Submitted:
27 December 2024
Posted:
30 December 2024
You are already at the latest version
Abstract
One of the most common ideas for finding the zero of a nonlinear function is to replace it by a series of suitably chosen linear functions, for which the zeros can easily be determined and the sequence of zeros approximate the zero of the nonlinear function. Widely used classic methods are Newton’s method and a large family of quasi-Newton methods (secant, Broyden’s, discretized Newton, Steffensen’s,...). This strategy can be called “linearization” and such methods may be called “linearization methods”. An efficient linearization method for solving a system of nonlinear equations was developed which showed good stability and convergence properties. It uses an unconventional and simple strategy to improve the performance of classic methods by full-rank update of the Jacobian approximates. It can be considered both as a discretized Newton’s method or as a quasi-Newton method with full-rank update of the Jacobian approximates. A solution to the secant equation presented in [] was based on the Wolfe-Popper procedure [,]. The secant equation was splitted into two equations by introducing an auxiliary variable. A simplified algorithm is given in this paper for the full-rank update procedure described in []. It directly solves the secant equation with the pseudo-inverse of the Jacobian approximate matrix. Numerical examples are shown for demonstration purpose. The convergence and efficiency of the suggested method are discussed and compered with the convergence and efficiency of classic linearization methods.
Keywords:
quasi-Newton methods
; least-squares solution
; multi-variable nonlinear equations
; full-rank Jacobian approximate update
; convergence
; efficiency
1. Introduction
A mathematical model with some parameters is constructed for an observed system which gives observable response sampled at locations () to an observable external effect. It is assumed that the simulated system response is sensitive to the perturbations of all parameters. The n adjustable parameters of the mathematical model are determined so that the distance
between the observed and the simulated system responses ( and ) is minimized, where is a q norm
If is chosen, then we get the Euclidean or least-squares norm
that is well computable and safely usable for a great class of problems. Then minimizing the distance 1.1 leads to the problem of minimizing the least squares norm
(, and ). The minimum value of this norm is zero, but for “real life” problems it is not reachable in most cases due to modeling inaccuracies and measurement noises. The suggested procedure gives a least-squares solution to the overdetermined system of nonlinear equations
where the solution minimizes the least squares norm 1.4 of the nonlinear residual function
Least squares minimizations are successively made within the actual iteration steps. The basic concept of solving Equation 1.5 is that the function is “linearized” by repeatedly replacing it with a linear function as
for the Newton’s method, where is the function value, is the Jacobian matrix of the function (p is iteration counter) and
for the quasi-Newton methods methods, where is the finite-difference Jacobian approximate of the function . Then the nonlinear problem is solved by solving a series of linear problems
and it follows that the new approximate to the solution can be given from Equations
(Newton’s method) and
(quasi-Newton methods) where the iteration stepsize is
in both cases.
The system of simultaneous multi-variable nonlinear Equations 1.5 can be solved by the Newton’s method when the derivatives of are available analytically and a new iterate can be determined. In many cases, explicit formulas for the function are not available and the Jacobian can only be approximated. The partial derivatives of the analytic Jacobian may be replaced by suitable finite-difference quotients (discretized Newton’s iteration [12,25]) with properly chosen step sizes. For most problems, Newton’s method using analytic derivatives and Newton’s method using properly chosen divided differences are virtually indistinguishable [12]. However, the determination of the finite-difference stepsizes is not clearly defined. The suggested full-rank update procedure helps to overcome this deficit.
Let be a full column rank matrix (all column vectors of matrix are linearly independent). As (there are more rows than columns), is not invertible and the solution to the overdetermined system of Equation 1.11 doesn’t exist. However, is invertible and the pseudo-inverse
of matrix is a unique left inverse which allows finding a least-squares approximate solution to Equation 1.11. The pseudo-inverse can be determined in different ways (e.g. rank factorization [14], singular value decomposition [31]). Singular value decomposition is a widely used technique, and it has an advantage, that it gives solution even if is singular (not a full column rank matrix). Matrix can be factorized as
where ( matrix) and ( matrix) are orthogonal matrices with orthonormal column eigenvectors, and
with singular values of matrix and . Then the least square solution to Equation 1.11 exists and the iteration stepsize is
where
is the pseudoinverse of and
The pseudoinverse gives a unique least squares solution to Equation 1.11 for which the norm (Euclidean norm) 1.4 of the residual function 1.6 is minimum. If the rank of matrix is less than n (the column vectors of are not linearly independent and some singular values are zero), then unique solution to Equation 1.11 doesn’t exist. The spectral condition number
of matrix measures the linear dependency of the column vectors. If they are linearly independent (non of the singular values are zero) and the condition number is not much larger than one, then the matrix is well-conditioned. This is a desirable situation through the whole iteration process. Then the column vectors of matrix are in “general positions” and the Ortega-Rheinboldt condition [25] satisfies. If then the matrix is ill-conditioned and the solution (iteration stepsize) to the Equation 1.11 may be sensitive to small changes in or .
Classic quasi-Newton linearization methods generate a sequence of improved iterates so that the next approximate to the solution is determined on the basis of rank-1 update of the Jacobian approximate . Such linearization update is not unique if only a single new approximate exists. In single variable case , there are two possible updates (secant lines) from which the selection is not obvious (see details in Section 3). In multi variable case, only rank-1 update is possible if one single new approximate exists.
The solution to Equation 1.11 presented in [2] and applied to the identification of physically nonlinear dynamic systems [3,4,5] was based on the Wolfe-Popper procedure [29,42]. The secant equation 1.11 was splitted into two equations by introducing an auxiliary variable. The simplified solution presented in Section 4 directly solves Equation 1.11 with the pseudo-inverse 1.13 of matrix . The simplified algorithm given in Section 5 gives an unconventional and simple strategy to improve the performance of Newton and quasi-Newton iterations for the solution of system of nonlinear equations 1.5. It can be considered both as a discretized Newton’s method or as a quasi-Newton method with full-rank update of the Jacobian approximates.
The rate of convergence of the classic secant method equals to the golden section ratio () for simple root in single variable case. The suggested method gives an additional new independent approximate to the solution x*, then rank-n linearization update can be made with the classic approximate (notated as in the followings) and the suggested new approximate . The results of single- and multi-variable numerical examples are given in Section 6. The efficiency of the proposed method is discussed in Section 7 and it is compared with other classic rank-one update and line-search methods on the basis of available test data. Concluding remarks are summarized in Section 8.
2. Notations
Vectors and matrices are denoted by bold-face letters. Subscripts refer to components of vectors and matrices, superscripts A and B refer to interpolation base points. Notations A and B are introduced to be able to clearly distinguish between the two new approximates and . Vectors and matrices may also be given by their general elements. ▵ refers to a difference of two elements. x and denotes unknown quantities, f and denotes function values and matrices. t and denotes multiplier scalars and scaling transformation matrices. e, and E denotes approximate error, p is iteration counter, is convergence rate, is termination criterion. n is the number of unknowns, m is the number of function values, i, j and k and are running indexes of matrix columns and rows. Superscripts S and refer to the traditional Secant-method and to the suggested full-rank update method (T-Secant) receptively.
3. Linearization Methods
The origin of the secant method can be traced back to ancient time to the “rule of double false position” method, described in the century B.C. on the Egyptian Rhind Papyrus [28] and it predates Newton’s method by more than 3000 years. It is also well-known that the local convergence rate of the classic Newton’s and the classic secant methods for simple roots are quadratic and super-linear respectively [8,11,26,38]. Weerakson and Fernando’s third order Newton variant [40] involves evaluation of a function value and two derivatives, similarly like in Traub’s suggestion [38]. Secant method variations with improved convergence have been reported in literature [13,15,16,17,23,27,33,34,40]. Mueller’s method [24] uses a quadratic approximation. A class of variations employs two function value and a derivative evaluation [37]. Third order methods are obtained by a second derivative evaluation, such as Halley’s [23] and the “super Halley” [1] method. Further improvements with higher degree polynomial approximations are proposed by Chen [9], Kanwar [17], Zhang [43] and Wang [39].
3.1. Single-Variable Case
The zero of a scalar nonlinear function (, , ) has to be determined, where
Linearization means that is locally replaced by a linear function (, , ) (secant- or tangent line) as shown on Figure 1 (Left) and operations are made on the linear function in the iteration. may be defined through two points and of the nonlinear function , where and are function values, or through one point and by the “slope”
of the secant line , where and are differences, or by the “slope”
at of the tangent line , where is the derivative function of . The successive local replacement of the nonlinear function by a secant- or tangent line gives a simple and efficient numerical root finding procedure. It follows from the condition
that the zero
of the linear function approximates the zero of the nonlinear function and the new point can be determined for the next iteration as shown on Figure 1 (Right). With the iteration step length
from point , Equation 3.5 can be rewritten as
that is called secant equation or we may also call it “linearization” equation as it also includes Newton’s method as a special case (tangent line). The secant based procedure has an advantage that it doesn’t need the calculation of function derivatives, it only uses function values and the order of asymptotic convergence is super-linear with convergence rate . However, the “slope” of the updated secant line can be determined in two ways from the secant (quasi-Newton) conditions as
or
where
is the iteration step length from point . The decision is far not obvious, as shown on Figure 1 (Right). The tangent line based iteration (Newton’s method) has an advantage that the “slope”
of the updated tangent line is always well-defined. The iteration then continues with updated secant- or tangent line .
3.2. Multi-Variable Case
The scalar linearization procedure can be extended to multi-dimensions. The zero of a nonlinear vector-valued function
of n variables
(, ) has to be determined, where
Then is locally replaced by an n-dimensional hyperplane
and operations are made on the hyperplane in the iteration. may be defined through points and () of the nonlinear function , where and () are function values, or by one point and by the “slope” (divided differences)
, , of the n-dimensional secant hyperplane , where and are difference vectors with n and m components respectively, and
The n-dimensional tangent hyperplane through point may be defined by the “slope”
that corresponds to the Jacobian matrix of the nonlinear vector-valued function and accordingly, Definition 3.16 corresponds to the approximation of the Jacobian matrix. It follows from the condition
that the zero
of the n-dimensional hyperplane approximates the zero of the nonlinear vector-valued function , where stands for the pseudo-inverse. Then the element of the new approximate in the iteration will be
.With the iteration stepsize
Equation 3.21 can be rewritten as
that is called “secant equation” or “linearization equation” in multi-variable case. With the new approximate and with the corresponding function value , an updated Jacobian or Jacobian approximate has to be determined. Table 1 summarizes the basic equations of the above detailed linearization methods.
If all partial derivatives of the function is known, then the Jacobian update can easily be calculated. Newton’s method is one of the most widely used algorithm with very attractive theoretical and practical properties and with some limitations. The computational costs of Newton’s method is high, since the Jacobian and the solution to the linear system 3.24 must be computed at each iteration. It is well-known that the local convergence of Newton’s method is q-quadratic if the initial trial approximate is close enough to the solution , if is non-singular and if satisfies the Lipschitz condition
for all close enough to .
However, in many cases, the function is not an analytical function, the partial derivatives are not known or difficult to evaluate and Newton’s method cannot be applied. Quasi-Newton methods are widely used for solving systems of nonlinear equations when the Jacobian is not known or difficult to determine. The Jacobian is approximated by divided differences 3.16, and the system of nonlinear equations 1.5 is solved by repeatedly solving systems of linear equations 3.24 providing the new approximates .
The Jacobian approximate 3.16 should be updated according to the fundamental equation of the quasi-Newton methods (“quasi-Newton condition” or “secant condition”)
for all . However, the condition 3.26 doesn’t uniquely specify the update , so the iterative procedure is not well-defined and further constraints are needed. Different methods offer their own specific solution, but new quasi-Newton approximate will never allow full-rank update of the Jacobian approximate (Equation 3.26 is an underdetermined system of m linear equations with unknowns). A large family of methods are available with different additional conditions or assumptions. Martinez [21] has been made a thorough survey on the family of practical quasi-Newton methods.
The partial derivatives of the Jacobian matrix may be replaced by suitable difference quotients (discretized Newton iteration, see [12,25])
, with n additional function value evaluations, where is the Cartesian unit vector. However, it is difficult to choose the stepsize . If any is too large, then Expression 3.27 can be a bad approximation to the Jacobian so the iteration converges much more slowly, if it converges at all. On the other hand, if any is too small, then , and cancellations can occur which reduces the accuracy of the difference quotients 3.27 (see [35]). Another modification is the inexact-Newton approach, when the nonlinear equation is solved by an iterative linear solver (see [6,10,22]). Wolfe [42] and Popper [29] suggested column update of matrix 3.17.
One of the most widely used Broyden-formula [7] makes a rank-one update for the Jacobian approximate as
where is a rank-one matrix and by using the Sherman-Morrison formula, the inverse Jacobian approximate update is given as
Broyden’s secant condition 3.26 can be re-written as
and with the secant Equation 3.24 we have
As is a rank-one matrix, then this equation has infinitely large number of solutions (the left nullspace of matrix is an dimensional vector space [36]) and the Ortega-Rheinboldt [25] condition will not be satisfied (the column vectors of matrix should be linearly independent and have to be “in general position” through the whole iteration process) and it may result an ill-conditioned Broyden update .
4. T-Secant Method
A numerical procedure has been developed for solving an overdetermined system of nonlinear equations 1.5. It can be considered both as a discretized Newton’s method or as a quasi-Newton method with full-rank update of the Jacobian approximates. The suggested full-rank update procedure (“T-Secant” method [2]) provides an unconventional and simple strategy to improve the performance of quasi-Newton iterations. It is based on the classic secant linearization, that was completed with a new independent approximate . The secant equation was modified by a suitably chosen non-uniform scaling transformation and a new independent approximate was determined from the modified secant equation. The solution to the secant equation presented in [2] was based on the Wolfe-Popper procedure [29,42] so that the secant equation was splitted into two equations by introducing an auxiliary variable. The simplified algorithm, presented in the paper, directly solves the secant equation by using the pseudo-inverse of the transformed Jacobian approximate.
4.1. Single-Variable Case
The suggested procedure uses the information on the improvement of the classic secant procedure and gives a new approximate in the vicinity of the classic secant approximate as follows. Given two initial approximates and with function values and and the new approximate with function value is known from the solution of the classic secant Equation 3.7. An independent new approximate
is planned to be determined in the vicinity of the classic secant approximate . Let the ratio
of the function value improvement and the ratio
of the desired iteration stepsize change be defined. The single variable secant equation 3.7 is then modified as
where
Then the new approximate can be expressed from Equation 4.4
After re-arrangement
and with the secant Equation 3.7
the desired new iteration stepsize
can be given. The suggested procedure can also be applied to the Newton’s method (T-Newton method). Then the “slope” corresponds to the derivative of function .
The geometrical representation of the suggested method can be derived as follows ([2]). Let the new approximate be the zero of a function :
Then by replacing with x in Equation 4.8 gives the function
with zero at
Equation 4.11 is a hyperbolic function with vertical and horizontal asymptotes and , and its root will be in the vicinity of in “appropriate distance” that is regulated by the function value (see Figure 2). This virtue of the suggested procedure ensures an automatic mechanism for having the actual approximates and in general positions through the whole iteration process providing stable and efficient numerical performance. The suggested method’s performance is demonstrated with the results of numerical tests on test functions in Section 6.
4.2. Multi-Variable Case
Let two independent approximates and to the zero of the nonlinear vector-valued function be given in the iteration . Let the series of n approximates be constructed by individually increment the elements of the approximate by an increment
as
where is the Cartesian unit vector. It follows from this special construction of the approximates , that for and for and matrix 3.18 will be a diagonal matrix :
Let the ratios
of the function value improvements and the ratios
of the desired iteration stepsize changes be defined similarly like in the single variable case. Let the secant equation 3.24 be modified as
where
, , or in explicit form :
and
is the pseudoinverse of . Then Equation 4.18 can be re-written as
Then the element of the new approximate in the iteration will be
where , and . Let the ratios
be introduced . By using Equation 3.23, the new iteration stepsize can be expressed from Equation 4.23 as
Table 2 summarizes the basic equations of the above detailed multi-variable update method. The suggested procedure can also be applied to the Newton’s method (T-Newton method). Then matrix corresponds to the Jacobian matrix of function . The function value improvement parameter in Equation 4.24, defined as 4.16 has a key role in the suggested iteration process and the absolute value of the denominator has to be low bounded with a pre-given value to avoid division by zero. When the values tend to zero with increasing iteration counter p, then
Figure 3 shows the effect of iteration parameter on the iteration process (). It is clear that too high value of has negative effect on the iteration efficiency. It can be seen on the example that a value causes the iteration process failure, and there is almost no effect with lower values .
The suggested procedure may also be repeated without using the classic secant approximates and without updating the previously known Jacobian approximate as
where
until the new approximates
are sufficiently improved. A numerical example is shown in Table 3 with test function
for demonstration purpose. The results indicate linear convergence with convergence rate . is the computed convergence rate, is the number of function value evaluations and L is the mean convergence rate, suggested by Broyden [7] in Table 3.
5. Algorithm
Let be the error bound for termination criterion and if is known then
is the error vector of approximate in the iteration with elements . Let the error norm
be defined, where is Euclidean norm and let the iteration be terminated when
holds. Choose as lower bound for and let be a lower bound for . Let and let the approximate and the difference vector be given. Calculate the corresponding function values and assure that . Iteration constants and are necessary to avoid division by zero and to avoid computed values be near the numerical precision.
- Step 1 : Generate a set of n additional approximates (Equation 4.14) and evaluate function values . Assure that .
- Step 2 (Classic secant update method) : Construct the Jacobian approximate matrix , determine its pseudo-inverse [31], calculate from Equation 3.21 and from Equation 5.2.
- Step 3 : If then terminate iteration, else continue with Step 4.
- Step 4 (suggested update method) : Calculate (assure that ), from Equation 4.16 and from Equation 4.24. Let and determine from Equation 4.25.
- Step 5 : Continue iteration from Step 1 with , and .
If is the number of necessary iterations for satisfying the termination criterion and n is the number of unknowns to be determined, then the suggested update method needs function evaluations in each iterations and altogether
function evaluations to reach the desired termination criterion. is depending on many circumstances such as the nature of the function , termination criteria ( or others), the distance of the initial approximate from the solution and from the iteration constants and .
6. Numerical Tests Results
6.1. Single Variable Test Function
A numerical example is given with a single-variable test function
with root The results of the classic secant iteration process are shown on Table 4 and Figure 4. Iterations were made with initial approximates and providing . The first secant approximate is found as the zero of the first secant line providing . The next iteration () will continue with approximate and with .
The results of the suggested iteration process are shown on Table 5 and Figure 5. Iterations were made with the same initial approximates as in case of the classic secant iteration and the first secant approximate is found. The first T-secant approximate is given as the zero of the first hyperbola function (Figure 5, left). Iteration then goes on with approximates and providing , and new approximates and as the zeros of the second secant and hyperbola functions and receptively (Figure 5, left). The next iteration () will then continue with approximates and and with and gives and (Figure 5, right).
6.2. Solution of an Inverse Problem
An example is given for an imaginary modeling problem. Modeling of systems on the basis of observed or specified system responses plays a key role in scientific research. A central problem of modeling is to fit a structured mathematical model to available data so that the values of the unknown model parameters are determined providing that the simulated data is as near to the available data as possible. A system response can generally be represented by a curve in a two (or three) dimensional space and can be simulated by a computer program. Parameter identification corresponds to minimize the distance between observed and simulated system responses. Parameter identification problems can generally be formulated as non-linear least squares problems so that some unknown model parameters are determined providing minimal deviation between observed and simulated system responses. Solving non-linear least squares problems is often a difficult task especially if the number of unknowns is high.
A rational system under investigation produces measurable response to a known measurable external effect. A mathematical model with n unknown parameters simulates the behavior of the system providing response to the same external effect as acted on the system during observation. Let, the observed and the simulated system responses be represented by two dimensional curves and sampled in k discrete points with coordinates and . The coordinates of a synthetic observed response were generated as
(an epicycloid) with parameters , , , , and and with . The parameters
were were considered to be unknown, and the system response was simulated with initial approximate
Distance between observed and simulated system responses was defined for arbitrary two-dimensional curves. This definition can be extended to n dimensions making wide range of parameter identification problems possible to formulate. The value of the defined distance is dimensionless and it expresses the ratio of area between system response graphs in normalized coordinate system to the area of a rectangle with unit area.
The distance between the observed and the simulated system responses was quantified by area between the graphs of system responses in a normalized coordinate system. Partial area was defined as the area of a quadrangle among the and division points on the system response graphs as shown on Figure 6. These division points were selected equidistantly along system response graphs.
Thus, parameter identification problems can be formulated as solving a system of nonlinear equations
where , , and is residual vector with components . The unknown parameters of an epicycloid 6.2 and 6.3 were determined according to the suggested update algorithm. The variation of parameters through iterations and the observed and the simulated system responses for the initial approximate are shown on Figure and Figure 6. The observed and simulated system response pairs are shown on Figure 7 7, 13, 19, 25, 31 and 43 simulations (S).
The results of numerical tests with different initial approximates showed that the optimal solutions were not reached in all cases. The convergence was especially sensitive for the initial values of parameters a, b and c. Several local optimal solutions were detected as shown on Figure 8.
7. Efficiency
The efficiency of an algorithm for the solution of nonlinear equations is thoroughly discussed by Traub [38] as follows. Let be the order of the iteration sequence such that for the approximate errors , there exists a nonzero constant C (asymptotic error constant) for which
A natural measure of the information used by an algorithm is the “informational usage” d, which is defined as the number of new pieces of information (values of the function and its derivatives) required per iteration (called “horner” by Ostrowski [26]). Then the efficiency of the algorithm within one iteration can be measured by the “informational efficiency”
An alternative definition of efficiency is
called “efficiency index” by Ostrowski [26]. Another measure of efficiency, called “computational efficiency” takes into account the “cost” of calculating different derivatives. The concept of informational efficiency () and efficiency index () doesn’t take into account the cost of evaluating f and its derivatives, nor does they take into account the total number of pieces of information needed to achieve a certain accuracy in the root of the function. If f is composed of elementary functions, then the derivatives are also composed of elementary functions, thus the cost of evaluating the derivatives is merely the cost of combining the elementary functions.
Broyden [7] suggested the mean convergence rate
as a measure of efficiency of an algorithm for solving a particular problem, where is the total number of function evaluations, is the initial approximate, is the last approximate to the solution when the termination criteria is satisfied after iterations. is the Euclidean norm of .
Zang’s two-step method [43] is similar to King-Werner method [18,41] with convergence rate [32]. Chen’s [9] and Wang’s [39] three-step methods show asymptotic convergence order . Chen’s [9] method require two function and one derivative evaluations by using a second-order polynomial, proposed in [39] and shows Ostrowski’s [26] efficiency index. Wang’s [39] method require three function and two derivative evaluations shows Ostrowski-index. Zhang [43] published a finite difference based secant method with asymptotic convergence order. Later Ren [32] showed that Zhang’s [43] method has only convergence order due to some mistakes in the derivation. Table 6 compares the efficiencies of classic (Rows 1-2 : Secant, Newton) and improved algorithms (Rows 3, 5 : T-Secant, T-Newton with the suggested full-rank update and from references [9,39]), the T-Secant method with constant Jacobian approximate (row 4 : TS-const. , see data in Table 3), Chen’s [9] and Wang’s [39] methods.
Very limited data are available to compare the performance of the suggested update method (T-Secant) with other classic methods, especially for large number of unknowns. Efficiency results were given by Broyden [7] for the Rosenbrock function for . The calculated convergence rates for the two Broyden method variants [7], for the Powell’s method [30], for the adaptive coordinate descent method [19] and for the Nelder-Mead simplex method [20] were compared with the calculated values for the T-secant method in Table 7 [2]. Rows 1-5 are data from referenced papers, rows 6-8 are T-secant results with the referenced initial approximates and rows 9-15 are calculated data for . If the value of (for ) is zero, then the mean convergence rates (L and ) are not countable (zero in the denominator). A substitute value was used when (for ) in rows 6, 7, 10 and 13.
Results show that the mean convergence rate L (Equation 7.4) for is much higher for the T-secant method () than for the other listed methods ( ). However it is obvious that the mean convergence rate values decrease rapidly with increasing N values (more unknowns need more function evaluations). A modified convergence rate
is suggested to use as an independent measure of efficiency (see Table 7). The values of L and are at least 10 times larger for the T-secant method than for the referenced classic methods for (see Table 7).
The efficiency measures (L and ) are also depending on the initial conditions (distance of the initial approximate from the optimal solution, termination criterion). Results from large number of numerical tests indicate an average with standard deviation around for the T-secant method even for large N values.
8. Conclusions
A numerical procedure has been developed for solving an overdetermined system of nonlinear equations 1.5. It can be considered both as a discretized Newton’s method or as a quasi-Newton method with full-rank update of the Jacobian approximates. Quasi-Newton methods are widely used for solving systems of nonlinear equations when the function derivatives (Jacobian) are not known or difficult to determine. The derivatives (Jacobian) are approximated by divided differences 3.16, and the system of nonlinear equations 1.5 is solved by repeatedly solving systems of linear equations 3.24. The new approximate is determined from the classic secant equation and the divided differences are updated according to the secant condition 3.26. However, the secant condition doesn’t uniquely specify the Jacobian approximate, so the update procedure is not well-defined and further constraints are needed. Different methods offer specific update solutions.
The suggested numerical procedure (“T-Secant” method [2]) provides an unconventional and simple strategy to improve the performance of quasi-Newton iterations by full-rank update of the Jacobian approximates. It is based on the classic secant linearization and allows full-rank update of the Jacobian approximates. The classic secant iteration was completed with a new independent approximate , that was determined from a modified secant equation 4.18. Modification was made by a suitably chosen non-uniform scaling transformation. Scaling was made by the difference quotients of the classic secant function value improvements 4.16 and the difference quotients of the desired new iteration stepsizes and the classic secant stepsizes 4.17. A new independent approximate was determined from the modified secant equation 4.18. The solution to the secant equation presented in [2] was based on the Wolfe-Popper procedure [29,42] so that the secant equation was splitted into two equations by introducing an auxiliary variable. The simplified algorithm, presented in the paper, directly solves the secant equation by using the pseudo-inverse 4.21 of the transformed Jacobian approximate 4.19.
It has been shown that the new T-secant approximate will be in the vicinity of the classic secant approximate if the classic secant iterates converge to the root of the nonlinear function [2]. The Jacobian approximate was then full-rank updated by constructing new divided differences (Jacobian approximates) from the classic secant and from the T-secant approximates.
It was shown that the iterative procedure possesses super-quadratic asymptotic convergence property with convergence rate for simple root in single variable case ([2]), where is the golden section ratio. The suggested procedure can also be applied to the Newton’s method (matrix corresponds to the Jacobian matrix ). Numerical test results indicate that the quadratic convergence () of the Newton’s method increases to cubic ().
The efficiency has been studied in multi-variable case and compared with other classic rank-one update and line-search methods on the basis of available data. Results show that its efficiency is considerably better than the efficiency of other classic low-rank update methods. The suggested method’s performance was demonstrated by the results of numerical tests with widely used single- and multi-variable benchmark test functions. A Rosenbrock test function was used with up to 1000 variables [2]. The method has also been successfully applied for the solution of different “real life” inverse problems [3,4,5] on physically nonlinear dynamic systems. Further studies can be made on convergence properties in case of multiple roots and on the efficiency characteristics in cases of more benchmark test functions. The suggested procedure may be used for other applications especially with large number of unknowns and when low number of function evaluations is crucial.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
A considerable part of the research work has been done between years 1988 -1992 at Technical University of Budapest (Hungary), at TNO-BOUW Structural Division (The Netherlands) and at Technical High-school of Lulea (Sweden). The work has been sponsored by the Technical University of Budapest (Hungary), by the Hungarian Academy of Sciences (Hungary), by TNO-BOUW (The Netherlands), by Sandvik Rock Tools (Sweden), by CP Test a/s (Denmark) and by Óbuda University (Hungary). Valuable discussions and personal supports from Géza Petrasovits, György Popper, Peter Middendorp, Rikard Skov, Bengt Lundberg, Mario Martinez and Csaba J. Hegedűs are greatly appreciated
Conflicts of Interest
The author declares no conflict of interest..
References
- Amat, S.; Busquier, S.; Gutiérrez, J.M. Geometric constructions of iterative functions to solve nonlinear equations. J. Comput. Appl. Math. 2003, 157, 197–205. [Google Scholar] [CrossRef]
- Berzi, P. Convergence and Stability Improvement of Quasi-Newton Methods by Full-Rank Update of the Jacobian Approximates. MDPI AppliedMath 2024, 4, 143–181. [Google Scholar] [CrossRef]
- Berzi, P.; Beccu, R.; Lundberg, B. Identification of a Percussive Drill Rod Joint from its Response to Stress Wave Loading. International Journal of Impact Engineering 1994, 18, 281–290. [Google Scholar] [CrossRef]
- Berzi, P. Pile-Soil Interaction due to Static and Dynamic Load. Proceedings of the 13th International Conference on Soil Mechanics and Foundation Engineering, 1994, 1994-01-05, New Delhi, India, pp. 609–612.
- Berzi, P.; Popper, Gy. Evaluation of dynamic load test results on piles. Proceedings of the International Symposium on Identification of Nonlinear Mechanical Systems from Dynamic Tests (Euromech 280), 1991 1991-10-29, Ecully, France, pp. 121–128.
- Birgin, E.G.; Krejic, N.; Martinez, J.M. Globally convergent inexact quasi-Newton methods for solving nonlinear systems. Num. Algorithms. 2003, 32, 249–260. [Google Scholar] [CrossRef]
- Broyden, C. G. A class of Methods for Solving Nonlinear Simultaneous Equations. Mathematics of Computation. American Mathematical Society 1965, 19, 577–593. [Google Scholar]
- Broyden, C.G.; Dennis, J.E. , Mor, J.J. On the local and superlinear convergence of quasi-Newton methods. J. Inst. Math. Appl. 1973, 12, 223–245. [Google Scholar] [CrossRef]
- Chen, L.; Ma, Y. A new modified King–Werner method for solving nonlinear equations. Computers and Mathematics with Applications 2011, 62, 3700–3705. [Google Scholar] [CrossRef]
- Dembo, R.S.; Eisenstat, S.C.; Steihaug, T. Inexact Newton methods. SIAM J. Numer. Anal. 1971, 19, 400–408. [Google Scholar] [CrossRef]
- Dennis, J.E.; Mor, J.J. A characterization of superlinear convergence and its application to quasi-Newton methods. Mathematics and Computation 1974, 28, 543–560. [Google Scholar] [CrossRef]
- Dennis, J.E. Jr.; Schnabel, R.B. Numerical Methods for Unconstrained Optimization and Nonlinear Equations. Prentice-Hall, Englewood Cliffs, NJ, 1983.
- Gerlach, J. Accelerated convergence in Newton’s method. SIAM Rev. 1994, 36, 272–276. [Google Scholar] [CrossRef]
- Hegedus, Cs. Numerical Methods I. ELTE, Faculty of Informatics, Budapest, 2015.
- Homeier, H.H.H. On Newton-type methods with cubic convergence. J. Comput. Appl. Math. 2005, 176, 425–432. [Google Scholar] [CrossRef]
- Jisheng, K.; Yitian, L. , Xiuhua, W.; Third-order modification of Newton’s method. J. Comput. Appl. Math. 2007, 205, 1–5. [Google Scholar] [CrossRef]
- Kanwar, V.; Sharma, J.R. , Mamta J. A new family of Secant-like method with super-linear convergence. Appl. Math. Comput. 2005, 171, 104–107. [Google Scholar]
- King, R.F. ; Tangent method for nonlinear equations. Numer. Math. 1972, 18, 298–304. [Google Scholar] [CrossRef]
- Loshchilov, I.; Schoenauer, M.; Sebag, M. Adaptive Coordinate Descent. Genetic and Evolutionary Computation Conference (GECCO), ACM Press, 2011, 885–892.
- Nelder, J.A.; Mead, R. A simplex method for function minimization. Computer Journal. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Martínez, J.M. Practical quasi-Newton methods for solving nonlinear systems. Journal of Computational and Applied Mathematics 2000, 124, 97–121. [Google Scholar] [CrossRef]
- Martinez, J.M.; Qi, L. Inexact Newton methods for solving non-smooth equations. J. Comput. Appl. Math. 1995, 60, 127–145. [Google Scholar] [CrossRef]
- Melman, A. Geometry and convergence of Euler’s and Halley’s methods. SIAM Rev. 1997, 39, 728–735. [Google Scholar] [CrossRef]
- Muller, D.E. A Method for Solving Algebraic Equations Using an Automatic Computer. Math. Tables and Other Aids to Computation 1956, 10, 208–215. [Google Scholar] [CrossRef]
- Ortega, J.M.; Rheinboldt, W.C. Iterative Solution of Nonlinear Equations in Several Variables, Academic Press, New York, 1970.
- Ostrowski, A.M. Solution of Equations and Systems of Equations. Academic Press, New York, 1966.
- Özban, A.Y. Some new variants of Newton’s method. Appl. Math. Letter. 2004, 17, 677–682. [Google Scholar] [CrossRef]
- Papakonstantinou, J.M.; Tapia, R.A. Origin and evolution of the secant method in one dimension. The American Mathematical Monthly 2013, 120/6, 500–518. [Google Scholar] [CrossRef]
- Popper, Gy. Numerical method for least square solving of nonlinear equations. Periodica Polytechnica. 1985, 29, 67–69. [Google Scholar]
- Powell, M. Powell, M.; J.; D. An efficient method for finding the minimum of a function of several variables without calculating derivatives. Computer Journal. 1964, 7, 155–162. [Google Scholar] [CrossRef]
- Press, W.H.; Flannery, B.P.; Teukolsky, S.A. , Wetterling, W.T. Numerical recepies. Cambridge University Press, Cambridge, 1986.
- Ren, H.; Wu, Q.; Bi, W. On convergence of a new secant-like method for solving nonlinear equations. Appl. Math. Comput. 2010, 217, 583–589. [Google Scholar] [CrossRef]
- Scavo, T.R.; Thoo, J.B. ; On the geometry of Halley’s method. American Math. Monthly. 1995, 102, 417–426. [Google Scholar] [CrossRef]
- Shaw, S.; Mukhopadhyay, B. An improved regula falsi method for finding simple roots of nonlinear equations. Appl. Math. and Computation 2015, 254, 370–374. [Google Scholar] [CrossRef]
- Stoer, J.; Bulirsch, R. Introduction to Numerical Analysis. Springer -Verlag, 2002.
- Strang, G. Introduction to Linear Algebra. Revised International Edition, Wellesley-Cambridge Press, 2005.
- Thukral, R. A New Secant-type method for solving nonlinear equations. Amer. J. Comput. Appl. Math. 2018, 8, 32–36. [Google Scholar]
- Traub, J.F. Iterative Methods for the Solution of Equations, 1st ed.; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1964. [Google Scholar]
- Wang, X.; Kou, J.; Gu, C. A new modified secant-like method for solving nonlinear equations. Comput. Math. Appl. 2010, 60, 1633–1638. [Google Scholar] [CrossRef]
- Weerakoon, S.; Fernando, T.G.I. ; A variant of Newton’s method with accelerated third-order convergence. Appl. Math. Letter. 2000, 13, 87–93. [Google Scholar] [CrossRef]
- Werner, W. ; Über ein Verfarhren der Ordnung 1 + √ 2 zur Nullstellenbestimmung. Numer. Math. 1979, 32, 333–342. [Google Scholar] [CrossRef]
- Wolfe, P. The Secant Method for Simultaneous Nonlinear Equations. Communications of the ACM 1959, 2, 12–13. [Google Scholar] [CrossRef]
- Zhang, H.; Li, D.-S.; Liu, Y.-Z. A new method of secant-like for nonlinear equations. Commun. Nonlinear Sci. numer. Simul. 2009, 14, 2923–2927. [Google Scholar]
Figure 1.
Left :Linearization of a nonlinear function,Right :Classic secant method
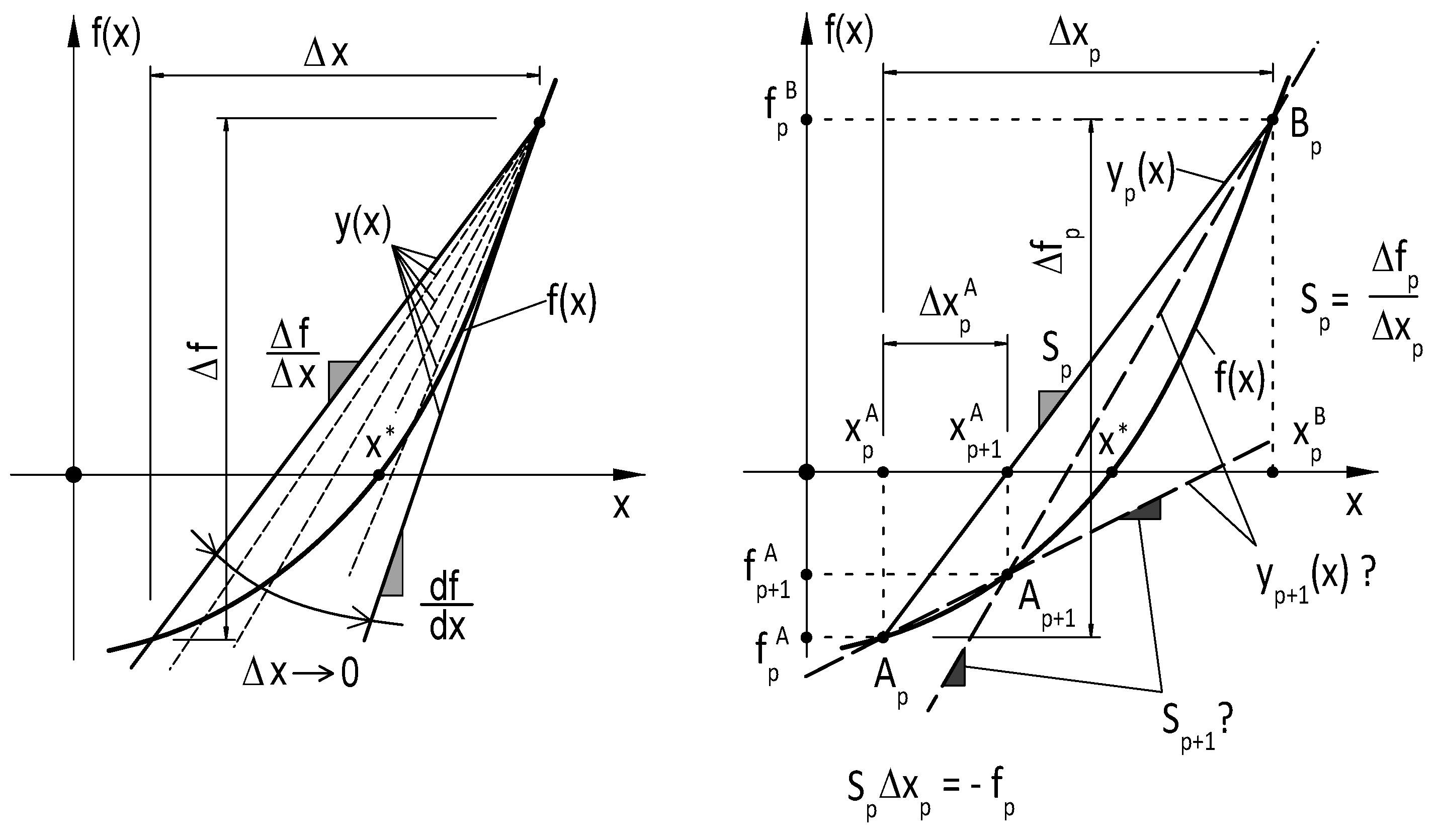
Figure 2.
Suggested full-rank update method (T-secant)
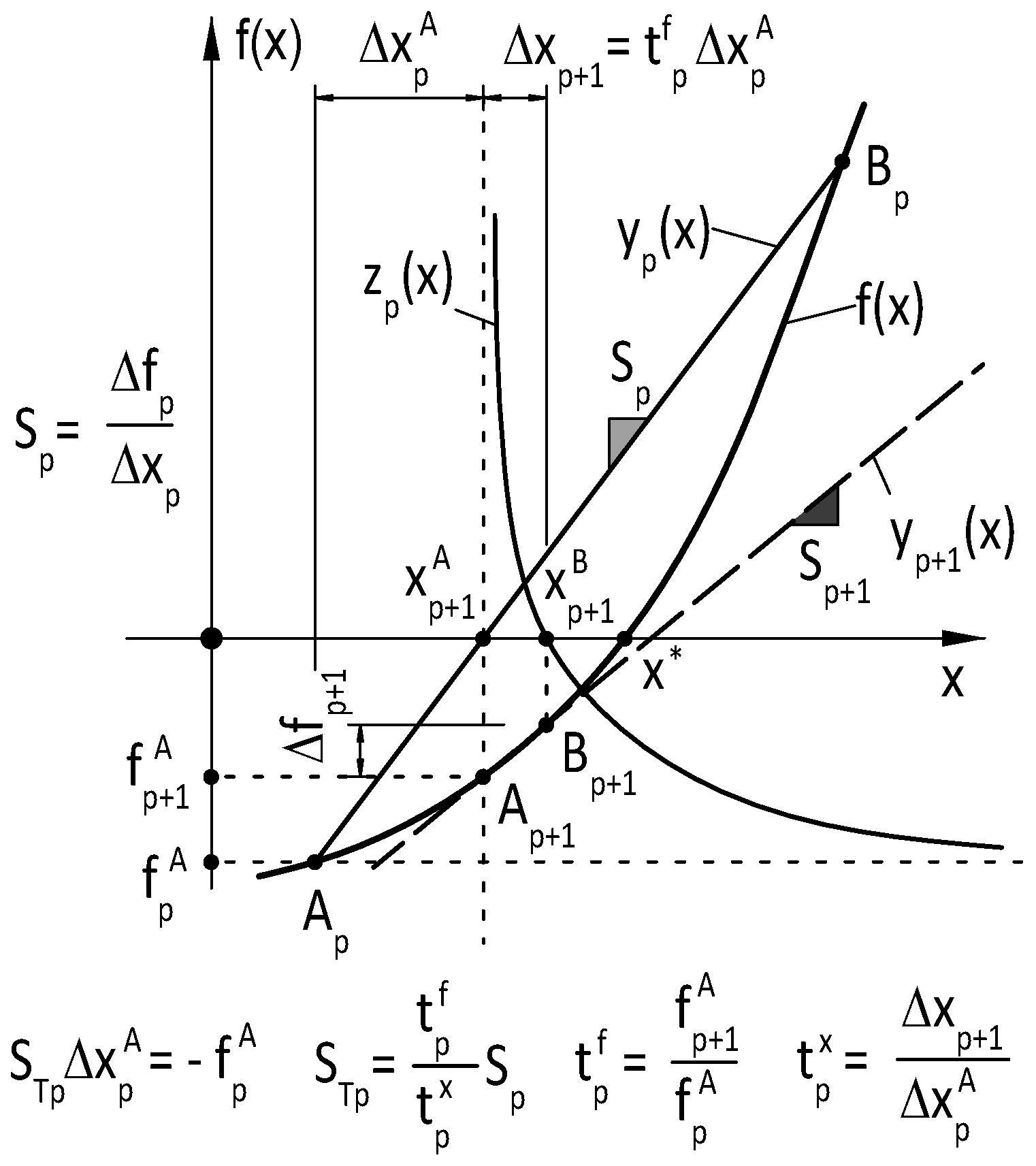
Figure 3.
Effect of the iteration parameter on the iteration process ()
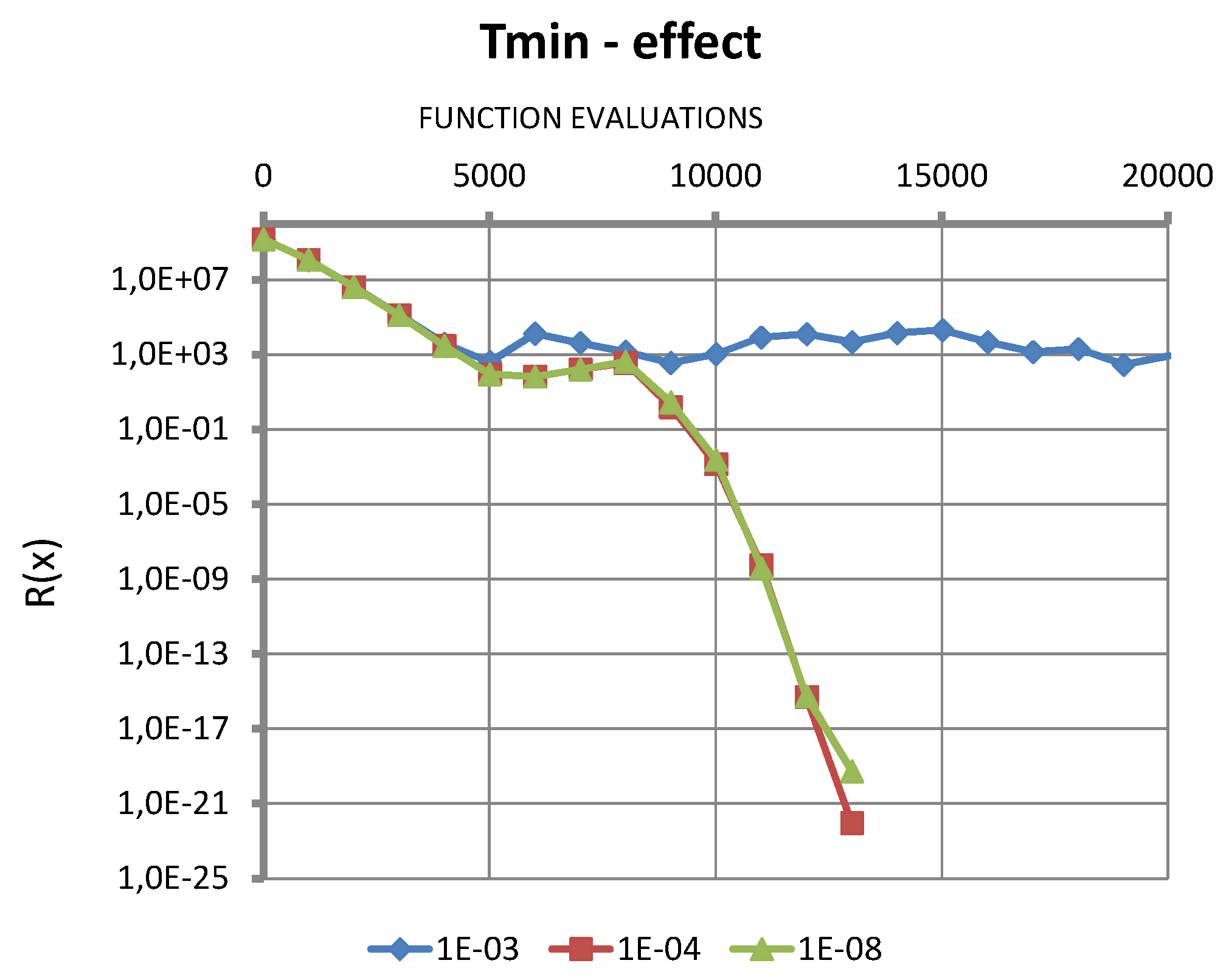
Figure 4.
Classic secant iterations with test function 6.1 (see Table 4). ( : is the root of , then is the root of . : is the root of and is the root of : is the root of and is the root of )
Figure 4.
Classic secant iterations with test function 6.1 (see Table 4). ( : is the root of , then is the root of . : is the root of and is the root of : is the root of and is the root of )
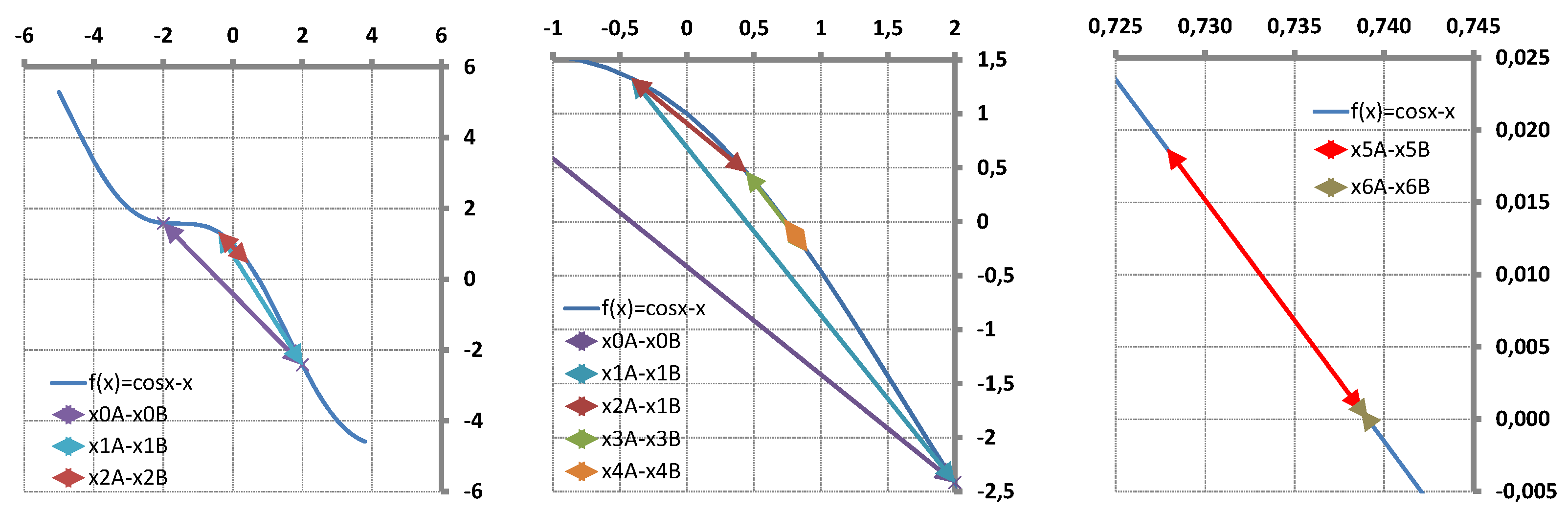
Figure 5.
T-Secant iterations with test function 6.1 (see Table 5) ( : is the root of , is the root of , then is the root of , is the root of . : is the root of , is the root of )
Figure 5.
T-Secant iterations with test function 6.1 (see Table 5) ( : is the root of , is the root of , then is the root of , is the root of . : is the root of , is the root of )
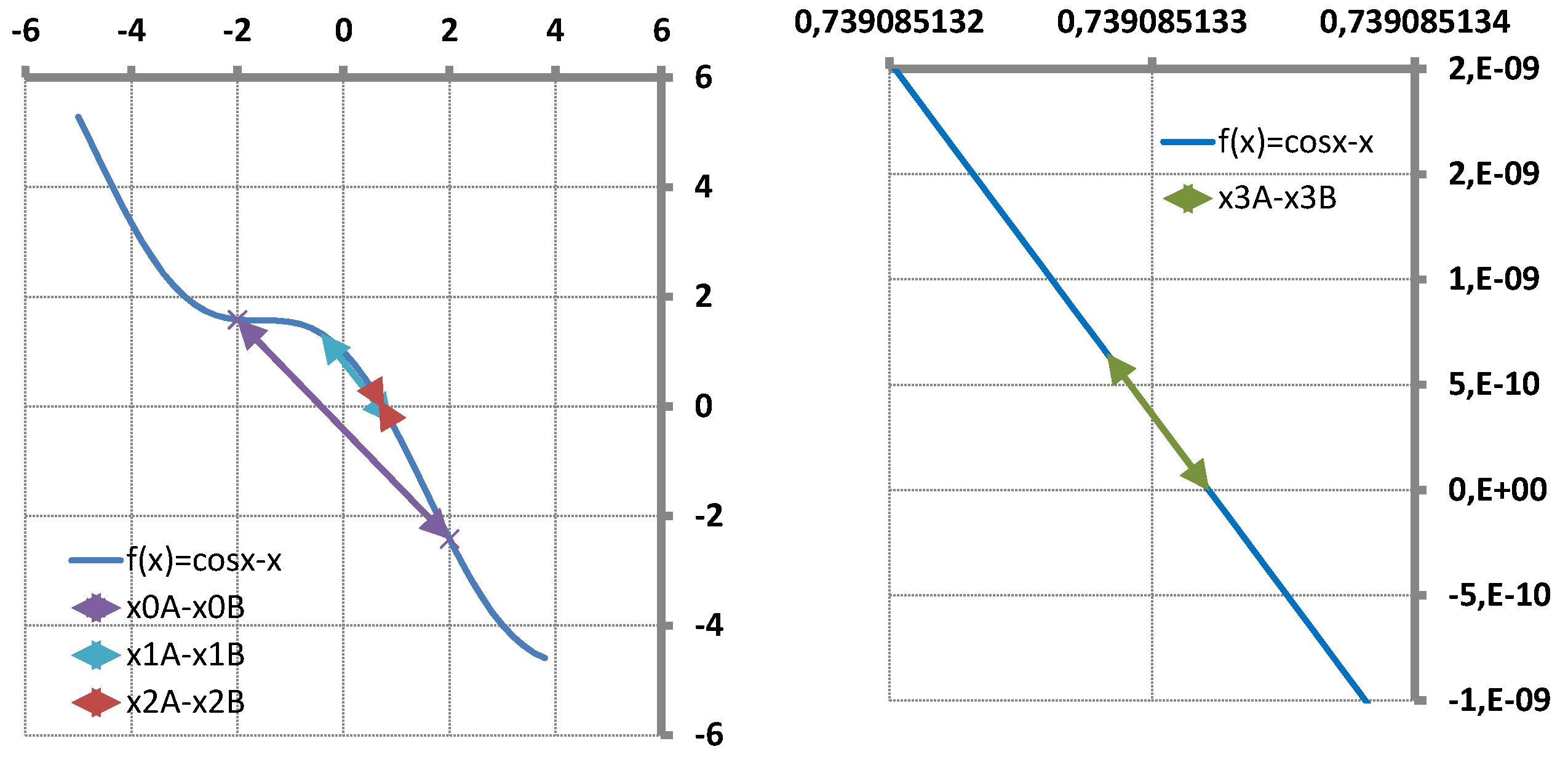
Figure 6.
Definition of the distance between system responses (left) and variation of parameters through iterations (right)
Figure 6.
Definition of the distance between system responses (left) and variation of parameters through iterations (right)
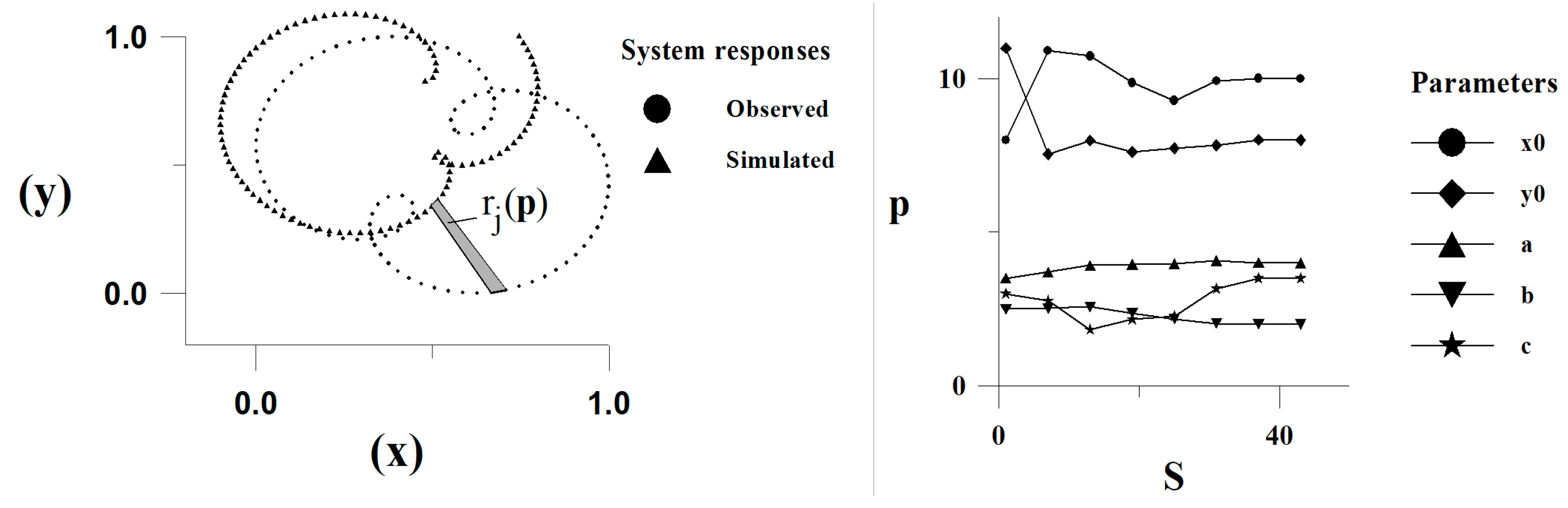
Figure 7.
Observed and simulated system response pairs after “S” function value evaluations
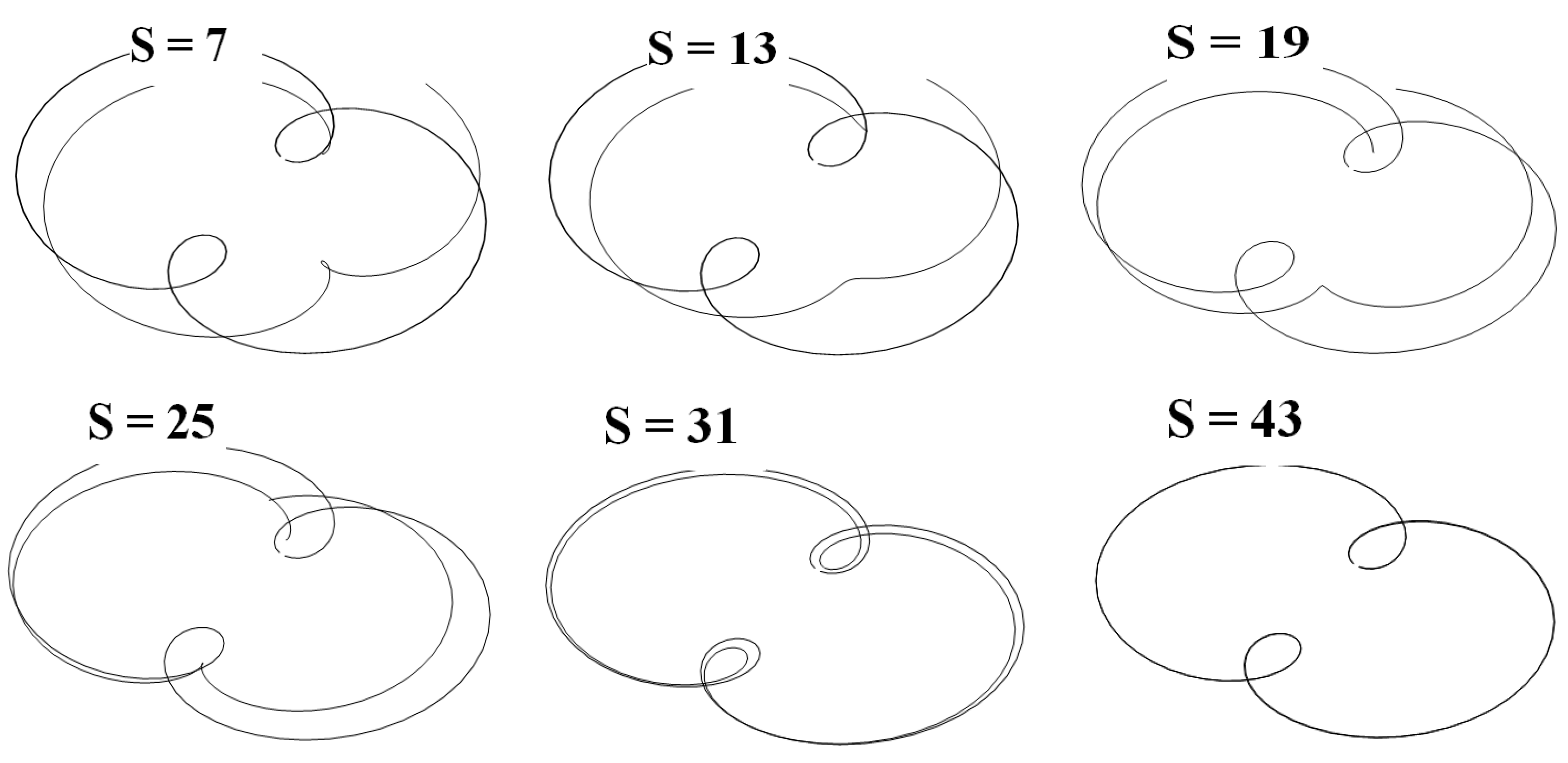
Figure 8.
Local optimal solutions
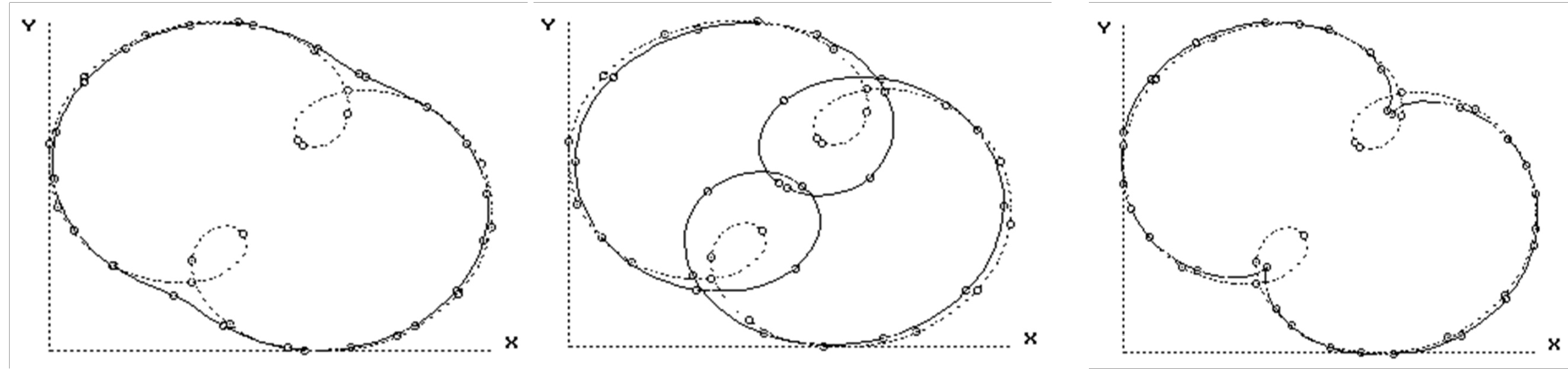

Table 1.
Linearization method’s basic equations (single- and multi-variable cases)
| Single-variable | Multi-variable | Equations | |
|---|---|---|---|
| 1 | 3.18 | ||
| 2 | 3.17 | ||
| 3 | 3.2, 3.16 | ||
| 4 | 3.5, 3.21 | ||
| 5 | 3.8, 3.26 |
Table 2.
Basic equations of classic and suggested multi-variable update methods
| Classic secant method | Suggested update method | Equations | |
|---|---|---|---|
| 1 | 4.14 | ||
| 2 | 3.18, 4.15 | ||
| 3 | 3.17 | ||
| 4 | 4.17 | ||
| 5 | 4.16 | ||
| 6 | 3.16, 4.19 | ||
| 7 | 3.24, 4.18 | ||
| 8 | 3.23, 4.22 | ||
| 9 | 3.22, 4.23 | ||
| 10 | 4.24 | ||
| 11 | 4.25 |
Table 3.
T-Secant iteration with constant Jacobian approximate (Equation 4.27)
| 0 | 1.700 | 2.000 | 0.421 | -0.085 | 0.036 | 2 | 1.23 | ||
| 1 | 2.121 | 2.156 | -0.036 | -0.359 | -0.013 | 4 | 0.87 | ||
| 2 | 2.085 | 2.072 | 0.013 | -0.342 | 0.0044 | 1.08 | 6 | 0.76 | |
| 3 | 2.098 | 2.102 | -0.0044 | -0.348 | -0.0015 | 0.97 | 8 | 0.70 | |
| 4 | 2.093 | 2.092 | 0.0015 | -0.346 | 0.00053 | 1.01 | 10 | 0.67 | |
| 5 | 2.0949 | 2.0955 | -0.00053 | -0.347 | -0.00018 | 0.997 | 12 | 0.65 | |
| 6 | 2.0944 | 2.0942 | 0.00018 | -0.346 | 0.000063 | 1.001 | 14 | 0.63 | |
| 7 | 2.0946 | 2.0947 | -0.000063 | -0.346 | 0.000022 | 0.9997 | 16 | 0.62 |
Table 4.
Classic secant iterations with test function 6.1 (see Figure 4)
Table 4.
Classic secant iterations with test function 6.1 (see Figure 4)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
Table 5.
T-Secant iterations with test function 6.1 (see Figure 5)
Table 5.
T-Secant iterations with test function 6.1 (see Figure 5)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
Table 6.
Efficiencies of classic and improved algorithms
| Method | [38] | [26] | [7] | |||
|---|---|---|---|---|---|---|
| 1 | Secant | 1 | 1.618… | 1.618… | 1.618… | 4.0 |
| 2 | Newton | 2 | 2.0 | 1.0 | 1.414… | 3.0 |
| 3 | T-Secant | 2 | 2.618… | 1.309… | 1.618… | 4.5 |
| 4 | TS - const. | 2 | 1.0 | 0.5 | 1.0 | 0.6 |
| 5 | T-Newton | 3 | 3.0 | 1.0 | 1.442… | 3.0 |
| 6 | Chen [9] | 3 | 1.618… | 0.539… | 1.173… | − |
| 7 | Wang [39] | 5 | 1.618… | 0.323… | 1.101… | − |
Table 7.
Calculated values of the mean convergence rates
| Method | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | Broyden 1. [7] | 4.92 | - | 59 | 0.391 | 0.78 | |
| 2 | 2 | Broyden 2. [7] | 4.92 | - | 39 | 0.607 | 1.22 | |
| 3 | 2 | Powell [30] | 4.92 | - | 151 | 0.150 | 0.30 | |
| 4 | 2 | ACD [19] | 130.1 | - | 325 | 0.086 | 0.17 | |
| 5 | 2 | Nelder-Mead [20] | 2.00 | - | 185 | 0.127 | 0.25 | |
| 6 | 2 | T-secant [7][30] | 4.92 | 3 | 9 | 6.573 | 13.15 | |
| 7 | 2 | T-secant [19] | 130.1 | 3 | 9 | 6.937 | 13.87 | |
| 8 | 2 | T-secant [20] | 2.00 | 2 | 6 | 5.556 | 11.11 | |
| 9 | 3 | T-secant | 72.72 | 5 | 20 | 1.809 | 5.43 | |
| 10 | 3 | 32.47 | 4 | 16 | 3.815 | 11.45 | ||
| 11 | 5 | 93.53 | 8 | 48 | 0.760 | 3.80 | ||
| 12 | 5 | 7.19 | 4 | 24 | 1.351 | 6.76 | ||
| 13 | 10 | 202.6 | 14 | 154 | 0.408 | 4.08 | ||
| 14 | 200 | 92.78 | 10 | 2010 | 0.042 | 8.44 | ||
| 15 | 1000 | 212.4 | 6 | 6006 | 0.006 | 5.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



