4.1. Experimental Setup
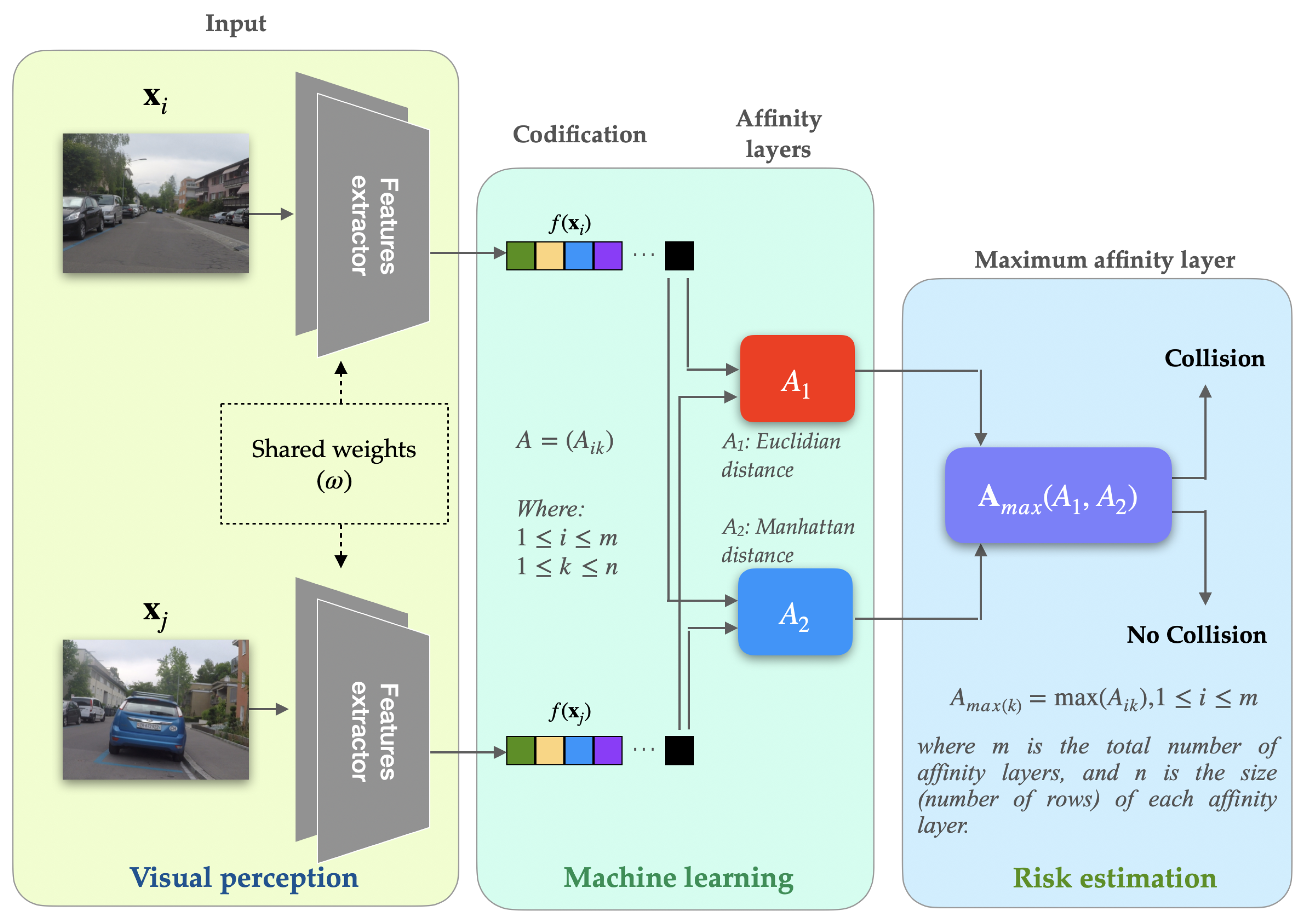
In our experimental phase, two CNN networks were used: EfficientNet-B0 and ResNet-18. These two neural networks were chosen mainly for their characteristics as feature extractors, generalized use in other One-Shot learning models and to be able to compare our results against those in the state of the art. For our model, the ResNet-18 implementation was similar to the one shown in [
28], except that the input image size was set to 100 x 100. On the other hand, the EfficientNet-B0 network implementation is similar to the one presented by [
29], except also that the input image size was also set to 100 x 100. The outputs are then passed through the proposed combined affinity layer with a sigmoid activation to determine similarity or dissimilarity.
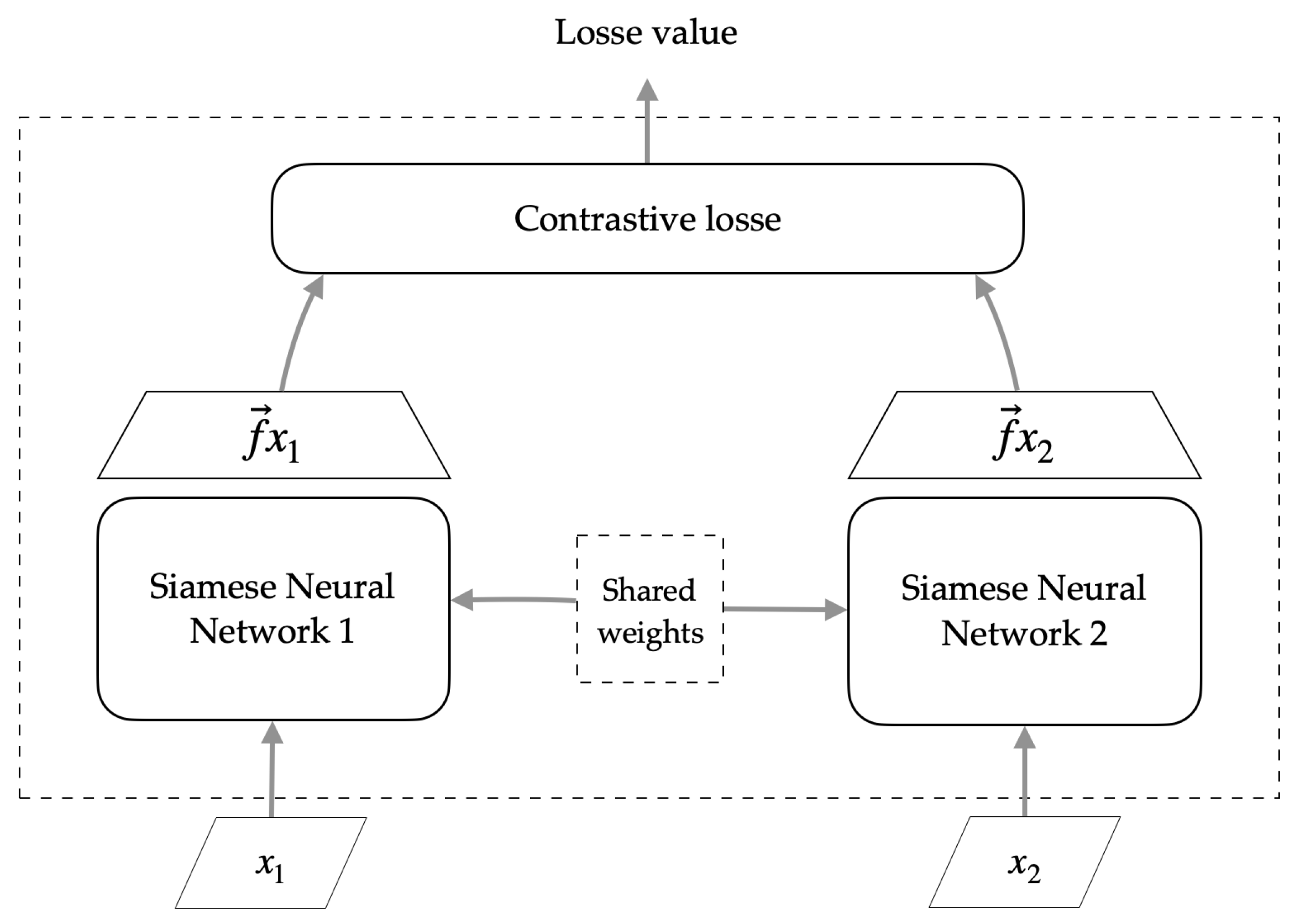
In the experimental design, the number of epochs was established as 200, as well as the size of the processing block was defined as 18. For the training part of the Siamese network, the contrastive loss function (Equation
4) was used as an objective function. Likewise, an Adam Optimiser was also used with an initial learning rate set to 0.0005.
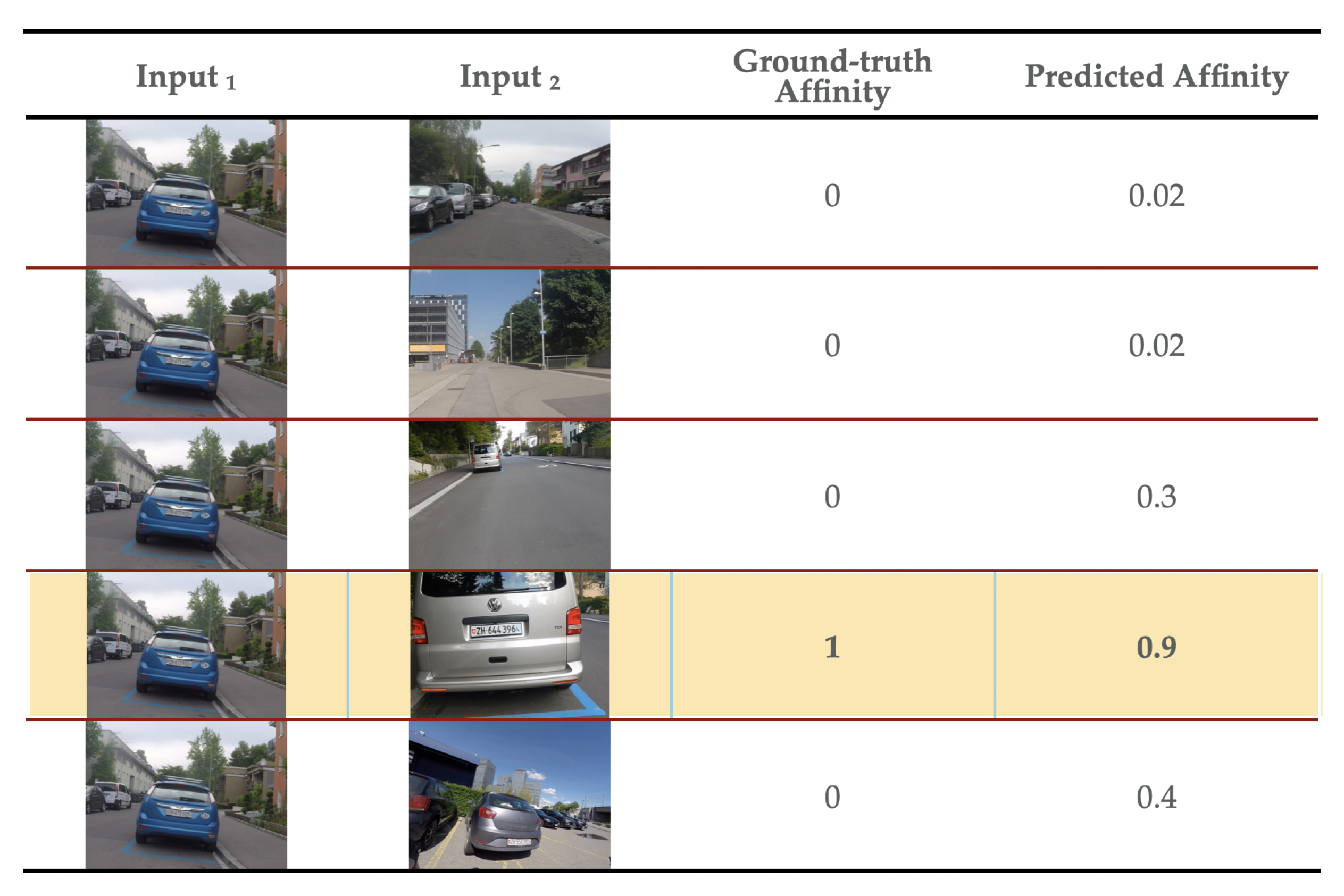
A comparison was made with the current reference models in the literature, which are based on the cosine, Manhattan and Euclidean similarity layers, with the combined affinity layers proposed for the four datasets MiniImageNet, CIFAR-100, CUB-200–2011 and DroNET detailed in previous section. The evaluation was specifically performed on the accuracy of five random example images in 1-Shot mode and five random example images in 5-Shot mode. The above described is exemplified below in
Figure 8
The following section presents a comparison of our experimental results in a descriptive and detailed manner, using representative tables and figures.
4.2. Comparison of the Model Against Reference Data
Once the experimental phase has been carried out, the results obtained with each of the data sets used to evaluate the behavior, performance and efficiency of the model are presented below. Likewise, a comparison is made of the model developed in this research against the various models present in the state of the art to also observe its performance and efficiency.
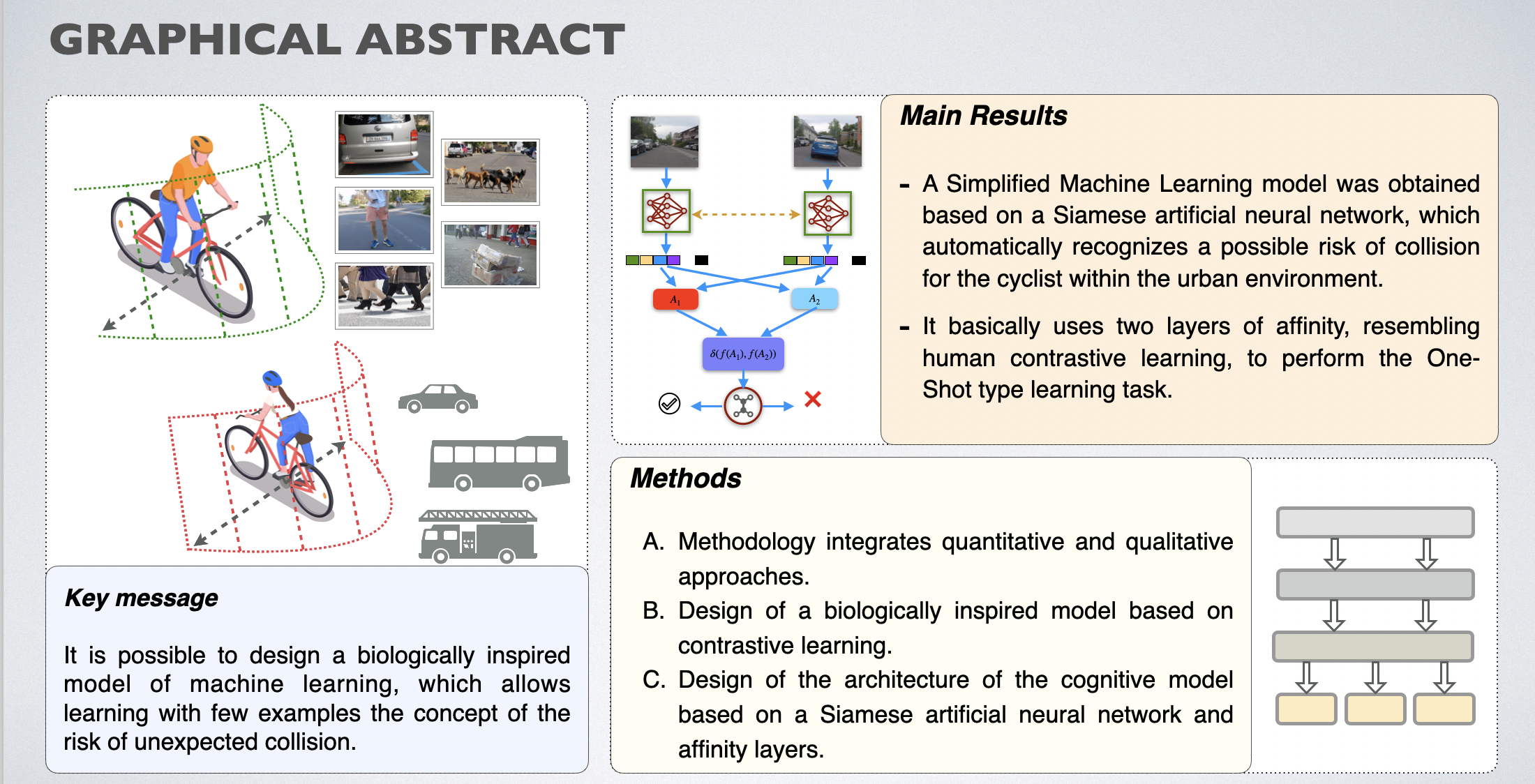
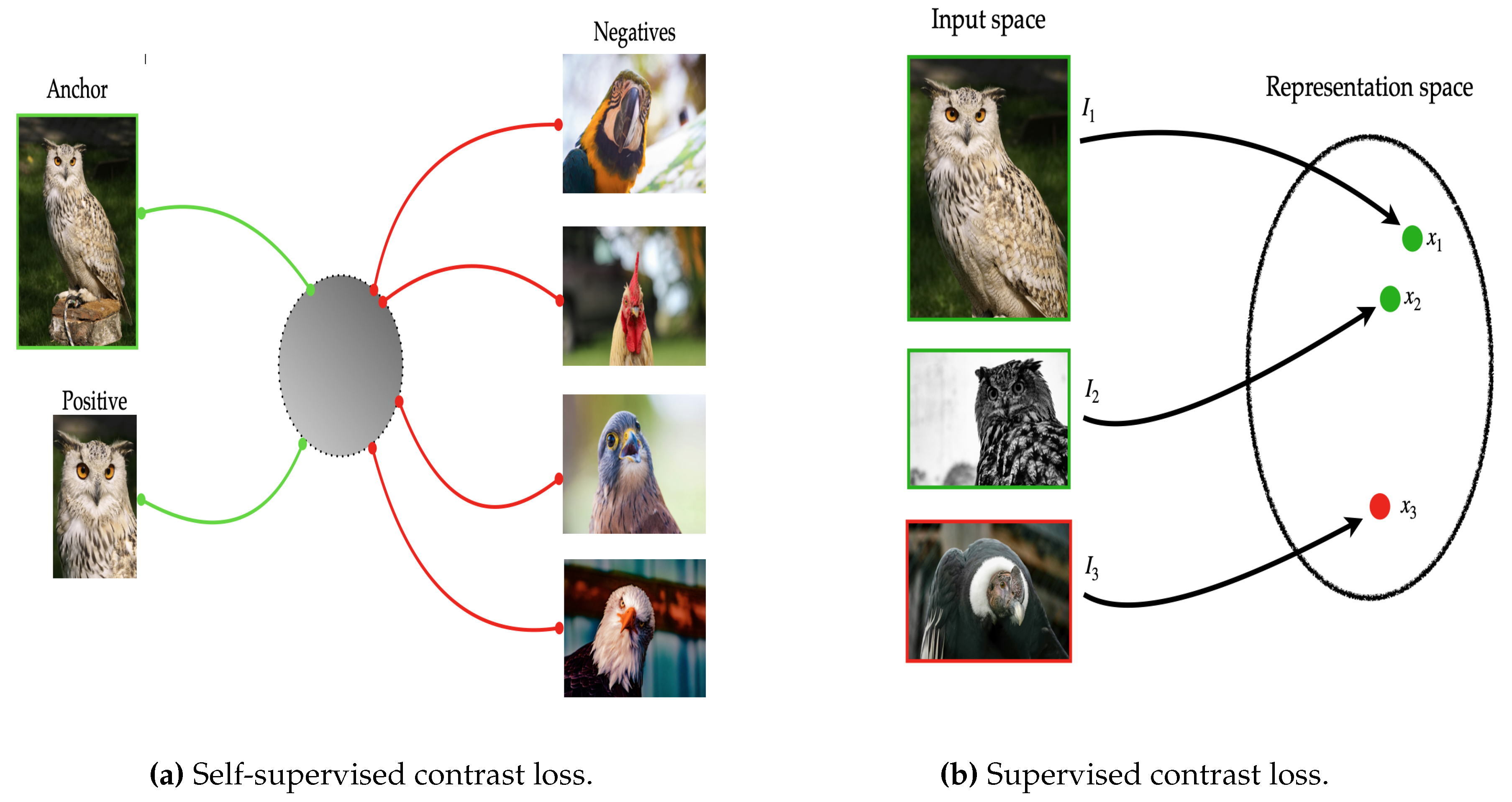
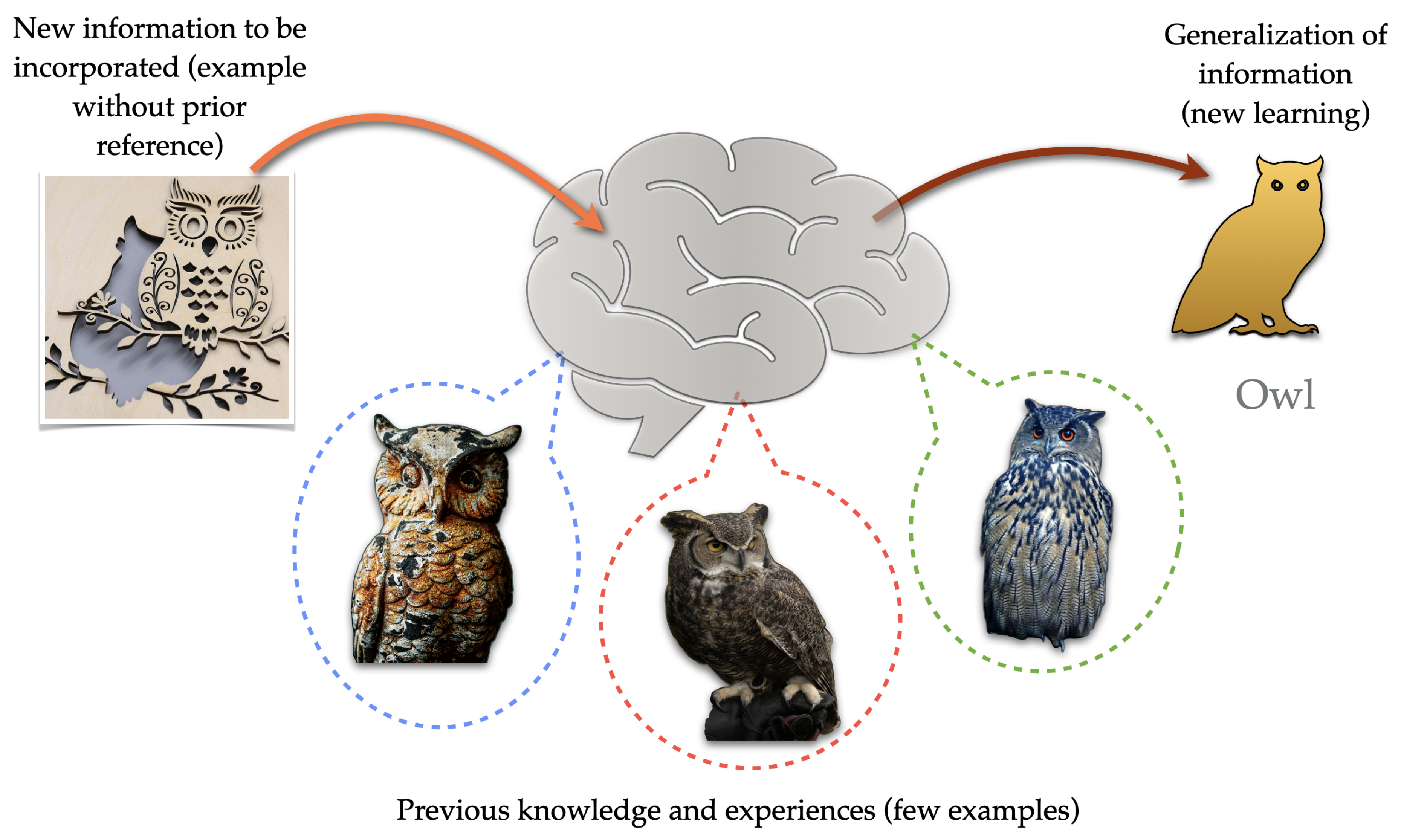
The main objective of the present research focused on developing a biologically inspired computational model, which would allow simplified machine learning using few examples to detect a possible risk of unexpected collision and thereby assist the cyclist in driving within an urban environment. Therefore, the model was specifically evaluated in the accuracy in the identification of perceived information (images) using the single example mode (1-Shot) and for the five-example mode (5-Shot), likewise a comparison with the data sets, using the two feature extractors indicated.
Table 2 and
Table 3 shows the average accuracy with 95% confidence when performing image classification using the four data sets, the affinity methods separately, and the proposed SML model (
layer). Training was performed using the MiniImageNet dataset and the ResNet-18 and EfficientNet-b0 CNNs as feature extractors.
The results show that for all datasets and feature extractor networks our SML model outperformed one-shot mode learning methods (1-shot classification accuracy) using separate similarity layers (Euclidean), (Manhattan). Therefore, our SML model using both the ResNet-18 and EfficientNet-B0 feature extractors had the best performance in all cases.
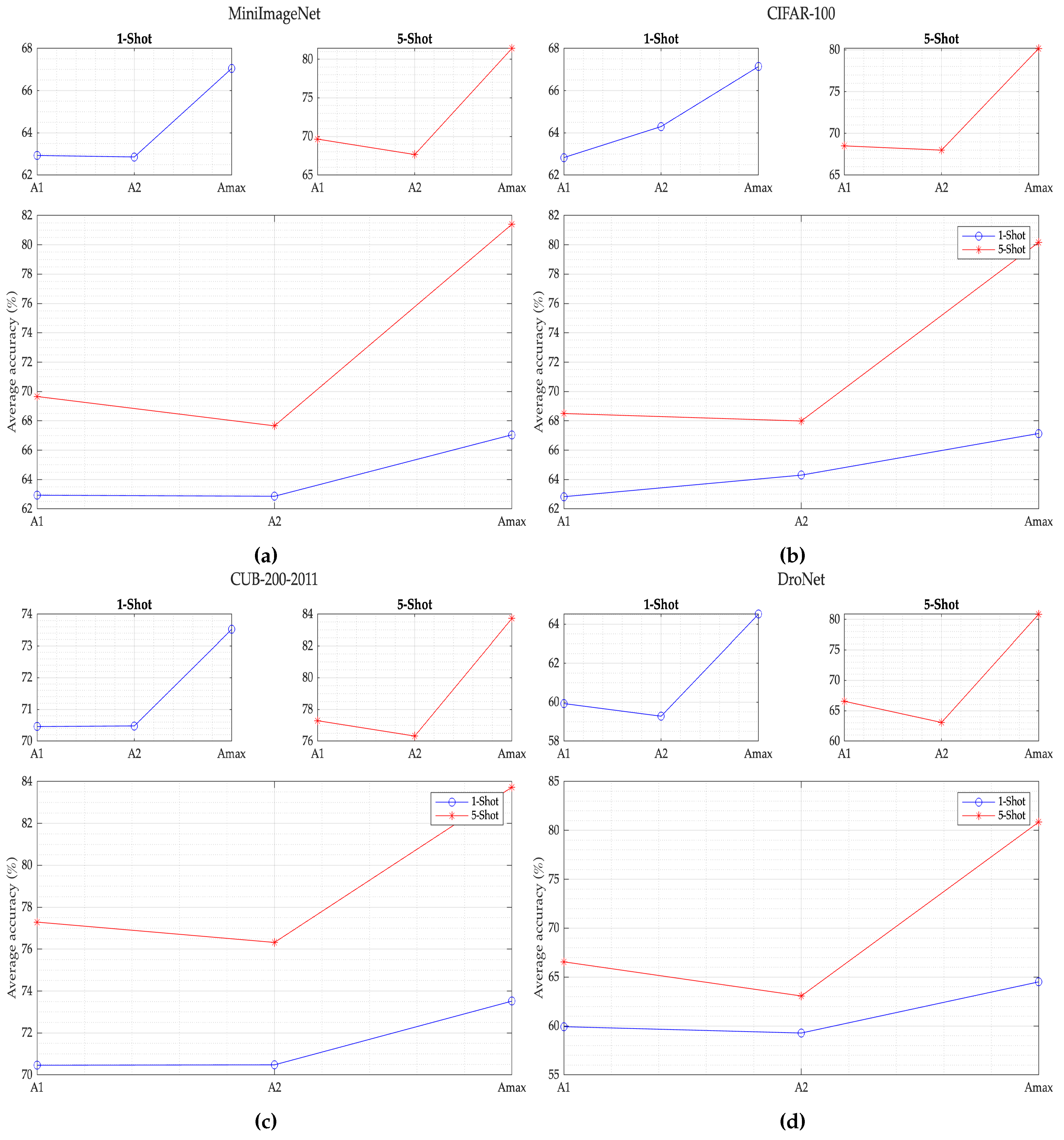
As can be seen in
Figure 9, the proposed SML model for the MiniImageNet dataset, with ResNet-18 feature extractor, in 5-Shot mode, performs better by
compared to the best result which is similarity layer A1. On the other hand, in the 1-Shot mode, the model performs only
better compared to the best result for this mode which is the similarity layer A1.
Next for the CIFAR-100 dataset dataset as shown in
Figure 9, the SML model with the same feature extractor ResNet-18, in 5-Shot mode, performs better by
compared to the best result which is the similarity layer A1. Likewise, in the 1-Shot mode, the model performs better only by
compared to the best result for this mode which is the similarity layer A2.
Continuing with the analysis, as shown in
Figure 9, the proposed SML model using CUB-200–2011 dataset, with ResNet-18 feature extractor in 5-Shot mode, performs better by
compared to the best result which is similarity layer A1. Now in the 1-Shot mode, the model performs only
better compared to the best result for this mode which is the similarity layer A2.
Finally, as seen in
Figure 9, for the DroNet dataset the SML model with a similar feature extractor (ResNet-18), in 5-Shot mode, performs better by
compared to the best result which is the similarity layer A1, being the best performance within the four datasets used for the 5-Shot mode. Similarly, in the 1-Shot mode, the model performs better by
compared to the best result for this mode which is also the similarity layer A1, this being also the best performance within the four datasets used for 1-Shot mode.
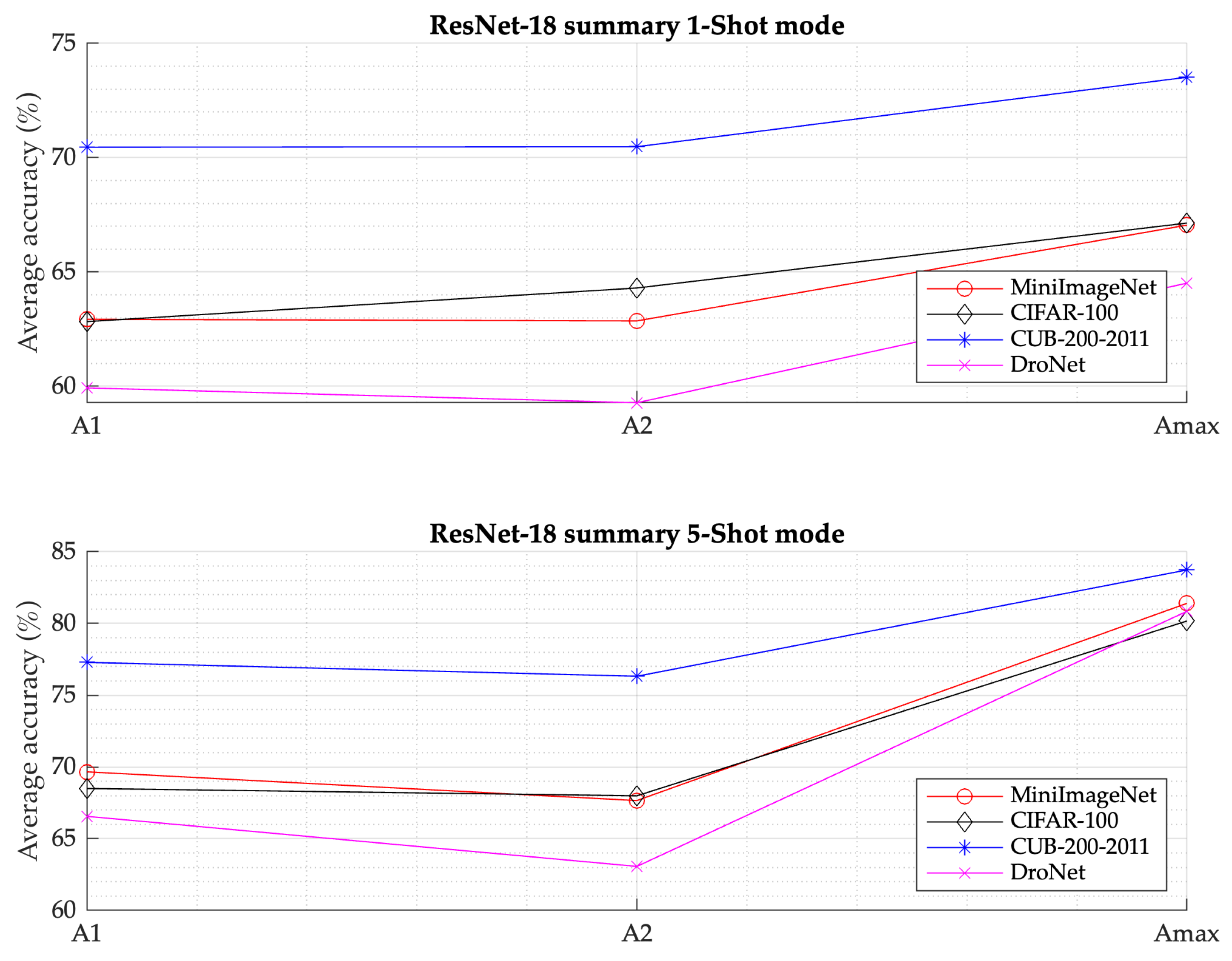
Figure 10 summarizes the previous results comparatively, as well as the behavior of the four datasets using the ResNet-18 convolutional network as a feature extractor, as well as the affinity layers (
,
and
, used in the comparative.
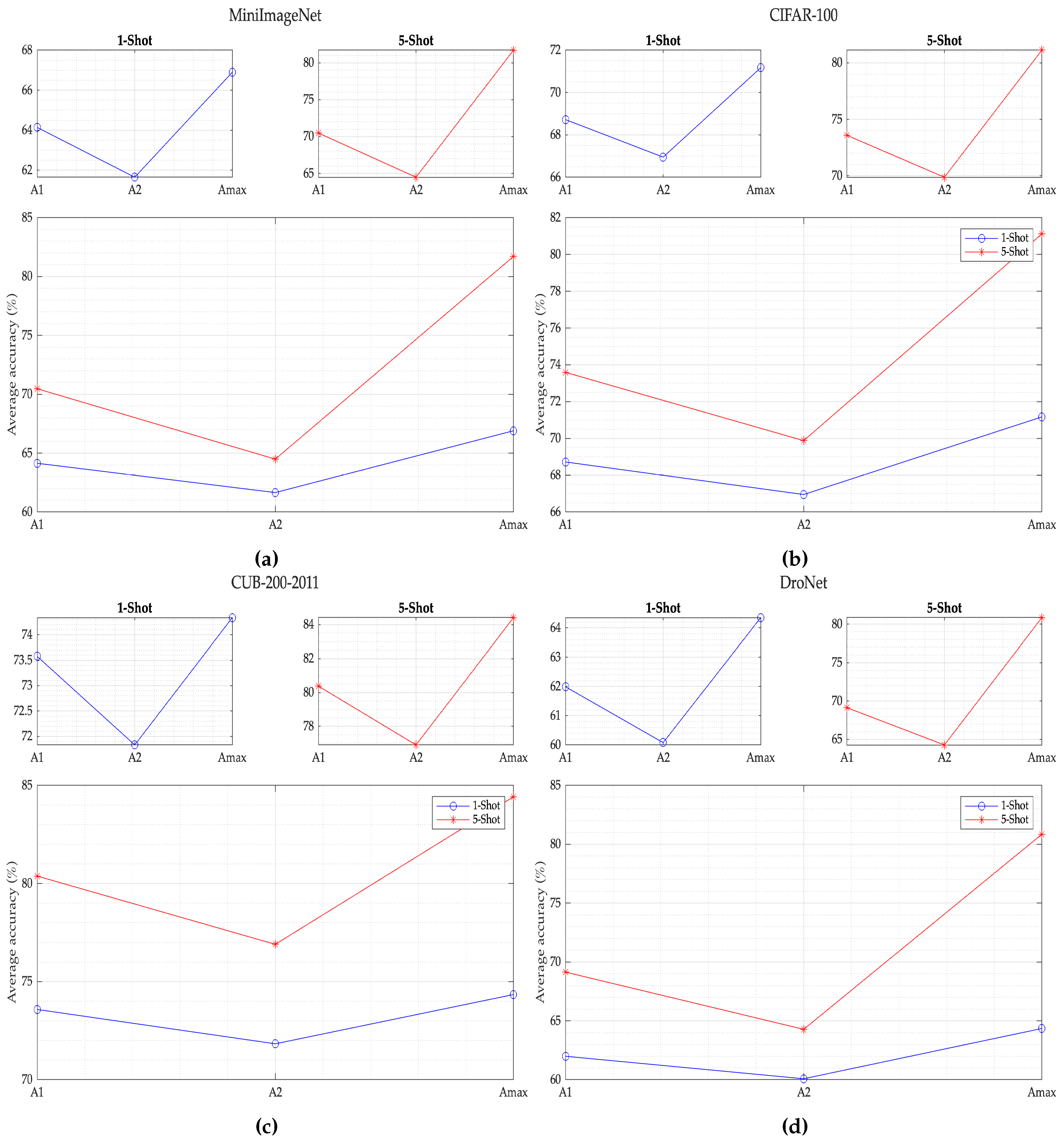
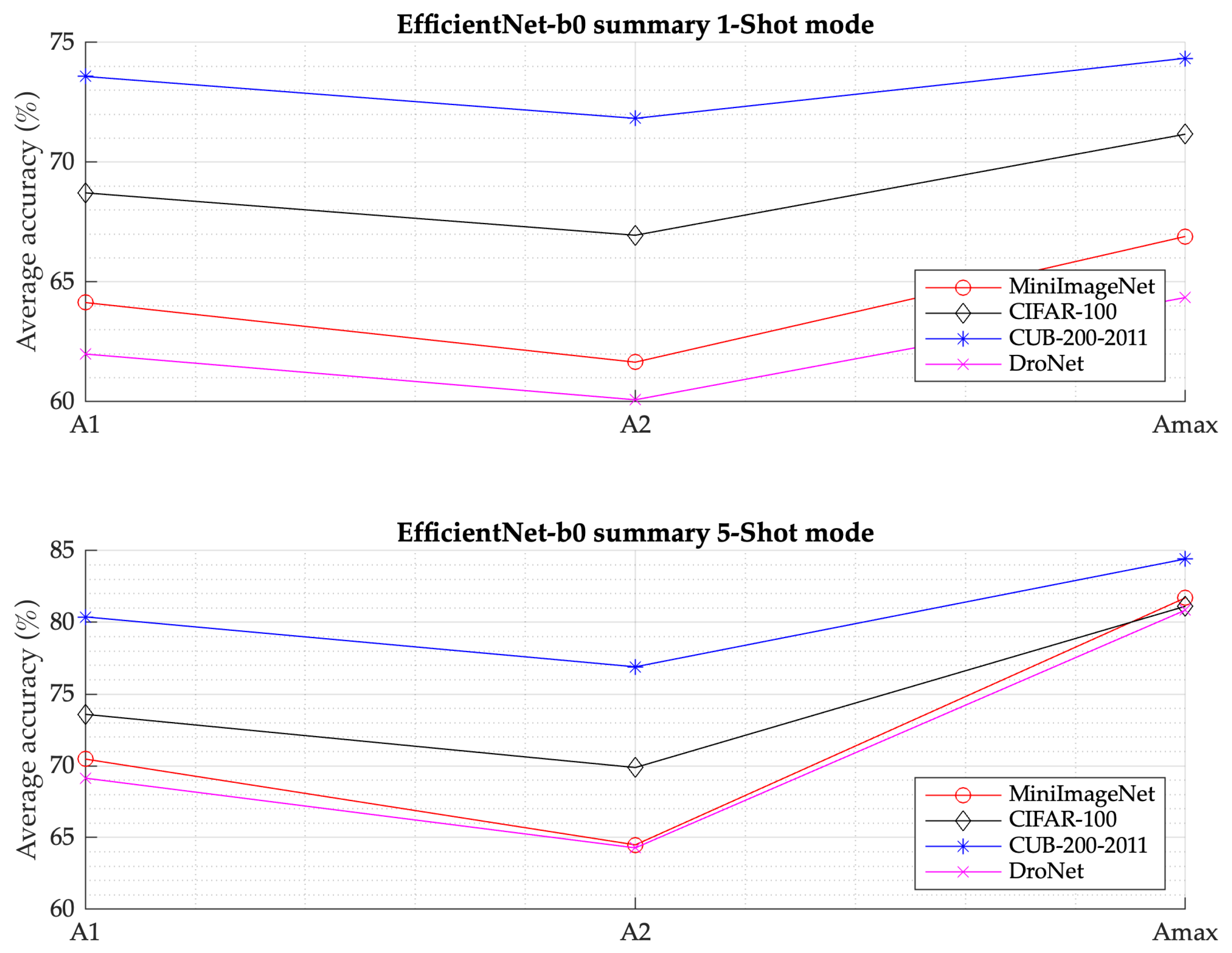
Continuing with the analysis of the results, it can be seen in
Figure 11 that the proposed SML model for the MiniImageNet dataset, the SML model with the EfficientNet-b0 as a feature extractor, in 5-Shot mode performs best way with
compared to the best result which is the similarity layer A1 . Likewise, in the 1-Shot mode, the model performs better by
compared to the best result for this mode, which is the similarity layer A1. It should be noted that this is the best performance among the four data sets used in 1-Shot mode.
Now, for the CIFAR-100 dataset as shown in
Figure 11 the SML model with the same EfficientNet-b0 feature extractor, in the 5-Shot mode it performs better by
compared to the best result which is the A1 similarity layer. On the other hand, in the 1-Shot mode, the model performs only
better compared to the best result for this mode which is the similarity layer A1.
Continuing with the analysis, as shown in
Figure 11, the proposed SML model using CUB-200–2011 dataset, with EfficientNet-b0 feature extractor in 5-Shot mode, performs better by
compared to the best result which is similarity layer A1. Instead in the 1-Shot mode, the model performs only
better compared to the best result for this mode which is the similarity layer A1.
Finally, as seen in
Figure 11, for the DroNet dataset, the SML model with EfficientNet-b0 as a feature extractor, in 5-Shot mode, performs best way by
compared to the best result which is the similarity layer A1, being the best performance within the three data sets used for the 5-Shot mode. Besides in the 1-Shot mode, the model performs better by
compared to the best result for this mode which is also the similarity layer A1.
Figure 12 summarizes the previous results comparatively, as well as the behavior of the four datasets using the EfficientNet-B0 convolutional network as a feature extractor, as well as the affinity layers (
,
and
, used in the comparative.
As a summary on the performance of the SML model, evaluating both feature extractors and the datasets in each of the similarity layers, we can state that the model has the best average accuracy with the ResNet-18 feature extractor for the DroNet dataset both in the 1-Shot mode and for the 5-Shot mode, achieving the best percentages of and respectively.
4.3. Performance and Generalization in the State-of-the-Art
When classifying new data with state-of-the-art reference models, the accuracy tends to decrease due to the change in data distribution as they could demonstrate in Li et al. [
30], where all the data have the same statistical distribution even if they come from different classified groups. Our Siamese network, being the basis of the SML model, used the ResNet-18 and EfficientNet-B0 networks as feature extractors, was trained with the MiniImagenet data set and was also validated with the CIFAR-100, CUB-200–2011 and DroNet data sets. For the state-of-the-art models used in the comparison, very similar networks and datasets and CNNs were used, thus allowing the results to be evaluated using their classification accuracies in the two modes, 1-Shot and 5-Shot, with a
trusted. Below on the
Table 4,
Table 5,
Table 6 and
Table 7 we present the results about what we have described.
The results presented in the
Table 4,
Table 5,
Table 6 and
Table 7 allow us to observe the comparison of accuracy in the average classification, which includes the models selected in the state of the art and the proposed SML model. Models using very similar feature extractors and datasets were explored and considered, allowing us to evaluate our SML model results with classification accuracy in both modes (1-Shot and 5-Shot) at
trustworthy. Training for the SML model was performed with the MiniImageNet dataset and the ResNet-18 and EfficientNet-B0 CNNs as feature extractors.
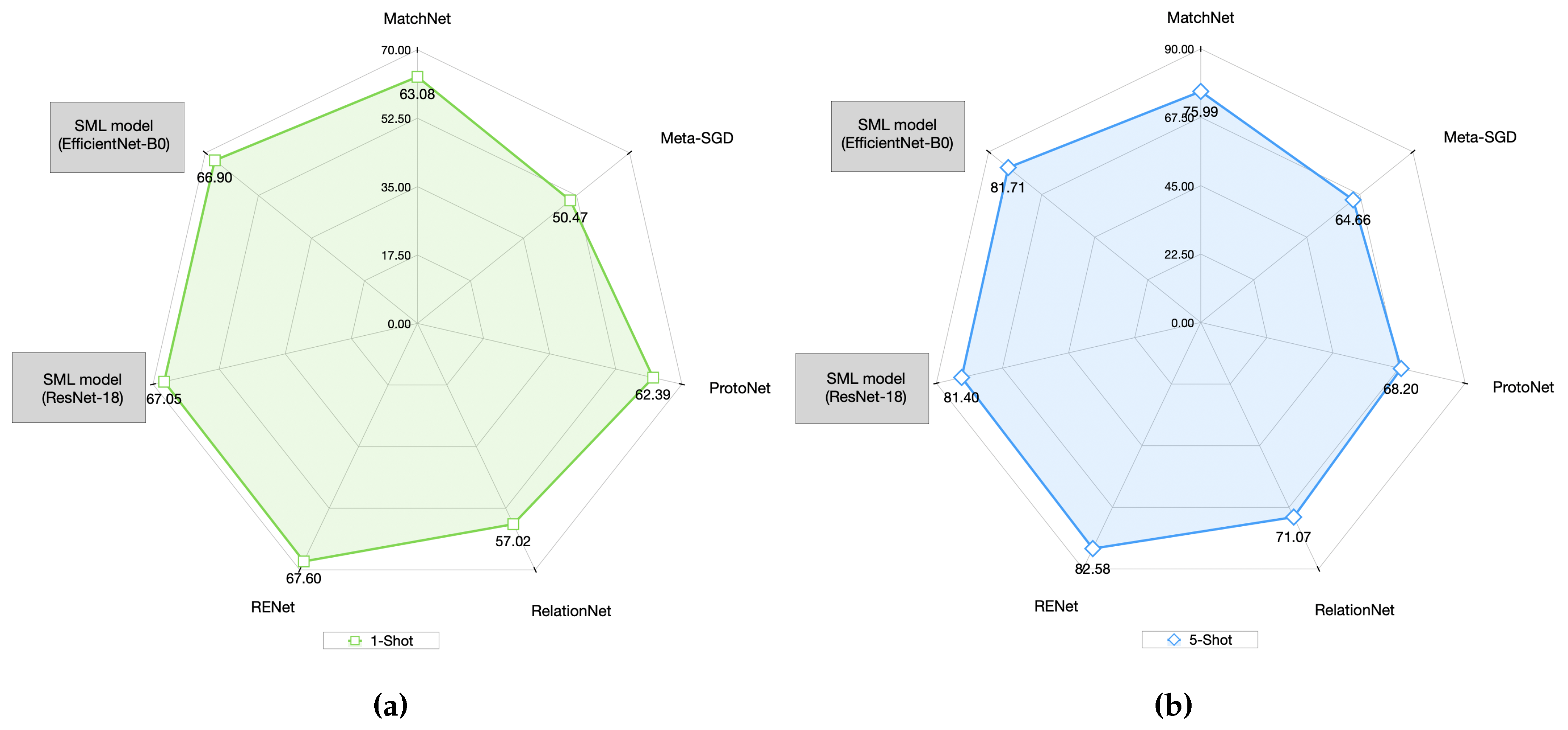
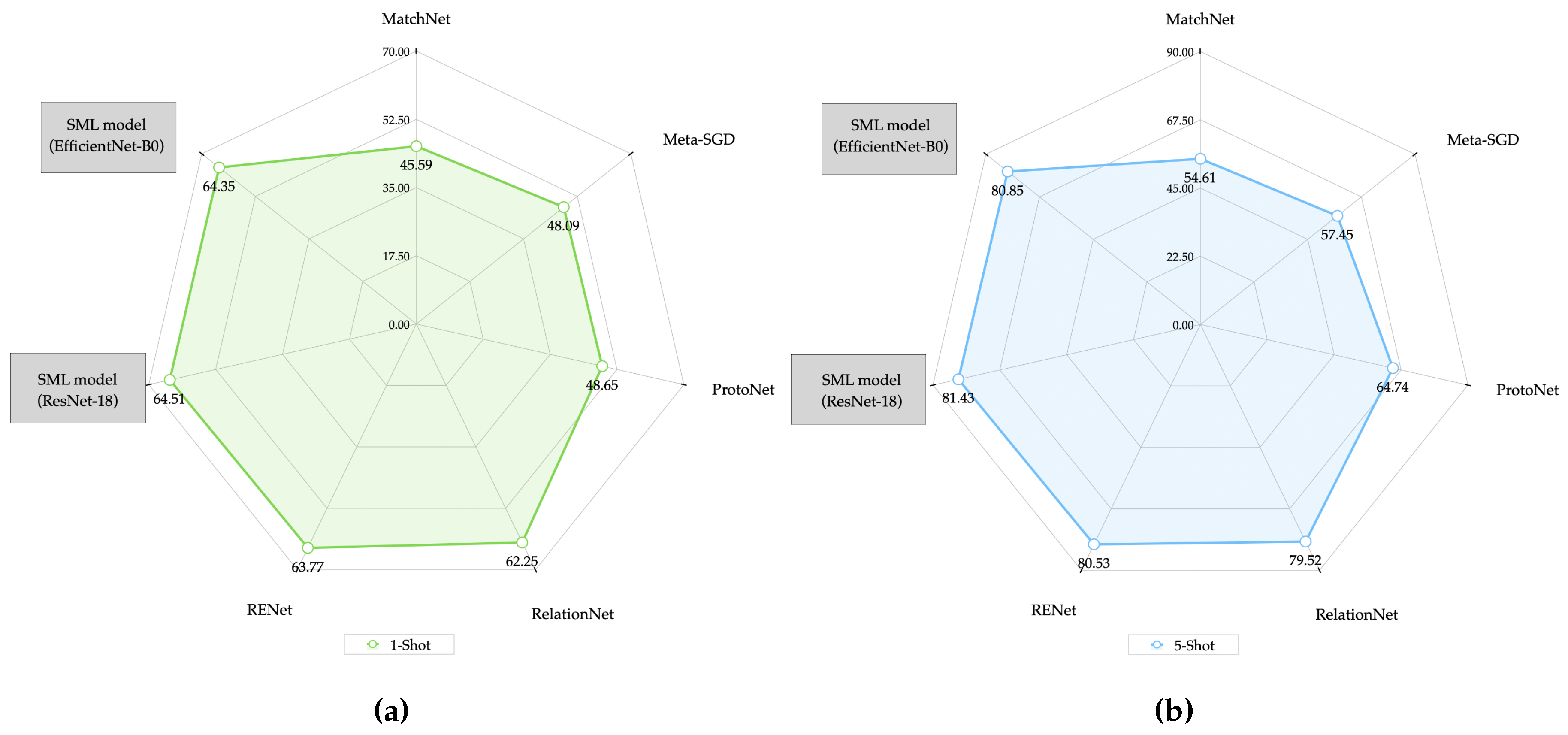
Graphically in
Figure 13 it can be seen that the proposed SML model for the MiniImageNet dataset in 1-Shot mode and as an EfficientNet-B0 feature extractor, performs better than all models except RENet, which was better by
. Similarly in performance for the 5-Shot mode (
Figure 13), the model RENet was also
better than the SML model. Therefore, RENet was the model that presented the best result for both modes (1-Shot and 5-Shot) of the comparative models using the MiniImageNet dataset.
Similarly, in
Figure 14b,b it can be observed that for the CUB-200-2011 dataset, the SML model in both modes (1-Shot and 5-Shot) did not have an average precision as close to the RENet model, since the latter was better by
and
for the 1-Shot and 5-Shot modes respectively.
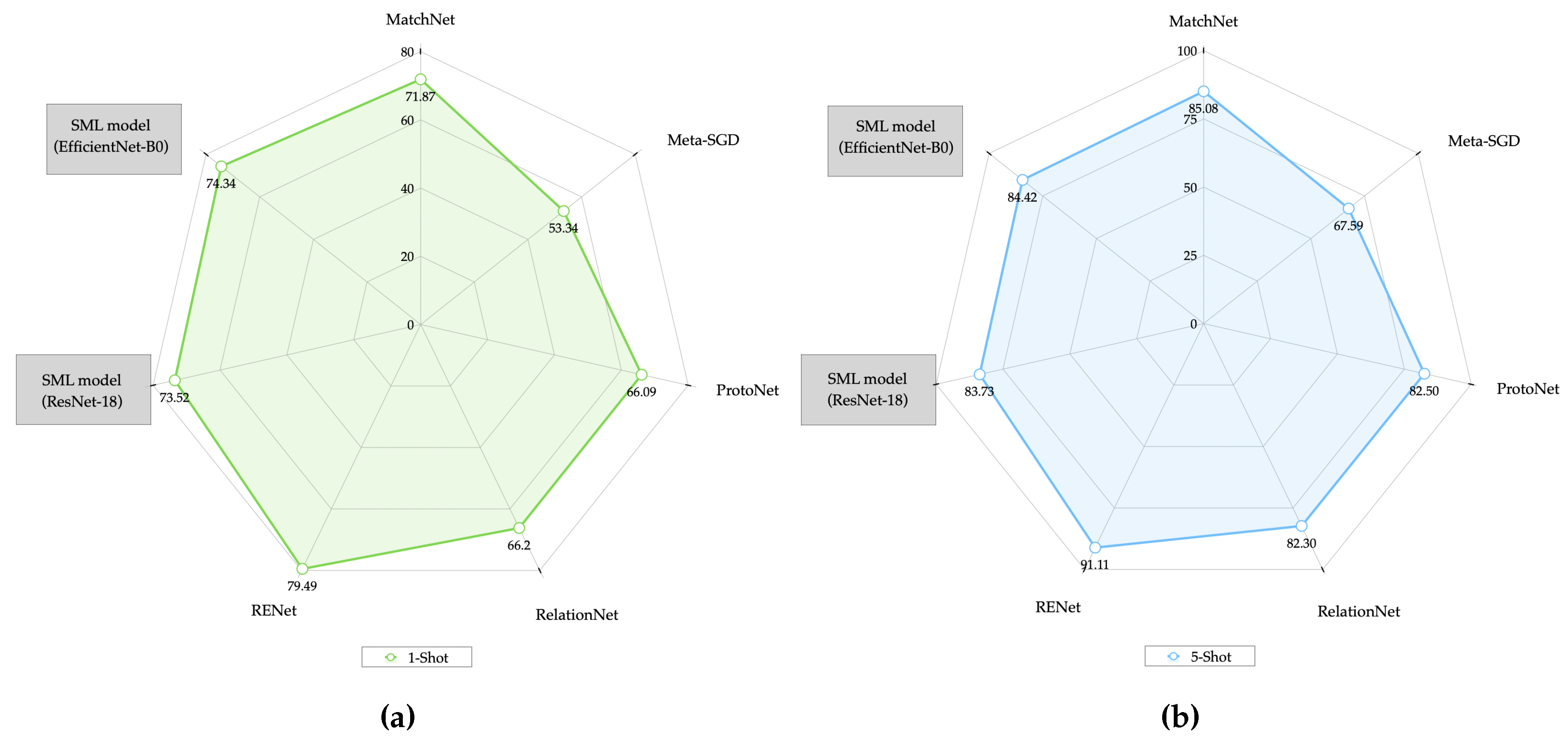
Continuing with the results obtained,
Figure 15a,b show us how the SML model using the CIFAR-100 dataset and when compared with the state-of-the-art models, surpassed the Dual Trinet model on average in accuracy by
in 1-Shot mode and by
in 5-Shot mode to the model, whose results had been the best as observed in
Table 6.
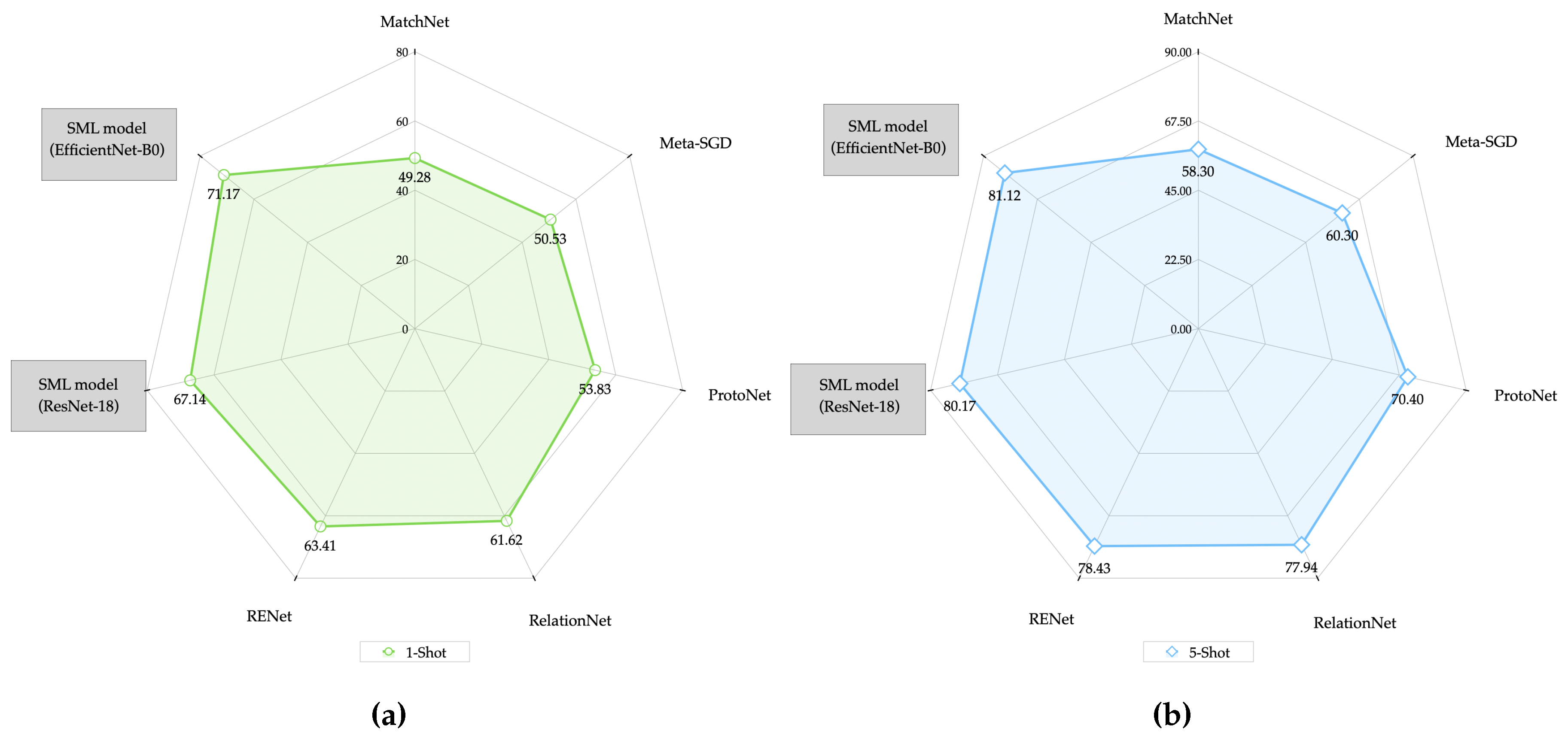
Finally, for the DroNet dataset, as can be seen in
Figure 16, the SML model using the 1-Shot mode outperforms the Dual Trinet model by only
, the latter being the model that presented the best average accuracy of the analyzed models for that particular mode. Similarly, the Dual Trinet model for the 5-Shot mode was outperformed by our SML model in average accuracy but only by
as seen in
Figure 16.
The above results allow us to conclude that our SML model compared to the state-of-the-art models, using two of the data sets (CIFAR-100 and DroNet), has a better performance and generalization in the 1-Shot and 5-Shot mode using both the ResNet-18 and EfficientNet-B0 feature extractors. However, for the MiniImageNet and CUB-200-2011 data sets, results close to the RENet model were obtained, which was the one that obtained the best results in terms of average accuracy.