Submitted:
14 May 2025
Posted:
15 May 2025
Read the latest preprint version here
Abstract
The rise of generative artificial intelligence (GenAI) is transforming the education industry. GenAI models, particularly large language models (LLMs), have emerged as powerful tools capable of driving innovation, improving efficiency, and delivering superior services for educational purposes. This paper provides an overview of GenAI for educational purposes, from theory to practice. We have developed a chatbot for summarizing dialogues. In our research work, we have used strategies like zero-shot, one-shot, and few-shot inferencing and also fine-tuned the FLAN-T5 model to serve our purpose of summarization for educational tasks using PEFT (Parameter-Efficient Fine-Tuning) techniques like LoRA (Low-Rank Adaptation) and Prompt Tuning. We have also utilized the technique of Reinforcement Learning with PPO (Proximal Policy Optimization) and PEFT to generate less toxic summaries. The model's performance is quantitatively evaluated using the ROUGE metric and toxicity evaluation metrics. The chatbot can summarize dialogues and is of immense interest to users in the real world. In our research work, our findings demonstrate significant improvements in summarization quality and toxicity reduction, contributing to the development of safer and more effective AI systems.
Keywords:
GenAI
; LLMs
; PEFT
; LoRA
; Prompt Tuning
; PPO
; Reinforcement Learning
; Fine-Tuning
I. Introduction
The rise of generative artificial intelligence is powered by many factors like vast amounts of data, deep learning algorithms, transformer architecture, and high-performance computing accelerated by graphics processing units (GPUs). These technological advancements have led to the creation of powerful GenAI models, particularly large language models (LLMs) like generative pretrained transformers (GPT). The exceptional performance of GenAI models (e.g., OpenAI’s GPT-3.5 Turbo, GPT-4, and GPT-4o) and their access through user-friendly interfaces have brought text and image generation to the forefront of daily and commonplace conversations. Techniques like Prompt Engineering are involved in building application features like Deep Research, Reason, along with useful additional features in LLMs like Web Search. Now, GenAI is transforming the world, driving innovations in a wide range of industries and emerging applications.
The education industry is among the first to embrace GenAI and benefits significantly from the resources provided through applications like GenAI-powered chatbots [1]. Chatbots powered by GenAI can assist customers with their queries and troubleshoot technical issues. GenAI is helping customers get a better experience in a variety of domains related to education. Today, there are various fine-tuned LLMs that are domain-specific, like those for healthcare, which can help answer queries related to healthcare. Overall, the potential of GenAI for education is vast and will continue to grow as the technology evolves [2]. Recent research works applying a multitude of GenAI models to the education domain include an overview of the current state and future directions of generative AI in education along with applications, challenges, and research opportunities [3]. The work [4] explains how large language models like GPT-4 can enhance personalized education through dynamic content generation, real-time feedback, and adaptive learning pathways within Intelligent Tutoring. The work [5] investigates the perceived benefits and challenges of generative AI in higher education from the perspectives of both teachers and students. It further explores concerns regarding the potential of AI to replace educators and examines its implications for digital literacy through the lenses of the SAMR and UTAUT models. The work [6] discusses the role of generative AI in education and research, emphasizing its potential to support educational goals while also addressing ethical concerns and the professional use of AI-generated content.
While existing work has explored the potential of GenAI for the education sector, there remains a gap between research outcomes and real-world applications. The existing literature primarily focuses on the theory or vision of GenAI for education, often overlooking the implications and challenges that exist in practice. To that end, we first examine the commonly used GenAI models for education by highlighting their theoretical foundations and relevance to key use cases. Then, we specifically focus on LLMs and provide an overview of the practical applications of LLMs as found in the education industry today. The developed LLM-based application utilizes innovative fine-tuning and evaluation strategies. In our research work, we have used inference strategies like zero-shot, one-shot, and few-shot techniques and fine-tuning approaches using PEFT (Parameter-Efficient Fine-Tuning) techniques like LoRA (Low-Rank Adaptation) and Prompt Tuning. We have also utilized the technique of Reinforcement Learning with PPO (Proximal Policy Optimization) and PEFT to generate less toxic summaries. The model’s performance is quantitatively evaluated using the ROUGE metric and toxicity evaluation metrics. The chatbot can summarize dialogues and is of immense interest to users in the real world, leading to the development of safer and more effective AI systems.
II. Preliminaries of Generative AI Models for Education
GenAI is used to produce new but similar samples distributed according to some unknown distribution of the existing samples. The goal of GenAI modeling is to develop a model that learns the unknown distribution so that we can use it for sampling. A multitude of GenAI models have been applied to educational problems, including transformer, diffusion models (DF), variational autoencoder (VAE), and generative adversarial network (GAN) based models. In this section, we present the preliminaries of these GenAI models, as illustrated in Figure 1.
A. Variational Autoencoders
Variational Autoencoders (VAEs) are a class of generative models that learn to represent complex data distributions using a latent variable framework. They combine variational inference with deep learning by optimizing a lower bound on the data likelihood using stochastic gradient descent. The model consists of two parts: an encoder (inference network) that maps input data to a distribution over latent variables, and a decoder (generative network) that reconstructs the data from the latent space. A key innovation is the reparameterization trick, which allows backpropagation through stochastic nodes, making the training efficient and scalable with deep networks [7].
B. Generative Adversarial Networks
Generative Adversarial Networks (GANs) introduce a novel framework for estimating generative models via an adversarial process. This involves training two models simultaneously: a generator that captures the data distribution and a discriminator that estimates the probability that a sample came from the training data rather than the generator. The generator aims to produce data that is indistinguishable from real data, while the discriminator strives to differentiate between real and generated data. This setup corresponds to a minimax two-player game. The entire system can be trained using backpropagation without the need for Markov chains or unrolled approximate inference networks. Experiments demonstrate the potential of this framework through qualitative and quantitative evaluations of the generated samples [8].
C. Normalizing Flows
Normalizing Flows enhance variational inference by applying a sequence of invertible transformations to a simple initial density, thereby constructing flexible and scalable approximate posterior distributions. This approach enables more expressive variational approximations, leading to improved inference quality in complex probabilistic models. By utilizing invertible transformations, the method allows for the modeling of more complex distributions while maintaining tractability, making it an effective tool for enhancing variational inference in various probabilistic settings [9].
D. Diffusion Models
Diffusion Models are a class of generative models that learn to reverse a gradual noising process, effectively generating data by iteratively denoising samples. These models have demonstrated remarkable success in generating high-quality images and have been applied to various domains, including image synthesis and inpainting. By modeling the data distribution through a diffusion process, these models can capture complex data structures and generate samples that closely resemble real-world data [10].
E. Autoregressive Models
Autoregressive Models are a class of generative models that generate data sequentially, with each data point conditioned on the previous ones. This approach allows for the modeling of complex dependencies in data, making these models particularly effective for tasks such as language modeling, speech synthesis, and image generation. By capturing the conditional distributions of data points, autoregressive models can generate high-quality samples that reflect the underlying data distribution [11].
The different types of GenAI models have varying levels of performance in terms of the quality of generation outputs, the diversity of mode coverage, and the speed of sampling. Combining the advantages of the GenAI models, when possible, can create more powerful GenAI models for education. While GenAI models have shown great potential for enabling various emerging educational use cases in simulated or lab environments, transformer-based LLMs are among the most popular GenAI models that are already finding practical applications in the current education industry. These real-world applications of LLMs in the education domain are detailed in the next section.
III. LLMs for Education
Large Language Models (LLMs) have become pivotal in educational applications due to their ability to process and generate human-like text. This section explores their practical implementations, focusing both on theoretical advancements and real-world deployments.
A. Student Support and Personalized Learning
Domain-specific LLMs are transforming academic support and personalized education. LLM-based tutoring platforms assist students in real-time with subject-specific doubts, curate personalized learning plans based on performance history, and generate explanations aligned with individual understanding levels. These systems can also engage in natural language check-ins to ensure student progress and offer targeted supplemental materials.
Platforms such as Khanmigo by Khan Academy illustrate these capabilities. They employ fine-tuned LLMs to offer interactive AI tutors that explain mathematical problems step-by-step or simulate historical conversations for immersive learning. These tutors are grounded in educational content and best pedagogical practices to provide contextual and adaptive support.
Moreover, LLM-powered virtual academic advisors enhance student engagement by interpreting behavioral signals, summarizing professor feedback, and initiating proactive interventions to maintain academic progress.
B. Faculty and Administrative Assistance
LLMs streamline repetitive academic and administrative tasks, increasing educator productivity. These assistants can draft lesson plans, summarize research articles, generate quizzes from textbook material, and communicate professionally with students and parents.
For instance, Microsoft’s Copilot for Education, integrated into platforms like Microsoft Teams and Word, helps educators create assignments, summarize lectures, and design assessments aligned with curriculum standards.
In parallel, LLM-powered bots handle routine administrative inquiries—such as course registration, deadlines, and financial aid—thus reducing staff workload and enhancing the student experience.
C. Curriculum Planning and Educational Analytics
Educational leaders are leveraging LLMs to interact with academic data through natural language. These systems analyze student performance, detect learning gaps, and provide actionable insights for curriculum enhancement.
Tools like Ivy.ai and Gradescope with AI assistance support real-time feedback, pattern recognition in assignment submissions, and identification of learning bottlenecks. They can recommend course redesign strategies and prioritize interventions using longitudinal performance data.
Generative AI can also simulate new learning environments using synthetic data, supporting curriculum development and strategic planning.
D. Educational Standards Chatbots and Knowledge Access
Comprehending evolving academic standards (e.g., Common Core, NGSS, Bloom’s Taxonomy) across disciplines is complex. LLM-based systems, especially those powered by Retrieval-Augmented Generation (RAG), simplify access to these documents, aiding educators and curriculum developers.
RAG-powered curriculum alignment bots enable teachers to instantly understand how lesson objectives relate to standards or compare regional benchmarks. These tools support transparency, alignment, and compliance with evolving frameworks.
Additionally, LLMs support inclusive education by translating content across languages, simplifying academic jargon, and adapting materials for diverse learner needs.
E. Research Implementation: Dialogue Summarization Chatbot
Our own research demonstrates a practical implementation of LLMs in education through the development of a dialogue summarization chatbot. This chatbot leverages zero-shot, one-shot, and few-shot inferencing with fine-tuned FLAN-T5 using PEFT techniques such as LoRA and Prompt Tuning. We also employed Reinforcement Learning with Proximal Policy Optimization (PPO) to reduce toxic content in the generated summaries. The system is quantitatively evaluated using the ROUGE metric and toxicity evaluation tools, achieving strong results in both summarization quality and safety, thereby supporting real-world classroom integration.
IV. Design Aspects
The development and deployment of generative AI (GenAI) applications, particularly large language models (LLMs), require careful consideration of design aspects to ensure they meet the specific requirements of the education sector. While cloud-based GenAI services offer a rapid entry point, their general-purpose nature often lacks the depth of training on education-specific datasets, limiting their effectiveness for targeted educational applications. This section discusses key design aspects for building customized AI applications tailored to educational needs, as illustrated in Figure 2.
A. High-Performance Computing for AI
The transformer architecture, foundational to modern large language models (LLMs), demands substantial computational resources due to its intricate design. Unlike other AI systems, which have seen relatively modest growth in compute needs, transformer-based models experience exponential increases in resource requirements, driven by their complex layers and vast parameter sets. In educational environments, where processing large volumes of data—such as student engagement metrics, instructional content, or real-time feedback—is essential, high-performance hardware like multi-GPU clusters is critical for training and deploying these models effectively.
Advanced GPUs, such as NVIDIA’s latest architectures, provide tailored optimizations that enhance training efficiency, minimize memory usage, and enable scalable AI infrastructure. For instance, these GPUs support low-precision formats like FP8, which accelerate computations but risk degrading model quality if not carefully managed. To address this, modern GPU architectures incorporate mixed-precision engines that dynamically balance FP8 and FP16 operations, automatically adjusting to preserve accuracy. This capability is particularly valuable for educational tools, such as AI-driven essay grading systems or virtual tutoring platforms, where rapid inference ensures seamless user interactions.
In academic settings, high-performance computing systems enable efficient analysis of extensive datasets, such as course enrollment patterns, learning management system logs, or multilingual educational resources. Compared to traditional CPU-based setups, these platforms consume less energy, promoting sustainable operations. For example, AI-powered language translation tools for diverse classrooms or predictive analytics for student retention require low-latency processing to deliver timely insights, enhancing both teaching quality and administrative efficiency. As educational institutions increasingly adopt AI-driven solutions, high-performance computing will drive innovation, ensuring scalability without computational limitations.
B. Information Retrieval and Customization
While foundation LLMs are pre-trained on vast datasets using accelerated computing, their effectiveness in education depends on incorporating domain-specific knowledge and institutional data. Techniques like Retrieval-Augmented Generation (RAG), prompt engineering, and parameter-efficient fine-tuning (PEFT) enable customization to meet educational needs.
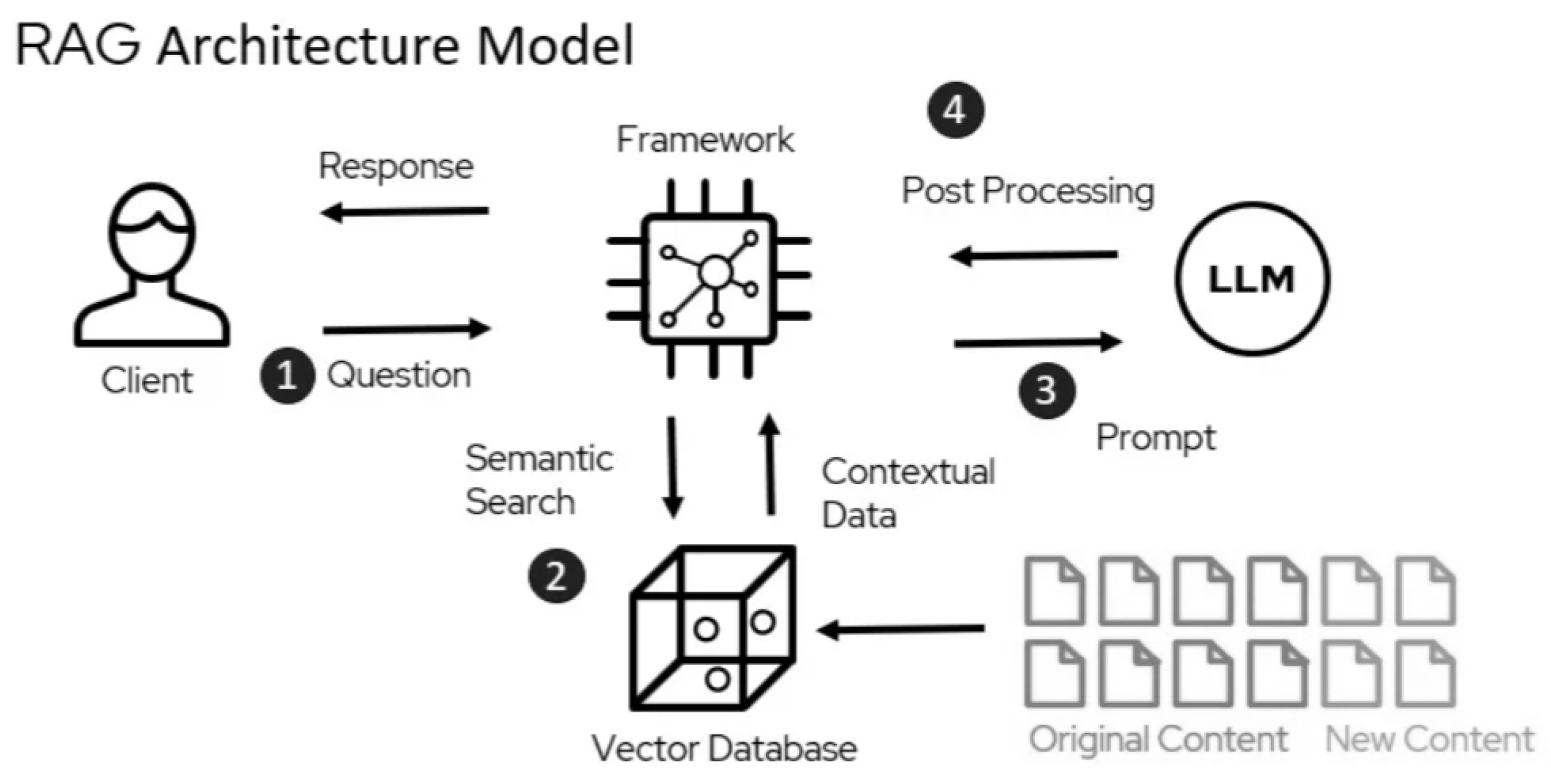
Retrieval-Augmented Generation (RAG): RAG enhances LLMs by integrating external data sources, improving the accuracy and relevance of responses. Figure 3 illustrates a typical RAG architecture model for educational applications, such as curriculum standards chatbots:
- Step 1 (Question Submission): The process begins with a client, such as a teacher or student, submitting a question (e.g., querying a curriculum standard or seeking topic clarification).
- Step 2 (Semantic Search): The question triggers a semantic search in a vector database, which stores embeddings of educational resources, including both original content (e.g., textbooks, academic standards) and new content (e.g., updated lesson plans or student data).
- Step 3 (Prompt Construction): Relevant contextual data is retrieved from the vector database and used to construct a prompt, which is then fed into a Large Language Model (LLM).
- Step 4 (Response Generation and Post-Processing): The LLM generates a response based on the prompt, which undergoes post-processing within a framework to ensure coherence and relevance before being delivered back to the client.
For example, a curriculum standards chatbot can use RAG to integrate educational standards (e.g., Common Core) into an LLM, enabling precise answers to domain-specific queries. This approach is particularly effective for applications like lesson planning, student support systems, or compliance with educational frameworks.
Customization Techniques: Beyond RAG, techniques like PEFT (e.g., LoRA and Prompt Tuning) and reinforcement learning with human feedback (RLHF) allow further customization. PEFT selectively updates a small subset of model parameters, making fine-tuning resource-efficient while adapting the LLM to educational datasets, such as student feedback, course materials, or assessment records. RLHF, combined with techniques like Proximal Policy Optimization (PPO), can reduce toxicity in generated outputs, as demonstrated in our dialogue summarization chatbot for classroom discussions, ensuring safer and more appropriate interactions in educational settings.
RAG and fine-tuning are complementary. RAG offers a quick way to enhance accuracy by grounding responses in external data, while fine-tuning provides deeper customization for applications requiring high precision, such as personalized learning systems or automated grading tools. The choice of approach depends on the application’s requirements, resource availability, and computational constraints. For instance, a chatbot for summarizing classroom dialogues can initially use RAG to incorporate lecture transcripts and later apply PEFT for improved performance, as shown in our research implementation.
V. Case Study: Dialog Summarization Chatbot
In our research, we have used inference techniques such as zero-shot, one-shot, and few-shot to evaluate the model’s performance on dialogue summarization tasks. These techniques are demonstrated through various implementations, as shown in the figures below. Additionally, we have applied fine-tuning methods including LoRA (Low-Rank Adaptation), PEFT (Parameter-Efficient Fine-Tuning), Prompt Tuning, and Reinforcement Learning with PPO (Proximal Policy Optimization) to enhance the model’s capabilities. The following figures illustrate the implementation details, code, and outputs of these techniques.
Figure 4.
Dialogue summarization without prompt engineering (Part 1).

Figure 5.
Dialogue summarization without prompt engineering (Part 2).
Figure 6.
Encode and decode string implementation.

Figure 7.
Model generation without prompt engineering (Part 1).
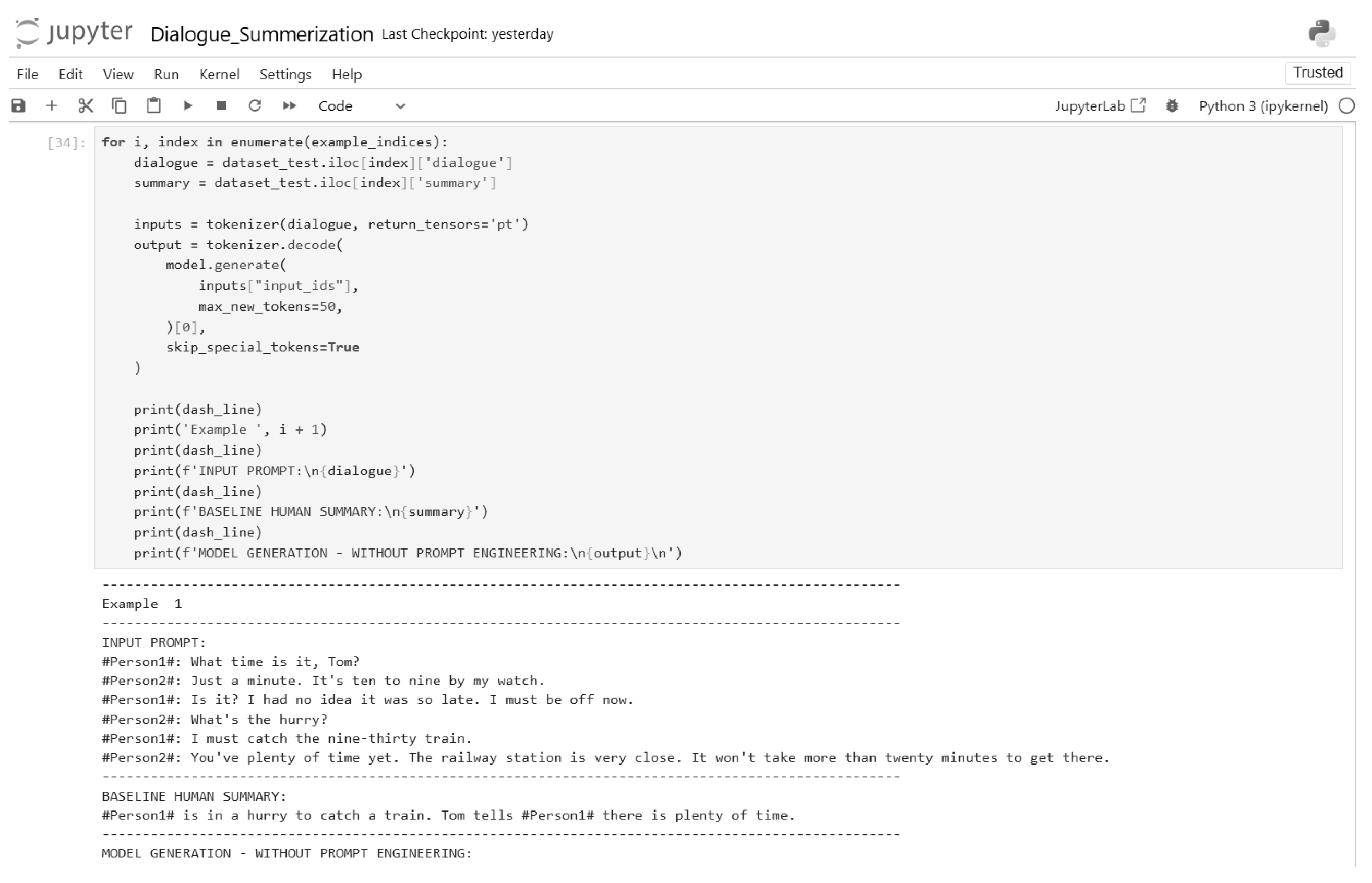
Figure 8.
Model generation without prompt engineering (Part 2).

Figure 9.
Zero-shot inference instruction prompt.

Figure 10.
Zero-shot inference code (Part 1).

Figure 11.
Zero-shot inference code (Part 2).
Figure 12.
Zero-shot inference code (Part 3).
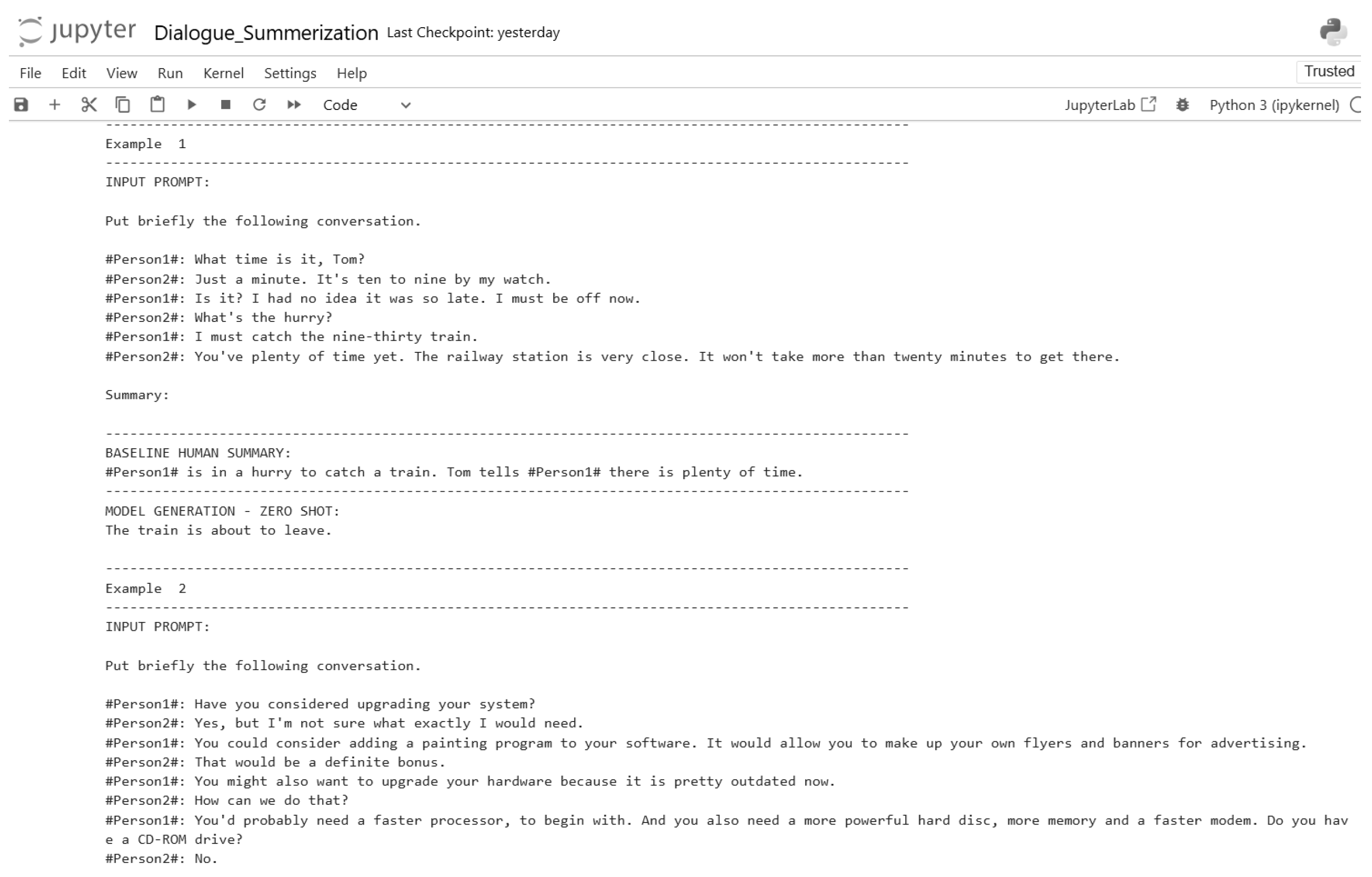
Figure 13.
Zero-shot inference code (Part 4).
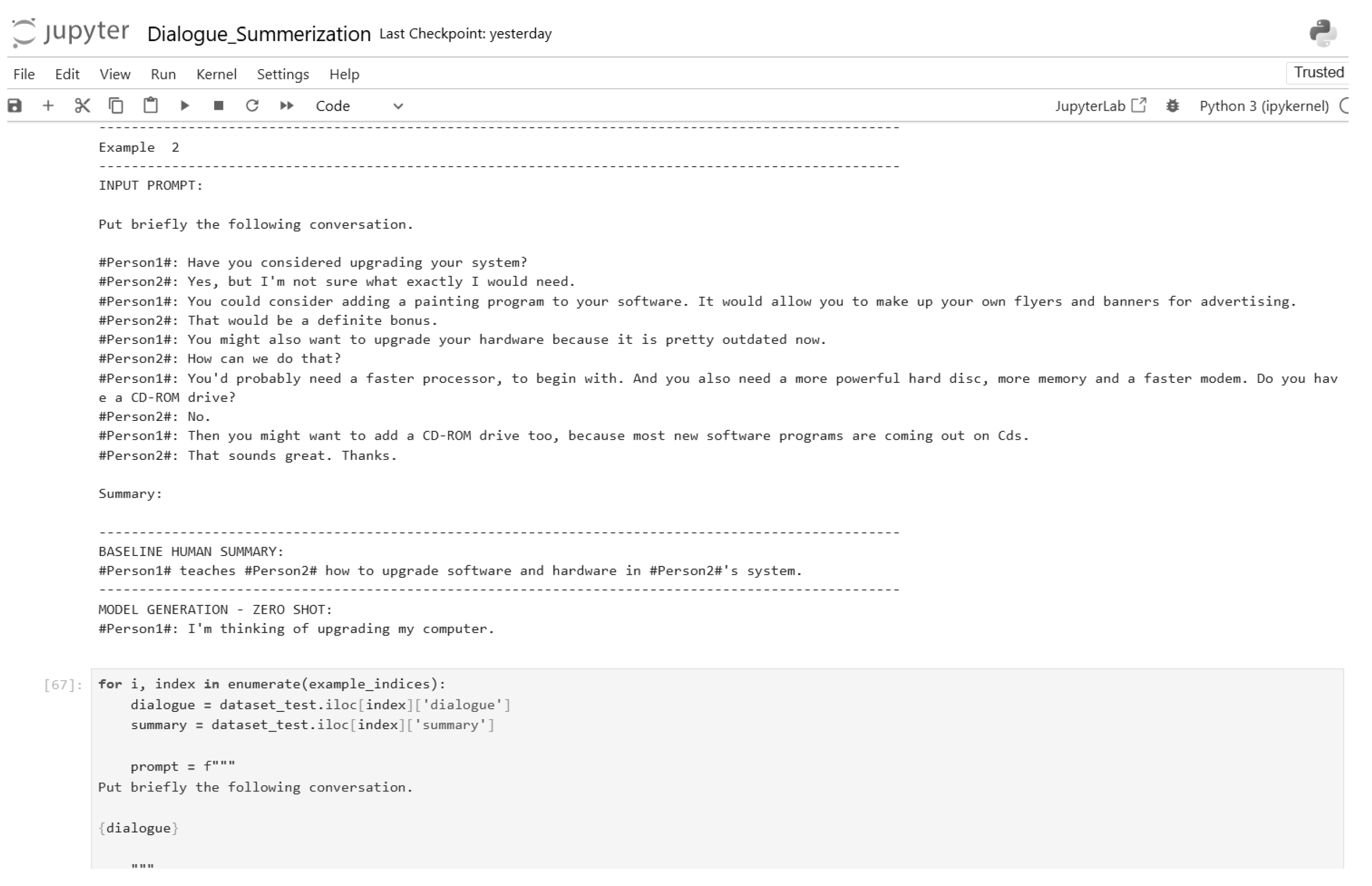
Figure 14.
Zero-shot inference code (Part 5).
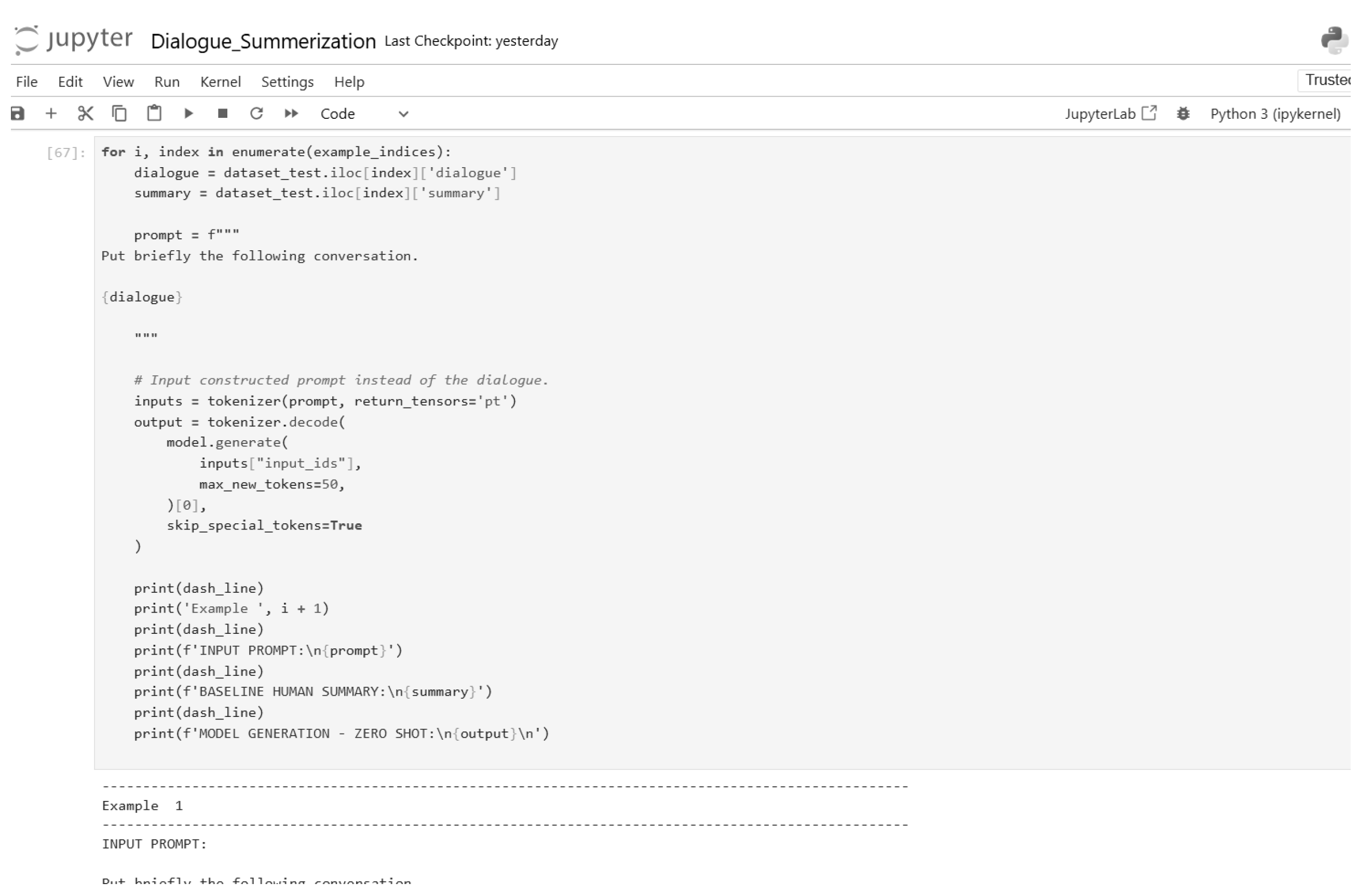
Figure 15.
Zero-shot inference code (Part 6).

Figure 16.
Zero-shot inference code (Part 7).
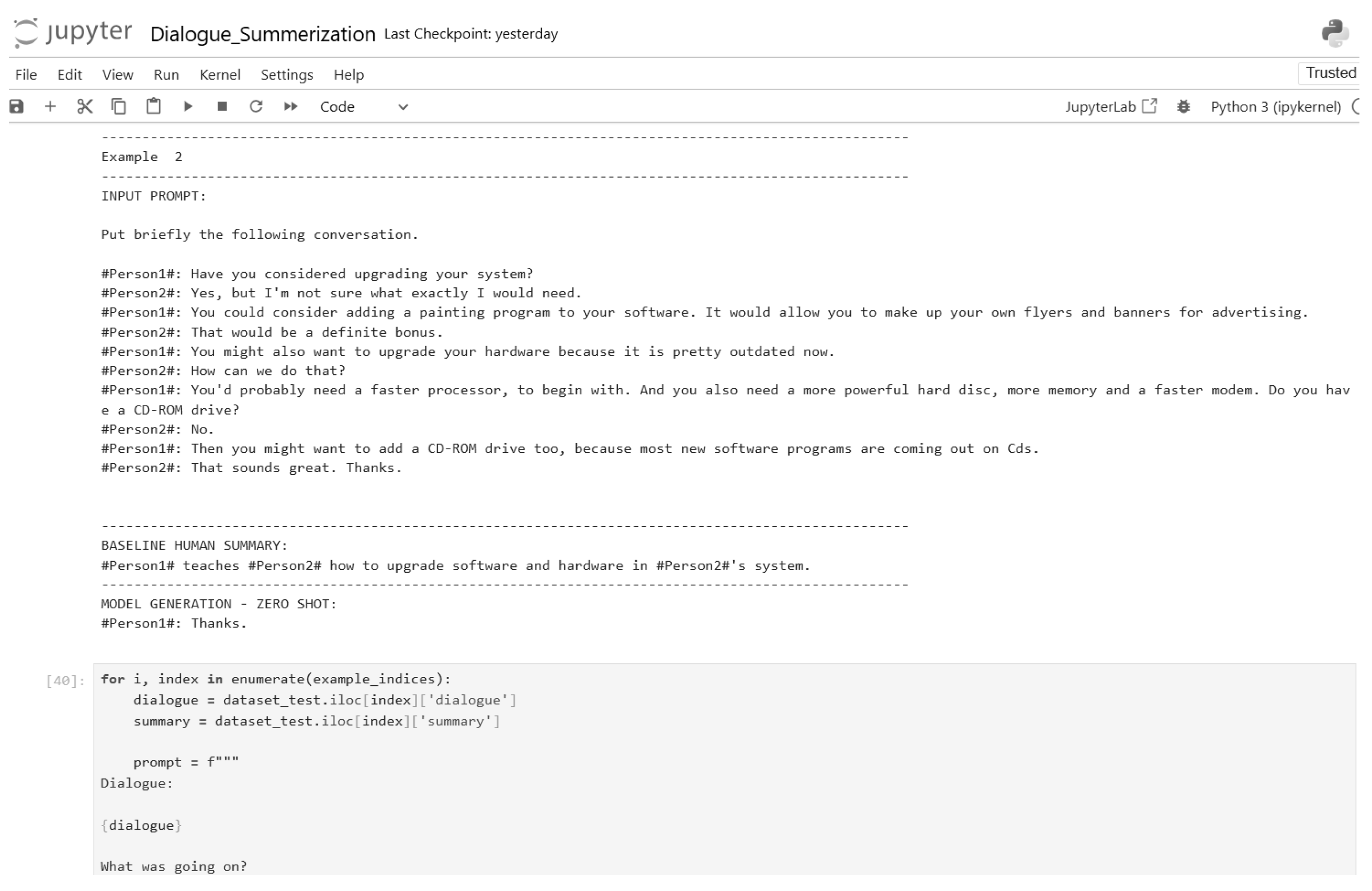
Figure 17.
Zero-shot inference code (Part 8).
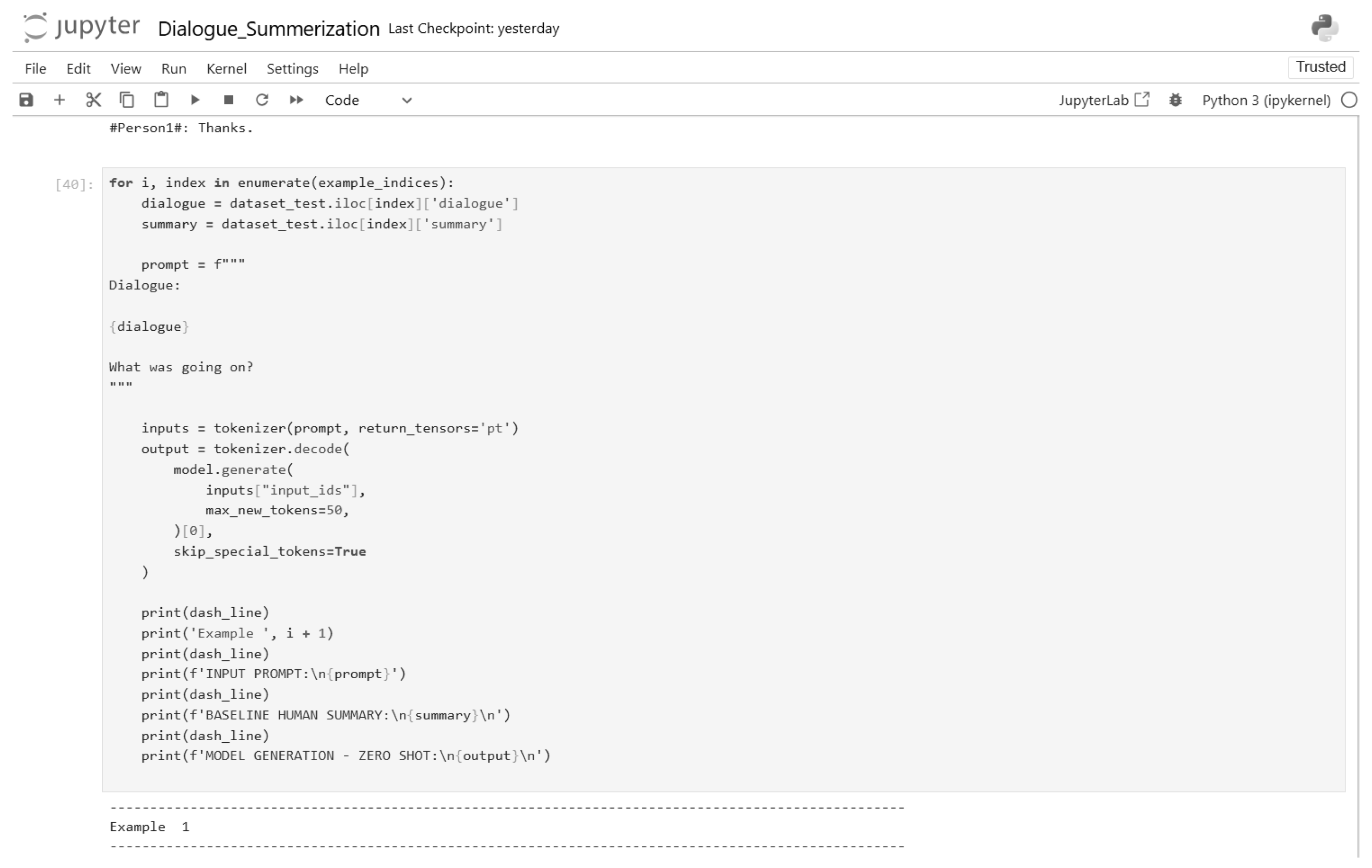
Figure 18.
Zero-shot inference code (Part 9).

Figure 19.
Zero-shot inference code (Part 10).
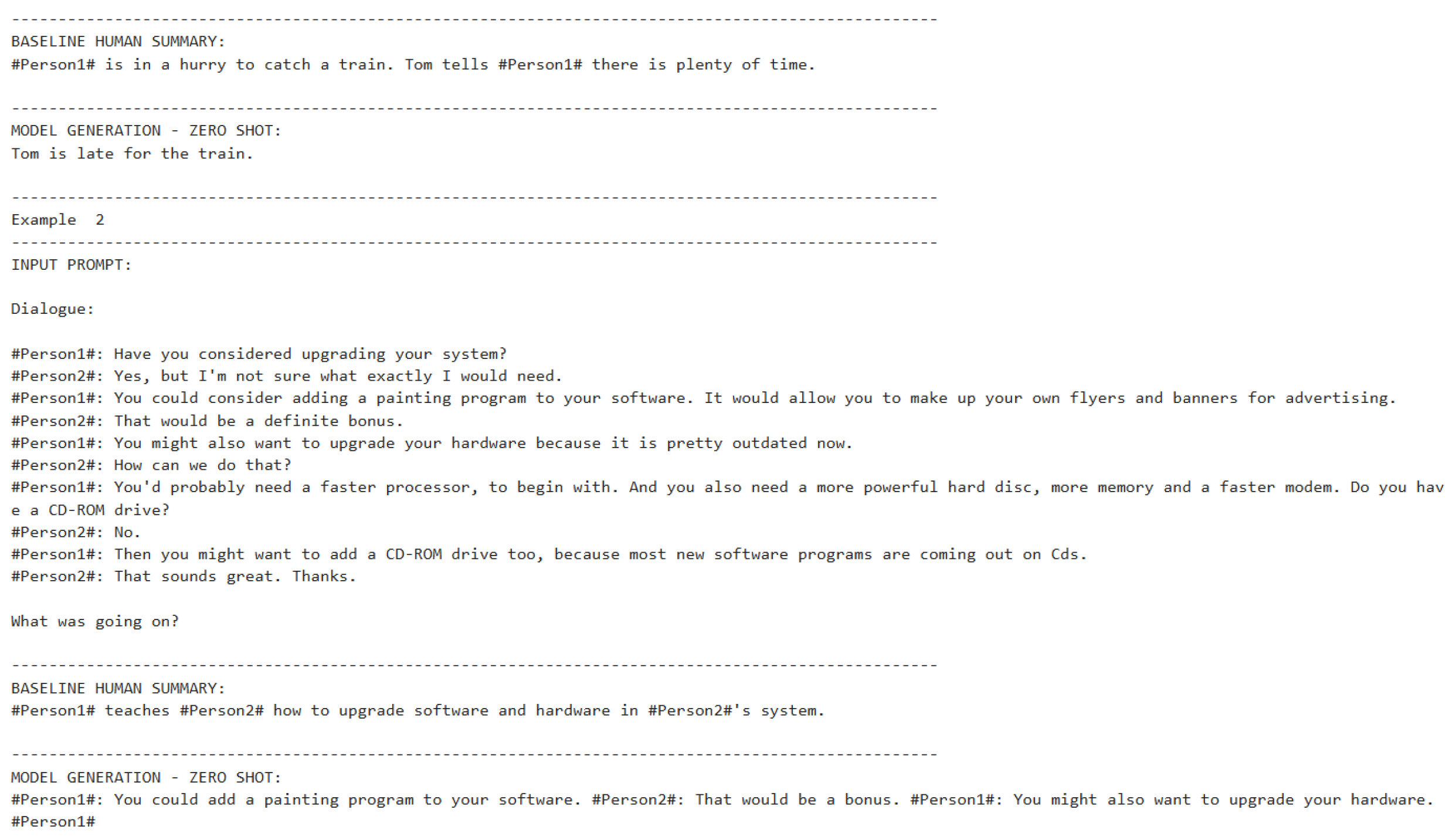
Figure 20.
Zero-shot inference code (Part 11).

Figure 21.
Zero-shot inference input and output (Part 1).
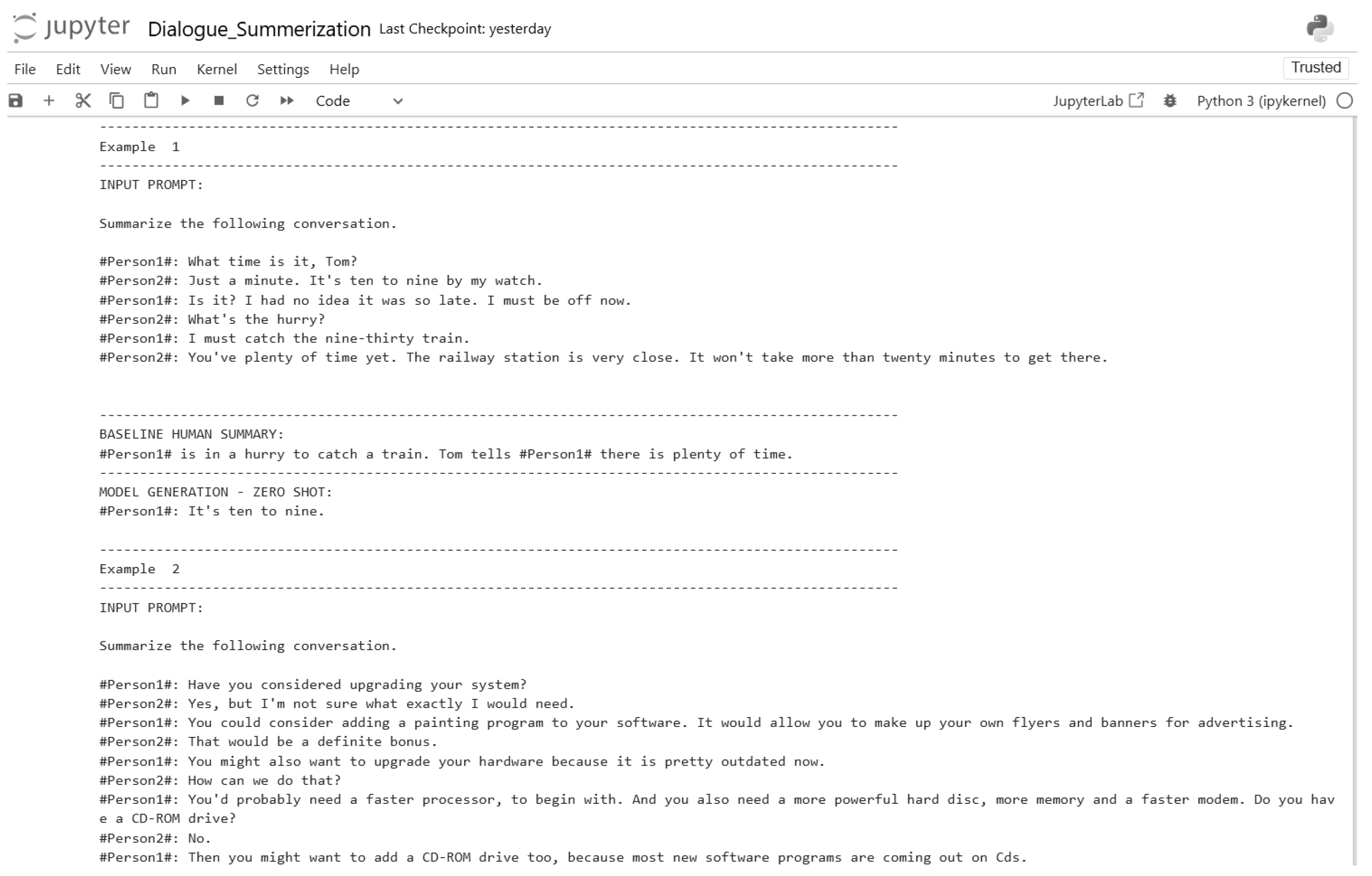
Figure 22.
Zero-shot inference input and output (Part 2).
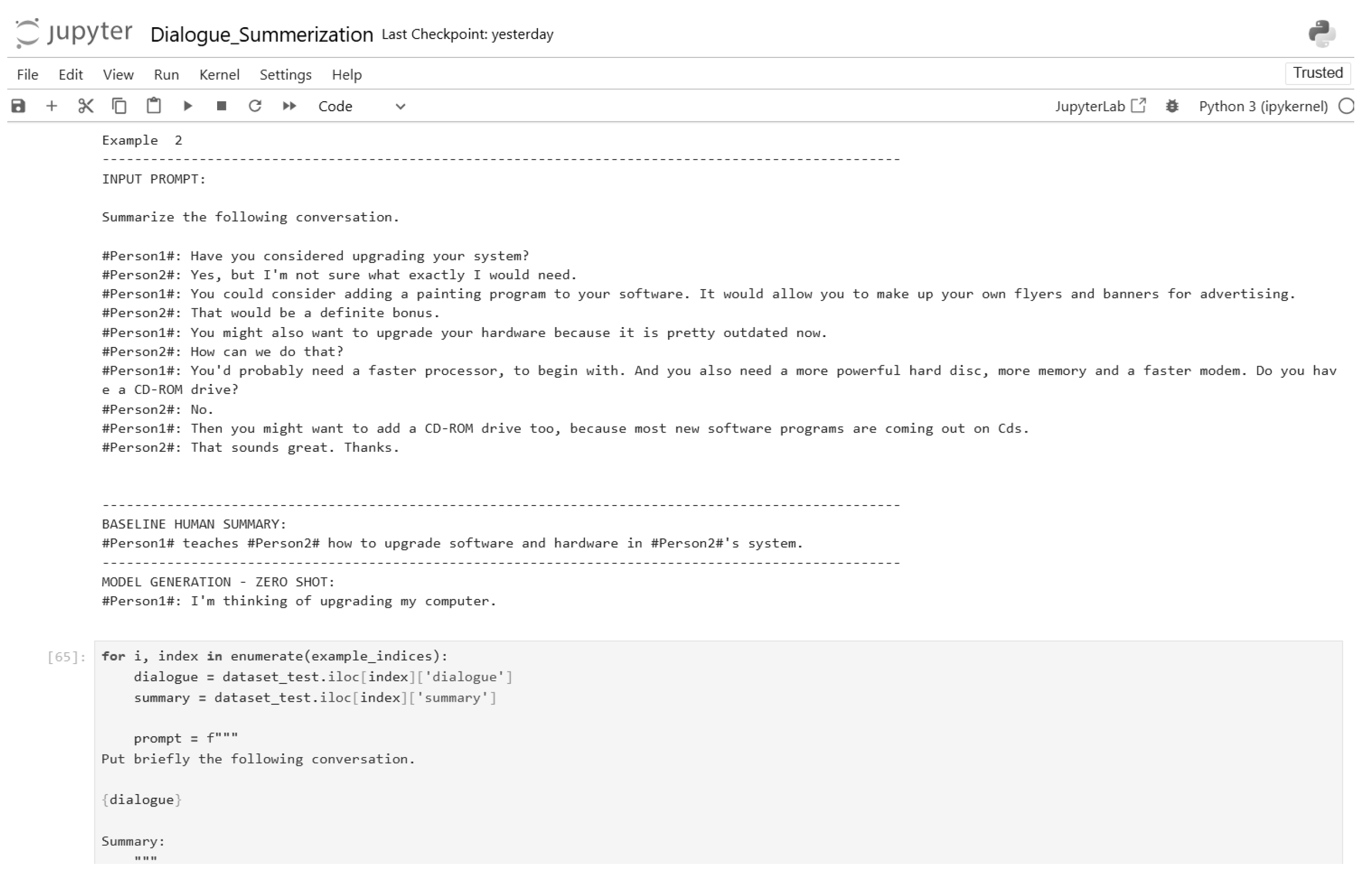
Figure 23.
Zero-shot inference input and output (Part 3).
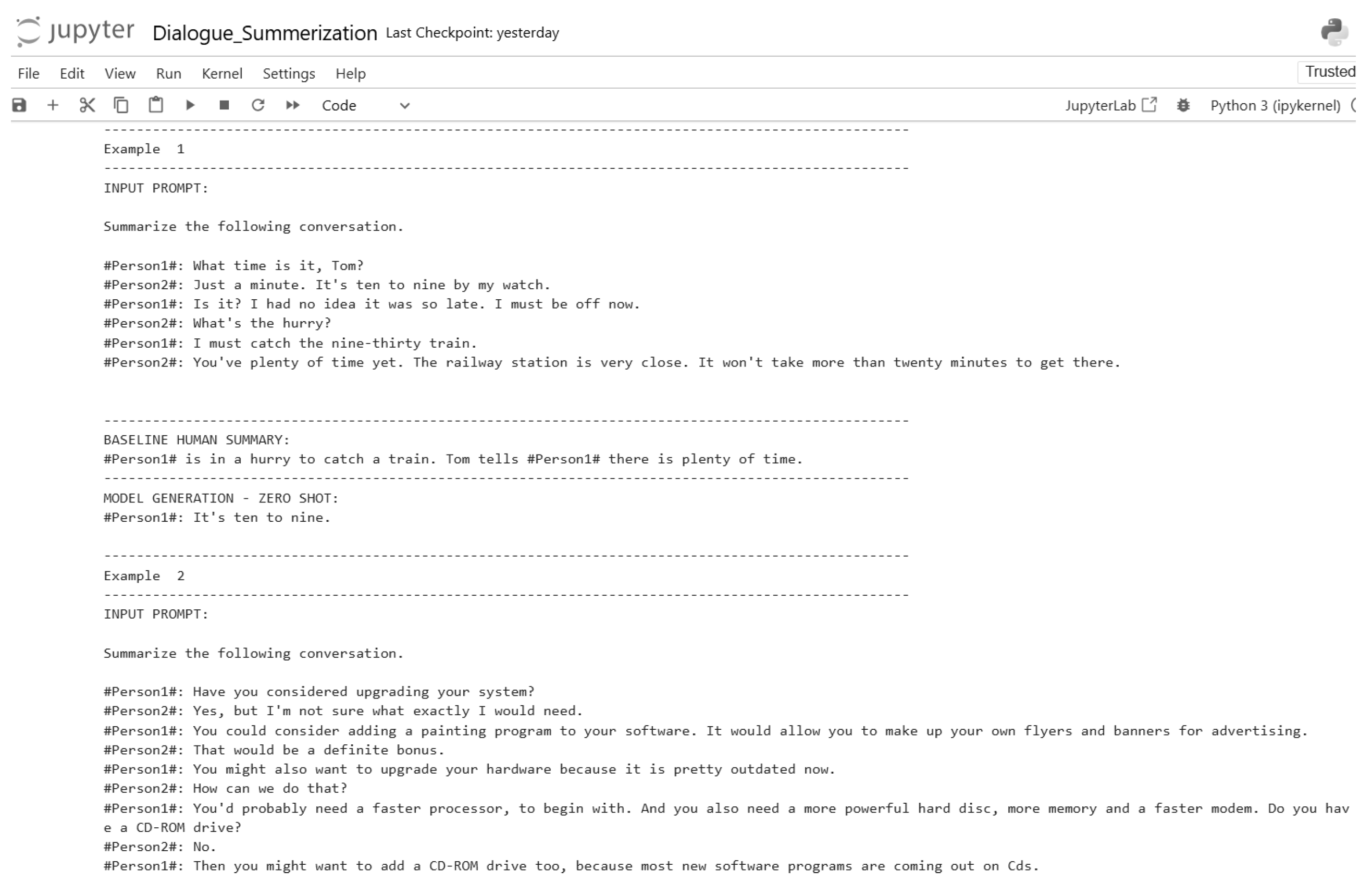
Figure 24.
Zero-shot inference input and output (Part 4).
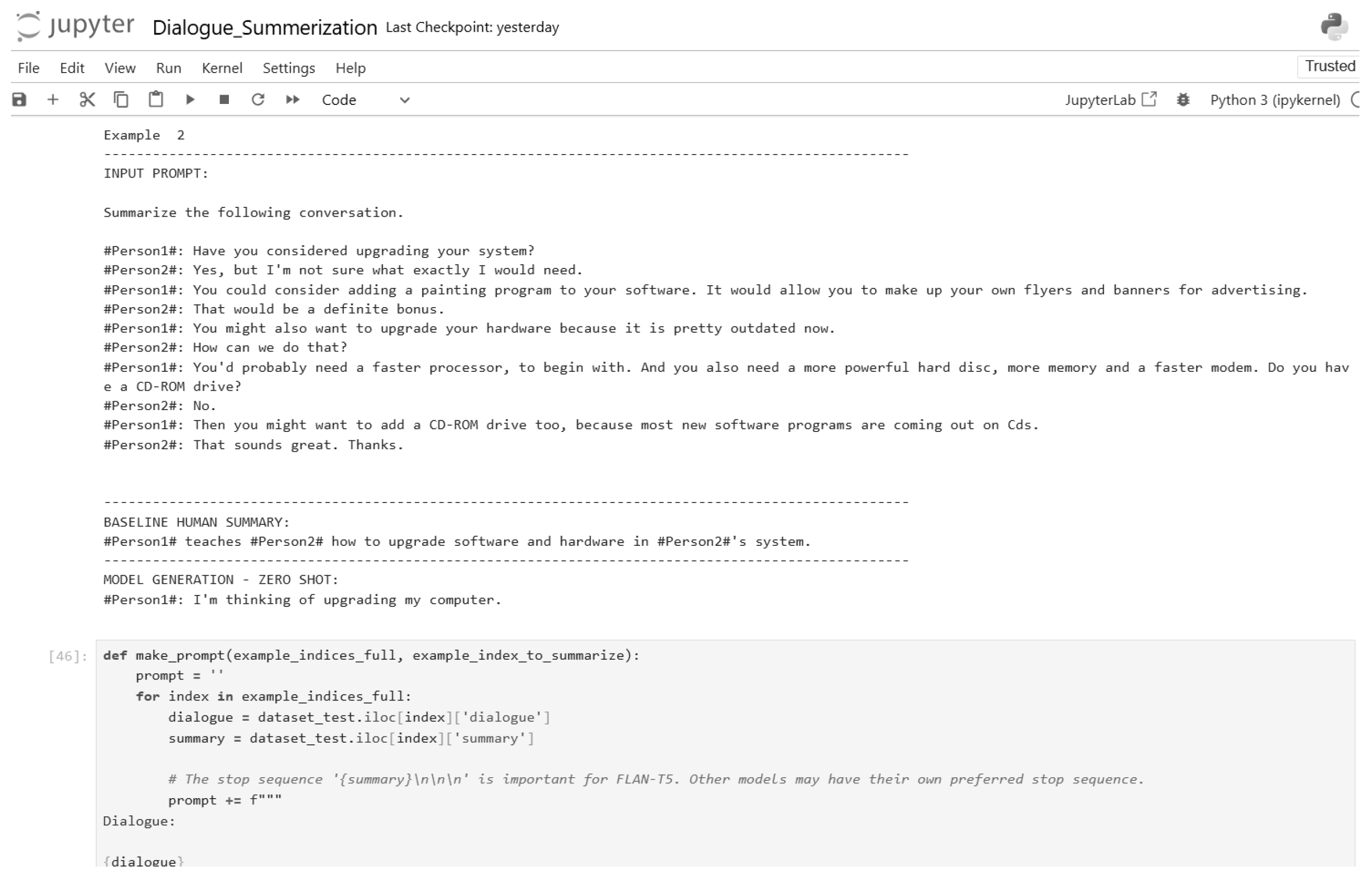
Figure 25.
Zero-shot inference input and output (Part 5).
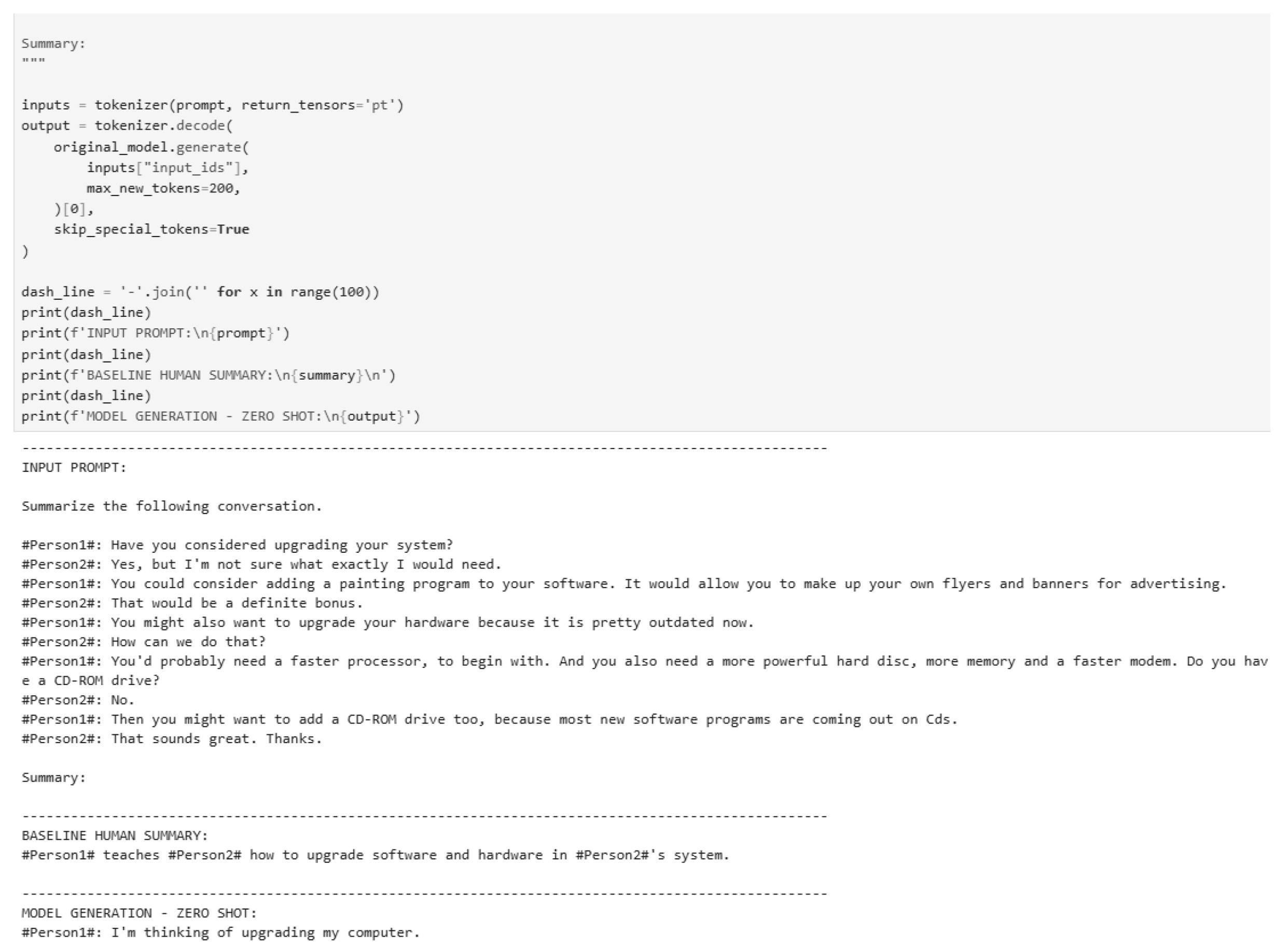
Figure 26.
Zero-shot inference testing (Part 1).
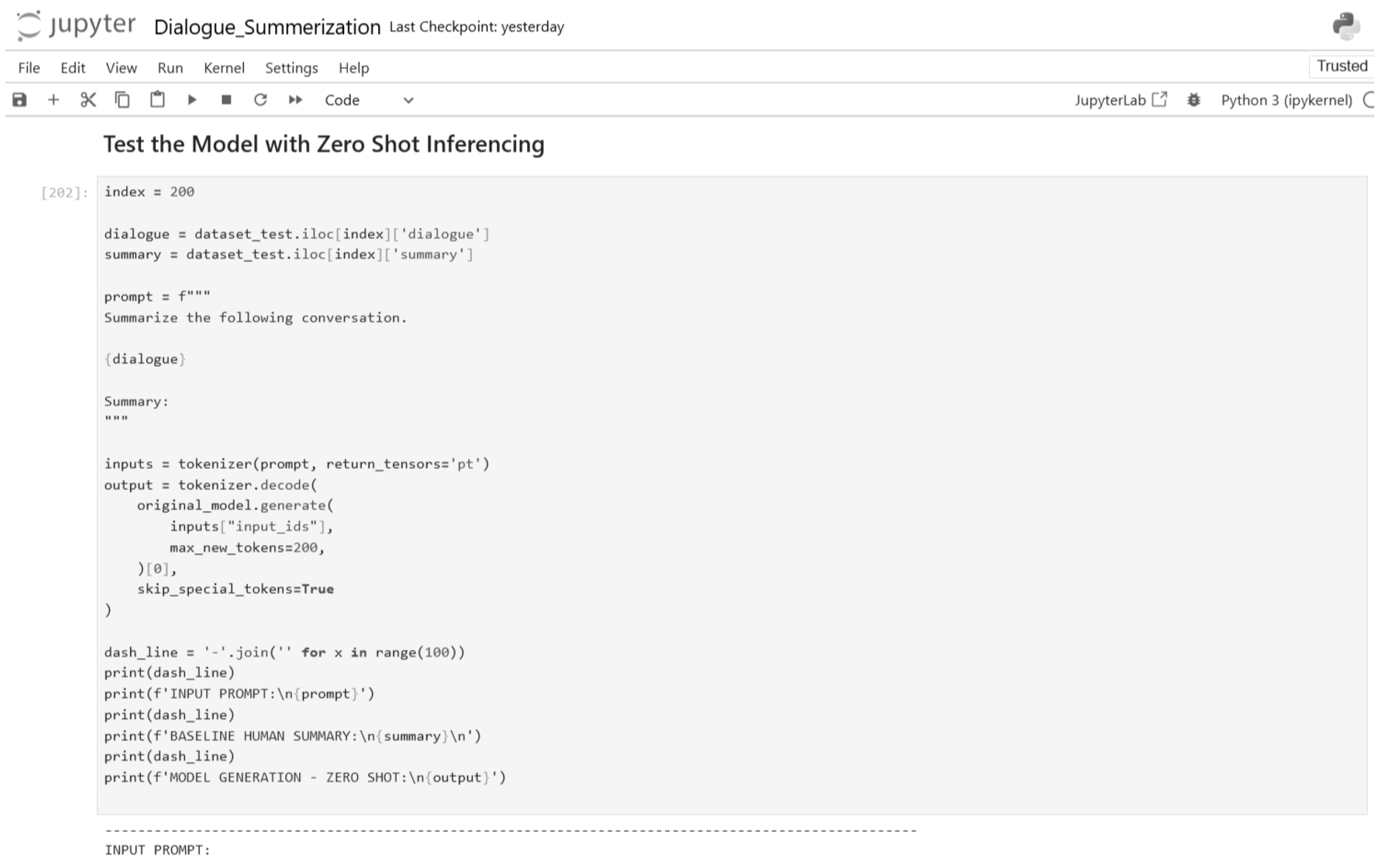
Figure 27.
Zero-shot inference testing (Part 2).
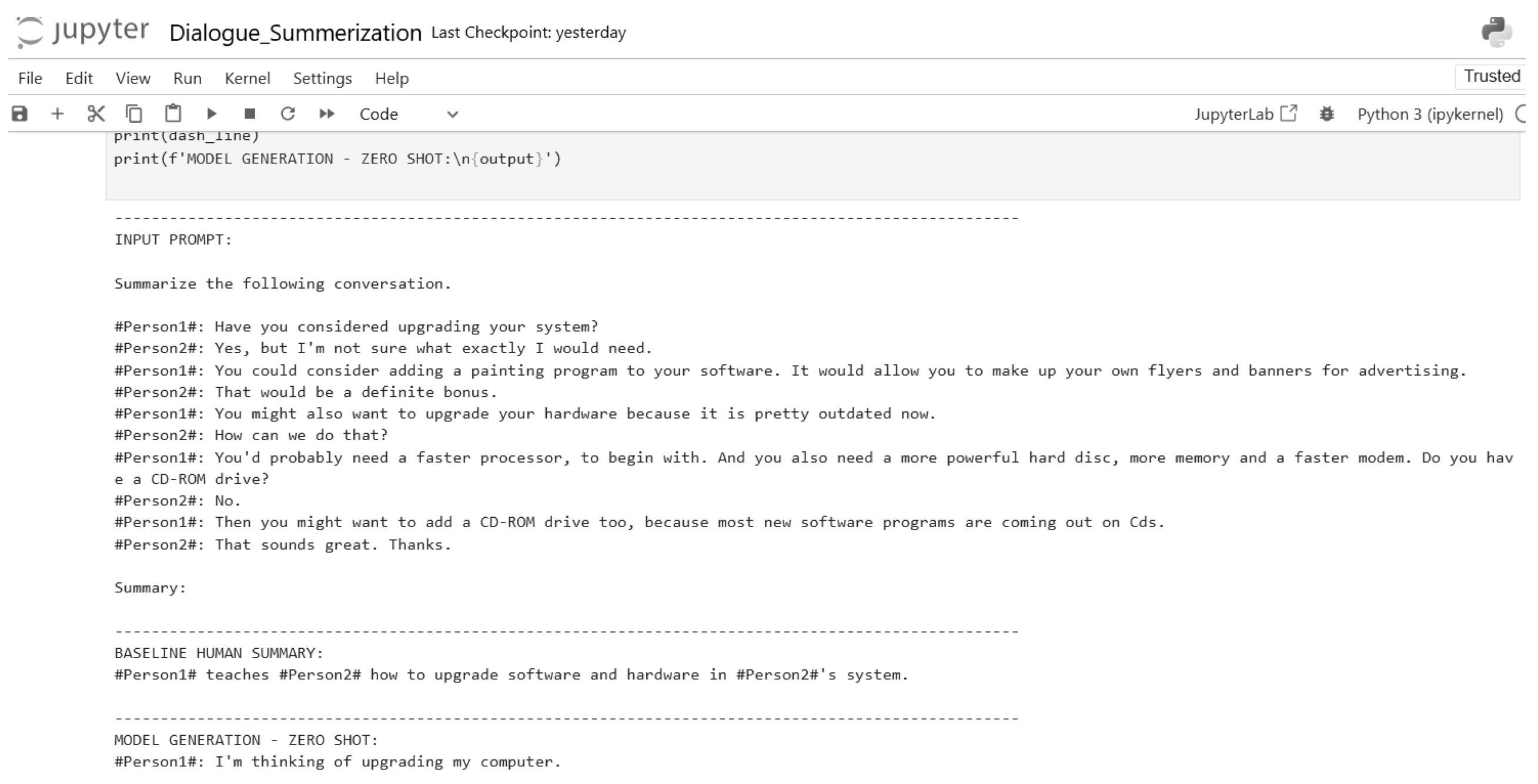
Figure 28.
Testing model with zero-shot inferencing (Part 1).
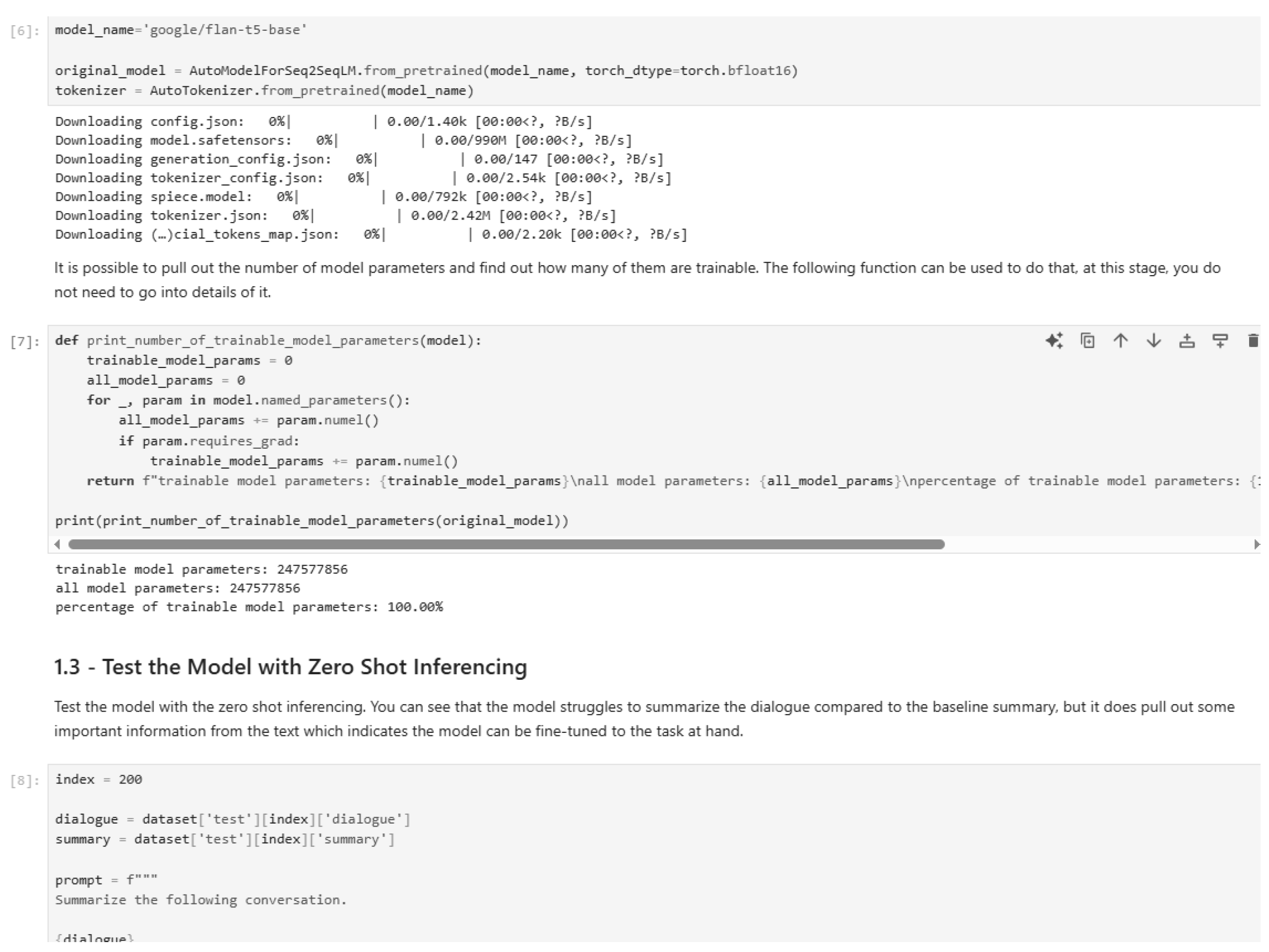
Figure 29.
Testing model with zero-shot inferencing (Part 2).
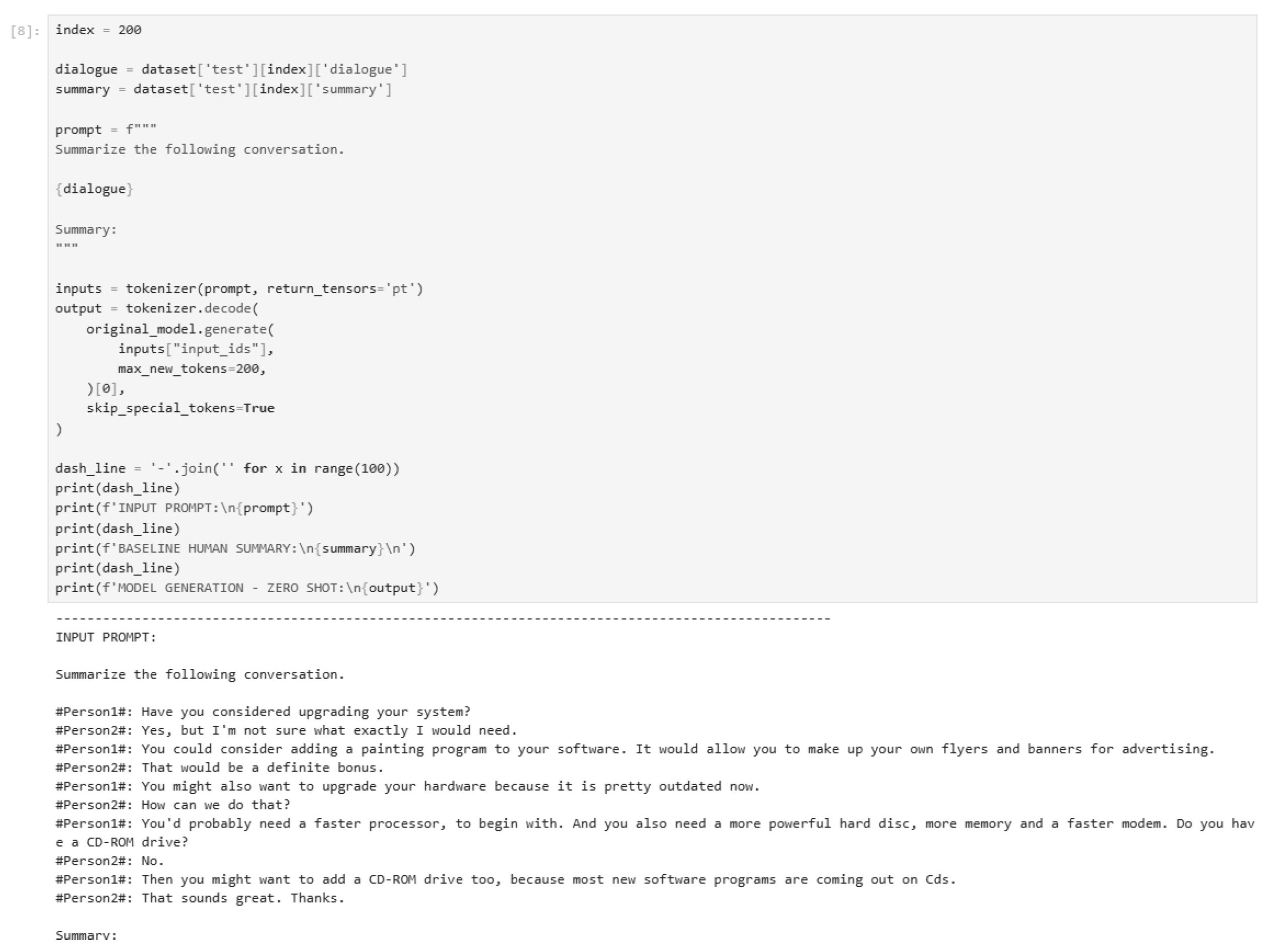
Figure 30.
One-shot inference code (Part 1).
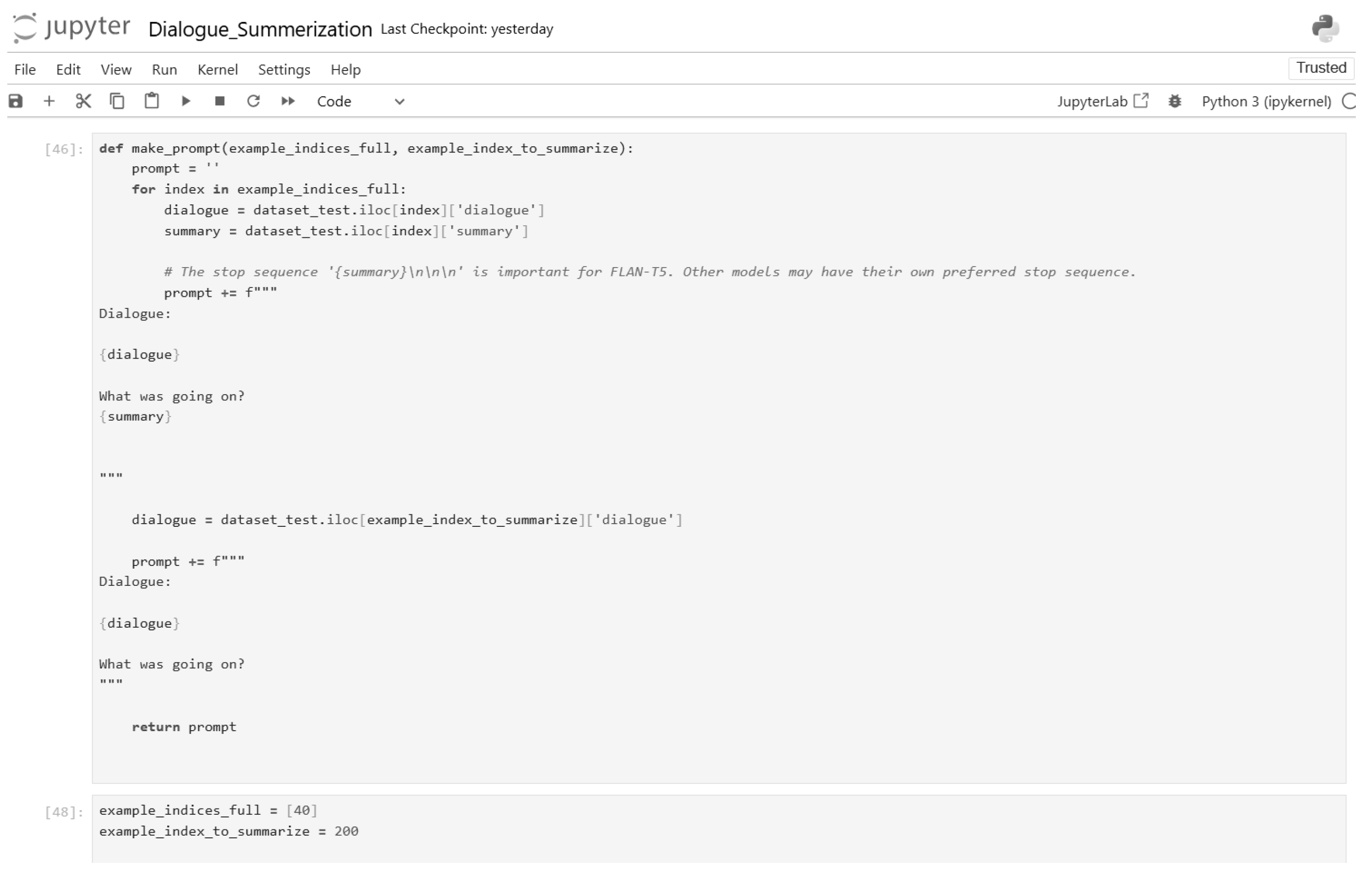
Figure 31.
One-shot inference code (Part 2).
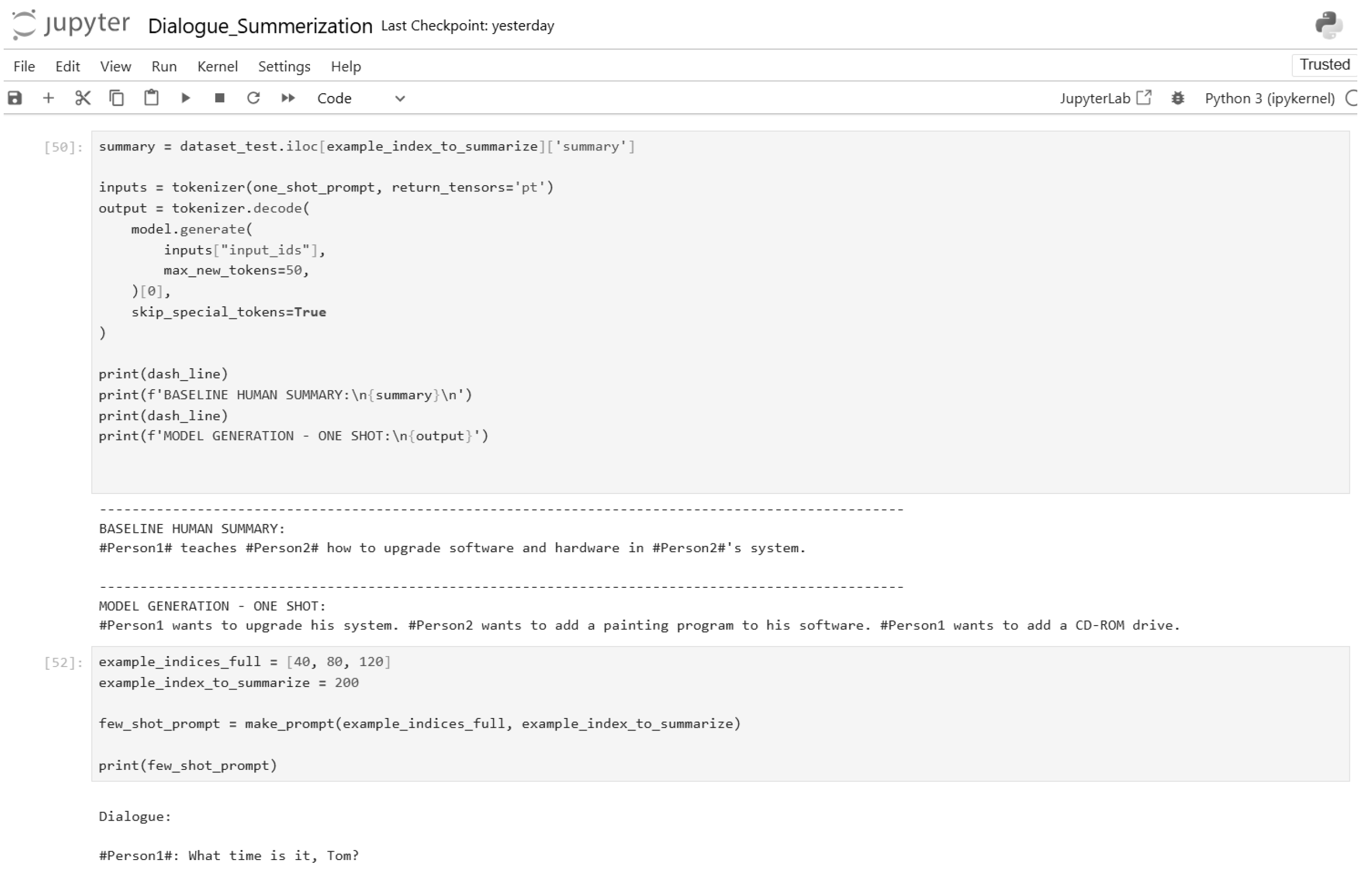
Figure 32.
One-shot inference code (Part 3).

Figure 33.
One-shot inference code (Part 4).
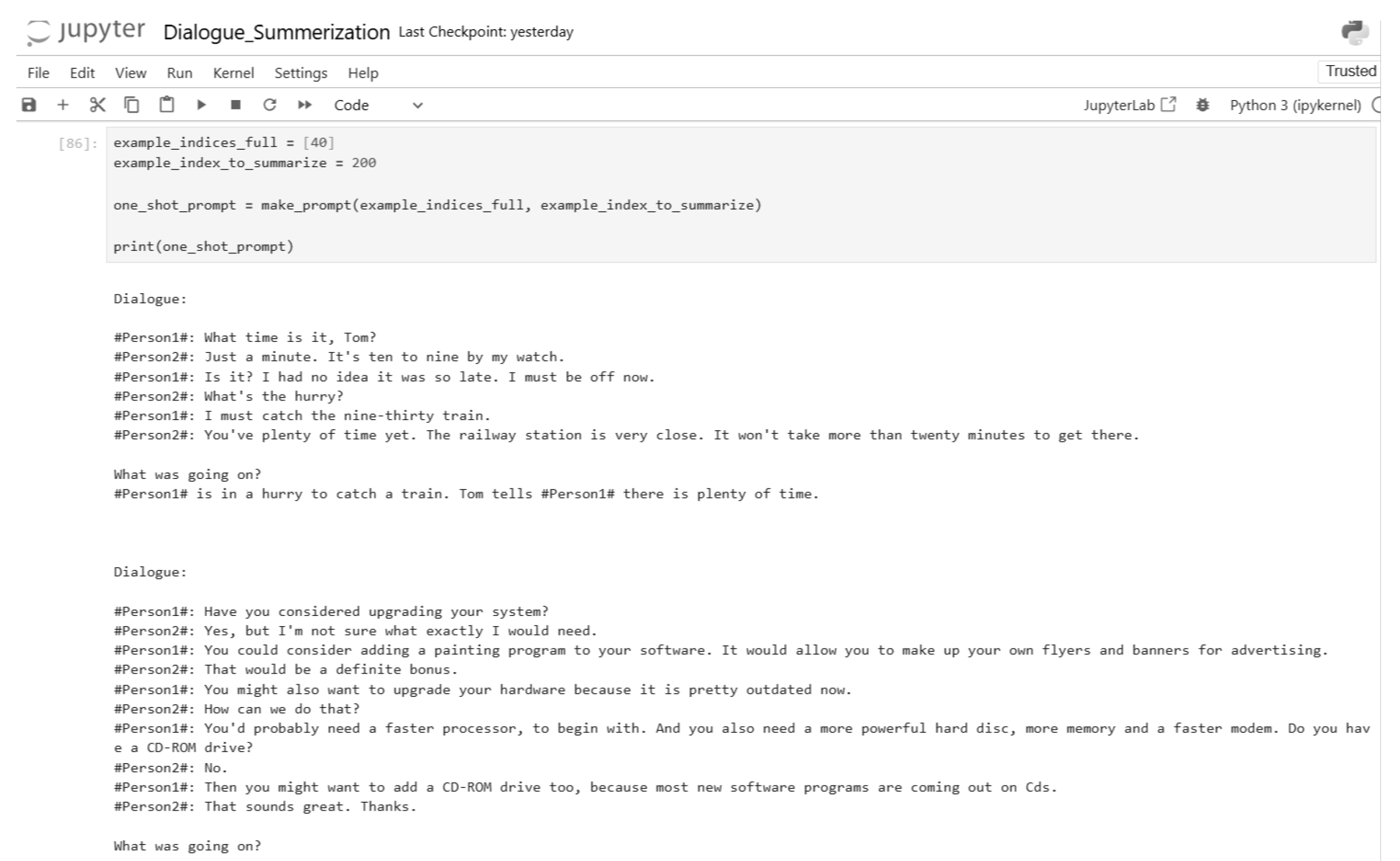
Figure 34.
One-shot inference input and output (Part 1).
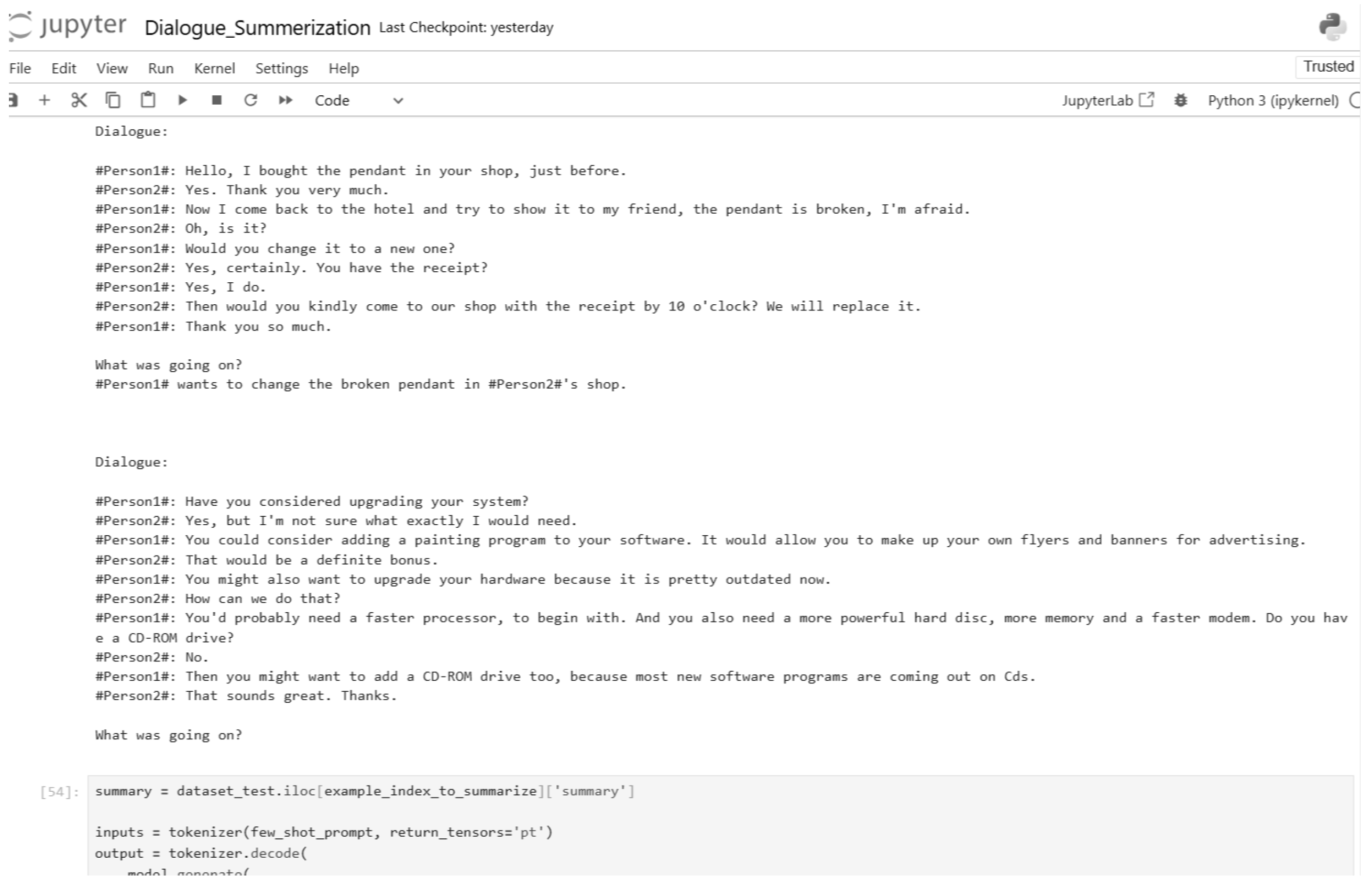
Figure 35.
One-shot inference input and output (Part 2).
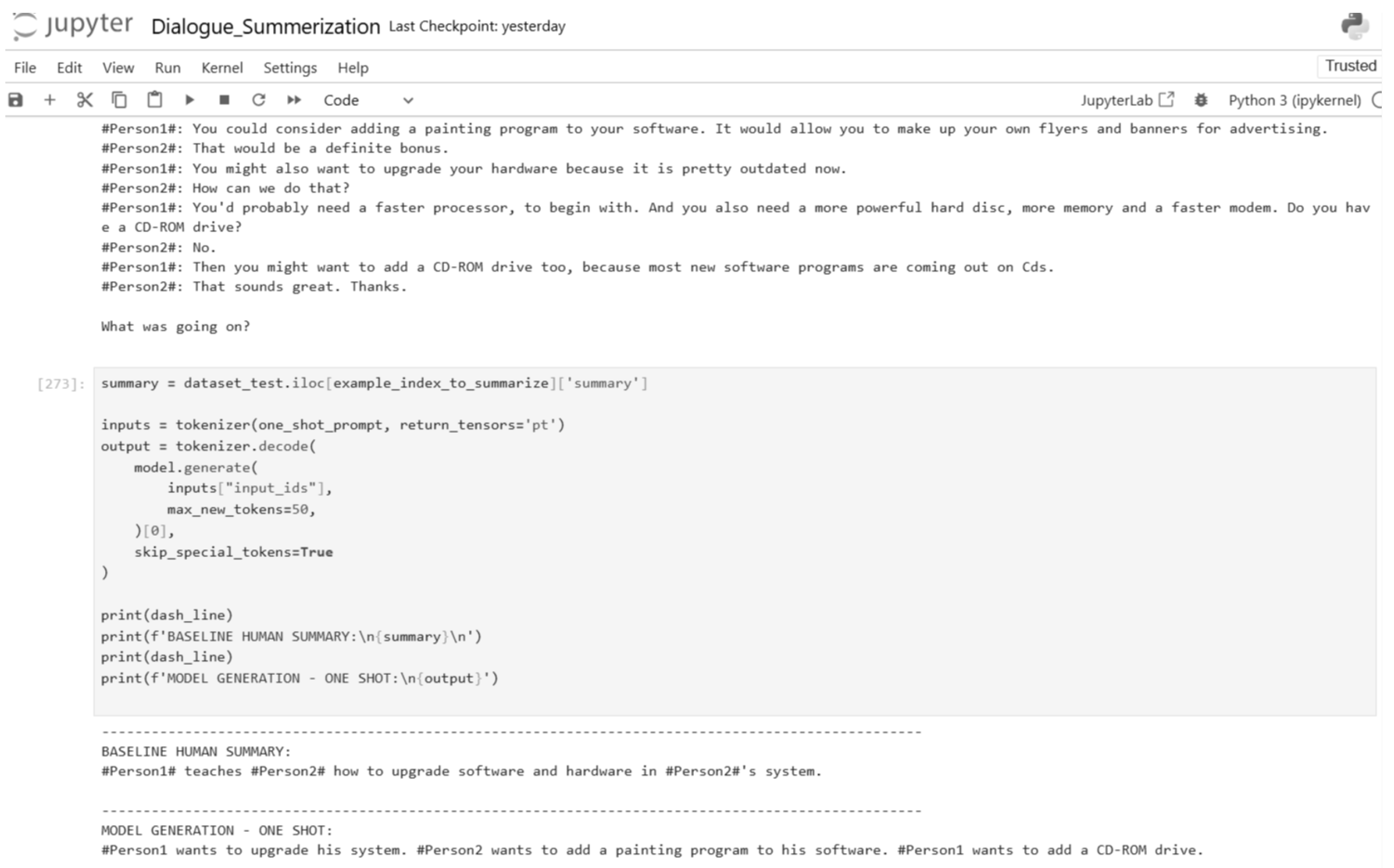
Figure 36.
Loading the dataset for training.
Figure 37.
LoRA and PEFT training implementation.
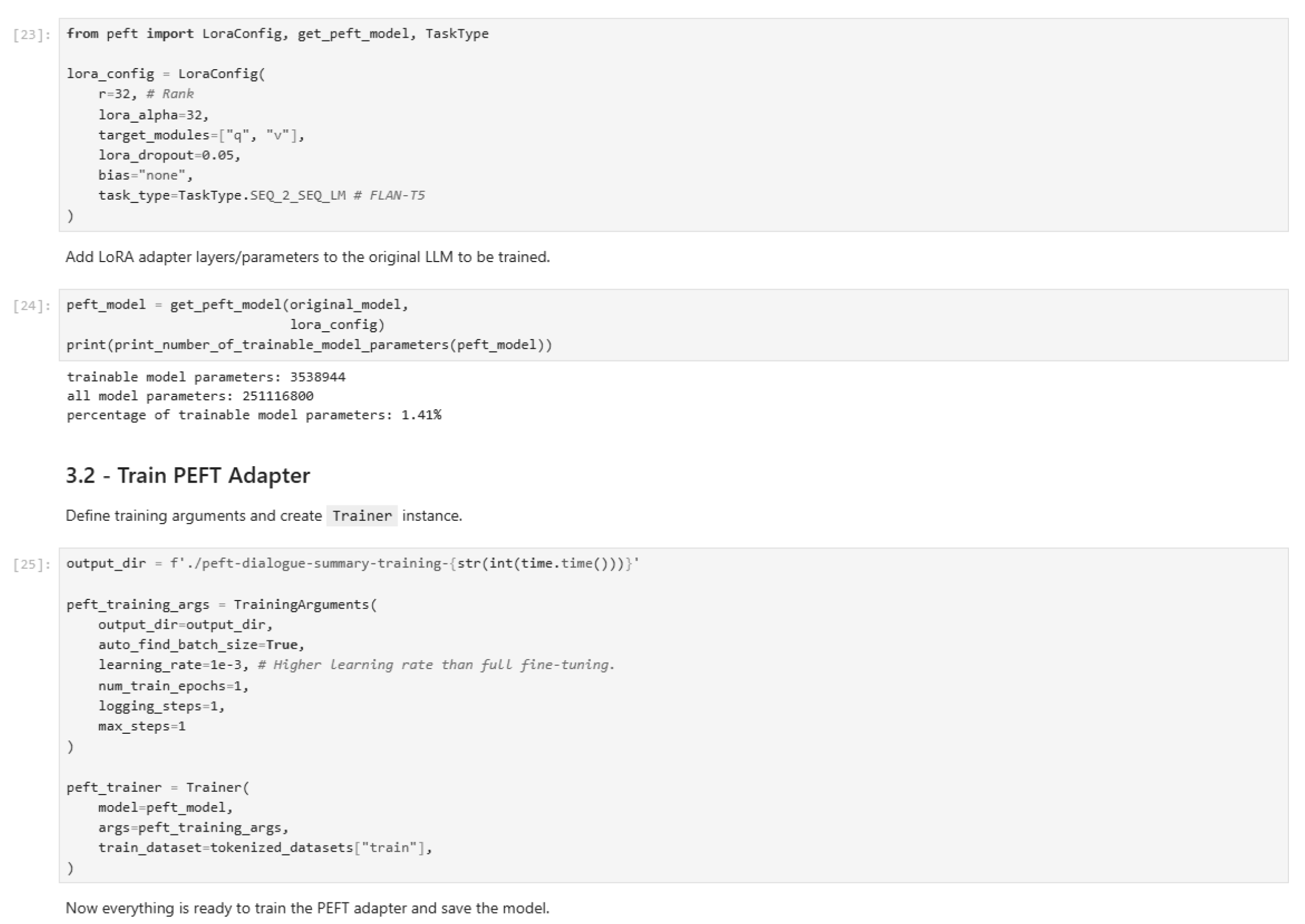
Figure 38.
PEFT training implementation.
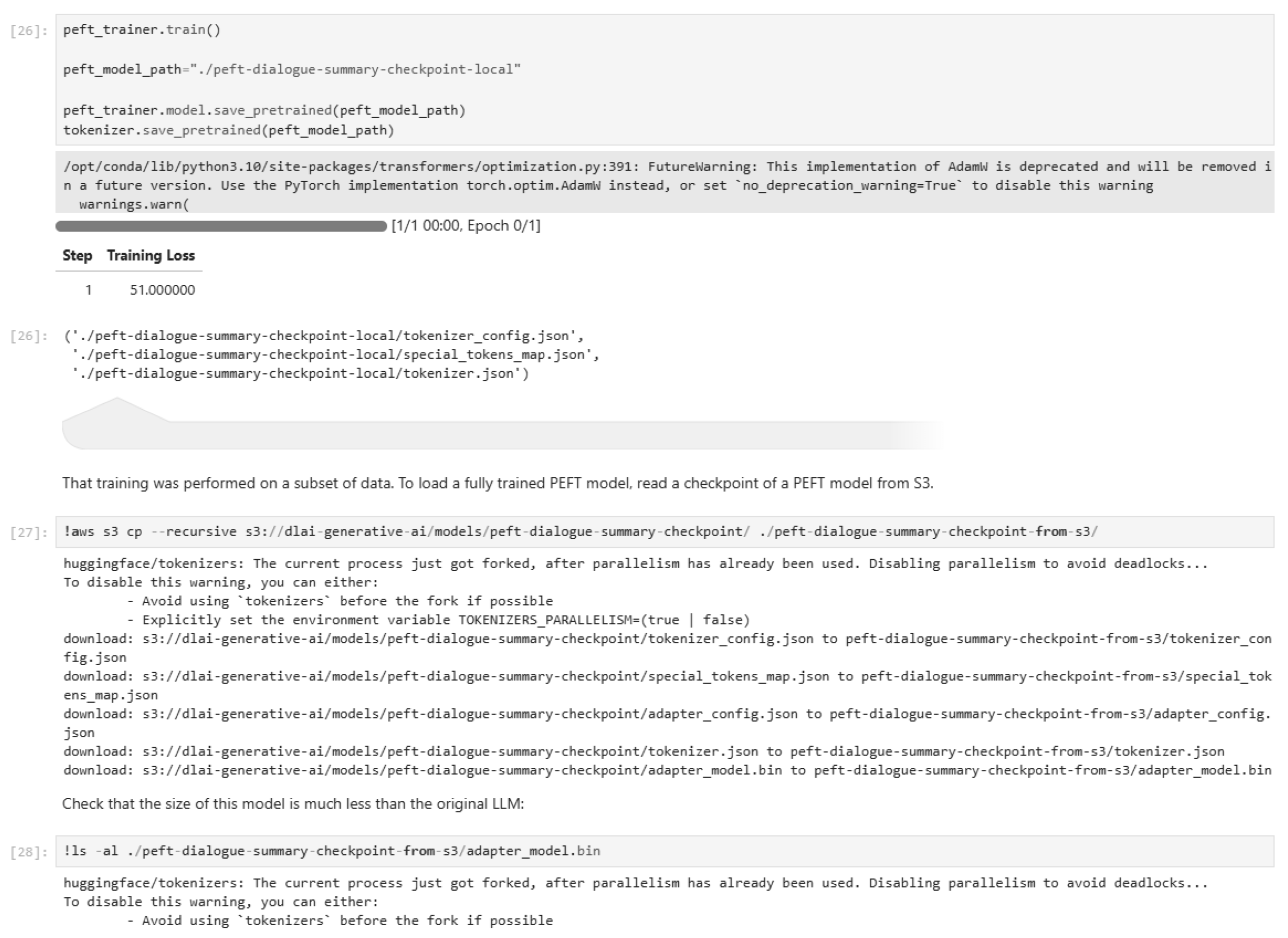
Figure 39.
Performing full fine-tuning (Part 1).
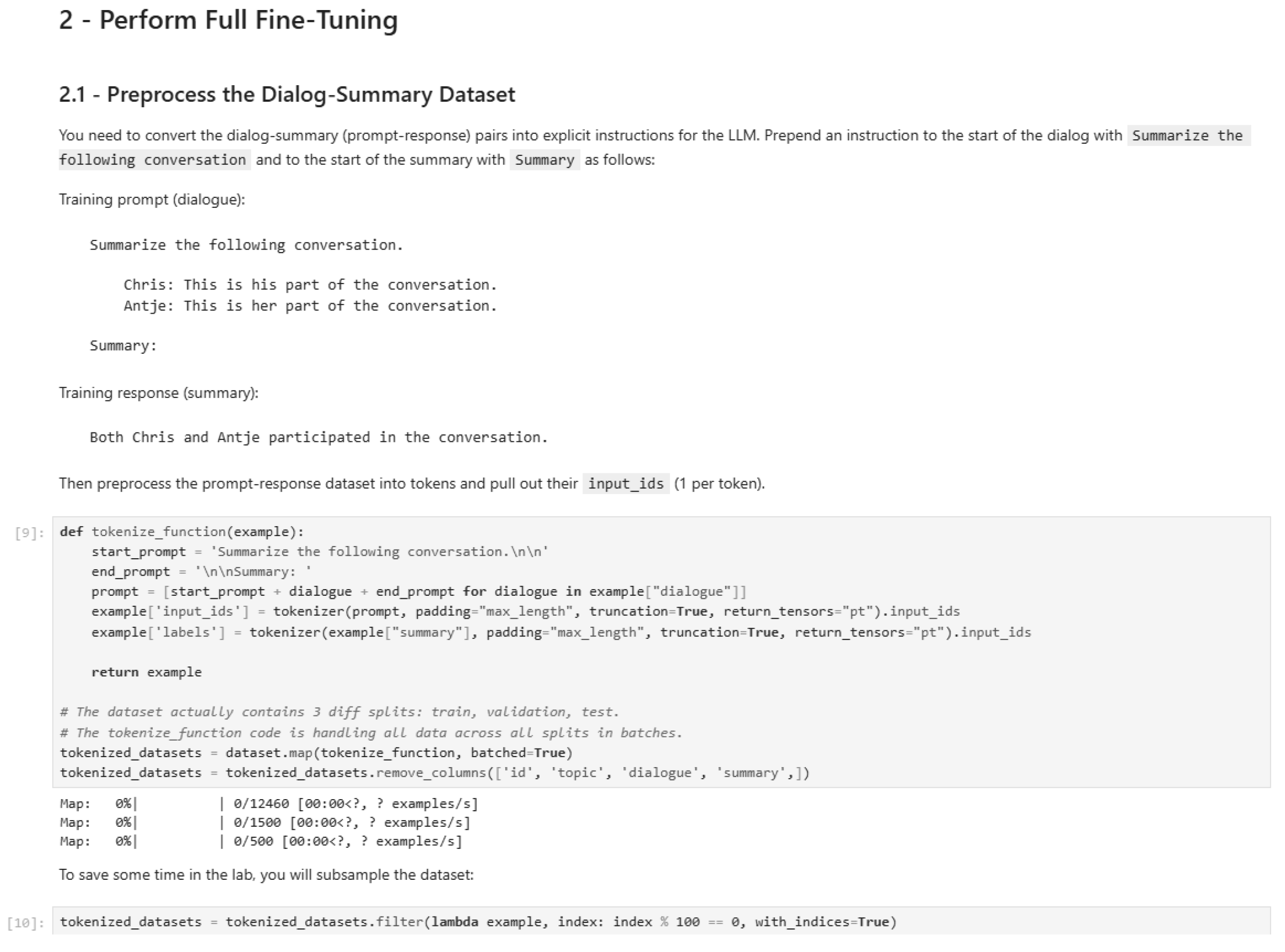
Figure 40.
Performing full fine-tuning (Part 2).

Figure 41.
PPO fine-tuning implementation.
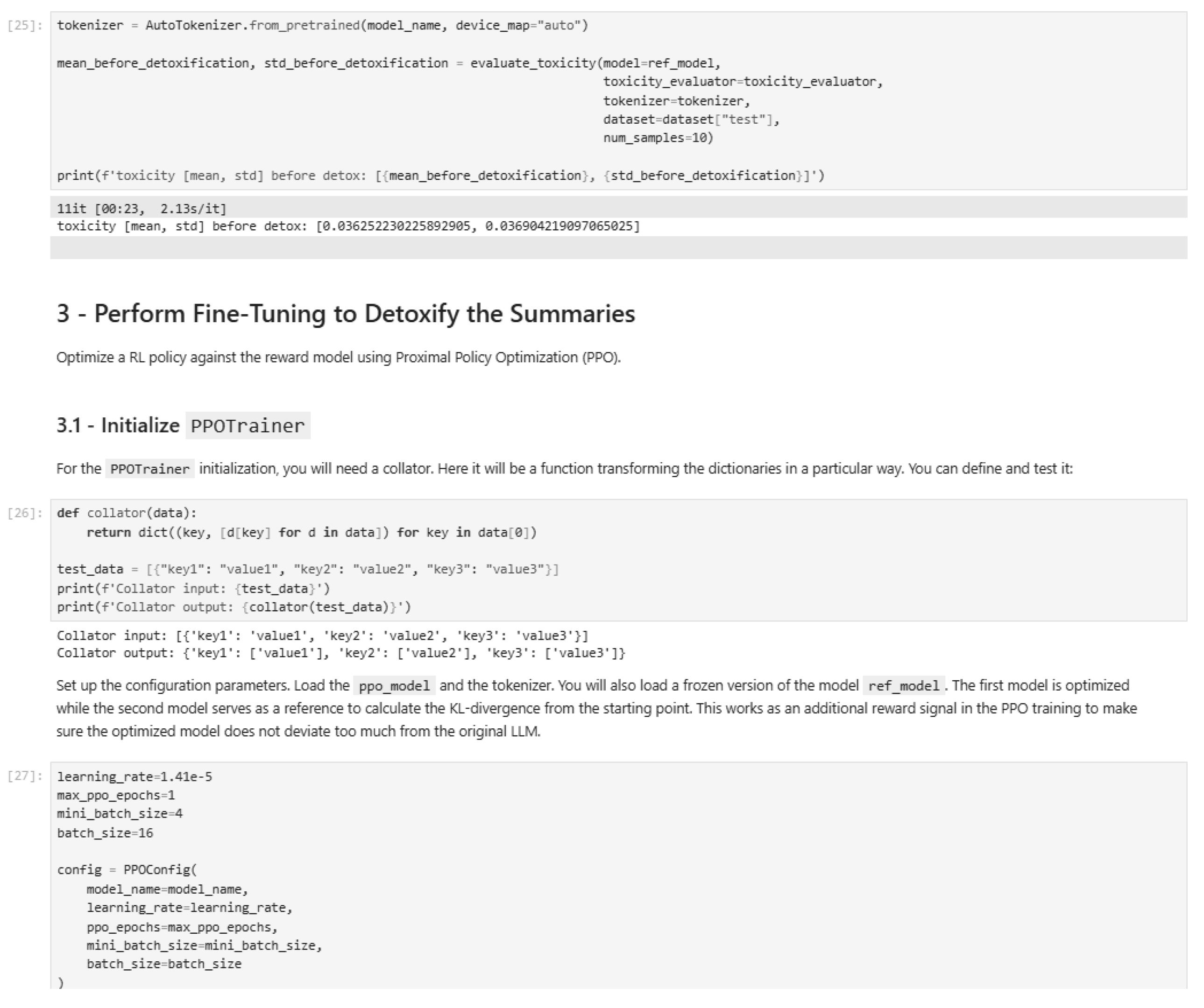
Figure 42.
PPO model implementation.
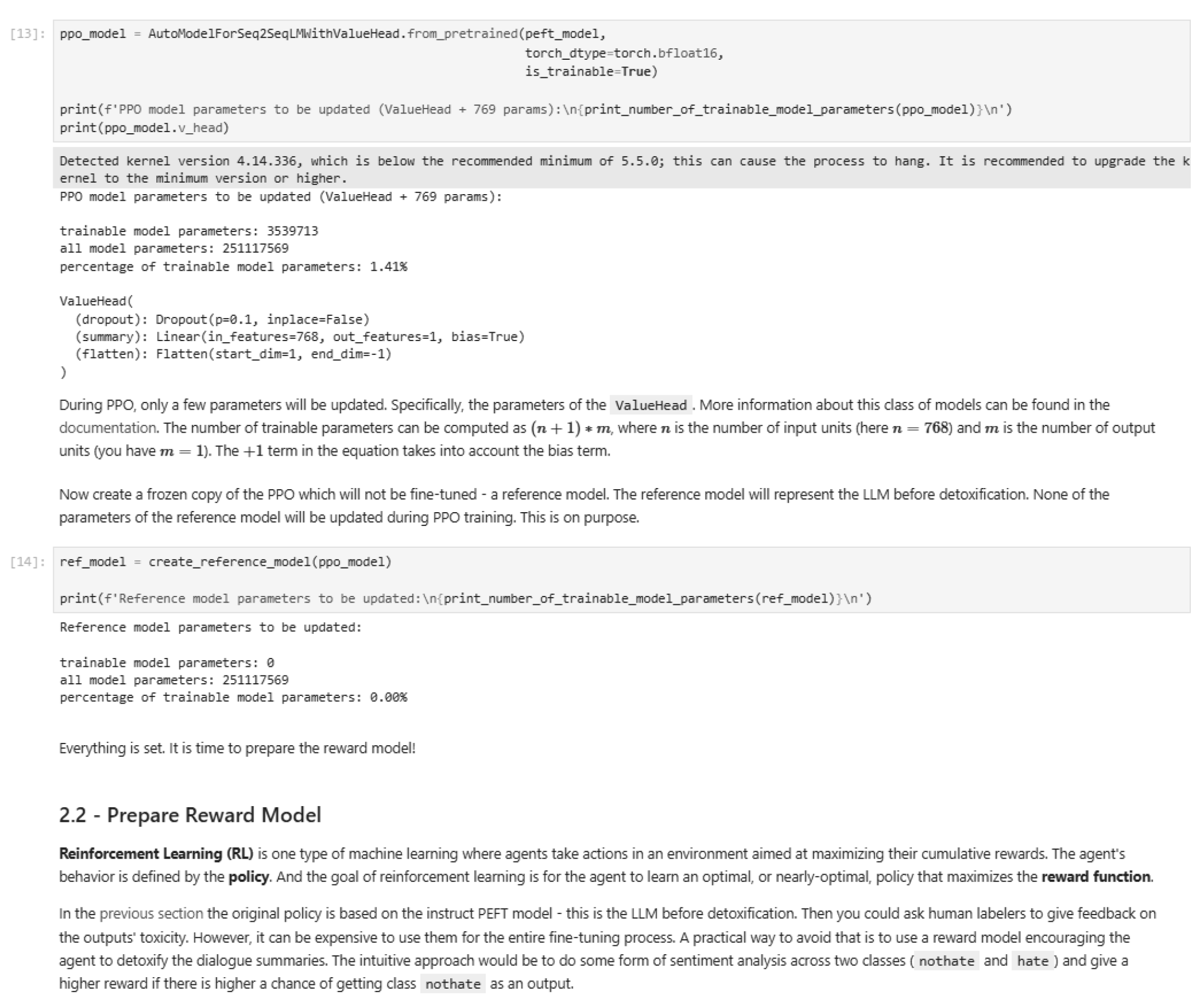
Figure 43.
Reward model output for PPO fine-tuning.
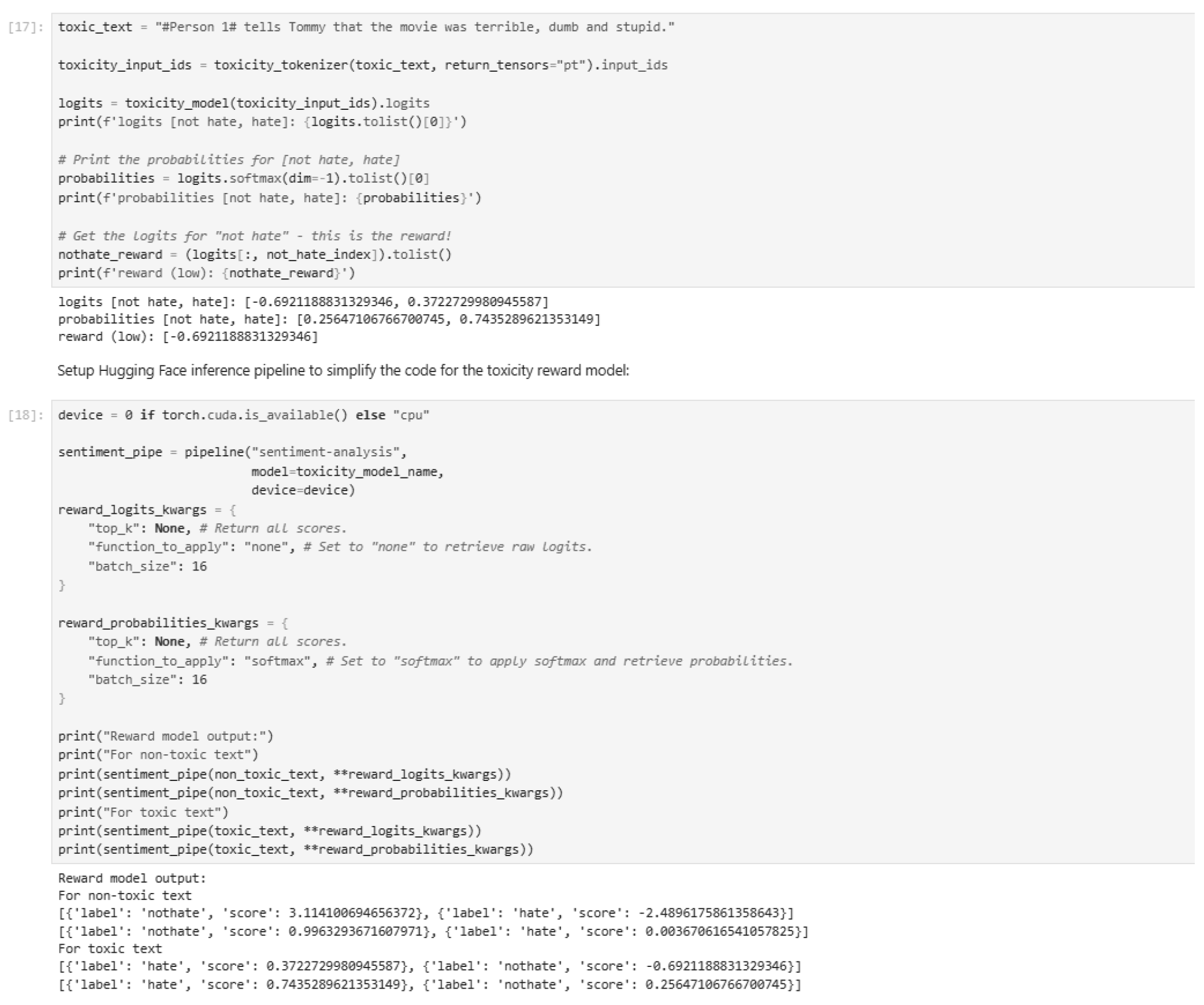
Figure 44.
Qualitative evaluation of the model (Part 1).

Figure 45.
Qualitative evaluation of the model (Part 2).
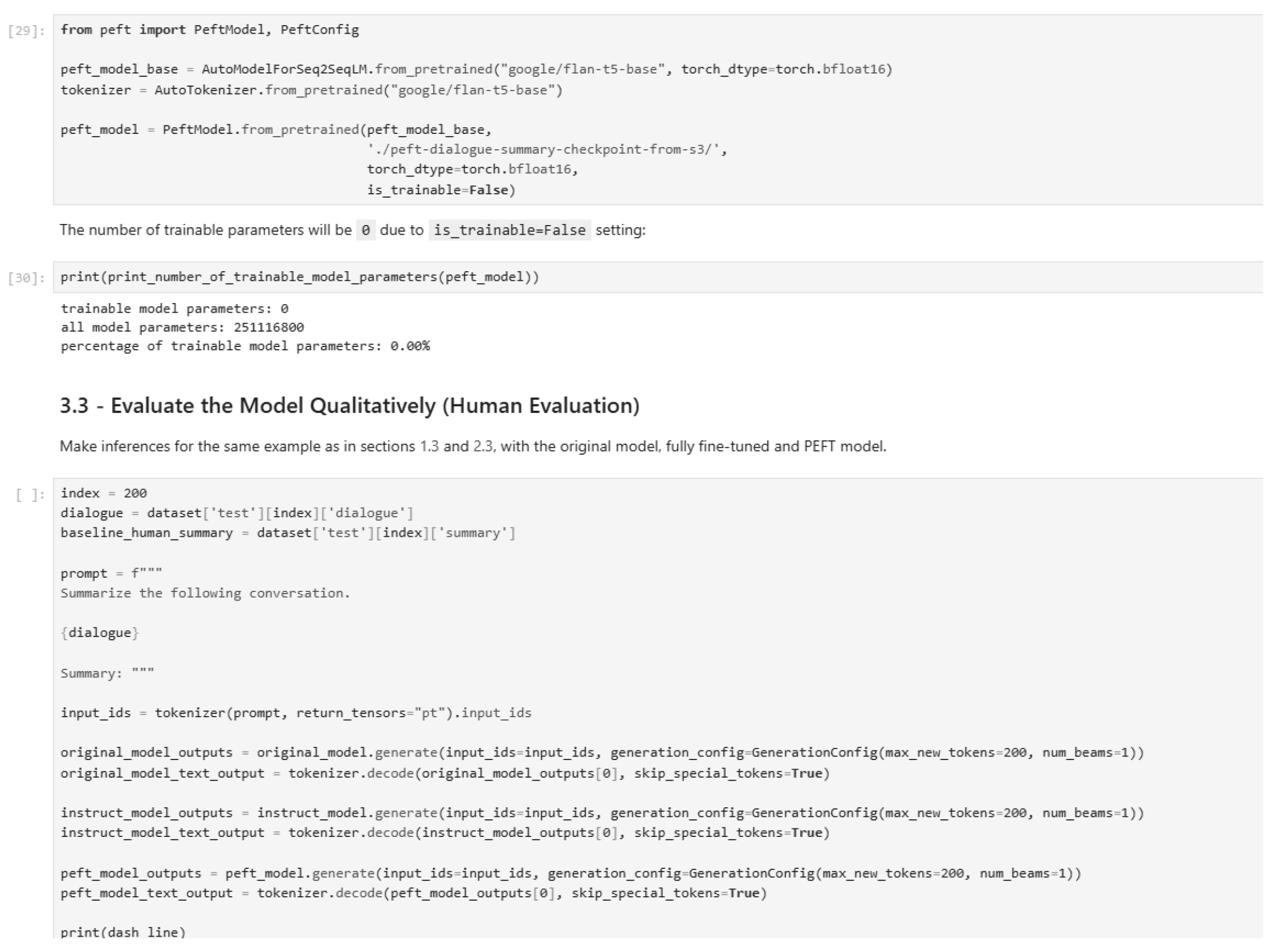
Figure 46.
Quantitative evaluation of the model (Part 1).
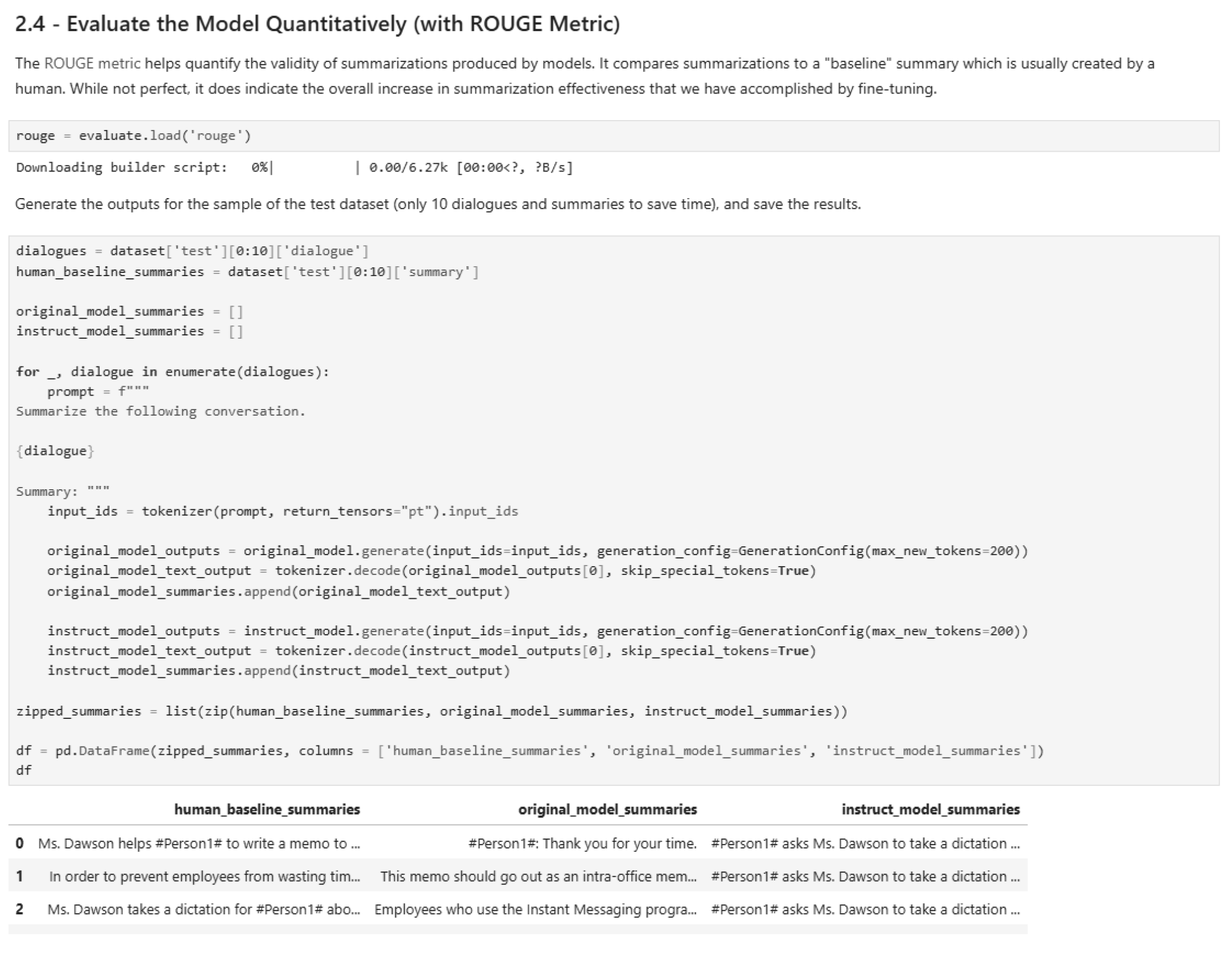
Figure 47.
Quantitative evaluation of the model (Part 2).

Figure 48.
Quantitative evaluation of the model (Part 3).

Figure 49.
Quantitative evaluation of the model (Part 4).
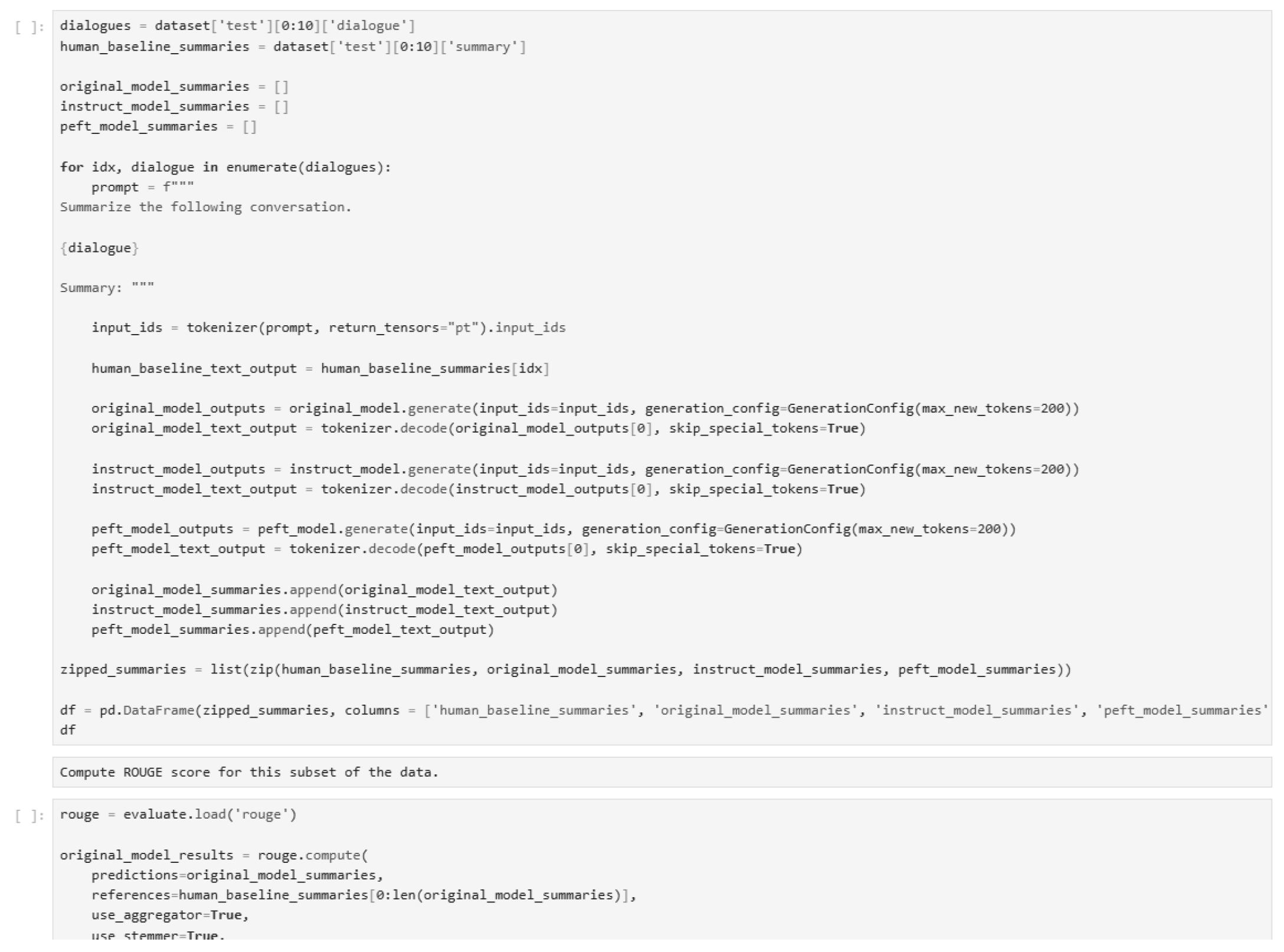
Figure 50.
Quantitative evaluation of the model (Part 5).
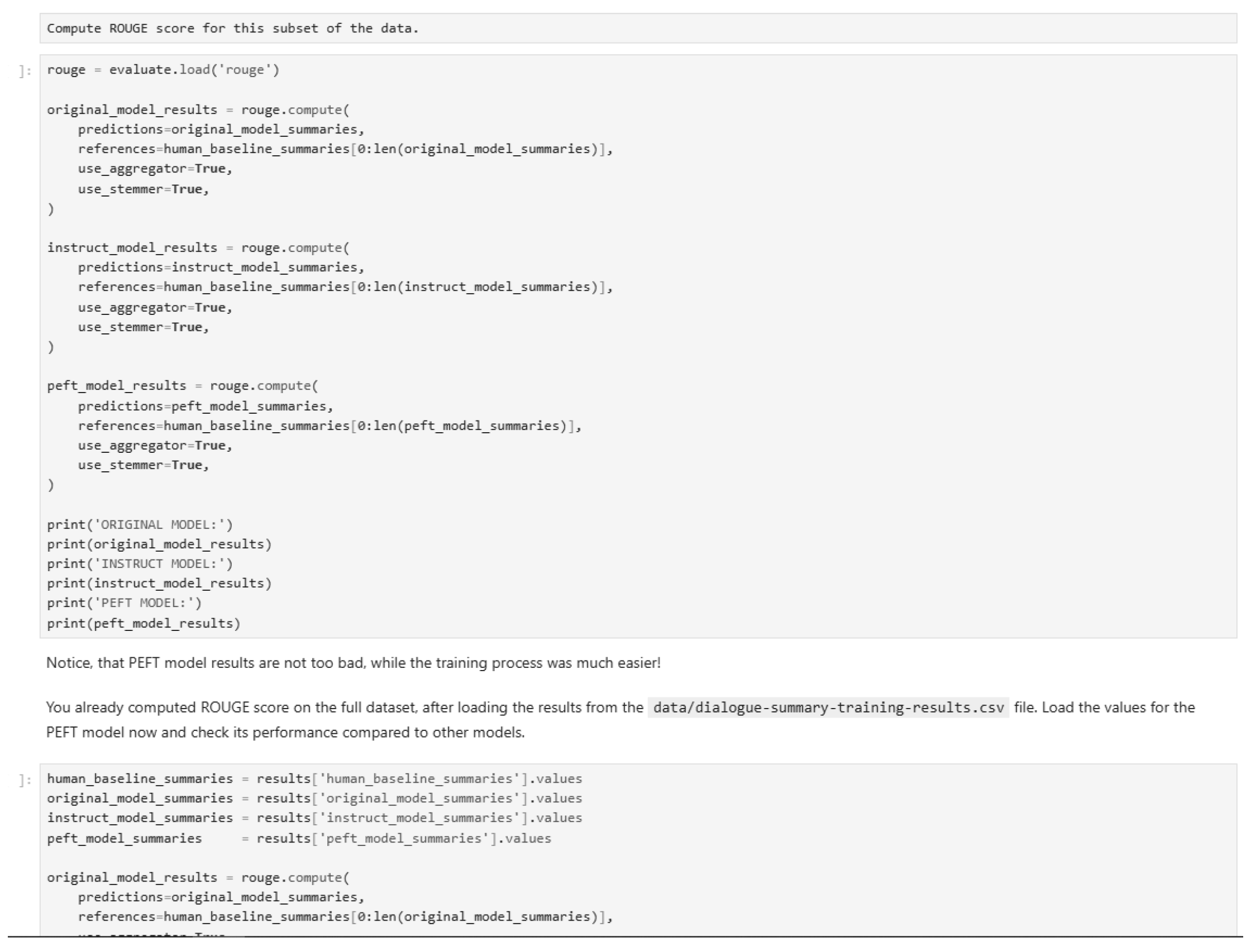
Figure 51.
Quantitative evaluation of the model (Part 6).

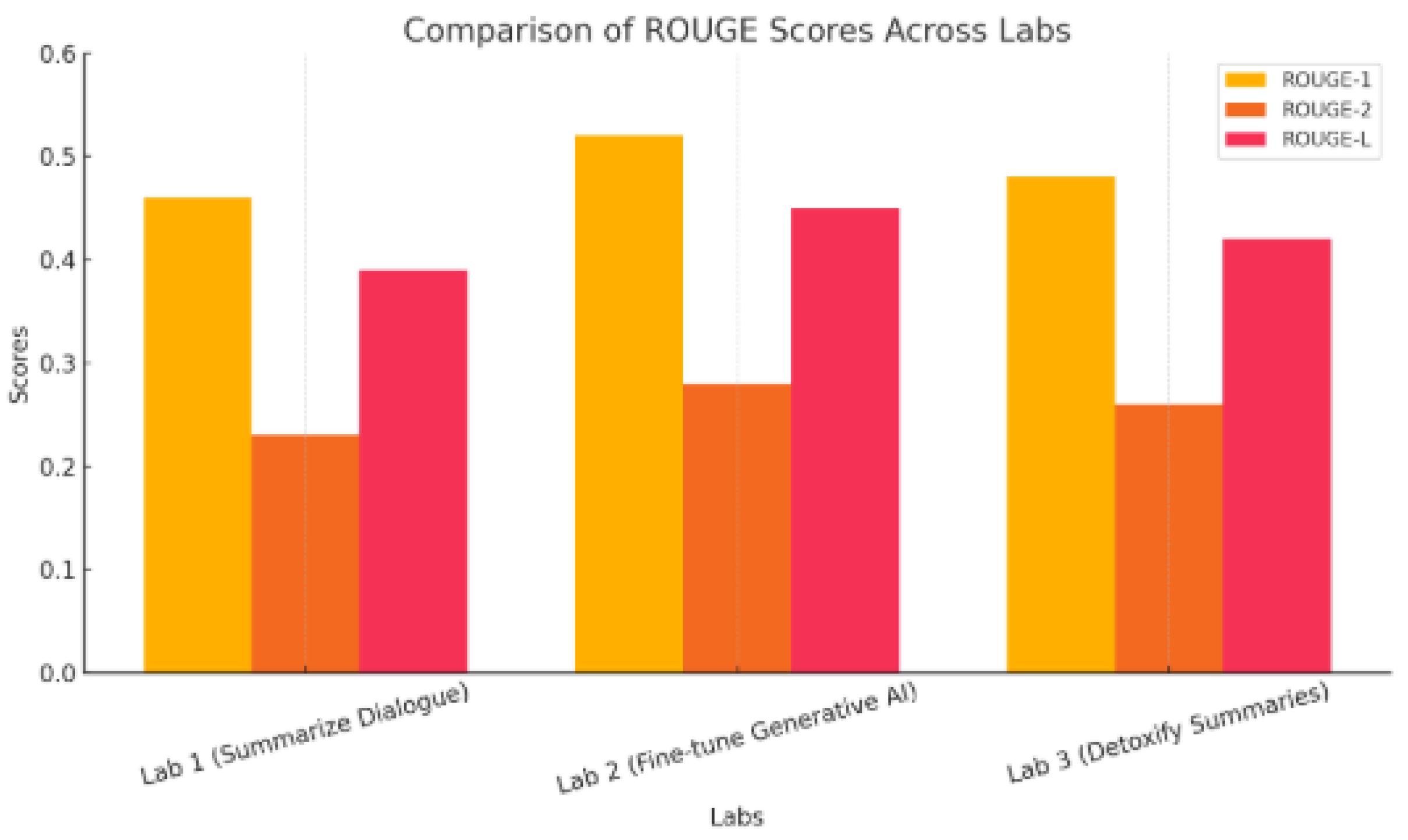
Figure 52.
Comparison of Rouge Scores Across Labs.
VI. Conclusion and Future Outlook
The integration of generative AI, particularly large language models, into education has demonstrated significant potential to enhance learning experiences, streamline administrative tasks, and support personalized education. Our research on the dialogue summarization chatbot highlights the practical applicability of advanced techniques like zero-shot, one-shot, and few-shot inferencing, along with fine-tuning using PEFT and reinforcement learning with PPO. These advancements contribute to safer and more effective AI systems for educational contexts. Looking forward, continued research into domain-specific fine-tuning, ethical considerations, and scalable deployment will further bridge the gap between theoretical advancements and real-world educational impact.
References
- J. Yao, “The Application of Generative Artificial Intelligence in Education: Potential, Challenges, and Strategies,” SHS Web of Conferences, vol. 200, p. 02008, 2024. [Online]. Available:. [CrossRef]
- D. Lee et al., “The impact of generative AI on higher education learning and teaching: A study of educators’ perspectives,” Computers and Education: Artificial Intelligence, vol. 6, p. 100221, 2024. [Online]. Available:. [CrossRef]
- P. Denny et al., “Generative AI for Education (GAIED): Advances, Opportunities, and Challenges,” arXiv preprint arXiv:2402.01580, 2024. [Online]. Available: https://arxiv.org/abs/2402.01580.
- S. Maity et al., “Generative AI and Its Impact on Personalized Intelligent Tutoring Systems,” arXiv preprint arXiv:2410.10650, 2024. [Online]. Available: https://arxiv.org/abs/2410.10650.
- L. Balderas et al., “Generative AI in Higher Education: Teachers’ and Students’ Perspectives on Support, Replacement, and Digital Literacy,” Education Sciences, vol. 15, no. 4, Art. no. 396, Apr. 2024. [Online]. Available: https://www.mdpi.com/2227-7102/15/4/396.
- S. Haroud and N. Saqri, “Generative AI in Higher Education: Teachers’ and Students’ Perspectives on Support, Replacement, and Digital Literacy,” Education Sciences, vol. 15, no. 4, Art. no. 396, Mar. 2025. [Online]. Available:. [CrossRef]
- D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,” International Conference on Learning Representations (ICLR), Apr. 2014. [Online]. Available: https://arxiv.org/abs/1312.6114.
- I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 27, 2014. [Online]. Available: https://arxiv.org/abs/1406.2661.
- D. J. Rezende and S. Mohamed, “Variational Inference with Normalizing Flows,” in Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, Jul. 2015, pp. 1530–1538. [Online]. Available: https://proceedings.mlr.press/v37/rezende15.
- J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” Advances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020. [Online]. Available: https://arxiv.org/abs/2006.11239.
- A. van den Oord, S. Dieleman, H. Zen, et al., “WaveNet: A Generative Model for Raw Audio,” arXiv preprint arXiv:1609.03499, 2016. [Online]. Available: https://arxiv.org/abs/1609.03499.
Figure 1.
Overview of Generative AI Models in Education.
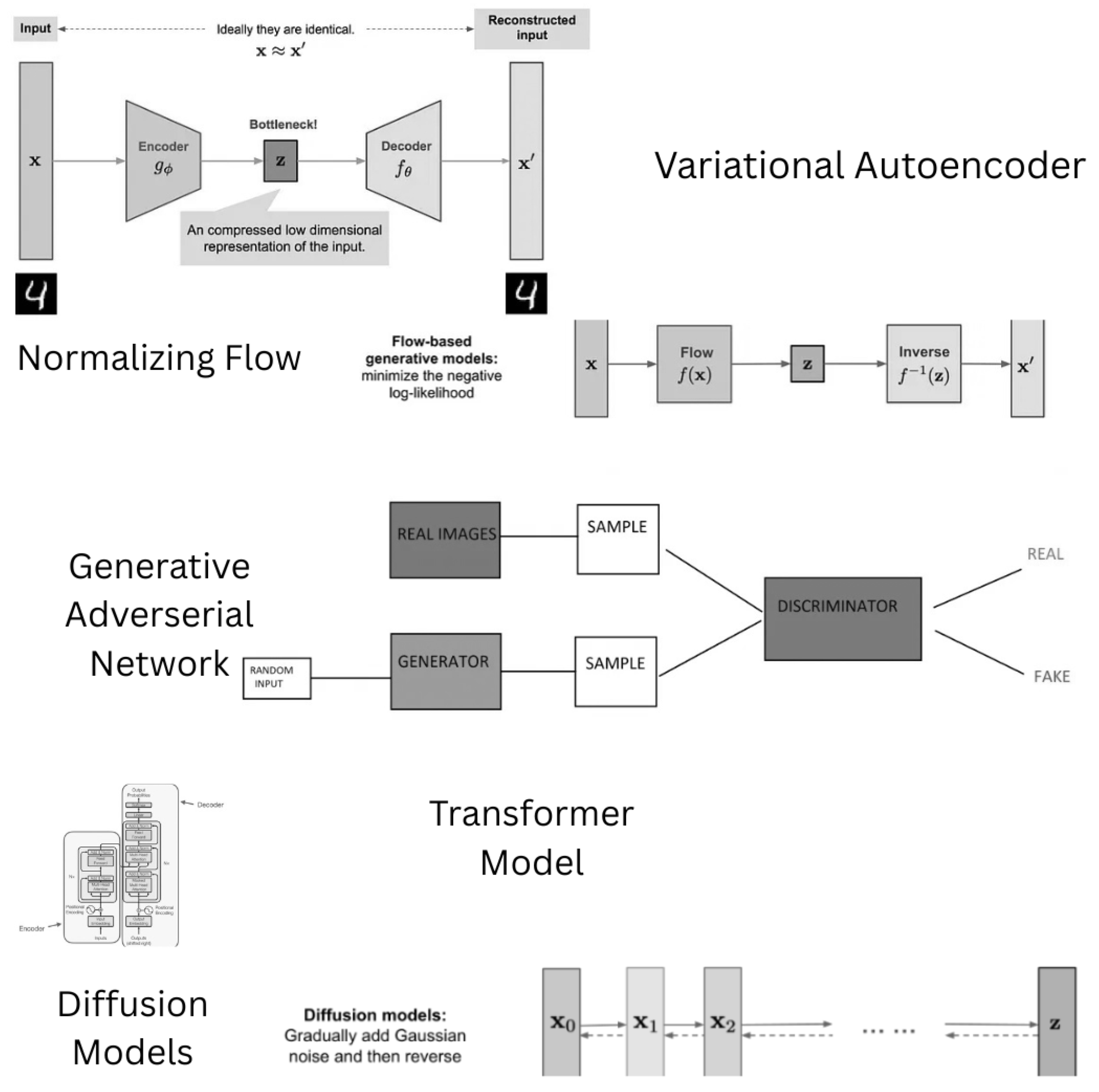
Figure 2.
An overview of the life cycle of building GenAI applications for educational contexts, such as AI tutors and curriculum chatbots.
Figure 2.
An overview of the life cycle of building GenAI applications for educational contexts, such as AI tutors and curriculum chatbots.
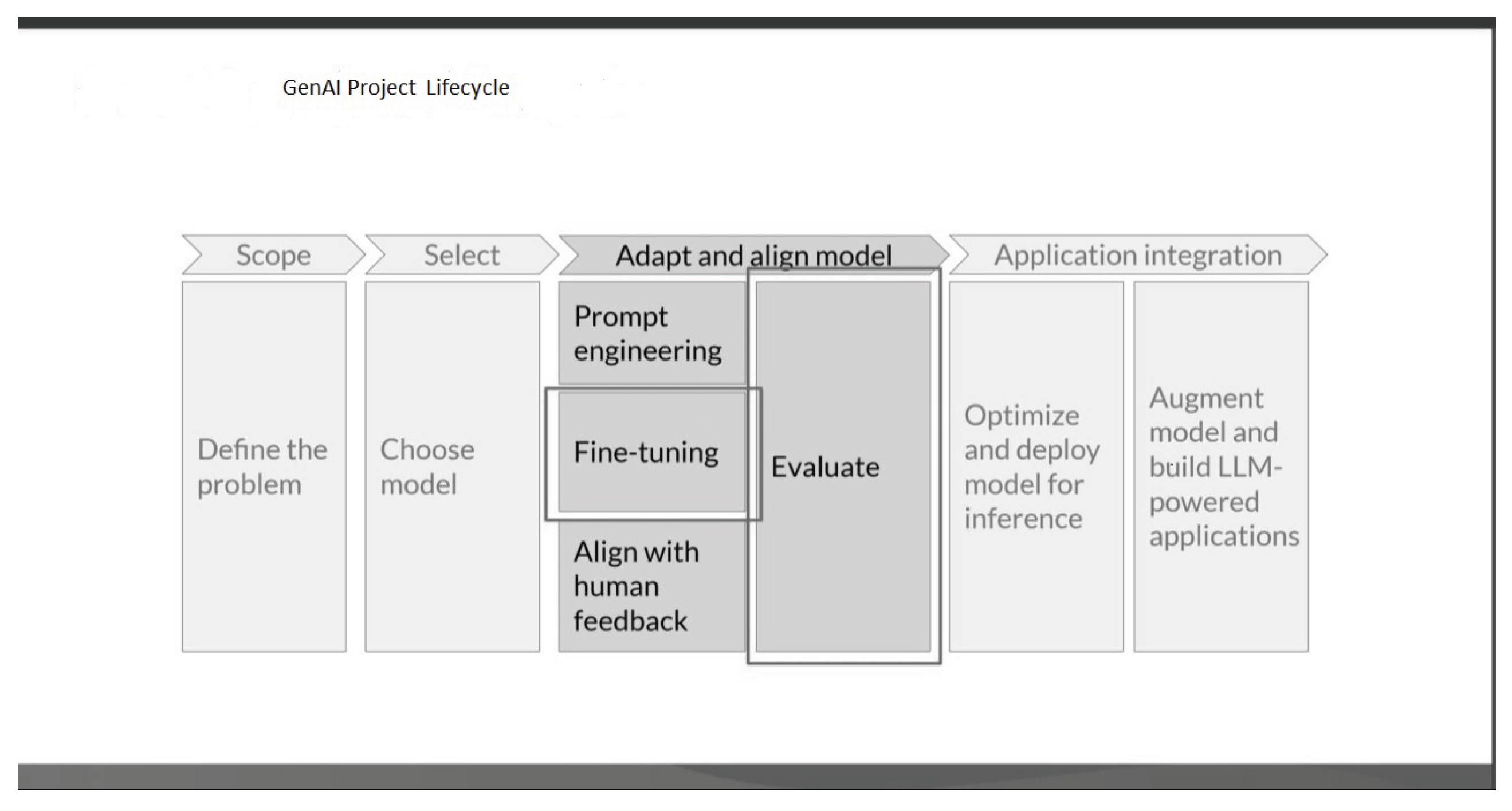
Figure 3.
RAG architecture model illustrating the flow of information retrieval and response generation for educational applications.
Figure 3.
RAG architecture model illustrating the flow of information retrieval and response generation for educational applications.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



