
Submitted:
23 December 2024
Posted:
24 December 2024
You are already at the latest version
Abstract
Machine learning (ML) and artificial intelligence are revolutionizing macromolecular and polymeric sciences. This review comprehensively explores ML methodologies, including supervised and unsupervised learning strategies, reinforcement and deep learning, generative and coarse-grained models, and their applications in predicting material properties and behaviors, optimizing synthesis, processes, and advancing polymer design and computational strategies. We focus on foundational studies, recent advancements, and future directions.
Keywords:
polymers
; few-shot and zero-shot learning
; graph neural networks
; dimensional reduction
; clustering algorithms
; random forests
; support vector machines
; classification trees
; Bayesian deep learning
; gradient boosting
; reinforcement learning
; coarse-grained models
1. Introduction
1.1. A brief history of machine learning
The origins of machine learning (ML) are deeply rooted in the broader field of artificial intelligence (AI), which emerged in the 1940s and 1950s with the goal of creating machines capable of simulating human intelligence. Early AI research focused on symbolic reasoning and rule-based systems, epitomized by the work of Alan Turing and his foundational concepts like the Turing Test [1]. By contrast, ML began to take shape as a distinct subfield in the 1950s when Arthur Samuel coined the term while developing a checkers-playing program that improved its performance through experience [2]. Early ML approaches were primarily based on statistical methods, such as linear regression and nearest neighbors, which laid the foundation for modern algorithms [3].
Despite progress, both AI and ML experienced periods of stagnation, known as the "AI winters" of the 1970s and 1990s, caused by limited computational resources and unmet expectations. During these periods, symbolic AI faced challenges in handling complex tasks like image recognition or natural language understanding, while ML quietly advanced with the development of methods like decision trees, support vector machines (SVMs), and neural networks (NNs). The resurgence of ML in the 2000s was driven by the confluence of abundant data, increased computational power (particularly GPUs), and breakthroughs in algorithms, particularly deep learning and reinforcement learning. Today, ML underpins many transformative technologies, including natural language processing, autonomous vehicles, and personalized recommendations.
While ML is a subset of AI, the two fields differ in focus and approach. AI encompasses the broader aim of replicating human intelligence, including techniques like symbolic reasoning and robotics, which do not necessarily rely on data-driven learning. In contrast, ML focuses specifically on enabling systems to learn patterns and make predictions from data. By leveraging supervised, unsupervised, and reinforcement learning [4], ML has become the engine driving most modern AI applications, making it a cornerstone of advancements in technology and science.
Reflecting on our early works, particularly the 1996 articles titled "Optimization of classification trees: strategy and algorithm improvement" and "A novel algorithm to optimize classification trees" [5,6], I am motivated to write this review. In that papers, we explored the application of classification and regression trees (CART) in data analysis, highlighting their effectiveness in handling complex datasets without relying on parametric assumptions. The study demonstrated how CART could identify significant variables in medical diagnosis, providing a robust alternative to traditional statistical methods.
1.2. Why another review?
The rapid advancements in ML have revolutionized numerous scientific domains, including chemistry, biology, and materials science. While there are already several comprehensive reviews on ML in materials science, the unique challenges and opportunities presented by polymers and macromolecules necessitate a focused and timely discussion. Polymers exhibit unparalleled complexity due to their diverse architectures, multiscale behavior, and intricate structure-property relationships. This review addresses these distinct aspects, providing insights into how ML is tailored to overcome such challenges in polymer science. Moreover, the transformative potential of ML has been highlighted by the 2024 Nobel prizes in Physics, emphasizing the profound influence of data-driven approaches in advancing scientific discovery. These accolades underscore the need for domain-specific reviews that guide researchers through the nuanced applications of ML, particularly in emerging fields like macromolecular science.
A significant feature of this review is its focus on recent developments, providing an up-to-date synthesis of the latest advancements in ML techniques and their applications to polymers. This includes breakthroughs in predictive modeling, high-throughput screening, and multi-objective optimization, as well as insights into techniques that extend beyond conventional methodologies. Existing reviews have dealt with emerging trends in ML [7], ML challenges, progress, and potential in polymer science [8], ML interpretability methods [9], methods and applications of ML for materials design [10], ML towards multiscale soft materials design [11], or trends in extreme learning machines [12], to mention a few. For those who prefer to read a more extensive introduction to the various ML methods for polymer informatics, see [13]. The present review adopts a dual perspective by classifying contributions both by methods and techniques (e.g., deep learning, Bayesian optimization, graph NNs) and by application types (e.g., mechanical properties, thermal stability, biodegradability). This structured approach offers researchers a clear framework for understanding how different ML approaches align with specific goals in polymer design and engineering. Through this focused and methodical exploration, this review aims to bridge gaps in the literature, offer fresh perspectives, and inspire innovative research at the intersection of ML and polymer science.
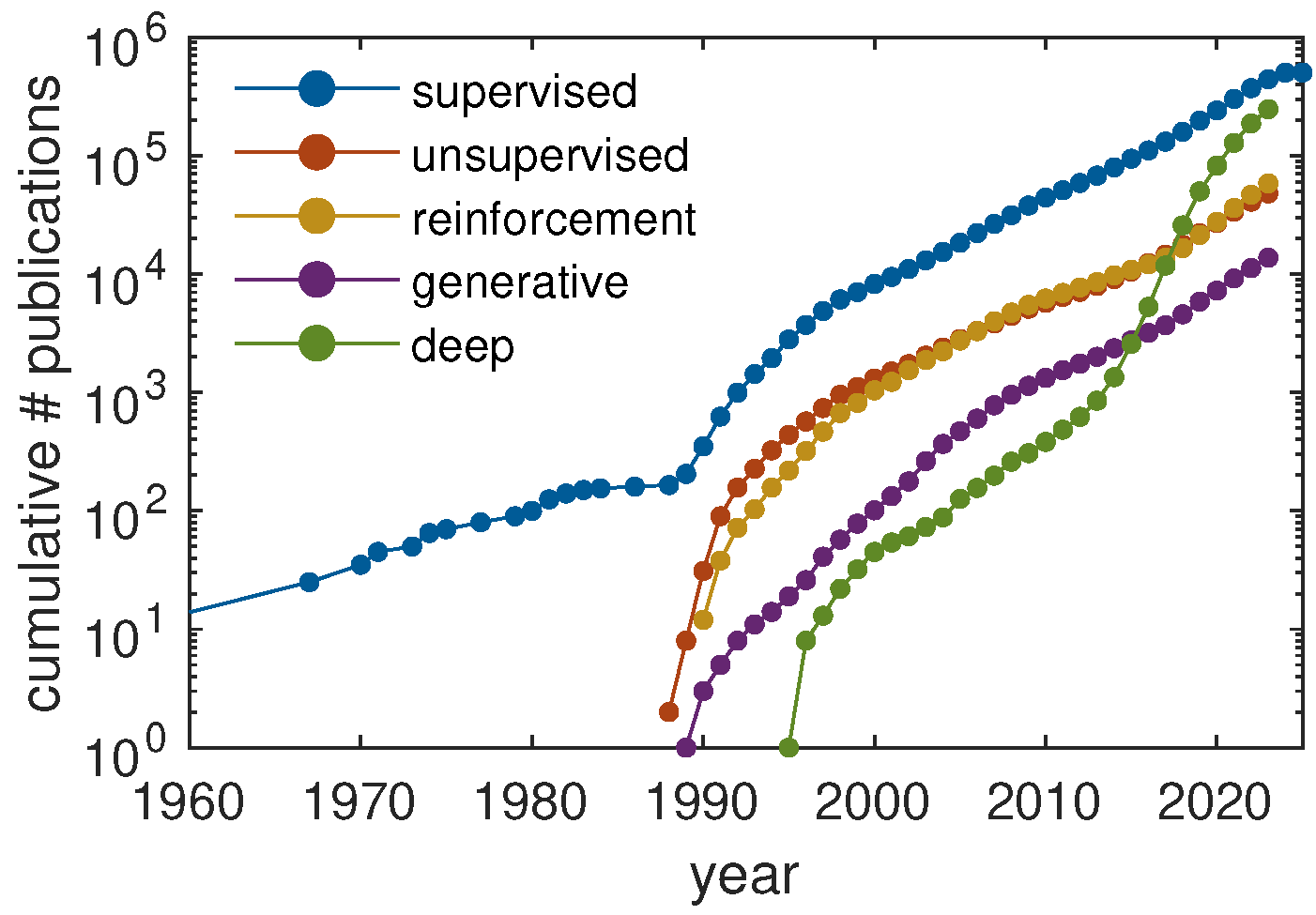
Figure 1.
Cumulative number of publications in the course of time belonging to the five areas: Supervised learning (Section 2.1), Unsupervised learning (Section 2.2), Reinforcement learning (Section 2.3), Generative models (Section 2.4), and Deep learning (Section 2.5).
Figure 1.
Cumulative number of publications in the course of time belonging to the five areas: Supervised learning (Section 2.1), Unsupervised learning (Section 2.2), Reinforcement learning (Section 2.3), Generative models (Section 2.4), and Deep learning (Section 2.5).
1.3. Outline
ML has redefined scientific inquiry by providing tools to analyze complex data and predict outcomes with precision. In polymer science, where material performance often depends on subtle molecular variations, ML offers unparalleled opportunities. Early studies focused on property prediction using statistical models, evolving into deep learning applications for polymer informatics. Emerging trends include the integration of generative AI for creating novel polymer architectures. Macromolecular and polymeric sciences have long been at the forefront of material innovation, contributing significantly to industries such as automotive, healthcare, and packaging. However, the field faces challenges that require increasingly complex and high-throughput experimental workflows. The rise of ML offers solutions by enabling predictive modeling, automated optimization, and data-driven decision-making. Traditional experimental approaches are inherently resource-intensive and time-consuming. For example, the iterative process of synthesizing and testing polymer candidates can take weeks or months. ML addresses these limitations by leveraging computational algorithms to analyze large datasets, uncover structure-property relationships, and optimize synthesis pathways.
This review provides a comprehensive exploration of ML applications in polymer science, focusing on: (i) Core ML methodologies, including supervised, unsupervised, reinforcement, generative and deep learning. (ii) Applications in property prediction, synthesis optimization, and sustainable materials design. (iii) Challenges and limitations, such as data scarcity and interpretability. (iv) Future directions. For each of the methods we have created a schematic drawing along with a short description of its distinctive feature. For those readers primarily interested in a specific application rather than a method, we prepared Table 1. While this review attempts to present and discuss the primary ML methods of relevance for polymer research, additional methods and variations (such as principle component analysis, domain adaption, multitask learning, sample selection bias, covariate shift, semi-supervised and self-supervised learning, anomaly detection, feature learning, sparse dictionary learning, robot learning, association rule learning etc.) certainly exist, and their amount keeps growing on a monthly basis. We suspect that the diversity of machine learning "methods" is nearly matched by the multitude of programs developed to tackle problems that could often be addressed using variations, combinations, or adaptations of existing approaches. Thats why we focus on the core ML methodolgies.
2. Current Machine Learning Strategies in Polymer Science
ML encompasses a diverse array of algorithms and approaches, each suited to specific tasks. Here we provide a detailed overview of the primary ML techniques used in the field along with typical applications.
2.1. Supervised Learning
Supervised learning (Figure 2) is the most widely used ML technique in polymer science. It involves training a model on labeled data, where the relationship between input features (e.g., polymer composition) and output targets (e.g., tensile strength) is known [14]. Kotsiantis [14] reviewed various supervised ML classification techniques, emphasizing their role in building models that generalize from labeled data to predict future instances. The paper covers key algorithms, such as decision trees, SVMs, and ensemble methods, and discusses their theoretical foundations and practical applications. The study underscores the importance of feature selection and bias-variance trade-offs in optimizing classifier performance, providing a foundational guide for researchers exploring supervised learning methods.
(A) Neural Networks (NNs), particularly convolutional NNs (CNNs), which will be discussed in detail in Section 2.5, excel in analyzing polymer microstructures. The principle behind the learning feature of a NN (Figure 4) is iterative optimization. NNs learn by adjusting their internal parameters (weights and biases) to minimize the error between predicted outputs and actual targets. This process involves forward propagation, where data passes layer by layer through the network, and backpropagation, which computes gradients of the loss function with respect to network parameters using the chain rule of calculus. These gradients guide an optimizer in updating the parameters over multiple epochs, enabling the network to learn general patterns in the data while avoiding overfitting.
Recent contributions demonstrate the versatility of NNs across various applications in polymer science. In polymer property prediction, Saingam et al. [15] used NNs to predict the compressive strength of hemp fiber-reinforced polymer composites, showing strong agreement with experimental results. Alhulaybi and Otaru [16] utilized deep NNs (DNNs) to model the thermal decomposition behavior of biodegradable composites, achieving near-perfect correlation with experimental data. Similarly, Malashin et al. [17] optimized NNs and SVMs for predicting textile polymer composite properties using multi-objective optimization techniques. In polymer processing and structural analysis, Yang et al. [18] employed multitask NNs to predict gas permeability and selectivity in polymer chemistry, leading to novel membrane designs. Cassola et al. [19] reviewed ML’s integration with Computer Aided Engineering tools for efficient simulation of polymer composite processes. Bejagam et al. [20] introduced a novel ANN framework for force-field optimization in coarse-grained molecular dynamics (CG-MD), bridging simulation data with experimental properties. NNs have also found utility in advanced material design. Axelrod et al. [21] explored their integration with atomistic simulations, advancing the design of materials like polymer electrolytes. Alesadi et al. [22] leveraged NNs to predict the glass transition temperature of conjugated polymers, utilizing molecular dynamics and chemical structure features. Wu et al. [23] introduce a ML-enhanced computational reverse-engineering analysis method for analyzing small-angle scattering profiles of polymer solutions containing semiflexible fibrils with variable diameters, such as methylcellulose fibrils. By incorporating neural networks (NN), the improved method enhances workflow speed while maintaining accuracy. Validation with in silico scattering profiles confirms its precision in determining fibril dimensions. Application to experimental data from methylcellulose fibrils yields diameter distributions consistent with previous analytical model fits (15–20 nm). Several reviews highlight broader implications of NNs in polymer science. McDonald et al. [24] emphasize their role in accelerating biomaterial design, addressing challenges in data standardization and characterization. Malashin et al. [25,26] explore NN techniques in 3D/4D printing and LSTM applications for polymer property prediction. Loh et al. [27] discuss the integration of NNs with traditional methods for modeling damage in fiber-reinforced composites. These studies underscore the transformative potential of NNs in polymer science, from property prediction and material design to advanced processing and simulation.
(B) Random Classification Tree is a type of decision tree used for categorizing data into distinct classes (Figure 5). These parameter-free, supervised learning algorithms model data by recursively splitting it into subsets based on feature values, following a tree-like structure. At each node, a decision partitions the data into groups, ultimately assigning a classification label at the leaf nodes. The algorithm evaluates all possible splits at each node, aiming to maximize class separation. Known for their clarity and interpretability, classification trees represent each decision as a simple rule, making them easy to visualize and understand [14].
Fakhry et al. [28] employed decision tree models to enhance the prediction of Cr(VI) sorption by fungal biomass and extracellular melanin. By integrating equilibrium isotherms and kinetic studies, they showcased the efficacy of decision trees in biosorption predictions, complementing traditional methods. Saber et al. [29] utilized a decision tree learning algorithm alongside Taguchi’s optimization approach to enhance the biosynthesis of pullulan, a biodegradable hydrogel polymer. This method identified key process variables, reducing sucrose usage by 33% while maintaining high yield, achieving 7.23% pullulan under optimal conditions, and highlighting AI-driven methods’ potential in fermentation optimization. Koinig et al. [30] applied classification methods to improve the sorting of monolayer and multilayer films in recycling. By combining near-infrared spectroscopy with Fourier transforms to optimize spectral data, they significantly enhanced classification accuracy for material separation. Bhowmik et al. [31] use decision tree and principal component analysis, to predict polymers’ specific heat at room temperature, providing insights into the influence of polymer descriptors and guiding the design of novel materials with tailored thermal properties.
(C) Random Forests are a popular parameter-free ML algorithm used for classification and regression tasks (Figure 6). This ensemble learning method constructs multiple decision trees and combines their outputs to enhance performance, stability, and robustness compared to individual trees. While individual decision trees are interpretable, Random Forests sacrifice some interpretability due to their ensemble nature.
Several studies have demonstrated the versatility of Random Forests in addressing diverse challenges across polymer sciences. In the context of material sustainability, Guarda et al. [32] reviewed the application of ML algorithms, including Random Forests, to improve plastics’ life cycle sustainability, addressing challenges from production to end-of-life processes. Similarly, Nelon et al. [33] emphasized Random Forests’ predictive capabilities for damage mechanism detection and life estimation in fiber-reinforced composite materials when combined with structural health monitoring and nondestructive evaluation methods. Random Forests have proven effective in predicting material properties and optimizing processes. Munir et al. [34] employed RFE-RF models to monitor molecular weight degradation in PLA during extrusion, providing interpretable and robust predictions across varying process conditions. Similarly, Pelzer et al. [35] leveraged Random Forests to analyze process parameter dependencies in extrusion-based additive manufacturing, identifying optimal settings and key parameter interactions. Chavez-Angel et al. [36] applied Random Forests in conjunction with k-nearest neighbor algorithms to generate hyperspectral temperature maps of polymer thin films, enabling precise heat distribution analysis for applications in CMOS technologies. Optimization and anomaly detection also benefit from Random Forest applications. Huang et al. [37] integrated a mixed whale optimization algorithm (MWOA) with Random Forests to predict the chloride permeability coefficient of rubber concrete, achieving a 62.9% improvement in prediction accuracy. Gope et al. [38] used Random Forests to detect abnormal processing parameters in polypropylene fiber melt spinning, enhancing parameter identification and quality control. In structural and mechanical property prediction, Random Forests have shown exceptional accuracy. Amin et al. [39] predicted the bond strength of FRP laminates with concrete (), while Anjum et al. [40] achieved an of 0.91 for compressive strength prediction of fiber-reinforced nano-silica concrete. Alabdullh et al. [41] proposed a hybrid ensemble (HENS) model for FRP bond strength prediction, where Random Forest served as a baseline, achieving robust results before HENS demonstrated superior accuracy (). Random Forests have also been applied in composite material performance prediction. Karamov et al. [42] predicted fracture toughness of pultruded composites, correlating strongly with bending and tension properties. Similarly, Joo et al. [43] used Random Forests to predict physical properties of polypropylene composites, supporting recipe optimization for industrial applications. Aminabadi et al. [44] integrated Random Forests in an Industry compliant injection molding setup, effectively predicting part geometry and surface quality for automated quality control. Lastly, Random Forests have proven invaluable in concrete reinforcement studies. Khan et al. [45] applied Random Forests to predict the compressive strength of steel-fiber-reinforced concrete (SFRC), achieving an and identifying cement content as the most influential factor. Another study by Khan et al. [46] demonstrated Random Forests’ reliable performance () in predicting the flexural strength of FRP-reinforced beams, using sensitivity analysis to reveal critical influencing factors.
(D) Gradient Boosting is a powerful ML technique widely used for regression, classification, and ranking tasks. It constructs an ensemble of weak learners (typically decision trees) sequentially, where each model corrects the residual errors of its predecessors (Figure 7). By iteratively optimizing a loss function, Gradient Boosting achieves high predictive accuracy and robustness, making it an effective tool across various domains.
For property prediction, Ascencio-Medina et al. [47] used Gradient Boosting Regressor models to predict dielectric permittivity in polymers, achieving high coefficients and providing molecular insights through Accumulated Local Effect analysis. Fatriansyah et al. [48] investigated extreme gradient boosting (XGBoost) for predicting the glass transition temperature of polymers, demonstrating stable performance () while emphasizing SMILES descriptor optimization for improved reliability. Yan et al. [49] employed Gradient Boosting Regression to predict tribological properties of PTFE composites, effectively capturing the influence of load and speed on wear and friction rates. In composite materials, Zhao et al. [50] utilized an extreme gradient boosting model to predict the residual compressive strength of composite laminates post-impact, achieving exceptional accuracy () and showcasing acoustic emission parameters’ utility for structural health monitoring. Similarly, Hu et al. [51] integrated XGBoost and Gradient Boosting to optimize the stacking sequence and orientation of CFRP/metal composite laminates, achieving reliable predictions for tensile and bending strengths. Gradient Boosting has also advanced sustainable material design and process optimization. Cao and Xu [52] employed Gradient Boosting Decision Trees to predict photovoltaic performance in ternary polymer solar cells, achieving a relative error of less than 5%. Okada et al. [53] combined Gradient Boosting with feature selection to analyze molecular descriptors and TD-NMR data, enabling accurate hydrophilic polymer coating predictions for water treatment membranes. Mayorova et al. [54] applied Gradient Boosting alongside Random Forest and Raman spectroscopy to study structural changes in whey protein isolate-hyaluronic acid complexes, identifying key Raman bands indicative of modifications. Gradient Boosting has proven effective in manufacturing and machining applications. Biruk-Urban et al. [55] employed Gradient Boosting Regressor to simulate drilling parameters in GFRP composites, identifying feed per tooth as the most influential factor on delamination and optimizing machining processes. Rahimi et al. [56] used Gradient Boosting to classify moisture content in kiln-dried wood, aiding in moisture uniformity optimization and effectively grouping timber into acceptable, over-, and under-dried categories. In polymer-based systems, Deshpande et al. [57] achieved high prediction accuracy () for the specific wear rate of glass-filled PTFE composites using Gradient Boosting, identifying key parameters via Pearson’s correlation. Chen et al. [58] utilized extreme gradient boosting to analyze molecular dynamics simulations of natural rubber, identifying hydrogen-bond interactions as critical to stress-strain behavior and strain-induced crystallization. Martinez et al. [59] leveraged Bayesian Additive Regression Trees (BART) and Gradient Boosting to predict dispersancy efficiency in oil and lubricant additives, enhancing discovery through interactive tools for chemical library screening. Ethier et al. [60] use ML to predict polymer-solvent phase behavior, utilizing a curated database of 21 polymers, 61 solvents, and 6524 cloud point temperatures. Models incorporating molecular descriptors and Hansen solubility parameters achieved high accuracy in cloud point predictions and replicated phase diagrams. While extrapolation to dissimilar polymers is limited, minimal additional data improves predictions.
(E) Support Vector Machines (SVMs) are particularly effective for classification tasks, aiming to find the hyperplane that best separates data points of different classes in a high-dimensional space. By maximizing the margin between the closest points (support vectors) of each class, SVMs achieve robust classification performance (Figure 8). Through the use of kernel functions, they can handle non-linear separations by mapping data to higher-dimensional spaces where linear separation becomes possible.
In non-destructive testing, Ashebir et al. [61] reviewed advanced techniques for defect detection in fiber-reinforced thermoplastic composites. Integrating ML algorithms, including SVMs, improved defect detection sensitivity by up to 30%, enhancing the structural integrity of additively manufactured components. Liu et al. [62] used support vector regression to analyze 3D printing parameters’ influence on outcomes, identifying critical factors such as extrusion expansion ratio, elastic modulus, and elongation at break through feature importance and SHapley Additive exPlanations (SHAP) values. In process optimization, Malashin et al. [63] combined finite element modeling with ML methods, including SVMs, to predict tensile properties of selective laser-sintered polyamide components under various loading conditions. Similarly, Subeshan et al. [64] highlighted the potential of SVMs in optimizing electrospinning parameters to produce nanofibers with precise properties for applications ranging from tissue engineering to sensors. Chen et al. [65] used SVMs to predict piezoelectric output from material and synthesis parameters in electrospun PVDF and composite fibers, advancing high-performance energy-harvesting systems. SVMs also play a critical role in materials design and property prediction. Yue et al. [66] integrated high-throughput stochastic breakdown simulation with SVMs to predict energy storage performance in polymer composites, providing valuable insights for designing high-density capacitors. Shen et al. [67] combined phase-field modeling with ML, including SVMs, to study breakdown mechanisms in polymer-based dielectrics. This approach yielded predictive models for breakdown strength and identified optimal nanofiller properties, verified through experiments, contributing to the design of enhanced dielectric materials. In broader polymer applications, Jongyingcharoen et al. [68] applied ML models, including SVMs, to classify crosslink density in para rubber gloves using near-infrared spectroscopy, achieving reliable classification for production screening. Qin et al. [69] developed an AI-assisted approach for analyzing bicomponent fibers, utilizing SVMs for accurate and cost-effective component identification in industrial testing. Uddin and Fan [70] used SVMs within an interpretable ML framework to predict the glass transition temperature of polymers, combining feature elimination and SHAP analysis for enhanced interpretability.
2.2. Unsupervised Learning
Unsupervised learning techniques are essential for exploring large, unlabeled datasets (Figure 9). They enable researchers to uncover patterns and groupings that may not be immediately apparent.
(A) Clustering Algorithms, such as k-means and hierarchical clustering (Figure 10), are widely used in polymer informatics for tasks like classifying polymers by molecular weight distributions or chemical compositions [71]. These methods are essential for exploratory data analysis, uncovering hidden patterns in datasets, and aiding in hypothesis generation [13].
Clustering plays a critical role in recycling and material optimization. Olivieri et al. [72] developed a classification system for recycled polymers using industrial sorting data, setting the stage for AI-driven databases to optimize recycling processes and enhance material properties. Wolf and Stammer [73] examined chemical recycling strategies for silicone polymers, emphasizing depolymerization techniques and the growing potential for closed-loop systems to minimize waste and conserve resources. Neo et al. [74] employed Random Forest Regression and Bagging to predict offline color data of extruded thermoplastic resins, significantly reducing time and material waste in color-matching processes. In polymer mechanics and composite design, Dairabayeva et al. [75] investigated the mechanical performance of continuous carbon-fiber reinforced composites, analyzing tensile and flexural properties alongside cost and printing time optimizations for additive manufacturing. Bounjoum et al. [76] used clustering techniques to identify distinct failure patterns in CFRP-reinforced concrete structures, revealing a 45% improvement in flexural strength and informing composite-reinforced infrastructure designs. Lee et al. [77] studied epoxy resin and crumb rubber powder-modified cement asphalt mortar, showcasing improved flowability, stability, and environmental resistance with applications in railway infrastructure durability. Unsupervised learning has also been used for novel analytical and structural insights. Scatigno et al. [78] applied clustering techniques to classify spectroscopic benchmarks in Italian pictorialism photography, identifying distinct molecular and elemental fingerprints to uncover stylistic practices. Younes et al. [79] used Principal Component Analysis (PCA) to study lignin degradation in tropical peatlands, linking molecular fingerprints to carbon and methane emission dynamics in anoxic environments. Clustering algorithms also enable molecular and mesoscopic structural analysis. Doi et al. [80] introduced the ML-aided Local Structure Analyzer (ML-LSA) for classifying mesoscopic structures of liquid crystal polymers (LCPs) using molecular dynamics simulations. This approach identified nematic- and smectic-like structures with high accuracy, revealing structural transitions without predefined order parameters. Similarly, Bejagam et al. [81] integrated nonmetric multidimensional scaling (NMDS) with CG-MD simulations to study the coil-to-globule transition in poly(N-isopropylacrylamide) (PNIPAM). [82] Their analysis uncovered multiple metastable states during the transition, providing mechanistic insights into polymer behavior above its lower critical solution temperature (LCST).
(B) Dimensionality Reduction techniques, such as principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE), simplify high-dimensional datasets, enabling more efficient analysis and visualization (Figure 11). For instance, [83] applied PCA to visualize spectroscopic data, revealing correlations between polymer structure and functionality. These methods are particularly valuable in polymer science for managing complex datasets and uncovering key structure-property relationships.
In materials discovery and polymer design, dimensionality reduction plays a crucial role. Zhao et al. [84] emphasized its use in managing large datasets, improving property prediction models, and accelerating polymer discovery. Martinez et al. [85] introduced a pipeline that leverages ML and dimensionality reduction to predict molecular weight, polydispersity index, and conversion rates in polymer synthesis, achieving values up to 0.93. Patra [86] highlighted its potential in navigating the vast configurational and chemical space of polymers, aiding in the identification of key structure-property relationships for data-driven design. Dimensionality reduction also enhances simulation and experimental workflows. Karatrantos et al. [87] explored molecular simulations, emphasizing ML’s role in dimensionality reduction to study dynamic bond exchange reactions in vitrimers and covalent adaptable networks. Trienens et al. [88] used ML-assisted simulation models to predict melt quality during polymer extrusion, correlating process parameters with thermal and material homogeneity. Similarly, Knoll and Heim [89] proposed a "machine fingerprint" approach to reduce disparities between simulation and experimental injection molding results, enhancing transfer learning applications. For soft materials and nanoscale systems, dimensionality reduction has proven transformative. Noid [90] and Dhamankar and Webb [91] reviewed coarse-grained (CG) modeling techniques, highlighting the use of dimensionality reduction to enhance chemically specific simulations and predictive capabilities. Jacob et al. [92] developed an analytical model for FRET in flexible peptides, simplifying diffusion analysis through fluorescence spectroscopy. Jackson et al. [11] integrated ML with multiscale modeling frameworks, emphasizing dimensionality reduction to distill critical chemical and morphological features for inverse materials design. Ziolek et al. [93] reveal the detailed distribution of polymer conformations within Pluronic and Tetronic micelles, highlighting the structural organization in the disordered micellar corona. Their analysis demonstrates how the block architecture of these amphiphilic copolymers influences chain arrangement in core-shell morphologies, providing new insights into their nanoscale structure and dynamics. Dimensionality reduction also supports optimization in advanced material systems. Saleh et al. [94] optimized TPMS lattice structures using adaptive neuro-fuzzy inference systems, achieving superior accuracy in mechanical property predictions. Yan et al. [95] applied response surface methodology (RSM) and central composite design (CCD) to optimize the preparation of CNT-GN nanocomposites, achieving high sensitivity and modulus while minimizing experimental costs. Bessa et al. [96] employed dimensionality reduction in computational frameworks for uncertainty modeling, mitigating the "curse of dimensionality" and enhancing design space exploration. Lastly, dimensionality reduction facilitates property optimization in polymer dielectrics and energy systems. Wang et al. [97] reviewed quantum mechanical and molecular dynamics strategies, highlighting the role of QSPR and ML in dielectric property optimization. Li et al. applied PCA and t-SNE to study molecular orientation tensors, uncovering mechanisms of shear thinning in squalane under high strain rates.
2.3. Reinforcement Learning
Reinforcement learning (RL) is a promising but underexplored area in polymer science. It involves training an agent to make sequential decisions by maximizing a reward signal (Figure 12). By autonomously exploring large decision spaces, RL has shown potential for optimizing polymerization pathways [98] and advancing data-driven approaches in material design.
The application of RL and related methodologies in polymer science is gaining attention. Gomez-Flores et al. [99] critically reviewed the role of ML in fiber and nanocomposites, emphasizing the underutilized potential of RL. They proposed a control loop framework to enhance process integration across scales, enabling more efficient and adaptive design strategies. Wang et al. [100] demonstrated the potential of RL-inspired Bayesian optimization (BO) integrated with CG-MD to design solid polymer electrolytes (SPEs) with enhanced ionic conductivity. Their framework autonomously explored high-dimensional design spaces using physically interpretable descriptors, uncovering molecular-level insights into how properties such as molecule size and interaction strength affect conductivity. This approach provided actionable guidance for improving SPE components and showcased RL’s utility in materials optimization. RL-related techniques have also been applied to industrial polymer processing. Malashin et al. [101] integrated multi-objective evolutionary algorithms with data mining to optimize extrusion barrier screw geometry for processing low-density polyethylene and polypropylene. This study highlights the role of AI in refining complex industrial processes and improving material efficiency. Jeon et al. [102] developed ML models incorporating energy flow-related features to predict melt temperature during injection molding, providing insights into process control and optimization.
2.4. Generative Models
Generative models, such as generative adversarial networks (GANs) and variational autoencoders (VAEs), are revolutionizing polymer design by enabling the creation of novel polymer structures and architectures (Figure 13). GANs, for instance, have been used to generate realistic polymer architectures, opening new possibilities for material innovation [103]. These models excel in exploring vast design spaces, accelerating discovery, and optimizing material properties.
Fan et al. [104] reviewed smart-responsive hydrogels for skin wound therapy, highlighting the integration of AI to optimize material properties for improved clinical outcomes. Adetunji and Erasmus [105] discussed green synthesis techniques for bioplastics derived from microalgae, emphasizing AI’s role in optimizing sustainable production. Zhu et al. [106] reviewed the application of generative models in the design of polymer-based dielectrics, focusing on inverse design methods to establish structure-property linkages. Similarly, Zhou et al. [10] emphasized the transformative role of big data and ML in materials design, showcasing how generative models facilitate large-scale screening and rational design of advanced polymers and porous materials. Generative models have also enhanced molecular simulations and multiscale modeling by bridging scales and uncovering complex structural dynamics. Li et al. [107] employed conditional GANs (cGANs) for backmapping CG macromolecules to atomistic resolutions, achieving high fidelity in modeling cis-1,4 polyisoprene melts. Pan et al. [108] applied dissipation particle dynamics simulations to study lipid-nanoparticle mixtures, providing insights into interfacial tension and mechanical properties for molecular-level composite design. Guda et al. [109] used ML-driven approaches to analyze X-ray absorption near-edge structure (XANES) spectra, revealing active site dynamics in catalytic systems and demonstrating the ability of generative models to uncover structural features in complex materials. In soft material and composite design, Chiu et al. [110] combined a Genetic Algorithm (GA) with a Conditional Variational Autoencoder (CVAE) to design bioinspired composite materials with optimized stiffness and toughness. Their approach was validated through finite element simulations and 3D-printed tensile tests, showcasing generative models’ efficiency in soft material placement optimization. Wang et al. [111] developed a polyurethane-based triboelectric nanogenerator incorporating zirconium boride, demonstrating AI’s role in improving thermal conductivity and electrical output for wearable electronics. Tan et al. [112] introduced a conductive hydrogel system for targeted drug delivery, leveraging generative design to enhance therapeutic outcomes and material performance. Generative models are also driving advancements in high-throughput material discovery. Tao et al. [113] utilized DNNs to discover over 65,000 high-temperature polymer candidates () through high-throughput screening. Zhang et al. [114] investigated fluorine-containing benzoxazine and epoxy co-curing, achieving low dielectric constants and high thermal stability, showcasing applications in integrated circuits. Patra et al. [115] introduced a NN-biased Genetic Algorithm (NBGA) to optimize material properties, combining the strengths of genetic algorithms and NNs for accelerated discovery in soft material design. Generative models are reshaping how polymers and materials are developed, enabling efficient exploration of design spaces, optimizing properties, and uncovering structure-property relationships. By integrating these models with domain-specific knowledge and experimental validation, researchers can accelerate the discovery of next-generation materials and expand the possibilities of polymer science and engineering.
2.5. Deep Learning
Deep Learning represents a subset of ML characterized by the use of multi-layered artificial NNs that automatically learn complex patterns from data (Figure 14). Unlike traditional supervised or unsupervised learning methods, which often rely on manual feature engineering or simpler models, deep learning leverages hierarchical representations to extract features directly from raw data, enabling breakthroughs in tasks such as image recognition, natural language processing, and generative modeling.
While the earlier sections focus on more traditional ML approaches, such as supervised methods (e.g., Random Forests, SVMs) and unsupervised techniques (e.g., clustering, dimensionality reduction), deep learning introduces highly flexible architectures, such as CNNs, Generative Adversarial Networks, and Transformer models. These methods excel in handling large-scale datasets and unstructured data (e.g., images, text) and have applications that often blur the boundaries between supervised, unsupervised, and reinforcement learning paradigms.
(A) Transfer Learning is a ML approach where a model trained on one task is adapted to perform a related but distinct task [116]. By leveraging knowledge from large datasets—commonly used in fields like image classification or natural language processing—transfer learning significantly reduces computational and data requirements for training models on specialized tasks (Figure 15). Pre-trained models, such as those based on ImageNet or language models like BERT, can be fine-tuned for domain-specific applications, making this method highly effective in scenarios with limited labeled data.
In polymer science, transfer learning has emerged as a powerful tool for improving material and process predictions with minimal experimental data. Lockner et al. [117] employed transfer learning to optimize machine parameters for injection molding across different polymer materials. By reusing prior process data, the study achieved improved model accuracy and quality even with small datasets. Similarly, Zhang et al. [118] developed a novel transfer learning framework combined with optimal transport to predict stress-strain curves for fiber-reinforced polymer composites, demonstrating accurate performance with limited experimental inputs. In the domain of material property prediction, Lee et al. [119] utilized transfer learning with GNNs to model the optoelectronic properties of conjugated oligomers. By pretraining on short oligomer datasets, the study achieved high accuracy in predicting excited-state energies despite data scarcity. Hu et al. [120] introduced a machine-learning-assisted materials genome approach that integrated graph convolutional networks, transfer learning, and classical gel theory. This approach enabled rapid high-throughput screening and experimental validation of highly tough thermosetting polymers, significantly accelerating the design cycle. Transfer learning has also been applied to bridge the gap between simulated and real-world performance. Huang et al. [121] applied transfer learning with backpropagation NNs (BPNNs) to predict shrinkage and warpage characteristics of injection-molded products. By combining computer-aided engineering (CAE) data with real-world machine performance, the study improved prediction reliability and demonstrated the practical utility of transfer learning in industrial polymer processing.
These studies underscore the versatility of transfer learning in polymer science, enabling accurate predictions for mechanical, thermal, and optoelectronic properties. By reducing data and computational demands, transfer learning is particularly suited for data-scarce domains, supporting adaptive process control and high-throughput material design. The integration of transfer learning with techniques like SHAP analysis further enhances feature reliability and interpretability.
(B) Convolutional NNs (CNNs) are a specialized type of NN designed to process data with a grid-like topology, such as images. CNNs are particularly effective in tasks involving spatial data due to their ability to capture spatial hierarchies and features (Figure 16). By applying convolution operations with sliding filters (kernels) over the input, CNNs compute feature maps that highlight essential patterns in the data [122].
CNNs have been extensively applied to polymer science and engineering, particularly in defect detection, process optimization, and structure-property predictions. Liu et al. [122] demonstrated the use of CNNs for defect detection and impact dynamics in fiber composite materials, highlighting their ability to extract mechanical performance information from images. Similarly, Sepasdar et al. [123] employed CNNs in a physics-informed deep learning framework to predict full-field nonlinear stress distributions and failure patterns in composite materials, achieving an impressive 90% accuracy using synthetically generated microstructural data. Applications of CNNs in process optimization have also been notable. Schmid et al. [124] developed ML models incorporating CNNs to predict key parameters in the plasticizing process during injection molding, achieving a mean absolute error of 0.27% and validating the model in real-machine experiments. Gim and Rhee [125] utilized NN-based interpretations, including CNNs, to analyze cavity pressure profiles in injection molding processes, linking process state points to part quality and demonstrating the industrial potential of CNNs. In structure-property prediction, Kojima et al. [126] applied CNNs to analyze microstructure-property relationships in filled rubber, training models to identify stress-contributing filler morphologies. Their results were validated using CG-MD simulations, providing insights into the mechanics of filled rubber systems. Rahman et al. [127] used a CNN model trained on molecular dynamics simulation data to predict the interfacial shear strength of carbon nanotube-polymer interfaces, with applications in lightweight aerospace materials. CNNs have also facilitated material behavior predictions. Chen et al. [128] employed a chemical language processing model utilizing SMILES embeddings and recurrent NNs to predict the glass transition temperature () of polymers. While not a CNN-specific application, their approach aligns with CNN methodologies in leveraging sequential data for property prediction, achieving high-throughput screening potential. Sepasdar et al. [123] further illustrated CNNs’ role in predicting nonlinear material behaviors, emphasizing their adaptability in synthetic data scenarios. Yan et al. [129] addressed challenges in applying ML to thermoset shape memory polymers (TSMPs) by introducing methodologies like BigSMILES-based fingerprinting, mixed-dimension inputs, and a dual-convolutional model framework. The ML model, trained on a small dataset with supplemented approximations, predicted recovery stresses and identified 14 novel TSMPs with superior recovery stress. Validation through synthesis, testing, and molecular dynamics simulations confirmed the approach’s effectiveness, showcasing its potential for discovering TSMPs with tailored properties.
(C) Generative Adversarial Networks (GANs) are a class of deep learning models introduced by Goodfellow et al. [130] that consist of two NNs—a generator and a discriminator—trained simultaneously in a competitive setting (Figure 17). The generator aims to produce synthetic data that mimics the real data distribution, while the discriminator evaluates whether a given data sample is real or generated. This adversarial process drives both networks to improve iteratively, resulting in highly realistic synthetic data.
GANs have been widely applied in tasks such as image synthesis, style transfer, and data augmentation, as well as in generating high-quality samples for domains like audio and video processing.
(D) Transformer Architectures, introduced by Vaswani et al. [131], represent a significant breakthrough in deep learning, particularly for sequence-to-sequence tasks in natural language processing (NLP). Unlike traditional recurrent or convolutional architectures, Transformers rely on a self-attention mechanism, which dynamically weighs the importance of different input tokens (Figure 18). This design enables efficient parallel processing of data and better handling of long-range dependencies, making Transformers particularly effective for tasks involving complex relationships. Transformers have become the backbone of state-of-the-art models such as BERT, GPT, and T5, revolutionizing applications like machine translation, text summarization, and language modeling. Their flexibility has extended beyond NLP to domains like computer vision and protein structure prediction, showcasing their broad applicability across diverse fields.
In polymer science, Transformer architectures are emerging as powerful tools for predictive modeling and material characterization. Lee et al. [132] applied a transformer-based model to predict mechanical properties of polymer matrix composites, achieving superior performance in modeling complex material systems. For delamination detection, Liu et al. [133] employed a transformer-based NN combined with enhanced terahertz time-domain spectroscopy (THz-TDS) techniques to analyze quartz fiber-reinforced polymer structures. This approach enabled accurate and automated characterization, addressing challenges in non-destructive testing. Additionally, Han et al. [134] introduced a multimodal transformer framework for property prediction in polymers, effectively integrating diverse data types—such as molecular structures, processing parameters, and experimental properties—to improve predictive accuracy. This study highlights the versatility of Transformers in handling heterogeneous data and providing insights into polymer design.
(E) Few-shot and Zero-shot Learning are advanced paradigms in machine learning designed to address the challenge of training models with limited or no labeled data for a target task [135]. Few-shot learning enables models to generalize from a small number of labeled examples by leveraging prior knowledge obtained through large-scale pretraining or related tasks (Figure 19). Zero-shot learning extends this capability by allowing models to perform tasks they have not encountered during training, relying on semantic or contextual information provided by embeddings or pre-trained language models. These approaches have gained prominence with the development of models like GPT and CLIP, which utilize pre-trained representations to generalize across tasks. They are particularly valuable in scenarios where labeled data is scarce or expensive to obtain, making them powerful tools for text classification, image recognition, and natural language understanding.
Few-shot learning has also found impactful applications in materials science, including addressing the challenges of data scarcity in polymer research. Chen et al. [136] reviewed advancements in few-shot learning, emphasizing its role in transfer learning and data augmentation to improve material design workflows. In polymer science, Wu et al. [137] demonstrated an AI-guided few-shot inverse design framework for HDP-mimicking polymers aimed at combating drug-resistant bacteria. By leveraging multi-modal representations and reinforcement learning, the study optimized polymer generation with limited data. Similarly, Waite et al. [138] applied few-shot learning to atomic force microscopy (AFM), enabling automated and sample-efficient analysis of force-extension curves for single-molecule interactions.
(F) Federated Learning is a distributed ML paradigm that enables training models across multiple decentralized devices or servers holding local data, without the need to share the data itself (Figure 20). Introduced by McMahan et al. [139], this approach is designed to address privacy concerns, data security, and regulatory compliance by keeping data localized while only sharing model updates with a central server.
Federated Learning has been widely adopted in applications like mobile device personalization, healthcare, and IoT, where sensitive data cannot be easily centralized. Challenges in Federated Learning include handling data heterogeneity, communication efficiency, and ensuring model performance under limited data availability and system constraints. We are not aware of any application of this principle in the area of polymer research. There are, however, applications using federated learning-based graph convolutional networks for non-Euclidean spatial data, including protein structures [140].
(G) Graph Neural Networks (GNNs) are a class of deep learning models designed to process and analyze data structured as graphs, which consist of nodes and edges (Figure 21). GNNs leverage graph convolutions and message-passing mechanisms to learn representations of nodes, edges, or entire graphs by aggregating information from their neighbors. This makes GNNs particularly effective for tasks where the relationships between entities are as important as the entities themselves. Applications of GNNs span diverse domains, including social network analysis, molecular property prediction, recommendation systems, and knowledge graph reasoning. The foundational work by Kipf and Welling [141] on graph convolutional networks (GCNs) is widely regarded as a milestone in the development of GNNs.
Kai et al. [142] present a ML workflow integrated with quantum calculations and a GNNs to identify ionic liquids (ILs) for ionic polymer electrolytes (IPEs) in lithium metal batteries. The resulting IPE membranes exhibit exceptional mechanical strength and electrochemical performance, enabling high critical current densities, outstanding capacity retention, fast charge/discharge capabilities, and excellent efficiency without flammable organics. Xie at al. [143] introduce a multi-task GNN to accelerate the screening of polymer electrolytes for lithium-ion batteries, overcoming the high computational cost of MD simulations in amorphous systems. By leveraging noisy, short MD data and limited long MD data, the method accurately predicts converged properties, enabling the exploration of a vastly larger polymer space and uncovering design principles for polymer electrolytes.
(H) Bayesian Deep Learning (BDL) combines the flexibility of DNNs with the principled framework of Bayesian inference, enabling models to quantify uncertainty in their predictions [144]. Unlike traditional deterministic NNs, BDL approaches treat model parameters as probabilistic distributions, allowing for the capture of both epistemic (model-related) and aleatoric (data-related) uncertainties (Figure 22). This capability is particularly valuable in high-stakes applications such as healthcare, autonomous driving, and financial modeling, where robust decision-making requires an understanding of prediction uncertainty.
In polymer science, Bayesian Deep Learning has emerged as a powerful tool for addressing complex design and optimization challenges. Wheatle et al. [145] utilized Bayesian optimization to design polymer blend electrolytes, balancing ionic conductivity and mechanical properties. By incorporating molecular simulations and proxy variables, their method optimized trade-offs efficiently, paving the way for high-performance material development. Bayesian methods have also been instrumental in computational phase discovery and molecular simulations. Dorfman [146] reviewed the use of Bayesian optimization in computational phase discovery for block polymers, improving predictions from self-consistent field theory (SCFT)-based models. Similarly, Wheatle et al. [145] applied Bayesian optimization to explore multi-objective design spaces in polymer blend electrolytes, identifying high-performance blends by navigating trade-offs between mechanical and electrical properties. In molecular simulations, Peng et al. [147] used Bayesian inference to backmap CG molecular models into atomic-resolution structures. This approach enhanced the accuracy of molecular dynamics simulations, particularly for biomolecules, by refining the structural details of CG models.
(I) Neural Architecture Search (NAS) is a technique for automating the design of NN architectures, enabling the discovery of optimal configurations tailored to specific tasks. By systematically exploring a search space of candidate architectures, NAS eliminates much of the trial-and-error associated with manual network design (Figure 23). Popular NAS methods include reinforcement learning [148], evolutionary algorithms [149], and gradient-based optimization [150], which iteratively refine architectures to achieve superior performance.
NAS has demonstrated remarkable success in domains such as image classification and object detection, often surpassing human-designed networks [151]. By automating the architecture search, NAS reduces the need for domain-specific expertise while uncovering novel and efficient designs. However, challenges such as high computational costs and the development of efficient search strategies remain active areas of research.
In polymer science and materials engineering, the adoption of NAS is an emerging trend, promising to accelerate the development of predictive models and optimize performance in data-scarce environments. While specific applications of NAS in polymer research are still developing, its proven ability to enhance NN performance in other domains underscores its potential to drive innovation in polymer informatics and related fields.
2.6. Coarse-Grained (CG) Models
CG models have become invaluable in the study of soft materials, offering computational efficiency by simplifying atomically detailed systems while retaining critical observable properties. These models have facilitated significant progress in exploring complex phenomena. Noid [90] provides a comprehensive review of predictive CG models, highlighting their success in modeling liquids and polymers. However, challenges such as transferability and thermodynamic accuracy persist, particularly in complex biomolecular systems. Advances in CG mapping techniques, modeling of many-body interactions, and addressing state-point dependence of effective potentials have paved the way for accurate and transferable CG models, combining rigorous theoretical approaches with modern computational tools.
The integration of machine learning (ML) has enhanced CG methodologies. Bhattacharya et al. [152] introduce dPOLY, a ML framework leveraging DNNs to analyze molecular dynamics (MD) trajectories and predict polymer phases and phase transitions. Using CG-MD, dPOLY accurately identifies critical temperatures for coil-to-globule transitions across various polymer sizes. This generic method can be extended to study other phase transitions and significantly accelerate phase prediction and characterization in polymers and soft materials. Axelrod et al. [21] discuss the application of ML to materials design, emphasizing its potential in identifying high-quality candidates and accelerating simulations. Similarly, Ye et al. [153] review ML techniques for CG modeling of organic molecules and polymers, focusing on descriptors, training datasets, and loss function optimization to improve model accuracy and thermodynamic consistency. These studies underscore ML’s ability to address challenges of transferability and efficiency in CG modeling. Alessandri and de Pablo [154] introduce a ML-enhanced CG method to efficiently predict electronic properties of soft electronic materials, bypassing computationally demanding backmapping and quantum-chemical calculations. Applied to radical-containing polymers for energy storage, the method trains models to link electronic properties with CG conformations, enabling direct prediction from CG simulations. Validation shows strong agreement with traditional methods, highlighting the approach’s potential to accelerate multiscale workflows and design CG models retaining electronic structure details. Karuth et al. [155] integrate cheminformatics and CG-MD simulations to predict the glass-transition temperature of diverse polymers. The quantitative structure-property relationsip model identifies key molecular descriptors influencing , while simulations reveal how cohesive interactions, chain stiffness, and grafting density affect , offering mechanistic insights. Dhamankar and Webb [91] explore chemically specific CG modeling for polymers, emphasizing the ability to capture polymer behavior over relevant spatiotemporal scales. Joshi and Deshmukh [156] review advancements in CG-MD simulations, showcasing transferable models for solvents, polymers, and biomolecules. Their work illustrates how ML and hybrid approaches have enabled studies of solute-solvent interactions and polymer architectures, offering experimentally verifiable insights. Applications of ML-enhanced CG models have also driven innovation in materials design. Wheatle et al. [145] combined ML with Bayesian optimization to design polymer blend electrolytes, revealing trade-offs between ionic conductivity and mechanical properties. Wang et al. [100] integrated CG-MD with ML and Bayesian optimization to uncover relationships between lithium conductivity and intrinsic material properties. These studies demonstrate the value of combining molecular simulations with ML to optimize material performance for energy applications. Innovative techniques continue to expand CG modeling capabilities. Bejagam et al. [81] developed a temperature-independent CG model to study the coil-to-globule transition of PNIPAM, leveraging ML-based nonmetric multidimensional scaling (NMDS) to analyze simulation trajectories and uncover new insights into polymer transitions. Bejagam et al. [20] introduced a framework combining particle swarm optimization, artificial NNs (ANN), and molecular dynamics simulations to optimize force-field parameters for CG models, demonstrating its utility for solvents like D2O and DMF. Li et al. [107] tackled the challenge of backmapping CG configurations to atomistic structures using conditional generative adversarial networks (cGANs), demonstrating a versatile and efficient approach for multiscale modeling across varying molecular weights. Lenzi et al. [157] discuss the challenges and progress in modeling aliphatic isocyanates and polyisocyanates, emphasizing the potential of ML in overcoming barriers to accurate parametrizations. Schneider et al. [158] introduce a ML model to simulate defect kinetics during the self-assembly of symmetric diblock copolymers into lamellar phases. Trained on intermediate time-scale simulations of a CG model, the artificial neural network (ANN) predicts time-independent transition probabilities based on the Markov chain framework. This approach enables efficient generation of long-time trajectories, providing novel insights into late-stage defect dynamics and relaxation. The ANN’s input-size independence allows training on small systems and application to larger ones. The method is demonstrated by analyzing defect motion and lifetimes during long-range ordering processes.
ML methods have increasingly been used also to perform atomistic computations of energies and atomic forces, with greater accuracy than empirical functions [159,160,161,162,163,164,165]. Mariloa et al. [166] present a staggered neural network force field (NNFF) architecture that accelerates molecular dynamics simulations by directly predicting atomic force vectors without relying on computationally expensive spatial derivatives. By combining rotation-invariant and rotation-covariant features, the method achieves a 2.2x speed-up over state-of-the-art engines and enables efficient modeling of complex multi-element systems, such as long polymer chains and surface chemical reactions, with broader applicability beyond computational material science.
3. Summary and Conclusions
ML has started to become an indispensable tool in polymer and macromolecular science, offering a suite of techniques that complement and surpass traditional experimental and computational methods. The relevance of these methods varies depending on the specific challenges in polymer research, but several approaches stand out for their transformative potential.
NNs and ensemble methods have been applied to predict tensile strength [42,43,51,61,63,68,75,110,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185] and elastic modulus [38,39,42,46,62,75,94,95,122,170,173,177,180,182,186,187,188,189,190,191,192,193,194,195,196], and other rheological properties [87,114,191,197,198,199]. Random forests and gradient boosting algorithms have proven effective for predicting glass transition temperatures [22,48,70,87,113,128,167,176,180,200,201], thermal stability [114,202,203,204,205,206], and thermal conductivity [111,207,208]. These models rely on structure-property relationships derived from experimental datasets. Recent studies, such as [209], have demonstrated the application of SVMs in predicting the refractive index [200], dielectric constants [66,114,194], and conductivity [112,208] of polymeric materials. Emerging trends such as nanoparticle doping, photosensitive polyimides, and ML-assisted molecular design were identified as key to advancing PI films for flexible displays, solar cells, and high-performance devices [202]. Optimizing polymer synthesis pathways is another critical application of ML. By reducing the number of experimental trials, ML-driven techniques enable rapid prototyping and material discovery. Bayesian optimization techniques [59,62,100,145,182] have been successfully applied to minimize experimental costs while maximizing efficiency [83,209]. These methods utilize prior knowledge to iteratively improve synthesis outcomes. Current approaches leverage combinatorial and high-throughput experimental designs to mitigate data limitations; however, challenges persist due to the lack of standardized characterization for critical biomedical parameters like degradation time and biocompatibility. Significant gaps at the intersection of applied ML and biomaterial design, offering insights into current advancements and future directions for overcoming these obstacles have been identified [24]. Reinforcement learning has emerged as a powerful tool for optimizing complex reaction networks. It has been used to identify optimal conditions and reaction pathways for synthesizing high-performance polymers [85,98,109,210]. Ensemble methods, such as gradient boosting, are increasingly used to design scalable manufacturing processes for specialty polymers [85,206]. As environmental concerns grow, ML has become an invaluable tool for designing sustainable and biodegradable polymers. Researchers are leveraging ML to predict degradation rates, optimize recyclability, and reduce the environmental footprint of materials. SVMs and NNs have been applied to classify polymers based on their biodegradability and polymer degradation rates [16,105,203,211]. Studies such as [30,71,212] focus on predicting the recyclability of polymers, enabling more effective recycling strategies. ML techniques have also been used to conduct lifecycle assessments, evaluating the environmental impacts of polymer production and disposal [205,213,214]. So-called multitask ML has been employed to predict polymer-solvent miscibility using Flory-Huggins interaction parameters [215]. Chen et al. [216] demonstrate a novel approach to automated scientific discovery by integrating machine learning with physical principles to construct macroscopic dynamical models directly from microscopic trajectory observations. Using a framework based on the generalized Onsager principle, the authors identify interpretable thermodynamic coordinates and map the dynamical landscape of stochastic dissipative systems. The method is validated experimentally by studying polymer stretching in elongational flow, revealing stable and transition states while enabling control over the stretching rate, with broad applicability to complex scientific phenomena.
Critical evaluations of these works reveal both opportunities and challenges. While supervised and unsupervised learning methods have achieved significant successes, the scarcity of high-quality, labeled datasets remains a bottleneck [129,129]. Moreover, the interpretability of complex ML models, such as DNNs, continues to be a concern for researchers and practitioners. Addressing these limitations will be essential for advancing the integration of ML into polymer science further.
Overall, the integration of ML into polymer science not only enhances our ability to model and predict polymer behavior but also accelerates the discovery and optimization of new materials. Future advancements will likely stem from hybrid approaches that combine different ML methods, leveraging their unique strengths to tackle increasingly complex challenges in polymer research. While the reviewed studies provide a strong foundation for ML-driven polymer design, significant opportunities remain to address limitations in data diversity, model interpretability, and real-world validation.
Funding
This research received no external funding.
Data Availability Statement
Data is contained within the article. Numbers for scatter plots have been retrieved from the Web of Science Core Collection (Clarivate).
Acknowledgments
During the preparation of this manuscript, the author used chatGPT 4o for the purposes of suggesting some of the schematic drawings and summarizing the key findings of several research works. The author has reviewed and edited the output and takes full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Turing, A.M. Computing machinery and intelligence. Mind 1950, 236, 433–460. [Google Scholar] [CrossRef]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Development 1959, 3, 211. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugenics 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic programming. Science 1966, 153, 34. [Google Scholar] [CrossRef] [PubMed]
- Kröger, M.; Kröger, B. A novel algorithm to optimize classification trees. Computer Physics Communications 1996, 96, 58–72. [Google Scholar] [CrossRef]
- Kröger, M. Optimization of classification trees: strategy and algorithm improvement. Comput. Phys. Commun. 1996, 99, 81–93. [Google Scholar] [CrossRef]
- Martin, T.B.; Audus, D.J. Emerging trends in machine learning: a polymer perspective. ACS Polymers Au 2023, 3, 239–258. [Google Scholar] [CrossRef] [PubMed]
- Struble, D.C.; Lamb, B.G.; Ma, B. A prospective on machine learning challenges, progress, and potential in polymer science. MRS Commun. 2024, 1–19. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Zhou, T.; Song, Z.; Sundmacher, K. Big Data Creates New Opportunities for Materials Research: A Review on Methods and Applications of Machine Learning for Materials Design. Eng. 2019, 5, 1017–1026. [Google Scholar] [CrossRef]
- Jackson, N.E.; Webb, M.A.; de Pablo, J.J. Recent advances in machine learning towards multiscale soft materials design. Curr. Opin. Chem. Eng. 2019, 23, 106–114. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.B.; Song, S.J.; You, K.Y. Trends in extreme learning machines: A review. Neural Networks 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Yue, T. Machine Learning for Polymer Informatics. 2024. [Google Scholar]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. J. Comput. Inform. 2007, 31, 249–268. [Google Scholar]
- Saingam, P.; Hussain, Q.; Sua-iam, G.; Nawaz, A.; Ejaz, A. Hemp Fiber-Reinforced Polymers Composite Jacketing Technique for Sustainable and Environment-Friendly Concrete. Polymers 2024, 16, 1774. [Google Scholar] [CrossRef] [PubMed]
- Alhulaybi, Z.A.; Otaru, A.J. Machine Learning Analysis of Enhanced Biodegradable Phoenix dactylifera L./HDPE Composite Thermograms. Polymers 2024, 16, 1515. [Google Scholar] [CrossRef]
- Malashin, I.; Tynchenko, V.; Gantimurov, A.; Nelyub, V.; Borodulin, A. A Multi-Objective Optimization of Neural Networks for Predicting the Physical Properties of Textile Polymer Composite Materials. Polymers 2024, 16, 1752. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Tao, L.; He, J.L.; McCutcheon, J.R.; Li, Y. Machine learning enables interpretable discovery of innovative polymers for gas separation membranes. Sci. Adv. 2022, 8, eabn9545. [Google Scholar] [CrossRef] [PubMed]
- Cassola, S.; Duhovic, M.; Schmidt, T.; May, D. Machine learning for polymer composites process simulation - a review. Composites B 2022, 246, 110208. [Google Scholar] [CrossRef]
- Bejagam, K.K.; Singh, S.; An, Y.X.; Deshmukh, S.A. Machine-Learned Coarse-Grained Models. J. Phys. Chem. Lett. 2018, 9, 4667–4672. [Google Scholar] [CrossRef]
- Axelrod, S.; Schwalbe-Koda, D.; Mohapatra, S.; Damewood, J.; Greenman, K.P.; Gomez-Bombarelli, R. Learning Matter: Materials Design with Machine Learning and Atomistic Simulations. Acc. Mater. Res. 2022, 3, 343–357. [Google Scholar] [CrossRef]
- Alesadi, A.; Cao, Z.Q.; Li, Z.F.; Zhang, S.; Zhao, H.Y.; Gu, X.D.; Xia, W.J. Machine learning prediction of glass transition temperature of conjugated polymers from chemical structure. Cell Rep. Phys. Sci. 2022, 3, 100911. [Google Scholar] [CrossRef]
- Wu, Z.J.; Jayaraman, A. Machine Learning-Enhanced Computational Reverse-Engineering Analysis for Scattering Experiments (CREASE) for Analyzing Fibrillar Structures in Polymer Solutions. Macromolecules 2022, 55, 11076–11091. [Google Scholar] [CrossRef]
- McDonald, S.M.; Augustine, E.K.; Lanners, Q.; Rudin, C.; Brinson, L.C.; Becker, M.L. Applied machine learning as a driver for polymeric biomaterials design. Nat. Commun. 2023, 14, 133692. [Google Scholar] [CrossRef] [PubMed]
- Malashin, I.; Masich, I.; Tynchenko, V.; Gantimurov, A.; Nelyub, V.; Borodulin, A.; Martysyuk, D.; Galinovsky, A. Machine Learning in 3D and 4D Printing of Polymer Composites: A Review. Polymers 2024, 16, 3125. [Google Scholar] [CrossRef] [PubMed]
- Malashin, I.; Tynchenko, V.; Gantimurov, A.; Nelyub, V.; Borodulin, A. Applications of Long Short-Term Memory (LSTM) Networks in Polymeric Sciences: A Review. Polymers 2024, 16, 2607. [Google Scholar] [CrossRef] [PubMed]
- Loh, J.Y.Y.; Yeoh, K.M.; Raju, K.; Pham, V.N.H.; Tan, V.B.C.; Tay, T.E. A Review of Machine Learning for Progressive Damage Modelling of Fiber-Reinforced Composites. Appl. Compos. Mater. 2024, 59, 113247. [Google Scholar] [CrossRef]
- Fakhry, H.; Ghoniem, A.A.; Al-Otibi, F.O.; Helmy, Y.A.; El Hersh, M.S.; Elattar, K.M.; Saber, W.I.A.; Elsayed, A. A Comparative Study of Cr(VI) Sorption by Aureobasidium pullulans AKW Biomass and Its Extracellular Melanin: Complementary Modeling with Equilibrium Isotherms, Kinetic Studies, and Decision Tree Modeling. Polymers 2023, 15, 3754. [Google Scholar] [CrossRef]
- Saber, W.I.A.; Al-Askar, A.A.; Ghoneem, K.M. Exclusive Biosynthesis of Pullulan Using Taguchi’s Approach and Decision Tree Learning Algorithm by a Novel Endophytic Aureobasidium pullulans Strain. Polymers 2023, 15, 1419. [Google Scholar] [CrossRef] [PubMed]
- Koinig, G.; Kuhn, N.; Barretta, C.; Friedrich, K.; Vollprecht, D. Evaluation of Improvements in the Separation of Monolayer and Multilayer Films via Measurements in Transflection and Application of Machine Learning Approaches. Polymers 2022, 14, 3926. [Google Scholar] [CrossRef] [PubMed]
- Bhowmik, R.; Sihn, S.; Pachter, R.; Vernon, J.P. Prediction of the specific heat of polymers from experimental data and machine learning methods. Polymer 2021, 220, 123558. [Google Scholar] [CrossRef]
- Guarda, C.; Caseiro, J.; Pires, A. Machine learning to enhance sustainable plastics: A review. J. Clean. Product. 2024, 474, 143602. [Google Scholar] [CrossRef]
- Nelon, C.; Myers, O.; Hall, A. The intersection of damage evaluation of fiber-reinforced composite materials with machine learning: A review. J. Compos. Mater. 2022, 56, 1417–1452. [Google Scholar] [CrossRef]
- Munir, N.; McMorrow, R.; Mulrennan, K.; Whitaker, D.; McLoone, S.; Kellomski, M.; Talvitie, E.; Lyyra, I.; McAfee, M. Interpretable Machine Learning Methods for Monitoring Polymer Degradation in Extrusion of Polylactic Acid. Polymers 2023, 15, 3566. [Google Scholar] [CrossRef] [PubMed]
- Pelzer, L.; Schulze, T.; Buschmann, D.; Enslin, C.; Schmitt, R.; Hopmann, C. Acquiring Process Knowledge in Extrusion-Based Additive Manufacturing via Interpretable Machine Learning. Polymers 2023, 15, 3509. [Google Scholar] [CrossRef]
- Chavez-Angel, E.; Ng, R.C.; Sandell, S.; He, J.Y.; Castro-Alvarez, A.; Torres, C.M.S.; Kreuzer, M. Application of Synchrotron Radiation-Based Fourier-Transform Infrared Microspectroscopy for Thermal Imaging of Polymer Thin Films. Polymers 2023, 15, 536. [Google Scholar] [CrossRef]
- Huang, X.Y.; Wang, S.; Lu, T.; Li, H.M.; Wu, K.Y.; Deng, W.C. Chloride Permeability Coefficient Prediction of Rubber Concrete Based on the Improved Machine Learning Technical: Modelling and Performance Evaluation. Polymers 2023, 15, 308. [Google Scholar] [CrossRef]
- Gope, A.K.; Liao, Y.S.; Kuo, C.F.J. Quality Prediction and Abnormal Processing Parameter Identification in Polypropylene Fiber Melt Spinning Using Artificial Intelligence Machine Learning and Deep Learning Algorithms. Polymers 2022, 14, 2739. [Google Scholar] [CrossRef] [PubMed]
- Amin, M.N.; Salami, B.A.; Zahid, M.; Iqbal, M.; Khan, K.; Abu-Arab, A.M.; Alabdullah, A.A.; Jalal, F.E. Investigating the Bond Strength of FRP Laminates with Concrete Using LIGHT GBM and SHAPASH Analysis. Polymers 2022, 14, 4717. [Google Scholar] [CrossRef] [PubMed]
- Anjum, M.; Khan, K.; Ahmad, W.; Ahmad, A.; Amin, M.N.; Nafees, A. Application of Ensemble Machine Learning Methods to Estimate the Compressive Strength of Fiber-Reinforced Nano-Silica Modified Concrete. Polymers 2022, 14, 3906. [Google Scholar] [CrossRef]
- Alabdullh, A.A.; Biswas, R.; Gudainiyan, J.; Khan, K.; Bujbarah, A.H.; Alabdulwahab, Q.A.; Amin, M.N.; Iqbal, M. Hybrid Ensemble Model for Predicting the Strength of FRP Laminates Bonded to the Concrete. Polymers 2022, 14, 3505. [Google Scholar] [CrossRef]
- Karamov, R.; Akhatov, I.; Sergeichev, I. Prediction of Fracture Toughness of Pultruded Composites Based on Supervised Machine Learning. Polymers 2022, 14, 3619. [Google Scholar] [CrossRef]
- Joo, C.; Park, H.; Kwon, H.; Lim, J.; Shin, E.; Cho, H.; Kim, J. Machine Learning Approach to Predict Physical Properties of Polypropylene Composites: Application of MLR, DNN, and Random Forest to Industrial Data. Polymers 2022, 14, 3500. [Google Scholar] [CrossRef] [PubMed]
- Aminabadi, S.S.; Tabatabai, P.; Steiner, A.; Gruber, D.P.; Friesenbichler, W.; Habersohn, C.; Berger-Weber, G. Industry 4.0 In-Line AI Quality Control of Plastic Injection Molded Parts. Polymers 2022, 14, 3551. [Google Scholar] [CrossRef] [PubMed]
- Khan, K.; Ahmad, W.; Amin, M.N.; Ahmad, A.; Nazar, S.; Alabdullah, A.A. Compressive Strength Estimation of Steel-Fiber-Reinforced Concrete and Raw Material Interactions Using Advanced Algorithms. Polymers 2022, 14, 3065. [Google Scholar] [CrossRef] [PubMed]
- Khan, K.; Iqbal, M.; Salami, B.A.; Amin, M.N.; Ahamd, I.; Alabdullah, A.A.; Abu Arab, A.M.; Jalal, F.E. Estimating Flexural Strength of FRP Reinforced Beam Using Artificial Neural Network and Random Forest Prediction Models. Polymers 2022, 14, 2270. [Google Scholar] [CrossRef] [PubMed]
- Ascencio-Medina, E.; He, S.; Daghighi, A.; Iduoku, K.; Casanola-Martin, G.M.; Arrasate, S.; Gonzalez-Diaz, H.; Rasulev, B. Prediction of Dielectric Constant in Series of Polymers by Quantitative Structure-Property Relationship (QSPR). Polymers 2024, 16, 2731. [Google Scholar] [CrossRef]
- Fatriansyah, J.F.; Linuwih, B.D.P.; Andreano, Y.; Sari, I.S.; Federico, A.; Anis, M.; Surip, S.N.; Jaafar, M. Prediction of Glass Transition Temperature of Polymers Using Simple Machine Learning. Polymers 2024, 16, 2464. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.N.; Du, J.L.; Ren, S.W.; Shao, M.C. Prediction of the Tribological Properties of Polytetrafluoroethylene Composites Based on Experiments and Machine Learning. Polymers 2024, 16, 356. [Google Scholar] [CrossRef]
- Zhao, J.Y.; Guo, Z.Y.; Lyu, Q.; Wang, B. Prediction of Residual Compressive Strength after Impact Based on Acoustic Emission Characteristic Parameters. Polymers 2024, 16, 1780. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.C.; Wei, Q.; Wang, T.N.; Ma, Q.J.; Jin, P.; Pan, S.P.; Li, F.Q.; Wang, S.X.; Yang, Y.X.; Li, Y. Experimental and Numerical Investigation Integrated with Machine Learning (ML) for the Prediction Strategy of DP590/CFRP Composite Laminates. Polymers 2024, 16, 1589. [Google Scholar] [CrossRef]
- Cao, J.Y.; Xu, Z. Providing a Photovoltaic Performance Enhancement Relationship from Binary to Ternary Polymer Solar Cells via Machine Learning. Polymers 2024, 16, 1496. [Google Scholar] [CrossRef] [PubMed]
- Okada, M.; Amamoto, Y.; Kikuchi, J. Designing Sustainable Hydrophilic Interfaces via Feature Selection from Molecular Descriptors and Time-Domain Nuclear Magnetic Resonance Relaxation Curves. Polymers 2024, 16, 824. [Google Scholar] [CrossRef] [PubMed]
- Mayorova, O.A.; Saveleva, M.S.; Bratashov, D.N.; Prikhozhdenko, E.S. Combination of Machine Learning and Raman Spectroscopy for Determination of the Complex of Whey Protein Isolate with Hyaluronic Acid. Polymers 2024, 16, 666. [Google Scholar] [CrossRef] [PubMed]
- Biruk-Urban, K.; Bere, P.; Jazwik, J. Machine Learning Models in Drilling of Different Types of Glass-Fiber-Reinforced Polymer Composites. Polymers 2023, 15, 4609. [Google Scholar] [CrossRef] [PubMed]
- Rahimi, S.; Nasir, V.; Avramidis, S.; Sassani, F. The Role of Drying Schedule and Conditioning in Moisture Uniformity in Wood: A Machine Learning Approach. Polymers 2023, 15, 792. [Google Scholar] [CrossRef] [PubMed]
- Deshpande, A.R.; Kulkarni, A.P.; Wasatkar, N.; Gajalkar, V.; Abdullah, M. Prediction of Wear Rate of Glass-Filled PTFE Composites Based on Machine Learning Approaches. Polymers 2024, 16, 2666. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.H.; Zhang, Z.Y.; Huang, Y.D.; Zhao, H.H.; Chen, Z.D.; Gao, K.; Yue, T.K.; Zhang, L.Q.; Liu, J. Structure-Mechanics Relation of Natural Rubber: Insights from Molecular Dynamics Simulations. ACS Appl. Polym. Mater. 2022, 4, 3575–3586. [Google Scholar] [CrossRef]
- Martinez, M.J.; Naveiro, R.; Soto, A.J.; Talavante, P.; Lee, S.H.K.; Arrayas, R.G.; Franco, M.; Mauleon, P.; Ordonez, H.L.; Lopez, G.R.; Bernabei, M.; Campillo, N.E.; Ponzoni, I. Design of New Dispersants Using Machine Learning and Visual Analytics. Polymers 2023, 15, 1324. [Google Scholar] [CrossRef]
- Ethier, J.G.; Casukhela, R.K.; Latimer, J.J.; Jacobsen, M.D.; Rasin, B.; Gupta, M.K.; Baldwin, L.A.; Vaia, R.A. Predicting Phase Behavior of Linear Polymers in Solution Using Machine Learning. Macromolecules 2022, 55, 2691–2702. [Google Scholar] [CrossRef]
- Ashebir, D.A.; Hendlmeier, A.; Dunn, M.; Arablouei, R.; Lomov, S.V.; Di Pietro, A.; Nikzad, M. Detecting Multi-Scale Defects in Material Extrusion Additive Manufacturing of Fiber-Reinforced Thermoplastic Composites: A Review of Challenges and Advanced Non-Destructive Testing Techniques. Polymers 2024, 16, 2986. [Google Scholar] [CrossRef]
- Liu, F.G.; Chen, Z.R.; Xu, J.; Zheng, Y.Y.; Su, W.Y.; Tian, M.Z.; Li, G.D. Interpretable Machine Learning-Based Influence Factor Identification for 3D Printing Process-Structure Linkages. Polymers 2024, 16, 2680. [Google Scholar] [CrossRef] [PubMed]
- Malashin, I.; Martysyuk, D.; Tynchenko, V.; Nelyub, V.; Borodulin, A.; Galinovsky, A. Mechanical Testing of Selective-Laser-Sintered Polyamide PA2200 Details: Analysis of Tensile Properties via Finite Element Method and Machine Learning Approaches. Polymers 2024, 16, 737. [Google Scholar] [CrossRef]
- Subeshan, B.; Atayo, A.; Asmatulu, E. Machine learning applications for electrospun nanofibers: a review. J. Mater. Sci. 2024, 59, 14095–14140. [Google Scholar] [CrossRef]
- Chen, J.; Ayranci, C.; Tang, T. Piezoelectric performance of electrospun PVDF and PVDF composite fibers: a review and machine learning-based analysis. Mater. Today Chem. 2023, 30, 101571. [Google Scholar] [CrossRef]
- Yue, D.; Feng, Y.; Liu, X.X.; Yin, J.H.; Zhang, W.C.; Guo, H.; Su, B.; Lei, Q.Q. Prediction of Energy Storage Performance in Polymer Composites Using High-Throughput Stochastic Breakdown Simulation and Machine Learning. Adv. Sci. 2022, 9, 2105773. [Google Scholar] [CrossRef] [PubMed]
- Shen, Z.H.; Wang, J.J.; Jiang, J.Y.; Huang, S.X.; Lin, Y.H.; Nan, C.W.; Chen, L.Q.; Shen, Y. Phase-field modeling and machine learning of electric-thermal-mechanical breakdown of polymer-based dielectrics. Nat. Commun. 2019, 10, 1843. [Google Scholar] [CrossRef] [PubMed]
- Jongyingcharoen, J.S.; Howimanporn, S.; Sitorus, A.; Phanomsophon, T.; Posom, J.; Salubsi, T.; Kongwaree, A.; Lim, C.H.; Phetpan, K.; Sirisomboon, P.; Tsuchikawa, S. Classification of the Crosslink Density Level of Para Rubber Thick Film of Medical Glove by Using Near-Infrared Spectral Data. Polymers 2024, 16, 184. [Google Scholar] [CrossRef]
- Qin, J.Y.; Lu, M.X.; Li, B.; Li, X.R.; You, G.M.; Tan, L.J.; Zhai, Y.K.; Huang, M.L.; Wu, Y.Z. A Rapid Quantitative Analysis of Bicomponent Fibers Based on Cross-Sectional In-Situ Observation. Polymers 2023, 15, 842. [Google Scholar] [CrossRef] [PubMed]
- Uddin, M.J.; Fan, J.T. Interpretable Machine Learning Framework to Predict the Glass Transition Temperature of Polymers. Polymers 2024, 16, 1049. [Google Scholar] [CrossRef]
- Dębska, B.; Wianowska, E. Application of cluster analysis method in prediction of polymer properties. Polym. Testing 2002, 21, 43–47. [Google Scholar] [CrossRef]
- Olivieri, F.; Caputo, A.; Leonetti, D.; Castaldo, R.; Avolio, R.; Cocca, M.; Errico, M.E.; Iannotta, L.; Avella, M.; Carfagna, C.; Gentile, G. Compositional Analysis and Mechanical Recycling of Polymer Fractions Recovered via the Industrial Sorting of Post-Consumer Plastic Waste: A Case Study toward the Implementation of Artificial Intelligence Databases. Polymers 2024, 16, 2898. [Google Scholar] [CrossRef] [PubMed]
- Wolf, A.T.; Stammer, A. Chemical Recycling of Silicones-Current State of Play (Building and Construction Focus). Polymers 2024, 16, 2220. [Google Scholar] [CrossRef] [PubMed]
- Neo, P.K.; Leong, Y.W.; Soon, M.F.; Goh, Q.S.; Thumsorn, S.; Ito, H. Development of a Machine Learning Model to Predict the Color of Extruded Thermoplastic Resins. Polymers 2024, 16, 481. [Google Scholar] [CrossRef] [PubMed]
- Dairabayeva, D.; Auyeskhan, U.; Talamona, D. Mechanical Properties and Economic Analysis of Fused Filament Fabrication Continuous Carbon Fiber Reinforced Composites. Polymers 2024, 16, 2656. [Google Scholar] [CrossRef] [PubMed]
- Bounjoum, Y.; Hamlaoui, O.; Hajji, M.K.; Essaadaoui, K.; Chafiq, J.; El Fqih, M.A. Exploring Damage Patterns in CFRP Reinforcements: Insights from Simulation and Experimentation. Polymers 2024, 16, 2057. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.Y.; Yun, Y.M.; Le, T.H.M. Enhancing Railway Track Stabilization with Epoxy Resin and Crumb Rubber Powder-Modified Cement Asphalt Mortar. Polymers 2023, 15, 4462. [Google Scholar] [CrossRef]
- Scatigno, C.; Teodonio, L.; Di Rocco, E.; Festa, G. Spectroscopic Benchmarks by Machine Learning as Discriminant Analysis for Unconventional Italian Pictorialism Photography. Polymers 2024, 16, 1850. [Google Scholar] [CrossRef] [PubMed]
- Younes, K.; Moghnie, S.; Khader, L.; Obeid, E.; Mouhtady, O.; Grasset, L.; Murshid, N. Application of Unsupervised Learning for the Evaluation of Burial Behavior of Geomaterials in Peatlands: Case of Lignin Moieties Yielded by Alkaline Oxidative Cleavage. Polymers 2023, 15, 1200. [Google Scholar] [CrossRef]
- Doi, H.; Takahashi, K.Z.; Tagashira, K.; Fukuda, J.; Aoyagi, T. Machine learning-aided analysis for complex local structure of liquid crystal polymers. Sci. Rep. 2019, 9, 16370. [Google Scholar] [CrossRef]
- Bejagam, K.K.; An, Y.X.; Singh, S.; Deshmukh, S.A. Machine-Learning Enabled New Insights into the Coil-to-Globule Transition of Thermosensitive Polymers Using a Coarse-Grained Model. J. Phys. Chem. Lett. 2018, 9, 6480–6488. [Google Scholar] [CrossRef] [PubMed]
- Halperin, A.; Kröger, M.; Winnik, F.M. Poly(N-isopropylacrylamide) phase diagrams: Fifty years of research. Angew. Chem. Int. Ed. 2015, 54, 15342–15367. [Google Scholar] [CrossRef] [PubMed]
- Mysona, J.A.; Nealey, P.F.; de Pablo, J.J. Machine Learning Models and Dimensionality Reduction for Prediction of Polymer Properties. Macromolecules 2024, 57, 1988–1997. [Google Scholar] [CrossRef]
- Zhao, Y.K.; Mulder, R.J.; Houshyar, S.; Le, T.C. A review on the application of molecular descriptors and machine learning in polymer design. Polym. Chem. 2023, 14, 3325–3346. [Google Scholar] [CrossRef]
- Martinez, A.D.; Navajas-Guerrero, A.; Bediaga-Baaeres, H.; Sanchez-Bodan, J.; Ortiz, P.; Vilas-Vilela, J.L.; Moreno-Benitez, I.; Gil-Lopez, S. AI-Driven Insight into Polycarbonate Synthesis from CO<sub>2</sub>: Database Construction and Beyond. Polymers 2024, 16, 2936. [Google Scholar] [CrossRef]
- Patra, T.K. Data-Driven Methods for Accelerating Polymer Design. ACS Polym. AU 2022, 2, 8–26. [Google Scholar] [CrossRef]
- Karatrantos, A.V.; Couture, O.; Hesse, C.; Schmidt, D.F. Molecular Simulation of Covalent Adaptable Networks and Vitrimers: A Review. Polymers 2024, 16, 1373. [Google Scholar] [CrossRef] [PubMed]
- Trienens, D.; Schoppner, V.; Krause, P.; Back, T.; Lontsi, S.T.N.; Budde, F. Method Development for the Prediction of Melt Quality in the Extrusion Process. Polymers 2024, 16, 1197. [Google Scholar] [CrossRef]
- Knoll, J.; Heim, H.P. Analysis of the Machine-Specific Behavior of Injection Molding Machines. Polymers 2024, 16, 54. [Google Scholar] [CrossRef] [PubMed]
- Noid, W.G. Perspective: Advances, Challenges, and Insight for Predictive Coarse-Grained Models. J. Phys. Chem. B 2023, 127, 4174–4207. [Google Scholar] [CrossRef]
- Dhamankar, S.; Webb, M.A. Chemically specific coarse-graining of polymers: Methods and prospects. J. Polym. Sci. 2021, 59, 2613–2643. [Google Scholar] [CrossRef]
- Jacob, M.H.; D’Souza, R.N.; Lazar, A.I.; Nau, W.M. Diffusion-Enhanced Forster Resonance Energy Transfer in Flexible Peptides: From the Haas-Steinberg Partial Differential Equation to a Closed Analytical Expression. Polymers 2023, 15, 705. [Google Scholar] [CrossRef]
- Ziolek, R.M.; Smith, P.; Pink, D.L.; Dreiss, C.A.; Lorenz, C.D. Unsupervised Learning Unravels the Structure of Four-Arm and Linear Block Copolymer Micelles. Macromolecules 2021, 54, 3755–3768. [Google Scholar] [CrossRef]
- Saleh, M.; Anwar, S.; Al-Ahmari, A.M.; AlFaify, A.Y. Prediction of Mechanical Properties for Carbon fiber/PLA Composite Lattice Structures Using Mathematical and ANFIS Models. Polymers 2023, 15, 1720. [Google Scholar] [CrossRef] [PubMed]
- Yan, S.Q.; Tang, Y.; Bi, G.P.; Xiao, B.W.; He, G.T.; Lin, Y.C. Optimal Design of Carbon-Based Polymer Nanocomposites Preparation Based on Response Surface Methodology. Polymers 2023, 15, 1494. [Google Scholar] [CrossRef] [PubMed]
- Bessa, M.A.; Bostanabad, R.; Liu, Z.; Hu, A.; Apley, D.W.; Brinson, C.; Chen, W.; Liu, W.K. A framework for data-driven analysis of materials under uncertainty: Countering the curse of dimensionality. Comput. Meth. Appl. Mech. Eng. 2017, 320, 633–667. [Google Scholar] [CrossRef]
- Wang, C.C.; Pilania, G.; Boggs, S.A.; Kumar, S.; Breneman, C.; Ramprasad, R. Computational strategies for polymer dielectrics design. Polymer 2014, 55, 979–988. [Google Scholar] [CrossRef]
- Zhang, C.; Lapkin, A.A. Reinforcement learning optimization of reaction routes on the basis of large, hybrid organic chemistry–synthetic biological, reaction network data. Reaction Chem. Eng. 2023, 8, 2491–2504. [Google Scholar] [CrossRef]
- Gomez-Flores, A.; Cho, H.; Hong, G.; Nam, H.; Kim, H.; Chung, Y. A critical review on machine learning applications in fiber composites and nanocomposites: Towards a control loop in the chain of processes in industries. Mater. Design 2024, 245, 113247. [Google Scholar] [CrossRef]
- Wang, Y.M.; Xie, T.; France-Lanord, A.; Berkley, A.; Johnson, J.A.; Shao-Horn, Y.; Grossman, J. Toward Designing Highly Conductive Polymer Electrolytes by Machine Learning Assisted Coarse-Grained Molecular Dynamics. Chem. Mater. 2020, 32, 4144–4151. [Google Scholar] [CrossRef]
- Gaspar-Cunha, A.; Costa, P.; Delbem, A.; Monaco, F.; Ferreira, M.J.; Covas, J. Evolutionary Multi-Objective Optimization of Extrusion Barrier Screws: Data Mining and Decision Making. Polymers 2023, 15, 2212. [Google Scholar] [CrossRef]
- Jeon, J.; Rhee, B.; Gim, J. Melt Temperature Estimation by Machine Learning Model Based on Energy Flow in Injection Molding. Polymers 2022, 14, 5548. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Schroeder, C.M.; Jackson, N.E. Open macromolecular genome: Generative design of synthetically accessible polymers. ACS Polymers Au 2023, 3, 318–330. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.N.; Wang, H.; Wang, C.X.; Xing, Y.H.; Liu, S.Y.; Feng, L.H.; Zhang, X.Y.; Chen, J.D. Advances in Smart-Response Hydrogels for Skin Wound Repair. Polymers 2024, 16, 2818. [Google Scholar] [CrossRef]
- Adetunji, A.I.; Erasmus, M. Green Synthesis of Bioplastics from Microalgae: A State-of-the-Art Review. Polymers 2024, 16, 1322. [Google Scholar] [CrossRef]
- Zhu, M.X.; Deng, T.; Dong, L.; Chen, J.M.; Dang, Z.M. Review of machine learning-driven design of polymer-based dielectrics. IET Nanodielectrics 2022, 5, 24–38. [Google Scholar] [CrossRef]
- Li, W.; Burkhart, C.; Polinska, P.; Harmandaris, V.; Doxastakis, M. Backmapping coarse-grained macromolecules: An efficient and versatile machine learning approach. J. Chem. Phys. 2020, 153, 041101. [Google Scholar] [CrossRef]
- Pan, F.; Sun, L.L.; Li, S.B. Dynamic Processes and Mechanical Properties of Lipid-Nanoparticle Mixtures. Polymers 2023, 15, 1828. [Google Scholar] [CrossRef] [PubMed]
- Guda, A.A.; Guda, S.A.; Lomachenko, K.A.; Soldatov, M.A.; Pankin, I.A.; Soldatov, A.V.; Braglia, L.; Bugaev, A.L.; Martini, A.; Signorile, M.; Groppo, E.; Piovano, A.; Borfecchia, E.; Lamberti, C. Quantitative structural determination of active sites from in situ and operando XANES spectra: From standard ab initio simulations to chemometric and machine learning approaches. Catalysis Today 2019, 336, 3–21. [Google Scholar] [CrossRef]
- Chiu, Y.H.; Liao, Y.H.; Juang, J.Y. Designing Bioinspired Composite Structures via Genetic Algorithm and Conditional Variational Autoencoder. Polymers 2023, 15, 281. [Google Scholar] [CrossRef]
- Wang, X.; Liu, J.M.; Chen, H.M.; Zhou, S.H.; Mao, D.S. Non-Woven Fabric Thermal-Conductive Triboelectric Nanogenerator via Compositing Zirconium Boride. Polymers 2024, 16, 778. [Google Scholar] [CrossRef]
- Tan, Y.; Li, J.R.; Nie, Y.L.; Zheng, Z. Novel Approach for Cardioprotection: In Situ Targeting of Metformin via Conductive Hydrogel System. Polymers 2024, 16, 2226. [Google Scholar] [CrossRef]
- Tao, L.; Chen, G.; Li, Y. Machine learning discovery of high-temperature polymers. Patterns 2021, 2, 100225. [Google Scholar] [CrossRef]
- Zhang, T.H.; Zhang, W.Z.; Ding, Z.C.; Jiao, J.J.; Wang, J.Y.; Zhang, W. A Fluorine-Containing Main-Chain Benzoxazine/Epoxy Co-Curing System with Low Dielectric Constants and High Thermal Stability. Polymers 2023, 15, 4487. [Google Scholar] [CrossRef] [PubMed]
- Patra, T.K.; Meenakshisundaram, V.; Hung, J.H.; Simmons, D.S. Neural-Network-Biased Genetic Algorithms for Materials Design: Evolutionary Algorithms That Learn. ACS Combin. Sci. 2017, 19, 96–107. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowledge Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Lockner, Y.; Hopmann, C.; Zhao, W. Transfer learning with artificial neural networks between injection molding processes and different polymer materials. J. Manufact. Proc. 2022, 73, 395–408. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wu, D. Predicting stress-strain curves using transfer learning: Knowledge transfer across polymer composites. Mater. Design 2022, 218. [Google Scholar] [CrossRef]
- Lee, C.K.; Lu, C.; Yu, Y.; Sun, Q.; Hsieh, C.Y.; Zhang, S.; Liu, Q.; Shi, L. Transfer learning with graph neural networks for optoelectronic properties of conjugated oligomers. J. Chem. Phys. 2021, 154. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Zhao, W.; Wang, L.; Lin, J.; Du, L. Machine-Learning-Assisted Design of Highly Tough Thermosetting Polymers. ACS Appl. Mater. Interf. 2022, 14, 55004–55016. [Google Scholar] [CrossRef]
- Huang, Y.M.; Jong, W.R.; Chen, S.C. Transfer Learning Applied to Characteristic Prediction of Injection Molded Products. Polymers 2021, 13, 3874. [Google Scholar] [CrossRef]
- Liu, M.Z.; Li, H.T.; Zhou, H.Y.; Zhang, H.; Huang, G.Y. Development of machine learning methods for mechanical problems associated with fibre composite materials: A review. Compos. Commun. 2024, 49, 101988. [Google Scholar] [CrossRef]
- Sepasdar, R.; Karpatne, A.; Shakiba, M. A data-driven approach to full-field nonlinear stress distribution and failure pattern prediction in composites using deep learning. Comput. Meth. Appl. Mech. Eng. 2022, 397, 115126. [Google Scholar] [CrossRef]
- Schmid, M.; Altmann, D.; Steinbichler, G. A Simulation-Data-Based Machine Learning Model for Predicting Basic Parameter Settings of the Plasticizing Process in Injection Molding. Polymers 2021, 13, 2652. [Google Scholar] [CrossRef] [PubMed]
- Gim, J.; Rhee, B. Novel Analysis Methodology of Cavity Pressure Profiles in Injection-Molding Processes Using Interpretation of Machine Learning Model. Polymers 2021, 13, 3297. [Google Scholar] [CrossRef]
- Kojima, T.; Washio, T.; Hara, S.; Koishi, M.; Amino, N. Analysis on Microstructure-Property Linkages of Filled Rubber Using Machine Learning and Molecular Dynamics Simulations. Polymers 2021, 13, 2683. [Google Scholar] [CrossRef] [PubMed]
- Rahman, A.; Deshpande, P.; Radue, M.S.; Odegard, G.M.; Gowtham, S.; Ghosh, S.; Spear, A.D. A machine learning framework for predicting the shear strength of carbon nanotube-polymer interfaces based on molecular dynamics simulation data. Compos. Sci Techn. 2021, 207, 108627. [Google Scholar] [CrossRef]
- Chen, G.; Tao, L.; Li, Y. Predicting Polymers’ Glass Transition Temperature by a Chemical Language Processing Model. Polymers 2021, 13, 1898. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Feng, X.M.; Wick, C.; Peters, A.; Li, G.Q. Machine learning assisted discovery of new thermoset shape memory polymers based on a small training dataset. Polymer 2021, 214, 123351. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Assoc. Inc.: United States, 2014; pp. 2672–2680. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; 2017; pp. 5998–6008. [Google Scholar]
- Lee, J.; Son, J.; Lim, J.; Kim, I.; Kim, S.; Cho, N.; Choi, W.; Shin, D. Transformer-Based Mechanical Property Prediction for Polymer Matrix Composites. Kor. J. Chem. Eng. 2024, 41, 3005–3018. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, Q.; Guo, J.; Liu, W.; Xia, R.; Yu, J.; Wang, X. A Transformer-based neural network for automatic delamination characterization of quartz fiber-reinforced polymer curved structure using improved THz-TDS. Compos. Struct. 2024, 343. [Google Scholar] [CrossRef]
- Han, S.; Kang, Y.; Park, H.; Yi, J.; Park, G.; Kim, J. Multimodal Transformer for Property Prediction in Polymers. ACS Appl. Mater. Interf. 2024, 16, 16853–16860. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Computing Surveys 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Chen, Y.; Long, P.; Liu, B.; Wang, Y.; Wang, J.; Ma, T.; Wei, H.; Kang, Y.; Ji, H. Development and application of Few-shot learning methods in materials science under data scarcity. J. Mater. Chem. A 2024, 12, 30249–30268. [Google Scholar] [CrossRef]
- Wu, T.; Zhou, M.; Zou, J.; Chen, Q.; Qian, F.; Kurths, J.; Liu, R.; Tang, Y. AI-guided few-shot inverse design of HDP-mimicking polymers against drug-resistant bacteria. Nat. Commun. 2024, 15. [Google Scholar] [CrossRef]
- Waite, J.R.; Tan, S.Y.; Saha, H.; Sarkar, S.; Sarkar, A. Few-shot deep learning for AFM force curve characterization of single-molecule interactions. Patterns 2023, 4. [Google Scholar] [CrossRef] [PubMed]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS). PMLR; 2017; pp. 1273–1282. [Google Scholar]
- Hu, K.; Wu, J.; Li, Y.; Lu, M.; Weng, L.; Xia, M. FedGCN: Federated Learning-Based Graph Convolutional Networks for Non-Euclidean Spatial Data. Mathematics 2022, 10. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. International Conference for Learning Representations (ICLR), 2017.
- Li, K.; Wang, J.; Song, Y.; Wang, Y. Machine learning-guided discovery of ionic polymer electrolytes for lithium metal batteries. Nat. Commun. 2023, 14. [Google Scholar] [CrossRef] [PubMed]
- Xie, T.; France-Lanord, A.; Wang, Y.; Lopez, J.; Stolberg, M.A.; Hill, M.; Leverick, G.M.; Gomez-Bombarelli, R.; Johnson, J.A.; Shao-Horn, Y.; Grossman, J.C. Accelerating amorphous polymer electrolyte screening by learning to reduce errors in molecular dynamics simulated properties. Nat. Commun. 2022, 13. [Google Scholar] [CrossRef] [PubMed]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33rd International Conference on Machine Learning (ICML); 2016; pp. 1050–1059. [Google Scholar]
- Wheatle, B.K.; Fuentes, E.F.; Lynd, N.A.; Ganesan, V. Design of Polymer Blend Electrolytes through a Machine Learning Approach. Macromolecules 2020, 53, 9449–9459. [Google Scholar] [CrossRef]
- Dorfman, K.D. Computational Phase Discovery in Block Polymers. ACS Macro Lett. 2024. [Google Scholar] [CrossRef]
- Peng, J.; Yuan, C.; Ma, R.; Zhang, Z. Backmapping from Multiresolution Coarse-Grained Models to Atomic Structures of Large Biomolecules by Restrained Molecular Dynamics Simulations Using Bayesian Inference. J. Chem. Theor. Comput. 2019, 15, 3344–3353. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. International Conference on Learning Representations (ICLR), 2017.
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. Proc. AAAI Conf. Artifical Intelligence 2019, 33, 4780–4789. [Google Scholar] [CrossRef]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable architecture search. International Conference on Learning Representations (ICLR), 2019.
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 8697–8710.
- Bhattacharya, D.; Patra, T.K. dPOLY: Deep Learning of Polymer Phases and Phase Transition. Macromolecules 2021, 54, 3065–3074. [Google Scholar] [CrossRef]
- Ye, H.L.; Xian, W.K.; Li, Y. Machine Learning of Coarse-Grained Models for Organic Molecules and Polymers: Progress, Opportunities, and Challenges. ACS Omega 2021, 6, 1758–1772. [Google Scholar] [CrossRef] [PubMed]
- Alessandri, R.; de Pablo, J.J. Prediction of Electronic Properties of Radical-Containing Polymers at Coarse-Grained Resolutions. Macromolecules 2023, 56, 3574–3584. [Google Scholar] [CrossRef]
- Karuth, A.; Alesadi, A.; Xia, W.J.; Rasulev, B. Predicting glass transition of amorphous polymers by application of cheminformatics and molecular dynamics simulations. Polymer 2021, 218, 123495. [Google Scholar] [CrossRef]
- Joshi, S.Y.; Deshmukh, S.A. A review of advancements in coarse-grained molecular dynamics simulations. Molec. Simul. 2021, 47, 786–803. [Google Scholar] [CrossRef]
- Lenzi, V.; Crema, A.; Pyrlin, S.; Marques, L. Current State and Perspectives of Simulation and Modeling of Aliphatic Isocyanates and Polyisocyanates. Polymers 2022, 14, 1642. [Google Scholar] [CrossRef]
- Schneider, L.; De Pablo, J.J. Combining Particle-Based Simulations and Machine Learning to Understand Defect Kinetics in Thin Films of Symmetric Diblock Copolymers. Macromolecules 2021, 54, 10074–10085. [Google Scholar] [CrossRef]
- Gupta, A.; Zou, J. Feedback GAN for DNA optimizes protein functions. Nat. Machine Intelligence 2019, 1, 105–111. [Google Scholar] [CrossRef]
- Rajak, P.; Kalia, R.K.; Nakano, A.; Vashishta, P. Neural Network Analysis of Dynamic Fracture in a Layered Material. MRS Adv. 2019, 4, 1109–1117. [Google Scholar] [CrossRef]
- Bassman, L.; Rajak, P.; Kalia, R.K.; Nakano, A.; Sha, F.; Sun, J.; Singh, D.J.; Aykol, M.; Huck, P.; Persson, K.; Vashishta, P. Active learning for accelerated design of layered materials. NPJ Comput. Mater. 2018, 4. [Google Scholar] [CrossRef]
- Jha, D.; Ward, L.; Paul, A.; Liao, W.k.; Choudhary, A.; Wolverton, C.; Agrawal, A. ElemNet: Deep Learning the Chemistry of Materials From Only Elemental Composition. Sci. Rep. 2018, 8. [Google Scholar] [CrossRef]
- Brooks, D.J.; Merinov, B.V.; Goddard, W.A., III; Kozinsky, B.; Mailoa, J. Atomistic Description of Ionic Diffusion in PEO-LiTFSI: Effect of Temperature, Molecular Weight, and Ionic Concentration. Macromolecules 2018, 51, 8987–8995. [Google Scholar] [CrossRef]
- Molinari, N.; Mailoa, J.P.; Kozinsky, B. Effect of Salt Concentration on Ion Clustering and Transport in Polymer Solid Electrolytes: A Molecular Dynamics Study of PEO-LiTFSI. Chem. Mater. 2018, 30, 6298–6306. [Google Scholar] [CrossRef]
- Chmiela, S.; Sauceda, H.E.; Mueller, K.R.; Tkatchenko, A. Towards exact molecular dynamics simulations with machine-learned force fields. Nat. Commun. 2018, 9. [Google Scholar] [CrossRef]
- Mailoa, J.P.; Kornbluth, M.; Batzner, S.; Samsonidze, G.; Lam, S.T.; Vandermause, J.; Ablitt, C.; Molinari, N.; Kozinsky, B. A fast neural network approach for direct covariant forces prediction in complex multi-element extended systems. Nat. Machine Intelligence 2019, 1, 471–479. [Google Scholar] [CrossRef]
- Malashin, I.P.; Tynchenko, V.S.; Nelyub, V.A.; Borodulin, A.S.; Gantimurov, A.P. Estimation and Prediction of the Polymers’ Physical Characteristics Using the Machine Learning Models. Polymers 2024, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Feng, J.P.; Zhan, L.H.; Ma, B.L.; Zhou, H.; Xiong, B.; Guo, J.Z.; Xia, Y.N.; Hui, S.M. Metal-Metal Bonding Process Research Based on Xgboost Machine Learning Algorithm. Polymers 2023, 15, 4085. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, C.H.; Huang, C.C.; Kuo, C.F.J.; Ahmad, N. Integration of Multivariate Statistical Control Chart and Machine Learning to Identify the Abnormal Process Parameters for Polylactide with Glass Fiber Composites in Injection Molding; Part I: The Processing Parameter Optimization for Multiple Qualities of Polylactide/Glass Fiber Composites in Injection Molding. Polymers 2023, 15, 3018. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.J.; Wu, Y.C.; Liu, W.D.; Fu, T.F.; Qiu, R.H.; Wu, S.Y. Tensile Performance Mechanism for Bamboo Fiber-Reinforced, Palm Oil-Based Resin Bio-Composites Using Finite Element Simulation and Machine Learning. Polymers 2023, 15, 2633. [Google Scholar] [CrossRef]
- Bao, Q.; Zhang, Z.H.; Luo, H.; Tao, X.M. Evaluating and Modeling the Degradation of PLA/PHB Fabrics in Marine Water. Polymers 2023, 15, 82. [Google Scholar] [CrossRef] [PubMed]
- Leon-Becerra, J.; Gonzalez-Estrada, O.A.; Sanchez-Acevedo, H. Comparison of Models to Predict Mechanical Properties of FR-AM Composites and a Fractographical Study. Polymers 2022, 14, 3546. [Google Scholar] [CrossRef]
- Aizen, A.; Ganzosch, G.; Vallmecke, C.; Auhl, D. Characterization and Multiscale Modeling of the Mechanical Properties for FDM-Printed Copper-Reinforced PLA Composites. Polymers 2022, 14, 3512. [Google Scholar] [CrossRef]
- Huang, Y.D.; Chen, Q.H.; Zhang, Z.Y.; Gao, K.; Hu, A.W.; Dong, Y.N.; Liu, J.; Cui, L.H. A Machine Learning Framework to Predict the Tensile Stress of Natural Rubber: Based on Molecular Dynamics Simulation Data. Polymers 2022, 14, 1897. [Google Scholar] [CrossRef]
- Nafees, A.; Khan, S.; Javed, M.F.; Alrowais, R.; Mohamed, A.M.; Mohamed, A.; Vatin, N.I. Forecasting the Mechanical Properties of Plastic Concrete Employing Experimental Data Using Machine Learning Algorithms: DT, MLPNN, SVM, and RF. Polymers 2022, 14, 1583. [Google Scholar] [CrossRef] [PubMed]
- Selvamany, P.; Varadarajan, G.S.; Chillu, N.; Sarathi, R. Investigation of XLPE Cable Insulation Using Electrical, Thermal and Mechanical Properties, and Aging Level Adopting Machine Learning Techniques. Polymers 2022, 14, 1614. [Google Scholar] [CrossRef]
- Amin, M.N.; Iqbal, M.; Khan, K.; Qadir, M.G.; Shalabi, F.I.; Jamal, A. Ensemble Tree-Based Approach towards Flexural Strength Prediction of FRP Reinforced Concrete Beams. Polymers 2022, 14, 1303. [Google Scholar] [CrossRef] [PubMed]
- Belei, C.; Joeressen, J.; Amancio, S.T. Fused-Filament Fabrication of Short Carbon Fiber-Reinforced Polyamide: Parameter Optimization for Improved Performance under Uniaxial Tensile Loading. Polymers 2022, 14, 1292. [Google Scholar] [CrossRef]
- Liu, Z.; Xiong, Y.Q.; Hao, J.H.; Zhang, H.; Cheng, X.; Wang, H.; Chen, W.; Zhou, C.J. Liquid Crystal-Based Organosilicone Elastomers with Supreme Mechanical Adaptability. Polymers 2022, 14, 789. [Google Scholar] [CrossRef] [PubMed]
- Lee, F.L.; Park, J.; Goyal, S.; Qaroush, Y.; Wang, S.H.; Yoon, H.; Rammohan, A.; Shim, Y. Comparison of Machine Learning Methods towards Developing Interpretable Polyamide Property Prediction. Polymers 2021, 13, 3653. [Google Scholar] [CrossRef]
- Meiabadi, M.S.; Moradi, M.; Karamimoghadam, M.; Ardabili, S.; Bodaghi, M.; Shokri, M.; Mosavi, A.H. Modeling the Producibility of 3D Printing in Polylactic Acid Using Artificial Neural Networks and Fused Filament Fabrication. Polymers 2021, 13, 3219. [Google Scholar] [CrossRef]
- Gunasekara, C.; Atzarakis, P.; Lokuge, W.; Law, D.W.; Setunge, S. Novel Analytical Method for Mix Design and Performance Prediction of High Calcium Fly Ash Geopolymer Concrete. Polymers 2021, 13, 900. [Google Scholar] [CrossRef]
- Pereira, A.B.; Fernandes, F.A.O.; de Morais, A.B.; Quintao, J. Mechanical Strength of Thermoplastic Polyamide Welded by Nd:YAG Laser. Polymers 2019, 11, 1381. [Google Scholar] [CrossRef]
- Mani, M.P.; Jaganathan, S.K.; Faudzi, A.A.; Sunar, M.S. Engineered Electrospun Polyurethane Composite Patch Combined with Bi-functional Components Rendering High Strength for Cardiac Tissue Engineering. Polymers 2019, 11, 705. [Google Scholar] [CrossRef]
- Le, T.T. Prediction of tensile strength of polymer carbon nanotube composites using practical machine learning method. J. Compos. Mater. 2021, 55, 787–811. [Google Scholar] [CrossRef]
- Ergan, H.; Ergan, M.E. Modeling Xanthan Gum Foam’s Material Properties Using Machine Learning Methods. Polymers 2024, 16, 740. [Google Scholar] [CrossRef]
- Zhao, Y.M.; Chen, Z.Y.; Jian, X.B. A High-Generalizability Machine Learning Framework for Analyzing the Homogenized Properties of Short Fiber-Reinforced Polymer Composites. Polymers 2023, 15, 3962. [Google Scholar] [CrossRef] [PubMed]
- Fouly, A.; Albahkali, T.; Abdo, H.S.; Salah, O. Investigating the Mechanical Properties of Annealed 3D-Printed PLA-Date Pits Composite. Polymers 2023, 15, 3395. [Google Scholar] [CrossRef] [PubMed]
- Di, B.; Qin, R.Y.; Zheng, Y.; Lv, J.M. Investigation of the Shear Behavior of Concrete Beams Reinforced with FRP Rebars and Stirrups Using ANN Hybridized with Genetic Algorithm. Polymers 2023, 15, 2857. [Google Scholar] [CrossRef] [PubMed]
- Liao, Z.H.; Qiu, C.; Yang, J.; Yang, J.L.; Yang, L. Accelerating the Layup Sequences Design of Composite Laminates via Theory-Guided Machine Learning Models. Polymers 2022, 14, 3229. [Google Scholar] [CrossRef] [PubMed]
- Castéran, F.; Delage, K.; Hascoet, N.; Ammar, A.; Chinesta, F.; Cassagnau, P. Data-Driven Modelling of Polyethylene Recycling under High-Temperature Extrusion. Polymers 2022, 14, 800. [Google Scholar] [CrossRef] [PubMed]
- Mairpady, A.; Mourad, A.H.I.; Mozumder, M.S. Statistical and Machine Learning-Driven Optimization of Mechanical Properties in Designing Durable HDPE Nanobiocomposites. Polymers 2021, 13, 3100. [Google Scholar] [CrossRef]
- Kopal, I.; Vrskova, J.; Bakosova, A.; Harnicarova, M.; Labaj, I.; Ondrusova, D.; Valacek, J.; Krmela, J. Modelling the Stiffness-Temperature Dependence of Resin-Rubber Blends Cured by High-Energy Electron Beam Radiation Using Global Search Genetic Algorithm. Polymers 2020, 12, 2652. [Google Scholar] [CrossRef] [PubMed]
- Park, S.K.; Park, B.J.; Choi, M.J.; Kim, D.W.; Yoon, J.W.; Shin, E.J.; Yun, S.; Park, S. Facile Functionalization of Poly(Dimethylsiloxane) Elastomer by Varying Content of Hydridosilyl Groups in a Crosslinker. Polymers 2019, 11, 1842. [Google Scholar] [CrossRef] [PubMed]
- Kopal, I.; Harnicarova¡, M.; Valicek, J.; Krmela, J.; Lukac, O. Radial Basis Function Neural Network-Based Modeling of the Dynamic Thermo-Mechanical Response and Damping Behavior of Thermoplastic Elastomer Systems. Polymers 2019, 11, 1074. [Google Scholar] [CrossRef]
- Kopal, I.; Harnicarova, M.; Valacek, J.; Kusnerova, M. Modeling the Temperature Dependence of Dynamic Mechanical Properties and Visco-Elastic Behavior of Thermoplastic Polyurethane Using Artificial Neural Network. Polymers 2017, 9, 519. [Google Scholar] [CrossRef] [PubMed]
- Kopal, I.; Labaj, I.; Vrskova, J.; Harnicarova, M.; Valicek, J.; Tozan, H. Intelligent Modelling of the Real Dynamic Viscosity of Rubber Blends Using Parallel Computing. Polymers 2023, 15, 3636. [Google Scholar] [CrossRef] [PubMed]
- Li, W.H.; Kadupitiya, J.C.S.; Jadhao, V. Rheological Properties of Small-Molecular Liquids at High Shear Strain Rates. Polymers 2023, 15, 2166. [Google Scholar] [CrossRef] [PubMed]
- Carrero, K.C.N.; Velasco-Merino, C.; Asensio, M.; Guerrero, J.; Merino, J.C. Rheological Method for Determining the Molecular Weight of Collagen Gels by Using a Machine Learning Technique. Polymers 2022, 14, 3683. [Google Scholar] [CrossRef] [PubMed]
- Venkatraman, V.; Alsberg, B.K. Designing High-Refractive Index Polymers Using Materials Informatics. Polymers 2018, 10, 103. [Google Scholar] [CrossRef] [PubMed]
- Tao, L.; Varshney, V.; Li, Y. Benchmarking Machine Learning Models for Polymer Informatics: An Example of Glass Transition Temperature. J. Chem. Inf. Model. 2021, 61, 5395–5413. [Google Scholar] [CrossRef] [PubMed]
- Li, L.R.; Jiang, W.D.; Yang, X.Z.; Meng, Y.D.; Hu, P.; Huang, C.; Liu, F. From Molecular Design to Practical Applications: Strategies for Enhancing the Optical and Thermal Performance of Polyimide Films. Polymers 2024, 16, 2315. [Google Scholar] [CrossRef]
- Champa-Bujaico, E.; Daez-Pascual, A.M.; Garcia-Diaz, P. Poly(3-hydroxybutyrate-co-3-hydroxyhexanoate) Bionanocomposites with Crystalline Nanocellulose and Graphene Oxide: Experimental Results and Support Vector Machine Modeling. Polymers 2023, 15, 3746. [Google Scholar] [CrossRef]
- Li, L.L.; Huang, Y.T.; Tang, W.; Zhang, Y.; Qian, L.J. Synergistic Effect between Piperazine Pyrophosphate and Melamine Polyphosphate in Flame Retardant Coatings for Structural Steel. Polymers 2022, 14, 3722. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Li, D.; Wan, H.; Liu, M.; Liu, J. Unsupervised machine learning methods for polymer nanocomposites data via molecular dynamics simulation. Molec. Simul. 2020, 46, 1509–1521. [Google Scholar] [CrossRef]
- Brown, N.K.; Deshpande, A.; Garland, A.; Pradeep, S.A.; Fadel, G.; Pilla, S.; Li, G. Deep reinforcement learning for the design of mechanical metamaterials with tunable deformation and hysteretic characteristics. Mater. Design 2023, 235, 112428. [Google Scholar] [CrossRef]
- Lobos, J.; Thirumuruganandham, S.P.; Rodriguez-Perez, M.A. Density Gradients, Cellular Structure and Thermal Conductivity of High-Density Polyethylene Foams by Different Amounts of Chemical Blowing Agent. Polymers 2022, 14, 4082. [Google Scholar] [CrossRef]
- Wen, F.Y.; Li, S.; Chen, R.; He, Y.S.; Li, L.; Cheng, L.; Ma, J.R.; Mu, J.X. Improved Thermal and Electromagnetic Shielding of PEEK Composites by Hydroxylating PEK-C Grafted MWCNTs. Polymers 2022, 14, 1328. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Rubín de Celis Leal, D.; Rana, S.; Gupta, S.; Sutti, A.; Greenhill, S.; Slezak, T.; Height, M.; Venkatesh, S. Rapid Bayesian optimisation for synthesis of short polymer fiber materials. Sci. Rep. 2017, 7, 5683. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.Y.; Lin, J.P.; Du, L.; Zhang, L.S. Harnessing Data Augmentation and Normalization Preprocessing to Improve the Performance of Chemical Reaction Predictions of Data-Driven Model. Polymers 2023, 15, 2224. [Google Scholar] [CrossRef]
- Elsayad, A.M.; Zeghid, M.; Ahmed, H.Y.; Elsayad, K.A. Exploration of Biodegradable Substances Using Machine Learning Techniques. Sustainability 2023, 15, 12764. [Google Scholar] [CrossRef]
- Li, B.X.; Zhang, S.Y.; Xu, L.; Su, Q.; Du, B. Emerging Robust Polymer Materials for High-Performance Two-Terminal Resistive Switching Memory. Polymers 2023, 15, 4374. [Google Scholar] [CrossRef] [PubMed]
- Ghoroghi, A.; Rezgui, Y.; Petri, I.; Beach, T. Advances in application of machine learning to life cycle assessment: a literature review. The International Journal of Life Cycle Assessment 2022, 27, 433–456. [Google Scholar] [CrossRef]
- Ibn-Mohammed, T.; Mustapha, K.B.; Abdulkareem, M.; Fuensanta, A.U.; Pecunia, V.; Dancer, C.E. Toward artificial intelligence and machine learning-enabled frameworks for improved predictions of lifecycle environmental impacts of functional materials and devices. MRS Commun. 2023, 13, 795–811. [Google Scholar] [CrossRef]
- Aoki, Y.; Wu, S.; Tsurimoto, T.; Hayashi, Y.; Minami, S.; Tadamichi, O.; Shiratori, K.; Yoshida, R. Multitask Machine Learning to Predict Polymer-Solvent Miscibility Using Flory-Huggins Interaction Parameters. Macromolecules 2023, 56, 5446–5456. [Google Scholar] [CrossRef]
- Chen, X.; Soh, B.W.; Ooi, Z.E.; Vissol-Gaudin, E.; Yu, H.; Novoselov, K.S.; Hippalgaonkar, K.; Li, Q. Constructing custom thermodynamics using deep learning. Nat. Comput. Sci. 2024, 4. [Google Scholar] [CrossRef]
Figure 2.
Schematic representation of supervised learning. Input data, paired with corresponding labels, is fed into a ML model during training. The model learns to map inputs to outputs by minimizing a loss function that quantifies the difference between predicted and true labels. Once trained, the model generalizes to make predictions on unseen data, reflecting its ability to capture underlying patterns in the labeled dataset.
Figure 2.
Schematic representation of supervised learning. Input data, paired with corresponding labels, is fed into a ML model during training. The model learns to map inputs to outputs by minimizing a loss function that quantifies the difference between predicted and true labels. Once trained, the model generalizes to make predictions on unseen data, reflecting its ability to capture underlying patterns in the labeled dataset.
Figure 3.
Cumulative number of publications in the course of time belonging to Supervised learning (Section 2.1: Neural networks (NNs), random classification trees, Random forests, Gradient boosting, and Support vector machines (SVM).
Figure 3.
Cumulative number of publications in the course of time belonging to Supervised learning (Section 2.1: Neural networks (NNs), random classification trees, Random forests, Gradient boosting, and Support vector machines (SVM).
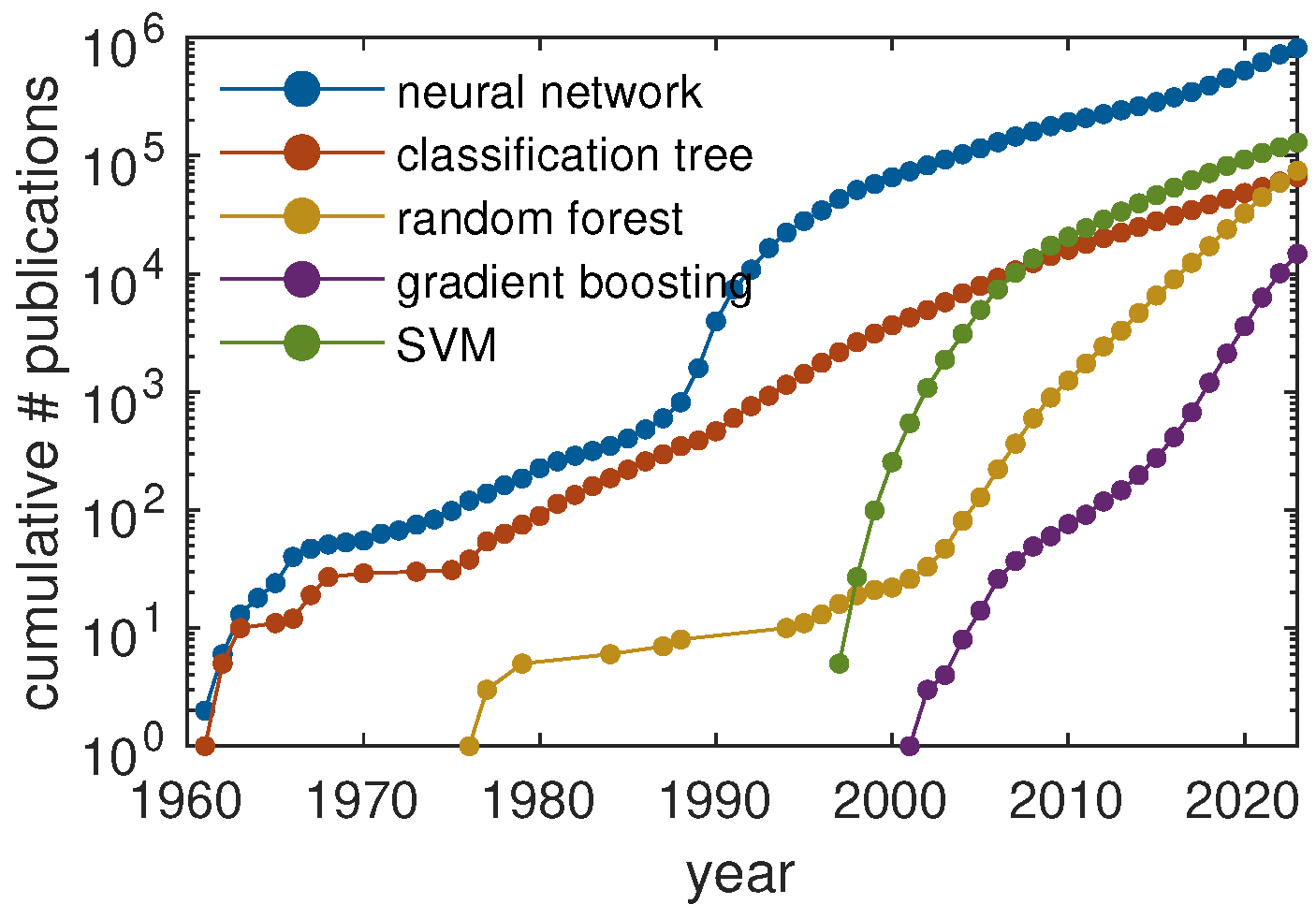
Figure 4.
Schematic representation of a neural network (NN). The network consists of an input layer, one or more hidden layers, and an output layer. Each layer contains interconnected nodes (neurons) that process input data by applying weights, biases, and activation functions. Information flows from the input layer through the hidden layers to the output layer, enabling the network to learn complex patterns and relationships in the data.
Figure 4.
Schematic representation of a neural network (NN). The network consists of an input layer, one or more hidden layers, and an output layer. Each layer contains interconnected nodes (neurons) that process input data by applying weights, biases, and activation functions. Information flows from the input layer through the hidden layers to the output layer, enabling the network to learn complex patterns and relationships in the data.
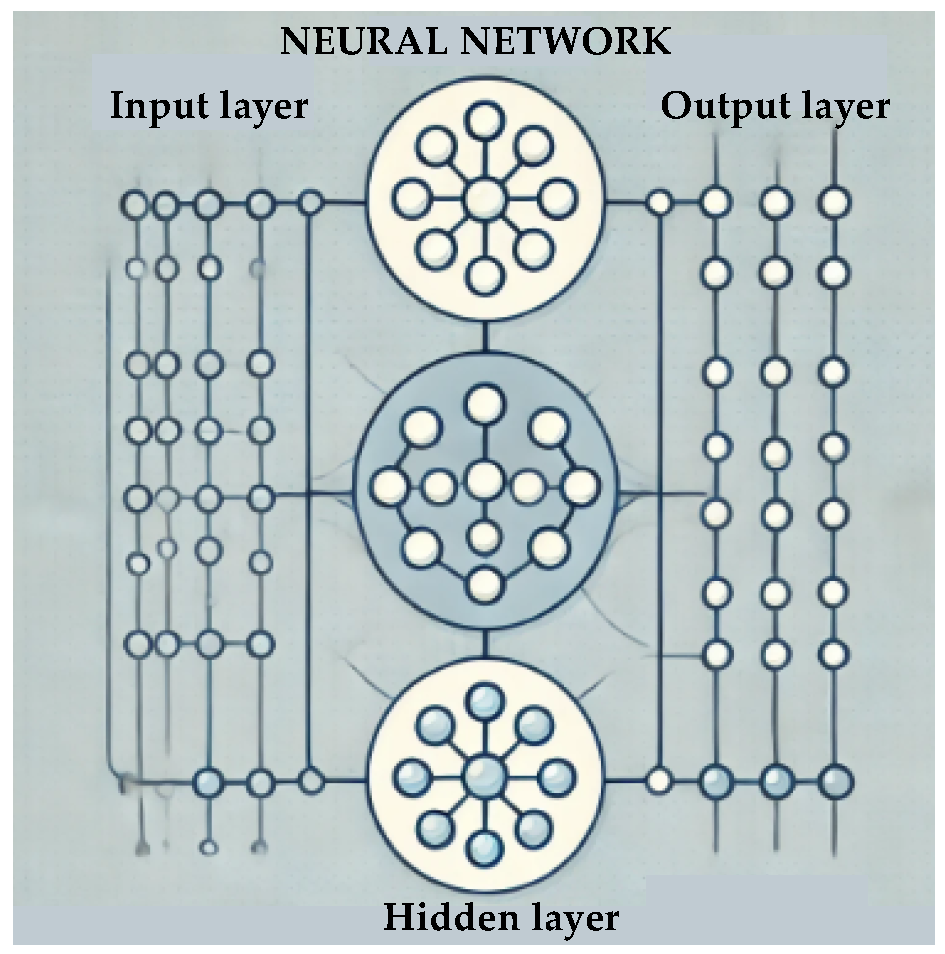
Figure 5.
Schematic representation of a random classification tree. The tree structure consists of nodes representing decision criteria and branches representing possible outcomes of these criteria. At the leaf nodes, class labels are assigned based on the majority class of the data reaching that point. The tree splits data recursively based on selected features, aiming to maximize classification accuracy while reducing uncertainty at each step. This method provides an interpretable model for classifying data into predefined categories.
Figure 5.
Schematic representation of a random classification tree. The tree structure consists of nodes representing decision criteria and branches representing possible outcomes of these criteria. At the leaf nodes, class labels are assigned based on the majority class of the data reaching that point. The tree splits data recursively based on selected features, aiming to maximize classification accuracy while reducing uncertainty at each step. This method provides an interpretable model for classifying data into predefined categories.
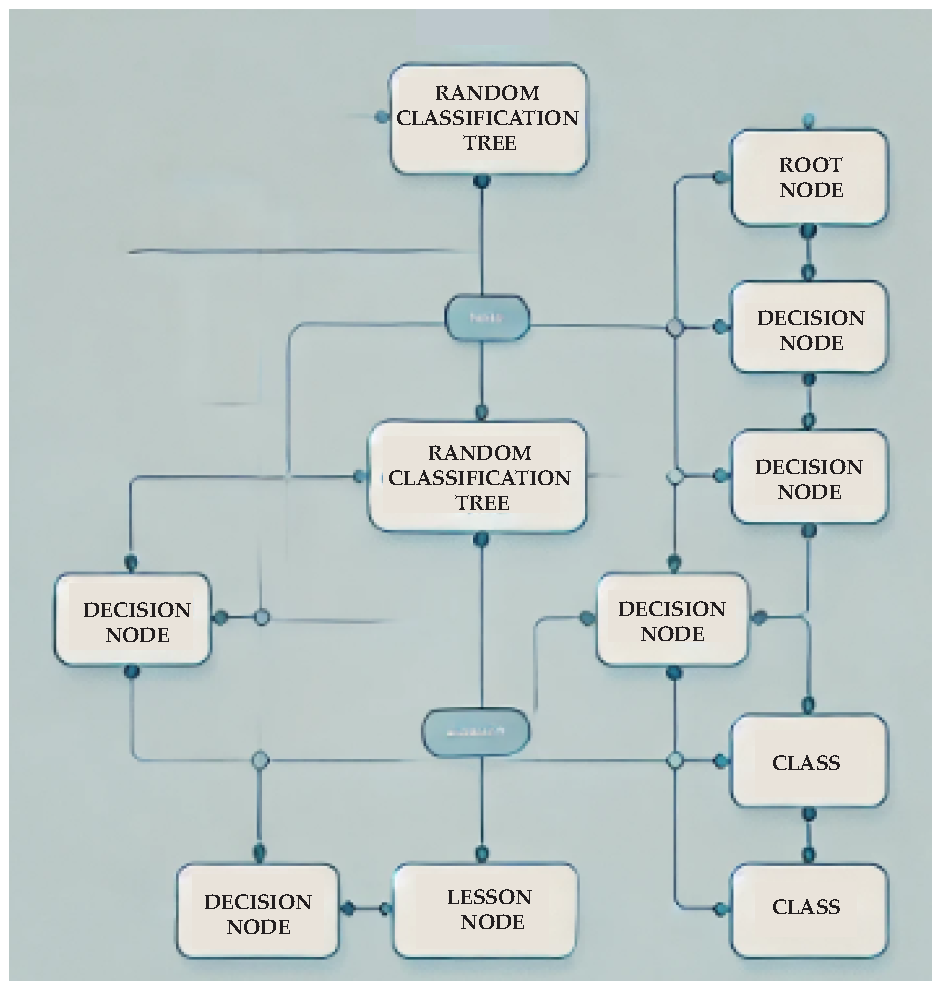
Figure 6.
Schematic representation of a random forest. The model consists of an ensemble of decision trees, each trained on a different random subset of the data using randomly selected features. During classification, each tree independently predicts a class label, and the final prediction is determined by aggregating the outputs (e.g., majority voting). This approach enhances predictive accuracy and robustness by reducing overfitting compared to a single decision tree.
Figure 6.
Schematic representation of a random forest. The model consists of an ensemble of decision trees, each trained on a different random subset of the data using randomly selected features. During classification, each tree independently predicts a class label, and the final prediction is determined by aggregating the outputs (e.g., majority voting). This approach enhances predictive accuracy and robustness by reducing overfitting compared to a single decision tree.
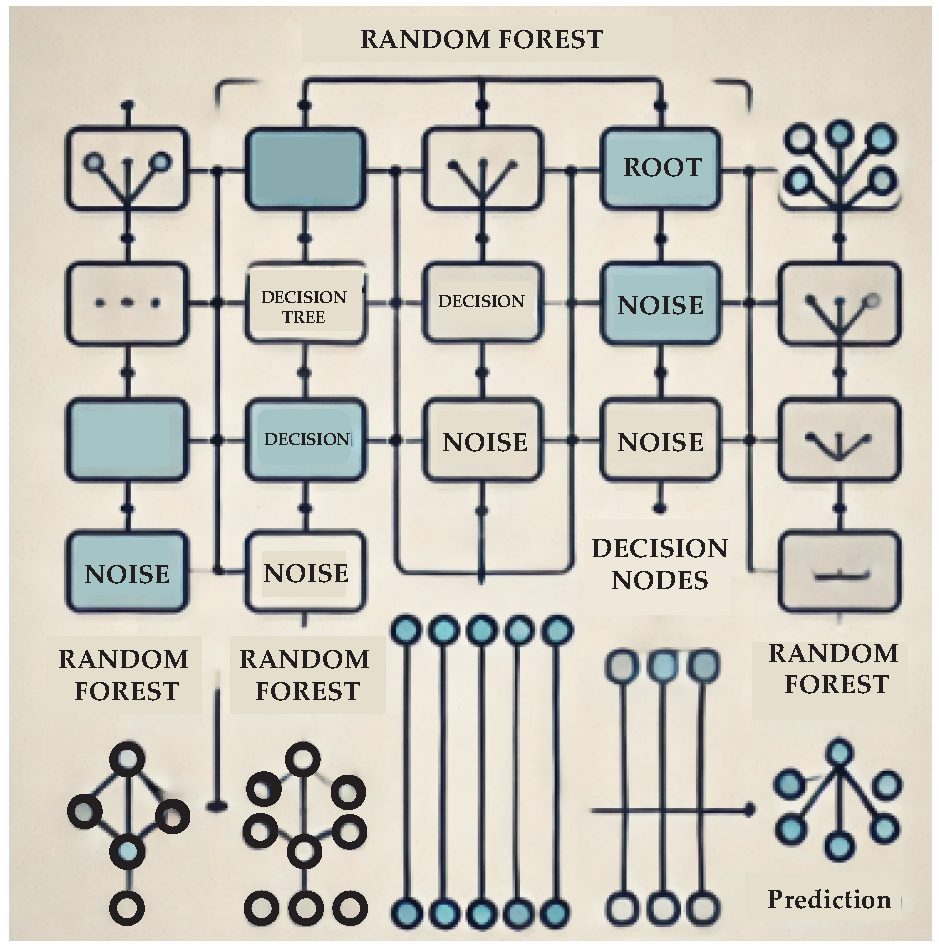
Figure 7.
Schematic representation of gradient boosting. The model builds an ensemble of weak learners, typically decision trees, in a sequential manner. Each tree is trained to correct the errors of the previous trees by minimizing a loss function. Predictions are made by combining the outputs of all trees, often through a weighted sum. This iterative approach improves model accuracy and performance, effectively capturing complex patterns in the data while maintaining interpretability.
Figure 7.
Schematic representation of gradient boosting. The model builds an ensemble of weak learners, typically decision trees, in a sequential manner. Each tree is trained to correct the errors of the previous trees by minimizing a loss function. Predictions are made by combining the outputs of all trees, often through a weighted sum. This iterative approach improves model accuracy and performance, effectively capturing complex patterns in the data while maintaining interpretability.
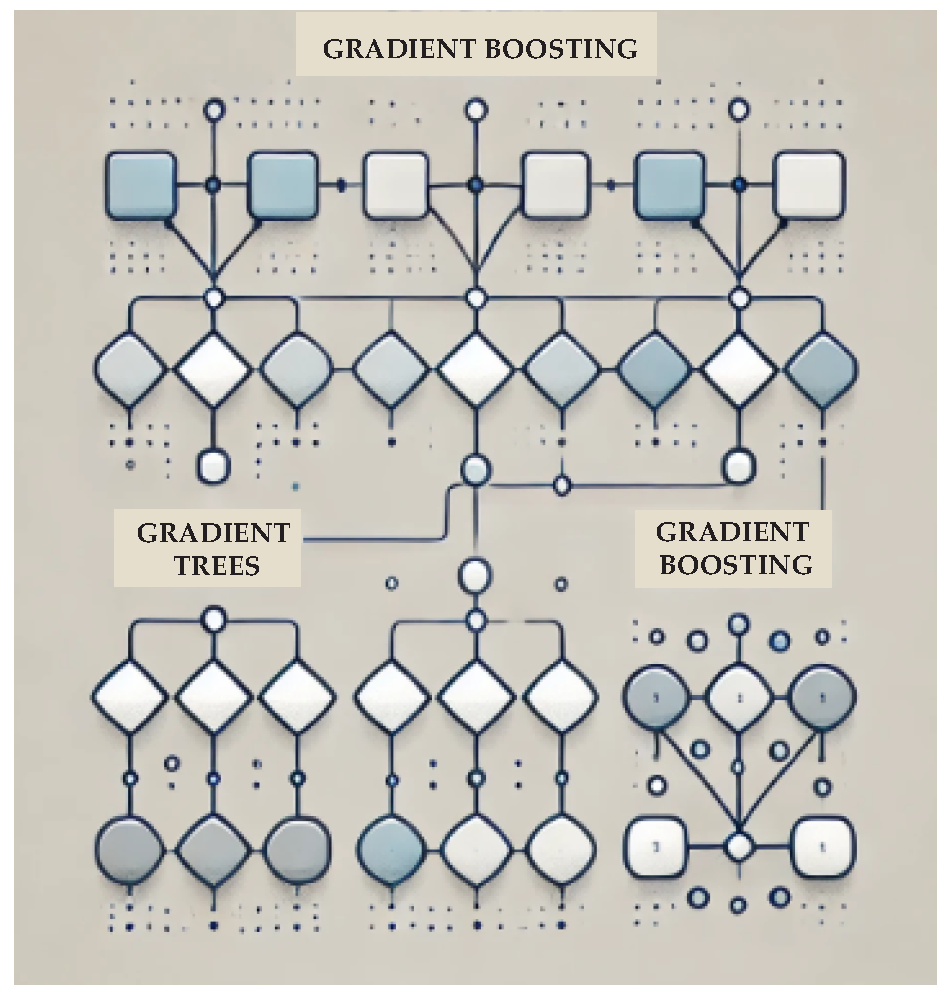
Figure 8.
Schematic representation of a Support Vector Machine (SVM). The model separates data points into different classes by finding the optimal hyperplane that maximizes the margin between class boundaries. Support vectors, the data points closest to the hyperplane, are used to define the margin. SVMs are effective for both linear and nonlinear classification tasks, with kernel functions enabling the transformation of data into higher-dimensional spaces to handle complex patterns.
Figure 8.
Schematic representation of a Support Vector Machine (SVM). The model separates data points into different classes by finding the optimal hyperplane that maximizes the margin between class boundaries. Support vectors, the data points closest to the hyperplane, are used to define the margin. SVMs are effective for both linear and nonlinear classification tasks, with kernel functions enabling the transformation of data into higher-dimensional spaces to handle complex patterns.
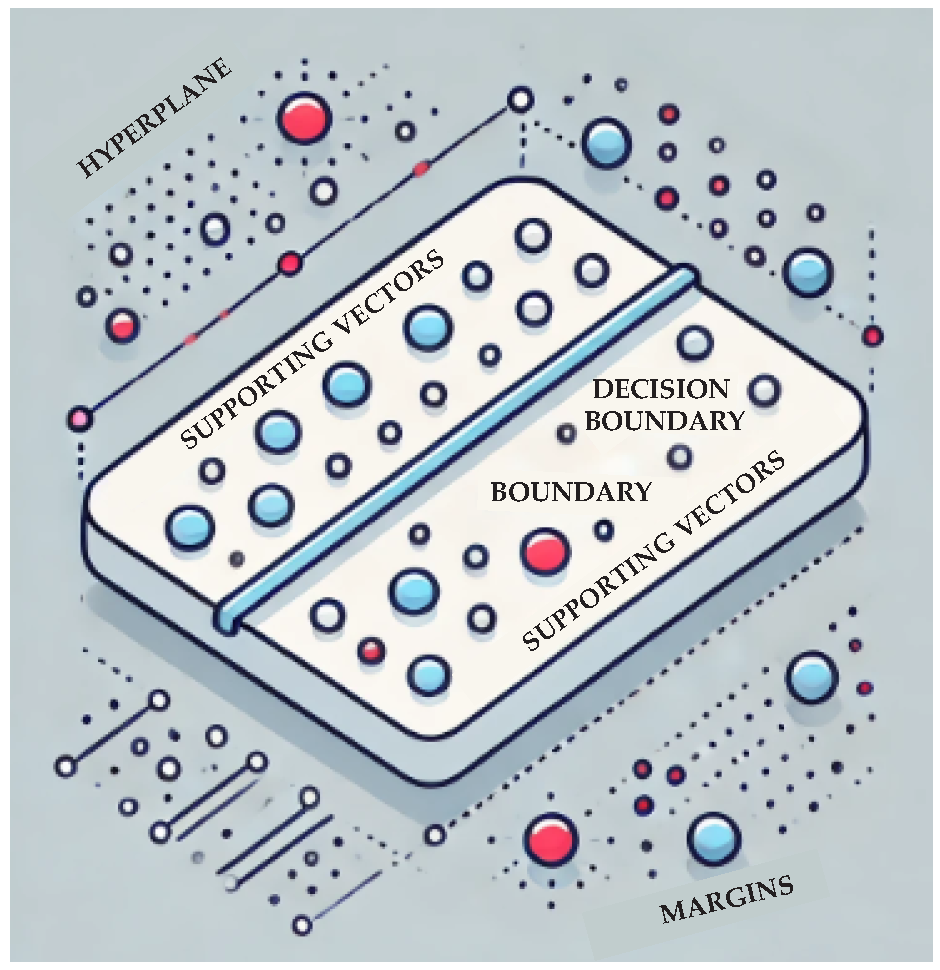
Figure 9.
Schematic representation of unsupervised learning. Input data without labels is processed by a ML model to identify hidden patterns or structures. The model groups similar data points through clustering, dimensionality reduction, or other techniques. This approach enables insights into the data’s inherent characteristics, facilitating tasks such as segmentation, anomaly detection, and feature extraction.
Figure 9.
Schematic representation of unsupervised learning. Input data without labels is processed by a ML model to identify hidden patterns or structures. The model groups similar data points through clustering, dimensionality reduction, or other techniques. This approach enables insights into the data’s inherent characteristics, facilitating tasks such as segmentation, anomaly detection, and feature extraction.
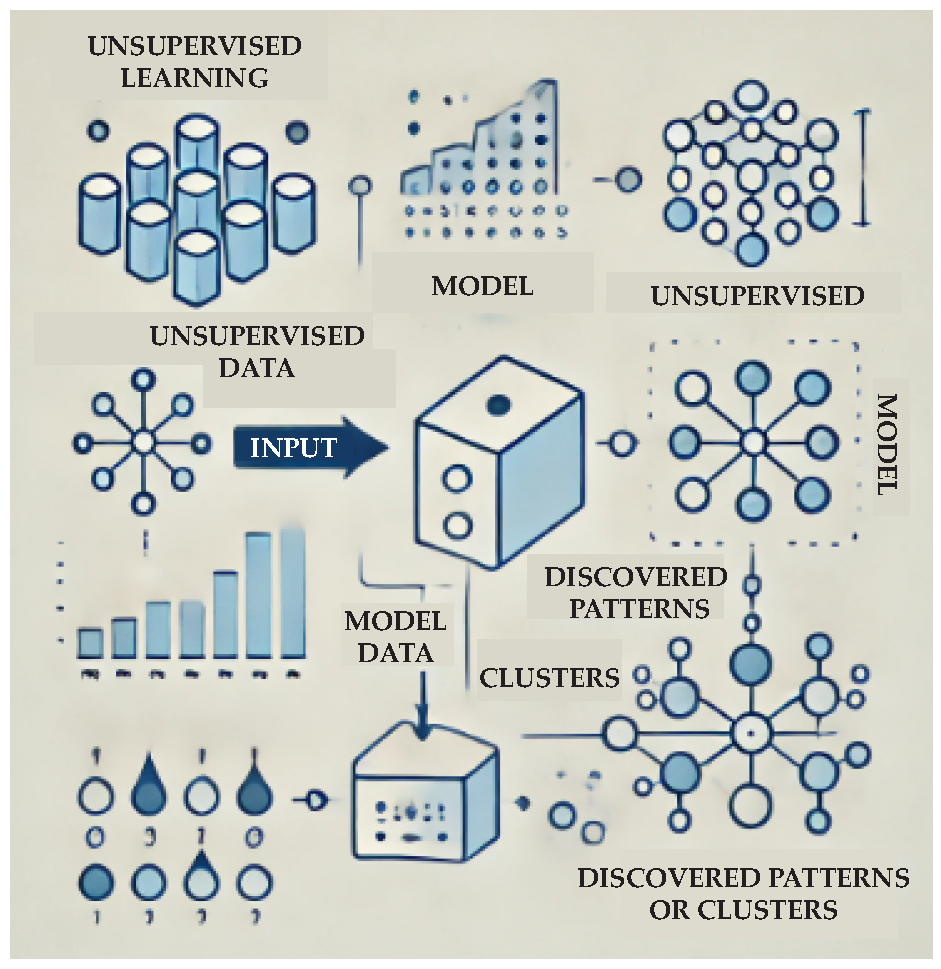
Figure 10.
Schematic representation of a clustering algorithm. Input data points are grouped into clusters based on their similarity or proximity in feature space. The algorithm iteratively assigns data points to clusters by minimizing a defined distance metric or optimizing a clustering objective. Each cluster represents a set of data points with shared characteristics, enabling tasks such as segmentation, pattern discovery, and anomaly detection.
Figure 10.
Schematic representation of a clustering algorithm. Input data points are grouped into clusters based on their similarity or proximity in feature space. The algorithm iteratively assigns data points to clusters by minimizing a defined distance metric or optimizing a clustering objective. Each cluster represents a set of data points with shared characteristics, enabling tasks such as segmentation, pattern discovery, and anomaly detection.
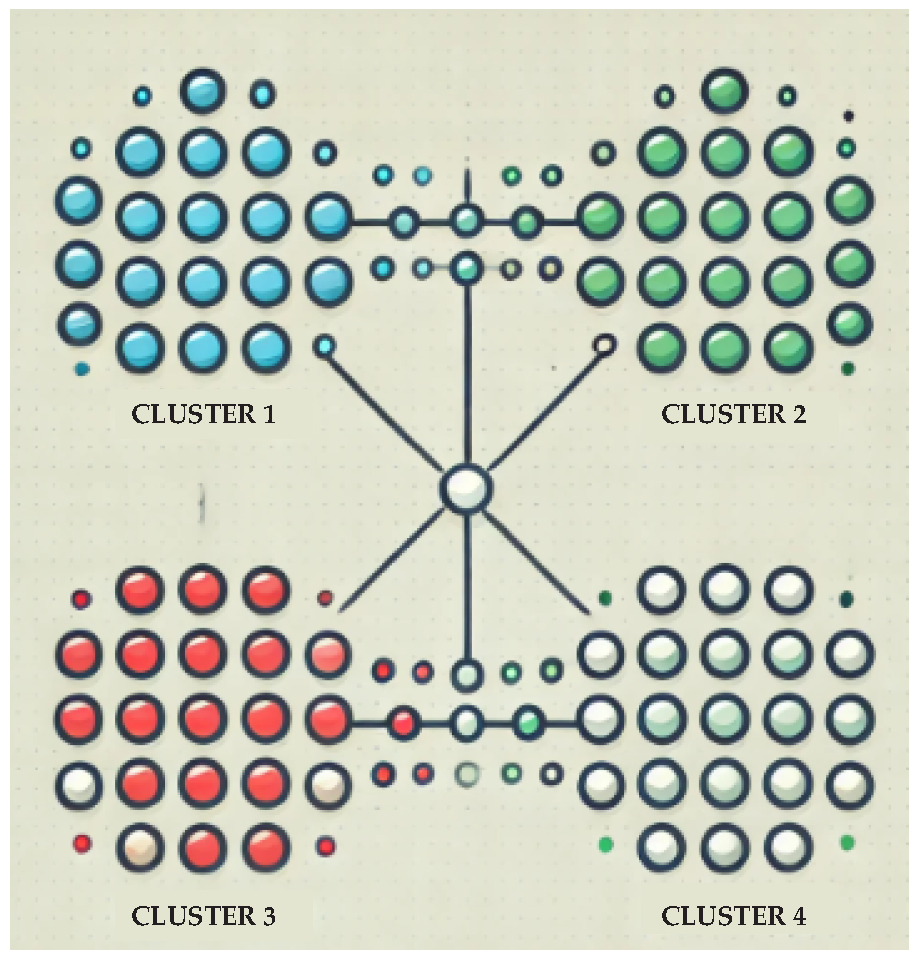
Figure 11.
Schematic representation of dimensionality reduction. High-dimensional input data is transformed into a lower-dimensional space while preserving its essential structure and relationships. This process reduces computational complexity and enables better visualization and interpretation of the data. Techniques like PCA (Principal Component Analysis) and t-SNE (t-Distributed Stochastic Neighbor Embedding) are commonly used for dimensionality reduction in ML and data analysis.
Figure 11.
Schematic representation of dimensionality reduction. High-dimensional input data is transformed into a lower-dimensional space while preserving its essential structure and relationships. This process reduces computational complexity and enables better visualization and interpretation of the data. Techniques like PCA (Principal Component Analysis) and t-SNE (t-Distributed Stochastic Neighbor Embedding) are commonly used for dimensionality reduction in ML and data analysis.
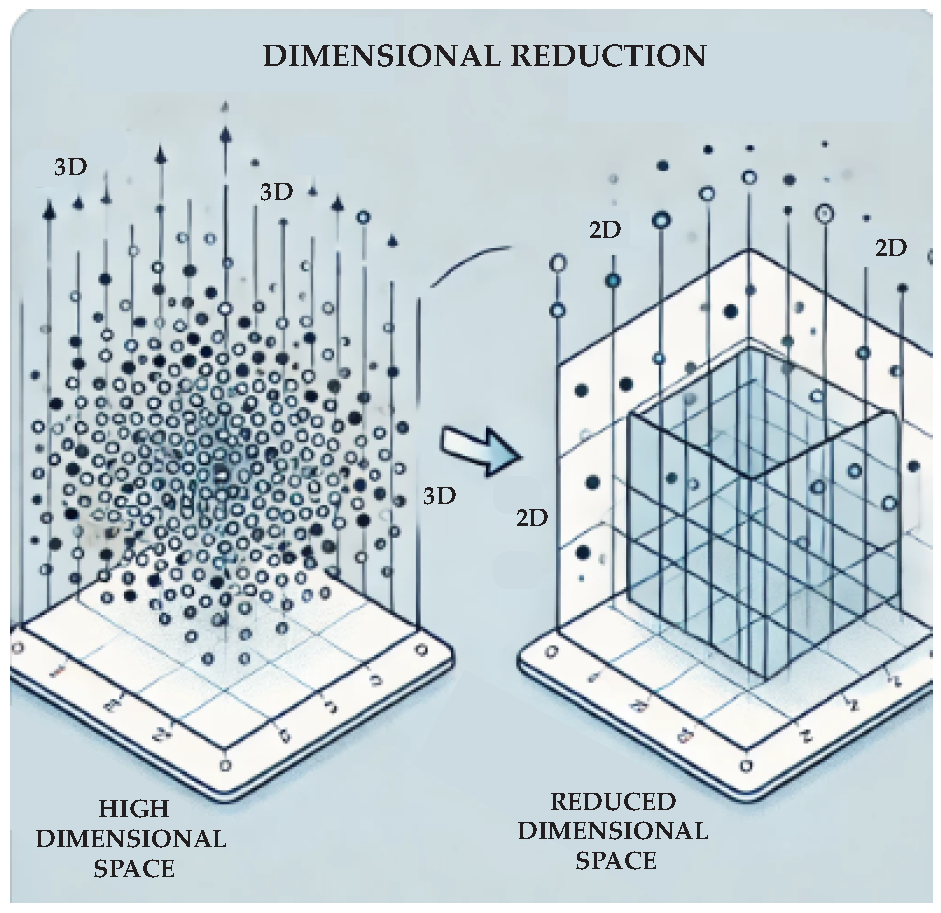
Figure 12.
Schematic representation of reinforcement learning. An agent interacts with an environment by taking actions based on a policy. The environment responds with a new state and a reward signal, which the agent uses to learn and improve its policy. Through trial and error, the agent aims to maximize cumulative rewards over time, enabling it to solve tasks by optimizing its behavior.
Figure 12.
Schematic representation of reinforcement learning. An agent interacts with an environment by taking actions based on a policy. The environment responds with a new state and a reward signal, which the agent uses to learn and improve its policy. Through trial and error, the agent aims to maximize cumulative rewards over time, enabling it to solve tasks by optimizing its behavior.
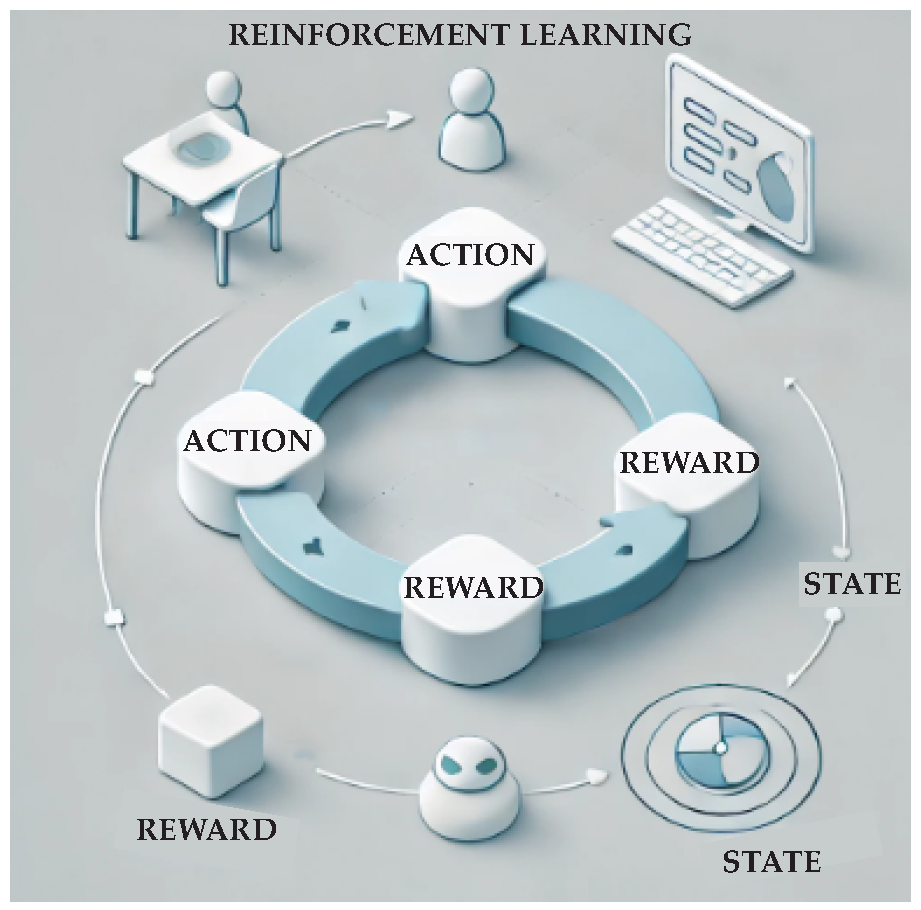
Figure 13.
Schematic representation of a generative model. The model maps data from a random space (e.g., sampled noise) to a latent space, where it captures the underlying structure and features of the input data. From the latent space, the model generates new samples in the output space, resembling the original dataset. This process enables tasks such as data synthesis, image generation, and anomaly detection, leveraging probabilistic frameworks like variational autoencoders (VAEs) or generative adversarial networks (GANs).
Figure 13.
Schematic representation of a generative model. The model maps data from a random space (e.g., sampled noise) to a latent space, where it captures the underlying structure and features of the input data. From the latent space, the model generates new samples in the output space, resembling the original dataset. This process enables tasks such as data synthesis, image generation, and anomaly detection, leveraging probabilistic frameworks like variational autoencoders (VAEs) or generative adversarial networks (GANs).
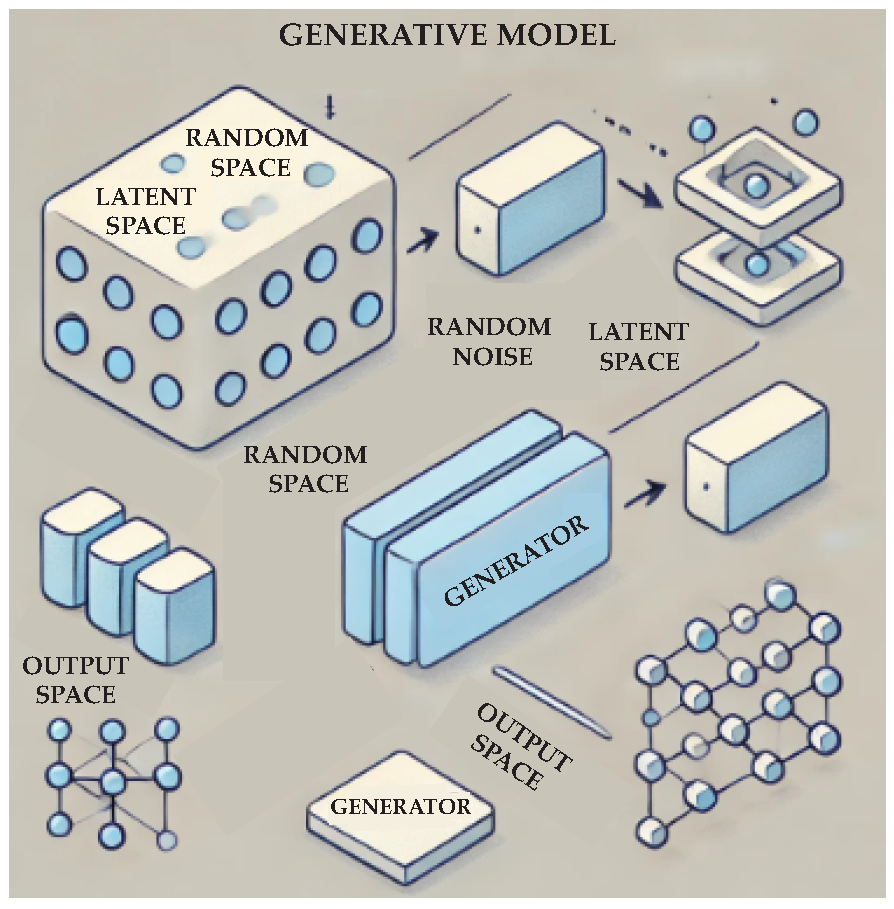
Figure 14.
Schematic representation of deep learning. The model consists of an input layer, multiple hidden layers, and an output layer. Data flows from the input space through the hidden layers, where transformations are applied to learn abstract representations in a latent space. The final output layer maps these learned features to the output space, producing predictions or classifications. This layered architecture enables the model to extract and learn hierarchical patterns from data.
Figure 14.
Schematic representation of deep learning. The model consists of an input layer, multiple hidden layers, and an output layer. Data flows from the input space through the hidden layers, where transformations are applied to learn abstract representations in a latent space. The final output layer maps these learned features to the output space, producing predictions or classifications. This layered architecture enables the model to extract and learn hierarchical patterns from data.
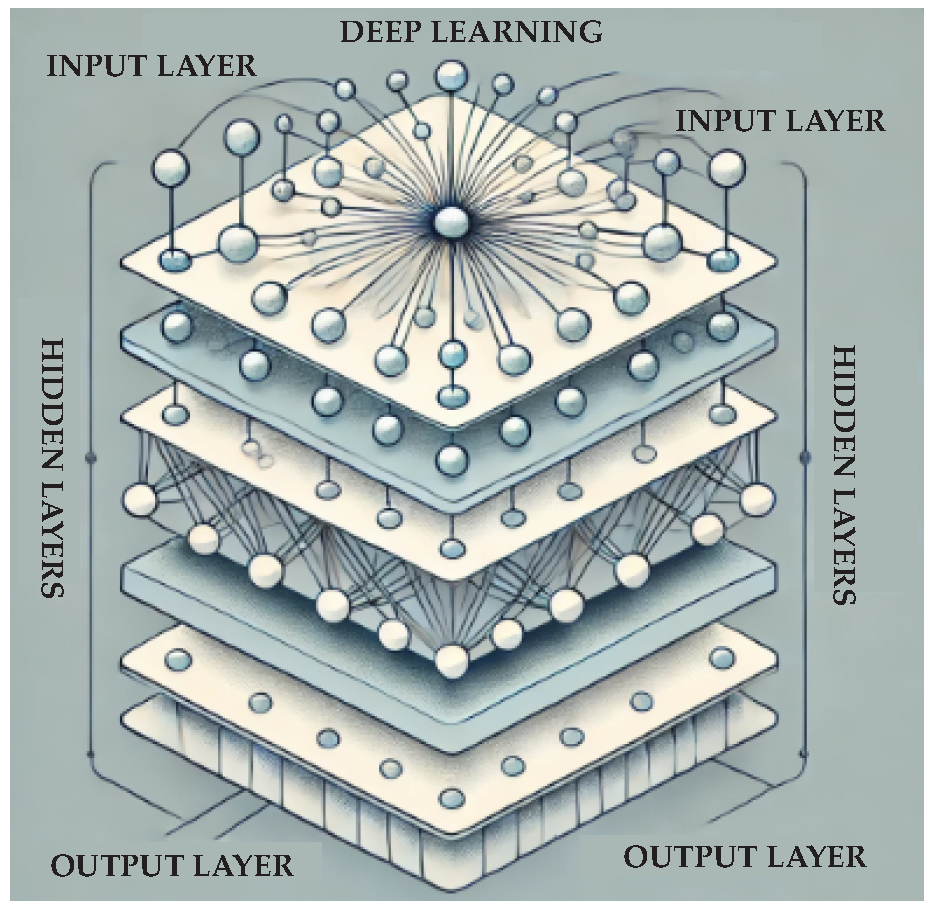
Figure 15.
Schematic representation of transfer learning. A pre-trained model, developed on a source task with abundant data, is adapted to a target task with limited data. The model’s earlier layers capture general features from the source task, which are reused for the target task, while later layers are fine-tuned to learn task-specific features. This approach leverages knowledge from the source space to improve performance in the target space, reducing training time and data requirements.
Figure 15.
Schematic representation of transfer learning. A pre-trained model, developed on a source task with abundant data, is adapted to a target task with limited data. The model’s earlier layers capture general features from the source task, which are reused for the target task, while later layers are fine-tuned to learn task-specific features. This approach leverages knowledge from the source space to improve performance in the target space, reducing training time and data requirements.
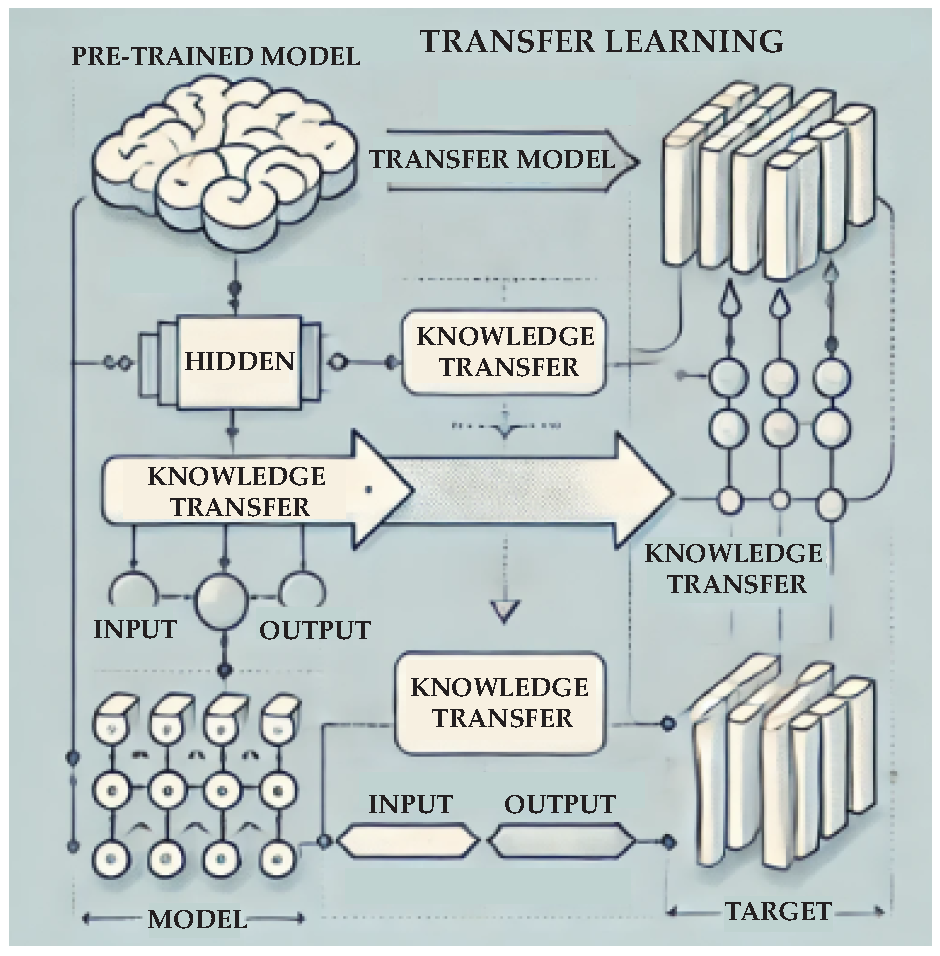
Figure 16.
Schematic representation of a convolutional NN (CNN). The network processes input data through a series of layers, including convolutional layers that extract spatial features, pooling layers that reduce dimensionality, and fully connected layers that map features to the output space. The hierarchical structure enables the network to capture patterns, such as edges and shapes, from the input space and combine them into complex features for tasks like image classification and object detection.
Figure 16.
Schematic representation of a convolutional NN (CNN). The network processes input data through a series of layers, including convolutional layers that extract spatial features, pooling layers that reduce dimensionality, and fully connected layers that map features to the output space. The hierarchical structure enables the network to capture patterns, such as edges and shapes, from the input space and combine them into complex features for tasks like image classification and object detection.
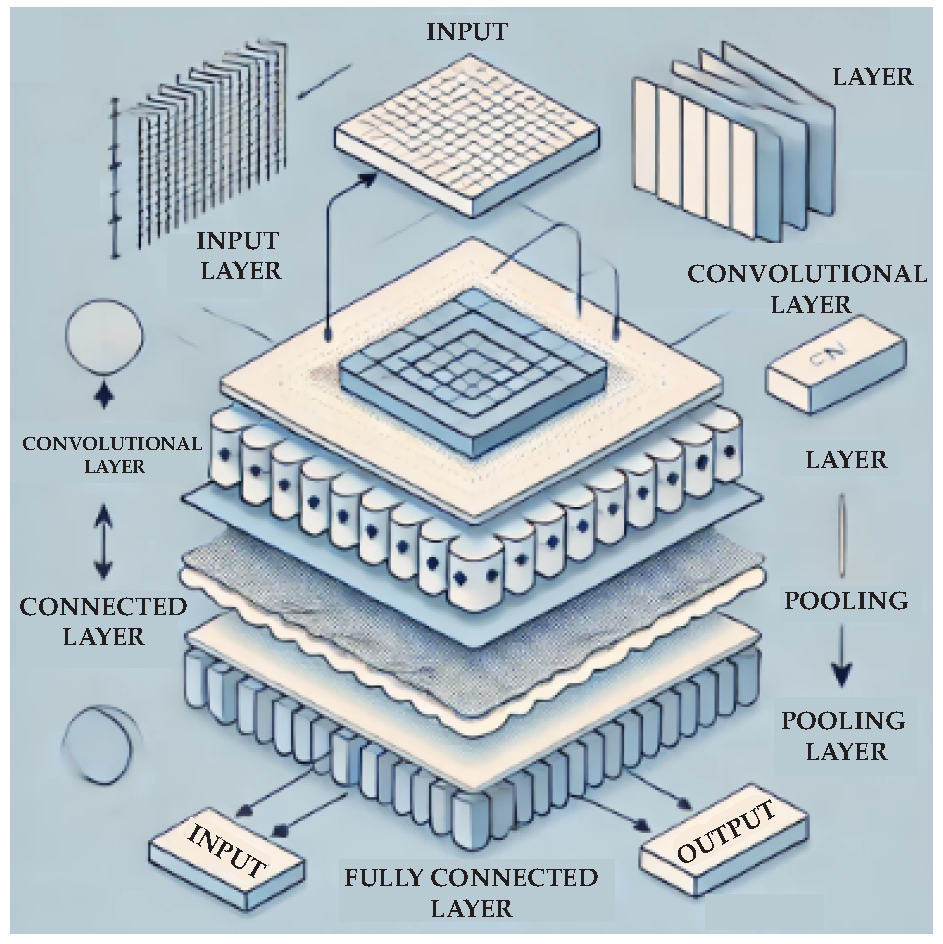
Figure 17.
Schematic representation of a Generative Adversarial Network (GAN). The model consists of two components: a generator, which maps data from a random space (e.g., noise) to the output space by generating realistic samples, and a discriminator, which evaluates whether the samples are real or fake. The generator and discriminator compete in a minimax game, improving each other iteratively until the generator produces data indistinguishable from real data. This process enables the generation of high-quality synthetic samples.
Figure 17.
Schematic representation of a Generative Adversarial Network (GAN). The model consists of two components: a generator, which maps data from a random space (e.g., noise) to the output space by generating realistic samples, and a discriminator, which evaluates whether the samples are real or fake. The generator and discriminator compete in a minimax game, improving each other iteratively until the generator produces data indistinguishable from real data. This process enables the generation of high-quality synthetic samples.
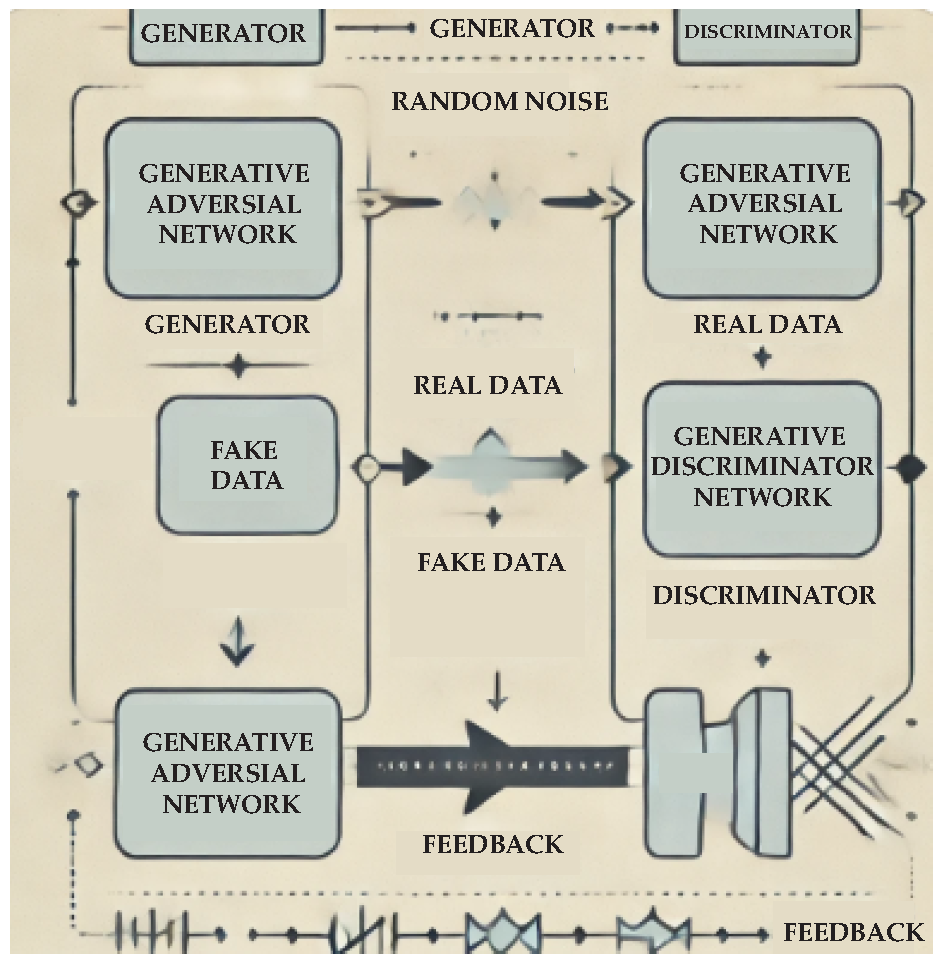
Figure 18.
Schematic representation of the Transformer architecture. The model processes an input sequence through a stack of encoders, which apply self-attention and feed-forward layers to generate an encoded sequence. The decoders use cross-attention to focus on relevant parts of the encoded sequence while generating the final output. This design enables the model to effectively capture complex dependencies in sequential data for tasks like machine translation and text generation.
Figure 18.
Schematic representation of the Transformer architecture. The model processes an input sequence through a stack of encoders, which apply self-attention and feed-forward layers to generate an encoded sequence. The decoders use cross-attention to focus on relevant parts of the encoded sequence while generating the final output. This design enables the model to effectively capture complex dependencies in sequential data for tasks like machine translation and text generation.
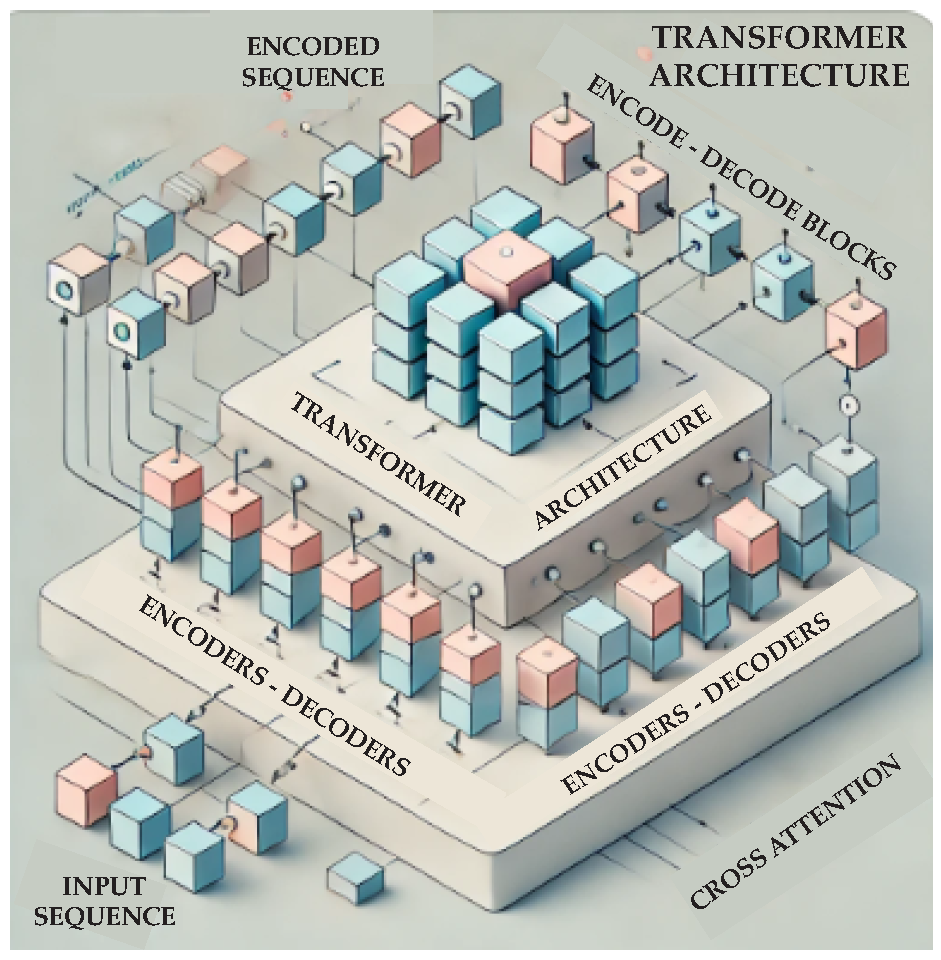
Figure 19.
Schematic representation of few-shot and zero-shot learning approaches in ML. On the left, few-shot learning is depicted with a small dataset represented as circles feeding into a model. On the right, zero-shot learning uses a prior description or knowledge base, symbolized by a rectangle, as input to a similar model. Both models produce predictions, represented by the single output box at the bottom. The diagram emphasizes the minimal input data for few-shot learning and the absence of labeled examples for zero-shot learning.
Figure 19.
Schematic representation of few-shot and zero-shot learning approaches in ML. On the left, few-shot learning is depicted with a small dataset represented as circles feeding into a model. On the right, zero-shot learning uses a prior description or knowledge base, symbolized by a rectangle, as input to a similar model. Both models produce predictions, represented by the single output box at the bottom. The diagram emphasizes the minimal input data for few-shot learning and the absence of labeled examples for zero-shot learning.
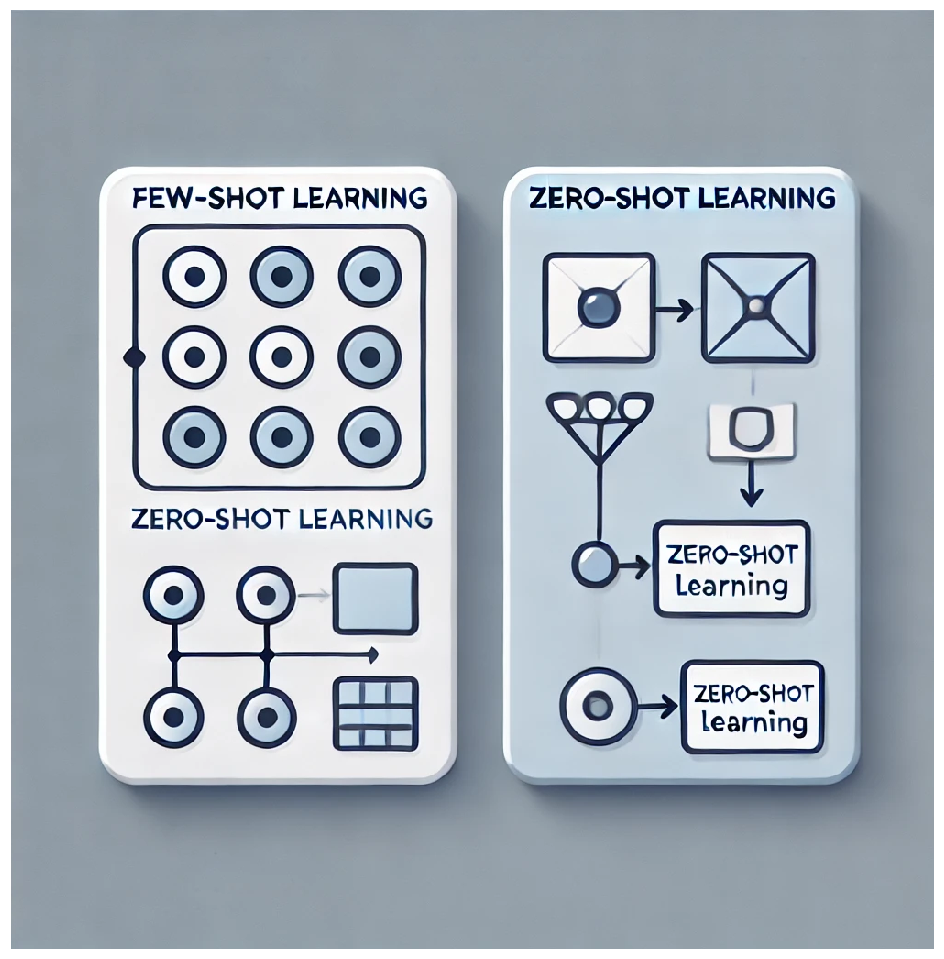
Figure 20.
Schematic representation of federated learning. Multiple client devices, represented as small circles or rectangles (e.g., phones or computers), collaboratively train a shared model by sending model updates to a central server (depicted as a larger central circle). Arrows indicate the flow of model updates from the clients to the server and the distribution of the aggregated model back to the clients, emphasizing decentralized data training while maintaining data privacy.
Figure 20.
Schematic representation of federated learning. Multiple client devices, represented as small circles or rectangles (e.g., phones or computers), collaboratively train a shared model by sending model updates to a central server (depicted as a larger central circle). Arrows indicate the flow of model updates from the clients to the server and the distribution of the aggregated model back to the clients, emphasizing decentralized data training while maintaining data privacy.
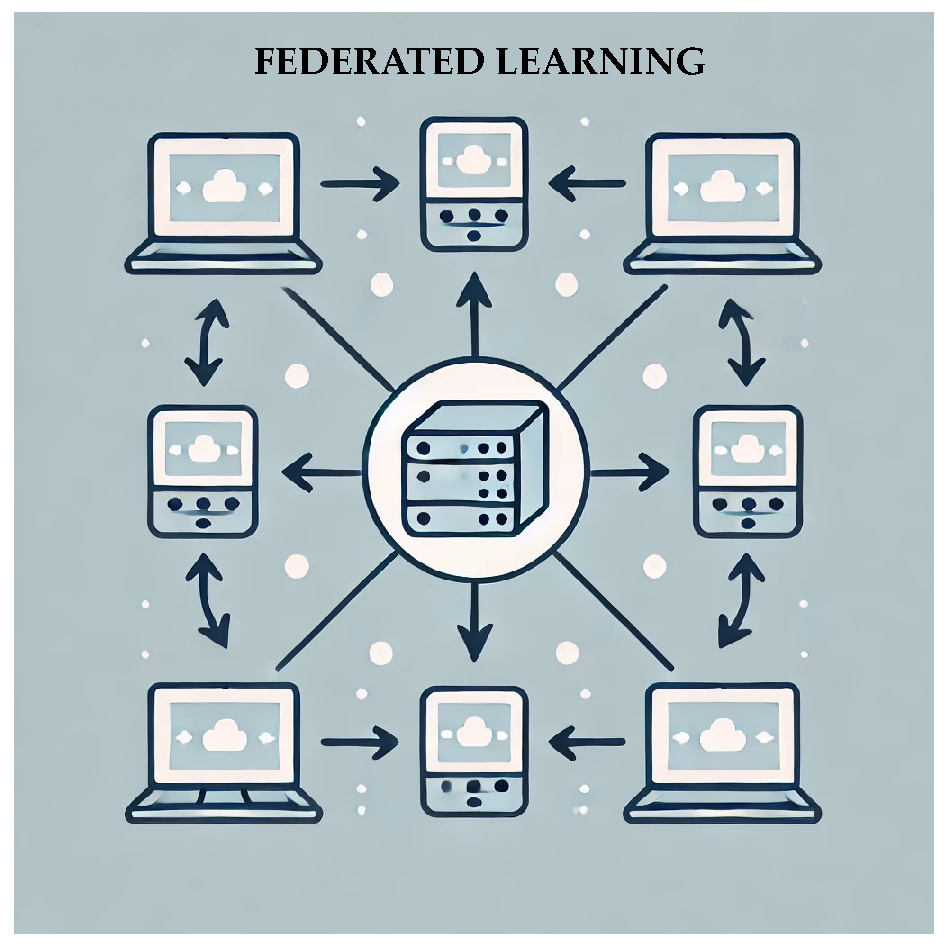
Figure 21.
Schematic representation of a graph NN (GNN). The input graph consists of nodes and edges, with each node containing feature information. The GNN aggregates information from neighboring nodes through iterative message-passing operations, combining node features with edge information. This process updates node embeddings to reflect the graph’s structure and contextual relationships. The final embeddings can be used for tasks such as node classification, link prediction, or graph-level classification.
Figure 21.
Schematic representation of a graph NN (GNN). The input graph consists of nodes and edges, with each node containing feature information. The GNN aggregates information from neighboring nodes through iterative message-passing operations, combining node features with edge information. This process updates node embeddings to reflect the graph’s structure and contextual relationships. The final embeddings can be used for tasks such as node classification, link prediction, or graph-level classification.
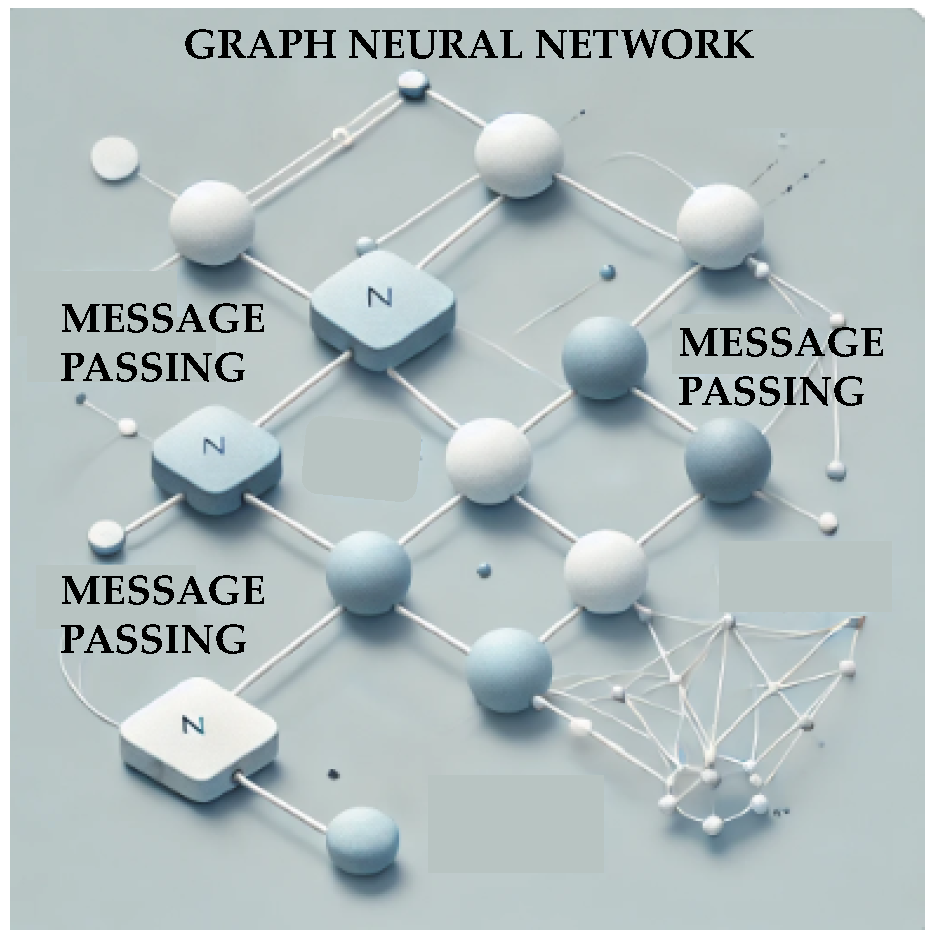
Figure 22.
Schematic representation of Bayesian deep learning. A NN, represented by stacked layers of circles and lines, processes input data to generate predictions. The Bayesian aspect is symbolized by a Gaussian distribution (bell curve) above the network, representing the modeling of uncertainty. This approach incorporates prior knowledge and updates it with observed data to compute posterior probabilities, providing a measure of confidence in the predictions.
Figure 22.
Schematic representation of Bayesian deep learning. A NN, represented by stacked layers of circles and lines, processes input data to generate predictions. The Bayesian aspect is symbolized by a Gaussian distribution (bell curve) above the network, representing the modeling of uncertainty. This approach incorporates prior knowledge and updates it with observed data to compute posterior probabilities, providing a measure of confidence in the predictions.
Figure 23.
Schematic representation of Neural Architecture Search (NAS). The process involves exploring a search space of candidate NN architectures (represented as simple diagrams of nodes and edges), evaluating their performance, and optimizing the architecture iteratively. Arrows indicate the flow of information between the search space, evaluation, and optimization, highlighting the automated and iterative nature of NAS in designing efficient NNs.
Figure 23.
Schematic representation of Neural Architecture Search (NAS). The process involves exploring a search space of candidate NN architectures (represented as simple diagrams of nodes and edges), evaluating their performance, and optimizing the architecture iteratively. Arrows indicate the flow of information between the search space, evaluation, and optimization, highlighting the automated and iterative nature of NAS in designing efficient NNs.


Table 1.
Table summarizing selected, alhabetically sorted, keywords and their corresponding (linked) sections, if not mentioned in the conclusions (Section 3).
Table 1.
Table summarizing selected, alhabetically sorted, keywords and their corresponding (linked) sections, if not mentioned in the conclusions (Section 3).
| keyword (section) | keyword (section) | keyword (section) |
|---|---|---|
| absorption (Section 2.4) | failure patterns (Section 2.5) | phase diagrams (Section 2.1) |
| accelerating polymer discovery (Section 2.2) | fermentation optimization (Section 2.1) | phase discovery (Section 2.5) |
| accelerating simulations (Section 2.6) | fiber composite materials (Section 2.5) | photovoltaic performance (Section 2.1) |
| active site dynamics (Section 2.4) | fiber melt spinning (Section 2.1) | plasticizing process (Section 2.5) |
| adaptive design strategies (Section 2.3) | fiber-reinforced polymer composites (Section 2.5) | polydispersity index (Section 2.2) |
| analytical and structural insights (Section 2.2) | fibril dimensions (Section 2.1) | polymer-based dielectrics (Section 2.4) |
| backmapping CG macromolecules (section ) | filled rubber (Section 2.5) | polymer blend electrolytes (Section 2.5) |
| bioinspired composite materials (Section 2.4) | flexural strength (Section 2.1) | polymer coating predictions (Section 2.1) |
| biomaterial design (Section 2.1) | force-extension curves (Section 2.5) | polymer composite processes (Section 2.1) |
| biosorption predictions (Section 2.1) | force-field parameters (Section 2.1) | polymer matrix composites (Section 2.5) |
| biosynthesis (Section 2.1) | fracture toughness (Section 2.1) | polymer mechanics and composite design (Section 2.2) |
| block polymers (Section 2.5) | gas permeability (Section 2.1) | polymer processing (Section 2.5) |
| bond exchange reactions (Section 2.2) | glass transition temperature (Section 2.1) | preparation of CNT-GN nanocomposites (Section 2.2) |
| bond strength (Section 2.1) | green synthesis techniques (Section 2.4) | process control (Section 2.3) |
| breakdown mechanisms (Section 2.1) | HDP-mimicking polymers (Section 2.5) | process integration across scales (Section 2.3) |
| bridging scales (Section 2.4) | heat distribution analysis (Section 2.1) | process predictions (Section 2.5) |
| carbon nanotube-polymer interfaces (Section 2.5) | high-temperature polymers (Section 2.4) | quality control (Section 2.1) |
| cavity pressure profiles (Section 2.5) | hydrogen-bond interactions (Section 2.1) | recipe optimization (Section 2.1) |
| cloud point predictions (Section 2.1) | hyperspectral temperature maps (Section 2.1) | recycling and material optimization (Section 2.2) |
| coil-to-globule transition (Section 2.6) | impact dynamics (Section 2.5) | semiflexible fibrils (Section 2.1) |
| component identification (Section 2.1) | injection-molded products (Section 2.5) | shear thinning (Section 2.2) |
| compressive strength (Section 2.1) | injection molding (Section 2.3) | skin wound therapy (Section 2.4) |
| concrete reinforcement (Section 2.1) | integrated circuits (Section 2.4) | smart-responsive hydrogels (Section 2.4) |
| conductivity (Section 2.3) | interfacial shear strength (Section 2.5) | SMILES embeddings (Section 2.5) |
| conjugated oligomers (Section 2.5) | interfacial tension (Section 2.4) | soft material design (Section 2.4) |
| conversion rates (Section 2.2) | inverse design methods (Section 2.4) | solute-solvent interactions (Section 2.6) |
| crosslink density (Section 2.1) | inverse materials design (Section 2.2) | specific heat (Section 2.1) |
| damage mechanism detection (Section 2.1) | ionic conductivity (Section 2.3) | stacking sequence and orientation (Section 2.1) |
| damage (Section 2.1) | large-scale screening (Section 2.4) | stiffness (Section 2.4) |
| data-driven design (Section 2.2) | life cycle sustainability (Section 2.1) | strain-induced crystallization (Section 2.1) |
| data standardization (Section 2.1) | lightweight aerospace materials (Section 2.5) | stress-contributing filler morphologies (Section 2.5) |
| defect detection (Section 2.1) | material efficiency (Section 2.3) | stress-strain curves (Section 2.5) |
| defect kinetics (Section 2.6) | material homogeneity (Section 2.2) | structural changes (Section 2.1) |
| delamination detection (Section 2.5) | material separation (Section 2.1) | surface quality (Section 2.1) |
| diblock copolymers (Section 2.6) | mechanical performance (Section 2.5) | sustainable production (Section 2.4) |
| dielectric materials (Section 2.1) | mechanical properties (Section 2.5) | synthetically generated microstructural data (Section 2.5) |
| dielectric permittivity (Section 2.1) | mechanical property predictions (Section 2.2) | targeted drug delivery (Section 2.4) |
| dielectric property optimization (Section 2.2) | melt quality (Section 2.2) | tensile properties (Section 2.1) |
| diffusion analysis (Section 2.2) | melt temperature (Section 2.3) | textile polymer composite properties (Section 2.1) |
| dispersancy efficiency (Section 2.1) | membrane designs (Section 2.1) | thermal conductivity (Section 2.4) |
| drilling parameters (Section 2.1) | micelles (Section 2.2) | thermal decomposition (Section 2.1) |
| drug-resistant bacteria (Section 2.5) | miscibility (Section 3) | thermal stability (Section 2.4) |
| elastic modulus (Section 2.1) | moisture uniformity optimization (Section 2.1) | thermodynamic consistency (Section 2.6) |
| electronic structure (Section 2.6) | molecular and mesoscopic structural analysis (Section 2.2) | tissue engineering (Section 2.1) |
| electrospinning (Section 2.1) | molecular weight degradation (Section 2.1) | toughness (Section 2.4) |
| elongation at break (Section 2.1) | molecular weight (Section 2.2) | tough thermosetting polymers (Section 2.5) |
| energy-harvesting systems (Section 2.1) | non-destructive testing (Section 2.5) | tribological properties (Section 2.1) |
| energy storage performance (Section 2.1) | nonlinear material behaviors (Section 2.5) | uncertainty modeling (Section 2.2) |
| excited-state energies (Section 2.5) | nonlinear stress distributions (Section 2.5) | uncovering complex dynamics (Section 2.4) |
| extrusion barriers (Section 2.3) | optoelectronic properties (Section 2.5) | wearable electronics (Section 2.4) |
| extrusion-based manufacturing (Section 2.1) | permeability coefficient (Section 2.1) | wear rate prediction (Section 2.1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



