
Submitted:
12 November 2024
Posted:
12 November 2024
You are already at the latest version
Abstract
Background and Objectives: The use of Artificial intelligence (AI) and, in particular, Machine Learning (ML) techniques is growing rapidly in the healthcare field. Their application in pharma-cokinetics is of potential interest due to the need to relate enormous amounts of data and to the more efficient development of new predictive dose models. The development of pharmacokinetic models based on these techniques simplifies the process, reduces time and allows more factors to be con-sidered than with classical methods, and is therefore of special interest in the pharmacokinetic monitoring of anti-biotics. This review aims to describe the studies that use AI, mainly oriented to ML techniques, to dose prediction and analyze their results in comparison with the results obtained by classical methods. Furthermore, in the review, the techniques employed and the metrics to evaluate the precision are described to improve the compression of the results. Methods: A sys-tematic search was carried out in the EMBASE, OVID and PubMed databases and the results ob-tained were analyzed in detail. Results: Of the 13 articles selected, 10 were published in the last three years. Vancomycin was monitored in 7 and none of the studies were performed on new an-tibiotics. The most used techniques were XGBoost and neural networks. Comparison was conducted in most cases against population pharmacokinetic models. Conclusion: AI techniques offer prom-ising results. However, the diversity in terms of the statistical metrics used and the low power of some of the articles make the overall assessment difficult. For now, AI-based ML techniques should be used in addition to classical population pharmacokinetic models in clinical practice.
Keywords:
pharmacokinetics
; artificial intelligence
; machine learning
; therapeutic drug monitoring
; antibiotics
1. Introduction
Artificial intelligence (AI) is a rapidly growing and highly useful area when working with large amounts of data. For this reason, it is being rapidly developed and implemented to automate decision-making in health systems [1,2]. The digital transformation in healthcare has been promoted in recent years by global institutions [3].
Automatic learning techniques, also known as Machine Learning (ML), constitute a field of statistical research within AI whose objective is the formation of computational algorithms that divide, classify and transform a data set to maximize the capacity to classify, predict, group, or discover patterns.
In the area of pharmacology, the application of ML is being explored in several fields: pharmacokinetics/pharmacodynamics (PK/PD) and dose optimization [4,5], relationship between structure and pharmacological activity [6,7,8], prediction of adverse effects [9,10,11], prediction of drug interactions [12,13] and simulation of clinical trials [14,15]. The most explored field so far has been the relationship between structure and biological activity. However, the area of PK/PD and dose optimization is progressing [16].
The use of ML in PK is mainly focused on pharmacokinetic modeling and dose adjustment based on this approach [2,17]. The primary purpose of studying the PK/PD characteristics of a biologically active product is to deduce significant correlations between measurable variables (e.g., drug concentration) and the response [18]. The optimization of the model is often based on an accumulation of trial-error tests through which changes are made and adjusted again until it is optimized [19]. This is a perfect scenario for the implementation of AI techniques, with the aim of automating the iterative process of building the model. Growing access to big data in recent years has increased the interest in using ML directly for predictions. Starting from large databases from which the ML learns, it is able to establish relationships between different parameters that can influence the variability of the observed concentration and estimate it correctly [20].
ML has the advantage of being fast, efficient, and able to handle large data sets so can be used to identify complex relationships [21]. This is of particular interest for the development of predictive dose models for newly developed drugs [22]. In the other hand, physiologically based biopharmaceutics models (PBPK) are based on biological mechanisms, facilitating mechanistic understanding, biological interpretability of results, and the ability to conduct in silico experiments using model simulations. In this sense, ML carries the inherent risk of producing clinically irrelevant results. For all these reasons, it seems that the key is to combine these two disciplines and work together, taking advantage of the benefits that each of them offers [23].
PK are especially useful and necessary for therapeutic monitoring of antimicrobial drugs, in which effectiveness and toxicity depends in most cases on the concentration of the drug [24,25,26]. Due to the widespread emergence of antimicrobial resistance, the optimal use of both common and newly developed antibiotics is of vital importance [27,28,29]. With the aim of reducing the appearance of resistance and extending its useful life, pharmacokinetic monitoring is a tool that should be used in clinical practice whenever possible. The need for rapid development of new antibiotics means that in many cases it is not possible to develop pharmacokinetic models of all of them in time, so ML techniques would have special relevance in this field [30,31].
In this review, we aim to analyze the evidence for the use of AI and ML techniques in the pharmacokinetic modeling and therapeutic drug monitoring of antimicrobials. As well as evaluate the accuracy and precision in comparison with conventional monitoring techniques. This is the first review carried out on this topic and, consequently, it will help to understand the current paradigm of the use of these techniques in pharmacokinetic model of antibiotics and clarify their potential.
2. Results
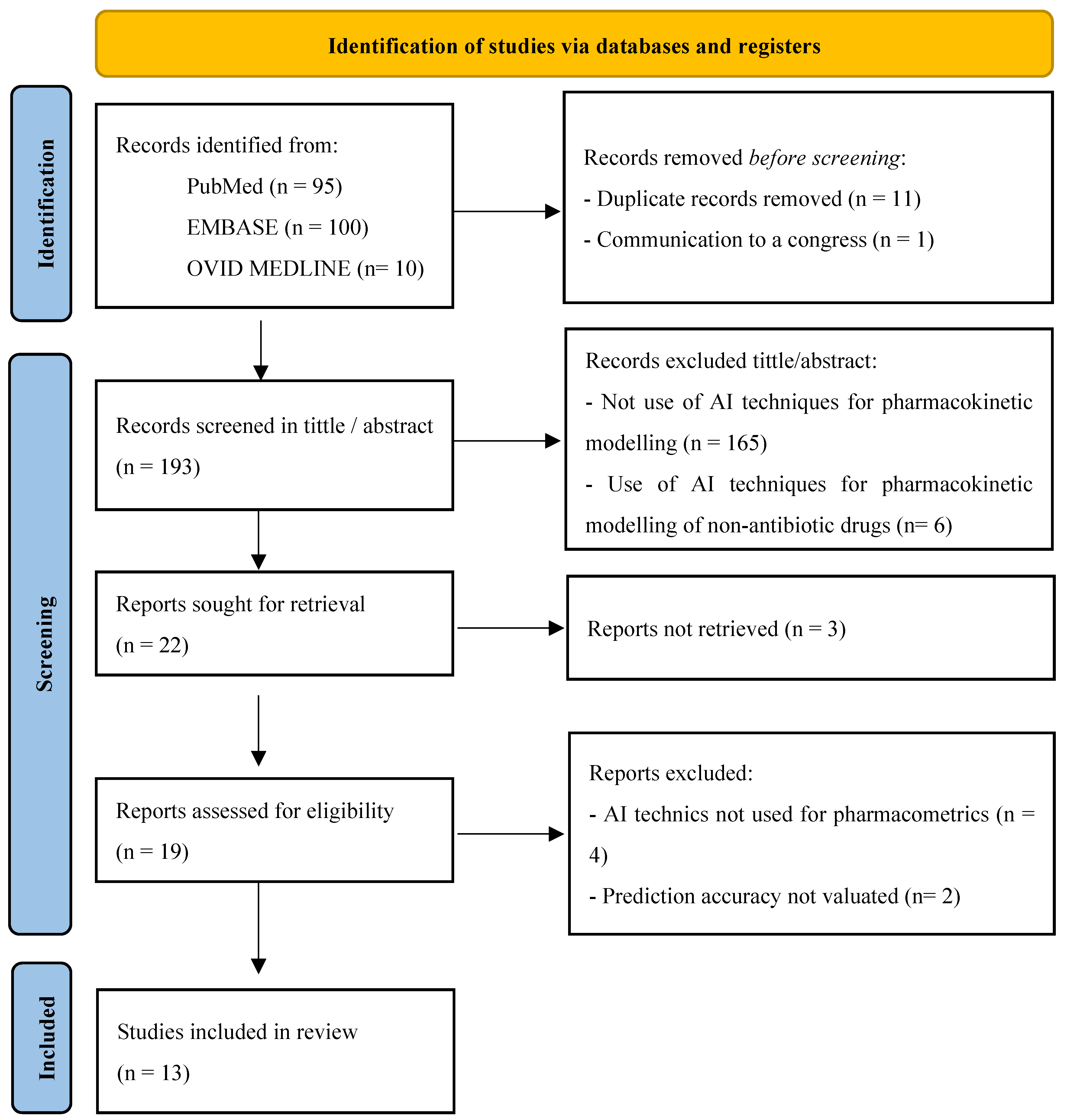
The PRISMA flowchart of the review is shown in Figure 1. In total, 205 publications were identified. After removing duplicates and screening by title/abstract, 183 publications were excluded and 22 were selected for full-text screening. Of these, 3 of them were eliminated because they were not in full text and 5 were subsequently excluded after retrieval, leaving 13 studies for evaluation. All of them were original articles.
2.1. AI and ML Techniques Used for PK Modelling and Dose Prediction
In the studies selected and described in this review a wide variety of ML techniques are used, and, in most cases, they test several of them and then choose the one that performs best or combine them to obtain an ensemble method. In order to clarify and adequately understand the paradigm of the use of AI and ML techniques in the pharmacokinetics of antibiotics, which is the objective of this review, the techniques used are classified and explained below.
First, we need to know that the term AI covers a variety of technologies, methods and algorithms, focusing on different applications. In the field of PK, ML algorithms have been the most studied ones [32]. ML techniques are divided into three main types: supervised learning, unsupervised learning and reinforcement learning. In supervised learning, both the input (e.g., drug dose) and output (e.g., plasma concentration) are known, and the algorithm searches for the mathematical function that best describes the relationship between the two. Unsupervised learning techniques are most applicable when finding subgroups or clusters in large datasets (e.g. patients with a higher probability of developing a certain adverse effect) [33]. Reinforcement learning is a ML training method based on rewarding desired behaviors and punishing unwanted ones. In pharmacometrics, supervised learning algorithms are the most commonly used [16,34].
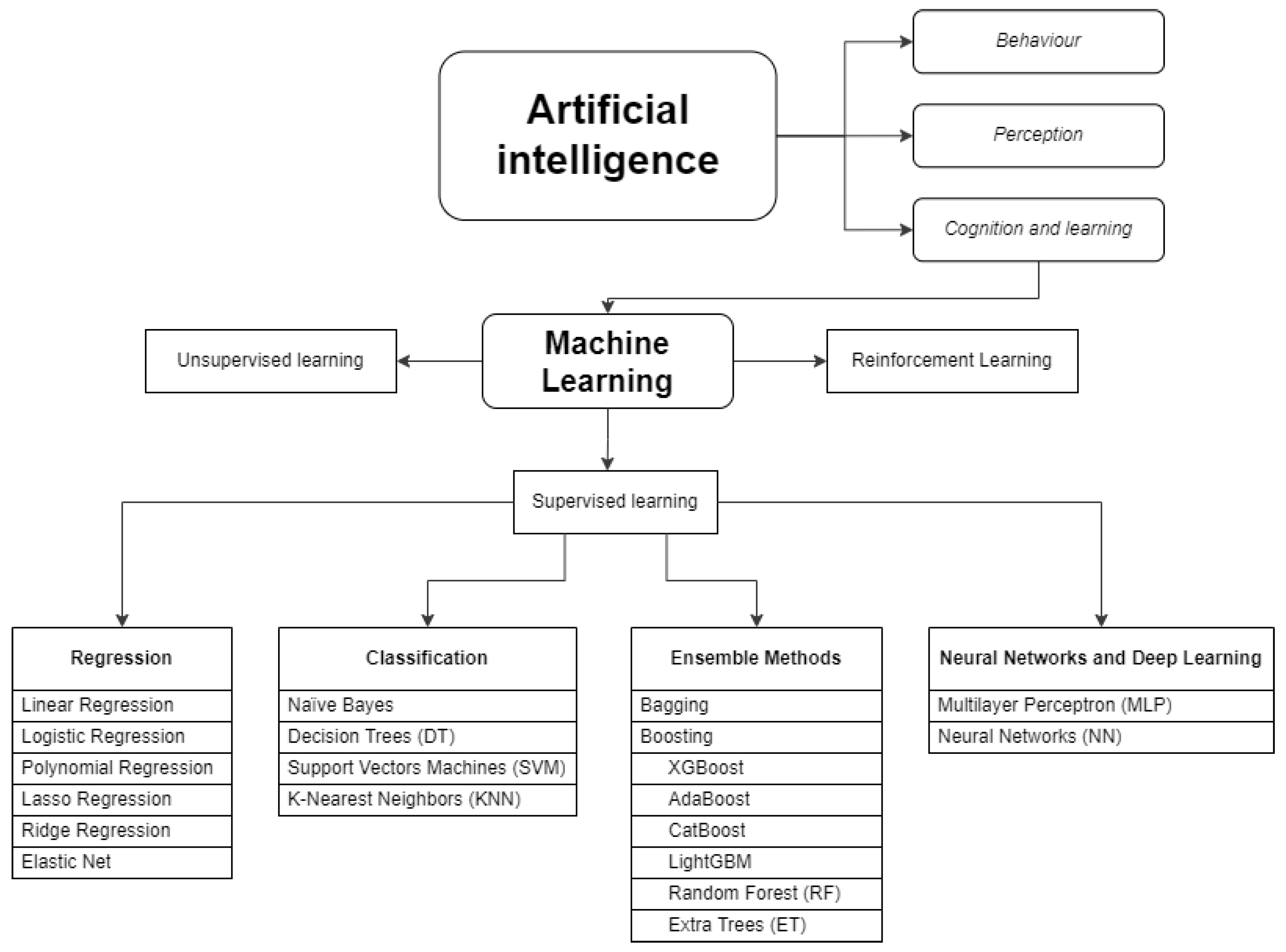
Supervised learning algorithms include regression such as linear, logistic, lasso, ridge, and elastic nets, random forests, support vector machines, k-nearest neighbors, decision trees, naïve bayes, neural networks and gradient boosting algorithms [33,35]. The classification of algorithms is not clear and differs greatly depending on the literature. Furthermore, in many cases the same algorithm can be used for both regression and classification, and in others the final technique used is often the result of a combination of several algorithms. The ML algorithms most used in pharmacokinetic analysis and those that have been used in the articles selected in this review are classified in Error! Reference source not found. and explained in Supplementary Information.
Figure 2.
Artificial Intelligence and Machine Learning techniques classification.
2.2. Evaluation of the Available Data
The selected articles on this review and all the analyzed parameters of each one is depicted in Error! Reference source not found.. Of the 13 articles finally selected, 7 focus on vancomycin dose prediction [36,37,38,39,40,41,42]. Aminoglycosides are the second most used group of antibiotics to test AI techniques, with 3 in total (1 gentamicin, 1 arbekacin and 1 tobramycin)[43,44,45]. Beta-lactams are used in 2 articles (1 of piperacillin and another in which cefepime, azlocillin, ceftazidime and amoxicillin are used) [46,47]. Finally, another article uses rifampicin as an example to evaluate algorithms developed using ML [23].
It is important to highlight that, despite the novelty of the use of AI techniques in pharmacometrics and their special interest in reducing the development times of population PK models for the new antibiotics developed, now these techniques are being tested with the antibiotics for which there is more experience in monitoring by typical pharmacokinetic models, such as vancomycin and aminoglycosides. This fact shows that the use of these techniques is still in a preliminary phase and needs to be compared and validated against conventional pharmacokinetic monitoring techniques.
Another notable aspect is the growing interest in this topic in recent years, with 10 of the 13 articles analyzed published in the last 3 years. This exponential growth is in line with the growing interest in the application of Artificial Intelligence in health systems [1,48] and, also, in the field of clinical PK [35,49].
The studies analyzed that evaluate the capacity of these new techniques in pharmacometrics are studies with a retrospective design based on large volumes of data. Most are carried out on real patients, although some studies are realized on mathematical simulations of patients, either for the development of the method or for its validation [23,36,37]. In most studies, these databases are created from medical records from different hospitals. There are differences in the types of population studied. In 4 of the selected articles, the study population is adult patients who are being treated with the selected antibiotic, without any other specific parameter. A total of 3 works focus on more complex patients admitted to intensive care units (critical, burned or post-surgical patients). One of the articles includes exclusively patients with tuberculosis. It is notable that in 5 of the selected articles the study population included pediatric patients, 3 of them neonates (see

Table 2.
Statistical metrics to evaluate the prediction accuracy of techniques employed. ,
| Metric | Type of statistical metric | Type of evaluation | Definition | Formula | Units | Interpretation |
| Coefficient of determination (R-squared) R² |
regression metric | accuracy or bias | proportion of the total variance of the variable explained by the regression | no units | Represents the proportion of the variance in the dependent variable which is explained by the linear regression model. Values between 0 to 1, where 1 is the best value. |
|
| Prediction error (PE) | difference | accuracy or bias | difference between the predicted and observed concentrations | concentration units | Values between 0 to ∞ A lower PE indicates superior model accuracy |
|
| Prediction error percentage (PE%) | percentage metric |
accuracy or bias | percentage of PE | % | Values between 0 to 100. A lower PE% indicates superior model accuracy |
|
| Absolute prediction error (AE) | difference | accuracy or bias | difference between the predicted and observatory concentrations in absolute values. |
|
concentration units | Values between 0 to ∞ A lower APE indicates superior model accuracy |
| Absolute prediction error percentage (APE or AE%) | percentage metric | accuracy or bias | percentage of APE | % | Values between 0 to 100. A lower APE% indicates superior model accuracy |
|
| Mean prediction error (ME) | media of the difference | accuracy or bias | sum of prediction errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MPE indicates superior model accuracy |
|
| Mean prediction error percentage (MPE or ME%) | percentage metric | accuracy or bias | percentage of MPE | % | Values between 0 to 100. A lower MPE% indicates superior model accuracy |
|
| Mean absolute prediction error (MAE) | media of the difference | precision | sum of absolute errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MAE indicates superior model accuracy. |
|
| Mean absolute prediction error percentage (MAPE or MAE%) | percentage metric | precision | percentage of MAPE | % | Values between 0 to 100. A lower MAPE% indicates superior model accuracy |
|
| Root mean squared error (RMSE) | squared root | precision | It quantifies the differences between predicted values and actual values, squaring the errors, taking the mean, and then finding the square root. It is computed by taking the square root of MSE. | concentration units | Values between 0 to ∞ Lower values indicating better predictive accuracy. |
|
| Root mean squared error percentage (RMSE%) | squared root relative | precision | percentage of the RMSE | % | Values between 0 to 100. A lower RMSE% indicates superior model accuracy. |
|
| Median prediction error percentage (MDPE%) | median | precision | MDPE is found by ordering PE from smallest to largest, and using this middle value |
% | Values between 0 to 100- A lower MDPE indicates superior model accuracy. |
|
| Median absolute prediction error percentage (MDAPE%) | median | precision | MDAPE is found by ordering the APE from smallest to largest and using this middle value. |
concentration units | Values between 0 to ∞ A lower MDAPE indicates superior model accuracy. |
|
| Mean relative error (MRE) | relative ratio | accuracy or bias | MRE was defined as the ratio between MAPE and the reference E-field magnitude within the corresponding target region. | no units |
Values between 0 to 1 |
|
| Mean relative error percentage (MRE% or rMPE) | relative percentage | accuracy or bias | percentage of MRE | % | Values between 0 to 100. A lower MRE% indicates superior model accuracy. |
|
| Square prediction error (SPE) | square of the difference | precision | measures the expected squared distance between what your predictor predicts for a specific value and what the true value | square concentration units | Values between 0 to ∞ A lower SPE indicates a better model. |
|
| Mean square error (MSE) | mean of the difference | precision | squaring the difference between the predicted value and actual value and averaging it across the dataset. | concentration units | Values between 0 to ∞ MSE increases exponentially with an increase in error. A good model will have an MSE value closer to zero. |
|
| relative mean prediction error (RMPE or rMPE) |
relative percentage | accuracy or bias | is a variant of Root MPE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. Lower rMPE shows lower deviation. |
|
| relative root mean squared error (RRMSE or rRMSE) |
relative percentage | accuracy or bias | is a variant of RMSE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. < 10% is an excellent value for RRMSE. > 30 %is a poor value for RRMSE. |
). This last point is especially interesting since one of the postulates of the use of AI and ML techniques in pharmacometrics is the ability to estimate pharmacokinetic parameters a priori (without having previous samples), an aspect that is especially interesting in this subpopulation due to the difficulty for sampling [50,51].
Another relevant aspect when analyzing this type of study is the type of variables included in the model. One of the most promising aspects of using ML techniques is their ability to include large types of variables and study their possible effect on pharmacometrics. In the selected articles, some novel clinical variables are included such as type of infection [45], medications administered during the last year [38], percentage of burned area [44] or numerous analytical parameters that are not common to use in conventional pharmacokinetic models such as albumin, bilirubin, fluid balance, complete blood counts or inflammation parameters [42,46]. However, most studies include more common covariates such as weight, height, race, age or creatinine clearance. The most used AI techniques were approaches XGBoost (5/13) and neural networks (NN) (5/13), followed by decision or regression trees (DT or RT) (4/13) or others such as random forest (RF) (3/ 13) or lasso (2/13). In many of the articles, several techniques are used in the same model.
Many works initially use several methods and finally split the one that allows for better prediction. In others, several approaches are combined to form “ensemble models”. In most of the articles the new models are compared with classic population PK models (11/13), seven of them in NONMEM. In other cases, they are compared against previously published nomograms [40] or by multivariate logistic regression [44].
The metrics used to measure the precision of AI techniques are highly variable throughout the studies analyzed (see
Table 2.
Statistical metrics to evaluate the prediction accuracy of techniques employed. ,
| Metric | Type of statistical metric | Type of evaluation | Definition | Formula | Units | Interpretation |
| Coefficient of determination (R-squared) R² |
regression metric | accuracy or bias | proportion of the total variance of the variable explained by the regression | no units | Represents the proportion of the variance in the dependent variable which is explained by the linear regression model. Values between 0 to 1, where 1 is the best value. |
|
| Prediction error (PE) | difference | accuracy or bias | difference between the predicted and observed concentrations | concentration units | Values between 0 to ∞ A lower PE indicates superior model accuracy |
|
| Prediction error percentage (PE%) | percentage metric |
accuracy or bias | percentage of PE | % | Values between 0 to 100. A lower PE% indicates superior model accuracy |
|
| Absolute prediction error (AE) | difference | accuracy or bias | difference between the predicted and observatory concentrations in absolute values. |
|
concentration units | Values between 0 to ∞ A lower APE indicates superior model accuracy |
| Absolute prediction error percentage (APE or AE%) | percentage metric | accuracy or bias | percentage of APE | % | Values between 0 to 100. A lower APE% indicates superior model accuracy |
|
| Mean prediction error (ME) | media of the difference | accuracy or bias | sum of prediction errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MPE indicates superior model accuracy |
|
| Mean prediction error percentage (MPE or ME%) | percentage metric | accuracy or bias | percentage of MPE | % | Values between 0 to 100. A lower MPE% indicates superior model accuracy |
|
| Mean absolute prediction error (MAE) | media of the difference | precision | sum of absolute errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MAE indicates superior model accuracy. |
|
| Mean absolute prediction error percentage (MAPE or MAE%) | percentage metric | precision | percentage of MAPE | % | Values between 0 to 100. A lower MAPE% indicates superior model accuracy |
|
| Root mean squared error (RMSE) | squared root | precision | It quantifies the differences between predicted values and actual values, squaring the errors, taking the mean, and then finding the square root. It is computed by taking the square root of MSE. | concentration units | Values between 0 to ∞ Lower values indicating better predictive accuracy. |
|
| Root mean squared error percentage (RMSE%) | squared root relative | precision | percentage of the RMSE | % | Values between 0 to 100. A lower RMSE% indicates superior model accuracy. |
|
| Median prediction error percentage (MDPE%) | median | precision | MDPE is found by ordering PE from smallest to largest, and using this middle value |
% | Values between 0 to 100- A lower MDPE indicates superior model accuracy. |
|
| Median absolute prediction error percentage (MDAPE%) | median | precision | MDAPE is found by ordering the APE from smallest to largest and using this middle value. |
concentration units | Values between 0 to ∞ A lower MDAPE indicates superior model accuracy. |
|
| Mean relative error (MRE) | relative ratio | accuracy or bias | MRE was defined as the ratio between MAPE and the reference E-field magnitude within the corresponding target region. | no units |
Values between 0 to 1 |
|
| Mean relative error percentage (MRE% or rMPE) | relative percentage | accuracy or bias | percentage of MRE | % | Values between 0 to 100. A lower MRE% indicates superior model accuracy. |
|
| Square prediction error (SPE) | square of the difference | precision | measures the expected squared distance between what your predictor predicts for a specific value and what the true value | square concentration units | Values between 0 to ∞ A lower SPE indicates a better model. |
|
| Mean square error (MSE) | mean of the difference | precision | squaring the difference between the predicted value and actual value and averaging it across the dataset. | concentration units | Values between 0 to ∞ MSE increases exponentially with an increase in error. A good model will have an MSE value closer to zero. |
|
| relative mean prediction error (RMPE or rMPE) |
relative percentage | accuracy or bias | is a variant of Root MPE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. Lower rMPE shows lower deviation. |
|
| relative root mean squared error (RRMSE or rRMSE) |
relative percentage | accuracy or bias | is a variant of RMSE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. < 10% is an excellent value for RRMSE. > 30 %is a poor value for RRMSE. |
) and not all are used for external validation and comparison with the conventional pharmacokinetic model. Therefore, it is difficult to realize a global evaluation of the results of these techniques compared to conventional models, which makes it impossible to reach a clear result. This limitation had already been previously postulated by Mehdi et al. [52]. However, by analyzing the studies one by one, quite acceptable prediction error values are obtained, consistent with those obtained by conventional methods. In many of them, a numerical reduction in the errors is observed compared to the usual models, without being able to say that the improvement is significant. In all articles, the authors conclude that AI techniques are one more tool that can help improve the prediction of pharmacokinetic parameters and dose prediction, positioning itself for the moment as a complementary technique that can be very useful especially for pharmacometricians with little experience or when a faster analysis is required. The main limitations found in the studies are that some use very small sample sizes and that ML techniques predict worse than conventional methods when it comes to values outside the usual range.
Table 1.
Articles included. ATB: antibiotic, N: number of sample, ML: Machine Learning, XGBoost: extreme gradient boosting, RF: random forest, GBM: Gradient Boosting Machine, LASSO: lasso regression, BMI: body mass index, s-Cr: serum creatinine, CrCl: creatinine clearance, LightGBM: light gradient boosting machine , GLMNET: generalized linear model via penalized maximum likehood, MARS: multivariate adaptative regression splines, KNN: K-nearest neighbors, DT: decision tree, Adaboost: adaptive boosting, ETR: extra tree regressor, GBR: gradient boosting regression (with ridge, lasso or elastic net regularization), CV: cardiovascular, MAA: model averaging approach, MSA: model-selection algorithm, NN: neural networks, GBT: Gradient Boosting Trees, GP: gaussian processes, MLP: multilayer perceptron model, SVR: support vector regression, PCR: C-reactive protein, CART: Classification and regression tree, AST: aspartate aminotransferase, ALT: alanine aminotransferase, GBDT: Boosting decision tree, CatBoost: categorical boosting, LBHM: Light gradient boosting machine, LR: logistic regression , Tabnet: tabular neural network, ANN: approximate nearest neighbor. popPK: population pharmacokinetic model, *Metrics abbreviations explained in Table 2. **PAR: “percentage of dose in the acceptable range” not common metric, defined by the authors of the article.
Table 1.
Articles included. ATB: antibiotic, N: number of sample, ML: Machine Learning, XGBoost: extreme gradient boosting, RF: random forest, GBM: Gradient Boosting Machine, LASSO: lasso regression, BMI: body mass index, s-Cr: serum creatinine, CrCl: creatinine clearance, LightGBM: light gradient boosting machine , GLMNET: generalized linear model via penalized maximum likehood, MARS: multivariate adaptative regression splines, KNN: K-nearest neighbors, DT: decision tree, Adaboost: adaptive boosting, ETR: extra tree regressor, GBR: gradient boosting regression (with ridge, lasso or elastic net regularization), CV: cardiovascular, MAA: model averaging approach, MSA: model-selection algorithm, NN: neural networks, GBT: Gradient Boosting Trees, GP: gaussian processes, MLP: multilayer perceptron model, SVR: support vector regression, PCR: C-reactive protein, CART: Classification and regression tree, AST: aspartate aminotransferase, ALT: alanine aminotransferase, GBDT: Boosting decision tree, CatBoost: categorical boosting, LBHM: Light gradient boosting machine, LR: logistic regression , Tabnet: tabular neural network, ANN: approximate nearest neighbor. popPK: population pharmacokinetic model, *Metrics abbreviations explained in Table 2. **PAR: “percentage of dose in the acceptable range” not common metric, defined by the authors of the article.
| Study | ATB | N |
Subject characteristics |
Objective |
AI technique used |
Clinical parameters involved | Model compared | Precision metrics* | Results | Remarks and conclusions |
| Keutzer et al., 2022 [23] | Rifampicin | 1826 simulations | Tuberculosis patients | To examine the ability of various ML algorithms to predict time-varying plasma concentrations and derive PK parameters | XGBoost, RF, GBM, LASSO | Age, BMI, dose, fat-free-mass, infection by VIH, VIH coinfection, height, treatment week, race, gender, time after dose, weight. | popPK model in NONMEM | R2, RMSE, MAE | -For concentration prediction, the best AI technique was XGBoost using 6 rifampicin concentrations (R2=0,84, RMSE=6,9 mg/L, MAE= 4 mg/L. -For AUC0-24h prediction, the best AI technique was LASSO using 6 rifampicin concentrations (R2=0,97, RMSE: 29.1 h.mg/L, MAE: 18.8 h.mg/L) |
Prediction was according to the PK model. AI was 22 times faster. |
| Wang et al., 2022 [38] | Vancomycin | 2282 real patients | Patients who received at least one vancomycin injection. | To develop an innovative method to suggest the initial and subsequent daily dose of vancomycin. | LightGBM | s-Cr, CrCl, age, weight, gender, age, albumin, medicines on CV system, on alimentary tract or metabolism and on blood forming organs, hemodialysis, daily dose and concentration, administration timing. | popPK model | MAE, PAR** | -Initial dose model: MAE: 450.2 mg/day (AI model) vs 727.5 mg/day (popPK model); PAR: 51,7% (AI model) vs 28,3% (popPK model) -Subsequent dose model: MAE: 267,1 mg/day (AI model) vs 392,1 mg/day (popPK model); PAR: 73,4% (AI model) vs 60,4% (popPK model) |
ML performed better than the popPK model. |
| Bouoda et al., 2022 [36] | Vancomycin | 28 real patients/ 6000 simulations | Obese, critically ill, hospitalized patients with sepsis, trauma and post- heart surgery. | To train a ML algorithm to predict vancomycin AUC from early concentrations and few features and Predict vancomycin AUC from early concentrations | XGBoost | Concentration, s-Cr, age, weight, height, gender, dose, administration timing. | popPK models: MAA, MSA, PKJust program |
rMPE, rRMSE | rMPE 0,97 and rRMSE 12.7% ; when compared with PKJust; rMPE 0,8 and rRMSE 11,9% when compared with MSA; rMPE 1,2 and rRMPE 11,8% with MAA. | XGBoost algorithms seem complementary to standard popPK approaches. |
| Ponthier et al., 2022 [37] | Vancomycin |
82 real patients / 1900 simulations | Term and preterm neonates | To obtain a ML algorithm to estimate the best vancomycin initial dose and compare it to a popPK model previously validated. | XGBoost, GLMNET, MARS | Gestational age, time of infection after birth, post menstrual age at first infection, current weight, s-Cr. | popPK model | rMPE, rRMSE | XGBoost was the best. In the training set, rRMSE was 36.1 and rMPE was 7.2 in the train set. In the test set, rRMSE was 35,7 and rMPE was 8,6. Numerical best target attainment rate was obtained with ML algorithm (35,3% vs 28%). |
ML algorithm improves the exposure target attainment rate. |
| Tang et al., 2021 [47] | Vancomycin, latamofex, cefepime, azlocillin, ceftazidime and amoxicillin | 2272 real patients | Neonates | To evaluate whether the combination of ML methods and popPK methods can accurately predict individual clearance of renally eliminated drugs. | KNN, DT, adaboost, ETR, RF, GBR | Birth weight, current weight, gestational age, postnatal age, postmenstrual age, s-Cr. | popPK model in NONMEM | R2, MSE, MRE% | ETR was selected as the final uniform ML approach. Combined predictive method (popPK + AI) had a MRE of 15,4%, 2,2%, 2,8%, 10,1% and 2% for vancomycin, cefepime, latamoxef, azlocillin amoxicillin and ceftazidime, respectively. Except for azlocillin (9,9% of MRE in the popPK model), all the MRE were lower with the combined method. |
The combination of popPK and machine learning approach provided consistent information. |
| Brier et al., 1995 [43] | Gentamicin | 144 real patients | Patients who received gentamicin in the service of the Veterans Administration Medical Center in Louisville | To use a neural network to predict peak and trough gentamicin concentrations and compare the results with the NONMEM model. | NN | Age, height, weight, s-Cr, CrCl, dose, dose/weight, dose interval, BMI. | popPK model in NONMEM | PE, PE%, SPE, AE, APE (or AE%) | -Gentamicin´s peak: PE was - 0,02 in NN vs 0,14 in NONMEN, PE% was - 2,45% in NN vs 1.04% in NONMEN, SPE was 0,67 in NN vs 0,83 in NONMEN, and APE was 16,5% in NN vs 18,6% in NONMEN. -Gentamicin´s trough: PE was 0.002 in NN vs 0.049 in NONMEN, PE% was - 11,11% in NN vs -14.5% in NONMEN, SPE was 0.58 in NN vs 0.67 in NONMEN, and APE was 48.3% in NN vs 59% in NONMEN. NONMEM was more precise in the prediction of concentration outside the range 2,5-6 µg/ml (p=0,098) |
NN perform well when they are used in the range of concentrations that they have trained. NN has limitations in predicting out-of-range concentrations. |
| Verhaeghe et al., 2022 [46] | Piperacillin | 282 real patients | Surgical critically ill patients treated with piperacillin/tazobactam in continuous infusion. | To use ML model to predict total plasma concentrations of piperacillin in critically ill patients a priori and a posteriori and compare the results with a popPK model. | GBT, GP, MLP | Piperacillin previous concentrations, sex, weight, s-Cr, CrCl, albumin, bilirubin, fluid balance, height, lactate, platelets, red blood cells, sex, hours since start of treatment. | popPK model in NONMEM | PE, MAE, RMSE, R2, MdAPE, MdPE. | -A priori method: RMSE (GBT 34,27; GP 37,41; MLP 38,56; PK 57,97), MAE (GBT 21,55; GP 23,54; MLP 27,35; PK 39,67), ME (GBT -4.09; GP 2.04; MLP 2.58; PL -30.27), MdAPE (GBT 17.29%; GP 21.39%; MLP 23.09%; PL 40.79%), MdPE (GBT 0.06%; GP -3.83%; MLP -5.34%; PK 38.33%) -A posteriori method: RMSE (GBT 32.93; GP 34.03; MLP 37.20; PK 49.58), MAE (GBT 18.22; GP 19.41; MLP 23.64; PK 31.28), ME (GBT -6.55; GP -3.83; MLP -4.87; PK 4.91), MdAPE (GBT 12.75%; GP 16.48%; MLP 17.06%; PK 26.09%), MdPE (GBT 1.77%; GP -376%; MLP 0.73%; PK -1.85%) |
ML models can consistently estimate piperacillin concentrations with high predictive accuracy, especially in a priori method. |
| Huang et al., 2021 [42] | Vancomycin | 407 real patients | Pediatric patients who received vancomycin intravenously | To establish an optimal model to predict vancomycin through concentrations in pediatric patients by using ML. | DT, SVR, RF, Adaboost, Bagging, ETR, GBRT, XGBoost. Then, the best five were selected and perform an "ensemble model" | vancomycin dose concentrations and intervals, age, height, weight, gender, CrCl, uric acid, procalcitonin, PCR, AST, ALT, bilirubin, complete hemogram. | popPK model in NONMEM | R2, MSE, RMSE, MAE | The results of ML were superior to the popPK model. Ensemble model: MSE 34,39, R2 0,614, MAE 3,32, RMSE 4,94. Accuracy of the predicted through concentration (± 30%) was 51,22% in ML model vs 36.59% in popPK model. | The results of ML are better than the popPK model in predicting vancomycin concentration. |
| Yamamura et al., 2004 [44] | Arbekacin (Aminoglycoside used in Japan) |
30 real patients | Burn patients hospitalized in an intensive care unit in Japan. | Use artificial neural network modeling to predict arbekacin plasma concentration and compare with logistic regression analysis. | NN | Dose, parenteral fluid, BMI, CrCl, burn area after operation. | Multivariate logistic regression models | R2 | Artificial neural networks had a r of 0,9862 and logistic regression had a r of 0,8829. | Artificial neural networks were superior compared with logistic regression analysis. |
| Tang et al., 2023 [41] | Vancomycin | 1631 real patients | Neonates and young infants with postmenstrual age ranging from 23.3 to 52.4 weeks | To assess whether ML can be used in clinical practice to predict treatment targets and calculate optimal dosing regimens for individual patients. | GBDT, CatBoost, XGBoost, LBHM, LR, SVR, Tabnet, and ANN | s-Cr, sampling time, single dose per unit body weight, frequency of dosing within 24h, postnatal age, vancomycin concentration assay method, gestational age at birth, birth weight. | popPK model | RMSE, R2, MAPE (or MAE%), MPE (or ME%) | CatBoost was the optimal ML method. For Cmin prediction, RMSE was 5.02 for ML model vs 6.18 for popPK; MAPE was 29.5% for ML model vs 53% for popPK and MPE was -4.20% for ML vs 12.4 for popPK. |
The ML model was developed to be accurate and precise and can be used for individual dose recommendations in neonates. |
| Chow et al., 1997 [45] | Tobramycin | 101 real patients | Pediatric patients who received tobramycin intravenously in Tucson. | To explore the applicability of the neural networks approach to capture the relationship between patient-related prognostic factors and plasma drug levels. | NN: test I (with accumulated times), test II (without accumulated times) | Age, weight, gender, illness, dose, dosing interval, time of blood drawn. | popPK model in NONMEM | MSE, ME, ME% (or MPE), AE% (or APE) | Test I turned out worse than NONMEN. Test II provided precision of the predicted concentrations comparable to that NONMEN analysis: MSE 1,88 NONMEN vs 1,78 NN. AE% was better for NN test II: 33,9% vs 39,9% in NONMEN. ME was smaller in NONMEN (0,077 vs 0,32), PE% was better in NN (2,59% vs 17,3% in NONMEN) | NN could capture the relationships between patient-related factors and plasma drugs levels. |
| Nigo et al., 2022 [39] | Vancomycin | 5483 real patients | Adults who had at least one serum vancomycin level after their first vancomycin dose. Patients with ECMO, hemodialysis, and renal replacement therapy were excluded. | To develop a new PK approach with RNN-based methods with electronic medical record (EHR) to achieve more accurate and individualized predictions for vancomycin serum concentration in hospitalized patients. | NN | Weight, height, vital signs, laboratory biochemistry and complete hemogram, vancomycin dose and previous concentration, concomitant medications. | popPK model in NONMEM (VTDM model) |
RMSE, MAPE (or MAE%), MAE | PK-RNN-V E vs VTDM: RMSE 5,39 vs 6,29; MAE 3,64 vs 4,26; MAPE 25,41% vs 29,15%. | PK-RNN-V E exhibits better RMSE, MAE and MAPE compared to any of the VTDM models. PK-RNN-V E can integrate real-time patient-specific data from an EHR. |
| Miyai et al., 2022 [40] | Vancomycin | 822 real patients | Patients who received vancomycin intravenously and had the concentration measured at least once. | To construct a model for estimating the vancomycin maintenance dose to achieve the target. | CART | Age, BMI, CrCl. | Other nomograms (Oda et al.[53], Thomson et al. [54]) | ME% (or MPE), MAE% (or MAPE) | DT model: ME 10%, MAE 26,7%; Nomogram Oda et al.: ME 0,77%, MAE 26,6%; Nomogram Thomson et al: ME 8,67%, MAE 26,5%. | The constructed model can help construct clinical models for dose setting of initial vancomycin administration. |
2.3. Quality Assessment on Prediction Accuracy of Techniques Employed
To compare the prediction capacity of a pharmacokinetic method based on AI or ML against the conventional population PK model, common statistical metrics used for the external validation of any pharmacokinetic method are applied. These metrics evaluate mainly the accuracy or bias and the precision of the models. There is no consensus on how to appropriately design and interpret external evaluation of pharmacokinetic models. The section dedicated to “model validation” in the FDA's guidelines for industry on population PK, does not contain clear criteria on what tests should be performed, what metrics should be applied or how to interpret them correctly [55]. Furthermore, some guidelines for reporting population PK studies do not consider the issue of external evaluation at all [56,57]. The absence of clear recommendations on how to carry out external validation and comparison of population methods has triggered wide variability in terms of the statistical parameters calculated in the different studies. Therefore, there are significant differences in study design, statistical methods, and reporting, making it very difficult to compare studies and interpret pooled results [52]. This problem is so serious that, in the articles analyzed in this review, we have found several inconsistencies regarding the name or abbreviation used for the statistical metrics used, as well as in the formula used for each of them, an aspect already noted by Meng et al. [58].
With the aim of clarifying this aspect and facilitating the understanding and interpretation of the results obtained in the articles collected in this review, the
Table 2.
Statistical metrics to evaluate the prediction accuracy of techniques employed. ,
| Metric | Type of statistical metric | Type of evaluation | Definition | Formula | Units | Interpretation |
| Coefficient of determination (R-squared) R² |
regression metric | accuracy or bias | proportion of the total variance of the variable explained by the regression | no units | Represents the proportion of the variance in the dependent variable which is explained by the linear regression model. Values between 0 to 1, where 1 is the best value. |
|
| Prediction error (PE) | difference | accuracy or bias | difference between the predicted and observed concentrations | concentration units | Values between 0 to ∞ A lower PE indicates superior model accuracy |
|
| Prediction error percentage (PE%) | percentage metric |
accuracy or bias | percentage of PE | % | Values between 0 to 100. A lower PE% indicates superior model accuracy |
|
| Absolute prediction error (AE) | difference | accuracy or bias | difference between the predicted and observatory concentrations in absolute values. |
|
concentration units | Values between 0 to ∞ A lower APE indicates superior model accuracy |
| Absolute prediction error percentage (APE or AE%) | percentage metric | accuracy or bias | percentage of APE | % | Values between 0 to 100. A lower APE% indicates superior model accuracy |
|
| Mean prediction error (ME) | media of the difference | accuracy or bias | sum of prediction errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MPE indicates superior model accuracy |
|
| Mean prediction error percentage (MPE or ME%) | percentage metric | accuracy or bias | percentage of MPE | % | Values between 0 to 100. A lower MPE% indicates superior model accuracy |
|
| Mean absolute prediction error (MAE) | media of the difference | precision | sum of absolute errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MAE indicates superior model accuracy. |
|
| Mean absolute prediction error percentage (MAPE or MAE%) | percentage metric | precision | percentage of MAPE | % | Values between 0 to 100. A lower MAPE% indicates superior model accuracy |
|
| Root mean squared error (RMSE) | squared root | precision | It quantifies the differences between predicted values and actual values, squaring the errors, taking the mean, and then finding the square root. It is computed by taking the square root of MSE. | concentration units | Values between 0 to ∞ Lower values indicating better predictive accuracy. |
|
| Root mean squared error percentage (RMSE%) | squared root relative | precision | percentage of the RMSE | % | Values between 0 to 100. A lower RMSE% indicates superior model accuracy. |
|
| Median prediction error percentage (MDPE%) | median | precision | MDPE is found by ordering PE from smallest to largest, and using this middle value |
% | Values between 0 to 100- A lower MDPE indicates superior model accuracy. |
|
| Median absolute prediction error percentage (MDAPE%) | median | precision | MDAPE is found by ordering the APE from smallest to largest and using this middle value. |
concentration units | Values between 0 to ∞ A lower MDAPE indicates superior model accuracy. |
|
| Mean relative error (MRE) | relative ratio | accuracy or bias | MRE was defined as the ratio between MAPE and the reference E-field magnitude within the corresponding target region. | no units |
Values between 0 to 1 |
|
| Mean relative error percentage (MRE% or rMPE) | relative percentage | accuracy or bias | percentage of MRE | % | Values between 0 to 100. A lower MRE% indicates superior model accuracy. |
|
| Square prediction error (SPE) | square of the difference | precision | measures the expected squared distance between what your predictor predicts for a specific value and what the true value | square concentration units | Values between 0 to ∞ A lower SPE indicates a better model. |
|
| Mean square error (MSE) | mean of the difference | precision | squaring the difference between the predicted value and actual value and averaging it across the dataset. | concentration units | Values between 0 to ∞ MSE increases exponentially with an increase in error. A good model will have an MSE value closer to zero. |
|
| relative mean prediction error (RMPE or rMPE) |
relative percentage | accuracy or bias | is a variant of Root MPE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. Lower rMPE shows lower deviation. |
|
| relative root mean squared error (RRMSE or rRMSE) |
relative percentage | accuracy or bias | is a variant of RMSE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. < 10% is an excellent value for RRMSE. > 30 %is a poor value for RRMSE. |
shows all the statistical metrics used in the articles analyzed, as well as their possible abbreviations, formula, definition and interpretation. There are different ways to measure errors [59,60]. The simplest is to do it like a difference. Within this type are the prediction error (PE) and the absolute prediction error (AE), which is the same as the previous one but in terms of absolute value. Another widely used possibility is to use square errors (SPE) or root square errors (RMSE). Squaring the error gives higher weight to the outliers, which results in a smooth gradient for small errors. Another way to express them is by calculating the mean (ME, MAE, MSE) or the median (MDE, MDAE) of all the errors in the sample. These errors present units of concentration (squared concentration units in case of SPE or MSE) and the desired value would be the minimum possible. Another way to express the error is to express it relative to the range of the target variable (MRE, RMPE, RRMSE). These types of expression limit the values between 0 and 1, with values closer to 1 being better. Most of these errors can also be expressed as a percentage (PE%, AE%, ME% or MPE, MAE% or MAPE, MDPE%, MDAPE%, MRE%, RMSE%...), presenting values between 0 and 100. Some of these metrics are more focused on the measurement of accuracy or bias and others on precision, as expressed in Error! Reference source not found..
Likewise, there is no consensus regarding the model acceptability criteria once external validation has been carried out. Across all published studies, there is consensus that models accept bias thresholds between -20% and 20% and imprecision thresholds between <30% [61,62]. However, it is not uncommon for each article to use a different model acceptance range or that these are not expressed as a percentage, which in turn makes comparisons between publications very difficult [52].
Figure 3.
Classification of the main metrics for prediction accuracy measurement.
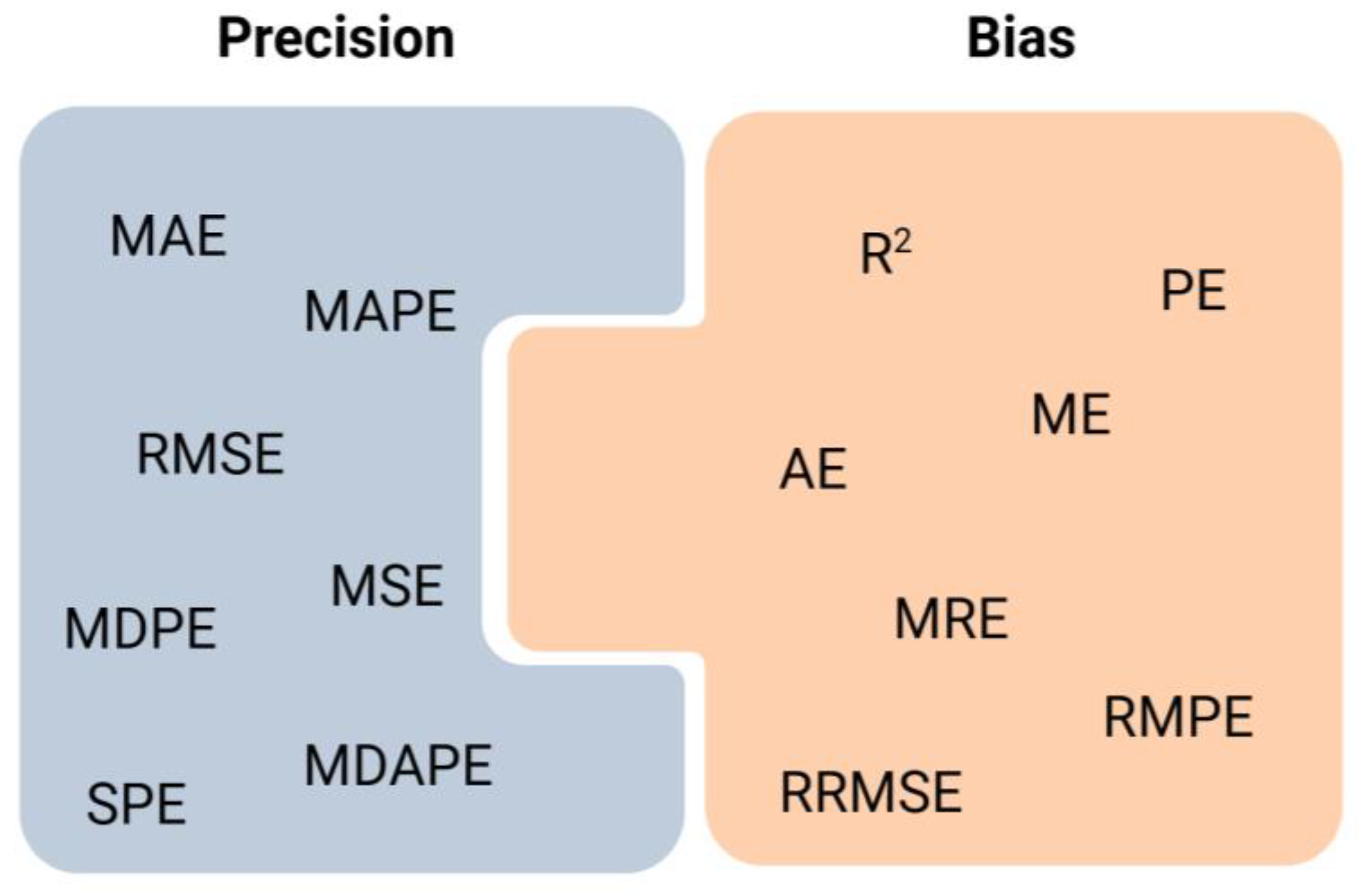
Table 2.
Statistical metrics to evaluate the prediction accuracy of techniques employed. ,
| Metric | Type of statistical metric | Type of evaluation | Definition | Formula | Units | Interpretation |
| Coefficient of determination (R-squared) R² |
regression metric | accuracy or bias | proportion of the total variance of the variable explained by the regression | no units | Represents the proportion of the variance in the dependent variable which is explained by the linear regression model. Values between 0 to 1, where 1 is the best value. |
|
| Prediction error (PE) | difference | accuracy or bias | difference between the predicted and observed concentrations | concentration units | Values between 0 to ∞ A lower PE indicates superior model accuracy |
|
| Prediction error percentage (PE%) | percentage metric |
accuracy or bias | percentage of PE | % | Values between 0 to 100. A lower PE% indicates superior model accuracy |
|
| Absolute prediction error (AE) | difference | accuracy or bias | difference between the predicted and observatory concentrations in absolute values. |
|
concentration units | Values between 0 to ∞ A lower APE indicates superior model accuracy |
| Absolute prediction error percentage (APE or AE%) | percentage metric | accuracy or bias | percentage of APE | % | Values between 0 to 100. A lower APE% indicates superior model accuracy |
|
| Mean prediction error (ME) | media of the difference | accuracy or bias | sum of prediction errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MPE indicates superior model accuracy |
|
| Mean prediction error percentage (MPE or ME%) | percentage metric | accuracy or bias | percentage of MPE | % | Values between 0 to 100. A lower MPE% indicates superior model accuracy |
|
| Mean absolute prediction error (MAE) | media of the difference | precision | sum of absolute errors divided by the sample size. | concentration units | Values between 0 to ∞ A lower MAE indicates superior model accuracy. |
|
| Mean absolute prediction error percentage (MAPE or MAE%) | percentage metric | precision | percentage of MAPE | % | Values between 0 to 100. A lower MAPE% indicates superior model accuracy |
|
| Root mean squared error (RMSE) | squared root | precision | It quantifies the differences between predicted values and actual values, squaring the errors, taking the mean, and then finding the square root. It is computed by taking the square root of MSE. | concentration units | Values between 0 to ∞ Lower values indicating better predictive accuracy. |
|
| Root mean squared error percentage (RMSE%) | squared root relative | precision | percentage of the RMSE | % | Values between 0 to 100. A lower RMSE% indicates superior model accuracy. |
|
| Median prediction error percentage (MDPE%) | median | precision | MDPE is found by ordering PE from smallest to largest, and using this middle value |
% | Values between 0 to 100- A lower MDPE indicates superior model accuracy. |
|
| Median absolute prediction error percentage (MDAPE%) | median | precision | MDAPE is found by ordering the APE from smallest to largest and using this middle value. |
concentration units | Values between 0 to ∞ A lower MDAPE indicates superior model accuracy. |
|
| Mean relative error (MRE) | relative ratio | accuracy or bias | MRE was defined as the ratio between MAPE and the reference E-field magnitude within the corresponding target region. | no units |
Values between 0 to 1 |
|
| Mean relative error percentage (MRE% or rMPE) | relative percentage | accuracy or bias | percentage of MRE | % | Values between 0 to 100. A lower MRE% indicates superior model accuracy. |
|
| Square prediction error (SPE) | square of the difference | precision | measures the expected squared distance between what your predictor predicts for a specific value and what the true value | square concentration units | Values between 0 to ∞ A lower SPE indicates a better model. |
|
| Mean square error (MSE) | mean of the difference | precision | squaring the difference between the predicted value and actual value and averaging it across the dataset. | concentration units | Values between 0 to ∞ MSE increases exponentially with an increase in error. A good model will have an MSE value closer to zero. |
|
| relative mean prediction error (RMPE or rMPE) |
relative percentage | accuracy or bias | is a variant of Root MPE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. Lower rMPE shows lower deviation. |
|
| relative root mean squared error (RRMSE or rRMSE) |
relative percentage | accuracy or bias | is a variant of RMSE, gauging predictive model accuracy relative to the target variable range. | % | Value between 0 to 100. < 10% is an excellent value for RRMSE. > 30 %is a poor value for RRMSE. |
3. Discussion
The findings of this review reveal that the application of pharmacokinetics for antibiotics with artificial intelligence and machine learning is very promising but, in its infancy, and there is no regulatory framework to facilitate its proper clinical implementation. This is consistent with other reviews on the use of AI techniques in healthcare [63,64]. Population models have traditionally been used for pharmacokinetics of antibiotics. The AI models seem to present several advantages compared to the traditional population models, particularly speed and capacity with ample data. Nevertheless, at this juncture, evidence suggests that these models do not consistently outperform conventional approaches in terms of accuracy and clinical feasibility.
One of the key features of AI is its ability to incorporate many clinical variables, such as inclusion of specific biomarkers or patient conditions impacting PK [35]. This could be of help in complex populations, such as pediatric or critically ill patients, for whom the traditional models are of limited use. However, we must note that many of the studies included in this review are retrospective and may thus suffer from inherent biases and may be less generalizable to wider clinical populations. In addition, variability among chosen AI techniques and evaluation metrics further complicates comparison between studies and strongly underscores such a necessity in this area. Currently, there is no consensus on the metrics used to compare these models with conventional PK methods. Since there is no standard, it becomes impossible to conduct a general examination of the outputs received, thereby underscoring the urgency for framed guidelines that would facilitate a consistent review of the precision and feasibility of AI models in practice. This lack of a proper set of guidelines makes it impossible for researchers to check and correlate results, thereby putting in the way further application in clinical settings.
Despite these challenges, the prospects for AI in PK are bright [4,16,34]. In particular, in the field of antibiotics, fast progress of these techniques may support the building of predictive models for newly developed antibiotics which require strict monitoring as a function of antimicrobial resistance. The incorporation of AI with mechanistic approaches like PBPK models therefore provides a promising opportunity for enhancing the precision and clinical relevance of PK models. Thus, the promising results of AI techniques and their marriage with classical PK methods maybe be auspicious; however, more consistent studies using similar evaluation metrics are needed before their general application in antibiotic therapeutic monitoring. At least for the time being, such algorithms need to be considered as adjuncts that will help clinicians and pharmacokinetic experts to make decisions rather than alternatives to the existing methods.
This review has several limitations. First, as already mentioned, the enormous heterogeneity in the studies analyzed makes it difficult to draw conclusions from their joint analysis. Each study uses different AI approaches, such as neural networks, decision trees and boosting methods, which complicates direct comparison of the results. Although it is understandable, due to the emerging use of these techniques, that different approaches are taken in the studies, it would be advisable to standardize the way they are carried out in the future. Similarly, the use of different techniques for measuring precision and accuracy error and, in many cases, even the absence of the difference between these two measures makes the joint interpretation of the results extremely difficult. Another significant limitation is that most of the included studies have a retrospective design, using large previously collected databases or a prospective design but based on automated patient simulations. These approaches entail population selection biases and limit the translation of the results to the real population, where conditions can vary considerably. Furthermore, the lack of external validations in different cohorts, which are not present in most of the studies, is noted. On the other hand, despite the potential usefulness of these techniques for the development of pharmacokinetic models of new antibiotics, it is important to highlight that the studies analyzed focus on conventional antibiotics, highlighting, once again, the emerging state of this field of research. It is important to note the lack of explanation of the type of AI technique and its way of working in most of the studies analyzed, which undermines confidence in the results obtained. Finally, due to the use of a scoping review approach [65], no quality assessment was performed on the included studies.
4. Material and Methods
This study is based on the guidance framework for conducting scoping reviews in accordance with the Preferred Reporting Items for Systematic Review and Meta-Analysis (PRISMA) extension for scoping reviews (PRISMA-ScR) [65]. The project was preregistered on the OSF Database, accessed on 5 November 2024. A comprehensive search strategy was employed to gather relevant data from multiple databases. The reference lists of all included studies were manually reviewed to identify other relevant papers. This section details the databases searched, the time frame of the searches, and the specific search terms used.
4.1. Objectives
The objective of this review is to analyze the studies published to date on PK/PD modeling for antibiotic dose optimization using AI techniques. In addition, this review aims to evaluate in detail the different AI techniques used and the statistical metrics applied to assess the accuracy of the prediction and its comparison with the conventional monitoring techniques.
4.2. Search Strategy
The EMBASE, MEDLINE (by PubMed and OVID) databases were searched from inception to January 2024 using the following terms: (“Artificial Intelligence” OR “Machine Learning” OR “neural network”) AND “pharmacokinetics” AND antibiotics.
Reference lists of relevant studies were analyzed for additional literature. Furthermore, after the analysis of the included studies, specific searches were carried out to define and interpret the AI techniques used and the statistical parameters used for the evaluation of prediction accuracy.
4.3. Eligibility Criteria
All articles that met the following inclusion criteria were included in the review: (1) Use some Artificial Intelligence technique to predict concentrations of antibiotics. The following studies were excluded: (1) articles that use AI for other aspects than PK; (2) papers that use AI for PK of non-antibiotics drugs; (3) articles not written in English or no full text available and (4) studies in which the accuracy of the prediction with the technique used has not been evaluated (See Error! Reference source not found.) .
4.4. Data Extraction
Screening was carried out independently by two reviewers (IVR and EBV), with full texts of potentially relevant articles considered for inclusion. Disagreements between reviewers were resolved by consensus or with a third reviewer (FJTC). Study descriptors were extracted, including first author, year of publication, antibiotic analyzed, number of patients or simulations, participant characteristics, study objective, AI technique used for modeling software, clinical parameters involved, PK model with which it is compared, quality assessment on prediction accuracy, results and conclusions of the study.
4.5. Synthesis of Results
A narrative synthesis was produced for the included studies. As recommended in the methodology for scoping reviews, no formal assessment of the risk of bias in the studies was pursued [65]. Identification of gaps was through review of areas covered by the studies following the aspect of care considered. The research team reviewed study findings and formulated questions that would be useful in addressing the identified gaps.
5. Conclusions and Future Perspectives
The use of AI, particularly ML techniques, in PK has shown growing interest in recent years. Its application is of special interest in the PK of antibiotics due to two main factors: firstly, due to the reduction of time in the development of models, which would allow the monitoring of new antibiotics that are being discovered, and secondly, due to the possibility of introducing more clinical variables that may affect the scope of the pharmacokinetic objective.
This review shows the current paradigm for using these techniques for the pharmacokinetic monitoring of antibiotics. Mainly, these are retrospective studies on large databases in which new algorithms developed by ML-based models such as XGBoost, neural networks or decision trees, among others, are tested and compared to population PK. No studies have been found that use them for therapeutic drug monitoring of newly developed antibiotics.
The current reality is that we are still at a fairly preliminary point in the use of these techniques. Most of these models are inherently complex and lack explanations of the decision-making process, which makes their clinical application difficult. The design and methodology of the studies carried out, as well as the metrics used to evaluate their precision, are highly variable. It would be necessary to standardize the comparison metrics against the standard pharmacokinetic models. Therefore, although the results are promising, more robust studies are needed to be able to say that these techniques represent a revolution in the clinical PK of antibiotics. For now, AI algorithms appear to be complementary to standard population PK approaches.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org., Figure S1: title; Table S1: title; Video S1: title.
Author Contributions
Conceptualization, F.J.T.-C, C.M.-G and A.F-F; methodology, I.V.-R , E.B.-V; software, I.V.-R , E.B.-V, F.J.T.-C; validation, C.M.-G, M.G.-B, M.O.-H, V.M.-S and A.F-F; formal analysis, F.J.T.-C, A.C-O, F.C.-P., M.O.-H, V.M.-S; investigation, I.V.-R , E.B.-V; resources, M.G.-B, I.Z.-F, A.F-F; data curation, I.V.-R , E.B.-V. F.C.-P; writing—original draft preparation, I.V.-R, E.B.-V; writing—review and editing, , F.J.T.-C, A.C-O, C.M.-G, M.O.-H, V.M.-S and A.F-F; visualization, A.C-O, F.C.-P; supervision, C.M.-G. A.F-F; project administration M.G.-B, A.F-F I.Z.-F, funding acquisition I.Z.-F, A.F-F. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by Axencia Galega Innovación (Grupos de Referencia Competitiva IN607A2023/04 and Excelencia (N607D2023/05). I.V.-R, E.B.-V., F.J.T.-C., C.M.-G. and A.F.-F. acknowledge the support of the Instituto de Salud Carlos III (ISCIII) (research grants CM22/00055, CM20/00135, CM22/00146, JR20/00026 and JR18/00014. C.M.-G. and A.F.-F. acknowledge the support of the Instituto de Salud Carlos III (ISCIII) PI22/00038 and ICI21/00043. .
Data Availability Statement
No new data were created or analyzed in this study.
Acknowledgments
Research and Innovation FarmaCHUSLab Group.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Schwalbe, N.; Wahl, B. Artificial Intelligence and the Future of Global Health. Lancet 2020, 395, 1579–1586. [CrossRef]
- Haymond, S.; McCudden, C. Rise of the Machines: Artificial Intelligence and the Clinical Laboratory. J Appl Lab Med 2021, 6, 1640–1654. [CrossRef]
- Organización Mundial de la Salud (OMS) Organización Mundial de la Salud: Cibersalud. Cibersalud y bienestar Digital 2018.
- Chaturvedula, A.; Calad-Thomson, S.; Liu, C.; Sale, M.; Gattu, N.; Goyal, N. Artificial Intelligence and Pharmacometrics: Time to Embrace, Capitalize, and Advance? CPT Pharmacometrics Syst Pharmacol 2019, 8, 440–443. [CrossRef]
- Hutchinson, L.; Steiert, B.; Soubret, A.; Wagg, J.; Phipps, A.; Peck, R.; Charoin, J.-E.; Ribba, B. Models and Machines: How Deep Learning Will Take Clinical Pharmacology to the Next Level. CPT Pharmacometrics Syst Pharmacol 2019, 8, 131–134. [CrossRef]
- Serrano, D.R.; Luciano, F.C.; Anaya, B.J.; Ongoren, B.; Kara, A.; Molina, G.; Ramirez, B.I.; Sánchez-Guirales, S.A.; Simon, J.A.; Tomietto, G.; et al. Artificial Intelligence (AI) Applications in Drug Discovery and Drug Delivery: Revolutionizing Personalized Medicine. Pharmaceutics 2024, 16, 1328. [CrossRef]
- Hinkson, I.V.; Madej, B.; Stahlberg, E.A. Accelerating Therapeutics for Opportunities in Medicine: A Paradigm Shift in Drug Discovery. Front Pharmacol 2020, 11, 770. [CrossRef]
- Revolutionizing Drug Discovery: A Comprehensive Review of AI Applications Available online: https://www.mdpi.com/2813-2998/3/1/9 (accessed on 1 November 2024).
- Raja, K.; Patrick, M.; Elder, J.T.; Tsoi, L.C. Machine Learning Workflow to Enhance Predictions of Adverse Drug Reactions (ADRs) through Drug-Gene Interactions: Application to Drugs for Cutaneous Diseases. Sci Rep 2017, 7, 3690. [CrossRef]
- Salas, M.; Petracek, J.; Yalamanchili, P.; Aimer, O.; Kasthuril, D.; Dhingra, S.; Junaid, T.; Bostic, T. The Use of Artificial Intelligence in Pharmacovigilance: A Systematic Review of the Literature. Pharmaceut Med 2022, 36, 295–306. [CrossRef]
- Basile, A.O.; Yahi, A.; Tatonetti, N.P. Artificial Intelligence for Drug Toxicity and Safety. Trends Pharmacol Sci 2019, 40, 624–635. [CrossRef]
- Reker, D.; Shi, Y.; Kirtane, A.R.; Hess, K.; Zhong, G.J.; Crane, E.; Lin, C.-H.; Langer, R.; Traverso, G. Machine Learning Uncovers Food- and Excipient-Drug Interactions. Cell Rep 2020, 30, 3710-3716.e4. [CrossRef]
- Zhang, W.; Chen, Y.; Liu, F.; Luo, F.; Tian, G.; Li, X. Predicting Potential Drug-Drug Interactions by Integrating Chemical, Biological, Phenotypic and Network Data. BMC Bioinformatics 2017, 18, 18. [CrossRef]
- Allen, R.J.; Rieger, T.R.; Musante, C.J. Efficient Generation and Selection of Virtual Populations in Quantitative Systems Pharmacology Models. CPT Pharmacometrics Syst Pharmacol 2016, 5, 140–146. [CrossRef]
- Gal, J.; Milano, G.; Ferrero, J.-M.; Saâda-Bouzid, E.; Viotti, J.; Chabaud, S.; Gougis, P.; Le Tourneau, C.; Schiappa, R.; Paquet, A.; et al. Optimizing Drug Development in Oncology by Clinical Trial Simulation: Why and How? Brief Bioinform 2018, 19, 1203–1217. [CrossRef]
- McComb, M.; Bies, R.; Ramanathan, M. Machine Learning in Pharmacometrics: Opportunities and Challenges. Br J Clin Pharmacol 2022, 88, 1482–1499. [CrossRef]
- Janssen, A.; Bennis, F.C.; Mathôt, R.A.A. Adoption of Machine Learning in Pharmacometrics: An Overview of Recent Implementations and Their Considerations. Pharmaceutics 2022, 14, 1814. [CrossRef]
- Gobburu, J.V.; Chen, E.P. Artificial Neural Networks as a Novel Approach to Integrated Pharmacokinetic-Pharmacodynamic Analysis. J Pharm Sci 1996, 85, 505–510. [CrossRef]
- Otalvaro, J.D.; Yamada, W.M.; Hernandez, A.M.; Zuluaga, A.F.; Chen, R.; Neely, M.N. A Proof of Concept Reinforcement Learning Based Tool for Non Parametric Population Pharmacokinetics Workflow Optimization. J Pharmacokinet Pharmacodyn 2022. [CrossRef]
- Ota, R.; Yamashita, F. Application of Machine Learning Techniques to the Analysis and Prediction of Drug Pharmacokinetics. J Control Release 2022, 352, 961–969. [CrossRef]
- Koch, G.; Pfister, M.; Daunhawer, I.; Wilbaux, M.; Wellmann, S.; Vogt, J.E. Pharmacometrics and Machine Learning Partner to Advance Clinical Data Analysis. Clinical Pharmacology & Therapeutics 2020, 107, 926–933.
- Priya, S.; Tripathi, G.; Singh, D.B.; Jain, P.; Kumar, A. Machine Learning Approaches and Their Applications in Drug Discovery and Design. Chem Biol Drug Des 2022, 100, 136–153. [CrossRef]
- Keutzer, L.; You, H.; Farnoud, A.; Nyberg, J.; Wicha, S.G.; Maher-Edwards, G.; Vlasakakis, G.; Moghaddam, G.K.; Svensson, E.M.; Menden, M.P.; et al. Machine Learning and Pharmacometrics for Prediction of Pharmacokinetic Data: Differences, Similarities and Challenges Illustrated with Rifampicin. Pharmaceutics 2022, 14, 1530. [CrossRef]
- Abdul-Aziz, M.H.; Alffenaar, J.-W.C.; Bassetti, M.; Bracht, H.; Dimopoulos, G.; Marriott, D.; Neely, M.N.; Paiva, J.-A.; Pea, F.; Sjovall, F.; et al. Antimicrobial Therapeutic Drug Monitoring in Critically Ill Adult Patients: A Position Paper#. Intensive Care Med 2020, 1–27. [CrossRef]
- Downes, K.J.; Goldman, J.L. Too Much of a Good Thing: Defining Antimicrobial Therapeutic Targets to Minimize Toxicity. Clin Pharmacol Ther 2021, 109, 905–917. [CrossRef]
- Rawson, T.M.; Wilson, R.C.; O’Hare, D.; Herrero, P.; Kambugu, A.; Lamorde, M.; Ellington, M.; Georgiou, P.; Cass, A.; Hope, W.W.; et al. Optimizing Antimicrobial Use: Challenges, Advances and Opportunities. Nat Rev Microbiol 2021, 19, 747–758. [CrossRef]
- Antimicrobial Resistance Available online: https://www.who.int/news-room/fact-sheets/detail/antimicrobial-resistance (accessed on 27 November 2023).
- Cunha, C.B. Antimicrobial Stewardship Programs: Principles and Practice. Med Clin North Am 2018, 102, 797–803. [CrossRef]
- Chua, H.C.; Tse, A.; Smith, N.M.; Mergenhagen, K.A.; Cha, R.; Tsuji, B.T. Combatting the Rising Tide of Antimicrobial Resistance: Pharmacokinetic/Pharmacodynamic Dosing Strategies for Maximal Precision. Int J Antimicrob Agents 2021, 57, 106269. [CrossRef]
- Cook, M.A.; Wright, G.D. The Past, Present, and Future of Antibiotics. Sci Transl Med 2022, 14, eabo7793. [CrossRef]
- Stokes, J.M.; Yang, K.; Swanson, K.; Jin, W.; Cubillos-Ruiz, A.; Donghia, N.M.; MacNair, C.R.; French, S.; Carfrae, L.A.; Bloom-Ackermann, Z.; et al. A Deep Learning Approach to Antibiotic Discovery. Cell 2020, 180, 688-702.e13. [CrossRef]
- Wang, L.; Liu, Z.; Liu, A.; Tao, F. Artificial intelligence in product lifecycle management. | International Journal of Advanced Manufacturing Technology | EBSCOhost Available online: https://openurl.ebsco.com/contentitem/doi:10.1007%2Fs00170-021-06882-1?sid=ebsco:plink:crawler&id=ebsco:doi:10.1007%2Fs00170-021-06882-1 (accessed on 10 January 2024).
- Talevi, A.; Morales, J.F.; Hather, G.; Podichetty, J.T.; Kim, S.; Bloomingdale, P.C.; Kim, S.; Burton, J.; Brown, J.D.; Winterstein, A.G.; et al. Machine Learning in Drug Discovery and Development Part 1: A Primer. CPT: Pharmacometrics & Systems Pharmacology 2020, 9, 129–142. [CrossRef]
- Stankevičiūtė, K.; Woillard, J.-B.; Peck, R.W.; Marquet, P.; van der Schaar, M. Bridging the Worlds of Pharmacometrics and Machine Learning. Clin Pharmacokinet 2023, 62, 1551–1565. [CrossRef]
- Poweleit, E.A.; Vinks, A.A.; Mizuno, T. Artificial Intelligence and Machine Learning Approaches to Facilitate Therapeutic Drug Management and Model-Informed Precision Dosing. Ther Drug Monit 2023, 45, 143–150. [CrossRef]
- Bououda, M.; Uster, D.W.; Sidorov, E.; Labriffe, M.; Marquet, P.; Wicha, S.G.; Woillard, J.-B. A Machine Learning Approach to Predict Interdose Vancomycin Exposure. Pharm Res 2022, 39, 721–731. [CrossRef]
- Ponthier, L.; Ensuque, P.; Destere, A.; Marquet, P.; Labriffe, M.; Jacqz-Aigrain, E.; Woillard, J.-B. Optimization of Vancomycin Initial Dose in Term and Preterm Neonates by Machine Learning. Pharm Res 2022, 39, 2497–2506. [CrossRef]
- Wang, Z.; Ong, C.L.J.; Fu, Z. AI Models to Assist Vancomycin Dosage Titration. Front Pharmacol 2022, 13, 801928. [CrossRef]
- Nigo, M.; Tran, H.T.N.; Xie, Z.; Feng, H.; Mao, B.; Rasmy, L.; Miao, H.; Zhi, D. PK-RNN-V E: A Deep Learning Model Approach to Vancomycin Therapeutic Drug Monitoring Using Electronic Health Record Data. Journal of Biomedical Informatics 2022, 133, 104166. [CrossRef]
- Miyai, T.; Imai, S.; Yoshimura, E.; Kashiwagi, H.; Sato, Y.; Ueno, H.; Takekuma, Y.; Sugawara, M. Machine Learning-Based Model for Estimating Vancomycin Maintenance Dose to Target the Area under the Concentration Curve of 400-600 Mg·h/L in Japanese Patients. Biol Pharm Bull 2022, 45, 1332–1339. [CrossRef]
- Tang, B.-H.; Zhang, J.-Y.; Allegaert, K.; Hao, G.-X.; Yao, B.-F.; Leroux, S.; Thomson, A.H.; Yu, Z.; Gao, F.; Zheng, Y.; et al. Use of Machine Learning for Dosage Individualization of Vancomycin in Neonates. Clin Pharmacokinet 2023, 62, 1105–1116. [CrossRef]
- Huang, X.; Yu, Z.; Bu, S.; Lin, Z.; Hao, X.; He, W.; Yu, P.; Wang, Z.; Gao, F.; Zhang, J.; et al. An Ensemble Model for Prediction of Vancomycin Trough Concentrations in Pediatric Patients. Drug Des Devel Ther 2021, 15, 1549–1559. [CrossRef]
- Brier, M.E.; Zurada, J.M.; Aronoff, G.R. Neural Network Predicted Peak and Trough Gentamicin Concentrations. Pharm Res 1995, 12, 406–412. [CrossRef]
- Yamamura, S.; Kawada, K.; Takehira, R.; Nishizawa, K.; Katayama, S.; Hirano, M.; Momose, Y. Artificial Neural Network Modeling to Predict the Plasma Concentration of Aminoglycosides in Burn Patients. Biomed Pharmacother 2004, 58, 239–244. [CrossRef]
- Chow, H.H.; Tolle, K.M.; Roe, D.J.; Elsberry, V.; Chen, H. Application of Neural Networks to Population Pharmacokinetic Data Analysis. J Pharm Sci 1997, 86, 840–845. [CrossRef]
- Verhaeghe, J.; Dhaese, S.A.M.; De Corte, T.; Vander Mijnsbrugge, D.; Aardema, H.; Zijlstra, J.G.; Verstraete, A.G.; Stove, V.; Colin, P.; Ongenae, F.; et al. Development and Evaluation of Uncertainty Quantifying Machine Learning Models to Predict Piperacillin Plasma Concentrations in Critically Ill Patients. BMC Med Inform Decis Mak 2022, 22, 224. [CrossRef]
- Tang, B.-H.; Guan, Z.; Allegaert, K.; Wu, Y.-E.; Manolis, E.; Leroux, S.; Yao, B.-F.; Shi, H.-Y.; Li, X.; Huang, X.; et al. Drug Clearance in Neonates: A Combination of Population Pharmacokinetic Modelling and Machine Learning Approaches to Improve Individual Prediction. Clin Pharmacokinet 2021, 60, 1435–1448. [CrossRef]
- Manickam, P.; Mariappan, S.A.; Murugesan, S.M.; Hansda, S.; Kaushik, A.; Shinde, R.; Thipperudraswamy, S.P. Artificial Intelligence (AI) and Internet of Medical Things (IoMT) Assisted Biomedical Systems for Intelligent Healthcare. Biosensors (Basel) 2022, 12, 562. [CrossRef]
- Chou, W.-C.; Lin, Z. Machine Learning and Artificial Intelligence in Physiologically Based Pharmacokinetic Modeling. Toxicol Sci 2023, 191, 1–14. [CrossRef]
- Mørk, M.L.; Andersen, J.T.; Lausten-Thomsen, U.; Gade, C. The Blind Spot of Pharmacology: A Scoping Review of Drug Metabolism in Prematurely Born Children. Front Pharmacol 2022, 13, 828010. [CrossRef]
- Arendrup, M.C.; Fisher, B.T.; Zaoutis, T.E. Invasive Fungal Infections in the Paediatric and Neonatal Population: Diagnostics and Management Issues. Clin Microbiol Infect 2009, 15, 613–624. [CrossRef]
- El Hassani, M.; Marsot, A. External Evaluation of Population Pharmacokinetic Models for Precision Dosing: Current State and Knowledge Gaps. Clin Pharmacokinet 2023, 62, 533–540. [CrossRef]
- Oda, K.; Katanoda, T.; Hashiguchi, Y.; Kondo, S.; Narita, Y.; Iwamura, K.; Nosaka, K.; Jono, H.; Saito, H. Development and Evaluation of a Vancomycin Dosing Nomogram to Achieve the Target Area under the Concentration-Time Curve. A Retrospective Study. J Infect Chemother 2020, 26, 444–450. [CrossRef]
- Thomson, A.H.; Staatz, C.E.; Tobin, C.M.; Gall, M.; Lovering, A.M. Development and Evaluation of Vancomycin Dosage Guidelines Designed to Achieve New Target Concentrations. J Antimicrob Chemother 2009, 63, 1050–1057. [CrossRef]
- FDA, U. Population Pharmacokinetics: Guidance for Industry. 2022; 2023;
- Agency, E.M. Guideline on Bioanalytical Method Validation; London, UK, 2011;
- Kanji, S.; Hayes, M.; Ling, A.; Shamseer, L.; Chant, C.; Edwards, D.J.; Edwards, S.; Ensom, M.H.H.; Foster, D.R.; Hardy, B.; et al. Reporting Guidelines for Clinical Pharmacokinetic Studies: The ClinPK Statement. Clin Pharmacokinet 2015, 54, 783–795. [CrossRef]
- Lv, M.; Zhang, S. Comment on: “External Evaluation of Population Pharmacokinetic Models for Precision Dosing: Current State and Knowledge Gaps.” Clin Pharmacokinet 2023, 62, 1183–1185. [CrossRef]
- Sheiner, L.B.; Beal, S.L. Some Suggestions for Measuring Predictive Performance. J Pharmacokinet Biopharm 1981, 9, 503–512. [CrossRef]
- Brendel, K.; Dartois, C.; Comets, E.; Lemenuel-Diot, A.; Laveille, C.; Tranchand, B.; Girard, P.; Laffont, C.M.; Mentré, F. Are Population Pharmacokinetic and/or Pharmacodynamic Models Adequately Evaluated? A Survey of the Literature from 2002 to 2004. Clin Pharmacokinet 2007, 46, 221–234. [CrossRef]
- Miyabe-Nishiwaki, T.; Masui, K.; Kaneko, A.; Nishiwaki, K.; Nishio, T.; Kanazawa, H. Evaluation of the Predictive Performance of a Pharmacokinetic Model for Propofol in Japanese Macaques (Macaca Fuscata Fuscata). J Vet Pharmacol Ther 2013, 36, 169–173. [CrossRef]
- Struys, M.; Absalom, A.; Shafer, S.L. “Intravenous Drug Delivery Systems” in Miller’s Anesthesia. In “Intravenous Drug Delivery Systems” in Miller’s Anesthesia; Elsevier, 2014; pp. 919–957 ISBN 978-0-7020-5283-5.
- Aung, Y.Y.M.; Wong, D.C.S.; Ting, D.S.W. The Promise of Artificial Intelligence: A Review of the Opportunities and Challenges of Artificial Intelligence in Healthcare. Br Med Bull 2021, 139, 4–15. [CrossRef]
- Jiang, F.; Jiang, Y.; Zhi, H.; Dong, Y.; Li, H.; Ma, S.; Wang, Y.; Dong, Q.; Shen, H.; Wang, Y. Artificial Intelligence in Healthcare: Past, Present and Future. Stroke Vasc Neurol 2017, 2, 230–243. [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann Intern Med 2018, 169, 467–473. [CrossRef]
Figure 1.
PRISMA flow diagram of search results and selection process of the studies. AI: Artificial Intelligence.
Figure 1.
PRISMA flow diagram of search results and selection process of the studies. AI: Artificial Intelligence.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



