enhancing its applicability to associative memory tasks [Bulla et al., 2025].
2.2.3. Positioning StudSar
StudSar synthesizes insights from these paradigms to create a neural associative memory system that diverges from traditional approaches. Unlike Word2Vec [Mikolov et al., 2013], StudSar operates at the sentence level, using Sentence-BERT embeddings [Reimers & Gurevych, 2019] for richer semantics. Compared to BERT [Devlin et al., 2019] and GPT-3 [Brown et al., 2020], StudSar prioritizes precise retrieval over generalization, leveraging a dynamic memory structure inspired by NTMs [Graves et al., 2014]. Its query-driven retrieval builds on Memory Networks [Weston et al., 2015; Sukhbaatar et al., 2015; Kumar et al., 2016], but its ability to update memory in real time and associate metadata (e.g., emotional tags, usage frequency) sets it apart. By addressing the limitations of static embeddings, predefined memory structures, and computational complexity, StudSar offers a scalable, human-inspired framework for next-generation AI memory systems, as detailed in this work [Bulla et al., 2025].
3. Methodology
StudSar operates through a structured workflow that mirrors human memory formation, processing extensive textual data into manageable, semantically rich segments. Implemented using PyTorch, a versatile deep learning framework, the system leverages the ‘all-MiniLM-L6-v2’ model from the Sentence Transformers library to generate 384-dimensional embedding vectors, enabling robust associative memory capabilities.
Workflow Overview
Figure 2.
Workflow Overview of the Text Segmentation and Query Processing Pipeline.
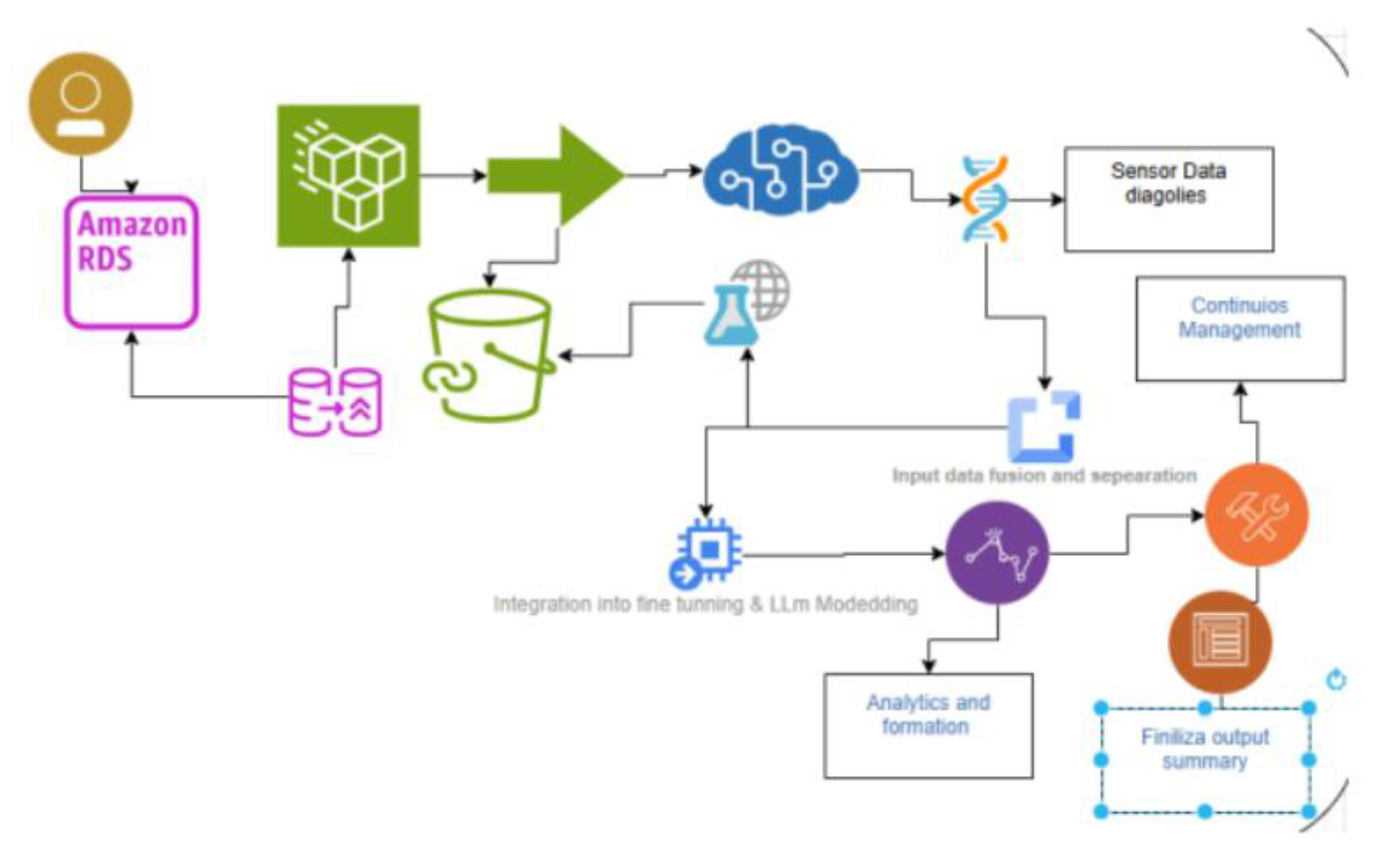
The operational pipeline consists of five key stages:
- Input Text Segmentation: Input text, potentially comprising millions of tokens (e.g., a corpus of 2 million inputs), is automatically segmented into logical blocks using natural language processing techniques. Currently, in the absence of SpaCy, word segmentation serves as a fallback mechanism, though plans are in place to adopt a transformer-based approach (e.g., DistilBERT) to enhance segment coherence.
- AI Processing per Segment: Each segment is processed by the ‘all-MiniLM-L6-v2’ model, producing a 384-dimensional embedding vector that encapsulates its semantic content.
- Generation of Associative Markers: These embeddings serve as synthetic associative markers, linking specific content to query prompts based on similarity. StudSar enhances this process by associating optional metadata, such as emotional tags (e.g., “curiosity”), numerical reputation scores, and usage frequency, with each marker to enrich contextual representation.
- Integration into the StudSar Network: Markers and their metadata are stored in a custom StudSarNeural network, which supports dynamic memory growth and operates on a CPU in its initial implementation. A StudSarManager handles metadata within dictionary structures (e.g., state_dict) to ensure efficient storage and retrieval.
- Query Processing and Continuous Updates: Upon receiving a query, the system embeds it similarly and performs a cosine similarity search against stored markers to retrieve relevant segments. Usage counts for retrieved markers are incremented, and the network is cyclically updated with new segments, ensuring adaptability to evolving data.
3.1. Technical Implementation
The StudSarNeural network is initialized with an embedding dimension of 384, matching the output size of the ‘all-MiniLM-L6-v2’ model. Its memory capacity is dynamic, expanding on-demand to accommodate new markers. Core memory storage is implemented as a PyTorch nn.Module, using torch.Tensor for embeddings and managing metadata (segment text, IDs, emotional tags, reputation scores, usage counts) via the StudSarManager. The network can resize its embedding tensor (e.g., torch.Size([3, 384]) after loading) and save its state to ‘studsar_neural_demo.pth’, ensuring persistent memory across sessions.
Figure 3.
Technical Implementation workflow.
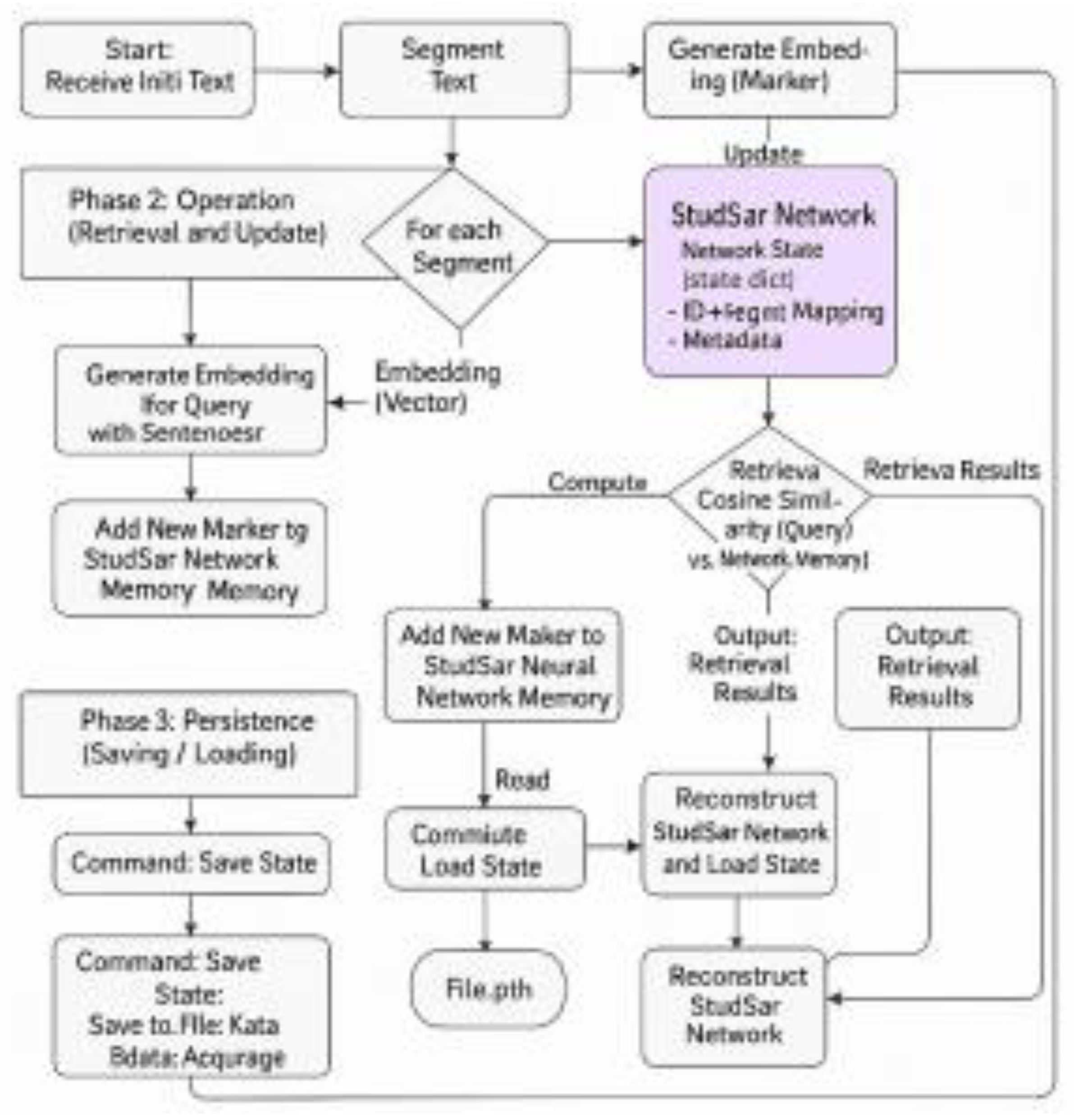
3.2. Integration Details
The segmentation model will be shipped as segmentation_model.pth and invoked in StudSar’s preprocessing stage before embedding with all-MiniLM-L6-v2. Documentation and example scripts will facilitate adoption.
4. Evaluation Metrics
StudSar’s performance was assessed using a set of quantitative metrics to evaluate its effectiveness in segmentation, retrieval, and scalability. The following metrics were targeted and measured during experiments:

Table 1.
Table Showing Evaluation Metrics Used For StudStar Experiment.
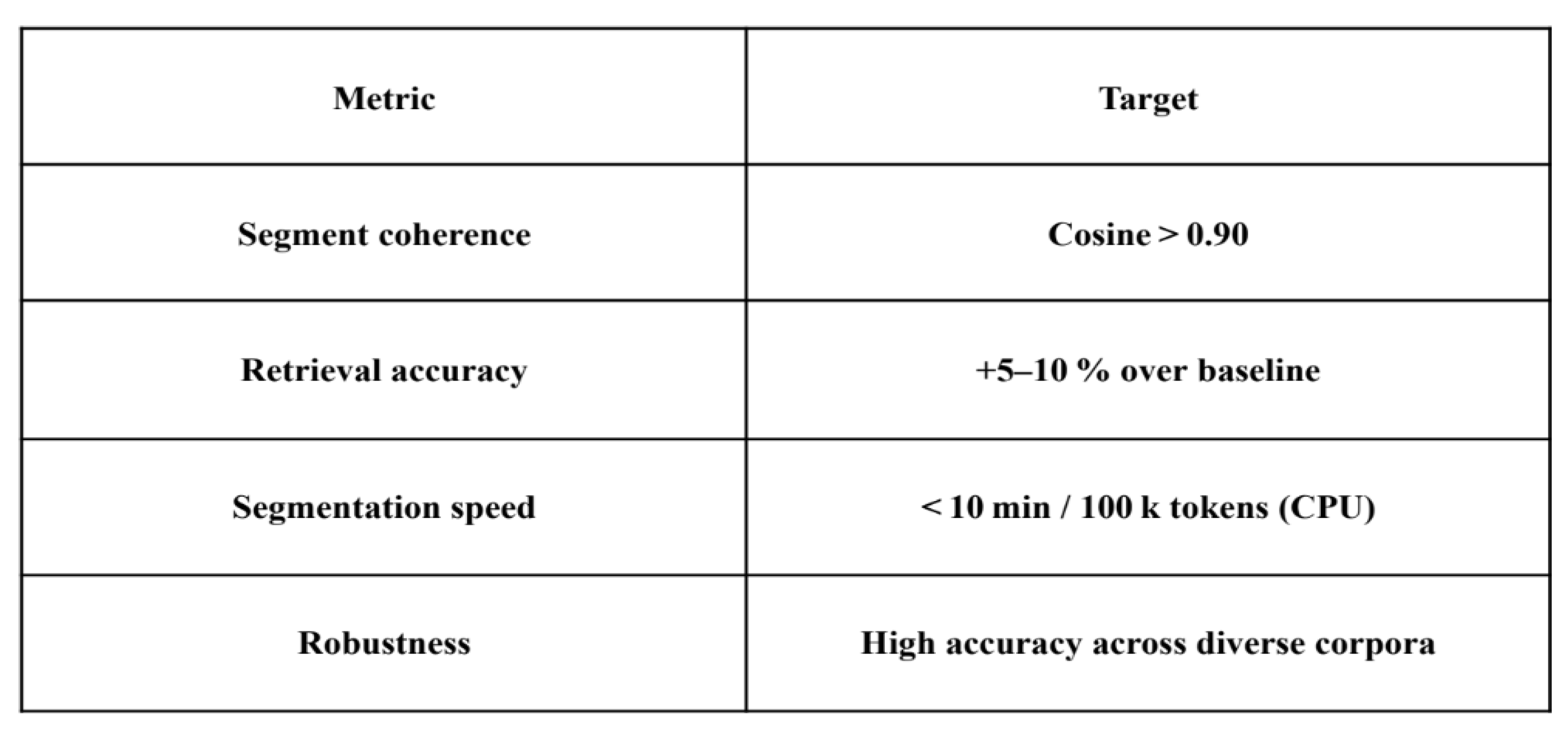 |
These metrics were derived from experimental results, with achieved similarity scores (e.g., 0.6652, 0.7981, 0.7725) indicating strong retrieval accuracy, though segment coherence and scalability require further optimization for large-scale applications.
4.1. Experimental Setup
StudSar was evaluated in a controlled environment using a CPU-based system (e.g., Intel i5, 16GB RAM) to test its core functionality. A text dataset was segmented into logical blocks, with the ‘all-MiniLM-L6-v2’ model from the Sentence Transformers library generating 384-dimensional embeddings. Metadata, including emotional tags (e.g., “curiosity”), reputation scores, and usage counts, was assigned to markers to simulate adaptive retrieval scenarios. Experiments involved iterative query processing, with network states saved to ‘studsar_neural_demo.pth’ and reloaded to verify persistence. Performance metrics, such as retrieval accuracy (via cosine similarity scores) and segmentation speed (via processing times), were recorded to assess StudSar’s efficacy and potential for broader applications.
5. Results
StudSar, a neural associative memory system, was evaluated through a series of experiments to validate its capabilities in text segmentation, associative marker generation, context-aware retrieval, and memory persistence. Conducted using text corpus, these experiments leveraged the ‘all-MiniLM-L6-v2’ model to generate 384-dimensional embeddings. The results demonstrate StudSar’s ability to accurately retrieve relevant information, dynamically integrate new content, and maintain persistent memory across sessions, with progressive enhancements in metadata management.
The initial evaluation involved segmenting the corpus into two logical blocks, generating corresponding embedding markers. A query, “What are AI applications?” yielded two results:
- Result 1: Similarity score of 0.6652, retrieving a segment defining artificial intelligence and its applications, such as problem-solving and strategic gaming.
- Result 2: Similarity score of 0.5224, retrieving a segment focused on machine learning as a core component of modern AI.
To test dynamic updates, a new segment on deep learning was added to the network. A subsequent query, “Tell me about deep learning,” accurately retrieved this segment with a similarity score of 0.7981, confirming StudSar’s ability to integrate and recall new information effectively. Memory persistence was validated by saving the network state to ‘studsar_neural_demo.pth’ and reloading it. A follow-up query, “What is the definition of AI?” retrieved the original segment with a similarity score of 0.7725, demonstrating that embeddings and associated data remained intact across sessions.
Further experiments enhanced StudSar’s functionality by introducing metadata, including emotional tags, reputation scores, and usage frequency tracking, to enrich marker representation. A detailed run, as shown below, illustrates these advancements:
Figure 3.
Images Showing StudStar Ability to Accurately Retrieve Relevant Information and Dynamically Integrate New Content.
Figure 3.
Images Showing StudStar Ability to Accurately Retrieve Relevant Information and Dynamically Integrate New Content.
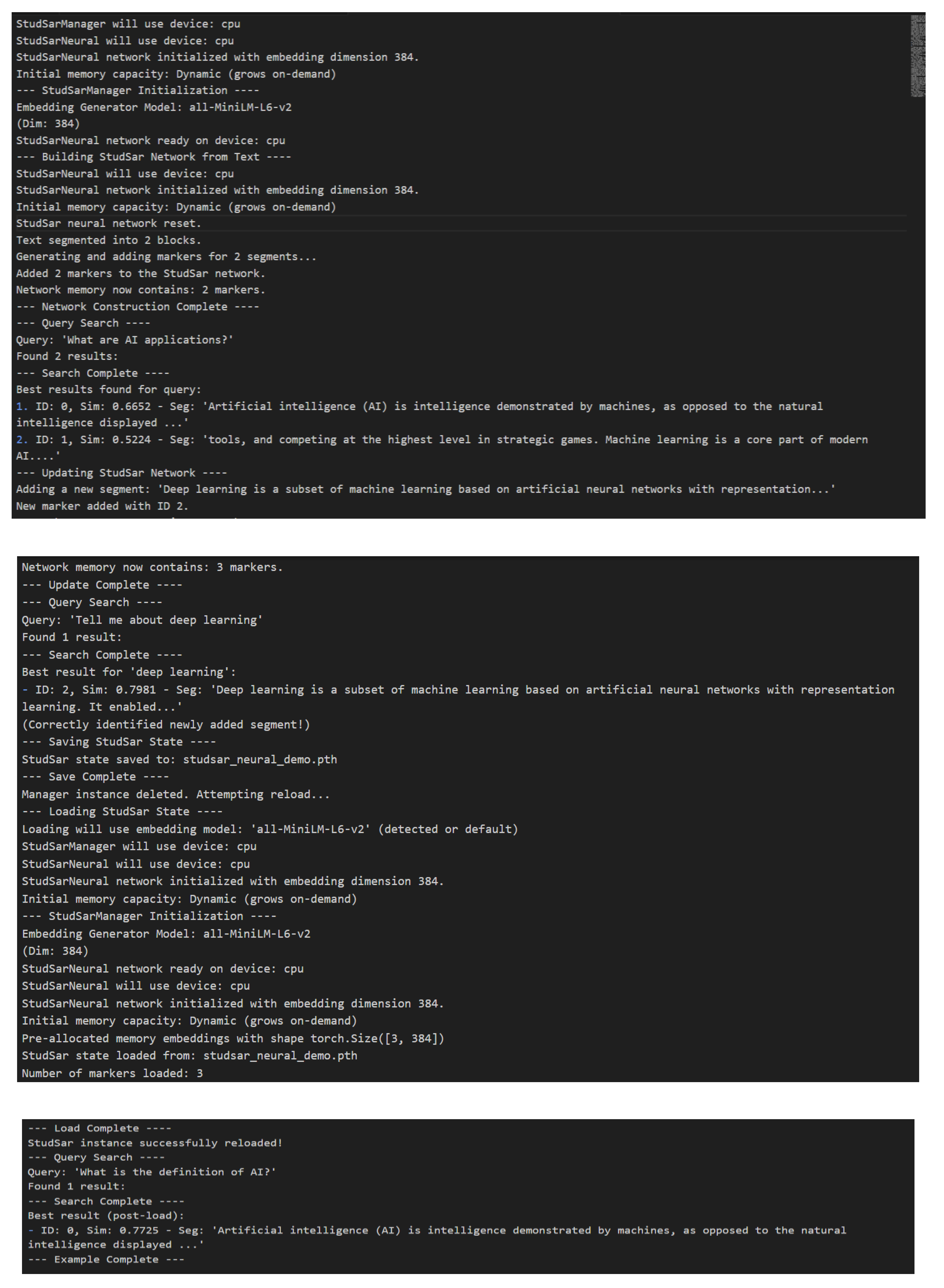
These experiments confirmed StudSar’s enhanced capabilities:
- Dynamic Memory Update: The network initialized with two markers, incorporated a third marker (ID 2, deep learning), and accurately reflected a memory size of three markers.
- Accurate Retrieval: The query “Tell me about deep learning” retrieved the newly added segment (ID 2) with a similarity score of 0.7981, with usage counts incremented to track access frequency.
- Robust Persistence: After saving and reloading the network state, including metadata, the query “What is the definition of AI?” retrieved the original segment (ID 0) with a similarity score of 0.7725, verifying data integrity.
Collectively, these findings demonstrate StudSar’s ability to segment text, generate and retrieve associative markers with high accuracy, and maintain persistent memory. The consistent similarity scores (0.6652 and 0.5224 for AI applications, 0.7981 for deep learning, 0.7725 for AI definition) across experiments highlight reliable performance. The addition of metadata management, including usage tracking and placeholders for emotional tags and reputation scores, enhances StudSar’s adaptability, positioning it as a scalable solution for larger corpora (e.g., 2 million inputs) and future cognitive features.
6. Discussion
StudSar distinguishes itself from traditional retrieval-augmented generation (RAG) systems and static vector databases by offering dynamic memory updates and autonomous knowledge integration. Through iterative development, the system has established a robust foundation for associative memory, demonstrating the ability to save and reload network states without data loss while accurately retrieving both original and newly added segments. This persistence is fundamental for applications requiring long-term interaction and knowledge accumulation, such as conversational agents, personalized learning platforms, and complex knowledge management systems.
A key advancement in StudSar is its infrastructure for associating metadata—emotional tags (e.g., “curiosity”), reputation scores, and usage frequency—with memory markers, moving beyond simple vector storage. This metadata enables adaptive, context-aware retrieval mechanisms, mirroring human memory dynamics where frequently accessed information is reinforced, and rarely accessed information may fade. For instance, usage tracking provides data for potential consolidation or pruning processes, enhancing the system’s ability to evolve with user interactions and external signals. While the full potential of these features awaits further exploration, their implementation lays critical scaffolding for future enhancements.
StudSar’s scalability, designed to handle extensive inputs (e.g., corpora of 2 million tokens), positions it for applications requiring real-time, contextually relevant information, such as educational tools and intelligent agents. Its informal origin, rooted in personal study methods and drafted in a notebook, underscores its practical applicability, bridging intuitive human learning processes with technical innovation. By integrating dynamic adaptability and feedback loops, StudSar offers a viable solution for real-world use cases where retaining specific details and context over extended periods is essential.
7. Future Work
Enhanced Text Segmentation
- Motivation: Sub-optimal segmentation (e.g., word-level fallback) fragments semantic context, degrading retrieval precision. Upgrading to a transformer-based model will yield contextually rich segments.
- Proposed Approach: Fine-tune a compact transformer (e.g., DistilBERT) to predict logical boundaries, using training data from WikiText, BookCorpus, and domain-specific corpora with ground-truth annotations. Hybrid parsing with rule-based checks will ensure robustness.
-
Objectives:
- Improved segment coherence (cosine similarity > 0.90).
- Scalability (real-time operation on corpora ≥ 2M tokens, CPU-only baseline, optional GPU extension).
- Versatility (multilingual and domain-adaptable).
- Integration Details: The segmentation model will be shipped as segmentation_model.pth, invoked in the preprocessing stage before embedding with ‘all-MiniLM-L6-v2’. Documentation and scripts will facilitate adoption.
Advanced Cognitive Features
Leveraging existing infrastructure, future version would integrate these enhancements:
- Emotional State of the Network: Implement logic to bias retrieval based on emotional tags (e.g., favoring “curious” memories for exploratory queries).
- Embeddings with Human Feedback: Use reputation scores to strengthen associations with positive feedback or trigger re-segmentation/pruning with negative feedback, refining search ranking.
- Visualization of the Internal Semantic Graph: Generate a graph view (nodes as markers, edges for cosine similarity > r) for interactive browsing and identifying sparse regions needing new data.
- “Dream Mode” (Offline Consolidation): At low-load intervals, revisit least-accessed markers, re-encode them, and form new links or prune irrelevant information, mirroring human sleep-driven consolidation.
- Memory Management: Explore pruning low-usage or low-reputation markers to manage scale efficiently with large corpora.
These developments aim to transform StudSar into an adaptive, emotionally aware, and self-optimizing memory system for applications in education, healthcare, and knowledge retrieval.
8. Limitations
StudSar’s current segmentation approach, reliant on word-level fallbacks in the absence of SpaCy, may impact embedding quality for complex texts. Additionally, the preliminary integration of metadata (e.g., emotional tags, reputation scores) requires further validation across diverse datasets to ensure robustness. Future enhancements, such as transformer-based segmentation and GPU support, are planned to address these constraints, improving scalability and generalizability for large-scale AI memory tasks.
9. Conclusion
This paper introduces StudSar, a neural associative memory system inspired by human learning techniques and realized through advanced AI methodologies. Developed through iterative refinements, StudSar provides a robust framework for text segmentation, embedding generation, associative retrieval, and metadata integration, including emotional tags, reputation scores, and usage tracking. The system excels at pinpointing and retrieving exact information fragments in a context-aware manner, addressing limitations in traditional AI memory models. While challenges remain in optimizing large-scale segmentation and fully implementing advanced cognitive features, StudSar offers a promising, scalable solution for enhancing AI memory, with potential applications in conversational agents, education, and knowledge management.
10. Ethical Considerations
The development of StudSar raises ethical considerations regarding data privacy and bias. As the system processes extensive textual data, including potentially sensitive information, robust anonymization and encryption protocols are essential to protect user data. The incorporation of emotional tags and feedback mechanisms must be designed to avoid reinforcing biases present in training corpora (e.g., WikiText, BookCorpus). Transparency in how memory consolidation and pruning decisions are made will be critical to maintain trust, especially in applications like education and healthcare.
References
- Vaswani, A., et al. (2017). “Attention is All You Need.” Advances in Neural Information Processing Systems (NeurIPS).
- Reimers, N., & Gurevych, I. (2019). “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). [CrossRef]
- Graves, A., Wayne, G., & Danihelka, I. (2014). “Neural Turing Machines.” arXiv preprint arXiv:1410.5401. [CrossRef]
- Sukhbaatar, S., et al. (2015). “End-To-End Memory Networks.” Advances in Neural Information Processing Systems (NeurIPS).
- Mikolov, T., et al. (2013). “Distributed Representations of Words and Phrases and their Compositionality.” Advances in Neural Information Processing Systems (NeurIPS).
- Devlin, J., et al. (2019). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). [CrossRef]
- Weston, J., Chopra, S., & Bordes, A. (2015). “Memory Networks.” International Conference on Learning Representations (ICLR).
- Kumar, A., et al. (2016). “Ask Me Anything: Dynamic Memory Networks for Natural Language Processing.” International Conference on Machine Learning (ICML).
- Brown, T. B., et al. (2020). “Language Models are Few-Shot Learners.” Advances in Neural Information Processing Systems (NeurIPS).
- Wolf, T., et al. (2020). “Hugging Face’s Transformers: State-of-the-Art Natural Language Processing.” arXiv preprint arXiv:1910.03771.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



