
Submitted:
09 July 2025
Posted:
11 July 2025
You are already at the latest version
Abstract
In this paper, the author introduces new methods to construct Archimedean copulas. The generator of each copula fulfills the sufficient conditions as regards the boundary and being continuous, decreasing, and convex. Each inverse generator also fulfills the necessary conditions as regards the boundary conditions, marginal uniformity, and 2-increasing properties. Although these copulas satisfy these conditions, they have some limitations. They do not cover the entire dependency spectrum, ranging from perfect negative dependency to perfect positive dependency, passing through the state of independence. Both copulas exhibit positive dependency and upper tail dependency, but neither has lower tail dependency. The product copula is present for each of them. For each copula, the author discusses the derivation, the properties, whether it has a singular part or not, the Kendall tau measure for dependency, and the upper and lower tail dependency. The article shows figures for depicting the generator function, joint CDF, and joint PDF for each copula. For each copula, inference is supported by real data analysis using the inference function for margins (IFM) for estimation.
Keywords:
Archimedean copula
; generator
; inverse generator
; MBUR
; Kendall tau
Introduction
A copula can express the nonlinear dependency between two or more variables, in comparison with correlation which can capture linear dependency between variables. It is a technique used to implement the joint distribution of the many variables (two or more). This has many wide applications in modern era of science like hydrology and geophysics (Valle & Kaplan, 2019) (Liu et al., 2018) (Salvadori et al., 2007), transportation research(Ma et al., 2017) (Bhat & Eluru, 2009), medicine (Kuss et al., 2014) (Lapuyade-Lahorgue et al., 2017) (Gomes et al., 2019), engineering (Kilgore & Thompson, 2011), biology (Konigorski et al., 2014) (Dokuzoğlu & Purutçuoğlu, 2017), climate research (Schölzel & Friederichs, 2008) (Oppenheimer et al., 2016), economics (Oh & Patton, 2018) (Kole et al., 2007) (De Lira Salvatierra & Patton, 2015). Sklar (Sklar, 1973) showed that a copula exists for any multivariate distribution, such that the joint distribution equals the copula applied to the marginal.
Definition 1 (Sklar’s theorem 1).
For any bivariate distribution function F with marginal and , there exists a copula such that
If F is continuous, then the copula C is unique. Otherwise, it is uniquely determined on the . The converse is also true, for any copula and univariate distribution functions and , the function is a bivariate distribution function with margins and .
A bivariate distribution function with marginal and is said to be generated by an Archimedean copula, if it can be written in the form of equation (1)
The generator should satisfy the following conditions (sufficient conditions):
- (1)
- is continuous, strictly decreasing and convex function mapping onto , in other words, (decreasing) and (convex)
- (2)
- (3)
Definition 2.
a bivariate copula is a non-decreasing and a right-continuous bivariate function mapping
which satisfies the following conditions
- (1)
- (Grounded)
- (2)
- and (uniform marginal)
- (3)
-
(2-increasing). This last property is equal tois the joint PDF of the copula.
So the copula links the marginal distributions through the dependency parameter.
The singular part of the copula is defined by (Genest & Mackay, 1986) in the following theorem.
Theorem 2.
the ratio between the generator and the first derivative of the generator evaluated at zero does not equal zero. The theorem states that the distribution generated by has a singular component iff in that case, with probability =
This paper is structured in 5 sections. Section 1 discusses the first copula, its derivation, properties and figures for its PDF and CDF. Section 2 explains the second copula with the same items. Section 3 illustrates the method of estimations. Section 4 discusses real data analysis for copula fitting. Section 5 comprehends the conclusion. Section 6 mentions the future work.
Section 1: (First Copula)
Let’s say the inverse generator is . The generator is and hence, . The generator . The generator should fulfill the sufficient conditions: , and ensures that the generator is a decreasing function. While; ensures that the generator is convex for .
for bivariate distribution: and
For a copula to be valid copula it should fulfill the boundary condition, the marginal uniformity and 2- increasing condition. And this is equivalent for the inverse generator the necessary conditions to be fulfilled are the following:
Preposition 1.
The boundary conditions are and marginal uniformity are .
Proof.
Preposition 2.
for copula to be valid it should be 2-increasing, in other words, .
Proof.
The second derivative is positive at alpha defined on the interval and this copula density integrate to one using MCMC simulation from zero to one, so it is a valid density function.
Preposition 3.
This copula is absolutely continuous copula and it has no singular part.
Proof.
To test for singularity:
Using L’Hopital:
As long as this limit is zero at u=0 so it has no singular part and it is absolutely continuous copula.
Preposition 4.
Kendall tau for this copula is and
Proof.
If indicating independence.
Preposition 5.
This copula is product copula at alpha =1, in other word, if alpha=1,
Proof.
Figure 1 , Figure 2 and Figure 3 illustrate the contour plot and the surface of the copula density and distribution with different values of the dependency parameter.
Figure 1.
shows the first copula density surface with dependency parameter 0.3.
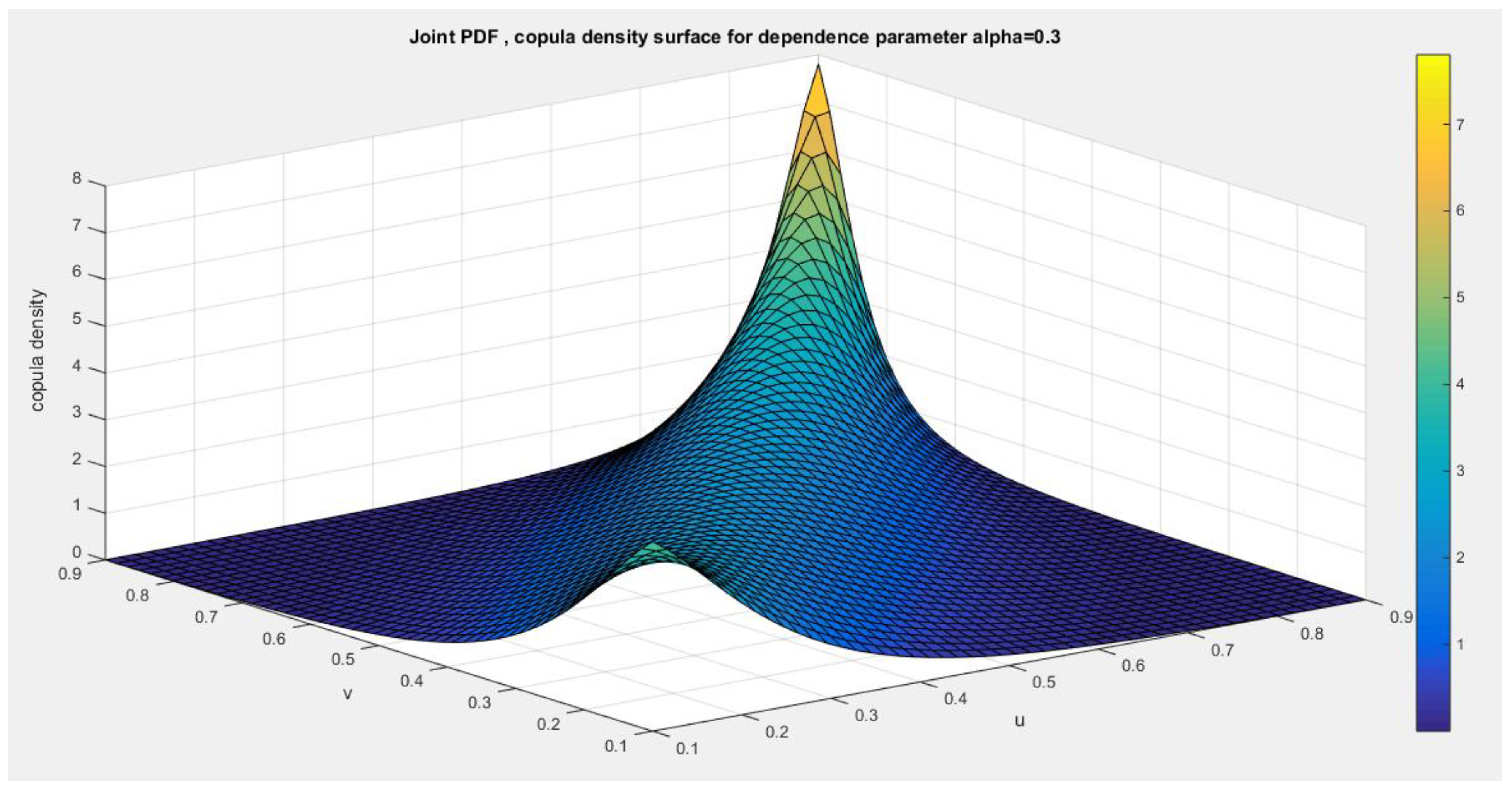
Figure 2.
shows the contour plot of the first copula density with dependency parameter 0.3.
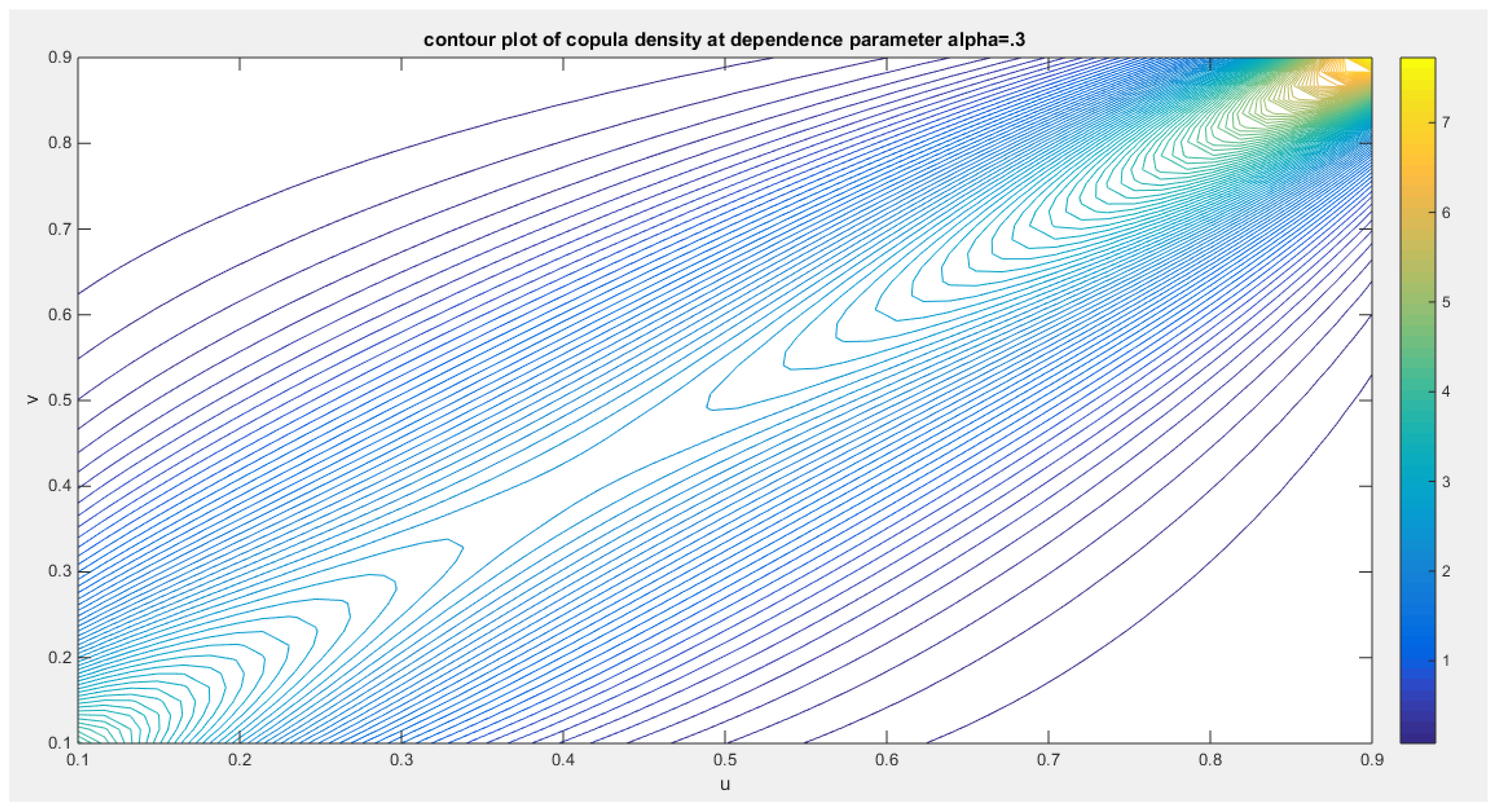
Figure 3.
shows the contour plot of the first copula distribution with dependency parameter 0.3.
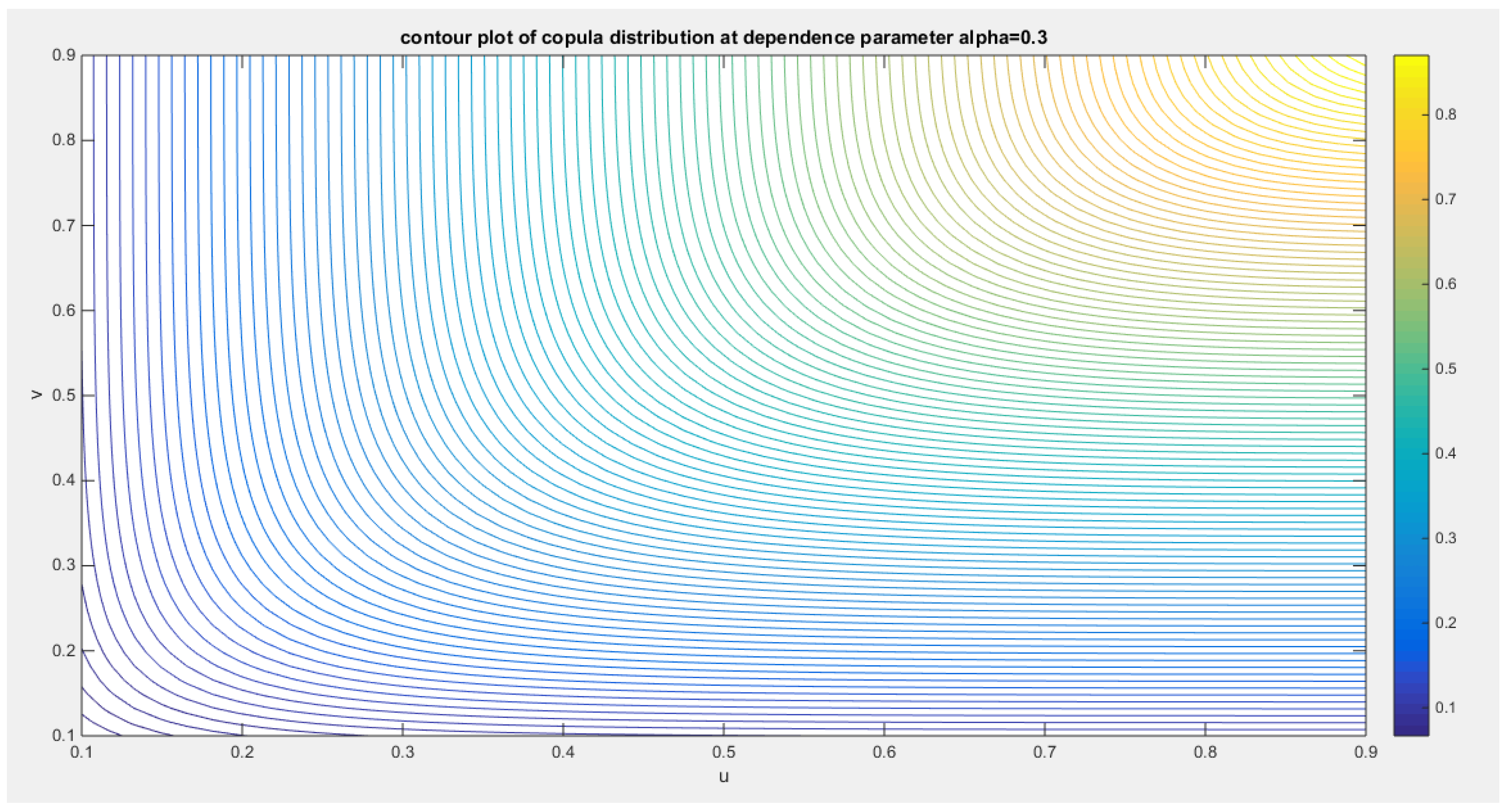
The limitation for this copula is that it does not cover the negative dependency between variables. This copula models only positive dependency.
Preposition 6.
This copula has no Lower tail dependency and the maximum upper tail dependency coefficient is one.
Proof.
Using L’Hopital rule
So the maximum upper tail dependence coefficient for of this copula is 1, however the copula has no lower tail dependency as the lower tail dependence coefficient is zero for. The , when dependency parameter approaches 0. While , when this parameter is 1, which is the product copula (state of independence). The when the dependency parameter . The copula has upper tail dependency for all theta less than one, and this dependence increases as theta decreases. Also the following equations support these findings.
Upper tail dependency:
Equation (4) is complementary to equation (2), as in equation (2) the upper limit for the upper tail coefficient cannot be attained, equation (4) explicitly satisfies this limit when the dependency parameter is approaching 0.
Lower tail dependency:
Using L’Hopital rule:
but the lower dependency tail coefficient should be between 0 and 1 so lower tail dependency coefficient is 0, and this is consistent with equation (3).
Section 2: (Second Copula)
Let’s say the inverse generator is , so the generator is and hence, the . The generator . And this generator should fulfill the sufficient conditions: , and the first derivative , ensures that the generator is a decreasing function. While the positive second derivative ensures that the generator is a convex function at excluding 0 i.e., ,
For bivariate distribution: and
For a copula to be a valid copula it should fulfill the boundary condition, the marginal uniformity and 2- increasing condition. And this is equivalent for necessary conditions of the inverse generator to be fulfilled which are the following:
Preposition 7.
The boundary conditions are and the marginal uniformity conditions are .
Proof.
and
Preposition 8.
for copula to be valid it should be 2-increasing, in other words;
Proof.
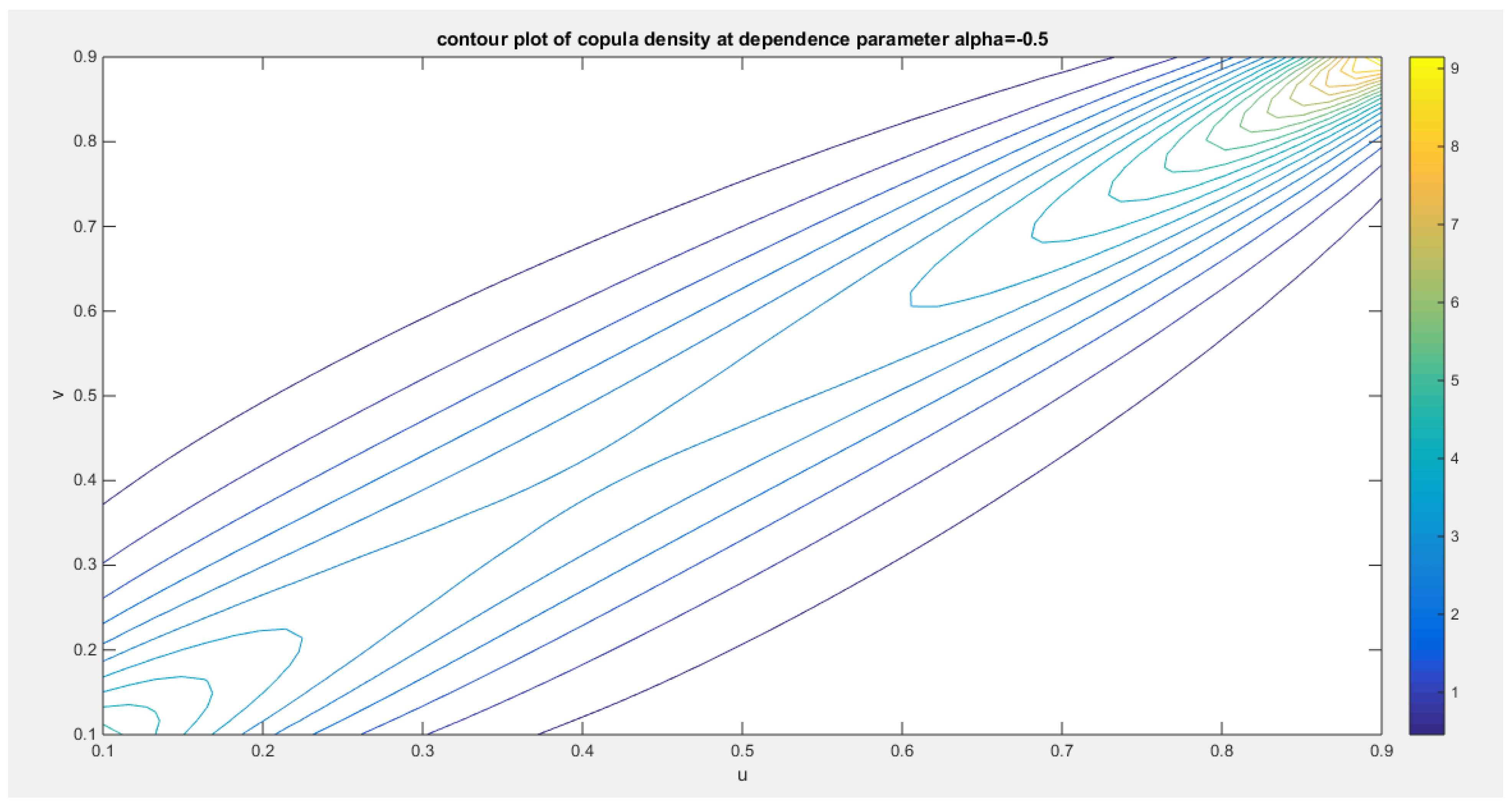
The second derivative is positive at. Integration of this copula density using MCMC simulation from zero to one is one and so it is a valid copula density. Figure 4, Figure 5 and Figure 6 show the surface and the contour plot of the copula density and distribution at different dependency parameters.
Figure 4.
shows second copula density surface with dependency parameter 0.1.
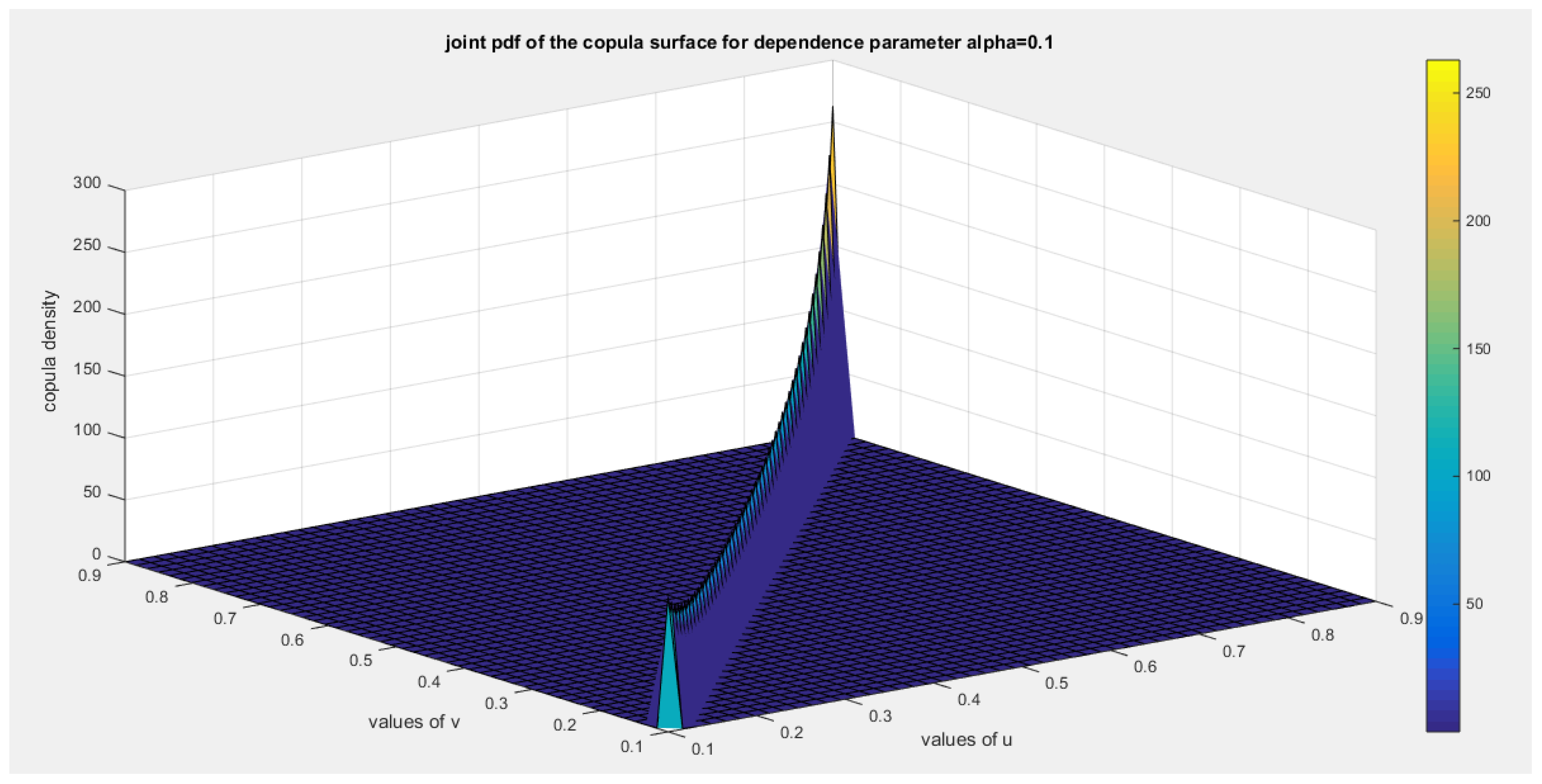
Figure 5.
shows the contour plot of the second copula distribution with dependency parameter -0.5.
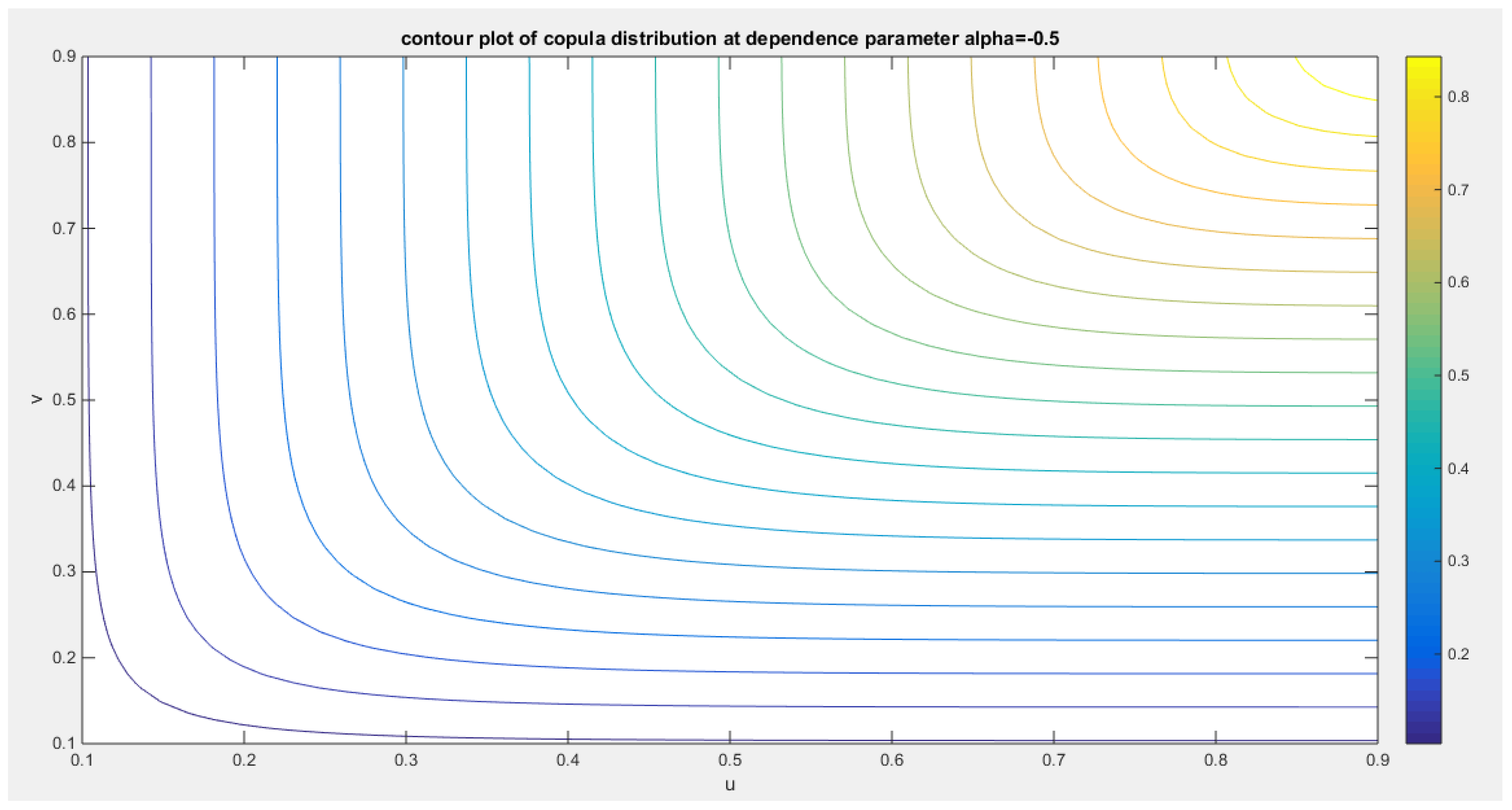
Figure 6.
shows the contour plot of the second copula distribution with dependency parameter -0.5.
Preposition 9.
this copula is absolutely continuous copula and it has no singular part.
Proof.
to test for singularity:
Using L’Hopital rule:
As long as this limit is zero at u=0 so the copula has no singular part and it is absolutely continuous copula.
Preposition 10.
Kendall tau for this copula is and
Proof.
using integration by parts for the following integrant
If indicating perfect positive dependency.
If denoting independency with product copula .
Preposition 11.
The product copula is attained at dependency parameter
Proof.
when
The limitation of this copula is that it models only positive dependency.
Preposition 12.
The copula has no lower tail dependency and the maximum upper tail dependency coefficient is 1.
Proof.
Using L’Hopital rule
So the maximum upper tail dependence coefficient for of this copula is 1, however the copula has no lower tail dependency as the lower tail dependence coefficient is zero for. The , when dependency parameter approaches 0. While , when this parameter is 1 or -1, at which the product copula is produced. The when the dependency parameter . Also the following equations support these findings.
Upper tail dependency:
Using L’Hopital rule:
Equation (5) is complementary to equation (7), as in equation (5) the upper limit for the upper tail coefficient cannot be explicitly attained, equation (7) explicitly satisfies this limit when the dependency parameter is approaching 0.
Lower tail dependency:
Using L’Hopital rule:
but the lower dependency tail should be between 0 and 1 so lower dependency tail is 0, and this is consistent with equation (6)
Section 3: Methods of Estimation
(Weiß, 2011), (Chen, 2007), and (Tsukahara, 2005) extensively introduced various methods of estimations like the following:
3.1. Maximum likelihood estimation (MLE)
It is one step where all the parameters marginal and copula are estimated for the full joint density function, taking the log-likelihood of this full joint function and differentiating it with respect to each of the marginal parameters and the copula parameter, then equating the resultant functions with zero and solving numerically this system of equations.
3.2. Inference function of margins (IFM)
For bivariate copula-base models for which the maximum likelihood is computationally difficult to estimate all the model parameters jointly in a one-step parametric method (Al Turk et al., 2017), two-stages estimation procedure has been proposed previously by (Joe, 2005) and (Xu, 2009). The first stage involves estimating the marginal parameters separately using maximum likelihood as shown in equation (8), where s stands for the score function or gradient
After estimating the marginal parameter, you get the marginal CDF for each variable as shown in equation (9)
The second stage involves maximum likelihood of the dependence parameters with the marginal parameters held fixed from the first stage, you get the log-likelihood of the copula density as shown in equation (10), then differentiate this log-likelihood with respect to the copula dependency parameter as shown in equation (11).
In this paper, the author used IFM for both the first and second copula.
For the first copula: first derivative of the log-likelihood with respect to copula parameter is in equation (12)
Let: , , ,
,
, ,
For second copula: first derivative of the log-likelihood with respect to copula parameter is in equation (13)
Let: , , ,
,
,
,
Applying Quasi-Newton method
where , and can approximate the variance of the dependency parameter estimator.
Each marginal parameter has its own variance from stage one, they are treated as fixed when moving to stage two in IFM approach, so they do not contribute to the variance of the estimated dependency parameter directly. The variance of the copula parameter is obtained from the second stage and it is valid under IFM but it underestimates the total uncertainty (because it ignores the variability in marginal parameter estimation). Therefore, in theory, the propagation of uncertainty from the first stage to the second requires the Godambe information matrix (sandwich estimator) (Godambe, 1991), or simultaneous estimator to obtain the joint variance-covariance matrix of all parameters (marginals and copula). Hence, the sandwich estimator also known as robust variance estimator is used to obtain the asymptotic variance of parameter estimates when the likelihood function is estimated in multiple stages or is mis-specified in cases where not using the full joint likelihood. The variance is defined in the following equation (14):
Where S is the outer product of the gradient of parameter estimator (marginal and copula) or the score function as shown in equation (15).
is the inverse of the negative of expectation of the information matrix, in other word, the variance of the parameter estimator (marginal and copula). It is a diagonal matrix. , the inverse of this H or inverse of this I is the variance of marginal parameter estimators in the first stage and variance of copula estimator in the second stage. So let’s call this inverse the A matrix, so sandwich estimator can be expressed as shown in Equations (16) and (17)
This variance covariance matrix captures the covariance between the marginal and the copula parameter estimators which are not captured in the naive block separated IFM variances.
3.3. Semiparametric method (SP)
The third method introduced by (Kim et al., 2007) is the estimation by semiparametric method (SP). It is carried out in two stages like IFM. The first stage involves transforming the variables into their marginal empirical distribution (eCDF), in other words, transforming the observations into pseudo-observations by using the empirical distribution function for each marginal distribution as shown in equation (18)
The second stage involves estimating the copula dependency parameter using the pseudo likelihood function as shown in equation (19-20) and maximizing this function.
Section 4: real data analysis
4.1. data description
The OECD data platform delivered by the OECD (organization for economic Cooperation and development) collects data on a wide range of economic, social, and environmental sectors including data about economy, health, trade, education, labor, innovation, and development. It contains many indicators describing these data. The data can be found on the following site: In this analysis, 3 indicators are used to find the dependency between and how the previously new copulas can model this dependency. The indicators are the quality of support network, water quality, and feeling safe walking alone at night. The data are collected from 41 countries as shown in Table 1. https://stats.oecd.org/index.aspx?DataSetCode=BLI.
The indicators (let’s call it the y variable) in Table 1 and in Table 5 are distributed as Median Based Unit Rayleigh (MBUR) previously discussed by Iman Attia (Attia, 2024) with the following PDF in equation (21), CDF in equation (22), and, quantile function in equation (23):

Table 1.
The three indicators of the OECD data.
| Country | Water quality | Feeling safe walking alone | Quality of support network |
|---|---|---|---|
| Australia | 0.92 | 0.67 | 0.93 |
| Austria | 0.92 | 0.86 | 0.92 |
| Belgium | 0.79 | 0.56 | 0.90 |
| Canada | 0.90 | 0.78 | 0.93 |
| Chile | 0.62 | 0.41 | 0.88 |
| Colombia | 0.82 | 0.50 | 0.80 |
| Costa Rica | 0.87 | 0.47 | 0.82 |
| Czechia | 0.89 | 0.77 | 0.96 |
| Denmark | 0.93 | 0.85 | 0.95 |
| Estonia | 0.86 | 0.79 | 0.95 |
| Finland | 0.97 | 0.88 | 0.96 |
| France | 0.78 | 0.74 | 0.94 |
| Germany | 0.91 | 0.76 | 0.90 |
| Greece | 0.67 | 0.69 | 0.78 |
| Hungary | 0.81 | 0.74 | 0.94 |
| Iceland | 0.97 | 0.85 | 0.98 |
| Ireland | 0.80 | 0.76 | 0.96 |
| Israel | 0.77 | 0.80 | 0.95 |
| Italy | 0.77 | 0.73 | 0.89 |
| Japan | 0.87 | 0.77 | 0.89 |
| Korea | 0.82 | 0.82 | 0.80 |
| Latvia | 0.83 | 0.72 | 0.92 |
| Lithuania | 0.83 | 0.62 | 0.89 |
| Luxembourg | 0.85 | 0.87 | 0.91 |
| Mexico | 0.75 | 0.42 | 0.77 |
| Netherlands | 0.91 | 0.83 | 0.94 |
| New Zealand | 0.85 | 0.66 | 0.95 |
| Norway | 0.98 | 0.93 | 0.96 |
| Poland | 0.82 | 0.71 | 0.94 |
| Portugal | 0.89 | 0.83 | 0.87 |
| Slovak Republic | 0.81 | 0.76 | 0.95 |
| Slovenia | 0.93 | 0.91 | 0.95 |
| Spain | 0.76 | 0.80 | 0.93 |
| Sweden | 0.97 | 0.79 | 0.94 |
| Switzerland | 0.96 | 0.86 | 0.94 |
| Turkey | 0.62 | 0.59 | 0.85 |
| United kingdom | 0.82 | 0.78 | 0.93 |
| United states | 0.88 | 0.78 | 0.94 |
| Brazil | 0.70 | 0.45 | 0.83 |
| Russia | 0.62 | 0.64 | 0.89 |
| South Africa | 0.72 | 0.40 | 0.89 |
The ‘water quality’ indicator measures the self-reported satisfaction with water quality as regard drinking clean water and extent of water pollution. It is expressed as the percentage of people who report satisfaction. The indicator of ‘feeling safe walking alone’ measures the percentage of people who report feeling safe when walking alone in their local area after dark. The ‘quality of support network’ indicator measures the accessibility and trustworthiness of social support for individuals and it is explicated as the percentage of population with social support who described having someone they can depend on for support when they need it. Table 2 shows the descriptive statistics of the 3 indicators. Table 3 shows the empirical Kendall tau coefficient and its associated p-value. Figure 7 shows the boxplot for each indicator. Figure 8, Figure 9 and Figure 10 show the scatter plot of the dependent indicators. Each indicator fits the Median Based Unit Rayleigh Distribution (MBUR). Table 4 shows the statistical validity indices for each indicator. Figure 11 shows the histogram and the fitted MBUR curve for each indicator.
Table 2.
descriptive statistics for the 3 indicators.
| indicator | min | mean | Standard deviation | skewness | kurtosis | 25percentile | 50percentile | 75percentile | max |
|---|---|---|---|---|---|---|---|---|---|
| Water quality | 0.62 | 0.8332 | 0.0972 | -0.6059 | 2.9144 | 0.7775 | 0.83 | 0.91 | 0.98 |
| Feeling safe walking alone | 0.4 | 0.7207 | 0.143 | -0.9486 | 3.0353 | 0.655 | 0.76 | 0.8225 | 0.93 |
| Quality of support network | 0.77 | 0.9078 | 0.0538 | -1.176 | 3.5406 | 0.89 | 0.93 | 0.95 | 0.98 |
Table 3.
empirical Kendall tau coefficient of the three indicators.
| Water quality | Feeling safe walking alone | Quality of support network | |
|---|---|---|---|
| Water quality | 1 |
0.5206 (0.000) |
0.3929 (0.0006) |
| Feeling safe walking alone |
0.5206 (0.000) |
1 |
0.4344 (0.0001) |
| Quality of support network |
0.3929 (0.0006) |
0.4344 (0.0001) |
1 |
Table 4.
statistical validity indices of the distributional fit (MBUR) of the three indicators.
| indicator | Estimated theta | variance | AIC | CAIC | BIC | HQIC | KS-test | Ho | p-value of KS-test |
|---|---|---|---|---|---|---|---|---|---|
| Water quality | 0.4776 | 0.00072157 | -78.9952 | -78.8926 | -77.2817 | -78.3712 | 0.0991 | Fail to reject | 0.7789 |
| Feeling safe walking alone | 0.6494 | 0.0013 | -47.1347 | -47.0321 | -45.4211 | -46.5107 | 0.1206 | Fail to reject | 0.5492 |
| Quality pf support network | 0.3444 | 0.00037494 | -131.6505 | -131.6505 | -131.5479 | -131.0265 | 0.1806 | Fail to reject | 0.1217 |
Figure 7.
shows the Boxplot for each indicator. The first two indicators show similar pattern of skewness (left sides skewness) while the third indicator exhibits more left sided skewness than the previous two indicators.
Figure 7.
shows the Boxplot for each indicator. The first two indicators show similar pattern of skewness (left sides skewness) while the third indicator exhibits more left sided skewness than the previous two indicators.
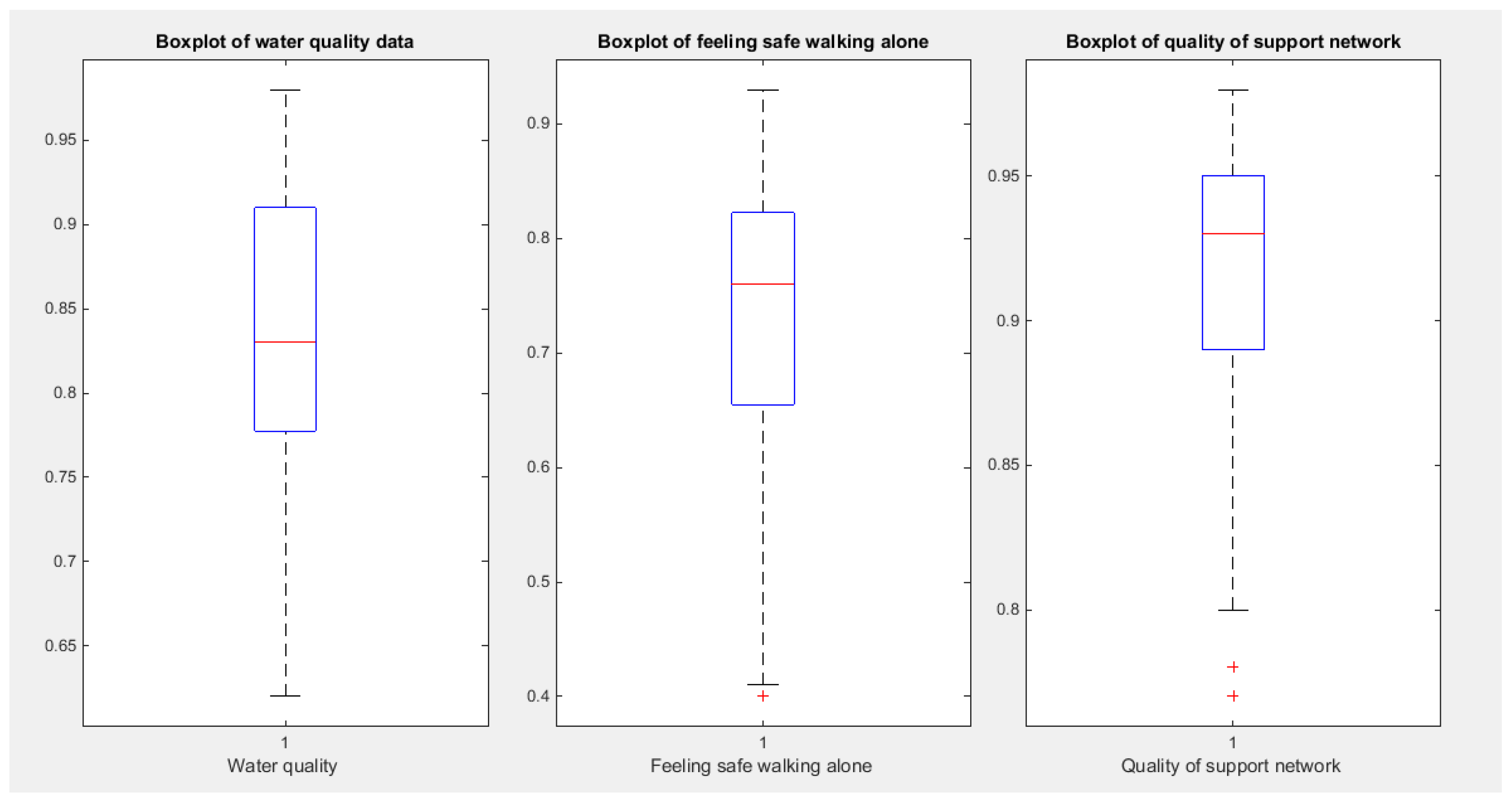
Figure 8.
shows the scatter plot of the water quality variable vs the variable describing feeling safe walking alone. The data are mainly concentrated on the upper left side of the graph most probably reflecting upper tail dependency.
Figure 8.
shows the scatter plot of the water quality variable vs the variable describing feeling safe walking alone. The data are mainly concentrated on the upper left side of the graph most probably reflecting upper tail dependency.
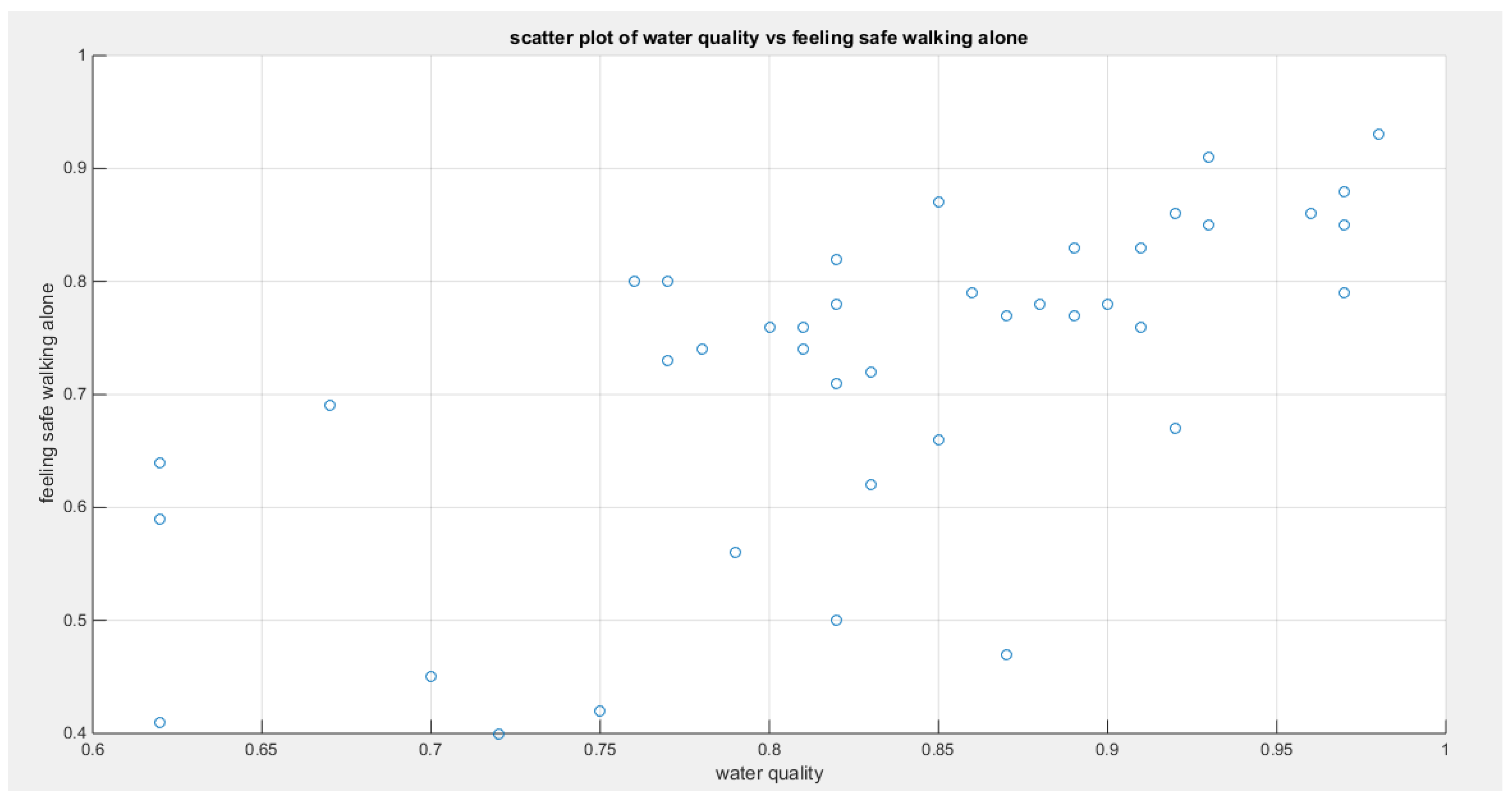
Figure 9.
shows the scatter plot of the variable water quality vs the variable quality of support network, also the data are mainly concentrated in the upper left corner of the scatter presumably reflecting upper tail dependency.
Figure 9.
shows the scatter plot of the variable water quality vs the variable quality of support network, also the data are mainly concentrated in the upper left corner of the scatter presumably reflecting upper tail dependency.
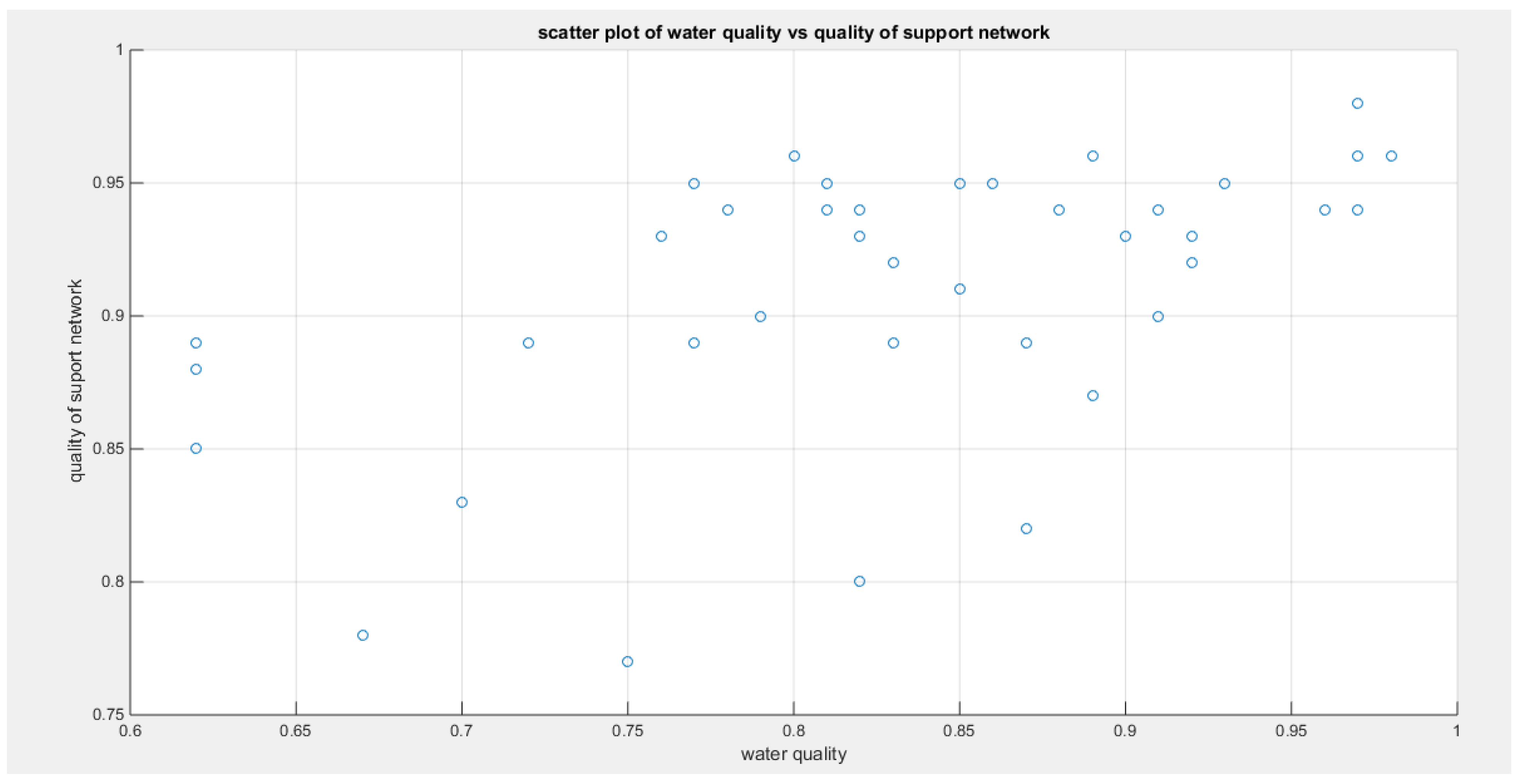
Figure 10.
shows the scatter plot of the variable feeling safe walking alone vs the variable of the quality of support network. The data are also concentrated on the right upper corner of the graph likely denoting the presence of upper tail dependency.
Figure 10.
shows the scatter plot of the variable feeling safe walking alone vs the variable of the quality of support network. The data are also concentrated on the right upper corner of the graph likely denoting the presence of upper tail dependency.
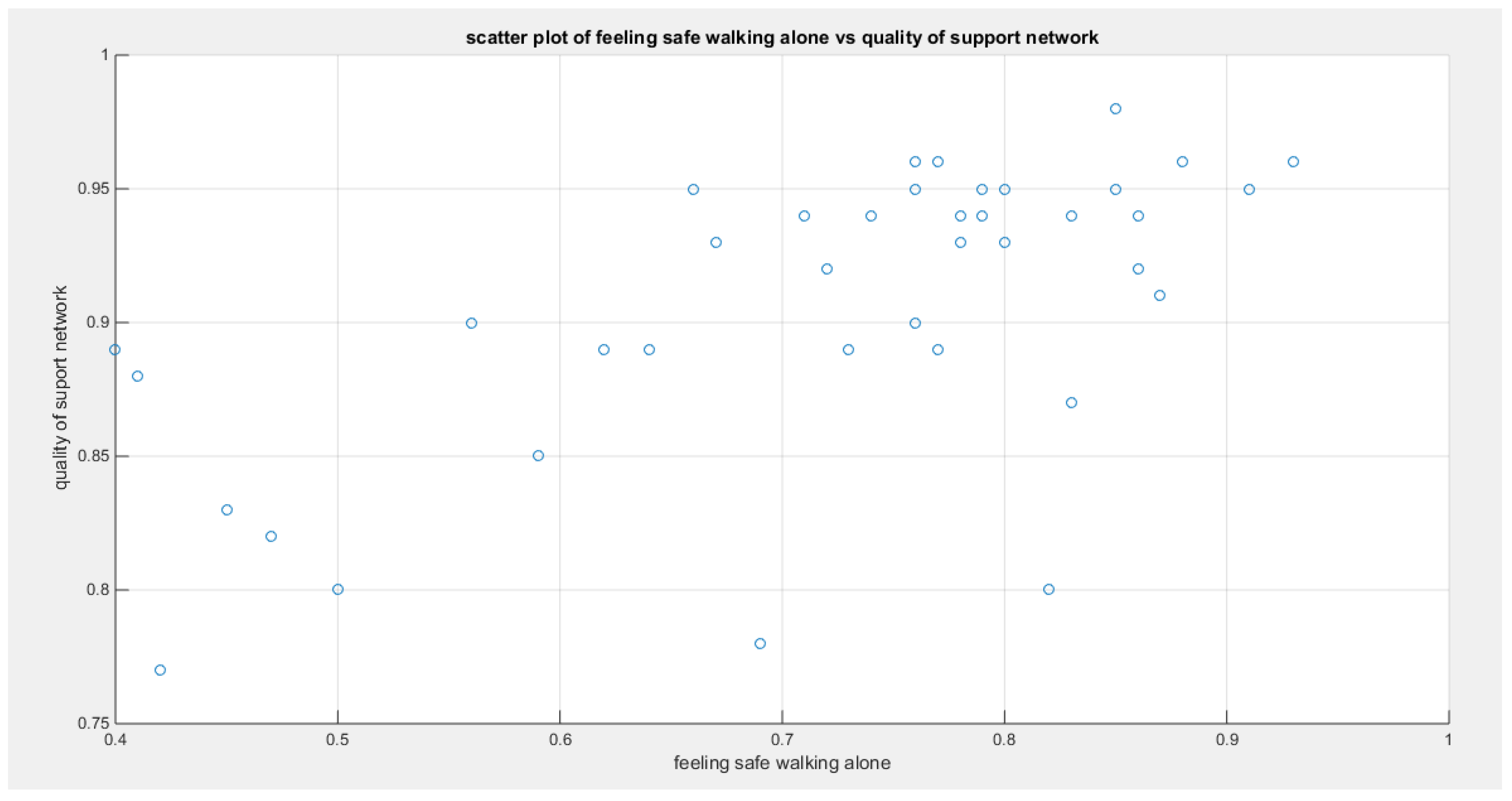
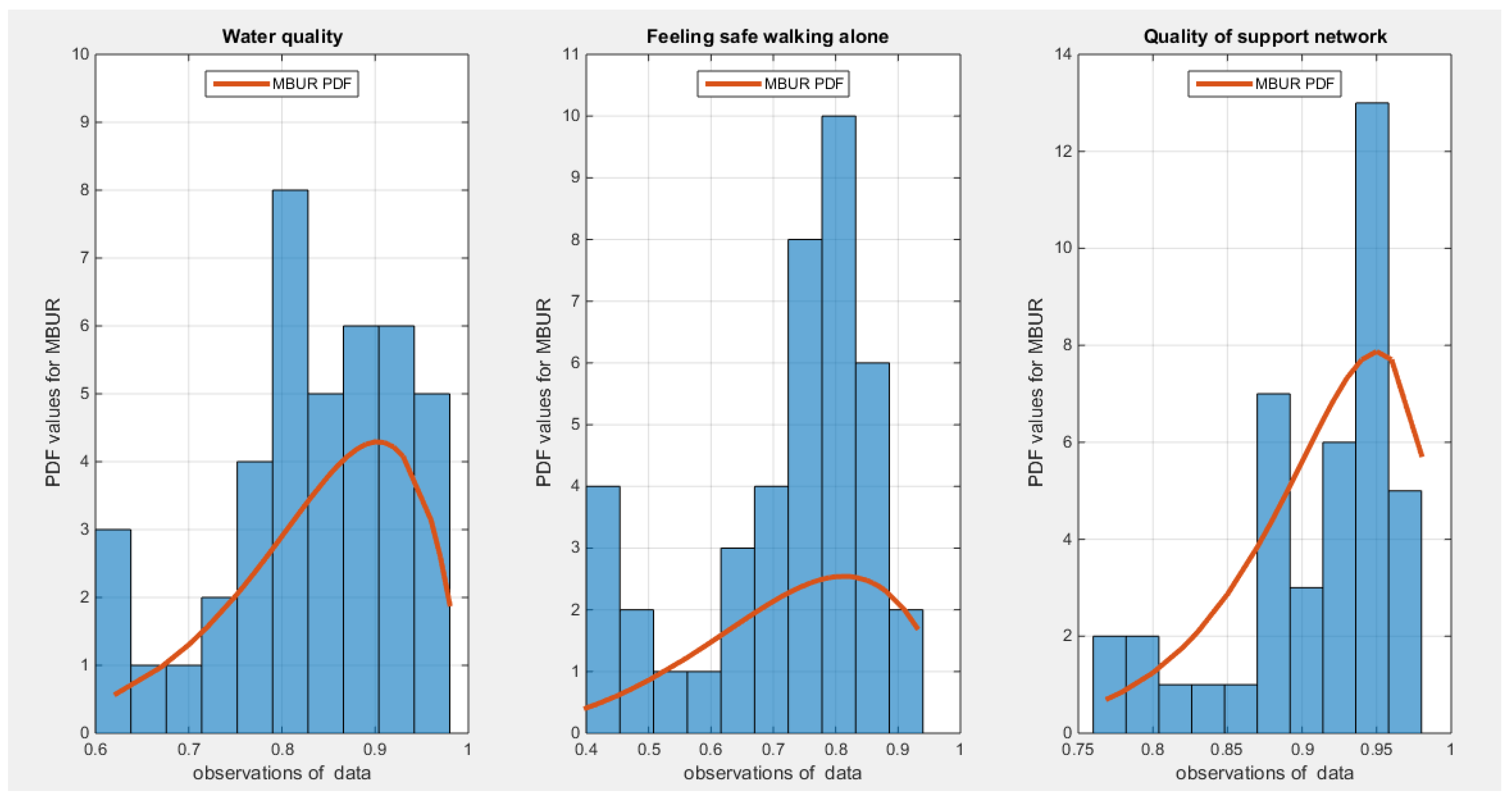
Figure 11.
shows the histogram of the three indicators which exhibit left sided skewness. The graph also shows the fitted MBUR curve for each indicator. The three indicators more or less have near similar kurtosis and skewness. Copula that can fit symmetrical dependency can model dependency between such variables.
Figure 11.
shows the histogram of the three indicators which exhibit left sided skewness. The graph also shows the fitted MBUR curve for each indicator. The three indicators more or less have near similar kurtosis and skewness. Copula that can fit symmetrical dependency can model dependency between such variables.
4.2. procedure of analysis (IFM)
After running the inference function for margins (IFM) and estimating the marginal parameter for each pair of variables then fitting each copula to estimate its parameter. Goodness of Fit tests are conducted to assess the dependence relationship for each pair of the variables.
The steps of analysis are as follows:
- Estimate the marginal parameters for each variable.
- Use the IFM procedure to estimate the dependency parameter of the proposed copula model.
- Obtain the theoretical tau from the specific relation between dependency parameter and the Kendall tau dor each copula.
- Obtain the Cramer Von Mises test from this estimation process and call it CVMdata that will be compared to CVMsamples
- Run sampling technique like Metropolis Hasting (MH) procedure to test the null hypothesis using the estimated dependency parameter and both the estimated marginal parameters.
- Construct sampling distribution for the estimated-thetasamples, theoretical-tausamples, and CVMsamples.
For each of the sample generated by MH using the estimated dependency parameter and the estimated marginal parameters, they will be transformed back into variables using the specific quantiles. These variables will be subjected to the IFM procedure; first estimate the marginal parameters then using the estimated marginal CDF for each variable to estimate the dependency parameter, in other words, repeat steps (1 to 4) for each sample so you can be able to construct the sampling distribution, hence, constructing the confidence interval for each of the statistical indices. denotes theta estimated from the data.
The null hypothesis for the dependency parameter is:
The alternative hypothesis for the dependency parameter is:
The null hypothesis for the Kendall tau coefficient is:
The alternative hypothesis for the Kendall tau coefficient is:
The null hypothesis for the CVM is:
The alternative hypothesis for the CVM is:
First Copula:
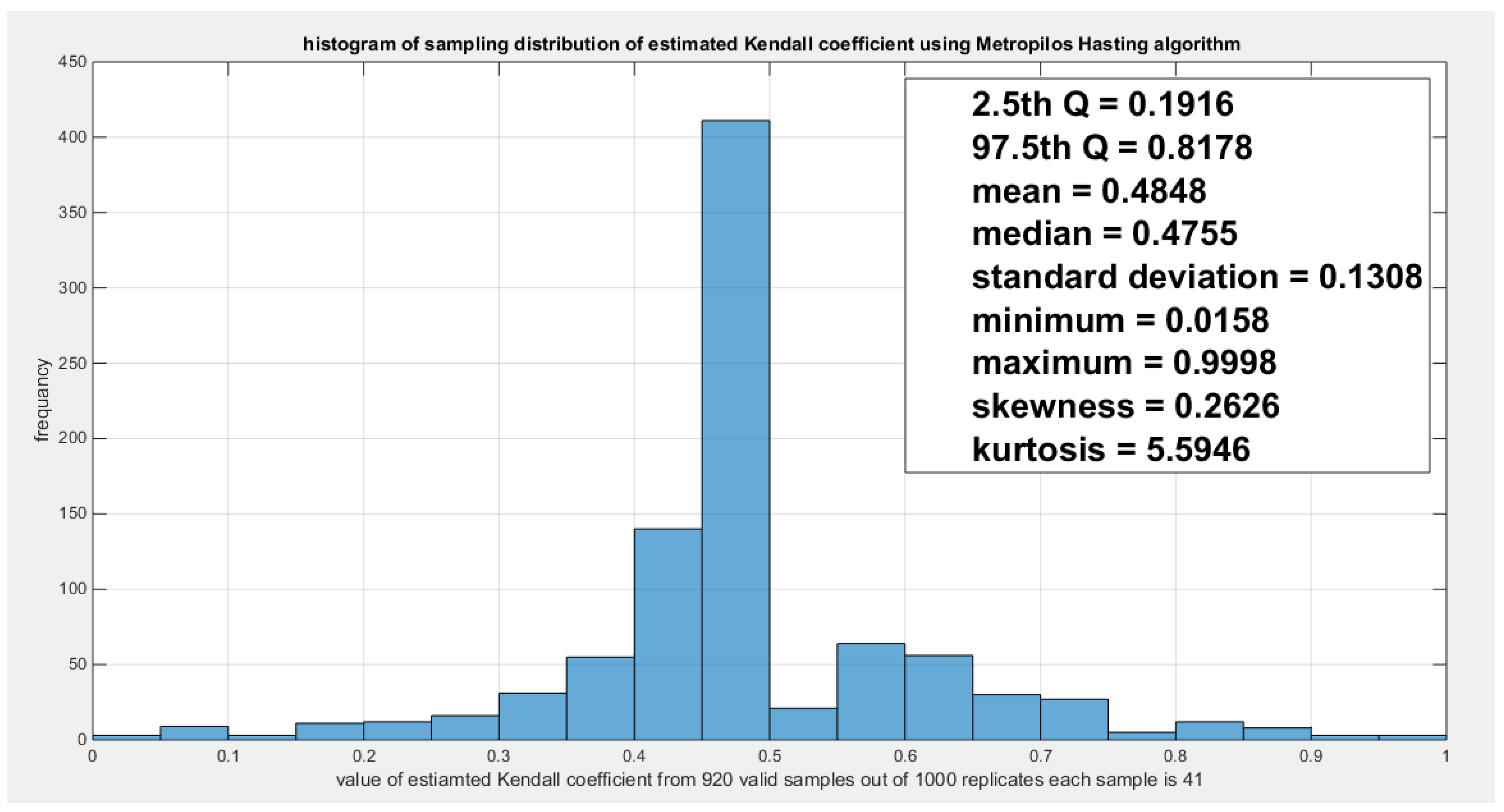
Model the dependency between the ‘water quality’ and ‘feeling safe walking alone’: The empirical tau equals 0.5206 while the theoretical tau is 0.5202 with difference value of 3.6968e-04. The estimated dependency parameter, theta , is 0.4798 with estimated variance of 8.3533e-06. The Cramer Von Mises test (CVM) is 0.1388. The null hypothesis for dependency was tested by conducting resampling using the Metropolis Hasting algorithm of MCMC procedure. The proposed null hypothesis was that the dependency parameter equals the estimated theta against the alternative hypothesis that the population dependency parameter does not equal the estimated theta. Also the null hypothesis for the population Kendall tau coefficient being equal to the theoretical tau against the alternative hypothesis of not being equal to it was tested. The null hypothesis for the CVM proposing that the sampling CVM equals observed CVM obtained from the estimation procedure was investigated. The sampling distribution of each of the previously mentioned indices, thetas, tau and CVM is shown in Figure 12, Figure 13 and Figure 14. For each figure, the descriptive statistics indices are shown. From the figures the indices are placed within the acceptance zone between the 2.5th and 97.5th quantiles. So the null hypotheses fail to be rejected. The copula fits the data well. And the dependence parameter models, within the context of the copula, the relation between the two variables. The confidence interval (CI) for the estimated dependence parameter is (0.1822, 0.8084), for the theoretical tau; it is (0.1916, 0.8178), and for CVM; it is (0.0316, 0.2937).
Figure 12.
shows the sampling distribution of the CVM. The CVM data is 0.1388 and it lays between the 2.5th and the 97.5th quantiles so null hypothesis is failed to be rejected and the copula fits the data well. The p-value (probability of values less than or equal to 0.1388) is 0.8207, in other words, this 0.1388 does not lay in either of the tail region of rejection.
Figure 12.
shows the sampling distribution of the CVM. The CVM data is 0.1388 and it lays between the 2.5th and the 97.5th quantiles so null hypothesis is failed to be rejected and the copula fits the data well. The p-value (probability of values less than or equal to 0.1388) is 0.8207, in other words, this 0.1388 does not lay in either of the tail region of rejection.
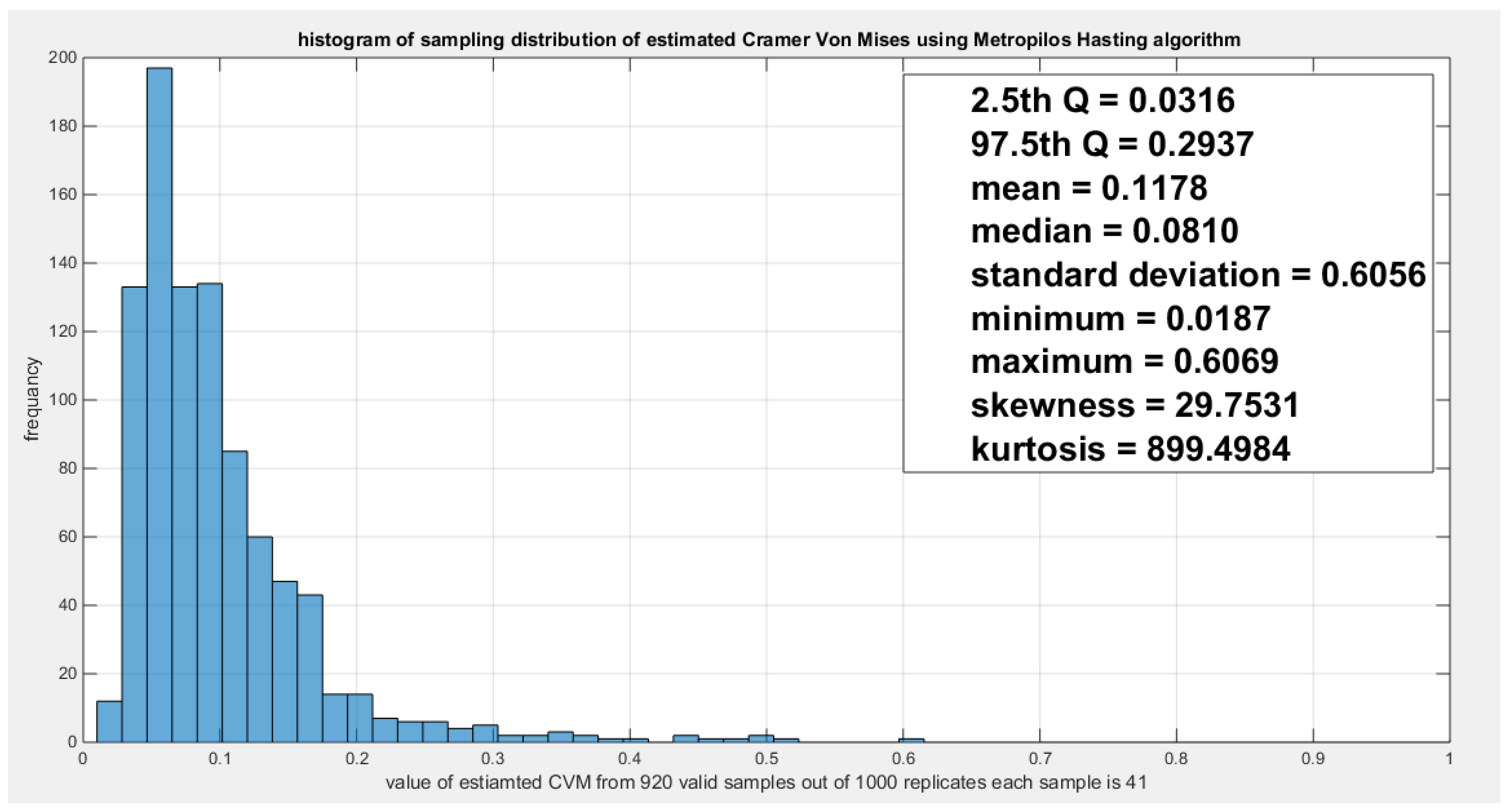
Figure 13.
shows the sampling distribution of the dependency parameter. The 0.4798 lays in the acceptance region between the two quantiles, the 2.5th and the 97.5th quantiles. So the null hypothesis fails to reject its assumption. The p-value (probability of the values being less than or equal to this 0.4798) is 0.2304 which indicates that 0.4798 is not placed in either zones of rejection.
Figure 13.
shows the sampling distribution of the dependency parameter. The 0.4798 lays in the acceptance region between the two quantiles, the 2.5th and the 97.5th quantiles. So the null hypothesis fails to reject its assumption. The p-value (probability of the values being less than or equal to this 0.4798) is 0.2304 which indicates that 0.4798 is not placed in either zones of rejection.
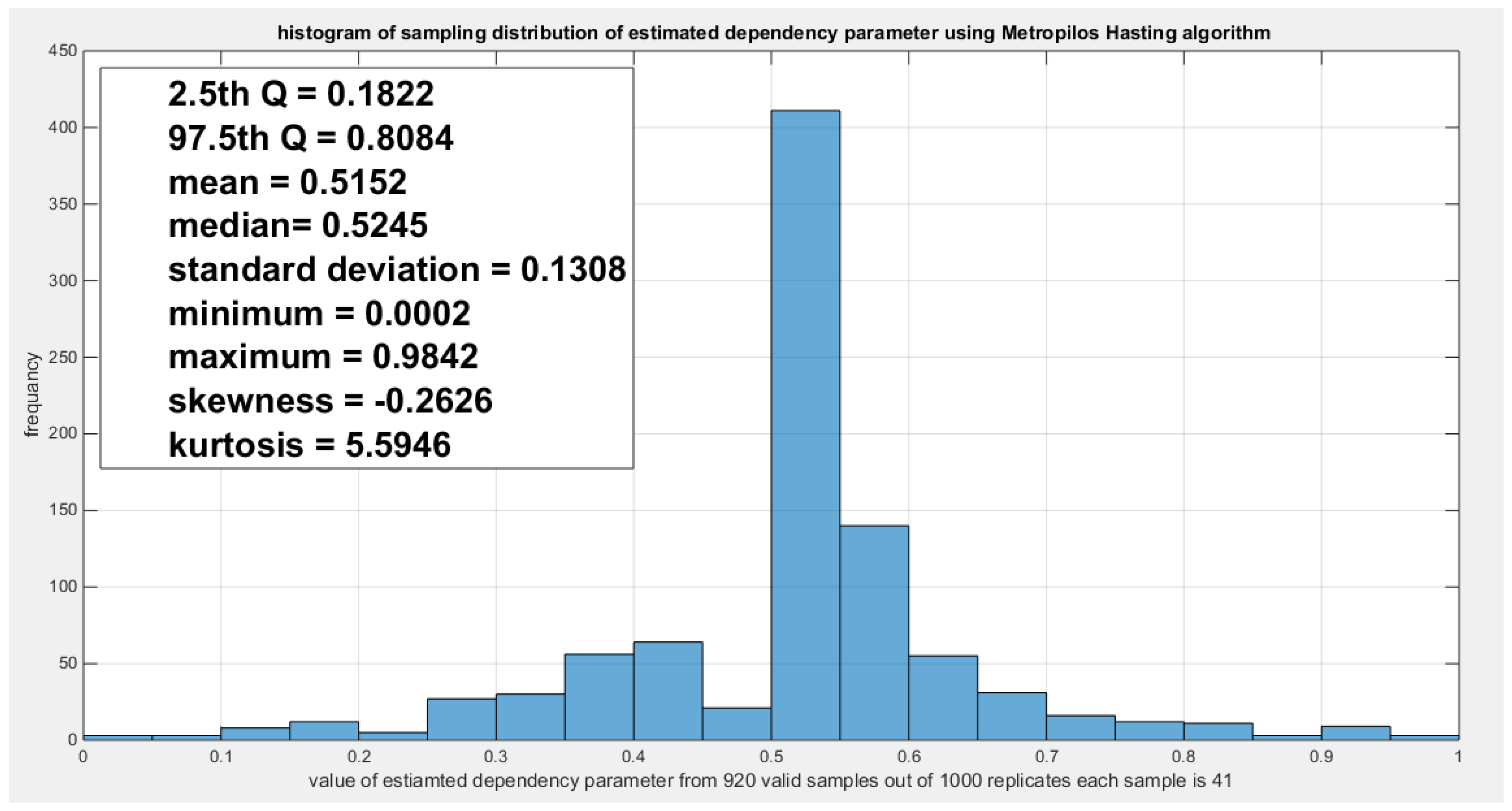
Figure 14.
shows the sampling distribution of the Kendal tau coefficient. Its value 0.5202 is between the two quantiles 2.5th and 97.5th which is the acceptance zones. So the null hypothesis fails to reject its assumption. The p-values (probability of the values less than or equal to 0.5202) is 0.7696 which denotes that this value is far away from both rejection zones.
Figure 14.
shows the sampling distribution of the Kendal tau coefficient. Its value 0.5202 is between the two quantiles 2.5th and 97.5th which is the acceptance zones. So the null hypothesis fails to reject its assumption. The p-values (probability of the values less than or equal to 0.5202) is 0.7696 which denotes that this value is far away from both rejection zones.
According to the sandwich variance the variance covariance matrix for this model is:
The validity indices for the second stage are:
The validity indices for the whole model is the summation of these indices for marginal (first stage) and copula (second stage):
Theoretical upper tail coefficient is 0.6054. At quantile 0.85; the empirical upper tail coefficient in the direction of the ‘water quality’ variable is 0.2 (one point showing joint match out of 5 points in the upper tail at this threshold, 0.85) and in the direction of the ‘feeling safe walk at night’ variable is 0.5 (one point showing joint match out of 2 points in the upper tail at this threshold, 0.85) while the confidence interval of the empirical distribution obtained from bootstrap sampling under the null hypothesis is [0,1]. This is expected because of the small sample size and left skewness of data.
Figure 15 shows the P-P plot of the empirical vs the theoretical copula. Figure 16, Figure 17 and Figure 18 show the surface of the copula density, the contour plot of the copula density, and the contour plot of the copula distribution at the estimated parameter.
Figure 15.
shows the P-P plot of the empirical vs the theoretical copula. The theoretical copula shows near perfect alignment of its lower part with the diagonal line than its upper part.
Figure 15.
shows the P-P plot of the empirical vs the theoretical copula. The theoretical copula shows near perfect alignment of its lower part with the diagonal line than its upper part.
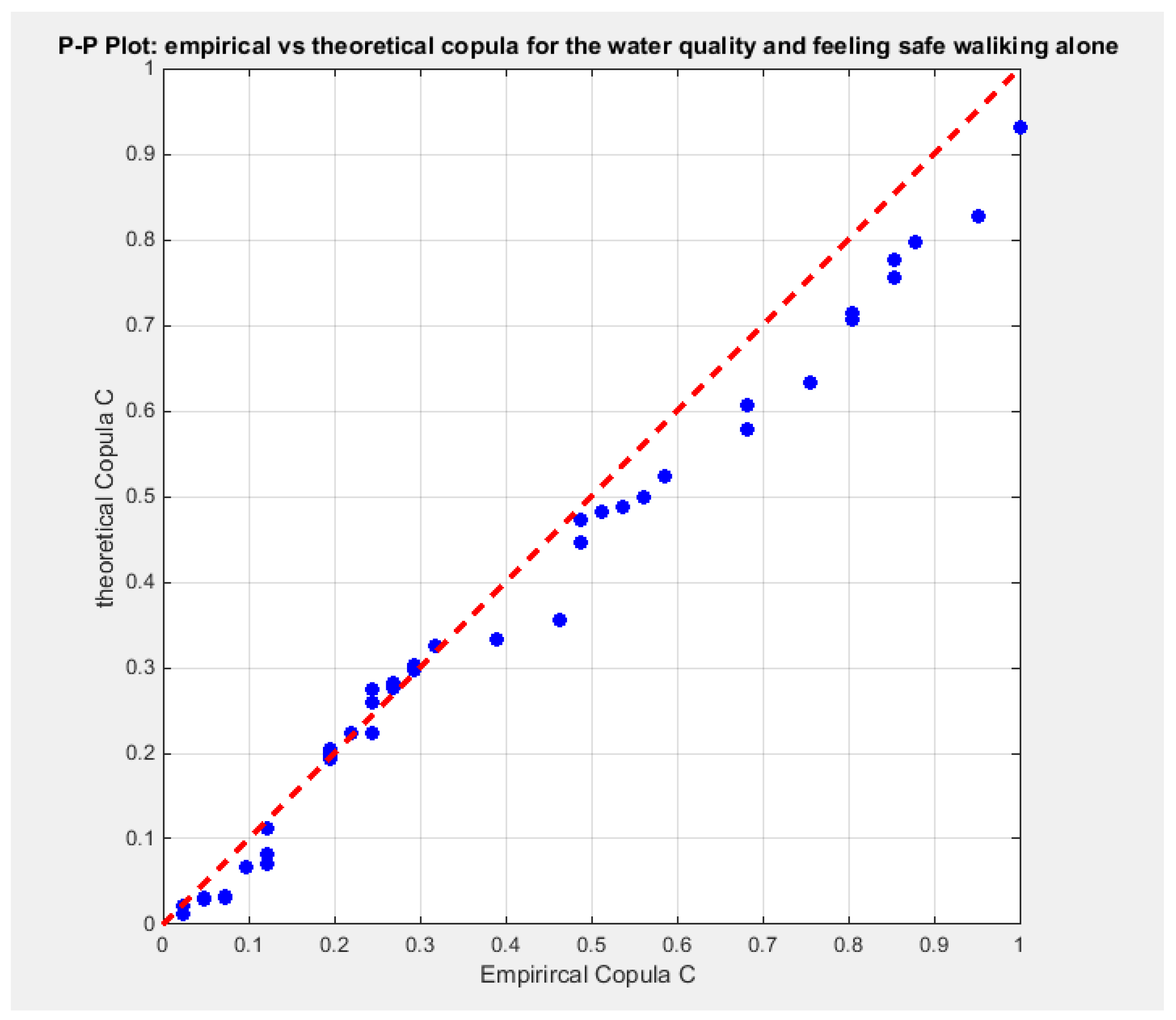
Figure 16.
shows the PDF surface of copula density with parameter 0.4798.
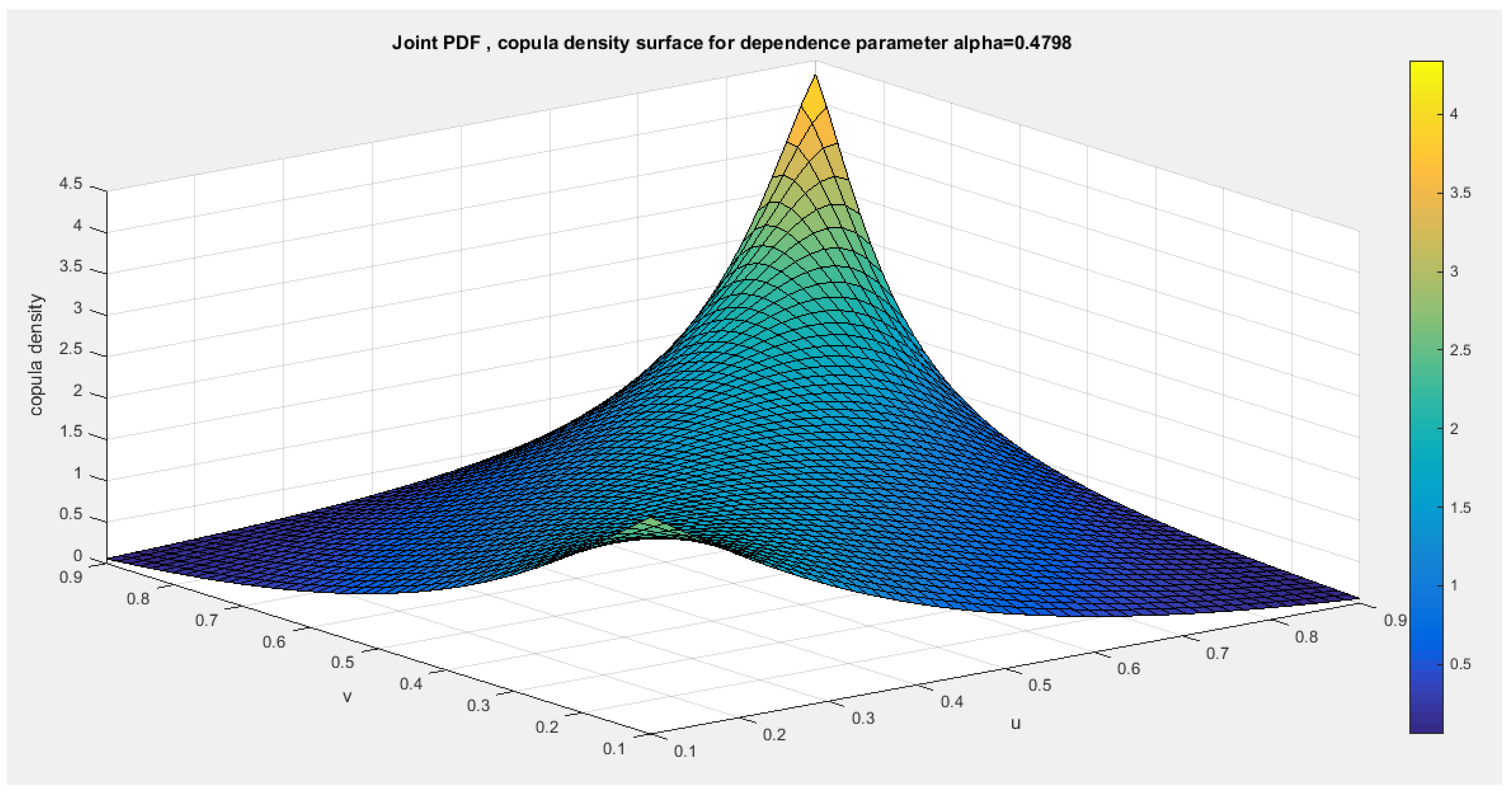
Figure 17.
shows the contour plot of the copula density with parameter 0.4798.
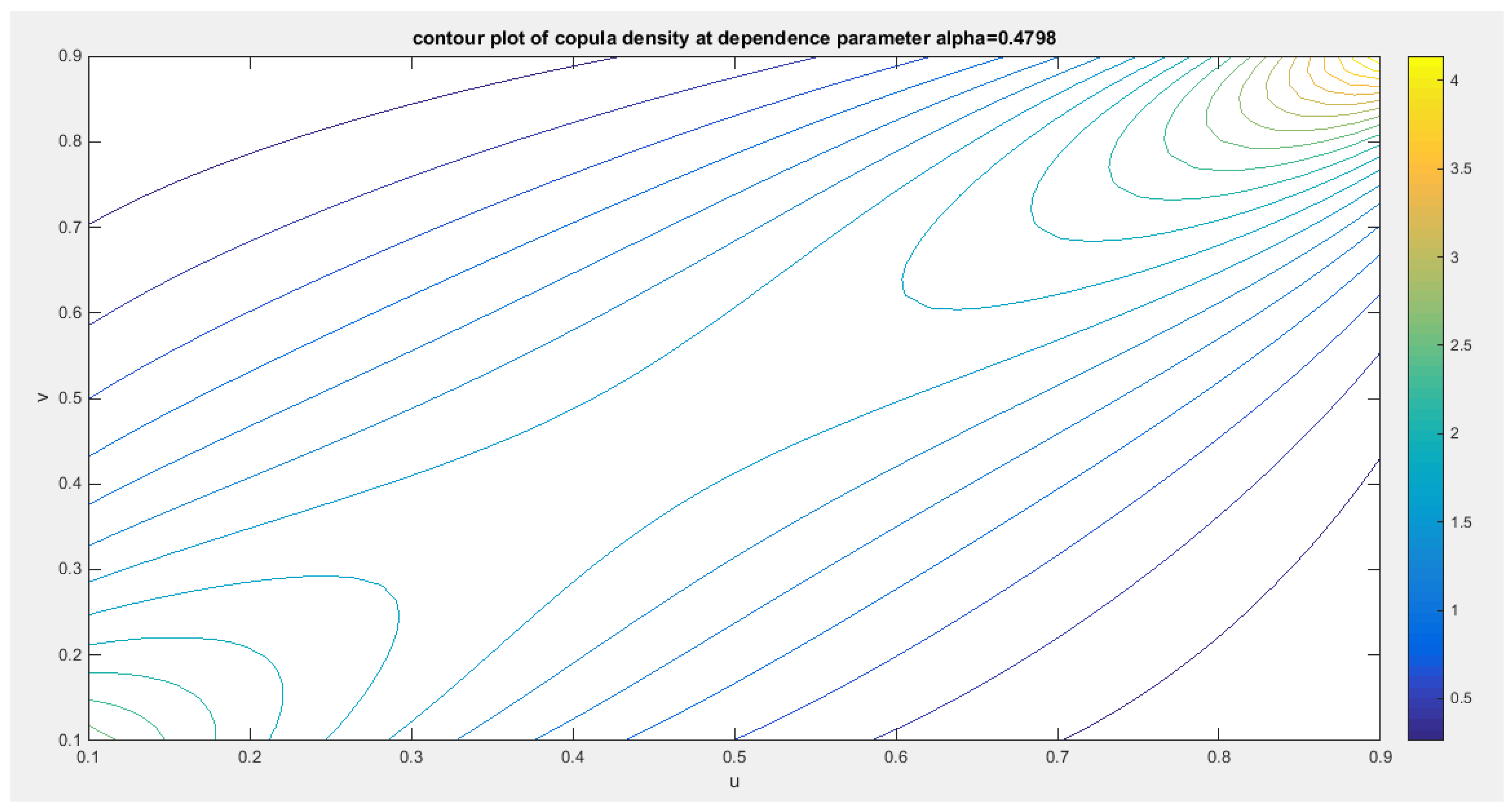
Figure 18.
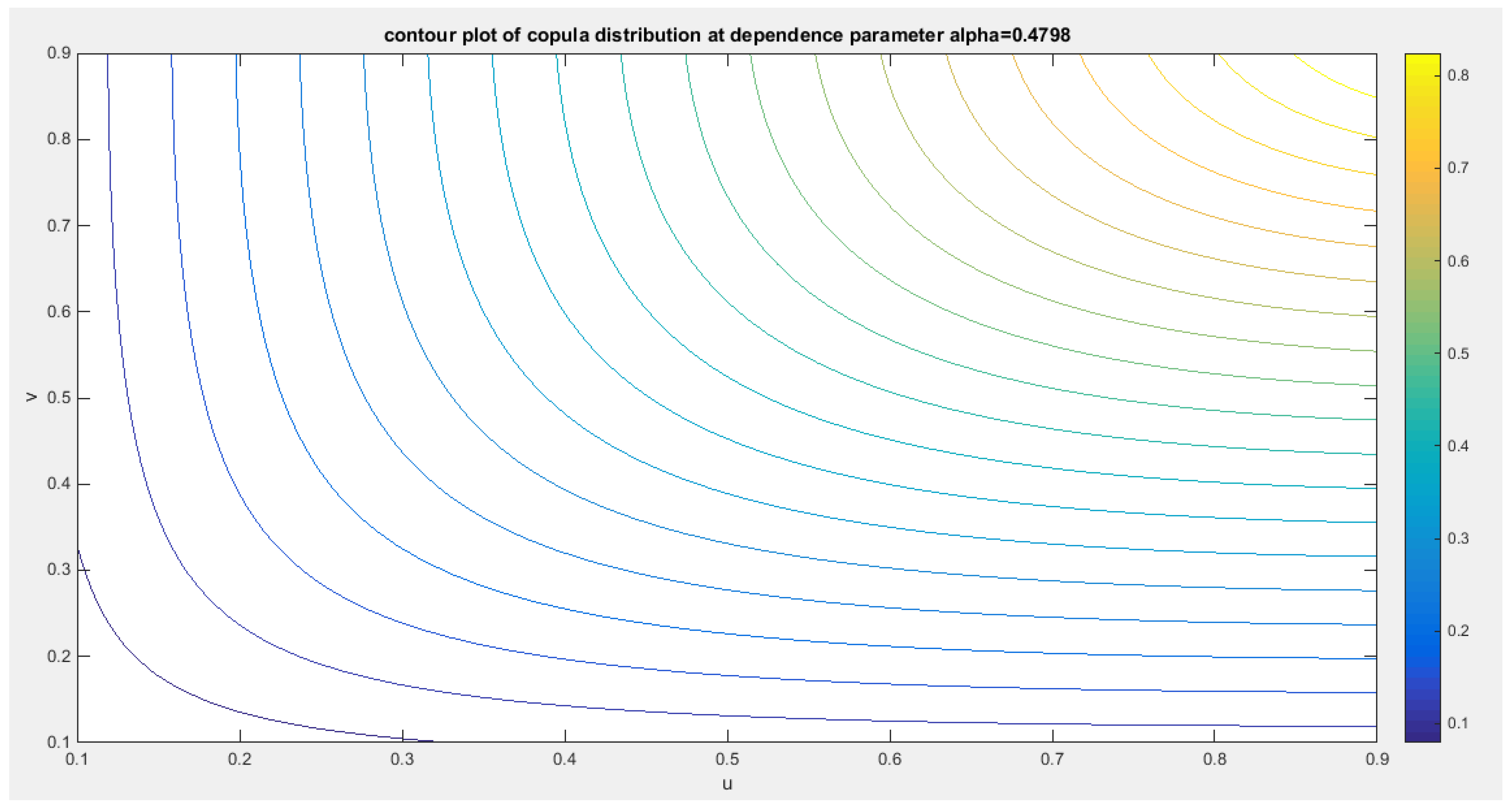
shows the contour plot of the copula distribution with dependency parameter 0.4798.
Second copula
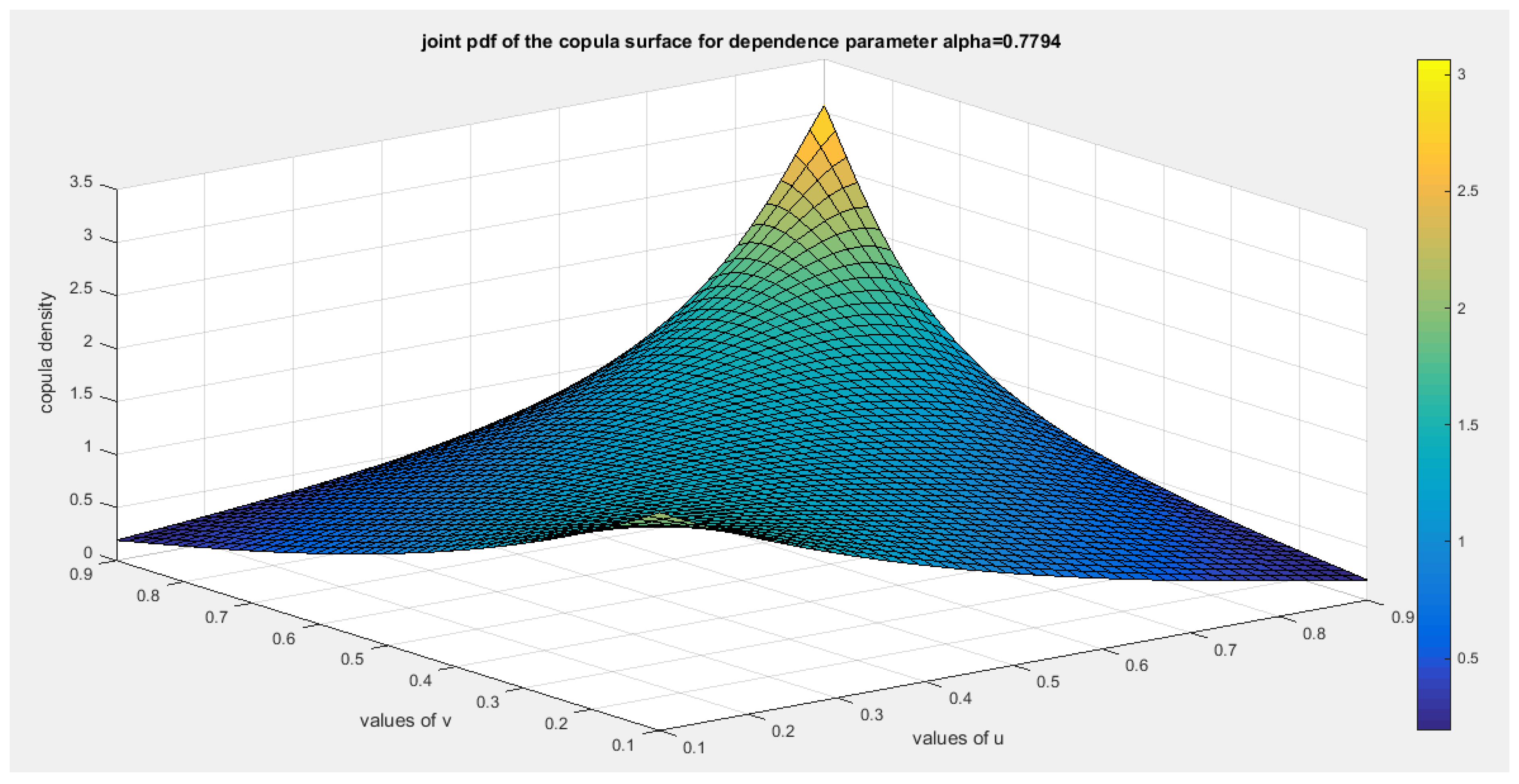
Model the dependency between the ‘water quality’ and ‘quality of support network’: The empirical tau is 0.3929 and the theoretical tau is 0.3926 with dissimilarity value of 3.8927e-04 The estimated dependency parameter, theta , is 0.7794 and estimated variance of 0.0018. The Cramer Von Mises test (CVM) is 0.2142. to test the null hypothesis for dependency, resampling using the Metropolis Hasting algorithm of MCMC procedure was performed. The propositional null hypothesis was stated that the population dependency parameter equals the estimated theta against the alternative hypothesis that the population dependency parameter does not equal the estimated theta. Moreover, the null hypothesis for the equality of the population Kendall tau with the theoretical tau is tested against the alternative hypothesis of not being equal to each other. The null hypothesis for the CVM suggesting that the sampling CVM equals the observed CVM attained from the estimation procedure was also investigated. These are all two sided tests. The sampling distribution of each of the previously mentioned indices, thetas, tau and CVM is shown in Figure 19, Figure 20 and Figure 21. The descriptive statistical indices are shown in each figure. Analysis of the figures denoted that the indices are located within the acceptance region between the 2.5th and 97.5th quantiles. So the null hypotheses fail to be rejected. The copula can be said to pass some of the goodness of fit (GOF) tests for this data. And the dependence parameter mockups, within the milieu of this copula, the connection between the two variables. The confidence interval (CI) for the estimated dependence parameter is (0.2571, 0.9530), for the theoretical tau; it is (0.0918, 0.9078), and for CVM; it is (0.0485, 0.3715).
Figure 19.
shows the sampling distribution of the CVM. The data obtained CVM is 0.2142 and it lies between the 2.5th and the 97.5th quantiles so the null hypothesis is failed to be rejected and the copula fits the data well. The p-value (probability of values less than or equal to 0.2142) is 0.7846, in other words, this 0.2142 does not lay in either of the tail region of rejection.
Figure 19.
shows the sampling distribution of the CVM. The data obtained CVM is 0.2142 and it lies between the 2.5th and the 97.5th quantiles so the null hypothesis is failed to be rejected and the copula fits the data well. The p-value (probability of values less than or equal to 0.2142) is 0.7846, in other words, this 0.2142 does not lay in either of the tail region of rejection.
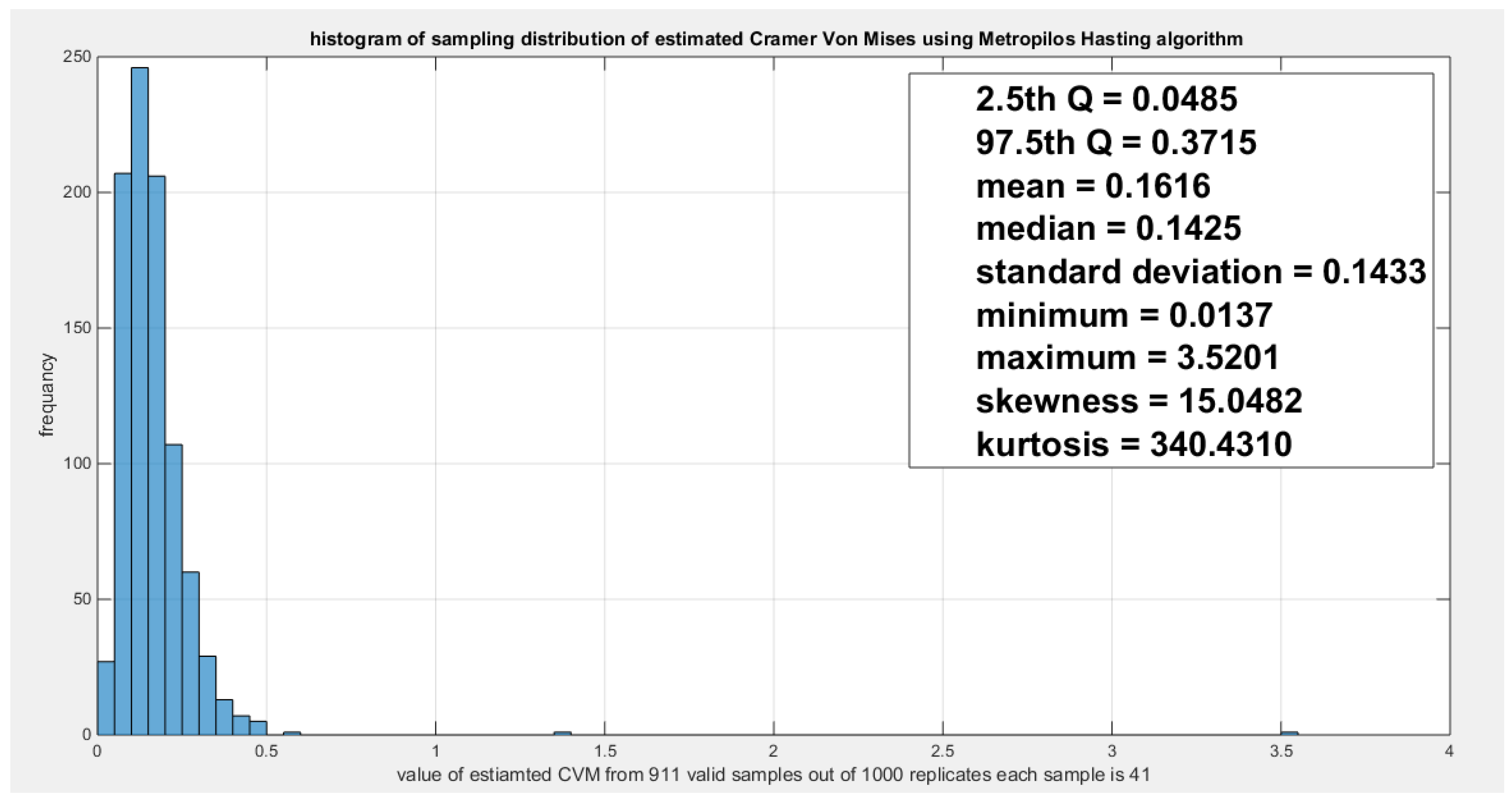
Figure 20.
shows the sampling distribution of the dependency parameter. The 0.7794 lies in the acceptance region between the two quantiles, the 2.5th and the 97.5th quantiles. So the null hypothesis fails to reject its assumption. The p-value (probability of the values being less than or equal to this 0.7794) is 0.3725which indicates that 0.7794 is not placed in either zones of rejection.
Figure 20.
shows the sampling distribution of the dependency parameter. The 0.7794 lies in the acceptance region between the two quantiles, the 2.5th and the 97.5th quantiles. So the null hypothesis fails to reject its assumption. The p-value (probability of the values being less than or equal to this 0.7794) is 0.3725which indicates that 0.7794 is not placed in either zones of rejection.
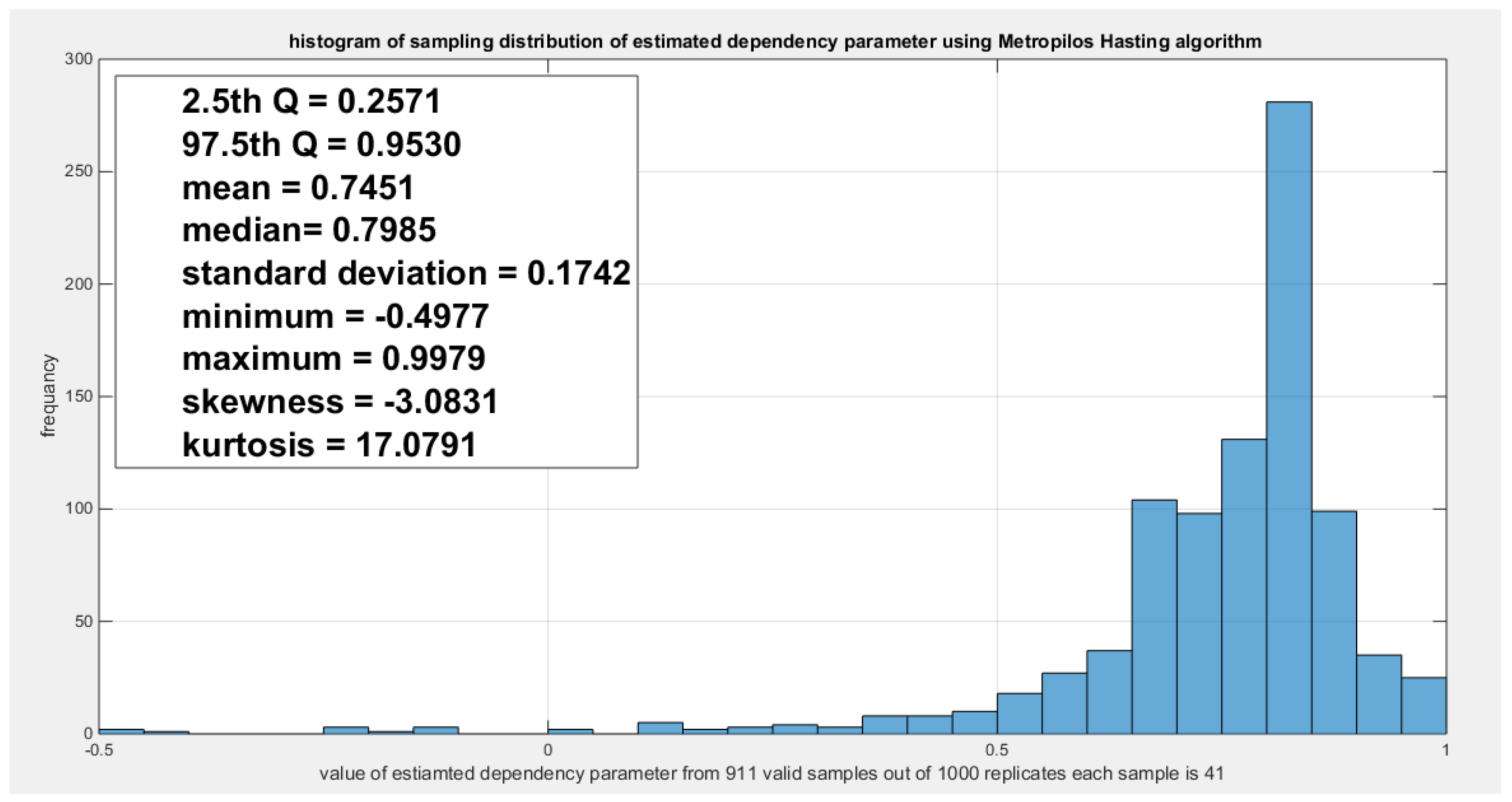
Figure 21.
shows the sampling distribution of the Kendal tau coefficient. Its value 0.3926 is between the two quantiles 2.5th and 97.5th which is the acceptance zones. So the null hypothesis fails to reject its assumption. The p-values (probability of the values less than or equal to 0.3926) is 0.6275 which denotes that this value 0.3926 is far away from both rejection zones on the right and the left.
Figure 21.
shows the sampling distribution of the Kendal tau coefficient. Its value 0.3926 is between the two quantiles 2.5th and 97.5th which is the acceptance zones. So the null hypothesis fails to reject its assumption. The p-values (probability of the values less than or equal to 0.3926) is 0.6275 which denotes that this value 0.3926 is far away from both rejection zones on the right and the left.
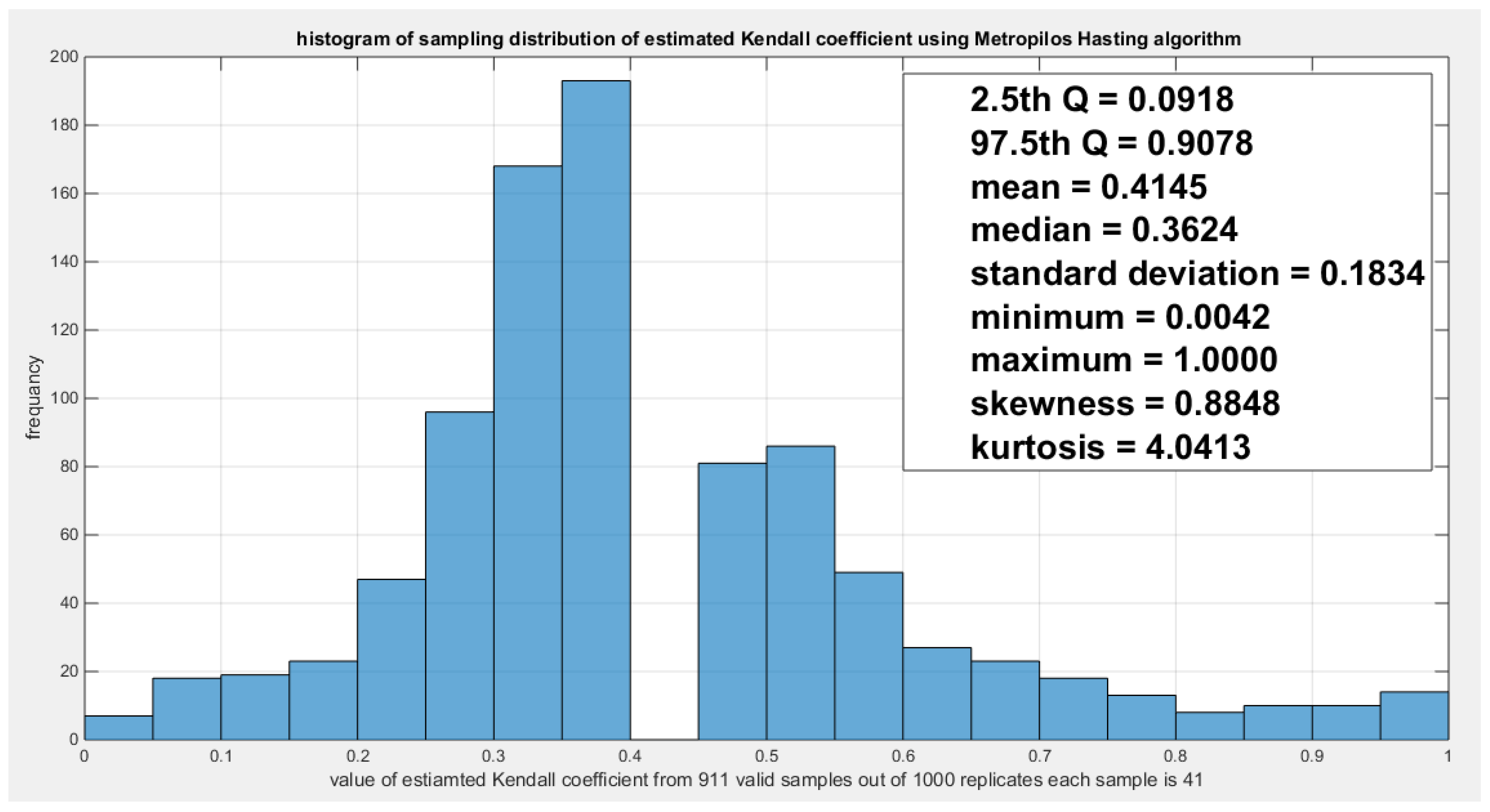
According to the sandwich variance the variance covariance matrix for this model is:
The validity indices for the second stage are:
The validity indices for the whole model is the summation of these indices for marginal (first stage) and copula (second stage):
Theoretical upper tail coefficient is 0.4764. At quantile 0.85; the empirical upper tail coefficient in the direction of the ‘water quality’ variable is 0.2 (one point showing joint match out of 5 points in the upper tail at this threshold, 0.85) and in the direction of the ‘Quality of support network’ variable is 1 (one point showing joint match out of 1 point in the upper tail at this threshold, 0.85) while the confidence interval of the empirical distribution obtained from bootstrap sampling under the null hypothesis is [0,1]. This is expected because of the small sample size and left skewness of data.
Figure 22 shows the P-P plot of the empirical vs the theoretical copula. Figure 23, Figure 24 and Figure 25 show the contour plot of the copula density, the contour plot of the copula distribution, and the surface of the copula density at the estimated parameter.
Figure 22.
shows the P-P plot of the empirical vs the theoretical copula. The theoretical copula shows near perfect alignment of its lower part and its center with the diagonal line than its upper part.
Figure 22.
shows the P-P plot of the empirical vs the theoretical copula. The theoretical copula shows near perfect alignment of its lower part and its center with the diagonal line than its upper part.
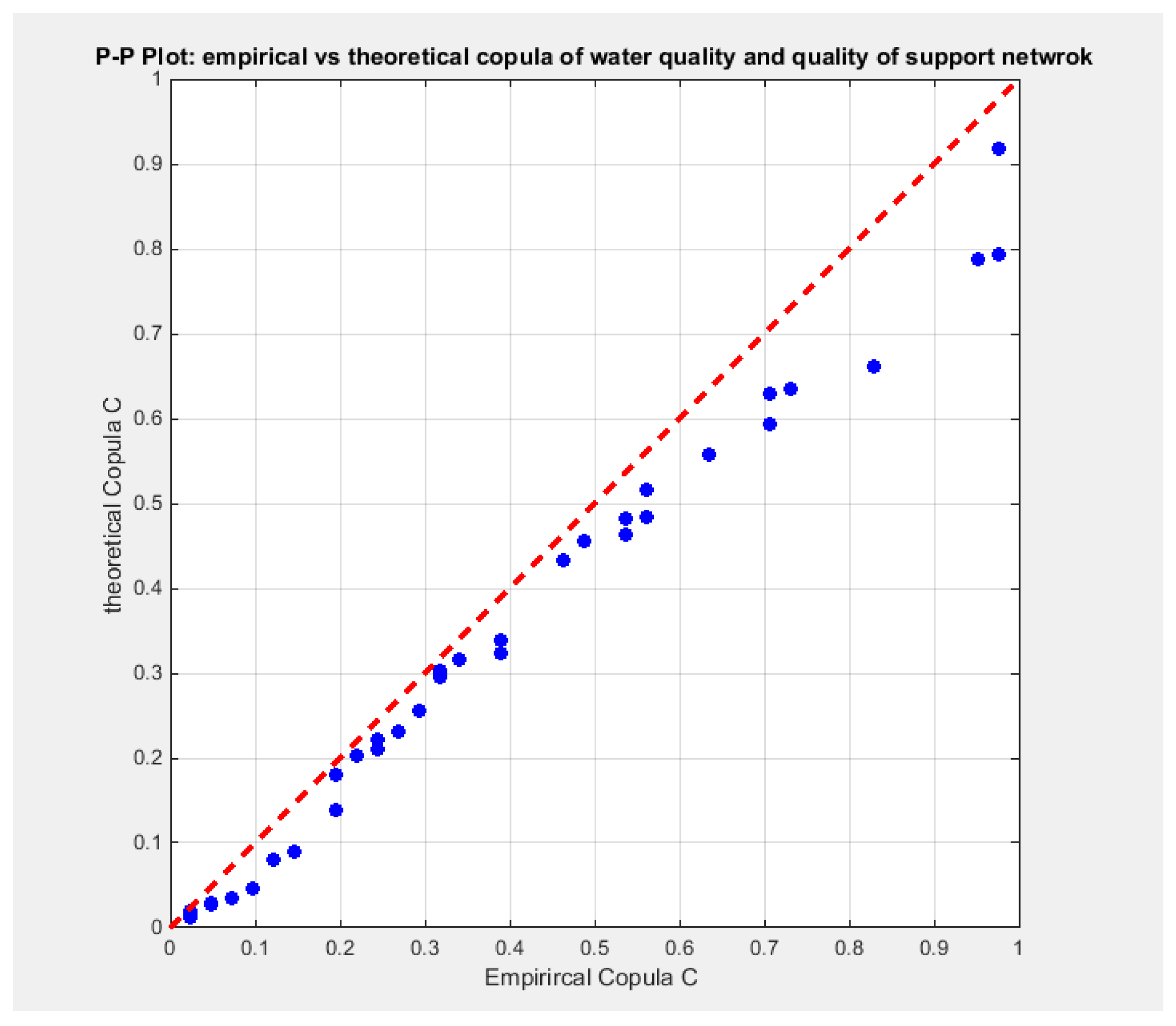
Figure 23.
shows the contour plot of the copula density with parameter 0.7794.
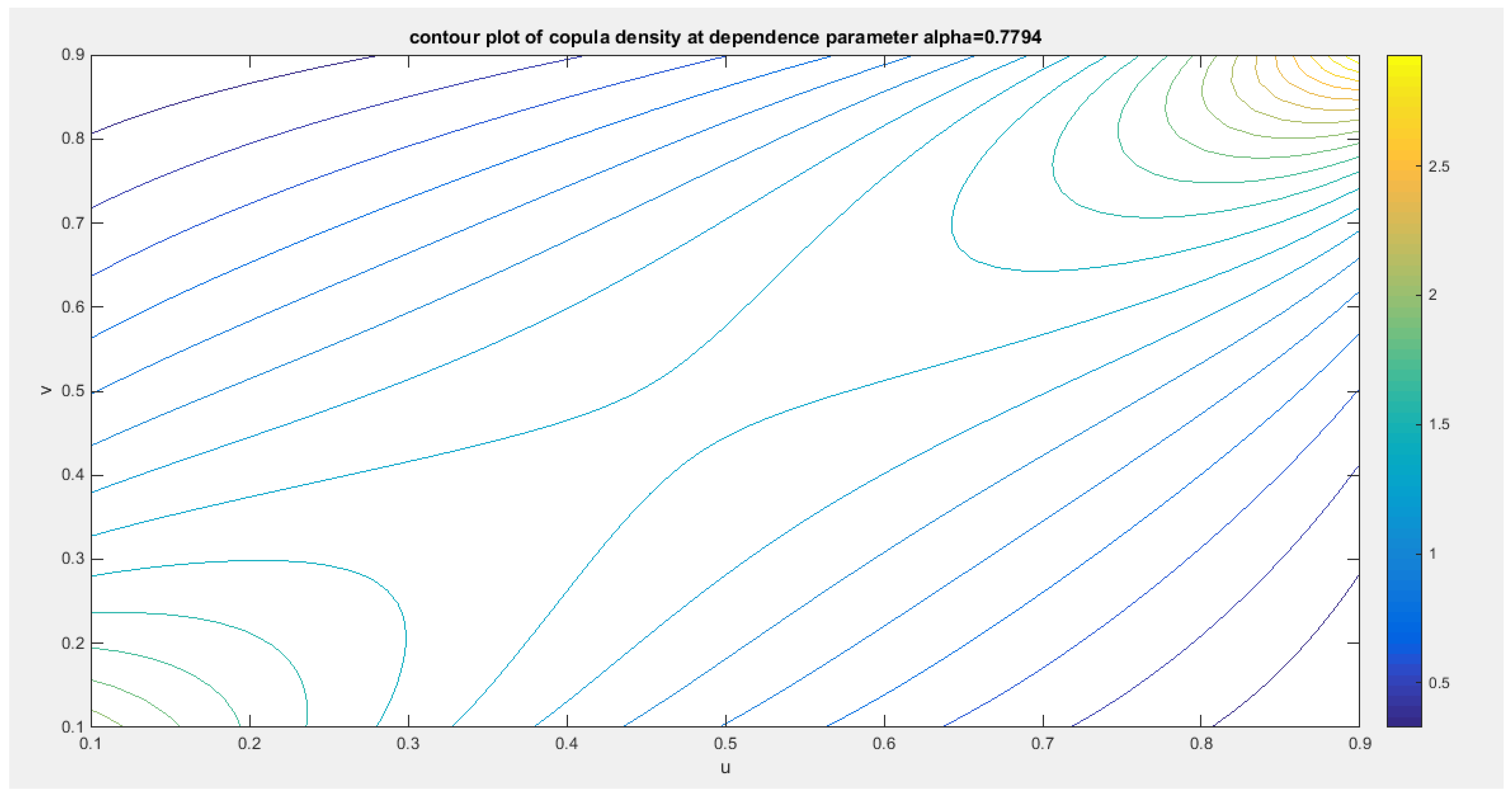
Figure 24.
shows the contour plot of the copula distribution with parameter 0.7794.
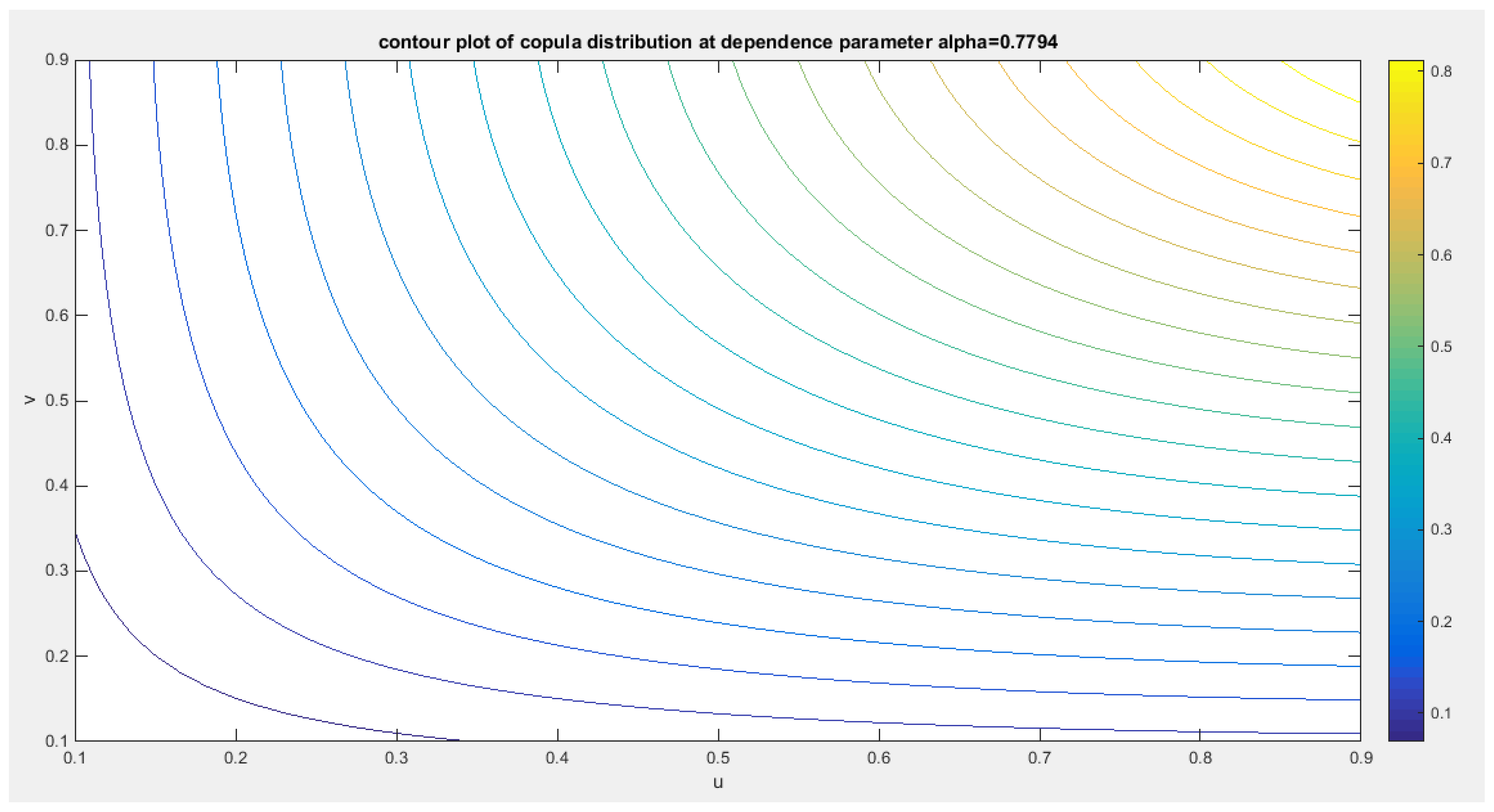
Figure 25.
shows the surface of the copula density with dependency parameter 0.7794.
Another 2 pair of variables for the second copula:
For the OECD data, another two pair of variables are analyzed the household net wealth and the personal earnings. The household net wealth measures the total value of assets possessed by the household minus their obligations like debts, loans, and mortgages. These data are available in USD, and converted to unit interval through division by 1000000. The personal earnings measure the average income earned by persons, typically on an annual or monthly basis, reflecting the income levels and earning potential of the workforce. These data are also expressed in USD and converted to belong to unit interval through division by 100000. These data are available for 24 countries in this same data platform as shown in Table 5.
Table 5.
Household net wealth indicator versus personal earnings indicator in the OECD countries.
| Austria | Belgium | Canada | Chile | Denmark | Estonia | Finland | |
| Household net wealth | 309637 | 447607 | 478240 | 135787 | 149864 | 188627 | 230032 |
| Personal earnings | 53132 | 54327 | 55342 | 26729 | 58430 | 30720 | 46230 |
| France | Germany | Greece | Hungary | Ireland | Italy | Latvia | |
| Household net wealth | 298639 | 304317 | 148323 | 150296 | 370341 | 295020 | 79245 |
| Personal earnings | 45581 | 53745 | 27207 | 25409 | 49474 | 37769 | 29876 |
| Lithuania | Luxembourg | Netherlands | Poland | Portugal |
Slovak Republic |
Slovenia | |
| Household net wealth | 182039 | 941162 | 248599 | 233221 | 255303 | 171425 | 233286 |
| Personal earnings | 31811 | 65854 | 58828 | 32527 | 28410 | 23619 | 41445 |
| Spain | United Kingdom | United states | |||||
| Household net wealth | 366534 | 524422 | 684500 | ||||
| Personal earnings | 37922 | 47147 | 69392 |
Table 6.
descriptive statistics of the indicators (household net wealth and personal earnings).
| indicator | min | mean | Standard deviation | skewness | kurtosis | 25percentile | 50percentile | 75percentile | max |
|---|---|---|---|---|---|---|---|---|---|
| Household net wealth | 0.0792 | 0.3094 | 0.1951 | 1.8194 | 6.9370 | 0.1767 | 0.252 | 0.3684 | 0.9412 |
| Personal earnings | 0.2362 | 0.4296 | 0.1369 | 0.2503 | 1.8851 | 0.3030 | 0.4351 | 0.5404 | 0.6939 |
Table 7.
Kendall tau coefficient of the indicators.
| Household net wealth | Personal earnings | |
|---|---|---|
| Household net wealth | 1 |
0.5507 (0.0001) |
| Personal earnings |
0.5507 (0.0001) |
1 |
Table 8.
statistical validity indices of the two indicators.
| indicator | Estimated theta | variance | AIC | CAIC | BIC | HQIC | KS-test | Ho | p-value of KS-test |
|---|---|---|---|---|---|---|---|---|---|
| Household net wealth | 1.2689 | 0.0087 | -10.423 | -10.2411 | -9.2449 | -10.1104 | 0.2341 | Fail to reject | 0.1219 |
| Personal earnings | 1.0418 | 0.0058 | -12.9361 | -12.7543 | -11.758 | -12.6236 | 0.2496 | Fail to reject | 0.0837 |
Figure 26.
shows Boxplot of household net wealth and the personal earnings denoting right side skewness.
Figure 26.
shows Boxplot of household net wealth and the personal earnings denoting right side skewness.
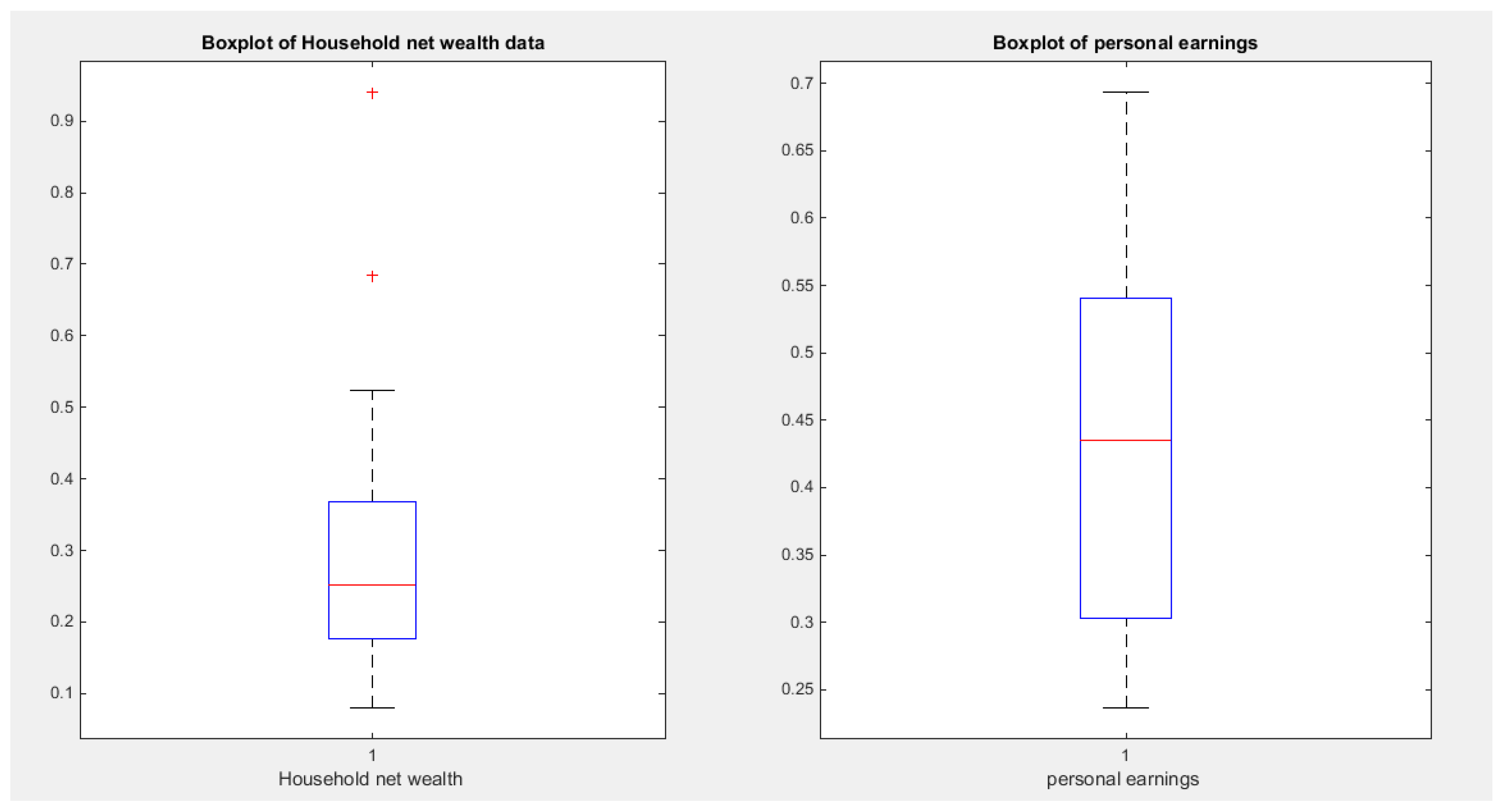
Figure 27.
shows scatter plot of the household net wealth vs personal earnings and the data are mainly concentrated on the left lower corner and the center pointing to the presence of lower tail dependency.
Figure 27.
shows scatter plot of the household net wealth vs personal earnings and the data are mainly concentrated on the left lower corner and the center pointing to the presence of lower tail dependency.
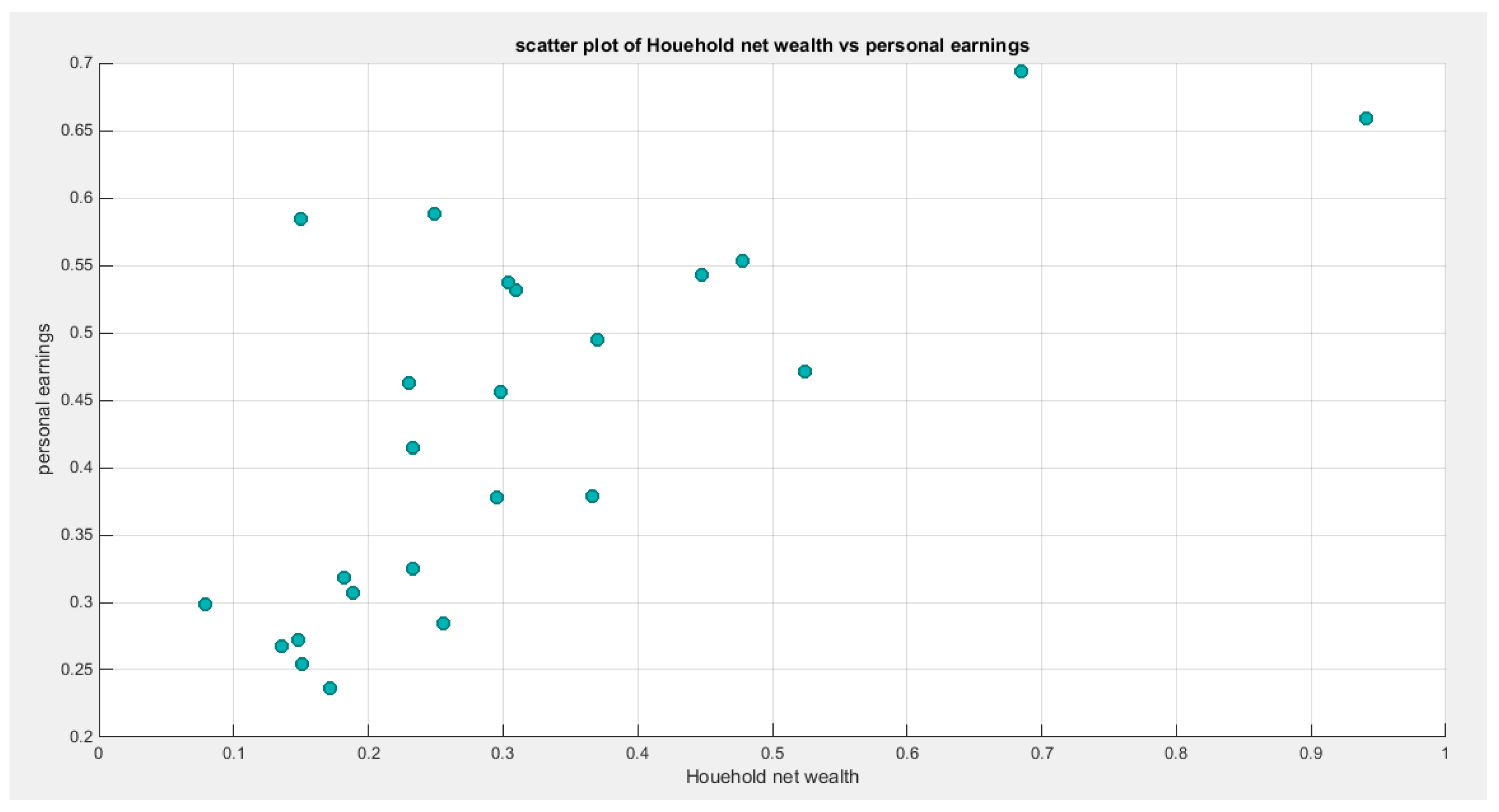
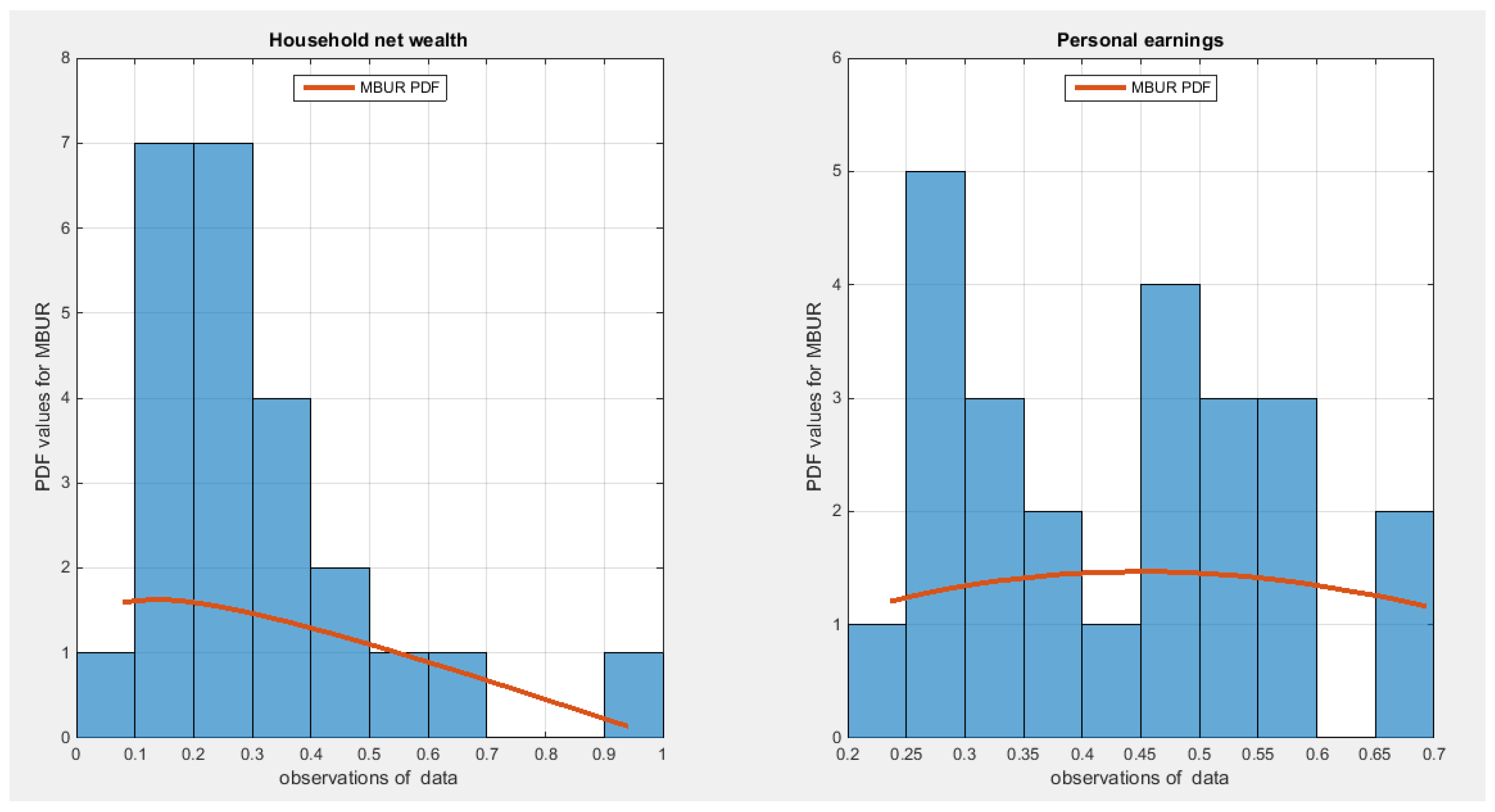
Figure 28.
shows the histogram of the two indicators which exhibit right sided skewness. The graph also shows the fitted MBUR curve for each indicator. The household net wealth indicator exhibits more kurtosis and skewness than the personal earnings indicator.
Figure 28.
shows the histogram of the two indicators which exhibit right sided skewness. The graph also shows the fitted MBUR curve for each indicator. The household net wealth indicator exhibits more kurtosis and skewness than the personal earnings indicator.
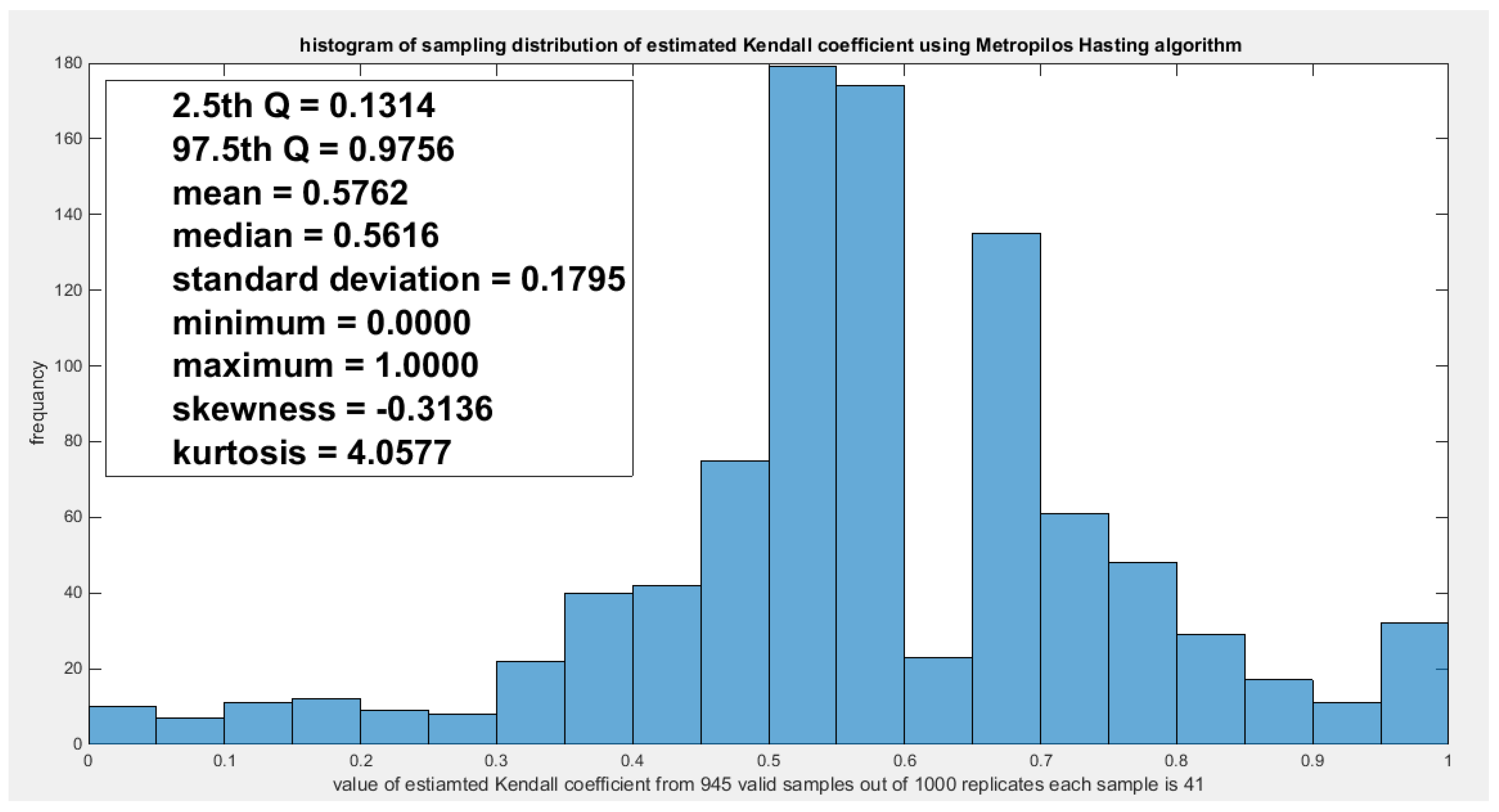
Second copula Model the dependency between the ‘household net wealth’ and ‘personal earnings’: The empirical tau is 0.5507 and the theoretical tau is 0.5507 with dissimilarity value of 7.1985e-05. The estimated dependency parameter, theta , is 0.6703 and estimated variance of 0.0018. The Cramer Von Mises test (CVM) is 0.4281. to test the null hypothesis for dependency, resampling using the Metropolis Hasting algorithm of MCMC procedure was performed. The propositional null hypothesis was stated that the population dependency parameter equals the estimated theta against the alternative hypothesis that the population dependency parameter does not equal the estimated theta. Moreover, the null hypothesis for the equality of the population Kendall tau with the theoretical tau is tested against the alternative hypothesis of not being equal to each other. The null hypothesis for the CVM suggesting that the sampling CVM equals the observed CVM attained from the estimation procedure was also investigated. These are all two sided tests. The sampling distribution of each of the previously mentioned indices, thetas, tau and CVM is shown in Figure 29, Figure 30 and Figure 31. The descriptive statistical indices are shown in each figure. Analysis of the figures denoted that the indices are located within the acceptance region between the 2.5th and 97.5th quantiles. So the null hypotheses fail to be rejected. The copula can be said to pass some of the goodness of fit (GOF) tests for this data. And the dependence parameter mockups, within the milieu of this copula, the connection between the two variables. The confidence interval (CI) for the estimated dependence parameter is (-0.0408, 0.9268), for the theoretical tau; it is (0.1314, 0.9756), and for CVM; it is (0.0368, 0.4871).
Figure 29.
shows the sampling distribution of the CVM. The data obtained CVM is 0.4281 and it lays between the 2.5th and the 97.5th quantiles so the null hypothesis is failed to be rejected and the copula fits the data well. The p-value (probability of values less than or equal to 0.4281) is 0.9683, in other words, this 0.4281 does not lay in either of the tail regions of rejection.
Figure 29.
shows the sampling distribution of the CVM. The data obtained CVM is 0.4281 and it lays between the 2.5th and the 97.5th quantiles so the null hypothesis is failed to be rejected and the copula fits the data well. The p-value (probability of values less than or equal to 0.4281) is 0.9683, in other words, this 0.4281 does not lay in either of the tail regions of rejection.
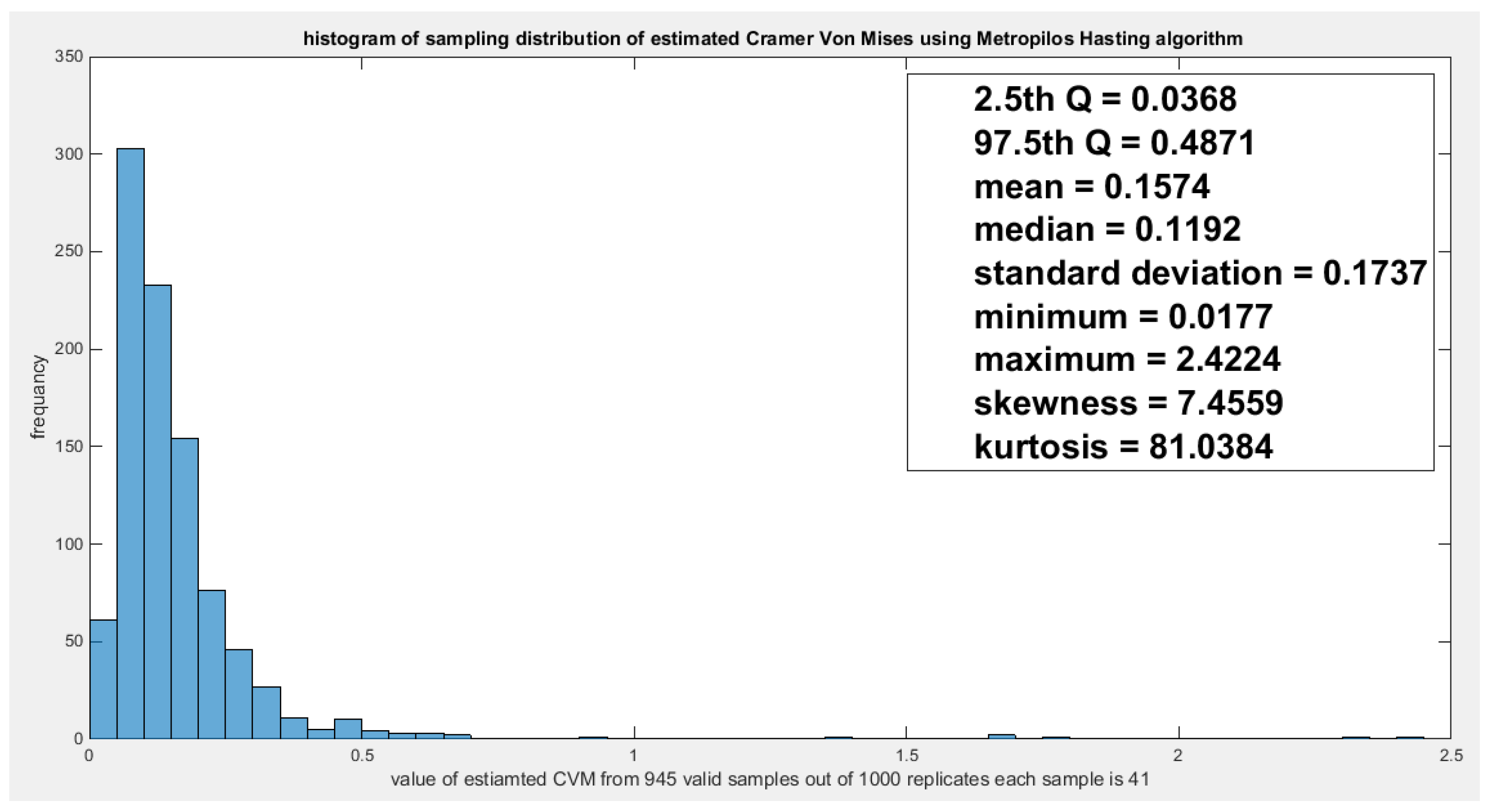
Figure 30.
shows the sampling distribution of the dependency parameter. The 0.6703 lays in the acceptance region between the two quantiles, the 2.5th and the 97.5th quantiles. So the null hypothesis fails to reject its assumption. The p-value (probability of the values being less than or equal to this 0.6703) is 0.5651, which indicates that 0.6703 is not placed in either zones of rejection.
Figure 30.
shows the sampling distribution of the dependency parameter. The 0.6703 lays in the acceptance region between the two quantiles, the 2.5th and the 97.5th quantiles. So the null hypothesis fails to reject its assumption. The p-value (probability of the values being less than or equal to this 0.6703) is 0.5651, which indicates that 0.6703 is not placed in either zones of rejection.
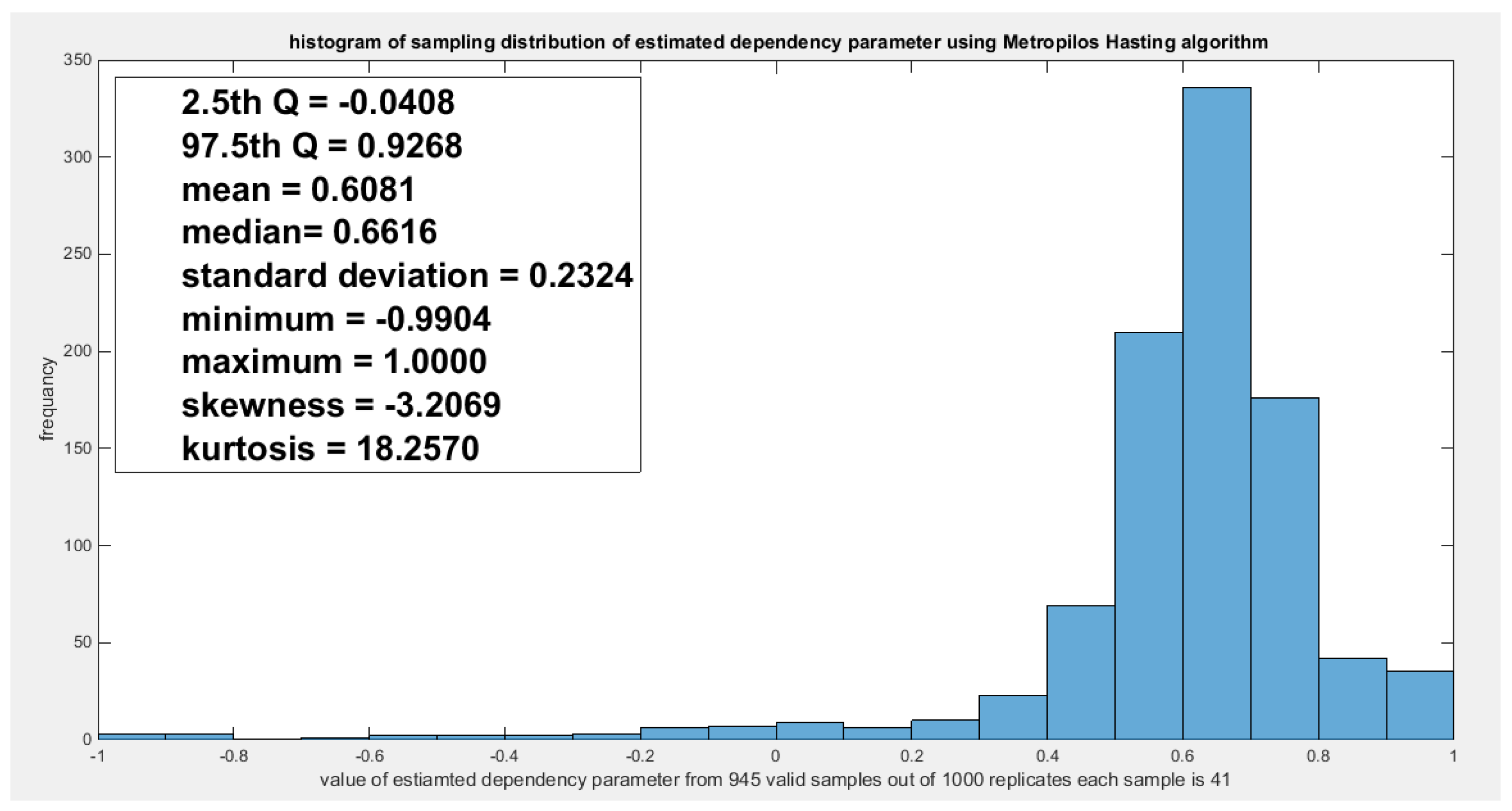
Figure 31.
shows the sampling distribution of the Kendal tau coefficient. Its value 0.5507 is between the two quantiles 2.5th and 97.5th which is the acceptance zone. So the null hypothesis fails to reject its assumption. The p-values (probability of the values less than or equal to 0.5507) is 0.4423 which denotes that this value 0.5507 is far away from both rejection zones on the right and the left.
Figure 31.
shows the sampling distribution of the Kendal tau coefficient. Its value 0.5507 is between the two quantiles 2.5th and 97.5th which is the acceptance zone. So the null hypothesis fails to reject its assumption. The p-values (probability of the values less than or equal to 0.5507) is 0.4423 which denotes that this value 0.5507 is far away from both rejection zones on the right and the left.
According to the sandwich variance the variance covariance matrix for this model is:
The validity indices for the second stage are:
The validity indices for the whole model is the summation of these indices for marginal (first stage) and copula (second stage):
Theoretical upper tail coefficient is 0.6346. At quantile 0.7; the empirical upper tail coefficient in the direction of the ‘households net wealth’ variable is 0.6667 (2 points showing joint match out of 3 points in the upper tail at this threshold, 0.7) and in the direction of the ‘personal earnings’ variable is 1 (2 points showing joint match out of 2 points in the upper tail at this threshold, 0.7) while the confidence interval of the empirical distribution obtained from bootstrap sampling under the null hypothesis is [333,1] in the ‘ households net wealth’ and [0.2857,1] in the direction of ‘personal earnings’. This is expected because of the small sample size and left skewness of data.
Figure 32 shows the P-P plot of the empirical and theoretical copula. Figure 33, Figure 34 and Figure 35 show the surface of the density copula, the contour plot of the density copula and the contour plot of the distribution copula at the estimated dependency parameter.
Figure 32.
shows the P-P plot of the empirical vs the theoretical copula. The theoretical copula shows near perfect alignment of its lower part with the diagonal line than its upper part.
Figure 32.
shows the P-P plot of the empirical vs the theoretical copula. The theoretical copula shows near perfect alignment of its lower part with the diagonal line than its upper part.
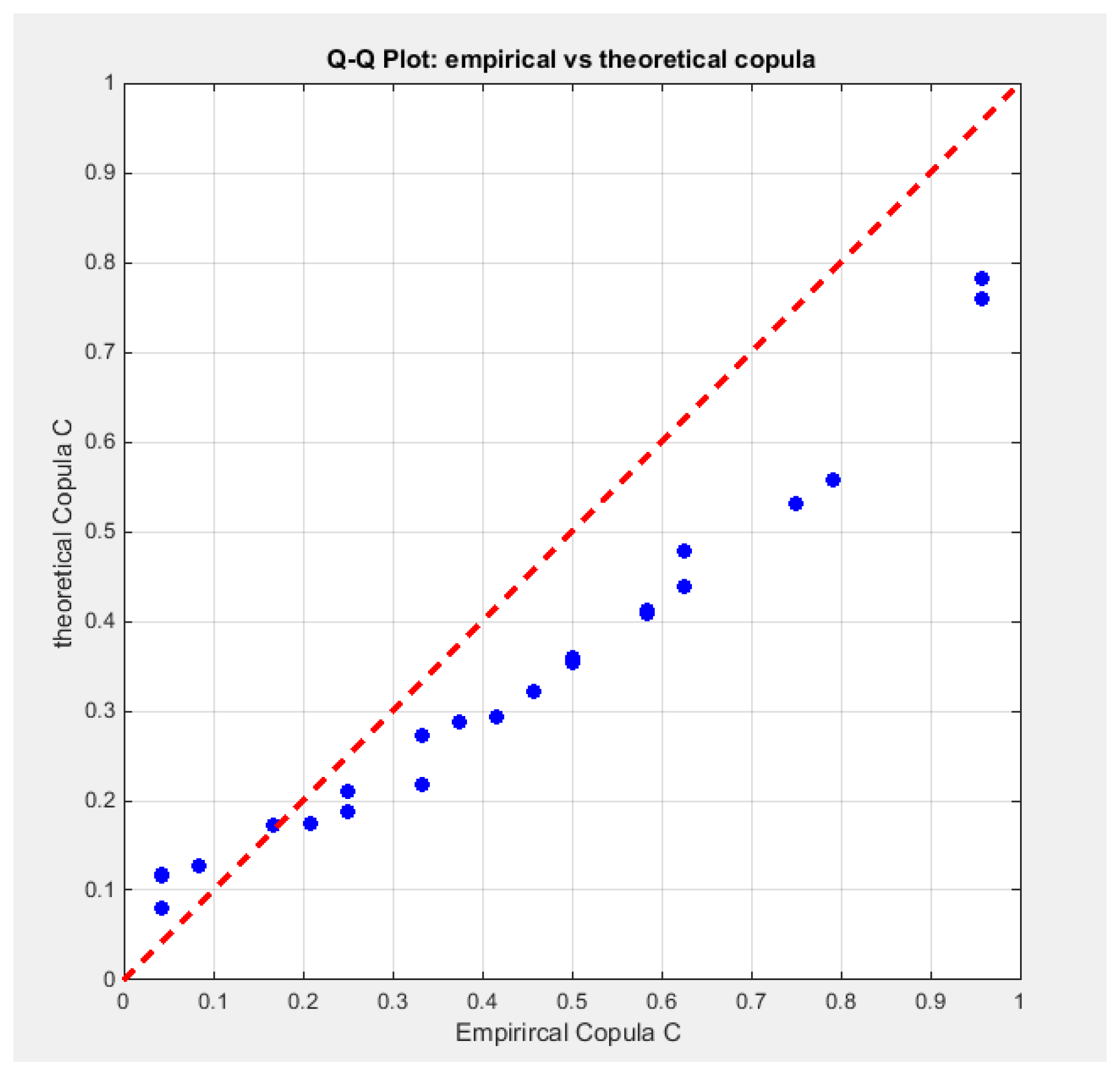
Figure 33.
shows the surface of the copula density with dependency parameter 0.6703.
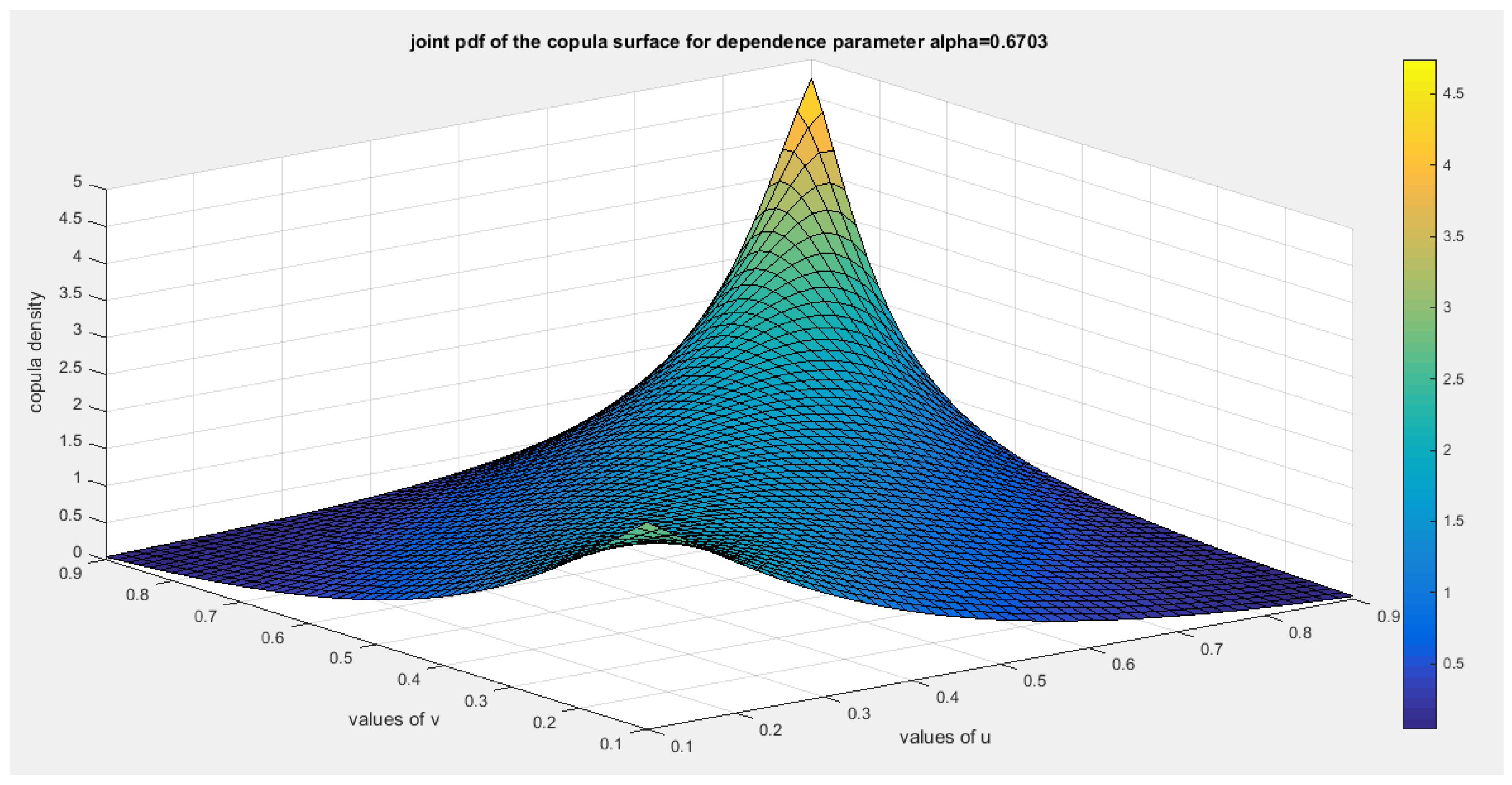
Figure 34.
shows the contour plot of the copula density with dependency parameter 0.6703.
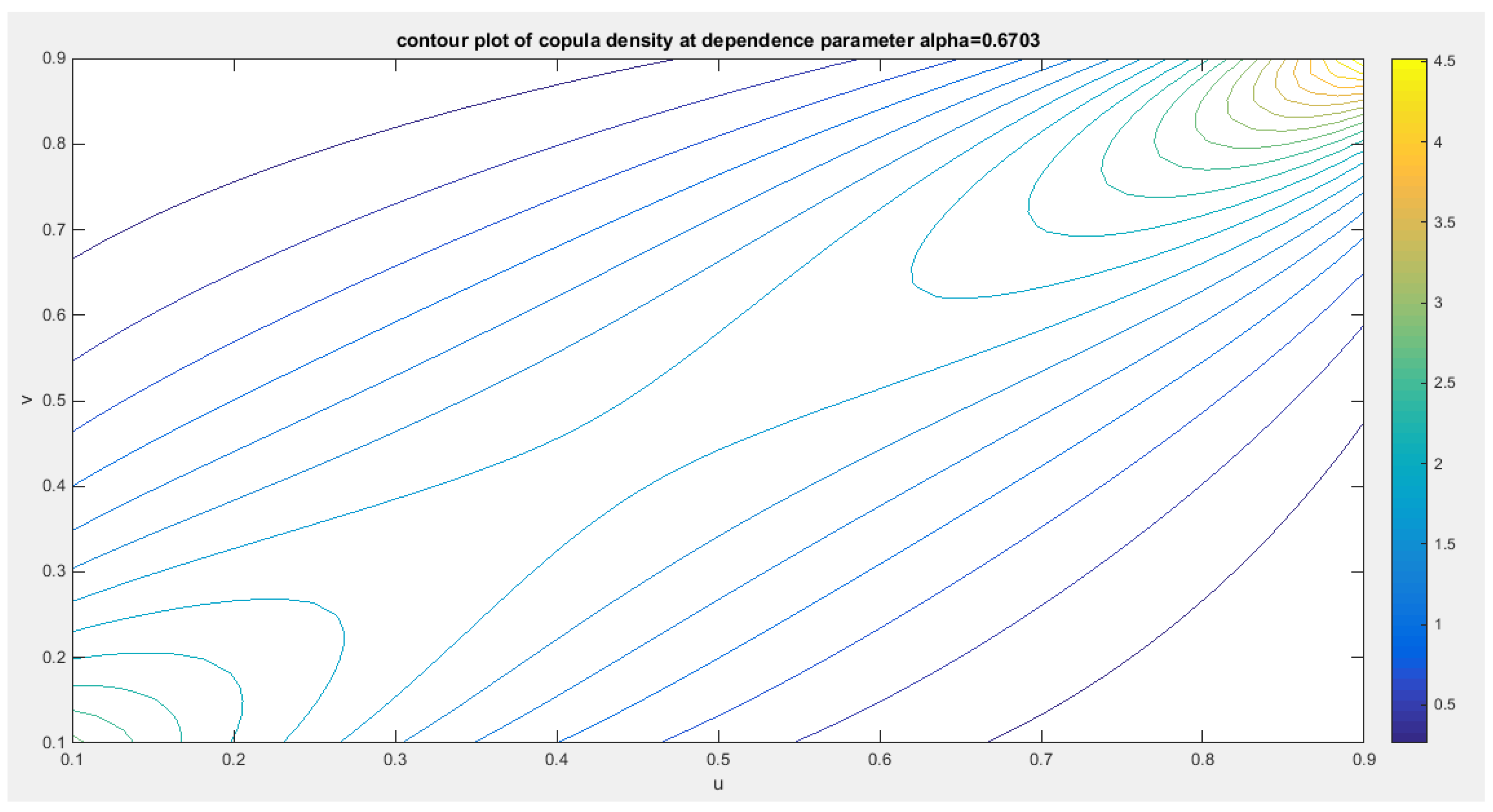
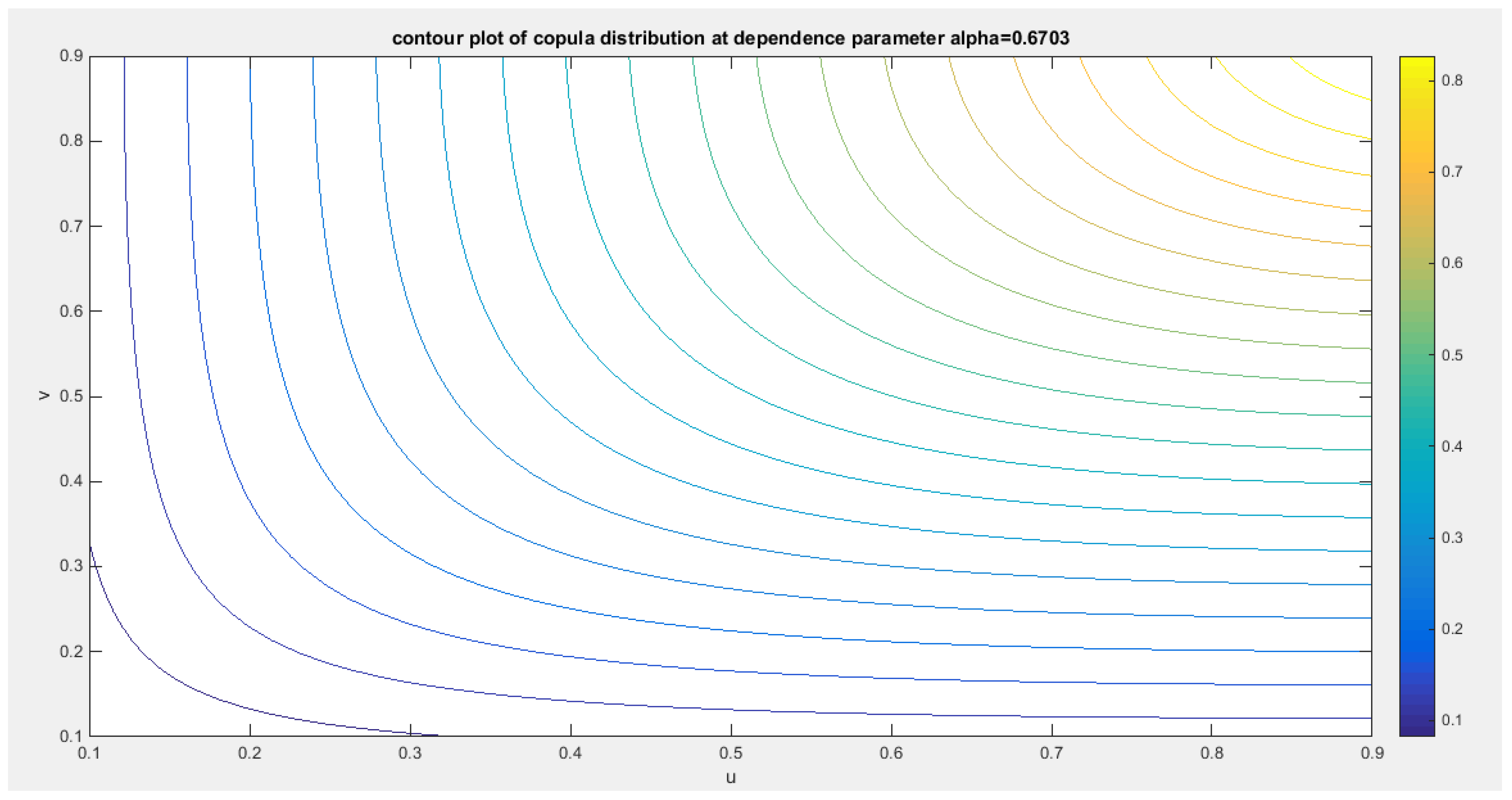
Figure 35.
shows the contour plot of the copula distribution with dependency parameter 0.6703.
Section 5: Conclusions
Both copulas model positive dependency. They can model upper tail dependency but they have no lower tail dependency. The author discussed 2 datasets exhibiting left skewness. Both copulas fit the data well. The author also discussed one dataset exhibiting right skewness and the second copula fit this set well. Both copula fits data that has more or less similar characteristics. The complexity of the the copula density function for both copulas mandates use of IFM method of estimation. This method is preferred over the MLE for its easiness. The robust variance or sandwich variance captures the covariance between the marginal and the copula parameter estimators which are not captures by estimating the variances separately in each stage. The variance of the estimators of marginal parameters increases while the variance of the estimator of copula parameter decreases. Although the sample sizes used in the analysis were small (n=24) and moderate(n=41) both copula model the upper tail dependency well and this was supported by the sampling distribution of the empirical upper tail coefficient.
Section 6: Future Work
These copulas can be mixed with other copulas to better model data with asymmetric dependency. Also other methods of estimation can be attempted like the semiparametric estimation and MLE. Bayesian inference can be considered.
Funding
No funding resource. No funding roles in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript are declared
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable
Availability of data and material
Not applicable. Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Competing interests
The author declares no competing interests of any type.
Authors’ contribution
AI (Attia Iman) carried the conceptualization by formulating the goals, aims of the research article, formal analysis by applying the statistical, mathematical and computational techniques to synthesize and analyze the hypothetical data, carried the methodology by creating the model, software programming and implementation, supervision, writing, drafting, editing, preparation, and creation of the presenting work.
Acknowledgement
Not applicable
References
- Al Turk, L.I.; Abd Elaal, M.K.; Jarwan, R.S. Inference of bivariate generalized exponential distribution based on copula functions. Applied Mathematical Sciences 2017, 11, 1155–1186. [Google Scholar] [CrossRef]
- Attia, I. A Novel One Parameter Unit Distribution: Median Based Unit Rayleigh: Properties and Estimations. Preprint 2024. [CrossRef]
- Bhat, C.R.; Eluru, N. A copula-based approach to accommodate residential self-selection effects in travel behavior modeling. Transportation Research Part B: Methodological 2009, 43, 749–765. [Google Scholar] [CrossRef]
- Chen, X. Chapter 76 Large Sample Sieve Estimation of Semi-Nonparametric Models. In Handbook of Econometrics; Elsevier, 2007; pp. 5549–5632. [Google Scholar]
- De Lira Salvatierra, I.; Patton, A.J. Dynamic copula models and high frequency data. Journal of Empirical Finance 2015, 30, 120–135. [Google Scholar] [CrossRef]
- Dokuzoğlu, D.; Purutçuoğlu, V. Comprehensive Analyses of Gaussian Graphical Model under Different Biological Networks. Acta Physica Polonica A 2017, 132, 1106–1111. [Google Scholar] [CrossRef]
- Genest, C.; Mackay, J. The Joy of Copulas: Bivariate Distributions with Uniform Marginals. The American Statistician 1986, 40, 280–283. [Google Scholar] [CrossRef]
- Godambe, V.P. (Ed.) . Estimating Functions; Oxford University Press: Oxford, UK, 1991. [Google Scholar] [CrossRef]
- Gomes, M.; Radice, R.; Camarena Brenes, J.; Marra, G. Copula selection models for non-Gaussian outcomes that are missing not at random. Statistics in Medicine 2019, 38, 480–496. [Google Scholar] [CrossRef]
- Joe, H. Asymptotic efficiency of the two-stage estimation method for copula-based models. Journal of Multivariate Analysis 2005, 94, 401–419. [Google Scholar] [CrossRef]
- Kilgore, R.T.; Thompson, D.B. Estimating Joint Flow Probabilities at Stream Confluences by Using Copulas. Transportation Research Record: Journal of the Transportation Research Board 2011, 2262, 200–206. [Google Scholar] [CrossRef]
- Kim, G.; Silvapulle, M.J.; Silvapulle, P. Comparison of semiparametric and parametric methods for estimating copulas. Computational Statistics & Data Analysis 2007, 51, 2836–2850. [Google Scholar] [CrossRef]
- Kole, E.; Koedijk, K.; Verbeek, M. Selecting copulas for risk management. Journal of Banking & Finance 2007, 31, 2405–2423. [Google Scholar] [CrossRef]
- Konigorski, S.; Yilmaz, Y.E.; Bull, S.B. Bivariate genetic association analysis of systolic and diastolic blood pressure by copula models. BMC Proceedings 2014, 8(S1), S72. [Google Scholar] [CrossRef]
- Kuss, O.; Hoyer, A.; Solms, A. Meta-analysis for diagnostic accuracy studies: A new statistical model using beta-binomial distributions and bivariate copulas. Statistics in Medicine 2014, 33, 17–30. [Google Scholar] [CrossRef]
- Lapuyade-Lahorgue, J.; Xue, J.-H.; Ruan, S. Segmenting Multi-Source Images Using Hidden Markov Fields with Copula-Based Multivariate Statistical Distributions. IEEE Transactions on Image Processing 2017, 26, 3187–3195. [Google Scholar] [CrossRef]
- Liu, Z.; Guo, S.; Xiong, L.; Xu, C.-Y. Hydrological uncertainty processor based on a copula function. Hydrological Sciences Journal 2018, 63, 74–86. [Google Scholar] [CrossRef]
- Ma, X.; Luan, S.; Du, B.; Yu, B. Spatial Copula Model for Imputing Traffic Flow Data from Remote Microwave Sensors. Sensors 2017, 17, 2160. [Google Scholar] [CrossRef]
- Oh, D.H.; Patton, A.J. Time-Varying Systemic Risk: Evidence from a Dynamic Copula Model of CDS Spreads. Journal of Business & Economic Statistics 2018, 36, 181–195. [Google Scholar] [CrossRef]
- Oppenheimer, M.; Little, C.M.; Cooke, R.M. Expert judgement and uncertainty quantification for climate change. Nature Climate Change 2016, 6, 445–451. [Google Scholar] [CrossRef]
- Salvadori, G.; Michele, C.D.; Kottegoda, N.T.; Rosso, R. Extremes in Nature: An Approach Using Copulas; Springer: The Netherlands, 2007. [Google Scholar] [CrossRef]
- Schölzel, C.; Friederichs, P. Multivariate non-normally distributed random variables in climate research—introduction to the copula approach. Nonlinear Processes in Geophysics 2008, 15, 761–772. [Google Scholar] [CrossRef]
- Sklar, A. Random Variables, Joint distribution functions, and copulas. Kybernetika 1973, 9, 449–460. [Google Scholar]
- Tsukahara, H. Semiparametric estimation in copula models. Canadian Journal of Statistics 2005, 33, 357–375. [Google Scholar] [CrossRef]
- Valle, D.; Kaplan, D. Quantifying the impacts of dams on riverine hydrology under non-stationary conditions using incomplete data and Gaussian copula models. Science of The Total Environment 2019, 677, 599–611. [Google Scholar] [CrossRef] [PubMed]
- Weiß, G. Copula parameter estimation by maximum-likelihood and minimum-distance estimators: A simulation study. Computational Statistics 2011, 26, 31–54. [Google Scholar] [CrossRef]
- Xu, J.J. Statistical modelling and inference for multivariate and longitudinal discrete response data. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 1996. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



