
Submitted:
06 January 2025
Posted:
07 January 2025
You are already at the latest version
Abstract
Large language models (LLMs) are AI-powered systems that have demonstrated significant potential in various fields, including medicine. Despite their promise, the methods for evaluating their performance in medical contexts remain inconsistent. This paper introduces the Standardized Assessment Framework for Evaluations of Large Language Models (SAFE-LLM) to streamline and standardize the evaluation of LLMs in healthcare. SAFE-LLM assesses five domains: accuracy, comprehensiveness, supplementation, consistency, and fluency. Accuracy refers to the correctness of the model's response, comprehensiveness to the detail and reasoning provided, supplementation to additional relevant information, consistency to uniformity in repeated answers, and fluency to the coherence of responses. Each prompt is given three times, with responses evaluated by two independent experts. Discrepancies between evaluations trigger a third assessment to ensure reliability. Grading is performed on a scale specific to each domain, with a maximum possible score of seven points. The SAFE-LLM score can be applied to individual answers or averaged across responses for a holistic assessment. This framework aims to unify evaluation standards, facilitating the comparison and improvement of LLMs in medical applications. Developing standardized evaluation tools like SAFE-LLM is critical for integrating AI into healthcare effectively. This framework is a preliminary step towards more rigorous and comparable assessments of LLMs, enhancing their applicability and trustworthiness in medical settings.
Keywords:
Large Language Models
; Artificial Intelligence
; Healthcare
; Evaluation Framework
; Medical Applications
; SAFE-LLM
Introduction
Large language models (LLMs) are artificial-intelligence-powered models capable of understanding and generating text, which have recently gained traction due to requiring minimal fine tuning [1]. They have shown exceptional performance in multiple areas including education and research [1,2], as well as more clinical settings such as oncology [3,4], neurosurgery [5], ophthalmology [6]. Although research on the accuracy of LLMs in different medical domains is growing, the methods for evaluating their performance remain heterogeneous within the literature [3,4,5,6,7].
In order to expedite the application of LLMs in healthcare, we propose a relatively simple framework for reporting evaluations and estimations of large language models (SAFE-LLM) for future studies based on existing literature and our own experience with LLMs and diagnosis of psychiatric conditions. It must be noted that this framework is only a preliminary version and only focuses on evolution of question-answers, while there are multiple methods available for evaluation of LLMs in medicine including multiple choice questions, case diagnosis, knowledge completion test [8]. This version is the result of multiple discussion and literature review sessions between medical and computer science researchers at Farzan Clinical Research institute.
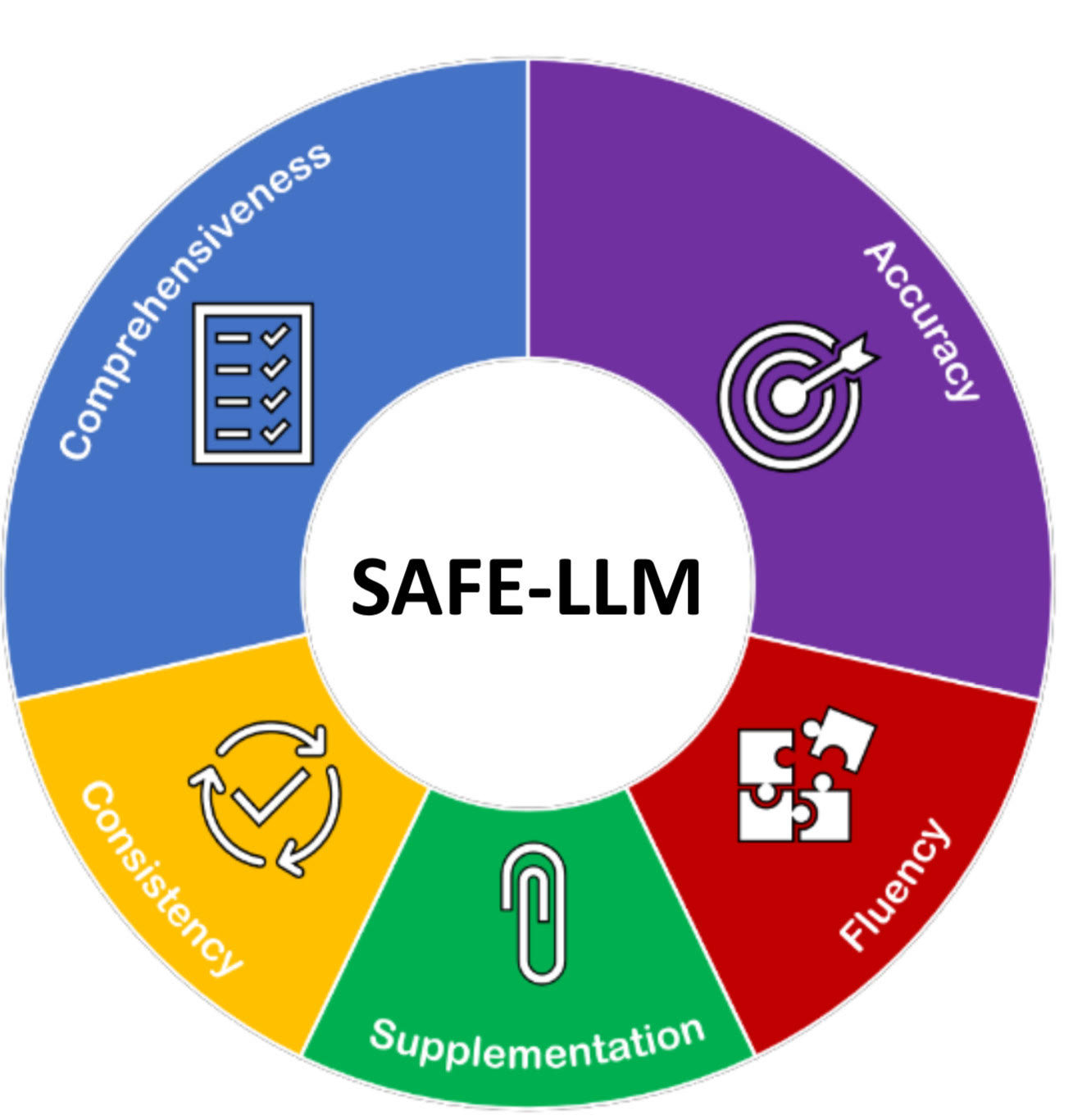
Main Text: This framework consists of 5 domains of assessment: accuracy, comprehensiveness, supplementation, consistency, and fluency (Figure 1), with accuracy defined as the correctness of each LLM’s provided answer, comprehensiveness as the amount of detail and reasoning provided adjacent to the answer, supplementation as additional relevant information in the answer, consistency as similar answers for repeated prompts, and fluency as the coherence of answers. Assessment using this tool will entail the following steps: Each prompt will be provided 3 times, yielding 3 answers from the LLM. Each answer should be evaluated separately for each domain and the average score of the 3 will count as the domain scores. The assessment of the answers should be carried out independently by two experts in accordance with established clinical guidelines or expert opinion as benchmarks. The average of their scores will ultimately be used as the final score for each domain. It is advisable that the graders be blinded to the identity of each LLM. In case of significant difference between the mean score of the two graders in any domain, a third grader should provide an independent assessment of each domain with the average of all three assessments used as the final score.
Accuracy should be graded on a 3-point scale of 0) inaccurate answer potentially harming the patient; 1) partially accurate answer containing some errors with minimal benefit for the patient; 2) accurate answers with no errors and maximum benefit for the patient. Comprehensiveness should be graded on a 3-point scale of 0) no reasoning or detail behind the answer; 1) relevant reasoning or detail yet lacking key components; 2) relevant reasoning or detail encompassing most necessary criteria. Supplementation should be graded on a 2-point scale of 0) no relevant additional reasoning or detail; 1) relevant additional reasoning or detail. Consistency should be evaluated on a 2-point scale of 0) heterogeneous accuracy scores for three consecutive repetitions; 1) similar accuracy scores for three consecutive repetitions of the prompt. Fluency should be graded on a 2-point scale of 0) hard to understand in one sitting; 1) understandable in one sitting. The sum of each domain score will produce the SAFE-LLM score out of a maximum of 7 points (Table 1).
The SAFE-LLM score can be reproduced for each differential answer and averaged for each prompt, or one overall score can be produced by using the most accurate answer for accuracy evaluation and the most comprehensive answer for comprehensiveness evaluation and any supplementary information for supplementation evaluation. In this scenario, however, consistency and fluency have to be assessed across all of the answers.
Outlook: As the present moment seems to be an era of burgeoning AI-based tools including LLMs, developing tools and frameworks to evaluate the performance of these tools in healthcare settings and scenarios is of outmost importance. We hope that SAFE-LLM can act as a unifier in the field of evaluating LLMs in medicine, thus facilitating assessments of applicability and comparisons among different models.
References
- Thirunavukarasu AJ, Ting DSJ, Elangovan K, Gutierrez L, Tan TF, Ting DSW. Large language models in medicine. Nature Medicine. 2023;29(8):1930-40. [CrossRef]
- Gargari OK, Mahmoudi MH, Hajisafarali M, Samiee R. Enhancing title and abstract screening for systematic reviews with GPT-3.5 turbo. BMJ Evidence-Based Medicine. 2024;29(1):69-70. [CrossRef]
- Rydzewski NR, Dinakaran D, Zhao SG, Ruppin E, Turkbey B, Citrin DE, Patel KR. Comparative Evaluation of LLMs in Clinical Oncology. NEJM AI. 2024:AIoa2300151. [CrossRef]
- Peng W, feng Y, Yao C, Zhang S, Zhuo H, Qiu T, et al. Evaluating AI in medicine: a comparative analysis of expert and ChatGPT responses to colorectal cancer questions. Scientific Reports. 2024;14(1):2840. [CrossRef]
- Duey AH, Nietsch KS, Zaidat B, Ren R, Ndjonko LCM, Shrestha N, et al. Thromboembolic prophylaxis in spine surgery: an analysis of ChatGPT recommendations. Spine J. 2023;23(11):1684-91. [CrossRef]
- Lim ZW, Pushpanathan K, Yew SME, Lai Y, Sun C-H, Lam JSH, et al. Benchmarking large language models’ performances for myopia care: a comparative analysis of ChatGPT-3.5, ChatGPT-4.0, and Google Bard. EBioMedicine. 2023;95.
- Shieh A, Tran B, He G, Kumar M, Freed JA, Majety P. Assessing ChatGPT 4.0’s test performance and clinical diagnostic accuracy on USMLE STEP 2 CK and clinical case reports. Scientific Reports. 2024;14(1):9330.
- Guo Z, Jin R, Liu C, Huang Y, Shi D, Yu L, et al. Evaluating large language models: A comprehensive survey. arXiv preprint arXiv:231019736. 2023.
Figure 1.
Domains of the Framework for Reporting Evaluations and Estimations of Large Language Models.

Table 1.
Details of grading each domain of SAFE-LLM.
| Evaluation | Points | Description | Example |
|---|---|---|---|
| Accuracy | 0 | Inaccurate answer potentially harming the patient | Diagnosis of a different cluster of disease, treatment recommendations which would worsen the disease, wrong prognosis which would lead to high fiscal or mental costs for the patient |
| 1 | Partially accurate answers containing some errors with minimal benefit for the patient | Diagnosis within the same cluster of disease, treatment recommendations which would not harm the patient or benefit them significantly, wrong prognosis which does not fiscally or mentally harm the patient | |
| 2 | Accurate answers with no errors and maximum benefit for the patient | Exact diagnosis of disease, treatment recommendation in accordance with common medical practice, similar prognosis with relevant literature | |
| Comprehensiveness | 0 | No reasoning or detail provided or irrelevant reasoning or detail | No sign or symptom or criteria is provided for diagnosis, no regimen is provided for treatment, no evidence is provided for prognosis |
| 1 | Relevant reasoning or detail yet lacking key components | Some sign or symptom or criteria is provided for diagnosis yet necessary ones are missing, treatment regimen is provided yet one of dose, duration, or daily intake is missing, prognosis is based on some evidence yet fails to account for all evidence | |
| 2 | Relevant reasoning or detail encompassing most necessary criteria | Most sign or symptom or criteria is provided for diagnosis with all necessary ones mentioned, treatment regimen is provided in full, prognosis is based on all relevant evidence provided in the prompt | |
| Supplementation | 0 | No relevant additional reasoning or detail | No helpful sign or symptom or criteria is provided for diagnosis, no additional tips regarding treatment regimen is provided, prognosis is not based on any additional evidence provided in the prompt |
| 1 | Relevant additional reasoning or detail | Additional helpful sign or symptom or criteria is provided for diagnosis, additional tips regarding treatment regimen is provided, prognosis is based on additional evidence provided in the prompt (i.e. gender or family history) | |
| Consistency | 0 | Heterogeneous accuracy scores for three consecutive repetitions | One answer receives an accuracy score of “partially accurate” while another receives “inaccurate” |
| 1 | Similar accuracy scores for three consecutive repetitions | All three answers receive a score of “accurate” or “partially accurate” or “inaccurate” | |
| Fluency | 0 | Hard to understand in one sitting | Grammatical mistakes, repetitions of whole sentences, incoherence |
| 1 | Understandable in one sitting | Minimal grammatical mistakes, repetitions limited to concepts, cohesive structure | |
| Sum Score | 7 | The total SAFE-LLM score for each answer provided by an LLM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



