
Submitted:
03 February 2025
Posted:
19 February 2025
You are already at the latest version
Abstract
This paper presents the mathematical framework of Recurrence Quantification Analysis (RQA) for dynamic video processing, exploring its applications in two primary tasks: scene change detection and adaptive foreground/background segmentation. Originally developed for time series analysis, RQA is employed to identify recurrent patterns within video streams, offering a computationally efficient and robust alternative to conventional deep learning methods. Our approach is evaluated on three annotated video datasets: Autoshot, RAI, and BBC Planet Earth, where it demonstrates effectiveness in detecting abrupt scene changes, achieving results comparable to state-of-the-art techniques. We also apply RQA to foreground/background segmentation using the UCF101 and DAVIS datasets, where it accurately distinguishes between foreground motion and static background regions. Through the examination of heatmaps based on the embedding dimension and Recurrence Plots (RPs), we show that RQA provides precise segmentation, with RPs offering clearer delineation of foreground objects. Our findings indicate that RQA is a promising, flexible, and computationally efficient approach to video analysis, with potential applications across various domains requiring dynamic video processing.
Keywords:
Recurrence Quantification Analysis (RQA)
; Dynamic Video Processing
; Scene Change Detection
; Foreground/Background Segmentation
; Video Analysis
1. Introduction
Recent statistics indicate that the volume of data captured, transmitted, or stored worldwide each day is approximately 149 zettabytes, which is double the amount recorded in 2021 [1]. Furthermore, videos account for the majority of internet data traffic, representing over of the total [2]. Therefore, there is an urgent need to enhance the algorithms currently employed for video analysis, understanding, and compression. Traditionally, videos are captured as a series of frames that contain significant spatial and temporal redundancy. Consequently, for a wide range of tasks, including scene change detection, video segmentation, object detection/tracking, and video compression, it is necessary to conduct extensive comparisons between consecutive frames to minimize redundancy and extract key information from the visual scene. However, this frame-based processing significantly increases computational costs, leading to energy-intensive algorithms that are inefficient, particularly for devices with limited battery life.
In the past decade, event-based technology has undergone extensive research and development to dynamically capture and process visual information in a way that mimics the neural architecture of the human eye and our perception of the world. This technology operates on the principle that crucial information is represented by rapid changes, referred to as "events," inspired by the spiking behavior of biological neurons. Event-based technology has found widespread application in sensors [3], neuromorphic hardware [4], and spiking neural networks [5], which function similarly to artificial neural networks while ensuring energy efficiency.
In this work, we present an alternative method for dynamic video stream processing using Recurrence Quantification Analysis (RQA). Originally developed for time series analysis to detect recurrent patterns, RQA leverages the concept of recurrence, which parallels redundancy in image and video processing—spatiotemporal redundant information refers to data that recurs over time. The application of RQA to video streams was first introduced in [6]. Here, we enhance the mathematical framework of RQA and explore its properties in two key applications: (i) scene change detection and (ii) adaptive foreground/background segmentation over time. Our experiments demonstrate that RQA is computationally efficient and robust, outperforming state-of-the-art deep learning methods in scene change detection. Furthermore, its application to adaptive foreground/background segmentation shows promising results, enabling motion detection approaches akin to event-based processing.
The structure of this paper is as follows: Section 2 provides a brief overview of RQA methods, initially developed for time-series analysis and subsequently adapted for images. Section 3 presents the mathematical framework of the proposed approach, enabling the application of RQA to video streams. The experimental results are discussed in Section 4, which is divided into two parts: the first focuses on the materials, methods, and results when RQA is applied to scene change detection, while the second addresses the materials, methods, and results for foreground/background segmentation. This section also includes all relevant discussions of the experimental findings. Finally, Section 5 summarizes the conclusions of this work.
2. Recurrence Quantification Analysis: Theoretical Framework
Recurrence Quantification Analysis (RQA) is a technique for analyzing time series data by examining the recurrence properties of dynamical systems. Its primary aim is to uncover patterns and dynamics within the system, including determining the optimal embedding dimensionality D and time delay for reconstructing the phase-space trajectory, as proposed by Takens [7]. This reconstructed phase space allows for the identification of recurrence structures, enabling the analysis of whether the original signal exhibits recurrence.
This phase-space reconstruction captures the underlying dynamics of the system by embedding the observable time series into a higher-dimensional space. Specifically, the reconstructed trajectory is represented as a set of vectors in the form:
where comprises a set of vectors generated by starting at an initial point and selecting consecutive points with a time offset of . This technique ensures that the reconstructed dynamics preserve the original system’s topological properties, allowing for the analysis of recurrence structures. By studying the recurrence patterns within this reconstructed space, one can gain insights into the system’s stability, periodicity, and chaotic behavior, even with a single observable variable.
To illustrate recurrence within dynamical systems Eckmann et al. [8] introduced the Recurrence plots (RP). In the recurrence plot (RP), recurrent points are displayed in black, while non-recurrent points are shown in white. The recurrent points are defined by all pairwise distances between vectors and . If the distance is smaller than a threshold then the point in RP is considered recurrent, following the formula:
where represents the Heaviside step function, which equals 0 for and 1 for . The selection of the threshold is critical for identifying recurrences within the RP. Striking the right balance is essential: must be small enough to maintain precision while still ensuring an adequate number of recurrences and recurrent structures [9]. Since there is no universal guideline for choosing , its value should be tailored to the specific application and experimental conditions.
The RP is symmetric, thus the main diagonal line inherently comprises recurrent points, as by definition. To be able to quantify the RPs, various metrics for recurrence quantification analysis have been developed [10,11,12]. Unclear dynamical behaviors in the original time series can be revealed by the measures of RQA. Some of these metrics are the recurrence rate (RR), which indicates the percentage of recurrent points in the RP, the Determinism (DET), which measures the recurrent points present in diagonal structures, the maximal diagonal length (Lmax) excluding the main diagonal, and the entropy (ENT), which quantifies the signal complexity in bits per bin.
2.1. RQA for Image Analysis
An extension of the one-dimensional method of the RPs and their quantification to higher dimensions was proposed by Marwan et al. [13] and later by Wallot et al. [14]. The extension of the method to higher dimensions can serve as an effective approach to manage and analyse multiple features[15]. Their method was applied in 2D images to reveal and quantify recurrent structures within images. For a d-dimensional system, they defined an n-dimensional RP using the following formula:
where is the d-dimensional coordinate vector and is the phase space vector at the location given by the coordinate vector . In other words, the vector stands for the coordinates where and are the row and column indexes of the input image, respectively. The dimension of the resulting RP is , and even though it cannot be visualized, its quantification is still possible by computing the RQA measures in the n-dimensional RP. In the one-dimensional approach, the RP features a main diagonal line. Similarly, in the n-dimensional RP, there are diagonally oriented structures of d dimensions. When the method’s input is a 2D image, the resulting RP is a 4D plot, and slices of that RP can be visualized as 3D subsections of the 4D RP.
The authors in [13] showed that using this extension typical spacial structures could be distinguished employing recurrences. They applied this method to biomedical images, to evaluate the bone structure from CT images of the human proximal tibia. The authors in [16] introduced a method that utilizes a fuzzy c-means clustering approach and RQA measures (FCM-RQAS) for extracting image features, which can then be employed for training a classifier.
3. Proposed Methodology
3.1. RQA for Foreground/Background Segmentation in Videos
In our previous work, we introduced an extension of the RQA method to handle higher-dimensional data. In this study, we build upon that initial approach by enhancing its mathematical framework and improving its representation. Consider a video stream consisting of m frames, where each frame has dimensions pixels, as defined below:
where represents the video and denotes the i-th frame. Each frame is divided into smaller patches, with the patch size determined by the frame dimensions . We assume no overlap between patches, thus, within a frame of size , there are non-overlapping patches. Eq. (5) illustrates the first frame of the video, , divided into patches , where i denotes the frame number, and j identifies the patch within that frame:
For two representative patches, and , corresponding to the top-left and bottom-right pixels of frame , respectively, the content of these patches is given as follows:
Here, represent the pixels of the frame, with coordinates for the top-left corner and for the bottom-right corner.
Each patch of size is finally flattened resulting in a row vector of pixel values, as shown in Eq. (7)
Next, we have to determine the RQA parameters, i.e. the embedding dimension (D) and the time lag (), and then calculate vector V (Equation (8)) for each patch through the frames of the video. We obtain as many vectors V as the number of patches the video is divided, then we apply Equation (2) to obtain the RP for each patch and we observe the recurrences of each patch over time (frames).
3.2. RQA for Scene Change Detection
When RQA is used for scene change detection, the video frames are not divided into smaller patches but run through whole frames. We have a resulting RP for each video. The RP is then scanned with a mask to identify the frames where a scene change occurs. We applied two masks, one to determine the starting frame of a scene and one for the ending frame of a scene. The mask shown in Figure 1 is named mask3 because it has three 1s in the square of 1s. As explained in the experimental results section, we tried the same mask but with different sizes of squares of 1s, and the mask that gave the best results was mask5 in terms of F1 score of our method compared to the ground truth for the data used.
One of the main parameters of RQA is the threshold . For scene change detection is set to low PSNR values, since the whole frame is analyzed and we want to detect a major difference between two frames. Figure 1 (b) shows the Recurrence Plot for one video with frames, each black block along the diagonal defines a scene, and this video according to the RP has 6 consecutive scenes. The masks we are using identify the starting and ending frame, by finding the edges of the black blocks along the diagonal.
4. Experimental Results
4.1. Dataset for Scene Change Detection
The use of RQA for scene change detection is evaluated in three annotated video datasets, each indicating the frame where a scene change occurs. These 3 datasets were also used by the Autoshot approach [17], which applies neural architecture search within a space that integrates advanced 3D ConvNets and Transformers. The first dataset, Autoshot [17], comprises 853 short videos, each lasting less than one minute. The second dataset, RAI [18], includes 10 randomly selected broadcast videos, each 3-4 minutes long, sourced from the Rai Scuola video archive and mainly featuring documentaries and talk shows. The third dataset is the BBC Planet Earth documentary series [19], consisting of 11 long videos, each approximately 50 minutes long.
4.2. Results for Scene Change Detection
We applied our method to the previously mentioned datasets: Autoshot, RAI, and BBC. Due to the sharpness of the masks used in our approach, our method is more effective at detecting abrupt scene changes compared to gradual transitions. We tested various values of ranging from 12 to 20, finding that the optimal values for F1 score were for Autoshot and RAI, and for the BBC dataset. Additionally, as shown in Table 1, the best results in terms of F1 score were achieved with mask5, when comparing our method to the ground truth for the tested data.
Table 2 presents the F1 scores for the three datasets, considering both all scene changes and only abrupt scene changes. Mask5 was used for all tests, with the corresponding values for each dataset listed. The F1 scores for abrupt changes alone are higher across all three datasets, demonstrating that our method more accurately detects instant scene changes. Next, we compare our method with other methods that identify scene changes. Table 3 shows the F1 scores for different video scene change detection methods across various datasets. Autoshot (2023) represents a state-of-the-art approach leveraging neural networks to analyze video data. In contrast, our proposed method, RQA, applies a mathematical framework directly to the video data. We need to highlight that despite the difference in approach, RQA has a comparable F1 score with Autoshot method. Additionally, in some cases, it outperforms other methods and/or has comparable results with them. Notably, most of the methods use neural networks, and the results for RQA highlight its effectiveness and potential.
4.3. Dataset for Adaptive Foreground/Background Segmentation
This application requires short videos that feature a single scene, ideally with no simultaneous motion in the foreground and background. This means that all parts of the frame have motion, making it difficult for our method to distinguish between the two categories. UCF101 dataset [26] is a large dataset of human action, consisting of 101 action classes and more than 13k short clips, making it a very suitable video collection to evaluate our method. DAVIS dataset (Densely Annotated VIdeo Segmentation) [27], consists of 50 high-quality full HD video sequences that cover common video object segmentation challenges such as occlusions, motion blur, and appearance changes. The videos used in this work and the result can be found in the following url https://github.com/dwrakyp/MDPI_videos_results.git.
4.4. Parameter Estimation
The False Nearest Neighbors (FNN) method [28], is used to determine the optimal embedding dimension D for Recurrence Quantification Analysis (RQA). This approach evaluates changes in the distance between neighboring points in phase space as the embedding dimension increases. Initially, neighboring points in a one-dimensional time series are identified, and their distances are recalculated after embedding in higher dimensions using a fixed time lag . If the distance changes significantly, the points are considered false neighbors and further embedding is performed until the distances stabilize, indicating true neighbors and the optimal dimension D. As introduced in [6] FNN is applied to each patch of video frames, reconstructing phase space vectors and calculating pairwise PSNR distance matrices for each D. For every row in the PSNR matrix, the maximum PSNR value is tracked and compared across successive dimensions. If the difference exceeds a threshold , the neighbors are deemed false. The percentage of false neighbors is computed for each D, repeating the process until the optimal embedding dimension is identified.
4.5. Results for Adaptive Foreground/Background Segmentation
We analyzed several videos from the UCF101 dataset [26] and the DAVIS dataset [27], selecting three videos from the UCF101 dataset to showcase the results of our RQA analysis. The first video, titled ’make-up’ and shown in Figure 2 (top), features a stable camera capturing a girl applying make-up with a stationary background and motion limited to the foreground. The second video, ’parade,’ illustrated in Figure 2 (middle), also uses a stable camera, focusing on a road where a parade is passing by, characterized by strong foreground motion (the parade) and minimal background motion. The third video, ’ball,’ represented in Figure 2 (bottom), depicts a stable camera view of a natural landscape with a person on the right throwing a ball; aside from minor leaf movement in the trees, the landscape remains static. These videos were chosen to demonstrate our method’s capability to handle varying types of motion: no movement, subtle movement (leaves), and significant movement (parade, make-up application).
Each video is segmented into patches, and for each patch, the optimal embedding dimension D is determined using the FNN algorithm, with , a value chosen experimentally. A grayscale heatmap illustrating the optimal D is displayed in the middle column of Figure 2. As anticipated, RQA effectively detects and highlights regions of motion in the image, categorizing them as foreground, while areas with minimal or no motion are classified as background. Furthermore, we investigated the role of Recurrence Plots (RPs), which convey critical insights derived from RQA beyond its standard features. The right column of Figure 2 presents a grayscale heatmap generated from the RP for each patch, where high-intensity values indicate background regions and low-intensity values represent foreground regions. Both heatmaps demonstrate effective foreground/background segmentation, but the RP-based heatmap is significantly more precise than the D-value heatmap, providing a more detailed representation of object shapes within the scene. Consequently, depending on the precision required for a given application, our method offers flexibility in achieving varying levels of segmentation accuracy.
5. Conclusions
In this work, we have evaluated the use of Recurrence Quantification Analysis (RQA) for video analysis, focusing on two tasks: scene change detection and adaptive foreground/background segmentation.
For scene change detection, we applied RQA to three video datasets: Autoshot, RAI, and BBC Planet Earth, comparing its performance with several state-of-the-art methods. Our experiments demonstrated that RQA achieves competitive results, particularly in detecting abrupt scene changes. We showed that with optimal parameter tuning, our method can effectively detect scene changes with high F1 scores, which are comparable to the neural network-based Autoshot method. Moreover, RQA performs robustly across different datasets, indicating its generalizability and potential for practical applications.
For adaptive foreground/background segmentation, we used videos from the UCF101 and DAVIS datasets to test our method’s ability to distinguish between foreground and background regions based on motion. We found that RQA successfully identifies regions with significant motion, such as the foreground, while static areas are classified as background. By analyzing the heatmaps of the embedding dimension D and Recurrence Plots (RPs), we demonstrated that our method can produce precise segmentation maps, with RPs offering clearer foreground/background distinctions. The method’s flexibility allows it to adjust to different levels of precision depending on the specific needs of the application.
Overall, RQA proves to be a promising approach for both scene change detection and adaptive foreground/background segmentation, offering high accuracy and flexibility while providing insights into the dynamics of video data. Future work can explore further refinements and the integration of RQA with deep learning-based methods to enhance its performance in more complex video analysis tasks.
Author Contributions
For research articles with several authors, a short paragraph specifying their individual contributions must be provided. The following statements should be used “Conceptualization, E.D.; methodology, T.K. and E.D.; software, T.K.; validation, T.K.; formal analysis, T.K. and E.D.; investigation, T.K.; writing—original draft preparation, T.K. and E.D.; writing—review and editing, P.T.; visualization,T.K.; supervision, P.T.; funding acquisition, E.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Hellenic Foundation for Research and Innovation (HFRI) and the General Secretariat for Research and Technology (GSRT) under grant agreement No. 330 (BrainSIM).
References
- 53 Important Statistics About How Much Data Is Created Every Day in 2024. https://financesonline.com/how-much-data-is-created-every-day/. Accessed: 2024-12-24.
- How Much Data is Generated Every Day (2024). https://whatsthebigdata.com/data-generated-every-day/. Accessed: 2024-05-14.
- Chakravarthi, B.; Verma, A.A.; Daniilidis, K.; Fermuller, C.; Yang, Y. Recent Event Camera Innovations: A Survey, 2024. arXiv:cs.CV/2408.13627.
- Gonzalez, H.A.; Huang, J.; Kelber, F.; Nazeer, K.K.; Langer, T.; Liu, C.; Lohrmann, M.; Rostami, A.; Schöne, M.; Vogginger, B.; et al. SpiNNaker2: A Large-Scale Neuromorphic System for Event-Based and Asynchronous Machine Learning, 2024. arXiv:cs.ET/2401.04491].
- Kundu, S.; Zhu, R.J.; Jaiswal, A.; Beerel, P.A. Recent Advances in Scalable Energy-Efficient and Trustworthy Spiking Neural Networks: from Algorithms to Technology. In Proceedings of the ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2024; pp. 13256–13260. [Google Scholar] [CrossRef]
- Kyprianidi, T.; Doutsi, E.; Tzagkarakis, G.; Tsakalides, P. Exploring the Potential of Recurrence Quantification Analysis for Video Analysis and Motion Detection. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP); 2024; pp. 2606–2612. [Google Scholar] [CrossRef]
- Takens, F. Dynamical systems and turbulence. Warwick, 1980 1981, pp. 366–381.
- Eckmann, J.P.; Kamphorst, S.O.; Ruelle, D.; et al. Recurrence plots of dynamical systems. World Scientific Series on Nonlinear Science Series A 1995, 16, 441–446. [Google Scholar]
- Marwan, N.; Webber Jr, C.L. Mathematical and computational foundations of recurrence quantifications. In Recurrence quantification analysis: Theory and best practices; Springer, 2014; pp. 3–43.
- Zbilut, J.P.; Webber Jr, C.L. Embeddings and delays as derived from quantification of recurrence plots. Physics letters A 1992, 171, 199–203. [Google Scholar] [CrossRef]
- Webber Jr, C.L.; Zbilut, J.P. Dynamical assessment of physiological systems and states using recurrence plot strategies. Journal of applied physiology 1994, 76, 965–973. [Google Scholar] [CrossRef] [PubMed]
- Marwan, N.; Wessel, N.; Meyerfeldt, U.; Schirdewan, A.; Kurths, J. Recurrence-plot-based measures of complexity and their application to heart-rate-variability data. Physical Review E 2002, 66, 026702. [Google Scholar] [CrossRef] [PubMed]
- Marwan, N.; Kurths, J.; Saparin, P. Generalised recurrence plot analysis for spatial data. Physics Letters A 2007, 360, 545–551. [Google Scholar] [CrossRef]
- Wallot, S.; Roepstorff, A.; Mønster, D. Multidimensional Recurrence Quantification Analysis (MdRQA) for the analysis of multidimensional time-series: A software implementation in MATLAB and its application to group-level data in joint action. Frontiers in psychology 2016, 7, 1835. [Google Scholar] [CrossRef] [PubMed]
- Zervou, M.A.; Tzagkarakis, G.; Tsakalides, P. Automated screening of dyslexia via dynamical recurrence analysis of wearable sensor data. In Proceedings of the 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE). IEEE; 2019; pp. 770–774. [Google Scholar]
- Chomiak, T. Recurrence quantification analysis statistics for image feature extraction and classification. Data-Enabled Discovery and Applications 2020, 4, 1–9. [Google Scholar] [CrossRef]
- Zhu, W.; Huang, Y.; Xie, X.; Liu, W.; Deng, J.; Zhang, D.; Wang, Z.; Liu, J. Autoshot: A short video dataset and state-of-the-art shot boundary detection. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2238–2247.
- http://imagelab.ing.unimore.it.
- https://www.bbc.co.uk/programmes/b006mywy.
- Tang, S.; Feng, L.; Kuang, Z.; Chen, Y.; Zhang, W. Fast video shot transition localization with deep structured models. In Proceedings of the Asian Conference on Computer Vision. Springer; 2018; pp. 577–592. [Google Scholar]
- Hassanien, A.; Elgharib, M.; Selim, A.; Bae, S.H.; Hefeeda, M.; Matusik, W. Large-scale, fast and accurate shot boundary detection through spatio-temporal convolutional neural networks. arXiv 2017, arXiv:1705.03281. [Google Scholar]
- Lokoč, J.; Kovalčík, G.; Souček, T.; Moravec, J.; Čech, P. A framework for effective known-item search in video. In Proceedings of the Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1777–1785.
- Soucek, T.; Lokoc, J. Transnet v2: An effective deep network architecture for fast shot transition detection. In Proceedings of the Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 11218–11221.
- Baraldi, L.; Grana, C.; Cucchiara, R. Shot and scene detection via hierarchical clustering for re-using broadcast video. In Proceedings of the Computer Analysis of Images and Patterns: 16th International Conference, CAIP 2015, Valletta, Malta, September 2-4 2015; Proceedings, Part I 16. Springer, 2015. pp. 801–811. [Google Scholar]
- Baraldi, L.; Grana, C.; Cucchiara, R. A deep siamese network for scene detection in broadcast videos. In Proceedings of the Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 1199–1202.
- Soomro, K.; Roshan Zamir, A.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. In Proceedings of the CRCV-TR-12-01; 2012. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Gool, L.V.; Gross, M.; Sorkine-Hornung, A. A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016. [Google Scholar]
- Kennel, M.B.; Brown, R.; Abarbanel, H.D. Determining embedding dimension for phase-space reconstruction using a geometrical construction. Physical review A 1992, 45, 3403. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
(a) (Left) This mask determines the first frame of the scene. (Right) This mask indicates the last frame of the scene. , (b) Recurrence Plot for whole frames each black block defines a scene.
Figure 1.
(a) (Left) This mask determines the first frame of the scene. (Right) This mask indicates the last frame of the scene. , (b) Recurrence Plot for whole frames each black block defines a scene.
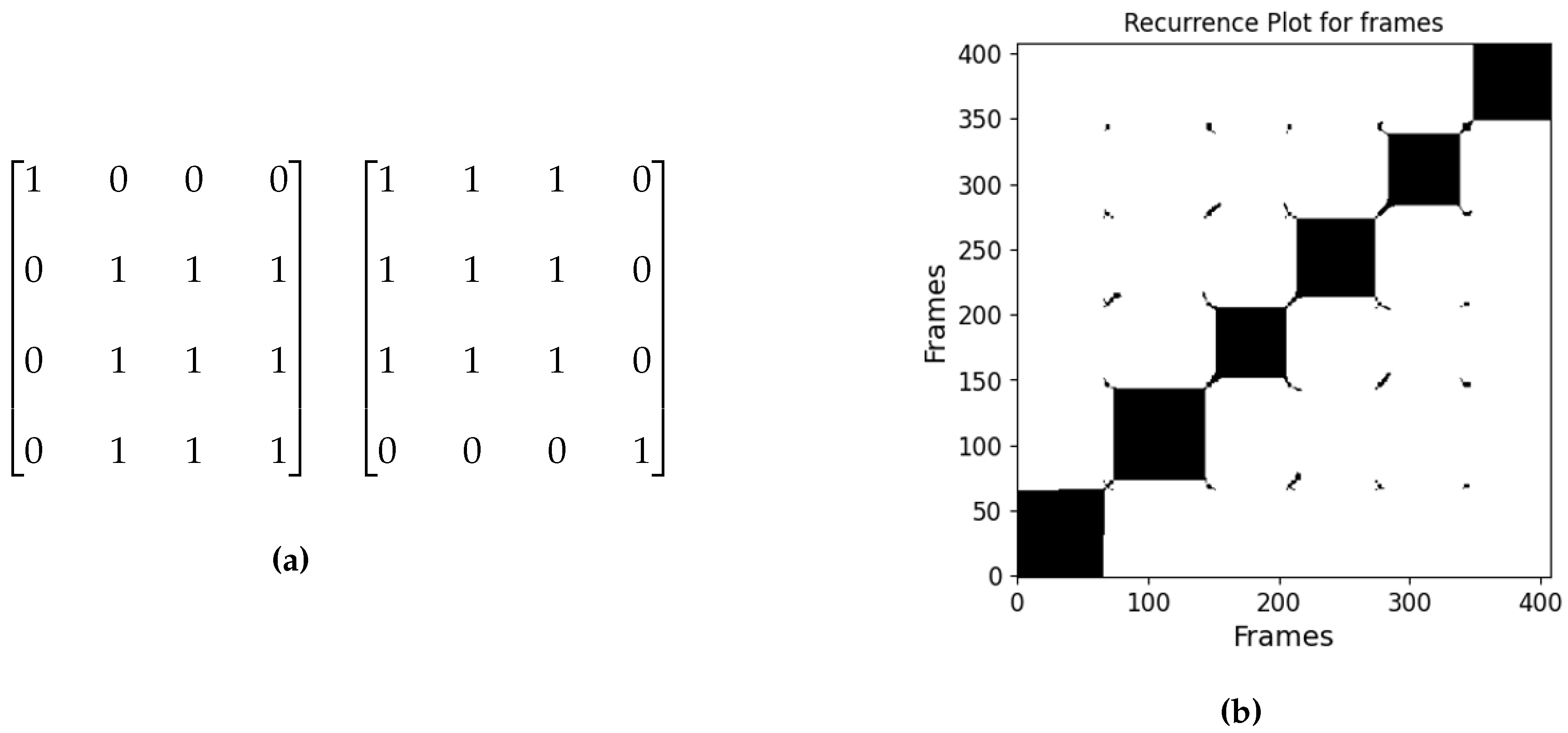
Figure 2.
Results on the makeup video (top row), the parade video (middle row), and the ball video (bottom row). (left column) Random frame which is split into patches of a size 8x8. (middle column) Grayscale heatmap generated for the D values. (right column) Grayscale heatmap based on the RR values
Figure 2.
Results on the makeup video (top row), the parade video (middle row), and the ball video (bottom row). (left column) Random frame which is split into patches of a size 8x8. (middle column) Grayscale heatmap generated for the D values. (right column) Grayscale heatmap based on the RR values


Table 1.
F1 scores for different mask sizes and datasets.
| F1 scores | RAI | Autoshot | BBC |
|---|---|---|---|
| mask9 | 0.823 | 0.750 | 0.778 |
| mask7 | 0.832 | 0.762 | 0.781 |
| mask5 | 0.835 | 0.757 | 0.783 |
| mask3 | 0.829 | 0.747 | 0.776 |
| mask2 | 0.588 | 0.529 | 0.547 |
Table 2.
(a) RQA results all scene changes, (b) RQA results only for instant scene change.
| Autoshot | RAI | BBC | Autoshot | RAI | BBC | ||
|---|---|---|---|---|---|---|---|
| TP | 1894 | 740 | 4100 | TP | 1748 | 782 | 4043 |
| FP | 632 | 48 | 521 | FP | 632 | 48 | 521 |
| FN | 581 | 244 | 747 | FN | 350 | 38 | 668 |
| pre | 0.749 | 0.939 | 0.887 | pre | 0.734 | 0.934 | 0.885 |
| rec | 0.765 | 0.752 | 0.846 | rec | 0.833 | 0.947 | 0.858 |
| F1 | 0.757 | 0.835 | 0.866 | F1 | 0.781 | 0.941 | 0.872 |
| (a) | (b) | ||||||
Table 3.
F1 scores for different methods. Autoshot [17], DSMs [20], ST ConvNets [21], TransNet [22], TransNetV2 [23], Hierarchical clustering [24], Deep Siamese Network [25].
| Method | Autoshot | RAI | BBC |
|---|---|---|---|
| Autoshot (2023) | 0.841 | 0.971 | 0.955 |
| DSMs (2018) | 0.893 | 0.939 | |
| ST ConvNets (2017) | 0.926 | 0.939 | |
| TransNet (2019) | 0.929 | 0.943 | |
| TransNetV2 (2024) | 0.962 | 0.939 | |
| RQA | 0.781 | 0.941 | 0.872 |
| Hierarchical clustering (2015) | 0.720 | ||
| Deep Siamese Network (2015) | 0.620 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



