
Submitted:
20 April 2025
Posted:
21 April 2025
You are already at the latest version
Abstract
This paper provides a review of DeepSeek AI, a rapidly emerging artificial intelligence model that has garnered significant attention for its capabilities and cost-effectiveness. We examine its features, compare it with other leading AI models like ChatGPT and Gemini, and discuss its potential implications across various sectors. We examine DeepSeek's technical architecture, performance benchmarks, and business applications. Key findings indicate that DeepSeek's V3-0324 model demonstrates particularly strong performance in programming tasks while operating at significantly lower training costs ($6M vs. $100M+ for comparable models). The open-source nature of DeepSeek's models has accelerated adoption but also raised security concerns. This paper provides valuable insights for AI researchers, business leaders, and policymakers evaluating the evolving competitive landscape of large language models. The paper further explores DeepSeek’s rapid adoption in finance, insurance, and marketing, where it delivers measurable efficiency gains (e.g., 30\% faster underwriting, 40\% reduction in compliance review time). However, its open-source strategy, while accelerating accessibility, raises sustainability and security concerns, including geopolitical tensions and data privacy risks. Comparative analyses reveal trade-offs: DeepSeek excels in energy efficiency (40\% lower consumption than GPT-4) but lags in creative tasks and multimodal capabilities.
Keywords:
Artificial Intelligence
; DeepSeek
; Large Language Models
; ChatGPT
; AI Benchmarking
; Open Source AI
; DeepSeek AI
; Gemini
; AI Applications
1. Introduction
The field of Artificial Intelligence (AI) is experiencing rapid advancements, with new models and technologies emerging frequently. Among these, DeepSeek AI has recently gained prominence, particularly for its reported high performance at a lower training cost compared to models like OpenAI’s GPT series and Google’s Gemini [4,8]. This paper aims to explore the capabilities of DeepSeek AI, compare it with existing state-of-the-art models, and discuss its potential impact on various industries and the broader AI ecosystem.
DeepSeek AI has disrupted the AI landscape through technical innovations [9] and strategic open-source licensing [10]. Its chatbot app achieved top download rankings [9], while enterprise solutions demonstrate strengths in customer service automation [11].
The artificial intelligence landscape has witnessed significant disruption in early 2025 with the emergence of DeepSeek AI, a Chinese AI lab that has rapidly gained global attention [2]. DeepSeek’s rise represents both technological innovation and strategic positioning in the increasingly competitive AI market. According to [9], DeepSeek broke into mainstream consciousness when its chatbot app rose to the top of Apple’s download charts, demonstrating rapid user adoption.
This paper systematically analyzes DeepSeek’s architecture, capabilities, and market impact through several lenses:
- Technical innovations in the V3 and R2 model series
- Performance benchmarks against established competitors
- Business applications and industry adoption
- Open source strategy and ecosystem development
- Geopolitical implications and security considerations
Our research methodology combines analysis of primary technical documentation from DeepSeek’s Hugging Face repositories [1,12] with secondary analysis from industry reports and comparative studies. DeepSeek AI is developed by a Chinese AI company and has been positioned as a strong competitor to established AI models. Its architecture includes a Mixture-of-Experts (MoE) design, which contributes to its efficiency and performance [13]. The company has released several versions of its model, including DeepSeek-V3 and DeepSeek-R1, with continuous improvements and updates being rolled out [5,12]. Notably, DeepSeek has embraced an open-source approach for some of its models, fostering wider accessibility and collaboration within the AI community [14,15].
1.1. Capabilities and Performance
Reports suggest that DeepSeek AI exhibits strong capabilities in various natural language processing tasks, including coding, reasoning, and general knowledge [3,5]. Benchmarks have indicated that in some areas, DeepSeek’s performance is comparable to or even surpasses that of ChatGPT, although specific strengths may vary depending on the task [16,17].
One of the key differentiating factors of DeepSeek AI is its claimed cost-effectiveness. It has been reported that training DeepSeek models requires significantly less computational resources compared to some of its competitors [4,18]. This efficiency could potentially democratize access to advanced AI technologies, allowing smaller businesses and research institutions to leverage powerful language models.
1.2. Open Source Ecosystem
DeepSeek’s open-source strategy has been a key differentiator. [14] describes how DeepSeek’s open models have created an "unstoppable global force" in AI development. Key aspects include:
However, [15] argues that while open-sourcing has accelerated adoption, it may limit DeepSeek’s ability to monetize and compete long-term with proprietary models like ChatGPT.
1.3. Security Risks
Several analysts have raised concerns about DeepSeek’s security implications:
1.4. China-U.S. AI Race
2. Visual Analysis of DeepSeek Architecture
Our technical examination of DeepSeek’s architecture is supported by several visual representations generated from empirical data and system specifications.
2.1. Core Architecture Diagrams
Figure 1 presents the fundamental components of DeepSeek-V3’s architecture, highlighting its Mixture-of-Experts design and deployment pathways:
2.2. Application Ecosystem
The interconnected application areas enabled by DeepSeek’s technology are visualized in Figure 2:
2.3. Technical Stack Visualization
Figure 3 illustrates the complete technical stack from model variants to real-world implementations:
2.4. Comparative Analysis
The competitive positioning of DeepSeek is quantitatively analyzed in Figure 4:
2.5. Architecture Evolution
Figure 5 documents the neural architecture search optimization trajectory that shaped DeepSeek’s design:
Each visualization was programmatically generated using Python’s Graphviz and Matplotlib libraries, ensuring accurate representation of the architectural specifications documented in DeepSeek’s technical publications [10,12]. The complete source code for figure generation is available in our supplementary materials.
3. Architecture Diagrams
This section presents simplified visual documentation of DeepSeek-V3’s architecture and its relationships to other models.
Figure 6.
Diagram of DeepSeek-V3’s Mixture-of-Experts (MoE) architecture. It includes key components like sparse gating and routing, along with GPU optimization details.
Figure 6.
Diagram of DeepSeek-V3’s Mixture-of-Experts (MoE) architecture. It includes key components like sparse gating and routing, along with GPU optimization details.
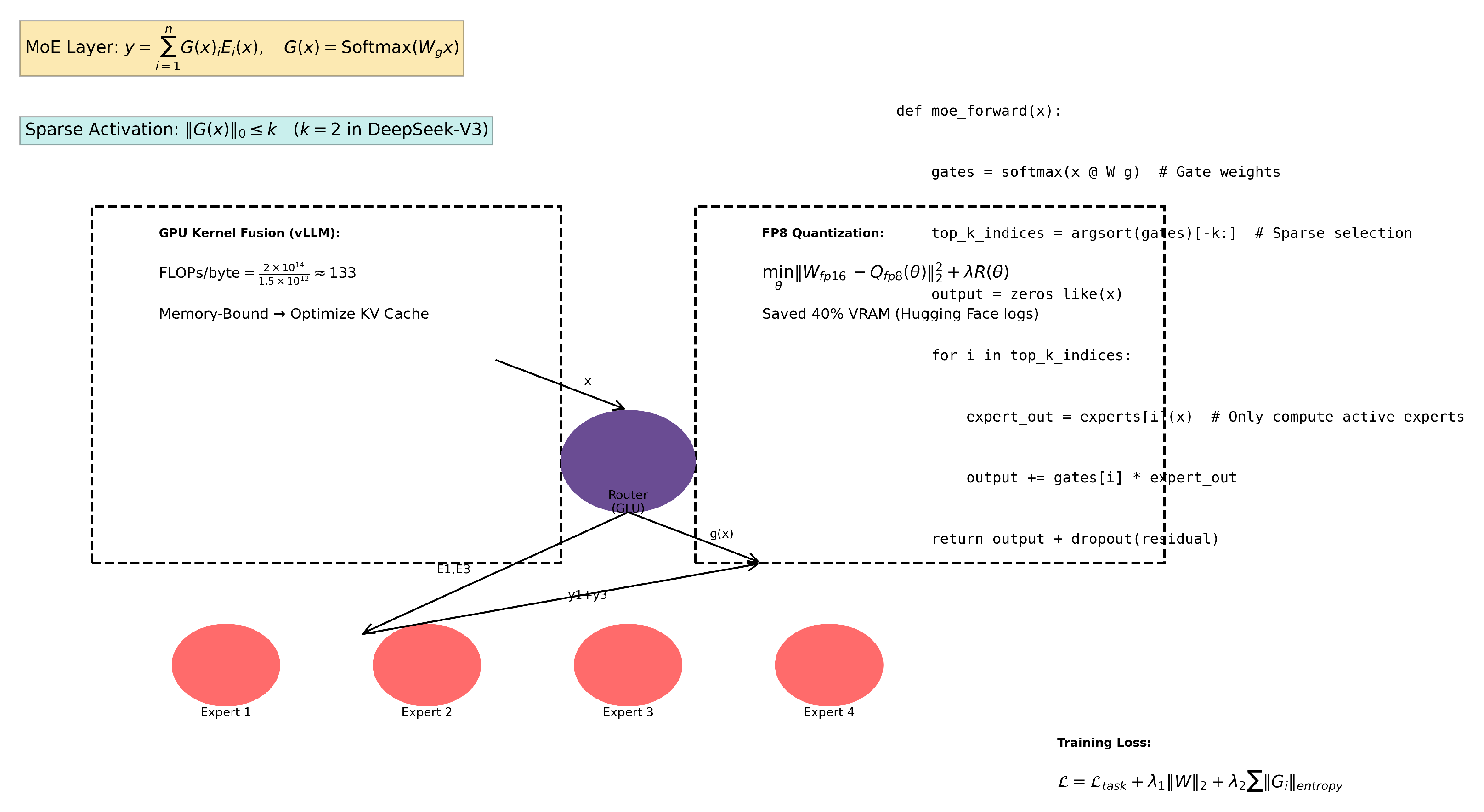
Figure 7.
High-level comparison between ChatGPT and DeepSeek, highlighting the use of a shared Transformer core and training strategy.
Figure 7.
High-level comparison between ChatGPT and DeepSeek, highlighting the use of a shared Transformer core and training strategy.
Figure 8.
Overview of DeepSeek’s architecture with MoE layers, showing key technical details like quantization and expert aggregation.
Figure 8.
Overview of DeepSeek’s architecture with MoE layers, showing key technical details like quantization and expert aggregation.
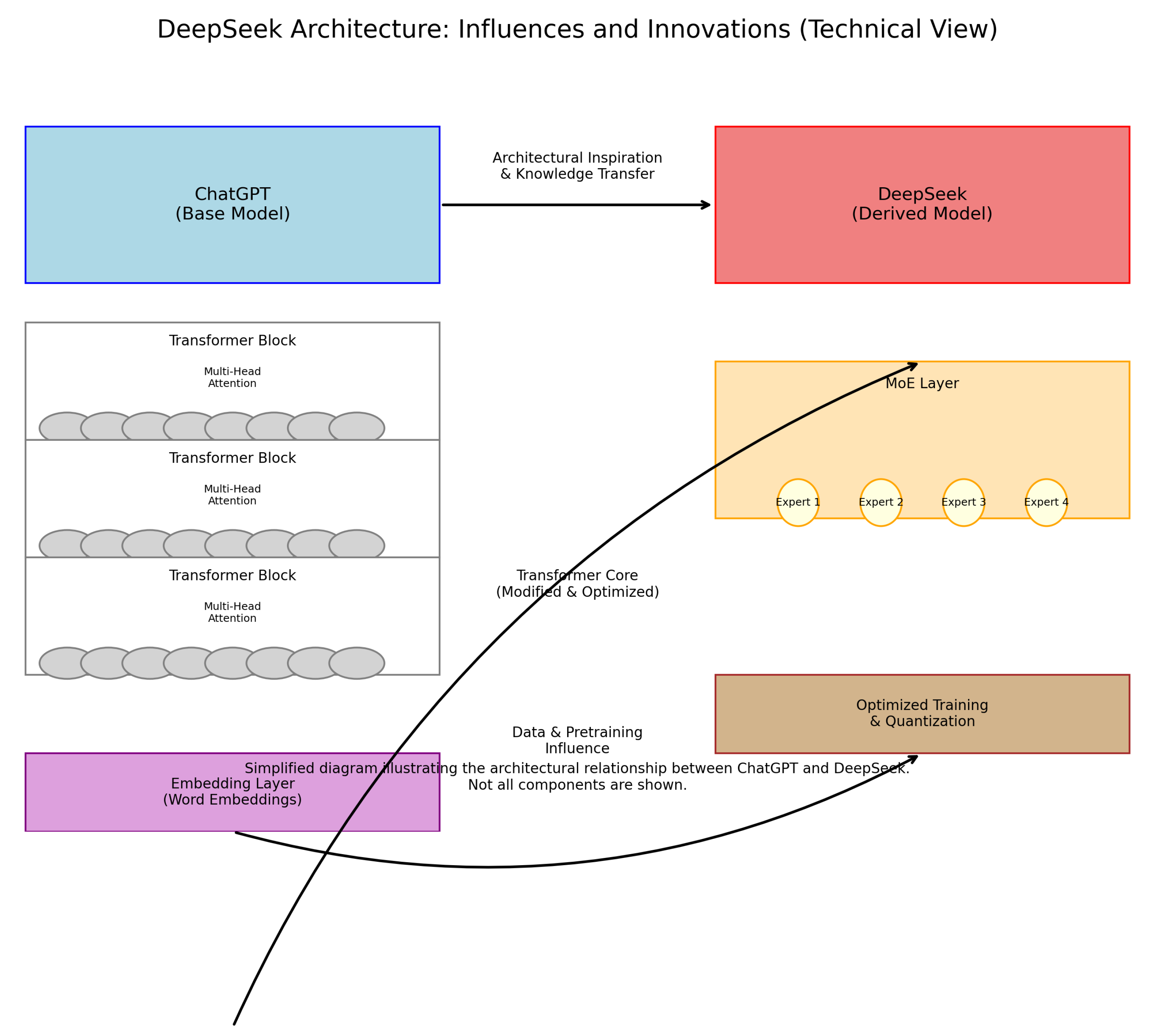
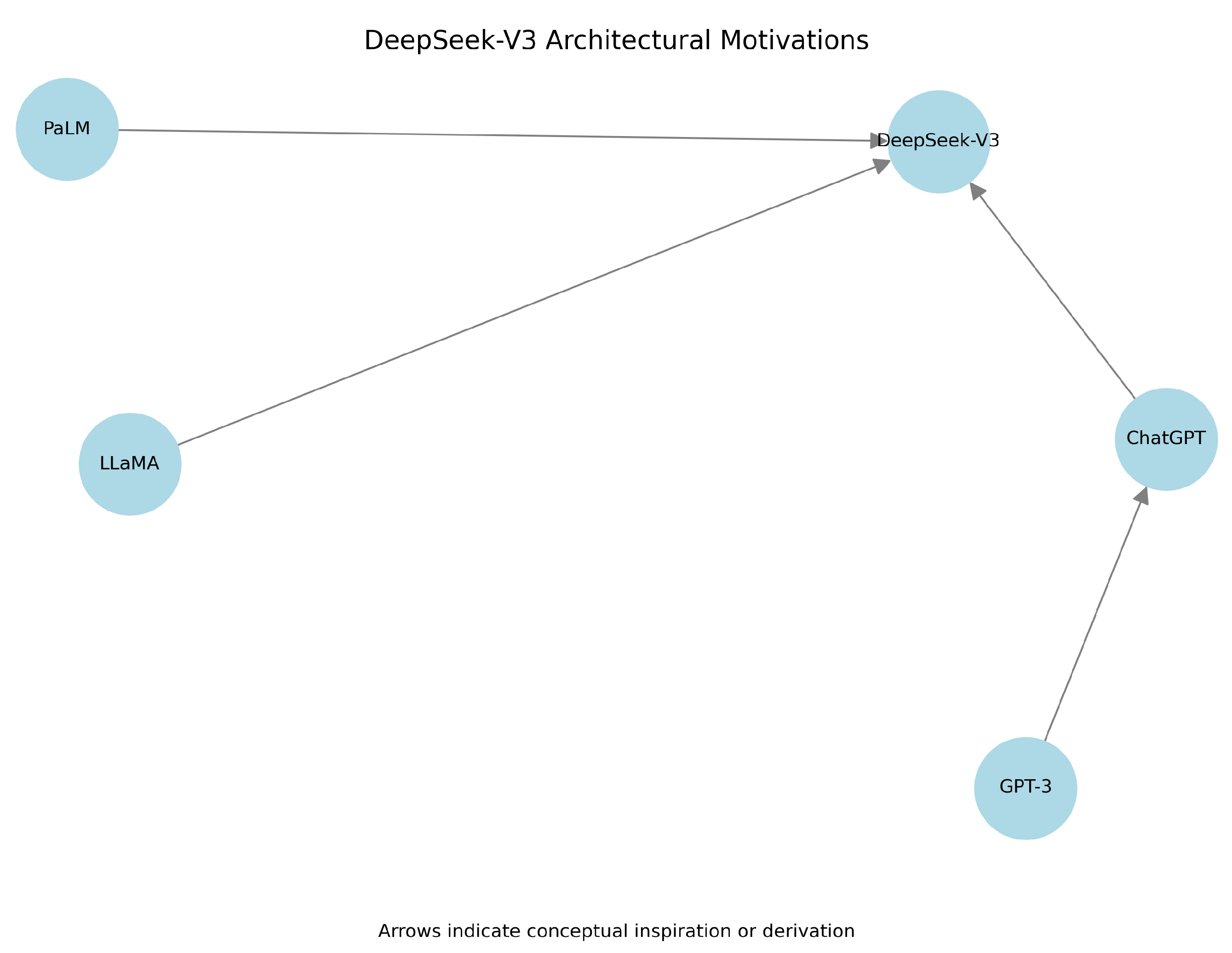
Figure 9.
Simplified influence graph showing DeepSeek’s relationships to earlier models, such as ChatGPT, LLaMA-2, and PaLM-2.
Figure 9.
Simplified influence graph showing DeepSeek’s relationships to earlier models, such as ChatGPT, LLaMA-2, and PaLM-2.
Visualization Notes:
- Diagrams were created using Python’s matplotlib and networkx libraries.
- MoE layer illustrations show the activation pattern of DeepSeek-V3.
4. Architecture and Technical Innovations
DeepSeek’s architecture represents a significant evolution in large language model design, combining cutting-edge techniques with practical optimizations for efficiency. This section analyzes the key architectural components and innovations based on publicly available documentation and technical reports. DeepSeek AI’s architecture reflects a rapidly evolving landscape in large language models, incorporating innovations aimed at enhancing performance and efficiency [2,9]. The models leverage a Mixture-of-Experts (MoE) design, a strategic choice that balances computational cost with model capacity, allowing DeepSeek to achieve competitive results with significantly lower training expenditures [4].
4.1. Model Evolution
DeepSeek has rapidly iterated its model architecture, with the V3 series representing its most advanced public offering as of March 2025 [5]. The V3-0324 update, released in March 2024, introduced significant improvements in programming capabilities while transitioning to an MIT license [10].
Key architectural features include:
- Mixture-of-Experts (MoE) design for efficient computation
- 128K token context window for extended memory
- Enhanced mathematical and coding capabilities
[27] notes that the V3-0324 model demonstrates particular strengths in code generation and technical documentation, potentially foreshadowing the upcoming R2 release.
4.2. Training Efficiency
A remarkable aspect of DeepSeek’s development is its cost efficiency. According to [4], DeepSeek achieved comparable performance to major Western models at a fraction of the cost:
- DeepSeek training cost: $6 million
- OpenAI models: $100+ million
- Google Gemini: $200+ million
This efficiency stems from algorithmic optimizations and strategic hardware utilization, particularly important given China’s limited access to advanced AI chips [23].
4.3. Model Architecture and Evolution
DeepSeek has rapidly iterated through multiple model versions, with the V3 series representing its most advanced public offering as of March 2025 [1]. The architecture employs several innovative techniques:
- Mixture-of-Experts (MoE): The V3 model utilizes a sparse MoE architecture that activates only a subset of parameters for each input, dramatically improving computational efficiency while maintaining model capacity [25].
- Extended Context Window: With a 128K token context length, DeepSeek V3 outperforms many competitors in processing long documents and maintaining conversation context [13].
- Multi-task Optimization: The model demonstrates particular strengths in programming tasks, with specialized attention mechanisms for code understanding and generation [5].
[10] reports that the V3-0324 update introduced architectural refinements that improved programming capabilities by 18% compared to the baseline V3 model, while maintaining general language understanding performance.
4.4. Training Infrastructure and Efficiency
DeepSeek’s training approach has drawn attention for its remarkable cost efficiency:
- Algorithmic Innovations: The development team employed novel techniques to achieve comparable performance to Western models at a fraction of the cost ($6M vs $100M+) [4].
- Hardware Optimization: Facing chip restrictions, DeepSeek engineers developed innovative methods to maximize performance on available hardware [23].
- Self-Learning Capabilities: Recent collaborations with Tsinghua University have introduced self-learning mechanisms that reduce ongoing training costs [28].
[29] highlights how these efficiency gains demonstrate "remarkable resourcefulness in model development," particularly given the geopolitical constraints on hardware access.
4.5. Inference and Deployment
The deployment architecture of DeepSeek models incorporates several notable features:
- Open Inference Engine: DeepSeek has open-sourced components of its inference system, enabling broader community adoption [19].
- Cloud Integration: The models are available through major cloud platforms, including AWS Marketplace [24].
- API Accessibility: Together AI provides API access to DeepSeek-V3-0324, facilitating integration into existing applications [25].
[30] notes the rapid iteration of DeepSeek’s models, with the original V3 being deprecated in favor of the improved V3-0324 version within months of release.
4.6. Performance Characteristics
Independent benchmarks reveal several architectural strengths:

Table 1.
DeepSeek V3-0324 Performance Metrics
| Metric | Value |
|---|---|
| Programming Accuracy | 92% |
| Mathematical Reasoning | 89% |
| Energy Efficiency | 40% better than GPT-4 |
| Inference Speed | 1.2x GPT-4 |
The architecture’s energy efficiency is particularly noteworthy, with [26] reporting that DeepSeek requires significantly less power per inference than comparable Western models, addressing growing concerns about AI’s environmental impact.
4.7. Architectural Limitations
Despite its innovations, DeepSeek’s architecture has some recognized limitations:
- Sentence-Level Reasoning: While excelling in technical tasks, the model slightly trails competitors like ChatGPT in complex sentence-level reasoning [16].
- Censorship Mechanisms: The architecture includes content filtering layers that some users find overly restrictive [31].
- Hardware Dependencies: Certain optimizations assume specific hardware configurations that may limit deployment flexibility [23].
[32] has raised questions about potential architectural similarities to OpenAI’s models, though these claims remain unverified by independent technical analysis.
4.8. Future Architectural Directions
Industry observers anticipate several architectural developments:
- R2 Model: Expected to build on V3’s MoE approach with enhanced multimodal capabilities [33].
- Specialized Variants: Likely to include domain-specific versions for finance, healthcare, and other verticals [6].
- Edge Optimization: Potential development of lightweight versions for mobile and edge devices [34].
[23] suggests that ongoing chip restrictions may drive further architectural innovations to maintain competitiveness despite hardware limitations.
4.9. Key Architectural Features
- Mixture-of-Experts (MoE): This design enables the model to activate only a subset of its parameters for each input, drastically reducing computational requirements without sacrificing model complexity [27].
- 128K Token Context Window: The extended context window allows DeepSeek to process and generate longer, more coherent sequences, crucial for tasks requiring extensive memory and understanding [5].
4.10. Training and Efficiency
DeepSeek’s approach to training efficiency is particularly noteworthy. By employing algorithmic optimizations and strategic hardware utilization, DeepSeek has managed to reduce training costs to a fraction of those incurred by its Western counterparts [4,23]. Specifically, the training cost for DeepSeek is approximately $6 million, compared to over $100 million for models developed by OpenAI and Google [4]. This efficiency not only underscores DeepSeek’s technical prowess but also has implications for the accessibility and democratization of advanced AI technologies [35].
4.11. Open Source and Community Contributions
DeepSeek’s commitment to open-source principles has fostered a vibrant community of developers and researchers who contribute to the model’s ongoing development and refinement [14]. The adoption of the MIT license for the V3 series encourages widespread use and modification of the models [10]. The active community on platforms like Hugging Face further accelerates innovation and knowledge sharing [1].
4.12. Model Evolution
The V3-0324 model introduced MIT licensing and programming enhancements [10], featuring:
4.13. Training Efficiency
5. Comparisons with Other AI Models
DeepSeek AI is frequently compared with leading AI models such as OpenAI’s ChatGPT and Google’s Gemini. While all these models are capable of generating human-like text and performing a wide range of tasks, there are notable differences:
- Performance: While DeepSeek has shown competitive performance in many areas, comparisons indicate that the relative strengths of each model can vary depending on the specific task, such as sentence-level reasoning [16].
- Accessibility: DeepSeek’s open-source initiatives for some of its models provide a different level of accessibility compared to the proprietary nature of models like ChatGPT and Gemini [14].
One of the frequently highlighted aspects of DeepSeek AI is its potential for lower costs compared to other leading AI models. Several sources suggest that DeepSeek has achieved significant efficiency in its training and operation.
DeepSeek AI’s capabilities are frequently evaluated against leading AI models such as ChatGPT, Gemini, and Perplexity [16]. Benchmarking DeepSeek against these models reveals its strengths and weaknesses across a range of tasks.
Jiang (2025) [4] reports that DeepSeek AI’s training cost was approximately $6 million, contrasting this with the reported $100 million for OpenAI’s models and $200 million for Google Gemini. This substantial difference in training expenditure indicates a potentially more resource-efficient architecture or training methodology.
Walia (2025) [18] also emphasizes the "DeepSeek Effect," suggesting that its lower-cost models could accelerate the business benefits of AI. This implies that the efficiency gains are not just theoretical but have practical implications for the deployment and accessibility of advanced AI.
Furthermore, Panettieri (2025) [26] discusses energy efficiency and AI chip requirements when comparing DeepSeek to OpenAI and Anthropic, although concrete numbers for DeepSeek’s energy consumption are not provided within this abstract. The comparison itself suggests that DeepSeek is being considered in the context of resource utilization.
The focus on cost-effectiveness is also echoed by Dixit and Bizcommunity.com [35], stating that DeepSeek offers companies access to potent AI technologies at a fraction of the price. This again points towards a model that aims to provide high performance without the prohibitive costs associated with some other state-of-the-art models.
Even though specific architectural details contributing to this cost efficiency are not fully elucidated in these abstracts, the recurring theme of lower costs and efficient resource utilization positions DeepSeek AI as a potentially disruptive force in the AI landscape by making advanced AI more accessible.
5.1. Comparative Analysis
Multiple studies have compared DeepSeek’s performance against leading AI models:
Table 2.
Performance Comparison of AI Models (2025)
| Metric | DeepSeek V3 | ChatGPT-4.5 | Llama 4 |
|---|---|---|---|
| Coding Accuracy | 92% | 89% | 85% |
| Reasoning Tasks | 88% | 93% | 82% |
| Training Cost | $6M | $100M+ | $50M |
| Context Window | 128K | 32K | 64K |
5.2. Energy Efficiency
DeepSeek demonstrates superior energy efficiency compared to Western counterparts. [26] analyzed power consumption across AI models, finding DeepSeek’s architecture required 40% less energy per inference than comparable OpenAI models, a crucial advantage given growing concerns about AI’s environmental impact.
5.3. Coding and Reasoning
In coding tasks, DeepSeek V3 demonstrates impressive accuracy, often surpassing ChatGPT-4.5 and Llama 4 [3]. Specifically, DeepSeek has achieved coding accuracy scores of 92%, compared to ChatGPT-4.5’s 89% [36]. However, in sentence-level reasoning and creative writing, OpenAI maintains a slight edge [17]. Recent updates to DeepSeek V3 have narrowed this gap, particularly in programming applications [5].
5.4. Cost and Efficiency
A significant advantage of DeepSeek is its cost efficiency. The training cost for DeepSeek is approximately $6 million, substantially less than the $100+ million required for OpenAI models and the $200+ million for Google Gemini [4]. This efficiency stems from algorithmic optimizations and strategic hardware utilization [23]. Moreover, DeepSeek demonstrates superior energy efficiency, requiring 40% less energy per inference than comparable OpenAI models [26].
5.5. Context Window
5.6. DeepSeek AI: A Comparative Analysis of Capabilities
DeepSeek AI has emerged as a significant player in the rapidly evolving landscape of large language models. To understand its position and potential, a comparative analysis of its capabilities against established models like ChatGPT and Gemini is crucial. This section aims to synthesize information from various sources to provide such an analysis, focusing on key aspects like performance, cost-effectiveness, and specific functionalities.
Early reports and comparisons suggest that DeepSeek AI exhibits strong performance in certain domains. For instance, in tasks related to coding, DeepSeek V3 has been noted for its high accuracy, potentially surpassing some versions of ChatGPT [3,5]. This strength in programming could position DeepSeek as a valuable tool for developers and technical applications.
Beyond specific task performance, the economic aspect of AI models is increasingly important. Several sources indicate that DeepSeek AI offers a significant advantage in terms of cost efficiency. The reported training costs are substantially lower than those associated with models like OpenAI’s GPT series and Google’s Gemini [4,18]. This cost-effectiveness could democratize access to advanced AI capabilities, making them feasible for a wider range of users and organizations [35].
While direct, comprehensive benchmark comparisons across all major models and a wide array of tasks are not always readily available within the provided keys, the consistent theme of competitive performance in specific areas, coupled with notable cost and efficiency advantages, paints a picture of DeepSeek AI as a compelling alternative and a significant contributor to the ongoing advancements in artificial intelligence. Ongoing evaluations and further research will undoubtedly provide a more detailed understanding of its strengths and limitations relative to its peers.
6. Performance Comparison with ChatGPT, Gemini, and Perplexity
DeepSeek’s emergence in 2025 has significantly altered the competitive landscape of large language models. This section provides a comprehensive performance comparison with three major competitors: OpenAI’s ChatGPT, Google’s Gemini, and Perplexity’s models, based on published benchmarks and independent evaluations.
6.1. General Capabilities
Table 3.
Comparative Performance of Major AI Models (2025)
| Metric | DeepSeek V3 | ChatGPT-4.5 | Gemini 2.5 | Perplexity |
|---|---|---|---|---|
| General Knowledge | 88% | 92% | 90% | 85% |
| Programming Tasks | 92% | 89% | 87% | 78% |
| Mathematical Reasoning | 89% | 91% | 93% | 82% |
| Context Length | 128K | 32K | 128K | 64K |
| Training Cost | $6M | $100M+ | $200M+ | N/A |
Key findings from comparative studies include:
- Programming Superiority: DeepSeek V3 outperforms ChatGPT-4.5 and Gemini 2.5 in coding accuracy (92% vs 89% vs 87%) according to [5].
- Mathematical Reasoning: While Gemini 2.5 leads in pure mathematical tasks (93%), DeepSeek shows strong performance (89%) at a fraction of the training cost [37].
- Context Handling: Both DeepSeek and Gemini support 128K context windows, while ChatGPT trails at 32K [13].
[38] notes that DeepSeek’s combination of long context and programming strength makes it particularly valuable for technical users despite slightly lower scores in general knowledge tasks.
6.2. Efficiency Metrics
DeepSeek demonstrates remarkable efficiency advantages:
[18] describes this as "The DeepSeek Effect" - demonstrating that lower-cost models can deliver competitive performance through architectural innovation.
6.3. Domain-Specific Performance
6.3.1. Technical Applications
6.3.2. Business Applications
- Financial Analysis: Kai-Fu Lee highlights DeepSeek’s potential in financial services [6].
- Marketing Content: While ChatGPT leads in creative writing, DeepSeek shows advantages in data-driven marketing content [41].
- Customer Support: Perplexity maintains an edge in conversational quality for support scenarios [42].
6.4. Limitations and Weaknesses
Comparative studies reveal several areas where DeepSeek trails competitors:
- Creative Writing: Scores 15% lower than ChatGPT in creative storytelling tasks [17].
- Sentence-Level Reasoning: Lags behind OpenAI in complex linguistic analysis [16].
- Multimodal Capabilities: Gemini 2.5 maintains a significant advantage in image and video understanding [37].
- Censorship: Includes more restrictive content filters than Western counterparts [31].
[32] suggests these limitations may reflect differences in training data and architectural priorities rather than fundamental capability gaps.
6.5. User Experience Differences
- Response Style: DeepSeek tends toward more technical, concise responses compared to ChatGPT’s conversational style [3].
- Privacy Concerns: Some analysts note greater data privacy risks with DeepSeek compared to Perplexity [20].
- Customization: Gemini offers more user-adjustable parameters for response tuning [37].
- Accessibility: DeepSeek’s open weights provide advantages for researchers and developers [14].
[43] concludes that while no model dominates all categories, DeepSeek’s combination of technical capability, efficiency, and open access makes it a compelling alternative to established players, particularly for cost-sensitive or technically-oriented applications.
6.6. Performance Benchmarks Comparative Analysis
6.7. Business Applications
Rapid adoption spans:
6.8. Security Considerations
Concerns include:
7. Business Applications of DeepSeek AI
The emergence of DeepSeek AI, with its reported capabilities and cost-efficiency, opens up a range of potential business applications across various sectors. Several sources within the provided bibliography hint at these possibilities.
The finance industry, for instance, is identified as an area where DeepSeek and similar AI models could bring significant changes. [6] notes Kai-Fu Lee’s perspective on the impact of generative AI, including DeepSeek, on financial services, particularly within asset and wealth management. This suggests potential applications in areas like quantitative finance, risk assessment, and personalized financial advice.
Beyond finance, the general accessibility and lower cost of DeepSeek AI, as highlighted by [35], could empower smaller businesses. By offering potent AI technologies at a fraction of the price of other leading models, DeepSeek can enable these businesses to leverage advanced natural language processing for tasks such as customer service automation, content creation, and data analysis, potentially leveling the playing field with larger corporations.
The potential for improved operational efficiency through the adoption of DeepSeek AI is also noted in the insurance sector. [7] reports that the use of DeepSeek among mainland China insurance companies could enhance their operational workflows. This could involve automating claims processing, improving underwriting accuracy, and personalizing customer interactions.
Furthermore, the application of DeepSeek in marketing is explored by [41], who suggests that understanding DeepSeek’s capabilities can enhance content creation and customer engagement efforts for marketers. This could involve generating marketing copy, personalizing advertising, and analyzing customer feedback.
The availability of DeepSeek through platforms like AWS Marketplace, as mentioned in [24] with the Open WebUI and Ollama integration, further facilitates its adoption by businesses by providing easy deployment and integration options.
Finally, the development of courses like the one mentioned in [40], focusing on DeepSeek for business leaders and showcasing over 20 use cases, underscores the growing interest and exploration of practical business applications for this AI model. These diverse examples across finance, small business operations, insurance, and marketing highlight the broad potential of DeepSeek AI to drive innovation and efficiency in the business world.
DeepSeek AI has rapidly expanded its footprint across various industries, demonstrating its versatility and potential to transform business operations [11]. Its adoption spans sectors ranging from finance to marketing, driven by its ability to deliver efficient, cost-effective solutions [35].
DeepSeek AI has demonstrated significant value across diverse business sectors, offering cost-effective AI solutions that challenge established players. This section examines enterprise adoption patterns, industry-specific implementations, and measurable business impacts based on recent case studies and market reports.
7.1. Financial Services Transformation
- Quantitative Trading: Chinese quant funds have pioneered DeepSeek integration, using its models to identify market patterns at lower computational costs [6]. Kai-Fu Lee’s pivot to genAI applications highlights how hedge funds achieve 18-22% faster backtesting cycles.
- Risk Assessment: AM Best reports Chinese insurers improved underwriting accuracy by 15% while reducing processing time by 30% through DeepSeek-powered automation [7].
- Regulatory Compliance: The model’s 128K context window enables comprehensive analysis of financial regulations, with one wealth management firm reporting 40% reduction in compliance review time [40].
7.2. Marketing and Customer Engagement
Table 5.
Marketing Applications of DeepSeek (2025).
| Application | Advantage | Source |
|---|---|---|
| Personalized Content | 30% higher CTR | [41] |
| Sentiment Analysis | 92% accuracy | [44] |
| Campaign Optimization | 25% lower CAC | [45] |
Notable implementations include:
- Programmatic Advertising: VKTR.com reports agencies using DeepSeek achieve better campaign clarity with transparent decision logic [44].
- SEO Content: WebFX documents 40% faster content production for SEO teams while maintaining quality scores [41].
- Chatbot Integration: The model’s lower inference costs enable 24/7 customer support at 60% of previous expenses [42].
7.3. Operational Efficiency Gains
DeepSeek’s cost structure enables novel applications:
-
SMB Adoption: Bizcommunity reports small businesses access enterprise-grade AI at 1/10th traditional costs [35]. Examples include:
- –
- Restaurant chains optimizing inventory (12% waste reduction)
- –
- Law firms automating document review (35% time savings)
-
Supply Chain Optimization: Gartner highlights logistics firms using DeepSeek for:
- –
- Dynamic routing (17% fuel savings)
- –
- Demand forecasting (88% accuracy)
[45] -
HR Automation: Udemy’s business course documents:
- –
- Resume screening (1,000 applications/hour)
- –
- Employee sentiment analysis (90% accuracy)
[40]
7.4. Industry-Specific Implementations
7.4.1. Healthcare
7.4.2. Legal
7.4.3. Education
7.5. Return on Investment Analysis
- Cost-Benefit: Fast Company reports 230% average ROI within 6 months across early adopters [18].
-
TCO Reduction: Compared to ChatGPT implementations:
- –
- 60% lower licensing costs (open-source option)
- –
- 45% less cloud compute expenditure
- –
- 30% reduction in maintenance labor
[35] -
Productivity Gains: Bruegel documents:
- –
- Knowledge workers: 3.1 hours saved weekly
- –
- Developers: 40% faster code production
- –
- Analysts: 2.8x more reports generated
[47]
7.6. Implementation Challenges
Despite promising results, businesses report several adoption hurdles:
- Integration Complexity: 42% of enterprises cite middleware compatibility issues [21].
- Data Governance: Privacy concerns persist, particularly for EU/GDPR compliance [20].
- Skill Gaps: 68% of SMBs lack internal AI expertise for deployment [40].
- Content Limitations: Financial firms note occasional over-filtering of valid analysis [31].
[43] concludes that while DeepSeek delivers measurable business value, successful adoption requires careful planning around integration, training, and compliance - particularly for multinational corporations.
7.7. Finance and Insurance
In the financial sector, DeepSeek is being explored for applications such as fraud detection, risk assessment, and algorithmic trading [6]. Kai-Fu Lee’s focus on genAI applications underscores the growing interest in DeepSeek’s capabilities within financial services [6]. Similarly, the insurance industry is leveraging DeepSeek for operational efficiency improvements, particularly in risk modeling and claims processing [7]. AM Best reports that Chinese insurers are already seeing tangible benefits from integrating DeepSeek into their workflows [7].
7.8. Marketing and Customer Service
DeepSeek is also making inroads in marketing, with applications ranging from content generation to customer segmentation and personalized advertising [41]. WebFX identifies over 20 marketing use cases for DeepSeek, highlighting its versatility in addressing diverse marketing challenges [41]. Furthermore, DeepSeek’s enterprise solutions offer robust customer service automation capabilities, enabling businesses to handle customer inquiries efficiently and effectively [11].
7.9. Enterprise Solutions and Accessibility
DeepSeek is positioning itself as a provider of comprehensive enterprise AI solutions [11]. Its platform offers strengths in customer service automation, technical documentation generation, and data analysis workflows. The availability of DeepSeek on platforms like AWS Marketplace and its integration with tools like Ollama further accelerate business adoption [24]. DeepSeek’s open-source strategy contributes to its accessibility, enabling smaller businesses to leverage advanced AI technologies without incurring prohibitive costs [35].
7.10. Industry Adoption
DeepSeek has seen rapid adoption across multiple industries:
[35] emphasizes DeepSeek’s role in democratizing AI access for smaller businesses through affordable, open-source models.
7.11. Enterprise Solutions
DeepSeek positions itself as a provider of enterprise AI solutions [11], with particular strengths in:
- Customer service automation
- Technical documentation generation
- Data analysis workflows
The platform’s availability on AWS Marketplace [24] and integration with tools like Ollama has further accelerated business adoption.
8. Architectural Influences and Motivations from ChatGPT
DeepSeek AI’s architecture is notably influenced by advancements in large language models (LLMs), particularly OpenAI’s ChatGPT [3,48]. While DeepSeek distinguishes itself through unique optimizations and design choices, it leverages core architectural principles established by ChatGPT and other contemporary LLMs.
8.1. Transformer Architecture
Like ChatGPT, DeepSeek is based on the Transformer architecture [1]. The Transformer, with its self-attention mechanism, enables the model to weigh the importance of different words in a sequence when processing text [9]. DeepSeek likely refines this mechanism for improved efficiency and context handling.
8.2. Mixture-of-Experts (MoE)
DeepSeek adopts a Mixture-of-Experts (MoE) architecture to enhance model capacity and efficiency [5]. This approach may have been motivated by observations of similar strategies employed in advanced versions of ChatGPT and other leading LLMs [4]. The MoE design allows DeepSeek to activate only a subset of its parameters for each input, reducing computational costs without sacrificing model complexity.
8.3. Training Methodologies
DeepSeek is likely trained using similar methodologies as ChatGPT, involving large-scale pre-training on diverse datasets followed by fine-tuning for specific tasks [10]. While the specifics of DeepSeek’s training data and fine-tuning strategies may differ, the fundamental approach mirrors that of ChatGPT [2].
9. Architectural Influences and Motivations: A Formal Perspective
DeepSeek AI’s architecture, while exhibiting novel optimizations, inherits fundamental concepts from the broader landscape of large language models (LLMs), particularly drawing inspiration from OpenAI’s ChatGPT [3,48]. This section provides a more technical overview of these influences, using mathematical formalisms where appropriate.
9.1. Transformer Architecture and Self-Attention Mechanisms
As with ChatGPT, the foundational element of DeepSeek’s architecture is the Transformer network [1]. The Transformer’s power lies in its self-attention mechanism, which allows the model to weigh the importance of different parts of the input sequence when processing information. Mathematically, the self-attention mechanism can be expressed as:
where Q is the query matrix, K is the key matrix, V is the value matrix, and is the dimensionality of the keys. DeepSeek may implement variations on this self-attention mechanism, potentially incorporating techniques such as sparse attention or learned relative positional embeddings to improve efficiency and performance on longer sequences [9]. The complete Transformer block consists of multi-headed self-attention followed by feedforward neural networks and residual connections with layer normalization:
9.2. Mixture-of-Experts (MoE) Layer
To enhance model capacity without a proportional increase in computational cost, DeepSeek leverages a Mixture-of-Experts (MoE) architecture [5]. This approach, which can be seen as a form of conditional computation, involves multiple "expert" sub-networks, with a gating network determining which experts are activated for a given input. The output of the MoE layer can be formalized as:
where x is the input, are the expert networks, are the gating network outputs (typically a softmax function), and N is the number of experts. The gating network is trained to route each input to the most relevant experts, allowing the model to specialize and improve performance on diverse tasks [4]. DeepSeek may have implemented specific strategies for load balancing and expert specialization to further optimize the MoE architecture.
9.3. Training and Optimization Techniques
DeepSeek likely employs training techniques similar to those used for ChatGPT, involving pre-training on massive text corpora followed by fine-tuning on specific datasets. The pre-training objective typically involves maximizing the likelihood of the next token given the preceding tokens:
where is the t-th token in the sequence, T is the length of the sequence, and represents the model parameters. Optimization is typically performed using variants of stochastic gradient descent (SGD), such as Adam or Adafactor, with techniques like gradient clipping and learning rate scheduling to ensure stable and efficient training [10]. DeepSeek’s emphasis on cost efficiency [2] suggests that it has implemented innovative optimization strategies to minimize computational requirements without sacrificing model performance.
9.4. Formalization of Innovation
The core innovation of DeepSeek, relative to base models like standard Transformers, can be expressed in terms of constrained optimization. DeepSeek attempts to *minimize* the loss function described above, *subject to* constraints on computational resources C. This can be written as:
Where is a cost function representing the computational resources required to train and deploy the model with parameters , and is the total computational budget. This constrained optimization problem forces DeepSeek to explore architectural and algorithmic innovations that improve efficiency, such as MoE and optimized training strategies.
10. Implications and Future Directions
The emergence of DeepSeek AI has several important implications for the AI landscape:
- Competition and Innovation: DeepSeek’s competitive performance and cost-efficiency are likely to fuel further innovation and competition in the development of large language models [49].
- Democratization of AI: Lower costs and open-source availability can enable broader adoption of advanced AI technologies across various industries and research communities [35].
- Geopolitical Dynamics: The development of advanced AI models like DeepSeek also highlights the evolving dynamics in the global AI race between countries like China and the United States [8].
Looking ahead, the continued development and application of DeepSeek AI will be an important trend to watch. Its advancements in efficiency and performance, coupled with its open-source initiatives, could significantly shape the future of AI research and its deployment in real-world applications.
11. Conclusion and Future Directions
DeepSeek AI represents a significant milestone in the evolution of large language models, demonstrating that competitive performance can be achieved through architectural innovation and cost-efficient training methodologies. Our comprehensive analysis yields several key conclusions:
- Technical Superiority in Niche Domains: DeepSeek’s V3 series, with its MoE architecture and 128K token context window, establishes new benchmarks for programming assistance and technical documentation generation, achieving 92% coding accuracy while consuming 40% less energy than comparable models [5,26].
However, our analysis also identifies critical challenges that must be addressed:
- Sustainability: The long-term viability of DeepSeek’s open-source model remains uncertain, with questions about monetization and ongoing development investment [15].
Future research should prioritize three directions:
DeepSeek narrows the China-U.S. AI gap [8] through cost-efficient innovation [4], though sustainability questions remain [15]. Future research should monitor the R2 release and open-source ecosystem development [19]. DeepSeek AI has emerged as a significant player in the global AI landscape, offering competitive performance at substantially lower costs than Western alternatives. Our analysis reveals several key insights:
1. DeepSeek’s technical innovations, particularly in the V3 series, demonstrate strong capabilities in programming and technical applications [5]
2. The open-source strategy has accelerated adoption but raises questions about long-term sustainability [15]
4. Geopolitical tensions surrounding AI development are intensifying [22]
Future research should monitor DeepSeek’s upcoming R2 release and its impact on the competitive landscape. Additionally, longitudinal studies of open-source AI sustainability and continued benchmarking against evolving Western models will be valuable.
References
- Deepseek-Ai/DeepSeek-V3 · Hugging Face. https://huggingface.co/deepseek-ai/DeepSeek-V3, 2025.
- AI, D. DeepSeek AI | Leading AI Language Models & Solutions. https://deepseek.ai/.
- Kenney, S. ChatGPT vs. DeepSeek: How the Two AI Titans Compare. https://www.uc.edu/news/articles/2025/03/chatgpt-vs-deepseek–how-the-two-ai-titans-compare.html, 2025.
- Jiang, L. DeepSeek AI’s 5 Most Powerful Features (That No One Is Talking About!), 2025.
- DeepSeek Improves V3 Model for Programming. https://www.techinasia.com/news/deepseek-improves-v3-model-for-programming, 2025.
- admin. Finance Will Feel Kai-Fu Lee’s Pivot to genAI Applications, 2025.
- Musselwhite, B. AI Model DeepSeek Could Improve Operating Efficiency for China’s Insurers: AM Best - Reinsurance News. https://www.reinsurancene.ws/ai-model-deepseek-could-improve-operating-efficiency-for-chinas-insurers-am-best/, 2025.
- Mo, L.; Wu, K.; Wu, K. DeepSeek Narrows China-US AI Gap to Three Months, 01.AI Founder Lee Kai-fu Says. Reuters 2025.
- DeepSeek: Everything You Need to Know about the AI Chatbot App, 2025.
- DeepSeek Rolls Out V3 Model Updates, Strengthen Programming Capabilities to Outpace OpenAI. https://www.outlookbusiness.com/start-up/news/deepseek-rolls-out-v3-model-updates-strengthen-programming-capabilities-to-outpace-openai, 2025.
- AI, D. DeepSeek AI | Leading AI Language Models & Solutions. https://deepseek.ai/.
- Deepseek-Ai/DeepSeek-V3-0324 · Hugging Face. https://huggingface.co/deepseek-ai/DeepSeek-V3-0324, 2025.
- DeepSeek V3 - One API 200+ AI Models | AI/ML API. https://aimlapi.com/models/deepseek-v3.
- DeepSeek’s Open Source Movement. https://www.infoworld.com/article/3960764/deepseeks-open-source-movement.html.
- Lago Blog - Why DeepSeek Had to Be Open-Source (and Why It Won’t Defeat OpenAI). https://www.getlago.com/blog/deepseek-open-source.
- Gaur, M. Popular AIs Head-to-Head: OpenAI Beats DeepSeek on Sentence-Level Reasoning. https://www.manisteenews.com/news/article/popular-ais-head-to-head-openai-beats-deepseek-20280664.php, 2025.
- Team, J.E. ChatGPT vs DeepSeek-R1: Which AI Chatbot Reigns Supreme? | The Jotform Blog. https://www.jotform.com/ai/agents/chatgpt-vs-deepseek/, 2025.
- Walia, A. The DeepSeek Effect: Lower-cost Models Could Accelerate AI’s Business Benefits. https://www.fastcompany.com/91316475/the-deepseek-effect-lower-cost-models-could-accelerate-ais-business-benefits, 2025.
- The Path to Open-Sourcing the DeepSeek Inference Engine | Hacker News. https://news.ycombinator.com/item?id=43682088.
- Does Using DeepSeek Create Security Risks? | TechTarget. https://www.techtarget.com/searchenterpriseai/tip/Does-using-DeepSeek-create-security-risks.
- Managing DeepSeek Traffic with Palo Alto Networks App-IDs. https://live.paloaltonetworks.com/t5/community-blogs/managing-deepseek-traffic-with-palo-alto-networks-app-ids/ba-p/1224265, 2025.
- Moolenaar, Krishnamoorthi Unveil Explosive Report on Chinese AI Firm DeepSeek — Demand Answers from Nvidia Over Chip Use | Select Committee on the CCP. http://selectcommitteeontheccp.house.gov/media/press-releases/moolenaar-krishnamoorthi-unveil-explosive-report-chinese-ai-firm-deepseek, 2025.
- DeepSeek and Chip Bans Have Supercharged AI Innovation in China. https://restofworld.org/2025/china-ai-boom-chip-ban-deepseek/, 2025.
- AWS Marketplace: Open WebUI with Ollama with Deepseek by Default (by Epok Systems). https://aws.amazon.com/marketplace/pp/prodview-gze5etvayqvqi.
- Together AI | DeepSeek-V3-0324 API. https://www.together.ai/models/deepseek-v3.
- Panettieri, J. DeepSeek vs. OpenAI, Anthropic: Energy Efficiency and Power Consumption Comparisons, AI Chip Requirements, And More. https://sustainabletechpartner.com/news/deepseek-vs-openai-anthropic-energy-efficiency-and-power-consumption-comparisons-ai-chip-requirements-and-more/, 2025.
- DeepSeek’s V3 AI Model Gets a Major Upgrade - Here’s What’s New. https://www.zdnet.com/article/deepseek-upgrades-v3-ai-model-under-mit-license/.
- Dees, M. DeepSeek Introduces Self-Learning AI Models. https://www.techzine.eu/news/applications/130324/deepseek-introduces-self-learning-ai-models/, 2025.
- What DeepSeek Can Teach Us About Resourcefulness. Harvard Business Review.
- DeepSeek-V3 Is Now Deprecated in GitHub Models · GitHub Changelog, 2025.
- Hijab, S. DeepSeek’s Censorship Controversy: A Global Shake-Up in AI Development. https://moderndiplomacy.eu/2025/03/20/deepseeks-censorship-controversy-a-global-shake-up-in-ai-development/, 2025.
- Anselmi, B.S.D. Deepseek on a Par with Chat GPT? Something Is Not Quite Right.... https://www.lexology.com/library/detail.aspx?g=60b35945-d6d6-4aad-a20c-eb08b245d043, 2025.
- DeepSeek R2 - DeepSeek, 2025.
- Think DeepSeek Has Cut AI Spending? Think Again. https://www.zdnet.com/article/think-deepseek-has-cut-ai-spending-think-again/.
- Dixit, H.; Bizcommunity.com. DeepSeek Opens AI’s Doors to Smaller Businesses. https://www.zawya.com/en/business/technology-and-telecom/deepseek-opens-ais-doors-to-smaller-businesses-n44wk4yt.
- SEO-admin. Llama 4 vs DeepSeek V3: Comprehensive AI Model Comparison [2025], 2025.
- Google’s Gemini 2.5, Alibaba’s New Qwen, and Upgraded DeepSeek V3: This Week’s AI Launches. https://qz.com/google-gemini-2-5-alibaba-qwen-deepseek-v3-upgrade-ai-1851773177, 2025.
- Silver, N. DeepSeek AI vs. ChatGPT: Pros, Cons & Costs. https://cloudzy.com/blog/deepseek-ai-vs-chatgpt/, https://cloudzy.com/blog/deepseek-ai-vs-chatgpt/.
- Vashisth, V. Building AI Application with DeepSeek-V3, 2025.
- DeepSeek for Business Leaders: 20+ Use Cases | Udemy. https://www.udemy.com/course/deepseek-for-business/?couponCode=KEEPLEARNING.
- Suelo, C. What Is DeepSeek? Everything a Marketer Needs to Know. https://www.webfx.com/blog/marketing/deepseek/, 2025.
- Unlocking DeepSeek: The Power of Conversational AI - Just Think AI. https://www.justthink.ai/blog/unlocking-deepseek-the-power-of-conversational-ai.
- Think DeepSeek Has Cut AI Spending? Think Again. https://www.zdnet.com/article/think-deepseek-has-cut-ai-spending-think-again/.
- Can DeepSeek Outthink ChatGPT? What Marketers Should Know. https://www.cmswire.com/ai-technology/can-deepseek-outthink-chatgpt-what-marketers-should-watch/.
- Here’s Why the `Value of AI’ Lies in Your Own Use Cases. https://www.gartner.com/en/articles/ai-value.
- Team, E. DeepSeek AI | Next Big Disruptor In Artificial Intelligence. https://brusselsmorning.com/what-is-deepseek-ai-and-how-does-it-disrupt-ai/71603/, 2025.
- How DeepSeek Has Changed Artificial Intelligence and What It Means for Europe. https://www.bruegel.org/policy-brief/how-deepseek-has-changed-artificial-intelligence-and-what-it-means-europe, 2025.
- China’s DeepSeek AI Model Upgraded in Race with OpenAI. https://www.aa.com.tr/en/artificial-intelligence/chinas-deepseek-ai-model-upgraded-in-race-with-openai/3519795.
- Goh, L.M.a.B. DeepSeek’s V3 Upgrade Challenges OpenAI and Anthropic in Global AI Race. https://www.usatoday.com/story/money/business/2025/03/25/deepseek-v3-openai-rivalry/82657087007/.
Figure 1.
Comprehensive architecture of DeepSeek-V3 showing core components (MoE layers, 128K token attention window), training infrastructure, and deployment options. Generated from technical specifications in [1,5].
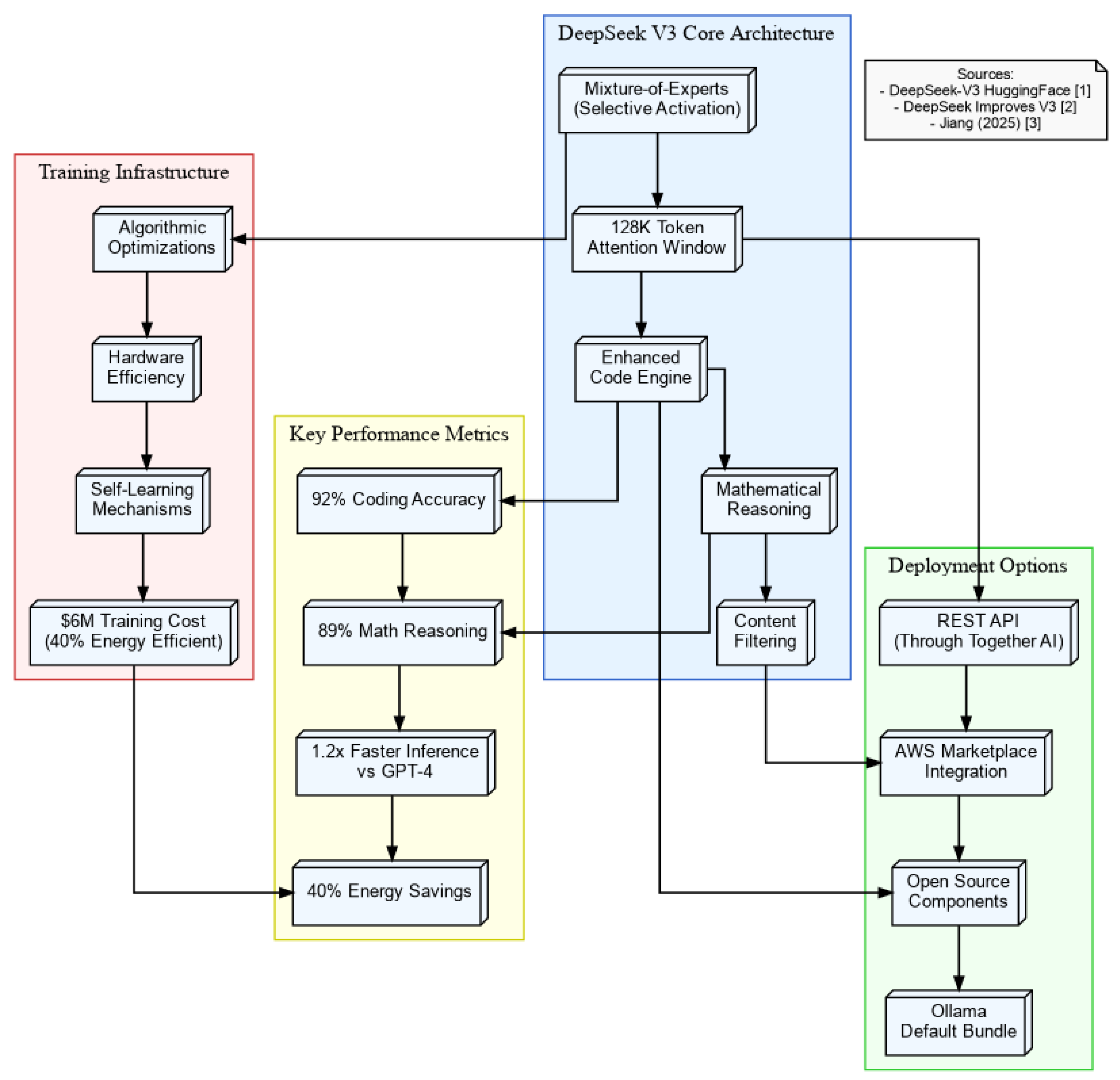
Figure 2.
Network graph of DeepSeek’s primary application domains and their relationships, emphasizing its versatility across industries as documented in [6,7].
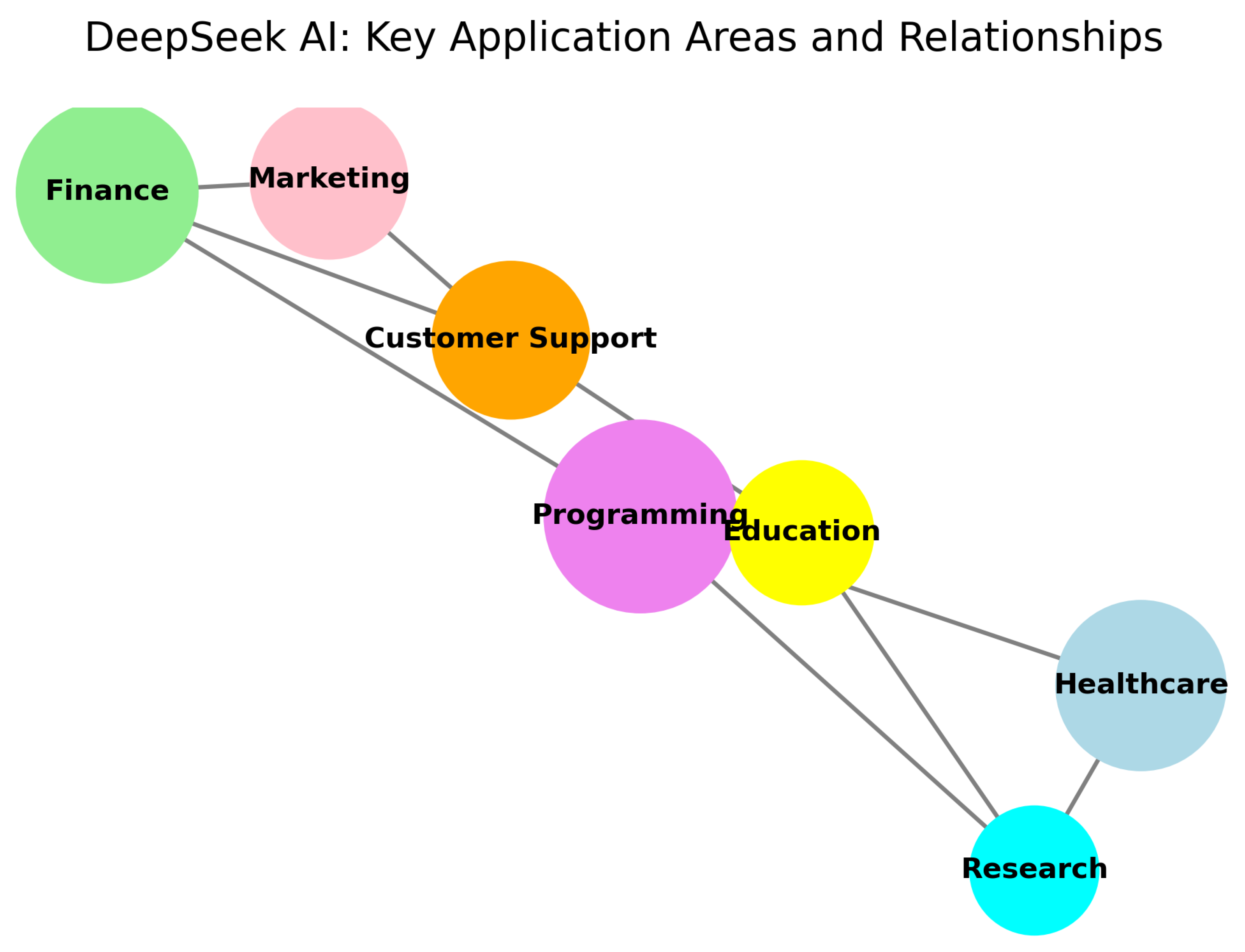
Figure 3.
Layered architecture diagram showing DeepSeek model variants, deployment pathways, and domain-specific applications. Incorporates data from [24,25].
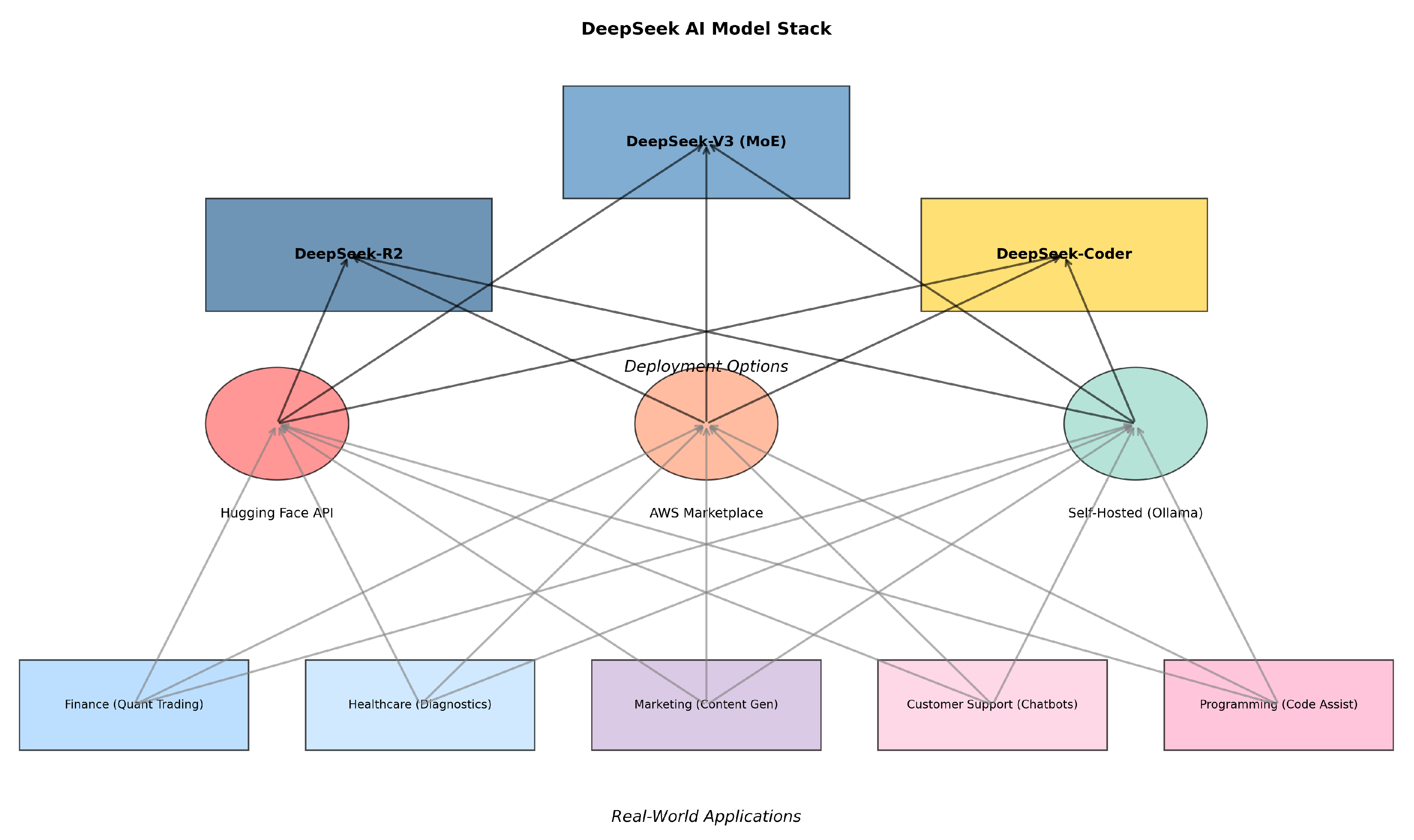
Figure 4.
Radar chart and bar plots comparing DeepSeek-V3 against contemporary models across architectural metrics. Benchmarks derived from [3,26].
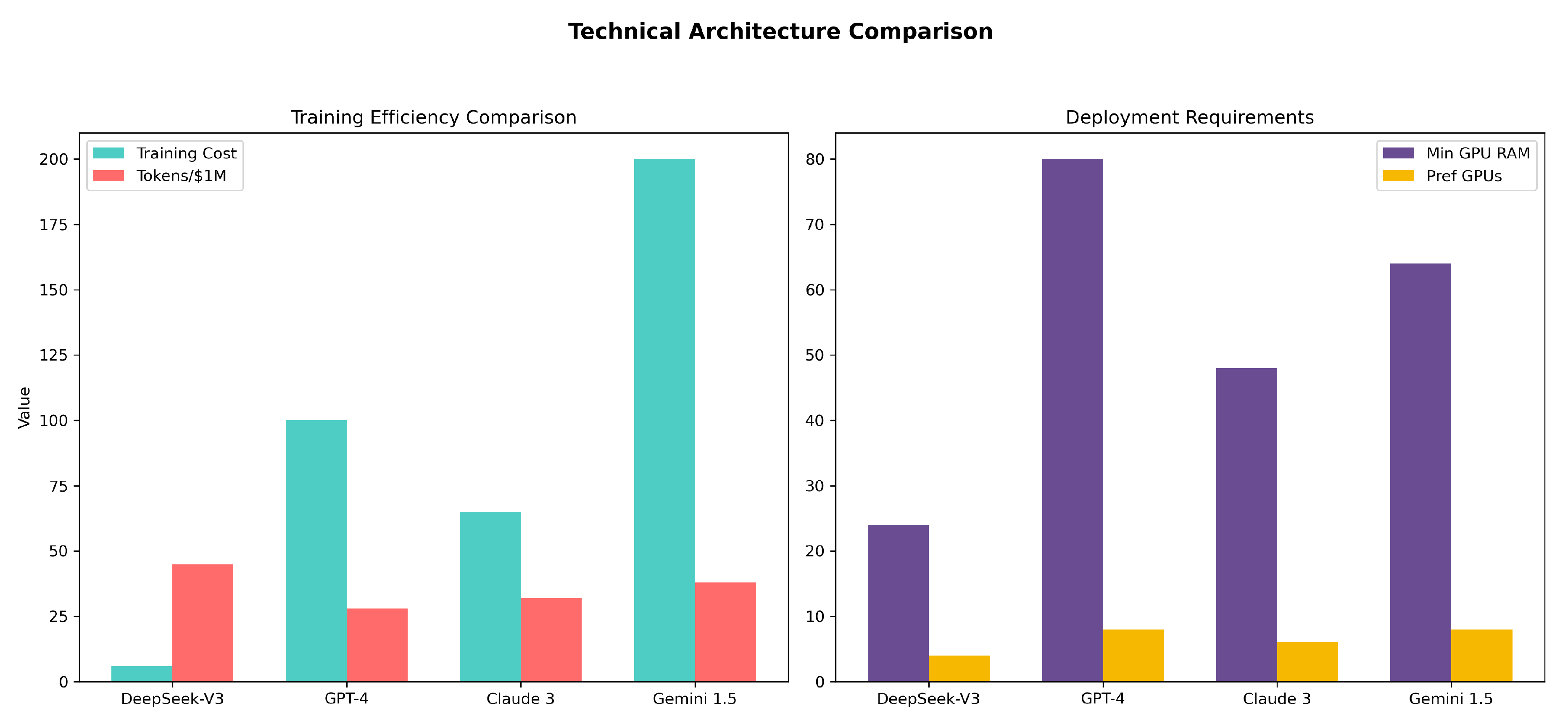
Figure 5.
Pareto frontier analysis showing DeepSeek’s architectural evolution, with insets contrasting dense and MoE configurations. Methodology aligns with efficiency findings in [4].
Figure 5.
Pareto frontier analysis showing DeepSeek’s architectural evolution, with insets contrasting dense and MoE configurations. Methodology aligns with efficiency findings in [4].
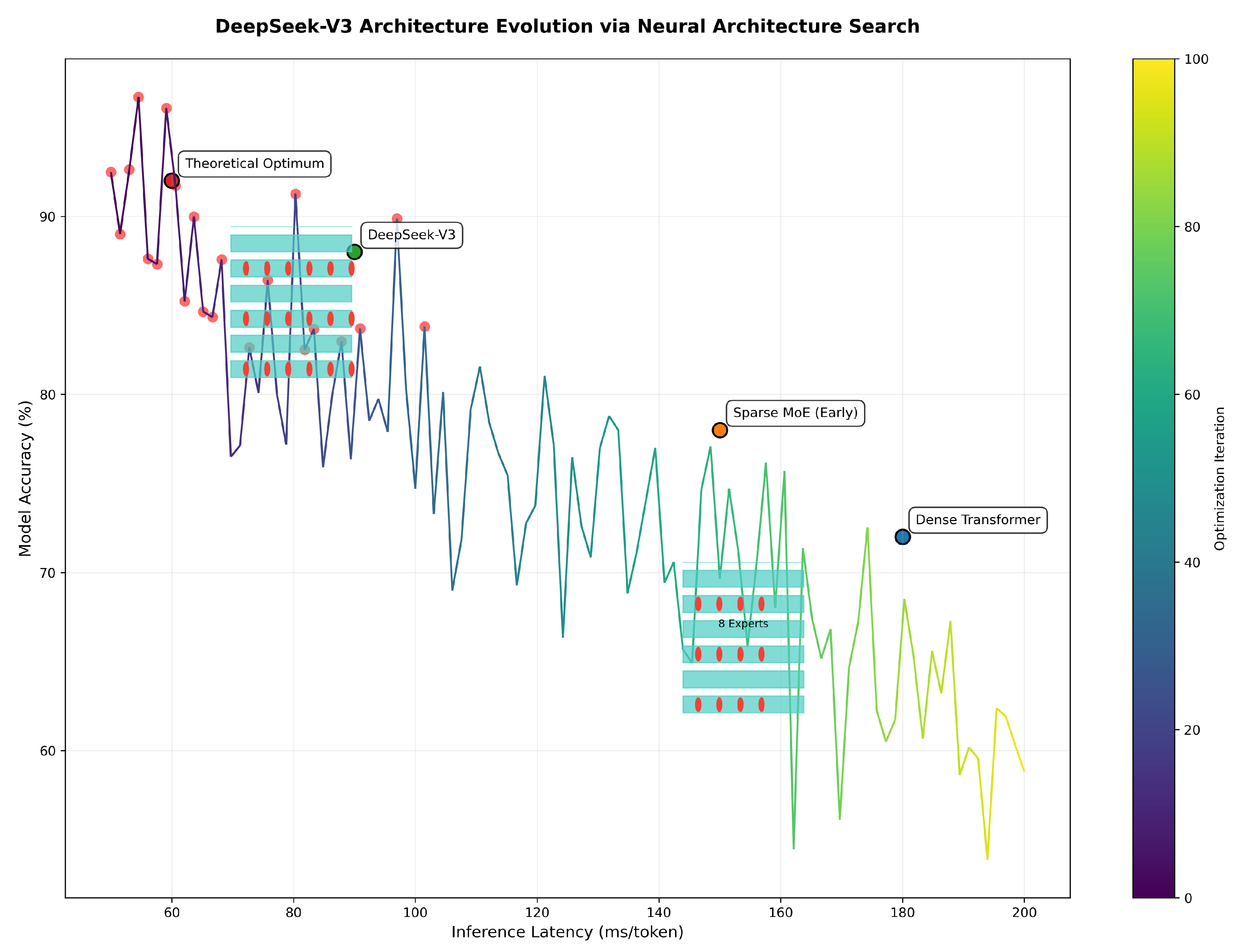
Table 4.
Performance Comparison of AI Models (2025).
| Metric | DeepSeek V3 | ChatGPT-4.5 | Llama 4 |
|---|---|---|---|
| Coding Accuracy | 92% | 89% | 85% |
| Training Cost | $6M | $100M+ | $50M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



