Submitted:
24 October 2024
Posted:
14 November 2024
You are already at the latest version
Abstract
Artificial Intelligence has led to tremendous progress in areas such as image and speech recognition, but both adoption and impact in biotech and pharma has been lagging behind in relative terms. While fundamental reasons for this exist - such as a very different nature of the data available, and the different decisions that need to be supported in biotech/pharma, compared to ‘tech’ - there are also very practical and organisational barriers in place that need addressing. This article outlines some of those challenges, potential solutions, and makes a case for the HitchhikersAI.org grassroots movement that is aiming to improve upon the status-quo.
Keywords:
artificial intelligence
; data
; biotechnology
1. Introduction: The Big Picture Problem
Traditional wet lab scientists working on target discovery, drug identification and drug optimisation have an opportunity to catch-up with their AI-enabled peers – but why should they, and how?
To calibrate our expectations over the use of AI, the following gives a sobering perspective [1]. According to Patrick Malone, a principal at KdT Ventures in the US, clinical wins are rarities in biotech, where an estimated five or 10 percent of drugs that head into human testing actually get approved [1]:
If you take the hype and PR at face value over the last 10 years, you would think it goes from five percent to 90 percent. But if you know how these models work, it goes from five percent to maybe six or seven percent.Patrick Malone, KdT Ventures
With the billions of dollars being invested in AI-led drug discovery programmes, it would appear that this is a pivotal moment in patient treatment – like Isomorphic Labs, Recursion, Exscientia, Flagship Pioneering, the big biopharmaceuticals, and even a “$1B+ bet” [2] on Xaira Therapeutics, who have invested heavily in the promise of AI.
Taking a close look at the different applications for AI (and data), there is an emerging pattern for where AI is being applied and why it cannot be avoided. Consider the following examples:
- Generating/deriving (e.g. from images etc.) and analysing existing data
- Designing structures of bioactive agents, across modalities
- Designing in vitro experiments (where data is needed to establish predictive value of experiments)
- Understanding and modelling biological mechanisms
- Summarising information across literature and study reports
The capability to perform the above activities quickly and cost-efficiently would be nice, which is of course an understatement, given the stresses that early stage (pre-clinical) biotechs are under these days with equity funding [3]. Funding for pre-clinical platform biotechs, however, has tightened as investors increasingly prefer companies with clinical-stage assets (according to Q1 2024 funding reports) [3]. The value being created here is more than just a greater number of FDA approvals, it is also about completing the milestone with limited capital - i.e. biotech survival.
Like most industries, you have those who are early adopters and those who are waiting for the technology to “cross the chasm” [4] and to become mainstream. The latter group (i.e., most of us) are waiting for wet lab validation, market demonstration (FDA approvals), and a few other things (which we often cannot define). However, this tactic runs its own risk: if we wait, we may be too late to the game – just like traditional automobile manufacturers have been when trying to catch up with Tesla [5]. Likewise, ‘waiting’ doesn’t allow a company to apply and evaluate novel technology on tasks that really matter internally (which differs hugely from entity to entity), risking lost opportunities.
There is no reason why the early-stage biotechs cannot also implement simple, but still effective, AI. There are several major technology areas foundational to drug discovery, such as cheminformatics and bioinformatics, where AI is already being applied. Below are other example technology areas for AI and data that are driving significant advancements in the above application areas:
- The elephant in the room is large language models - commonly called LLMs. This is the ChatGPT-like [6] environment that we have become rapidly familiar with over the last couple of years. In principle, LLMs could change the world of drug discovery (as they are often claiming to do), but biology and chemistry and derived data are full of nuances [7] and the expectations for how LLMs will actually impact drug discovery need to be kept reasonably low for the moment. Approaches such as neuro-symbolic reasoning [8] may be able to overcome some of the current, and inherent, challenges of LLMs [9].
- Another big field of advancement is protein modelling and simulation. There are several technologies and specific tools being rolled out in this area. The latest exciting advancement is AlphaFold 3, which was just released [10]. AlphaFold 3 has been built to model DNA, RNA and smaller molecules (ligands) [11], and various open source implementations of this and related approaches have followed, such as HelixFold [12] and others, which aimed to address the non-availability of AlphaFold3 to the public.
- The third area is predictive modelling (including both machine learning statistical techniques). This is a traditional application for AI (including machine learning). These methods are extensions of classical statistical techniques that we learnt at school, such as linear regression (fitting a straight line to data points). The big advancement over the last two to three decades has been the power of the new algorithms, which leverage cheap compute processing and storage (Moore’s Law), and in some areas also cheap data generation (for example, $100 whole genome sequencing). However, life science data is fundamentally different from elsewhere when it comes to clinically relevant endpoints, as described previously [13].
- AI technologies cannot work their magic without sufficient quality curated data, and generating such data is challenging - especially with in vitro lab tests. According to a prominent article ten years back [14] data scientists spend up to 80 percent of their time mired in the mundane labour of collecting and preparing unruly digital data, before it can be explored for useful nuggets. There are academics and companies actively working on solving this challenge, but biology and chemistry is hard and lab data is often messy and irreproducible. To learn the basics of data quality, a good start is the 7 C’s framework [15].
Although the potential of AI is broadly recognized, there are several key decisions that biotech CEOs and CSOs need to make and consider the associated risks (including costs) in adopting AI and data technologies. Given that early-stage biotechs are focused on survival until wet lab and/or animal data is generated that excites investors, many biotech CEOs and CSOs are asking, often sceptically, whether computational methods (dry lab) can help them gain the required data faster and more cheaply. Algorithms could substitute for parts of the wet lab workflows, helping to reduce the number of experiments conducted by contract research organisations (CROs), by qualifying and prioritising them such as in ‘Design-Make-Test’Analyze’ (DMTA) workflows in drug discovery [16].
There is often a bioinformatician in the biotech team, who has experience in crunching data. While this experience is valuable, giving them a sense of the work required and the nature of the data, it can also be dangerous because their background with AI techniques and the availability of vendor tools is often limited. Open source software is prominent in the bio- and cheminformatics areas and has its well-deserved place; however, in a production environment maintenance, support etc. can pose a limitation to their adoption. Furthermore, given that biotechs have relatively little funding available for computational tools, investments are often aimed at short-term wins; for example, Python scripts that take in study datasets and output interesting correlations - some nice graph plots are often helpful. This highlights that a more broad-based approach is needed, i.e. an approach that matches needs to capabilities, across all areas where data and AI could make a difference in decision making.
However, whichever approach you take, you may spend a lot of time reaching the conclusion that your data is not good enough for even simple analyses. Your first investment must be in your data strategy – understanding and developing the quality and utility of your wet lab (and/or animal) data. The following are initial recommended steps:
- Assess your data quality and utility and develop a data build vs buy strategy. Some limited knowledge of AI/statistical techniques will be needed for this, as it affects the utility calculation; this knowledge can be gained through experienced advisors.
- Develop a both short-term and longer-term computational strategy that leverages current data and planned new data. Be open to paying for datasets and tools, and even look at open-source software if you have the in-house software skills. Each phase of the strategy should be targeted at helping answer key scientific questions that your investors are expecting you to answer.
Importantly, take some risk in going after these steps; you are already taking (and one could argue: much more) risk in your wet lab analyses! Use this opportunity to develop relationships with data partners and tool vendors, as well as the life-sciences data science community. As a final point, it is important to remember with all the AI and data available, that the scientist must stay at the centre of the universe (Figure 1). Tools and data are only as good as the insights they generate; the creativity and invention will come from the scientists.
2. Voice of Industry
In order to understand how AI and data technologies can be integrated into biotechs, their perspectives in adopting these need to be understood. This includes scepticism around embracing AI, improving communication between scientists and technical teams, aligning AI strategies to business objectives, managing complex scientific data, the potential of automation and AI and treating data as IP.
2.1. Navigating Scepticism and Embracing AI
AI has the ability to accelerate processes and improve efficiency that could offer immense benefits for patients, healthcare, and economies, but there is widespread nervousness in the industry, particularly among those who are not familiar with the technical side of AI [17]. The resistance often stems from a lack of understanding, compounded by the complexity of interdisciplinary communication. People know an area very well—whether it’s biology, chemistry, or pharmacology—but venturing outside that comfort zone into tech can be daunting. To overcome this scepticism, a stepwise approach is recommended, starting with small pilot projects that demonstrate tangible benefits, which are communicated in a suitable language across the organisation, and which are paired with facts-based and honest education. Quick wins can help build trust in new technologies, easing nervousness and encouraging broader adoption.
2.2. Communication: The Key to Overcoming Barriers
Communication between scientific and technical teams is paramount to adopting new technologies. The convergence of disciplines, such as biology and AI, often leads to breakthroughs. However, the difficulty lies in ensuring both sides understand each other, with miscommunication increasing nervousness. To bridge this gap, agreeing on a common language and breaking down complex concepts are essential steps - the modeller needs to understand the variables that represent input and output into the model sufficiently well, while the wet lab scientist needs to grasp essentials of ‘AI-ready data’, hence forming a productive interface across the team A long-term relationship and understanding of the company’s specific needs is necessary, with technical vendors needing to take a big-picture view of how they can offer value beyond immediate solutions and not offer generic solutions that may not align with a company’s actual milestones or challenges.
There is a disconnect between individual scientific achievement and collective organisational goals. High-ranking scientists are often celebrated for their groundbreaking research but are not held accountable for ensuring their work is reproducible or that it benefits the broader scientific community.Mr Conway, CEO, 20/15 Visioneers
2.3. Understanding Biotech’s Board Commitments
From a business perspective, biotech companies are faced with the pressure of meeting board-driven milestones. These milestones—such as hit identification, lead optimization, and candidate nomination—are critical for securing investment and increasing company valuation. In practice, they can be both a constructive driver, or become destructive and a distraction, depending on the particular situation.
The pressure comes from improving efficiencies to deliver on these milestones as quickly as possible. For vendors and tech partners working with biotech companies, understanding these milestones is key to aligning their services and helping accelerate the drug discovery process.Dr Wilkie, CEO Mironid Ltd
2.4. Managing Scientific Data Complexity in Small Biotechs
Many early-stage biotech companies are highly data-driven, in particular those focusing on a particular technology enabler to generate said data, producing vast amounts of experimental data through cell-based assays, phenotypic screening, imaging analyses and various biological assays. However, storing, managing, analysing, and leveraging this data is no easy task, especially for a small company with limited resources. This challenge is compounded by the increasing complexity of biological data, particularly in imaging, which often contains hidden insights that are difficult to extract without advanced computational tools. In addition to data management, small companies may not have the expertise or resources to fully utilise the rich datasets they generate. This reflects a broader industry trend in which smaller biotechs struggle to fully capitalise on their experimental results.
You’ve got this mass amount of data, and how do you move it around? How do you even access it easily? And then, what do you do with it? This challenge is compounded by the increasing complexity of biological data, particularly in imaging, which often contains hidden insights that are difficult to extract without advanced computational tools.Dr Thomas, CEO, Five Alarm Biosciences
2.5. The Untapped Potential of Automation and AI
Automation has the potential to make basic tasks like measuring key parameters faster. Furthermore, AI is intrinsically able to provide insights into complex data patterns that humans may overlook, offering a force multiplier effect for companies with limited manpower. However, the practical implementation of these technologies remains challenging. Many small biotechs do not have the resources to invest in sophisticated AI tools or extensive automation systems. This creates a paradox: while AI and automation could revolutionise their operations, they often require significant upfront investment that small companies cannot easily afford. Some companies who do have automation as their main focus often tend to not have sufficient capability to translate their capabilities into value in projects, due to lack of capabilities in more translational areas.
2.6. Data as Intellectual Property
Data generated by biotechs holds significant intellectual property (IP) value, in particular data that is unique to an organisation that can be used to generate unique competitive insights. However, which data should be generated, and how? How is translation into later (such as clinical) stages performed? How does one know which data is needed in the future, and how are compatibilities in experimental setups addressed? (Etc.) This presents a dilemma: how to generate, store and manage data so that it remains useful in the long term, even as the company’s resources grow and new technologies become available. In big pharma these challenges are often addressed through large-scale projects with significant (but often still insufficient) funding. But smaller biotechs must navigate the same complex data issues with far fewer resources, making strategic decisions about what to prioritise and how to maximise the long-term value of their data and its utilisation.
3. The Impact of Culture
3.1. The Cultural Landscape in Drug Discovery
The culture within scientific research organisations, particularly in drug discovery, is a complex and often underappreciated aspect that significantly impacts the quality and efficiency of research outcomes [18]. The core of these challenges is due to brilliant scientists that are often permitted to operate outside standard protocols. This freedom, while potentially fostering innovation, frequently - when focusing on data in the AI context specifically - leads to inconsistency in research practices, poor data management, and ultimately, a lack of reproducibility. Also on the conceptual level, there is always the conflict between generating project-relevant data (e.g. in a particular disease tissue), or generating standardised data (e.g. in a consistent cell line), and the decision what weighs more heavily depends on the concrete situation, leading to inconsistent data as a result.
In many organisations, there is a disconnect between individual scientific achievement and collective organisational goals. High-ranking scientists are often celebrated for their groundbreaking research but are not held accountable for ensuring their work is reproducible or that it benefits the broader scientific community. This issue is further compounded by a lack of training in data stewardship and the understanding of data as a critical asset.
3.2. Addressing Cultural Challenges
To address these cultural issues, a fundamental shift in mindset is required—one that emphasises the collective responsibility of all researchers, from top-tier scientists to new hires, to uphold rigorous standards in data management and research practices. There are several strategies to foster a culture that values quality and reproducibility in scientific research:
1. Institutionalising data stewardship training: From secondary education through to graduate school, there is a pressing need to incorporate data stewardship into the curriculum. Scientists should be trained not just in their specific disciplines, such as chemistry or biology, but also in the principles of managing data as a valuable and reusable asset. This training would help inculcate a culture of meticulous data handling from the very beginning of a scientist’s career.
2. Implementing rigorous accountability mechanisms: Organisations need to develop and enforce protocols that hold all scientists accountable for the reproducibility and quality of their work. This could involve regular audits of research data and methodologies, ensuring that senior scientists adhere to the same standards as their junior colleagues.
3. Promoting a humble, collaborative culture: Drawing from examples like Sweden, where humility and collaboration are ingrained cultural values, organisations should strive to promote a work environment where self-promotion is secondary to the quality and impact of the research. Encouraging scientists to work collaboratively and share credit can lead to more reliable and comprehensive research outcomes.
4. Leadership by example: Cultural change must be driven from the top down. Leaders in research organisations should model the behaviour they expect from their teams, demonstrating a commitment to data quality, collaboration, and continuous learning. When leadership prioritises these values, it sets a precedent that permeates the entire organisation.
5. Rewarding reproducibility and data quality: Shifting the focus of recognition and rewards from individual achievements to reproducibility and data quality can help change the underlying cultural dynamics. By celebrating efforts that contribute to robust and reusable data, organisations can align incentives with long-term research success.
These strategies are aimed at changing the culture of research to ensure quality generation of data. Specific practices to address the impact of culture on data quality are discussed in section 6.
4. Data Quality and Its Impact
4.1. An Introduction to Data Quality and the Need for Data Scientists
Early drug discovery is about running experiments, data generation, and scientific hypotheses. For scientists in early drug discovery, our success is heavily dependent on the quality of the data generated. Are we generating the right data from the right experiments? Are we applying the best methods for data analysis and interpretation?
Data quality (sometimes called data integrity) is an often used term [19]. It is of special importance from data acquisition to data analysis in a workflow, as the effectiveness of data analyses (Machine Learning, AI etc) can be severely compromised by poor data quality. Characteristics that define data quality are i) completeness, ii) consistency, iii) lack of bias iv) accuracy and v) predictivity [13,20]. The last characteristic is significant because it comes under the banner of “doing the right things”.
Data quality is a big topic across many industries where data engineers specialise in “data ops” and build advanced test pipelines to automatically detect issues. In early drug discovery, the data pipelines tend to be more limited (with genomics data being the exception) and data quality is often about (for example):
- a measurement issue from a lab machine - e.g. missing data in a csv file
- a poorly designed experiment - related to both predictivity for the final human-relevant effect one wants to predict, as well as e.g. too much variability in the data
- poor data from non-controlled environments - e.g. observation data from human studies
Data-generation costs are forever reducing, as technology (both hardware and AI) becomes cheaper and more effective. This has led, over the last couple of decades, to ready access to large amounts of data - creating the paradigm of “big data”. In this new paradigm, the data quality issues multiply up, especially as the diversity in data also increases. An error that used to be easy to catch in a small dataset, saved as a csv file for example, can be much harder to detect in a large complex dataset (which may need to be part of a structured database). This then leads to a need for data scientists. Note that we are not quite at the point of needing data ops, but that may come soon.
4.2. The Impact of Poor Data Quality
As data quality is paramount to the effectiveness of data analyses by Machine Learning (ML) and AI, the key problems that poor data quality creates include:
- Irrelevant data for a given purpose - leading to the generation of machine learning models that predict other endpoints than those needed for decision making in practice (hence in the worst case even being misleading as a result)
- Incomplete data can cause ML models to miss patterns or relationships. For example, if crucial bioactivity data for certain compounds is missing, the model may not fully account for the structure-activity relationships, leading to inaccurate predictions.
- Inconsistencies, such as variations in how data is recorded (eg, different units of measurement or naming conventions), can confuse models and lead to erroneous predictions. For instance, if the same compound is labelled differently in different datasets (due to a different tautomer, salt form, there are many reasons why this can happen), the model might treat it as different entities, skewing the results.
- Bias in data can lead to models that are not generalisable or that perform poorly on certain subsets of data. For instance, if your training data is biased toward a particular chemical scaffold or a specific set of biological targets, the model will be less effective in predicting the activity of compounds outside these categories.
- Noise in data, which may arise from experimental errors, variability in biological assays, or inconsistent conditions, can obscure true signals and reduce the model's ability to learn relevant patterns. This can result in a higher rate of false positives or negatives.
- Duplicate records and redundant features or data points can inflate the dimensionality of the data without adding new information, leading to overfitting and reduced model performance.
- Scientific reproducibility is compromised when data quality is poor, as other researchers or systems might not replicate the findings.
5. Guidelines to Handle Data Quality Issues
Table 1 presents 15 pragmatic guidelines to ensure better data quality in early drug discovery and to identify potential issues with compromised data, with two examples of implementing each guideline.
6. Practises to Address Cultural Challenges Impacting Data Quality
The impact of cultural challenges on data quality necessitates specific strategies to improving data quality in drug discovery. The following practises aim to enforce structures to ensure the quality of generated data:
1. Adopting a unified data strategy: A critical first step is for organisations to develop and implement a unified scientific data strategy. This strategy should ensure that all data generated within the organisation is findable, accessible, interoperable, and reusable (FAIR) [21]. By aligning all departments and research teams to a common set of data management standards, organisations can prevent the fragmentation and inconsistency that often arise when different teams operate in silos.
2. Investing in data governance: Effective data governance [22] is essential to maintaining high data quality. This involves setting up governance structures that oversee the collection, management, and use of data across the organisation. Data governance should include the creation of standardised protocols for data capture, metadata generation, and data storage, ensuring that data is managed consistently and with the necessary context to be useful in the future.
3. Automating metadata capture: One of the significant challenges in data quality is the manual effort required to capture metadata [23]. Scientists are often too busy to dedicate extra time to this task, which can lead to incomplete or inaccurate metadata. To address this, organisations should invest in technologies that automate the capture of metadata at the point of data generation. By embedding metadata requirements into the design of experiments and data capture systems, organisations can ensure that data is accompanied by the necessary contextual information without placing additional burdens on researchers.
4. Implementing Standard Operating Procedures (SOPs): SOPs are essential for ensuring consistency in data generation and management [24]. These procedures should be designed to integrate seamlessly with the scientific workflow, providing clear guidelines on how data should be captured, stored, and analysed. SOPs should also be flexible enough to accommodate the specific needs of different research projects while maintaining a consistent approach to data quality.
5. Encouraging reproducibility through rigorous methodology: Reproducibility is a cornerstone of scientific research, and improving data quality is key to achieving it. Organisations should prioritise rigorous experimental design and methodology, ensuring that all experiments are conducted in a way that allows for accurate replication. This includes thorough documentation of experimental conditions, data collection methods, and any variables that may affect the outcomes.
6. Leveraging technology for data quality control: Advances in artificial intelligence and machine learning can play a significant role in improving data quality. These technologies can be used to monitor data in real time, flagging potential issues such as inconsistencies, missing metadata, or errors in data capture. By integrating these tools into the research process, organisations can proactively address data quality issues before they impact the research outcomes.
7. Continuous training and development: Finally, ensuring data quality requires ongoing education and training for all members of the research team. This includes not only formal training in data management best practices but also continuous professional development to keep pace with new technologies and methodologies. By fostering a culture of learning and adaptation, organisations can ensure that their teams are equipped to maintain high standards of data quality in an ever-evolving scientific landscape.
Addressing the cultural challenges impacting data quality in drug discovery is not an easy task, but it is essential for the advancement of scientific research and the development of new therapies. By fostering a culture that values data stewardship, accountability, and collaboration, and by implementing robust data management strategies, organisations can significantly improve the quality of their research outcomes. In doing so, they will not only enhance their competitive edge but also contribute to the broader goal of advancing human health and well-being through innovative drug discovery.
7. Way forward - The HitchhikersAI Community [Raminderpal]
In October 2023, the HitchhikersAI community [25] was formed as a grass-roots effort to address the challenges and opportunities described above.
HitchhikersAI aims to fix the disconnect between AI/ML and data and their practical application in early drug discovery by offering targeted non-profit consulting to biotech companies. This involves helping scientists clearly define their research questions (“killer” questions) and designing customised plans that integrate educational resources, computational tools, and curated data to effectively use AI/ML technologies in their research. The community is growing and currently consists of 250+ bench scientists, data scientists, mathematicians, business owners, executives, academics etc.
HitchhikersAI complements the work going on at Pistoia Alliance [26], where there has been over a decade of projects focusing on FAIR data [21] and Ontologies [27]. These projects have been critical to enabling the biotech industry.
Over the first year of activities, some interesting observations were made:
- Scientists and biotechs have not been motivated to participate in the HitchhikersAI, as direct value not clear to them - it does not seem to help them in their day-job and high priority challenges.
- The vendors most interested in HitchhikersAI are those in market discovery mode - early monetization, learning the voice of the customer, product-market-fit, new to the drug discovery world etc.
- The sole focus on early drug discovery is limiting the amount of vendors who could participate, because only a relatively few vendors are enabled enough to focus on early drug discovery.
- Market feedback (e.g. from biopharma exec talks at Bio Europe 2023) strongly pushing AI vendors to support late stage drug discovery needs.
- There are many science and AI consultants who would also participate if they could be helped.
These observations have led to a refinement in the approach taken by the HitchhikersAI community. This is reflected in Figure 2, which highlights key ecosystem participants and the focus on “Impact” opportunities (shown in the yellow boxes). These opportunities are aimed at supporting the vendor side of the community (both consultants and tool vendors). Specifically, the focus is on smaller vendors, helping them succeed in offering useful (science, AI, and data) services and technologies to biotech scientists. Once this barrier has been addressed, the community will decide on and evolve to address the next challenge in AI adoption.
In conclusion, the authors encourage readers to learn about the challenges / painpoints that keep the “other half” up at night. For example, for scientists the action would be to learn about data curation and analysis techniques. This can be achieved through communities such as HitchhikersAI and local meetups.
Author Contributions
Raminderpal Singh provided the content for the Introduction and HitchhikersAI sections. Andreas Bender provided the Abstract and the overall flow of the document. Nina Truter integrated the content pieces and did the necessary formatting. John Conway provided the content for the data quality and culture discussions. Neil Wilkie provided the content for the biotech business priorities discussions. Janette Thomas provided the content for data complexity challenges. All authors reviewed and helped refine the paper.
Acknowledgments
We would like to acknowledge Eli Pollock, Andre Franca and Sujeegar Jeevanandam for their valuable discussions and insights, which have contributed to the development of some of the concepts explored in this article.
Declaration of Interests
The authors have no competing interests to declare.
References
- Dunn, A. Endpoints News. After years of hype, the first AI-designed drugs fall short in the clinic. [Internet] 2023 [updated 2023 October 19; cited 2024 April]. Available online: https://endpts.com/first-ai-designed-drugs-fall-short-in-the-clinic-following-years-of-hype/.
- Cross R, Dunn A. Endpoints News. Exclusive: In $1B+ bet on AI, biopharma heavyweights back new startup to upend drug R&D. [Internet] 2024 [updated 2024 April 23; cited 2024 April]. Available online: https://endpts.com/in-biggest-ever-bet-on-using-ai-to-design-drugs-biotech-heavyweights-launch-xaira-with-1b-in-backing/.
- Buntz, B. Drug Discovery & Development. 20 biotech startups attracted almost $3B in Q1 2024. [Internet] [2024 April 5, cited 2024 April]. Available online: https://www.drugdiscoverytrends.com/20-biotech-startups-attracted-almost-3b-in-q1-2024-funding/.
- Moore GA, McKenna R. 1999. Crossing the Chasm: Marketing and Selling high-tech Products to Mainstream Customers. Harper Collins.
- Randall, T. Where is Tesla’s EV competition? The Economic Times [Internet] 2023 [updated 2023 October 5, cited 2024 April]. Available online: https://economictimes.indiatimes.com/industry/renewables/where-is-teslas-ev-competition/articleshow/104193382.cms?from=mdr.
- Wikipedia. ChatGPT [Internet] 2024 [updated 2024 May 12; cited 2024 May]. Available online: https://en.wikipedia.org/wiki/ChatGPT.
- Bender A, Cortés-Ciriano I. Artificial intelligence in drug discovery: what is realistic, what are illusions? Part 1: Ways to make an impact, and why we are not there yet. 2020. Drug Discovery Today. 26(2): 511–524. Available online: https://pubmed.ncbi.nlm.nih.gov/33346134/.
- DeLong LN, Mir RF, Fleuriot JD. Neurosymbolic AI for Reasoning over Knowledge.
- Graphs: A Survey. Arxiv.org [Internet] 2023 [updated 2024 May 16; cited 2024 September]. Available online: https://arxiv.org/abs/2302.07200.
- Saba, W. No Generalization without Understanding and Explanation. Communications of the ACM [Internet] 2024 [updated 2024 Sep 20; cited 2024 September]. Available online: https://cacm.acm.org/blogcacm/no-generalization-without-understanding-and-explanation/.
- Howe NP, Thompson B. Alphafold 3.0: the AI protein predictor gets an upgrade. Nature [Internet] 2024 [updated 2024 May 8; cited 2024 May]. Available online: https://www.nature.com/articles/d41586-024-01385-x.
- Emilia David. Google DeepMind’s new AI can model DNA, RNA, and ‘all life’s molecules’. The Verge [Internet] 2024 [updated 2024 May 8; cited 2024 May]. Available online: https://www.theverge.com/2024/5/8/24152088/google-deepmind-ai-model-predict-molecular-structure-alphafold.
- Liu L, Zhang S, Xue Y, Ye X, Zhu K, Li Y et al. Technical Report of HelixFold3 for Biomolecular Structure Prediction. Arxiv.org [Internet] 2024 [updated 2024 September 9; cited 2024 September]. Available online: https://arxiv.org/abs/2408.16975.
- Bender A, Cortés-Ciriano I. Artificial intelligence in drug discovery: what is realistic, what are illusions? Part 2: a discussion of chemical and biological data. 2021. Drug Discovery Today. 26(4): 1040-1052. Available online: https://pubmed.ncbi.nlm.nih.gov/33508423/.
- Lohr, S. For Big-Data Scientists, ‘Janitor Work’ Is Key Hurdle to Insights. The New York Times [Internet] 2014 [updated 2024; cited 2024 May]. Available online: https://www.nytimes.com/2014/08/18/technology/for-big-data-scientists-hurdle-to-insights-is-janitor-work.html.
- Agre JR, Gordon KD, Vassiliou MS. The Seven C’s of Data Curation for the Two C’s – Command and Control. Institute for Defense Analyses [Internet] 2015 [updated 2015 February; cited 2024 May]. Available online: https://www.ida.org/research-and-publications/publications/all/t/th/the-seven-cs-of-data-curation-for-the-two-cscommand-and-control.
- Ghiandoni GM, Evertsson E, Riley DJ, Tyrchan C, Rathi PC. 2024. Augmenting DMTA using predictive AI modelling at AstraZeneca. Drug Discovery Today. 29(4): 103945. Available online: https://pubmed.ncbi.nlm.nih.gov/38460568/.
- Narain, NR. AI Isn’t the Magic Bullet to Simplify Drug Discovery. Genetic Engineering & Biotechnology News [Internet] 2024 [updated 2024 June; cited 2024 September]. Available online: https://www.genengnews.com/bioperspectives/ai-isnt-the-magic-bullet-to-simplify-drug-discovery/.
- Biehler, K. The need for a data-driven culture in life sciences: What you don’t know can hurt you. Pharmaceutical Processing World [Internet] 2023 [updated 2023 May; cited 2024 September]. Available online: https://www.pharmaceuticalprocessingworld.com/the-need-for-a-data-driven-culture-in-life-sciences-what-you-dont-know-can-hurt-you/.
- Max Planck Digital Library. Data Quality [Internet] [cited 2024 September]. Available online: https://rdm.mpdl.mpg.de/before-research/data-quality/.
- Scannell JW, Bosley J, Hickman JA, Dawson GR, Truebel H, Ferreira GS et al. 2022. Predictive validity in drug discovery: what it is, why it matters and how to improve it. Nature Reviews Drug Discovery. 21(12):915-931. Available online: https://pubmed.ncbi.nlm.nih.gov/36195754/.
- Hardy K, Heyse S (2023). FAIR data policies can benefit biotech startups. Nature biotechnology. 41: 1060–1061. Available online: https://www.nature.com/articles/s41587-023-01892-8.
- Truong T, George R, Davidson J. Establishing an Effective Data Governance System. Pharmaceutical Technology. [Internet] 2017 [updated 2017 November 2, cited 2024 September]. Available online: https://www.pharmtech.com/view/establishing-effective-data-governance-system.
- Ulrich H, Kock-Schoppenhauer AK, Deppenwiese N, Gött R, Kern J, Lablans M et al. (2023). Understanding the Nature of Metadata: Systematic Review. Journal of Medical Internet Research. 24(1): e25440. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8790684/.
- Hollman S, Frohme M, Endrullat C, Kremer A, D’Elia D, Regierer B et al. Ten simple rules on how to write a standard operating procedure. Plos Computational Biology. 2022, 16, e1008095. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7470745/.
- HitchhikersAI [Internet] [cited 2024 September]. Available online: https://www.hitchhikersai.org/.
- Pistoia Alliance [Internet] [cited 2024 September]. Available online: https://www.pistoiaalliance.org/.
- Washington N, Lewis S (2008). Ontologies: Scientific Data Sharing Made Easy. Nature Education. 1(3):5. Available online: https://www.nature.com/scitable/topicpage/ontologies-scientific-data-sharing-made-easy-77972/.
Figure 1.
The scientist - and the problems the scientist is aiming to solve - should always be at the centre of any data and AI usage strategy, not vice versa (i.e. obtaining a technology-centric view).
Figure 1.
The scientist - and the problems the scientist is aiming to solve - should always be at the centre of any data and AI usage strategy, not vice versa (i.e. obtaining a technology-centric view).
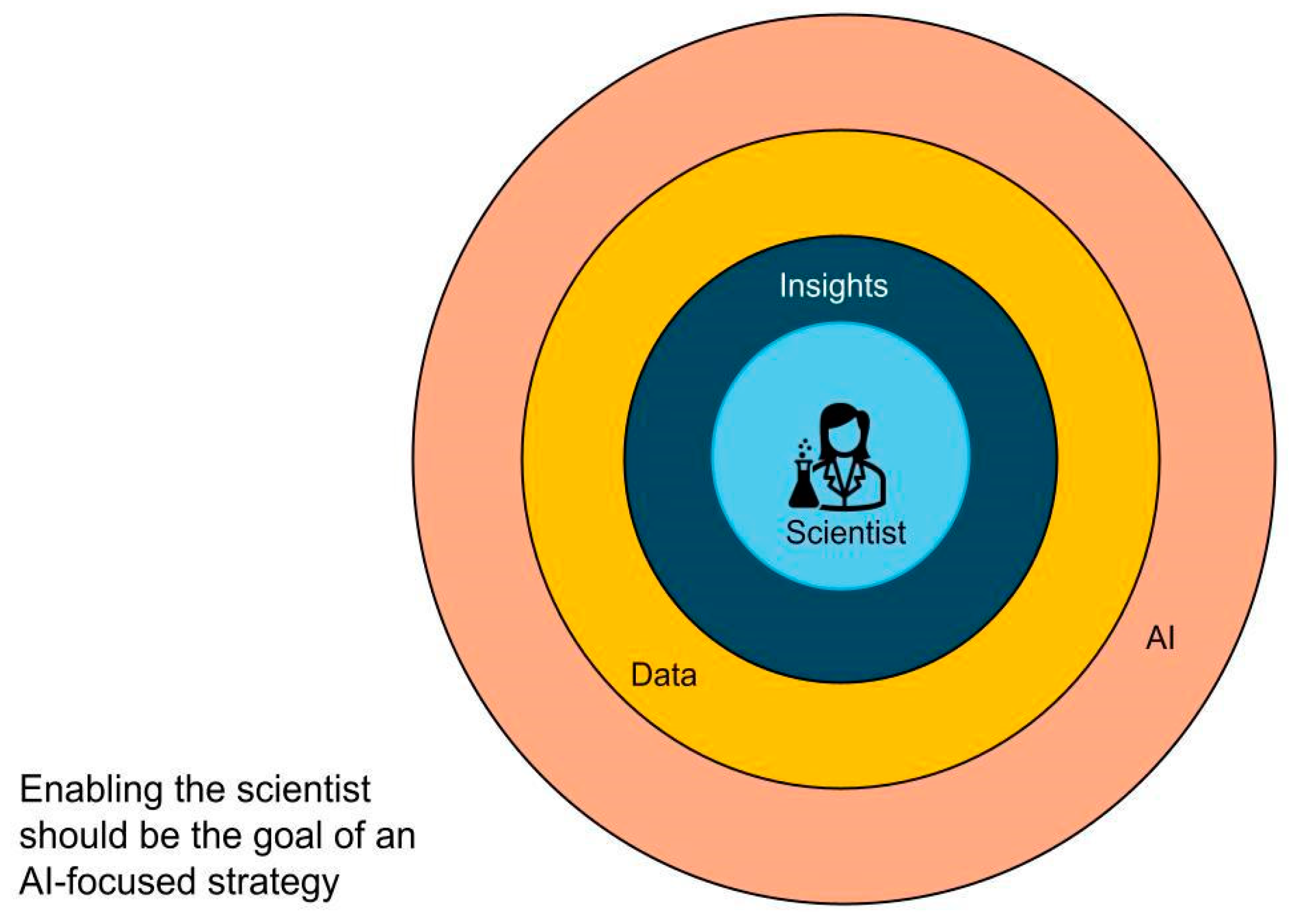
Figure 2.
The method that HHAI has adopted to accelerate AI adoption in the biotech industry, focusing on enabling the consultants and AI vendors initially.
Figure 2.
The method that HHAI has adopted to accelerate AI adoption in the biotech industry, focusing on enabling the consultants and AI vendors initially.
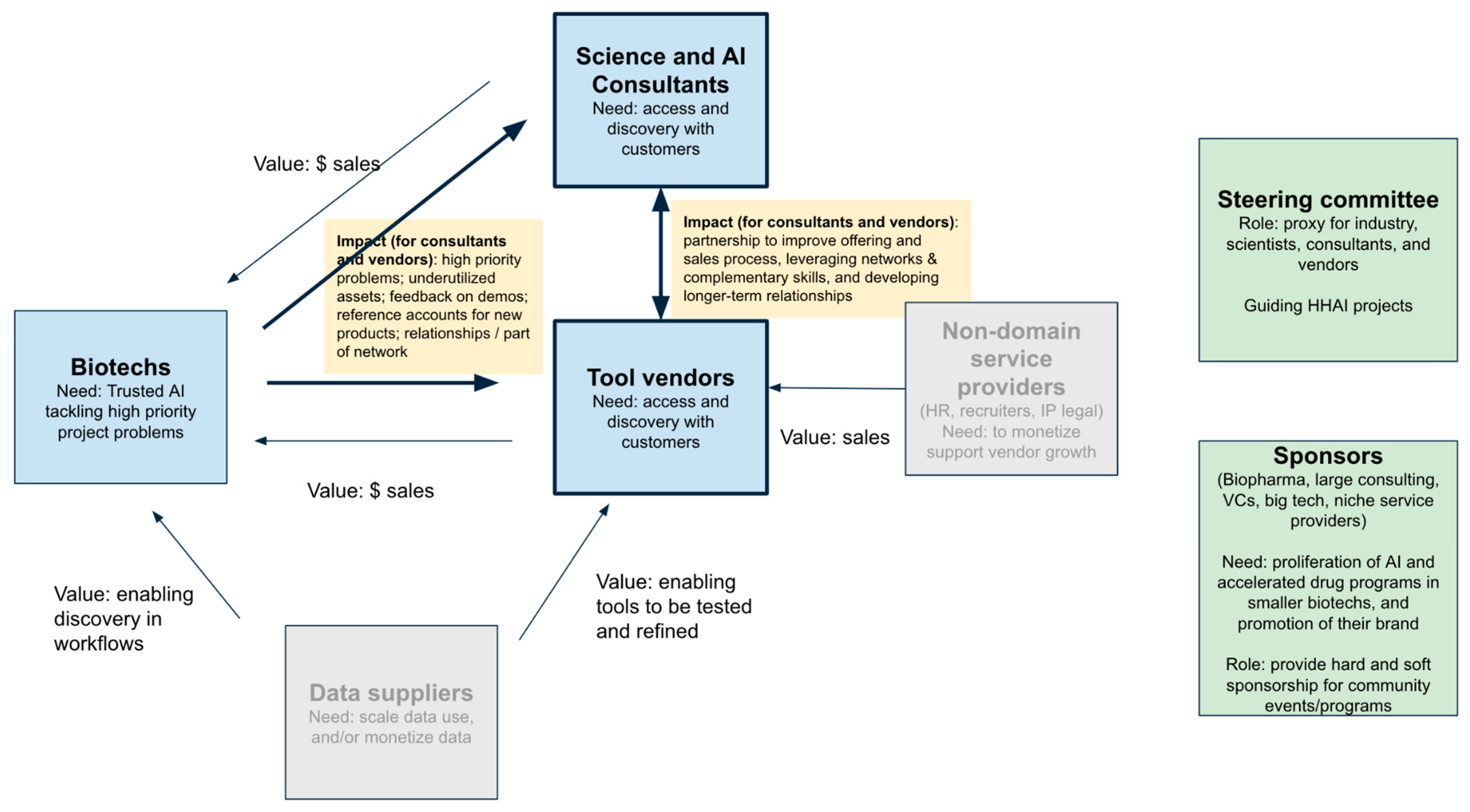

Table 1.
15 pragmatic guidelines to handle data quality issues and examples of each.
| Guideline | Implementation example 1 | Implementation example 2 |
|---|---|---|
| 1. Data Collection and Entry | Standardisation: Implement standardised operating procedures (SOPs) for data collection and entry, including consistent use of units, naming conventions, and data formats. | Training: Train the team involved in data collection on the importance of data quality and the specific protocols to follow to minimise errors. |
| 2. Data Validation | Automated Checks: Use automated validation scripts to check for common issues such as missing values, duplicates, outliers, and inconsistencies in units or formats. | Manual Review: Periodically perform manual reviews of a subset of the data to identify any issues that automated checks might miss. |
| 3. Data Cleaning | Missing Data Handling: Develop a strategy for handling missing data, such as deciding when to use imputation, exclude data points, or flag datasets for further investigation. | Outlier Detection: Implement methods to identify and investigate outliers, determining whether they represent true variability or errors. |
| 4. Data Integration | Harmonisation: Ensure that data from different sources or experiments are harmonised before integration. This includes reconciling different naming conventions, units, and formats. | Cross-Validation: Use cross-referencing methods to validate integrated datasets, checking for consistency and correctness. |
| 5. Data Documentation | Metadata: Maintain detailed metadata for each dataset, including information about the origin, collection method, and any preprocessing steps. This helps in tracking data provenance and understanding the context. | Version Control: Use version control systems for datasets to track changes and ensure that any modifications are well-documented and reversible. |
| 6. Data Monitoring | Continuous Monitoring: Implement ongoing monitoring of data quality metrics, such as completeness, accuracy, and consistency, throughout the data lifecycle. | Alerts: Set up automated alerts to notify relevant personnel if data quality metrics fall below predefined thresholds. |
| 7. Data Auditing | Regular Audits: Conduct regular data audits to assess the overall quality of your datasets. This involves checking for adherence to data quality standards and identifying any systemic issues. | Audit Trails: Maintain audit trails that log all data processing steps, transformations, and any changes made to the data. This ensures traceability and accountability. |
| 8. Bias and Variability Checks | Bias Analysis: Regularly assess your datasets for potential biases, such as over-representation of certain chemical scaffolds or biological targets. Use statistical techniques to quantify bias and take corrective actions. This involves a change in mindset in particular, from project-based data generation, to process-based data generation (where said process involves the use of AI models by default) | Variance Analysis: Analyse the variability in your data, especially in biological assays, to understand the level of noise and its impact on model performance. |
| 9. Data Redundancy and Duplication Checks | Duplicate Detection: Implement robust mechanisms to detect and remove duplicate records to prevent skewing of the data. | Feature Redundancy Check: Use techniques like correlation analysis to identify and eliminate redundant features that do not contribute new information. |
| 10. Data Imbalance Handling | Balance Check: Continuously monitor the balance of different classes in your data (e.g., active vs. inactive compounds). Address imbalances through methods like oversampling, undersampling, or synthetic data generation.#break# | Model Adaptation: If data imbalance is unavoidable, consider using model algorithms that are better suited to handle imbalanced data. |
| 11. Data Security and Access Control | Access Control: Restrict access to data based on roles and responsibilities to prevent unauthorised modifications or data entry errors. | Data Security: Implement security measures to protect data from corruption, loss, or unauthorised access, ensuring that data integrity is maintained. |
| 12. Communication and Collaboration | Interdisciplinary Collaboration: Foster collaboration between data scientists, domain experts, and IT professionals to ensure that data quality requirements are clearly understood and addressed. | Feedback Loop: Establish a feedback loop where issues identified by data scientists or model results are communicated back to the experimental team to refine data collection processes. |
| 13. Use of Quality Control Samples | Control Samples: Include quality control samples (e.g., known standards or replicates) in experimental runs to monitor and ensure consistency in assay performance. | QC Analysis: Regularly analyse the results of quality control samples to identify any drifts or deviations in experimental conditions that could impact data quality. |
| 14. Data Quality Metrics and Reporting | Define Metrics: Define specific data quality metrics such as predictivity for a downstream endpoint, accuracy, completeness, consistency, timeliness, and uniqueness. Use these metrics to evaluate and report on the quality of your data regularly. | Reporting: Regularly report on data quality metrics to stakeholders, ensuring transparency and facilitating continuous improvement. |
| 15. Continuous Improvement | Root Cause Analysis: When data quality issues are identified, perform root cause analysis to understand the underlying reasons and implement corrective actions. | Iterative Process: Treat data quality improvement as an iterative process, continuously refining and enhancing your strategies as new challenges and technologies emerge. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



