Submitted:
02 January 2025
Posted:
03 January 2025
You are already at the latest version
Abstract
At present, the pipeline-based English-Chinese place name translation method separates the process of transliteration and free translation of place names, which poses a risk of error propagation. This study proposes an end-to-end English-Chinese place name translation method based on a large language model (LLM). The aim is to achieve end-to-end English-Chinese place name translation, thereby improving the accuracy of large-scale place name translations. The proposed method is divided into two main parts: 1) Joint translation of common and specialized names. This study uses place name categories, and alphabetical sequences of place name words as prompts to achieve joint translation of common and specific names. 2) Knowledge graph enhancement. This study utilizes knowledge from a derived place name knowledge graph as a prompt to enhance the translation effect of derived place names. Experiments have shown that compared to traditional pipeline-based place name translation methods, the place name translation method proposed in this study based on a large language model has improved performance by 21.26% in the field of ordinary place name translation and an average of 27.70% in the field of derived place name translation. This method effectively improves the performance in the field of large-scale English-Chinese place name translation.
Keywords:
English-Chinese place name translation
; Common and specific names joint translation
; Derived place name translation
; Knowledge graph enhancement
1. Introduction
The translation of place names is the process of converting the names of geographical entities from the source language to the target language. English place names usually have two parts: a specific name that identifies the location and a generic name that describes the type of place [1]. Unlike general text translation, in translating English into Chinese place names, the strategy usually involves a "semantic translation of the common name and phonetic translation of the specific name" [2]. For example, in the translation process of English into Chinese place names, the specific name "Palms" in the Australian place name "Palms Restaurant" is transliterated as "帕姆斯" and the generic name "Restaurant" is translated into the semantically similar "餐厅". Furthermore, the derivation of place names is a common method of naming geographical entities [3], and there are many derived place names in the place name data. In the translation process, for original and derived place names with obvious derivation relationships, the semantic association between derived place names and native place names in the source language should be maintained [3,4]. For example, in place names with a generic name derivation relationship like "Jackson Park" and "Jackson Park Road", the derived part "Park" in both names should be translated as "公园", "Jackson Park" and "Jackson Park Road" being translated as "杰克逊公园" and "杰克逊公园路" respectively. In English-Chinese place name translation, the combined translation of common and specific names helps reduce error propagation during the translation process. At the same time, consistency in the translation of derived place names enhances the accuracy of place name translation. However, currently, the translation of English-Chinese place names based on prompt learning has not yet been explored. Therefore, this study aims to improve the performance of English-Chinese place name translation by prompt learning. This provides an efficient and well-performing machine translation tool for English-Chinese place-name translation. The main challenges faced in this study are the following:
1) How to design prompt words that can achieve joint translation of common and specific names?
2) How to construct prompt words to ensure consistency in the translation of derived place names?
By addressing the above issues, the main contributions of this study are as follows:
1) Construction of translation prompt words for ordinary place names. Based on the features of semantic association between common names and place name categories, this study selects place name categories as prompt words for generic name translation. At the same time, considering the phonetic translation of specific names, the alphabetical order of place names is used as a cue and placed to the right of the place names. This experiment shows that both the category of place names and the alphabetical sequence of place name words can effectively improve the accuracy of English-Chinese place name translation tasks.
2) Construction of translation prompt words for derived place names. In this study, a top-down approach is adopted to construct a knowledge map of derived geographical names, taking into account the translation needs of derived geographical names. Thus, the knowledge graph is used to realize the recognition of derived names and the acquisition of related information, so that the recognition results and the retrieved information of derived place names can be used as the prompt for the translation of derived names. Experiments show that this method effectively improves the translation of derived place names.
The structure of the article is as follows: Chapter 2 introduces the research status in the fields of machine translation and place name translation. Chapter 3 introduces an English-Chinese place name translation method based on prompt learning, which is mainly divided into ordinary place name translation prompt construction and derived place name translation prompt construction. Chapter 4 introduces a comparative experiment of translation prompts for the prompt-based translation of common place names and derived place names. Chapter 5 summarizes the achievements of this study, the existing shortcomings, and prospects.
2. Related Work
To produce English-Chinese place names more efficiently, machine translation of English-Chinese place names has always been a popular topic among place name translators. English-Chinese place name translation based on prompt learning mainly involves machine translation based on prompt learning and the field of place name translation, and researchers have conducted many studies on this.
1) Machine translation based on prompt learning
With the impressive performance of LLM in various natural language processing tasks, many researchers have applied large language models to machine translation tasks. Large language models, unlike traditional machine translation systems, use end-to-end learning to understand language correspondences, resulting in stronger translation capabilities [5]. Large language models mainly stimulate machine translation capabilities through methods such as contextual learning, prompt learning, and instruction fine-tuning [6]. Radford et al. (2019) [7] first demonstrated through research that prompt learning has great potential in the field of text generation (such as machine translation and summarization). Subsequently, many researchers have worked on improving machine translation using LLM, focusing on prompt optimization and model fine-tuning. In terms of prompt optimization, Jiang et al. (2024) [8] showed that correct prompts and contextual information can improve the performance of ChatGPT in machine translation tasks. In the area of few-shot prompting, Chen Yufeng (2023) [9], Moslem et al. (2023) [10] demonstrated that retrieving similar translation examples from the source language input as prompts can effectively improve machine translation results. In addition to using the source language context as prompts, Harritxu et al. (2024) [11] also considered the target language context as prompts, enhancing machine translation performance. In terms of model fine-tuning, Zhang et al. (2023) [12] compared the performance of zero-shot, few-shot, and QLoRA fine-tuning in machine translation tasks, showing that QLoRA fine-tuning has higher performance than the other two methods. Haoran et al. (2024) [13] studied the limits of using human-generated data for full fine-tuning in machine translation with medium-sized language models. They used the CPO (Contrastive Preference Optimization) method to help these models perform as well as large language models.
2) Place name translation
In place name translation, researchers typically use a pipeline method. They separate the task into parts like identifying common and specific names, transliterating specific names, and then combining the translations of both types. For these subtasks, many researchers have conducted studies using statistical and deep learning methods. On this basis, researchers have also considered the situation of derived place names and conducted related research on the translation of derived place names.
(1) In the aspect of distinguishing between common and specific names, Yan et al. (2021) [14] proposed a method that uses a grammatical structure tree for place names. It builds a structure tree by analyzing the relationships between place name words and decomposing place name phrases. Then, it classifies the tree nodes to differentiate between common and proper names.
(2) In terms of proper name transliteration, Zhao et al. (2016) [15] used a Russian-Chinese phonetic transcription table and the forward maximum matching principle to transcribe Russian-Chinese place names. Addressing the issues of phonetic generation and syllable division, Yan et al. (2019) [16] tackled phonetic generation and syllable division in English-Chinese name transliteration. They used an encoder-decoder model to treat phonetic generation as translating English words into Chinese characters. Their method, based on recurrent neural networks, achieved syllable segmentation using the minimum entropy principle. On this basis, Wang et al. (2020) improved phonetic segmentation for proper name transliteration. They used a bidirectional maximum matching method to resolve cross-type ambiguities. Additionally, they enhanced the transliteration results with prior knowledge.
(3) In terms of integrating the translation results of common names and specific names, Mao et al. [17] use an attention-based transliteration replacer to decide if the model’s result should be replaced, based on the input word vector’s attention weight, integrating translations of common and specific names. Based on the place name syntax tree, Ren et al. [18] use a nested translation method to combine the translation of each node in a place name syntax tree, achieving the final translation. This approach is applied to translate English and Arabic place names into Chinese.
(4) In the field of translation of derived place names, Huo Bocheng (2016) [3] analyzed the characteristics of derived place names and proposed some suggestions for their translation methods. Based on this, Liu Hanyou (2022) [4] proposed an English-Chinese derived place name translation method based on a derived place name knowledge graph. This method uses geostatistics to build a knowledge graph of place names and then uses this information as nodes in a grammar tree to translate the place names.
Currently, in the field of machine translation, LLM models have shown good performance in machine translation tasks compared to traditional machine translation models. To retain the knowledge of pretraining tasks in machine translation tasks, researchers mainly use "prompt learning + fine-tuning" for optimization. In the field of place name translation, a pipeline approach is mainly used, which separates the transliteration and translation processes of place names. This method poses a risk of error propagation. However, research on the joint translation of general names and specific names is still in its infancy. In response, this study adopts a prompt learning method, using large language models to achieve end-to-end English-Chinese place name translation.
3. Materials and Methods
Place names contain not only geographical environmental characteristics but also human environmental characteristics [19]. The human geographical information contained in English place names is widely available on the Internet. To retain the local geographical information of English-speaking countries, this study uses a large language model with Internet world knowledge to learn the mapping of English place names to Chinese place names through prompt learning [20]. This method is mainly divided into two parts (As shown in Figure 1): 1) Construction of translation prompt words for ordinary place names. This study analyzes the characteristics of general and specific name translations. It uses word letter sequences and place name categories as translation prompts. This approach enables the large language model to learn the mapping process from English place names and translation prompts to Chinese place names. 2) Construction of translation prompt words for derived place names. This study is based on the principle of translation consistency for derived place names. It uses a knowledge-enhanced method that relies on knowledge graphs. This method helps identify derived place names. It also retrieves related knowledge through knowledge retrieval. This information is used as a translation prompt for derived place names. As a result, the contextual information of the place names is enhanced. This approach improves the accuracy of place name translation. In this regard, this article uses the large language model ChatGLM based on the GLM [21] framework as the language model for place name translation. In natural language understanding and generation tasks, the GLM framework outperforms traditional models such as Bart [22] and UniLM. At the same time, in order to save computing power costs, this study used Lora fine-tuning [23] for model training.
3.1. Construction of Translation Prompt Words for Ordinary Place Names
In the process of translating ordinary place names, proper names and common names have different translation strategies. To achieve the joint translation of common names and proper names, this study combines the characteristics of common name transliteration and proper name transliteration to construct proper name transliteration prompts and common name transliteration prompts (The specific usage example is shown in Table 1).
1) Translation prompt for special names. From a linguistic perspective, the phonetic transcription of English-specific names is related to the pronunciation of the English-specific-names, which in turn is related to the letter sequences that make up the specific names [24,25]. Therefore, the phonetic transcription of English-specific names is related to those letter sequences. For the phonetic transcription of English-specific names, this study selects the letter sequences of place names as the prompt for phonetic transcription. To indicate the affiliation between place names and their letter sequences, each letter sequence of a place name is marked with special characters ’<’ and ’>’. These characters serve as the beginning and ending symbols of the sequence. Each letter sequence is placed to the right of its corresponding place name (As shown in the Formula 1, specific examples are shown in in Table 1).
In equations 1, L represents the function that maps words to a sequence of letters. represents the i-th place name word. The letter sequence represents the i-th place name word. N represents the number of words contained in an English place name. the prompt word for transliterating proper names.
2) Translation prompt for common names. In the semantic translation of English common names, the semantic translation is related not only to the semantics of the common name itself but also to the contextual information of the place-name category. In the process of translating place names, the category information of place names helps to eliminate the ambiguity of common names [18] [26]. For example, in the Australian place name ’Poatina Golf Course’, the common name ’Course’ can mean road, site, etc. Since the place name category is ’Golf Course’, it can be determined that the meaning of ’Course’ should be site. From the perspective of semantic association of place names, specific names have the function of distinguishing similar place names [15] [27], and have a weaker semantic association with place name categories; while common names have the function of describing place name categories and have a stronger semantic association with place name categories [28]. In the process of translating common names, place name category information has the function of eliminating the ambiguity of common names. Therefore, this study selects the category information of place names as the prompt for the semantic translation of common names (As shown in the Formula 2, specific examples are shown in C in Table 1).
In equations 2, C represents the category of English place names. represents the prompt words for generic translation.
3.2. Construction of Translation Prompt Words for Derived Place Names
Based on phonetically translating specific names and semantically translating generic names, the translation of the derived parts needs to be consistent with the translation of the original place names. Therefore, this study adopts a knowledge graph-enhanced approach, retrieving relevant information from the knowledge graph of derived place names as a prompt for the place name to be translated (As shown in Figure 2 below). Therefore, the construction of knowledge-enhanced derived place name translation prompts is roughly divided into two steps: the construction of the derived place name knowledge graph and the construction of the derived place name translation template.
1) Construction of a derived place name knowledge graph. According to the requirements of the derived place name translation task, this study adopts a top-down approach [29,30] to construct a derived place name knowledge graph, which is roughly divided into two steps: ontology design and entity filling. (1) Ontology design (As shown in the Figure 3). This study selects OWL as the ontology knowledge description framework for the derived place name knowledge graph. i) Class definition. This study chooses derived place names, original place names, fully derived parts, generic derived parts, and fully derived parts as classes of the derived place name knowledge graph. ii) Definition of relationship. Based on the types of place name derivation relationships, this study selects fully derived relationships, generic derived relationships, and specific name-derived relationships as object properties of the derived place name knowledge graph. These derived relationships are directional and asymmetric (pointing from original place names to derived place names). iii) Definition of attributes. This study selects the source language name and the target language name as data attributes for each class, the data attribute domain being each class, and the range being ’xsd: language’ (As shown in Table 2). (2) Entity filling. This study adopts a machine learning-based method to identify place name derivation relationships [31,32] to extract the corresponding entities and relationships from the vector data of geographical entities in the target area. The example of the English Chinese translation effect of place names in the bilingual map field is shown in Table 5.
2) Construction of derived place name translation prompt. In the process of translating place names, in order to maintain the semantic relationship between the original and derived place names in the source language. This study combines the characteristics of derived place names and adopts the strategy of ’identify first, enhance later’ to construct translation prompt words for derived place names. This method first uses a derived place name knowledge graph to recognize derived place names, and then adds translation prompts for derived place names based on the recognition results to enhance the translation effect of derived place names. Therefore, the prompt word engineering for derived place name translation mainly consists of two parts: derived place name discrimination information and derived place name translation prompt, and its specific examples are shown in Table 3 below.
(1) Derived place name discrimination information prompt. In the process of translating place names, there are significant differences in translation strategies between ordinary place names and derived place names. To enable the large language model to distinguish the translation strategies of these two, this study uses the results of derived place name discrimination as prompt words for derived place names. In this regard, this study first uses knowledge retrieval to search for relevant derived information of the input place name from the derived place name knowledge graph. Then, based on the search results, it is determined whether the place name to be translated is a derived place name. If there is relevant derived information about the place name, it is judged as a derived place name. Otherwise, it is a regular place name (As shown in Equation 3).
In formula 3, represents the prompt word for the recognition result of derived place names.
(2) Translation prompt for derived place names. Based on the semantic correlation with the derived parts of the English place name to be translated, this study selects the relevant information of the derived parts, patterns, and derivative relationship type as the prompt words for the derived place name (As shown in Equation 4). i) Derived part prompt. From a semantic association perspective, compared to native place names, derived parts contain less noise information. In the encoding stage, English derived parts can enhance the semantic features of the derived parts in the English place names to be translated. At the same time, in the decoding stage, the Chinese derived part can enhance the semantic features of Chinese place name words and the accuracy of their mapping results (As shown in Figure 4). Therefore, this article selects the English derived part and the Chinese derived part as prompt words for translating derived place names. ii) Derivative mode prompt. In the derivation relationship of place names, the derived pattern (derived place name category and native place name category) has a strong semantic correlation with the derived part. Therefore, this study adopts the derived pattern of derived place names as Prompt to enhance the semantic features of the derived part in the encoding stage (As shown in Figure 4). Due to the inclusion of category information for derived place names in the regular place name prompt, this study added native place name category information to the derived place name translation prompt. iii) Derivation relationship category prompt. Different translation strategies need to be adopted for derived place names with different derivative relationships during the translation process. To enable the large language model to learn translation strategies for derived place names under different derived relationships, this study selects the category of derived relationships as the prompt words for translating derived place names.
In the Formula 4, represents a derived place name translation prompt word. represents the derived part of English place names. represents the translation result of the English derived part. represents the category of the original place name. represents the type of derived relationship between place names.
4. Discussion
The experimental data is sourced from the Australian and American place name data on the Geoname official website, with a total of 30 069 English place name data. The English-Chinese place name translation supervision dataset was provided by the "Global Geographic Information Resource Construction and Maintenance Update" research group of the China Academy of Surveying and Mapping. The experiment is mainly divided into the prompt-based translation of ordinary place names and derived place name experiment. The experimental environment and parameters for these two experiments are shown in Table 4. In addition, the Bart model has an epoch of 40 and a batch size of 32, while the LLM model has an epoch of 15 and a batch size of 4. All experimental indicators are Rouge-1, Rouge-2, Rouge-L, and Bleu-2 (As shown in Equation 5 6 7 8).
In Formula 5 6 7 8, S represents the reference text. represents . represents . represents the number of matches in the candidate summary. represents the number of appearing in the reference summary. represents the length of the longest common sequence. refers to the precision of n-grams. refers to the weight of n-grams. c represents the length of the machine translation translation. r represents the length of the reference translation.
1) Translation of ordinary place names
The translation experiment of ordinary place names used 20 000 Australian English Chinese place name translation data. The experimental data is used to construct the training set, validation set, and test set in an 8:1:1 ratio. In the experiment, this study used the traditional pipeline-style place name translation method as the control group, selected word sequences, and place name categories from different locations as prompt words for comparative experiments. In order to compare the accuracy of place name translation between the experimental groups, Bleu is selected as the comprehensive evaluation indicator for this experiment. The experimental results are shown in Table 5 below.

Table 5.
Translation experiment of ordinary place names.
| ModelName | Rouge-1 | Rouge-2 | Rouge-L | Bleu-2 | Lift |
|---|---|---|---|---|---|
| Basepipeline | 71.99% | 55.96% | 69.94% | 60.50% | |
| ChatglmBase | 84.14% | 71.53% | 84.02% | 75.87% | 15.37% |
| ChatglmLSrd | 86.76% | 74.16% | 86.73% | 79.14% | 18.64% |
| ChatglmCLSrd | 88.37% | 77.46% | 88.32% | 81.76% | 21.26% |
| ChatglmCLSprefix | 87.71% | 76.26% | 87.68% | 80.22% | 19.72% |
| BartCLSrd | 85.07% | 73.94% | 84.98% | 77.93% | 17.43% |
- Basepipeline represents traditional pipeline style place name translation method;
- The subscript Base indicates that no prompt is added;
- Chatglm represents the ’Chatglm-6b’ large language model;
- Bart represents ’Bart-base’ pre-trained language model;
- The subscript LSrd indicates adding the letter sequence of the word to the right side of the word;
- The subscript CLSpre f ix uses the letter sequence of all words as the prefix of the entire input place name and adds the place name category;
- The subscript CLSrd indicates adding the letter sequence of the word to the right side of the word while also adding the place name category.
In Table 5, the experimental groups and showed that adding word letter sequences to the right of place name words improved the English Chinese place name translation effect by 3.27%. The experimental groups and showed that adding place name category prompt words improved the English Chinese place name translation effect by 2.62%. and indicate that the method of using word sequences located on the right side of words as place name prefixes has better place name translation performance compared to using the entire word letter sequence as a place name prefix. The experimental groups and demonstrate that compared to traditional pre trained models, large language models have higher performance in place name translation tasks. Compared with other experimental groups, indicates that the place name translation method based on Prompt learning has better performance than the pipeline based place name translation method, with the best performance achieved by using place name categories and word letter sequences located on the right side of words. The example of the English Chinese translation effect of place names in the bilingual map field is shown in Table 6 and Figure 5.
2) Derived place name translation experiment
The derived place name translation experiment used 10 069 American place name data. The ratio of positive and negative case data is 1:1, with positive case data being derived from place-name data and negative case data being ordinary place-name data. The experimental dataset is constructed with a ratio of 7:1.5:1.5 for the training set, validation set, and testing set. In this experiment, the method of selecting place name categories and word letter sequence information as prompt words were used as the control group, and prompt words composed of different derived place name-related information were compared and studied. To compare the performance of place name translation among different experimental groups, Bleu was selected as the comprehensive evaluation index for each experimental group in this experiment. The experimental results are shown in the Table 7.
In Table 7, the experiments of and show that compared to traditional pipeline-based derived place name translation methods, the method based on large language models has a performance improvement of 23.83%. Compared with the group, other experimental groups showed that adding derived place name-related information as prompt words can improve the translation effect of derived place names by an average of 27.70%. In multiple experiments, the experimental group showed the best performance, with both derived parts, derived part translation results, derived place name recognition information, original place name category information, and other prompt words, demonstrating the best performance in derived place name translation tasks. But overall, the experimental group using derived part-related information as prompt words performed slightly better in derived place name translation tasks than the experimental group using original place name-related information as prompt words. The former has a slightly higher average performance than the latter by 0.39%. Among the experimental groups, the experimental group that utilized derived part translation results, derived place name discrimination information, and place name categories had the relatively best performance. The experiment shows that the method of using derived place name-related information as prompt words in this article can effectively improve the translation performance of derived place names. The example of the English Chinese translation effect of place names in the bilingual map field is shown in Table 8 and Figure 6.
5. Conclusions
In order to improve the accuracy of English-Chinese place name translation, this study proposes a place name translation method based on prompt learning. Experiments have shown that this method effectively improves the performance of English-Chinese place name translation, and it helps to enhance the accuracy and efficiency of the translation quality of geographical names in the field of bilingual map production. However, in the process of translating place names between English and Chinese, the translation of place name words also needs to refer to existing translation results, as well as consider local customs, mineral resources, myths and legends, religion, and other cultural and geographical information. In this regard, in the future, efforts will be made to improve the accuracy of place name translation through few-shot learning and the integration of local cultural and geographical information into place name knowledge maps.
Author Contributions
Conceptualization, Liu Hanyou; methodology, Liu Hanyou; software, Liu Hanyou; validation, Liu Hanyou ; formal analysis, Liu Hanyou; investigation, Liu Hanyou; resources, LiuHanyou and Mao Xi.; data curation, Liu Hanyou; writing—original draft preparation, Liu Hanyou; writing—review and editing, Liu Hanyou; visualization, Liu Hanyou; supervision, Mao Xi; project administration, Mao Xi; funding acquisition, Mao Xi. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key Research and Development Program of China (2023YFF0611901) and the Exploration of Global Intelligent Positioning of Multilingual Place Names (AR2412)
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang Chunju, Zhang Xueying, J.L.W.H. Relation Mapping Between Generic Terms of Place Names and Geographical Feature Types. Geomatics and Information Science of Wuhan University 2011, 36, 857–861.
- Qida, X.; Shuping, W.; Linna, Z.; Senquan, P.; Jun, Z.; Yang, H.; Jing, L.; Shuo, T. Guidelines for the Chinese Transliteration of Foreign Geographical Names: English; General Administration of Quality Supervision, Inspection and Quarantine of the People’s Republic of China; Standardization Administration of China, 2008.
- bocheng, H. Exploration of Derived Place Names and Their Translation Methods. China Terminology 2016, 18, 5–8.
- Hanyou, L. Automatic Recognition and Translation Method for English Derived Place Names for Global Mapping. Master’s thesis, Liaoning Technical University, 2022.
- Yiping, C. Application and Research of Large Models in Natural Language Processing. China Science and Technology Journal Database Industrial A 2023, pp. 057–061.
- Zhu, W.; Zhou, H.; Gao, C.; Liu, S.; Huang, S. Research Development of Machine translation and Large Language Model. In Proceedings of the Proceedings of the 22nd Chinese National Conference on Computational Linguistics (Volume 2: Frontier Forum), 2023, pp. 30–39.
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. arXiv preprint 2019.
- Jiang, Z.; Zhang, Z. Can ChatGPT Rival Neural Machine Translation? A Comparative Study. arXiv preprint 2024.
- Chen, Y. Enhancing Machine Translation through Advanced In-Context Learning: A Methodological Strategy for GPT-4 Improvement. arXiv preprint 2023.
- Moslem, Y.; Haque, R.; Way, A. Adaptive Machine Translation with Large Language Models. arXiv preprint 2023.
- Gete, H.; Etchegoyhen, T. Promoting Target Data in Context-aware Neural Machine Translation. arXiv preprint 2024, [arXiv:cs.CL/2402.06342].
- Zhang, X.; Rajabi, N.; Duh, K.; Koehn, P. Machine Translation with Large Language Models: Prompting, Few-shot Learning, and Fine-tuning with QLoRA. In Proceedings of the Proceedings of the Eighth Conference on Machine Translation. Association for Computational Linguistics, dec 2023, pp. 468–481. [CrossRef]
- Xu, H.; Sharaf, A.; Chen, Y.; Tan, W.; Shen, L.; Durme, B.V.; Murray, K.; Kim, Y.J. Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation. arXiv preprint 2024, [arXiv:cs.CL/2401.08417].
- Yan Wen, Mao Xi, Q.S.M.W.Y.H.; Deqin, L. Research on Distinguishing Common and Proper Names in Machine Translation of Foreign Language Place Names. Surveying Geographic Information 2021, 46, 118–121. [CrossRef]
- Yunpeng, Z.; Xingui, L.; Huabiao, S.; Zheng, W.; Shaolong, M. A Fast Transliteration Method for Russian Place Names. Surveying and Spatial Geographic Information 2016, 39, 47–49+55.
- Yan Wen, Liu Deqin, M.X.M.W.; Hongmei, Y. Research on the Transliteration Technology of Place Names in Machine Learning. Geodesy and Geomatics 2019, 44, 87–92. [CrossRef]
- Xi, M.; Wen, Y.; Weijun, M.; Hongmei, Y. Attention based English Place Name Machine Translation Technology. Surveying Science 2019, 44, 296–300+316. [CrossRef]
- Ren, H.; Mao, X.; Ma, W.; Wang, J.; Wang, L. An English-Chinese Machine Translation and Evaluation Method for Geographical Names. ISPRS International Journal of Geo-Information 2020, 9. [CrossRef]
- Ying, W.; Ying, H. Research on the Chinese Translation of English Place Names from the Perspective of Functional Equivalence Theory. English teacher 2019, 19, 100–102.
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Computing Surveys 2023, p. 1–35. [CrossRef]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 320–335.
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jan 2020. [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.
- Kessler, B.; Treiman, R. The Relationship between Sound and Letter in English Monosyllabia. Journal of Memory and Language 2001, 44, 592–617. [CrossRef]
- Gibson, E.J.; Pick, A.; Osser, H.; Hammond, M. The Role of Grapheme-Phoneme Correspondence in the Perception of Words. The American Journal of Psychology 1962, 75, 554–570. [CrossRef]
- Kaichen, C.; Xing, L.; Yihong, Y.; Runqiang, L.; Yu, L. Type Representation and Management in Digital Place Names Dictionary. Geography and Geographic Information Science 2009, 25, 6–11.
- Ubaydullayeva, M. Semantic Peculiarities of Proper Nouns in English and Uzbek. Academic Research in Modern Science 2024, 3, 65–67.
- Gan, C. Matching Algorithm for Chinese Place Names by Similarity in Consideration of Semantics of General Names for Places. Acta Geodaetica et Cartographica Sinica 2014.
- Zhenyu, W.; Junjie, X.; Baohua, H.; Kui, W.; Jia, L.; Zhen, R. Research on Construction and Application of Regulation of the Multiple Energy Systems Based on Knowledge Graph. 2022 First International Conference on Cyber-Energy Systems and Intelligent Energy (ICCSIE) 2023, pp. 1–6. [CrossRef]
- LiuQiao.; Liyang.; DuanHong.; LiuYao.; QinZhiguang. Knowledge Graph Construction Techniques. Journal of Computer Research and Development 2016, 53, 582.
- Hanyou, L.; Xi, M. Recognition of Derived Semantic Relationships in Geographic Entity Generic Names. Preprints 2024. [CrossRef]
- Hanyou, L.; Jizhou, W. A Method for Identifying Proper Noun Derivative Semantic Relationships for Geographic Entities. Preprints 2024. [CrossRef]
Figure 1.
A place-name translation framework based on prompt learning.
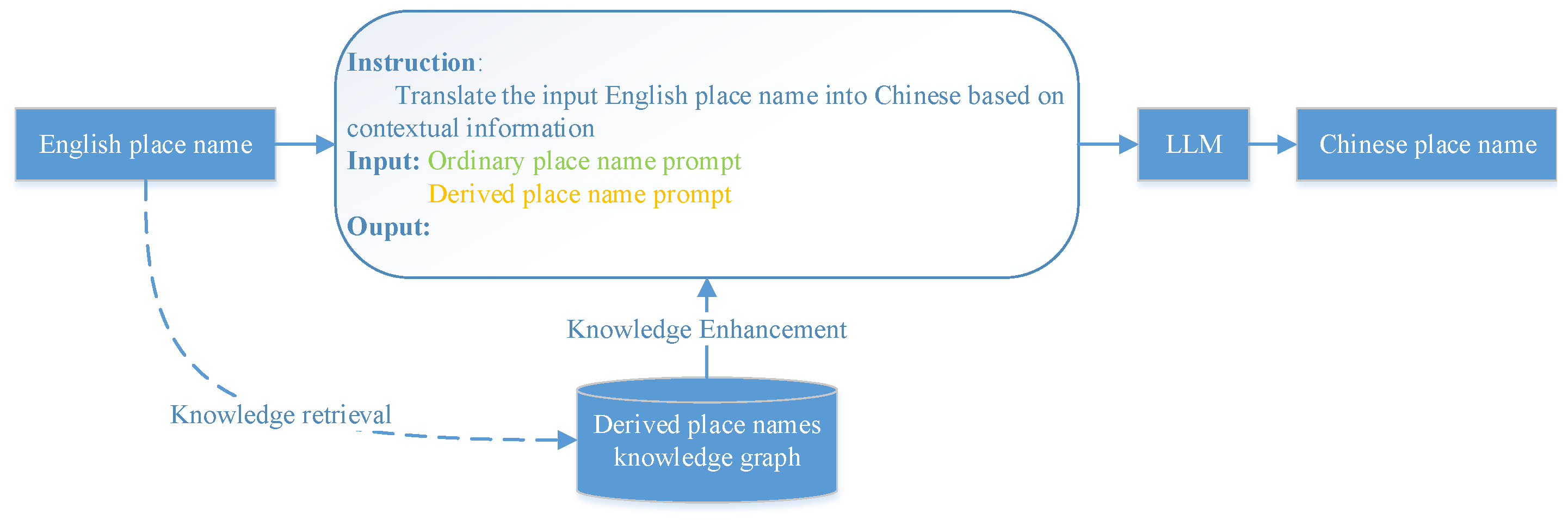
Figure 2.
Enhanced knowledge graph of derived place names.

Figure 3.
The classes and relationships of derived geographical names knowledge graph. In Figure 3, circles represent classes and lines represent relationships.
Figure 3.
The classes and relationships of derived geographical names knowledge graph. In Figure 3, circles represent classes and lines represent relationships.
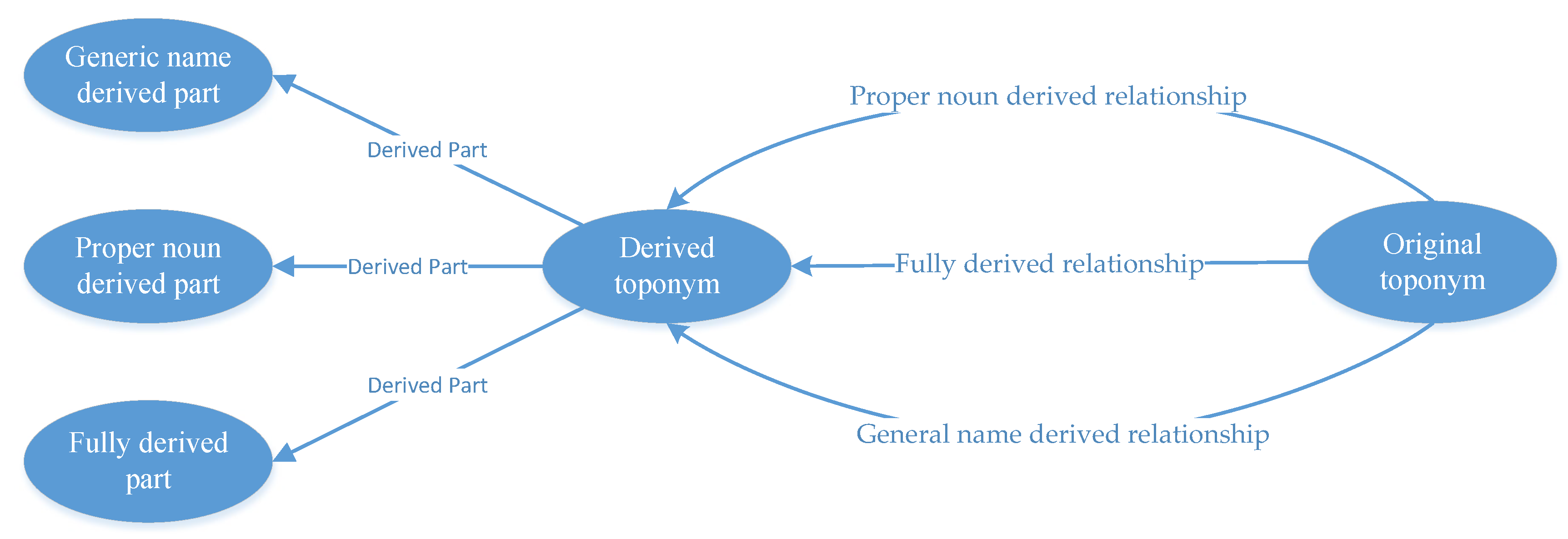
Figure 4.
Translation prompt words for derived place names. In Figure 4, the green square indicates the derived part prompt. The yellow square indicates the derived mode prompt. The gray square indicates the derivation relationship category prompt.
Figure 4.
Translation prompt words for derived place names. In Figure 4, the green square indicates the derived part prompt. The yellow square indicates the derived mode prompt. The gray square indicates the derivation relationship category prompt.
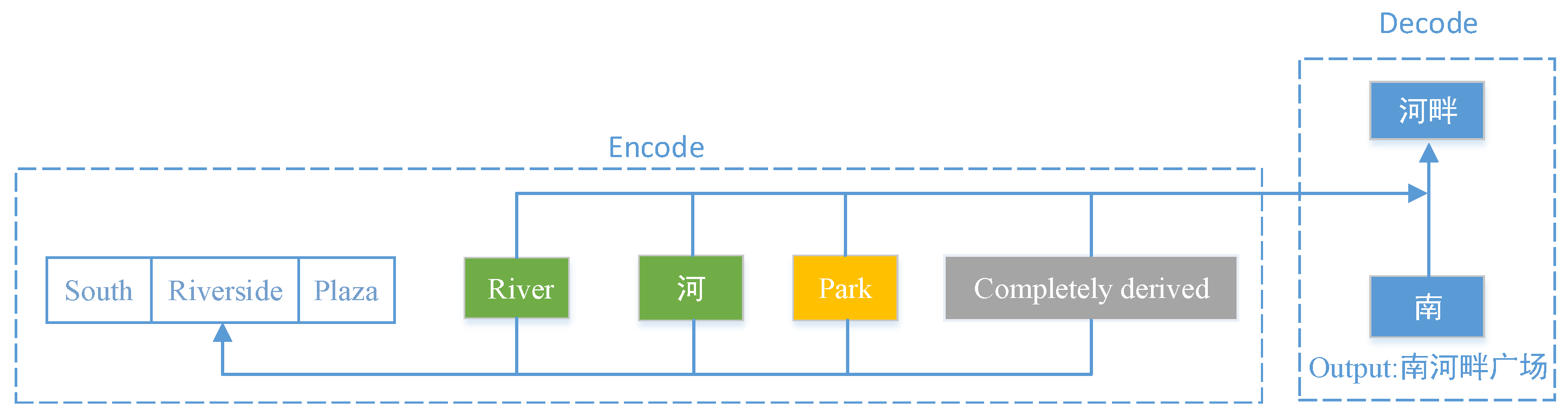
Figure 5.
Translation results of ordinary place name entities.
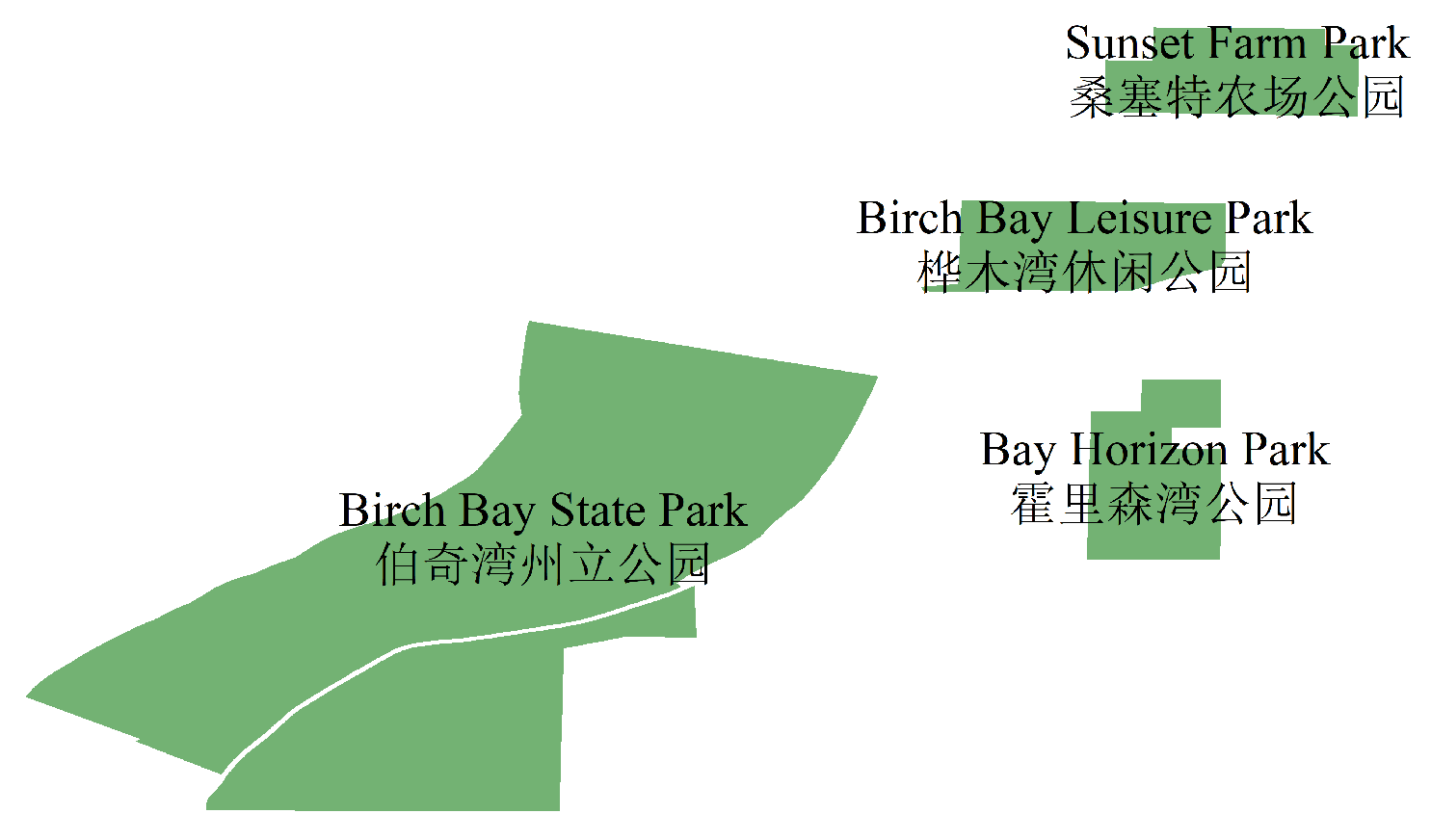
Figure 6.
Translation results of derived place name entities.
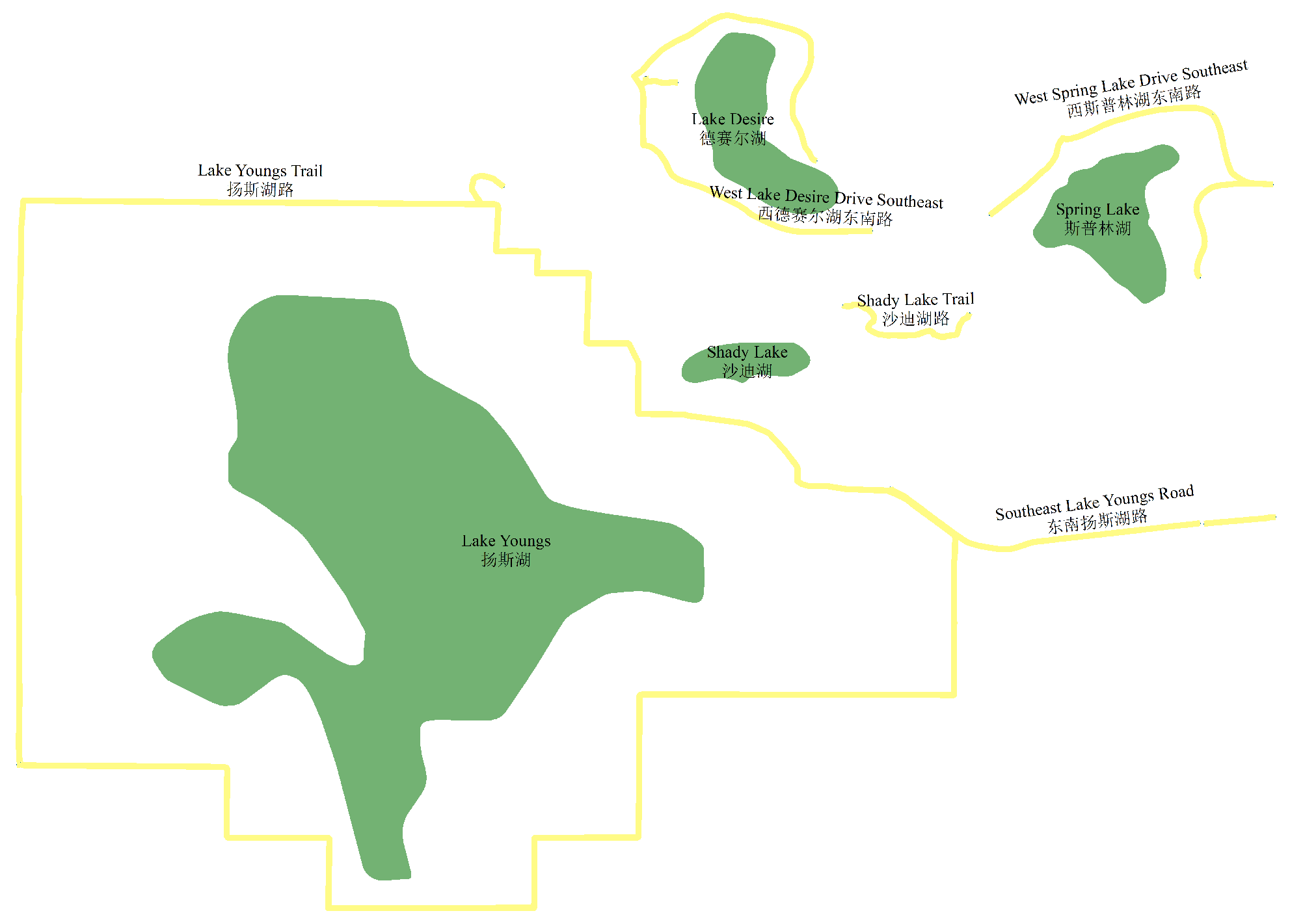
Table 1.
Prompt for joint translation of common and specific names.
| Template | English place name words and their letter sequences is [LS]. |
| The category information of geographic name is [C]. | |
| LS | Elder < E l d e r > Hill < H i l l > |
| C | Mountain |
In Table 1, is a prompt word for transliterating specific names. C is a prompt word for translating generic names.
Table 2.
Definition of attributes.
| Domain | Data Property | Range |
|---|---|---|
| Original toponym | Source language name | xsd:language |
| Derived toponym | ||
| Generic name-derived part | ||
| Proper noun-derived part | Target language name | |
| Fully derived part |
In Table 2, Each category has data attributes ’Source language name’ and ’Target language name’, both of which have a value range of ’xsd: language’.
Table 3.
Translation prompt words for derived place names.
| Derived toponym | Jackson Park Road | Stringybark Forest Reserve |
|---|---|---|
| Template | Is this a derived toponym? The answer is [DI]. | |
| The derived type is [DT]. | ||
| The derived part is [DP]. | ||
| The translation result of the derived part is [DPT]. | ||
| The original place name is [OP]. | ||
| The translation result of the original place name is [OPT]. | ||
| The category of native place names is [C]. | ||
| DI | Yes | No |
| DT | Completely derived | |
| DP | Park | |
| DPT | 公园 | |
| CO | Park | |
In table 3, , , , , and are placeholders for prompt words. DI forms the prompt words for identifying derived place names, while , , , and form the prompt words for translating derived place names.
Table 4.
Experimental environment and model parameters.
| Parameter Name | Parameter Values |
|---|---|
| Graphics card type | V100 32G |
| Programming language | Python 3.10.10 |
| Deep learning framework | Paddlepaddle 2.6.2 |
| Model training parameters | Learning rate: 1e-5, Max_length: 300, |
| Weight_decay: 1e-1 | |
| Lora fine-tuning parameters | Target_modules: ’.*query_key_value.*’, R: 128, Lora_alpha: 16*128 |
Table 6.
Translation results of derived place names.
| English Original Place Names | Geographical name category | China Original Place Names |
|---|---|---|
| Birch Bay Leisure Park | Park | 桦木湾休闲公园 |
| Bay Horizon Park | Park | 霍里森湾公园 |
| Birch Bay State Park | Park | 伯奇湾州立公园 |
| Sunset Farm Park | Park | 桑塞特农场公园 |
Table 7.
Derived place name translation experiment.
| ModelName | Rouge-1 | Rouge-2 | Rouge-L | Bleu-2 | Lift |
|---|---|---|---|---|---|
| Basepipeline | 60.28% | 46.61% | 59.05% | 42.93% | |
| LLMbase | 71.99% | 55.96% | 69.94% | 60.50% | 23.83% |
| LLMdpt_dt_di | 78.85% | 61.84% | 78.69% | 68.71% | 25.78% |
| LLMdp_dpt_dt_di | 81.21% | 66.30% | 81.10% | 71.99% | 29.06% |
| LLMdp_dpt_dt_di_c | 80.36% | 64.75% | 80.14% | 70.92% | 27.99% |
| LLMdp_dpt_di_c | 81.89% | 66.78% | 81.70% | 72.60% | 29.67% |
| LLMdp_dpt_dt_c | 80.80% | 66.10% | 80.64% | 71.91% | 28.98% |
| LLMop_opt_dt_di | 77.41% | 60.94% | 77.20% | 67.98% | 25.05% |
| LLMopt_dt_di | 80.37% | 65.95% | 80.20% | 71.82% | 28.89% |
| LLMop_opt_dt_di_c | 80.75% | 65.61% | 80.55% | 71.77% | 28.84% |
| LLMop_opt_di_c | 80.73% | 65.90% | 80.55% | 71.79% | 28.86% |
- Basepipeline represents the adoption of a pipeline-based derived place name translation method based on statistical models;
- LLM represents large language model (’Chatglm-6b’ large language model);
- base represents only selecting the category of the input place name and the letter sequence of the word located to the left of the place name word as prompt words;
- dpt represents translation results of derived parts;
- dp represents derived parts;
- dt represents derived type;
- di represents derived place name identification information;
- c represents the category information of place names;
- op representing original place names;
- opt represents translation results of original place names.
Table 8.
Translation results of derived place names.
| English Derived Place Names | China Derived Place Names | English Original Place Names | China Original Place Names |
|---|---|---|---|
| Lake Youngs Trail | 扬斯湖路 | Lake Youngs | 扬斯湖 |
| Southeast Lake Youngs Road | 东南扬斯湖路 | Lake Youngs | 扬斯湖 |
| Shady Lake Trail | 沙迪湖路 | Shady Lake | 沙迪湖 |
| East Spring Lake Drive Southeast | 东斯普林湖东南路 | Spring Lake | 斯普林湖 |
| West Lake Desire Court Southeast | 西德赛尔湖东南路 | Lake Desire | 德赛尔湖 |
| East Lake Desire Drive Southeast | 东德赛尔湖东南路 | Lake Desire | 德赛尔湖 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



