1. Introduction
Over the past decade, the role of Security Operations Centers (SOCs) has grown significantly due to the increasing frequency and sophistication of cyberattacks and the substantial costs associated with data breaches and service disruptions. However, SOCs still face challenges such as a shortage of skilled personnel, limited automation, and inconsistencies in process integration. Additionally, SOCs must balance rapid technological advancements with continuous staff training and retention requirements [
1]. The heavy reliance on Security Information and Event Management (SIEM) systems has also introduced issues like high false-positive rates and manual analysis burdens, creating operational challenges for traditional SOCs [
2].
The complementary adoption of NIST’s strategic breadth and MITRE’s tactical detail allows organizations to build a multi-layered defense that integrates high-level risk management with actionable intelligence [
3,
4]. The NIST Cybersecurity framework emphasizes a lifecycle approach to managing cybersecurity risks, spanning essential functions like Identify, Protect, Detect, Respond, and Recover [
5]. Whereas, the MITRE ATT&CK framework provides a granular understanding of adversary behaviors, offering a knowledge base for mapping attack methodologies and developing tailored defenses [
6].
Furthermore, AI has introduced transformative changes in cybersecurity, enabling more proactive, automated incident responses. AI-driven systems enhance the speed and accuracy of detecting and mitigating incidents by leveraging machine learning and natural language processing for automated threat analysis [
7]. Additionally, AI’s potential to orchestrate response processes that improve business continuity and streamline recovery in cyber incidents [
8]. These advancements highlight AI’s critical role in addressing traditional incident response’s scalability and accuracy challenges. However, many enterprises continue to adopt open-source SOC platforms as alternatives driven by budget constraints and access to a broader range of features.
Despite its cost advantages and flexibility, the open-source SOC ecosystem faces limitations in AI-driven innovation. Wazuh [
9], an open-source SIEM platform, has gained recognition for its flexibility, scalability, and powerful threat detection capabilities, making it a viable, cost-effective solution for organizations of various sizes [
10]. Wazuh’s compatibility with SOC environments allows seamless integration and enhanced threat monitoring [
11]. However, existing implementations of Wazuh in SOCs lack direct integration with advanced AI capabilities, which could significantly improve its detection accuracy and responsiveness.
In addressing these limitations, this paper contributes to the field by (1) enhancing threat data extraction methodologies using RAG, (2) embedding AI within Wazuh for improved incident response by giving mitigation guidance, (3) employing LLMs for precise, context-driven recommendations, and (4) comparing two different models [
12,
13] to evaluate performance outcomes. These contributions enhance the capabilities of Security Operations Centers (SOCs), advancing the adaptability, depth, and effectiveness of modern incident response practices.
2. Literature Review
2.1. Wazuh as a Versatile SIEM Solution
Among various SIEM options, Wazuh has gained significant traction due to its adaptability, scalability, and powerful threat detection capabilities, making it a viable alternative to proprietary solutions. As an open-source platform, Wazuh provides organizations with cost-effective, customizable options for managing cybersecurity risks across a wide range of environments, from small businesses to large enterprises [
14].
Comparative analyses have demonstrated Wazuh’s effectiveness relative to proprietary systems in areas such as threat detection and mitigation. For instance, a comparative analysis between IBM QRadar and Wazuh highlighted Wazuh’s cost-effectiveness and operational flexibility, showing that it can meet standard security requirements without the expenses associated with proprietary solutions [
15,
16]. Such evaluations reinforce Wazuh’s positioning as a competitive SIEM tool capable of delivering robust cybersecurity functions within a scalable, open-source framework.
Recent advancements in artificial intelligence (AI) and machine learning (ML) present significant opportunities to further enhance Wazuh’s capabilities, particularly in incident response and threat intelligence. Research indicates that the application of Large Language Models (LLMs) and AI-driven methodologies can streamline security operations by automating complex analytical processes and delivering real-time, contextually relevant insights. For instance, studies suggest that integrating LLMs within Security Operations Center (SOC) workflows has the potential to improve response accuracy, facilitate rapid decision-making, and mitigate analyst fatigue during incident response [
17]. Additionally, other research explores the potential for LLMs to provide dynamic, context-aware recommendations in incident response scenarios, thereby augmenting Wazuh’s operational efficacy through intelligent, real-time guidance [
18].
2.2. Role of Large Language Model Copilots in Enhancing Efficiency and Personalization
Large Language Models (LLMs), with their powerful natural language processing (NLP) capabilities, have emerged as transformative technologies, capable of automating complex workflows and providing contextualized assistance. The integration of LLMs as copilots has revolutionized productivity across domains such as academic research, software development, and cybersecurity, demonstrating their potential to support and augment human decision-making.
Recent studies have explored the applications of LLM copilots in different contexts. Lin et al. [
19] introduced an LLM-based system designed to provide personalized academic assistance. By employing thought-retrieval mechanisms and user profiling, Study of Copilot offers tailored support to researchers, enabling significant time savings in academic workflows. Similarly, Wei et al. [
20] presented a framework that leverages LLM agents for autonomous machine learning research. The study facilitates idea generation, experiment design, and execution, showcasing the ability of LLMs to automate complex tasks in scientific exploration. Moreover, Wen et al. [
21] developed OverleafCopilot, an extension of the popular academic writing tool Overleaf, which enhances writing efficiency by integrating LLMs for drafting, editing, and formatting tasks.
These applications underscore the versatility and adaptability of LLM copilots across various domains. A critical feature of these systems is their ability to retrieve and synthesize information dynamically, ensuring that outputs are contextually relevant and tailored to user needs. This capability is further enhanced by integrating LLMs with retrieval-augmented generation (RAG) systems, which enable the seamless combination of structured knowledge with generative AI capabilities.
2.3. Emerging Role of Large Language Models in SOC Operations
The escalating complexity and frequency of cyber threats have placed considerable demands on Security Operations Centers (SOCs) to identify, analyze, and respond to incidents rapidly and accurately. Traditional approaches often rely heavily on manual analysis, which is time-consuming and can lead to alert fatigue among security analysts. Recent advances in artificial intelligence, particularly with Large Language Models (LLMs), have introduced new possibilities for automating and enhancing SOC operations. LLMs, known for their proficiency in processing and generating human language, offer promising applications in cybersecurity where rapid understanding of diverse data sources—such as security logs, threat reports, and alerts—is essential for effective incident response by Yao et al [
22]. Integrations of LLMs within SOCs can streamline threat intelligence analysis, improve alert prioritization, and reduce the workload on security analysts, allowing them to focus on high-priority incidents.
However, traditional methods for adapting LLMs to specific domains, such as fine-tuning, come with limitations. Fine-tuning an LLM involves retraining the model on domain-specific data, which enables it to specialize in understanding cybersecurity language. While this approach enhances relevance, it is computationally intensive and requires frequent retraining to stay effective as new threats emerge [
23,
24]. Additionally, fine-tuned models may still struggle to incorporate the most recent threat intelligence, as their knowledge base is fixed post-training [
25].
To address these limitations, researchers have turned to Retrieval-Augmented Generation (RAG), an approach that enhances LLMs by dynamically retrieving relevant information from external knowledge sources during inference. RAG combines an LLM with a retrieval component that pulls information from an up-to-date database or knowledge base, allowing the model to produce responses based on the latest available information. This capability makes RAG particularly well-suited for SOC environments, where cybersecurity threats evolve rapidly, and the need for current intelligence is critical [
26,
27].
In contrast to fine-tuning, RAG enables a more flexible and scalable solution for SOCs. RAG allows organizations to maintain an LLM’s core language capabilities while continuously feeding it real-time threat intelligence, without the overhead of retraining the model itself [
27]. This integration of external data sources during inference supports SOC analysts by providing timely, context-rich responses, which enhances situational awareness and facilitates more accurate and responsive decision-making. By focusing on RAG, this paper seeks to address key challenges in incident response, such as alert fatigue and data relevance, by harnessing real-time data retrieval to produce actionable intelligence.
Building on the foundational studies by Yao et al [
22]. and Xu et al [
28]., the study explores how RAG can be leveraged within SOC workflows to overcome the limitations of fine-tuned LLMs and achieve a higher degree of adaptability and efficiency. The implementation of RAG in SOCs aims to establish a robust framework that not only improves detection accuracy but also enables swift, data-driven responses that are essential for mitigating today’s sophisticated cyber threats.
Tseng et al [
29]. explores the integration of LLMs into SOC workflows, demonstrating how these models can be leveraged to enhance response accuracy and efficiency. By automating critical aspects of analysis and providing context-aware recommendations, LLMs reduce the cognitive load on analysts and accelerate decision-making during security incidents [
30,
31].
2.4. RAG Components
2.4.1. Qdrant Vector Database
Among the many vector database solutions, Qdrant stands out as an open-source, scalable, and production-ready platform tailored for vector similarity search and hybrid retrieval tasks [
32]. Unlike conventional search engines, Qdrant facilitates dense vector searches, providing a robust infrastructure for applications in semantic search, content recommendation, and RAG systems. Its integration capabilities with popular machine learning frameworks make it a preferred choice for both academic and industrial applications.
Furthermore, Qdrant’s support for Retrieval-Augmented Generation (RAG) has proven instrumental in augmenting large language models (LLMs) with domain-specific knowledge through vectorized document retrieval [
33]. These integrations empower LLMs to generate context-aware and domain-specific responses.
2.4.2. Embedding Model: BAAI/bge-Large-en-v1.5
The open-source embedding model BAAI/bge-large-en-v1.5 from Hugging Face is utilized to transform text data into vector representations. This model is optimized specifically for English text, making it well-suited for RAG and information retrieval applications within the cybersecurity domain. The BAAI/bge-large-en-v1.5 model offers notable advantages [
26,
34]:
Efficiency and Scale: The model demonstrates high efficiency in processing large volumes of text data while maintaining high accuracy in similarity detection. It uses a technique known as Matryoshka Representation Learning [
35], which enables the model to generate embeddings in multiple dimensionalities (e.g., 1024, 768, 512, down to 64 dimensions) without significant loss of accuracy.
Performance Comparison: Compared to similar models such as OpenAI’s Ada [
36] and traditional BERT-based models [
37], BAAI/bge-large-en-v1.5 is optimized for faster responses and adaptability with large datasets. Its open-source nature also makes it more cost-effective than proprietary models, which is an important consideration for scalable cybersecurity applications.
2.4.3. Similarity Metric: Cosine Distance
Surrounded by various similarity measures, cosine similarity and its counterpart, cosine distance, have emerged as popular metrics due to their focus on the angular relationship between vectors, independent of magnitude. This attribute has made cosine-based measures highly effective in applications such as document retrieval, text classification, and embedding evaluations [
38].
The formula for cosine similarity is mathematically expressed as:
where:
and are the vectors being compared,
is their dot product,
and are the magnitudes of the vectors.
Cosine similarity is normalized, meaning it is independent of vector magnitude, making it well-suited for applications where the scale of the data varies significantly. The similarity score
s ranges from
to 1, where 1 indicates perfect similarity, 0 denotes orthogonality (no similarity), and
represents completely opposite vectors [
39].
2.5. Atomic Red Team: A Modular Framework for Adversary Simulation and Detection Validation
In the evolving landscape of cybersecurity, adversary emulation has become a cornerstone for assessing the robustness of detection and response capabilities. The Atomic Red Team project, spearheaded by Red Canary, has emerged as a pivotal open-source framework designed to empower security teams with a library of lightweight, modular tests that emulate real-world adversary tactics and techniques [
40].
Atomic Red Team fills a critical gap in cybersecurity operations by providing security teams with a practical, accessible, and standardized approach to adversary emulation. Unlike traditional penetration testing, which often lacks alignment with tactical frameworks, Atomic Red Team tests are structured to replicate specific techniques such as privilege escalation, credential dumping, and lateral movement. This approach ensures that detection and response mechanisms are thoroughly tested in a controlled yet realistic manner [
41].
Security professionals can implement and execute these tests with minimal configuration, enabling continuous validation of security controls without significant operational disruption. Moreover, the framework’s open-source nature fosters collaboration and innovation, allowing contributors to enhance its library and adapt tests to evolving threat landscapes [
42].
3. Methodology
3.1. Event Security Data Extraction and Refinement
Upon detecting a vulnerability attack, Wazuh captures critical details using the rules-based matching method [
43] and produces the security event log in JSON format [
44], is a common data exchange format and organizes data into hierarchical key-value pairs, facilitating efficient storage and retrieval. However, JSON’s rigid structure and metadata-rich format are suboptimal for LLMs, which are designed to interpret natural language text. Consequently, transforming JSON into plain text while preserving its semantic and contextual integrity is a critical preprocessing step in RAG pipelines [
45].
Wazuh generates two types of security event logs, those containing an MITRE ID and those without [
46]. The refined process ensures that key metadata such as associated MITRE tactics, alert severity, compliance concerns, and detailed log descriptions are extracted and presented in a structured format. Such an approach enhances the accuracy and relevance of retrieval in RAG systems, enabling effective cybersecurity responses. By enriching the logs with actionable insights, the system ensures alignment with cybersecurity frameworks and provides critical information for threat mitigation.
This approach ensures that all logs, regardless of their initial structure, are transformed into coherent and actionable entries that align with cybersecurity frameworks like MITRE ATT&CK. The refined outputs are subsequently used to construct prompts for large language models (LLMs), enabling accurate and context-aware retrieval of information for threat detection and mitigation.
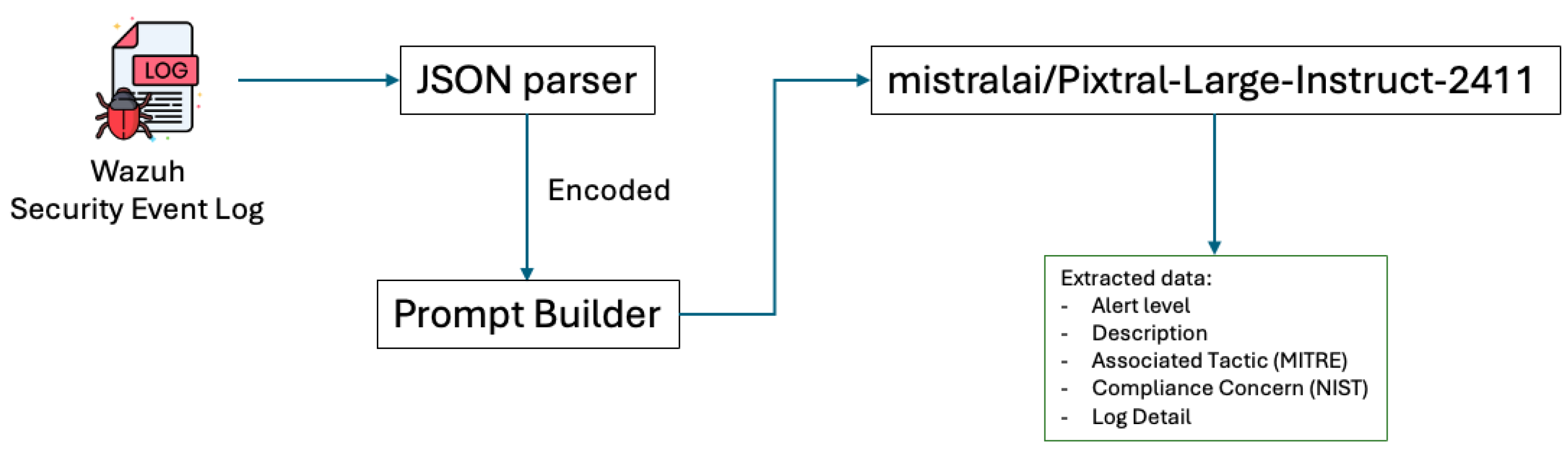
The diagram illustrated in
Figure 4 shows a structured pipeline for transforming JSON-formatted input logs into determined plain text. In order to refine, the process involves several steps. First, the raw JSON event log is parsed into an encoded JSON format, preparing the data for subsequent handling. Next, the encoded JSON is embedded into a user prompt, as illustrated in
Table 4. This step employs a one-shot output approach to ensure consistency in the format of the generated responses.
Figure 1.
Event Security Data Extraction Pipeline
Figure 1.
Event Security Data Extraction Pipeline
Table 1.
One-shot Prompt Format
Table 1.
One-shot Prompt Format
| Prompt Format |
|---|
| Extract the primary issue or problem from the following Wazuh JSON log. |
| Focus on details like the alert description, severity level, associated tactics, compliance tags, and any specific event data that |
| clarifies the problem: |
| {input_event_json} |
| Present the extracted issue in a concise format, describing the main problem indicated in the log. |
| Expected Output Example: |
| ”’ |
| Given the JSON log provided, here’s how the response might look: |
| Extracted Problem: |
| Description: Wazuh agent ’suricata-nids’ has stopped, indicating a potential disruption in NIDS monitoring. |
| Alert Level: 3 (Medium severity) |
| Associated Tactic: Defense Evasion (MITRE ID: T1562.001 - Disable or Modify Tools) |
| Compliance Concerns: PCI DSS (10.6.1, 10.2.6), HIPAA (164.312.b), TSC (CC7.2, CC7.3, CC6.8), NIST 800-53 (AU.6, AU.14, AU.5), GDPR (IV_35.7.d) |
| Log Details: Full log message reads "Agent stopped: ’suricata-nids->any’," suggesting possible interruption in security monitoring. |
| ”’ |
| Expected output above focuses on the core issue, making it easily readable and actionable for SOC and RAG systems. |
This refined, text-based structure facilitates more efficient tokenization and compatibility with vector-based similarity searches in vector databases, enhancing the retrieval process within RAG systems. By translating structured JSON logs into a format optimized for natural language processing, this method supports more accurate and contextually relevant document retrieval, enabling SOC analysts to access real-time, actionable intelligence for enhanced threat detection and incident response.
3.2. RAG Workflow
3.2.1. Data Collections
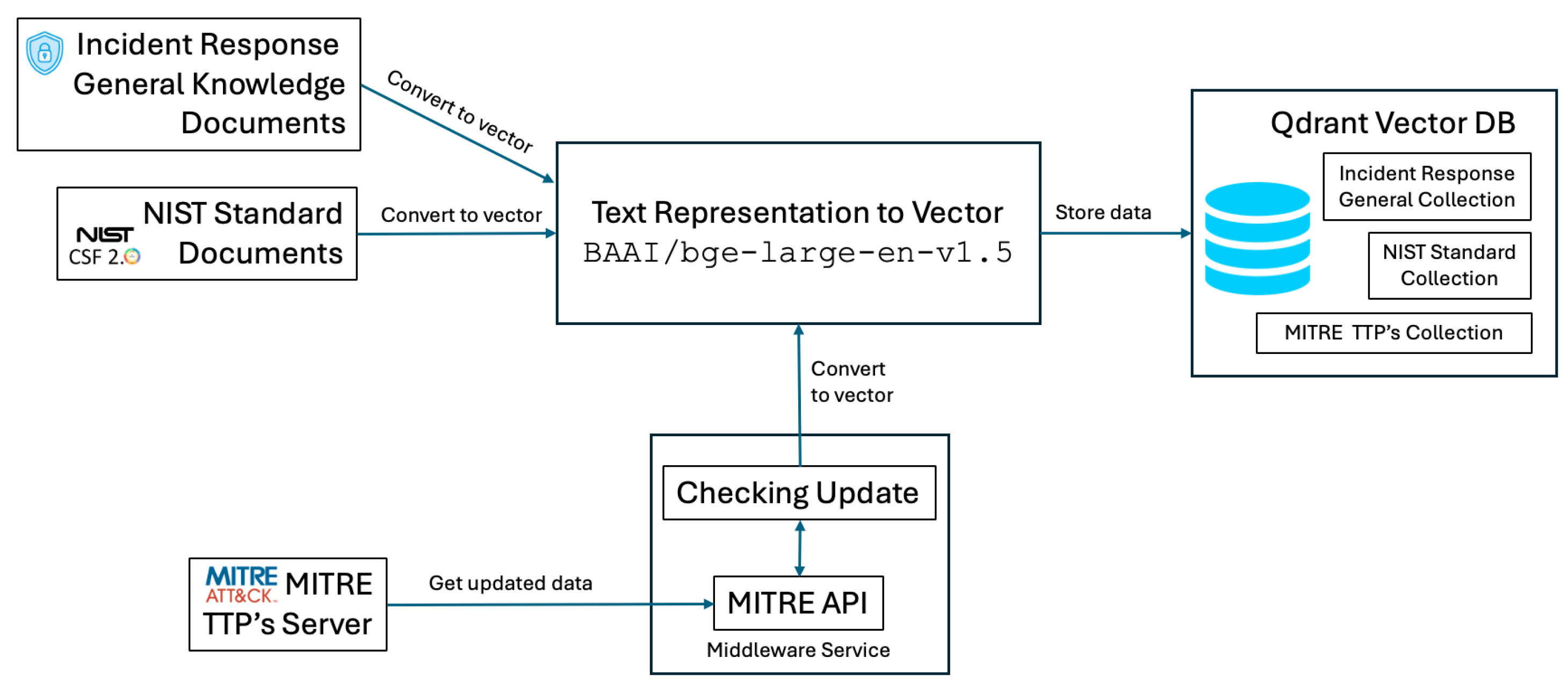
To support the effective retrieval of documents relevant to cybersecurity incidents, three distinct collections were designed within the vector database. Each collection serves a specialized function within the RAG model, ensuring that query results are both contextually relevant and aligned with industry-standard frameworks.
Figure 2.
Augmentation workflows
Figure 2.
Augmentation workflows
Table 2.
Categories and Related Content
Table 2.
Categories and Related Content
| Category |
Content |
| General Knowledge |
Incident Response Guide [47,48,49,50,51]IRP [52,53] |
| NIST Knowledge |
CSF 2.0 [54] |
| MITRE Knowledge |
MITRE ATT&CK [55] |
General Knowledge: This collection provides foundational knowledge for computer security incident handling, derived from sources such as security operations and automation response (SOAR) playbooks and general cybersecurity incident handling guides. It serves as a primary resource for addressing general security incident management needs.
NIST Knowledge: Specifically structured to align with the NIST Cybersecurity Framework, it includes guidelines, policies, and standards that ensure relevance to regulatory frameworks and assist in the compliance verification process.
MITRE Knowledge: Designed around the MITRE ATT&CK framework, this collection supports the retrieval of documents directly relevant to threat mitigation and response strategies. By mapping queries to specific MITRE tactics and techniques, this collection enhances the precision of actionable insights for mitigating cyber threats. To ensure that the collection remains aligned with the state-of-the-art MITRE tactics and techniques, a dedicated service periodically checks the MITRE servers for updates and synchronizes the local collection in the vector database, enabling real-time adaptability to emerging threats and maintaining the relevance of the system.
3.2.2. Chunking Techniques
Based on observations, two types of documents are identified for storage in the database as primary references for the RAG system. For instance, guideline books containing multiple subtopics with cross-contextual information are processed by segmenting them into smaller chunks using the Natural Language Toolkit (NLTK) splitter [
56], ensuring each chunk is contextually coherent.
In contrast, a single document encompassing a specific use case, attack context, mitigation strategies, and response procedures can be stored as a unified index. This approach ensures the preservation of contextual integrity and provides a comprehensive guideline for effective mitigation and incident response. This approach ensures that the system can retrieve documents accurately and consistently with the correct contextual alignment in future queries.
3.2.3. Large Language Model Config
3.3. Copilot: Generative AI Incident Response Workflow System
The copilot system is designed to respond by analyzing the extracted data for the presence of a given MITRE ID and subsequently retrieving relevant contextual information directly from a server or database. This retrieval process involves querying three distinct sources: the MITRE ATT&CK framework, general incident response guidelines, and the NIST Cybersecurity Framework (CSF) collection, as detailed in
Table 2. These three data sources play a critical role in ensuring the relevance and accuracy of the system’s output. The retrieved information is then consolidated and serves as input for the prompt builder, which integrates the contextual data to construct a coherent and contextually informed prompt for the AI model. Leveraging this enriched context, the AI model generates a tailored instruction guide that is delivered to the user. This structured workflow ensures that the copilot system provides precise, actionable, and context-aware guidance, enhancing its utility in real-time incident response and decision-making scenarios.
Figure 3.
Security Event Response Copilot (SERC) Workflow
Figure 3.
Security Event Response Copilot (SERC) Workflow
Table 3.
Configuration Parameters for Model Generation
Table 3.
Configuration Parameters for Model Generation
| Parameter |
Value |
| Temperature |
Set to 0.1, ensuring high determinism by minimizing randomness in the model’s predictions, favoring the most probable outputs. |
| Top-k |
Configured at 50, restricting token sampling to the top 50 most likely candidates, reducing the likelihood of low-probability tokens. |
| Top-p (Nucleus Sampling) |
Set to 0.9, allowing dynamic token selection by considering tokens with a cumulative probability of 90%, ensuring a balance between determinism and contextual diversity. |
| Max Tokens |
Defined as 4096, specifying the upper limit for the total number of tokens in the generated output, suitable for applications requiring concise yet comprehensive responses. |
The SERC is further equipped with a chat response feature designed to facilitate follow-up interactions for specific cases related to the initial response. This feature enables a dynamic and iterative communication process, allowing users to query the system for additional details, clarifications, or guidance tailored to the nuances of a given incident. By integrating conversational capabilities, the SERC enhances its utility as a responsive and adaptive tool, ensuring that users receive comprehensive support throughout the incident management lifecycle. This functionality is particularly valuable in addressing complex scenarios where continuous interaction is required to refine and implement effective cybersecurity measures.
Table 4.
Copilot Prompt Format
Table 4.
Copilot Prompt Format
| Copilot Prompt Format |
|---|
| This is the context information for general knowledge purposes: |
| {context_general} |
| This is the context information knowledge of planning for generating the incident response playbook based on The NIST Cybersecurity Framework (CSF) 2.0: |
| {context_nist} |
| This is the context information knowledge from MITRE ATT&CK for security incident response mitigation purposes: |
| {context_mitre} |
| Based on the above context information, hope you can use and elaborate on the knowledge you have to analyze this incident and tell me what action to take: |
| json |
| Based on that incident, what should be done to mitigate the risk? Make sure to use knowledge of the NIST CSF 2.0 and the MITRE ATT&CK |
| framework to identify the tactics and techniques associated with the incident. |
| Do not mention the source of JSON or text input, just tell what action to take with Markdown format. |
This study evaluates the performance of two distinct models, Pixtral [
13] and OpenAI [
12], with a focus on assessing their consistency and accuracy. The primary objective is to compare these models in their ability to process input data and produce outputs aligned with predefined benchmarks. Consistency is measured by analyzing the stability and repeatability of the models’ outputs across multiple iterations under similar conditions. Accuracy, on the other hand, is evaluated by comparing the models’ outputs against ground truth data to determine the correctness and relevance of their predictions. By conducting a systematic analysis of both metrics, the study aims to highlight the relative strengths and limitations of Pixtral and OpenAI, offering valuable insights into their effectiveness and reliability for specific use cases. This comparative approach contributes to a deeper understanding of model behavior and informs recommendations for their application in real-world scenarios.
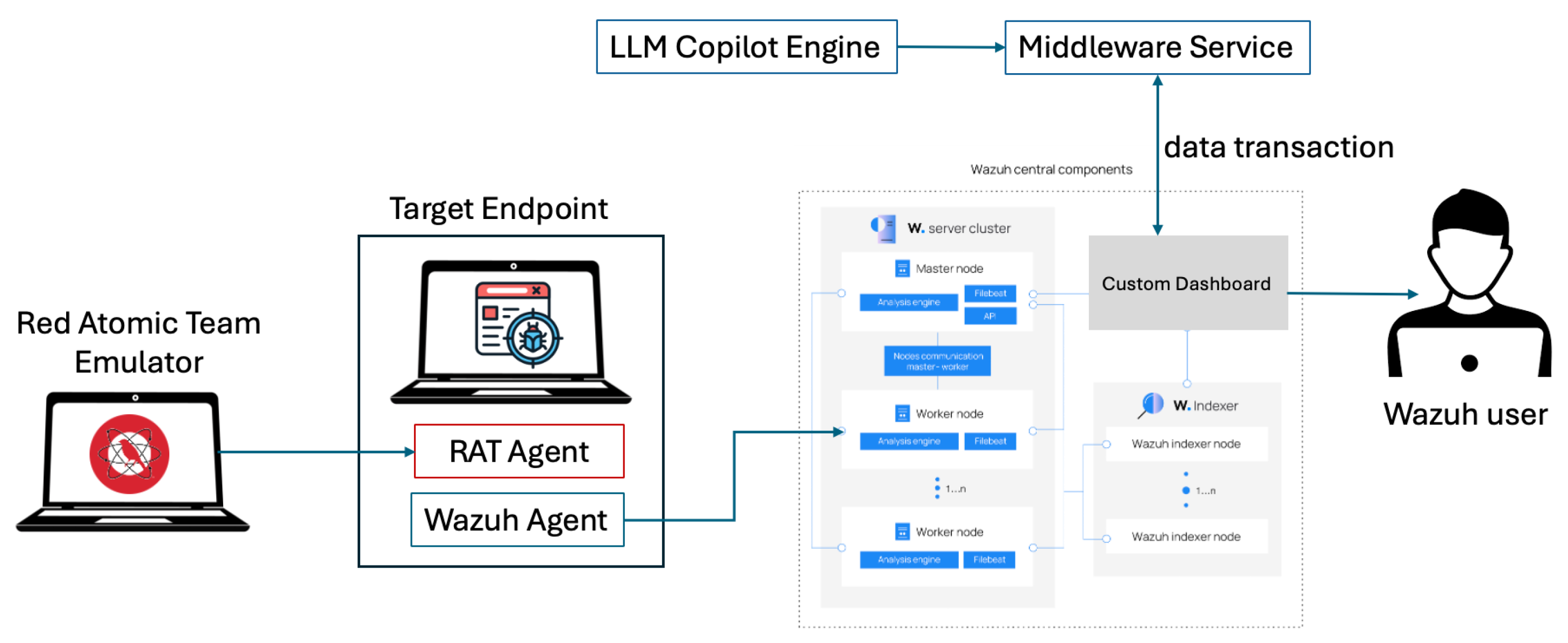
3.4. Simulation Scenario
This study conducts an end-to-end simulation of attack and defense mechanisms to evaluate the integration of automated detection and mitigation procedures. The simulation framework uses a well-defined methodology incorporating the Atomic Red Team tool to emulate predefined adversarial attack scenarios. These scenarios are carefully crafted with expected outcomes and executed on a target endpoint monitored by Wazuh agents, ensuring the generation of corresponding security events.
Figure 4.
simulation workflow
Figure 4.
simulation workflow
Upon detection, these security events are processed to trigger user interaction via a copilot interface, which provides mitigation guidelines tailored to the specific attack type, as defined in the MITRE ATT&CK framework. This workflow ensures that users can respond effectively by following context-specific mitigation instructions. The selected attack scenarios are designed to facilitate clear measurement of the inputs (attack actions) and outputs (detection and response), enabling a streamlined evaluation of the system’s performance in real-world settings.
This simulation approach not only validates the operational capability of the integrated system but also demonstrates its effectiveness in aligning detection and response with standardized threat models.
4. Experiment Results and Analysis
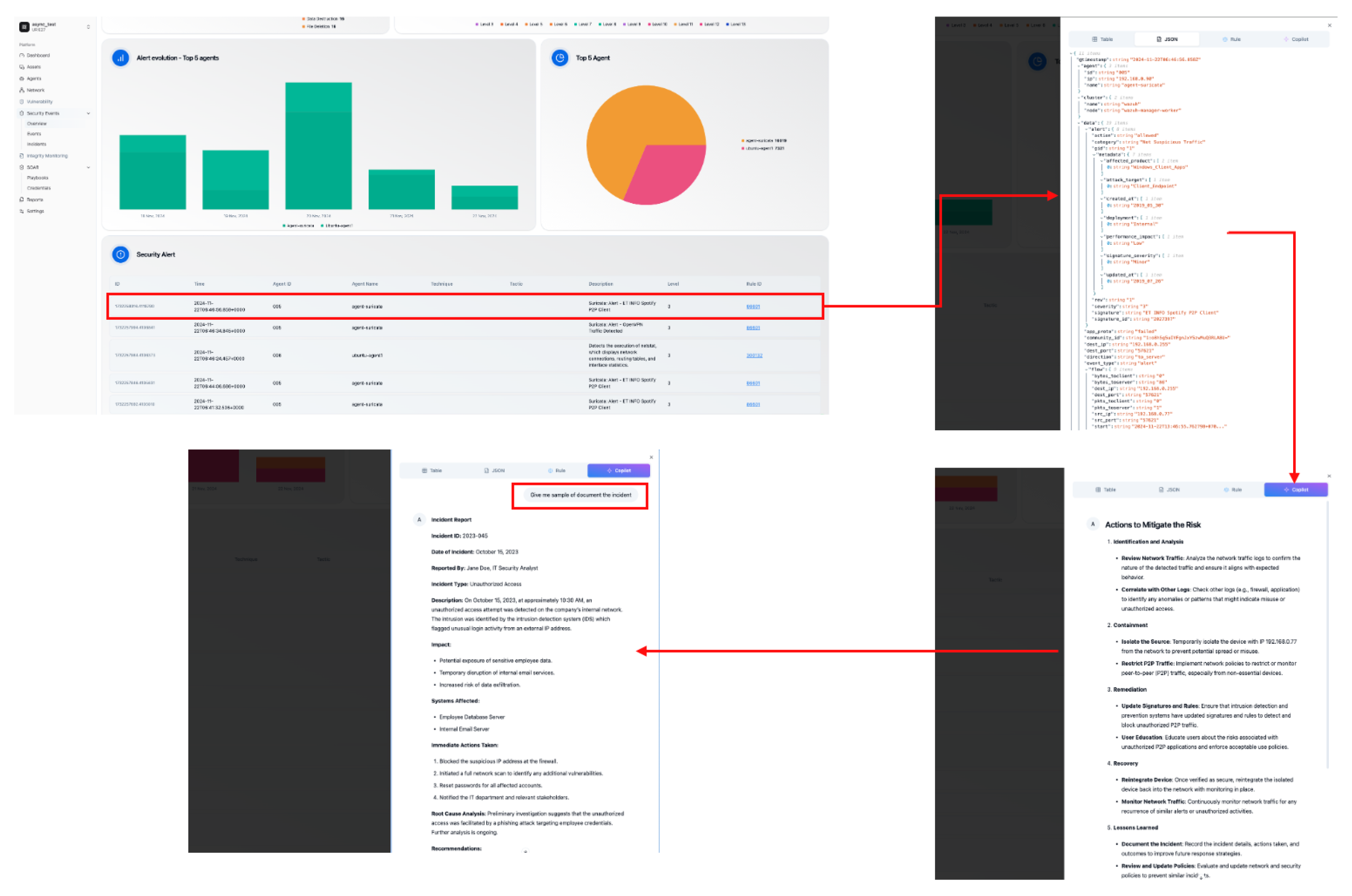
4.1. Copilot Integration for Security Event Analysis in Wazuh
The custom dashboard presented in
Figure 5 illustrates the implementation of a streamlined workflow for managing security events within the Wazuh platform. The image depicts several key features that enhance user interaction and event analysis. The primary section of the dashboard shows a detailed list of security events detected by Wazuh. A new tab labeled Copilot is prominently featured in the event details section. This tab serves as an interface for leveraging the advanced analytical capabilities of the SERC (Security Event Response Copilot) system.
The results from the SERC system are rendered in real time within the Copilot tab. This enables users to view critical findings, such as risk assessments, recommended actions, or contextual insights, directly within the Wazuh interface without switching applications. A dynamic chat section is integrated into the Copilot, allowing users to interact with the system by providing additional instructions or querying specific aspects of the processed data. This feature enhances the decision-making process by enabling a tailored response to the presented insights.
4.2. Performance Evaluation
To evaluate the effectiveness of the proposed simulation framework, we conducted five distinct attack scenarios across two different models using an observational method. The simulation aimed to compare predefined expected outputs with the mitigation responses generated by the Copilot interface. The findings revealed notable differences in structure consistency and instruction accuracy among the models, highlighting areas for improvement and adaptation.
The evaluation framework was built on four key criteria: (1) Alignment with MITRE ATT&CK, assessing how well the recommended actions correspond to established tactics and techniques; (2) NIST CSF Compliance, measuring adherence to cybersecurity functions such as Identify, Protect, Detect, Respond, and Recover; (3) Technical Depth, examining the level of detail and specificity in the provided mitigation steps; and (4) Operational Feasibility, evaluating the clarity and practicality of the recommendations for real-world execution. By combining these criteria with simulation results, the study provides a comprehensive assessment of the system’s accuracy, reliability, and usability in handling security incidents.
As shown in
Figure 6 OpenAI excels in technical depth and comprehensive alignment with MITRE ATT&CK, scoring 92%, by incorporating detailed detection mechanisms such as network traffic analysis, process monitoring, and API inspection to identify unauthorized use of commands like
netstat,
ipconfig, and similar tools. Its actions also emphasize strong mitigations like network segmentation and privilege management to limit adversarial reconnaissance. In contrast, Pixtral’s approach focuses on operational practicality, achieving 85%, with straightforward steps like isolating systems, preserving evidence, and conducting initial forensic analysis, making it more accessible to resource-constrained environments.
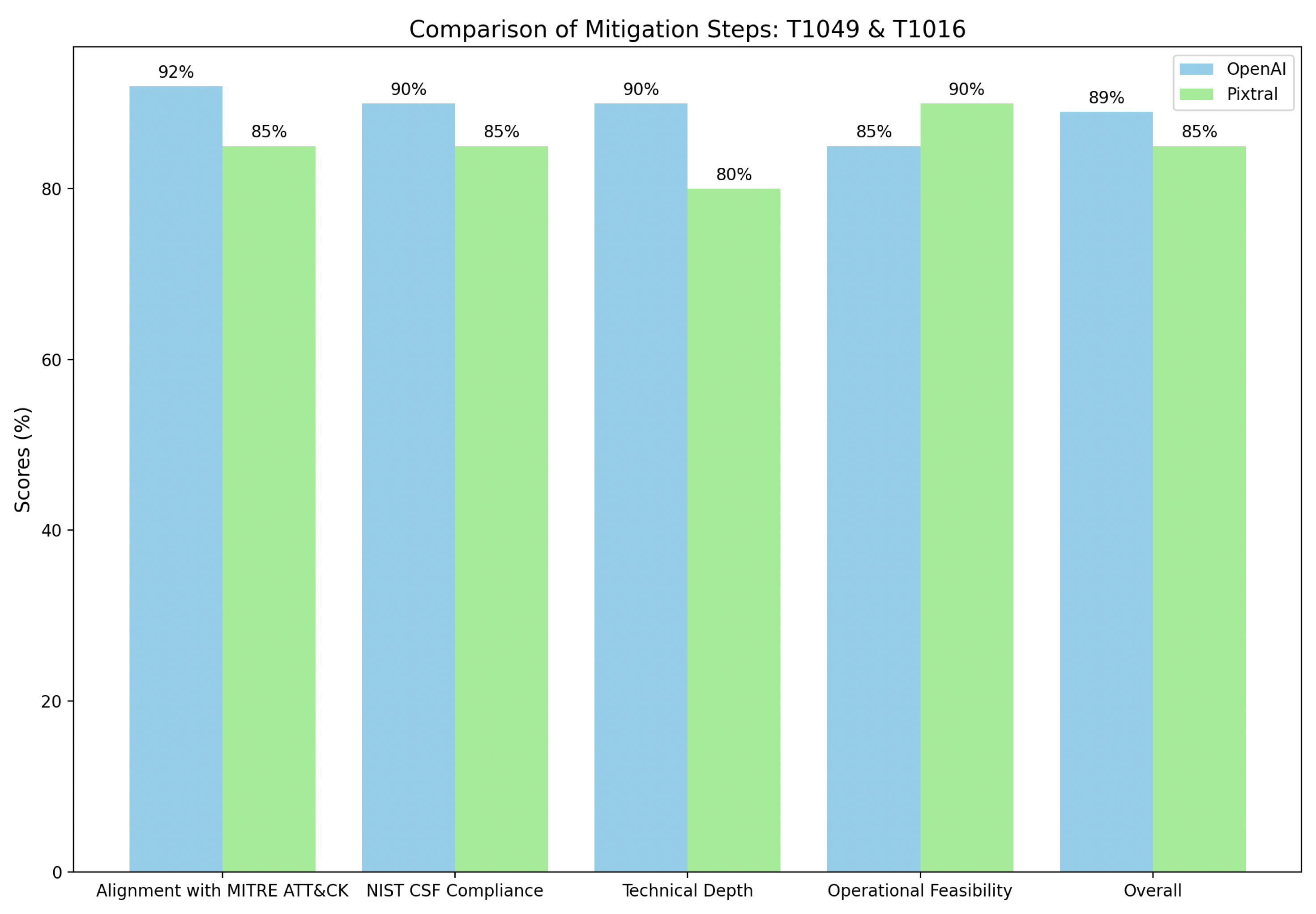
Furthermore, in
Figure 7 OpenAI demonstrates superior alignment with MITRE ATT&CK, achieving a score of 90% due to its strong coverage of mitigation techniques (e.g., Multi-factor Authentication and Network Segmentation) and advanced detection mechanisms such as anomaly monitoring and forensic log analysis. Furthermore, OpenAI’s detailed and technically robust actions align closely with NIST CSF functions, earning it a 92% compliance score, making it an excellent choice for organizations with mature security operations capable of deploying resource-intensive strategies. However, Pixtral excels in operational feasibility, scoring 90%, by focusing on immediate and practical actions like system isolation and basic traffic analysis, making it more accessible for smaller organizations or teams with limited resources. While Pixtral offers simplicity and rapid implementation, its lower scores in technical depth 75% and overall alignment 82% highlight its limited coverage of advanced configurations and detection mechanisms.
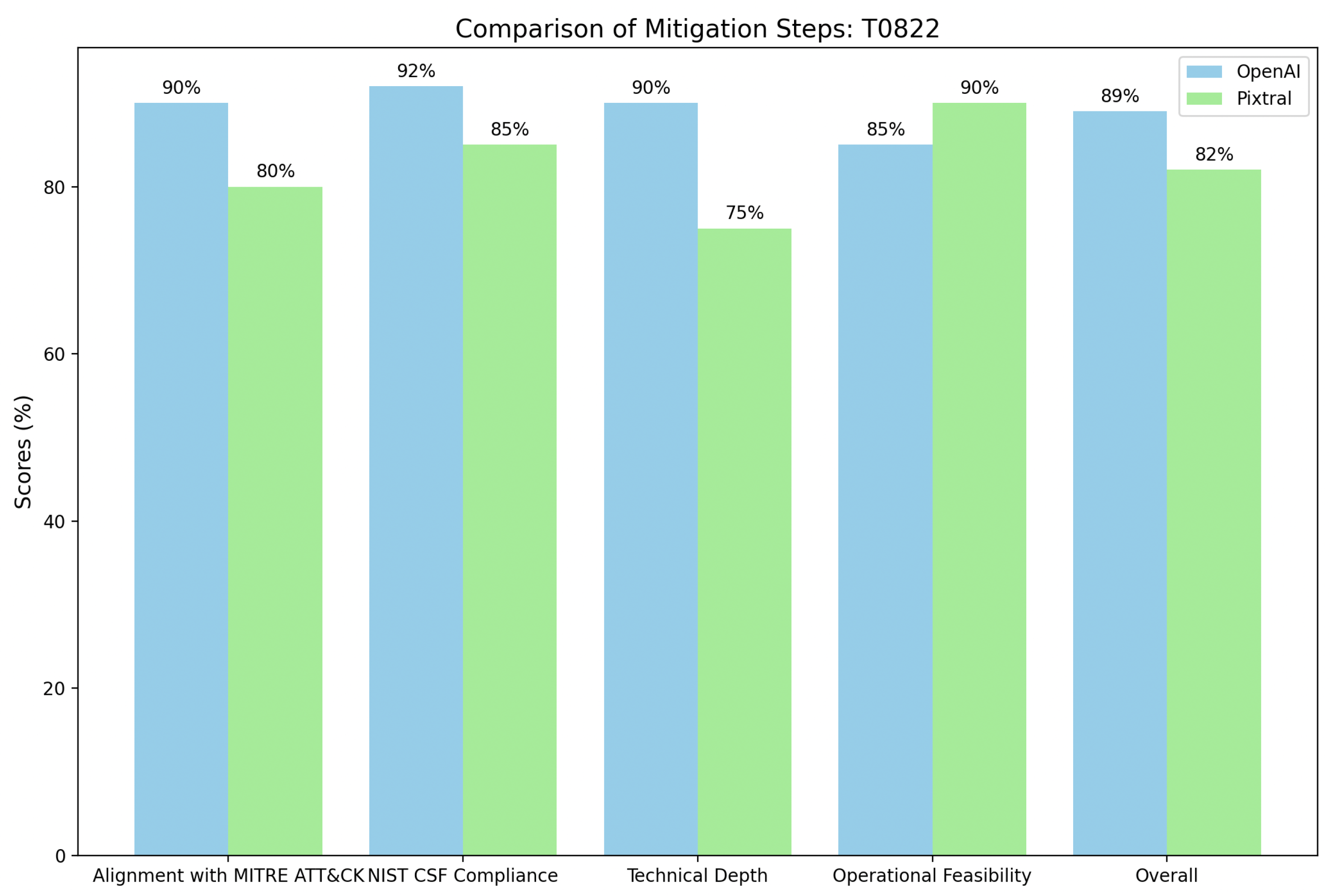
Moreover,
Figure 8 shows Mitigation steps for
/etc/passwd and
/etc/shadow (T1003.008) highlighting key differences between OpenAI and Pixtral in addressing credential access risks. OpenAI demonstrates stronger alignment with MITRE ATT&CK, scoring 95%, by integrating advanced mitigations such as enforcing complex password policies (M1027), implementing privileged account management (M1026), and utilizing monitoring tools like
AuditD to detect unauthorized file access and command execution. Its detailed response plan includes forensic analysis, remediation of root-level threats, and comprehensive recovery actions, making it well-suited for organizations with advanced security capabilities. Pixtral, scoring 88%, emphasizes practical and immediate actions such as isolating affected systems, preserving forensic evidence, and restricting file permissions. While Pixtral’s operational feasibility makes it accessible for rapid incident containment, it provides less technical depth in detection and long-term remediation strategies.
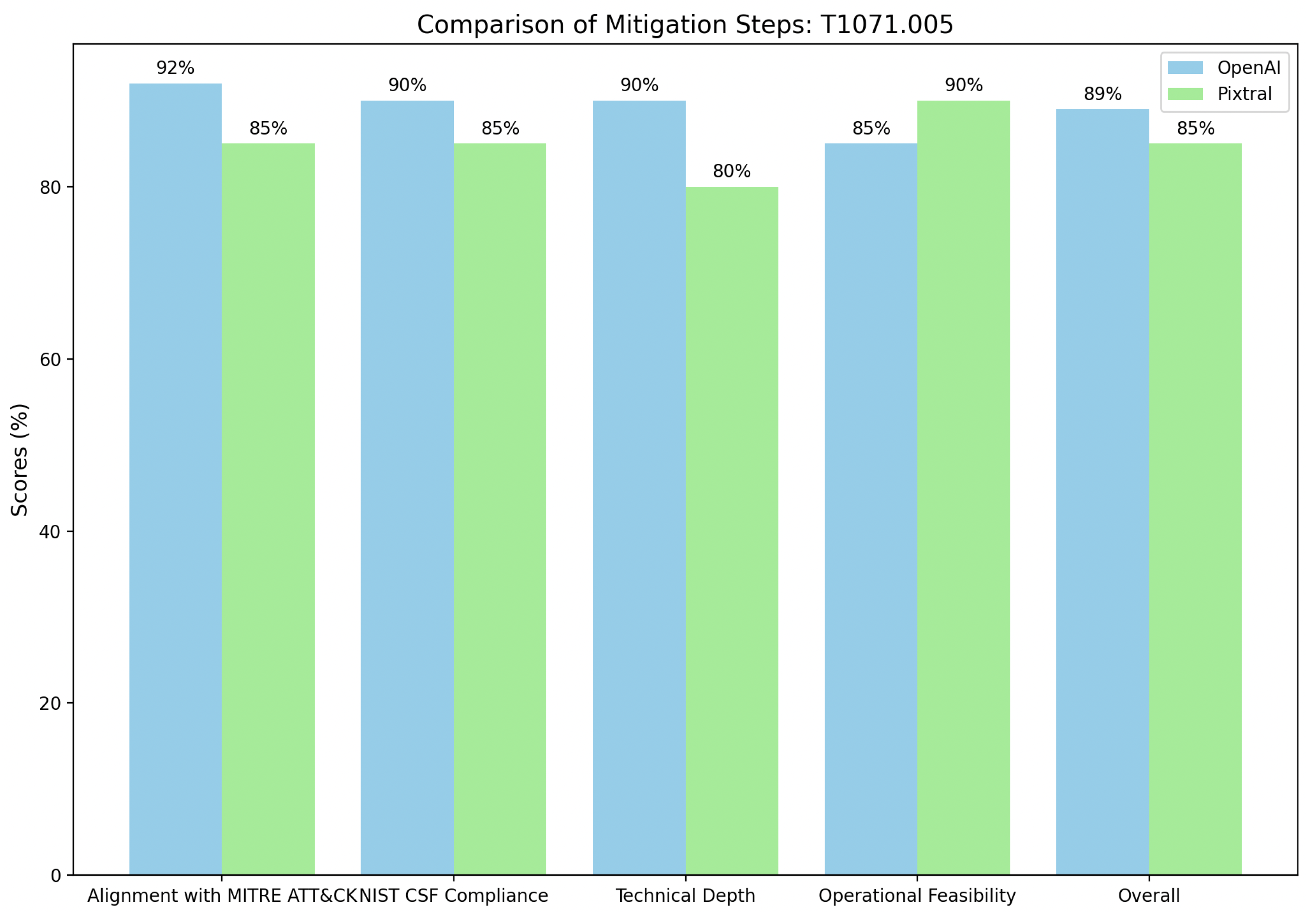
Additionally, the evaluation of mitigation steps for Publish/Subscribe Protocols (T1071.005) as shown in
Figure 9 reveals differing strengths between OpenAI and Pixtral approaches. OpenAI demonstrates stronger alignment with MITRE ATT&CK, scoring 92%, by integrating robust mitigations such as traffic filtering (M1037) and intrusion prevention (M1031), while employing advanced detection techniques like SSL/TLS inspection, traffic flow analysis, and correlation with process monitoring. Its focus on comprehensive monitoring and anomaly detection makes it suitable for mature security operations. Pixtral, scoring 85%, emphasizes immediate, practical actions such as isolating systems and updating intrusion detection rules, making it more accessible for organizations with limited resources.
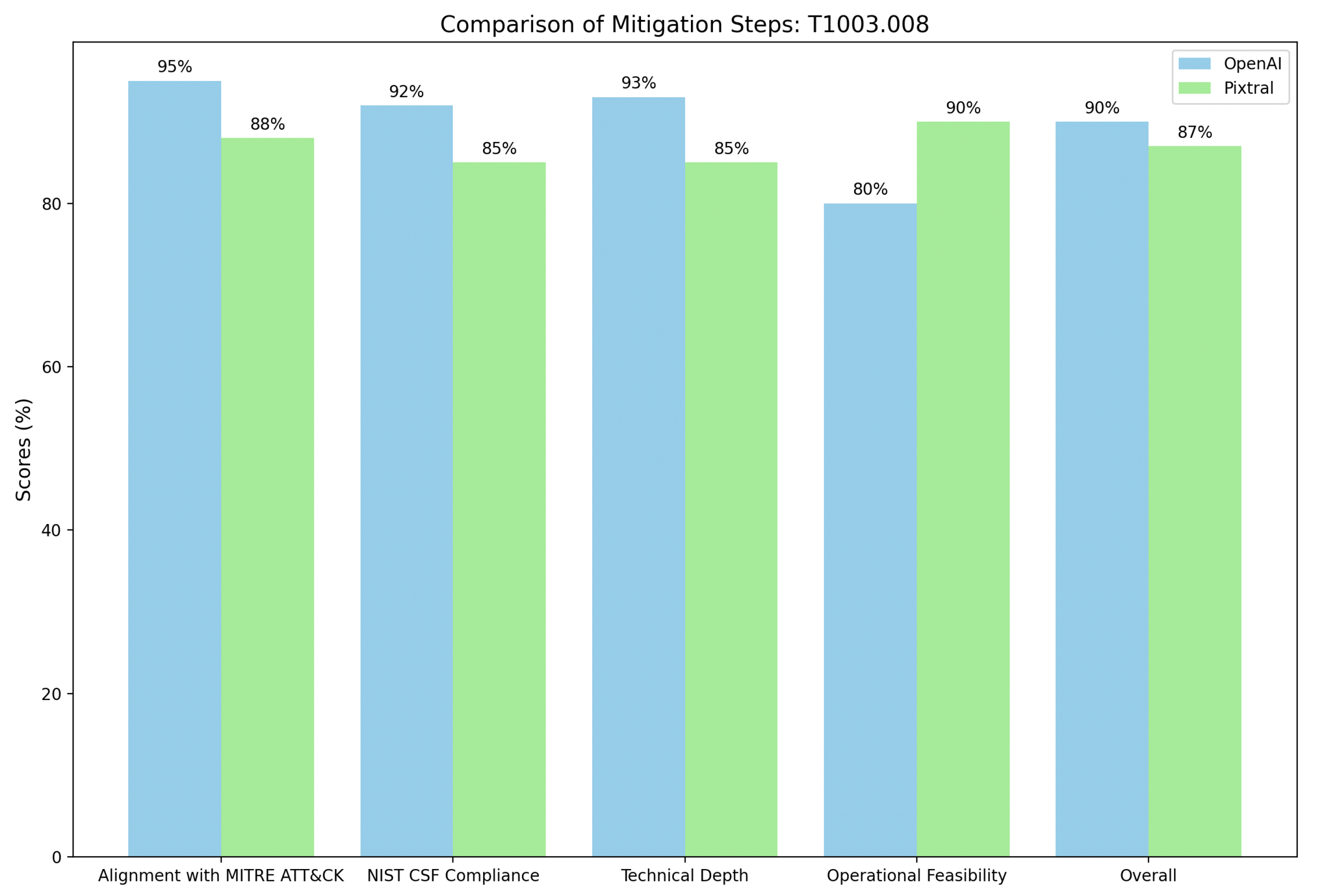
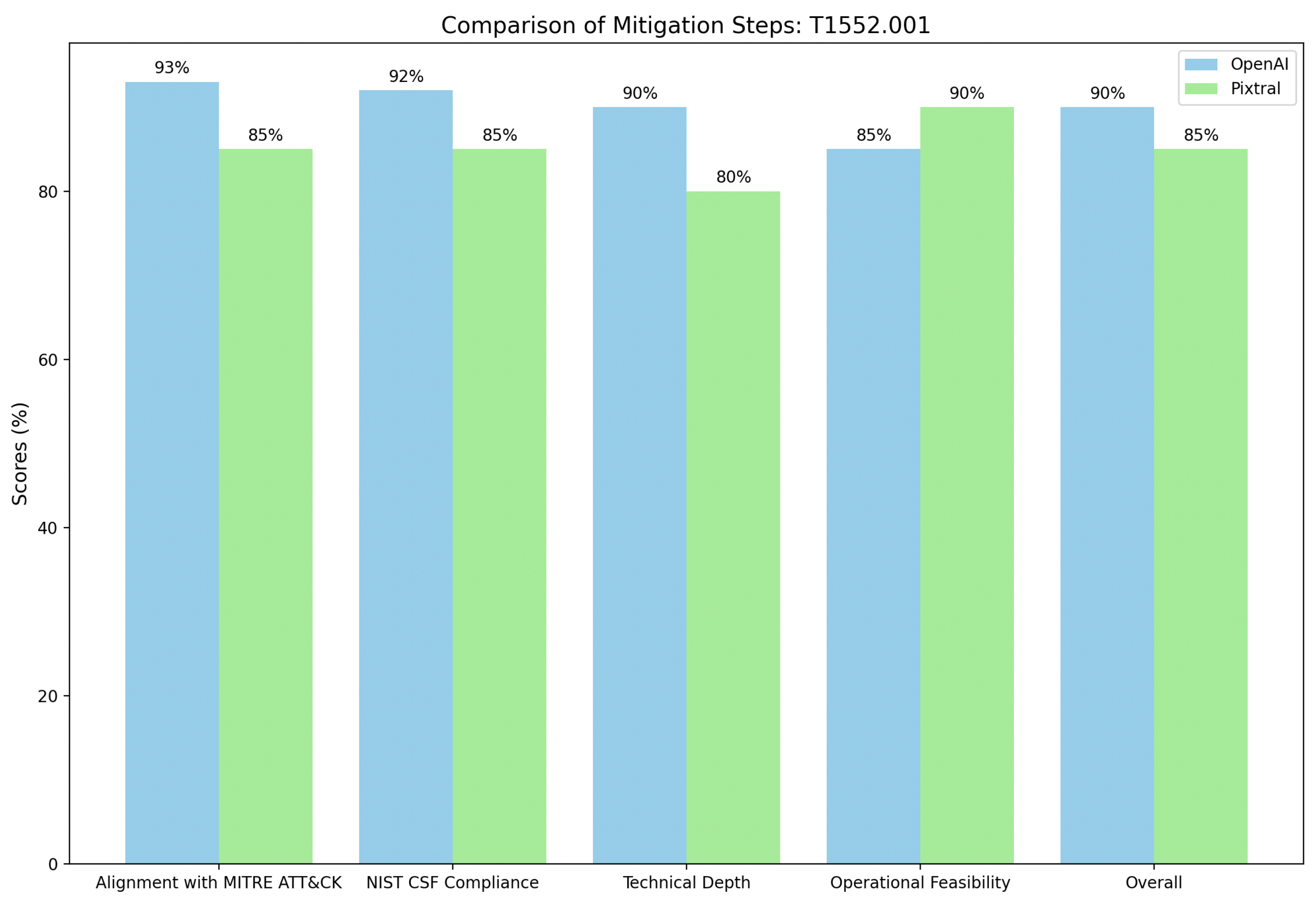
Finally, the mitigation steps for Credentials in Files (T1552.001) in
Figure 10 demonstrate contrasting strengths in OpenAI and Pixtral approaches. OpenAI excels in alignment with MITRE ATT&CK, scoring 93%, by offering a technically detailed strategy that includes enforcing file access restrictions (M1022), auditing for insecurely stored credentials (M1047), and implementing robust detection mechanisms such as command-line monitoring for suspicious keywords and file access anomalies. Its comprehensive approach also integrates advanced recovery actions, such as credential revocation and system reinstalls, making it well-suited for organizations with mature cybersecurity frameworks. Pixtral, scoring 85%, focuses on practicality and immediate actions like isolating compromised systems, restricting file permissions, and changing exposed credentials.
5. Discussion and Future Work
In incident response steps generated by OpenAI and Pixtral across multiple MITRE ATT&CK techniques, OpenAI consistently demonstrated higher alignment with MITRE ATT&CK frameworks and NIST CSF standards. It scored particularly well in areas requiring technical depth, such as forensic analysis, detection of adversarial activity, and detailed remediation processes. This makes OpenAI’s approach more suitable for organizations with mature security operations and resources to implement advanced detection and response mechanisms. OpenAI achieved an average score of 91% for alignment with MITRE ATT&CK and NIST CSF compliance across all evaluated techniques, compared to Pixtral’s 86%, reflecting its stronger integration of technical and procedural recommendations.
In contrast, Pixtral’s approach stood out for its emphasis on operational feasibility, prioritizing immediate, practical actions such as system isolation, memory imaging, and rapid incident containment. Pixtral scored 89% on average for operational feasibility, higher than OpenAI’s 85%, making it particularly effective for smaller organizations or teams with limited resources. While Pixtral’s simplicity may lack some technical depth, it provides a straightforward path for quick containment during critical incidents. Both approaches offer valuable strengths, with OpenAI excelling in depth and alignment for comprehensive mitigation and Pixtral focusing on accessibility and ease of implementation for fast responses.
Building upon these findings, future research will focus on extending the capabilities of the simulation framework to incorporate integration with Security Orchestration, Automation, and Response (SOAR) systems. The addition of SOAR functionality has the potential to enhance the practical utility of AI-driven copilots in SOC environments by enabling end-to-end automation of the incident response lifecycle.
Funding
This research was funded by the Korea government(MSIT) grant number RS-2024-00402782
Institutional Review Board Statement
Not applicable
Informed Consent Statement
Not applicable
Data Availability Statement
Not applicable
Acknowledgments
This work was supported by the Institute of Infomation & Communications Technology Planning & Evaluation(IITP) grant funded by the Korea government(MSIT)(RS-2024-00402782, Development of virtual commissioning technology that interconnects manufacturing data for global expansion).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Vielberth, M.; Bohm, F.; Fichtinger, I.; Pernul, G. Security Operations Center: A Systematic Study and Open Challenges. IEEE Access 2020, 8, 227756–227779. [Google Scholar] [CrossRef]
- Perera, A.; Rathnayaka, S.; Perera, N.D.; Madushanka, W.W.; Senarathne, A.N. The Next Gen Security Operation Center. 2021 6th International Conference for Convergence in Technology, I2CT 2021. Institute of Electrical and Electronics Engineers Inc., 2021. [CrossRef]
- Arora, A. MITRE ATT&CK vs. NIST CSF: A Comprehensive Guide to Cybersecurity Frameworks.
- Farouk, M. The Application of MITRE ATT&CK Framework in Mitigating Cybersecurity Threats in the Public Sector. Issues In Information Systems 2024. [Google Scholar] [CrossRef]
- Stine, K.; Quinn, S.; Witte, G.; Gardner, R.K. Integrating Cybersecurity and Enterprise Risk Management (ERM), 2020. [CrossRef]
- Wainwright, T. Aligning MITRE ATT&CK for Security Resilience - Security Risk Advisors.
- Freitas, S.; Kalajdjieski, J.; Gharib, A.; McCann, R. AI-Driven Guided Response for Security Operation Centers with Microsoft Copilot for Security 2024.
- Fysarakis, K.; Lekidis, A.; Mavroeidis, V.; Lampropoulos, K.; Lyberopoulos, G.; Vidal, I.G.M.; i Casals, J.C.T.; Luna, E.R.; Sancho, A.A.M.; Mavrelos, A.; Tsantekidis, M.; Pape, S.; Chatzopoulou, A.; Nanou, C.; Drivas, G.; Photiou, V.; Spanoudakis, G.; Koufopavlou, O. PHOENI2X – A European Cyber Resilience Framework With Artificial-Intelligence-Assisted Orchestration, Automation and Response Capabilities for Business Continuity and Recovery, Incident Response, and Information Exchange 2023.
- Wazuh - Open Source XDR. Open Source SIEM.
- Companies Using Wazuh, Market Share, Customers and Competitors.
- Younus, Z.S.; Alanezi, M. Detect and Mitigate Cyberattacks Using SIEM. Proceedings - International Conference on Developments in eSystems Engineering, DeSE. Institute of Electrical and Electronics Engineers Inc., 2023, pp. 510–515. [CrossRef]
- Hello GPT-4o | OpenAI.
- Pixtral Large | Mistral AI | Frontier AI in your hands.
- wazuh. Wazuh documentation.
- Šuškalo, D.; Morić, Z.; Redžepagić, J.; Regvart, D. 34th DAAAM International Symposium on Intelligent Manufacturing and Automation: Comparative Analysis of IBM QRadar and Wazuh for Security Information and Event Management. [CrossRef]
- IBM Security QRadar vs Wazuh Comparison 2024 | PeerSpot.
- Dunsin, D.; Ghanem, M.C.; Ouazzane, K.; Vassilev, V. A Comprehensive Analysis of the Role of Artificial Intelligence and Machine Learning in Modern Digital Forensics and Incident Response Article info, 2023.
- Hays, S.; White, J. Employing LLMs for Incident Response Planning and Review 2024.
- Lin, G.; Feng, T.; Han, P.; Liu, G.; You, J. Paper Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance 2024.
- Li, R.; Patel, T.; Wang, Q.; Du, X. MLR-Copilot: Autonomous Machine Learning Research based on Large Language Models Agents 2024.
- Haque, S.; Eberhart, Z.; Bansal, A.; McMillan, C. Semantic Similarity Metrics for Evaluating Source Code Summarization. IEEE International Conference on Program Comprehension. IEEE Computer Society, 2022, Vol. 2022-March, pp. 36–47. [CrossRef]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models 2022.
- Han, Z.; Gao, C.; Liu, J.; Zhang, J.; Zhang, S.Q. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey 2024.
- Outshift | Fine-tuning methods for LLMs: A comparative guide.
- Challenges & limitations of LLM fine-tuning | OpsMatters.
- Wang, X.; Wang, Z.; Gao, X.; Zhang, F.; Wu, Y.; Xu, Z.; Shi, T.; Wang, Z.; Li, S.; Qian, Q.; Yin, R.; Lv, C.; Zheng, X.; Huang, X. Searching for Best Practices in Retrieval-Augmented Generation 2024.
- Explainer: What Is Retrieval-Augmented Generation? | NVIDIA Technical Blog.
- Xu, H.; Wang, S.; Li, N.; Wang, K.; Zhao, Y.; Chen, K.; Yu, T.; Liu, Y.; Wang, H. Large Language Models for Cyber Security: A Systematic Literature Review 2024.
- Tseng, P.; Yeh, Z.; Dai, X.; Liu, P. Using LLMs to Automate Threat Intelligence Analysis Workflows in Security Operation Centers 2024.
- Enhancing Cybersecurity: The Role of AI & ML in SOC and Deploying Advanced Strategies.
- Ferrag, M.A.; Alwahedi, F.; Battah, A.; Cherif, B.; Mechri, A.; Tihanyi, N. Generative AI and Large Language Models for Cyber Security: All Insights You Need 2024.
- What is Qdrant? - Qdrant.
- GitHub - qdrant/qdrant-rag-eval: This repo is the central repo for all the RAG Evaluation reference material and partner workshop.
- BAAI/bge-large-en · Hugging Face.
- Matryoshka Representation Learning 2022.
- openai. New and improved embedding model | OpenAI.
- bert. [1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Steck, H.; Ekanadham, C.; Kallus, N. Is Cosine-Similarity of Embeddings Really About Similarity? 2024. [CrossRef]
- Guo, K.H. Testing and Validating the Cosine Similarity Measure for Textual Analysis.
- GitHub - redcanaryco/atomic-red-team: Small and highly portable detection tests based on MITRE’s ATT&CK.
- Test your defenses with Red Canary’s Atomic Red Team.
- Landauer, M.; Mayer, K.; Skopik, F.; Wurzenberger, M.; Kern, M. Red Team Redemption: A Structured Comparison of Open-Source Tools for Adversary Emulation 2024.
- Rules - Data analysis · Wazuh documentation.
- Event logging - Wazuh server · Wazuh documentation.
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; tau Yih, W.; Rocktäschel, T.; Riedel, S.; Kiela, D. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 2020.
- Vulnerability detection - Use cases · Wazuh documentation.
- Cichonski, P.; Millar, T.; Grance, T.; Scarfone, K. Computer Security Incident Handling Guide : Recommendations of the National Institute of Standards and Technology, 2012. [CrossRef]
- IRM/EN at main · certsocietegenerale/IRM.
- socfortress/Playbooks: Playbooks for SOC Analysts.
- Diogenes, Y.; Ozkaya, E. Cybersecurity, attack and defense strategies : infrastructure security with Red Team and Blue Team tactics; Packt Publishing, 2018.
-
Nccic.; Ics-cert. Recommended Practice: Improving Industrial Control System Cybersecurity with Defense-in-Depth Strategies Industrial Control Systems Cyber Emergency Response Team, 2016.
- Cybersecurity_incident_response_1731275000.
- Cybersecurity Incident & Vulnerability Response Playbooks Operational Procedures for Planning and Conducting Cybersecurity Incident and Vulnerability Response Activities in FCEB Information Systems.
- The NIST Cybersecurity Framework (CSF) 2.0, 2024. [CrossRef]
- MITRE ATT&CK®.
- How to split text by tokens | LangChain.
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).